Open Data and Machine Learning to Model the Occurrence of Fire in the Ecoregion of “Llanos Colombo–Venezolanos”



Abstract
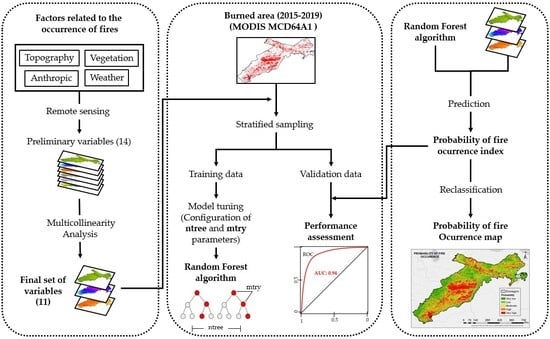
:
1. Introduction
2. Study Area and Data
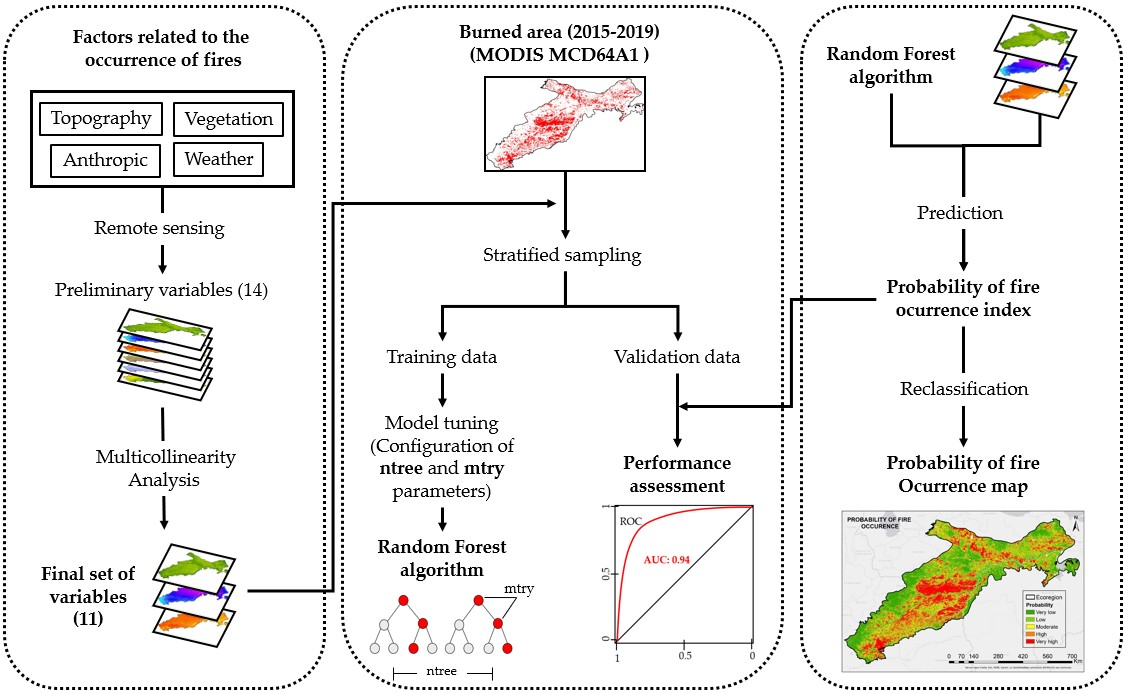
2.1. Study Area
2.2. Data Collection and Pre-Processing
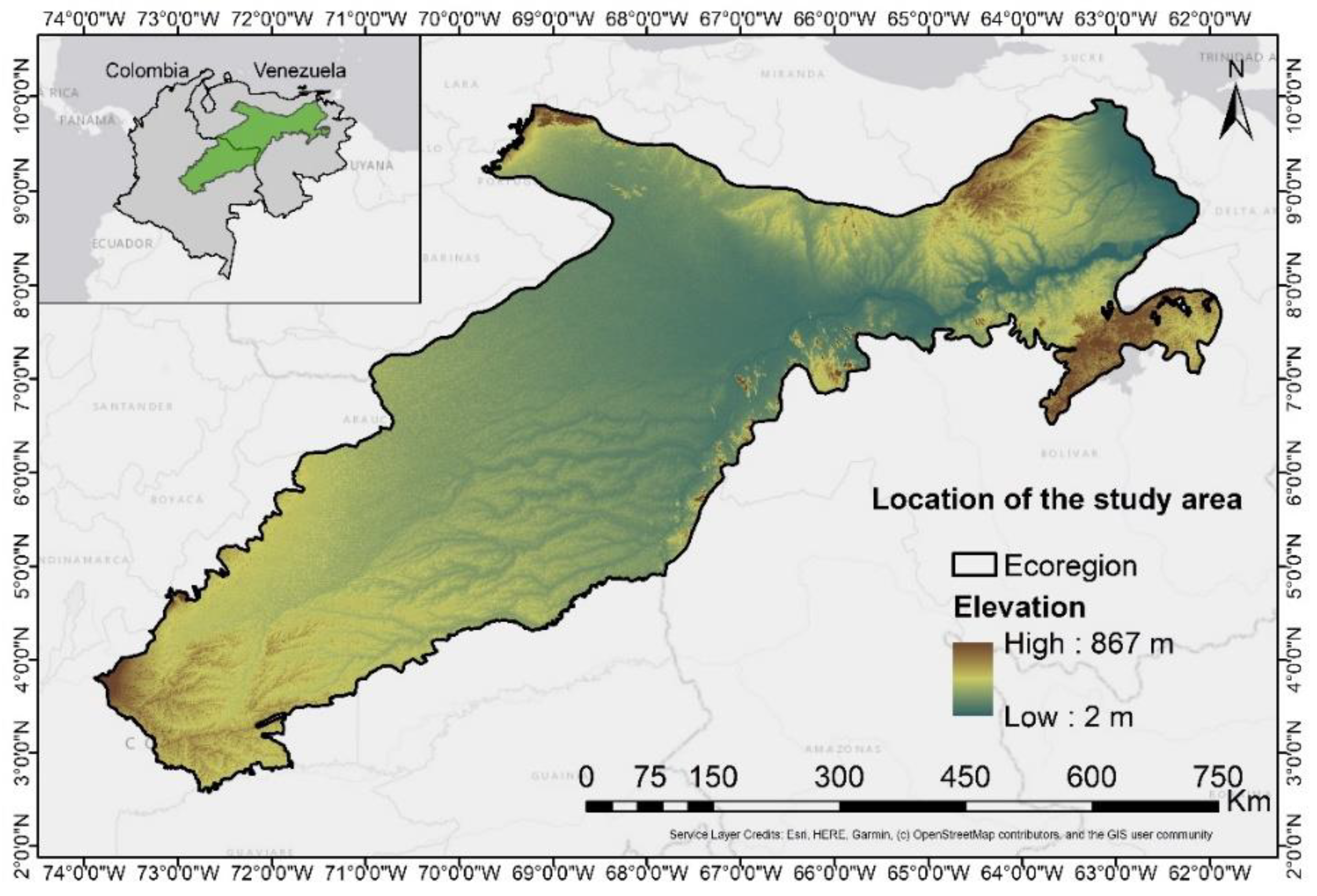
2.2.1. Fire Database
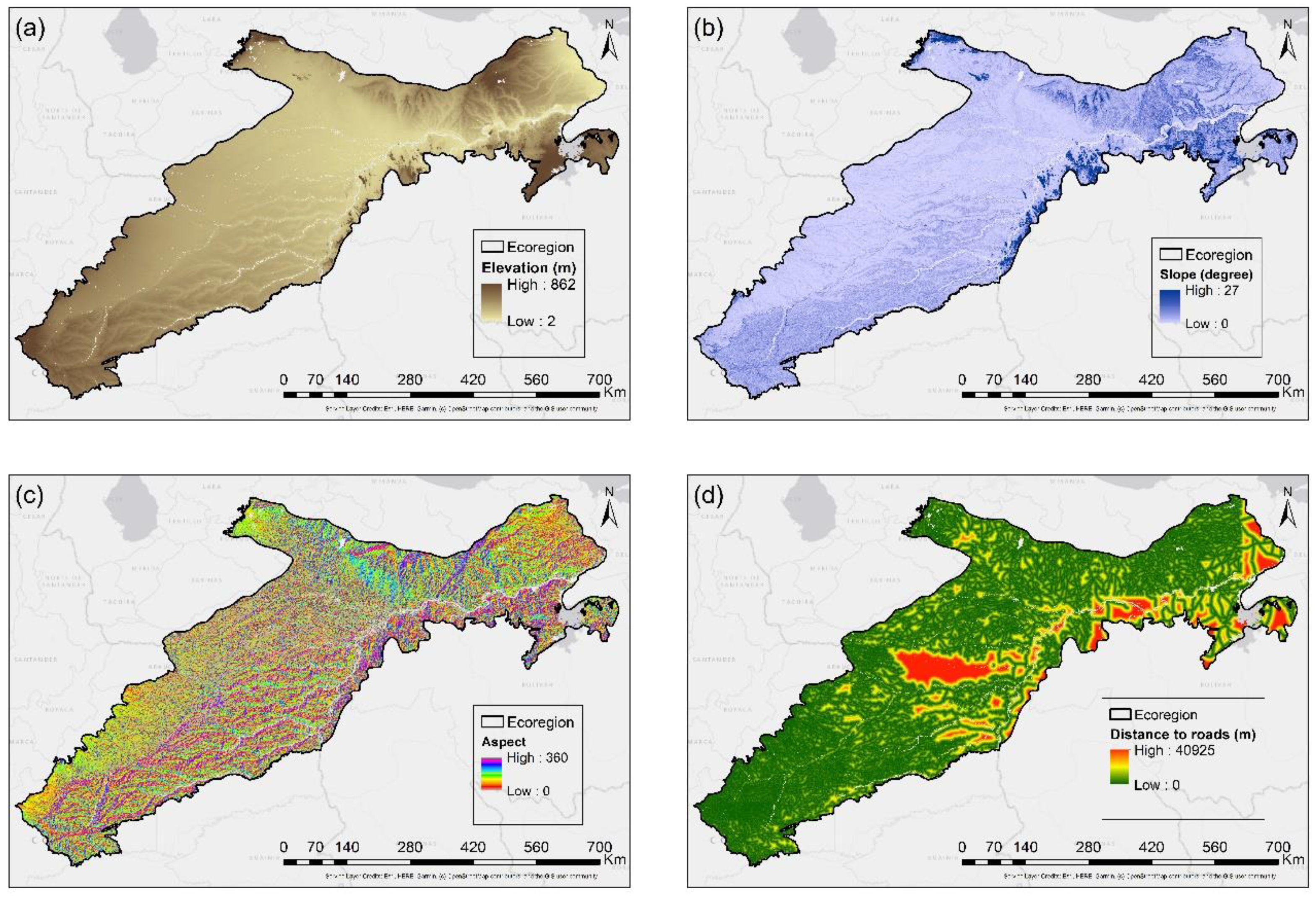
2.2.2. Factors Relating to the Occurrence of Fires
2.2.3. Preprocessing
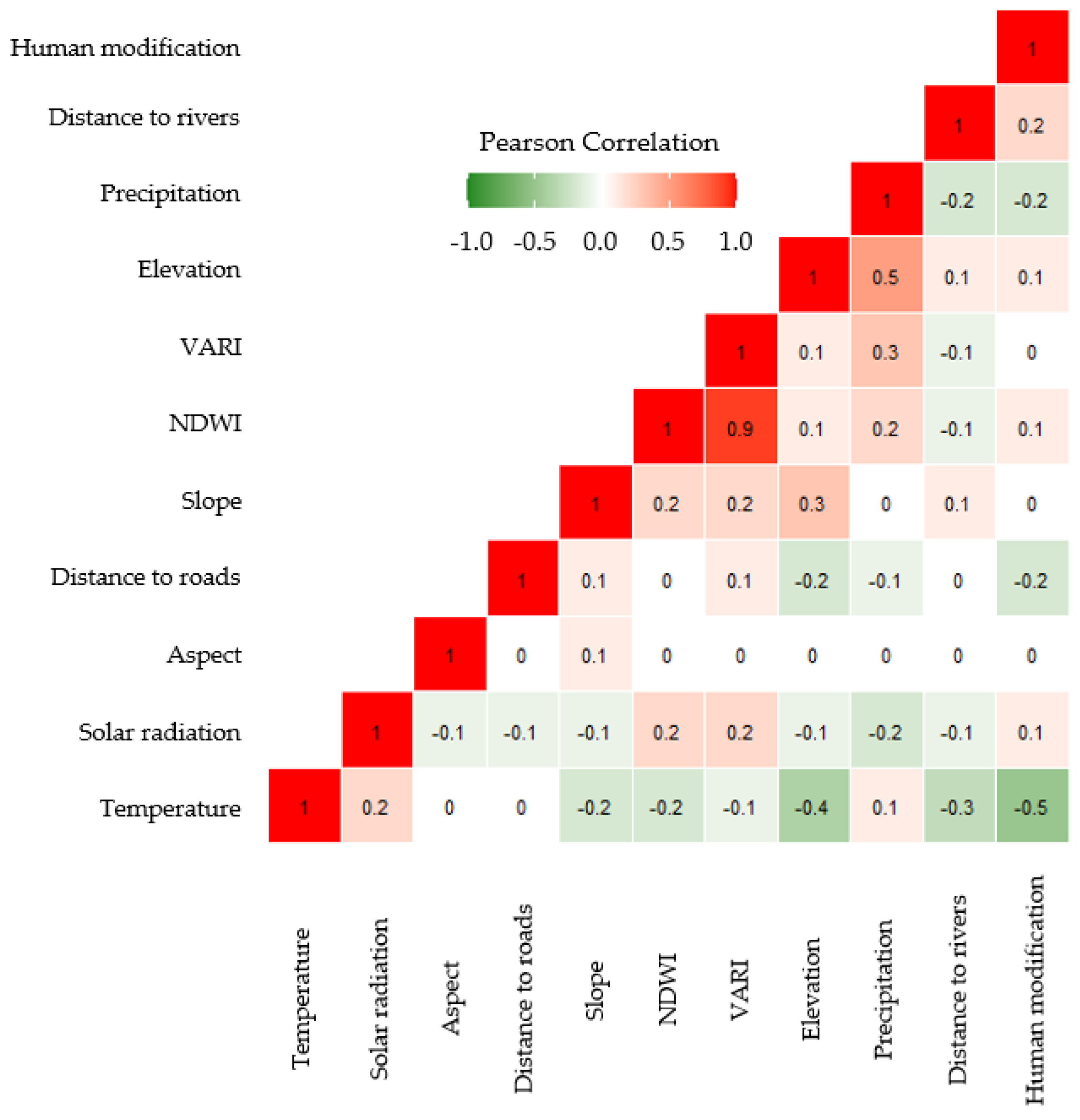
2.3. Variable Selection
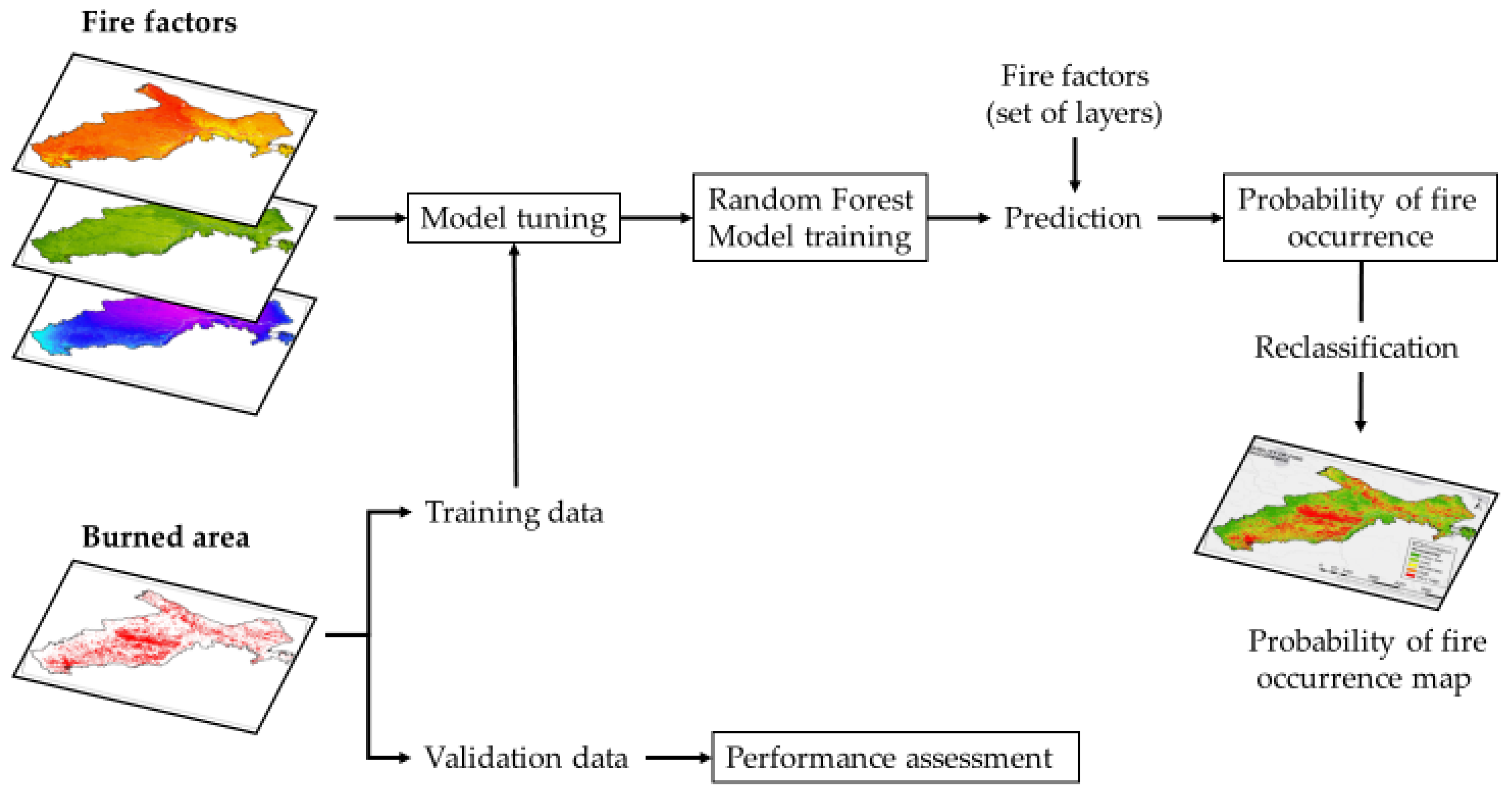
3. Methodology
3.1. Random Forest Algorithm
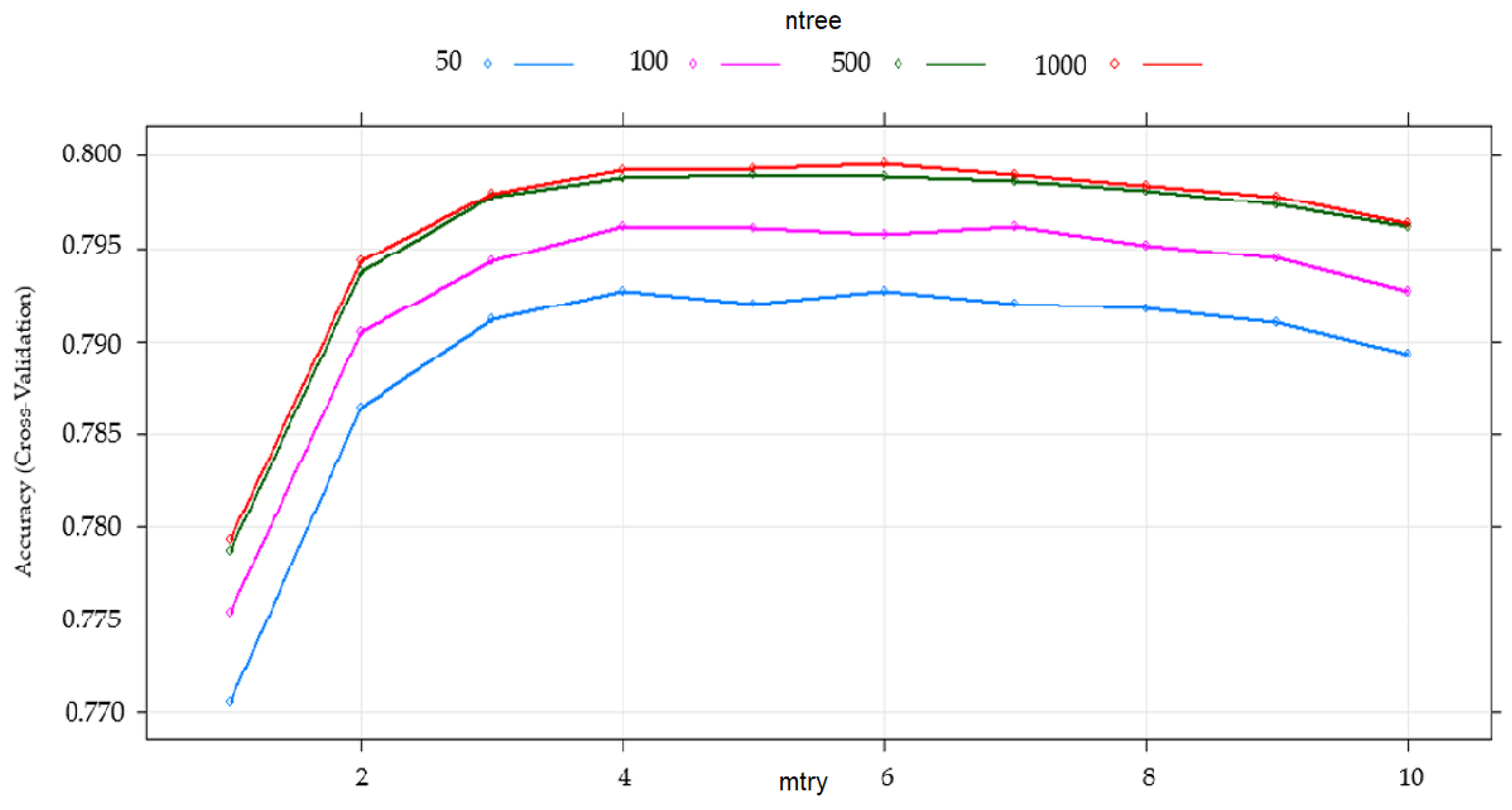
3.2. Tuning Model
3.3. Performance Assessment
3.4. Probability of Fire Occurrence
4. Results
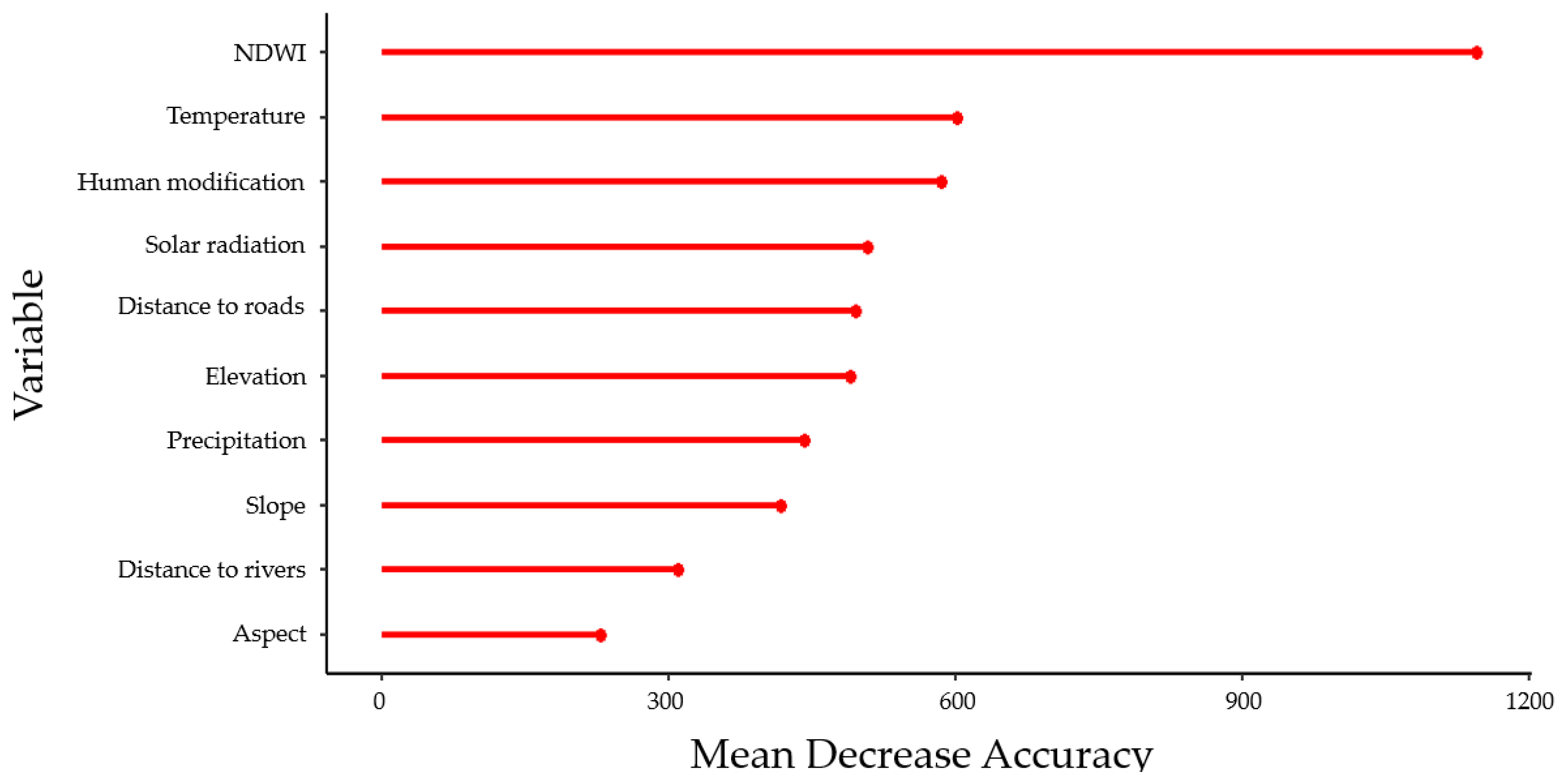
