Automatic Tree Detection from Three-Dimensional Images Reconstructed from 360° Spherical Camera Using YOLO v2

Abstract
:
1. Introduction
2. Materials and Methods
2.1. Plant Materials
2.2. Tree Trunk Diameter and Tree Height Measurement
2.3. Tree Measurement with 360° Spherical Camera and 3D Reconstruction
2.4. Evaluating the Trunk Diameter and Height Estimation
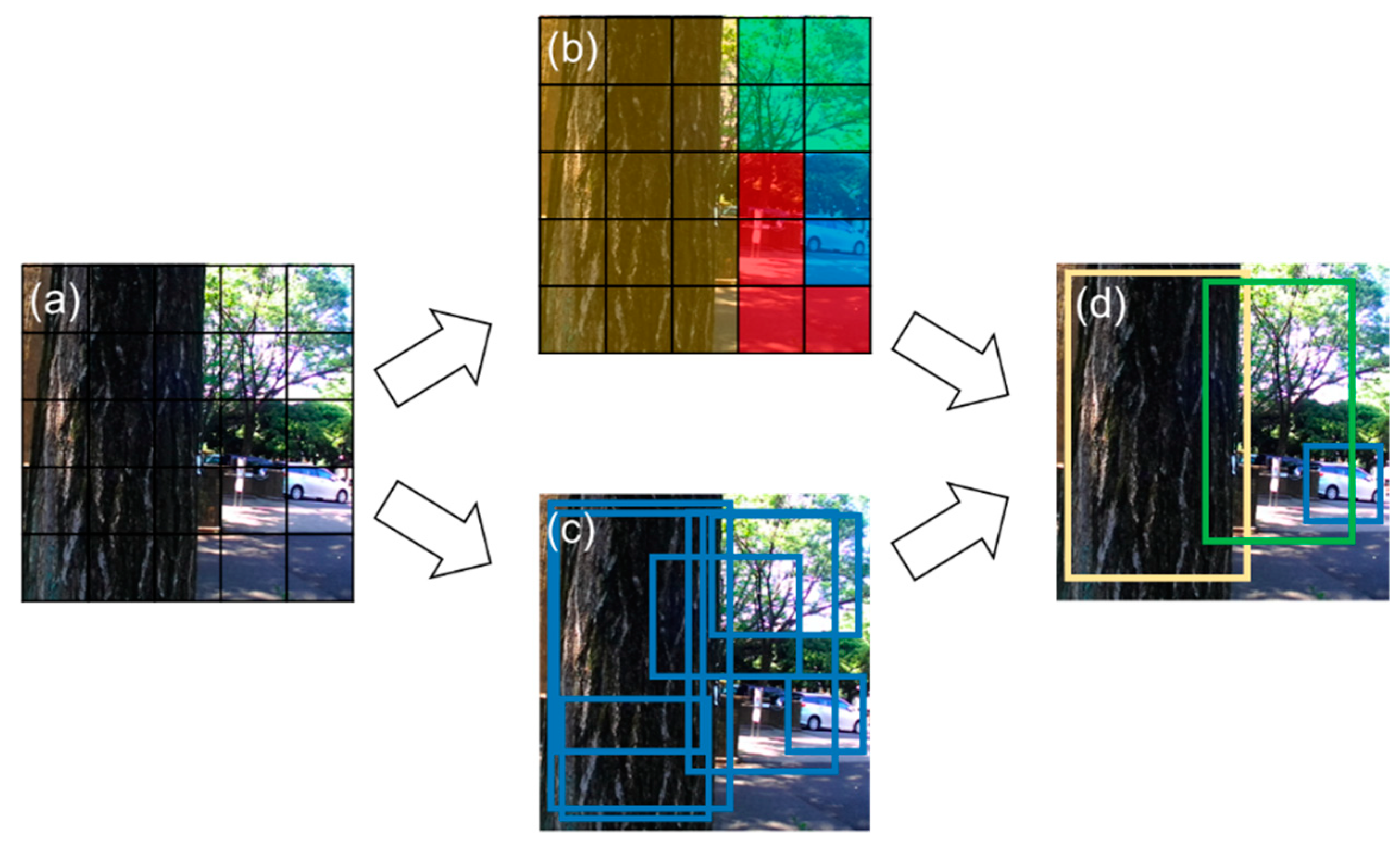
2.5. About YOLO Detector
2.5.1. Overview of YOLO Detector
2.5.2. Network Architecture
2.5.3. Anchor Box
2.5.4. Cost Calculation
2.5.5. Number of Grid Cells and Output Sizes of the Final Feature Map is Determined
2.5.6. Dimensions of Final Feature Map
2.6. Training the YOLO v2 Detector
2.6.1. Training and Test Dataset
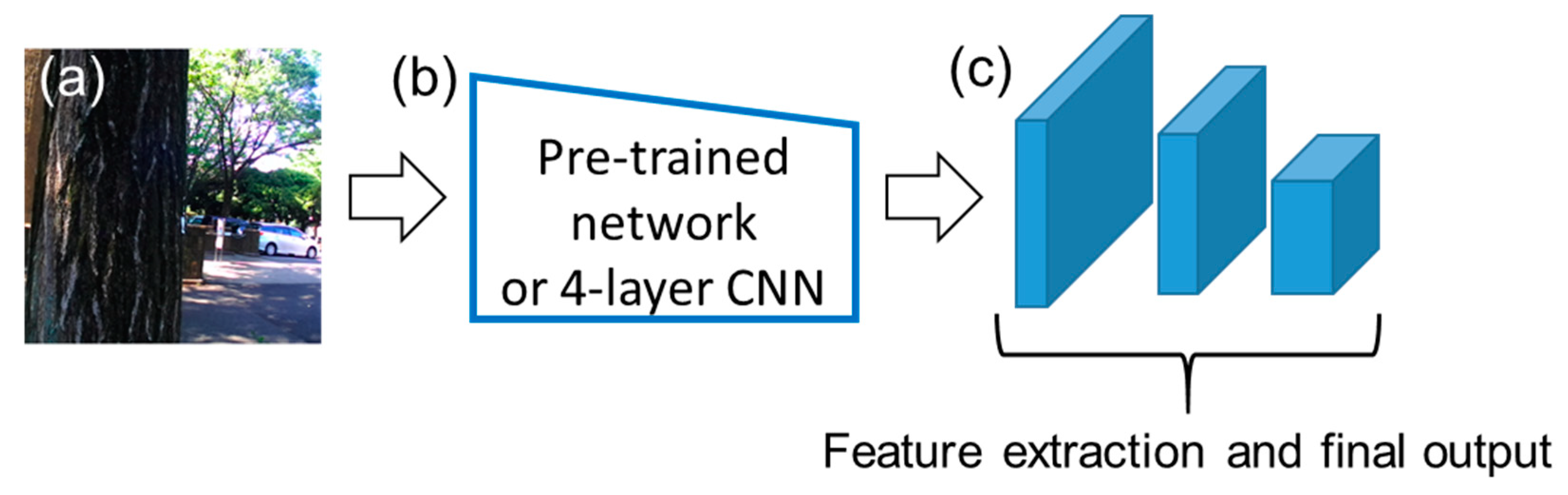
2.6.2. Pre-Training of the Feature Extractor in YOLO v2 Detector
2.6.3. Determination of the Number and Size of the Anchor Box and Other Parameters
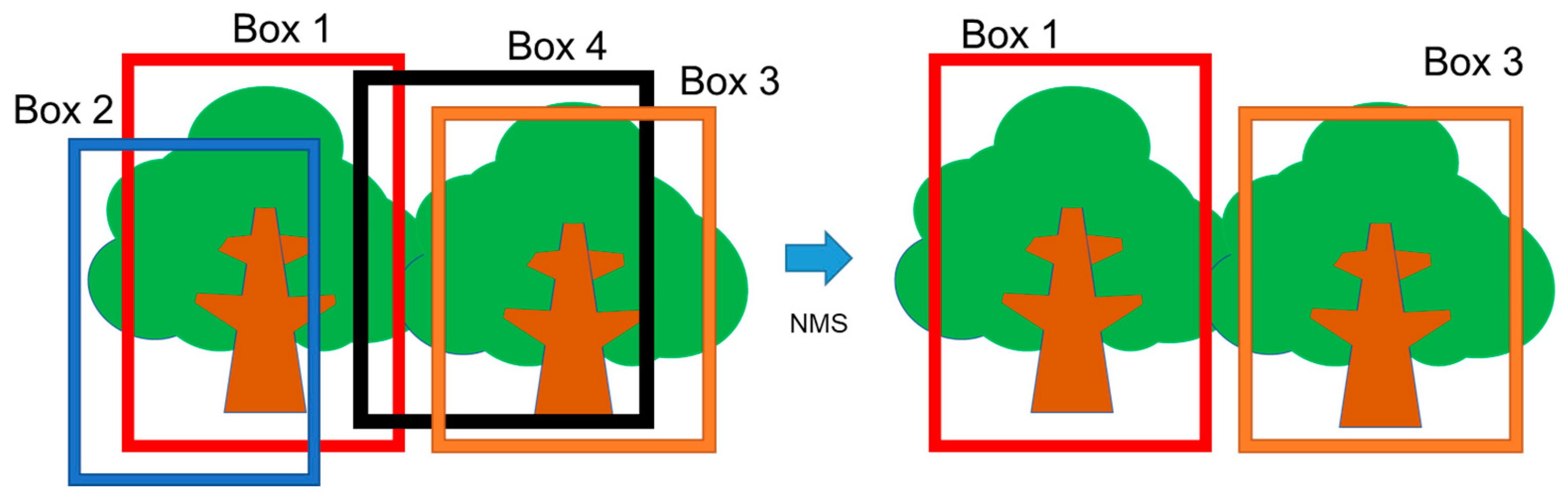
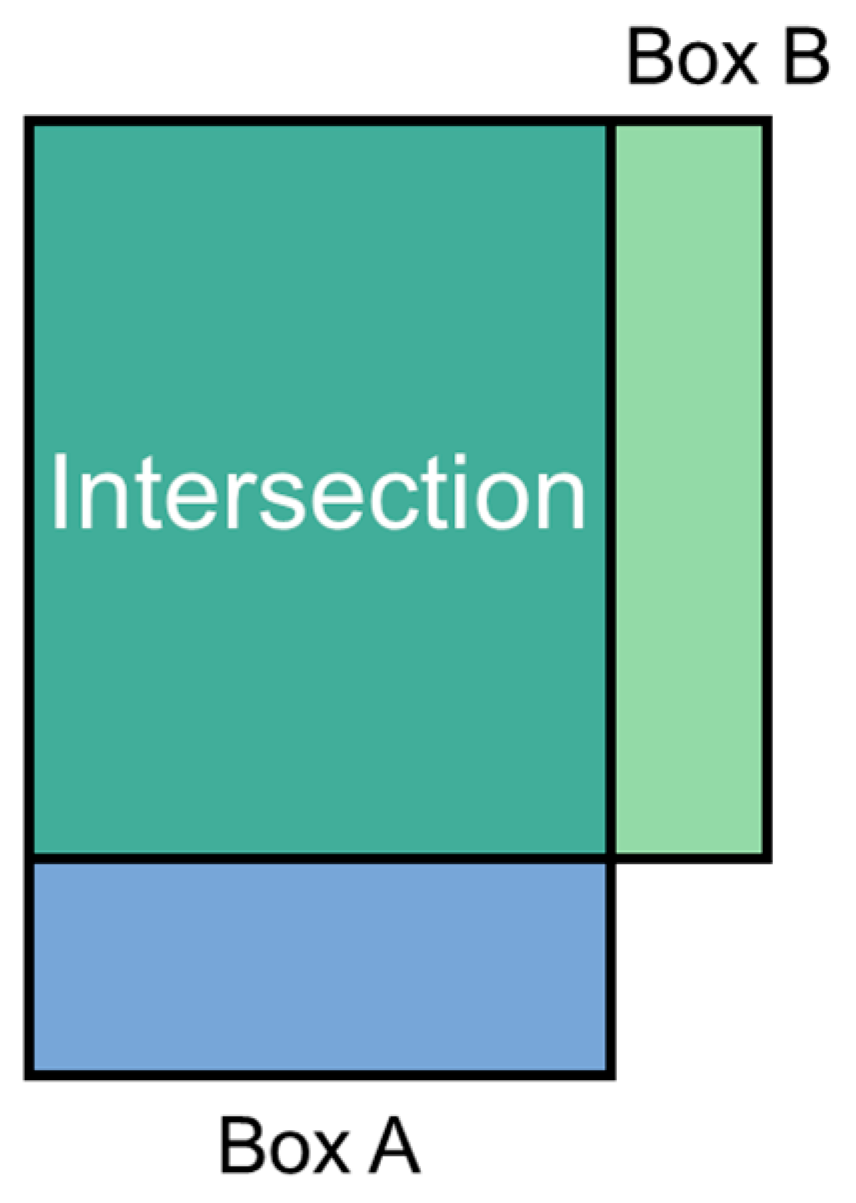
2.7. Post Processing after 3D Reconstruction
3. Results
3.1. Tree Trunk Diameter and Height Estimation
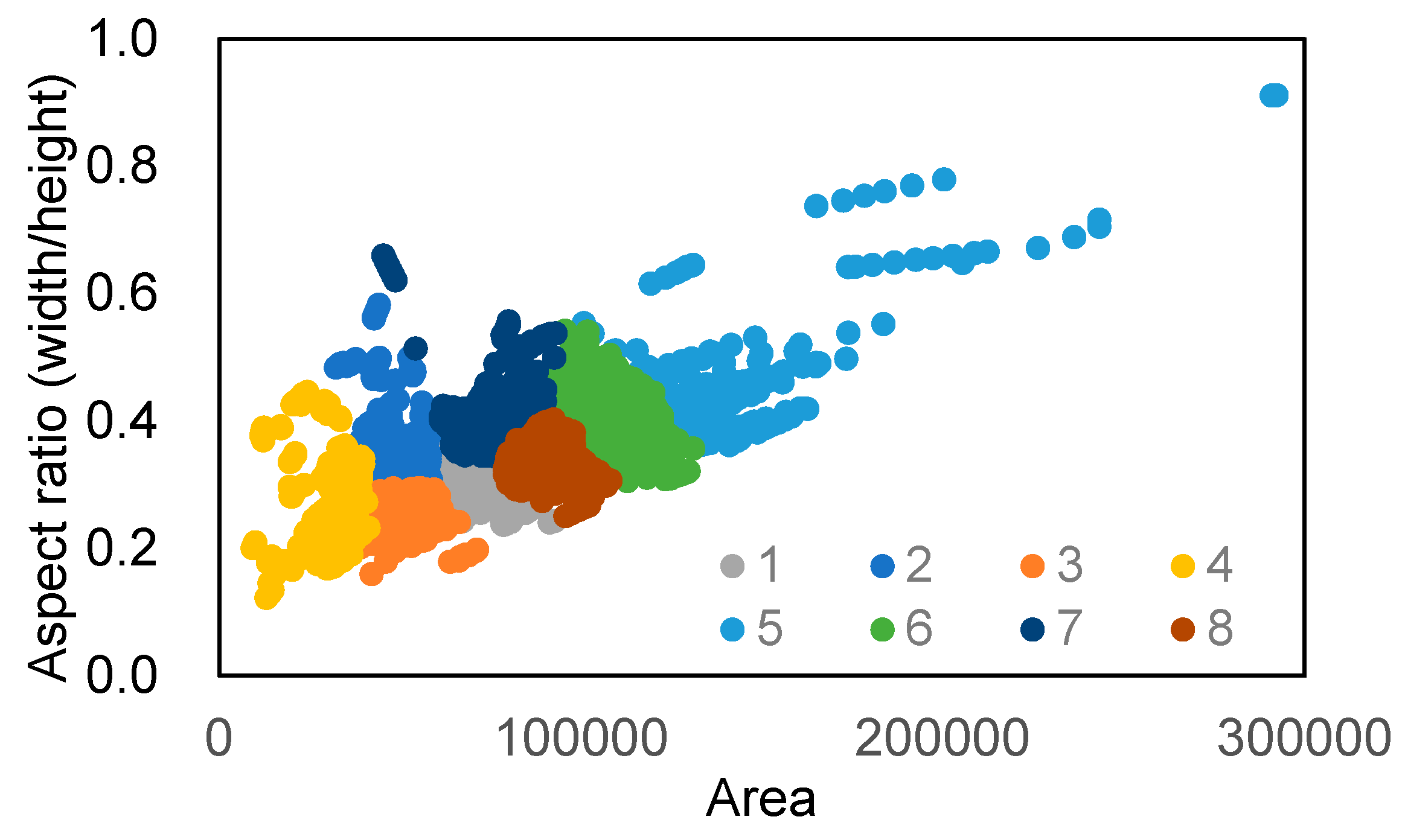
3.2. Automatic Tree Detection
3.2.1. Pre-Training of the Feature Extractor of YOLO v2 Detector
3.2.2. Tree Detection from 360° Spherical Images Using YOLO v2
3.2.3. Tree Detection from the 3D Images Constructed by SfM
