Flood Detection and Susceptibility Mapping Using Sentinel-1 Remote Sensing Data and a Machine Learning Approach: Hybrid Intelligence of Bagging Ensemble Based on K-Nearest Neighbor Classifier

 ,
,  ,
,  , ,
, ,  ,
,  ,
,  , ,
, ,  ,
,
Abstract
:
1. Introduction
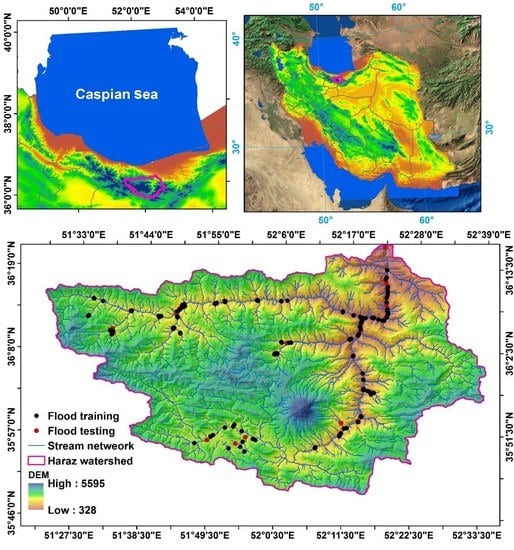
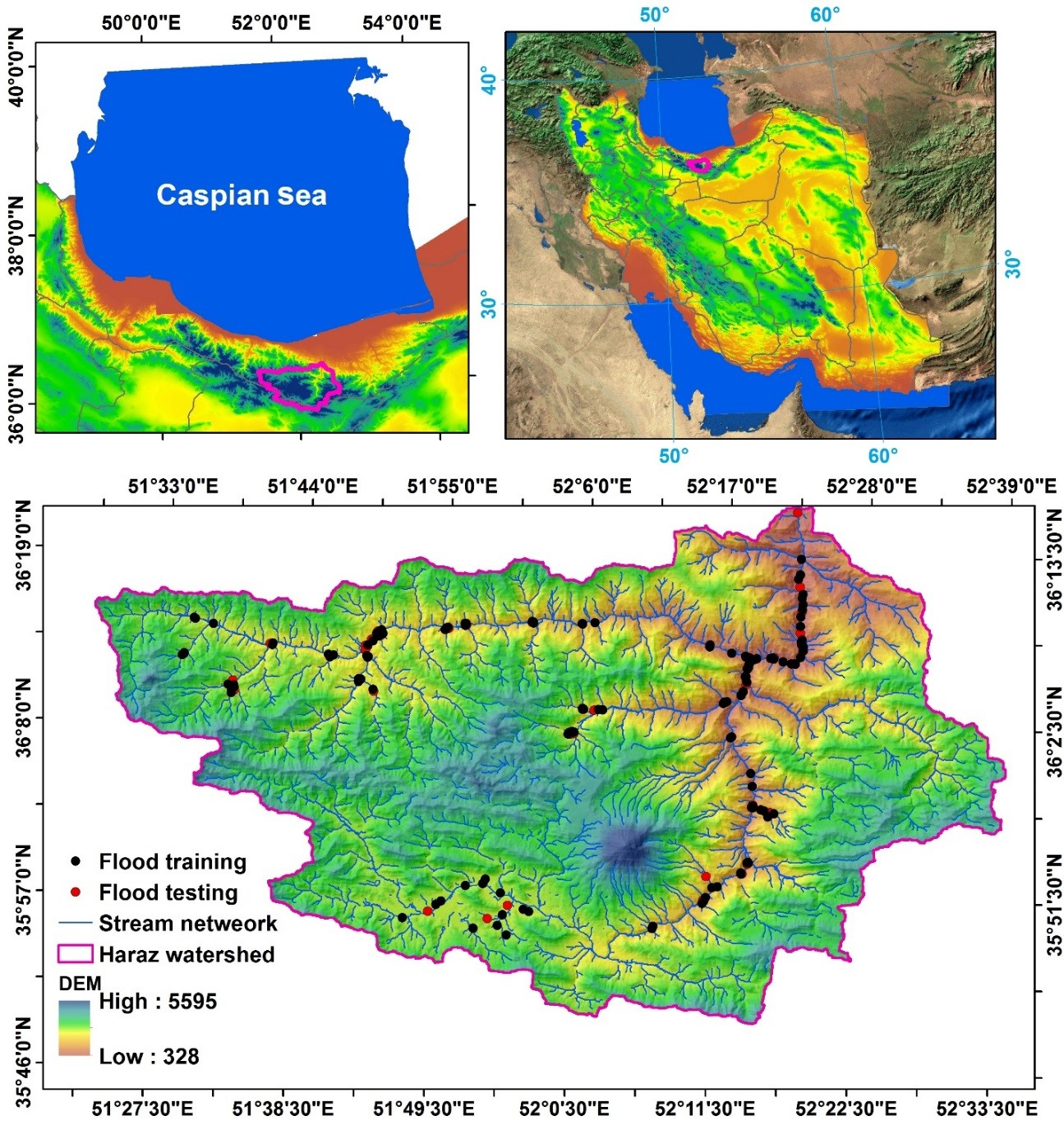
2. Description of Study Area
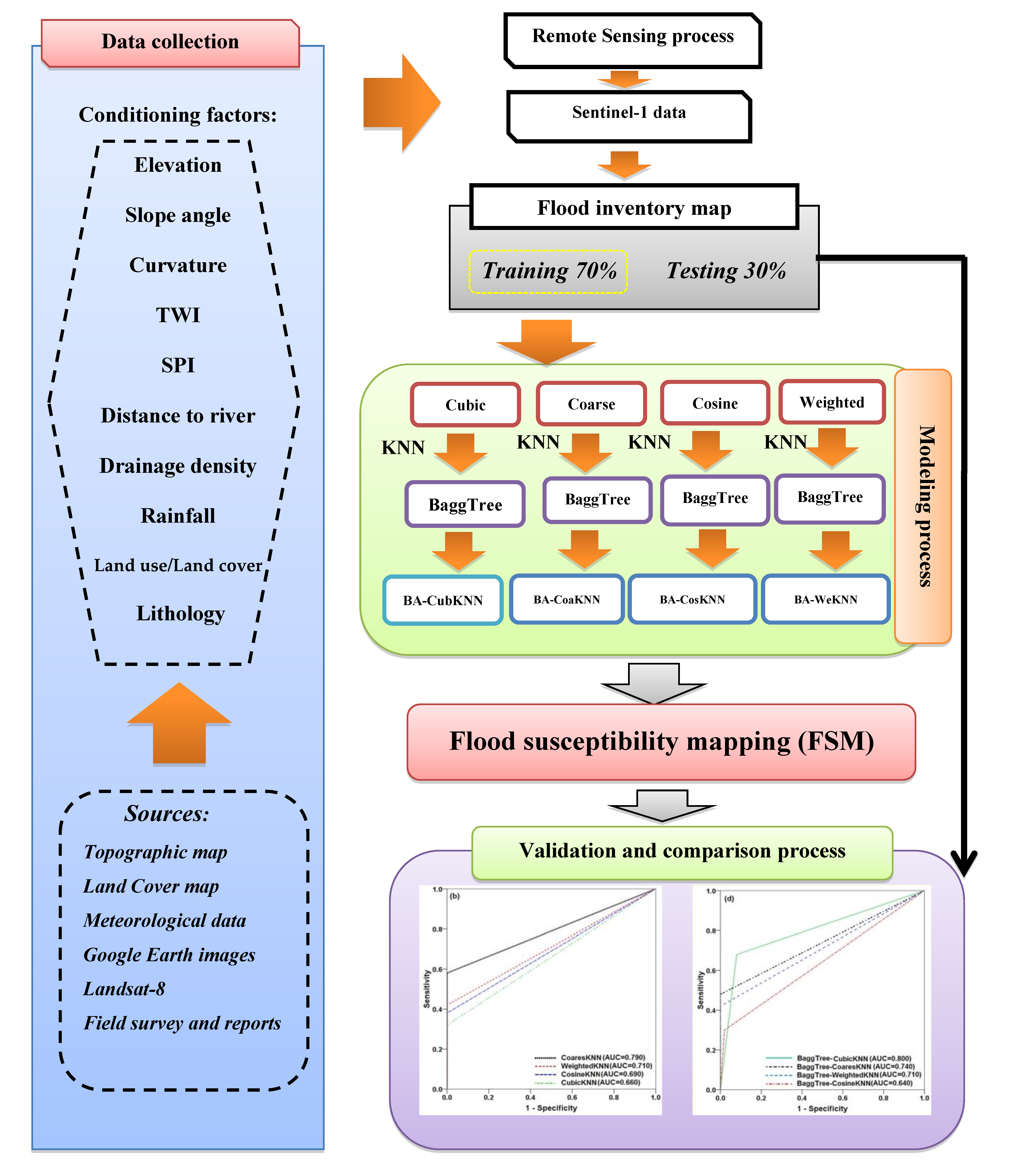
3. Methodology
3.1. Data Acquisition
3.1.1. Flood Inventory Map
3.1.2. Flood Conditioning Factors
