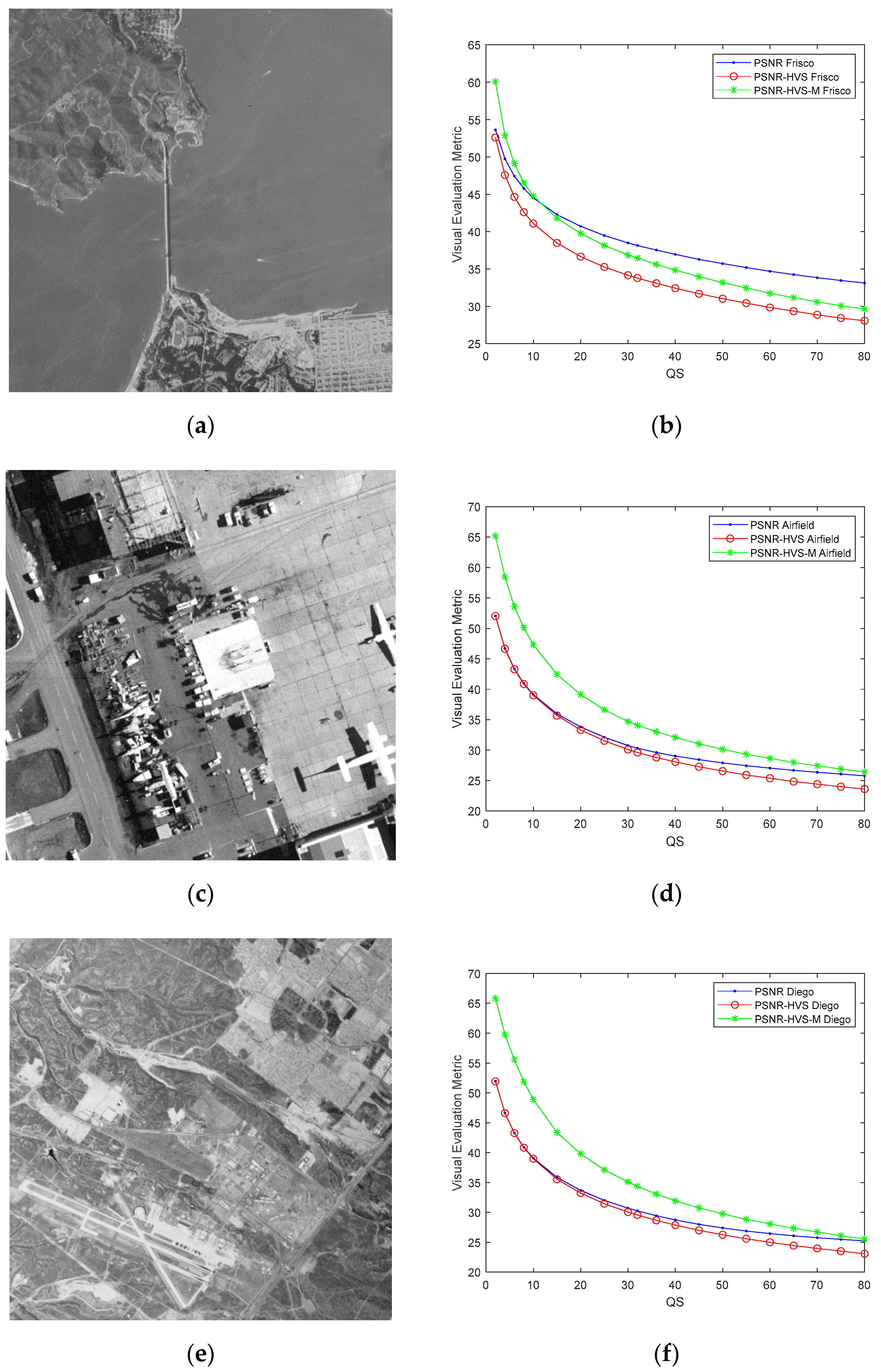
Figure 1.
Test grayscale images Frisco (a), Airfield (c), and Diego (e), all of size 512 × 512 pixels, and dependences of the considered metrics (PSNR, PSNR-HVS, PSNR-HVS-M, all in dB) on the quantization step (QS) for the coder AGU for these test images ((b), (d), and (f), respectively).
Figure 1.
Test grayscale images Frisco (a), Airfield (c), and Diego (e), all of size 512 × 512 pixels, and dependences of the considered metrics (PSNR, PSNR-HVS, PSNR-HVS-M, all in dB) on the quantization step (QS) for the coder AGU for these test images ((b), (d), and (f), respectively).
Figure 2.
Three-channel test image: original (a), its three components (b–d), compressed with providing PSNR-HVS-M = 36 dB (e), compressed with providing PSNR-HVS-M = 30 dB (f).
Figure 2.
Three-channel test image: original (a), its three components (b–d), compressed with providing PSNR-HVS-M = 36 dB (e), compressed with providing PSNR-HVS-M = 30 dB (f).
