
Assessment of Ensemble Learning to Predict Wheat Grain Yield Based on UAV-Multispectral Reflectance

 ,
,  ,
, 
Abstract
:1. Introduction
2. Materials and Methods
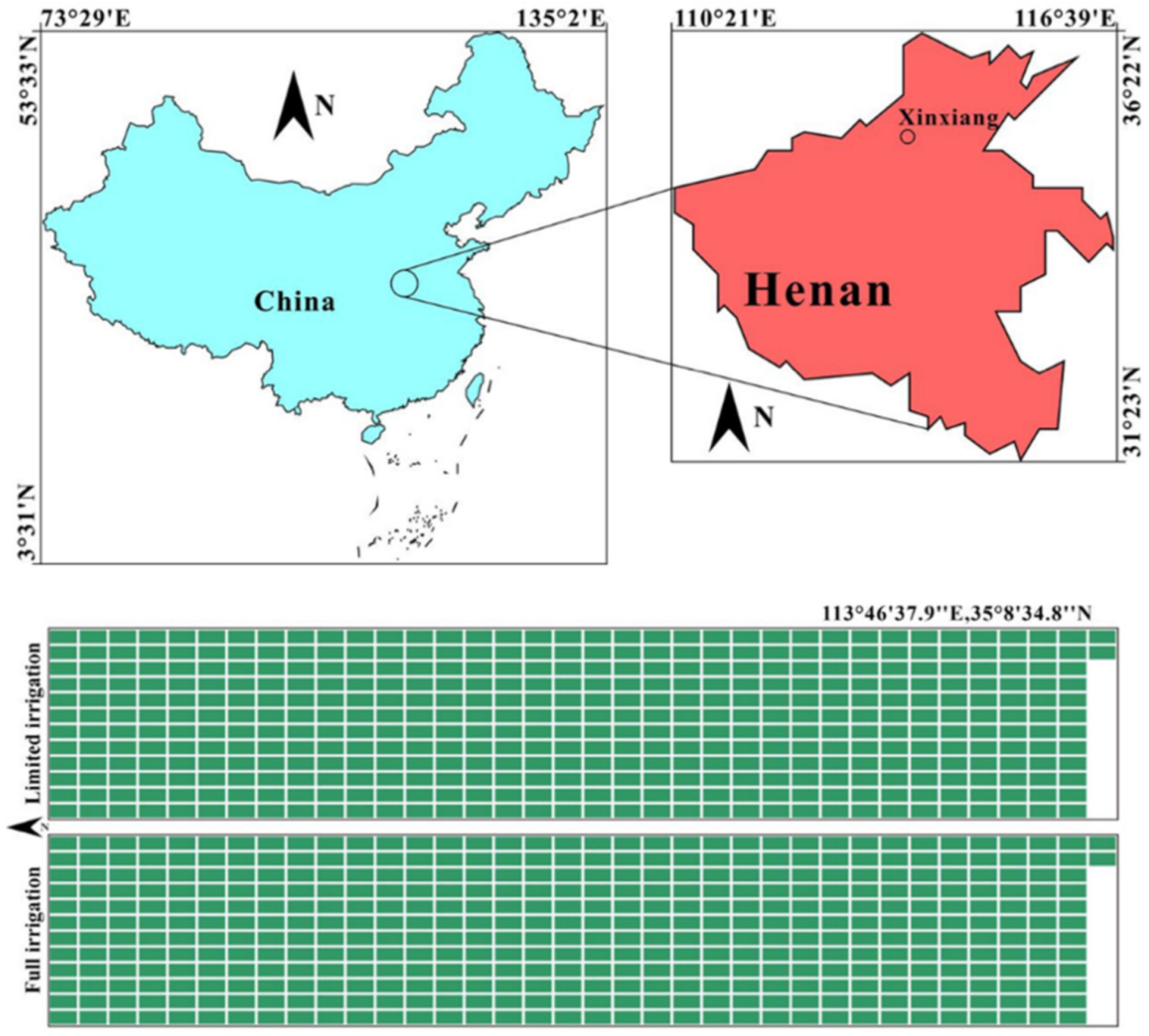
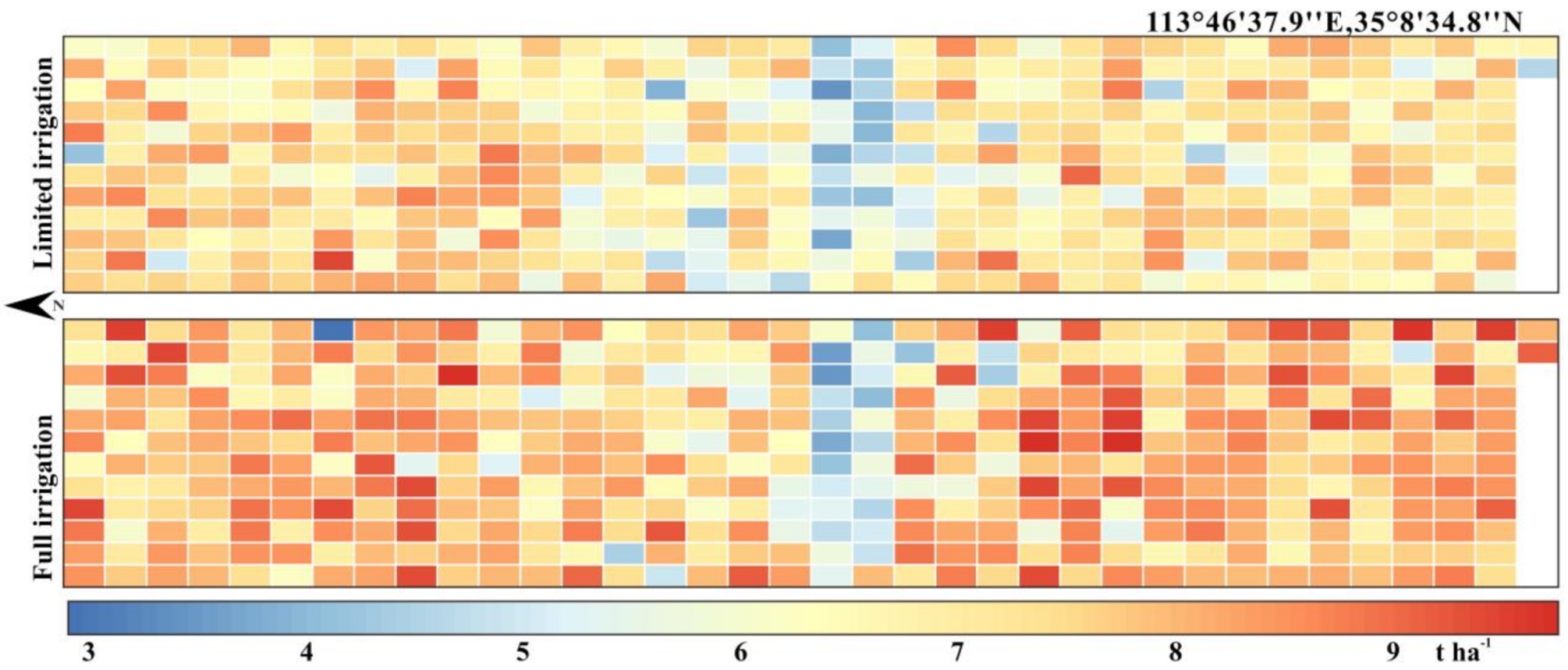
2.1. Plant Materials and Field Trials
2.2. UAV Platform and Flight Mission
2.3. Vegetation Indices and Ground Data
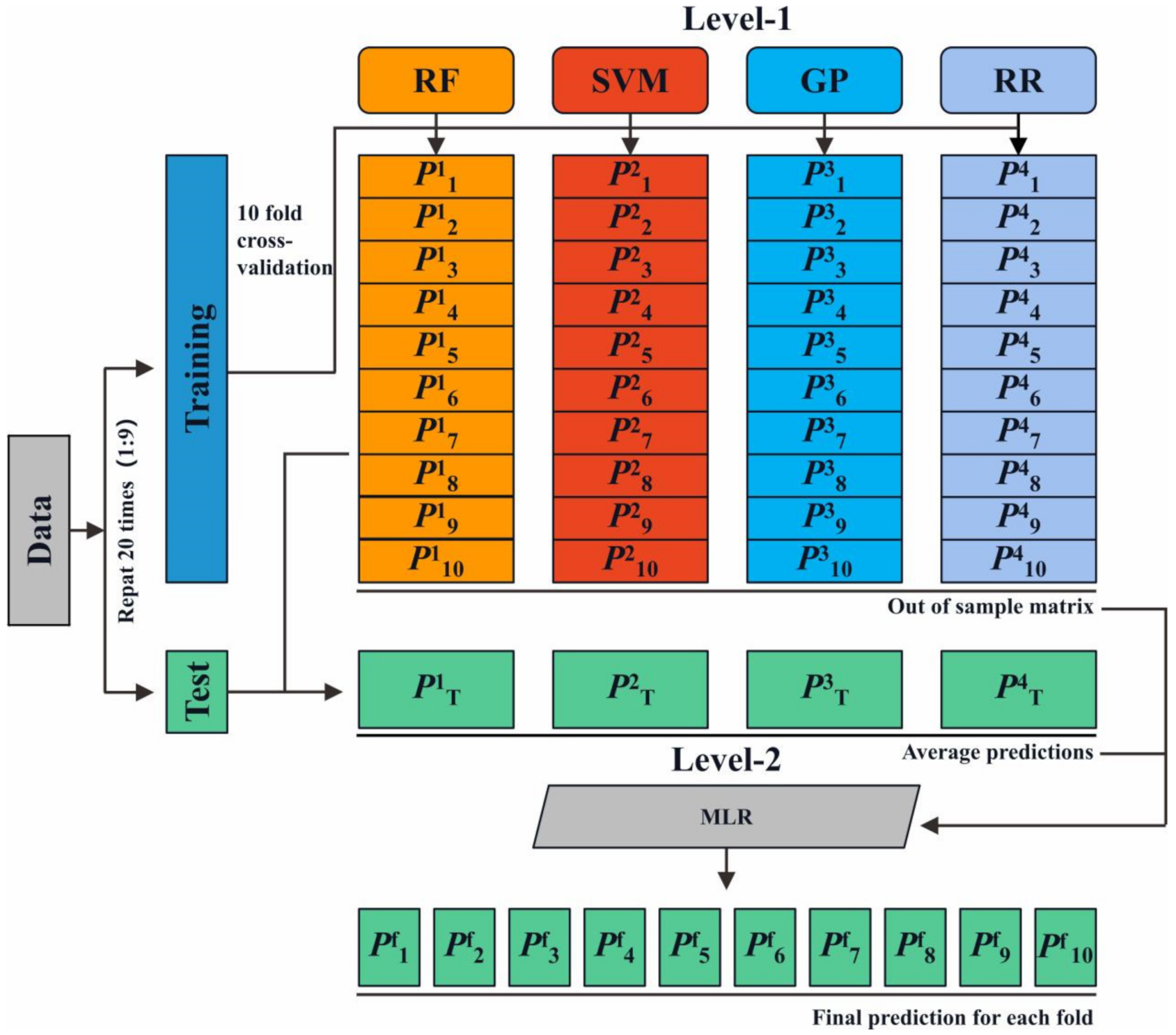
2.4. Stacking Regression Models for Ensemble Learning
2.4.1. Random Forest
2.4.2. Support Vector Machine
2.4.3. Gaussian Process
2.4.4. Ridge Regression
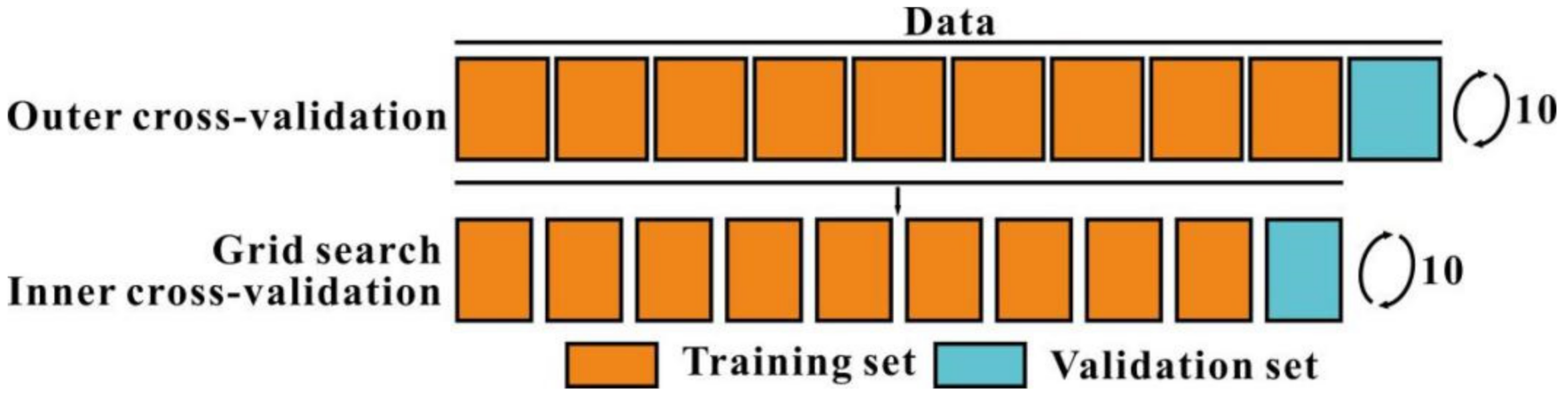
2.4.5. Cross-Validation and Hyperparameter Tune
2.5. Model Performance Evaluation
2.6. Statistical Analysis
3. Results
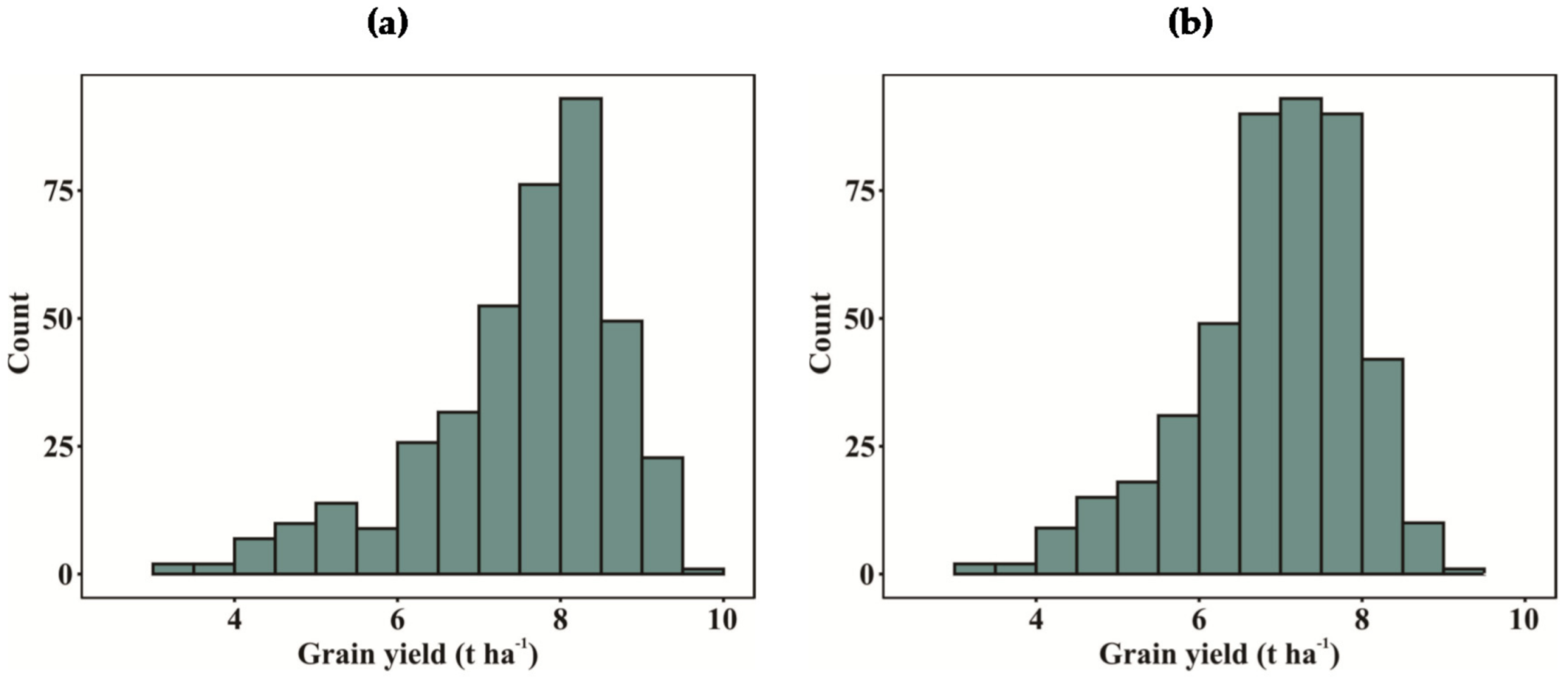
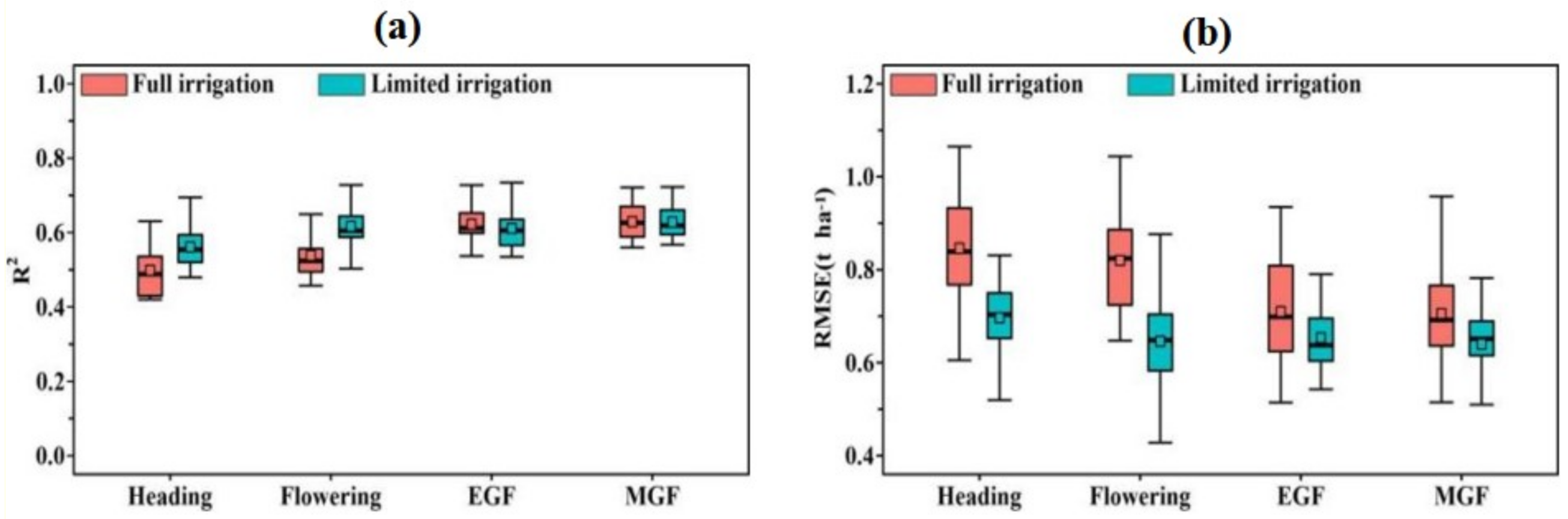
3.1. Phenotypic Analysis
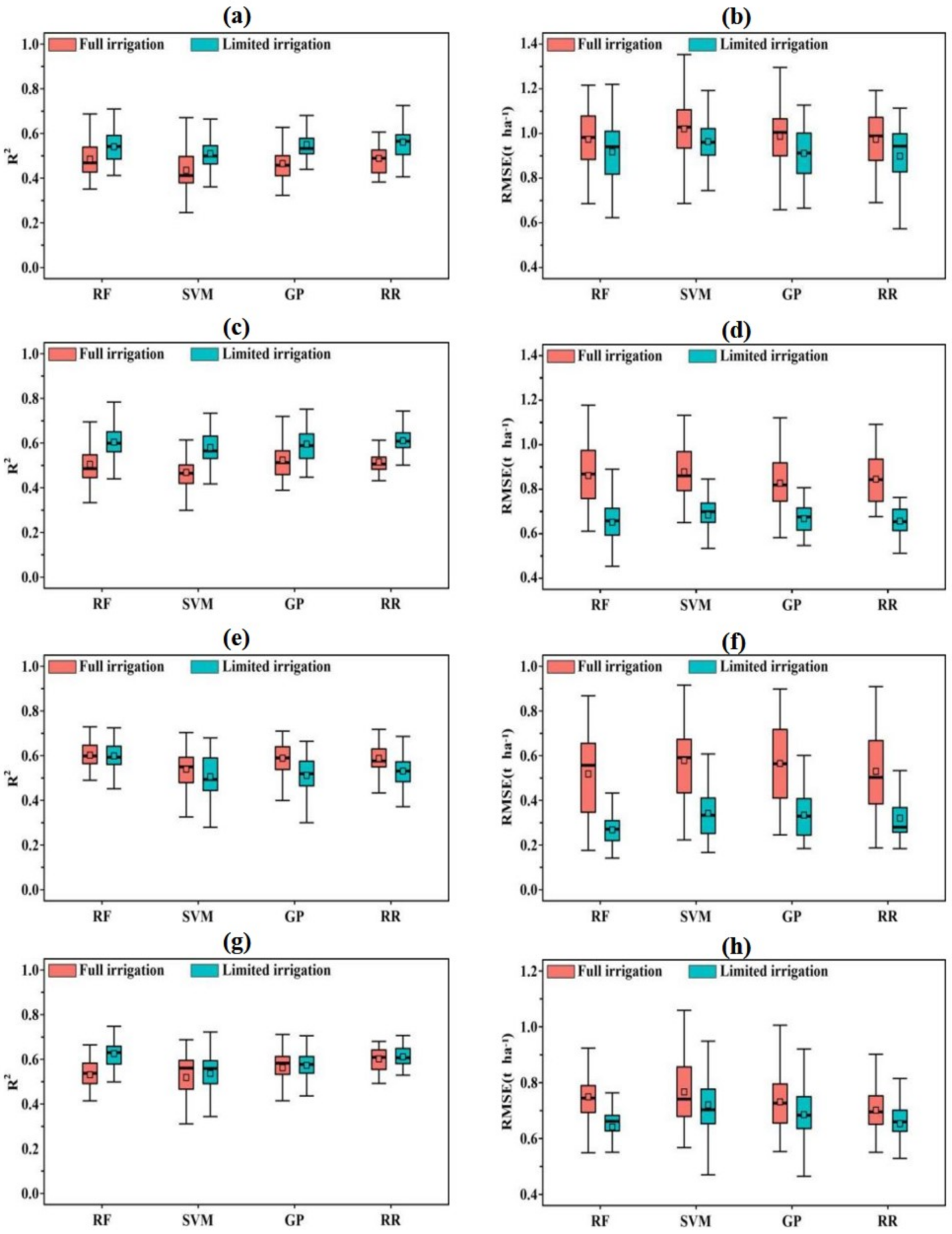
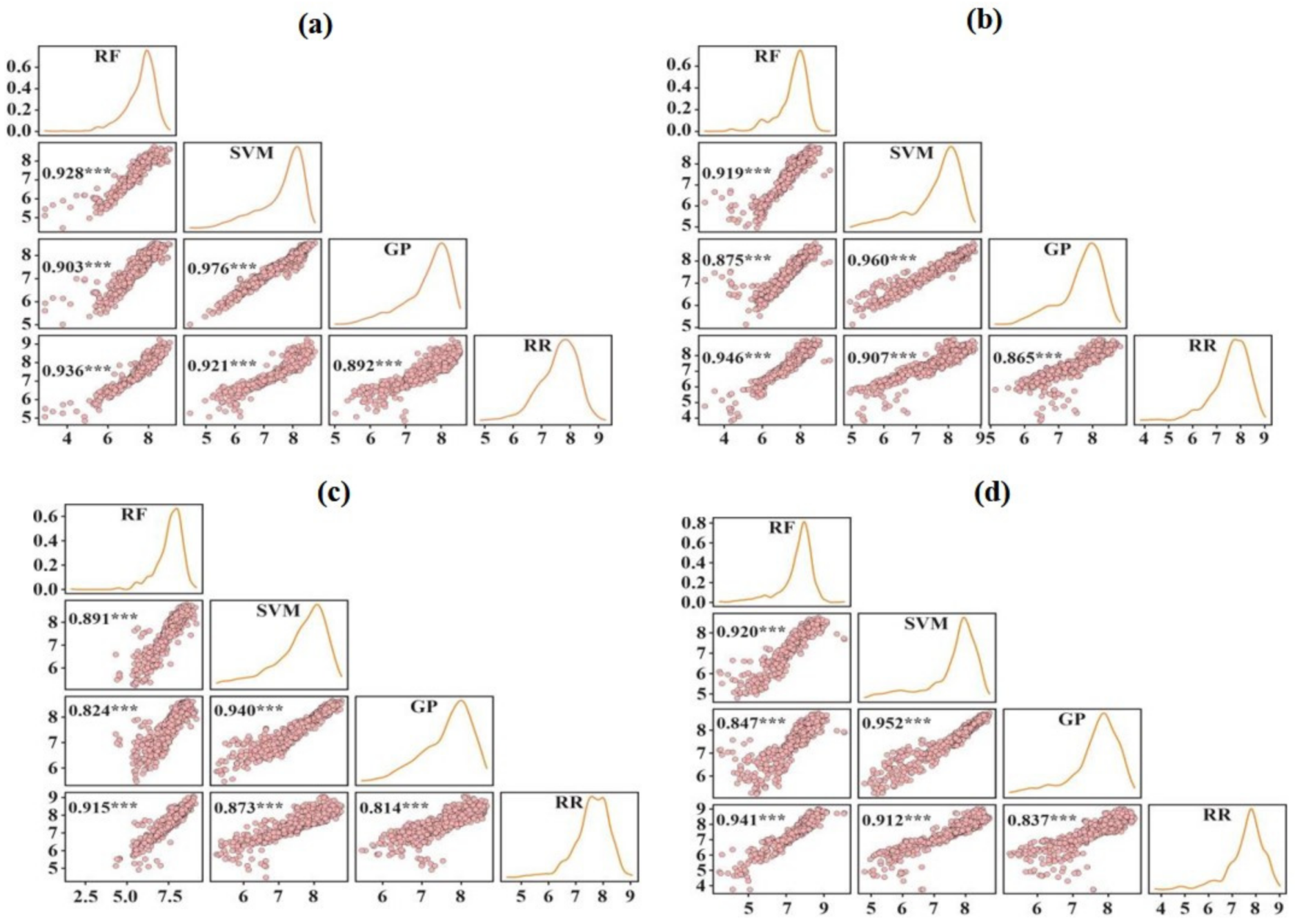
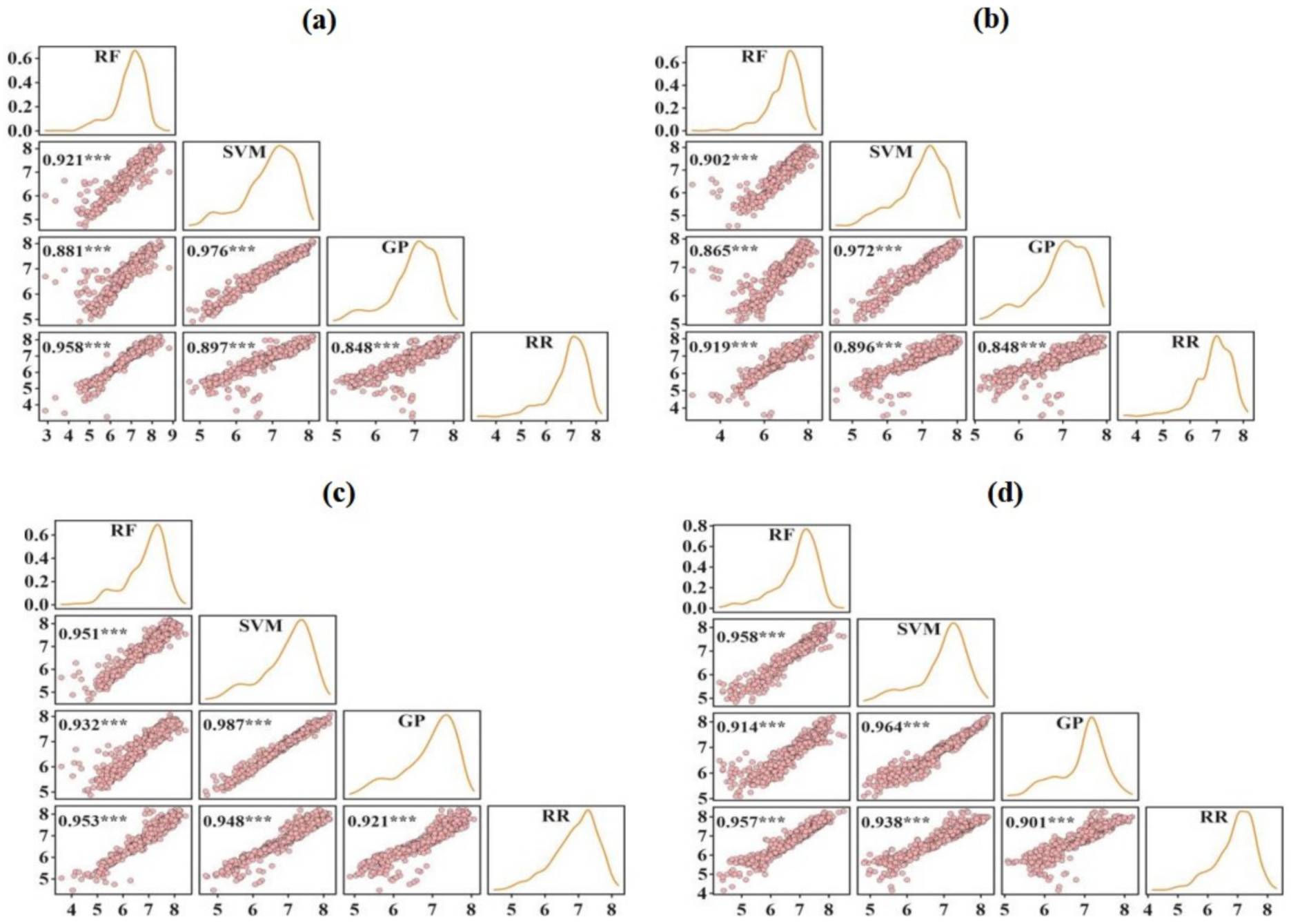
3.2. Performance Base Learners for Grain Yield Prediction
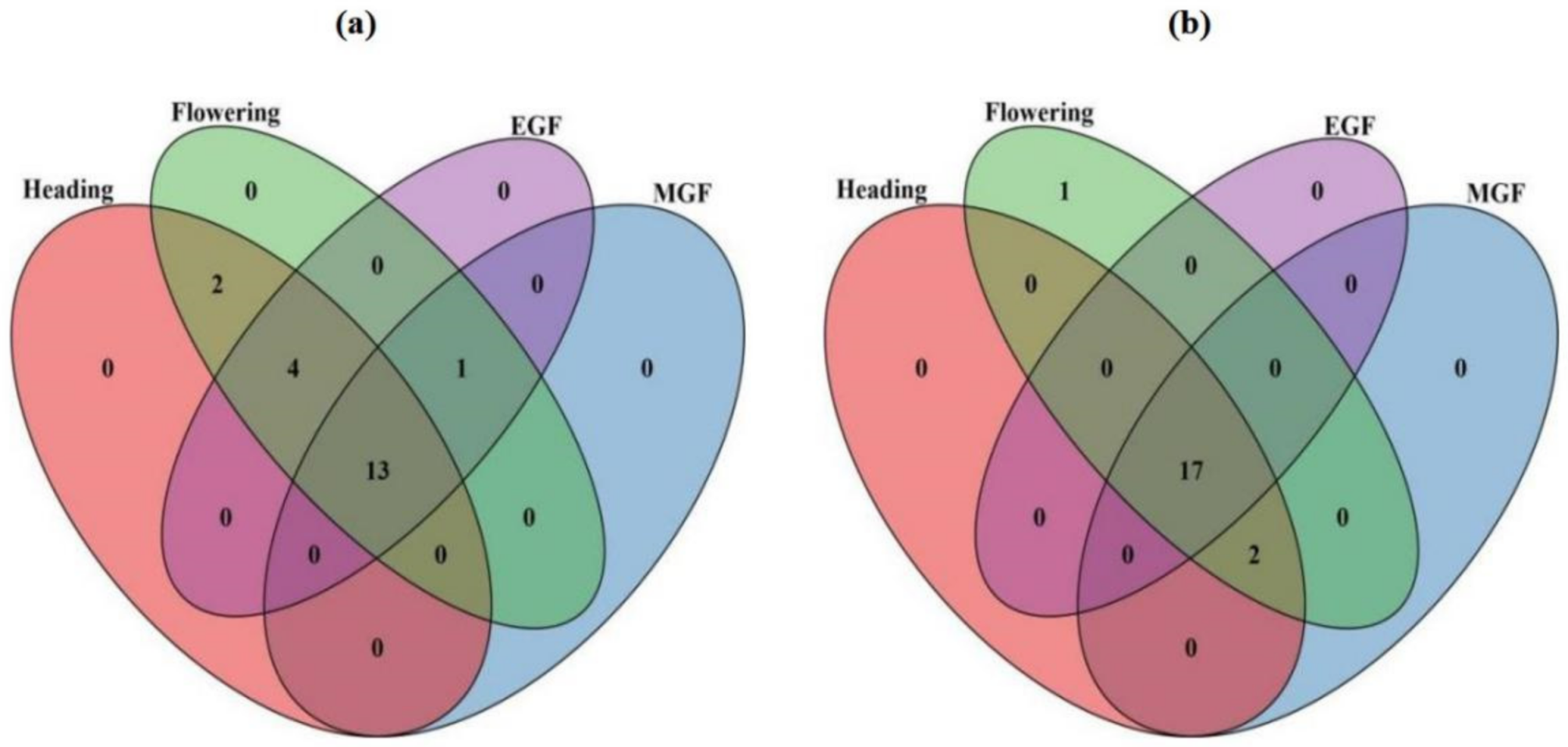
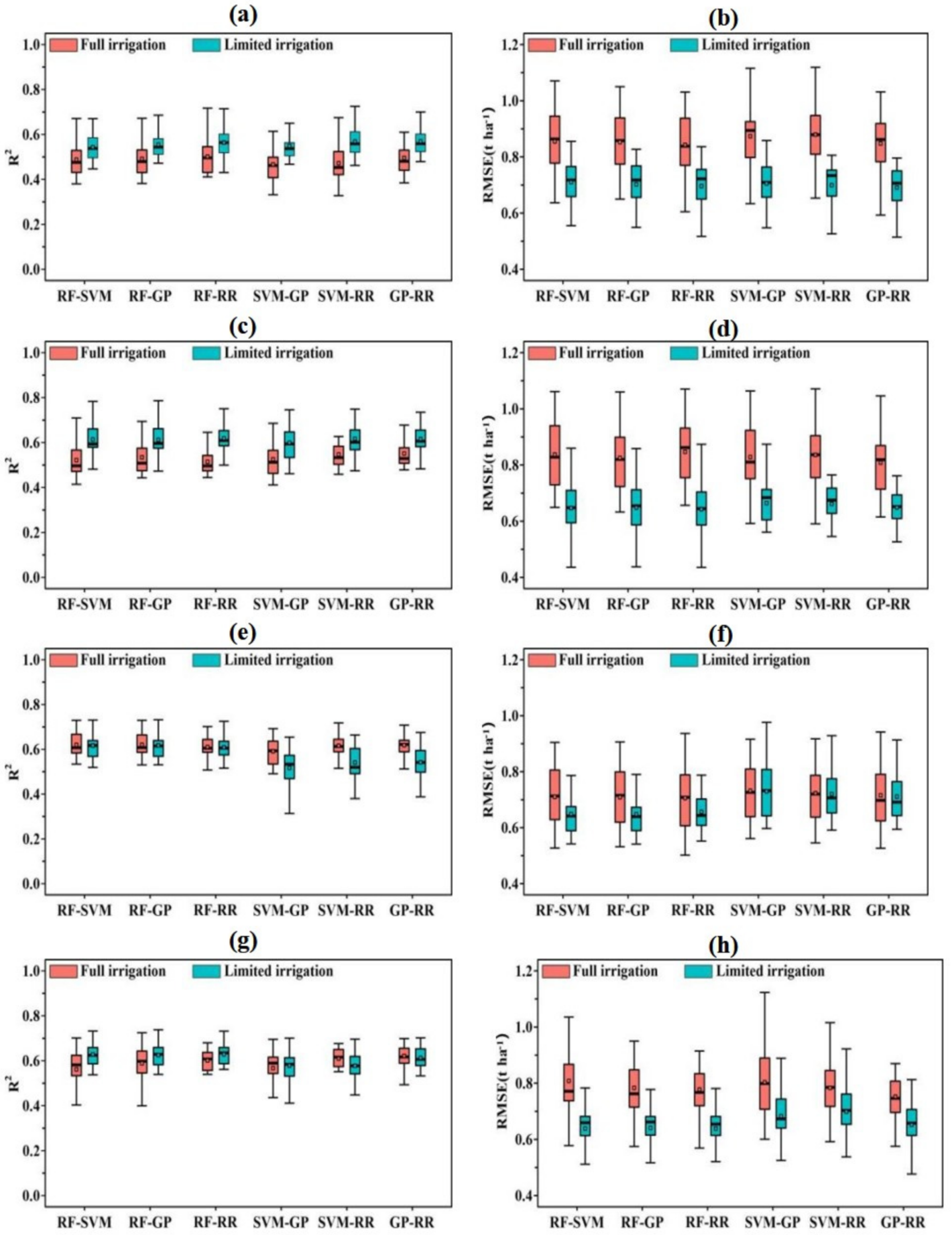
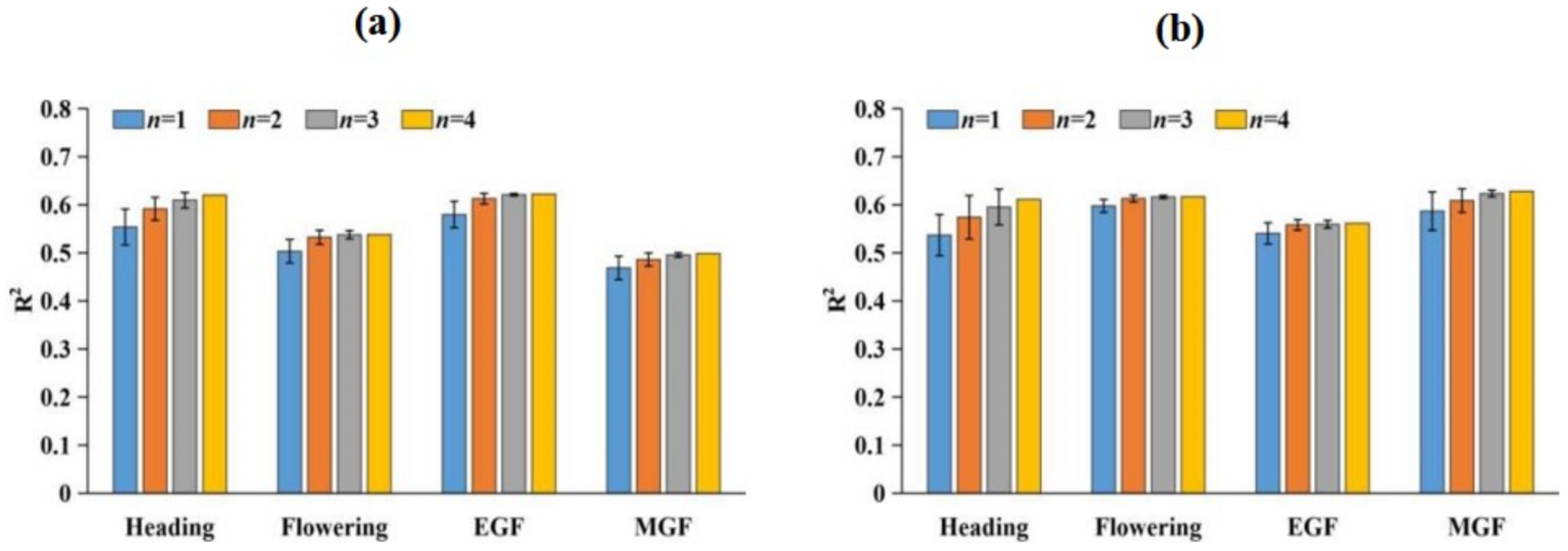
3.3. Ensemble Approach for Grain Yield Prediction