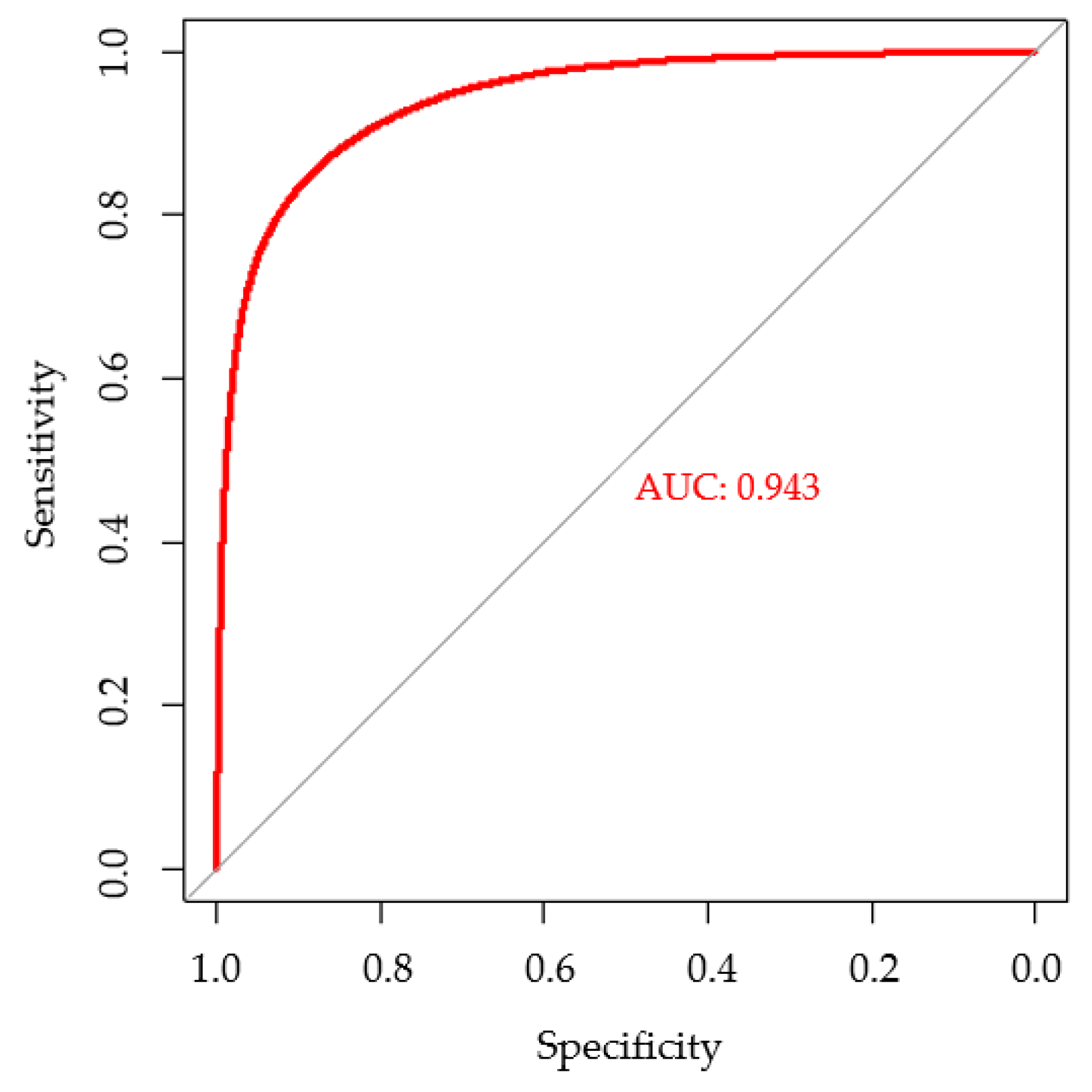
4.1. Predictive Performance and Variable Importance
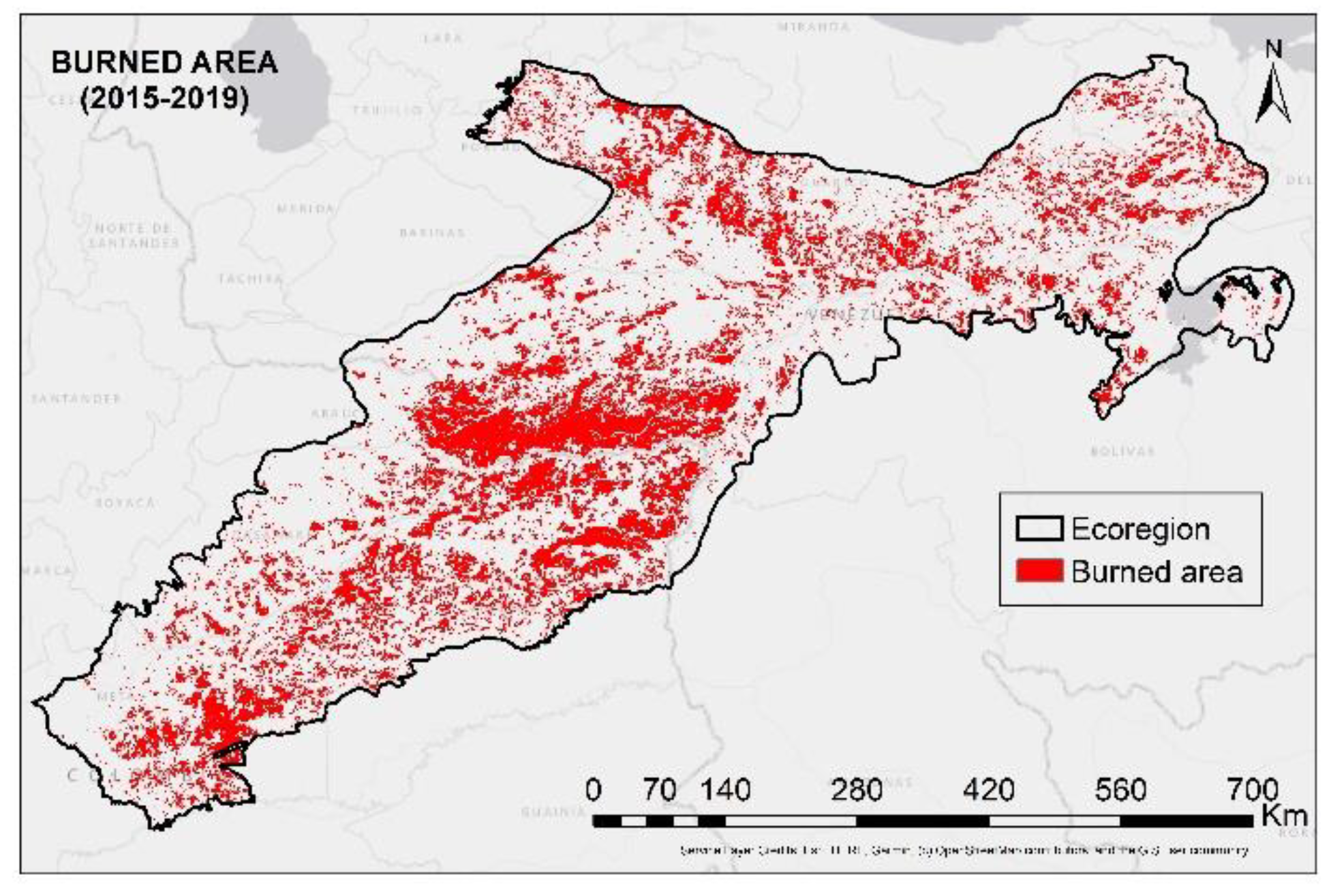
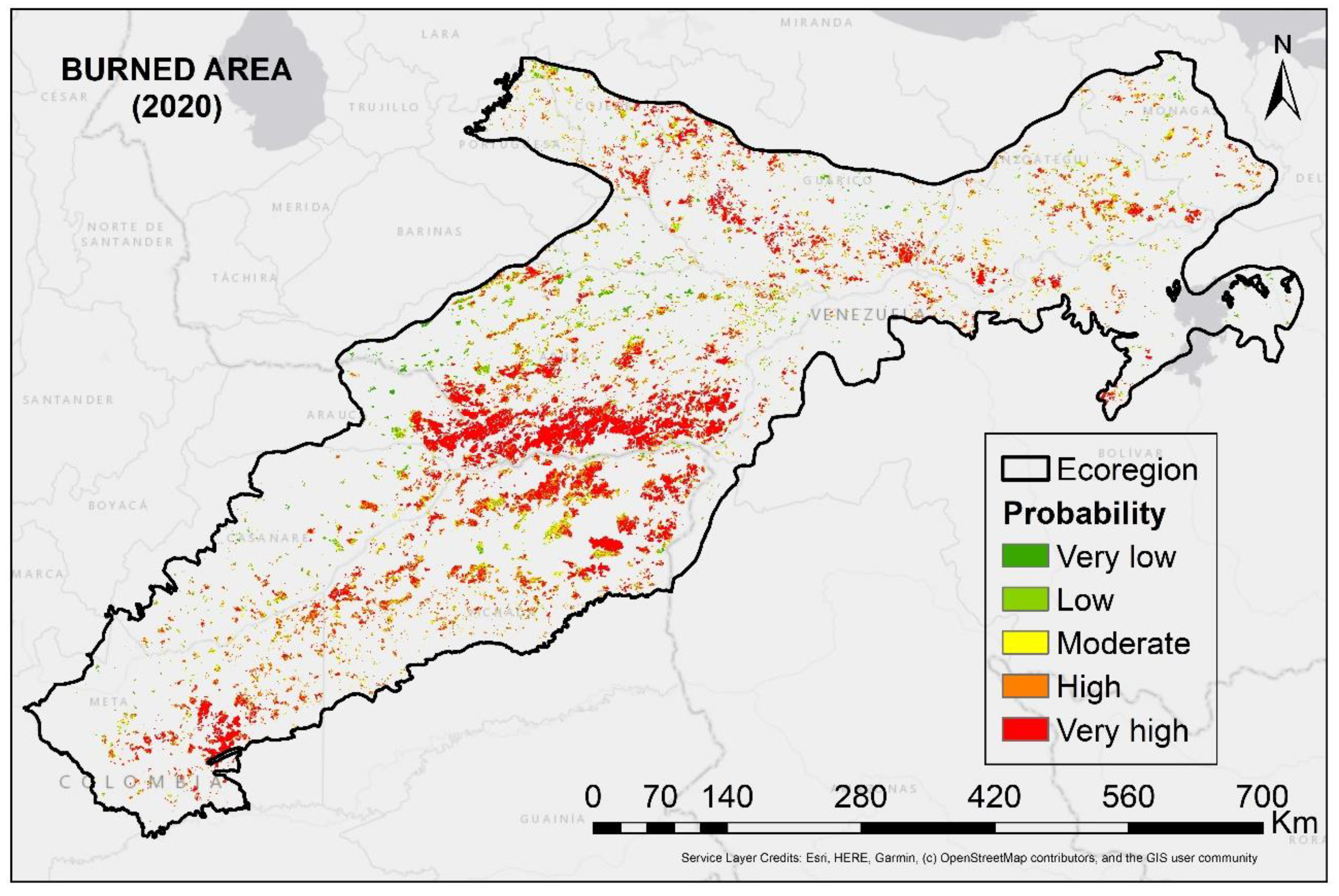
4.2. Probability of Fire Occurrence Map
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Armenteras, D.; Bernal, F.H.; González, F.; Morales, M.; Pabón, J.D.; Páramo, G.E.; González Alonso, F.; Morales, M.; Pabón Caicedo, J.; Páramo Rocha, G.; et al. Incendios de la Cobertura Vegetal en Colombia, Primera ed.; Parra, Á., Ed.; Universidad Autónoma de Occidente: Cali, Colombia, 2011; ISBN 9789588713021. [Google Scholar]
- Martell, D. Forest fire management, current practices and new challenges for operational researchers. In Handbook of Operations Research in Natural Resources, International Series in Operations