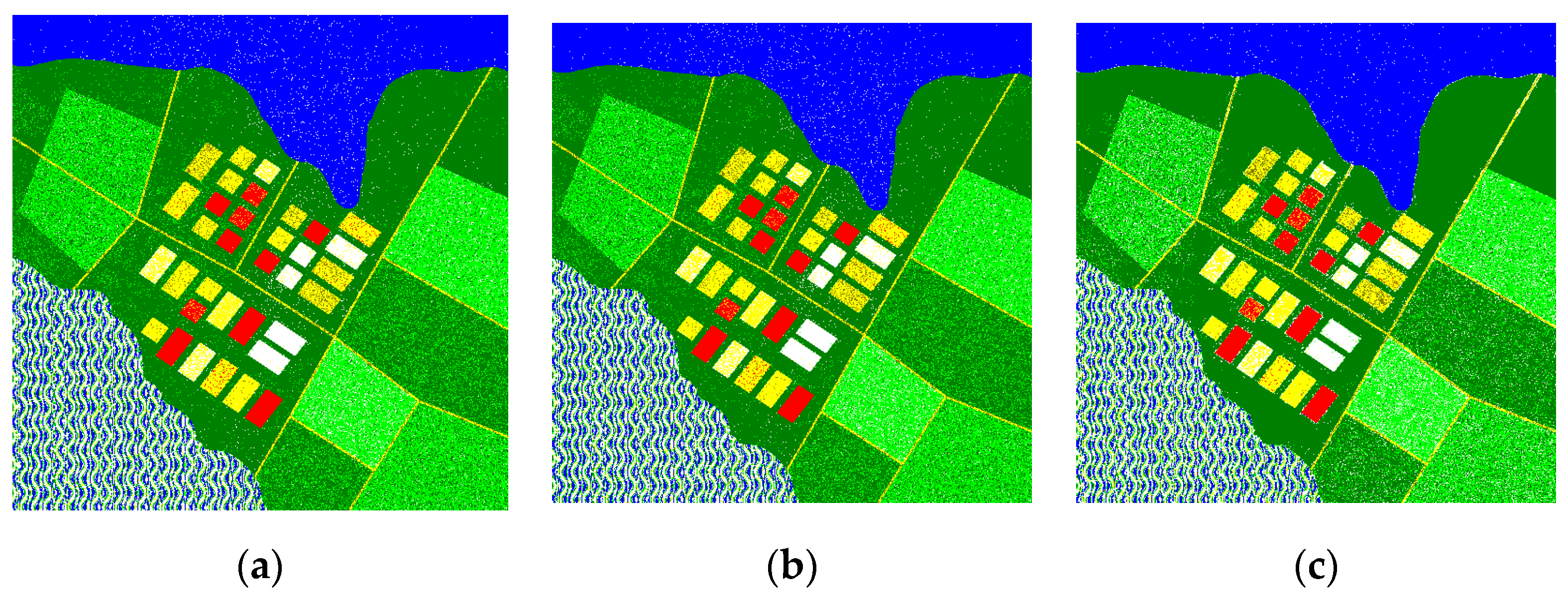
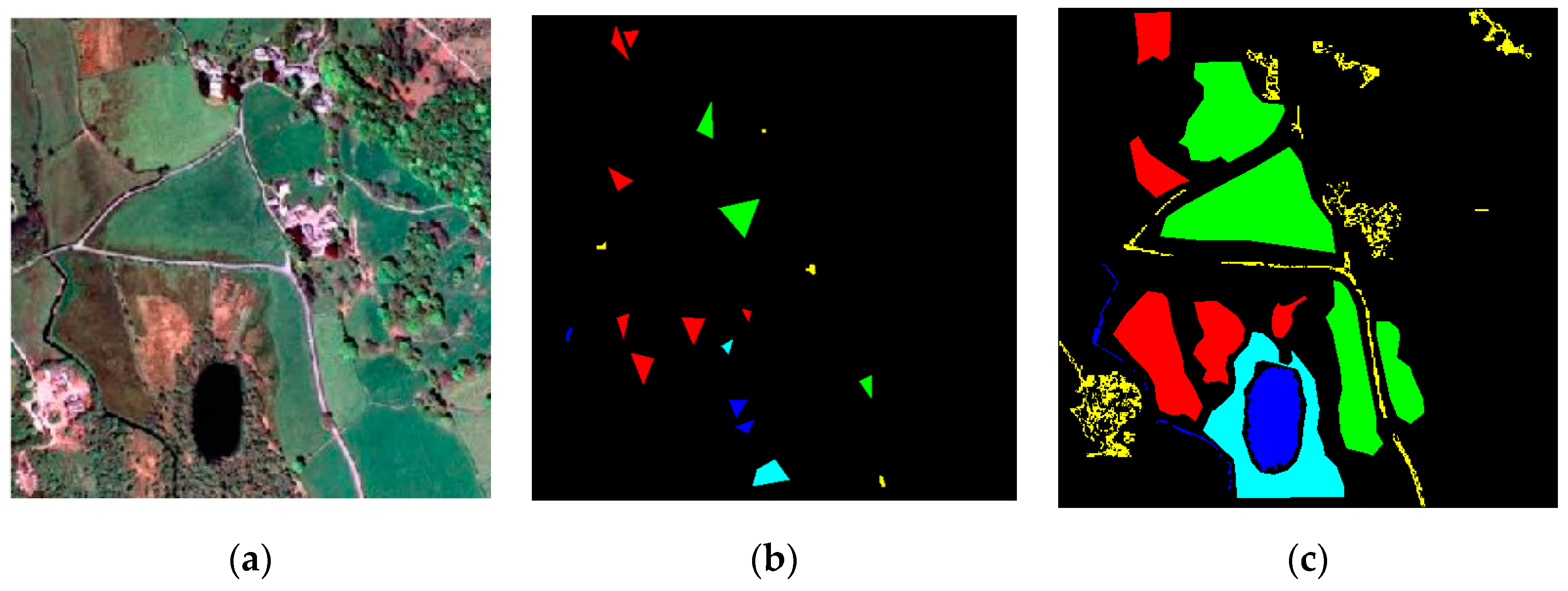
Figure 3.
Classification results: true map (a); classification map for original image (b); classification map for image compressed with PSNR-HVS-M = 36 dB (c); classification map for image compressed with PSNR-HVS-M = 30 dB (d).
Figure 3.
Classification results: true map (a); classification map for original image (b); classification map for image compressed with PSNR-HVS-M = 36 dB (c); classification map for image compressed with PSNR-HVS-M = 30 dB (d).
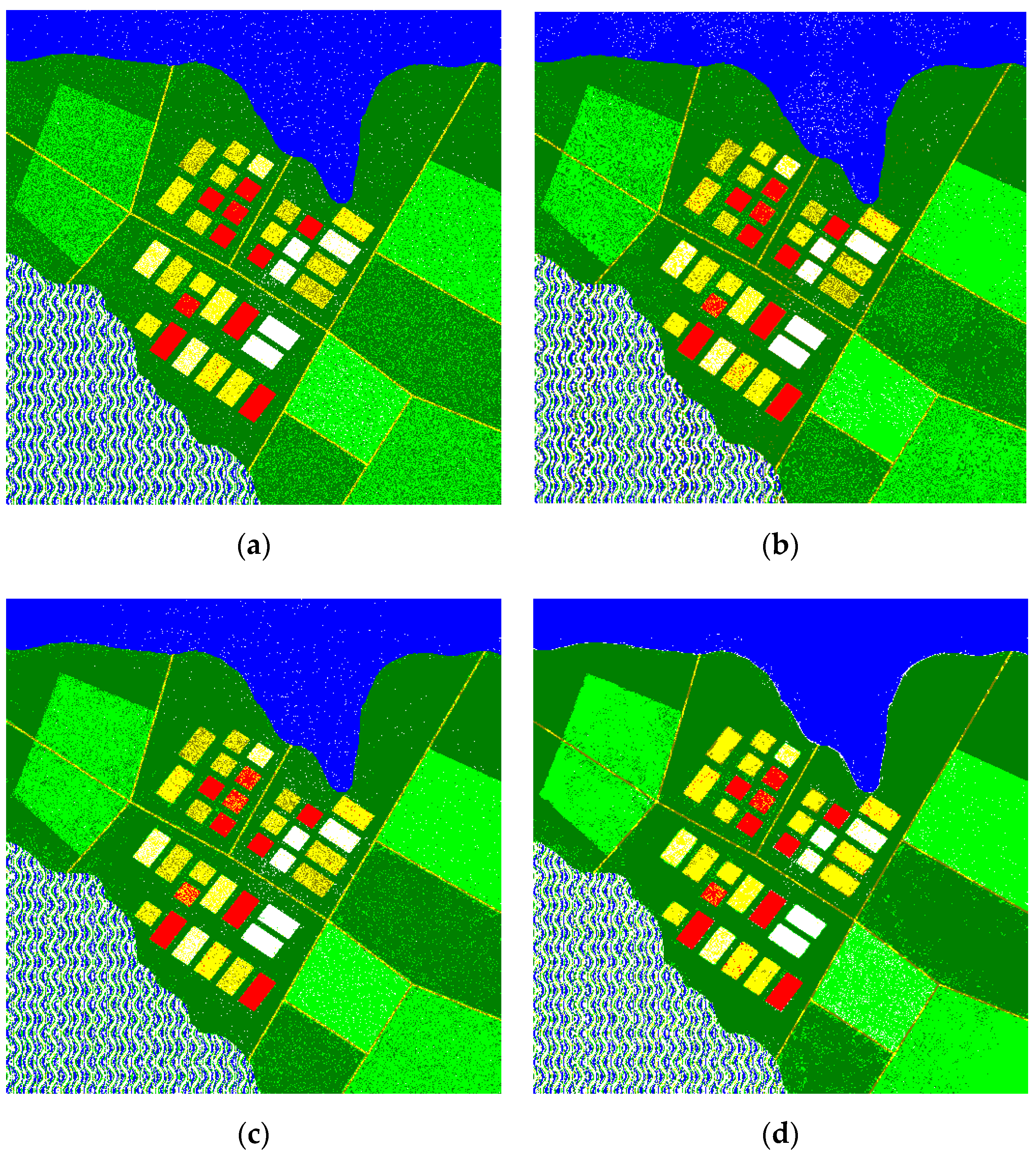
Figure 4.
