1. Introduction
Natural hazards such as floods, landslides, and typhoons pose severe threats to people’s lives and property. Among them, floods are the most frequent, widespread, and deadly natural disasters. They affect more people globally each year than any other disaster [
1,
2,
3]. Floods not only cause injuries, deaths, losses of livelihoods, infrastructure damage, and asset losses, but they can also have direct or indirect effects on health [
4]. In the past decade, there have been 2850 disasters that triggered natural hazards globally, of which 1298 were floods, accounting for approximately
[
1]. In 2019, there were 127 floods worldwide, affecting 69 countries, causing 1586 deaths and more than 10 million displacements [
2]. In the future, floods may become a frequent disaster that poses a huge threat to human society due to sea-level rise, climate change, and urbanization [
5,
6].
The effective way to reduce flood losses is to enhance our ability of flood risk mitigation and response. In recent years, timely and accurate flood detection products derived from satellite remote sensing imagery are becoming effective methods of responding flood disaster, and city and infrastructure planners, risk managers, disaster emergency response agency, and property insurance company are benefiting from it in worldwide [
7,
8,
9,
10,
11], while identifying permanent water and temporary water in flood disasters efficiently is a remaining challenge.
In recent years, researchers have done a lot of work in flood detection based on satellite remote sensing images. The most commonly used method to distinguish between water and non-water areas is a threshold split-based method [
12,
13,
14,
15]. However, the optimal threshold is affected by the geographical area, time, and atmospheric conditions of image collection. Therefore, the generalization ability of the above methods is greatly limited. In recent years, the European Space Agency (ESA) developed a series of Sentinel missions to provide free available datasets including Synthetic Aperture Radar (SAR) data from Sentinel-1 sensor and optical data from Sentinel-2 sensor, taking into account the respective advantages of optical imagery and SAR imagery in flood information extraction [
5,
14,
16,
17,
18], and the investigation of combining SAR images with optical images for more accurate flood mapping is of great interest for researchers [
16,
19,
20,
21,
22]. Although the data fusion method improves the accuracy of flood extraction, it is still very challenging to distinguish permanent water from temporary water problems in flood disasters. The identification of temporary waters in flood disasters and permanent waters mainly rely on multi-temporal change detection methods [
23,
24,
25,
26,
27,
28]. This type of approach requires at least one pair of multi-temporal remote sensing scenes which were acquired before and after a flood event. Although the method based on multi-temporal change detection can better detect the temporary water in flood disaster events, the multi-temporal method was greatly limited due to the mandatory demand for satellite imagery before disasters.
Deep learning methods represented by convolutional neural networks have been proven to be effective in the field of flood damage assessment, and related research has grown rapidly since 2017 [
29]. However, most algorithms are focusing on affected buildings in flood events [
22,
30], with very few examples of flood water detection. The latest research focuses on the application of deep learning algorithms for enhancing flood water detection [
31,
32]. Early research focused on the extraction of surface water [
33,
34,
35]. Furkan et al. proposed a deep-learning-based approach for surface water mapping from Landsat imagery. The results demonstrated that the deep learning method outperform the traditional threshold and Multi-Layer Perceptron model. Considering the difference in the characteristics of surface water and floods in satellite imagery, which will increase the difficulty of flood extraction. Maryam et al. developed a semantic segmentation method for extracting the flood boundary from UAV imagery. The semantic segmentation-based flood extraction method was further applied to identify the flood inundation caused by mounting destruction [
36]. Experimental results validate the efficiency and effectiveness of the proposed method. Muñoz et al. [
37] combined the multispectral Landsat imagery and dual-polarized synthetic aperture radar imagery to evaluate the performance of integrating convolutional neural network and data fusion framework for generating compound flood mapping. The usefulness of this method was verified by comparing with other methods. These studies show that deep learning algorithms play an important role in enhancing flood classification. However, research in this field is still in its infancy, due to the lack of high-quality large-scale flood annotation satellite datasets.
