1. Introduction
Forests play an important role in the global carbon cycle, thus forest monitoring is critical to understanding and quantifying forest dynamics and the impact of climate change on forest ecosystems [
1,
2]. Alaska is the largest state in the USA and the boreal forests within the interior region of the state account for approximately 17% (520,000 km
2) of the nation’s forestland. [
3]. Interior Alaska is also warming faster than many places on Earth, with a mean annual temperature increase of 2.06 degrees Celsius between 1949–2016 [
4,
5]. Climate projections indicate continued increases in average annual temperature and precipitation in the coming years, with some models predicting up to five degrees Celsius increase in annual temperature and 50% increase in precipitation by 2080 [
6]. These projected changes have potential impacts on livelihoods and resource management. Although much of interior Alaska’s forests are remote and inaccessible, many households within the rural communities of interior Alaska are dependent on the nearby forest resources for heat/energy, building materials, and wildlife habitat [
7]. As a result, interior Alaska’s communities are interested in assessing the available supply of forest biomass in Alaska’s forests for use in the production of bioenergy [
8]. In addition, understanding biomass and how it is distributed within different forest types in Alaska helps us to quantify and measure changes in boreal forests under climate change [
9].
The USDA Forest Service Forest Inventory and Analysis (FIA) program provides vital information for assessing the status of forests in the United States. Prior to 2014, interior Alaska was not included in the FIA program due to the extreme remoteness and inaccessibility of the region. In 2014, a pilot project was established to begin the work of surveying interior Alaska, starting with the Tanana valley region of the state. This area included the Tanana Valley State Forest and Tetlin National Wildlife Refuge, which were sampled at a 1:4 intensity (or one plot per 97.12 km
2, or 24,000 acres) on a hexagonal grid [
10].
While these new FIA plots were being established for the 2014 Tanana pilot project, high-resolution airborne remote sensing data were acquired by NASA Goddard’s Lidar, Hyperspectral and Thermal (G-LiHT) Airborne Imager to augment the relatively sparse sample of FIA field plots. This new suite of sensors developed by scientists at NASA maps the composition, structure, and function of terrestrial ecosystems with coincident, high (~1 m
2) spatial resolution hyperspectral, thermal, and lidar data. [
11]. Together, these multi-sensor data provide a novel opportunity to assess forest conditions in the areas covered by the G-LiHT swaths at the scale of individual tree crowns.
One of the standard measures in the FIA plot protocol is the condition class within each plot. Forest type is a primary condition class attribute recorded at each plot and is defined as the species of tree with the dominant stocking of live trees that are not overtopped [
12]. In Alaska this essentially records the dominant canopy tree species present at a given plot. If there are no trees present or if the trees do not meet a specific tree canopy cover threshold (10%), then the plot is considered non-forest [
13]. These data provide a field reference for the distribution of different species throughout the forests. For species that frequently occur in mixed stands, the dominant species information is a categorical indicator of condition class, not a continuous measure of canopy cover by species. In combination with the G-LiHT data, condition class data for each plot location can be used to classify forest type throughout that Tanana valley of interior Alaska.
