Arbitrary-Oriented Inshore Ship Detection based on Multi-Scale Feature Fusion and Contextual Pooling on Rotation Region Proposals


Abstract
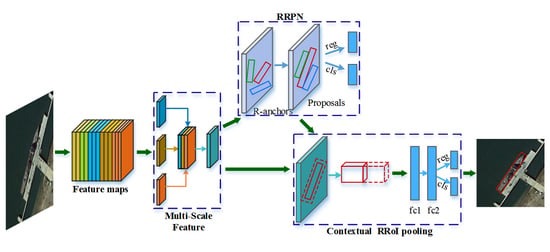
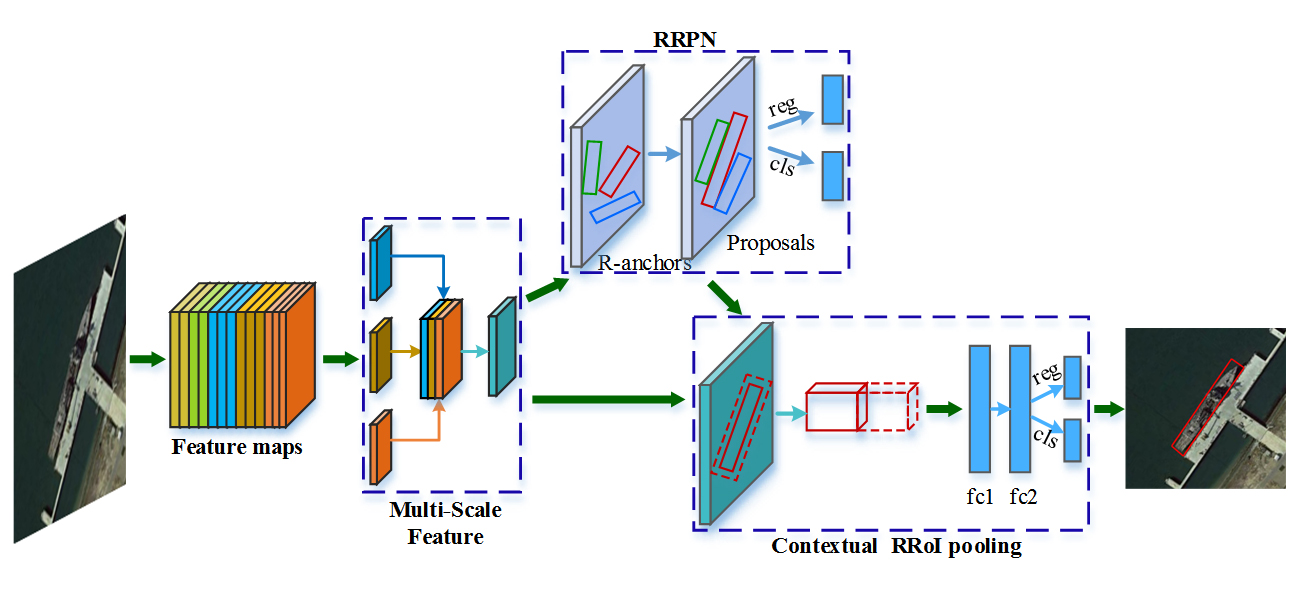
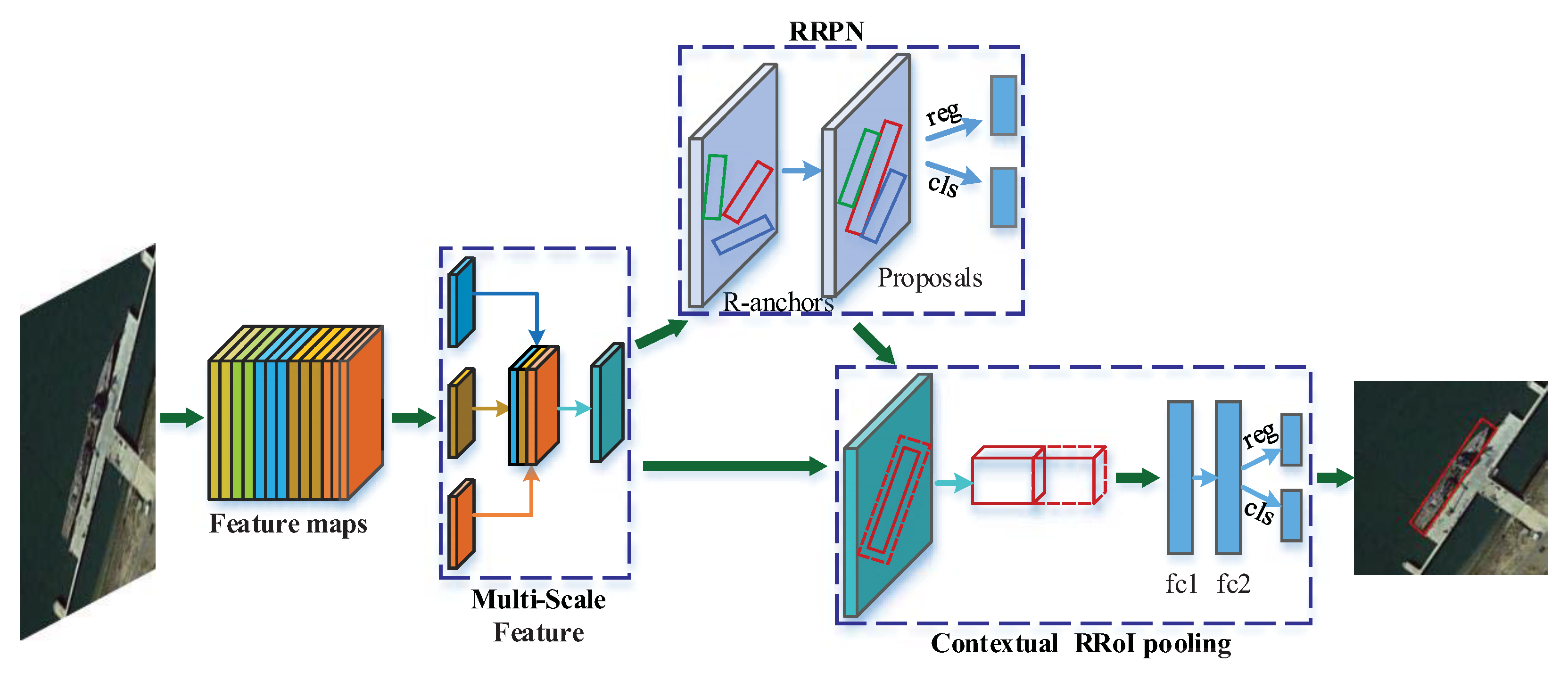
:
1. Introduction
- We propose a novel and concise framework for arbitrary-oriented inshore ship detection which can handle complex port scenes and targets of different sizes.
- For better detection of various target sizes, we design a multi-scale feature extraction and fusion network to build the multi-scale features, which contribute to the promotion of precision on different ships.
- In order to obtain accurate target locating and an arbitrary-oriented bounding box, we adopt the rotation region proposal network and skew non-maximum suppression. Consequently, densely moored ships are able to be distinguished, which results in an increase of recall rates.
- We implement rotated contextual feature pooling of a rotation region of interest to better describe ship targets and their surrounding backgrounds. As a result, the description weakness of rotation bounding boxes is improved with a decrease of false alarms.
2. Related Work
3. Proposed Method
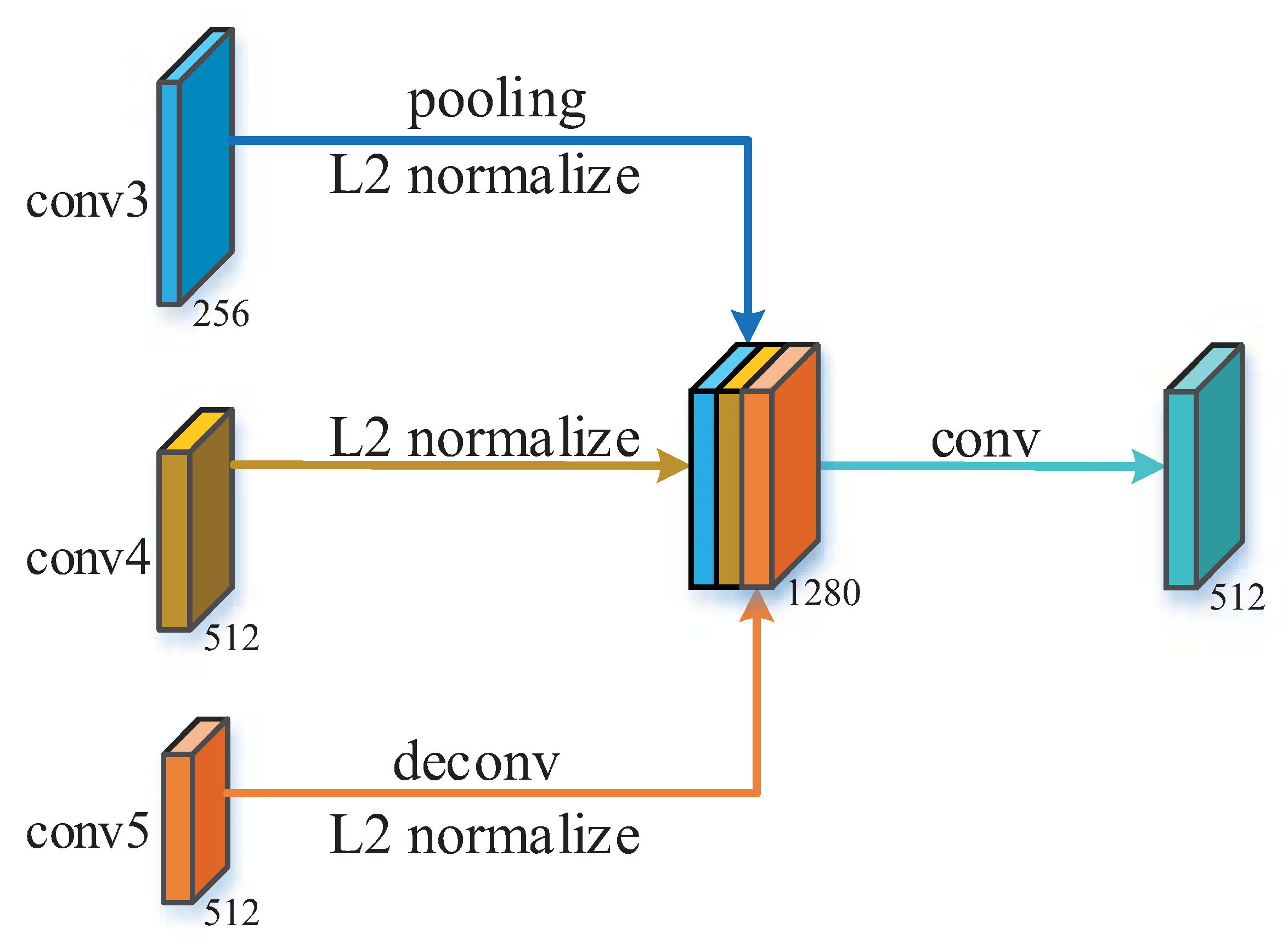
3.1. Multi-Scale Features
3.2. Rotation Region Proposal Network
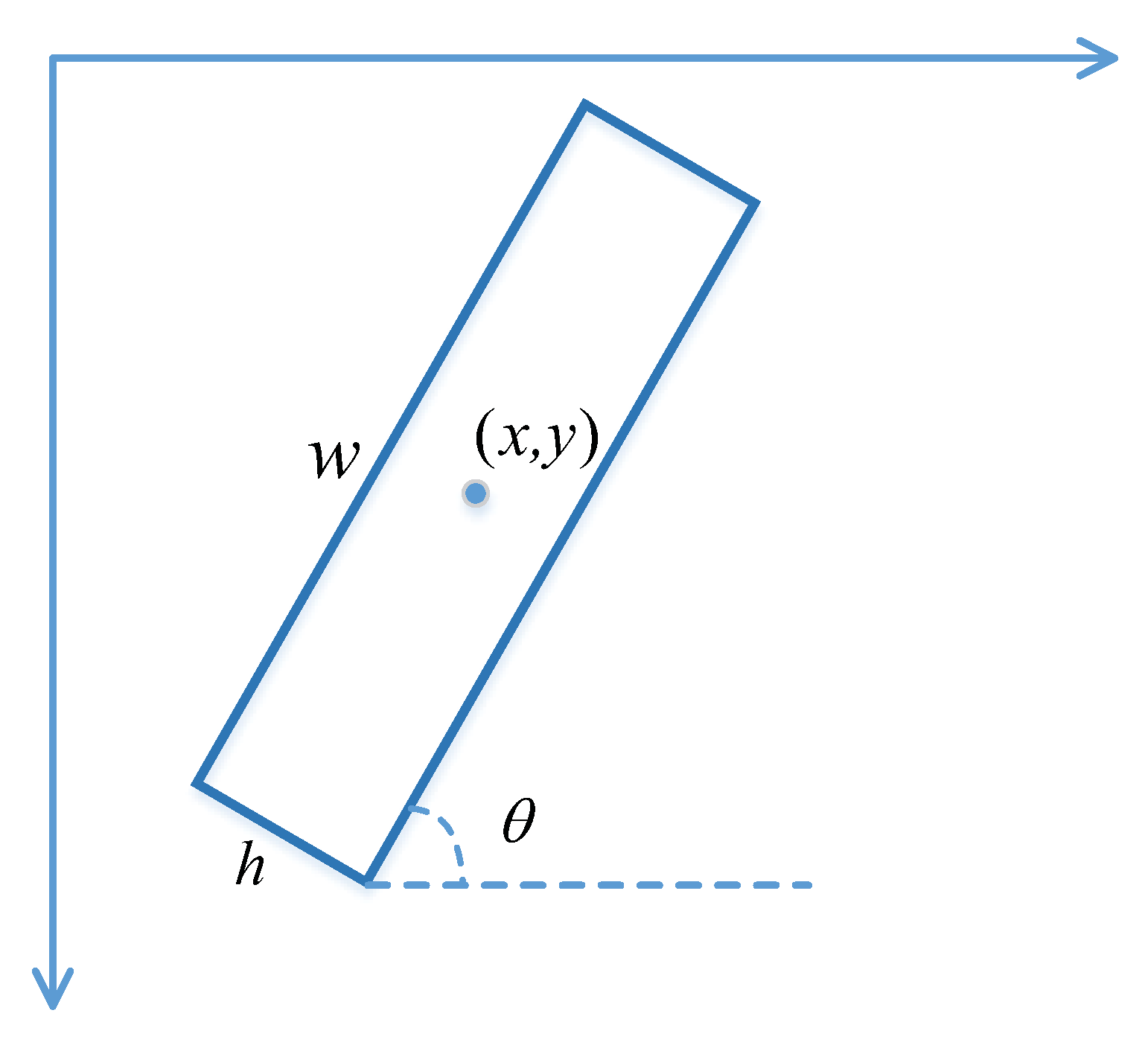
3.2.1. Rotation Bounding Box
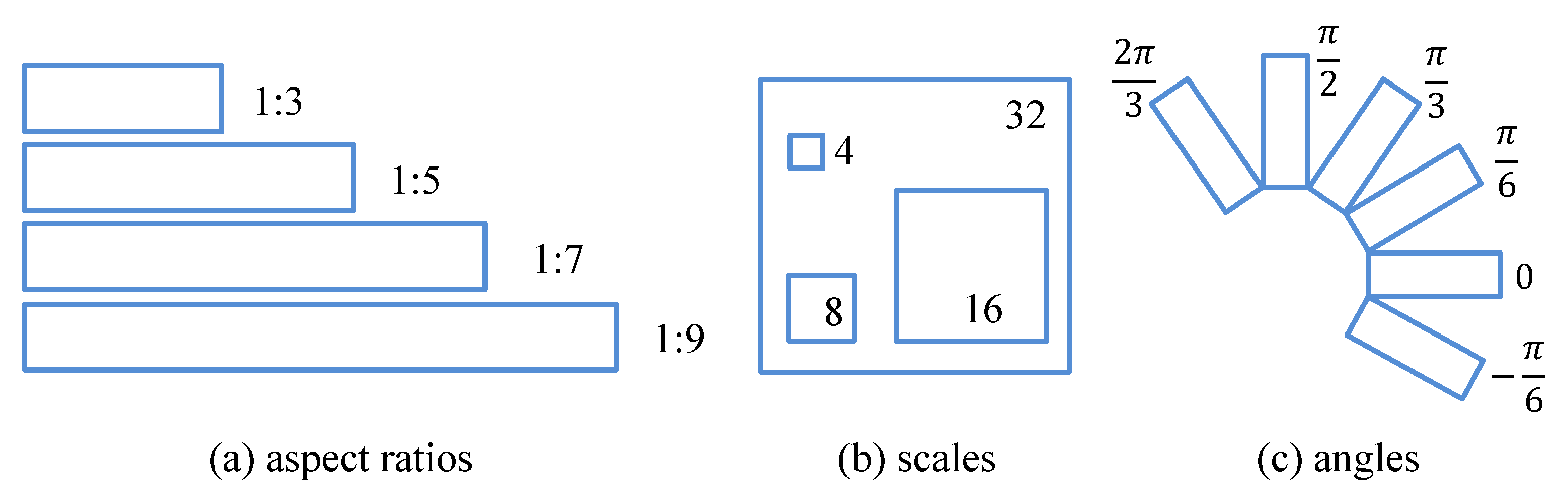
3.2.2. Rotation Anchors