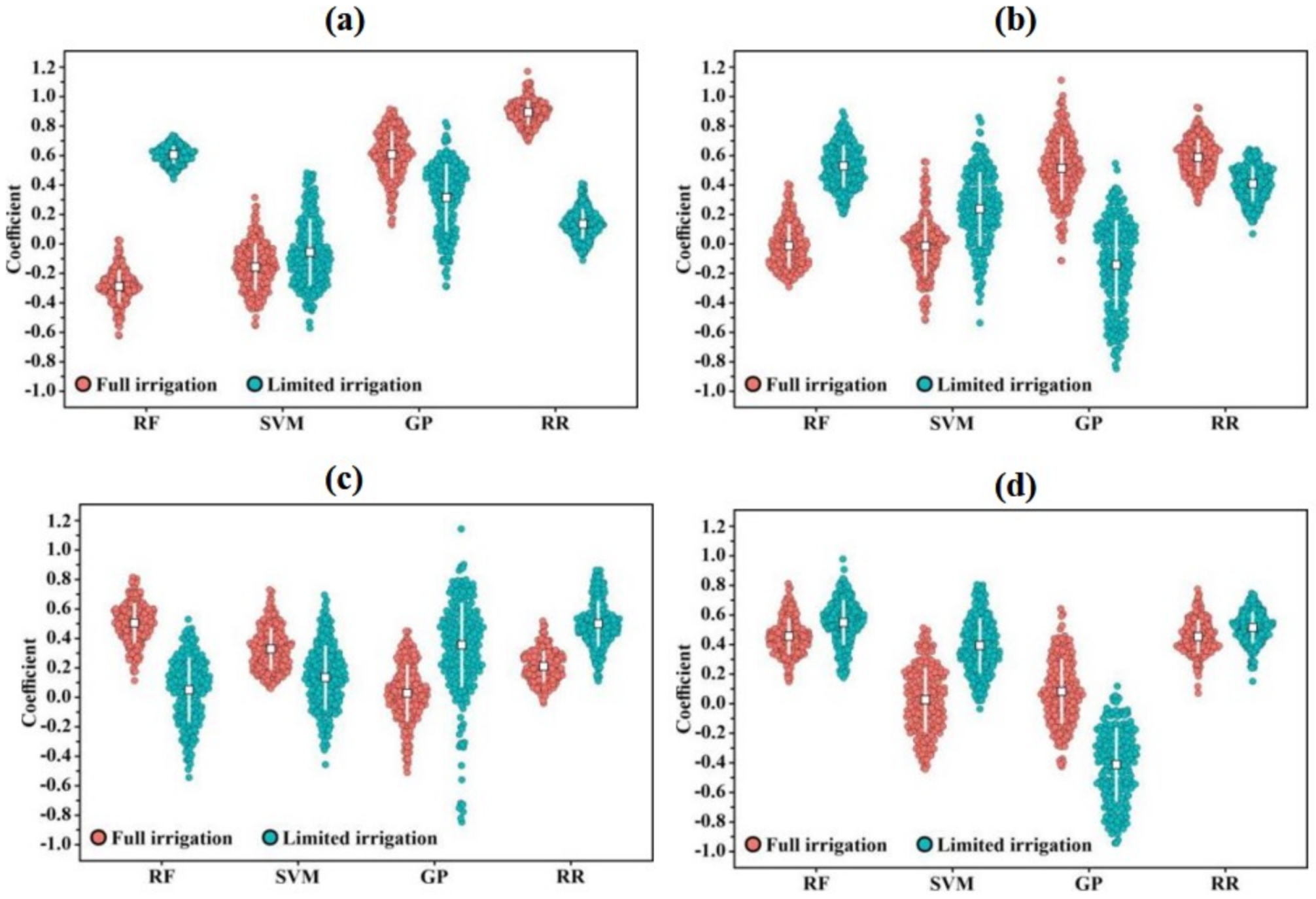
3.4. Regression Coefficient Results for a Secondary Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Treatment | Mean (t ha−1) | CV (%) | F-Value | H2 | ||
|---|---|---|---|---|---|---|
| Genotype (G) | Treatment (T) | G × T | ||||
| Full Irrigation | 7.59 | 15.7 | 10.401 *** | 264.432 *** | 0.98 | 0.85 |
| Limited Irrigation | 6.92 | 14.6 | 0.89 | |||
| Vegetation Index | Genotype (G) | Treatment (T) | G × T | H2 | |
|---|---|---|---|---|---|
| F-Value | F-Value | F-Value | Full Irrigation | Limited Irrigation | |
| NDVI | 4.854 *** | 743.179 *** | 1.263 * | 0.51 | 0.78 |
| SAVI | 4.855 *** | 743.178 *** | 1.262 * | 0.51 | 0.78 |
| OSAVI | 4.856 *** | 743.226 *** | 1.262 * | 0.51 | 0.78 |
| NRI | 4.599 *** | 1284.147 *** | 1.344 * | 0.52 | 0.80 |
| GNDVI | 5.998 *** | 235.842 *** | 1.104 | 0.70 | 0.74 |
| SIPI | 3.439 *** | 564.833 *** | 1.222 * | 0.50 | 0.62 |
| PSRI | 1.148 | 0.771 | 1.156 | 0.14 | 0.13 |
| CRI | 7.058 *** | 7.053 ** | 0.968 | 0.78 | 0.72 |
| EVI | 7.777 *** | 480.102 *** | 1.482 ** | 0.82 | 0.71 |
| MSR | 3.952 *** | 710.450 *** | 1.022 | 0.47 | 0.75 |
