Building Extraction of Aerial Images by a Global and Multi-Scale Encoder-Decoder Network


Abstract
:1. Introduction
- How to explore local and global information is the first key point. Note that, in this paper, we define the detailed structure (e.g., buildings’ outlines and shapes) as the local information. Meanwhile, the overall structure (e.g., buildings’ context within an aerial image) is defined as the global information.
- How to capture the multi-scale information is the second key point. Due to the specific characteristics of the aerial images, the buildings within an aerial image are different in size. The buildings with bigger sizes may contain hundreds of pixels while the buildings with smaller sizes occupy dozens of pixels. In this paper, we define the mentioned issue as the multi-scale information contained in the aerial images.
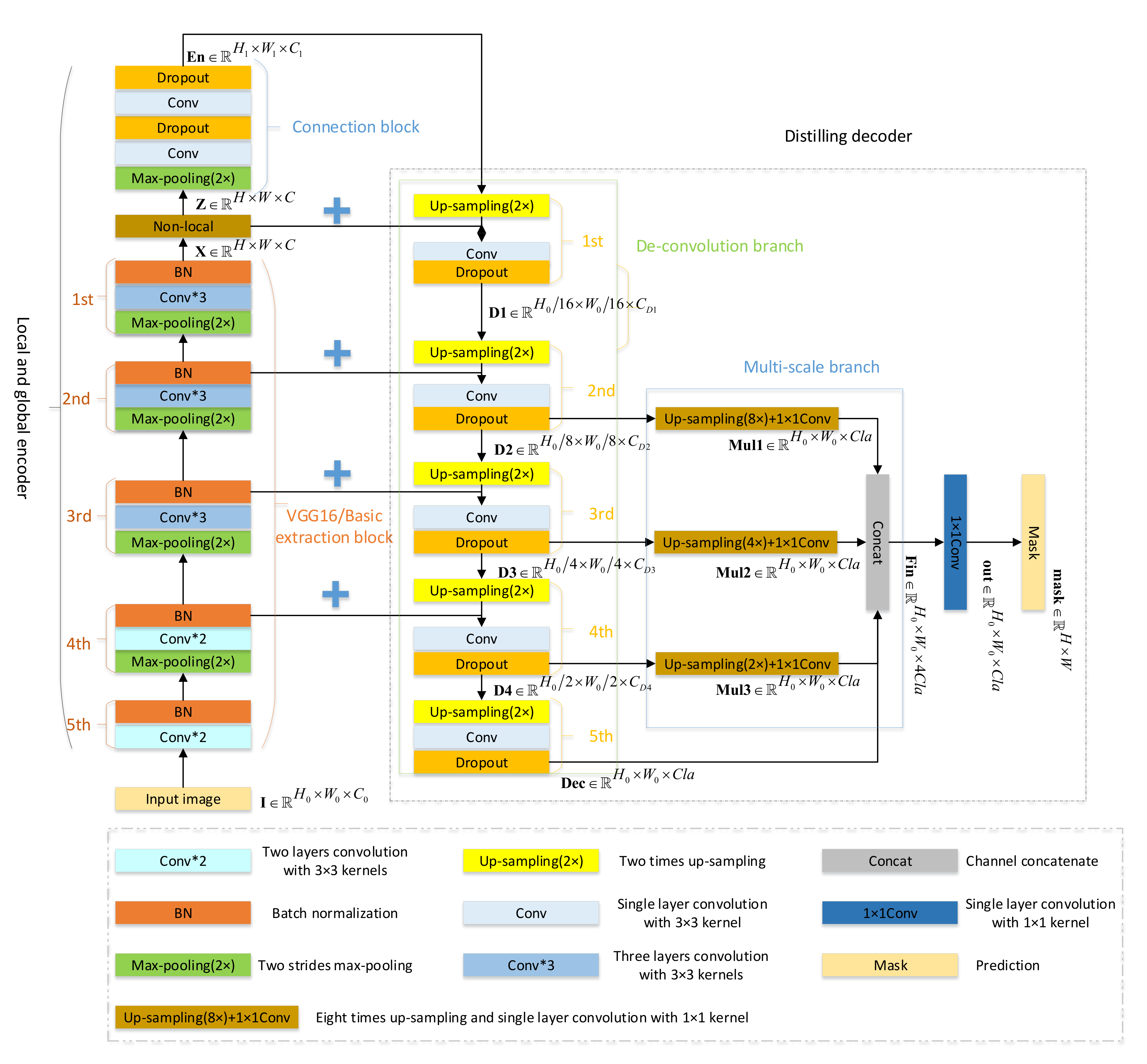
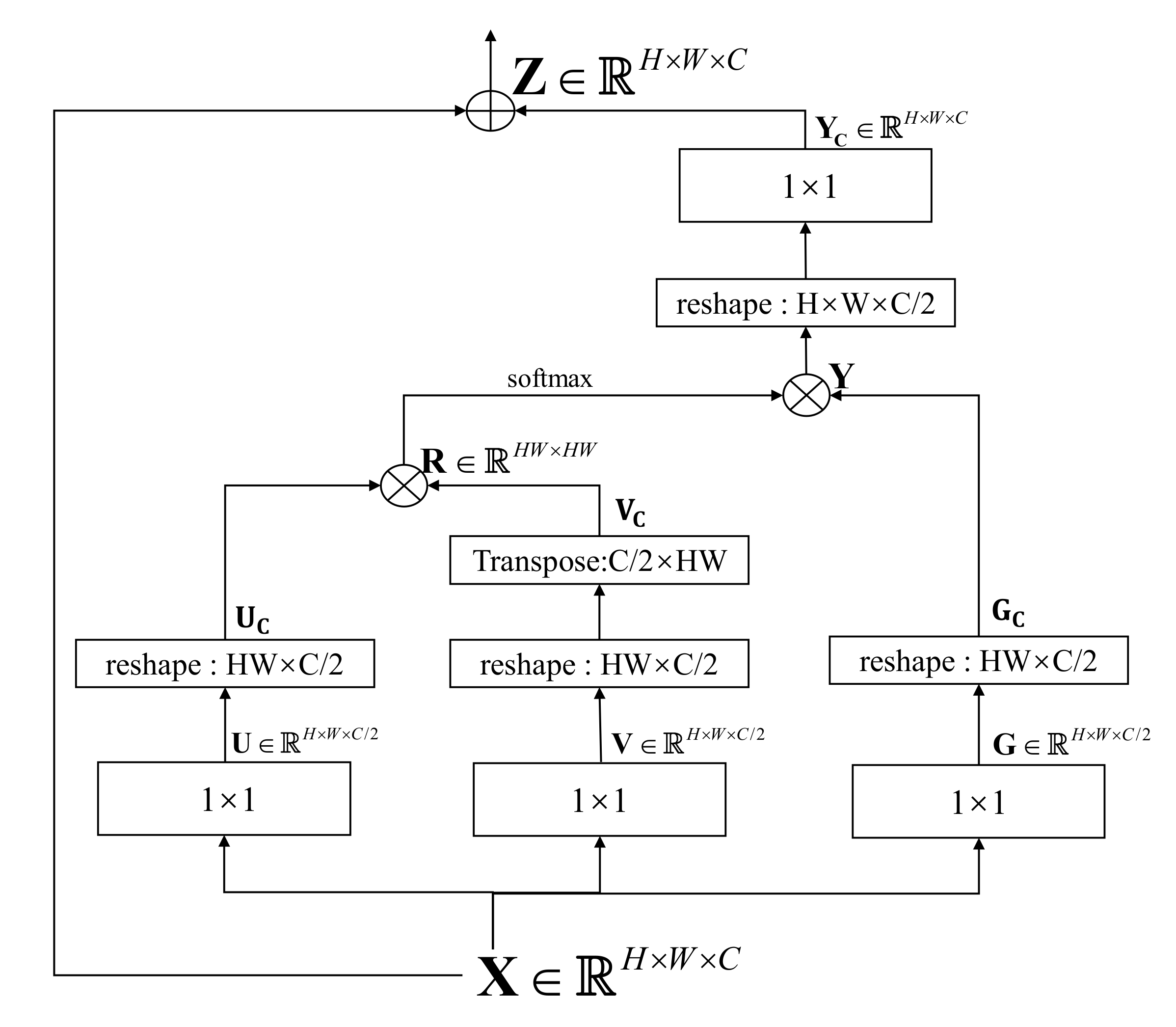
- The proposed GMEDN adopts the encoder-decoder framework with a simple skip connection scheme as the backbone. For the local and global encoder, a VGG16 is used to capture the local information from the aerial images. Based on this, the non-local block is introduced to explore the global information from the aerial images. Combing local and global information, the buildings with diverse shapes can be segmented.
- A distilling decoder is developed for our GMEDN, in which the de-convolution and the multi-scale branches are combined to explore the fundamental and multi-scale information from the aerial building images. Through the de-convolution branch, not only the low-level features (e.g., edge and texture) but also the high-level features (e.g., semantics) can be extracted from the images for segmenting the buildings. We name these features the fundamental information. By the multi-scale branch, the multi-scale information that is used to predict the buildings with different sizes can be captured. Integrating the fundamental and multi-scale information, the buildings with various sizes can be segmented.