4. Discussion
4.1. Tree Trunk Diameter and Height Estimation
4.2. Automatic Tree Detection
4.3. Tree Detection in 3D Images
4.4. Comparison with the Automatic Tree Detection from LiDAR 3D Images
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Miller, J.; Morgenroth, J.; Gomez, C. 3D modelling of individual trees using a handheld camera: Accuracy of height, diameter and volume estimates. Urban Fore. Urban Green. 2015, 14, 932–940. [Google Scholar] [CrossRef]
- Oshio, H.; Asawa, T.; Hoyano, A.; Miyasaka, S. Estimation of the leaf area density distribution of individual trees using high-resolution and multi-return airborne LiDAR data. Remote Sens. Environ. 2015, 166, 116–125. [Google Scholar] [CrossRef]
- Chen, C.; Wang, Y.; Li, Y.; Yue, T.; Wang, X. Robust and Parameter-Free Algorithm for Constructing Pit-Free Canopy Height Models. ISPRS Int. J. Geo-Info. 2017, 6, 219. [Google Scholar] [CrossRef] [Green Version]
- Nelson, R.; Krabill, W.; Tonelli, J. Estimating forest biomass and volume using airborne laser data. Remote sensing of environment. Remote Sens. Environ. 1988, 24, 247–267. [Google Scholar] [CrossRef]
- Omasa, K.; Hosoi, F.; Konishi, A. 3D lidar imaging for detecting and understanding plant responses and canopy structure. Exp. Bot. 2007, 58, 881–898. [Google Scholar] [CrossRef] [Green Version]
