1. Introduction
Knowledge of sea surface temperature (SST) is essential for many applications, including for use as boundary conditions for numerical weather prediction and reanalyses, and for climate change research. The most popular way that users receive SST data is in the form of gridded, spatially complete products known as level 4 (L4) products [
1], such as the Operational Sea Surface Temperature and Sea ice Analysis (OSTIA) [
2,
3].
The OSTIA system generates daily, global SST analyses, which are provided to users on a 0.05° regular latitude-longitude grid. The system ingests in situ and satellite data that contain gaps, for example due to clouds. These may either be on the original satellite projection (level 2; L2) or regridded (level 3; L3). It then uses statistical methods to combine the observational data and a first guess SST field (the ‘background’) and fill in any remaining gaps in the coverage. In OSTIA’s primary configuration it produces, in near real time, a daily analysis of the foundation sea surface temperature (the SST free of diurnal variability). In situ observations from the Global Telecommunication System (GTS) and satellite data from the Group for High Resolution Sea Surface Temperature (GHRSST) are obtained in near real time and are submitted to quality control. A reference data set, consisting of in situ observations and observations from the Visible Infrared Imaging Radiometer Suite (VIIRS) aboard the Suomi National Polar-orbiting Partnership (Suomi-NPP) satellite, is used to bias correct the other satellite datasets. The background is a forecast produced from the previous day’s analysis by damped persistence of climatological anomalies. The data are used as the boundary condition for numerical weather predictions and are provided to users by the Copernicus Marine Environment Monitoring Service (CMEMS; marine.copernicus.eu). OSTIA also has a climate configuration. This is used within the European Space Agency Sea Surface Temperature Climate Change Initiative (ESA SST CCI) [
4,
5] and the Copernicus Climate Change Service (C3S; climate.copernicus.eu) to generate climate datasets. These use input satellite data that have been adjusted to represent the temperature at a consistent depth and local time in order to generate analyses that approximate the daily average temperature at 20 cm depth [
5].
OSTIA has recently moved from using an optimal interpolation scheme [
2] to using the variational data assimilation scheme NEMOVAR [
3,
6]. NEMOVAR aims to iteratively minimise the value of the incremental cost function J by varying the ocean state
x [
7]:
where δ
x is the increment between the background state and
x,
B is the background error covariance matrix,
R is the observation error covariance matrix,
H is the linearised observation operator which interpolates from the model space to the observation space and
d is the vector of innovations between the observations and their model equivalents. The data assimilation is run on the extended ORCA12 configuration—a nominally one twelfth degree tripolar grid. The analysis is then interpolated on to a 0.05° regular grid.
The background error covariance matrix,
B, is a dense, full rank matrix, and so is defined by a parameterised covariance model rather than being stored explicitly [
6]. The background error covariances are decomposed into two spatial scales, one representing errors that are correlated over small-scales and one representing errors that are correlated over large-scales. [
7] describes in detail how this dual length scale formulation has been applied in OSTIA. The small and large-scale error variances, which were originally derived by [
8], have associated length scales of approximately 15 km and 300 km respectively. The ratio of these two components is determined, with modifications near coasts, near ice and in regions of high SST variability [
3]. This ratio of small to large scale determines the resulting effective background error correlation length scale which varies in time and space.
In common with many L4 systems, the assumption is made that observation errors are uncorrelated, so in the context of Equation (1), R is a diagonal matrix. Together, B and R determine how much weight is given to the observation information and how far it is allowed to propagate spatially. With the assumption that observation errors are uncorrelated, and therefore R is diagonal, the spatial influence of an observation is completely determined by the effective background error correlation length scale.
The approach of assuming uncorrelated observation errors is chosen for computational simplicity, and is based on the assumption that (random) instrumental errors dominate other types of observation errors. However, correlated errors in satellite retrievals of SST can originate from retrieval algorithms or from the presence of certain weather systems [
9], and when used within a data assimilation scheme the errors in representation of the model field can also be correlated (e.g. [
10,
11]). The result of not taking these observation error correlations into account is a suboptimal representation of small-scale features [
12] and an overfitting of the observations. Studies have shown that if there are correlated errors, there can be a detrimental effect from having a highly dense observing system [
13].
