Improved Anchor-Free Instance Segmentation for Building Extraction from High-Resolution Remote Sensing Images



Abstract
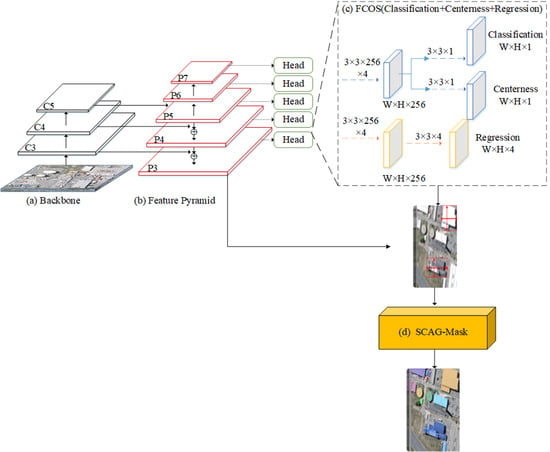
:
1. Introduction
- An improved anchor-free instance segmentation architecture is proposed for building extraction from high-resolution remote sensing images, which is composed of an efficient one-stage anchor-free object detector FCOS [33] and a novel spatial and channel attention-guided mask branch.
- Besides, we design a more effective backbone network by improving VoVNetV2 that is designed in Reference [37], and receives better performance than ResNet and VoVNetV2.
- In order to improve the segmentation performance of CenterMask, we also develop the mask branch in CenterMask. A spatial and channel attention-guided mask (SCAG-Mask) branch is designed in this paper to effectively optimize the building extraction behavior.
2. Methods
2.1. Improved VoVNetV2
2.2. FCOS
2.3. Spatial and Channel Attention-Guided Mask
2.4. Multi-Task Loss
3. Dataset and Evaluation Metrics
3.1. Dataset Description
3.2. Evaluation Metrics
4. Results and Discussion
4.1. Parameter Setting Experiments
4.2. Comparison with State-of-the-Art Methods
4.3. Usability Analysis in Practical Application
5. Conclusions
Funding
Conflicts of Interest
References
- Ding, Z.; Wang, X.; Li, Y.; Zhang, S. Study on Building Extraction from High-Resolution Images Using Mbi. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci 2018, 42, 283–287. [Google Scholar] [CrossRef] [Green Version]
- Shinohara, T.; Xiu, H.; Matsuoka, M. FWNet: Semantic Segmentation for Full-Waveform LiDAR Data Using Deep Learning. Sensors 2020, 20, 3568. [Google Scholar] [CrossRef]
- Colaninno, N.; Roca, J.; Pfeffer, K. An automatic classification of urban texture: Form and compactness of morphological homogeneous structures in Barcelona. In Proceedings of the 51st Congress of the European Regional Science Association: New Challenges for European Regions and Urban Areas in a Globalised World, Barcelona, Spain, 30 August–3 September 2011. [Google Scholar]
- Hermosilla, T.; Palomar-Vázquez, J.; Balaguer-Beser, Á.; Balsa-Barreiro, J.; Ruiz, L.A. Using street based metrics to characterize urban typologies. Comput. Environ. Urban Syst. 2014, 44, 68–79. [Google Scholar] [CrossRef] [Green Version]
- Van de Voorde, T.; Jacquet, W.; Canters, F. Mapping form and function in urban areas: An approach based on urban metrics and continuous impervious surface data. Landsc. Urban Plan. 2011, 102, 143–155. [Google Scholar] [CrossRef]
- Huertas, A.; Nevatia, R. Detecting buildings in aerial images. Comput. Vision Graph. Image Process. 1988, 41, 131–152. [Google Scholar] [CrossRef]
- Irvin, R.B.; McKeown, D.M. Methods for exploiting the relationship between buildings and their shadows in aerial imagery. IEEE Trans. Syst. Man Cybern. 1989, 19, 1564–1575. [Google Scholar] [CrossRef] [Green Version]
- Inglada, J. Automatic recognition of man-made objects in high resolution optical remote sensing images by SVM classification of geometric image features. ISPRS J. Photogramm. Remote. Sens. 2007, 62, 236–248. [Google Scholar] [CrossRef]
- Meng, Y.; Peng, S. Object-oriented building extraction from high-resolution imagery based on fuzzy SVM. In Proceedings of the 2009 International Conference on Information Engineering and Computer Science, Wuhan, China, 19–20 December 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–6. [Google Scholar]