Slope
Elevation
Curvature
Stream Power Index
Topographic Wetness Index
Lithology
Rainfall
Land Use/Land Cover
River Density
Distance to River
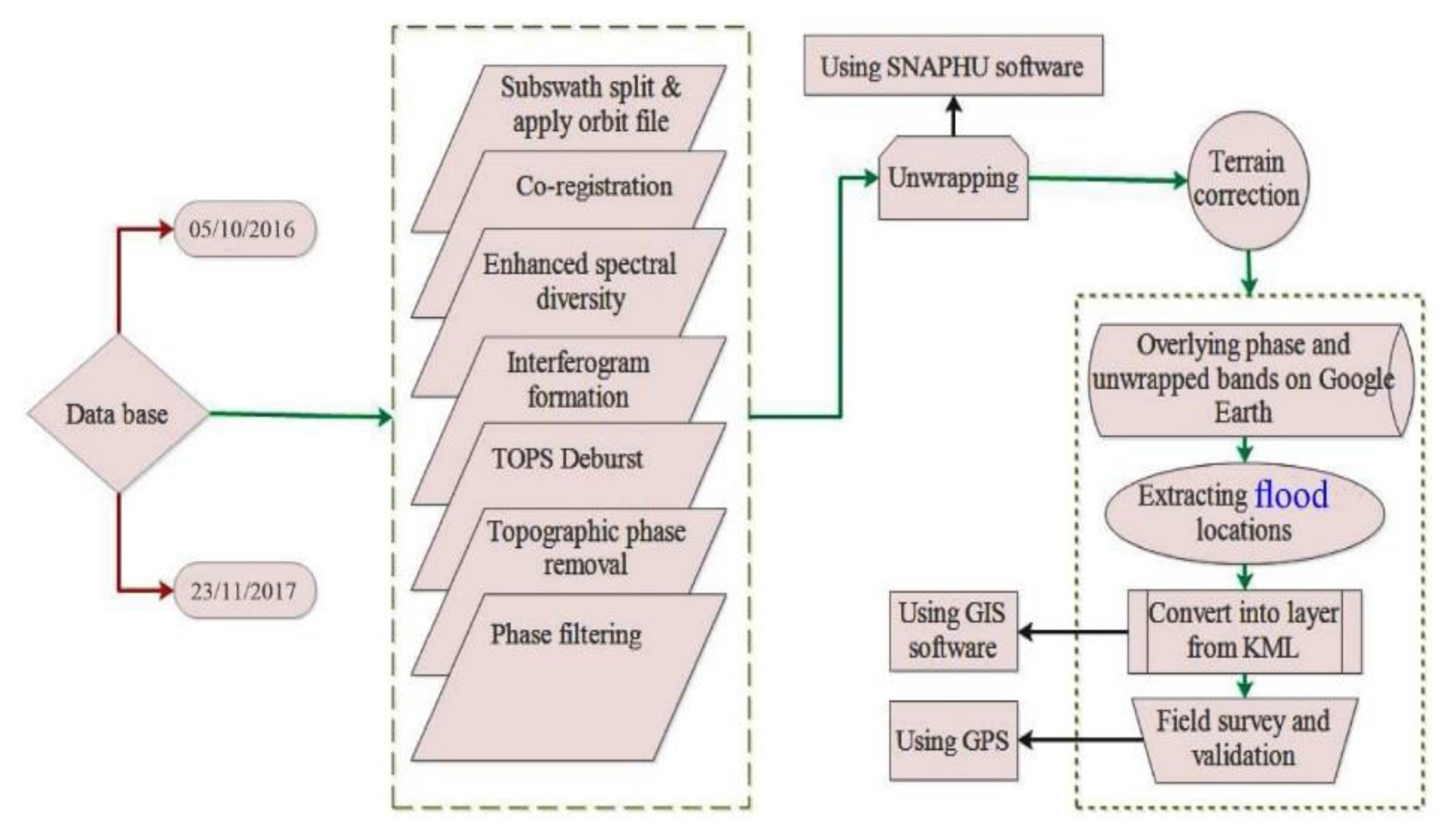
3.2. Detection of Flood-Prone Area by Sentinel-1
Data Preprocessing and Processing
3.3. Background of Flood Susceptibility Models
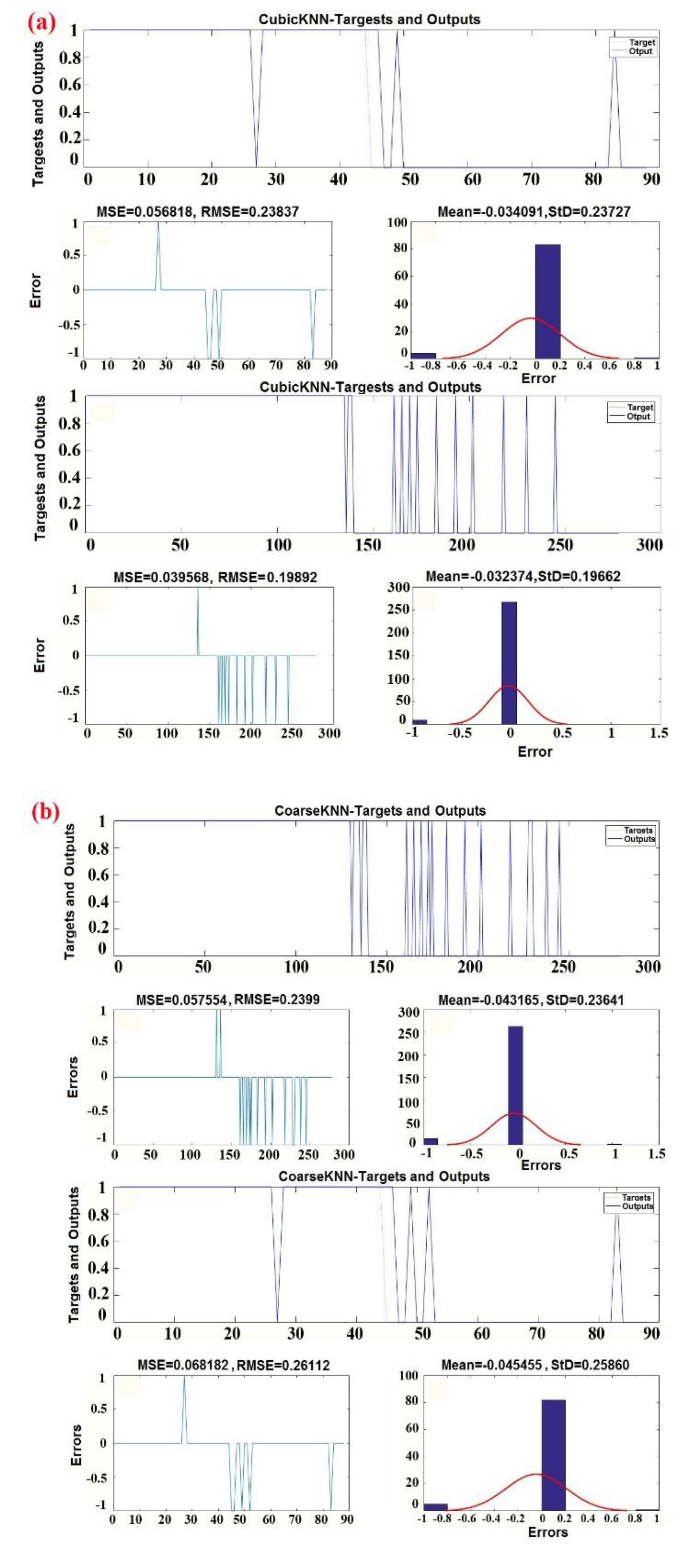
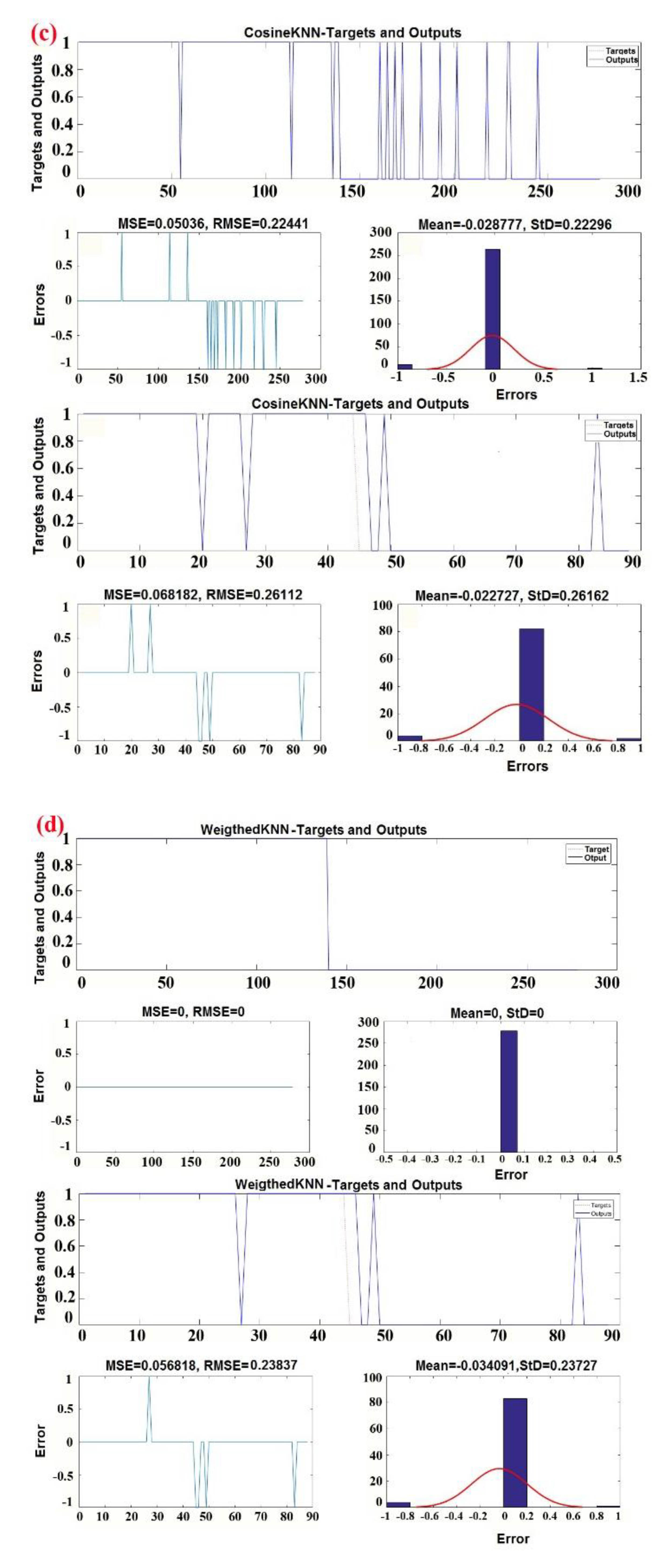
3.3.1. K-Nearest Neighbor Classifier
- There are typically only a few probable choices of K (e.g., from 3–10 or 50–100).