- Hosoi, F.; Omasa, K. Voxel-based 3-D modeling of individual trees for estimating leaf area density using high-resolution portable scanning lidar. IEEE Trans. Geosci. Remote. 2006, 44, 3610–3618. [Google Scholar] [CrossRef]
- Hosoi, F.; Omasa, K. Factors contributing to accuracy in the estimation of the woody canopy leaf-area-density profile using 3D portable lidar imaging. J. Exp. Bot. 2007, 58, 3464–3473. [Google Scholar] [CrossRef] [Green Version]
- Hosoi, F.; Nakai, Y.; Omasa, K. 3-D voxel-based solid modeling of a broad-leaved tree for accurate volume estimation using portable scanning lidar. ISPRS J. Photogramm. 2013, 82, 41–48. [Google Scholar] [CrossRef]
- Bailey, B.N.; Mahaffee, W.F. Rapid measurement of the three-dimensional distribution of leaf orientation and the leaf angle probability density function using terrestrial LiDAR scanning. Remote Sens. Environ. 2017, 194, 63–76. [Google Scholar] [CrossRef] [Green Version]
- Itakura, K.; Hosoi, F. Estimation of Leaf Inclination Angle in Three-Dimensional Plant Images Obtained from Lidar. Remote Sens. 2019, 11, 344. [Google Scholar] [CrossRef] [Green Version]
- Pan, Y.; Kuo, K.; Hosoi, F. A study on estimation of tree trunk diameters and heights from three-dimensional point cloud images obtained by SLAM. Eco Eng. 2017, 29, 17–22. [Google Scholar]