| NLI | 4.184 *** | 1446.413 *** | 1.261 * | 0.44 | 0.74 |
| RDVI | 4.298 *** | 325.237 *** | 0.988 | 0.56 | 0.73 |
| TVI | 4.890 *** | 741.107 *** | 1.278 * | 0.51 | 0.78 |
| MTVI2 | 8.176 *** | 1005.586 *** | 1.436 ** | 0.81 | 0.76 |
| NDRE | 17.346 *** | 139.202 *** | 1.166 | 0.88 | 0.90 |
| DVIREG | 7.126 *** | 1302.732 *** | 0.928 | 0.65 | 0.82 |
| OSAVIREG | 17.346 *** | 139.204 *** | 1.166 | 0.88 | 0.90 |
| RDVIREG | 9.764 *** | 1103.257 *** | 1.349 * | 0.73 | 0.87 |
| MSRREG | 17.958 *** | 138.719 *** | 1.177 | 0.88 | 0.91 |
| MTCI | 17.304 *** | 184.176 *** | 1.187 | 0.88 | 0.91 |
| Vegetation Index | Genotype (G) | Treatment (T) | G × T | H2 | |
|---|---|---|---|---|---|
| F-Value | F-Value | F-Value | Full Irrigation | Limited Irrigation | |
| NDVI | 6.436 *** | 948.477 *** | 1.408 * | 0.71 | 0.77 |
| SAVI | 6.436 *** | 948.481 *** | 1.408 * | 0.71 | 0.77 |
| OSAVI | 6.436 *** | 948.440 *** | 1.408 * | 0.71 | 0.77 |
| NRI | 3.687 *** | 502.703 *** | 1.132 | 0.59 | 0.57 |
| GNDVI | 6.622 *** | 740.962 *** | 1.463 ** | 0.73 | 0.78 |
| SIPI | 5.619 *** | 2053.124 *** | 1.565 *** | 0.67 | 0.75 |
| PSRI | 1.153 | 2.017 | 1.158 | 0.64 | 0.13 |
