Detection of Insect Damage in Green Coffee Beans Using VIS-NIR Hyperspectral Imaging


Abstract
:
1. Introduction
2. Materials and Methods
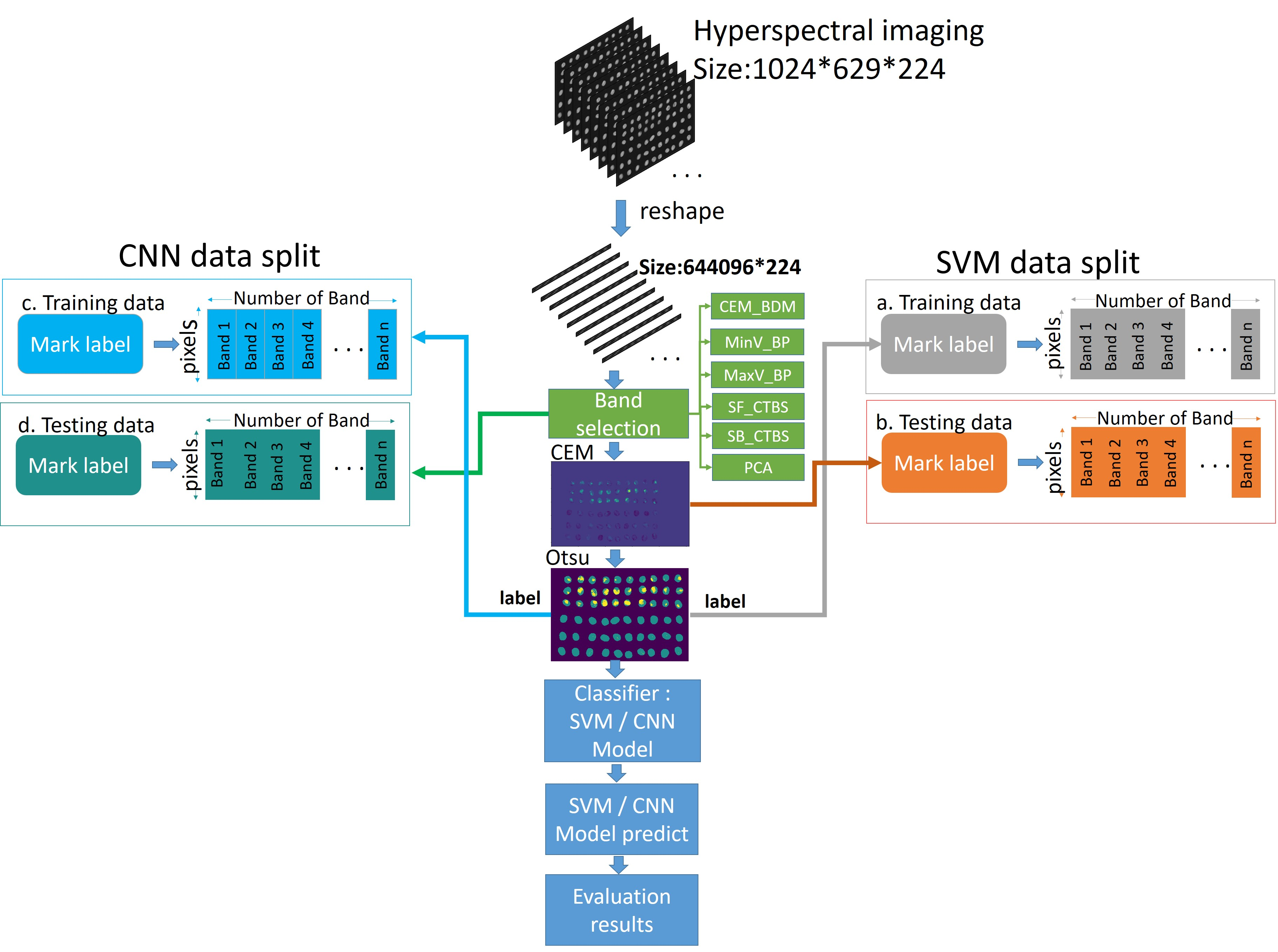
2.1. Hyperspectral Imaging System and Data Collection
2.2. Coffee Bean Samples
- Healthy beans: The entire post-processed bean should appear free of defects. The color of the beans should be blue-green, light green, or yellow-green, as shown in Figure 4a.
- Insect damaged beans: The insect damaged bean shown in Figure 4c is a result of coffee cherry bugs laying eggs on a coffee tree and the hatched larvae biting the coffee drupes to form wormholes. This type of defective bean produces a turbid odor or strange taste in coffee.