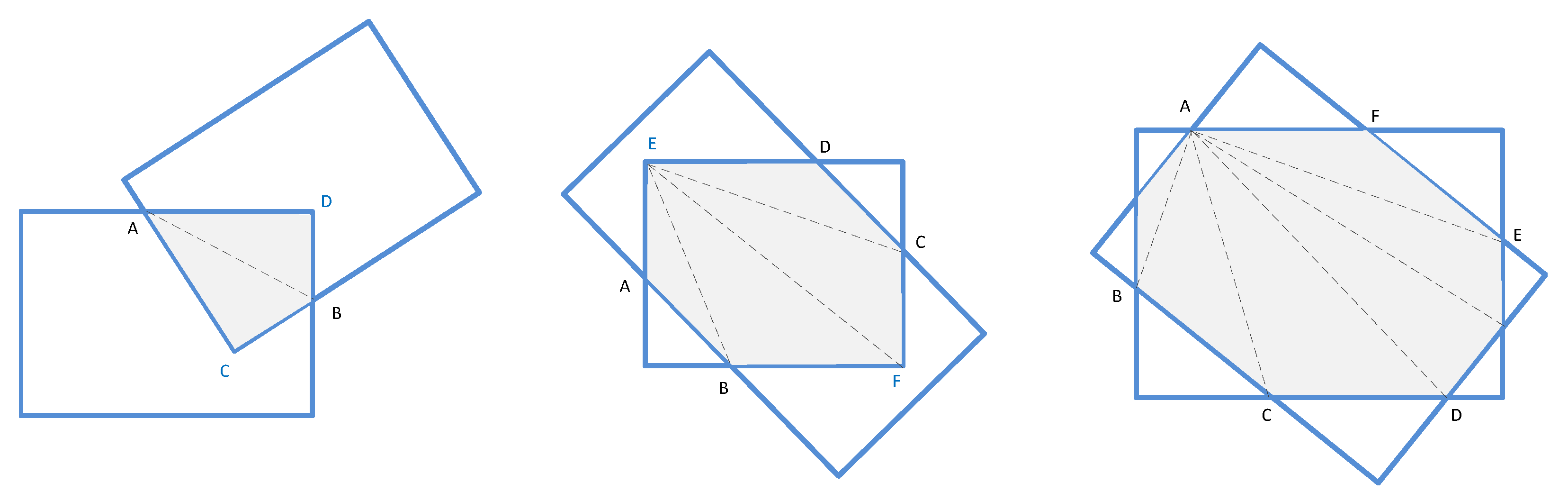
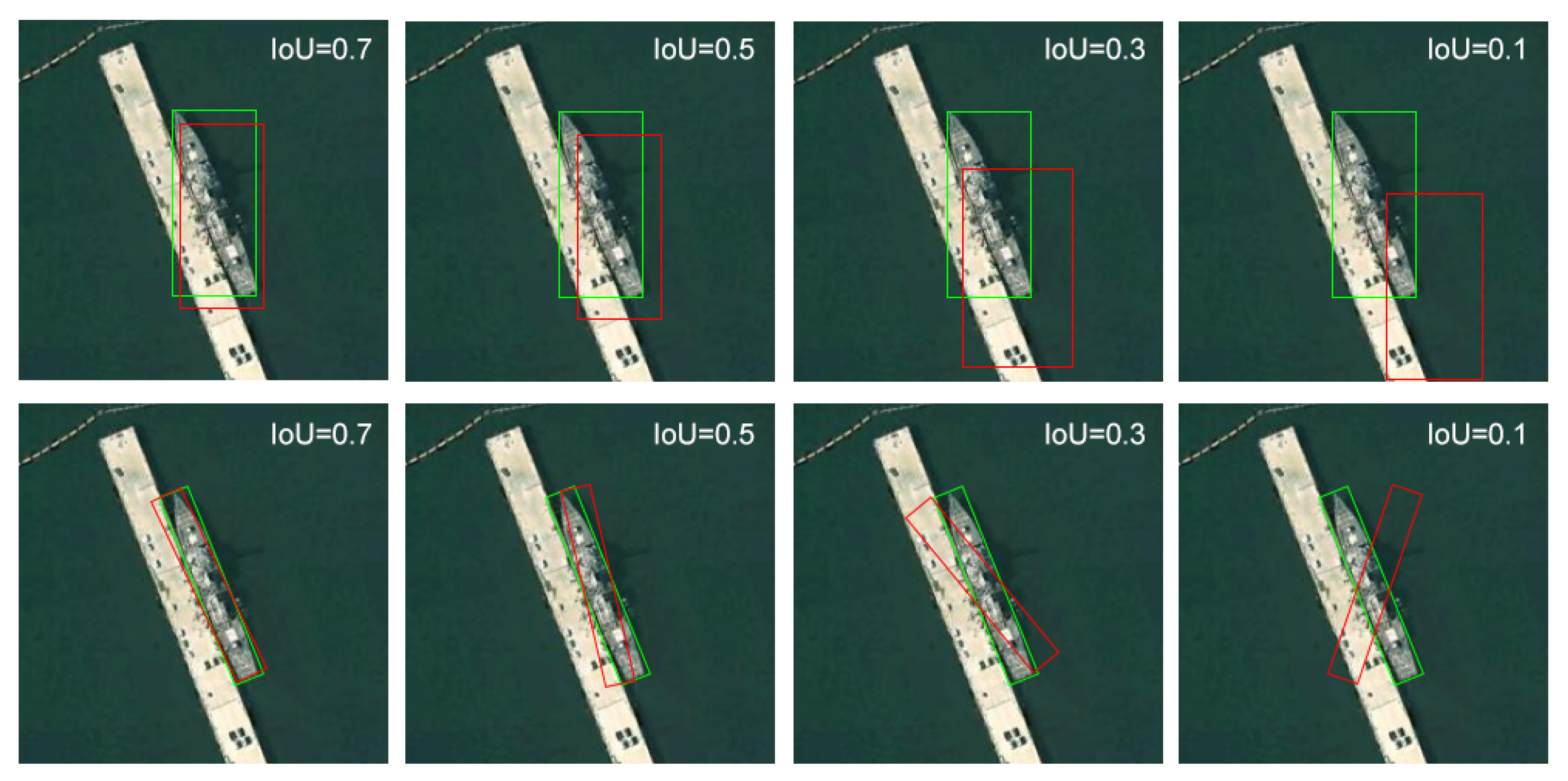
3.2.3. Skew Intersection over Union and Non-Maximum Suppression
| Algorithm 1 Calculate skew IoU |
| Input: Rotation rectangles |
| Output: |
|
3.2.4. Loss Function for RRPN Training
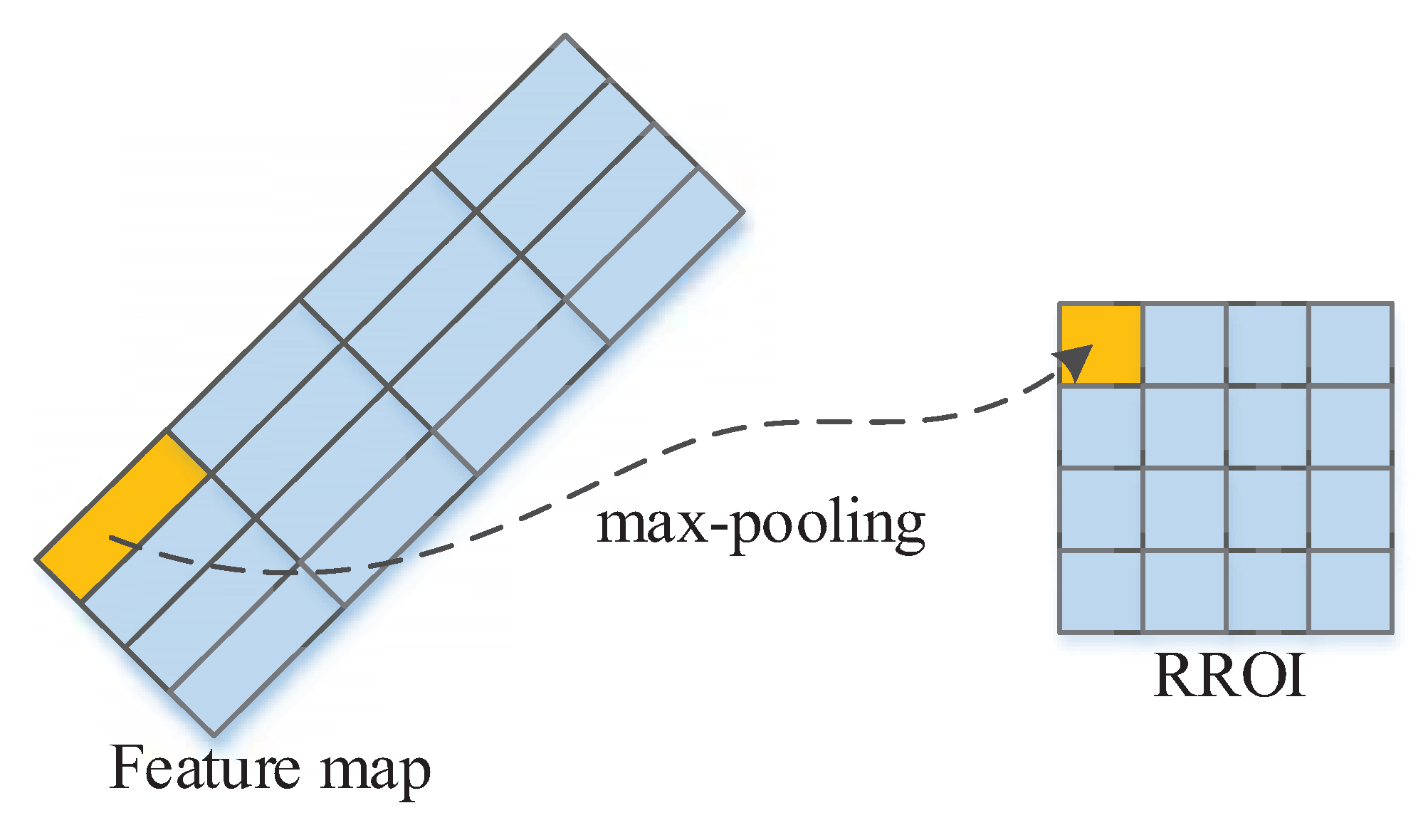
3.3. Contextual RRoI pooling
3.3.1. Pooling of Rotation RoI
3.3.2. Contextual Information
4. Experimental Results and Discussions
4.1. Data Sets and Evaluation Criteria
4.2. Experimental Settings
4.3. Model Analysis
4.4. Contrast Experiments
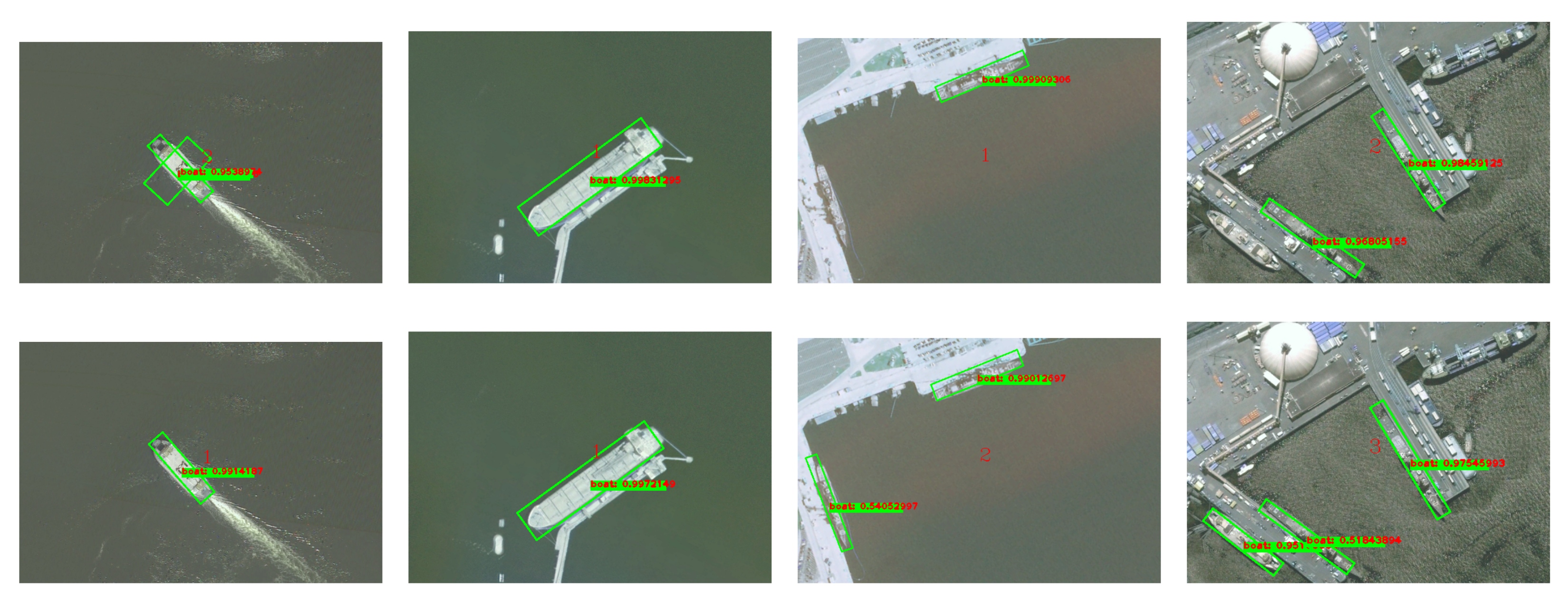
4.5. Visualized Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| SAR | Synthetic Aperture Radar |
| CNNs | Convolutional Neural Networks |
| R-CNN | Region proposal Convolutional Neural Network |
| RPN | Region Proposal Network |
| NMS | Non-Maximum Suppression |
| SSP-Net | Spatial Pyramid Pooling Network |
| YOLO | You Only Look Once |
| SSD | Single Shot Multibox Detector |
| Bbox | Bounding box |
| RCNN | Rotational Region CNN |
| RRPN | Rotation Region Proposal Network |
| RRoI | Rotation Region of Interest |
| MSF | Multi-Scale Feature |
| RoI | Region of Interest |
| BN | Batch Normalization |
| IoU | Intersection over Union |
References
- Kang, M.; Ji, K.; Leng, X.; Lin, Z. Contextual region-based convolutional neural network with multilayer fusion for SAR ship detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Li, X.; He, H.; Wang, L. A review of fine-scale land use and land cover classification in open-pit mining areas by remote sensing techniques. Remote Sens. 2018, 10, 15. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Tang, Z.; Chen, W.; Wang, L. Multimodal and multi-model deep fusion for fine classification of regional complex landscape areas using ZiYuan-3 imagery. Remote Sens. 2019, 11, 2716. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Zhou, H.; Zhao, J.; Gao, Y.; Jiang, J.; Tian, J. Robust feature matching for remote sensing image registration via locally linear transforming. IEEE Trans. Geosci. Remote Sens. 2015, 53, 6469–6481. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, J.; Zhou, H.; Zhao, J.; Guo, X. Guided locality preserving feature matching for remote sensing image registration. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4435–4447. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic ship detection in remote sensing images from google earth of complex scenes based on multiscale rotation dense feature pyramid networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Zhang, J.; Liu, P.; Choo, K.K.R.; Huang, F. Spectral–spatial multi-feature-based deep learning for hyperspectral remote sensing image classification. Soft Comput. 2017, 21, 213–221. [Google Scholar] [CrossRef]
- Bi, F.; Chen, J.; Zhuang, Y.; Bian, M.; Zhang, Q. A decision mixture model-based method for inshore ship detection using high-resolution remote sensing images. Sensors 2017, 17, 1470. [Google Scholar] [CrossRef]
- Ma, J.; Wang, X.; Jiang, J. Image super-resolution via dense discriminative network. IEEE Trans. Ind. Electron. 2019. [Google Scholar] [CrossRef]
- Zhu, C.; Zhou, H.; Wang, R.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship rotated bounding box space for ship extraction from high-resolution optical satellite images with complex backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- He, H.; Lin, Y.; Chen, F.; Tai, H.M.; Yin, Z. Inshore ship detection in remote sensing images via weighted pose voting. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3091–3107. [Google Scholar] [CrossRef]
- Liu, G.; Zhang, Y.; Zheng, X.; Sun, X.; Fu, K.; Wang, H. A new method on inshore ship detection in high-resolution satellite images using shape and context information. IEEE Geosci. Remote Sens. Lett. 2014, 11, 617–621. [Google Scholar] [CrossRef]
- Ma, L.; Crawford, M.M.; Zhu, L.; Liu, Y. Centroid and covariance alignment-based domain adaptation for unsupervised classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2305–2323. [Google Scholar] [CrossRef]
- Dong, C.; Liu, J.; Xu, F. Ship detection in optical remote sensing images based on saliency and a rotation-invariant descriptor. Remote Sens. 2018, 10, 400. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Zhang, S.; Wu, R.; Xu, K.; Wang, J.; Sun, W. R-CNN-based ship detection from high resolution remote sensing imagery. Remote Sens. 2019, 11, 631. [Google Scholar] [CrossRef] [Green Version]
