
Application of Machine-Learning-Based Fusion Model in Visibility Forecast: A Case Study of Shanghai, China

Abstract
:
1. Introduction
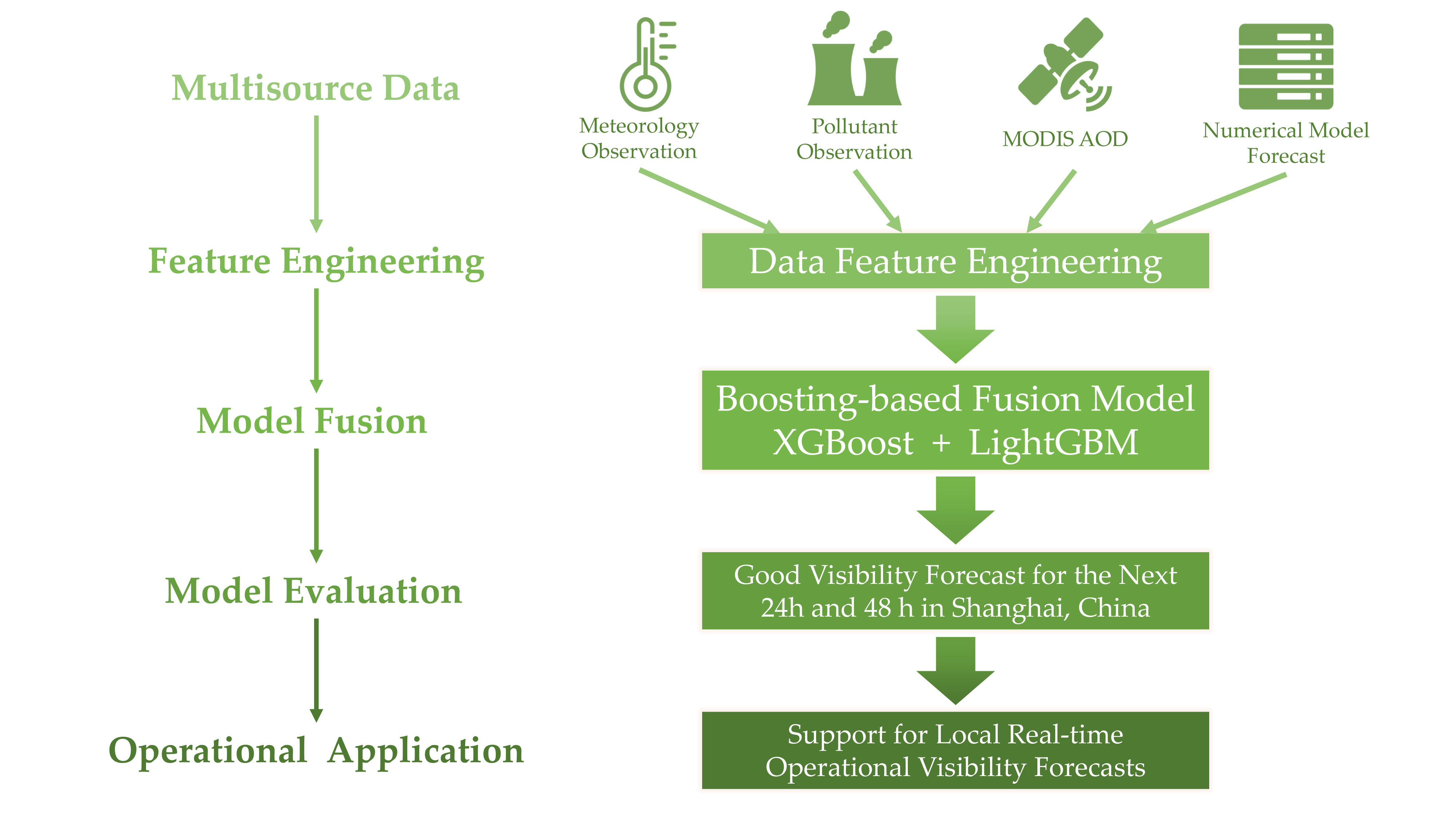
2. Materials and Methods
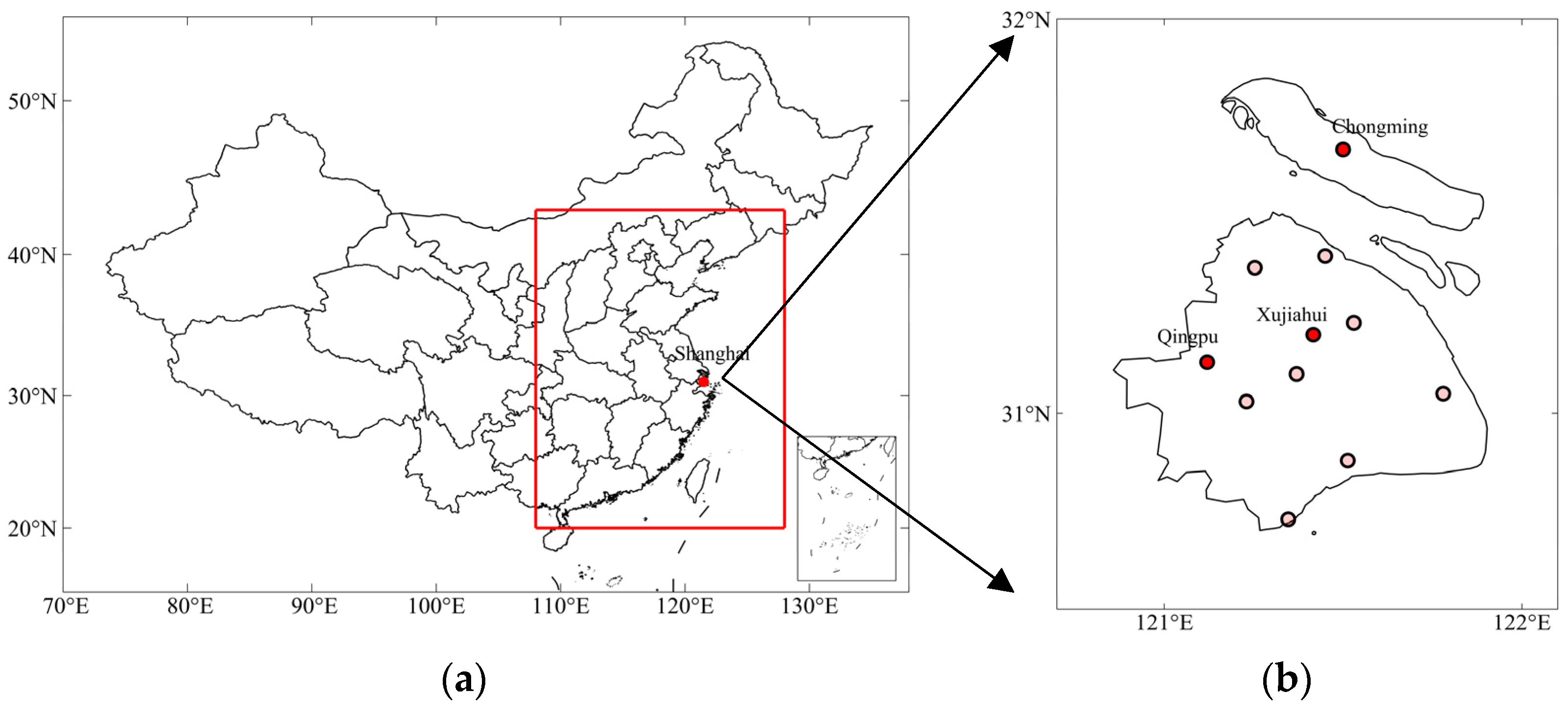
2.1. Data Introduction
2.2. Introduction to RAEMS
2.3. Machine-Learning-Based Model Fusion
2.3.1. Feature Extraction
2.3.2. Data Sampling
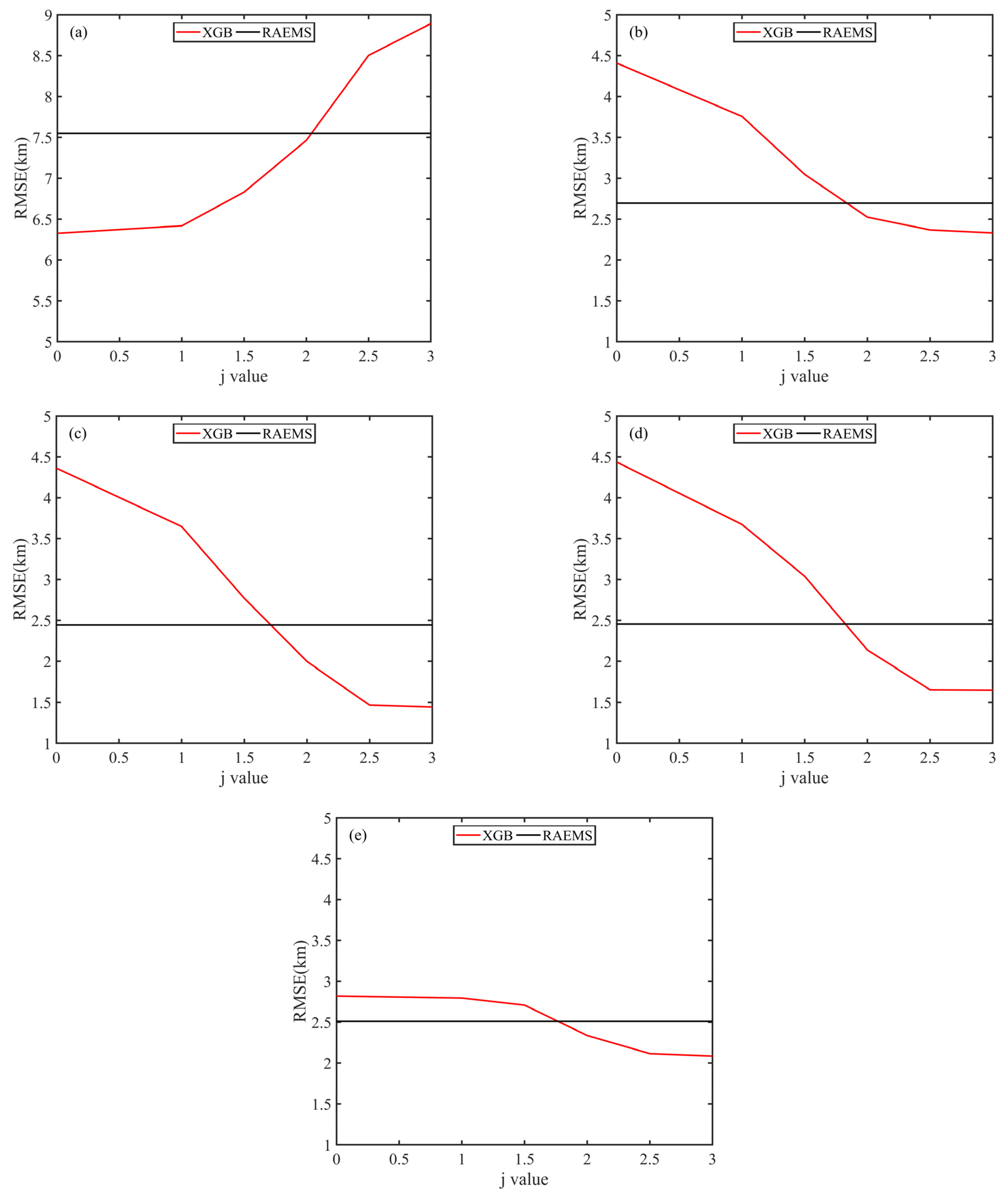
2.3.3. Loss Function Adjustment
2.3.4. Model Fusion
2.4. Statistical Scores
3. Results
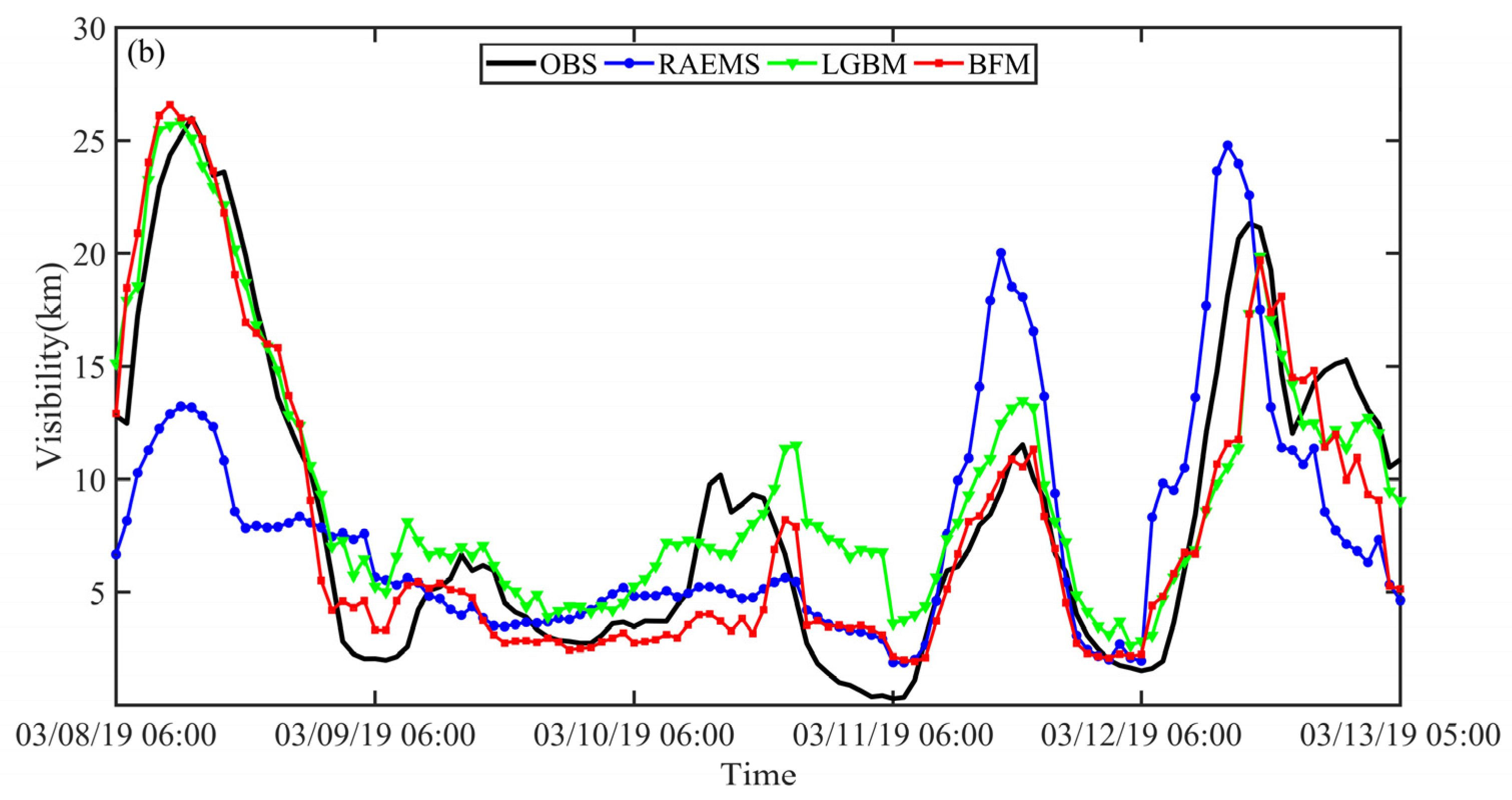
3.1. A Case Study Evaluation
3.2. Forecast Evaluation
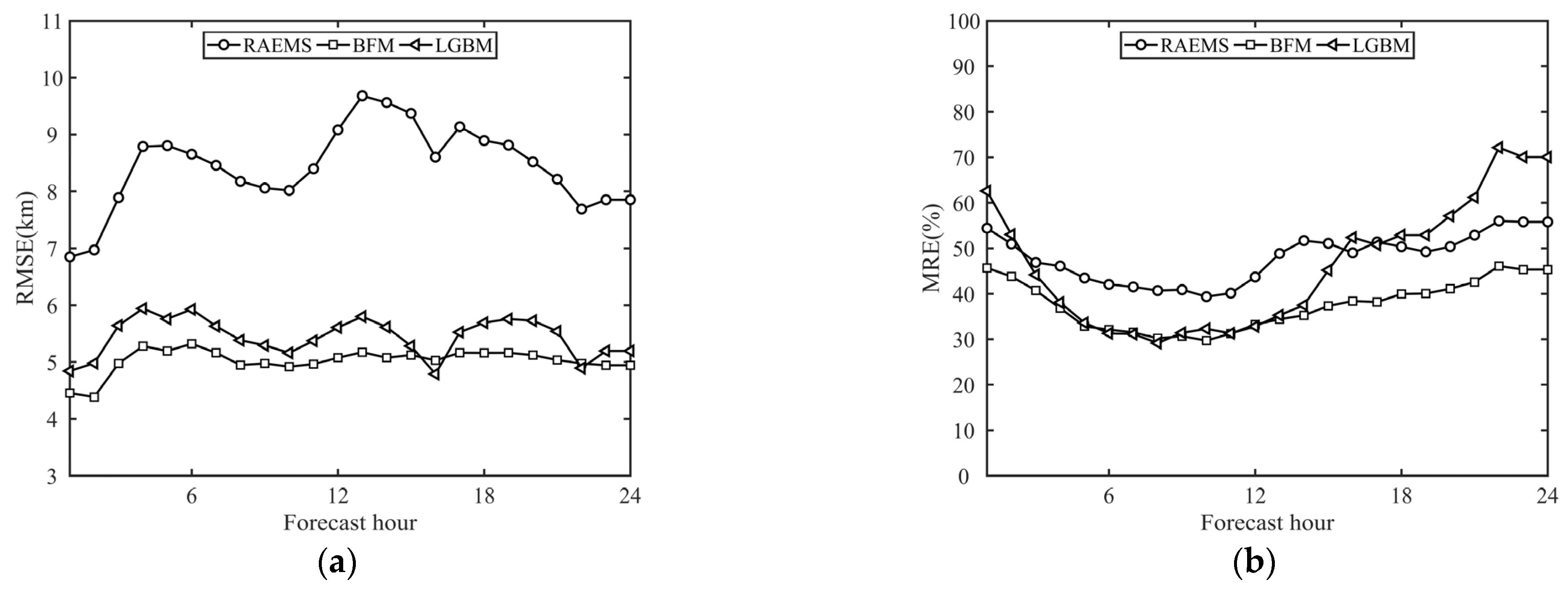
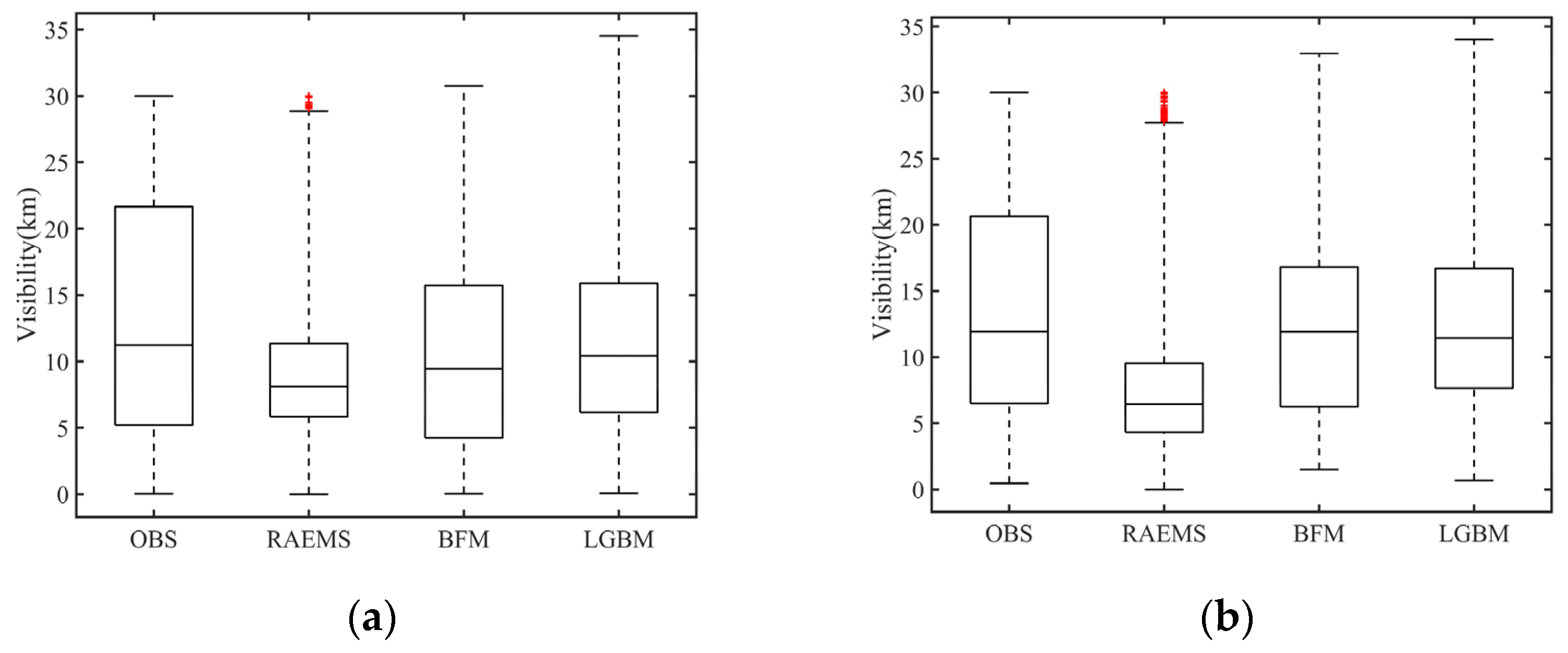
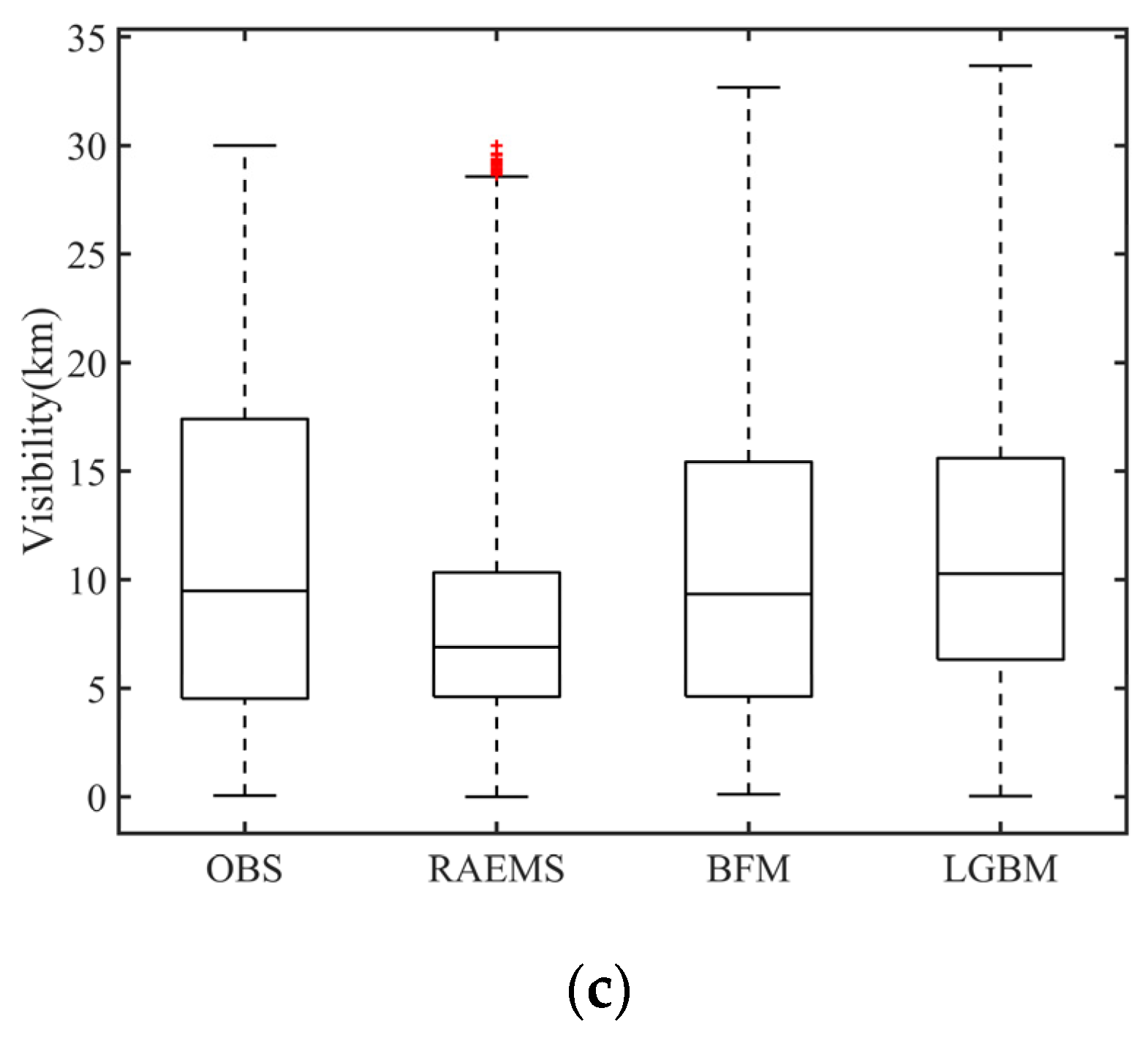
3.2.1. Overall City Evaluation
3.2.2. Station Evaluation
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Horvath, H. Atmospheric visibility. Atmos. Environ. 1981, 15, 1785–1796. [Google Scholar] [CrossRef]
- Deng, X.; Tie, X.; Wu, D.; Zhou, X.; Bi, X.; Tan, H.; Li, F.; Jiang, C. Long-term trend of visibility and its characterizations in the Pearl River Delta (PRD) region, China. Atmos. Environ. 2008, 42, 1424–1435. [Google Scholar] [CrossRef]
- Qian, W.; Leung, J.C.-H.; Chen, Y.; Huang, S. Applying anomaly-based weather analysis to the prediction of low visibility associated with the coastal fog at Ningbo-Zhoushan Port in East China. Adv. Atmos. Sci. 2019, 36, 1060–1077. [Google Scholar] [CrossRef] [Green Version]
- Gultepe, I.; Sharman, R.; Williams, P.D.; Zhou, B.; Ellrod, G.; Minnis, P.; Trier, S.; Griffin, S.; Yum, S.S.; Gharabaghi, B.; et al. A review of high impact weather for aviation meteorology. Pure Appl. Geo-Phys. 2019, 176, 1869–1921. [Google Scholar] [CrossRef]
