Optimization of Computational Intelligence Models for Landslide Susceptibility Evaluation


Abstract
:
1. Introduction
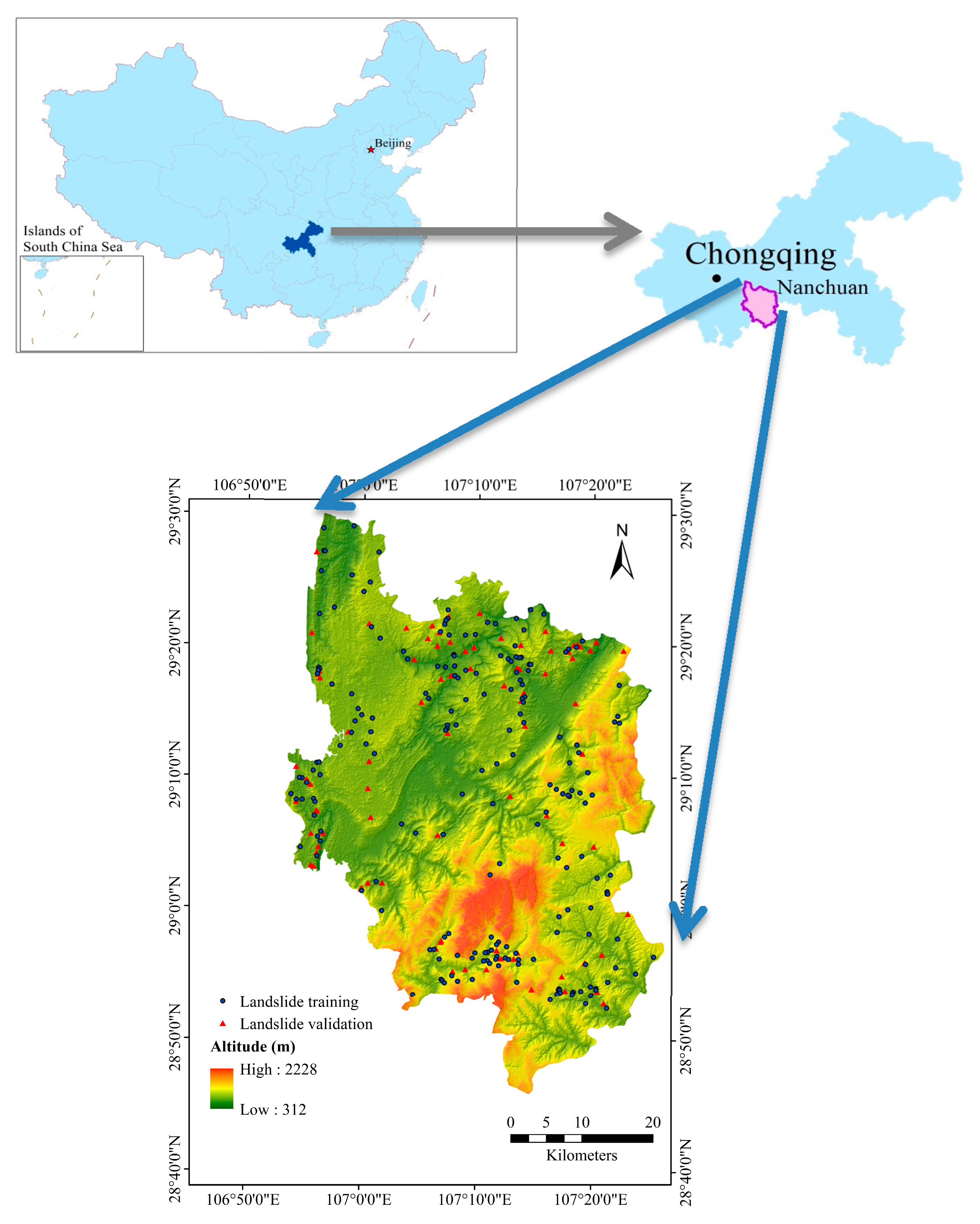
2. Description of the Study Area
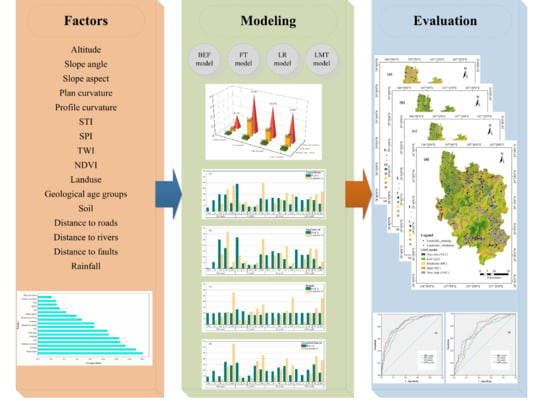
3. Methodology
3.1. Evidential Belief Function
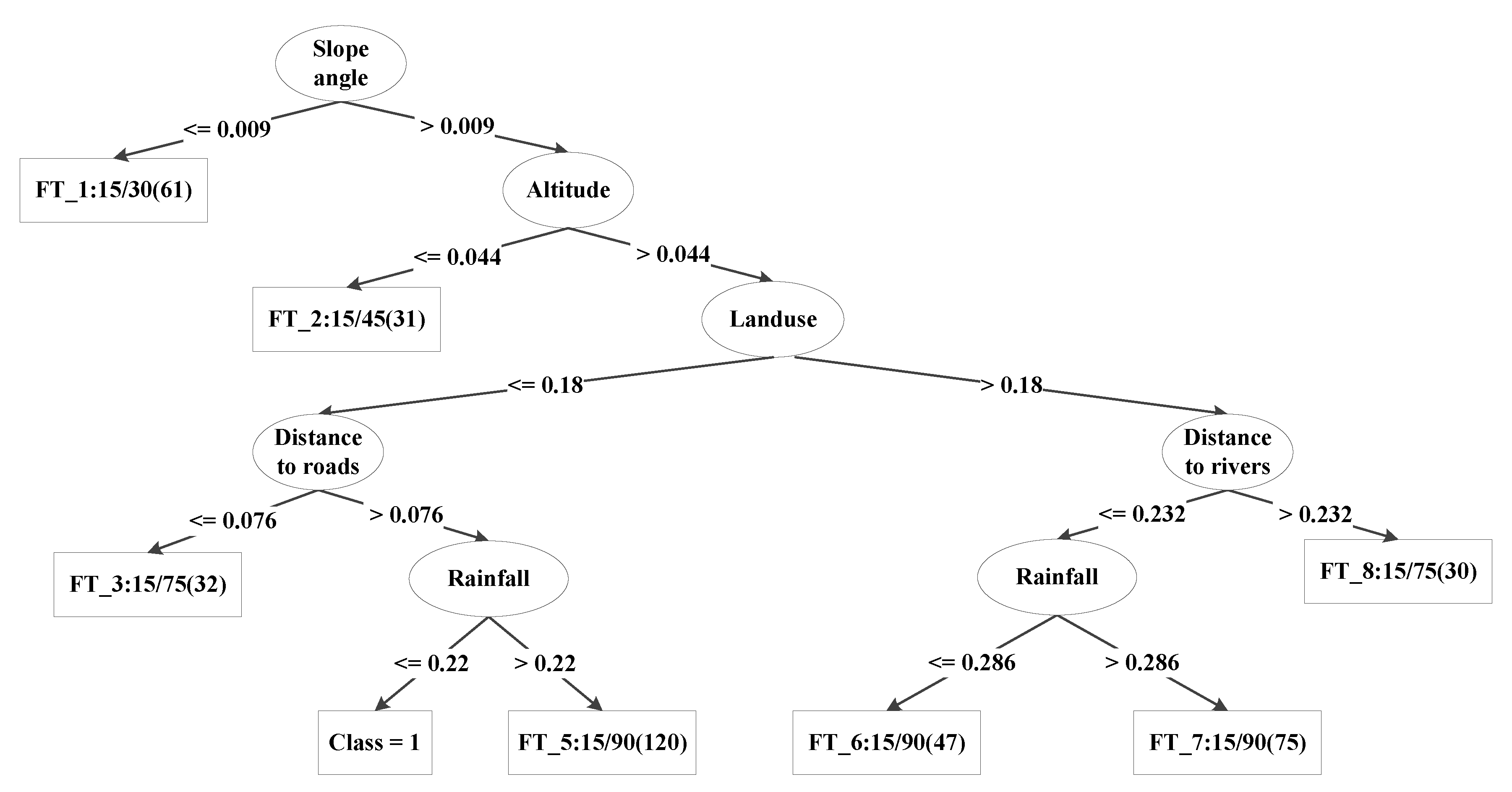
3.2. Function Tree
3.3. Logistic Regression
3.4. Logistic Model Tree
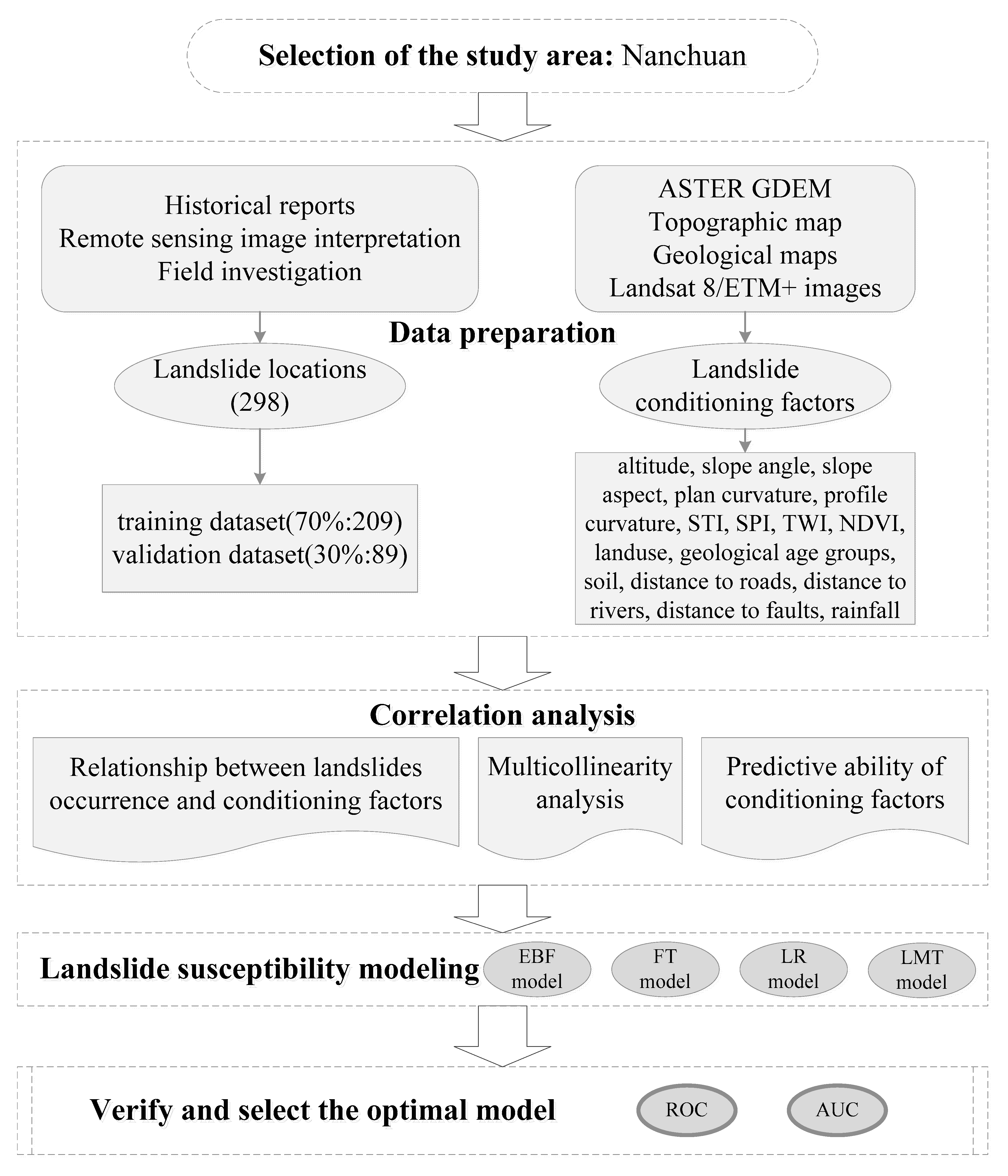
4. Data Preparation
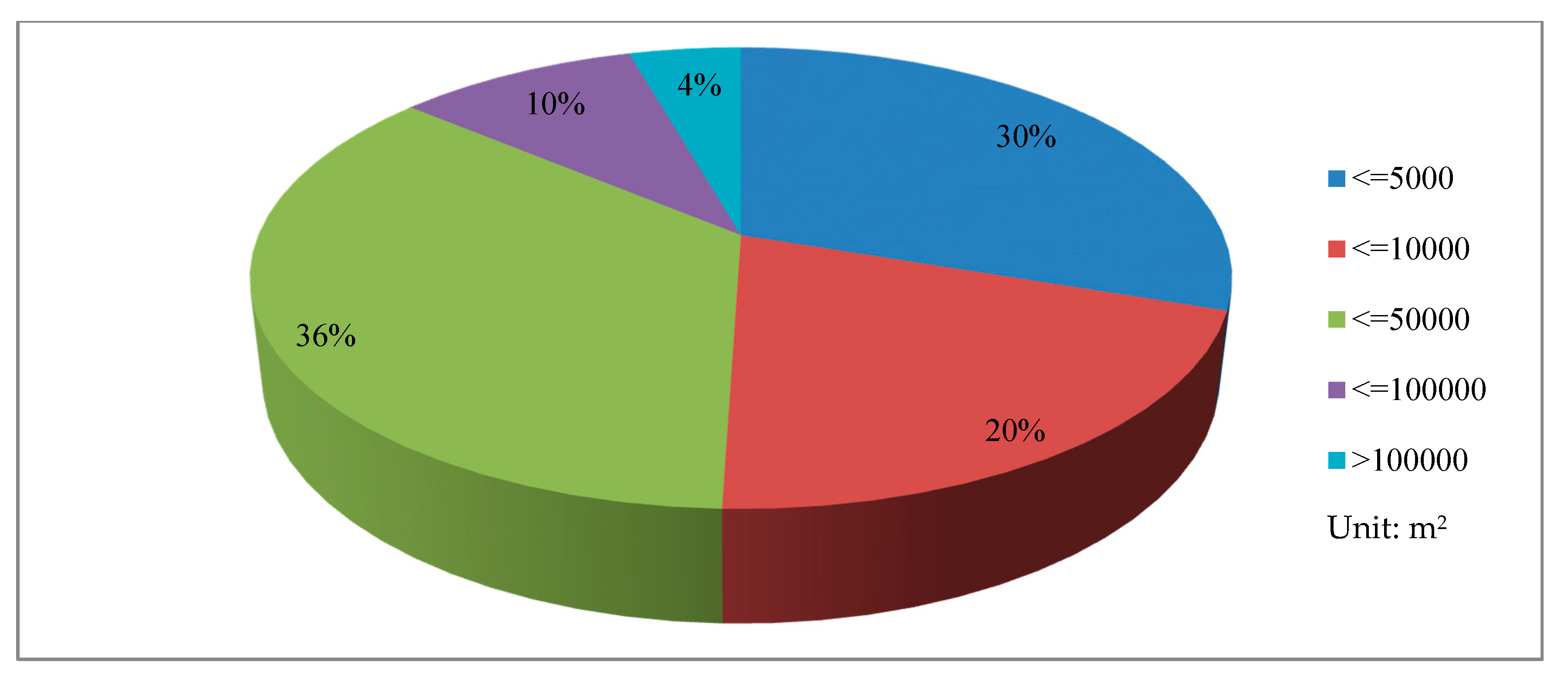
4.1. Landslide Inventory
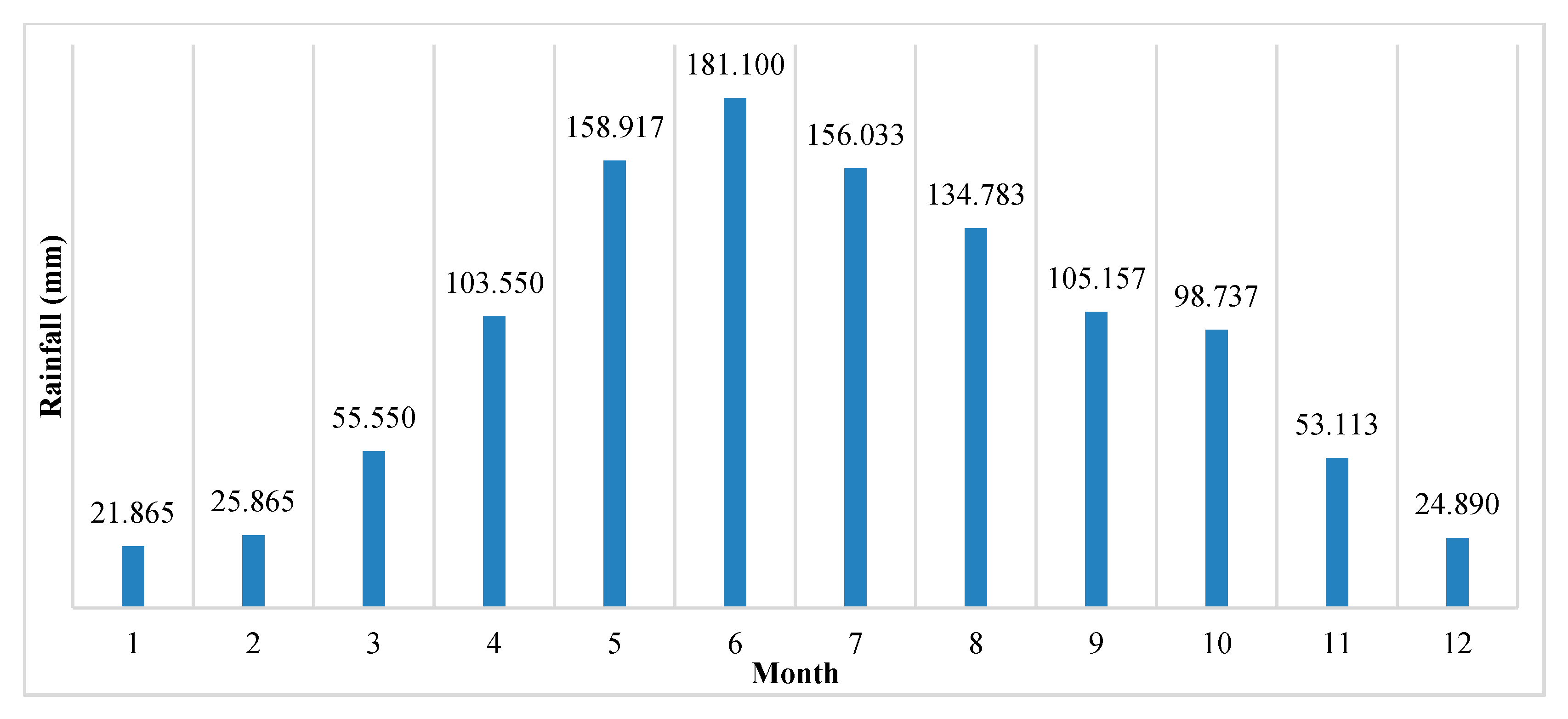
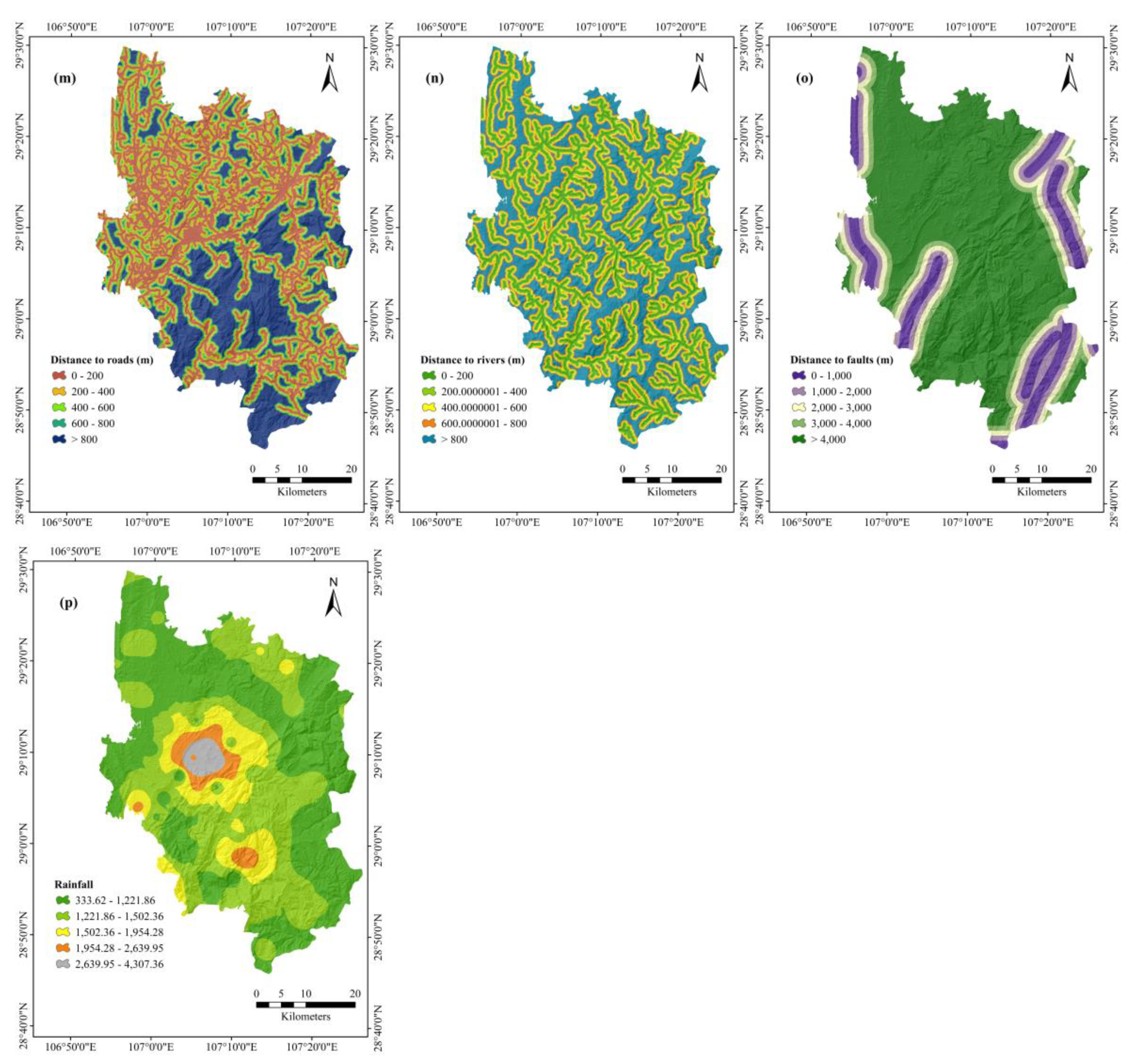
4.2. Landslide Conditioning Factors
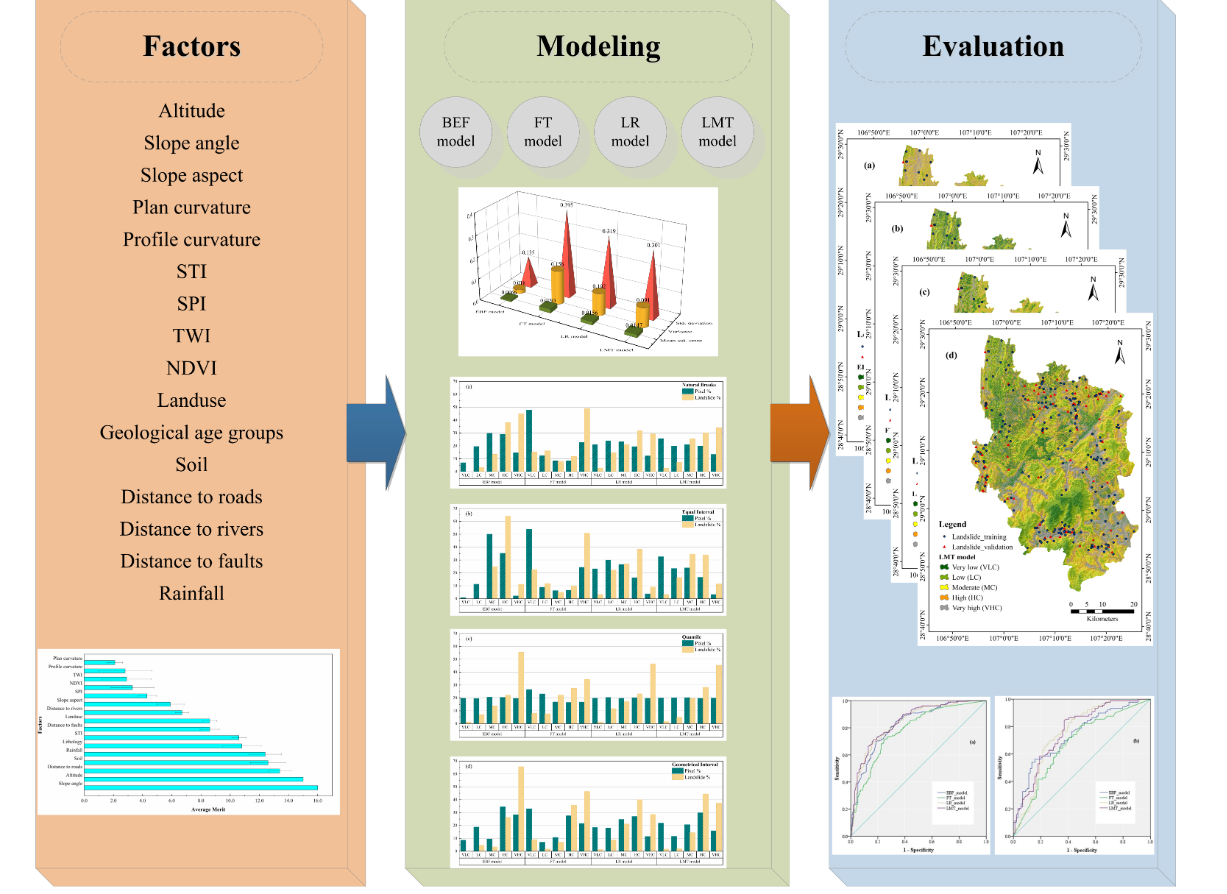
5. Results
5.1. Analysis of Landslide Conditioning Factors
5.1.1. Relationship between Landslide Conditioning Factors and Landslide Occurrence
5.1.2. Multicollinearity Analysis of Conditioning Factors
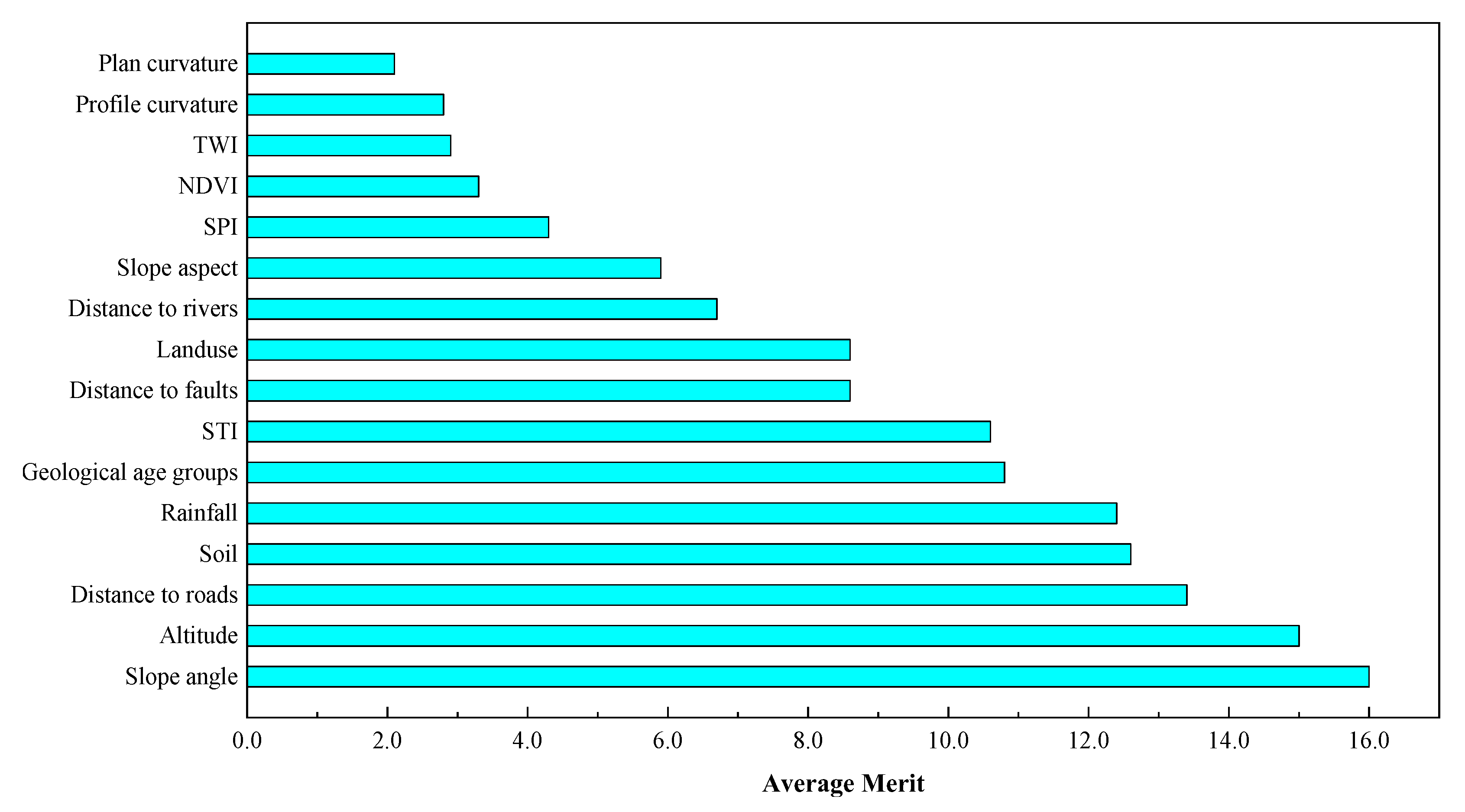
5.1.3. The Prediction Ability of the Conditioning Factors
5.2. Model Configuration
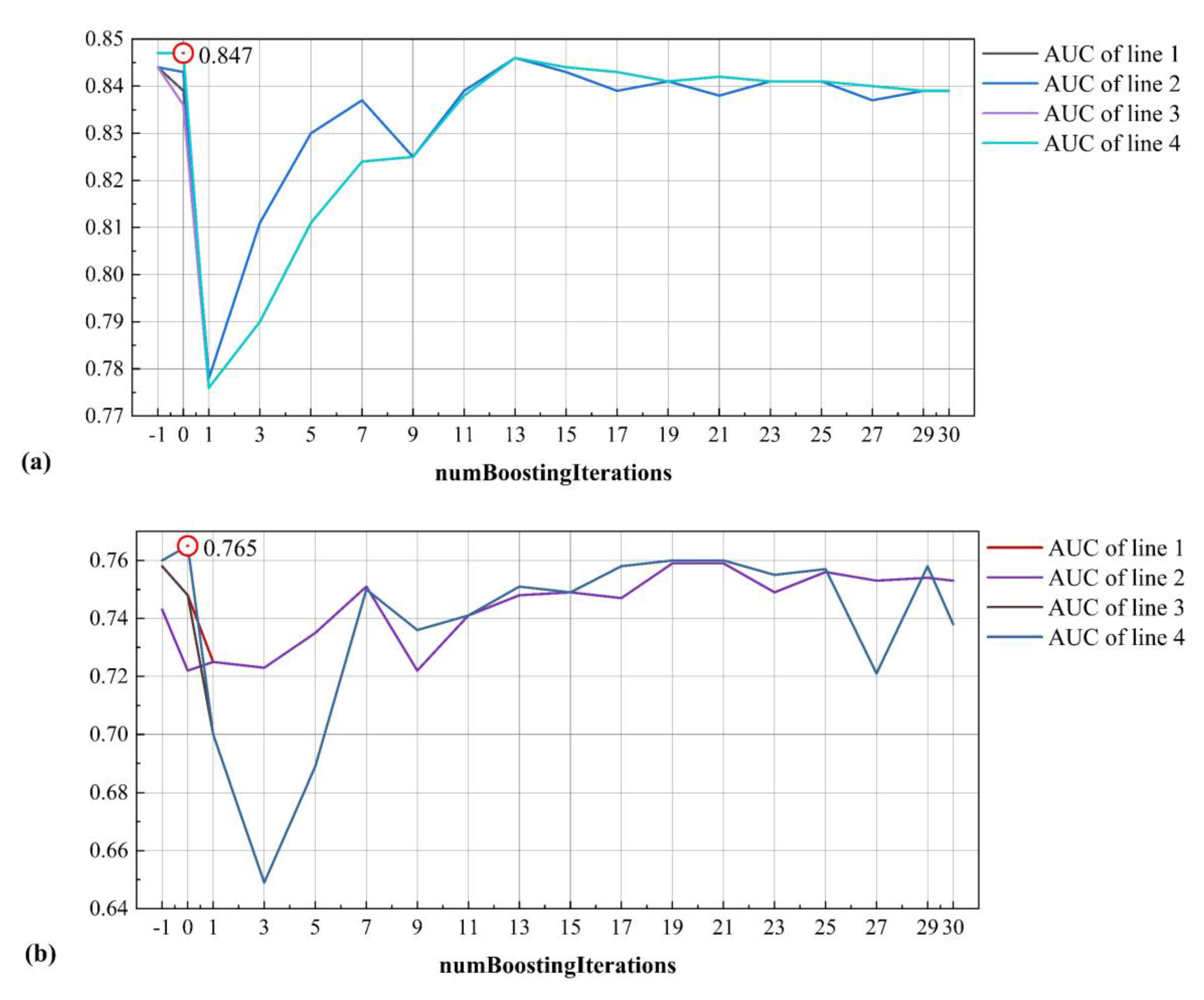
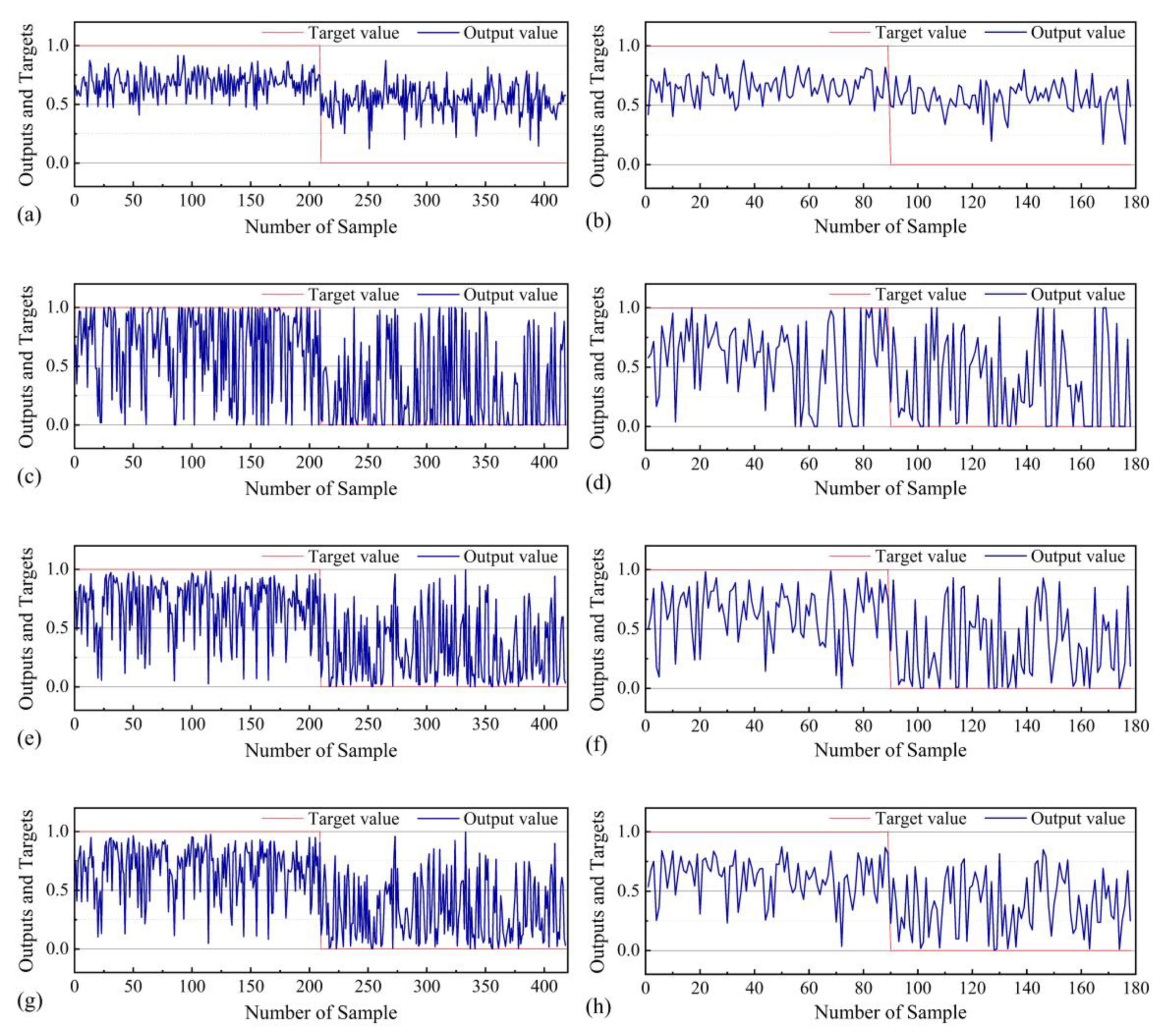
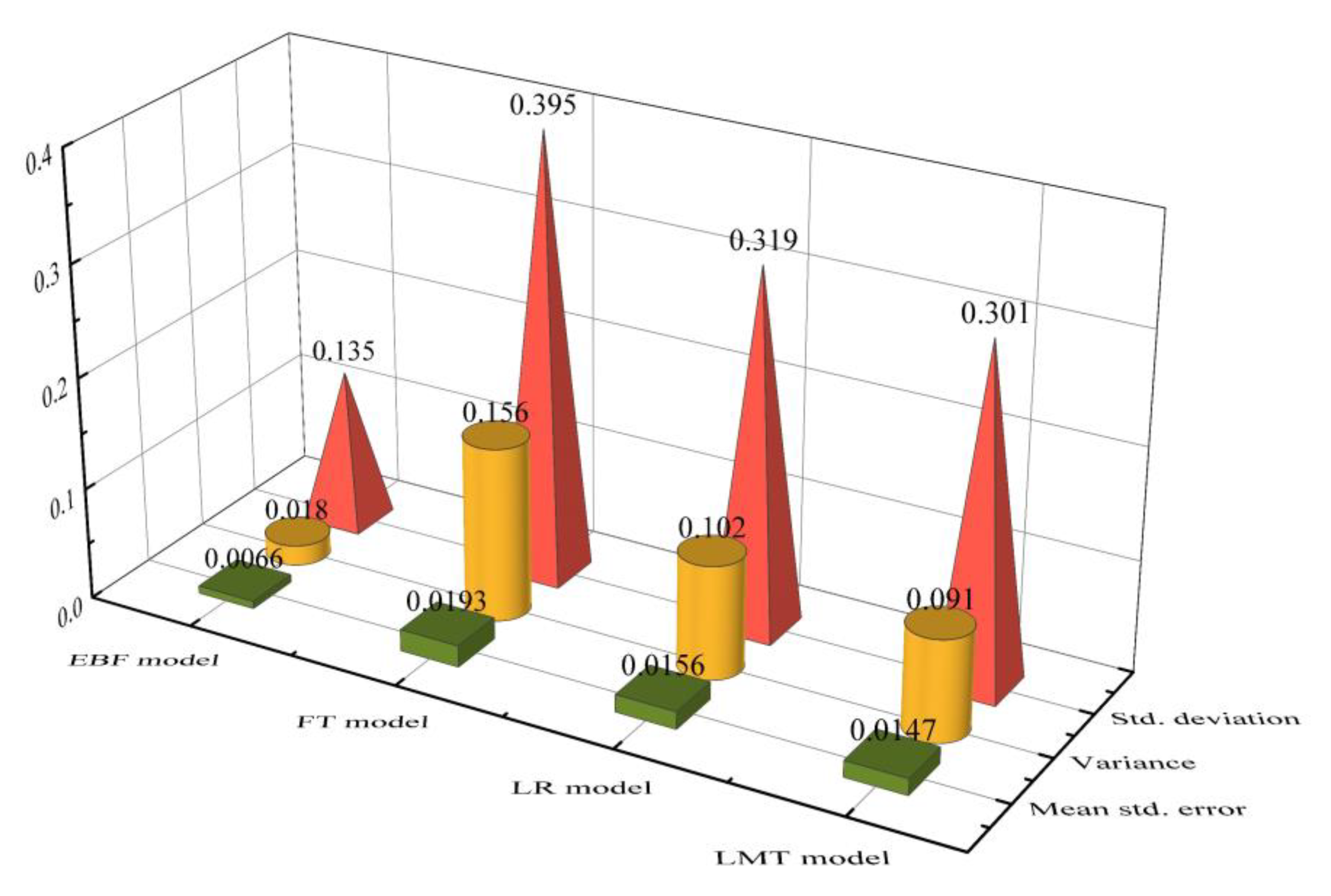
5.3. Model Validation
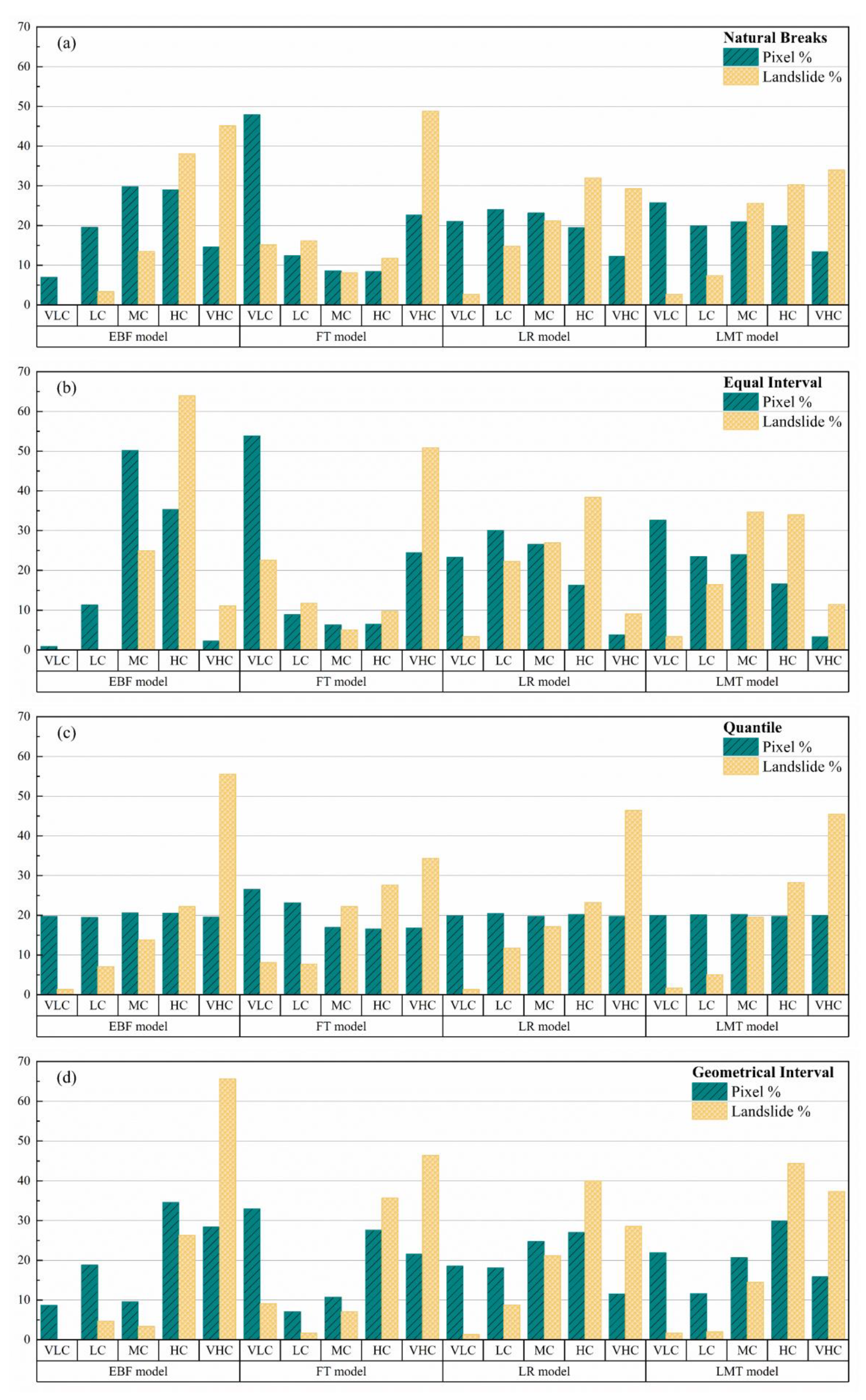
5.4. Generating Landslide Susceptibility Maps
6. Discussion
7. Conclusions
- (1)
- The maps showed that the four landslide susceptibility models were adequate for landslide susceptibility zoning. Compared with the EBF, LR, and FT models, the LMT model showed the best performance.
- (2)
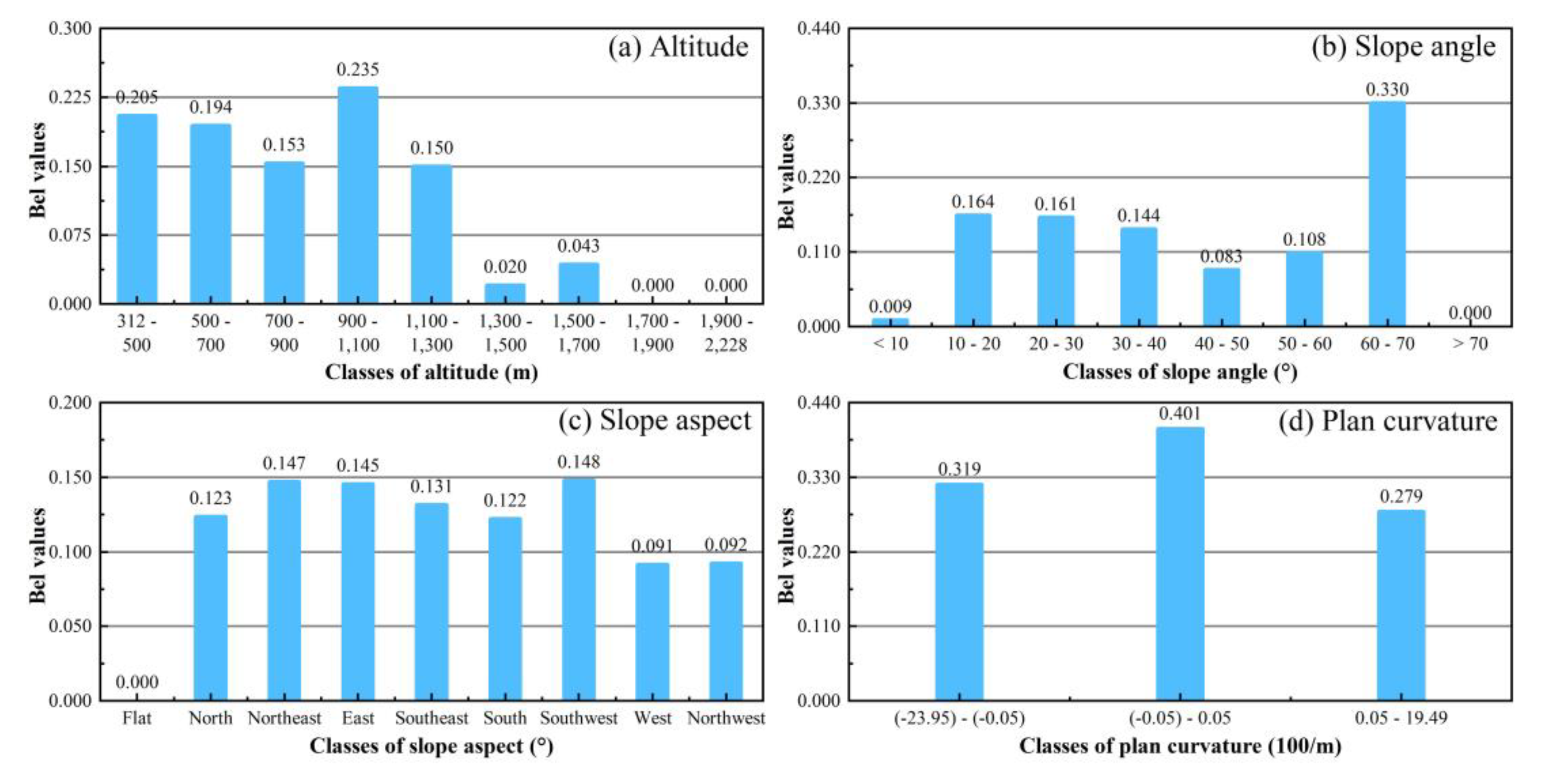
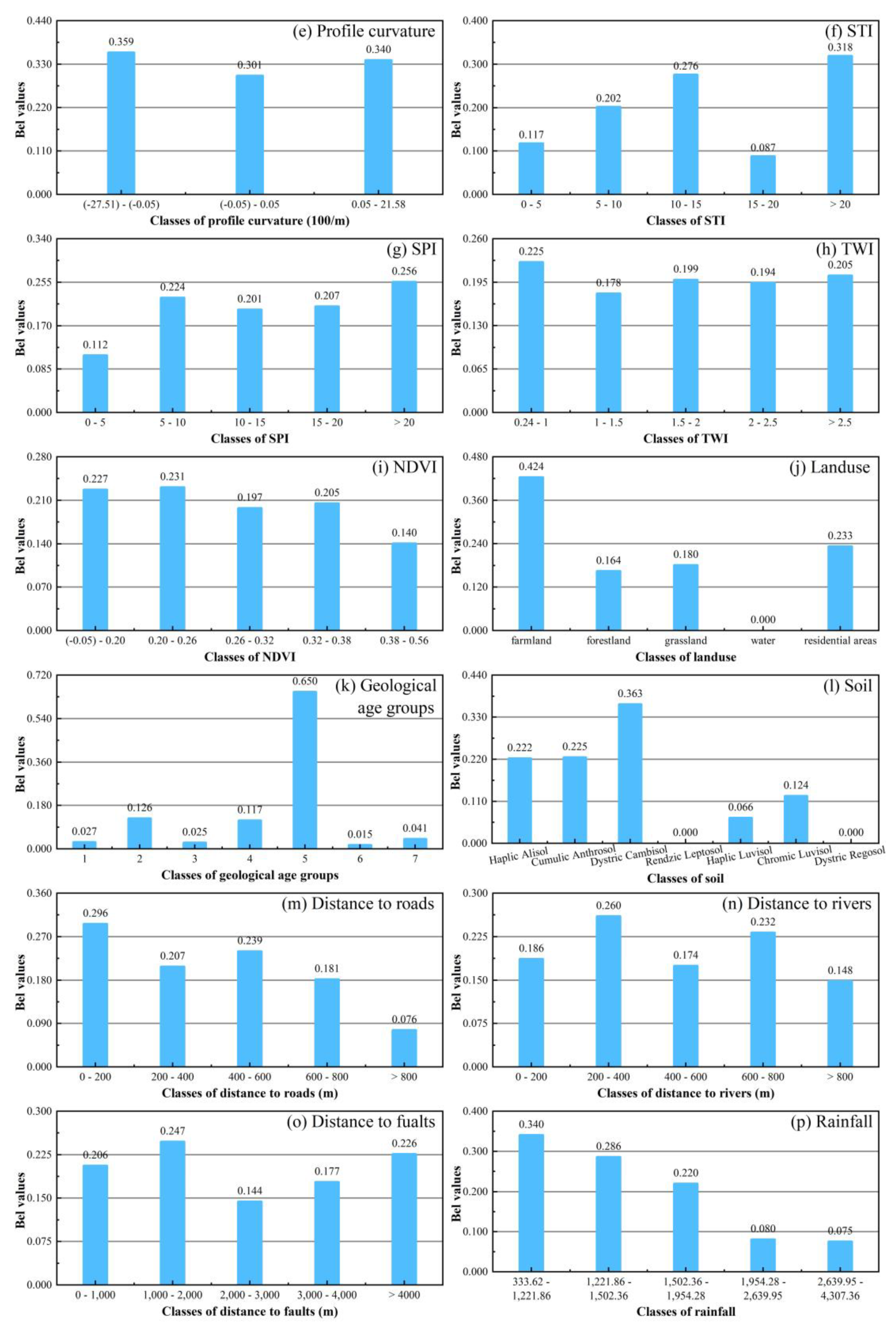
- According to the results of the EBF model, most landslides occur at altitudes of 900–1100 m in the southwest, with a slope angle of 10–20°, plan curvature of −0.05 to 0.05, profile curvature of −27.51 to −0.05, STI > 20, SPI > 20, TWI of 0.24–1, NDVI of 0.20–0.26, farmland category in land use, the fifth group (Ordovician: greyish-black charcoal shale, siliceous base) in lithology, the Dystric Cambisol category in soil, 0–200 m distance to roads, 200–400 m distance to rivers, 1000–2000 m distance to faults, 333.62–1221.86 category in rainfall.
- (3)
- According to the results of the attribute evaluation method, the most factors influencing the occurrence of landslide were the altitude, slope angle, slope aspect, plan curvature, profile curvature, STI, SPI, TWI, NDVI, land use, geological age groups, soil, distance to roads, distance to rivers, distance to faults, and rainfall.