Recent development in earth observation has contributed a series of open-sourced large scale disaster related satellite imagery datasets, which has greatly spurred the advance of leveraging deep learning algorithm for disaster mapping from satellite imagery. For building damage classification, the xBD dataset has provided large scale satellite imagery data that collected from the multi-type disasters with four category damage level labels to worldwide researchers, and the research spawned by this public data has also verified the great potential of deep learning in building damage recognition [
38,
39]. For flooded building damage assessment in Hurricane disaster events, FloodNet provides a high-resolution UAV image dataset and has done the same task [
40]. The recent release of the large-scale open-source Sen1Floods11 dataset [
5] is boosting the research of utilizing deep learning algorithms for water type detection in flood disasters [
41]. For water type detection in flood disaster events, Sen1Flood should take on a similar role. Unfortunately, so far, only one preliminary work has been conducted.
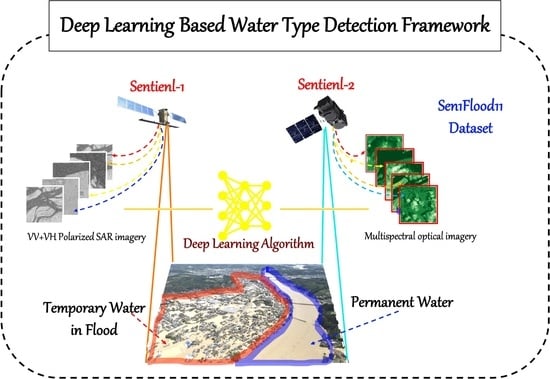
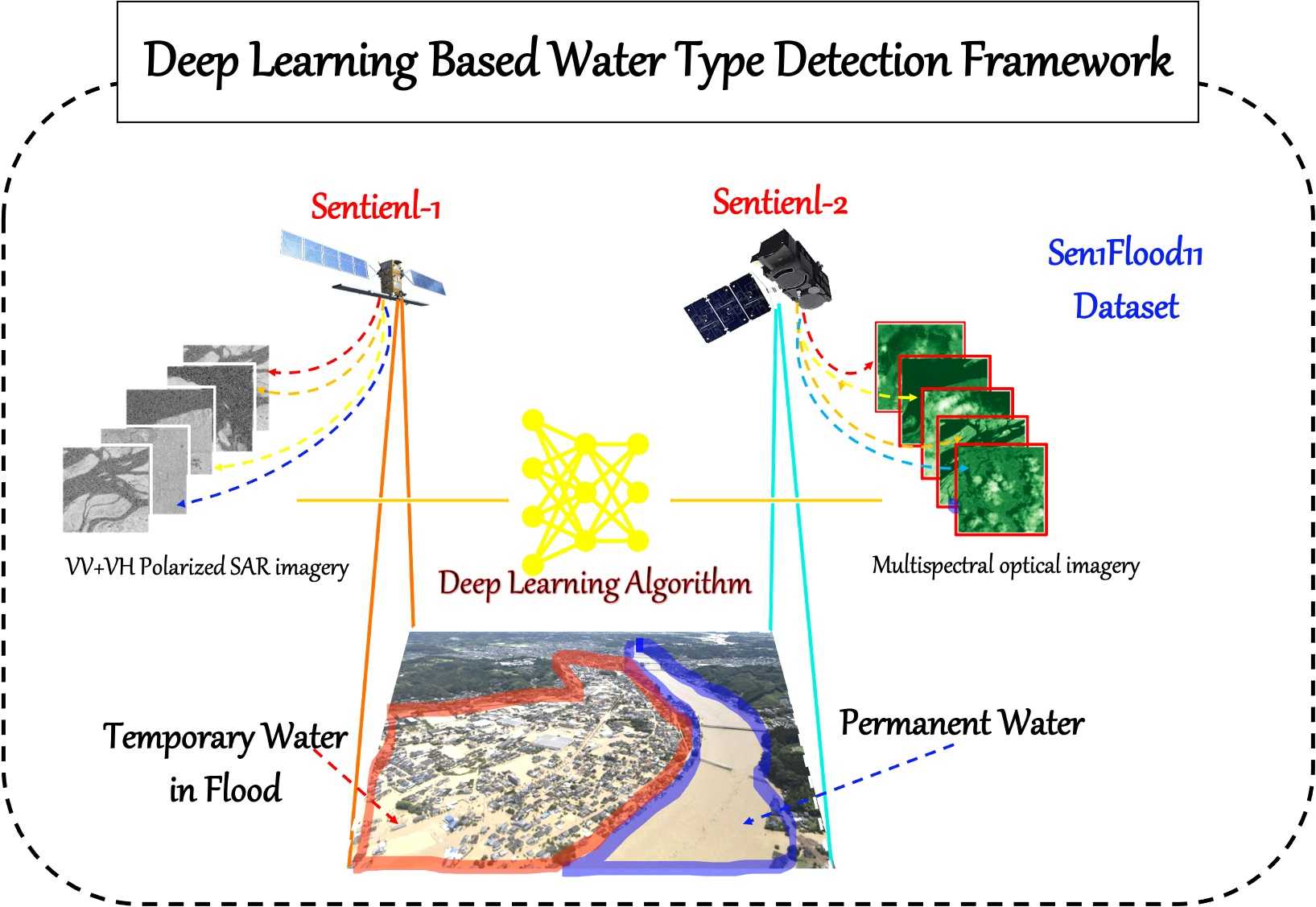
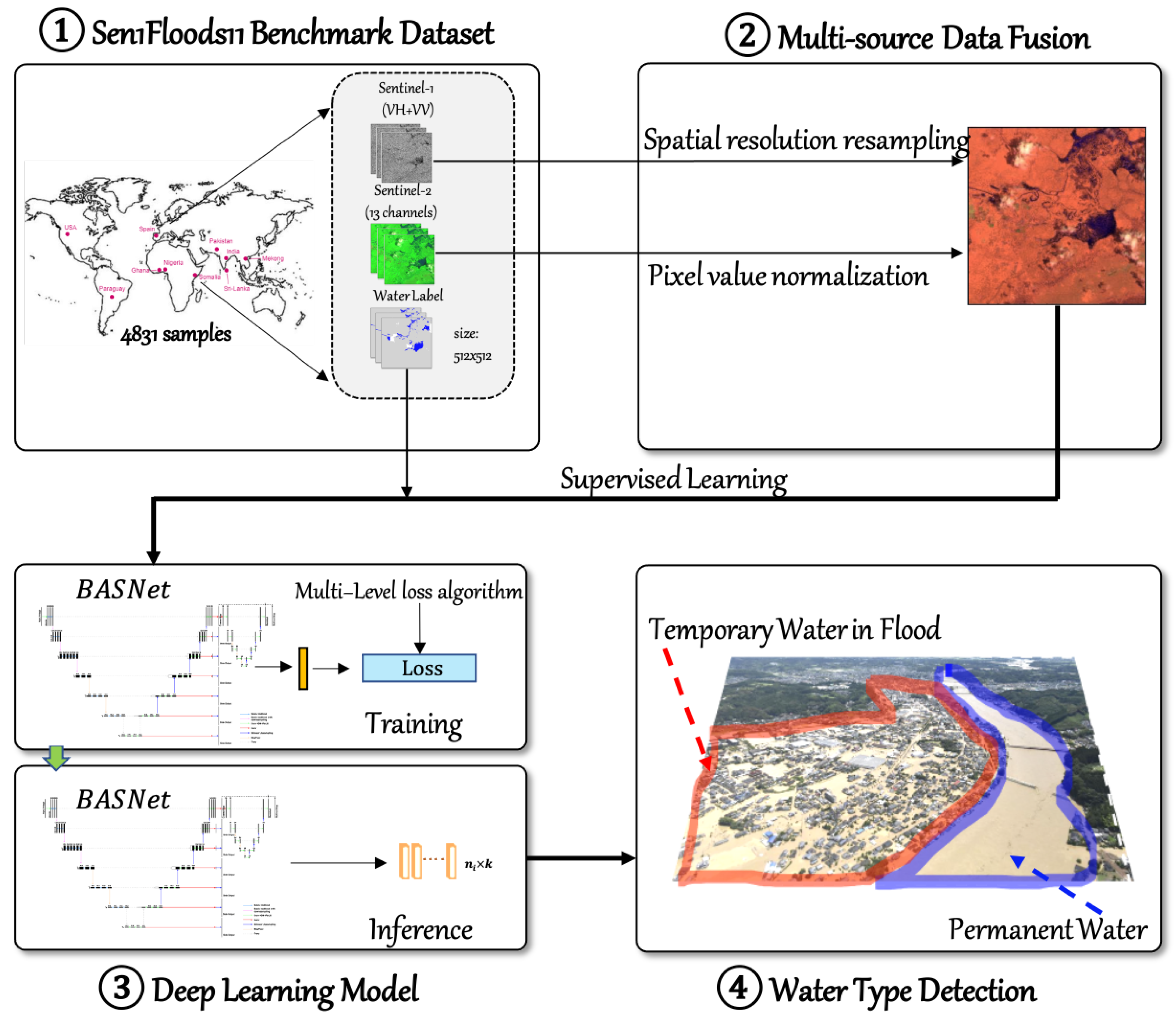
With the purpose of developing an efficient benchmark algorithm for distinguishing between permanent water and temporary water in flood disasters based on the Sen1Flood dataset to boost the research in this area, the contributions and originality of this research are as follows.
Effectiveness: To the best of our knowledge, in terms of the sen1flood11 dataset, the accuracy of our proposed algorithm is the highest so far.