- Cheung, K.; Daher, N.; Kam, W.; Shafer, M.; Ning, Z.; Schauer, J.; Sioutas, C. Spatial and temporal variation of chemical composition and mass closure of ambient coarse particulate matter (PM10–2.5) in the Los Angeles area. Atmos. Environ. 2011, 45, 2651–2662. [Google Scholar] [CrossRef]
- Hu, Y.; Yao, L.; Cheng, Z.; Wang, Y. Long-term atmospheric visibility trends in megacities of China, India and the United States. Environ. Res. 2017, 159, 466–473. [Google Scholar] [CrossRef]
- Grell, G.A.; Peckham, S.E.; Schmitz, R.; McKeen, S.A.; Frost, G.; Skamarock, W.C.; Eder, B. Fully coupled ’online’ chemistry in the WRF model. Atmos. Environ. 2005, 39, 6957–6976. [Google Scholar] [CrossRef]
- Zhou, G.; Xu, J.; Xie, Y.; Chang, L.; Gao, W.; Gu, Y.; Zhou, J. Numerical air quality forecasting over eastern China: An operational application of WRF-Chem. Atmos. Environ. 2017, 153, 94–108. [Google Scholar] [CrossRef]
- Binkowski, F.S.; Roselle, S.J. Models-3 community multiscale air quality (cmaq) model aerosol component 1. model description. J. Geophys. Res. Atmos. 2003, 108, 4183. [Google Scholar] [CrossRef]
- Cheng, F.; Feng, C.; Yang, Z.; Hsu, C.; Chan, K.; Lee, C.; Chang, S. Evaluation of real-time PM2.5 forecasts with the WRF-CMAQ modeling system and weather-pattern-dependent bias-adjusted PM2.5 forecasts in Taiwan. Atmos. Environ. 2020, 244. [Google Scholar] [CrossRef]
- An, X.; Zhai, S.; Jin, M.; Gong, S.; Wang, Y. Development of an adjoint model of GRAPES–CUACE and its application in tracking influential haze source areas in north China. Geosci. Model Dev. 2016, 9, 2153–2165. [Google Scholar] [CrossRef]