- (4)
- The landslide susceptibility mapping by quantile classification scheme can be a promising tool for government decision makers and engineering technicians.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tsangaratos, P.; Ilia, I. Comparison of a logistic regression and naïve bayes classifier in landslide susceptibility assessments: The influence of models complexity and training dataset size. Catena 2016, 145, 164–179. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Zhang, S.; Khosravi, K.; Shirzadi, A.; Chapi, K.; Pham, B.T.; Zhang, T.; Zhang, L.; Chai, H.; et al. Landslide Susceptibility Modeling Based on GIS and Novel Bagging-Based Kernel Logistic Regression. Appl. Sci. 2018, 8, 2540. [Google Scholar] [CrossRef] [Green Version]
- Hadmoko, D.S.; Lavigne, F.; Samodra, G. Application of a semiquantitative and gis-based statistical model to landslide susceptibility zonation in Kayangan Catchment, Java, Indonesia. Nat. Hazards 2017, 87, 437–468. [Google Scholar] [CrossRef]
- Zhou, J.W.; Peng, C.; Yang, X.G. Dynamic process analysis for the initiation and movement of the donghekou landslide-debris flow triggered by the Wenchuan earthquake. J. Asian Earth Sci. 2013, 76, 70–84. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Prakash, I. Bagging based support vector machines for spatial prediction of landslides. Environ. Earth Sci. 2018, 77, 146. [Google Scholar] [CrossRef]
- Ayalew, L.; Yamagishi, H. The application of gis-based logistic regression for landslide susceptibility mapping in the Kakuda-yahiko mountains, central Japan. Geomorphology 2005, 65, 15–31. [Google Scholar] [CrossRef]
- Soyoung, P.; Se-Yeong, H.; Hang-Tak, J.; Jinsoo, K. Evaluation of logistic regression and multivariate adaptive regression spline models for groundwater potential mapping using r and gis. Sustainability 2017, 9, 1157. [Google Scholar]
- Pham, B.T.; Pradhan, B.; Tien Bui, D.; Prakash, I.; Dholakia, M.B. A comparative study of different machine learning methods for landslide susceptibility assessment: A case study of Uttarakhand area (India). Environ. Modell. Softw. 2016, 84, 240–250. [Google Scholar] [CrossRef]