Ideally, L4 analysis systems would take full account of correlations in the observations errors as this could yield improvements to the analysis quality [
14]. Dense observations can benefit the representation of small scales by the analysis even if there are correlated errors [
15]. In practice, it is computationally impractical for systems to process a full observation error covariance matrix due to the number of observations (of the order of 10 million observations per day in the operational OSTIA system) and the unstructured nature of the observation positions. Instead, systems sometimes employ subsampling to help reduce the effects of correlated errors [
16]. Indeed, in the OSTIA system, satellite observations are subsampled to approximately the grid resolution of the final output data. Reducing the number of observations inhibits the ability of the analysis to represent small-scale features and so a balance has to be struck between reducing error correlations and adequately representing features. Alternatively, systems may try to partly account for the assumption that observation errors are uncorrelated by inflating observation error variances [
12,
16]. The amount of inflation is typically an arbitrary amount.
The OSTIA configuration used to generate climate datasets currently makes use of the estimate of total uncertainty provided by the ESA SST CCI project for each SST retrieval. However, the ESA SST CCI project also provides information on observation error correlations. They supply observational uncertainties that have been decomposed depending on the spatial scales over which the errors they represent are correlated [
5]. Uncertainty due to errors that are spatially uncorrelated, correlated on synoptic scales (given as approximately 100 km) and correlated on large scales are provided as standard deviations. There is also an uncertainty estimate for the component of the errors due to the adjustment of the SST observations from a skin-SST to a depth-SST—this adjustment has errors that are spatially correlated on a scale of approximately 100 km.
This study aimed to make use of the observation error correlation information provided in the SST CCI observational data by using it to improve upon the standard method of inflating observation error variances by an arbitrary amount, by attempting to determine an ‘optimal’ method for inflating observation error variances.
Section 2 details an investigation into the observation error inflation method using a set of idealised tests.
Section 3 discusses the translation of the results from
Section 2 to the OSTIA system and describes a set of trials that were performed to test the new system. Discussion and conclusions can be found in
Section 4.
3. Application to the OSTIA System
3.1. Methods
The remainder of the study considered a case study in which observation error variance inflation was used in the real OSTIA system. The results of the idealised tests were used to inspire the design of a method of observation error variance inflation for this case study, while also taking into account the practical considerations necessary when working with a real assimilation system.
The results of the idealised tests revealed that simply inflating the diagonal of the observation error covariance matrix may not be appropriate for regions which do not satisfy the idealised test condition, and to apply this method in regions where this is not satisfied could actually degrade the analysis. It was found that the appropriateness of this method is very sensitive to the specification of the error statistics. Of course, the idealised tests worked on the concept of knowing the ‘true’ background statistics, and in a real assimilation system the estimated background statistics cannot be assumed to be entirely accurate. This introduces another level of difficulty in the diagnosis of an ‘optimal inflation’. Therefore, a conservative approach to applying this method in the OSTIA system would be to define a conservative version of the idealised test condition, only inflate observation error variances (OEVs) in the cases that pass and to apply no inflation otherwise.
To determine when the idealised test condition is satisfied, one approach would be to directly compare the background and observation effective correlation length scales (CLSs). However, effective CLSs can be dominated by the small component and therefore not necessarily give a full picture of the spread of the error distribution. Instead, the background and observation error correlation functions were considered, and the areas under the functions up to 100 km—the prescribed CLS for the synoptic scale correlated component of uncertainty in the SST CCI observations—were compared. An appropriate representation of the idealised test condition can be given by the condition that the area under the observation error correlation function up to 100 km is less than that for the background. This allows better consideration of the spread of error correlations for the region of interest, and is a practical approach given the assumptions that both background and observation error correlations can be modelled as Gaussian.