- Yumimoto, K.; Uno, I. Adjoint inverse modeling of CO emissions over Eastern Asia using four-dimensional variational data assimilation. Atmos. Environ. 2006, 40, 6836–6845. [Google Scholar] [CrossRef]
- Yang, D.; Ritchie, H.; Desjardins, S.; Pearson, G.; MacAfee, A.; Gultepe, I. High-resolution GEM-LAM application in marine fog prediction: Evaluation and diagnosis. Weather Forecast. 2010, 25, 727–748. [Google Scholar] [CrossRef]
- Duynkerke, P.G. Radiation fog: A comparison of model simulation with detailed observations. Mon. Weather Rev. 1991, 119, 324–341. [Google Scholar] [CrossRef] [Green Version]
- Guedalia, D.; Bergot, T. Numerical forecasting of radiation fog. Part II: A comparison of model simulation with several observed fog events. Mon. Weather Rev. 1994, 122, 1231–1246. [Google Scholar] [CrossRef] [Green Version]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE. 2018, 13, e0194889. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Eddy Patuwo, B.; Hu, Y. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Xiao, Q.; Chang, H.H.; Geng, G.; Liu, Y. An ensemble machine-learning model to predict historical PM2.5 concentrations in China from satellite data. Environ. Sci. Technol. 2018, 52, 13260–13269. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Ho, H.C.; Wong, M.S.; Deng, C.; Shi, Y.; Chan, T.-C.; Knudby, A. Evaluation of machine learning techniques with multiple remote sensing datasets in estimating monthly concentrations of ground-level PM2.5. Environ. Pollut. 2018, 242, 1417–1426. [Google Scholar] [CrossRef] [PubMed]