- Awrangjeb, M.; Zhang, C.; Fraser, C.S. Automatic extraction of building roofs using LIDAR data and multispectral imagery. ISPRS J. Photogramm. Remote. Sens. 2013, 83, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Awrangjeb, M.; Fraser, C.S. Automatic segmentation of raw LiDAR data for extraction of building roofs. Remote Sens. 2014, 6, 3716–3751. [Google Scholar] [CrossRef] [Green Version]
- Gilani, S.A.N.; Awrangjeb, M.; Lu, G. Segmentation of airborne point cloud data for automatic building roof extraction. Gisci. Remote Sens. 2018, 55, 63–89. [Google Scholar] [CrossRef] [Green Version]
- Gilani, S.A.N.; Awrangjeb, M.; Lu, G. An automatic building extraction and regularisation technique using lidar point cloud data and orthoimage. Remote Sens. 2016, 8, 258. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building Extraction in Very High Resolution Remote Sensing Imagery Using Deep Learning and Guided Filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, S.; Vanneschi, L. Improved fully convolutional network with conditional random fields for building extraction. Remote Sens. 2018, 10, 1135. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Yao, X.; Fang, Y. Building-A-Nets: Robust Building Extraction from High-Resolution Remote Sensing Images with Adversarial Networks. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3680–3687. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach City, CA, USA, 16–20 June 2019; pp. 6409–6418. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving Into High Quality Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z.X. Scale-Aware Trident Networks for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6053–6062. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9156–9165. [Google Scholar]
- Potlapally, A.; Chowdary, P.S.R.; Shekhar, S.R.; Mishra, N.; Madhuri, C.S.V.D.; Prasad, A. Instance Segmentation in Remote Sensing Imagery using Deep Convolutional Neural Networks. In Proceedings of the 2019 International Conference on contemporary Computing and Informatics (IC3I), Singapore, 12–14 December 2019; pp. 117–120. [Google Scholar]
- Ji, S.; Shen, Y.; Lu, M.; Zhang, Y. Building instance change detection from large-scale aerial images using convolutional neural networks and simulated samples. Remote Sens. 2019, 11, 1343. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Mou, L.; Hua, Y.; Sun, Y.; Jin, P.; Shi, Y.; Zhu, X.X. Instance segmentation of buildings using keypoints. arXiv 2020, arXiv:2006.03858. [Google Scholar]
- Su, H.; Wei, S.; Liu, S.; Liang, J.; Wang, C.; Shi, J.; Zhang, X. HQ-ISNet: High-Quality Instance Segmentation for Remote Sensing Imagery. Remote Sens. 2020, 12, 989. [Google Scholar] [CrossRef] [Green Version]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. Int. J. Comput. Vis. 2020, 128, 642–656. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation. In Proceedings of the CVPR 2020: Computer Vision and Pattern Recognition, Virtual, Seattle, WA, USA, 14–19 June 2020; pp. 8573–8581. [Google Scholar]