Classification maps for the compressed image with providing PSNR-HVS-M = 36 dB using maximum likelihood method (MLM) classifier trained for the same compressed image (a); compressed image with providing PSNR-HVS-M = 30 dB using MLM classifier trained for the same compressed image (b).
Figure 4.
Classification maps for the compressed image with providing PSNR-HVS-M = 36 dB using maximum likelihood method (MLM) classifier trained for the same compressed image (a); compressed image with providing PSNR-HVS-M = 30 dB using MLM classifier trained for the same compressed image (b).
Figure 5.
Classification results: for compressed image (PSNR-HVS-M = 42 dB) (a), for compressed image (PSNR-HVS-M = 36 dB) (b); for compressed (PSNR-HVS-M = 30 dB) (c).
Figure 5.
Classification results: for compressed image (PSNR-HVS-M = 42 dB) (a), for compressed image (PSNR-HVS-M = 36 dB) (b); for compressed (PSNR-HVS-M = 30 dB) (c).
Figure 6.
Results of image classification by NN trained for the same image: original (a), compressed with PSNR-HVS-M = 42 dB (b), compressed with PSNR-HVS-M = 36 dB (c), compressed with PSNR-HVS-M = 30 dB (d).
Figure 6.
Results of image classification by NN trained for the same image: original (a), compressed with PSNR-HVS-M = 42 dB (b), compressed with PSNR-HVS-M = 36 dB (c), compressed with PSNR-HVS-M = 30 dB (d).
Figure 7.
The three-channel image in pseudo-color representation (a); pixel groups used for training (b), pixel groups used for verification (c).
Figure 7.