- Cecaj, A.; Lippi, M.; Mamei, M.; Zambonelli, F. Comparing deep learning and statistical methods in forecasting crowd distribution from aggregated mobile phone data. Appl. Sci. 2020, 10, 6580. [Google Scholar] [CrossRef]
- Wei, C.C.; Hsieh, P.Y. Estimation of hourly rainfall during typhoons using radar mosaic-based convolutional neural networks. Remote Sens. 2020, 12, 896. [Google Scholar] [CrossRef] [Green Version]
- Bouget, V.; Béréziat, D.; Brajard, J.; Charantonis, A.; Filoche, A. Fusion of rain radar images and wind forecasts in a deep learning model applied to rain nowcasting. Remote Sens. 2021, 13, 246. [Google Scholar] [CrossRef]
- Kianian, B.; Liu, Y.; Chang, H. Imputing satellite-derived aerosol optical depth using a multi-resolution spatial model and random forest for PM2.5 prediction. Remote Sens. 2021, 13, 126. [Google Scholar] [CrossRef]
- Fan, Z.; Zhan, Q.; Yang, C.; Liu, H.; Bilal, M. Estimating PM2.5 concentrations using spatially local xgboost based on full-covered SARA AOD at the urban scale. Remote Sens. 2020, 12, 3368. [Google Scholar] [CrossRef]
- Wei, J.; Li, Z.; Lyapustin, A.; Sun, L.; Peng, Y.; Xue, W.; Su, T.; Cribb, M. Reconstructing 1-km-resolution high-quality PM2.5 data records from 2000 to 2018 in China: Spatiotemporal variations and policy implications. Remote Sens. Environ. 2021, 252, 112136. [Google Scholar] [CrossRef]
- Wei, J.; Li, Z.; Xue, W.; Sun, L.; Fan, T.; Liu, L.; Su, T.; Cribb, M. The ChinaHighPM10 dataset: Generation, validation, and spatiotemporal variations from 2015 to 2019 across China. Environ. Int. 2021, 146, 106290. [Google Scholar] [CrossRef]