| CRI | 1.929 *** | 3.624 | 1.281 * | 0.34 | 0.54 |
| EVI | 1.725 *** | 154.691 *** | 1.481 ** | 0.35 | 0.51 |
| MSR | 5.995 *** | 1008.409 *** | 1.371 * | 0.70 | 0.76 |
| NLI | 3.189 *** | 694.061 *** | 1.511 ** | 0.46 | 0.72 |
| RDVI | 2.950 *** | 253.226 *** | 1.195 | 0.44 | 0.70 |
| TVI | 6.458 *** | 937.304 *** | 1.413 * | 0.71 | 0.77 |
| MTVI2 | 2.009 *** | 292.869 *** | 1.487 ** | 0.39 | 0.59 |
| NDRE | 10.989 *** | 35.906 *** | 1.044 | 0.77 | 0.91 |
| DVIREG | 3.525 *** | 244.143 *** | 1.347 * | 0.49 | 0.80 |
| OSAVIREG | 10.989 *** | 35.908 *** | 1.044 | 0.77 | 0.91 |
| RDVIREG | 4.918 *** | 209.064 *** | 1.526 *** | 0.56 | 0.85 |
| MSRREG | 11.078 *** | 34.183 *** | 1.046 | 0.77 | 0.91 |
| MTCI | 10.682 *** | 73.627 *** | 1.053 | 0.77 | 0.90 |
| Vegetation Index | Genotype (G) | Treatment (T) | G × T | H2 | |
|---|---|---|---|---|---|
| F-Value | F-Value | F-Value | Full Irrigation | Limited Irrigation | |
| NDVI | 6.407 *** | 131.876 *** | 1.484 ** | 0.69 | 0.79 |
| SAVI | 6.407 *** | 131.873 *** | 1.484 ** | 0.69 | 0.79 |
| OSAVI | 6.407 *** | 131.889 *** | 1.484 ** | 0.69 | 0.79 |
| NRI | 5.019 *** | 906.706 *** | 1.424 ** | 0.51 | 0.79 |