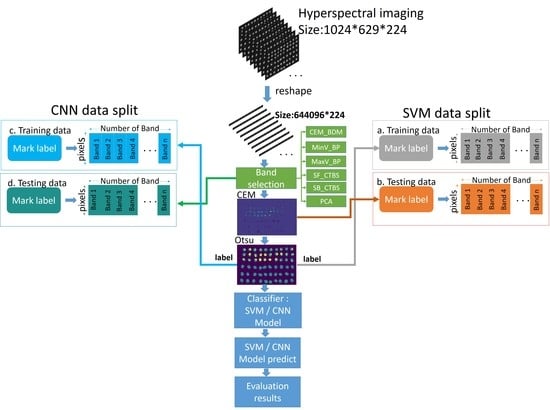
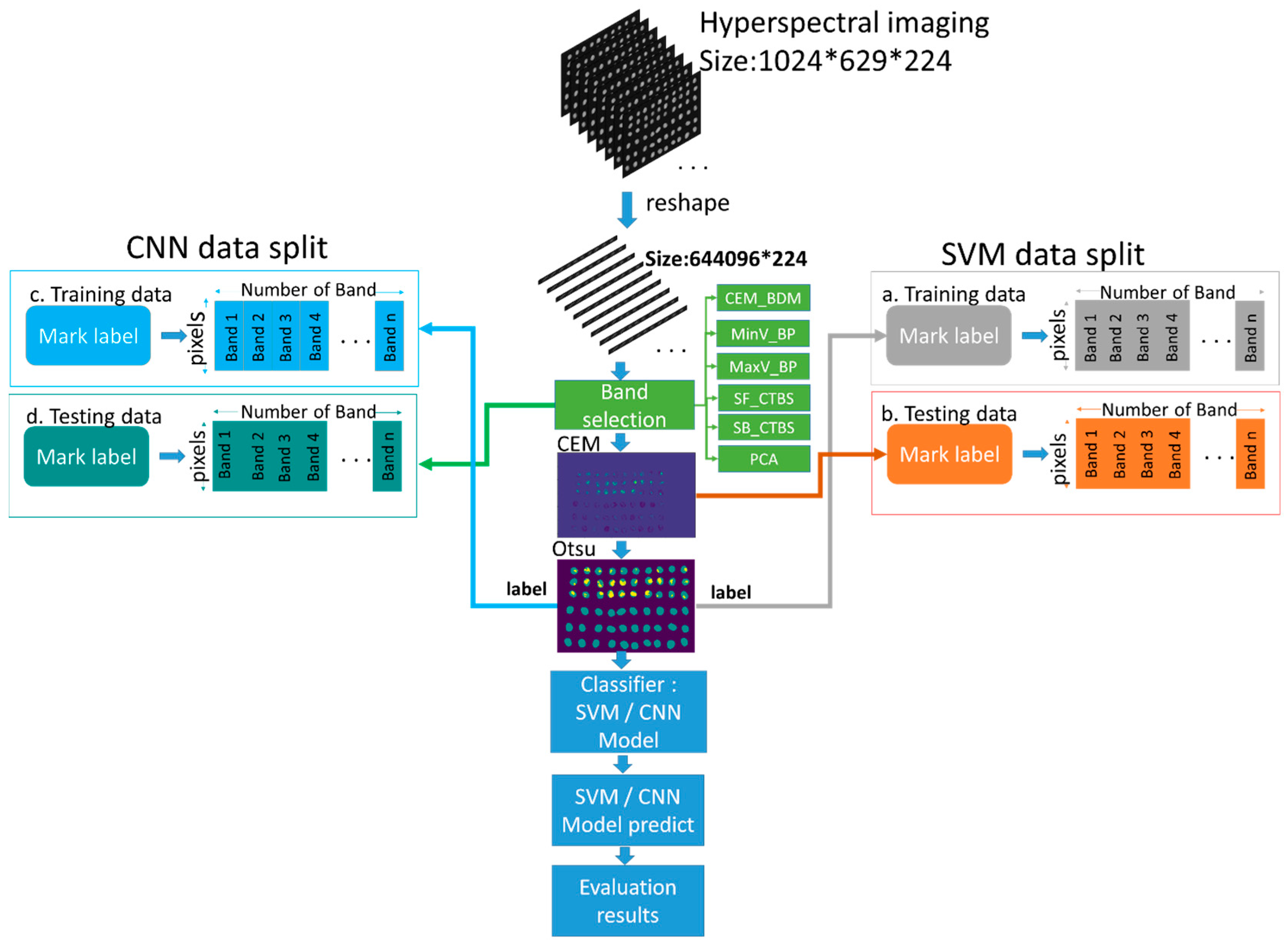
2.3. Hyperspectral Band Selection
2.3.1. Constrained Energy Minimization (CEM)
2.3.2. Constrained Energy Minimization-Constrained Band Dependence Minimization (CEM-BDM)
2.3.3. Minimum Variance Band Prioritization (MinV-BP)
2.3.4. Maximum Variance Band Prioritization (MaxV-BP)
2.3.5. Sequential Forward-Constrained-Target Band Selection (SF-CTBS)
2.3.6. Sequential Backward-Target Band Selection (SB-CTBS)
2.3.7. Principal Component Analysis (PCA)
2.4. Optimal Signature Generation Process
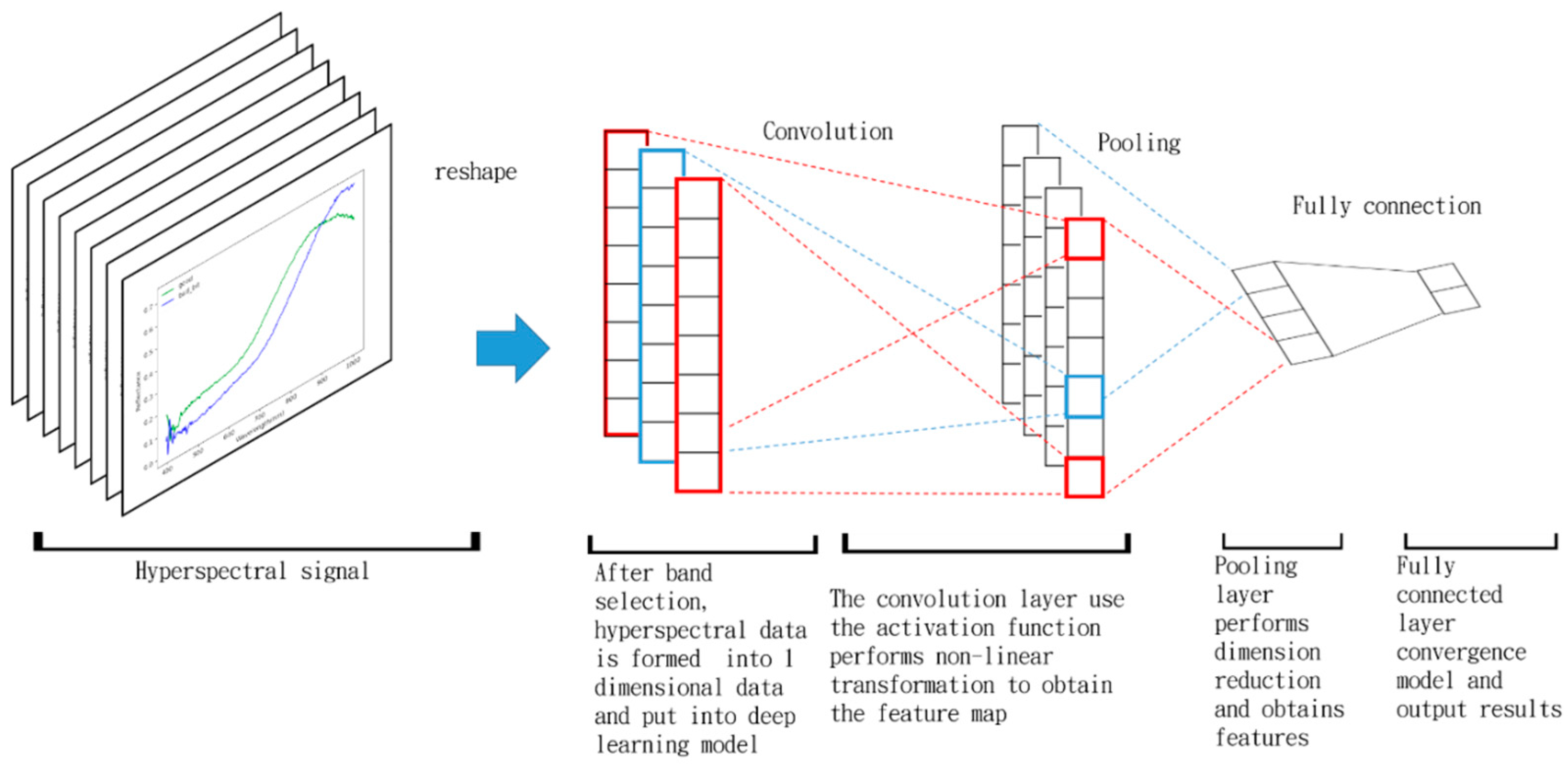
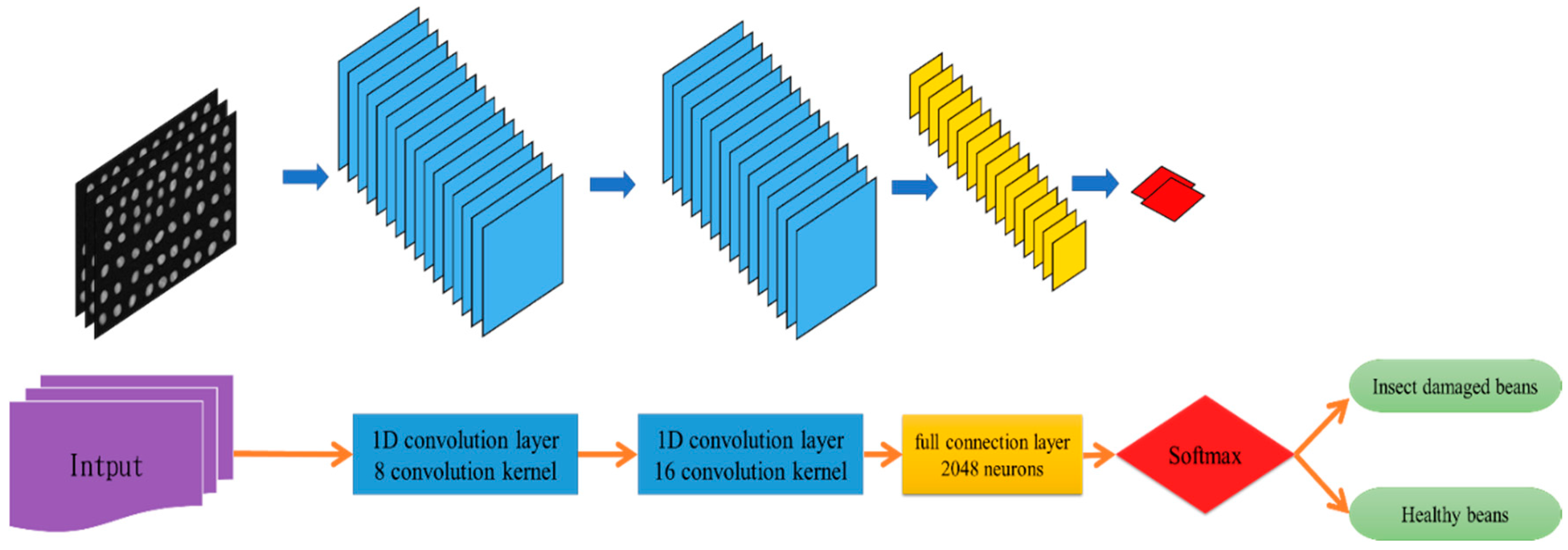
2.5. Convolutional Neural Networks (CNN)