- Lee, Y.; Park, J. CenterMask: Real-Time Anchor-Free Instance Segmentation. In Proceedings of the CVPR 2020: Computer Vision and Pattern Recognition, Virtual, Seattle, WA, USA, 14–19 June 2020; pp. 13906–13915. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lee, Y.; Hwang, J.W.; Lee, S.; Bae, Y.; Park, J. An energy and gpu-computation efficient backbone network for real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach City, CA, USA, 16–20 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction From an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Suzuki, S.; Abe, K. Topological Structural Analysis of Digitized Binary Images by Border Following. Graph. Model. Graph. Model. Image Process. Comput. Vis. Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Setting Details |
|---|---|
| No. of FILTERS | |
| BATCH SIZE | 8 |
| EPOCHS | 200 |
| WEIGHT DECAY | 0.0001 |
| MOMENTUM | 0.9 |
| WARMUP_FACTOR | 0.333 |
| WARMUP_ITERS | 500 |
| POOLER_ScALES | (0.125, 0.0625, 0.03125) |
| POOLER_SAMPLING_RATIO | 2.0 |
| POOLER_RESOLUTION | 14 |
| FPN_STRIDES | [8, 16, 32, 64, 128] |
| FCOS_CENTER_SAMPLE_POS_RADIUS | 1.5 |
| FOCAL_LOSS_ALPHA | 0.25 |
| FOCAL_LOSS_GAMMA | 2.0 |
| Feature Extraction Network | Learning Rate | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ResNet101 | 0.01 | 0.6444 | 0.4483 | 0.8142 | 0.7344 | 0.6085 | 0.4009 | 0.7758 | 0.7672 |
| ResNet101 | 0.005 | 0.6544 | 0.4552 | 0.8285 | 0.747 | 0.6116 | 0.3972 | 0.7836 | 0.7725 |
| ResNet101 | 0.0001 | 0.629 | 0.4287 | 0.8047 | 0.6741 | 0.5981 | 0.3884 | 0.7694 | 0.7311 |
| VoVNetV2-57 | 0.0005 | 0.6773 | 0.4869 | 0.8436 | 0.7205 | 0.6272 | 0.4234 | 0.7933 | 0.7323 |
| VoVNetV2-57 | 0.001 | 0.6799 | 0.4915 | 0.8451 | 0.7208 | 0.6296 | 0.4274 | 0.7959 | 0.7437 |
| Model | ||||||||
|---|---|---|---|---|---|---|---|---|
| CenterMask with VoVNetV2-57 | 0.6799 | 0.4915 | 0.8451 | 0.7208 | 0.6296 | 0.4274 | 0.7959 | 0.7437 |
| CenterMask with improved VoVNetV2-57(ours) | 0.6847 | 0.4923 | 0.846 | 0.7365 | 0.6307 | 0.4279 | 0.7969 | 0.7542 |
| CenterMask with SCAG-Mask(ours) | 0.6778 | 0.488 | 0.8434 | 0.7296 | 0.631 | 0.4269 | 0.7985 | 0.7561 |
| CenterMask with improved VoVNetV2-57+SCAG-Mask(ours) | 0.6841 | 0.492 | 0.8444 | 0.7377 | 0.6342 | 0.4309 | 0.7992 | 0.7574 |
| Method | Average Detection Time (ms) | GPU | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN | 0.6585 | 0.5049 | 0.789 | 0.7121 | 0.6384 | 0.4663 | 0.771 | 0.7468 | 69.49 | Xp |
| Mask scoring R-CNN | 0.6604 | 0.5058 | 0.7881 | 0.7124 | 0.6451 | 0.4705 | 0.7806 | 0.756 | 72.83 | Xp |
| CenterMask | 0.6799 | 0.4915 | 0.8451 | 0.7208 | 0.6296 | 0.4274 | 0.7959 | 0.7437 | 49.88 | Xp |
| Improved CenterMask | 0.6841 | 0.492 | 0.8444 | 0.7377 | 0.6342 | 0.4309 | 0.7992 | 0.7574 | 49.88 | Xp |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, T.; Hu, Y.; Peng, L.; Chen, R. Improved Anchor-Free Instance Segmentation for Building Extraction from High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 2910. https://doi.org/10.3390/rs12182910
Wu T, Hu Y, Peng L, Chen R. Improved Anchor-Free Instance Segmentation for Building Extraction from High-Resolution Remote Sensing Images. Remote Sensing. 2020; 12(18):2910. https://doi.org/10.3390/rs12182910
Chicago/Turabian StyleWu, Tong, Yuan Hu, Ling Peng, and Ruonan Chen. 2020. "Improved Anchor-Free Instance Segmentation for Building Extraction from High-Resolution Remote Sensing Images" Remote Sensing 12, no. 18: 2910. https://doi.org/10.3390/rs12182910
APA StyleWu, T., Hu, Y., Peng, L., & Chen, R. (2020). Improved Anchor-Free Instance Segmentation for Building Extraction from High-Resolution Remote Sensing Images. Remote Sensing, 12(18), 2910. https://doi.org/10.3390/rs12182910