- Su, T.; Laszlo, I.; Li, Z.; Wei, J.; Kalluri, S. Refining aerosol optical depth retrievals over land by constructing the relationship of spectral surface reflectances through deep learning: Application to Himawari-8. Remote Sens. Environ. 2020, 251, 112093. [Google Scholar] [CrossRef]
- Bari, D.; El Khlifi, M. LVP conditions at Mohamed V airport, Morocco: Local characteristics and prediction using neural networks. Int. J. Basic. Appl. Sci. 2015, 4, 354–363. [Google Scholar] [CrossRef] [Green Version]
- Marzban, C.; Leyton, S.; Colman, B. Ceiling and visibility forecasts via neural networks. Weather Forecast. 2007, 22, 466–479. [Google Scholar] [CrossRef] [Green Version]
- Bartoková, I.; Bott, A.; Bartok, J.; Gera, M. Fog prediction for road traffic safety in a coastal desert region: Improvement of nowcasting skills by the machine-learning approach. Boundary-Layer Meteorol. 2015, 157, 501–51617. [Google Scholar] [CrossRef]
- Glahn, B.; Schnapp, A.D.; Ghirardelli, J.E.; Im, J.S. A LAMP-HRRR Meld for improved aviation guidance. Weather Forecast. 2017, 32, 391–405. [Google Scholar] [CrossRef]
- Jiang, F.; Yu, X.; Du, J.; Gong, D.; Zhang, Y.; Peng, Y. Ensemble learning based on approximate reducts and bootstrap sampling. Inform. Sci. 2020, 547, 797–813. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, M.; Chen, J.; Chen, K.; Zhang, C.; Xie, C.; Huang, B.; He, Z.C. Weather visibility prediction based on multimodal fusion. IEEE Access 2019, 7, 74776–74786. [Google Scholar] [CrossRef]