2. Related Work
2.1. Semantic Segmentation Architecture
2.2. Aerial Building Extraction
3. Methodology
3.1. Overall Framework
3.2. Local and Global Encoder
3.3. Distilling Decoder
4. Experiments and Discussion
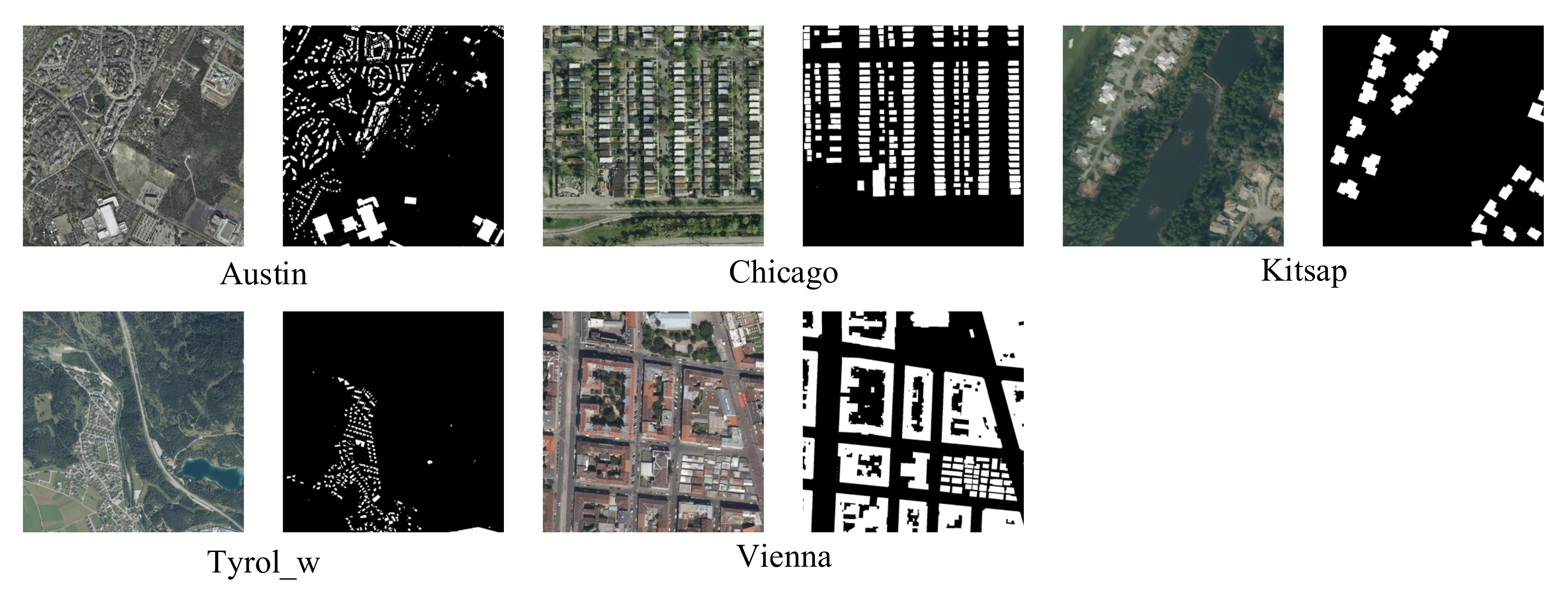
4.1. Datasets Introduction
4.2. Experimental Settings
4.3. Performance of GMEDN
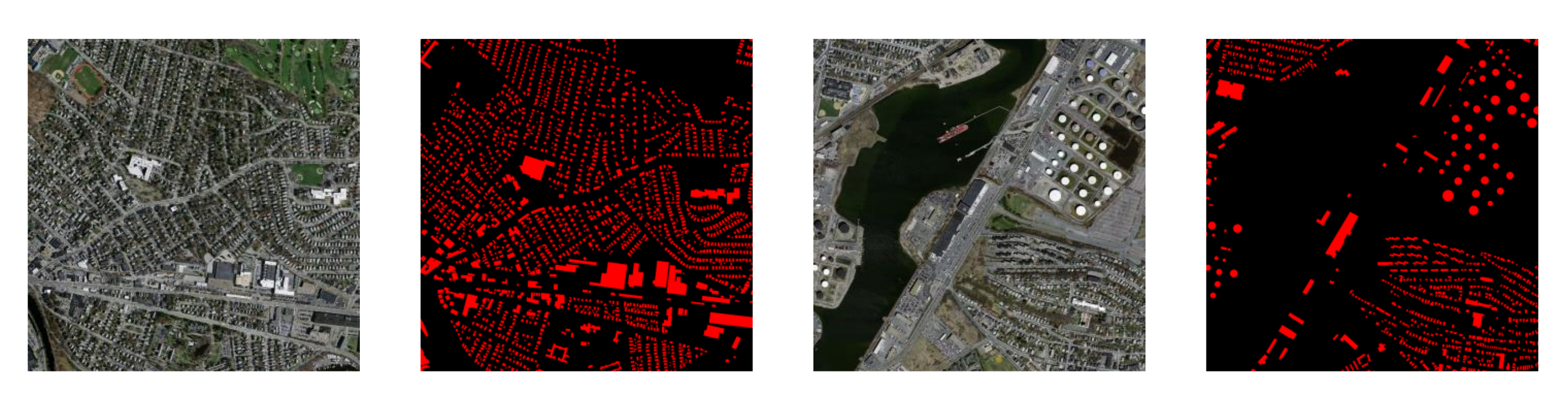
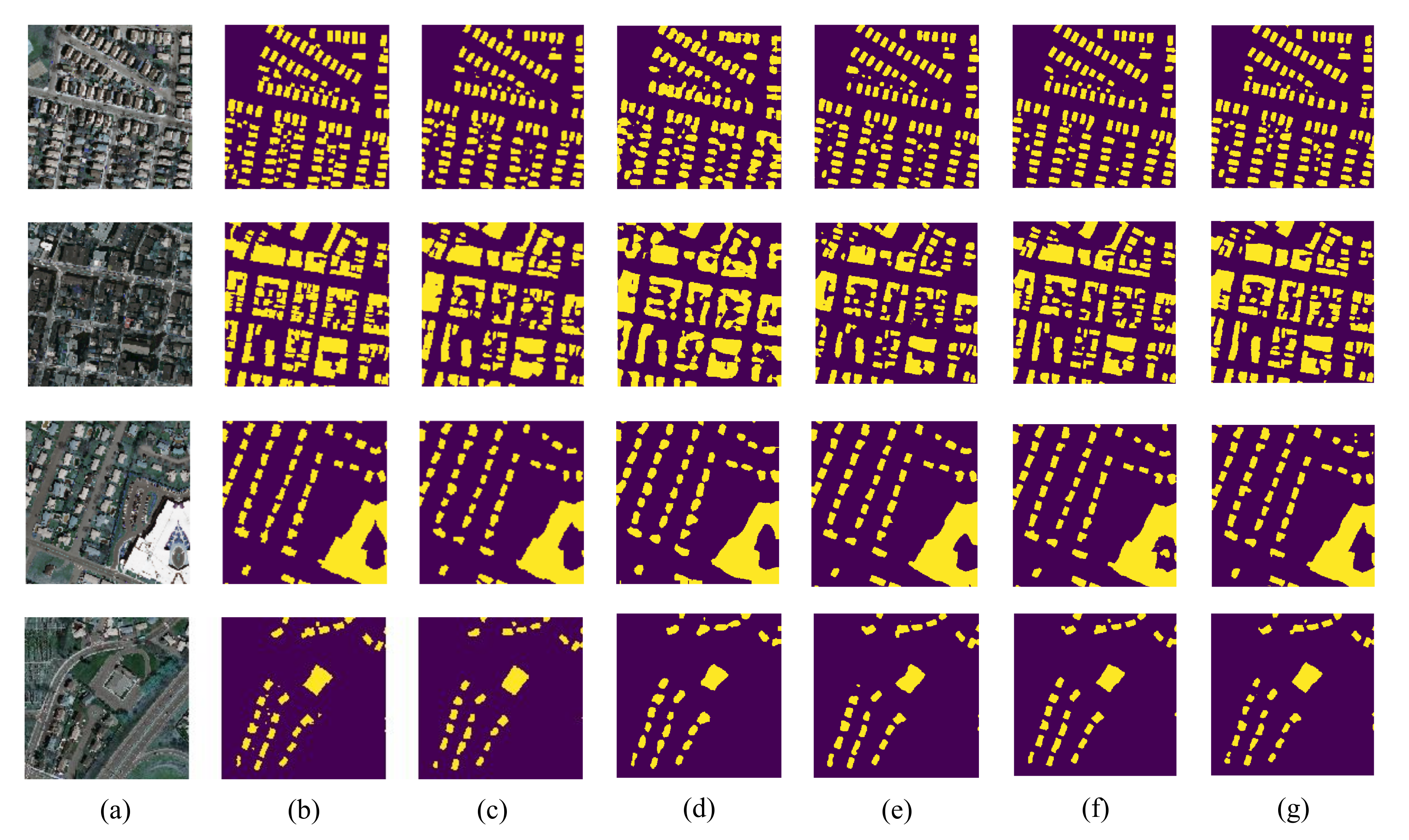
4.3.1. Building Extraction Examples
4.3.2. Comparisons with Different Methods
- Fully convolutional network (FCN). This may be the first general-purpose semantic segmentation network was proposed in 2015 [27]. The network consists of a common classification CNN (e.g., AlextNet [54] and VGG16 [29]) and several de-convolution layers. The CNN aims to learn the high-level features from the images while the deconvolution layers are used to predict the dense labels for pixels. Compared with the traditional methods, its cracking performance attracts scholars’ attention successfully.
- Deep convolutional segmentation network (SegNet). SegNet was introduced in the literature [55], which is an encoder-decoder model. SegNet first selects VGG16 as the encoder for extracting the semantic features. Then, a symmetrical network is established to be the decoder for transforming the low-resolution feature maps into the full input resolution maps and obtaining the segmentation results. Furthermore, a non-linear up-sampling scheme is developed to reduce the difficulty of the model training and generate the sparse decoder maps for the final prediction.
- U-Net with pyramid pooling layers (UNetPPL). The UNetPPL model was introduced in [56] for segmenting the buildings from high-resolution aerial images. By adding the pyramid pooling layers (PPL) in the U-Net [48], not only the shapes but also the global context information of the buildings can be explored, which ensures the segmentation performance.
- Symmetric fully convolutional network with discrete wavelet transform (FCNDWT). Taking the properties of aerial images into account, the FCNDWT model [49] fuses the deep features with the textural features to explore the objects from both spatial and spectral aspects. Furthermore, by introducing DWT into the network, FCNDWT is able to leverage the frequency information to analyze the images.