- The K-fold CV offers a greater computational advantage than other methods.
- The K-fold CV yields more accurate estimates of the test error than bootstrapping and LOOCV.
- Coarse KNN: The number of neighbors is 100. The classifier is defined as the nearest neighbor among all classes.
- Cosine KNN: The cosine distance metric is the nearest neighbor classifier. It is generally used as a metric for distances when vector magnitudes are irrelevant. The following equation is used to measure the distance between two vectors, u and v [113]:
- Cubic KNN: The number of neighbors is 10, and the cubic distance metric is the nearest neighbor classifier [109]. The following equation is used to measure the distance between two n-dimensional vectors, u and v:
- Weighted KNN: The number of neighbors is 10, and the weighted Euclidean distance is used as the nearest neighbor classifier. The following equation is used to measure the weighted Euclidean distance between two n-dimensional vectors, u and v:where 0 < < 1 and .
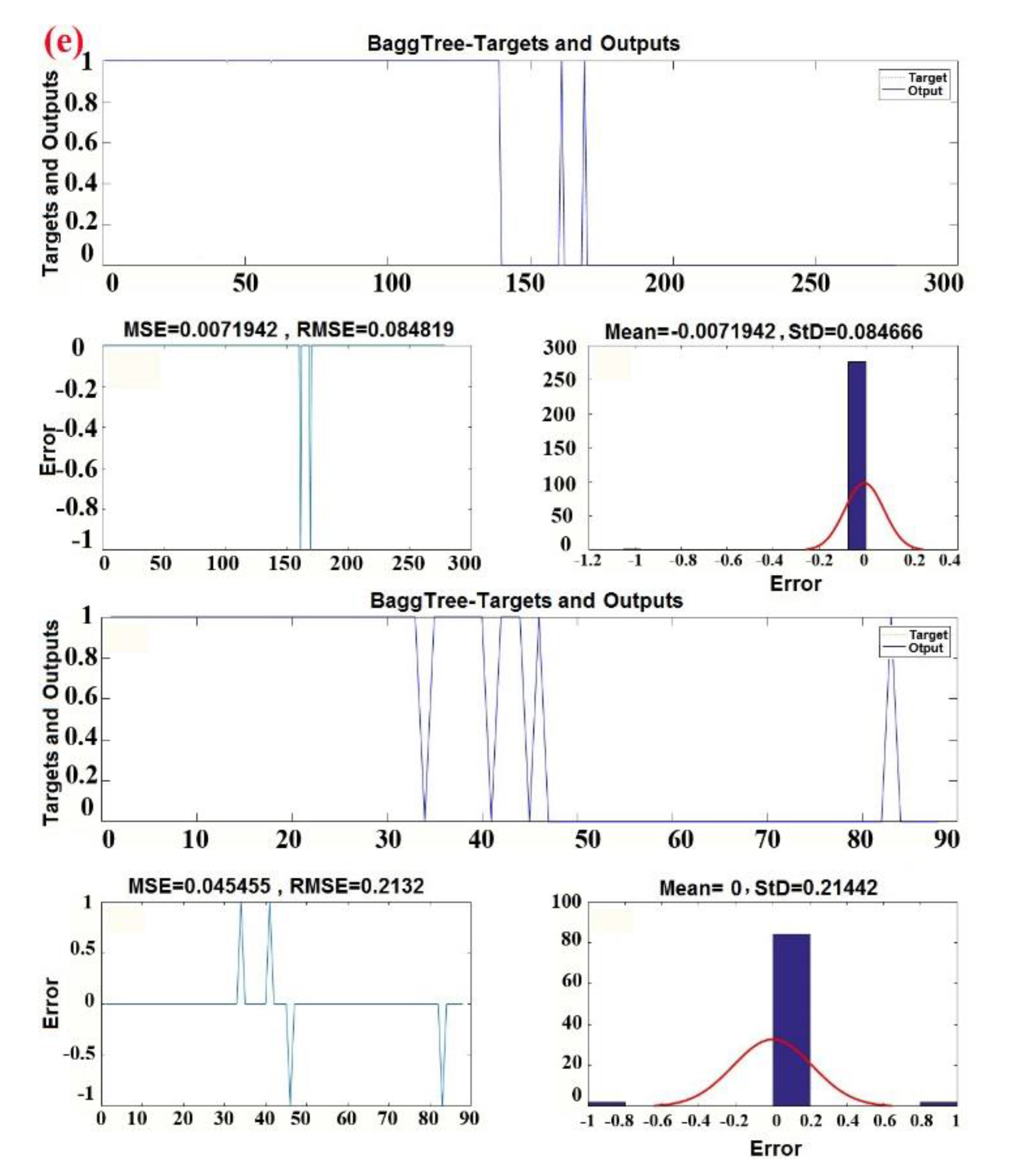
3.3.2. Bagged Tree Ensemble Algorithm
- Training set D initialization.
- Range selection for m = 1, …, M.
- 2.1.
- Random selection of the set D to create a new set .
- 2.2.
- Machine-learning application on the base of to train a classifier .
- Creation of a composite classifier H from .
- 3.1.