| GNDVI | 9.13 *** | 45.687 *** | 1.452 ** | 0.79 | 0.83 |
| SIPI | 7.784 *** | 17.953 *** | 1.705 *** | 0.75 | 0.83 |
| PSRI | 1.156 | 0.303 | 1.162 | 0.75 | 0.13 |
| CRI | 5.786 *** | 442.256 *** | 1.082 | 0.69 | 0.72 |
| EVI | 4.652 *** | 751.814 *** | 1.129 | 0.64 | 0.67 |
| MSR | 5.834 *** | 139.053 *** | 1.327 * | 0.65 | 0.79 |
| NLI | 3.265 *** | 812.713 *** | 1.144 | 0.45 | 0.56 |
| RDVI | 5.635 *** | 2.048 | 1.104 | 0.64 | 0.78 |
| TVI | 6.404 *** | 131.186 *** | 1.49 ** | 0.69 | 0.78 |
| MTVI2 | 4.417 *** | 886.16 *** | 1.106 | 0.60 | 0.66 |
| NDRE | 19.785 *** | 67.904 *** | 1.349 * | 0.88 | 0.93 |
| DVIREG | 2.376 *** | 450.393 *** | 0.804 | 0.37 | 0.35 |
| OSAVIREG | 19.785 *** | 67.9 *** | 1.349 * | 0.88 | 0.93 |
| RDVIREG | 3.432 *** | 342.097 *** | 0.746 | 0.58 | 0.48 |
| MSRREG | 20.303 *** | 67.16 *** | 1.375 * | 0.88 | 0.93 |
| MTCI | 19.822 *** | 45.575 *** | 1.401 * | 0.88 | 0.93 |
| Vegetation Index | Genotype (G) | Treatment (T) | G × T | H2 | |
|---|---|---|---|---|---|
| F-Value | F-Value | F-Value | Full Irrigation | Limited Irrigation | |
| NDVI | 9.091 *** | 1121.021 *** | 1.365 * | 0.80 | 0.81 |