- Wu, F.; Zhou, Z.; Wang, B.; Ma, J. Inshore ship detection based on convolutional neural network in optical satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4005–4015. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational region CNN for orientation robust scene text detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H.; Wang, L.; Wang, H.; Zheng, Y.; Xue, X. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Hu, J.; Weng, L.; Yang, Y. Rotated region based CNN for ship detection. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 Septmber 2017; pp. 900–904. [Google Scholar]
- Xiao, X.; Zhou, Z.; Wang, B.; Li, L.; Miao, L. Ship detection under complex backgrounds based on accurate rotated anchor boxes from paired semantic segmentation. Remote Sens. 2019, 11, 2506. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H.; Wu, F. Ship detection in optical satellite images via directional bounding boxes based on ship center and orientation prediction. Remote Sens. 2019, 11, 2173. [Google Scholar] [CrossRef] [Green Version]
- Qi, S.; Ma, J.; Lin, J.; Li, Y.; Tian, J. Unsupervised ship detection based on saliency and S-HOG descriptor from optical satellite images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1451–1455. [Google Scholar]
- Yang, F.; Xu, Q.; Li, B. Ship detection from optical satellite images based on saliency segmentation and structure-LBP feature. IEEE Geosci. Remote Sens. Lett. 2017, 14, 602–606. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Jiang, J.; Zhou, H.; Guo, X. Locality preserving matching. Int. J. Comput. Vis. 2019, 127, 512–531. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Zhang, L. An efficient and robust integrated geospatial object detection framework for high spatial resolution remote sensing imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Zhu, C.; Xiao, S. Deformable Faster R-CNN with aggregating multi-layer features for partially occluded object detection in optical remote sensing images. Remote Sens. 2018, 10, 1470. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.; Shi, Z.; Zou, Z. Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1665–1669. [Google Scholar] [CrossRef]
- Li, S.; Zhang, Z.; Li, B.; Li, C. Multiscale rotated bounding Box-based deep learning method for detecting ship targets in remote sensing images. Sensors 2018, 18, 2702. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward arbitrary-oriented ship detection with rotated region proposal and discrimination networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the 6th International Conference on Pattern Recognition Application and Methods (ICPRAM 2017), Porto, Portugal, 24–26 February 2017; pp. 324–331. [Google Scholar]
- Simon, M.; Rodner, E.; Denzler, J. ImageNet pre-trained models with batch normalization. arXiv 2016, arXiv:1612.01452. [Google Scholar]