- Chen, W.; Fan, L.; Li, C.; Pham, B.T. Spatial prediction of landslides using hybrid integration of artificial intelligence algorithms with frequency ratio and index of entropy in Nanzheng county, China. Appl. Sci. 2020, 10, 29. [Google Scholar] [CrossRef] [Green Version]
- Corominas, J.; Westen, C.V.; Frattini, P.; Cascini, L.; Malet, J.P.; Fotopoulou, S.; Catani, F.; Eeckhaut, M.V.D.; Mavrouli, O.; Agliardi, F. Recommendations for the quantitative analysis of landslide risk. Bull. Eng. Geol. Environ. 2014, 73, 209–263. [Google Scholar] [CrossRef]
- Zêzere, J.L.; Pereira, S.; Melo, R.; Oliveira, S.C.; Garcia, R.A. Mapping landslide susceptibility using data-driven methods. Sci. Total Environ. 2017, 589, 250–267. [Google Scholar] [CrossRef]
- Saha, A.K.; Gupta, R.P.; Sarkar, I.; Arora, M.K.; Csaplovics, E. An approach for gis-based statistical landslide susceptibility zonation—With a case study in the Himalayas. Landslides 2005, 2, 61–69. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I. A novel hybrid intelligent approach of random subspace ensemble and reduced error pruning trees for landslide susceptibility modeling: A case study at mu cang chai district, yen bai province, viet nam. In Advances and Applications in Geospatial Technology and Earth Resources; Tien Bui, D., Ngoc Do, A., Bui, H.-B., Hoang, N.-D., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 255–269. [Google Scholar]
- Mathew, J.; Jha, V.K.; Rawat, G.S. Application of binary logistic regression analysis and its validation for landslide susceptibility mapping in part of Garhwal Himalaya, India. Int. J. Remote Sens. 2007, 28, 2257–2275. [Google Scholar] [CrossRef]
- Mathew, J.; Jha, V.K.; Rawat, G.S. Landslide susceptibility zonation mapping and its validation in part of garhwal lesser himalaya, india, using binary logistic regression analysis and receiver operating characteristic curve method. Landslides 2009, 6, 17–26. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Pourghasemi, H.R.; Indra, P.; Dholakia, M.B. Landslide susceptibility assesssment in the uttarakhand area (india) using gis: A comparison study of prediction capability of naïve bayes, multilayer perceptron neural networks, and functional trees methods. Theor. Appl. Climatol. 2015, 122, 1–19. [Google Scholar] [CrossRef]
- Long, N.T.; Smedt, F.D. Slope stability analysis using a physically based model: A case study from a luoi district in Thua Thien-Hue province, Vietnam. Landslides 2014, 11, 897–907. [Google Scholar]