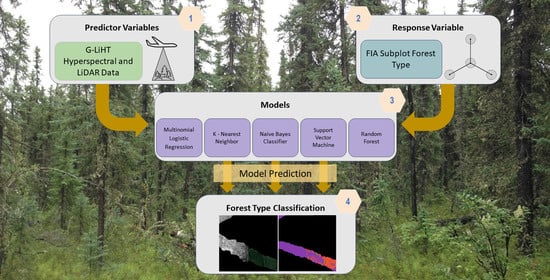
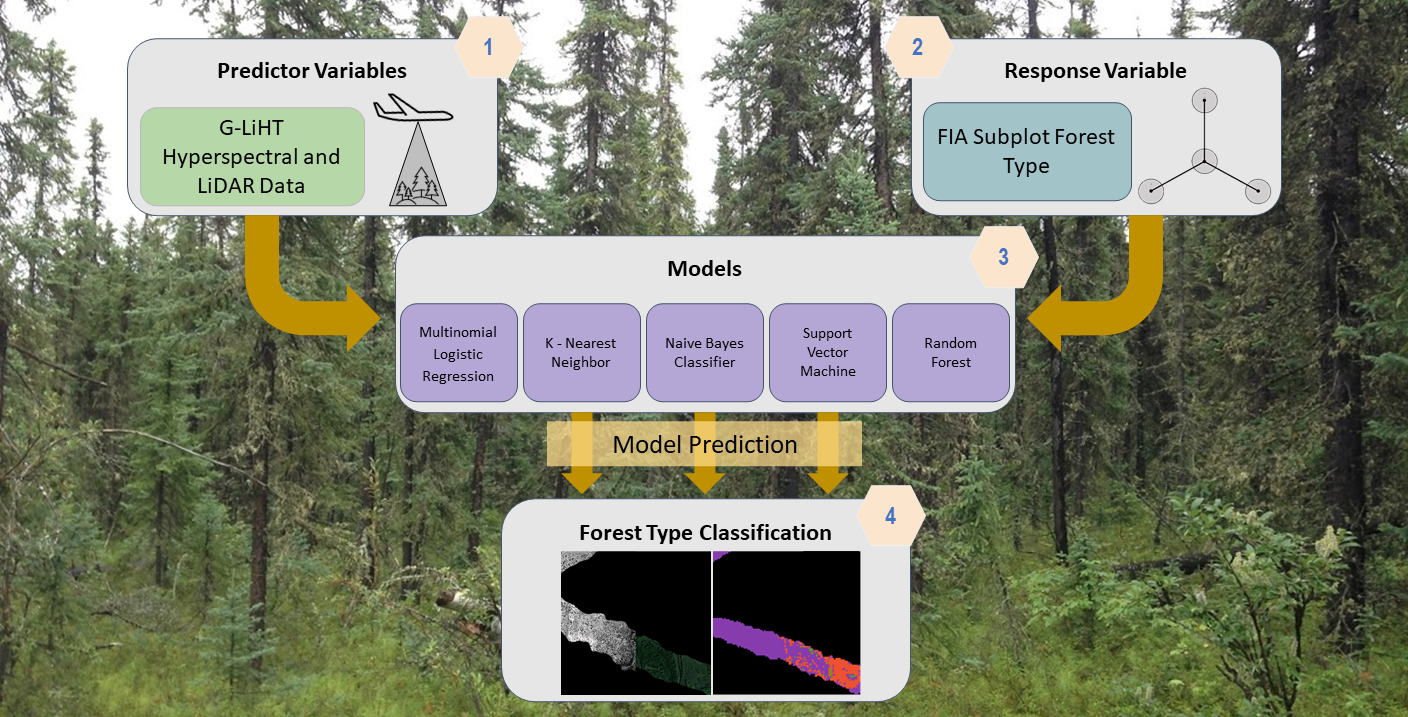
In this study, we developed and applied a methodology for classifying FIA-defined forest type across the Tanana Inventory Unit (TIU) of interior Alaska using the fusion of G-LiHT hyperspectral and lidar data [
10,
11]. These structural and spectral data from G-LiHT, and the field data from the newly installed FIA plots, provide the information necessary to predict forest type within the TIU. We evaluated different classification algorithms and combinations of hyperspectral and lidar data to identify the model with the highest classification accuracy, and then applied the best model to G-LiHT data across the TIU to compare modeled versus observed forest type information from FIA forest inventory plots. Although interior Alaska has only six main canopy tree species, the combination of small crown sizes, open canopy structure, and mixed stands creates challenges for classifying forest type, even with high-resolution multi-sensor airborne data. Similar studies have used hyperspectral and lidar data to classify tree species with machine learning models [
14,
15], but none have used the combination to classify forest type, a unique metric in the USDA Forest Service FIA inventory. The potential to accurately classify forest type using airborne remote sensing data is important to support multi-level forest inventories as well as broader assessments in regions where FIA plots were not installed but hyperspectral and lidar data are available.
4. Discussion
This study aimed to provide an exploratory comparison of techniques for classifying forest type using well known accuracy statistics and widely available FIA data. Previous studies have worked to answer similar questions and achieved promising results. One study compared the accuracies of Support Vector Machines (SVM), K-Nearest Neighbor, and Gaussian maximum likelihood with leave-one-out-covariance algorithms for the classifications of tree species using both hyperspectral and lidar data [
14]. They found that the SVM classifier was the most accurate, yielding just over 89% kappa accuracy.