Research & Management Science; Weintraub, A., Romero, C., Bjorndal, T., Epstein, R., Eds.; Springer: New York, NY, USA, 2007; Volume 99, pp. 419–506. ISBN 9788476661987. [Google Scholar]
- Jain, P.; Coogan, S.C.P.; Subramanian, S.G.; Crowley, M.; Taylor, S.; Flannigan, M.D. A review of machine learning applications in wildfire science and management. arXiv 2020, arXiv:2003.00646. [Google Scholar] [CrossRef]
- Giglio, L.; Boschetti, L.; Roy, D.P.; Humber, M.L.; Justice, C.O. The Collection 6 MODIS burned area mapping algorithm and product. Remote Sens. Environ. 2018, 217, 72–85. [Google Scholar] [CrossRef]
- Ngoc Thach, N.; Bao-Toan Ngo, D.; Xuan-Canh, P.; Hong-Thi, N.; Hang Thi, B.; Nhat-Duc, H.; Tien Bui, D. Spatial pattern assessment of tropical forest fire danger at Thuan Chau area (Vietnam) using GIS-based advanced machine learning algorithms: A comparative study. Ecol. Inform. 2018, 46, 74–85. [Google Scholar] [CrossRef]
- Tien Bui, D.; Hung Le, V.; Hoang, N.-D.; Dieu, T.B.; Hung, V. GIS-Based Spatial Prediction of Tropical Forest Fire Danger Using a New Hybrid Machine Learning Method. Ecol. Inform. 2018, 48, 104–116. [Google Scholar] [CrossRef]
- North, B.M.P.; Stephens, S.L.; Collins, B.M.; Agee, J.; Aplet, G.; Franklin, J.F.; Fulé, P.Z. Reform forest fire management. Science 2015, 349, 1280–1281. [Google Scholar] [CrossRef] [PubMed]
- Bachmann, A.; Allgöwer, B. A consistent wildland fire risk terminology is needed! Fire Manag. Today 2001, 61, 28–33. [Google Scholar]