- Wang, H.J.; Xiao, T.; Li, X.Y.; Zhang, L.L.; Zhang, L.M. A novel physically-based model for updating landslide susceptibility. Eng. Geol. 2019, 251, 71–80. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Rahmati, O. Prediction of the landslide susceptibility: Which algorithm, which precision? Catena 2017, 162, 177–192. [Google Scholar] [CrossRef]
- Bui, D.T.; Tuan, T.A.; Klempe, H.; Pradhan, B.; Revhaug, I. Spatial prediction models for shallow landslide hazards: A comparative assessment of the efficacy of support vector machines, artificial neural networks, kernel logistic regression, and logistic model tree. Landslides 2016, 13, 361–378. [Google Scholar]
- Pourghasemi, H.R.; Kerle, N. Random forests and evidential belief function-based landslide susceptibility assessment in western Mazandaran province, Iran. Environ. Earth Sci. 2016, 75, 185. [Google Scholar] [CrossRef]
- Yesilnacar, E.; Topal, T. Landslide susceptibility mapping: A comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Eng. Geol. 2005, 79, 251–266. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Peng, J.; Shahabi, H.; Hong, H.; Tien Bui, D.; Duan, Z.; Li, S.; Zhu, A.-X. GIS-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. Catena 2018, 164, 135–149. [Google Scholar] [CrossRef]
- Zhao, X.; Chen, W. Gis-based evaluation of landslide susceptibility models using certainty factors and functional trees-based ensemble techniques. Appl. Sci. 2020, 10, 16. [Google Scholar] [CrossRef] [Green Version]
- Park, N.W. Application of dempster-shafer theory of evidence to gis-based landslide susceptibility analysis. Environ. Earth Sci. 2011, 62, 367–376. [Google Scholar] [CrossRef]
- Feizizadeh, B.; Blaschke, T.; Nazmfar, H. Gis-based ordered weighted averaging and dempster–shafer methods for landslide susceptibility mapping in the Urmia Lake Basin, Iran. Int. J. Digit. Earth 2014, 7, 688–708. [Google Scholar] [CrossRef]
- Devkota, K.C.; Regmi, A.D.; Pourghasemi, H.R.; Yoshida, K.; Pradhan, B.; Ryu, I.C.; Dhital, M.R.; Althuwaynee, O.F. Landslide susceptibility mapping using certainty factor, index of entropy and logistic regression models in gis and their comparison at Mugling–Narayanghat road section in Nepal Himalaya. Nat. Hazards 2013, 65, 135–165. [Google Scholar] [CrossRef]