In practice, as described in
Section 1, within the assimilation step in OSTIA a ratio (0 to 1) is used to weight the small and large-scale components of the background error covariances. The area under the background error correlation function has a linear relationship with this ratio. Calculations revealed that the condition described above is equivalent to the ratio of the small-scale error variance component to the total background error variance being below approximately 0.4. Hereafter this is known as the ‘ratio condition’.
The other main result from the idealised test was that the optimal inflation increases linearly with the number of nearby observations. To be able to apply this concept practically in OSTIA, we define for each observation the ‘observation density’ as the number of other observations from that satellite platform within a radius of 100 km. 100 km, being the length scale of the observation error correlations, was deemed an appropriate way of considering observations to be ‘close’. Tests revealed that the typical maximum ‘observation density’ (by this definition) for each observation type was approximately 1000. In order for the scaling to be coded in a practical way, this was used to define the scaling of the inflation, so that when ‘observation density’ = 1000 the inflation was at its maximum, and when ‘observation density’ = 1 (i.e. no other observations present within 100 km), no inflation is applied.
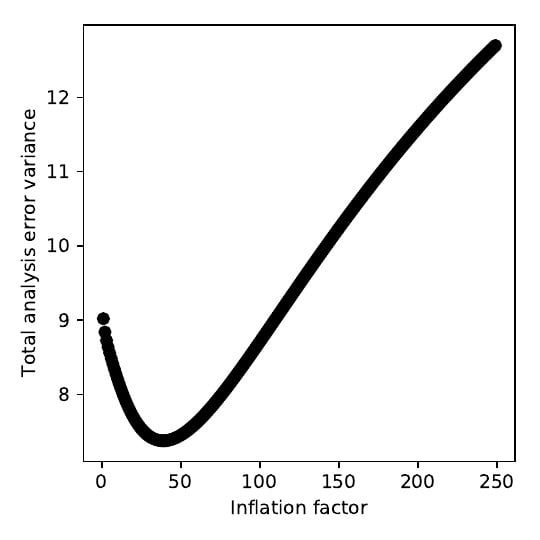
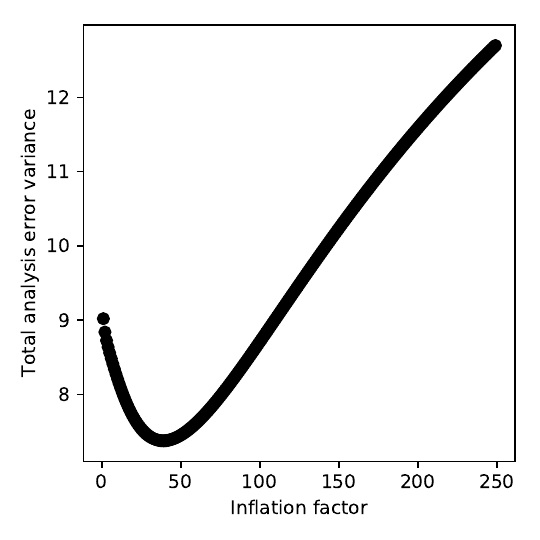
The results from
Section 2 clearly show that over-inflating observation error variances can degrade the analysis by a large amount. [
18] suggested that an appropriate limit to the inflation factor would be 2–4. A limit of this size is also supported by the results shown in
Figure 4. Therefore, a limit of this order should avoid excessive error inflation.
Several OSTIA trials were run for a selected portion of the ESA SST CCI processing described in [
5] to investigate the effect of inflating OEVs on the (re)analysis. Each trial was run from January to August 2010, with the first month treated as a spin up period. For this period the available SST CCI observations were from the Advanced Along-Track Scanning Radiometer (AATSR) and the Advanced Very High Resolution Radiometers (AVHRRs) on board the National Oceanic and Atmospheric Administration (NOAA) 17, 18, 19 and MetOp-A platforms.
In the main inflation scheme that was tested (Scheme A), an inflation factor f was applied to OEVs for each satellite as defined in Equations (6)–(8). Inflation was only applied if the ‘ratio condition’ of 0.4 was met.