| SAVI | 9.091 *** | 1121.035 *** | 1.365 * | 0.80 | 0.81 |
| OSAVI | 9.091 *** | 1121.020 *** | 1.365 * | 0.80 | 0.81 |
| NRI | 4.860 *** | 1682.199 *** | 1.275 * | 0.63 | 0.69 |
| GNDVI | 13.186 *** | 614.600 *** | 1.223 * | 0.86 | 0.86 |
| SIPI | 8.883 *** | 765.657 *** | 1.357 * | 0.78 | 0.82 |
| PSRI | 8.278 *** | 779.147 *** | 1.544 *** | 0.75 | 0.81 |
| CRI | 6.456 *** | 2.374 | 0.928 | 0.71 | 0.76 |
| EVI | 4.408 *** | 576.88 *** | 1.096 | 0.60 | 0.68 |
| MSR | 7.881 *** | 1353.925 *** | 1.104 | 0.76 | 0.79 |
| NLI | 5.014 *** | 1205.454 *** | 1.184 | 0.62 | 0.71 |
| RDVI | 6.774 *** | 785.527 *** | 1.080 | 0.72 | 0.79 |
| TVI | 9.124 *** | 1073.981 *** | 1.398 * | 0.80 | 0.81 |
| MTVI2 | 4.487 *** | 791.938 *** | 1.113 | 0.61 | 0.68 |
| NDRE | 17.429 *** | 528.708 *** | 1.089 | 0.88 | 0.91 |
| DVIREG | 8.626 *** | 997.224 *** | 1.044 | 0.78 | 0.81 |
| OSAVIREG | 17.429 *** | 528.698 *** | 1.089 | 0.88 | 0.91 |
| RDVIREG | 7.046 *** | 761.566 *** | 1.144 | 0.73 | 0.77 |
| MSRREG | 18.188 *** | 526.719 *** | 1.106 | 0.88 | 0.91 |
| MTCI | 17.312 *** | 636.939 *** | 1.111 | 0.88 | 0.90 |



References