- Kayastha, P.; Smedt, F.D. Landslide susceptibility mapping using the weight of evidence method in the Tinau watershed, Nepal. Nat. Hazards 2012, 63, 479–498. [Google Scholar] [CrossRef]
- Ozdemir, A.; Altural, T. A comparative study of frequency ratio, weights of evidence and logistic regression methods for landslide susceptibility mapping: Sultan mountains, sw Turkey. J. Asian Earth Sci. 2013, 64, 180–197. [Google Scholar] [CrossRef]
- Wang, G.; Chen, X.; Chen, W. Spatial prediction of landslide susceptibility based on gis and discriminant functions. ISPRS Int. J. Geo-Inf. 2020, 9, 144. [Google Scholar] [CrossRef] [Green Version]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef]
- Chen, W.; Hong, H.; Panahi, M.; Shahabi, H.; Wang, Y.; Shirzadi, A.; Pirasteh, S.; Alesheikh, A.A.; Khosravi, K.; Panahi, S.; et al. Spatial prediction of landslide susceptibility using gis-based data mining techniques of anfis with whale optimization algorithm (woa) and grey wolf optimizer (gwo). Appl. Sci. 2019, 9, 3755. [Google Scholar] [CrossRef] [Green Version]
- Zhou, C.; Yin, K.; Cao, Y.; Ahmed, B.; Li, Y.; Catani, F.; Pourghasemi, H.R. Landslide susceptibility modeling applying machine learning methods: A case study from longju in the three gorges reservoir area, China. Comput. Geosci. 2018, 112, 23–37. [Google Scholar] [CrossRef] [Green Version]
- Goetz, J.N.; Brenning, A.; Petschko, H.; Leopold, P. Evaluating machine learning and statistical prediction techniques for landslide susceptibility modeling. Comput. Geosci. 2015, 81, 1–11. [Google Scholar] [CrossRef]
- Pham, B.T.; Bui, D.T.; Dholakia, M.B.; Prakash, I.; Pham, H.V.; Mehmood, K.; Le, H.Q. A novel ensemble classifier of rotation forest and naïve bayer for landslide susceptibility assessment at the luc yen district, yen bai province (viet nam) using gis. Geomat. Nat. Hazards Risk 2017, 8, 649–671. [Google Scholar] [CrossRef] [Green Version]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using gis. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Lin, G.-F.; Chang, M.-J.; Huang, Y.-C.; Ho, J.-Y. Assessment of susceptibility to rainfall-induced landslides using improved self-organizing linear output map, support vector machine, and logistic regression. Eng. Geol. 2017, 224, 62–74. [Google Scholar] [CrossRef]