- Jozkow, G.; Totha, C.; Grejner-Brzezinska, D. UAS topographic mapping with velodyne lidar sensor. ISPRS Ann. Photogram. Remote Sens. Spatial Info. Sci. 2016, 3, 201–208. [Google Scholar] [CrossRef]
- Elaksher, A.F.; Bhandari, S.; Carreon-Limones, C.A.; Lauf, R. Potential of UAV lidar systems for geospatial mapping. In Lidar Remote Sensing for Environmental Monitoring 2017. Int. Soc. Opt. Photon. 2017, 10406, 104060L. [Google Scholar]
- Liu, K.; Shen, X.; Cao, L.; Wang, G.; Cao, F. Estimating forest structural attributes using UAV-LiDAR data in Ginkgo plantations. ISPRS J. Photogram. Remote Sens. 2018, 146, 465–482. [Google Scholar] [CrossRef]
- Westoby, M.J.; Brasington, J.; Glasser, N.F.; Hambrey, M.J.; Reynolds, J.M. ‘Structure-from-Motion’photogrammetry: A low-cost, effective tool for geoscience applications. Geomorphology 2012, 179, 300–314. [Google Scholar] [CrossRef] [Green Version]
- Liang, X.; Jaakkola, A.; Wang, Y.; Hyyppä, J.; Honkavaara, E.; Liu, J.; Kaartinen, H. The use of a hand-held camera for individual tree 3D mapping in forest sample plots. Remote Sens. 2014, 6, 6587–6603. [Google Scholar] [CrossRef] [Green Version]
- Piermattei, L.; Karel, W.; Wang, D.; Wieser, M.; Mokroš, M.; Surový, P.; Koreň, M.; Tomaštík, J.; Pfeifer, N.; Hollaus, M. Terrestrial Structure from Motion Photogrammetry for Deriving Forest Inventory Data. Remote Sens. 2019, 11, 950. [Google Scholar] [CrossRef] [Green Version]