- Berger, A.; Pietra, S.D.; Pietra, V.D. A maximum entropy approach to natural language processing. Comput. Linguist. 1996, 22, 39–71. Available online: https://www.aclweb.org/anthology/J96-1002/ (accessed on 9 May 2020).
- Platt, J.C. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; Technical Report MSR-TR-98-14; Microsoft Research: Redmond, WA, USA, 1998. [Google Scholar]
- Schapire, R.E. A brief introduction to boosting. In Proceedings of the 16th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 31 July–6 August 1999; Volume 99, pp. 1401–1406. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T. LightGBM: A highly efficient gradient boosting decision tree. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 6637–6647. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Dietterich, T.G. An experimental comparison of three methods for constructing ensembles of decision trees: Bagging, boosting, and randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Feng, L.; Li, Y.; Wang, Y.; Du, Q. Estimating hourly and continuous ground-level PM2.5 concentrations using an ensemble learning algorithm: The ST-stacking model. Atmos. Environ. 2020, 223, 117242. [Google Scholar] [CrossRef]
- Lee, J.; Wang, W.; Harrou, F.; Sun, Y. Reliable solar irradiance prediction using ensemble learning-based models: A comparative study. Energ Convers. Manag. 2020, 208, 112582. [Google Scholar] [CrossRef] [Green Version]
- Lyapustin, A.; Wang, Y. MCD19A2 MODIS/Terra+Aqua Land Aerosol Optical Depth Daily L2G Global 1km SIN Grid V006. 2018. Distributed by NASA EOSDIS Land Processes DAAC. Available online: https://doi.org/10.5067/MODIS/MCD19A2.006 (accessed on 9 May 2020).