- classification based on classes, depending on the number of votes gained from
3.3.3. Proposed New Ensemble Machine Learning Models of Bagging with KNNs Functions
3.3.4. Flood Factor Selection Using the Relief Attribute Evaluation (RFAE) Technique
3.4. Evaluation and Comparison
4. Result and Analysis
4.1. Flood Detection Using AIRSAR and Optical Satellite Images
4.2. The Most Important Factors for Flood Modelling
4.3. Flood Modelling Process
4.4. Development of Flood Susceptibility Maps
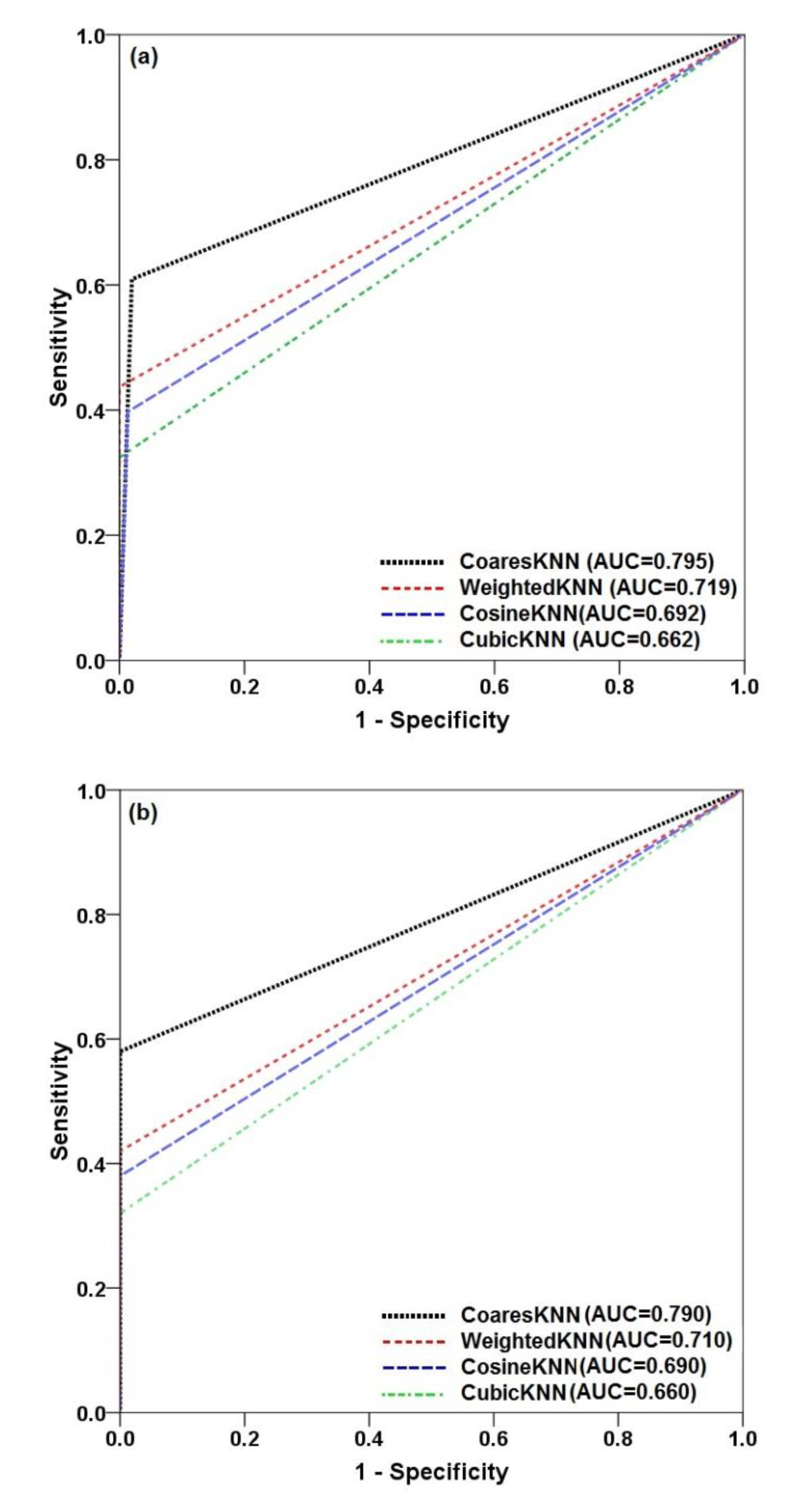
4.5. Evaluation and Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hirabayashi, Y.; Mahendran, R.; Koirala, S.; Konoshima, L.; Yamazaki, D.; Watanabe, S.; Kim, H.; Kanae, S. Global flood risk under climate change. Nat. Clim. Chang. 2013, 3, 816. [Google Scholar] [CrossRef]
- Khosravi, K.; Nohani, E.; Maroufinia, E.; Pourghasemi, H.R. A gis-based flood susceptibility assessment and its mapping in iran: A comparison between frequency ratio and weights-of-evidence bivariate statistical models with multi-criteria decision-making technique. Nat. Hazards 2016, 83, 947–987. [Google Scholar] [CrossRef]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at haraz watershed, northern iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef]
- Kron, W. Keynote lecture: Flood risk = hazard × exposure × vulnerability. Flood Def. 2002, 30, 82–97. [Google Scholar]
- Messner, F.; Meyer, V. Flood damage, vulnerability and risk perception–challenges for flood damage research. In Flood Risk Management: Hazards, Vulnerability and Mitigation Measures; Springer: Berlin/Heidelberg, Germany, 2006; pp. 149–167. [Google Scholar]
- Yu, J.; Qin, X.; Larsen, O. Joint monte carlo and possibilistic simulation for flood damage assessment. Stoch. Environ. Res. Risk Assess. 2013, 27, 725–735. [Google Scholar] [CrossRef]
- Sarhadi, A.; Soltani, S.; Modarres, R. Probabilistic flood inundation mapping of ungauged rivers: Linking gis techniques and frequency analysis. J. Hydrol. 2012, 458, 68–86. [Google Scholar] [CrossRef]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Tien Bui, D.; Khosravi, K.; Li, S.; Shahabi, H.; Panahi, M.; Singh, V.; Chapi, K.; Shirzadi, A.; Panahi, S.; Chen, W. New hybrids of anfis with several optimization algorithms for flood susceptibility modeling. Water 2018, 10, 1210. [Google Scholar] [CrossRef] [Green Version]
- Alfieri, L.; Bisselink, B.; Dottori, F.; Naumann, G.; de Roo, A.; Salamon, P.; Wyser, K.; Feyen, L. Global projections of river flood risk in a warmer world. Earth’s Future 2017, 5, 171–182. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in gis. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Ouchi, K. Recent trend and advance of synthetic aperture radar with selected topics. Remote Sens. 2013, 5, 716–807. [Google Scholar] [CrossRef] [Green Version]
- Teshebaeva, K.; Roessner, S.; Echtler, H.; Motagh, M.; Wetzel, H.-U.; Molodbekov, B. Alos/palsar insar time-series analysis for detecting very slow-moving landslides in southern kyrgyzstan. Remote Sens. 2015, 7, 8973–8994. [Google Scholar] [CrossRef] [Green Version]
- Joyce, K.E.; Belliss, S.E.; Samsonov, S.V.; McNeill, S.J.; Glassey, P.J. A review of the status of satellite remote sensing and image processing techniques for mapping natural hazards and disasters. Prog. Phys. Geogr. 2009, 33, 183–207. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Alizadeh, M.; Chen, W.; Mohammadi, A.; Ahmad, B.; Panahi, M.; Hong, H. Landslide detection and susceptibility mapping by airsar data using support vector machine and index of entropy models in cameron highlands, malaysia. Remote Sens. 2018, 10, 1527. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Khosravi, K.; Shahabi, H.; Daggupati, P.; Adamowski, J.F.; Melesse, A.M.; Thai Pham, B.; Pourghasemi, H.R.; Mahmoudi, M.; Bahrami, S. Flood spatial modeling in northern iran using remote sensing and gis: A comparison between evidential belief functions and its ensemble with a multivariate logistic regression model. Remote Sens. 2019, 11, 1589. [Google Scholar] [CrossRef] [Green Version]
- Khosravi, K.; Melesse, A.M.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Hong, H. Flood susceptibility mapping at ningdu catchment, china using bivariate and data mining techniques. In Extreme Hydrology and Climate Variability; Elsevier: Amsterdam, The Netherlands, 2019; pp. 419–434. [Google Scholar]
- Khosravi, K.; Pourghasemi, H.R.; Chapi, K.; Bahri, M. Flash flood susceptibility analysis and its mapping using different bivariate models in iran: A comparison between shannon’s entropy, statistical index, and weighting factor models. Environ. Monit. Assess. 2016, 188, 656. [Google Scholar] [CrossRef]
- Pradhan, B. Flood susceptible mapping and risk area delineation using logistic regression, gis and remote sensing. J. Spat. Hydrol. 2010, 9, 1–18. [Google Scholar]
- Al-Juaidi, A.E.; Nassar, A.M.; Al-Juaidi, O.E. Evaluation of flood susceptibility mapping using logistic regression and gis conditioning factors. Arab. J. Geosci. 2018, 11, 765. [Google Scholar] [CrossRef]
- Kazakis, N.; Kougias, I.; Patsialis, T. Assessment of flood hazard areas at a regional scale using an index-based approach and analytical hierarchy process: Application in rhodope–evros region, greece. Sci. Total Environ. 2015, 538, 555–563. [Google Scholar] [CrossRef]
- Rahmati, O.; Zeinivand, H.; Besharat, M. Flood hazard zoning in yasooj region, iran, using gis and multi-criteria decision analysis. Geomat. Nat. Hazards Risk 2016, 7, 1000–1017. [Google Scholar] [CrossRef] [Green Version]
- De Brito, M.; Evers, M. Multi-criteria decision making for flood risk management: A survey of the current state-of-the-art. Nat. Hazards Earth Syst. Sci. Discuss. 2015, 3, 6689–6726. [Google Scholar] [CrossRef]
- de Brito, M.M.; Evers, M.; Almoradie, A.D.S. Participatory flood vulnerability assessment: A multi-criteria approach. Hydrol. Earth Syst. Sci. 2018, 22, 373–390. [Google Scholar] [CrossRef] [Green Version]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamawoski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.-B.; Gróf, G.; Ho, H.L. A comparative assessment of flood susceptibility modeling using multi-criteria decision-making analysis and machine learning methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Leon, A.S.; Kanashiro, E.A.; Valverde, R.; Sridhar, V. Dynamic framework for intelligent control of river flooding: Case study. J. Water Resour. Plan. Manag. 2014, 140, 258–268. [Google Scholar] [CrossRef] [Green Version]