In these equations, r is the ratio (the weighting assigned to the small and large-scale background error covariance components at the observation position), rc is the ratio condition (0.4), ρ is the observation density (defined for each observation as the number of observations within a 100 km radius of itself), ρm is the maximum observation density (1000) above which the maximum inflation is applied, m is the chosen limit to the inflation factor and f* is the f found from Equation (7). The ramping between ratio values of 0.36 and 0.4 is applied in order to avoid a sudden change in OEVs in areas near the boundary of the ratio condition. In summary, the inflation is set to m if the ratio is less than 0.36 and the number of observations within 100 km is at least 1000. The inflation is reduced to 1 as the ratio increases towards 0.4 and number of observations reduces to 1.
An alternative scheme (Scheme B), which did not use the observation density, was also tested. In this scheme, Equation (9) replaces Equation (7).
Trials were performed as summarised in
Table 2. Two sets of trials were defined which were identical except for the observations that were used. In the first set, only AATSR data were used. These trials could give insight into the appropriateness of the inflation methods for a case in which relatively little data are available, for example in an early period. The second set of trials assimilated all available observations, to investigate the more common situation that several observation types are available.
Within each set, control runs were performed in which no inflation was applied, as in the current OSTIA system. There were also cases where the ratio condition was used or not, to evaluate the conclusion from
Section 2 that applying inflation everywhere would be detrimental. This is equivalent to assuming the ratio is <0.36 everywhere in Equations (6)–(9). There were also trials aimed at evaluating the use of the observation density to determine inflation (Scheme A compared to Scheme B) and to compare using a maximum inflation of 2, 4, 10 or 50 (note that these are factors applied to the observation error standard deviation).
3.2. Results
3.2.1. Argo Matchups
The outputs from the OSTIA trials were first evaluated by comparing them to Argo data. Matchups to Argo [
19] observations from the EN4 database [
20] were performed to validate the resulting OSTIA SST fields. Argo observations are not assimilated in OSTIA, so are a valuable independent dataset for validation. Measurements between 3 and 5 m depth have been shown to be representative of foundation SST, but have also been used to evaluate SST CCI L4 outputs [
21]. Bilinear interpolation was performed to calculate analysis minus observation statistics for the trial period. This was done for the global ocean and the North Atlantic in the months of June, July and August. This is a region where the ratio condition is met in a significant part in that season, as shown in
Figure 5c. This figure also reveals that, in general, the ratio condition is not met in the OSTIA system, i.e., the correlation length scale of the observations errors is sufficiently close to the length scale for the background errors that inflation is unwise.
Results of the Argo matchups are given in
Table 3. Differences are very small and hence it is not possible to distinguish between the versions of applying inflation (or not) based on these results. Using AATSR only or all observations does cause a difference in the results, as might be expected. However, the degradation in the standard deviation of differences when using all observations compared to only AATSR is unexpected. It might indicate that there is discrepancy between the AVHRR and AATSR data.
In addition, the control_allobs and infl2_cond_dens_allobs cases were run for the whole of 2010 and global and regional Argo statistics calculated in order to determine if differences would emerge over a longer time period. However, the statistics for the two runs (not shown) contained only minor differences, similar to those seen in the results in
Table 3.