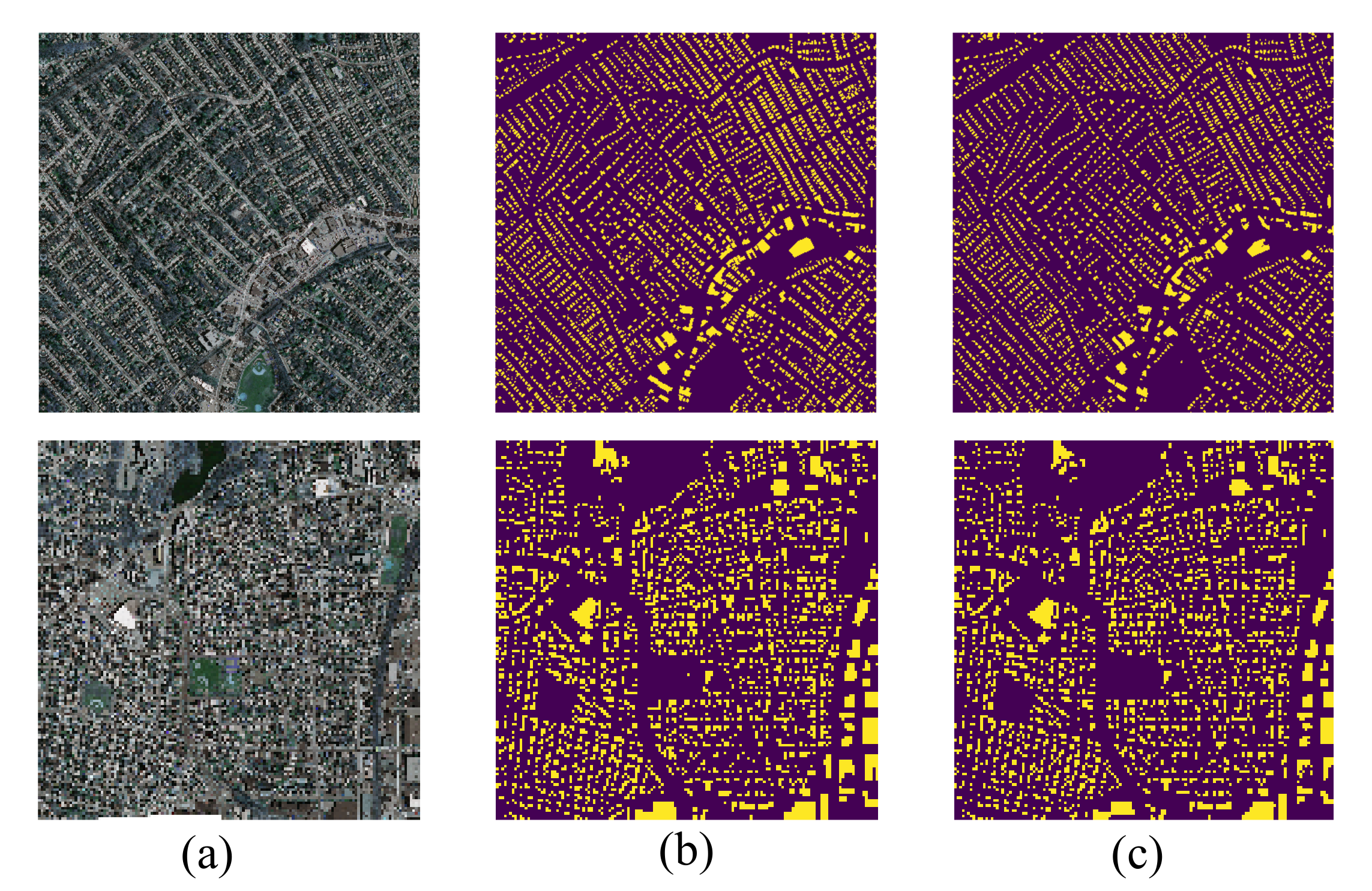
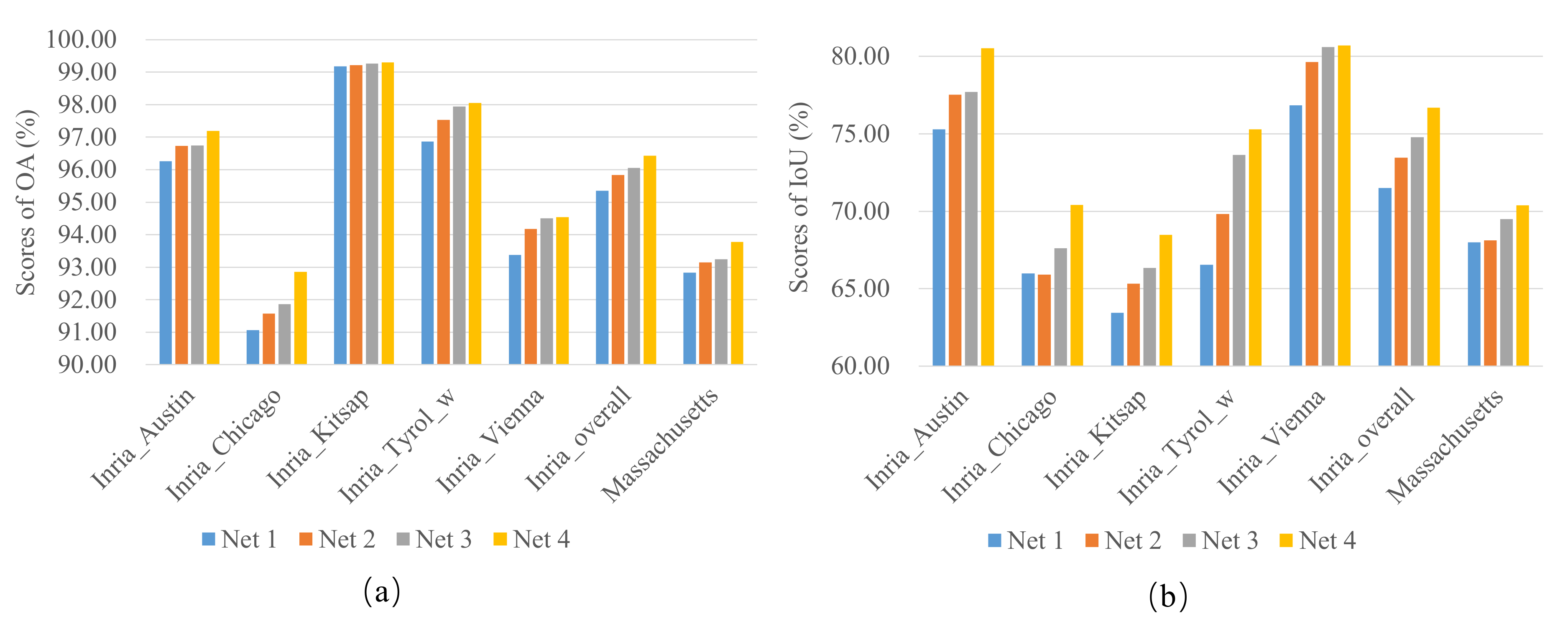
4.4. Ablation Study
- Net 1: Basic encoder-decoder network;
- Net 2: Basic encoder-decoder network + non-local block;
- Net 3: Basic encoder-decoder network + non-local block + connection block;
- Net 4: Basic encoder-decoder network + non-local block + connection block + multi-scale block.