- Lyapustin, A.; Martonchik, J.; Wang, Y.; Laszlo, I.; Korkin, S. Multi-Angle Implementation of Atmospheric Correction (MAIAC): 1. Radiative transfer basis and look-up tables. J. Geophys. Res. Atmos. 2011, 116, D03210. [Google Scholar] [CrossRef]
- Lyapustin, A.; Wang, Y.; Laszlo, I.; Kahn, R.; Korkin, S.; Remer, L.; Levy, R.; Reid, J.S. Multi-Angle Implementation of Atmospheric Correction (MAIAC): 2. Aerosol algorithm. J. Geophys. Res. Atmos. 2011, 116, D03211. [Google Scholar] [CrossRef]
- Lyapustin, A.; Wang, Y.; Laszlo, I.; Hilker, T.; Hall, F.; Sellers, P.; Tucker, C.; Korkin, S. Multi-Angle Implementation of Atmospheric Correction (MAIAC): 3. Atmospheric correction. Remote Sens. Environ. 2012, 127, 385–393. [Google Scholar] [CrossRef]
- Wei, J.; Huang, W.; Li, Z.; Xue, W.; Peng, Y.; Sun, L.; Cribb, M. Estimating 1-km-resolution PM2. 5 concentrations across China using the space-time random forest approach. Remote Sens. Environ. 2019, 231, 111221. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. B 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Schreiber-Gregory, D.N. Ridge Regression and multicollinearity: An in-depth review. Model. Assist. Stat. Appl. 2018, 13, 359–365. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Yu, Z.; Qu, Y.; Xu, J.; Cao, Y. Application of the XGBoost Machine Learning Method in PM2.5 Prediction: A Case Study of Shanghai. Aerosol Air Qual. Res. 2020, 20, 128–138. [Google Scholar] [CrossRef] [Green Version]
- Zhai, B.; Chen, J. Development of a stacked ensemble model for forecasting and analyzing daily average PM2.5 concentrations in Beijing, China. Sci. Total Environ. 2018, 635, 644–658. [Google Scholar] [CrossRef]
- Reid, C.E.; Jerrett, M.; Petersen, M.L.; Pfister, G.G.; Morefield, P.E.; Tager, I.B.; Raffuse, S.M.; Balmes, J.R. Spatiotemporal prediction of fine particulate matter during the 2008 Northern California wildfires using machine learning. Environ. Sci. Technol. 2015, 49, 3887–3896. [Google Scholar] [CrossRef]
- Zhong, J.; Zhang, X.; Gui, K.; Wang, Y.; Che, H.; Shen, X.; Zhang, L.; Zhang, Y.; Sun, J.; Zhang, W. Robust prediction of hourly PM2.5 from meteorological data using Light GBM. Natl. Sci. Rev. 2021, nwaa307. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. B Meteorol. 1974, 36, 111–147. [Google Scholar] [CrossRef]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Woodcock, F.; Engel, C. Operational consensus forecasts. Weather Forecast. 2005, 20, 101–111. [Google Scholar] [CrossRef]
- Bari, D.; Ouagabi, A. Machine-learning regression applied to diagnose horizontal visibility from mesoscale NWP model forecasts. SN Appl. Sci. 2020, 2, 556. [Google Scholar] [CrossRef] [Green Version]
- Gordon, N.; Shaykewich, J. Guidelines on Performance Assessment of Public Weather Services; WMO/TD No. 1023; World Meteorological Organization: Geneva, Switzerland, 2000. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd international conference on Machine-learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Zhou, G.; Yang, F.; Geng, F.; Xu, J.; Yang, X.; Tie, X. Measuring and Modeling Aerosol: Relationship with Haze Events in Shanghai, China. Aerosol Air Qual. Res. 2014, 14, 783–792. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Jiang, F.; Deng, J.; Shen, Y.; Fu, Q.; Wang, Q.; Fu, Y.; Xu, J.; Zhang, D. Urban air quality and regional haze weather forecast for Yangtze River Delta region. Atmos. Environ. 2012, 58, 70–83. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Range | [10 km, ∞) | [5 km, 10 km) | [3 km, 5 km) | [1 km, 3 km) | [0 km, 1 km) |
|---|---|---|---|---|---|
| Pieces | 206,617 | 88,766 | 46,042 | 38,570 | 5382 |
| Percentage | 53.6% | 23.0% | 12.0% | 10.0% | 1.4% |
| Visibility Range | [0 km, ∞) | [0 km, 10 km) | [0 km, 5 km) | [0 km, 3 km) | [0 km, 1 km) |
|---|---|---|---|---|---|
| XGBoost (j = 0) | 5.67 | 4.43 | 3.94 | 4.33 | 2.21 |
| XGBoost (j = 2) | 6.46 | 2.29 | 1.41 | 1.87 | 2.11 |