- Can, A.; Dagdelenler, G.; Ercanoglu, M.; Sonmez, H. Landslide susceptibility mapping at ovacık-karabük (turkey) using different artificial neural network models: Comparison of training algorithms. Bull. Eng. Geol. Environ. 2019, 78, 89–102. [Google Scholar] [CrossRef]
- Abbaszadeh Shahri, A.; Spross, J.; Johansson, F.; Larsson, S. Landslide susceptibility hazard map in southwest sweden using artificial neural network. Catena 2019, 183, 104225. [Google Scholar] [CrossRef]
- Huang, F.; Yin, K.; Huang, J.; Gui, L.; Wang, P. Landslide susceptibility mapping based on self-organizing-map network and extreme learning machine. Eng. Geol. 2017, 223, 11–22. [Google Scholar] [CrossRef]
- Doetsch, P.; Buck, C.; Golik, P.; Hoppe, N.; Kramp, M.; Laudenberg, J.; Steingrube, P.; Forster, J.; Mauser, A. Logistic model trees with AUC split criterion for the KDD cup 2009 small challenge. In Proceedings of the International Conference on KDD-Cup 2009 Competition, New York, NY, USA, 28 June 2009; Volume 7, pp. 77–88. [Google Scholar]
- Provost, F.; Hibert, C.; Malet, J. Automatic classification of endogenous landslide seismicity using the random forest supervised classifier. Geophys. Res. Lett. 2017, 44, 113–120. [Google Scholar] [CrossRef]
- Zhang, K.; Wu, X.; Niu, R.; Yang, K.; Zhao, L. The assessment of landslide susceptibility mapping using random forest and decision tree methods in the three gorges reservoir area, China. Environ. Earth Sci. 2017, 76, 405. [Google Scholar] [CrossRef]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Erratum to: Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 1315–1318. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.L.; Li, T.Y. A tentative study of the relationship between annual δ18o & δd variations of precipitation and atmospheric circulations—A case from southwest china. Quat. Int. 2018, 479, 117–127. [Google Scholar]
- Tao, W.; Hu, J.D. Analysis of influences on environment of chongqing wansheng-nanchuan expressway and countermeasures for environmental protection. Technol. Highw. Transp. 2009, 6, 38. [Google Scholar]
- Shafer, G. A theory of statistical evidence. In Foundations of Probability Theory, Statistical Inference, and Statistical Theories of Science: Proceedings of an International Research Colloquium Held at the University of Western Ontario, London, Canada, 10–13 May 1973 Volume II Foundations and Philosophy of Statistical Inference; Harper, W.L., Hooker, C.A., Eds.; Springer: Dordrecht, The Netherlands, 1976; pp. 365–436. [Google Scholar]