- Qiu, Z.; Feng, Z.; Jiang, J.; Lin, Y.; Xue, S. Application of a continuous terrestrial photogrammetric measurement system for plot monitoring in the Beijing Songshan national nature reserve. Remote Sens. 2018, 10, 1080. [Google Scholar] [CrossRef] [Green Version]
- Itakura, K.; Kamakura, I.; Hosoi, F. A Comparison study on three-dimensional measurement of vegetation using lidar and SfM on the ground. Eco Eng. 2018, 30, 15–20. [Google Scholar]
- Barazzetti, L.; Previtali, M.; Roncoroni, F. 3D modelling with the Samsung Gear 360. In Proceedings of the 2017 TC II and CIPA-3D Virtual Reconstruction and Visualization of Complex Architectures, International Society for Photogrammetry and Remote Sensing, Nafplio, Greece, 1–3 March 2017. [Google Scholar]
- Firdaus, M.I.; Rau, J.-Y. Accuracy analysis of three-dimensional model reconstructed by spherical video images. In Proceedings of the International Symposium on Remote Sensing (ISPRS 2018), Dehradun, India, 20–23 November 2018. [Google Scholar]
- Honjo, T.; Lin, T.-P.; Seo, Y. Sky view factor measurement by using a spherical camera. J. Agric. Meteol. 2019, 75, 59–66. [Google Scholar] [CrossRef] [Green Version]