This study also found SVM yielded higher accuracy than the K-Nearest Neighbor classifier, but the Gaussian maximum likelihood (GML) with leave-one-out-covariance algorithm was not tested. Instead, a naive Bayes classifier which is based on GML assumptions was tested and found to perform the worst of any model. This contradicts the findings with the GML model in [
14] which found their GML algorithm outperformed the K-Nearest Neighbor algorithm. This difference is likely due to differences in GML and KNN algorithm and model parameters used in each study.
A second study compared the results of classifying seven tree species and a non-forest class in the Southern Alps of Italy using hyperspectral and lidar data with Support Vector Machines and Random Forest [
15]. They found that SVM consistently outperformed Random Forest, achieving 95% overall accuracy. This differs from our findings which revealed that Random Forest outperformed SVM models, no matter the model input, achieving 77.53% overall accuracy with the best Random Forest model, and 73.89% with the best SVM model. This is likely due to differences in data pre-processing, especially in the case of hyperspectral data wherein [
15] performed a minimum noise fraction transformation to reduce the data dimensionality. Both minimum noise fraction transformations and principal component analyses (PCA) are common data reduction steps when working with hyperspectral data [
69]. Neither were performed in this study as it would impact the interpretability of the results and make it challenging to compare across the different algorithms.
A second factor that may have influenced the difference in results between both [
14,
15] and this study are the model parameters used. In both SVM and KNN models, users must supply parameters to build the models. In this study, optimization scripts were used to test different model parameters and choose those that resulted in the highest accuracy. In the case of the KNN model, 100 different k-values were tested. For the SVM, multiple cost and gamma values were tested. Additionally, this study used a radial kernel for the SVM, while studies [
14,
15] used different kernels (a Gaussian kernel was used in the 2008 paper [
14], and the kernel used in the 2012 paper [
15] was not specified). All these differences in parameters used makes for difference in the final results.
Within the training data there could be a significant difference between forest type as defined by the FIA protocol at the scale of a mapped condition (which must meet certain minimum size criteria, >1 acre, etc.) and the tree species present at a given location, or even subplot scale. In the FIA inventory, forest type (on conditions with >10% tree canopy cover) is based on the tree species with the dominant stocking. This means that on any given subplot, the actual forest composition may be much more mixed than is captured by a single forest type class. A subplot with 51% stocking (or tree cover) of white spruce is spectrally very different from a plot that is 100% white spruce, but the methods here treat both examples as the same