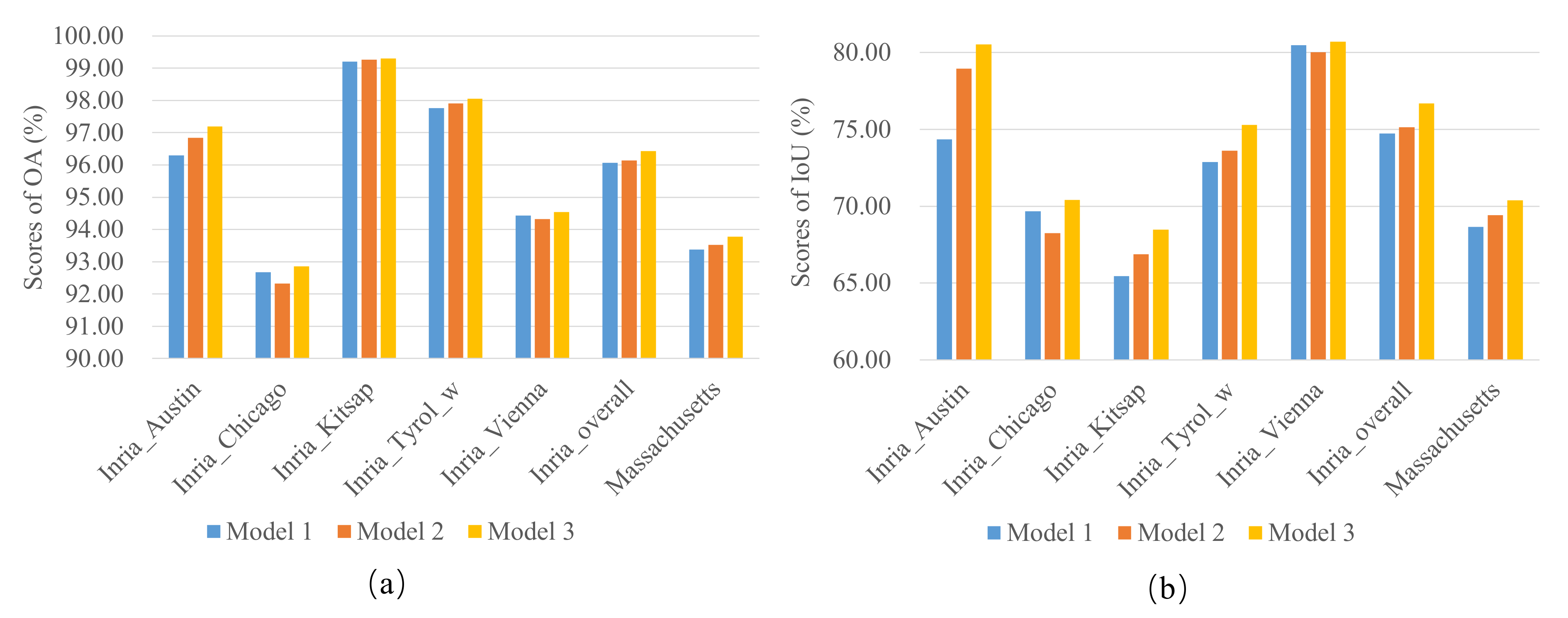
4.5. Robust Study of Non-Local Block
- Model 1: Embedding the non-local block after the third layer of VGG16;
- Model 2: Embedding the non-local block after the fourth layer of VGG16;
- Model 3: Embedding the non-local block after the fifth layer of VGG16.