The three-channel image in pseudo-color representation (a); pixel groups used for training (b), pixel groups used for verification (c).
Figure 8.
Three-channel image in pseudo-color representation: compressed with providing PSNR-HVS-M = 42 dB (a), compressed with providing PSNR-HVS-M = 36 dB (b); compressed with providing PSNR-HVS-M = 30 dB (c).
Figure 8.
Three-channel image in pseudo-color representation: compressed with providing PSNR-HVS-M = 42 dB (a), compressed with providing PSNR-HVS-M = 36 dB (b); compressed with providing PSNR-HVS-M = 30 dB (c).
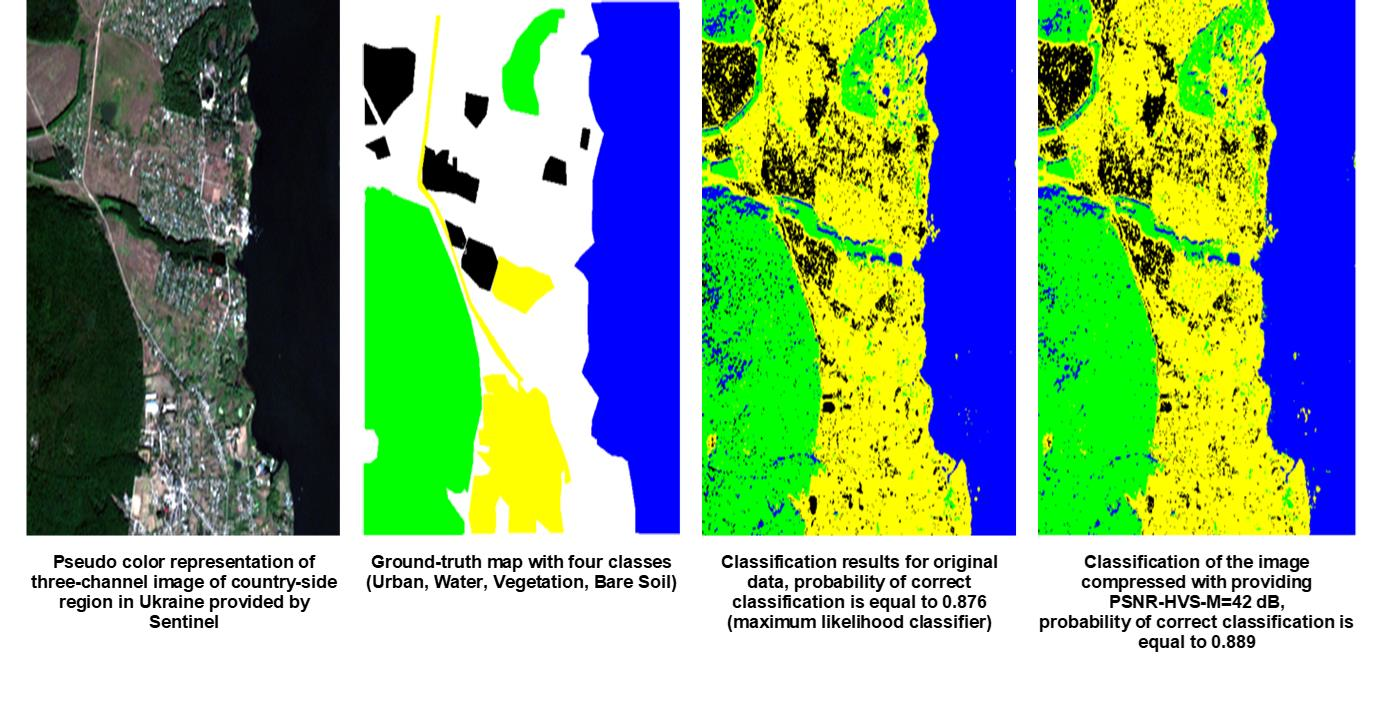
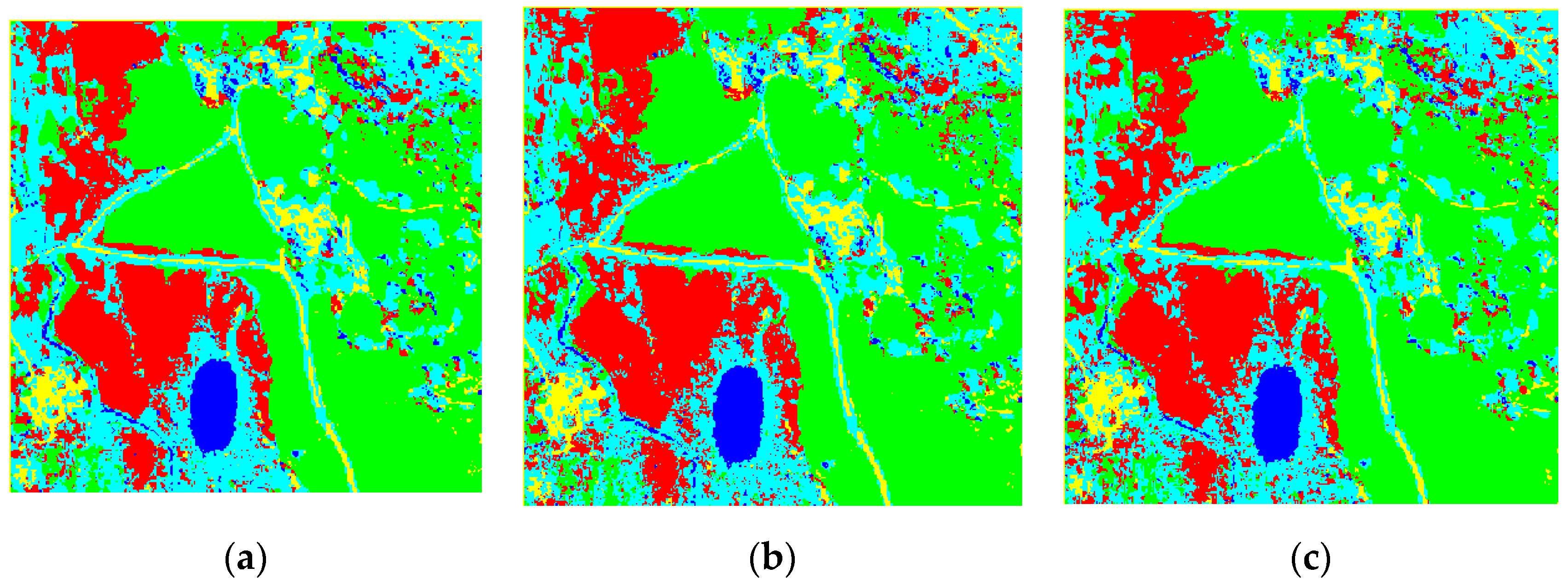
Figure 9.
Classification results: for original image (a), for compressed image (PSNR-HVS-M = 36 dB) (b), for compressed (PSNR-HVS-M = 30 dB) (c).
Figure 9.
Classification results: for original image (a), for compressed image (PSNR-HVS-M = 36 dB) (b), for compressed (PSNR-HVS-M = 30 dB) (c).
Figure 10.
Classification results provided by NN-based method: for original image (a), for compressed image (PSNR-HVS-M = 36 dB) (b); for compressed (PSNR-HVS-M = 30 dB) (c).
Figure 10.
Classification results provided by NN-based method: for original image (a), for compressed image (PSNR-HVS-M = 36 dB) (b); for compressed (PSNR-HVS-M = 30 dB) (c).
Figure 11.
Fragments of Sentinel-2 images of Staryi Saltiv (a) and north part of Kharkiv (b).
Figure 11.
Fragments of Sentinel-2 images of Staryi Saltiv (a) and north part of Kharkiv (b).
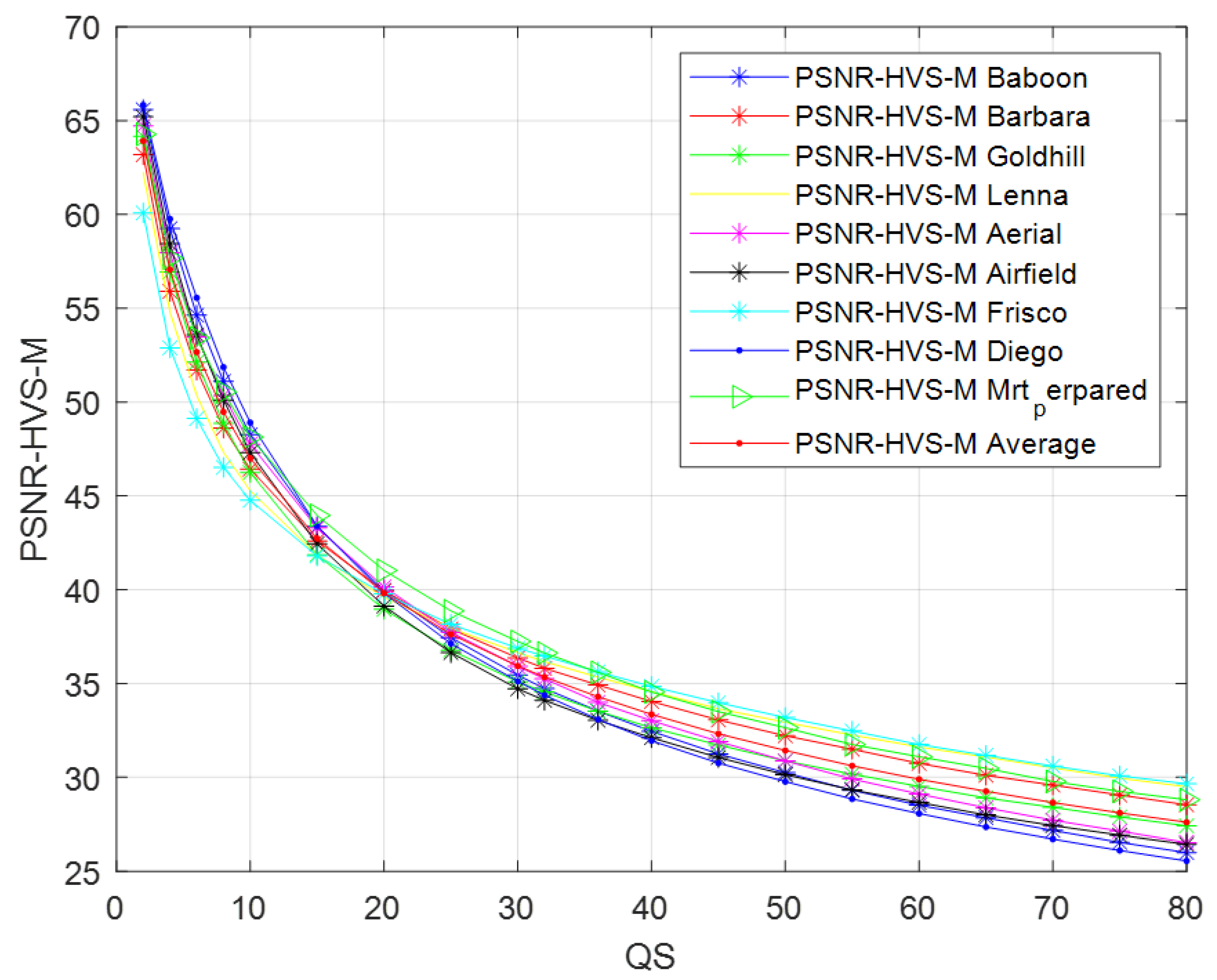
Figure 12.