- Aschoff, T.; Spiecker, H. Algorithms for the automatic detection of trees in laser scanner data. Proceedings of International Archives of Photogrammetry, Remote Sensing and Spatial Information Sciences 2004. Available online: https://www.isprs.org/proceedings/xxxvi/8-w2/aschoff.pdf (accessed on 25 October 2019).
- Henning, J.G.; Radtke, P.J. Detailed stem measurements of standing trees from ground-based scanning lidar. Forest Sci. 2006, 52, 67–80. [Google Scholar]
- Lovell, J.L.; Jupp, D.L.B.; Newnham, G.J.; Culvenor, D.S. Measuring tree stem diameters using intensity profiles from ground-based scanning lidar from a fixed viewpoint. ISPRS J. Photogram. Remote Sens. 2011, 66, 46–55. [Google Scholar] [CrossRef]
- Liang, X.; Hyyppä, J.; Kaartinen, H.; Wang, Y. International benchmarking of terrestrial laser scanning approaches for forest inventories. ISPRS J. Photogram. Remote Sens. 2018, 144, 137–179. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE conference on computer vision and pattern recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- A Zhang, T.; Zhang, X. High-Speed Ship Detection in SAR Images Based on a Grid Convolutional Neural Network. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast r-cnn. In Proceedings of the 28th IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the 29th Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: better, faster, stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Zhang, J.; Singh, S. 2014: LOAM: Lidar odometry and mapping in real-time. In Proceedings of the Robotics: Science and Systems Conference (RSS), Berkeley, CA, USA, 12–16 July 2014. [Google Scholar]
- RICHO THETA ACCESORY. Available online: https://theta360.com/en/ (accessed on 25 October 2019).
- RICHO THETA ACCESORY. Available online: https://theta360.com/en/about/theta/accessory.html (accessed on 25 October 2019).
- Verhoeven, G. Taking computer vision aloft–archaeological three-dimensional reconstructions from aerial photographs with photoscan. Archaeol. Prospect. 2011, 18, 67–73. [Google Scholar] [CrossRef]
- Neubeck, A.; Van Gool, L. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 28th IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, Sardinia, Italy, 13–15 May 2010. [Google Scholar]
- Mathworks Documentation, trainYOLOv2ObjectDetector, training Loss. Available online: https://jp.mathworks.com/help/vision/ref/trainyolov2objectdetector.html (accessed on 25 October 2019).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep learning; MIT press Cambridge: London, UK, 2016. [Google Scholar]
- Mathworks Documentation, trainingOptions, ValidationPatience. Available online: https://jp.mathworks.com/help/deeplearning/ref/trainingoptions.html?lang=en (accessed on 25 October 2019).