4.6. Running Time
5. Conclusions
- To extract the local and global information from the aerial images for fully describing the buildings with various shapes, a local and global encoder is developed. It consists of a VGG16, a non-local block, and a connection block. VGG16 is used to learn the local information through several convolutional layers, the non-local block aims at learning global information from the similarities of all pixels, and the connection block further integrates local and global information.
- To explore the fundamental and multi-scale information from the aerial images for capturing the buildings with different sizes, a distilling decoder is developed. It contains a de-convolution branch and a multi-scale branch. The de-convolution branch focuses on learning the buildings’ representation (low- and high-level visual features) under different scales by several de-convolutional layers, and the multi-scale branch aims at fusing them to improve the discrimination of the prediction mask.
- To reduce the information loss caused by the max-pooling (encoder) and the up-sampling (decoder) operations, the simple skip connection is added between the local and global encoder and the distilling decoder.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? The inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Marmanis, D.; Wegner, J.D.; Galliani, S.; Schindler, K.; Datcu, M.; Stilla, U. Semantic segmentation of aerial images with an ensemble of CNNs. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 3, 473. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Liu, C.; Ma, J.; Zhang, X.; Liu, F.; Jiao, L. Large-Scale Remote Sensing Image Retrieval Based on Semi-Supervised Adversarial Hashing. Remote Sens. 2019, 11, 2055. [Google Scholar] [CrossRef] [Green Version]
- Tang, X.; Zhang, X.; Liu, F.; Jiao, L. Unsupervised deep feature learning for remote sensing image retrieval. Remote Sens. 2018, 10, 1243. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Zhu, X.X. RiFCN: Recurrent network in fully convolutional network for semantic segmentation of high resolution remote sensing images. arXiv 2018, arXiv:1805.02091. [Google Scholar]
- Zhang, X.; Ma, W.; Li, C.; Wu, J.; Tang, X.; Jiao, L. Fully Convolutional Network-Based Ensemble Method for Road Extraction From Aerial Images. IEEE Geosci. Remote Sens. Lett. 2019. [Google Scholar] [CrossRef]
- Zhang, X.; Han, X.; Li, C.; Tang, X.; Zhou, H.; Jiao, L. Aerial image road extraction based on an improved generative adversarial network. Remote Sens. 2019, 11, 930. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Vehicle instance segmentation from aerial image and video using a multitask learning residual fully convolutional network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6699–6711. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Rother, C.; Kolmogorov, V.; Blake, A. GrabCut: Interactive foreground extraction using iterated graph cuts. ACM Trans. Graph. (TOG) 2004, 23, 309–314. [Google Scholar] [CrossRef]
- Shotton, J.; Johnson, M.; Cipolla, R. Semantic texton forests for image categorization and segmentation. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Vezhnevets, A.; Ferrari, V.; Buhmann, J.M. Weakly supervised semantic segmentation with a multi-image model. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 643–650. [Google Scholar]
- Thoma, M. A survey of semantic segmentation. arXiv 2016, arXiv:1602.06541. [Google Scholar]
- Li, A.; Bao, X. Extracting image dominant color features based on region growing. In Proceedings of the 2010 International Conference on Web Information Systems and Mining, Sanya, China, 23–24 October 2010; Volume 2, pp. 120–123. [Google Scholar]
- Hong, Z.; Xuanbing, Z. Texture feature extraction based on wavelet transform. In Proceedings of the 2010 International Conference on Computer Application and System Modeling (ICCASM 2010), Taiyuan, China, 22–24 October 2010; Volume 14, pp. V14–V146. [Google Scholar]
- Wang, J.; Xu, Z.; Liu, Y. Texture-based segmentation for extracting image shape features. In Proceedings of the 2013 19th International Conference on Automation and Computing, London, UK, 13–14 September 2013; pp. 1–6. [Google Scholar]
- Cui, S.; Schwarz, G.; Datcu, M. Remote sensing image classification: No features, no clustering. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 5158–5170. [Google Scholar] [CrossRef] [Green Version]
- Hsu, C.W.; Lin, C.J. A comparison of methods for multiclass support vector machines. IEEE Trans. Neural Netw. 2002, 13, 415–425. [Google Scholar] [PubMed] [Green Version]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Hong, X.; Guan, S.U.; Zhao, X.; Xin, H.; Xue, N. Maximum Gaussian mixture model for classification. In Proceedings of the 2016 8th International Conference on Information Technology in Medicine and Education (ITME), Fuzhou, China, 23–25 December 2016; pp. 587–591. [Google Scholar]