- Khosravi, K.; Sartaj, M.; Tsai, F.T.-C.; Singh, V.P.; Kazakis, N.; Melesse, A.M.; Prakash, I.; Bui, D.T.; Pham, B.T. A comparison study of drastic methods with various objective methods for groundwater vulnerability assessment. Sci. Total Environ. 2018, 642, 1032–1049. [Google Scholar] [CrossRef] [PubMed]
- Kia, M.B.; Pirasteh, S.; Pradhan, B.; Mahmud, A.R.; Sulaiman, W.N.A.; Moradi, A. An artificial neural network model for flood simulation using gis: Johor river basin, malaysia. Environ. Earth Sci. 2012, 67, 251–264. [Google Scholar] [CrossRef]
- Melesse, A.; Ahmad, S.; McClain, M.; Wang, X.; Lim, Y. Suspended sediment load prediction of river systems: An artificial neural network approach. Agric. Water Manag. 2011, 98, 855–866. [Google Scholar] [CrossRef]
- Khosravi, K.; Mao, L.; Kisi, O.; Yaseen, Z.M.; Shahid, S. Quantifying hourly suspended sediment load using data mining models: Case study of a glacierized andean catchment in chile. J. Hydrol. 2018, 567, 165–179. [Google Scholar] [CrossRef]
- Khozani, Z.S.; Khosravi, K.; Pham, B.T.; Kløve, B.; Mohtar, W.; Melini, W.H.; Yaseen, Z.M. Determination of compound channel apparent shear stress: Application of novel data mining models. J. Hydroinform. 2019, 21, 798–811. [Google Scholar] [CrossRef] [Green Version]
- Shafizadeh-Moghadam, H. Improving spatial accuracy of urban growth simulation models using ensemble forecasting approaches. Comput. Environ. Urban Syst. 2019, 76, 91–100. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Asghari, A.; Tayyebi, A.; Taleai, M. Coupling machine learning, tree-based and statistical models with cellular automata to simulate urban growth. Comput. Environ. Urban Syst. 2017, 64, 297–308. [Google Scholar] [CrossRef]
- Termeh, S.V.R.; Khosravi, K.; Sartaj, M.; Keesstra, S.D.; Tsai, F.T.-C.; Dijksma, R.; Pham, B.T. Optimization of an adaptive neuro-fuzzy inference system for groundwater potential mapping. Hydrogeol. J. 2019, 27, 2511–2534. [Google Scholar] [CrossRef]
- Khosravi, K.; Panahi, M.; Tien Bui, D. Spatial prediction of groundwater spring potential mapping based on adaptive neuro-fuzzy inference system and metaheuristic optimization. Hydrol. Earth Syst. Sci. 2018, 22, 4771–4792. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Zhao, X.; Shahabi, H.; Shirzadi, A.; Khosravi, K.; Chai, H.; Zhang, S.; Zhang, L.; Ma, J.; Chen, Y. Spatial prediction of landslide susceptibility by combining evidential belief function, logistic regression and logistic model tree. Geocarto Int. 2019, 1–25. [Google Scholar] [CrossRef]
- Wang, Y.; Hong, H.; Chen, W.; Li, S.; Panahi, M.; Khosravi, K.; Shirzadi, A.; Shahabi, H.; Panahi, S.; Costache, R. Flood susceptibility mapping in dingnan county (china) using adaptive neuro-fuzzy inference system with biogeography based optimization and imperialistic competitive algorithm. J. Environ. Manag. 2019, 247, 712–729. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Hong, H.; Li, S.; Shahabi, H.; Wang, Y.; Wang, X.; Ahmad, B.B. Flood susceptibility modelling using novel hybrid approach of reduced-error pruning trees with bagging and random subspace ensembles. J. Hydrol. 2019, 575, 864–873. [Google Scholar] [CrossRef]
- Bui, D.T.; Panahi, M.; Shahabi, H.; Singh, V.P.; Shirzadi, A.; Chapi, K.; Khosravi, K.; Chen, W.; Panahi, S.; Li, S. Novel hybrid evolutionary algorithms for spatial prediction of floods. Sci. Rep. 2018, 8, 15364. [Google Scholar] [CrossRef] [Green Version]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B. Modeling flood susceptibility using data-driven approaches of naïve bayes tree, alternating decision tree, and random forest methods. Sci. Total Environ. 2019, 701, 134979. [Google Scholar] [CrossRef]
- Choubin, B.; Soleimani, F.; Pirnia, A.; Sajedi-Hosseini, F.; Alilou, H.; Rahmati, O.; Melesse, A.M.; Singh, V.P.; Shahabi, H. Effects of drought on vegetative cover changes: Investigating spatiotemporal patterns. In Extreme Hydrology and Climate Variability; Elsevier: Amsterdam, The Netherlands, 2019; pp. 213–222. [Google Scholar]
- Jaafari, A.; Zenner, E.K.; Panahi, M.; Shahabi, H. Hybrid artificial intelligence models based on a neuro-fuzzy system and metaheuristic optimization algorithms for spatial prediction of wildfire probability. Agric. For. Meteorol. 2019, 266, 198–207. [Google Scholar] [CrossRef]
- Hong, H.; Jaafari, A.; Zenner, E.K. Predicting spatial patterns of wildfire susceptibility in the huichang county, china: An integrated model to analysis of landscape indicators. Ecol. Indic. 2019, 101, 878–891. [Google Scholar] [CrossRef]
- Taheri, K.; Shahabi, H.; Chapi, K.; Shirzadi, A.; Gutiérrez, F.; Khosravi, K. Sinkhole susceptibility mapping: A comparison between bayes-based machine learning algorithms. Land Degrad. Dev. 2019, 30, 730–745. [Google Scholar] [CrossRef]
- Roodposhti, M.S.; Safarrad, T.; Shahabi, H. Drought sensitivity mapping using two one-class support vector machine algorithms. Atmos. Res. 2017, 193, 73–82. [Google Scholar] [CrossRef]
- Lee, S.; Panahi, M.; Pourghasemi, H.R.; Shahabi, H.; Alizadeh, M.; Shirzadi, A.; Khosravi, K.; Melesse, A.M.; Yekrangnia, M.; Rezaie, F. Sevucas: A novel gis-based machine learning software for seismic vulnerability assessment. Appl. Sci. 2019, 9, 3495. [Google Scholar] [CrossRef] [Green Version]
- Alizadeh, M.; Alizadeh, E.; Asadollahpour Kotenaee, S.; Shahabi, H.; Beiranvand Pour, A.; Panahi, M.; Bin Ahmad, B.; Saro, L. Social vulnerability assessment using artificial neural network (ann) model for earthquake hazard in tabriz city, iran. Sustainability 2018, 10, 3376. [Google Scholar] [CrossRef] [Green Version]
- Azareh, A.; Rahmati, O.; Rafiei-Sardooi, E.; Sankey, J.B.; Lee, S.; Shahabi, H.; Ahmad, B.B. Modelling gully-erosion susceptibility in a semi-arid region, iran: Investigation of applicability of certainty factor and maximum entropy models. Sci. Total Environ. 2019, 655, 684–696. [Google Scholar] [CrossRef] [PubMed]
- Tien Bui, D.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Omidavr, E.; Pham, B.T.; Talebpour Asl, D.; Khaledian, H.; Pradhan, B.; Panahi, M. A novel ensemble artificial intelligence approach for gully erosion mapping in a semi-arid watershed (iran). Sensors 2019, 19, 2444. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Pradhan, B.; Chen, W.; Khosravi, K.; Panahi, M.; Bin Ahmad, B.; Saro, L. Land subsidence susceptibility mapping in south korea using machine learning algorithms. Sensors 2018, 18, 2464. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shirzadi, A.; Chapi, K.; Shahabi, H.; Pradhan, B.; Pham, B.T.; Singh, V.P.; Chen, W.; Khosravi, K.; Bin Ahmad, B. A hybrid computational intelligence approach to groundwater spring potential mapping. Water 2019, 11, 2013. [Google Scholar] [CrossRef] [Green Version]