3.2.2. Gradients
We now investigate the impact of the inflation method on small-scale features in the analysis since they are expected to be altered [
12]. An assimilation that over-fits to observations could result in spurious features in the analysis, so a method that corrects this might be expected to reduce the presence of spurious features. On the other hand, reduced resolution of realistic features in the analyses could point to having under-fitted to observations in the assimilation. Plots of the SST gradients in the region marked by the black box in
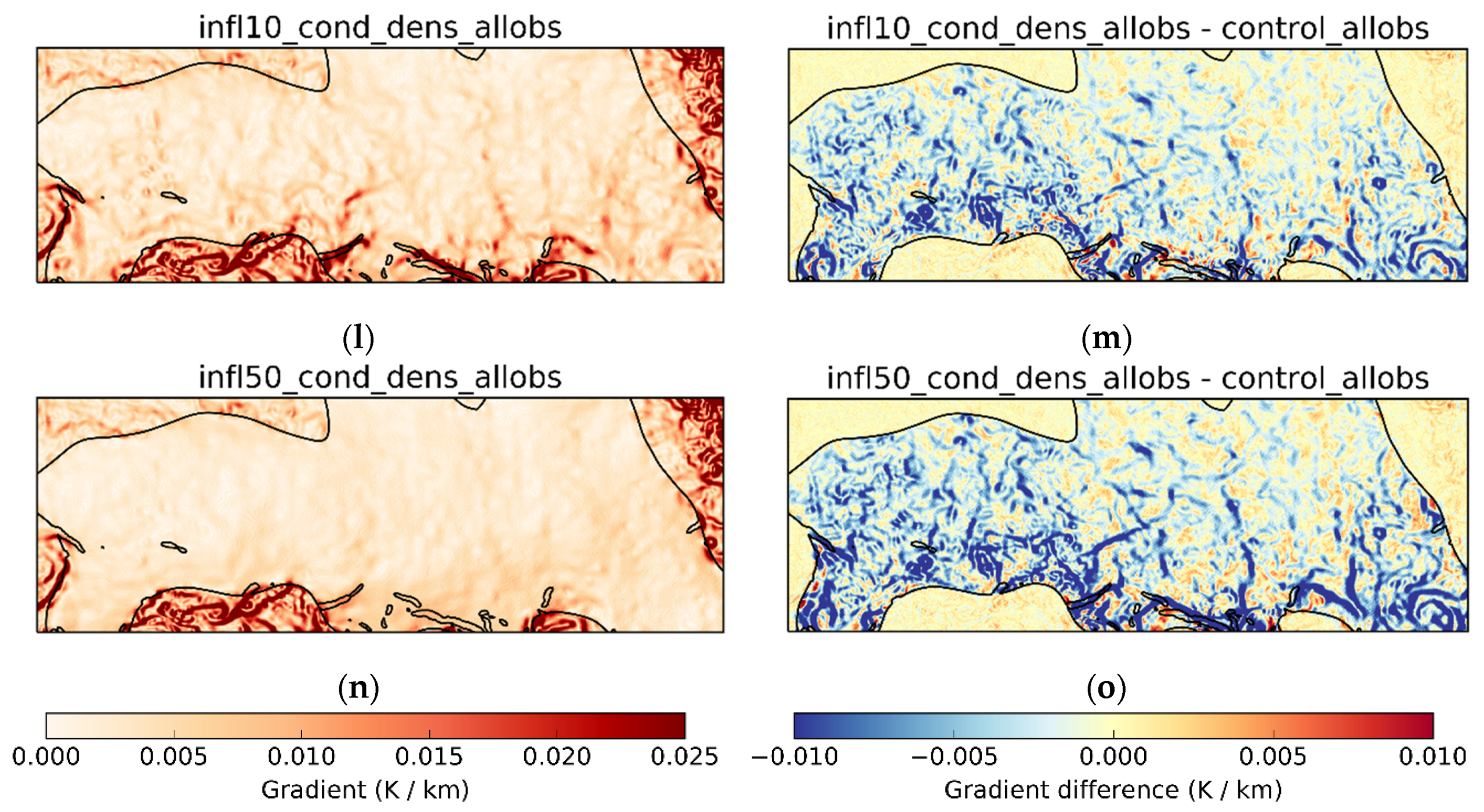
Figure 5a (−25° to 10° longitude and −30° to −18° latitude) were examined for evidence of these effects. Example outputs are shown in
Figure 6. The left column shows an example of the gradients in that region for the cases where all observations were used, and the right column the differences in gradients compared to the control trial. The black contour gives an indication of where the ratio condition is met.