- Hurley, M.J.; Gottuk, D.; Hall, J.R.; Harada, K.; Kuligowski, E.; Puchovsky, M.; Torero, J.; Watts, J.M.; Wieczorek, C. Introduction to Fire Risk Analysis. In SFPE Handbook of Fire Protection Engineering; Springer: New York, NY, USA, 2016; pp. 1–3493. ISBN 9781493925650. [Google Scholar]
- Tonini, M.; D’Andrea, M.; Biondi, G.; Degli Esposti, S.; Trucchia, A.; Fiorucci, P. A Machine Learning-Based Approach for Wildfire Susceptibility Mapping. The Case Study of the Liguria Region in Italy. Geosciences 2020, 10, 105. [Google Scholar] [CrossRef] [Green Version]
- Nami, M.H.; Jaafari, A.; Fallah, M.; Nabiuni, S. Spatial prediction of wildfire probability in the Hyrcanian ecoregion using evidential belief function model and GIS. Int. J. Environ. Sci. Technol. 2018, 15, 373–384. [Google Scholar] [CrossRef]
- Tien Bui, D.; Bui, Q.T.; Nguyen, Q.P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A hybrid artificial intelligence approach using GIS-based neural-fuzzy inference system and particle swarm optimization for forest fire susceptibility modeling at a tropical area. Agric. For. Meteorol. 2017, 233, 32–44. [Google Scholar] [CrossRef]
- Calviño-Cancela, M.; Chas-Amil, M.L.; García-Martínez, E.D.; Touza, J. Interacting effects of topography, vegetation, human activities and wildland-urban interfaces on wildfire ignition risk. For. Ecol. Manag. 2017, 397, 10–17. [Google Scholar] [CrossRef] [Green Version]
- Jaiswal, R.K.; Mukherjee, S.; Raju, K.D.; Saxena, R. Forest fire risk zone mapping from satellite imagery and GIS. Int. J. Appl. Earth Obs. Geoinf. 2002, 4, 1–10. [Google Scholar] [CrossRef]
- FAO Fire management—Global assessment 2006. FAO For. Pap. 2007, 151, 135.