- Ray, D.K.; Mueller, N.D.; West, P.C.; Foley, J.A. Yield Trends Are Insufficient to Double Global Crop Production by 2050. PLoS ONE 2013, 8, e66428. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reynolds, M.; Tattaris, M.; Cossani, C.M.; Ellis, M.; Yamaguchi-Shinozaki, K.; Pierre, C.S. Exploring Genetic Resources to Increase Adaptation of Wheat to Climate Change. In Advances in Wheat Genetics: From Genome to Field, Proceedings of the 12th International Wheat Genetics Symposium, Yokohama, Japan, 8–14 September 2013; Ogihara, Y., Takumi, S., Handa, H., Eds.; Springer Science and Business Media LLC: Tokyo, Japan, 2015; pp. 355–368. [Google Scholar]
- Lesk, C.; Rowhani, P.; Ramankutty, N. Influence of extreme weather disasters on global crop production. Nature 2016, 529, 84–87. [Google Scholar] [CrossRef] [PubMed]
- Montesinos-Lopez, O.A.; Montesinos-Lopez, A.; Crossa, J.; de Los Campos, G.; Alvarado, G.; Suchismita, M.; Rutkoski, J.; Gonzalez-Perez, L.; Burgueno, J. Predicting grain yield using canopy hyperspectral reflectance in wheat breeding data. Plant Methods 2017, 13, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hassan, M.A.; Yang, M.; Rasheed, A.; Yang, G.; Reynolds, M.; Xia, X.; Xiao, Y.; He, Z. A