- Rahmati, O.; Choubin, B.; Fathabadi, A.; Coulon, F.; Soltani, E.; Shahabi, H.; Mollaefar, E.; Tiefenbacher, J.; Cipullo, S.; Ahmad, B.B. Predicting uncertainty of machine learning models for modelling nitrate pollution of groundwater using quantile regression and uneec methods. Sci. Total Environ. 2019, 688, 855–866. [Google Scholar] [CrossRef]
- Chen, W.; Pradhan, B.; Li, S.; Shahabi, H.; Rizeei, H.M.; Hou, E.; Wang, S. Novel hybrid integration approach of bagging-based fisher’s linear discriminant function for groundwater potential analysis. Nat. Resour. Res. 2019, 28, 1239–1258. [Google Scholar] [CrossRef] [Green Version]
- Miraki, S.; Zanganeh, S.H.; Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Pham, B.T. Mapping groundwater potential using a novel hybrid intelligence approach. Water Resour. Manag. 2019, 33, 281–302. [Google Scholar] [CrossRef]
- Rahmati, O.; Naghibi, S.A.; Shahabi, H.; Bui, D.T.; Pradhan, B.; Azareh, A.; Rafiei-Sardooi, E.; Samani, A.N.; Melesse, A.M. Groundwater spring potential modelling: Comprising the capability and robustness of three different modeling approaches. J. Hydrol. 2018, 565, 248–261. [Google Scholar] [CrossRef]
- Chen, W.; Peng, J.; Hong, H.; Shahabi, H.; Pradhan, B.; Liu, J.; Zhu, A.-X.; Pei, X.; Duan, Z. Landslide susceptibility modelling using gis-based machine learning techniques for chongren county, jiangxi province, china. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef] [PubMed]
- Pham, B.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Shahabi, H.; Bui, D.T. Landslide susceptibility modeling using reduced error pruning trees and different ensemble techniques: Hybrid machine learning approaches. Catena 2019, 175, 203–218. [Google Scholar] [CrossRef]
- Shirzadi, A.; Bui, D.T.; Pham, B.T.; Solaimani, K.; Chapi, K.; Kavian, A.; Shahabi, H.; Revhaug, I. Shallow landslide susceptibility assessment using a novel hybrid intelligence approach. Environ. Earth Sci. 2017, 76, 60. [Google Scholar] [CrossRef]
- Pradhan, B. A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using gis. Comput. Geosci. 2013, 51, 350–365. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Shirzadi, A.; Hong, H.; Akgun, A.; Tian, Y.; Liu, J.; Zhu, A.-X.; Li, S. Novel hybrid artificial intelligence approach of bivariate statistical-methods-based kernel logistic regression classifier for landslide susceptibility modeling. Bull. Eng. Geol. Environ. 2019, 78, 4397–4419. [Google Scholar] [CrossRef]
- Jaafari, A.; Panahi, M.; Pham, B.T.; Shahabi, H.; Bui, D.T.; Rezaie, F.; Lee, S. Meta optimization of an adaptive neuro-fuzzy inference system with grey wolf optimizer and biogeography-based optimization algorithms for spatial prediction of landslide susceptibility. Catena 2019, 175, 430–445. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Dou, J.; Singh, S.K.; Trinh, P.T.; Tran, H.T.; Le, T.M.; Van Phong, T.; Khoi, D.K.; Shirzadi, A. A novel hybrid approach of landslide susceptibility modelling using rotation forest ensemble and different base classifiers. Geocarto Int. 2019, 1–25. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Minaei, M.; Shahabi, H.; Hagenauer, J. Big data in geohazard; pattern mining and large scale analysis of landslides in iran. Earth Sci. Inform. 2019, 12, 1–17. [Google Scholar] [CrossRef]
- Nguyen, V.V.; Pham, B.T.; Vu, B.T.; Prakash, I.; Jha, S.; Shahabi, H.; Shirzadi, A.; Ba, D.N.; Kumar, R.; Chatterjee, J.M. Hybrid machine learning approaches for landslide susceptibility modeling. Forests 2019, 10, 157. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Shirzadi, A.; Shahabi, H.; Omidvar, E.; Singh, S.K.; Sahana, M.; Asl, D.T.; Ahmad, B.B.; Quoc, N.K.; Lee, S. Landslide susceptibility assessment by novel hybrid machine learning algorithms. Sustainability 2019, 11, 4386. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shahabi, H.; Omidvar, E.; Shirzadi, A.; Geertsema, M.; Clague, J.J.; Khosravi, K.; Pradhan, B.; Pham, B.T.; Chapi, K. Shallow landslide prediction using a novel hybrid functional machine learning algorithm. Remote Sens. 2019, 11, 931. [Google Scholar] [CrossRef] [Green Version]
- Tien Bui, D.; Shahabi, H.; Shirzadi, A.; Chapi, K.; Hoang, N.-D.; Pham, B.; Bui, Q.-T.; Tran, C.-T.; Panahi, M.; Bin Ahamd, B. A novel integrated approach of relevance vector machine optimized by imperialist competitive algorithm for spatial modeling of shallow landslides. Remote Sens. 2018, 10, 1538. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Zhang, S.; Li, R.; Shahabi, H. Performance evaluation of the gis-based data mining techniques of best-first decision tree, random forest, and naïve bayes tree for landslide susceptibility modeling. Sci. Total Environ. 2018, 644, 1006–1018. [Google Scholar] [CrossRef]
- Chen, W.; Shahabi, H.; Zhang, S.; Khosravi, K.; Shirzadi, A.; Chapi, K.; Pham, B.; Zhang, T.; Zhang, L.; Chai, H. Landslide susceptibility modeling based on gis and novel bagging-based kernel logistic regression. Appl. Sci. 2018, 8, 2540. [Google Scholar] [CrossRef] [Green Version]
- Abedini, M.; Ghasemian, B.; Shirzadi, A.; Shahabi, H.; Chapi, K.; Pham, B.T.; Bin Ahmad, B.; Tien Bui, D. A novel hybrid approach of bayesian logistic regression and its ensembles for landslide susceptibility assessment. Geocarto Int. 2018, 1–31. [Google Scholar] [CrossRef]
- Chen, W.; Xie, X.; Peng, J.; Shahabi, H.; Hong, H.; Bui, D.T.; Duan, Z.; Li, S.; Zhu, A.-X. Gis-based landslide susceptibility evaluation using a novel hybrid integration approach of bivariate statistical based random forest method. Catena 2018, 164, 135–149. [Google Scholar] [CrossRef]
- Chen, W.; Shirzadi, A.; Shahabi, H.; Ahmad, B.B.; Zhang, S.; Hong, H.; Zhang, N. A novel hybrid artificial intelligence approach based on the rotation forest ensemble and naïve bayes tree classifiers for a landslide susceptibility assessment in langao county, china. Geomat. Nat. Hazards Risk 2017, 8, 1955–1977. [Google Scholar] [CrossRef] [Green Version]
- Shadman Roodposhti, M.; Aryal, J.; Shahabi, H.; Safarrad, T. Fuzzy shannon entropy: A hybrid gis-based landslide susceptibility mapping method. Entropy 2016, 18, 343. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M.; Ahmad, B.B. Remote sensing and gis-based landslide susceptibility mapping using frequency ratio, logistic regression, and fuzzy logic methods at the central zab basin, iran. Environ. Earth Sci. 2015, 73, 8647–8668. [Google Scholar] [CrossRef]