- Adab, H.; Kanniah, K.D.; Solaimani, K.; Sallehuddin, R. Modelling static fire hazard in a semi-arid region using frequency analysis. Int. J. Wildl. Fire 2015, 24, 763–777. [Google Scholar] [CrossRef]
- Sayad, Y.; Mousannif, H.; Al Moatassime, H. Predictive modeling of wildfires: A new dataset and machine learning approach. Fire Saf. J. 2019, 104, 130–146. [Google Scholar] [CrossRef]
- Rodrigues, M.; De La Riva, J.; Fotheringham, S. Modeling the spatial variation of the explanatory factors of human-caused wildfires in Spain using geographically weighted logistic regression. Appl. Geogr. 2014, 48, 52–63. [Google Scholar] [CrossRef]
- Soares-Filho, B.; Silvestrini, R.; Nepstad, D.; Brando, P.; Rodrigues, H.; Alencar, A.; Coe, M.; Locks, C.; Lima, L.; Hissa, L.; et al. Forest fragmentation, climate change and understory fire regimes on the Amazonian landscapes of the Xingu headwaters. Landsc. Ecol. 2012, 27, 585–598. [Google Scholar] [CrossRef]
- Armenteras, D.; Rodríguez, N.; Retana, J. Landscape Dynamics in Northwestern Amazonia: An Assessment of Pastures, Fire and Illicit Crops as Drivers of Tropical Deforestation. PLoS ONE 2013, 8, e54310. [Google Scholar] [CrossRef] [Green Version]
- Silvestrini, R.A.; Soares-Filho, B.S.; Nepstad, D.; Coe, M.; Rodrigues, H.; Assuncao, R. Simulating fire regimes in the Amazon in response to climate change and deforestation. Ecol. Appl. 2011, 21, 1573–1590. [Google Scholar] [CrossRef]
- Dinerstein, E.; Olson, D.; Joshi, A.; Vynne, C.; Burgess, N.; Wikramanayake, E.; Hahn, N.; Palminteri, S.; Hedao, P.; Noss, R.; et al. An Ecoregion-Based Approach to Protecting Half the Terrestrial Realm. Bioscience 2017, 67, 534–545. [Google Scholar] [CrossRef]
- Chacón, E.; Ulloa, A.; Llambí, L.; Acevedo, D.; Utrera, A. Paisajes Y Ecosistemas Llaneros: Ecología Y Conservación. In Tierras Llaneras de Venezuela …tierras de Buena Esperanza; Lopez, R., Hétier, J., López, D., Schargel, R., Zinck, A., Eds.; Consejo de Publicaciones de la Universidad de Los Andes: Mérida, Venezuela, 2015; pp. 195–240. ISBN 9789801117810. [Google Scholar]
- Tehrany, M.S.; Jones, S. Evaluating the variations in the flood susceptibility maps accuracies due to the alterations in the type and extent of the flood inventory. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. -ISPRS Arch. 2013, 42, 209–214. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Aryal, J. Forest Fire Susceptibility and Risk Mapping Using Social/Infrastructural Vulnerability and Environmental Variables. Fire 2019, 2, 50. [Google Scholar] [CrossRef] [Green Version]
- Giglio, L.; Justice, C.; Boschetti, L.; Roy, D. MCD64A1 MODIS/Terra+Aqua Burned Area Monthly L3 Global 500m SIN Grid V006 [Data set]. NASA EOSDIS Land Process. DAAC 2015. [CrossRef]
- Verde, J.; Zêzere, J. Assessment and validation of wildfire susceptibility and hazard in Portugal. Nat. Hazards Earth Syst. Sci. 2010, 10, 485–497. [Google Scholar] [CrossRef]
- Farr, T.; Rosen, P.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Kobrick, M.; Palller, M.; Rodriguez, E.; Roth, L.; et al. The Shuttle Radar Topography Mission. Rev. Geophys. 2007, 45, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Meijer, J.R.; Huijbregts, M.A.J.; Schotten, K.C.G.J.; Schipper, A.M. Global patterns of current and future road infrastructure. Environ. Res. Lett. 2018, 13, 064006. [Google Scholar] [CrossRef] [Green Version]
- Grill, G.; Lehner, B.; Thieme, M.; Geenen, B.; Tickner, D.; Antonelli, F.; Babu, S.; Borrelli, P.; Cheng, L.; Crochetiere, H.; et al. Mapping the world’s free-flowing rivers. Nature 2019, 569, 215–221. [Google Scholar] [CrossRef]
- Kennedy, C.M.; Oakleaf, J.R.; Theobald, D.M.; Baruch-Mordo, S.; Kiesecker, J. Managing the middle: A shift in conservation priorities based on the global human modification gradient. Glob. Chang. Biol. 2019, 25, 811–826. [Google Scholar] [CrossRef]
- Bannari, A.; Morin, D.; Bonn, F.; Huete, A.R. A review of vegetation indices. Remote Sens. Rev. 1995, 13, 95–120. [Google Scholar] [CrossRef]
- Didan, K. MOD13A1 MODIS/Terra Vegetation Indices 16-Day L3 Global 500m SIN Grid V006 [Data set]. NASA EOSDIS Land Process. DAAC 2015. [Google Scholar] [CrossRef]
- Running, S. Estimating Terrestrial Primary Productivity by Combining Remote Sensing and Ecosystem Simulation. In Remote Sensing of Biosphere Functioning; Hobbs, R.J., Mooney, H.A., Eds.; Springer: New York, NY, USA, 1990; pp. 65–86. ISBN 978-1-4612-3302-2. [Google Scholar]
- Huete, A.; Didan, K.; Miura, T.; Rodrigeuz, E.; Gao, X.; Ferreira, L. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 213. [Google Scholar] [CrossRef]
- Gao, B.-C. NDWI—A Normalized Difference Water Index for Remote Sensing of Vegetation Liquid Water from Space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Huang, J.; Chen, D.; Cosh, M.H. Sub-pixel reflectance unmixing in estimating vegetation water content and dry biomass of corn and soybeans cropland using normalized difference water index (NDWI) from satellites. Int. J. Remote Sens. 2009, 30, 2075–2104. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Stark, R.; Rundquist, D. Novel algorithms for remote estimation of vegetation fraction. Remote Sens. Environ. 2002, 80, 76–87. [Google Scholar] [CrossRef] [Green Version]
- Fick, S.E.; Hijmans, R.J. WorldClim 2: New 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 2017, 37, 4302–4315. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Aybar, C.; Wu, Q.; Bautista, L.; Yali, R.; Barja, A. An R package for interacting with Google Earth Engine. J. Open Source Softw. 2020, 2020, 2272. [Google Scholar] [CrossRef]
- Pekel, J.F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Sulla-Menashe, D.; Friedl, M.A. User Guide to Collection 6 MODIS Land Cover (MCD12Q1 and MCD12C1) Product; USGS: Reston, VA, USA, 2018; pp. 1–18. [CrossRef]
- Martínez-Álvarez, F.; Reyes, J.; Morales-Esteban, A.; Rubio-Escudero, C. Determining the best set of seismicity indicators to predict earthquakes. Two case studies: Chile and the Iberian Peninsula. Knowl. -Based Syst. 2013, 50, 198–210. [Google Scholar] [CrossRef]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.G.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 027–046. [Google Scholar] [CrossRef]
- Akinwande, M.O.; Dikko, H.G.; Samson, A. Variance Inflation Factor: As a Condition for the Inclusion of Suppressor Variable(s) in Regression Analysis. Open J. Stat. 2015, 05, 754–767. [Google Scholar] [CrossRef] [Green Version]
- Naimi, B.; Hamm, N.A.S.; Groen, T.A.; Skidmore, A.K.; Toxopeus, A.G. Where is positional uncertainty a problem for species distribution modelling? Ecography 2014, 37, 191–203. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, L. Comparison of spatial and non-spatial logistic regression models for modeling the occurrence of cloud cover in north-eastern Puerto Rico. Appl. Geogr. 2013, 37, 52–62. [Google Scholar] [CrossRef]