2.6. Hyperspectral Insect Damage Detection Algorithm (HIDDA)
3. Results and Discussion
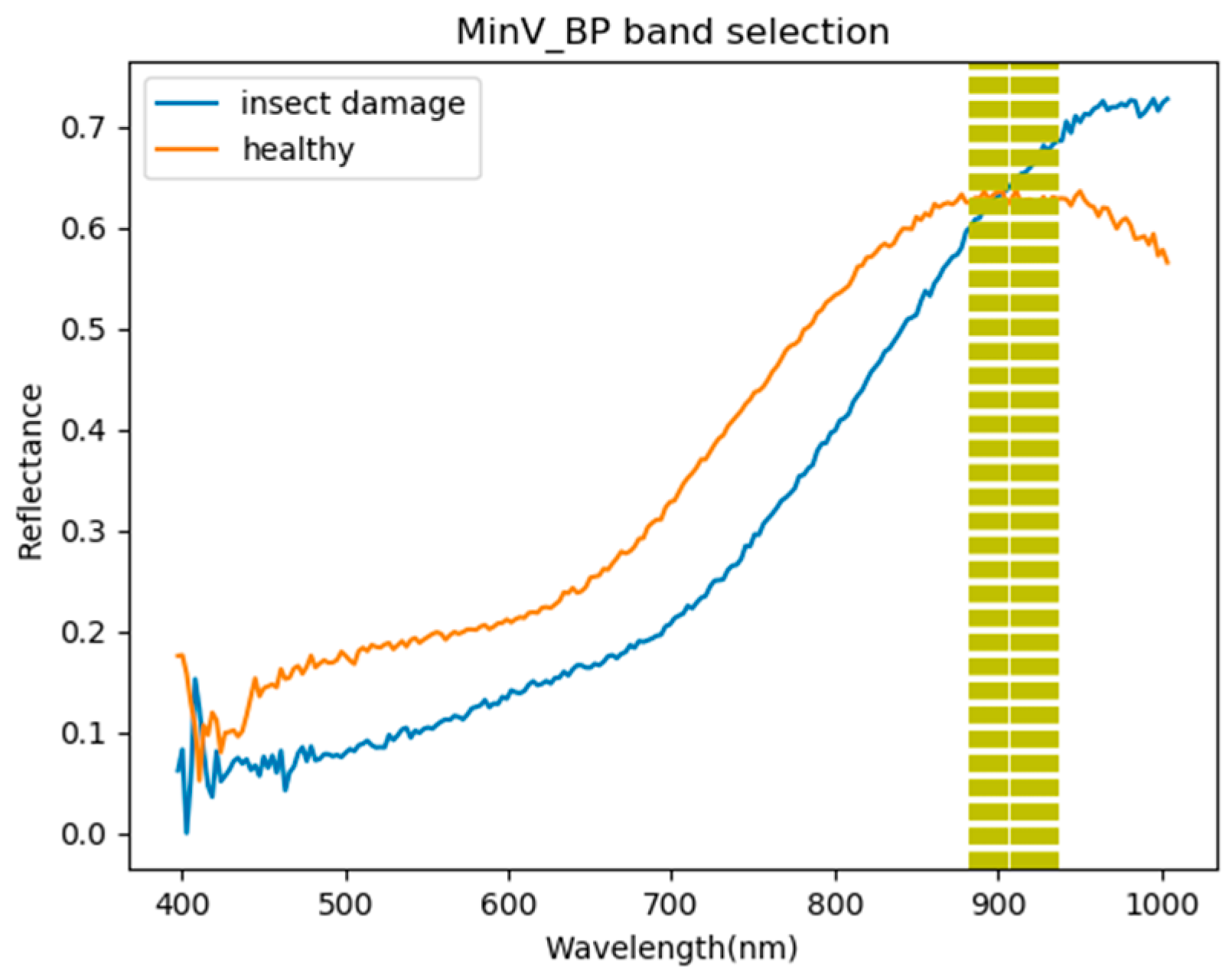
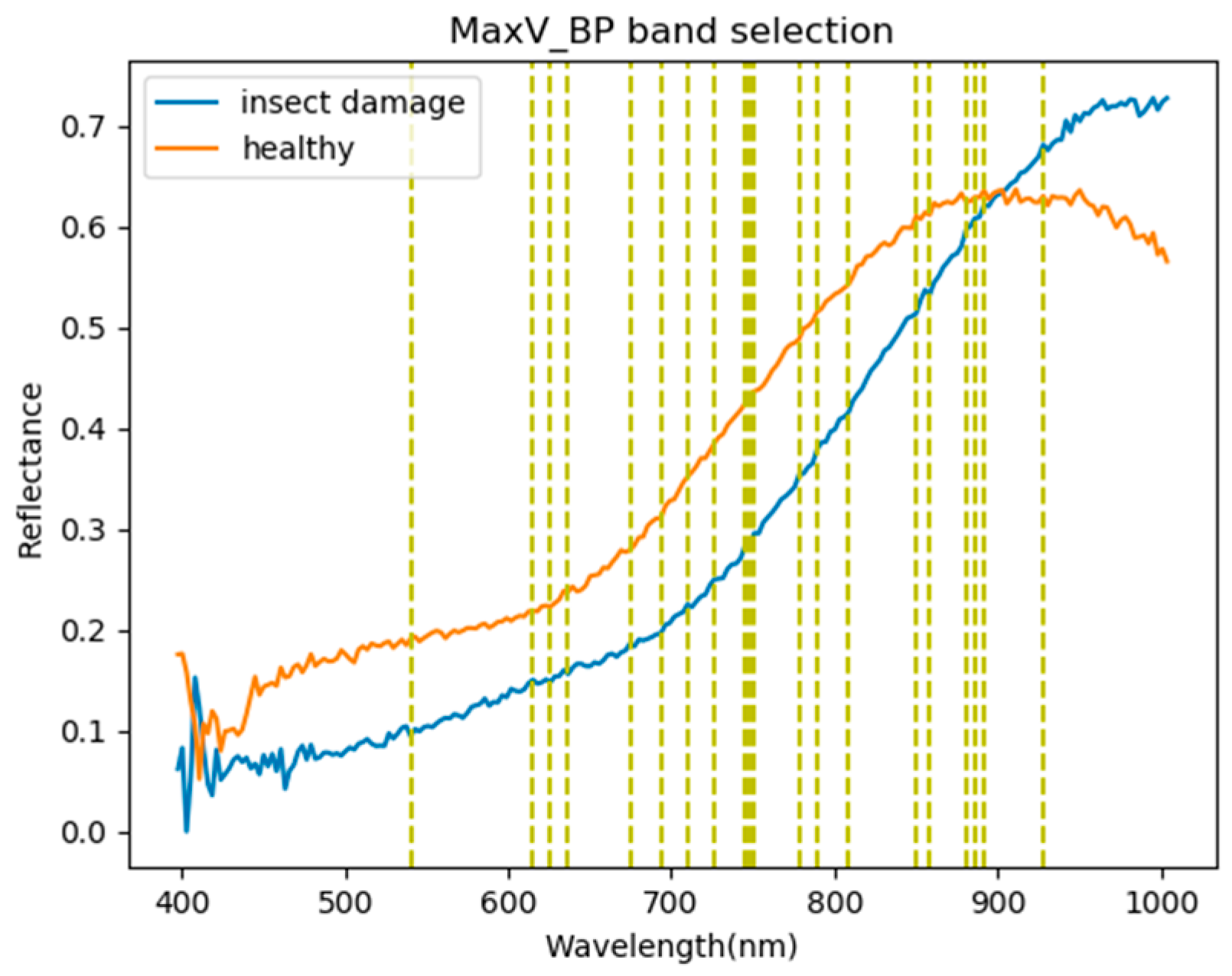
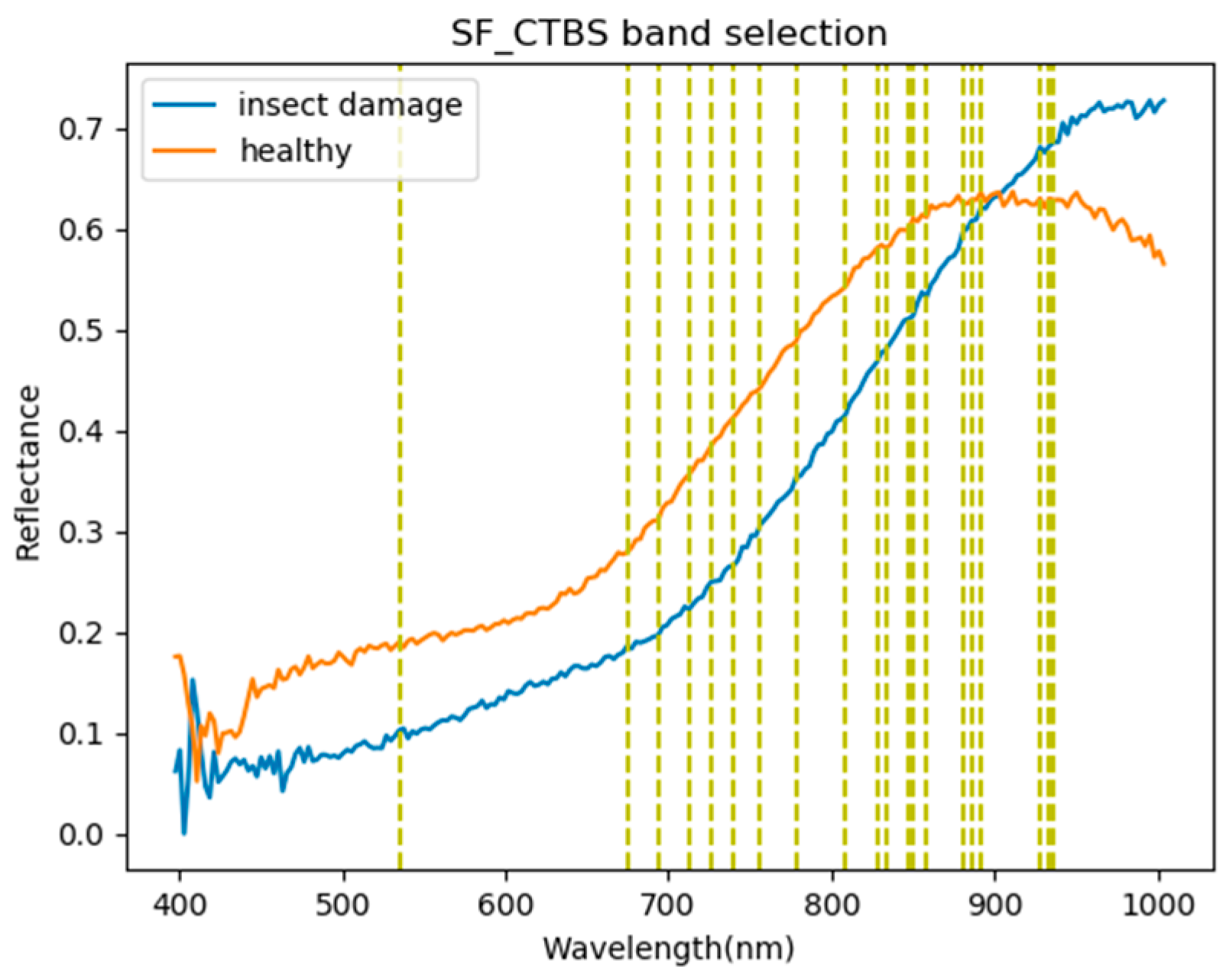
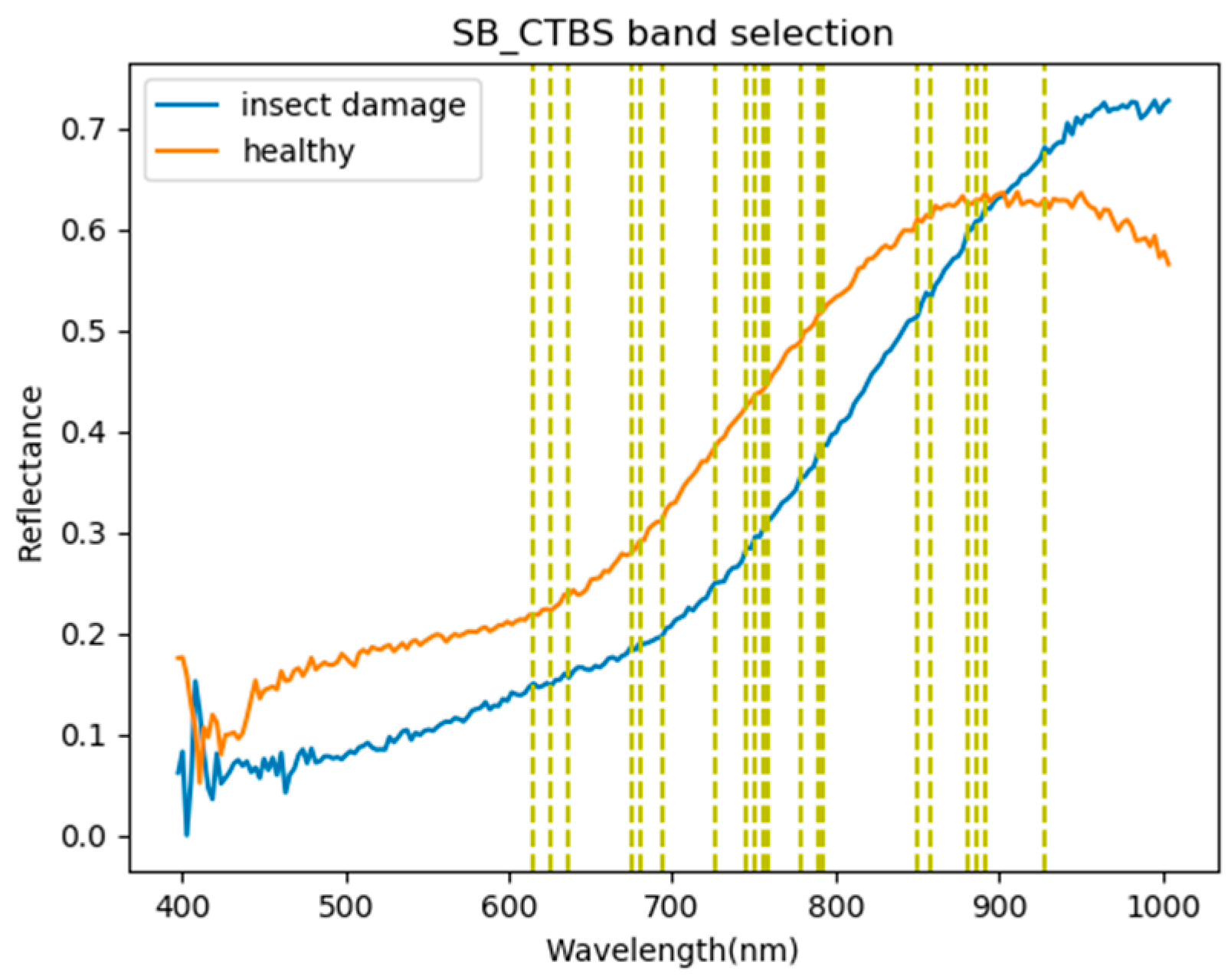
3.1. Band Selection Results
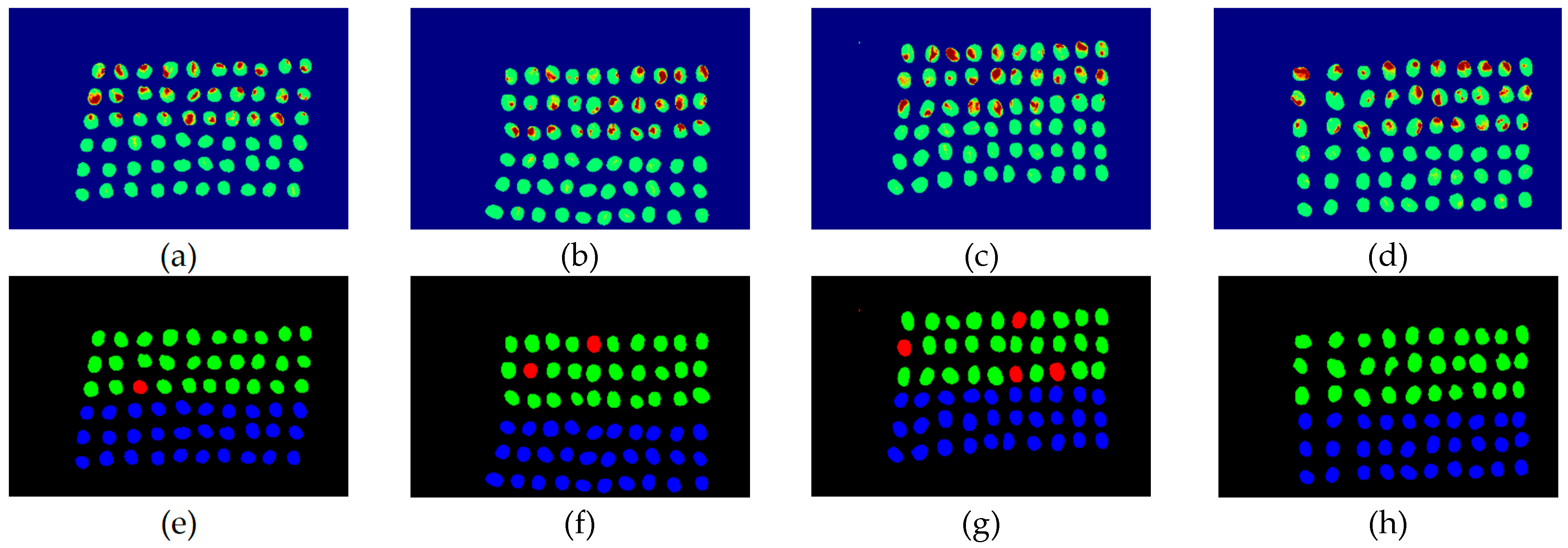
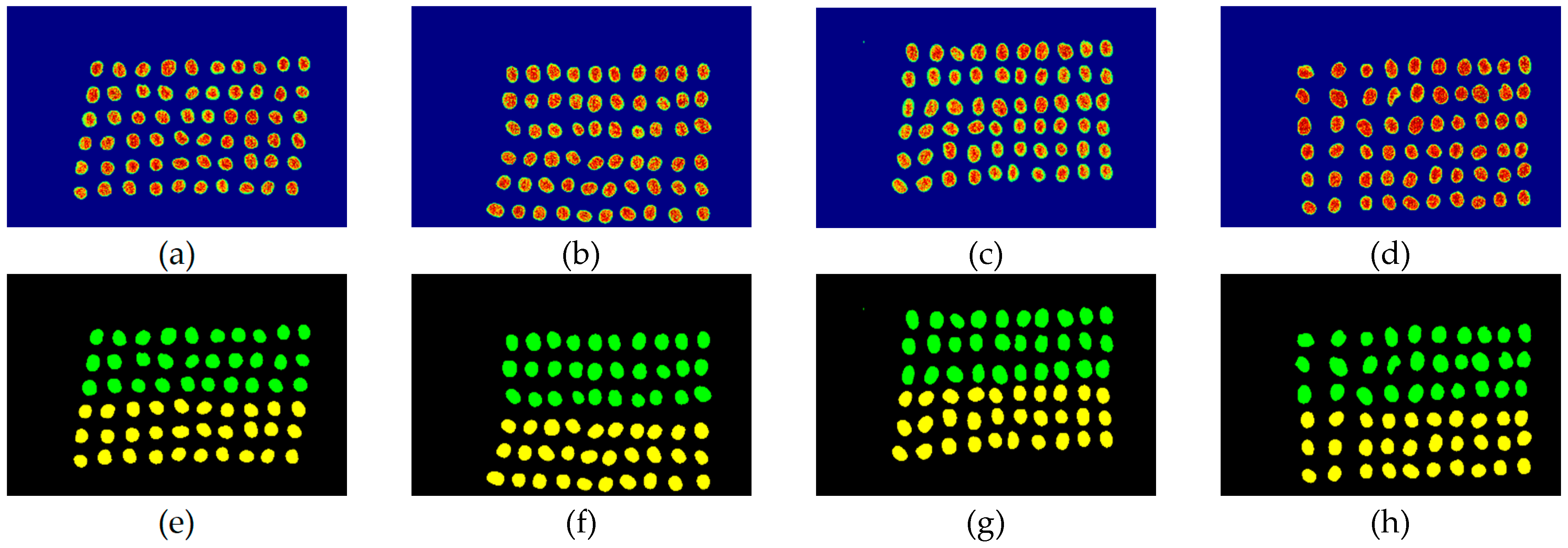
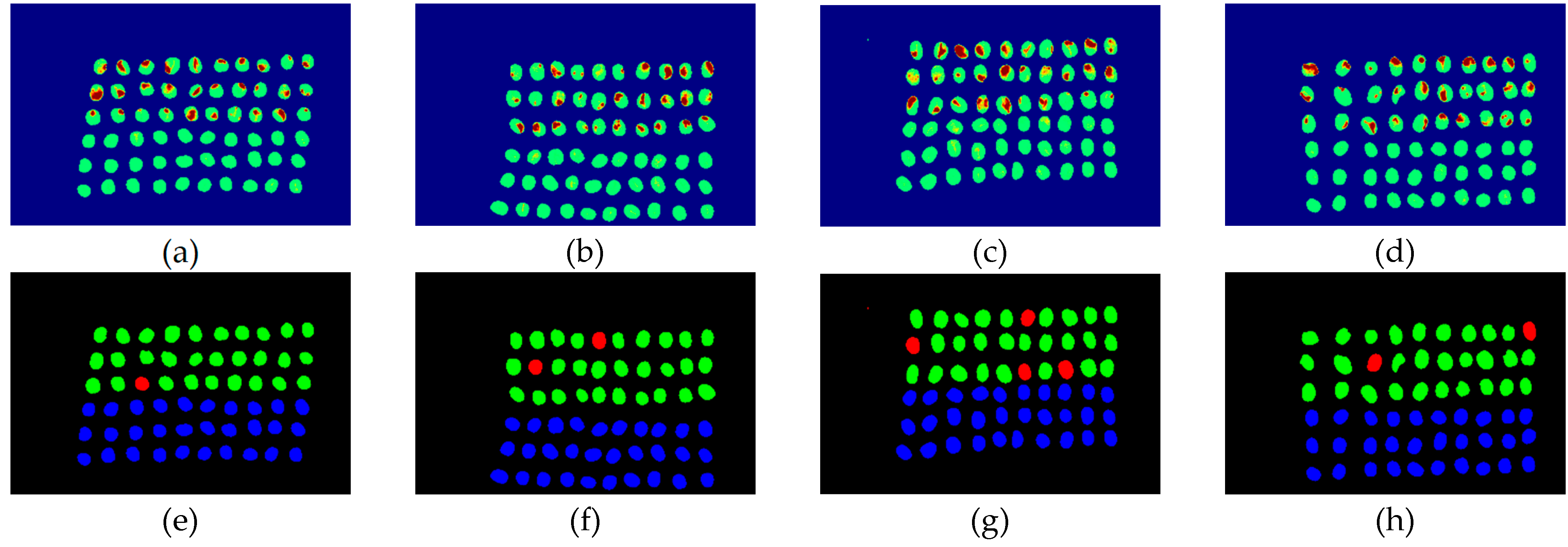
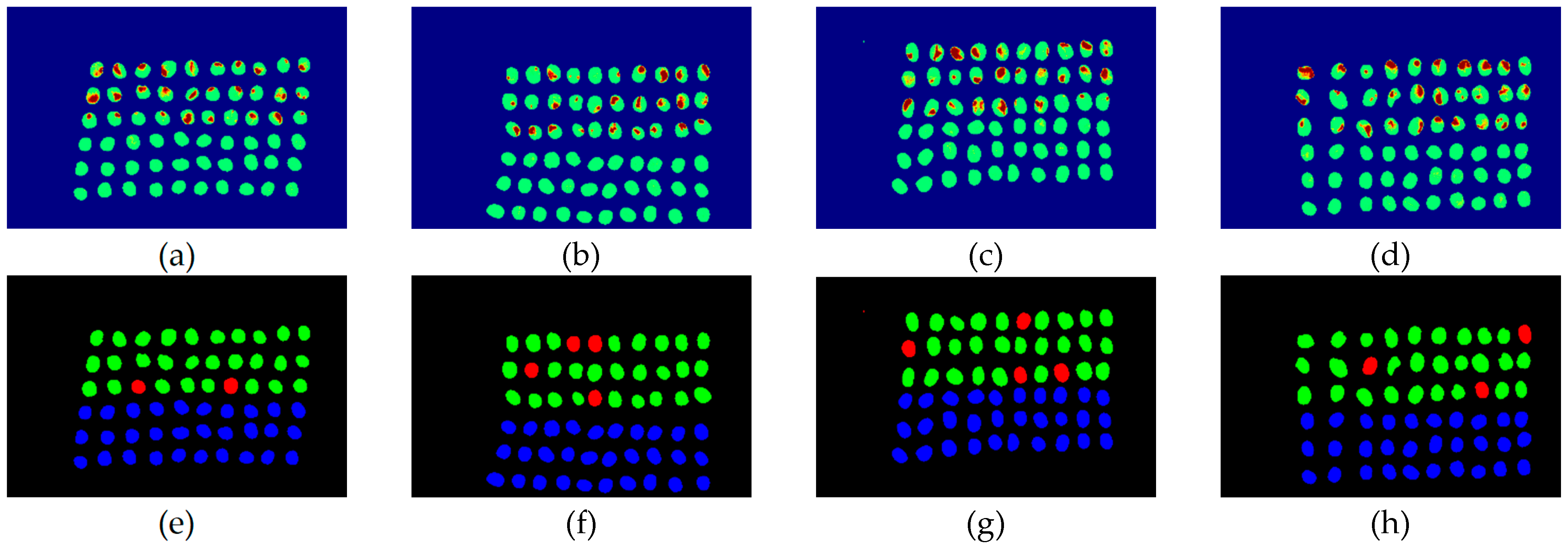
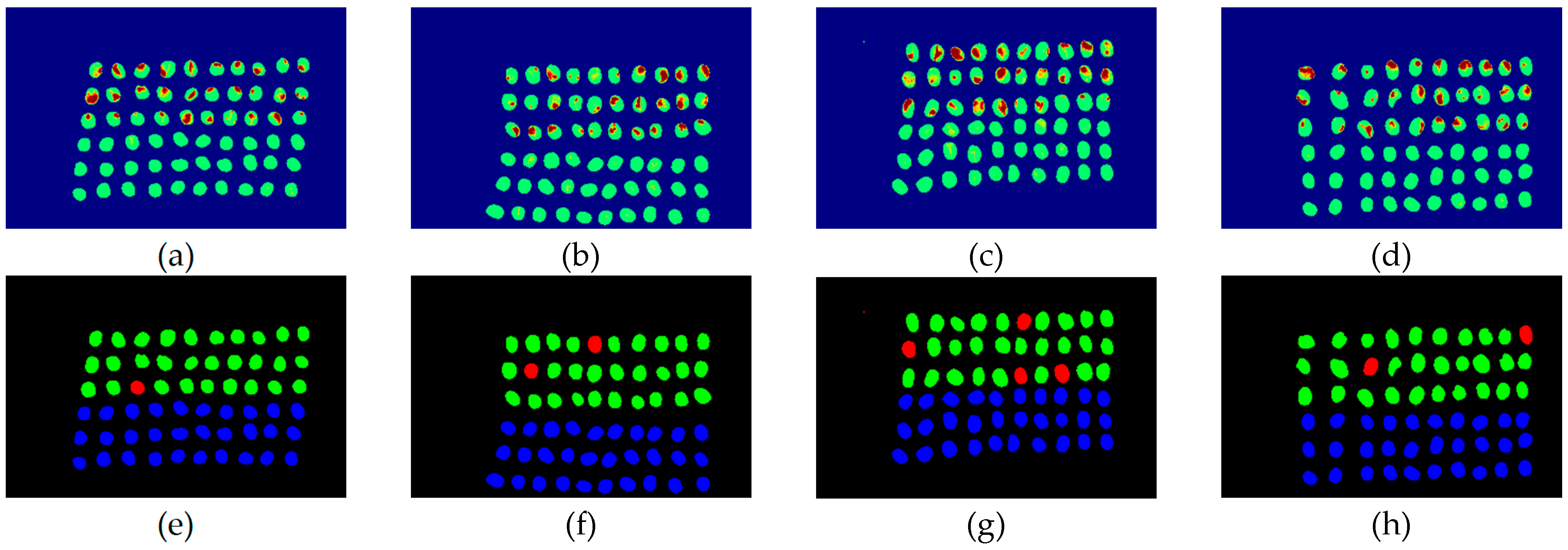
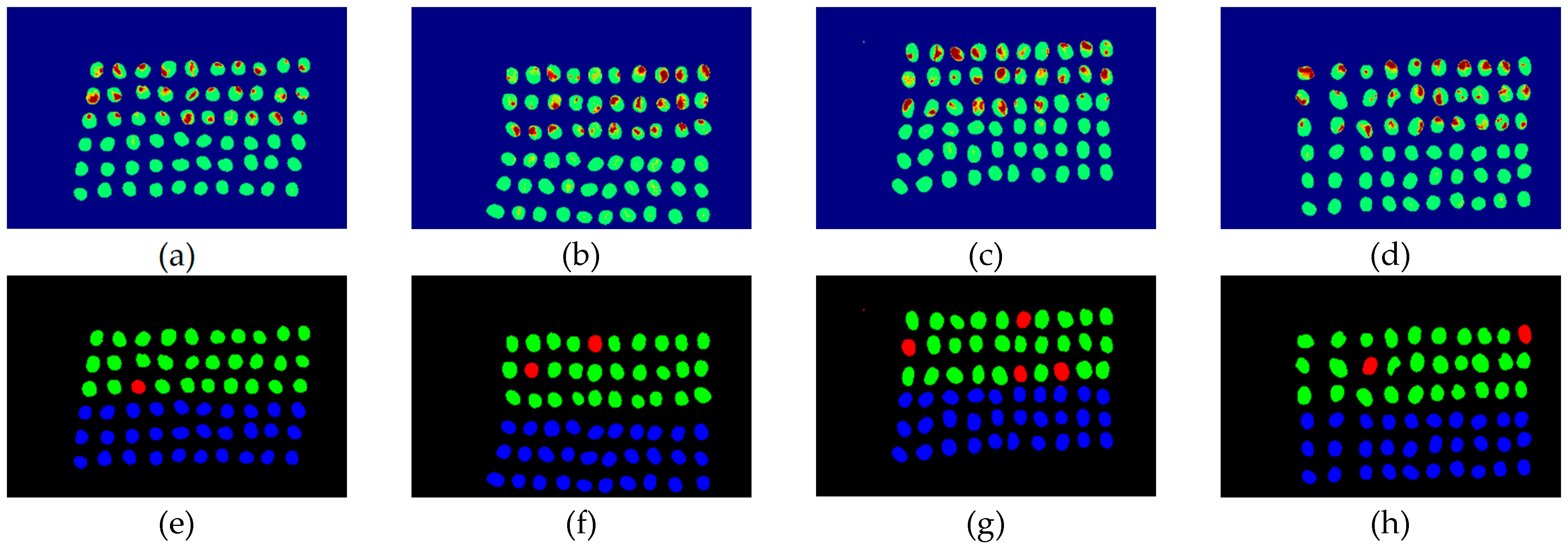
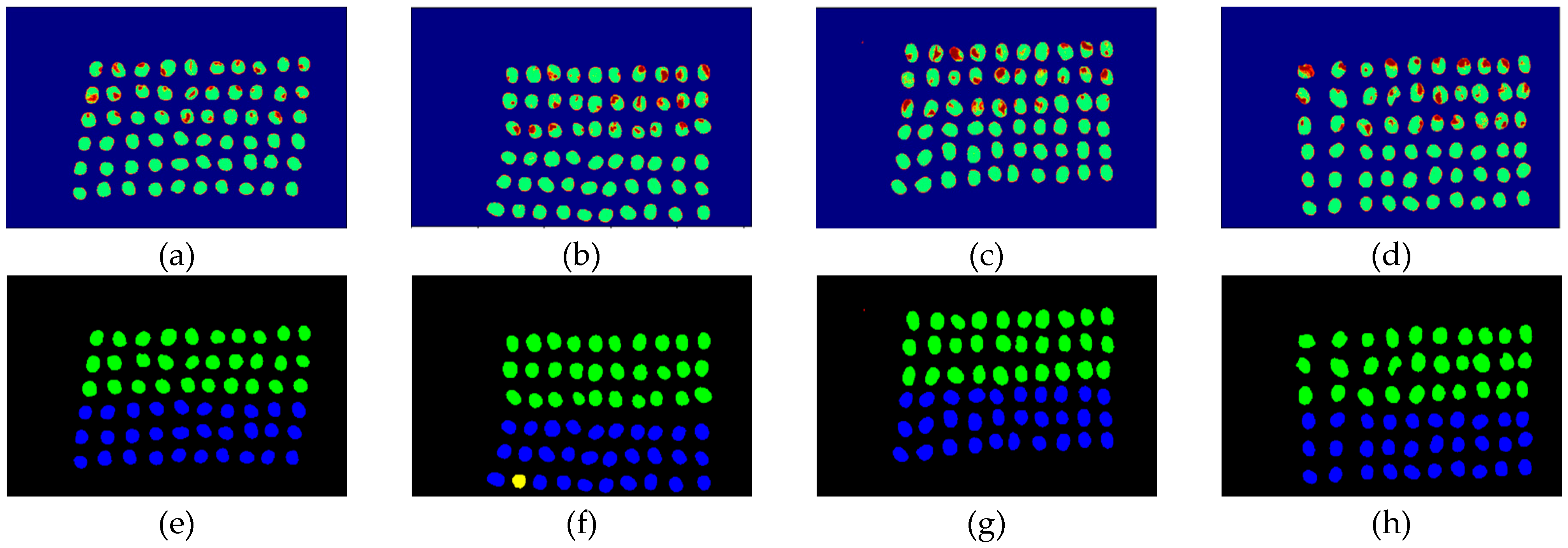
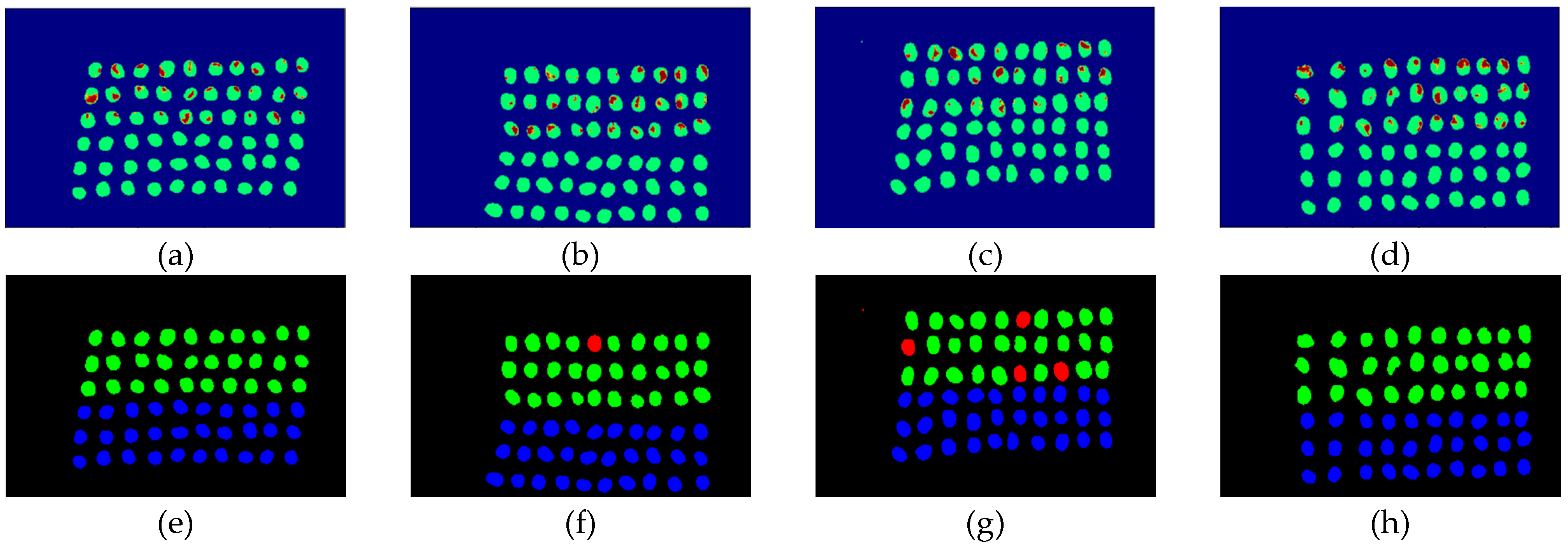
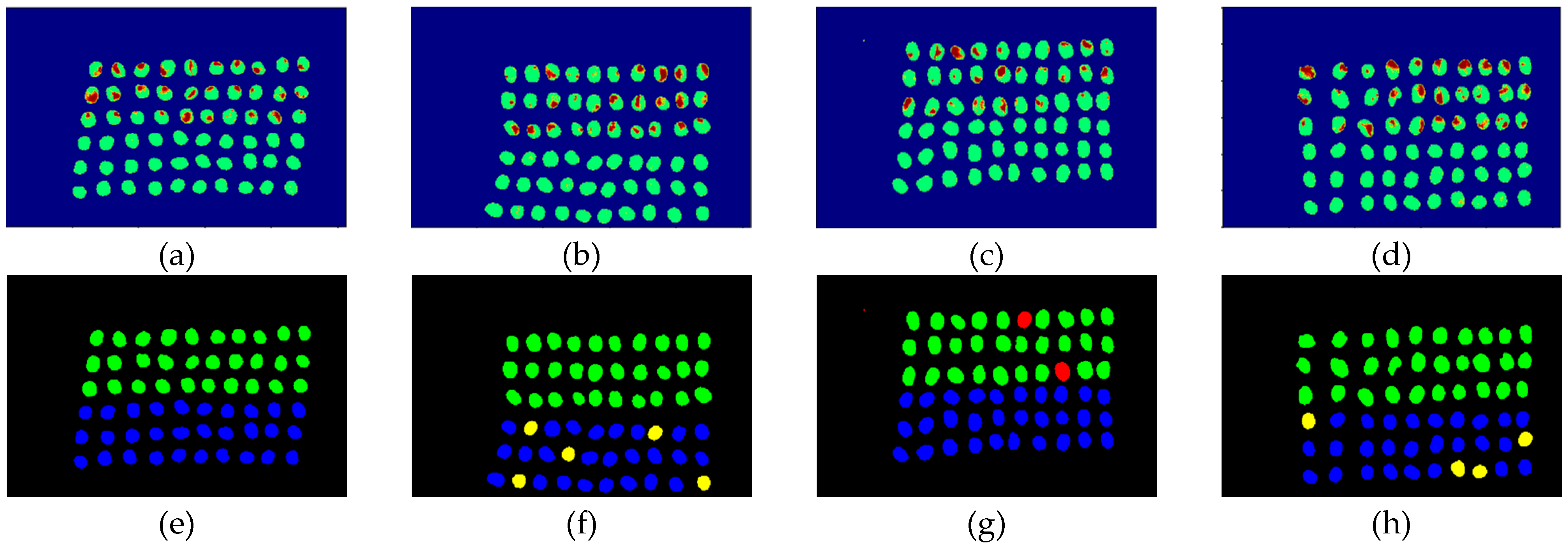
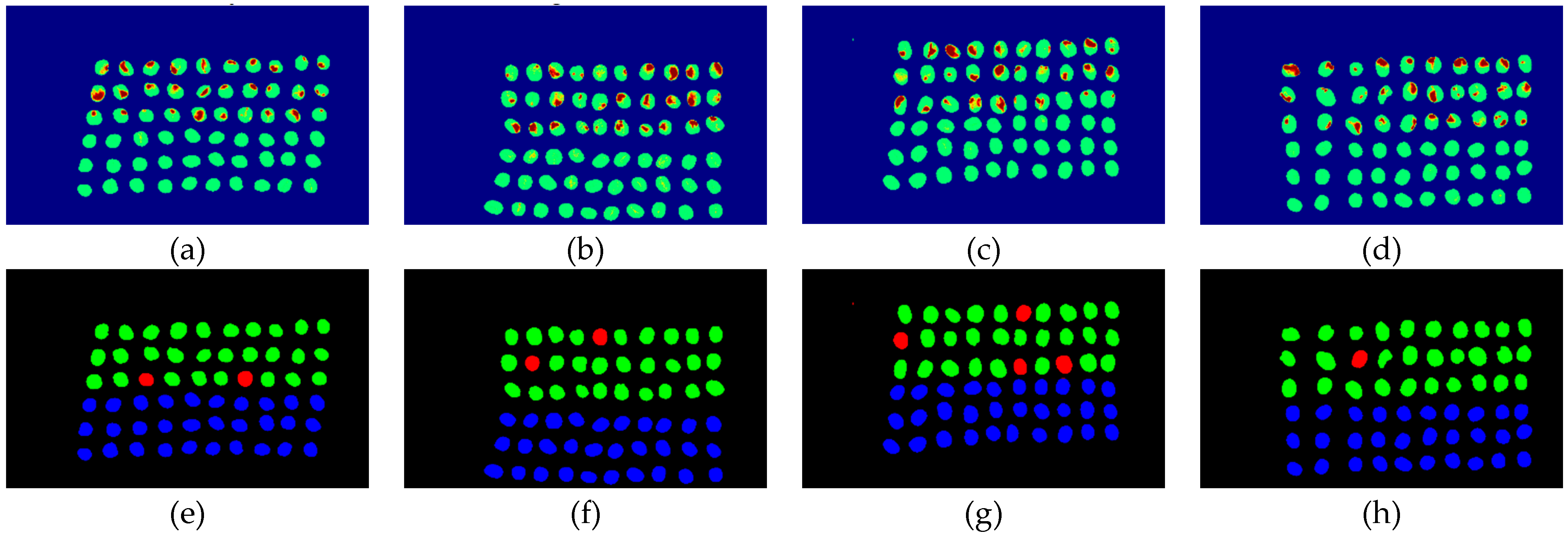
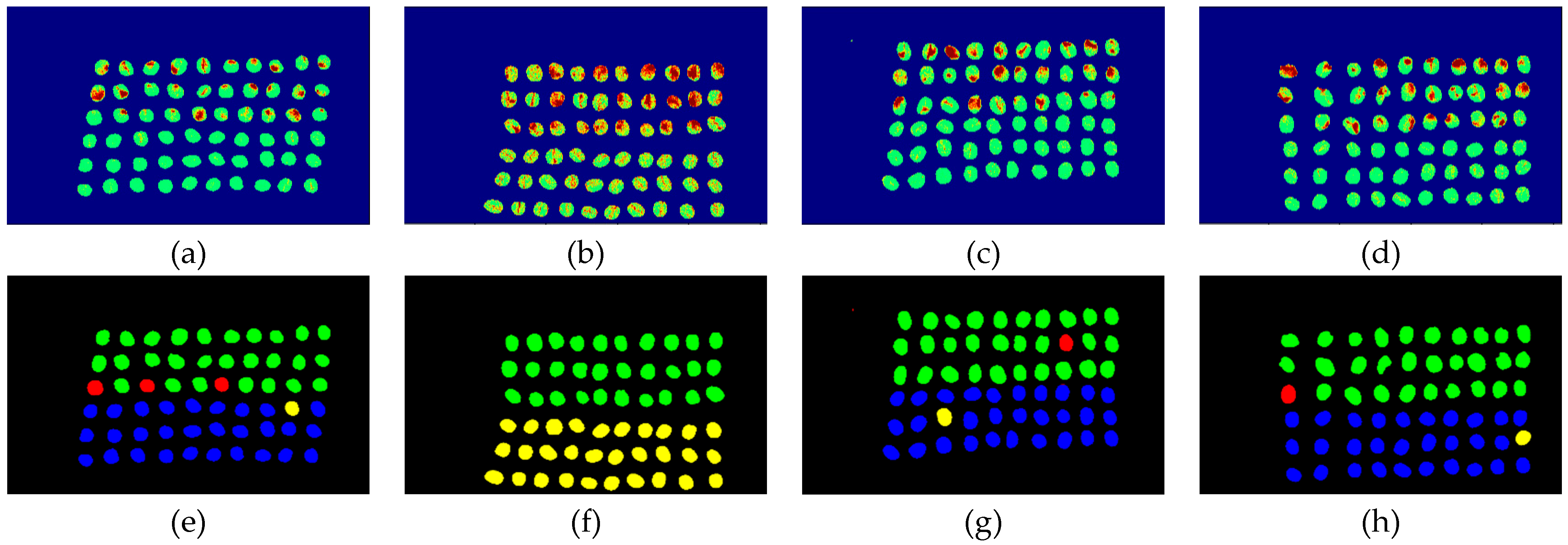