- Kuang, P.; Cao, W.N.; Wu, Q. Preview on structures and algorithms of deep learning. In Proceedings of the 2014 11th International Computer Conference on Wavelet Actiev Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 19–21 December 2014; pp. 176–179. [Google Scholar]
- Chen, X.; Xiang, S.; Liu, C.L.; Pan, C.H. Vehicle detection in satellite images by hybrid deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- Nguyen, K.; Fookes, C.; Sridharan, S. Improving deep convolutional neural networks with unsupervised feature learning. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 2270–2274. [Google Scholar]
- He, T.; Huang, W.; Qiao, Y.; Yao, J. Text-attentional convolutional neural network for scene text detection. IEEE Trans. Image Process. 2016, 25, 2529–2541. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wang, Y.; Chen, Q.; Zhu, Q.; Liu, L.; Li, C.; Zheng, D. A survey of mobile laser scanning applications and key techniques over urban areas. Remote Sens. 2019, 11, 1540. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-scnn: Gated shape cnns for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 5229–5238. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6409–6418. [Google Scholar]
- Alshehhi, R.; Marpu, P.R.; Woon, W.L.; Dalla Mura, M. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Shrestha, S.; Vanneschi, L. Improved fully convolutional network with conditional random fields for building extraction. Remote Sens. 2018, 10, 1135. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Yuan, J. Learning building extraction in aerial scenes with convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2793–2798. [Google Scholar] [CrossRef]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gross, L.; Li, Z.; Li, X.; Fan, X.; Qi, W. Automatic building extraction on high-resolution remote sensing imagery using deep convolutional encoder-decoder with spatial pyramid pooling. IEEE Access 2019, 7, 128774–128786. [Google Scholar] [CrossRef]
- Xie, Y.; Zhu, J.; Cao, Y.; Feng, D.; Hu, M.; Li, W.; Zhang, Y.; Fu, L. Refined Extraction of Building Outlines from High-resolution Remote Sensing Imagery Based on a Multifeature Convolutional Neural Network and Morphological Filtering. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1842–1855. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Swizerland, 2015; pp. 234–241. [Google Scholar]
- Azimi, S.M.; Fischer, P.; Körner, M.; Reinartz, P. Aerial LaneNet: Lane-marking semantic segmentation in aerial imagery using wavelet-enhanced cost-sensitive symmetric fully convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2920–2938. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling; University of Toronto: Toronto, ON, Canada, 2013. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Singh, P.; Komodakis, N. Effective Building Extraction by Learning to Detect and Correct Erroneous Labels in Segmentation Mask. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1288–1291. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.H.; Lee, H.; Hong, S.J.; Kim, S.; Park, J.; Hwang, J.Y.; Choi, J.P. Objects segmentation from high-resolution aerial images using U-Net with pyramid pooling layers. IEEE Geosci. Remote Sens. Lett. 2018, 16, 115–119. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Austin | Chicago | Kitsap | Tyrol_w | Vienna | Overall | |
|---|---|---|---|---|---|---|---|
| IoU | GMEDN | 80.53 | 70.42 | 68.47 | 75.29 | 80.72 | 76.69 |
| FCN | 76.44 | 67.28 | 66.05 | 71.25 | 75.43 | 72.33 | |
| SegNet | 78.46 | 68.37 | 60.29 | 59.61 | 78.37 | 72.83 | |
| UNetPPL | 80.04 | 67.40 | 64.83 | 61.61 | 78.87 | 73.33 | |
| FCNDWT | 78.34 | 69.99 | 65.41 | 73.19 | 79.70 | 75.30 | |
| OA | GMEDN | 97.19 | 92.86 | 99.30 | 98.05 | 94.54 | 96.43 |
| FCN | 96.56 | 91.90 | 99.24 | 97.44 | 93.01 | 95.63 | |
| SegNet | 96.84 | 92.28 | 99.15 | 96.73 | 93.76 | 95.75 | |
| UNetPPL | 97.13 | 91.96 | 99.23 | 97.00 | 93.90 | 95.84 | |
| FCNDWT | 96.85 | 92.70 | 99.22 | 97.86 | 94.26 | 96.17 |
| GMEDN | FCN | SegNet | UNetPPL | FCNDWT | |
|---|---|---|---|---|---|
| OA | 93.78 | 92.66 | 92.56 | 92.98 | 93.30 |
| IoU | 70.39 | 66.50 | 63.43 | 65.65 | 67.96 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Wu, L.; Tang, X.; Liu, F.; Zhang, X.; Jiao, L. Building Extraction of Aerial Images by a Global and Multi-Scale Encoder-Decoder Network. Remote Sens. 2020, 12, 2350. https://doi.org/10.3390/rs12152350
Ma J, Wu L, Tang X, Liu F, Zhang X, Jiao L. Building Extraction of Aerial Images by a Global and Multi-Scale Encoder-Decoder Network. Remote Sensing. 2020; 12(15):2350. https://doi.org/10.3390/rs12152350
Chicago/Turabian StyleMa, Jingjing, Linlin Wu, Xu Tang, Fang Liu, Xiangrong Zhang, and Licheng Jiao. 2020. "Building Extraction of Aerial Images by a Global and Multi-Scale Encoder-Decoder Network" Remote Sensing 12, no. 15: 2350. https://doi.org/10.3390/rs12152350
APA StyleMa, J., Wu, L., Tang, X., Liu, F., Zhang, X., & Jiao, L. (2020). Building Extraction of Aerial Images by a Global and Multi-Scale Encoder-Decoder Network. Remote Sensing, 12(15), 2350. https://doi.org/10.3390/rs12152350