- Park, H.-S.; Jun, C.-H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Itakura, K.; Hosoi, F. Automatic individual tree detection and canopy segmentation from three-dimensional point cloud images obtained from ground-based lidar. J. Agric. Meteol. 2018, 74, 109–113. [Google Scholar] [CrossRef] [Green Version]
- Itakura, K.; Hosoi, F. Automated tree detection from 3D lidar images using image processing and machine learning. Appl. Opt. 2019, 58, 3807–3811. [Google Scholar] [CrossRef]
- Torr, P.H.S.; Zisserman, A. MLESAC: A new robust estimator with application to estimating image geometry. Comput. Vis. Image Und. 2000, 78, 138–156. [Google Scholar] [CrossRef] [Green Version]
- Rusu, R.B.; Marton, Z.C.; Blodow, N.; Dolha, M.; Beetz, M. Towards 3D point cloud based object maps for household environments. Robot. Auton. Syst. 2008, 56, 927–941. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. In Proceedings of the 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016. [Google Scholar]
- Barazzetti, L.; Previtali, M.; Roncoroni, F. Can we use low-cost 360 degree cameras to create accurate 3D models? In Proceedings of the ISPRS TC II Mid-term Symposium “Towards Photogrammetry 2020”, Riva del Garda, Italy, 4–7 June 2018. [Google Scholar]
- Itakura, K.; Hosoi, F. Estimation of tree structural parameters from video frames with removal of blurred images using machine learning. J. Agric. Meteol. 2018, 74, 154–161. [Google Scholar] [CrossRef]
- Itakura, K.; Kamakura, I.; Hosoi, F. Three-Dimensional Monitoring of Plant Structural Parameters and Chlorophyll Distribution. Sensors 2019, 19, 413. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hosoi, F.; Umeyama, S.; Kuo, K. Estimating 3D chlorophyll content distribution of trees using an image fusion method between 2D camera and 3D portable scanning lidar. Remote Sens. 2019, 11, 2134. [Google Scholar] [CrossRef] [Green Version]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. Decaf: A deep convolutional activation feature for generic visual recognition. Proc. Int. Conf. Mach. Learn. 2014, 647–655. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ResNet-50 | 4-layer CNN | |
|---|---|---|
| Initial learn rate | 0.004 | 0.0007 |
| Optimizer | SGD with momentum | |
| Mini batch size | 67 | 16 |
| Max epochs | 10 | 8 |
| Momentum | 0.9 | 0.9 |
| Number of anchor box | 8 | 8 |
| L2 regularization | 1.0 | 1.0 |
| Parameter | Value |
|---|---|
| Initial learn rate | 0.001 |
| Mini batch size | 16 |
| Max epochs | 50 |
| Momentum | 0.9 |
| Number of anchor box | 8 |
| L2 regularization | 0.0001 |
| Feature Extractor | Initial Value | Average Precision | Approximate Model Size (MB) |
|---|---|---|---|
| ResNet-50 | Pre-training | 0.98 | 105 |
| No pre-training | 0.97 | ||
| 4-layer CNN | Pre-training | 0.95 | 0.664 |
| No pre-training | 0.95 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Itakura, K.; Hosoi, F. Automatic Tree Detection from Three-Dimensional Images Reconstructed from 360° Spherical Camera Using YOLO v2. Remote Sens. 2020, 12, 988. https://doi.org/10.3390/rs12060988
Itakura K, Hosoi F. Automatic Tree Detection from Three-Dimensional Images Reconstructed from 360° Spherical Camera Using YOLO v2. Remote Sensing. 2020; 12(6):988. https://doi.org/10.3390/rs12060988
Chicago/Turabian StyleItakura, Kenta, and Fumiki Hosoi. 2020. "Automatic Tree Detection from Three-Dimensional Images Reconstructed from 360° Spherical Camera Using YOLO v2" Remote Sensing 12, no. 6: 988. https://doi.org/10.3390/rs12060988
APA StyleItakura, K., & Hosoi, F. (2020). Automatic Tree Detection from Three-Dimensional Images Reconstructed from 360° Spherical Camera Using YOLO v2. Remote Sensing, 12(6), 988. https://doi.org/10.3390/rs12060988