class. Though this is the method for forest type classification used by the USDA Forest Service throughout the US, it can create challenges when using this data as ground truth for multispectral classification algorithms, and likely contributed to lower accuracies for white spruce and other species that commonly form mixed stands. Future studies may consider using different field validation data and carrying out a hypothesis test to determine if differences in accuracies between models are statistically significant. Additionally, future studies should consider reporting precision and recall, as opposed to overall accuracy, to compare between models [
70]. Each of these steps would allow for better reporting of the uncertainty associated with each measure of accuracy and make for better comparison between classification algorithms.
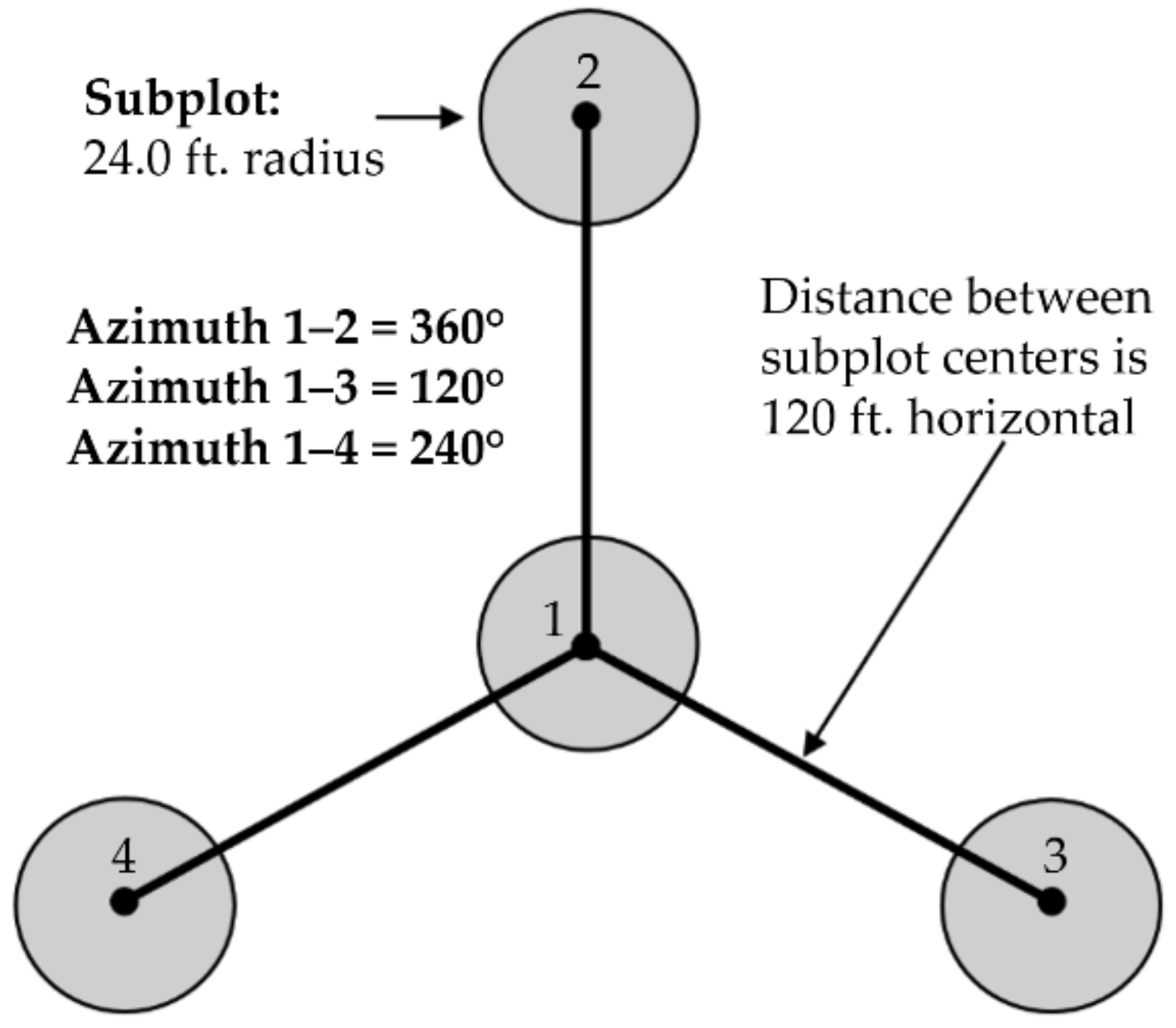
Unlike the potential loss of accuracy due to the spectral mixing within subplots, the nested plot design in this study likely inflated overall accuracy. The FIA protocol is designed such that, for each plot, there are four subplots on which forest type information is collected. There are just 36.576 m (120 ft) between the center subplot and the surrounding three subplots. This leads to an issue of pseudo replication and spatial autocorrelation as the outer three subplots are so close together that they are likely to include similar vegetation. In this study, each subplot was treated as if it was unique and independent of others. This likely led to an inflation in accuracy which cannot be overcome until a more balanced dataset with more equal representation of all forest types within the TIU is available.
Imbalanced datasets are common in ecological studies using natural datasets. While we hope that more data will become available for future research to improve the imbalanced nature of the data in this dataset, we identified multiple ways to overcome the impacts of imbalanced datasets. One common method is to sample the dataset so that there is an equal number of samples in each class that is equal to or less than the size of the smallest class. For example, in this case the smallest forest type class (Tamarack) has four subplots of that class. This methodology would require that for every other forest type class, just four subplots are sampled and used in model training and validation to ensure that the number of samples of each class is the same. This was not feasible in this study because only four samples per class is not enough to train and validate a representative model, so this type of down sampling was not performed.
A second method of overcoming this issue is to oversample the dataset so that each class is sampled with replacement until it reaches a quantity that is typically greater than or equal to the largest class in the dataset. This same methodology can be performed in an ensemble called bootstrap aggregating, or bagging. Bagging is the process by which one samples a dataset D of length
n with replacement, to generate a new dataset D1 of length
m wherein each class is equally represented [
48].