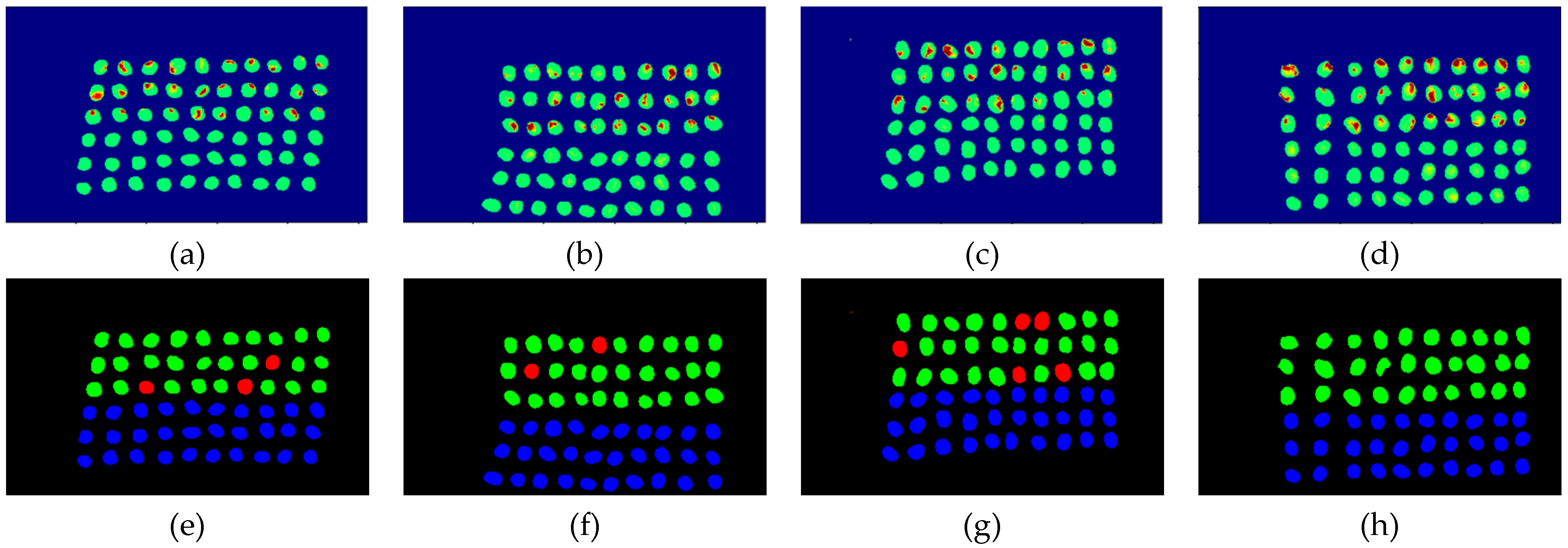
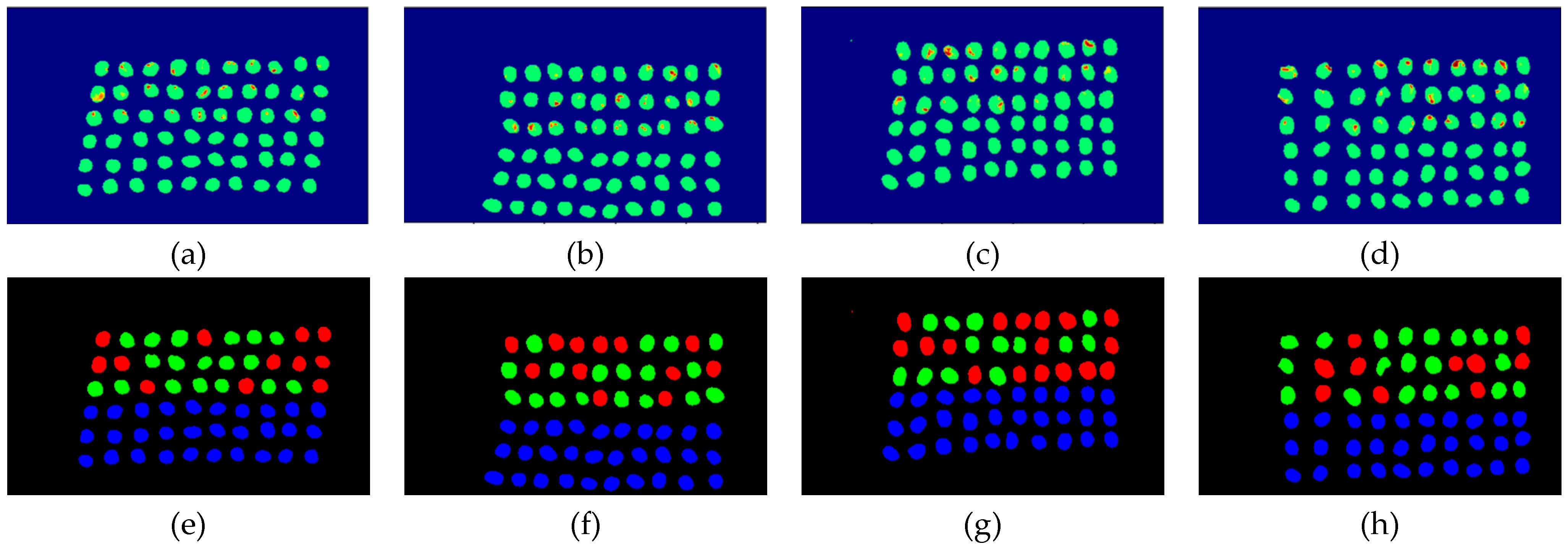
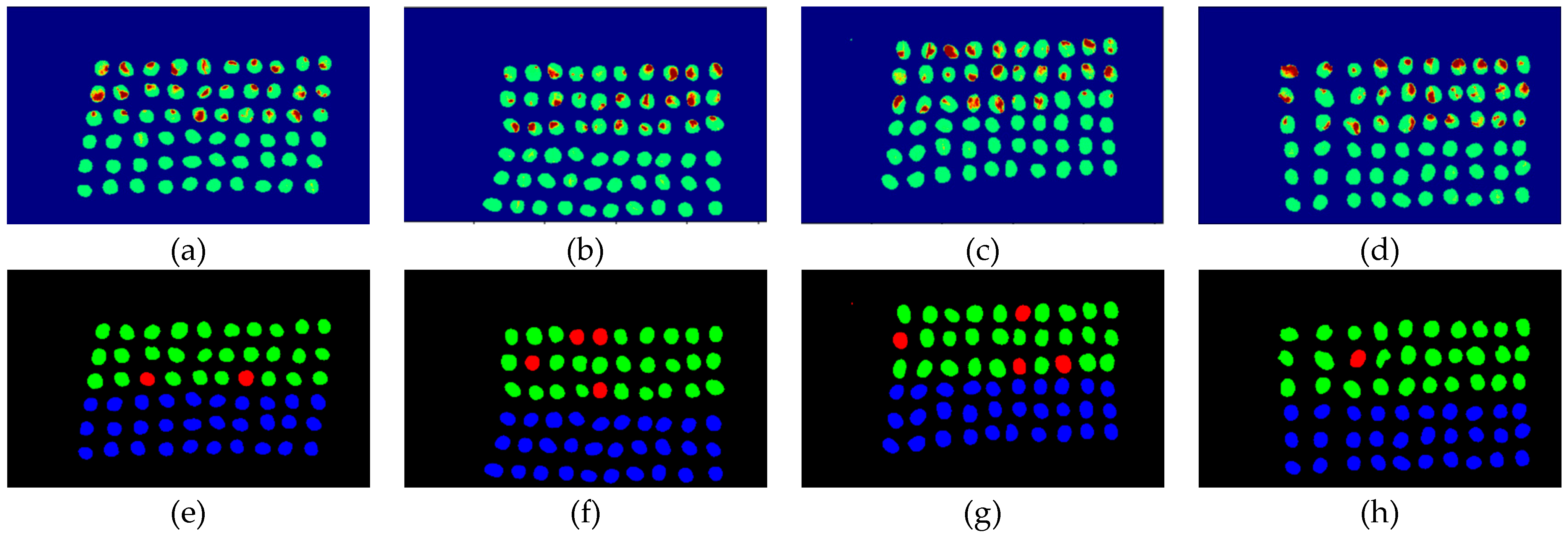
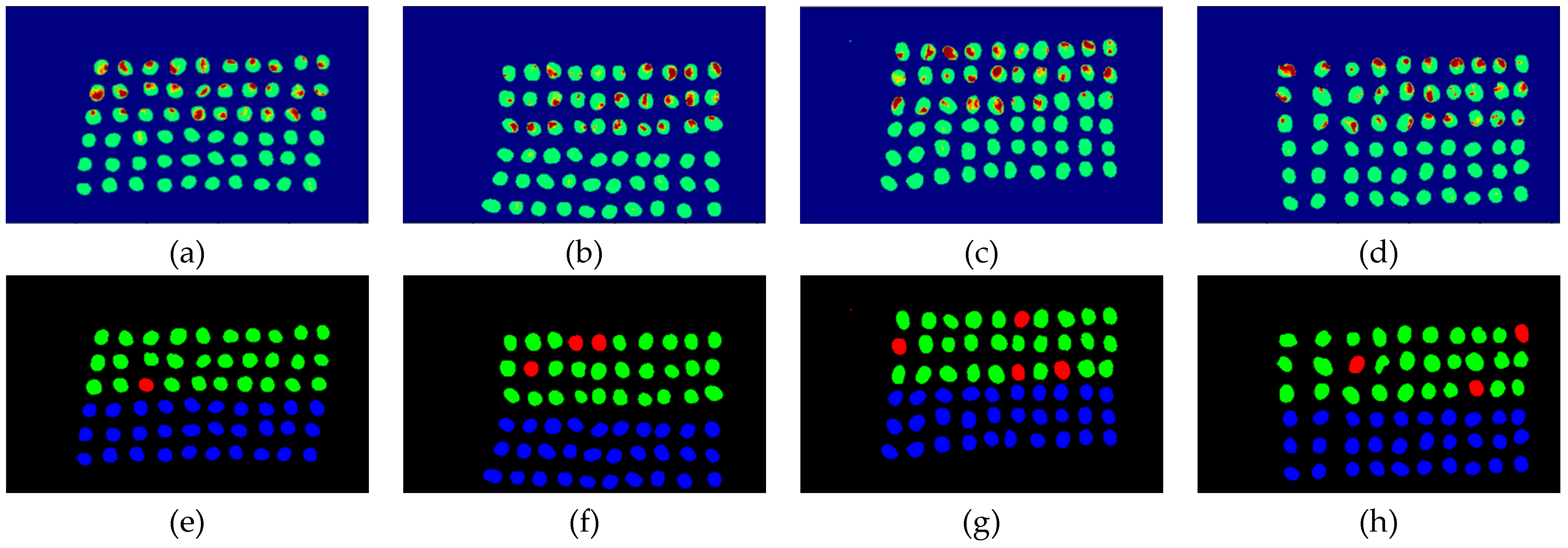
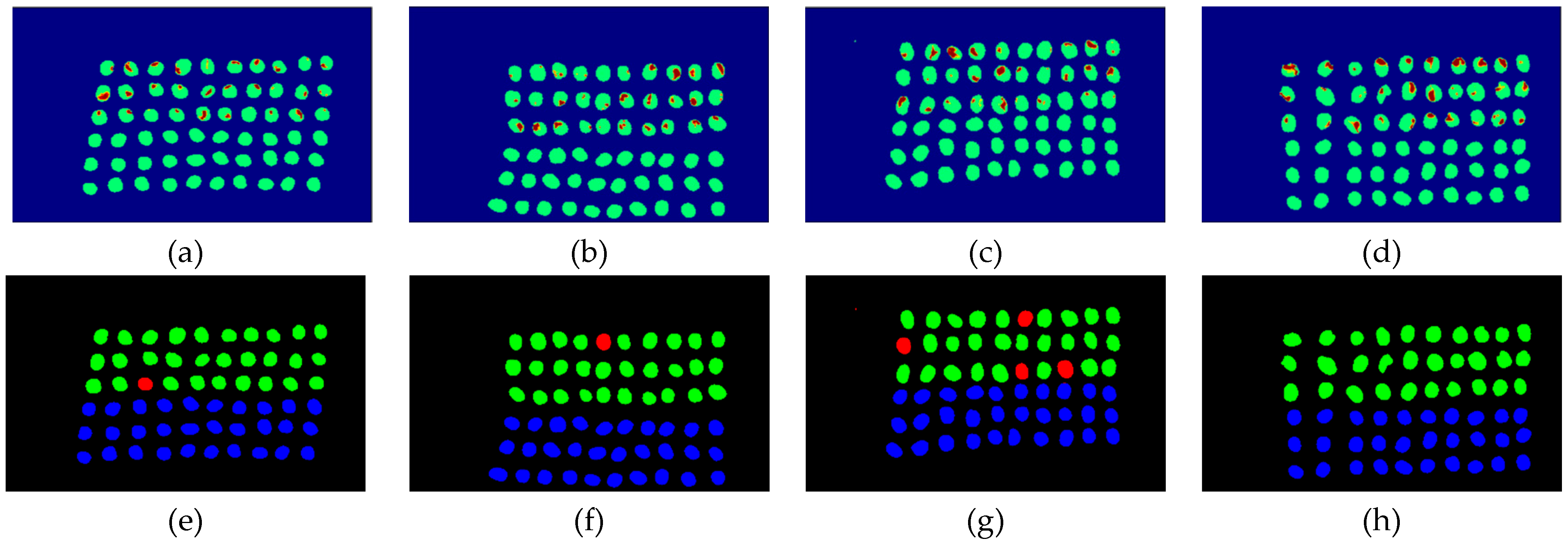
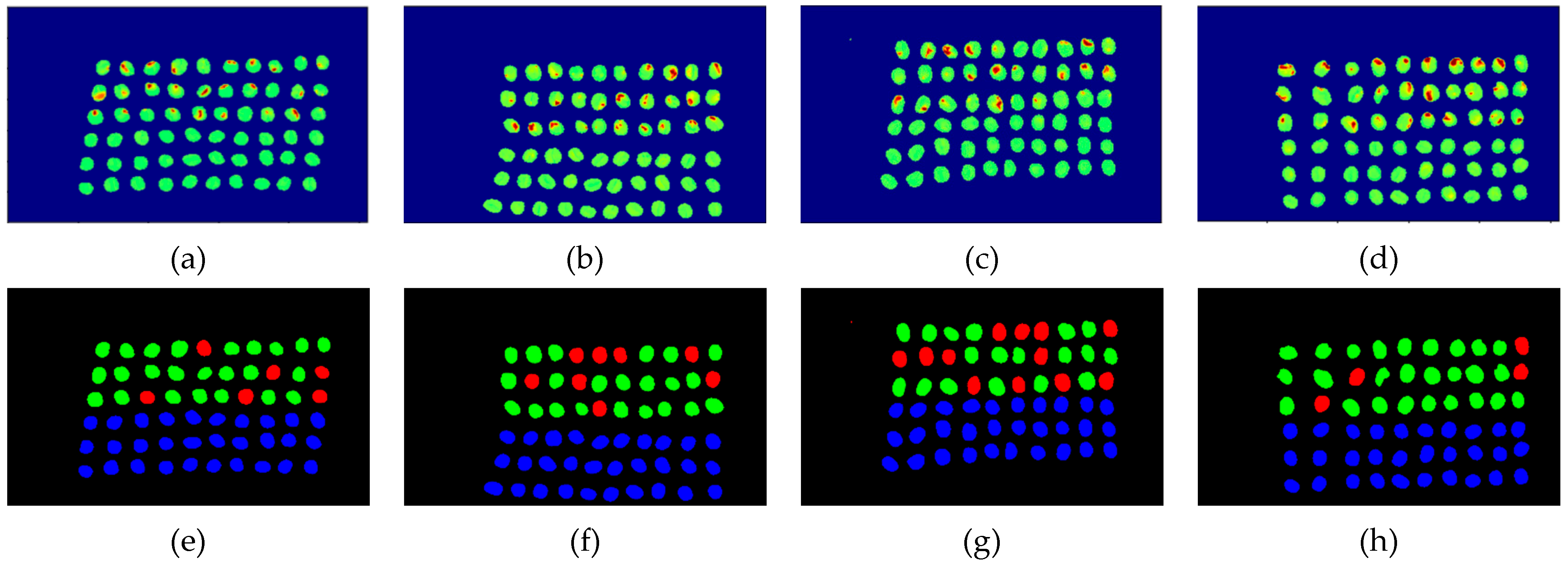
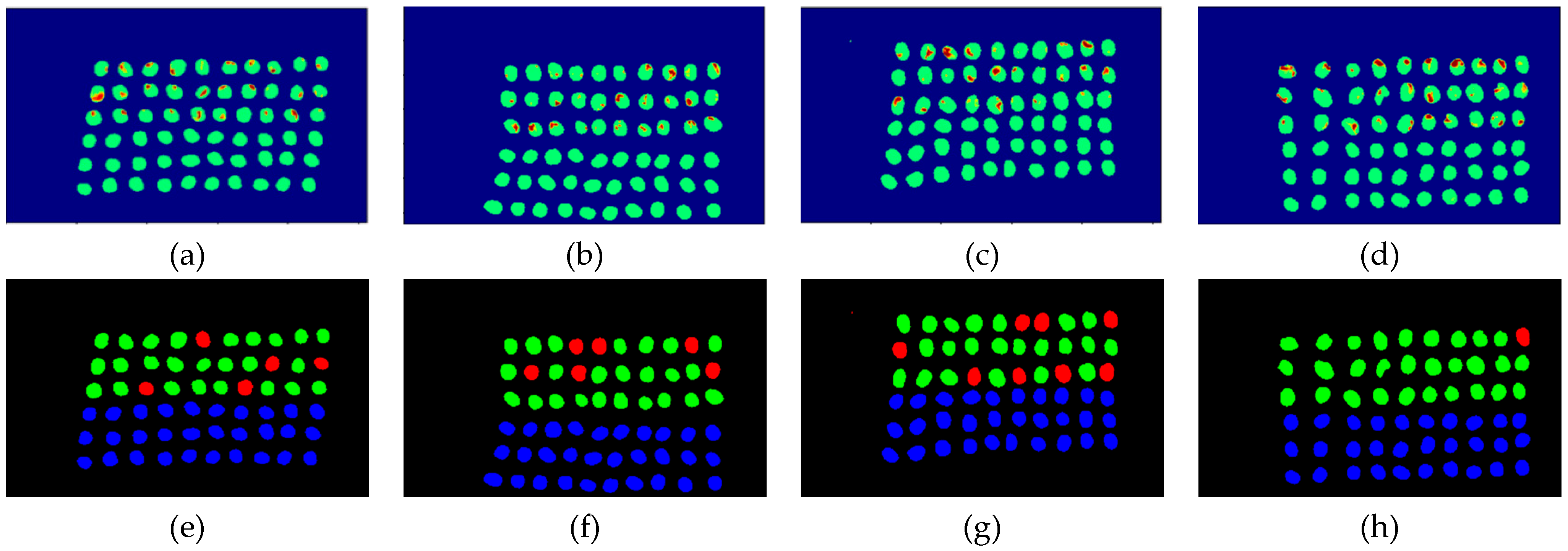
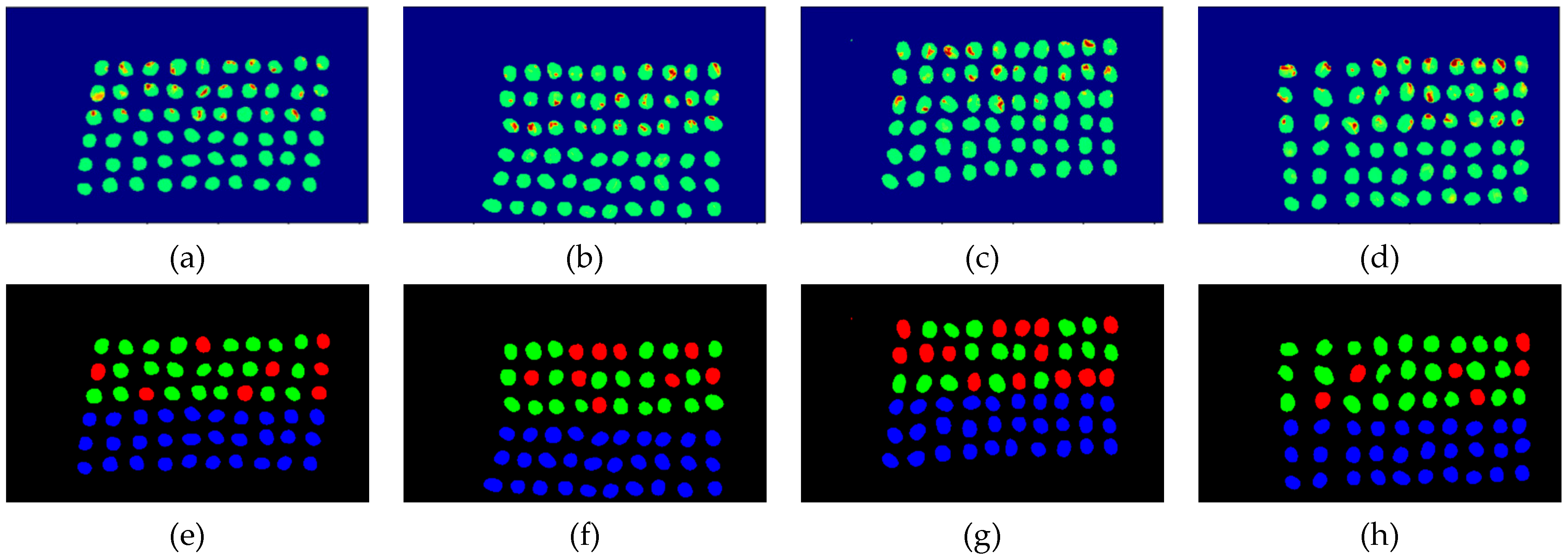
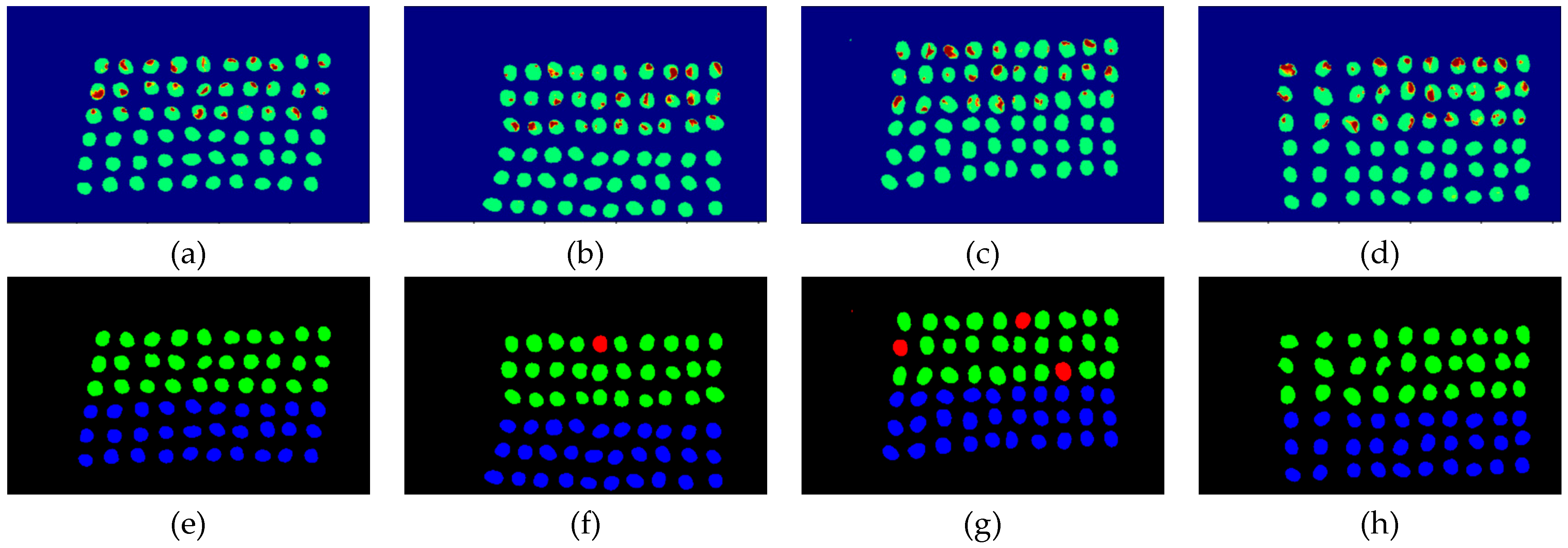
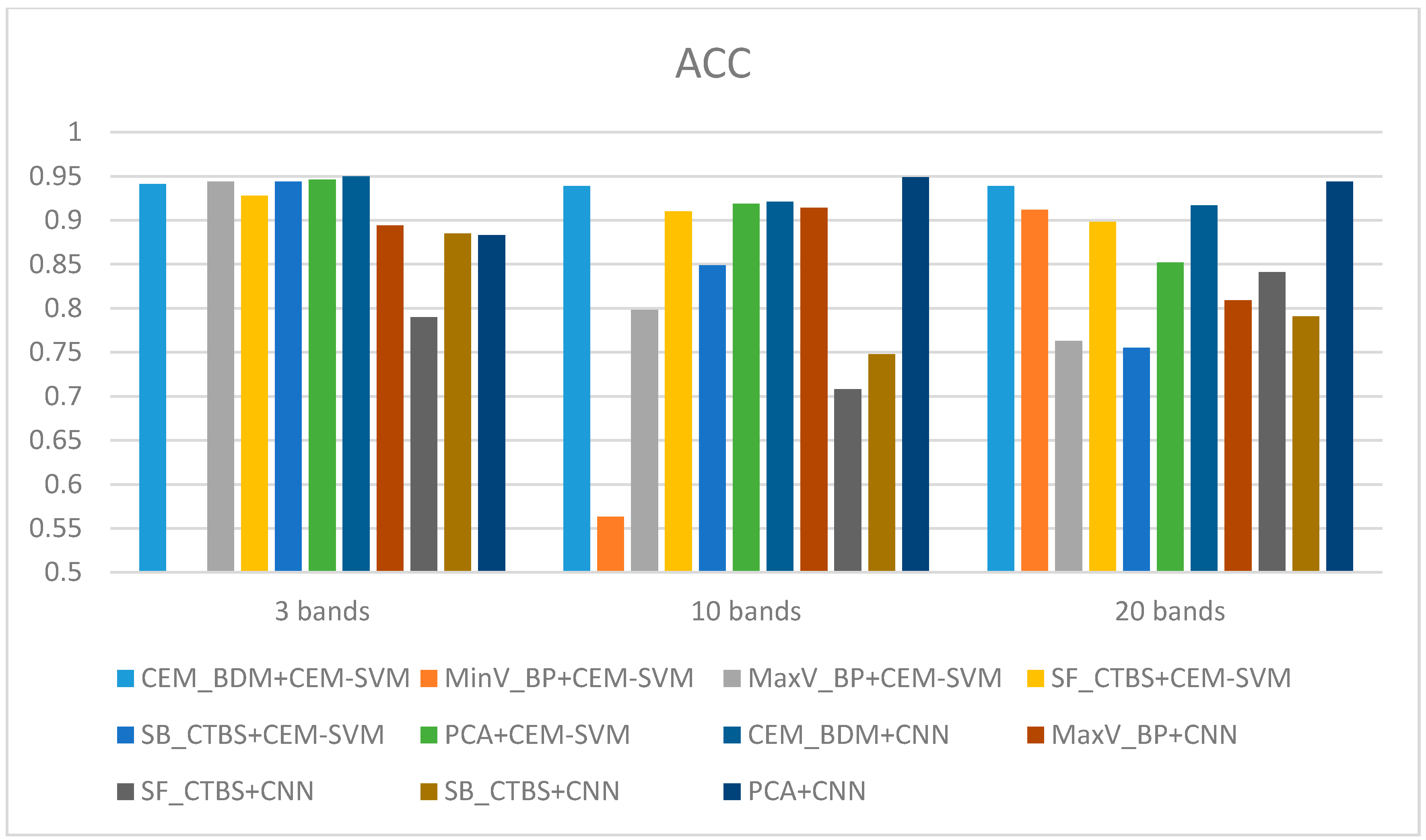
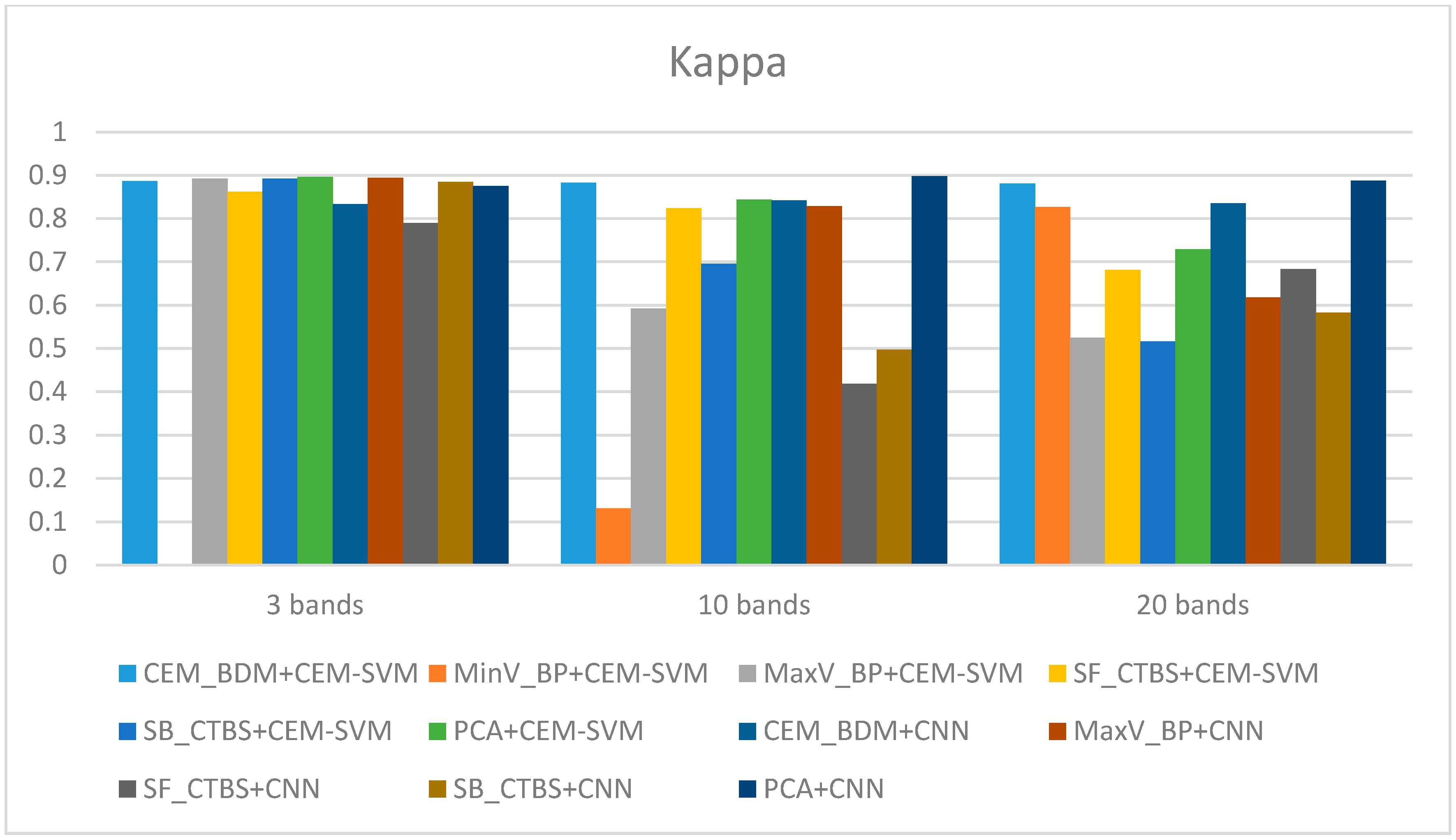
3.2. Detection Results by Using Three Bands
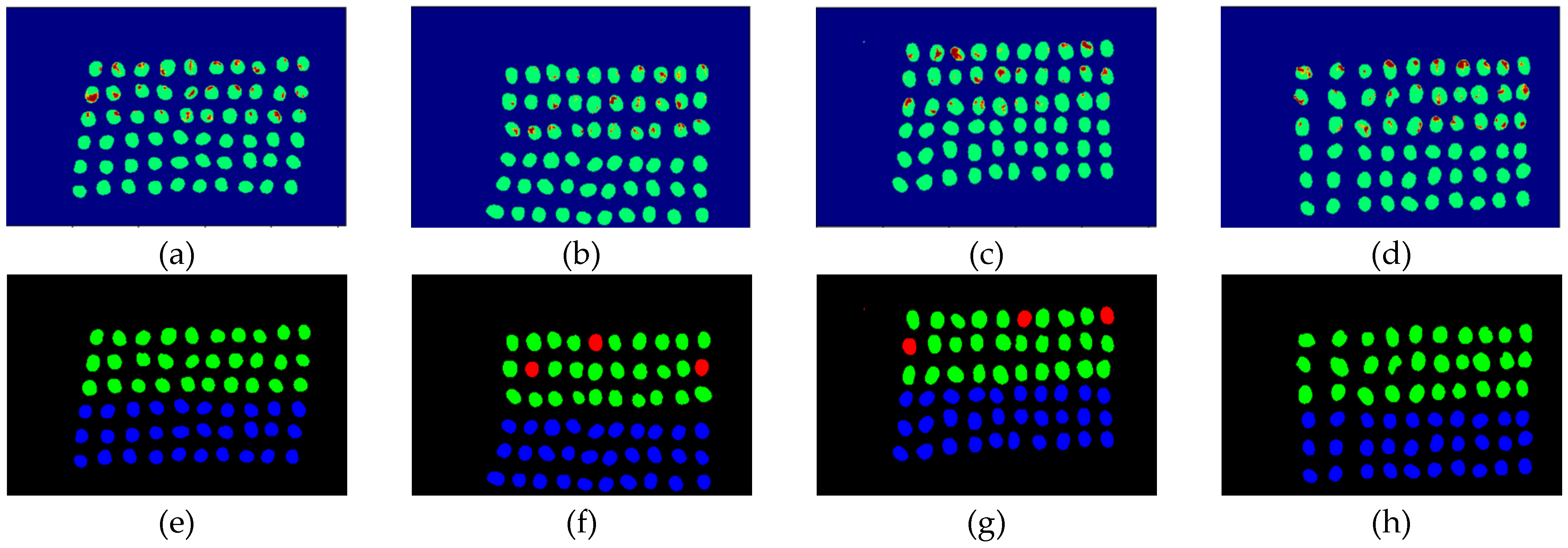
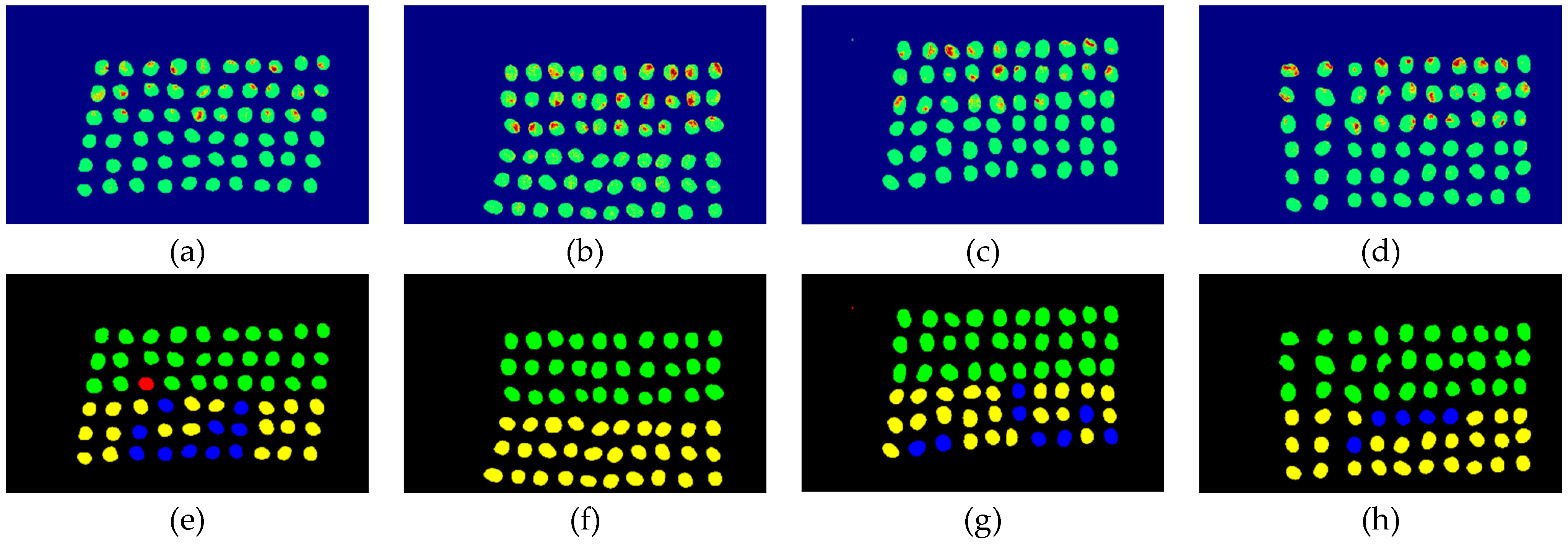
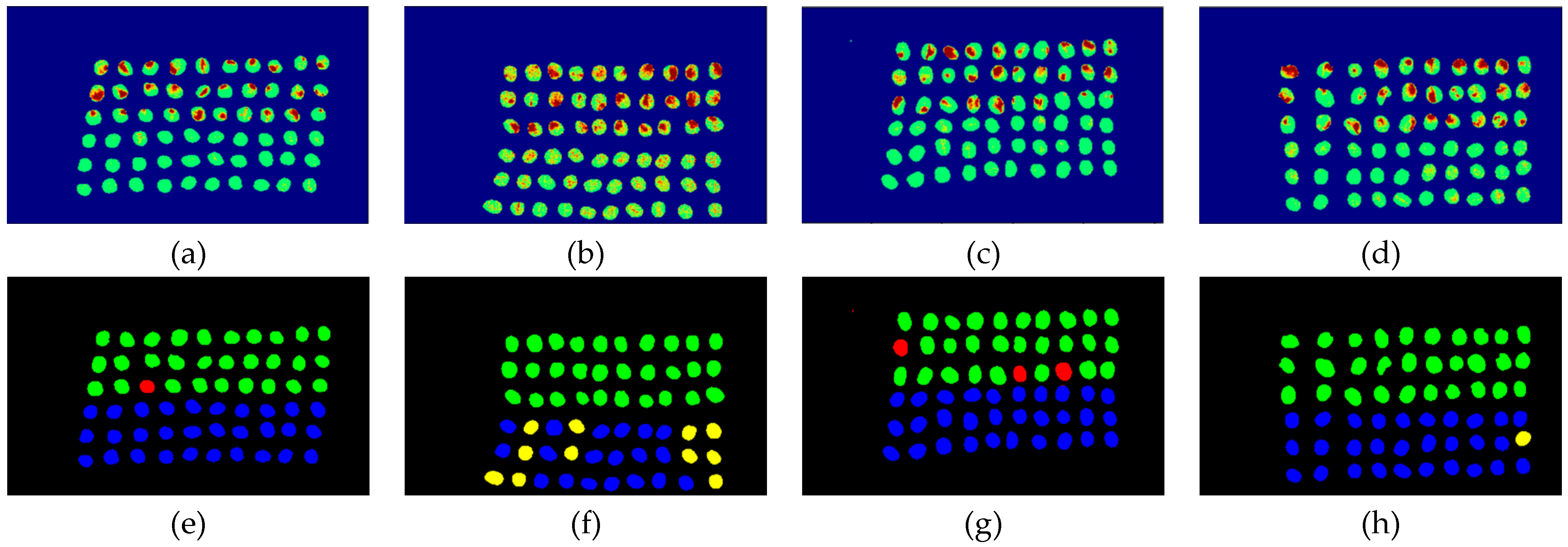
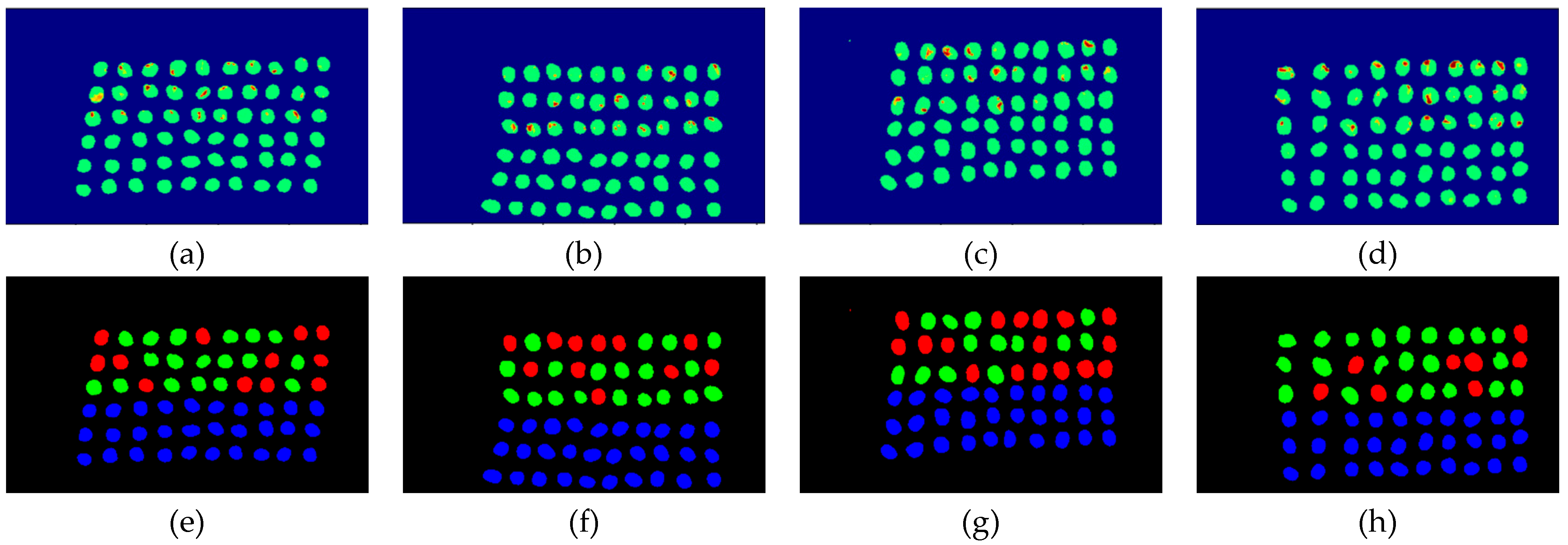
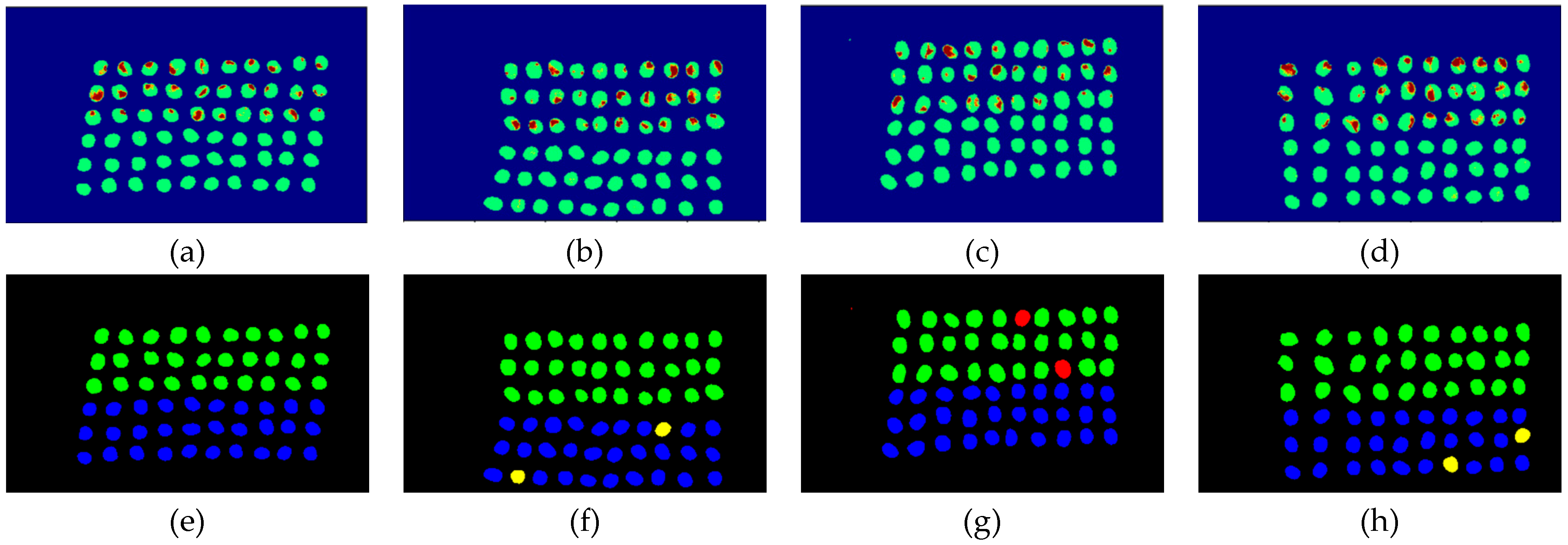
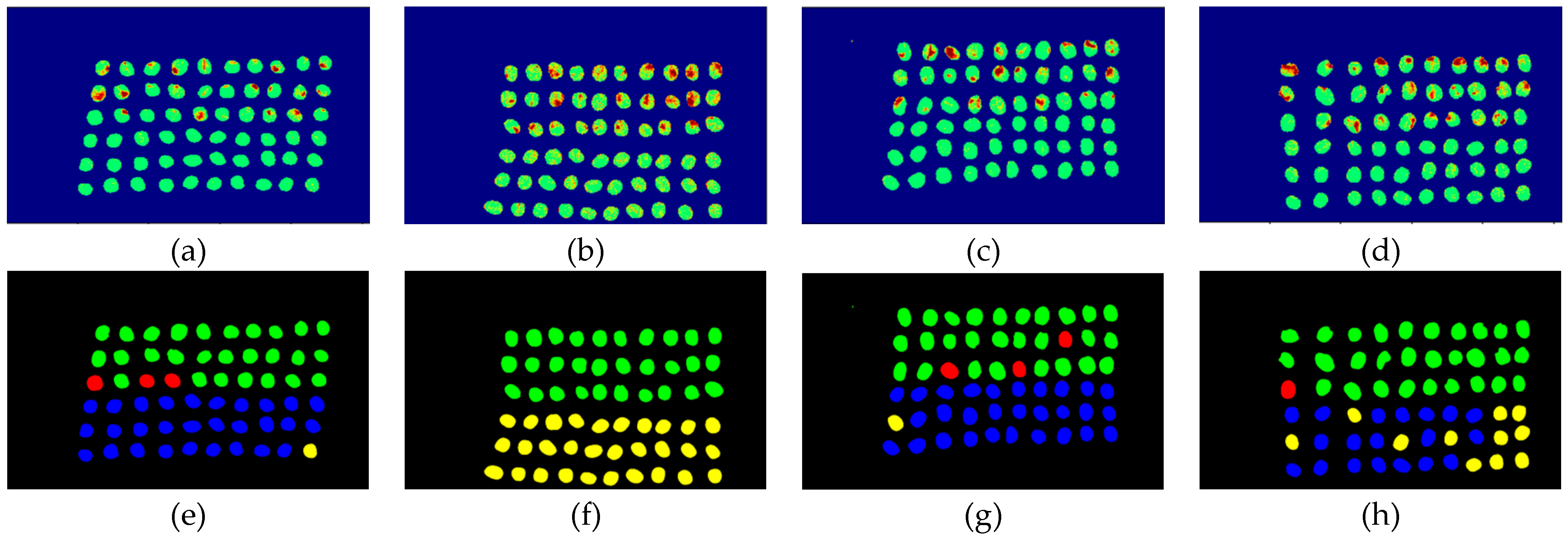