- Shahabi, H.; Khezri, S.; Ahmad, B.B.; Hashim, M. Landslide susceptibility mapping at central zab basin, iran: A comparison between analytical hierarchy process, frequency ratio and logistic regression models. Catena 2014, 115, 55–70. [Google Scholar] [CrossRef]
- Chen, W.; Hong, H.; Panahi, M.; Shahabi, H.; Wang, Y.; Shirzadi, A.; Pirasteh, S.; Alesheikh, A.A.; Khosravi, K.; Panahi, S. Spatial prediction of landslide susceptibility using gis-based data mining techniques of anfis with whale optimization algorithm (woa) and grey wolf optimizer (gwo). Appl. Sci. 2019, 9, 3755. [Google Scholar] [CrossRef] [Green Version]
- Jaafari, A. Lidar-supported prediction of slope failures using an integrated ensemble weights-of-evidence and analytical hierarchy process. Environ. Earth Sci. 2018, 77, 42. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R. Identification of critical flood prone areas in data-scarce and ungauged regions: A comparison of three data mining models. Water Resour. Manag. 2017, 31, 1473–1487. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R.; Zeinivand, H. Flood susceptibility mapping using frequency ratio and weights-of-evidence models in the golastan province, iran. Geocarto Int. 2016, 31, 42–70. [Google Scholar] [CrossRef]
- Fernández, D.; Lutz, M. Urban flood hazard zoning in tucumán province, argentina, using gis and multicriteria decision analysis. Eng. Geol. 2010, 111, 90–98. [Google Scholar] [CrossRef]
- Li, K.; Wu, S.; Dai, E.; Xu, Z. Flood loss analysis and quantitative risk assessment in china. Nat. Hazards 2012, 63, 737–760. [Google Scholar] [CrossRef]
- Nedkov, S.; Burkhard, B. Flood regulating ecosystem services-Mapping supply and demand, in the etropole municipality, bulgaria. Ecol. Indic. 2012, 21, 67–79. [Google Scholar] [CrossRef]
- Cardenas, M.B.; Wilson, J.; Zlotnik, V.A. Impact of heterogeneity, bed forms, and stream curvature on subchannel hyporheic exchange. Water Resour. Res. 2004, 40. [Google Scholar] [CrossRef] [Green Version]
- Moore, I.D.; Grayson, R.; Ladson, A. Digital terrain modelling: A review of hydrological, geomorphological, and biological applications. Hydrol. Process. 1991, 5, 3–30. [Google Scholar] [CrossRef]
- Barker, D.M.; Lawler, D.M.; Knight, D.W.; Morris, D.G.; Davies, H.N.; Stewart, E.J. Longitudinal distributions of river flood power: The combined automated flood, elevation and stream power (cafes) methodology. Earth Surf. Process. Landf. 2009, 34, 280–290. [Google Scholar] [CrossRef]
- Fuller, I.C. Geomorphic impacts of a 100-year flood: Kiwitea stream, manawatu catchment, new zealand. Geomorphology 2008, 98, 84–95. [Google Scholar] [CrossRef]
- Papaioannou, G.; Vasiliades, L.; Loukas, A. Multi-criteria analysis framework for potential flood prone areas mapping. Water Resour. Manag. 2015, 29, 399–418. [Google Scholar] [CrossRef]
- Soulsby, C.; Tetzlaff, D.; Hrachowitz, M. Spatial distribution of transit times in montane catchments: Conceptualization tools for management. Hydrol. Process. 2010, 24, 3283–3288. [Google Scholar] [CrossRef]
- Naito, A.T.; Cairns, D.M. Relationships between arctic shrub dynamics and topographically derived hydrologic characteristics. Environ. Res. Lett. 2011, 6, 045506. [Google Scholar] [CrossRef]
- Gokceoglu, C.; Sonmez, H.; Nefeslioglu, H.A.; Duman, T.Y.; Can, T. The 17 march 2005 kuzulu landslide (sivas, turkey) and landslide-susceptibility map of its near vicinity. Eng. Geol. 2005, 81, 65–83. [Google Scholar] [CrossRef]
- Hong, H.; Panahi, M.; Shirzadi, A.; Ma, T.; Liu, J.; Zhu, A.-X.; Chen, W.; Kougias, I.; Kazakis, N. Flood susceptibility assessment in hengfeng area coupling adaptive neuro-fuzzy inference system with genetic algorithm and differential evolution. Sci. Total Environ. 2018, 621, 1124–1141. [Google Scholar] [CrossRef]
- Kay, A.L.; Jones, R.G.; Reynard, N.S. Rcm rainfall for uk flood frequency estimation. Ii. Climate change results. J. Hydrol. 2006, 318, 163–172. [Google Scholar] [CrossRef]
- García-Ruiz, J.M.; Regüés, D.; Alvera, B.; Lana-Renault, N.; Serrano-Muela, P.; Nadal-Romero, E.; Navas, A.; Latron, J.; Martí-Bono, C.; Arnáez, J. Flood generation and sediment transport in experimental catchments affected by land use changes in the central pyrenees. J. Hydrol. 2008, 356, 245–260. [Google Scholar] [CrossRef] [Green Version]
- Glenn, E.P.; Morino, K.; Nagler, P.L.; Murray, R.S.; Pearlstein, S.; Hultine, K.R. Roles of saltcedar (tamarix spp.) and capillary rise in salinizing a non-flooding terrace on a flow-regulated desert river. J. Arid Environ. 2012, 79, 56–65. [Google Scholar] [CrossRef]
- Aalto, R.; Maurice-Bourgoin, L.; Dunne, T.; Montgomery, D.R.; Nittrouer, C.A.; Guyot, J.-L. Episodic sediment accumulation on amazonian flood plains influenced by el nino/southern oscillation. Nature 2003, 425, 493. [Google Scholar] [CrossRef] [PubMed]
- Predick, K.I.; Turner, M.G. Landscape configuration and flood frequency influence invasive shrubs in floodplain forests of the wisconsin river (USA). J. Ecol. 2008, 96, 91–102. [Google Scholar] [CrossRef]
- Geudtner, D.; Torres, R.; Snoeij, P.; Davidson, M.; Rommen, B. Sentinel-1 System Capabilities and Applications. In Proceedings of the 2014 IEEE Geoscience and Remote Sensing Symposium, Quebec City, QC, Canada, 13–18 July 2014; pp. 1457–1460. [Google Scholar]
- Massonnet, D.; Feigl, K.L. Radar interferometry and its application to changes in the earth’s surface. Rev. Geophys. 1998, 36, 441–500. [Google Scholar] [CrossRef] [Green Version]
- Bürgmann, R.; Rosen, P.A.; Fielding, E.J. Synthetic aperture radar interferometry to measure earth’s surface topography and its deformation. Annu. Rev. Earth Planet. Sci. 2000, 28, 169–209. [Google Scholar] [CrossRef]
- Hanssen, R.F. Radar Interferometry: Data Interpretation and Error Analysis; Springer Science & Business Media: Dordrecht, The Netherlands, 2001; Volume 2. [Google Scholar]
- Mohammadi, A.; Shahabi, H.; Bin Ahmad, B. Integration of insar technique, google earth images, and extensive field survey for landslide inventory in a part of cameron highlands, pahang, Malaysia. Appl. Ecol. Environ. Res. 2018, 16, 8075–8091. [Google Scholar] [CrossRef]
- Pepe, A.; Yang, Y.; Manzo, M.; Lanari, R. Improved emcf-sbas processing chain based on advanced techniques for the noise-filtering and selection of small baseline multi-look dinsar interferograms. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4394–4417. [Google Scholar] [CrossRef]
- ESA. Sentinel-1 Sar User Guide Introduction. Available online: https://sentinel.esa.int/web/sentinel/user-guides/sentinel-1-sar (accessed on 18 March 2017).