The differences in gradients between the no inflation control case and the case where an inflation factor of 2 is applied everywhere are small, which might suggest that the inflation factor is too low for the quantity of observations that are being assimilated. The case where the density of observations is used to scale the inflation factor has both increases and decreases in gradients compared to the control. This is likely to be because the spreading of observation information spatially has been affected by applying different amounts of inflation in different places. This is particularly evident in the case where inflation has been applied only where the ratio condition is met. Within that region, the gradients are lower than in the case where the inflation was applied everywhere, despite the inflation being the same inside the region. This may be because the observations that are inside the region, which provide the information on small-scale features, are being given less weight in the analysis. Instead, the observations that are outside the region and have not been subjected to inflation have more weight, giving a smoother analysis. However, this requires further investigation. Moving to the case where the density is used to determine inflation where the ratio condition is met largely restores the reduced gradients, but doubling the inflation amount reduces them again. Larger inflation factors further suppress the gradients.
4. Discussion and Conclusions
Correlations in observation errors are generally assumed to be non-existent in L4 SST processing systems such as OSTIA [
22]. However, correlations can occur, for example due to retrieval errors. Using information on satellite SST error correlations provided by the ESA SST CCI project, an investigation has been conducted to determine if a commonly used technique to mitigate for these correlations can be improved upon and used in the OSTIA system. This technique involves inflating the observation uncertainties by some amount.
Idealised tests were conducted to determine what the inflation factor should be and how it should be applied. It was found that in some regions the optimal inflation factor varies linearly with the number of observations present. This result could be seen as intuitive—the more observations are present, the greater the effect of ignoring correlated errors, and the higher the inflation needed to counteract the overuse of observations. However, this result was not always applicable to areas where the observation error correlation length scale was less than that for the background errors (known as the ratio condition). Theoretically, applying inflation elsewhere could lead to unpredictable results and a degraded analysis.
The results from the idealised tests were adapted to the OSTIA system and trials run to compare different choices in the inflation algorithm. These were (1) whether the inflation was applied everywhere or only where the observation error correlation length scale was shorter than that for the background errors; (2) whether the inflation should be scaled according to the density of observations; and (3) whether the maximum inflation factor applied to the error standard deviations was 2, 4, 10 or 50. Trials were also run where only AATSR data were assimilated and where all available observations were assimilated and results presented for the globe and for a trial region, which was selected because it mostly met the ratio condition.
The idealised tests indicated that applying inflation, if done correctly, would result in an improvement in the analysis accuracy. However, results from tests comparing the trial data to Argo reference observations were almost identical between all the different trials suggesting no significant advantage or disadvantage to applying the inflation, and no difference whether it was applied everywhere or only where it was thought to be beneficial. This was consistent whether only AATSR was in use or all observations.
Comparison of SST gradients in an example region showed that the choice of inflation algorithm does have an impact on the smoothness of the analysis. The largest impacts were seen when differential inflation was applied, i.e., where the density of observations or the ratio condition was used to control the inflation factor. The greatest impact was seen when only the ratio condition was used as it was found that the analysis became much smoother within the region where the condition applies. This is hypothesised to be because the analysis in those locations was giving extra weight to the observations outside the region where the ratio condition was met rather than the local observations which contain the information on small-scale features. If this is the case, a larger ramping region where the inflation factors are scaled to avoid a ‘shock’ to the analysis system may be beneficial. However, using the density factor and the ratio condition together was found to have a less detrimental impact on the gradients.
These results indicate that, in theory, the inflation method should be beneficial to the OSTIA system and SST analysis systems in general. However, the practical implementation is challenging. Improved understanding of the background and observation error covariances would be the key to applying the method in a broader way than was done in the case studies presented here. For example, the idealised test condition plays a large role in the experiments undertaken, but is based on several assumptions, including that the observation error correlations can be approximated by a Gaussian. This points to the importance of determining the length scale and distribution of the synoptic scale observation error correlations more accurately, for example using techniques such as described by [
23]. Another assumption made is that cross-platform observation error correlations are negligible. However, one source of error correlations is the presence of weather systems, whose effect on different platforms may well be correlated. It would be important to determine these correlations, if and where they exist.
Finally, these results point to needing more sophisticated data assimilation methods in the long term, which would allow observation error correlation information to be fully used within analysis systems such as OSTIA.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}