- Feng, Y.; Diao, W.; Sun, X.; Yan, M.; Gao, X. Towards Automated Ship Detection and Category Recognition from High-Resolution Aerial Images. Remote Sens. 2019, 11, 1901. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MSF | RRPN | C-RRoI | Target Type | Actual Number | Correct Detected Number | Recall(%) | False Alarm | Precision(%) |
|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | × | × | × | Large | 394 | 327 | 83.0 | 37 | 91.4 |
| Small | 92 | 68 | 73.9 | ||||||
| Model_1 | × | √ | × | Large | 394 | 334 | 84.8 | 39 | 91.2 |
| Small | 92 | 70 | 76.1 | ||||||
| Model_2 | × | √ | √ | Large | 394 | 357 | 90.6 | 37 | 92.2 |
| Small | 92 | 79 | 85.9 | ||||||
| Proposed Method | √ | √ | √ | Large | 394 | 365 | 92.6 | 22 | 95.3 |
| Small | 92 | 82 | 89.1 |
| Method | Target Type | Actual Number | Correct Detected Number | Recall(%) | False Alarm | Precision(%) |
|---|---|---|---|---|---|---|
| Faster R-CNN | Large | 394 | 327 | 83.0 | 37 | 91.4 |
| Small | 92 | 68 | 73.9 | |||
| SSD | Large | 394 | 293 | 74.4 | 95 | 76.8 |
| Small | 92 | 22 | 23.9 | |||
| RRPN | Large | 394 | 352 | 89.3 | 55 | 88.6 |
| Small | 92 | 77 | 83.7 | |||
| Proposed Method | Large | 394 | 365 | 92.6 | 22 | 95.3 |
| Small | 92 | 82 | 89.1 |
| Method | Faster R-CNN | RRPN | Proposed Method |
|---|---|---|---|
| Memory occupied | 2010 M | 2124 M | 2546 M |
| Average time | 0.11 s | 0.16 s | 0.25 s |
| No. | Method | End-to-End Model | Bbox Type | mAP |
|---|---|---|---|---|
| 1 | SRBBS (NRER-REG-BB) [39] | × | horizontal | 55.7 |