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. In Classic Works of the Dempster-Shafer Theory of Belief Functions; Yager, R.R., Liu, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 57–72. [Google Scholar]
- Lee, S.; Hwang, J.; Park, I. Application of data-driven evidential belief functions to landslide susceptibility mapping in jinbu, korea. Catena 2013, 100, 15–30. [Google Scholar] [CrossRef]
- Gama, J. Functional trees. Mach. Learn. 2004, 55, 219–250. [Google Scholar] [CrossRef]
- Pham, B.T.; Nguyen, V.-T.; Ngo, V.-L.; Trinh, P.T.; Ngo, H.T.T.; Tien Bui, D. A novel hybrid model of rotation forest based functional trees for landslide susceptibility mapping: A case study at kon tum province, vietnam. In Advances and Applications in Geo-Spatial Technology and Earth Resources; Tien, B.D., Ngoc, D.A., Bui, H.-B., Hoang, N.-D., Eds.; Springer: Berlin, Germany, 2018; pp. 186–201. [Google Scholar]
- Bui, D.T.; Ho, T.-C.; Pradhan, B.; Pham, B.-T.; Nhu, V.-H.; Revhaug, I. Gis-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with adaboost, bagging, and multiboost ensemble frameworks. Environ. Earth Sci. 2016, 75, 1–22. [Google Scholar]
- Shou, K.-J.; Lin, J.-F. Evaluation of the extreme rainfall predictions and their impact on landslide susceptibility in a sub-catchment scale. Eng. Geol. 2020, 265, 105434. [Google Scholar] [CrossRef]
- Ozdemir, A. Gis-based groundwater spring potential mapping in the sultan mountains (Konya, Turkey) using frequency ratio, weights of evidence and logistic regression methods and their comparison. J. Hydrol. 2011, 411, 290–308. [Google Scholar] [CrossRef]
- Salzberg, S.L. C4.5: Programs for Machine Learning by j. Ross Quinlan. Morgan Kaufmann Publishers, inc., 1993. Mach. Learn. 1994, 16, 235–240. [Google Scholar] [CrossRef] [Green Version]
- Pollett, W.G.; Gibbs, P.; Mclaughlin, S.; Eteuati, J.; Harold, M.; Marion, K.; Patel, S.; Jones, I. Outcomes in the Surgical Treatment of Low Rectal Cancer: Does Neoadjuvant Treatment Equalize Results? Available online: https://onlinelibrary.wiley.com/doi/abs/10.1111/ans.12786 (accessed on 1 May 2020).