- Mohammadi, A.; Bin Ahmad, B.; Shahabi, H. Extracting digital elevation model (dem) from sentinel-1 satellite imagery: Case study a part of cameron highlands, pahang, Malaysia. Int. J. Manag. Appl. Sci. 2018, 4, 109–114. [Google Scholar]
- He, Q.P.; Wang, J. Fault detection using the k-nearest neighbor rule for semiconductor manufacturing processes. IEEE Trans. Semicond. Manuf. 2007, 20, 345–354. [Google Scholar] [CrossRef]
- Wettschereck, D.; Aha, D.W.; Mohri, T. A review and empirical evaluation of feature weighting methods for a class of lazy learning algorithms. Artif. Intell. Rev. 1997, 11, 273–314. [Google Scholar] [CrossRef]
- Bahrami, S.; Wigand, E. Sensitivity analysis on daily streamflow forecasting. Int. J. Adv. Res. Sci. Eng. Technol. 2018, 5, 1–6. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Philip, S.Y. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. Knn Model-Based Approach in Classification. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Catania, Italy, 3–7 November 2003; Springer: Berlin/Heidelberg, Germany; pp. 986–996. [Google Scholar]
- Liu, C.-L.; Lee, C.-H.; Lin, P.-M. A fall detection system using k-nearest neighbor classifier. Expert Syst. Appl. 2010, 37, 7174–7181. [Google Scholar] [CrossRef]
- Hu, L.-Y.; Huang, M.-W.; Ke, S.-W.; Tsai, C.-F. The distance function effect on k-nearest neighbor classification for medical datasets. SpringerPlus 2016, 5, 1304. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Maclin, R.; Opitz, D. An empirical evaluation of bagging and boosting. In Proceedings of the Fourteenth National Conference on Artificial Intelligence, Providence, RI, USA, 17 July 1997; pp. 546–551. [Google Scholar]
- Lin, X.; Yacoub, S.; Burns, J.; Simske, S. Performance analysis of pattern classifier combination by plurality voting. Pattern Recognit. Lett. 2003, 24, 1959–1969. [Google Scholar] [CrossRef]
- Giacinto, G.; Roli, F. Design of effective neural network ensembles for image classification purposes. Image Vis. Comput. 2001, 19, 699–707. [Google Scholar] [CrossRef]
- Kamali, T.; Boostani, R.; Parsaei, H. A multi-classifier approach to muap classification for diagnosis of neuromuscular disorders. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 191–200. [Google Scholar] [CrossRef]
- Waske, B.; van der Linden, S.; Benediktsson, J.A.; Rabe, A.; Hostert, P. Sensitivity of support vector machines to random feature selection in classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2880–2889. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.-S.; Xiao, H.; Wang, T.-l. Rapid assessment of flood loss based on neural network ensemble. Trans. Nonferrous Metals Soc. China 2014, 24, 2636–2641. [Google Scholar] [CrossRef]
- Shirzadi, A.; Soliamani, K.; Habibnejhad, M.; Kavian, A.; Chapi, K.; Shahabi, H.; Chen, W.; Khosravi, K.; Thai Pham, B.; Pradhan, B. Novel gis based machine learning algorithms for shallow landslide susceptibility mapping. Sensors 2018, 18, 3777. [Google Scholar] [CrossRef] [PubMed]
- Ramaswami, M.; Bhaskaran, R. A study on feature selection techniques in educational data mining. arXiv 2009, arXiv:0912.3924. [Google Scholar]
- Dash, M.; Liu, H. Feature selection for classification. Intell. Data Anal. 1997, 1, 131–156. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Machine Learning Proceedings 1992; Elsevier: Amsterdam, The Netherlands, 1992; pp. 249–256. [Google Scholar]
- Kononenko, I. Estimating attributes: Analysis and extensions of relief. In Proceedings of the European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1994; pp. 171–182. [Google Scholar]
- Hall, M.A.; Holmes, G. Benchmarking attribute selection techniques for discrete class data mining. IEEE Trans. Knowl. Data Eng. 2002, 15, 1437–1447. [Google Scholar] [CrossRef] [Green Version]
- Park, S.; Hamm, S.-Y.; Kim, J. Performance evaluation of the gis-based data-mining techniques decision tree, random forest, and rotation forest for landslide susceptibility modeling. Sustainability 2019, 11, 5659. [Google Scholar] [CrossRef] [Green Version]
- Urbanowicz, R.J.; Meeker, M.; La Cava, W.; Olson, R.S.; Moore, J.H. Relief-based feature selection: Introduction and review. J. Biomed. Inform. 2018, 85, 189–203. [Google Scholar] [CrossRef]
- Bui, D.T.; Pradhan, B.; Nampak, H.; Bui, Q.-T.; Tran, Q.-A.; Nguyen, Q.-P. Hybrid artificial intelligence approach based on neural fuzzy inference model and metaheuristic optimization for flood susceptibilitgy modeling in a high-frequency tropical cyclone area using gis. J. Hydrol. 2016, 540, 317–330. [Google Scholar]
- Ahmadlou, M.; Karimi, M.; Alizadeh, S.; Shirzadi, A.; Parvinnejhad, D.; Shahabi, H.; Panahi, M. Flood susceptibility assessment using integration of adaptive network-based fuzzy inference system (anfis) and biogeography-based optimization (bbo) and bat algorithms (ba). Geocarto Int. 2018, 1–21. [Google Scholar] [CrossRef]
- Shahabi, H.; Hashim, M. Landslide susceptibility mapping using gis-based statistical models and remote sensing data in tropical environment. Sci. Rep. 2015, 5, 9899. [Google Scholar] [CrossRef] [Green Version]
- Kantardzic, M. Data Mining: Concepts, Models, Methods, and Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Hassanat, A.B. Visual passwords using automatic lip reading. arXiv 2014, arXiv:1409.0924. [Google Scholar]
- Hassanat, A.B.; Abbadi, M.A.; Altarawneh, G.A.; Alhasanat, A.A. Solving the problem of the k parameter in the knn classifier using an ensemble learning approach. arXiv 2014, arXiv:1409.0919. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Figure Type | Variable Type | GIS Data Type | Description | Scale or Resolution |
|---|---|---|---|---|
| Elevation | Independent variable | Grid | Elevation layer was extracted from a digital elevation model (DEM) | 30 m × 30 m |
| Slope | Independent variable | Grid | Slope layer was produced using the DEM layer. | 30 m × 30 m |
| Curvature | Independent variable | Grid | Curvature layer was generated from the DEM | 30 m × 30 m |
| Stream power index (SPI) | Independent variable | Grid | SPI factor was created based on topographical data | 30 m × 30 m |
| Topographic wetness index (TWI) | Independent variable | Grid | TWI is a topo-hydrological factor that is produced from the DEM. It is commonly used for evaluating soil water/wetness conditions | 30 m × 30 m |
| Lithology | Independent variable | Vector | Lithology layer was derived from a geological map produced by the Geological Survey of Iran | 1:100,000 |
| Rainfall | Independent variable | Grid | Rainfall layer was generated from meteorological databases | 30 m × 30 m |
| Land use/Land cover | Independent variable | Grid | Land use/Land cover layer was extracted from Operational Land Imager (OLI) of Landsat 8 image | 30 m × 30 m |
| River density | Independent variable | Grid | River density was extracted from river network | 30 m × 30 m |
| Distance to river | Independent variable | Grid | Distance to river was extracted from river network | 30 m × 30 m |
| Flood inventory | Dependent variable | Grid | Flood points were derived from records of flooding and field surveys | 30 m × 30 m |
| Platform | Sensor Mode | Product Type | Path | Dates |
|---|---|---|---|---|
| S1A | Interferometry wide swath (IW) | Ground range detected (GRD) | Ascending | 05/10/2016 23/11/2017 |
| Description | ||||
|---|---|---|---|---|
| Classifier Preset | Coarse KNN | Cosine KNN | Cubic KNN | Weighted KNN |
| Accuracy | 92.1% | 92.8% | 96.4% | 92.1% |
| Distance metric | Euclidean | Cosine | Minkowski (cubic) | Metric Euclidean |
| Distance weight | Equal standardize | Equal standardize | Equal standardize | Weight squared inverse standardize |
| Number of neighbors | 100 | 10 | 10 | 10 |
| Prediction speed (obs/sec) | ~27,000 | ~22,000 | ~15,000 | ~29,000 |
| Time training (Secs) | 0.255 | 0.282 | 0.293 | 0.211 |
| Description | ||||
|---|---|---|---|---|
| Classifier Preset | BaggingTree–Coarse KNN | Bagging Tree–Cosine KNN | Bagging Tree–Cubic KNN | Bagging Tree–Weighted KNN |
| Accuracy | 98.6% | 96.6% | 94.3% | 97.1% |
| Learner type | Decision tree | Decision tree | Decision tree | Decision tree |
| Number of learners | 30 | 30 | 30 | 30 |
| Ensemble method | Bag | Bag | Bag | Bag |
| Prediction speed (obs/sec) | ~2200 | ~3900 | ~5100 | ~5800 |
| Time training (secs) | 0.375 | 0.737 | 0.693 | 0.761 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shahabi, H.; Shirzadi, A.; Ghaderi, K.; Omidvar, E.; Al-Ansari, N.; Clague, J.J.; Geertsema, M.; Khosravi, K.; Amini, A.; Bahrami, S.; et al. Flood Detection and Susceptibility Mapping Using Sentinel-1 Remote Sensing Data and a Machine Learning Approach: Hybrid Intelligence of Bagging Ensemble Based on K-Nearest Neighbor Classifier. Remote Sens. 2020, 12, 266. https://doi.org/10.3390/rs12020266
Shahabi H, Shirzadi A, Ghaderi K, Omidvar E, Al-Ansari N, Clague JJ, Geertsema M, Khosravi K, Amini A, Bahrami S, et al. Flood Detection and Susceptibility Mapping Using Sentinel-1 Remote Sensing Data and a Machine Learning Approach: Hybrid Intelligence of Bagging Ensemble Based on K-Nearest Neighbor Classifier. Remote Sensing. 2020; 12(2):266. https://doi.org/10.3390/rs12020266
Chicago/Turabian StyleShahabi, Himan, Ataollah Shirzadi, Kayvan Ghaderi, Ebrahim Omidvar, Nadhir Al-Ansari, John J. Clague, Marten Geertsema, Khabat Khosravi, Ata Amini, Sepideh Bahrami, and et al. 2020. "Flood Detection and Susceptibility Mapping Using Sentinel-1 Remote Sensing Data and a Machine Learning Approach: Hybrid Intelligence of Bagging Ensemble Based on K-Nearest Neighbor Classifier" Remote Sensing 12, no. 2: 266. https://doi.org/10.3390/rs12020266
APA StyleShahabi, H., Shirzadi, A., Ghaderi, K., Omidvar, E., Al-Ansari, N., Clague, J. J., Geertsema, M., Khosravi, K., Amini, A., Bahrami, S., Rahmati, O., Habibi, K., Mohammadi, A., Nguyen, H., Melesse, A. M., Ahmad, B. B., & Ahmad, A. (2020). Flood Detection and Susceptibility Mapping Using Sentinel-1 Remote Sensing Data and a Machine Learning Approach: Hybrid Intelligence of Bagging Ensemble Based on K-Nearest Neighbor Classifier. Remote Sensing, 12(2), 266. https://doi.org/10.3390/rs12020266