- Schober, P.; Schwarte, L.A. Correlation coefficients: Appropriate use and interpretation. Anesth. Analg. 2018, 126, 1763–1768. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, E.H.; Hassan, Q.K. Operational perspective of remote sensing-based forest fire danger forecasting systems. ISPRS J. Photogramm. Remote Sens. 2015, 104, 224–236. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 32. [Google Scholar] [CrossRef] [Green Version]
- Arpaci, A.; Malowerschnig, B.; Sass, O.; Vacik, H. Using multi variate data mining techniques for estimating fire susceptibility of Tyrolean forests. Appl. Geogr. 2014, 53, 258–270. [Google Scholar] [CrossRef]
- Tien Bui, D.; Le, K.T.T.; Nguyen, V.C.; Le, H.D.; Revhaug, I. Tropical forest fire susceptibility mapping at the Cat Ba National Park area, Hai Phong City, Vietnam, using GIS-based Kernel logistic regression. Remote Sens. 2016, 8, 347. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Guo, F.; Wang, G.; Su, Z.; Liang, H.; Wang, W.; Lin, F.; Liu, A. What drives forest fire in Fujian, China? Evidence from logistic regression and Random Forests. Int. J. Wildl. Fire 2016, 25, 505–519. [Google Scholar] [CrossRef]
- Jaafari, A.; Gholami, D.M.; Zenner, E.K. A Bayesian modeling of wildfire probability in the Zagros Mountains, Iran. Ecol. Inform. 2017, 39, 32–44. [Google Scholar] [CrossRef]
- Schmidt, A.; Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of full waveform lidar data in the wadden sea. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1614–1618. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef] [Green Version]
- Hanley, J.; McNeil, B. The Meaning and Use of the Area under a Receiver Operating Characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mccune, B.; Grace, J. Analysis of Ecological Communities; MJM Software Design: Gleneden Beach, OR, USA, 2002. [Google Scholar]
- Hosmer, D.; Lemeshow, S.; Sturdivant, R. Applied Logistic Regression, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Pourghasemi, H.R.; Pradhan, B.; Gokceoglu, C. Application of fuzzy logic and analytical hierarchy process (AHP) to landslide susceptibility mapping at Haraz watershed, Iran. Nat. Hazards 2012, 63, 965–996. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăgu, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Xiao, J.; Shen, Y.; Ge, J.; Tateishi, R.; Tang, C.; Liang, Y.; Huang, Z. Evaluating urban expansion and land use change in Shijiazhuang, China, by using GIS and remote sensing. Landsc. Urban Plan. 2006, 75, 69–80. [Google Scholar] [CrossRef]
- Rodrigues, M.; De la Riva, J. An insight into machine-learning algorithms to model human-caused wildfire occurrence. Environ. Model. Softw. 2014, 57, 192–201. [Google Scholar] [CrossRef]
- Eskandari, S. A new approach for forest fire risk modeling using fuzzy AHP and GIS in Hyrcanian forests of Iran. Arab. J. Geosci. Roma 2017, 10, 190. [Google Scholar] [CrossRef]
- Peterson, S.H.; Roberts, D.A.; Dennison, P.E. Mapping live fuel moisture with MODIS data: A multiple regression approach. Remote Sens. Environ. 2008, 112, 4272–4284. [Google Scholar] [CrossRef]
- Maki, M.; Ishiahra, M.; Tamura, M. Estimation of leaf water status to monitor the risk of forest fires by using remotely sensed data. Remote Sens. Environ. 2004, 90, 441–450. [Google Scholar] [CrossRef]
- Verbesselt, J.; Somers, B.; Lhermitte, S.; Jonckheere, I.; van Aardt, J.; Coppin, P. Monitoring herbaceous fuel moisture content with SPOT VEGETATION time-series for fire risk prediction in savanna ecosystems. Remote Sens. Environ. 2007, 108, 357–368. [Google Scholar] [CrossRef]
- Guo, F.; Su, Z.; Wang, G.; Sun, L.; Tigabu, M.; Yang, X.; Hu, H. Understanding fire drivers and relative impacts in different Chinese forest ecosystems. Sci. Total Environ. 2017, 605, 411–425. [Google Scholar] [CrossRef] [PubMed]
- Bisquert, M.; Caselles, E.; Snchez, J.M.; Caselles, V. Application of artificial neural networks and logistic regression to the prediction of forest fire danger in Galicia using MODIS data. Int. J. Wildl. Fire 2012, 21, 1025–1029. [Google Scholar] [CrossRef]
- Huesca, M.; Litago, J.; Palacios-Orueta, A.; Montes, F.; Sebastián-López, A.; Escribano, P. Assessment of forest fire seasonality using MODIS fire potential: A time series approach. Agric. For. Meteorol. 2009, 149, 1946–1955. [Google Scholar] [CrossRef]
- CFS Aspects sociaux, economiques et culturels des incendies de forêts en Italie. In Proceedings of the Seminar on Forest Fire Prevention, Land Use and People; ECE/FAO/OIT: Athens, Greece, 1987.
- Taubenböck, H.; Post, J.; Roth, A.; Zosseder, K.; Strunz, G.; Dech, S. A conceptual vulnerability and risk framework as outline to identify capabilities of remote sensing. Nat. Hazards Earth Syst. Sci. 2008, 8, 409–420. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | General Equation |
|---|---|
| NDVI [34] | |
| EVI [35] | |
| NDWI [36,37] | |
| VARI [38] |
| Variable | Units | Source |
|---|---|---|
| Elevation | Meters | DEM SRTM |
| Aspect | Degrees | DEM SRTM |
| Slope | Degrees | DEM SRTM |
| Distance to roads | Metes | Global Roads Inventory Project |
| Distance to rivers | Meters | HydroSHEDS |
| Anthropic modification | Intensity | CSP gHM |
| NDVI | Index | MOD13A1.006 |
| EVI | Index | MOD13A1.006 |
| NDWI | Index | Landsat 8 images |
| VARI | Index | Landsat 8 images |
| Precipitation | mm | WorldClim V2 |
| Solar radiation | kJ m2/day | WorldClim V2 |
| Temperature | °C | WorldClim V2 |
| Winds velocity | m/s | WorldClim V2 |
| Variable | VIF |
|---|---|
| Aspect | 1.03 |
| Distance to roads | 1.14 |
| Distance to rivers | 1.18 |
| Slope | 1.40 |
| Human modification | 1.73 |
| Solar radiation | 2.44 |
| Elevation | 3.49 |
| Temperature | 5.75 |
| Precipitation | 6.26 |
| NDWI | 8.44 |
| VARI | 8.88 |
| Winds | 11.95 |
| EVI | 13.93 |
| NDVI | 14.68 |
| AUC Values | Model Performance |
|---|---|
| 0.5–0.6 | Poor |
| 0.6–0.7 | Moderate |
| 0.7–0.8 | Good |
| 0.8–0.9 | Very good |
| >0.9 | Excellent |
| Fire Probability (%) | Category | Area (km2) | % Area |
|---|---|---|---|
| 0–16 | Very low | 103,982.0 | 28.2 |
| 16–16 | Low | 85,254.3 | 23.2 |
| 16–57 | Moderate | 63,267.0 | 17.2 |
| 57–79 | High | 50,879.5 | 13.8 |
| 79–100 | Very high | 64,846.0 | 17.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barreto, J.S.; Armenteras, D. Open Data and Machine Learning to Model the Occurrence of Fire in the Ecoregion of “Llanos Colombo–Venezolanos”. Remote Sens. 2020, 12, 3921. https://doi.org/10.3390/rs12233921
Barreto JS, Armenteras D. Open Data and Machine Learning to Model the Occurrence of Fire in the Ecoregion of “Llanos Colombo–Venezolanos”. Remote Sensing. 2020; 12(23):3921. https://doi.org/10.3390/rs12233921
Chicago/Turabian StyleBarreto, Joan Sebastian, and Dolors Armenteras. 2020. "Open Data and Machine Learning to Model the Occurrence of Fire in the Ecoregion of “Llanos Colombo–Venezolanos”" Remote Sensing 12, no. 23: 3921. https://doi.org/10.3390/rs12233921
APA StyleBarreto, J. S., & Armenteras, D. (2020). Open Data and Machine Learning to Model the Occurrence of Fire in the Ecoregion of “Llanos Colombo–Venezolanos”. Remote Sensing, 12(23), 3921. https://doi.org/10.3390/rs12233921