- Landwehr, N.; Hall, M.; Frank, E. Logistic model trees. Mach. Learn. 2005, 59, 161–205. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Shoombuatong, W.; Hongjaisee, S.; Barin, F.; Chaijaruwanich, J.; Samleerat, T. Hiv-1 crf01_ae coreceptor usage prediction using kernel methods based logistic model trees. Comput. Biol. Med. 2012, 42, 885–889. [Google Scholar] [CrossRef] [PubMed]
- Galli, M.; Ardizzone, F.; Cardinali, M.; Guzzetti, F.; Reichenbach, P. Comparing landslide inventory maps. Geomorphology 2008, 94, 268–289. [Google Scholar] [CrossRef]
- Hungr, O.; Leroueil, S.; Picarelli, L. The varnes classification of landslide types, an update. Landslides 2014, 11, 167–194. [Google Scholar] [CrossRef]
- Chung, C.J.F.; Fabbri, A.G. Validation of spatial prediction models for landslide hazard mapping. Nat. Hazards 2003, 30, 451–472. [Google Scholar] [CrossRef]
- Wang, Y.; Duan, H.; Hong, H. A comparative study of composite kernels for landslide susceptibility mapping: A case study in Yongxin county, China. Catena 2019, 183, 104217. [Google Scholar] [CrossRef]
- Mandal, B.; Mandal, S. Analytical hierarchy process (ahp) based landslide susceptibility mapping of lish river basin of eastern Darjeeling Himalaya, India. Adv. Space Res. 2018, 62, 3114–3132. [Google Scholar] [CrossRef]
- Hong, H.; Liu, J.; Bui, D.T.; Pradhan, B.; Acharya, T.D.; Pham, B.T.; Zhu, A.X.; Wei, C.; Ahmad, B.B. Landslide susceptibility mapping using j48 decision tree with adaboost, bagging and rotation forest ensembles in the Guangchang area (China). Catena 2018, 163, 399–413. [Google Scholar] [CrossRef]
- Chalkias, C.; Ferentinou, M.; Polykretis, C. Gis-based landslide susceptibility mapping on the Peloponnese Peninsula, Greece. Geosciences 2014, 4, 176–190. [Google Scholar] [CrossRef] [Green Version]
- Kavzoglu, T.; Kutlug Sahin, E.; Colkesen, I. Selecting optimal conditioning factors in shallow translational landslide susceptibility mapping using genetic algorithm. Eng. Geol. 2015, 192, 101–112. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H. Comparison of convolutional neural networks for landslide susceptibility mapping in Yanshan county, China. Sci. Total Environ. 2019, 666, 975–993. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y. GIS-based evaluation of landslide susceptibility using hybrid computational intelligence models. Catena 2020, 195, 104777. [Google Scholar] [CrossRef]
- Wu, Y.; Li, W.; Liu, P.; Bai, H.; Wang, Q.; He, J.; Liu, Y.; Sun, S. Application of analytic hierarchy process model for landslide susceptibility mapping in the Gangu county, Gansu province, China. Environ. Earth Sci. 2016, 75, 1–11. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Bui, D.T. Spatial prediction of landslides using a hybrid machine learning approach based on random subspace and classification and regression trees. Geomorphology 2018, 303. [Google Scholar] [CrossRef]
- Oh, H.-J.; Kadavi, P.R.; Lee, C.-W.; Lee, S. Evaluation of landslide susceptibility mapping by evidential belief function, logistic regression and support vector machine models. Geomat. Nat. Hazards Risk 2018, 9, 1053–1070. [Google Scholar] [CrossRef] [Green Version]
- Pourghasemi, H.R.; Yousefi, S.; Kornejady, A.; Cerdà, A. Performance assessment of individual and ensemble data-mining techniques for gully erosion modeling. Sci. Total Environ. 2017, 609, 764–775. [Google Scholar] [CrossRef] [Green Version]
- Kornejady, A.O.M.; Rahmati, O.; Bahremand, A. Landslide susceptibility assessment using three bivariate models considering the new topo-hydrological factor: Hand. Geocarto Int. 2018, 11, 1155–1185. [Google Scholar] [CrossRef]
- Hong, H.; Pourghasemi, H.R.; Pourtaghi, Z.S. Landslide susceptibility assessment in lianhua county (china): A comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 2016, 259, 105–118. [Google Scholar] [CrossRef]
- Liu, A.; Zheng, L.; Deng, J.; Huang, Y. Landslide susceptibility of the xiangjiaba reservoir area associated with the yaziba fault. Bull. Eng. Geol. Environ. 2018, 77, 1–11. [Google Scholar] [CrossRef]
- Jaafari, A.; Najafi, A.; Pourghasemi, H.R.; Rezaeian, J.; Sattarian, A. Gis-based frequency ratio and index of entropy models for landslide susceptibility assessment in the Caspian forest, northern Iran. Int. J. Environ. Sci. Technol. 2014, 11, 909–926. [Google Scholar] [CrossRef] [Green Version]
- Skilodimou, H.; Bathrellos, G.; Koskeridou, E.; Soukis, K.; Rozos, D. Physical and anthropogenic factors related to landslide activity in the northern Peloponnese, Greece. Land 2018, 7, 85. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Fang, Z.; Wang, M.; Peng, L.; Hong, H. Comparative study of landslide susceptibility mapping with different recurrent neural networks. Comput. Geosci. 2020, 138, 104445. [Google Scholar] [CrossRef]
- Li, Y.; Chen, W. Landslide susceptibility evaluation using hybrid integration of evidential belief function and machine learning techniques. Water 2020, 12, 113. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Pradhan, B.; Sameen, M.I.; Kalantar, B.; Zhu, A.; Chen, W. Improving the accuracy of landslide susceptibility model using a novel region-partitioning approach. Landslides 2018, 15, 753–772. [Google Scholar] [CrossRef]
- Lee, J.-H.; Sameen, M.I.; Pradhan, B.; Park, H.-J. Modeling landslide susceptibility in data-scarce environments using optimized data mining and statistical methods. Geomorphology 2018, 303, 284–298. [Google Scholar] [CrossRef]
- Hong, H.; Liu, J.; Zhu, A.X. Modeling landslide susceptibility using logitboost alternating decision trees and forest by penalizing attributes with the bagging ensemble. Sci. Total Environ. 2020, 718, 137231. [Google Scholar] [CrossRef]
- Colkesen, I.; Sahin, E.K.; Kavzoglu, T. Susceptibility mapping of shallow landslides using kernel-based gaussian process, support vector machines and logistic regression. J. Afr. Earth Sci. 2016, 118, 53–64. [Google Scholar] [CrossRef]
- Chen, W.; Zhao, X.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Xue, W.; Wang, X.; Ahmad, B.B. Evaluating the usage of tree-based ensemble methods in groundwater spring potential mapping. J. Hydrol. 2020, 583, 124602. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Chen, W.; Li, Y.; Tsangaratos, P.; Shahabi, H.; Ilia, I.; Xue, W.; Bian, H. Groundwater spring potential mapping using artificial intelligence approach based on kernel logistic regression, random forest, and alternating decision tree models. Appl. Sci. 2020, 10, 425. [Google Scholar] [CrossRef] [Green Version]
- Wang, G.; Lei, X.; Chen, W.; Shahabi, H.; Shirzadi, A. Hybrid computational intelligence methods for landslide susceptibility mapping. Symmetry 2020, 12, 325. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Mason, L. The alternating decision tree learning algorithm. In Proceedings of the Sixteenth International Machine Learning Conference, Bled, Slovenia, 27–30 June 1999; Morgan Kaufmann: San Francisco, CA, USA, 2002; pp. 124–133. [Google Scholar]
- Youssef, A.M.; Pradhan, B.; Jebur, M.N.; El-Harbi, H.M. Landslide susceptibility mapping using ensemble bivariate and multivariate statistical models in Fayfa area, Saudi Arabia. Environ. Earth Sci. 2015, 73, 3745–3761. [Google Scholar] [CrossRef]
- Ciurleo, M.C.L.; Calvello, M. A comparison of statistical and deterministic methods for shallow landslide susceptibility zoning in clayey soils. Eng. Geol. 2017, 223, 71–81. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B.; et al. Modeling flood susceptibility using data-driven approaches of naïve bayes tree, alternating decision tree, and random forest methods. Sci. Total Environ. 2020, 701, 134979. [Google Scholar] [CrossRef]
- Abul Hasanat, M.H.; Ramachandram, D.; Mandava, R. Bayesian belief network learning algorithms for modeling contextual relationships in natural imagery: A comparative study. Artif. Intell. Rev. 2010, 34, 291–308. [Google Scholar] [CrossRef]
- Bai, S.-B.; Wang, J.; Lü, G.-N.; Zhou, P.-G.; Hou, S.-S.; Xu, S.-N. Gis-based logistic regression for landslide susceptibility mapping of the zhongxian segment in the three Gorges area, China. Geomorphology 2010, 115, 23–31. [Google Scholar] [CrossRef]
- Pradhan, B.; Lee, S. Delineation of landslide hazard areas on penang island, malaysia, by using frequency ratio, logistic regression, and artificial neural network models. Environ. Earth Sci. 2010, 60, 1037–1054. [Google Scholar] [CrossRef]
- Tsangaratos, P.; Benardos, A. Estimating landslide susceptibility through a artificial neural network classifier. Nat. Hazards 2014, 74, 1489–1516. [Google Scholar] [CrossRef]
- Arabameri, A.; Pourghasemi, H.R.; Yamani, M. Applying different scenarios for landslide spatial modeling using computational intelligence methods. Environ. Earth Sci. 2017, 76, 832. [Google Scholar] [CrossRef]
- Omid, G.; Thomas, B.; Jagannath, A.; Khalil, G. A new gis-based technique using an adaptive neuro-fuzzy inference system for land subsidence susceptibility mapping. J. Spat. Sci. 2018, 94, 1–18. [Google Scholar]
- Roy, D.P.; Jin, Y.; Lewis, P.E.; Justice, C.O. Prototyping a global algorithm for systematic fire-affected area mapping using modis time series data. Remote Sens. Environ. 2005, 97, 137–162. [Google Scholar] [CrossRef]
- Lee, S.; Jun, C.H. Fast incremental learning of logistic model tree using least angle regression. Expert Syst. Appl. 2017, 97, 137–145. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Landslide Conditioning Factor | Collinearity Statistics | |
|---|---|---|
| Tolerance | VIF | |
| Distance to rivers | 0.951 | 1.052 |
| Slope aspect | 0.936 | 1.069 |
| Distance to faults | 0.907 | 1.103 |
| Rainfall | 0.903 | 1.108 |
| Profile curvature | 0.896 | 1.116 |
| Land use | 0.886 | 1.129 |
| Plan curvature | 0.871 | 1.148 |
| Geological age groups | 0.863 | 1.158 |
| Distance to roads | 0.855 | 1.169 |
| NDVI | 0.845 | 1.183 |
| Slope angle | 0.84 | 1.19 |
| Soil | 0.804 | 1.244 |
| TWI | 0.769 | 1.300 |
| Altitude | 0.767 | 1.304 |
| STI | 0.536 | 1.867 |
| SPI | 0.464 | 2.157 |
| numBoostingIterations | splitOnResiduals | useAIC | |
|---|---|---|---|
| line1 | [−1, 30] | FALSE | FALSE |
| line2 | [−1, 30] | FALSE | TRUE |
| line3 | [−1, 30] | TRUE | FALSE |
| line4 | [−1, 30] | TRUE | TRUE |
| Selected parameters | 0 | TRUE | TRUE |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, X.; Chen, W. Optimization of Computational Intelligence Models for Landslide Susceptibility Evaluation. Remote Sens. 2020, 12, 2180. https://doi.org/10.3390/rs12142180
Zhao X, Chen W. Optimization of Computational Intelligence Models for Landslide Susceptibility Evaluation. Remote Sensing. 2020; 12(14):2180. https://doi.org/10.3390/rs12142180
Chicago/Turabian StyleZhao, Xia, and Wei Chen. 2020. "Optimization of Computational Intelligence Models for Landslide Susceptibility Evaluation" Remote Sensing 12, no. 14: 2180. https://doi.org/10.3390/rs12142180
APA StyleZhao, X., & Chen, W. (2020). Optimization of Computational Intelligence Models for Landslide Susceptibility Evaluation. Remote Sensing, 12(14), 2180. https://doi.org/10.3390/rs12142180