Convenience: All of the sentinel-1 and sentinel-2 imagery utilized in the model come from post-flood imagery, and this greatly reduces the reliance on satellite imagery data before the flood.
Refinement: We introduced salient object detection algorithm to modify the convolutional neural network classifier, in addition, the multi-scale loss algorithm and data augmentation were adopted to improve the accuracy of the model.
Robustness: the robustness of our proposed algorithm was verified in a new Bolivia flood dataset.
2. Sen1Floods11 Dataset
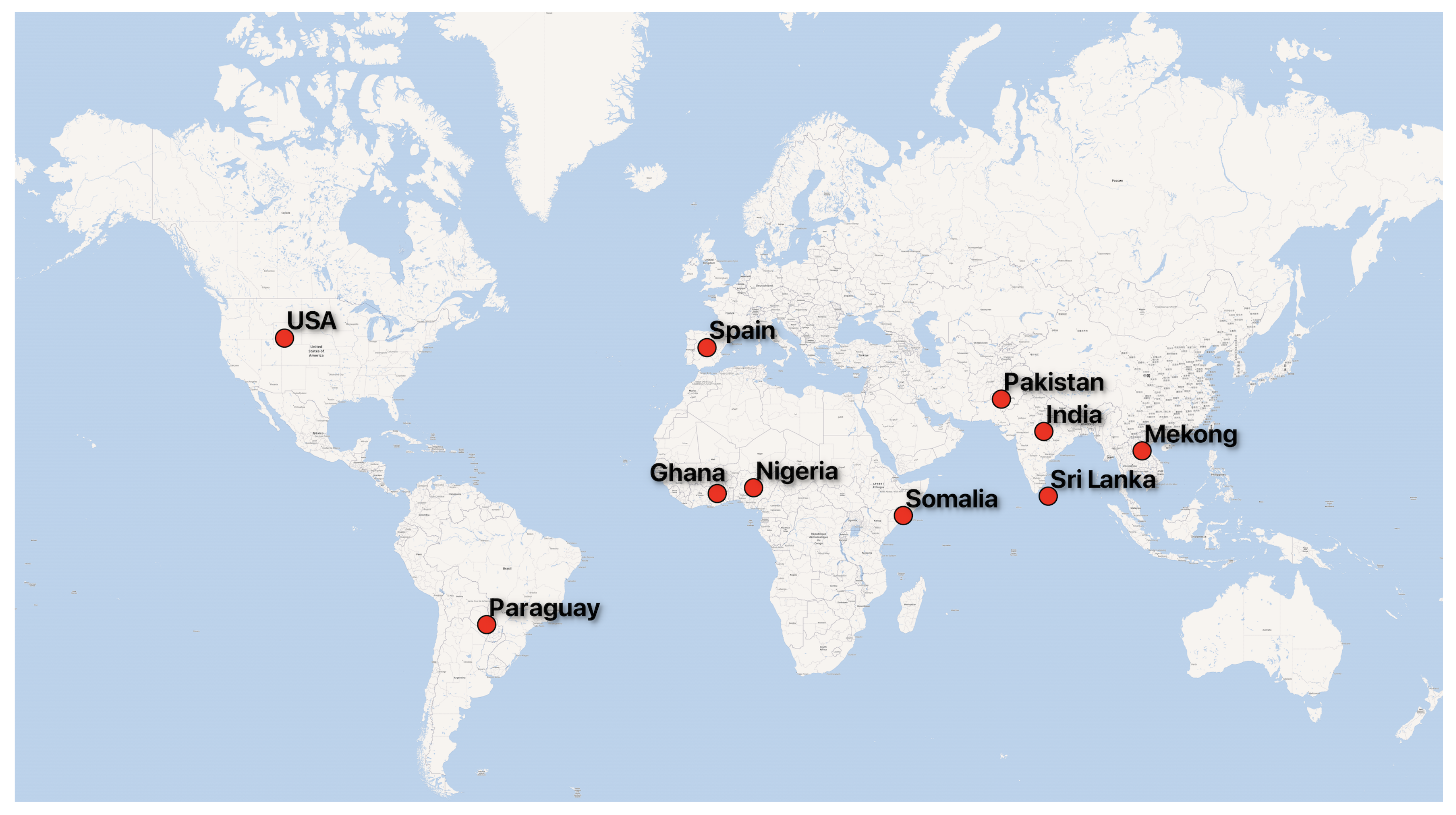
We utilize the Flood Event Data in the Sen1Floods11 dataset [
5] to train, validate, and test deep learning flood algorithms. This dataset provides raw Sentinel-1 SAR images (IW mode, GRD product), Sentinel-2 MSI Level-1C images, classified permanent water, and flood water. There are 4831 non-overlapping 512 × 512 tiles from 11 flood events. This dataset helps map flood at the global scale, covering 120,406 square kilometers, spanning 14 biomes, 357 ecological regions, and six continents. Locations for flood events are shown in
Figure 1.
For each selected flood event, the time interval between the acquisition of Sentinel-1 imagery and Sentinel-2 imagery shall not exceed two days. The Sentinel-1 imagery contains two bands, VV and VH, which are backscatter values; the Sentinel-2 imagery includes 13 bands, and all bands are TOA reflectance values. The imagery is projected to the WGS-84 coordinate system.The ground resolution of the imagery is different on different bands. In order to fuse images, the ground resolution is sampled to 10 m on all bands. Each band is visualized in
Figure 2.