Dependences PSNR-HVS-M on QS for nine test images (see the list in the upper part of the plot) and the average curve for AGU.
Figure 12.
Dependences PSNR-HVS-M on QS for nine test images (see the list in the upper part of the plot) and the average curve for AGU.
Figure 13.
Flowchart of the proposed processing approach.
Figure 13.
Flowchart of the proposed processing approach.
Table 1.
Information about classes.
Table 2.
Probabilities of correct classifications for particular classes depending on image quality.
Table 2.
Probabilities of correct classifications for particular classes depending on image quality.
| PSNR-HVS-M, dB | P11 | P22 | P33 | P44 | P55 | P66 | P77 |
|---|
| ∞ (original image) | 0.475 | 0.667 | 0.773 | 0.854 | 0.193 | 0.822 | 0.415 |
| 48 | 0.190 | 0.781 | 0.686 | 0.384 | 0.093 | 0.809 | 0.579 |
| 45 | 0.147 | 0.795 | 0.652 | 0.308 | 0.077 | 0.777 | 0.623 |
| 42 | 0.101 | 0.804 | 0.615 | 0.253 | 0.058 | 0.712 | 0.665 |
| 36 | 0.031 | 0.802 | 0.568 | 0.163 | 0.040 | 0.545 | 0.777 |
| 30 | 0.001 | 0.753 | 0.478 | 0.177 | 0.042 | 0.556 | 0.843 |
Table 3.
Illustration of distribution changes due to lossy compression for Class 1.
Table 4.
Illustration of distribution changes due to lossy compression for Class 2.
Table 5.
Total probabilities of correct classification Pcc for different images depending upon “training” data.
Table 5.
Total probabilities of correct classification Pcc for different images depending upon “training” data.
| Image Used for Training | Total Probabilities of Correct Classification for Compressed Images |
|---|
| PSNR-HVS-M = 42 dB | PSNR-HVS-M = 36 dB | PSNR-HVS-M = 30 dB |
|---|
| 0 | Original (uncompressed) | 0.501 | 0.434 | 0.442 |
| 1 | Compressed with providing PSNR-HVS-M = 42 dB | 0.579 | 0.566 | 0.563 |
| 2 | Compressed with providing PSNR-HVS-M = 36 dB | 0.519 | 0.597 | 0.599 |
| 3 | Compressed with providing PSNR-HVS-M = 30 dB | 0.408 | 0.446 | 0.527 |
Table 6.
Confusion matrix for the original image classified by neural networks (NN) trained for this image.
Table 6.
Confusion matrix for the original image classified by neural networks (NN) trained for this image.
| Class | Probability of Decision |
|---|
| Road | Field-Y | Field-R | Water | Grass | Trees | Texture |
|---|
| Road | 0.356 | 0.645 | 0 | 0 | 0 | 0 | 0 |
| Field-Y | 0.109 | 0.608 | 0.002 | 0 | 0 | 0 | 0.281 |
| Field-R | 0 | 0.004 | 0.996 | 0 | 0 | 0 | 0 |
| Water | 0 | 0 | 0 | 0.986 | 0 | 0 | 0.014 |
| Grass | 0 | 0 | 0 | 0 | 0.744 | 0.245 | 0.012 |
| Tree | 0 | 0 | 0 | 0 | 0.072 | 0.923 | 0.005 |
| Texture | 0 | 0.03 | 0 | 0.26 | 0.116 | 0.153 | 0.441 |
Table 7.
Confusion matrix for compressed image classified by NN trained for the original image and applied for the compressed image (PSNR-HVS-M = 42 dB).
Table 7.
Confusion matrix for compressed image classified by NN trained for the original image and applied for the compressed image (PSNR-HVS-M = 42 dB).
| Class | Probability of Decision |
|---|
| Road | Field-Y | Field-R | Water | Grass | Trees | Texture |
|---|
| Road | 0.299 | 0.699 | 0 | 0 | 0 | 0 | 0 |
| Field-Y | 0.089 | 0.627 | 0 | 0 | 0 | 0 | 0.276 |
| Field-R | 0 | 0.018 | 0.982 | 0 | 0 | 0 | 0 |
| Water | 0 | 0 | 0 | 0.980 | 0 | 0 | 0.020 |
| Grass | 0 | 0 | 0 | 0 | 0.753 | 0.219 | 0.028 |
| Tree | 0 | 0 | 0 | 0 | 0.084 | 0.911 | 0.006 |
| Texture | 0 | 0.03 | 0 | 0.26 | 0.116 | 0.153 | 0.441 |
Table 8.
Confusion matrix for compressed image classified by NN trained for original image and applied for the compressed image (PSNR-HVS-M = 36 dB).
Table 8.
Confusion matrix for compressed image classified by NN trained for original image and applied for the compressed image (PSNR-HVS-M = 36 dB).
| Class | Probability of Decision |
|---|
| Road | Field-Y | Field-R | Water | Grass | Trees | Texture |
|---|
| Road | 0.271 | 0.728 | 0.001 | 0 | 0 | 0 | 0 |
| Field-Y | 0.078 | 0.631 | 0.012 | 0 | 0.001 | 0 | 0.279 |
| Field-R | 0 | 0.027 | 0.973 | 0 | 0 | 0 | 0 |
| Water | 0 | 0 | 0 | 0.979 | 0 | 0 | 0.021 |
| Grass | 0 | 0 | 0 | 0 | 0.721 | 0.22 | 0.059 |
| Tree | 0 | 0 | 0 | 0 | 0.078 | 0.915 | 0.007 |
| Texture | 0 | 0.049 | 0 | 0.253 | 0.123 | 0.148 | 0.426 |
Table 9.
Confusion matrix for compressed image classified by NN trained for the original image and applied for the compressed image (PSNR-HVS-M = 30 dB).
Table 9.