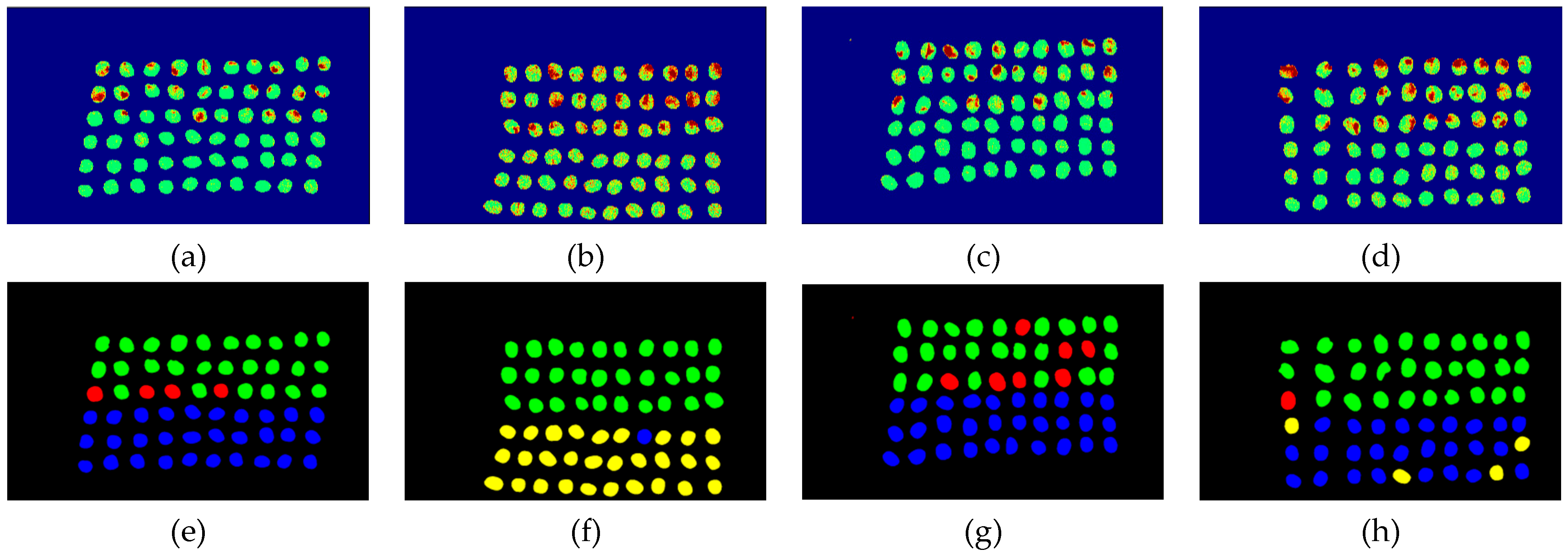
3.3. Detection Results Using 10 Bands
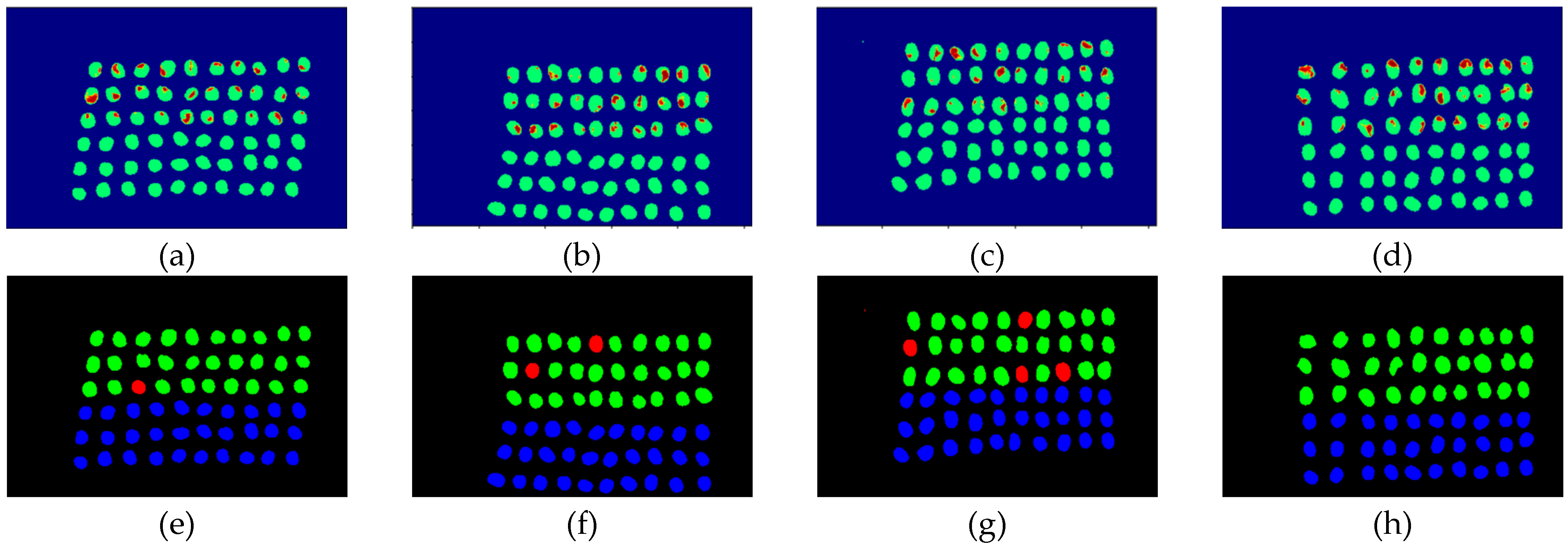
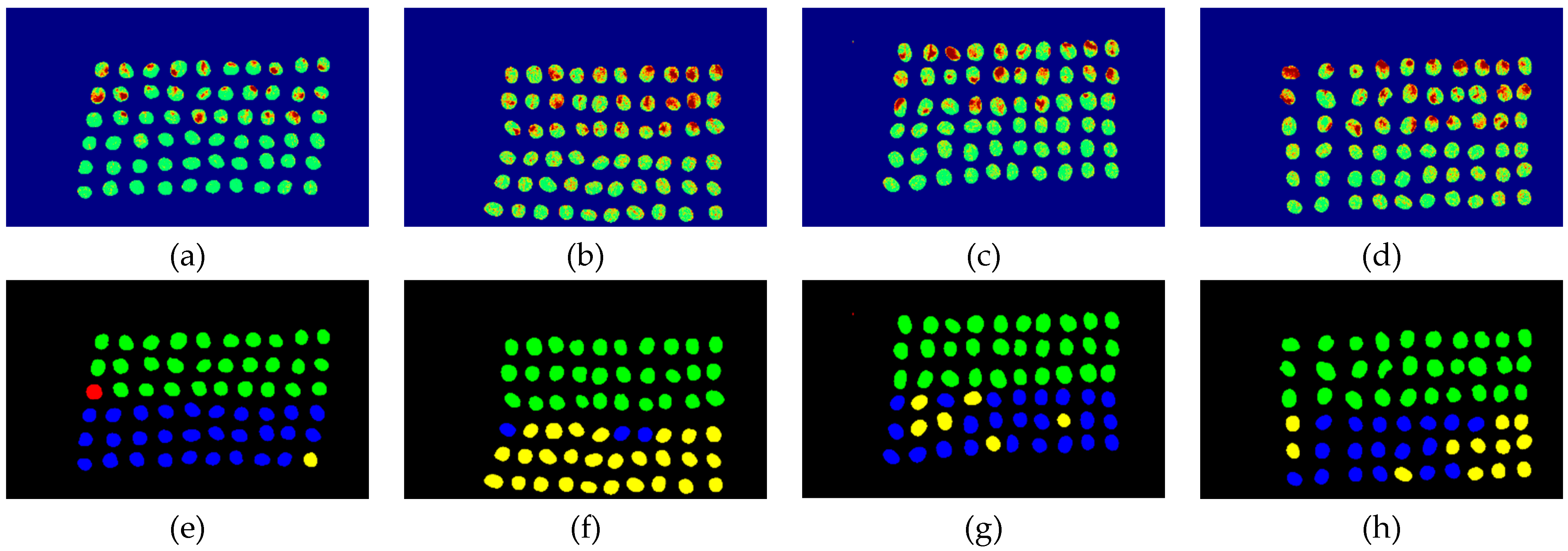
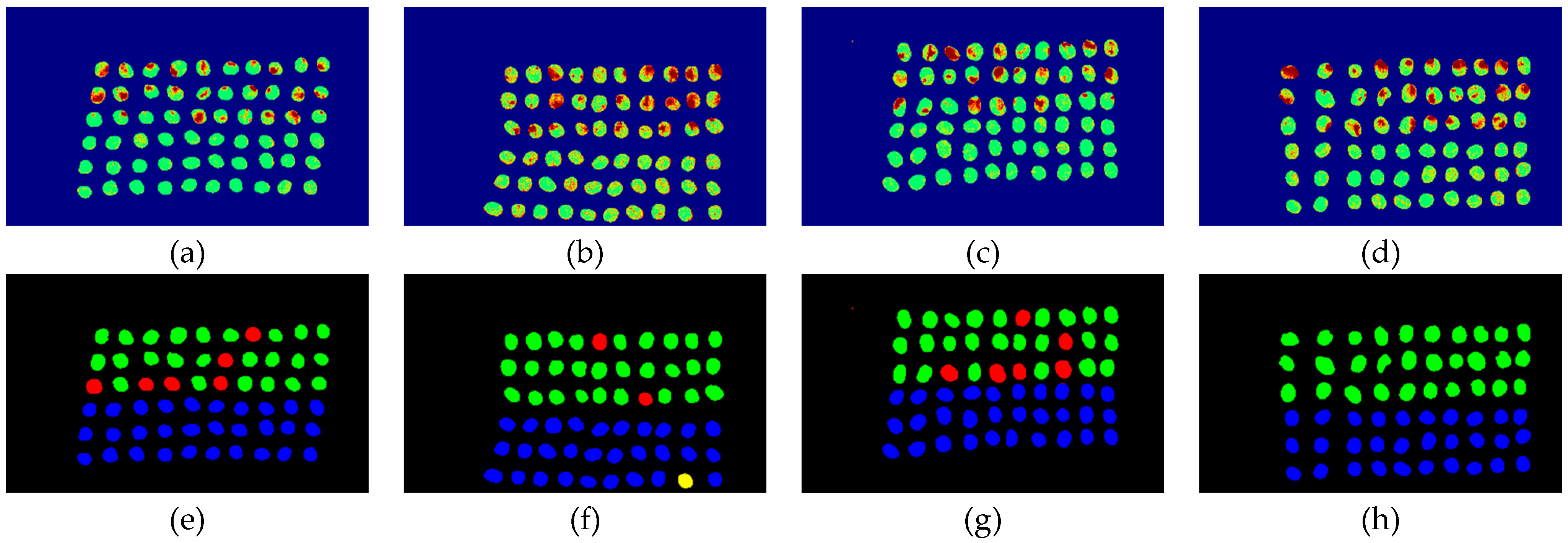
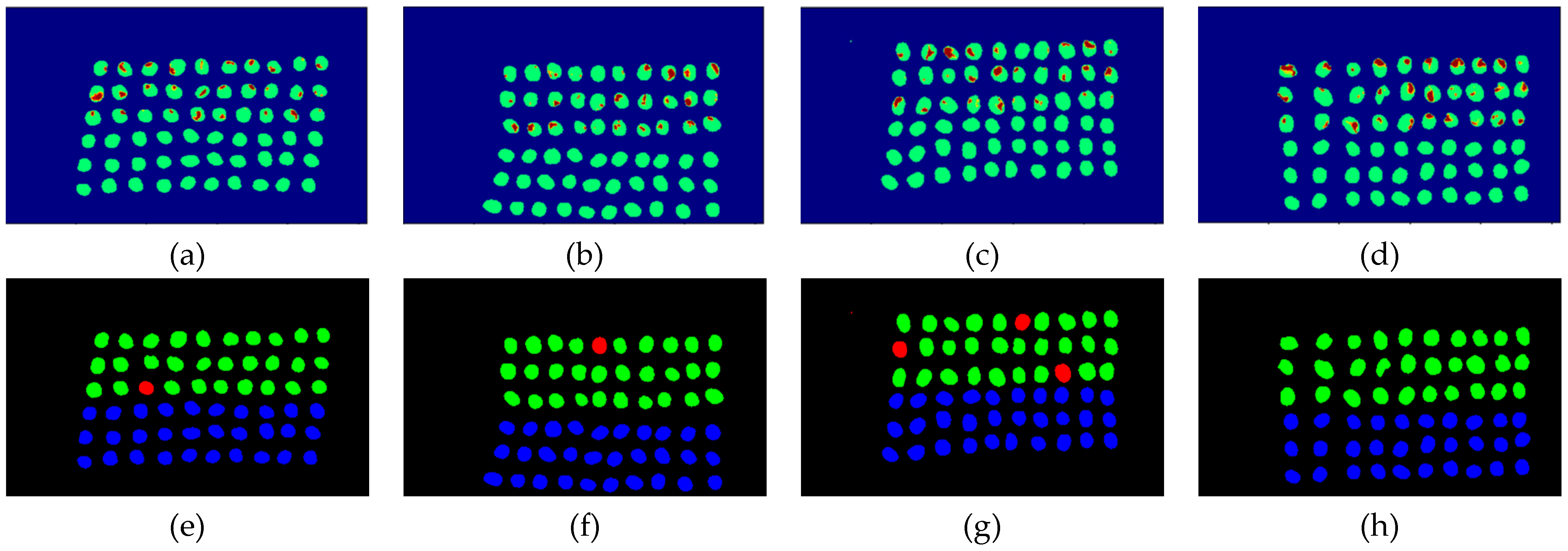
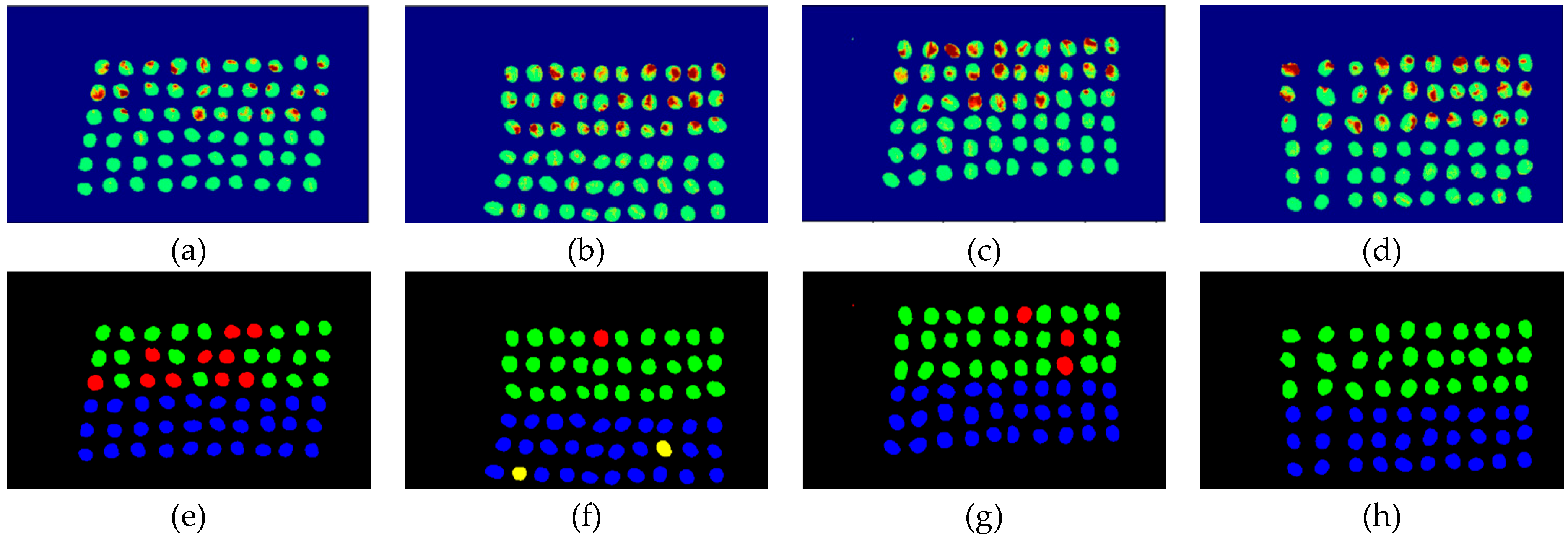
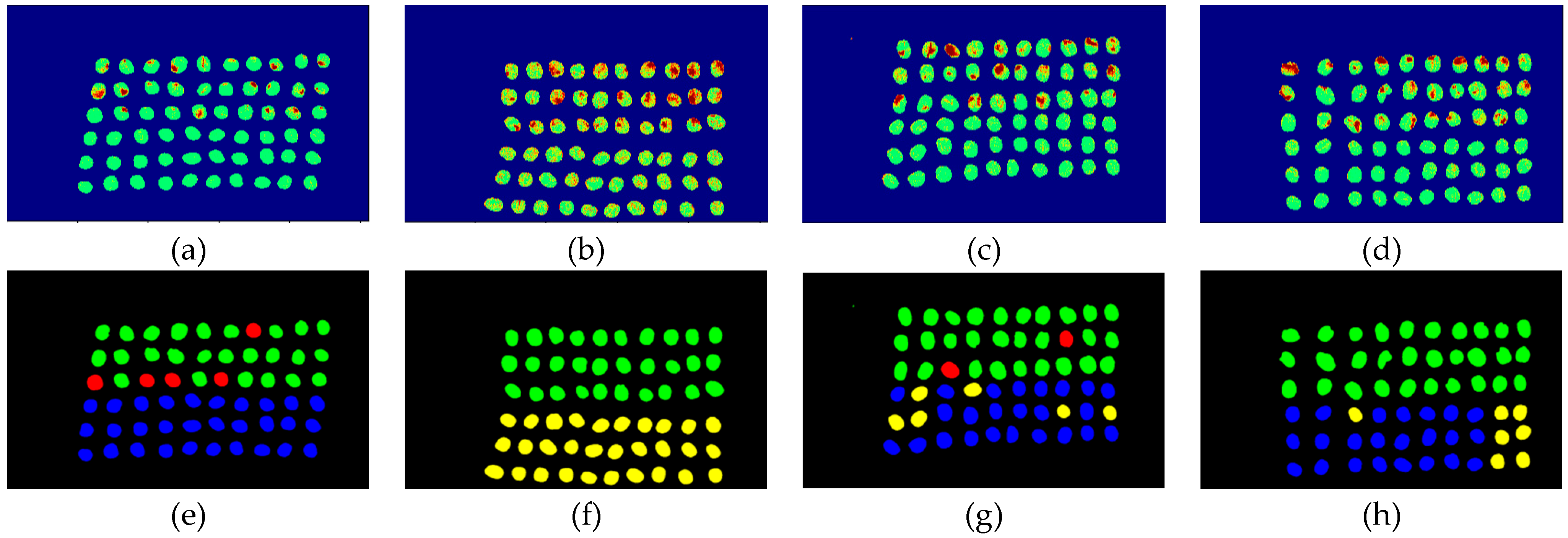
3.4. Detection Results by Using 20 Bands
3.5. Discussion
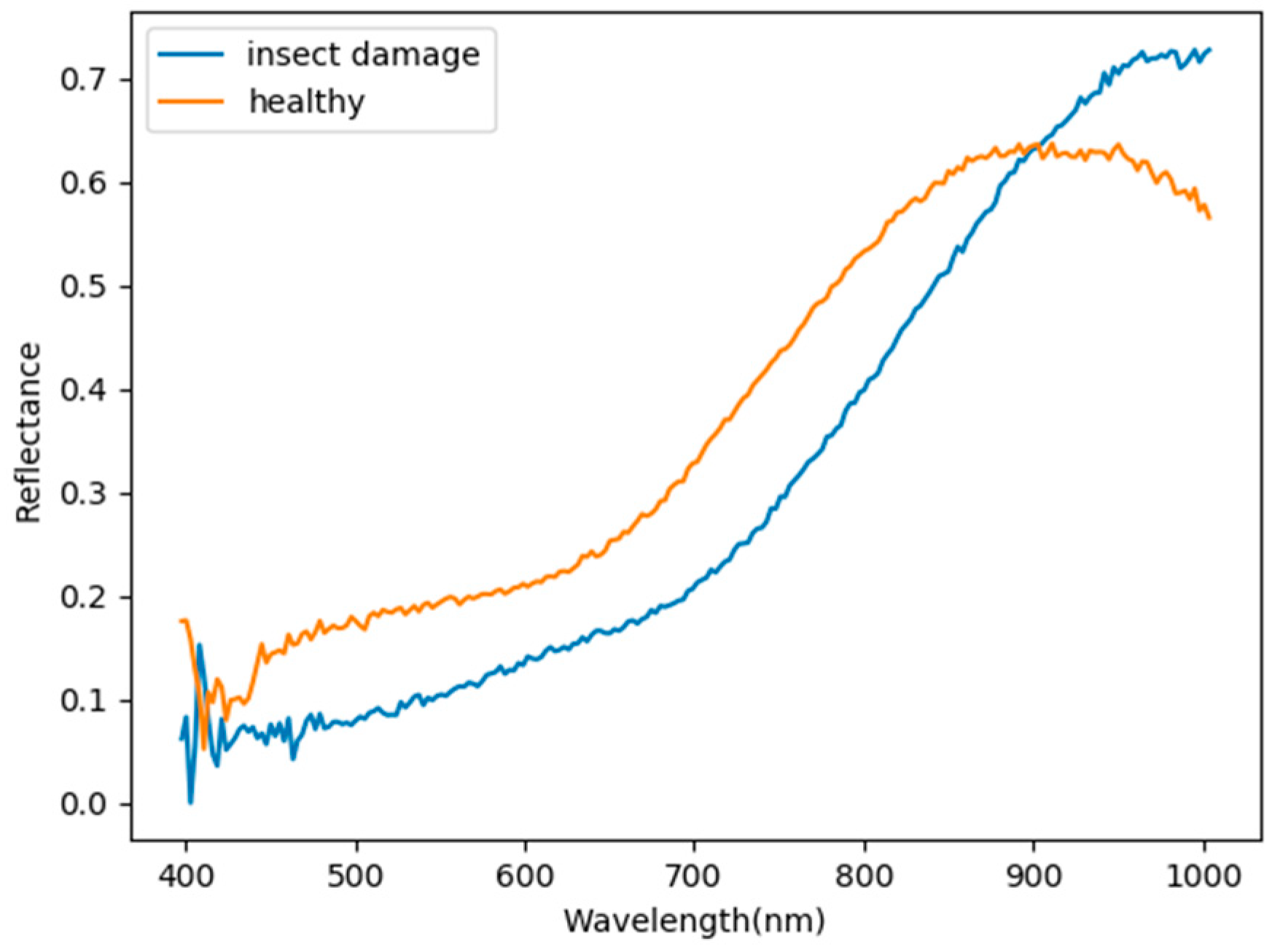
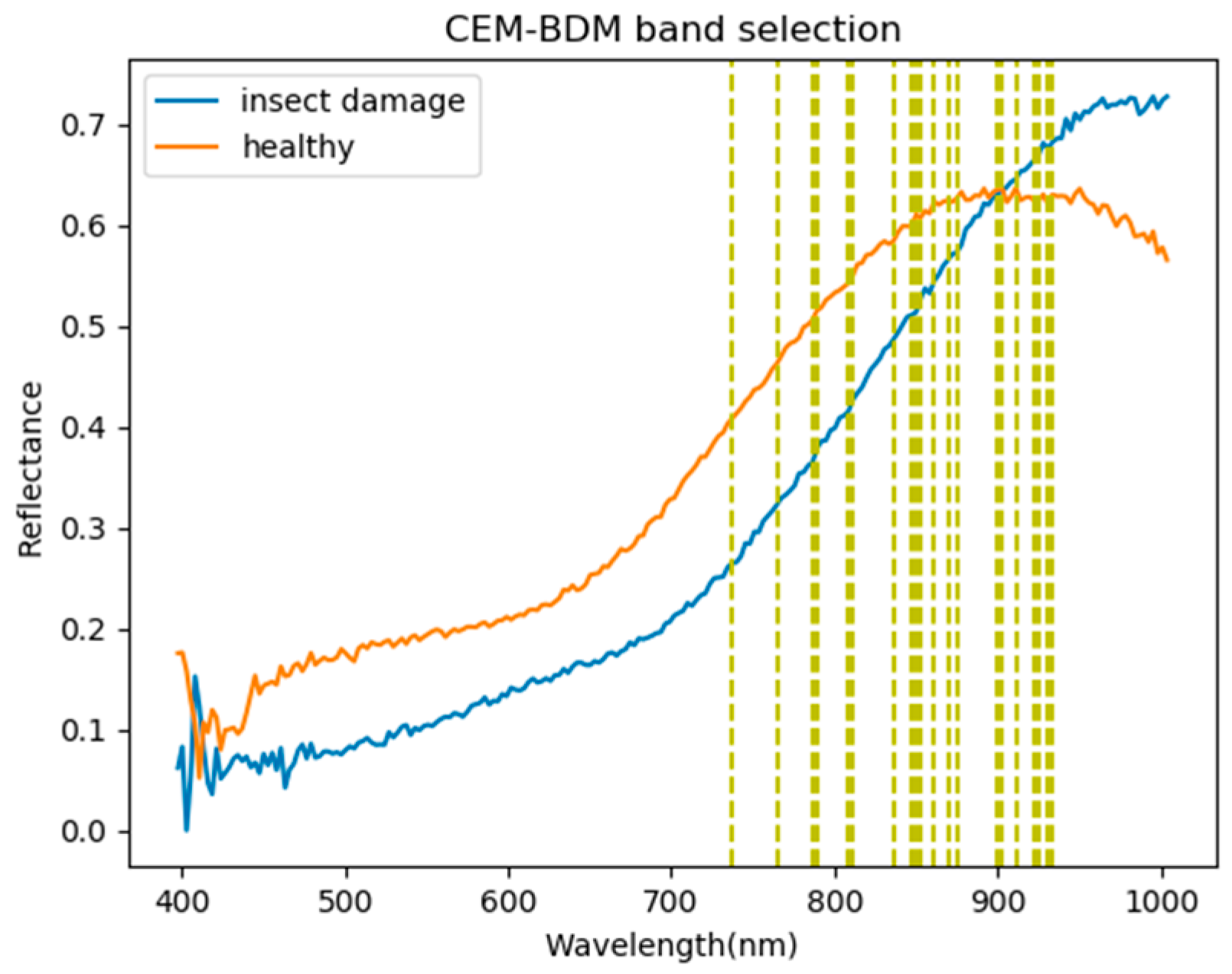
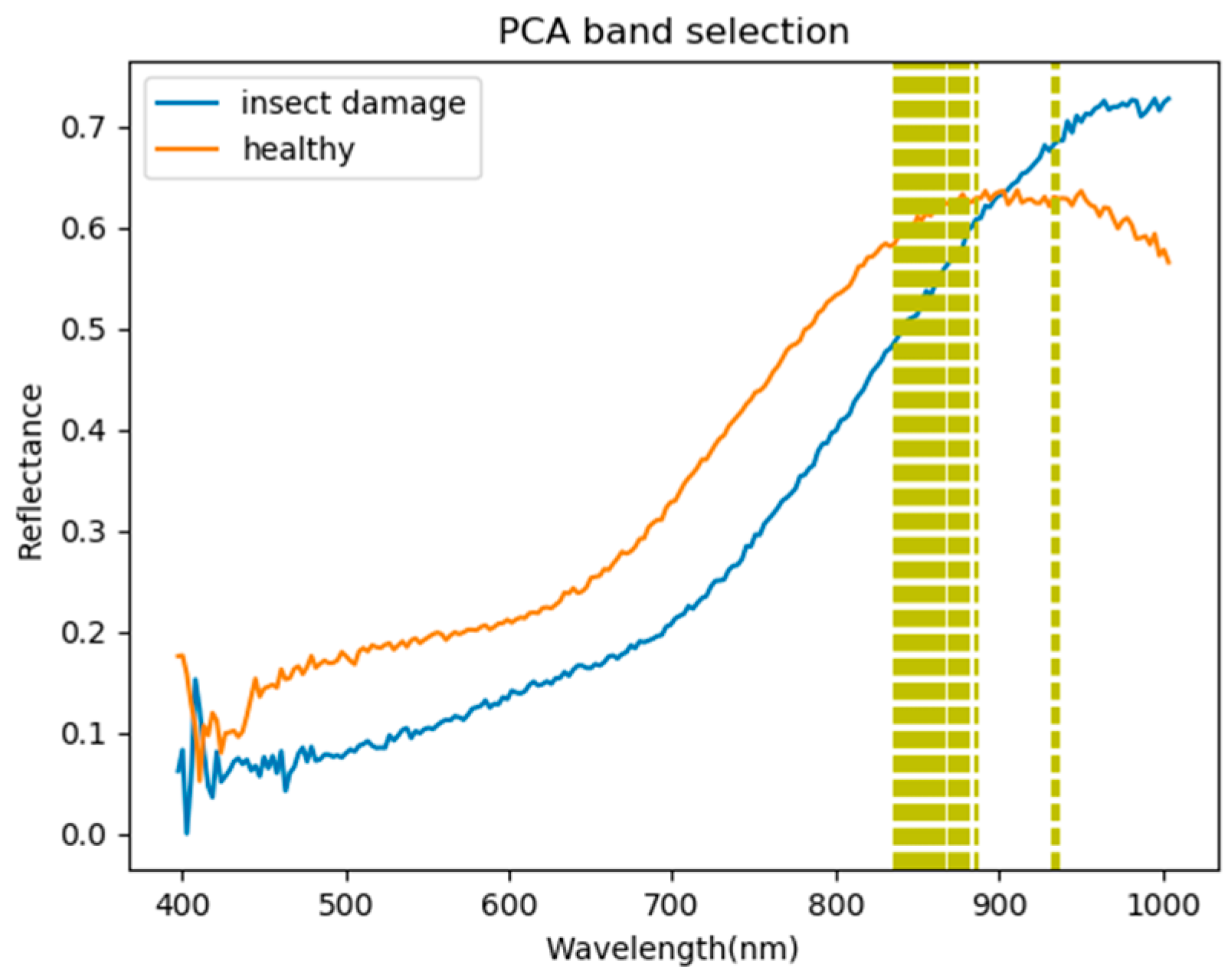
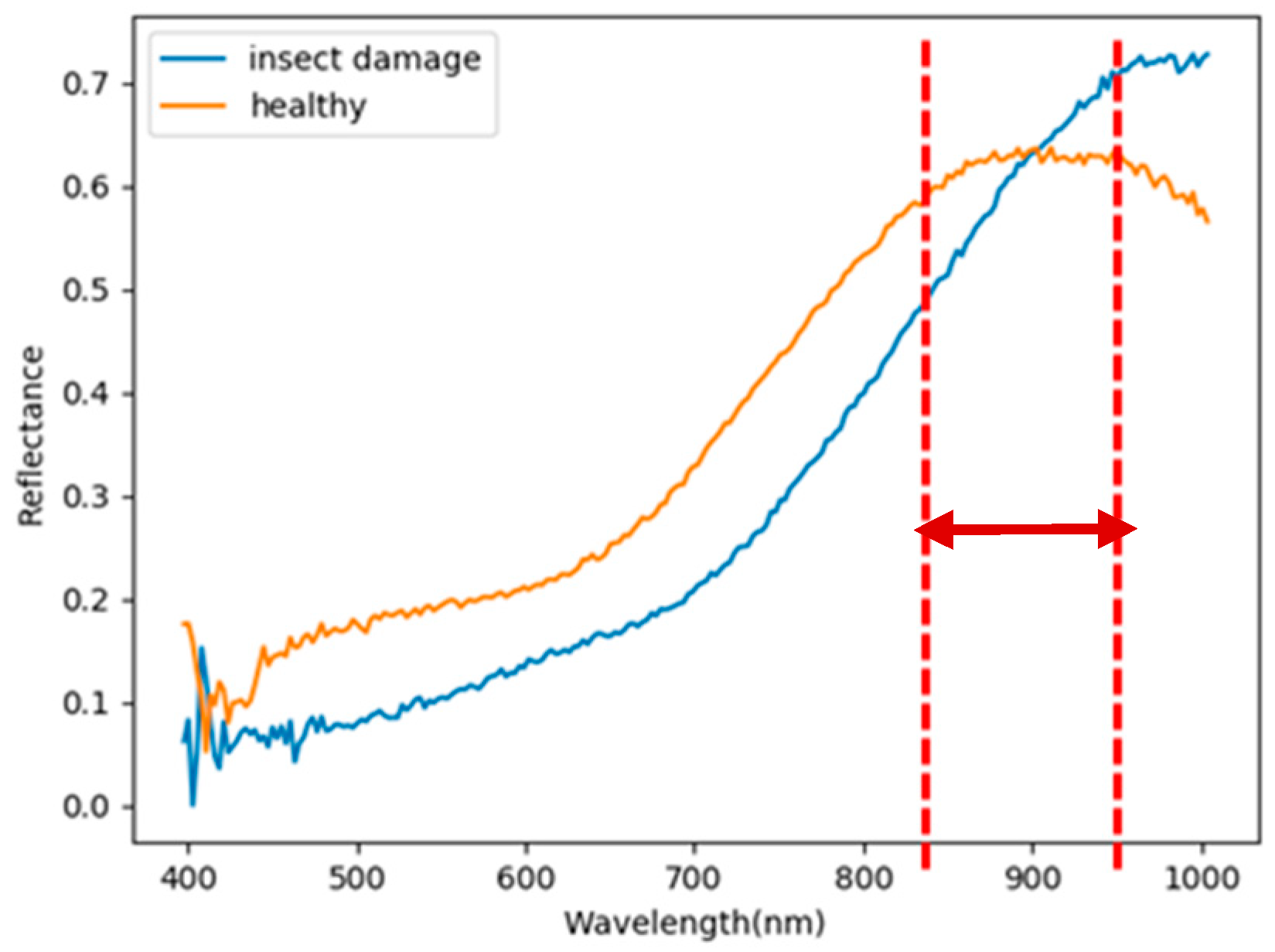
- As the background has many unknown signal sources responding to various wavelengths, the hyperspectral data collected in this paper were pre-processed to remove the background, which rendered the signal source in the image relatively simple. As too much spectral data increase the complexity of detection, only healthy coffee beans and insect damaged beans were included in the data for experimentation. Without other background noise interference, this experiment only required a few important bands to separate the insect damaged beans from healthy beans. The applied CEM-based band selection methods were based on the variance generated by CEM to rank the bands, where the top ranked bands are more representative and significant. Moreover, the basic assumption of PCA is that the data can find a vector projected in the feature space, and then the maximum variance of this group of data can be obtained, thus, it is also ranked by variance. In other words, the band selection methods with the variance as the standard can only use the top few bands to distinguish our experimental data with only two signal sources (healthy and unhealthy beans), which is supported by our experimental results. As the top few bandwidths are concentrated between 850 nm–950 nm, the difference between the spectral signature curves of the insect damaged beans and healthy beans could be easily observed between 850 nm–950 nm, as shown in Figure 51. The curve of healthy beans flattened, while the curve of the insect damaged beans rose beyond the range of 850 nm–950 nm, as shown in Figure 51.