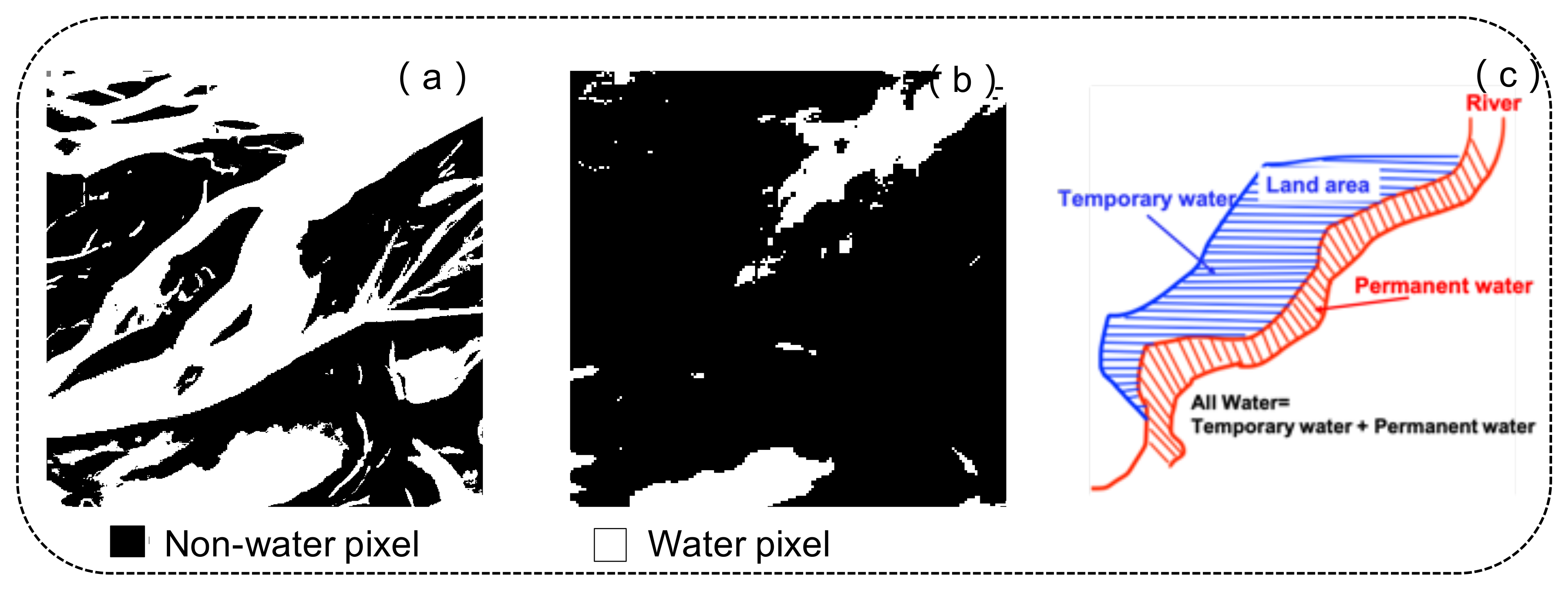
Due to the high cost of hand labels, 4370 tiles are not hand-labeled and exported with annotations automatically generated by the Sentinel-1 and Sentinel-2 flood classification algorithms, which can serve as weakly supervised training data. The remaining 446 tiles are manually annotated by trained remote sensing analysts for high-quality model training, validation and testing. The weakly supervised data contain two types of surface water labels. One is produced by the histogram thresholding method based on the Sentinel-1 image; the other is generated by the Normalized Difference Vegetation Index (NDVI), MNDWI and thresholding method based on the Sentinel-2 image. All cloud and cloud shadow pixels were masked and excluded from training and accuracy assessments. Hand labels include all water labels and permanent water labels. For all water labels, analysts exploited Google Earth Engine to correct the automated labels using Sentinel-1 VH band, two false color composites from Sentinel-2 and the reference water classification from Sentinel-2 by removing uncertain areas and adding to the water classification. For the permanent water label, with the help of the JRC (European Commission Joint Research Center) surface water data set, Bonafilia et al. [
5] labeled the pixels that were detected as water at both the beginning (1984) and end (2018) of the dataset as permanent water pixels. The pixels never observed as water during this period are treated as non-water pixels. The remaining pixels are masked. Examples of water label are visualized in
Figure 3.
Like most existing studies [
42], the Sen1Floods11 dataset shows the highly imbalanced distribution between flooded and unflooded area. As shown in
Table 1, for all water, water pixels account for only
, and non-water pixels account for
, which is about eight times the number of surface water pixels. The percentages of water pixels and non-water pixels in permanent waters are
and
, respectively, and the number of non-water pixels is about 32 times that of non-water pixels.