Confusion matrix for compressed image classified by NN trained for the original image and applied for the compressed image (PSNR-HVS-M = 30 dB).
| Class | Probability of Decision |
|---|
| Road | Field-Y | Field-R | Water | Grass | Trees | Texture |
|---|
| Road | 0.217 | 0.766 | 0 | 0 | 0 | 0 | 0.017 |
| Field-Y | 0.067 | 0.646 | 0.007 | 0 | 0.005 | 0 | 0.275 |
| Field-R | 0 | 0.05 | 0.946 | 0.004 | 0 | 0 | 0 |
| Water | 0 | 0 | 0 | 0.992 | 0 | 0 | 0.008 |
| Grass | 0 | 0 | 0 | 0 | 0.658 | 0.21 | 0.131 |
| Tree | 0 | 0 | 0 | 0 | 0.051 | 0.925 | 0.025 |
| Texture | 0 | 0.067 | 0 | 0.243 | 0.141 | 0.131 | 0.418 |
Table 10.
Confusion matrix for compressed image classified by NN trained for this image (PSNR-HVS-M = 42 dB).
Table 10.
Confusion matrix for compressed image classified by NN trained for this image (PSNR-HVS-M = 42 dB).
| Class | Probability of Decision |
|---|
| Road | Field-Y | Field-R | Water | Grass | Trees | Texture |
|---|
| Road | 0.455 | 0.545 | 0.001 | 0 | 0 | 0 | 0 |
| Field-Y | 0.137 | 0.561 | 0.014 | 0 | 0 | 0 | 0.289 |
| Field-R | 0 | 0.026 | 0.974 | 0 | 0 | 0 | 0 |
| Water | 0 | 0 | 0 | 0.961 | 0 | 0 | 0.039 |
| Grass | 0 | 0 | 0 | 0 | 0.820 | 0.165 | 0.015 |
| Tree | 0 | 0 | 0 | 0 | 0.068 | 0.929 | 0.004 |
| Texture | 0 | 0.029 | 0 | 0.234 | 0.124 | 0.153 | 0.461 |
Table 11.
Confusion matrix for compressed image classified by NN trained for this image (PSNR-HVS-M = 36 dB).
Table 11.
Confusion matrix for compressed image classified by NN trained for this image (PSNR-HVS-M = 36 dB).
| Class | Probability of Decision |
|---|
| Road | Field-Y | Field-R | Water | Grass | Trees | Texture |
|---|
| Road | 0.507 | 0.492 | 0.002 | 0 | 0 | 0 | 0 |
| Field-Y | 0.127 | 0.562 | 0.005 | 0 | 0.001 | 0 | 0.305 |
| Field-R | 0 | 0.069 | 0.931 | 0 | 0 | 0 | 0 |
| Water | 0 | 0 | 0 | 0.989 | 0 | 0 | 0.01 |
| Grass | 0 | 0 | 0 | 0 | 0.901 | 0.087 | 0.013 |
| Tree | 0 | 0 | 0 | 0 | 0.039 | 0.956 | 0.005 |
| Texture | 0 | 0.029 | 0 | 0.236 | 0.142 | 0.141 | 0.452 |
Table 12.
Confusion matrix for compressed image classified by NN trained for this image (PSNR-HVS-M = 30 dB).
Table 12.
Confusion matrix for compressed image classified by NN trained for this image (PSNR-HVS-M = 30 dB).
| Class | Probability of Decision |
|---|
| Road | Field-Y | Field-R | Water | Grass | Trees | Texture |
|---|
| Road | 0.692 | 0.304 | 0 | 0 | 0.002 | 0.001 | 0.01 |
| Field-Y | 0.055 | 0.654 | 0.009 | 0 | 0.019 | 0 | 0.263 |
| Field-R | 0 | 0.033 | 0.967 | 0.004 | 0 | 0 | 0 |
| Water | 0 | 0 | 0 | 0.994 | 0 | 0 | 0.006 |
| Grass | 0 | 0 | 0 | 0 | 0.939 | 0.035 | 0.026 |
| Tree | 0 | 0 | 0 | 0 | 0.023 | 0.972 | 0.005 |
| Texture | 0 | 0.049 | 0 | 0.221 | 0.113 | 0.131 | 0.486 |
Table 13.
Compression parameters.
Table 13.
Compression parameters.
| Component | PSNR-HVS-M Desired | QS | PSNR-HVS-M Provided | CR |
|---|
| Pseudo-red | 42 dB | 17.372 | 41.941 | 6.008 |
| 36 dB | 29.825 | 36.059 | 8.952 |
| 30 dB | 55.558 | 30.007 | 16.503 |
| Pseudo-green | 42 dB | 17.285 | 41.936 | 5.994 |
| 36 dB | 29.856 | 35.992 | 8.968 |
| 30 dB | 55.134 | 29.996 | 16.445 |
| Pseudo-blue | 42 dB | 17.227 | 41.847 | 6.016 |
| 36 dB | 29.729 | 35.998 | 8.993 |
| 30 dB | 55.014 | 30.0008 | 16.577 |
Table 14.
Classification probabilities for the MLM method trained for the original image and applied to it.
Table 14.
Classification probabilities for the MLM method trained for the original image and applied to it.
| Class | Probability of Decision |
|---|
| Soil | Grass | Water | Urban | Bushes |
|---|
| Soil | 0.747 | 0.027 | 0 | 0.037 | 0.189 |
| Grass | 0.173 | 0.812 | 0 | 0.008 | 0.007 |
| Water | 0 | 0 | 0.967 | 0 | 0.033 |
| Urban | 0.004 | 0 | 0 | 0.989 | 0.007 |
| Bushes | 0.091 | 0.068 | 0.013 | 0.016 | 0.812 |
Table 15.
Classification probabilities (confusion matrix) for the MLM method trained for the original image and applied to the compressed image (PSNR-HVS-M = 42 dB).
Table 15.
Classification probabilities (confusion matrix) for the MLM method trained for the original image and applied to the compressed image (PSNR-HVS-M = 42 dB).
| Class | Probability of Decision |
|---|
| Soil | Grass | Water | Urban | Bushes |
|---|
| Soil | 0.732 | 0.025 | 0 | 0.043 | 0.199 |
| Grass | 0.177 | 0.808 | 0 | 0.008 | 0.006 |
| Water | 0 | 0 | 0.963 | 0 | 0.037 |
| Urban | 0.005 | 0 | 0 | 0.987 | 0.008 |
| Bushes | 0.118 | 0.07 | 0.014 | 0.018 | 0.779 |
Table 16.
Classification probabilities (confusion matrix) for the MLM trained for the original image and applied to the compressed image (PSNR-HVS-M = 36 dB).
Table 16.