| 2 | SRBBS (NBEB-REG-BB) [39] | × | horizontal | 79.7 |
| 3 | SHD-HBB [41] | √ | horizontal | 69.5 |
| 4 | Faster R-CNN [19] | √ | horizontal | 84.0 |
| 5 | SRBBS (NRER-REG-RBB) [39] | × | rotated | 69.6 |
| 6 | SRBBS (NREB-REG-RBB) [39] | × | rotated | 79.0 |
| 7 | RR-CNN [27] | × | rotated | 75.7 |
| 8 | RDFPN [6] | √ | rotated | 76.2 |
| 9 | RRPN+RROI Pooling [37] | √ | rotated | 79.6 |
| 10 | Proposed Method | √ | rotated | 80.8 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, T.; Pan, Z.; Tan, X.; Chu, Z. Arbitrary-Oriented Inshore Ship Detection based on Multi-Scale Feature Fusion and Contextual Pooling on Rotation Region Proposals. Remote Sens. 2020, 12, 339. https://doi.org/10.3390/rs12020339
Tian T, Pan Z, Tan X, Chu Z. Arbitrary-Oriented Inshore Ship Detection based on Multi-Scale Feature Fusion and Contextual Pooling on Rotation Region Proposals. Remote Sensing. 2020; 12(2):339. https://doi.org/10.3390/rs12020339
Chicago/Turabian StyleTian, Tian, Zhihong Pan, Xiangyu Tan, and Zhengquan Chu. 2020. "Arbitrary-Oriented Inshore Ship Detection based on Multi-Scale Feature Fusion and Contextual Pooling on Rotation Region Proposals" Remote Sensing 12, no. 2: 339. https://doi.org/10.3390/rs12020339
APA StyleTian, T., Pan, Z., Tan, X., & Chu, Z. (2020). Arbitrary-Oriented Inshore Ship Detection based on Multi-Scale Feature Fusion and Contextual Pooling on Rotation Region Proposals. Remote Sensing, 12(2), 339. https://doi.org/10.3390/rs12020339