In this case, bagging was implemented in all models to test its impact overall and kappa accuracy. Each class was sampled with replacement until we reached a set equal in length to the largest class within the dataset (280 data points). In most cases, bagging did not improve overall or kappa accuracy. In the cases where accuracy was improved, most models were already performing so poorly that the improved accuracy still did not make the algorithm or model inputs a contender for the best algorithm and inputs. Thus, bagging was not included as a part of this study.
The primary objective of the study was to assess the potential for classifying forest type in the context of a national forest inventory program using high-resolution airborne data. While pseudo replication caused by the nested plot design used in this study, and overfitting of the model in the less common forest types, such as tamarack and poplar, are issues that should be addressed in future studies to provide a full accounting of the classification uncertainty, the results of this study indicate the potential for application of machine learning algorithms to classify forest types in the forest inventory context using a combination of field measurements and high-resolution airborne remote sensing data. As this FIA effort in Alaska continues, leading to more FIA plots and G-LiHT data collected throughout the state, the sample size for every forest type will increase significantly, possibly allowing pseudoreplication to be dealt with by using just one subplot from each plot to represent the entire plot. Alternatively, training and validation datasets could be selected using independent datasets distinct from the FIA field plot sample (at representative sites such as experimental forests, etc.) and then the resulting model could be applied to the FIA field data and G-LiHT data, which would allow for a straightforward assessment of accuracy across the FIA plot sample (although obviously also requiring the collection of an additional, expensive data set).
Future studies could use alternative methods for reducing correlation, and dimensionality, of the input data through PCAs or other techniques. It is also important to note that the variables used in this study are not the only lidar and hyperspectral data-derived metrics that can be used to describe forest composition. There are a multitude of other metrics, from lidar grid metrics to other hyperspectral vegetation indices that have been used in previous studies and may increase model performance [
71,
72]. Additionally, when aggregating the hyperspectral and lidar metrics over each subplot, using a standard deviation of the metrics instead of or in addition to the average of the metrics may also improve model performance.
5. Conclusions
Overall, the Random Forest classification algorithm resulted in the highest overall and kappa accuracy. There are many factors that make ecological data complex and difficult to model [
73,
74]. Many studies use Random Forests to overcome these complexities and still yield high prediction accuracies [
75,
76]. This was likely also the case in this study, resulting in the highest overall accuracy coming from Random Forest.
The MLR model with hyperspectral vegetation indices, DTM metrics, and CHM metrics had the best performance when predicting individual classes, especially rarer classes. This may indicate that the MLR model would be a more suitable model in cases where the objective is to accurately predict rare classes. It also indicates that it may be more suitable to use multiple models when predicting forest type. One could use Random Forest for predicting the more common forest types, and MLR for predicting the less common forest types.
This study also tested a multitude of model inputs and found that including hyperspectral vegetation indices, DTM metrics, and CHM metrics as model inputs yielded the highest overall and kappa accuracy with almost all classification algorithms. Each of these model input groups describe different ecological factors that are essential for distinguishing forest types.
Topography plays an important role in the distribution of vegetation across the landscape, and the topographic variables that can be derived from a DTM can in predicting vegetation distribution [
67,
77,
78]. Unsurprisingly, when these model inputs were tested with all subplots in one Random Forest model, roughness, topographic roughness index, and elevation were found to be extremely important in predicting forest type.
The canopy height model describes the over story structure and can be used to describe species composition when used alongside optical sensors [
79,
80,
81]. In this study, we used both the raw canopy height model and a multitude of CHM-derived metrics to describe the over story. Canopy height was found to be the most important predictor for forest type, with surface volume ratio following close behind.
When it comes to hyperspectral model inputs, including the raw hyperspectral band data with the hyperspectral vegetation indices and CHM and DTM metrics in the Random Forest model decreased accuracy. While it is unclear exactly why this is, we hypothesize that the 114 hyperspectral bands are so highly correlated that they had a negative impact on prediction accuracies. Additionally, transforming the raw hyperspectral data into vegetation indices allows for the data to be relativized, which can boost model performance in many cases.
In summary, this study concluded that:
Of all classification algorithms tested, Random Forest resulted in the highest overall and kappa accuracy.
A combination of structural and spectral metrics resulted in the highest overall accuracy, including Canopy Height and Digital Terrain model metrics with hyperspectral vegetation indices and five raw hyperspectral bands.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}