Classification probabilities (confusion matrix) for the MLM trained for the original image and applied to the compressed image (PSNR-HVS-M = 36 dB).
| Class | Probability of Decision |
|---|
| Soil | Grass | Water | Urban | Bushes |
|---|
| Soil | 0.744 | 0.028 | 0 | 0.043 | 0.185 |
| Grass | 0.185 | 0.799 | 0 | 0.009 | 0.007 |
| Wate» | 0 | 0 | 0.959 | 0 | 0.041 |
| Urban | 0.005 | 0 | 0 | 0.985 | 0.010 |
| Bushes | 0.133 | 0.074 | 0.016 | 0.018 | 0.758 |
Table 17.
Classification probabilities (confusion matrix) for the MLM trained for the original image and applied to the compressed image (PSNR-HVS-M = 30 dB).
Table 17.
Classification probabilities (confusion matrix) for the MLM trained for the original image and applied to the compressed image (PSNR-HVS-M = 30 dB).
| Class | Probability of Decision |
|---|
| Soil | Grass | Water | Urban | Bushes |
|---|
| Soil | 0.724 | 0.026 | - | 0.044 | 0.206 |
| Grass | 0.178 | 0.809 | 0 | 0.006 | 0.007 |
| Water | - | 0 | 0.942 | 0 | 0.058 |
| Urban | 0.007 | - | 0 | 0.982 | 0.011 |
| Bushes | 0.145 | 0.079 | 0.016 | 0.019 | 0.741 |
Table 18.
Classification probabilities for the NN-based method trained for the original image and applied to it.
Table 18.
Classification probabilities for the NN-based method trained for the original image and applied to it.
| Class | Probability of Decision |
|---|
| Soil | Grass | Water | Urban | Bushes |
|---|
| Soil | 0.950 | 0 | 0 | 0 | 0.05 |
| Grass | 0 | 1 | 0 | 0 | 0 |
| Water | 0 | 0 | 0.952 | 0 | 0.048 |
| Urban | 0.098 | 0 | 0 | 0.767 | 0.135 |
| Bushes | 0.187 | 0.009 | 0.02 | 0.009 | 0.774 |
Table 19.
Classification probabilities (confusion matrix) for the NN-based method trained for the original image and applied to the compressed image (PSNR-HVS-M = 42 dB).
Table 19.
Classification probabilities (confusion matrix) for the NN-based method trained for the original image and applied to the compressed image (PSNR-HVS-M = 42 dB).
| Class | Probability of Decision |
|---|
| Soil | Grass | Water | Urban | Bushes |
|---|
| Soil | 0.942 | 0 | 0 | 0 | 0.058 |
| Grass | 0 | 0.999 | 0 | 0 | 0.001 |
| Water | 0 | 0 | 0.942 | 0 | 0.058 |
| Urban | 0.01 | 0 | 0 | 0.765 | 0.136 |
| Bushes | 0.207 | 0.016 | 0.018 | 0.009 | 0.751 |
Table 20.
Classification probabilities (confusion matrix) for the NN-based method trained for original image and applied to the compressed image (PSNR-HVS-M = 36 dB).
Table 20.
Classification probabilities (confusion matrix) for the NN-based method trained for original image and applied to the compressed image (PSNR-HVS-M = 36 dB).
| Class | Probability of Decision |
|---|
| Soil | Grass | Water | Urban | Bushes |
|---|
| Soil | 0.944 | 0 | 0 | 0 | 0.057 |
| Grass | 0 | 1 | 0 | 0 | 0 |
| Water | 0 | 0 | 0.941 | 0 | 0.059 |
| Urban | 0.108 | 0 | 0 | 0.761 | 0.131 |
| Bushes | 0.236 | 0.022 | 0.017 | 0.007 | 0.718 |
Table 21.
Classification probabilities (confusion matrix) for the NN-based method trained for the original image and applied to the compressed image (PSNR-HVS-M = 30 dB).
Table 21.
Classification probabilities (confusion matrix) for the NN-based method trained for the original image and applied to the compressed image (PSNR-HVS-M = 30 dB).
| Class | Probability of Decision |
|---|
| Soil | Grass | Water | Urban | Bushes |
|---|
| Soil | 0.941 | 0 | 0 | 0 | 0.059 |
| Grass | 0 | 0.999 | 0 | 0 | 0.001 |
| Water | 0.001 | 0 | 0.919 | 0 | 0.08 |
| Urban | 0.099 | 0 | 0 | 0.747 | 0.153 |
| Bushes | 0.247 | 0.028 | 0.014 | 0.004 | 0.707 |
Table 22.
CR comparison for real-life data for three coders, both sets.
Table 22.
CR comparison for real-life data for three coders, both sets.
| Color | Desired PSNR-HVS-M | CR for AGU | CR for SPIHT | CR for ADCTC |
|---|
| Pseudo-Red, set 1 | 45.000 | 10.338 | 9.467 | 11.306 |
| 39.000 | 18.383 | 16.631 | 20.362 |
| 33.000 | 32.929 | 29.303 | 36.465 |
| Pseudo-Red, set 2 | 45.000 | 3.317 | 3.283 | 3.498 |
| 39.000 | 4.520 | 4.762 | 4.886 |
| 33.000 | 7.121 | 7.360 | 7.986 |
| Pseudo-Green, set 1 | 45.000 | 7.179 | 5.957 | 7.513 |
| 39.000 | 12.666 | 10.914 | 13.513 |
| 33.000 | 23.907 | 20.833 | 26.030 |
| Pseudo-Green, set 2 | 45.000 | 3.214 | 3.150 | 3.363 |
| 39.000 | 4.356 | 4.564 | 4.684 |
| 33.000 | 6.784 | 7.105 | 7.573 |
| Pseudo-Blue, set 1 | 45.000 | 6.665 | 5.727 | 7.216 |
| 39.000 | 11.942 | 10.336 | 12.740 |
| 33.000 | 24.914 | 22.346 | 27.191 |
| Pseudo-Blue, set 2 | 45.000 | 3.212 | 3.252 | 3.418 |
| 39.000 | 4.314 | 4.698 | 4.785 |
| 33.000 | 6.882 | 7.380 | 7.817 |
Table 23.
Probabilities of correct classification depending on compressed image quality for Set 1, AGU coder, NN classifier.
Table 23.
Probabilities of correct classification depending on compressed image quality for Set 1, AGU coder, NN classifier.
| Classes | SS1 | SS1_45 | SS1_42 | SS1_39 | SS1_36 | SS1_33 | SS1_30 |
|---|
| Urban | 0.774 | 0.777 | 0.775 | 0.777 | 0.778 | 0.773 | 0.786 |
| Water | 0.998 | 0.998 | 0.998 | 0.999 | 0.999 | 0.999 | 0.998 |
| Vegetation | 0.915 | 0.913 | 0.914 | 0.915 | 0.918 | 0.921 | 0.927 |
| Bare soil | 0.809 | 0.811 | 0.809 | 0.809 | 0.812 | 0.798 | 0.801 |
| Ptotal | 0.874 | 0.875 | 0.874 | 0.875 | 0.877 | 0.873 | 0.878 |
Table 24.
Probabilities of correct classification depending on compressed image quality for Set 2, AGU coder, NN classifier.