The dataset is split into three parts: training set, validation set, and test set. All 4370 images automatically labeled are used as the weakly supervised training set. The hand-labeled data are first randomly split into training, validation, and testing data in the proportion 6:2:2. In order to test the model’s ability to predict unknown flood events, all hand-labeled data related to the Bolivia flood event is held out for a distinct test set. Rest hand-labeled data in training, validation, and testing sets are composed of final training, validation, and testing set, respectively. Correspondingly, all data from Bolivia in the weakly-supervised training set are also excluded and do not participate in model training. The overall composition of the dataset is shown in
Table 2.
5. Discussion
Data augmentation can improve the generalization ability of the model, especially when there is only a little training data. Since the Bolivia test set consists of completely unknown flood event images, the gains indicate that the model’s generalization ability has been improved. Focal loss [
49] is designed to deal with the extreme imbalance between water/non-water, difficult/easy pixels during training. The ablation experimental results show the effectiveness of focal loss in dealing with a sample imbalance problem. Optical imagery contains information on the ground surface’s multispectral reflectivity, which is widely used in water indices and thresholding methods. Image fusion aims to use optical image data to assist SAR image prediction. Our experimental results demonstrate that optical imagery can provide useful supplementary information on water segmentation.
However, all water and temporary water have poor mIoU scores. There are two reasons to explain this phenomenon. One reason is the training process, as the image of all water and temporary water data have more water pixels and fewer non-water pixels. The difference in the sample size leads to differences in the learning effect. From OMISSION and COMMISSION, we can see that the all water and temporary water tasks perform better than permanent water on water pixels, and perform worse on non-water pixels. On the whole, non-water pixels dominate our data. The poorer prediction of non-water pixels leads to worse overall results. The other reason is the difference in image characteristics, and the images in all water and temporary water data contain more small tributaries and scattered areas from newly flooded areas. These areas are usually more challenging to identify.
With the help of hybrid loss, our model pays more attention to boundary pixels and increasing the confidence of the prediction. As a result, our method can not only produce richer details and sharper boundaries but also distinguish water and non-water pixels with a larger probability gap. The excellent feature extraction ability of deep learning model enables our model to deal with some challenging scenes.
6. Conclusions
In this paper, we developed an efficient model for detecting permanent water and temporary water in flood disasters by fusing Sentinel-1 and Sentinel-2 Imagery using a deep learning algorithm with the help of benchmark Sen1Floods11 datasets. The BASNet network adopted in this can capture both large-scale and detailed structural features. By combining with focal loss, our model achieved state-of-the-art accuracy for hard boundary pixels’ identification. The model’s performance was further improved by fusing the multi-source information, and the ablation study verified the effectiveness of each improvement measures. The comparison experiment results demonstrated that the implemented method could detect permanent water and temporary water flood more accurately than other methods. The proposed model performed well on the unknown Bolivia test set, which verifies its robustness. Due to the network architecture’s modularity, it can be easily adapted to data from other sensors. Finally, the method does not require prior knowledge, additional data pre-processing, and multi-temporal data, which significantly reduces the method’s complexity and increases the degree of automation.
Ongoing and future works focus on training water segmentation models on high spatial resolution remote sensing imagery. High spatial resolution remote sensing imagery has more complex background information, objects with larger-scale variation, and more unbalanced pixel classes [
58]. More sophisticated modules are required to extract and fuse richer image information. In addition, the existing pre-trained neural networks are all based on RGB images, and, directly applied to remote sensing images, may reduce the efficiency of transfer learning due to differences in the data distribution. McKay et al. [
61] dealt with this problem by discarding deep feature layers. Qin et al. [
60] designed a network that allows for training from scratch, but this lighter network may degrade the performance. Although we dramatically improved the results of flood mapping, there is still much work to do.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}