| O-XGB | 4.68 | 3.53 | 1.88 | 1.78 | 1.92 |
| RAEMS | 7.51 | 2.69 | 2.44 | 2.45 | 2.51 |
| Model | RMSE 24/48 h | MB 24/48 h | MAE 24/48 h | CC 24/48 h | RMSE (OBS < 5 km) 24/48 h |
|---|---|---|---|---|---|
| RAEMS | 5.34/5.23 | −0.13/−0.79 | 3.94/3.99 | 0.664/0.651 | 2.39/2.61 |
| LGBM | 2.83/2.91 | 1.890/1.10 | 2.42/2.29 | 0.952/0.921 | 3.23/3.41 |
| BFM | 2.25/2.63 | 0.20/−0.47 | 1.78/1.99 | 0.946/0.925 | 1.33/1.65 |
| Observation | RAEMS | BFM | LGBM | |
|---|---|---|---|---|
| Mean value (km) | 13.14 | 7.99/7.71 | 12.23/12.32 | 10.56/10.41 |
| Median (km) | 11.43 | 7.27/6.95 | 11.30/11.43 | 10.15/10.05 |
| 25% percentile (km) | 6.05 | 5.14/4.99 | 4.80/4.65 | 7.48/7.71 |
| 75% percentile (km) | 19.74 | 10.10/9.66 | 15.89/15.55 | 16.26/16.16 |
| MB (km) | −5.15/−5.44 | −0.83/−0.74 | −2.51/−2.65 | |
| MB [0, 5 km) | 1.44/1.41 | 0.68/0.95 | 2.71/2.77 | |
| MB [0, 3 km) | 2.05/1.99 | 1.06/1.42 | 2.39/2.65 | |
| MB [0, 1 km) | 1.96/2.28 | 1.28/1.85 | 2.74/3.74 | |
| RMSE (km) | 8.45/8.86 | 5.01/5.47 | 5.45/5.88 | |
| RMSE [0, 5 km) | 2.52/2.37 | 2.28/2.63 | 2.89/3.66 | |
| RMSE [0, 3 km) | 2.75/2.64 | 1.89/2.56 | 2.68/2.87 | |
| RMSE [0, 1 km) | 2.00/2.34 | 1.38/2.04 | 2.42/3.11 | |
| MAE (km) | 6.29/6.60 | 3.90/4.24 | 4.06/4.38 | |
| MRE (%) | 48.04/49.56 | 36.12/39.53 | 45.09/51.33 | |
| CC | 0.58/0.52 | 0.80/0.77 | 0.80/0.75 |
| Statistics | Station | RAEMS | BFM | LGBM |
|---|---|---|---|---|
| MB (km) | Chongming | −4.57/−4.91 | −1.95/−2.03 | −3.21/−2.60 |
| Xujiahui | −6.56/−6.82 | −1.28/−1.08 | −2.53/−2.60 | |
| Qingpu | −3.60/3.87 | −0.16/−0.08 | −1.98/−2.15 | |
| RMSE (km) | Chongming | 9.22/9.69 | 6.52/6.99 | 7.00/7.30 |
| Xujiahui | 10.04/10.37 | 4.32/5.69 | 6.19/6.72 | |
| Qingpu | 7.85/8.30 | 5.05/5.84 | 6.19/6.50 | |
| MAE (km) | Chongming | 6.91/7.23 | 5.73/6.10 | 6.30/6.74 |
| Xujiahui | 7.54/7.81 | 4.79/5.14 | 4.97/5.26 | |
| Qingpu | 5.60/5.93 | 4.44/4.78 | 4.48/4.72 | |
| MRE (%) | Chongming | 106.63/106.79 | 68.67/75.48 | 98.90/108.82 |
| Xujiahui | 52.85/54.04 | 44.75/47.42 | 51.64/56.39 | |
| Qingpu | 67.11/69.85 | 52.70/58.01 | 77.29/92.53 | |
| CC | Chongming | 0.54/0.48 | 0.77/0.71 | 0.69/0.59 |
| Xujiahui | 0.53/0.48 | 0.75/0.73 | 0.72/0.70 | |
| Qingpu | 0.60/0.58 | 0.75/0.74 | 0.76/0.71 |
| Station | Model | FB | PC | PO | POD | FAR | CSI | ETS |
|---|---|---|---|---|---|---|---|---|
| Chongming | RAEMS | 0.70 | 0.79 | 0.60 | 0.40 | 0.43 | 0.31 | 0.21 |
| BFM | 1.98 | 0.70 | 0.13 | 0.87 | 0.56 | 0.41 | 0.24 | |
| LGBM | 0.73 | 0.80 | 0.54 | 0.46 | 0.38 | 0.35 | 0.26 | |
| Xujiahui | RAEMS | 1.93 | 0.72 | 0.36 | 0.64 | 0.67 | 0.28 | 0.16 |
| BFM | 1.52 | 0.79 | 0.36 | 0.64 | 0.58 | 0.34 | 0.24 | |
| LGBM | 0.56 | 0.83 | 0.72 | 0.28 | 0.50 | 0.22 | 0.16 | |
| Qingpu | RAEMS | 1.03 | 0.78 | 0.38 | 0.62 | 0.40 | 0.44 | 0.29 |
| BFM | 1.52 | 0.77 | 0.16 | 0.84 | 0.44 | 0.50 | 0.33 | |
| LGBM | 0.59 | 0.79 | 0.58 | 0.42 | 0.28 | 0.36 | 0.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Z.; Qu, Y.; Wang, Y.; Ma, J.; Cao, Y. Application of Machine-Learning-Based Fusion Model in Visibility Forecast: A Case Study of Shanghai, China. Remote Sens. 2021, 13, 2096. https://doi.org/10.3390/rs13112096
Yu Z, Qu Y, Wang Y, Ma J, Cao Y. Application of Machine-Learning-Based Fusion Model in Visibility Forecast: A Case Study of Shanghai, China. Remote Sensing. 2021; 13(11):2096. https://doi.org/10.3390/rs13112096
Chicago/Turabian StyleYu, Zhongqi, Yuanhao Qu, Yunxin Wang, Jinghui Ma, and Yu Cao. 2021. "Application of Machine-Learning-Based Fusion Model in Visibility Forecast: A Case Study of Shanghai, China" Remote Sensing 13, no. 11: 2096. https://doi.org/10.3390/rs13112096
APA StyleYu, Z., Qu, Y., Wang, Y., Ma, J., & Cao, Y. (2021). Application of Machine-Learning-Based Fusion Model in Visibility Forecast: A Case Study of Shanghai, China. Remote Sensing, 13(11), 2096. https://doi.org/10.3390/rs13112096