- The greatest challenge in the detection of insect damaged coffee beans is that the damaged areas provide very limited spatial information and are generally difficult to visualize from data. CEM, which is a hyperspectral target detection algorithm, is effective in dealing with the subpixel detection problem [24,25,29,30]. As mentioned in Section 2.3.1, CEM requires only one desired spectral signature for detection, thus, the quality of the detection result is very sensitive to the desired spectral signature. To solve this problem, HIDDA applies OSGP to obtain a stable and improved spectral signature, thus the stability of detection can be increased. The second issue of CEM is that it only provides soft decision results; thus, this paper used linear SVM followed by CEM to obtain the hard decision results. The above-mentioned reasons are the key points that prove our proposed method, HIDDA, can perform well.
- The main problem of CNN during deep learning is that it requires a large number of training samples to learn more effectively and obtain suitable answers. Moreover, as our data consist of real images, there is no ground truth for us to label the insect damaged areas. To address this problem, HIDDA used CEM-OTSU to detect insect damaged beans, and used those pixels as the training samples for the CNN model. It is worth noting that we applied the results from CEM to generate more training samples for the CNN model, as CEM only requires one piece of knowledge of the target signature; hence, even though our training rate for CNN was low, the final results still performed well.
- In order for a comparison with prior studies, Table 7 lists the detailed comparison of coffee beans. Several issues regarding our datasets, methods, and performance render this paper noticeable. First, HIDDA is the only method that detects insect damaged beans, which are more difficult to identify than black, sour, and broken beans. Second, HIDDA had the lowest training rate and highest testing rate with very good performance. Third, HIDDA is the only method, as proposed by CEM-SVM and the CNN model, that uses only three bands in the detection of insect damaged coffee beans. The authors [2] also used hyperspectral imaging (VIS-NIR) to identify black and broken beans, which extracted features through PCA and used K-NN for classification. However, in that paper, the number of beans was relatively too small, and final detection rate was lower than the proposed method of this paper. Other studies [5,6] have used traditional RGB images, which can only address targets according to the color and shape based on the spatial information, meaning that it can only identify black and broken beans. In contrast with prior studies, HIDDA is based on spectral information provided by hyperspectral sensors, which can detect targets at the subpixel level of insect damage, which has very limited spatial information.
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mutua, J.M. Post Harvest Handling and Processing of Coffee in African Countries; Food Agriculture Organization: Rome, Italy, 2000. [Google Scholar]
- Oliveri, P.; Malegori, C.; Casale, M.; Tartacca, E.; Salvatori, G. An innovative multivariate strategy for HSI-NIR images to automatically detect defects in green coffee. Talanta 2019, 199, 270–276. [Google Scholar] [CrossRef] [PubMed]
- Caporaso, N.; Whitworth, M.B.; Grebby, S.; Fisk, I. Rapid prediction of single green coffee bean moisture and lipid content by hyperspectral imaging. J. Food Eng. 2018, 227, 18–29. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Liu, F.; He, Y. Identification of coffee bean varieties using hyperspectral imaging: Influence of preprocessing methods and pixel-wise spectra analysis. Sci. Rep. 2018, 8, 2166. [Google Scholar] [CrossRef] [PubMed]
- García, M.; Candelo-Becerra, J.E.; Hoyos, F.E. Quality and Defect Inspection of Green Coffee Beans Using a Computer Vision System. Appl. Sci. 2019, 9, 4195. [Google Scholar] [CrossRef] [Green Version]
- Arboleda, E.R.; Fajardo, A.C.; Medina, R.P. An image processing technique for coffee black beans identification. In Proceedings of the 2018 IEEE International Conference on Innovative Research and Development (ICIRD), Bangkok, Thailand, 11–12 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Clarke, R.J.; Macrae, R. Coffee; Springer Science and Business Media LLC: Berlin, Germany, 1987; p. 2. [Google Scholar]
- Mazzafera, P. Chemical composition of defective coffee beans. Food Chem. 1999, 64, 547–554. [Google Scholar] [CrossRef]
- Franca, A.S.; Oliveira, L.S. Chemistry of Defective Coffee Beans. In Food Chemistry Research Developments; Koeffer, E.N., Ed.; Nova Publishers: Newyork, NY, USA, January 2008; pp. 105–138. [Google Scholar]
- Chang, C.-I.; Du, Q.; Sun, T.-L.; Althouse, M. A joint band prioritization and band-decorrelation approach to band selection for hyperspectral image classification. IEEE Trans. Geosci. Remote. Sens. 1999, 37, 2631–2641. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.-I.; Wang, S. Constrained band selection for hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. Jun. 2006, 44, 1575–1585. [Google Scholar] [CrossRef]
- Liu, K.-H.; Chen, S.-Y.; Chien, H.-C.; Lu, M.-H. Progressive Sample Processing of Band Selection for Hyperspectral Image Transmission. Remote. Sens. 2018, 10, 367. [Google Scholar] [CrossRef] [Green Version]
- Su, H.; Du, Q.; Chen, G.; Du, P. Optimized Hyperspectral Band Selection Using Particle Swarm Optimization. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2014, 7, 2659–2670. [Google Scholar] [CrossRef]
- Su, H.; Gourley, J.J.; Du, Q. Hyperspectral Band Selection Using Improved Firefly Algorithm. IEEE Geosci. Remote. Sens. Lett. 2016, 13, 68–72. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhu, G.; Wang, Q. Hyperspectral Band Selection by Multitask Sparsity Pursuit. IEEE Trans. Geosci. Remote. Sens. 2015, 53, 631–644. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, X.; Lu, X. Discovering Diverse Subset for Unsupervised Hyperspectral Band Selection. IEEE Trans. Image Process. 2016, 26, 51–64. [Google Scholar] [CrossRef]
- Wang, C.; Gong, M.; Zhang, M.; Chan, Y. Unsupervised Hyperspectral Image Band Selection via Column Subset Selection. IEEE Geosci. Remote. Sens. Lett. 2015, 12, 1411–1415. [Google Scholar] [CrossRef]
- Dorrepaal, R.; Malegori, C.; Gowen, A. Tutorial: Time Series Hyperspectral Image Analysis. J. Near Infrared Spectrosc. 2016, 24, 89–107. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.-I. Hyperspectral Data Processing; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Harsanyi, J.C. Detection and Classification of Subpixel Spectral Signatures in Hyperspectral Image Sequences. Ph.D. Thesis, Department of Electrical Engineering, University of Maryland Baltimore County, College Park, MD, USA, August 1993. [Google Scholar]
- Farrand, W.H.; Harsanyi, J.C. Mapping the distribution of mine tailings in the Coeur d’Alene river valley, Idaho, through the use of a constrained energy minimization technique. Remote Sens. Environ. Jan. 1997, 59, 64–76. [Google Scholar] [CrossRef]
- Chang, C.-I. Target signature-constrained mixed pixel classification for hyperspectral imagery. IEEE Trans. Geosci. Remote. Sens. 2002, 40, 1065–1081. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.-I. Hyperspectral Imaging: Techniques for Spectral Detection and Classification; Kluwer Academic/Plenum Publishers: Dordrecht, The Netherlands, 2003. [Google Scholar]
- Lin, C.; Chen, S.-Y.; Chen, C.-C.; Tai, C.-H. Detecting newly grown tree leaves from unmanned-aerial-vehicle images using hyperspectral target detection techniques. ISPRS J. Photogramm. Remote. Sens. 2018, 142, 174–189. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Yu, C.; Zhao, E.; Song, M.; Wen, C.-H.; Chang, C.-I. Constrained-Target Band Selection for Multiple-Target Detection. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 6079–6103. [Google Scholar] [CrossRef]
- Chang, C.-I. Real-Time Progressive Hyperspectral Image Processing: Endmember Finding and Anomaly Detection; Springer: New York, NY, USA, 2016. [Google Scholar]
- Pudil, P.; Novovicova, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit. Lett. 1994, 15, 1119–1125. [Google Scholar] [CrossRef]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. Philos. Mag. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.-Y.; Lin, C.; Tai, C.-H.; Chuang, S.-J. Adaptive Window-Based Constrained Energy Minimization for Detection of Newly Grown Tree Leaves. Remote. Sens. 2018, 10, 96. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.-Y.; Lin, C.; Chuang, S.-J.; Kao, Z.-Y. Weighted Background Suppression Target Detection Using Sparse Image Enhancement Technique for Newly Grown Tree Leaves. Remote. Sens. 2019, 11, 1081. [Google Scholar] [CrossRef] [Green Version]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Bradshaw, D.; Gans, C.; Jones, P.; Rizzuto, G.; Steiner, N.; Mitton, W.; Ng, J.; Koester, R.; Hartzman, R.; Hurley, C. Novel HLA-A locus alleles including A*01012, A*0306, A*0308, A*2616, A*2617, A*3009, A*3206, A*3403, A*3602 and A*6604. Tissue Antigens 2002, 59, 325–327. [Google Scholar] [CrossRef] [PubMed]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Boil. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [Green Version]
- Zhao, B.; Lu, H.; Chen, S.; Liu, J.; Wu, D. Convolutional neural networks for time series classification. J. Syst. Eng. Electron. 2017, 28, 162–169. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D Convolutional Neural Networks and Applications: A Survey. arXiv 2019, arXiv:1905.03554. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Youden, W.J. Index for rating diagnostic tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Cohen, J. Weighted kappa: Nominal scale agreement with provision for scaled disagreement or partial credit. Psychol. Bull. 1968, 70, 213–220. [Google Scholar] [CrossRef] [PubMed]




















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tested Target Beans | Spectral Range (nm) | Data Volume | Data Analysis Method | Accuracy | Reference |
|---|---|---|---|---|---|
| Broken beans, dry beans, moldy beans, black beans | 1000–2500 nm (267 bands) | 662 beans | PCA + k-NN | 90% | [2] |
| Origin classification | 955–1700 nm (266 bands) | 432 beans | PLS + SVM | 97.1% | [3] |
| Origin classification | 900–1700 nm (256 bands) | 1200 beans | SVM | 80% | [4] |
| Sour beans, black beans, broken beans | RGB | 444 beans | k-NN | 95.66% | [5] |
| Black beans | RGB | 180 beans | Threshold (TH) | 100% | [6] |
| Class | Qty (pcs) |
|---|---|
| Healthy beans | 569 |
| Defective beans | 570 |
| Total | 1139 |
| Band | BDM | MinV_BP | MaxV_BP | SF_CTBS | SB_CTBS | PCA | Total Times |
|---|---|---|---|---|---|---|---|
| 850 nm | ● | X | ● | ● | ● | ● | 5 |
| 886 nm | X | ● | ● | ● | ● | ● | 5 |
| 858 nm | X | X | ● | ● | ● | ● | 4 |
| 933 nm | ● | ● | X | ● | X | ● | 4 |
| 891 nm | X | ● | ● | ● | ● | X | 4 |
| 880 nm | X | X | ● | ● | ● | ● | 4 |
| 927 nm | X | ● | ● | ● | ● | X | 4 |
| 3 Bands Green Coffee Beans CEM-SVM Results | |||||||||
| Analysis Method | TP | FN | FP | TN | TPR | FPR | ACC | Kappa | Time (s) |
| CEM_BDM + CEM-SVM | 520 | 50 | 17 | 552 | 0.912 | 0.298 | 0.941 | 0.887 | 11.57 |
| MinV_BP + CEM-SVM | 570 | 0 | 569 | 0 | 1.0 | 1.0 | 0.5 | 0 | 13.27 |
| MaxV_BP + CEM-SVM | 515 | 55 | 8 | 561 | 0.903 | 0.014 | 0.944 | 0.892 | 12.31 |
| SF_CTBS + CEM-SVM | 494 | 76 | 5 | 564 | 0.867 | 0.008 | 0.928 | 0.862 | 13.21 |
| SB_CTBS + CEM-SVM | 515 | 55 | 8 | 561 | 0.903 | 0.014 | 0.944 | 0.892 | 13.26 |
| PCA + CEM-SVM | 523 | 47 | 14 | 555 | 0.917 | 0.024 | 0.946 | 0.896 | 12.83 |
| 3 Bands Green Coffee Beans CNN Results | |||||||||
| Analysis Method | TP | FN | FP | TN | TPR | FPR | ACC | Kappa | Time (s) |
| CEM_BDM + CNN | 532 | 38 | 20 | 549 | 0.931 | 0.029 | 0.95 | 0.901 | 7.4 |
| MaxV_BP + CNN | 520 | 50 | 13 | 556 | 0.912 | 0.018 | 0.947 | 0.894 | 7.4 |
| SF_CTBS + CNN | 461 | 109 | 8 | 561 | 0.8 | 0.009 | 0.895 | 0.79 | 7.13 |
| SB_CTBS + CNN | 514 | 56 | 9 | 560 | 0.9 | 0.014 | 0.942 | 0.885 | 7.67 |
| PCA + CNN | 540 | 30 | 41 | 528 | 0.946 | 0.063 | 0.941 | 0.883 | 7.64 |
| 10 Bands Green Coffee Beans SVM Results | |||||||||
| Analysis Method | TP | FN | FP | TN | TPR | FPR | ACC | Kappa | Time (s) |
| CEM_BDM+CEM-SVM | 509 | 61 | 8 | 561 | 0.892 | 0.014 | 0.939 | 0.883 | 11.71 |
| MinV_BP+CEM-SVM | 565 | 5 | 492 | 77 | 0.991 | 0.864 | 0.563 | 0.131 | 11.35 |
| MaxV_BP+CEM-SVM | 554 | 16 | 213 | 356 | 0.971 | 0.374 | 0.798 | 0.592 | 11.47 |
| SF_CTBS+CEM-SVM | 505 | 65 | 37 | 532 | 0.885 | 0.065 | 0.910 | 0.824 | 11.31 |
| SB_CTBS+CEM-SVM | 545 | 25 | 146 | 423 | 0.956 | 0.256 | 0.849 | 0.696 | 11.44 |
| PCA+CEM-SVM | 541 | 29 | 63 | 506 | 0.949 | 0.110 | 0.919 | 0.844 | 11.40 |
| 10 Bands Green Coffee Beans SVM Results | |||||||||
| Analysis Method | TP | FN | FP | TN | TPR | FPR | ACC | Kappa | Time (s) |
| CEM_BDM+CNN | 484 | 86 | 5 | 564 | 0.85 | 0.007 | 0.921 | 0.842 | 7.16 |
| MaxV_BP+CNN | 473 | 97 | 2 | 567 | 0.833 | 0.003 | 0.914 | 0.829 | 7.34 |
| SF_CTBS+CNN | 246 | 324 | 1 | 568 | 0.420 | 0.001 | 0.708 | 0.418 | 6.98 |
| SB_CTBS+CNN | 289 | 281 | 1 | 568 | 0.5 | 0.001 | 0.748 | 0.497 | 7.41 |
| PCA+CNN | 532 | 38 | 21 | 548 | 0.931 | 0.033 | 0.949 | 0.898 | 7.41 |
| 20 Bands Green Coffee Beans SVM Results | |||||||||
| Analysis Method | TP | FN | FP | TN | TPR | FPR | ACC | Kappa | Time (s) |
| CEM_BDM+CEM-SVM | 522 | 48 | 21 | 548 | 0.915 | 0.036 | 0.939 | 0.881 | 12.03 |
| MinV_BP+CEM-SVM | 547 | 23 | 77 | 492 | 0.959 | 0.135 | 0.912 | 0.827 | 11.34 |
| MaxV_BP+CEM-SVM | 550 | 20 | 249 | 320 | 0.964 | 0.437 | 0.763 | 0.525 | 11.41 |
| SF_CTBS+CEM-SVM | 521 | 49 | 135 | 434 | 0.914 | 0.237 | 0.838 | 0.681 | 11.38 |
| SB_CTBS+CEM-SVM | 544 | 26 | 253 | 316 | 0.954 | 0.444 | 0.755 | 0.516 | 11.78 |
| PCA+CEM-SVM | 546 | 24 | 144 | 425 | 0.957 | 0.253 | 0.852 | 0.729 | 11.38 |
| 20 Bands Green Coffee Beans CNN Results | |||||||||
| Analysis Method | TP | FN | FP | TN | TPR | FPR | ACC | Kappa | Time (s) |
| CEM_BDM+CNN | 480 | 90 | 5 | 564 | 0.842 | 0.007 | 0.917 | 0.835 | 7.84 |
| MaxV_BP+CNN | 355 | 215 | 1 | 568 | 0.62 | 0.001 | 0.809 | 0.618 | 7.27 |
| SF_CTBS+CNN | 395 | 175 | 2 | 567 | 0.687 | 0.003 | 0.841 | 0.683 | 7.35 |
| SB_CTBS+CNN | 336 | 234 | 1 | 568 | 0.585 | 0.001 | 0.791 | 0.583 | 7.13 |
| PCA+CNN | 511 | 59 | 5 | 564 | 0.896 | 0.007 | 0.944 | 0.888 | 7.82 |
| Ref. | Types | Training Rate | No. of Training | Testing Rate | No. of Testing | ACC (%) | Method | Image |
|---|---|---|---|---|---|---|---|---|
| [2] | Normal | 76% | 200 | 24% | 61 | 90.2 | PCA+K-NN (k = 3) (5 PCA) | HSI |
| Black cherries | 71% | 5 | 29% | 2 | 50 | |||
| Black | 68% | 100 | 32% | 45 | 80 | |||
| Dehydrated | 52% | 100 | 48% | 89 | 89.9 | |||
| [5] | Normal | unknown | 444 | unknown | 161 | 97.52 | K-NN (k = 10) | RGB |
| Black | 169 | 97.04 | ||||||
| Sour | 165 | 92.12 | ||||||
| Broken | 166 | 94.45 | ||||||
| [6] | Normal | 66% | 70 | 34% | 35 | 100 | Thresholding | RGB |
| Black | 66% | 50 | 34% | 25 | 100 | |||
| HIDDA | Normal | 5% | 30 | 95% | 569 | 96.48 | CEM-SVM (3 bands) CNN (3 bands) | HSI |
| Insect damage | 5% | 30 | 95% | 570 | 93.33 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.-Y.; Chang, C.-Y.; Ou, C.-S.; Lien, C.-T. Detection of Insect Damage in Green Coffee Beans Using VIS-NIR Hyperspectral Imaging. Remote Sens. 2020, 12, 2348. https://doi.org/10.3390/rs12152348
Chen S-Y, Chang C-Y, Ou C-S, Lien C-T. Detection of Insect Damage in Green Coffee Beans Using VIS-NIR Hyperspectral Imaging. Remote Sensing. 2020; 12(15):2348. https://doi.org/10.3390/rs12152348
Chicago/Turabian StyleChen, Shih-Yu, Chuan-Yu Chang, Cheng-Syue Ou, and Chou-Tien Lien. 2020. "Detection of Insect Damage in Green Coffee Beans Using VIS-NIR Hyperspectral Imaging" Remote Sensing 12, no. 15: 2348. https://doi.org/10.3390/rs12152348
APA StyleChen, S. -Y., Chang, C. -Y., Ou, C. -S., & Lien, C. -T. (2020). Detection of Insect Damage in Green Coffee Beans Using VIS-NIR Hyperspectral Imaging. Remote Sensing, 12(15), 2348. https://doi.org/10.3390/rs12152348