Table 24.
Probabilities of correct classification depending on compressed image quality for Set 2, AGU coder, NN classifier.
| Classes | SS2 | SS2_45 | SS2_42 | SS2_39 | SS2_36 | SS2_33 | SS2_30 |
|---|
| Urban | 0.877 | 0.872 | 0.871 | 0.865 | 0.861 | 0.861 | 0.864 |
| Water | 0.654 | 0.659 | 0.662 | 0.661 | 0.654 | 0.644 | 0.647 |
| Vegetation | 0.857 | 0.825 | 0.815 | 0.801 | 0.788 | 0.797 | 0.788 |
| Bare soil | 0.890 | 0.867 | 0.865 | 0.869 | 0.866 | 0.860 | 0.870 |
| Ptotal | 0.820 | 0.810 | 0.803 | 0.799 | 0.792 | 0.791 | 0.792 |
Table 25.
Probabilities of correct classification depending on compressed image quality for Set 1, AGU coder, ML classifier.
Table 25.
Probabilities of correct classification depending on compressed image quality for Set 1, AGU coder, ML classifier.
| Classes | SS1 | SS1_45 | SS1_42 | SS1_39 | SS1_36 | SS1_33 | SS1_30 |
|---|
| Urban | 0.695 | 0.727 | 0.727 | 0.735 | 0.745 | 0.743 | 0.771 |
| Water | 0.979 | 0.99 | 0.992 | 0.992 | 0.993 | 0.992 | 0.988 |
| Vegetation | 0.9 | 0.896 | 0.896 | 0.895 | 0.899 | 0.901 | 0.902 |
| Bare soil | 0.85 | 0.852 | 0.851 | 0.849 | 0.852 | 0.831 | 0.826 |
| Ptotal | 0.856 | 0.866 | 0.866 | 0.868 | 0.872 | 0.867 | 0.872 |
Table 26.
Probabilities of correct classification depending on compressed image quality for Set 2, AGU coder, ML classifier.
Table 26.
Probabilities of correct classification depending on compressed image quality for Set 2, AGU coder, ML classifier.
| Classes | SS2 | SS2_45 | SS2_42 | SS2_39 | SS2_36 | SS2_33 | SS2_30 |
|---|
| Urban | 0.917 | 0.914 | 0.913 | 0.913 | 0.91 | 0.913 | 0.918 |
| Water | 0.923 | 0.902 | 0.893 | 0.885 | 0.873 | 0.873 | 0.857 |
| Vegetation | 0.691 | 0.667 | 0.647 | 0.645 | 0.634 | 0.631 | 0.619 |
| Bare soil | 0.856 | 0.819 | 0.815 | 0.817 | 0.812 | 0.802 | 0.812 |
| Ptotal | 0.847 | 0.826 | 0.817 | 0.815 | 0.807 | 0.805 | 0.801 |
Table 27.
Probabilities of correct classification depending on compressed image quality for Set 1, SPIHT coder, ML classifier.
Table 27.
Probabilities of correct classification depending on compressed image quality for Set 1, SPIHT coder, ML classifier.
| Classes | SS1 | SS1_45 | SS1_42 | SS1_39 | SS1_36 | SS1_33 | SS1_30 |
|---|
| Urban | 0.695 | 0.721 | 0.724 | 0.728 | 0.735 | 0.742 | 0.759 |
| Water | 0.979 | 0.991 | 0.991 | 0.993 | 0.993 | 0.992 | 0.985 |
| Vegetation | 0.9 | 0.899 | 0.901 | 0.9 | 0.904 | 0.908 | 0.906 |
| Bare soil | 0.85 | 0.856 | 0.864 | 0.858 | 0.858 | 0.848 | 0.816 |
| Ptotal | 0.856 | 0.866 | 0.87 | 0.87 | 0.872 | 0.873 | 0.867 |
Table 28.
Probabilities of correct classification depending on compressed image quality for Set 2, SPIHT coder, ML classifier.
Table 28.
Probabilities of correct classification depending on compressed image quality for Set 2, SPIHT coder, ML classifier.
| Classes | SS2 | SS2_45 | SS2_42 | SS2_39 | SS2_36 | SS2_33 | SS2_30 |
|---|
| Urban | 0.917 | 0.915 | 0.915 | 0.917 | 0.916 | 0.92 | 0.924 |
| Water | 0.923 | 0.918 | 0.913 | 0.903 | 0.892 | 0.884 | 0.875 |
| Vegetation | 0.691 | 0.686 | 0.688 | 0.692 | 0.697 | 0.699 | 0.707 |
| Bare soil | 0.856 | 0.847 | 0.858 | 0.862 | 0.853 | 0.861 | 0.859 |
| Ptotal | 0.847 | 0.841 | 0.843 | 0.843 | 0.839 | 0.841 | 0.841 |
Table 29.
Probabilities of correct classification depending on compressed image quality for Set 1, ADCTC, ML classifier.
Table 29.
Probabilities of correct classification depending on compressed image quality for Set 1, ADCTC, ML classifier.
| Classes | SS1 | SS1_45 | SS1_42 | SS1_39 | SS1_36 | SS1_33 | SS1_30 |
|---|
| Urban | 0.695 | 0.723 | 0.725 | 0.734 | 0.736 | 0.751 | 0.76 |
| Water | 0.979 | 0.992 | 0.994 | 0.995 | 0.995 | 0.995 | 0.995 |
| Vegetation | 0.9 | 0.898 | 0.9 | 0.901 | 0.901 | 0.91 | 0.913 |
| Bare soil | 0.85 | 0.863 | 0.855 | 0.85 | 0.864 | 0.84 | 0.827 |
| Ptotal | 0.856 | 0.869 | 0.869 | 0.87 | 0.874 | 0.874 | 0.874 |
Table 30.
Probabilities of correct classification depending on compressed image quality for Set 2, ADCTC coder, ML classifier.
Table 30.
Probabilities of correct classification depending on compressed image quality for Set 2, ADCTC coder, ML classifier.
| Classes | SS2 | SS2_45 | SS2_42 | SS2_39 | SS2_36 | SS2_33 | SS2_30 |
|---|
| Urban | 0.917 | 0.914 | 0.911 | 0.91 | 0.911 | 0.912 | 0.915 |
| Water | 0.923 | 0.918 | 0.912 | 0.906 | 0.909 | 0.901 | 0.898 |
| Vegetation | 0.691 | 0.674 | 0.688 | 0.682 | 0.664 | 0.67 | 0.693 |
| Bare soil | 0.856 | 0.848 | 0.848 | 0.847 | 0.843 | 0.859 | 0.868 |
| Ptotal | 0.847 | 0.838 | 0.84 | 0.836 | 0.832 | 0.836 | 0.844 |


 ,
, 

.png)
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















