Rapid monitoring of NDVI across the wheat growth cycle for grain yield prediction using a multi-spectral UAV platform. Plant Sci. 2019, 282, 95–103. [Google Scholar] [CrossRef]
- Rutkoski, J.; Poland, J.; Mondal, S.; Autrique, E.; Pérez, L.G.; Crossa, J.; Reynolds, M.; Singh, R. Canopy temperature and vegetation indices from high-throughput phenotyping improve accuracy of pedigree and genomic selection for grain yield in wheat. G3 Genes Genomes Genet. 2016, 6, 2799–2808. [Google Scholar] [CrossRef] [Green Version]
- Großkinsky, D.K.; Jesper, S.; Svend, C.; Thomas, R. Plant phenomics and the need for physiological phenotyping across scales to narrow the genotype-to-phenotype knowledge gap. J. Exp. Bot. 2015, 66, 5429–5440. [Google Scholar] [CrossRef] [Green Version]
- Furbank, R.T.; Tester, M. Phenomics—Technologies to relieve the phenotyping bottleneck. Trends Plant Sci. 2011, 16, 635–644. [Google Scholar] [CrossRef]
- Araus, J.L.; Cairns, J.E. Field high-throughput phenotyping: The new crop breeding frontier. Trends Plant Sci. 2014, 19, 52–61. [Google Scholar] [CrossRef]
- Xie, C.; Yang, C. A review on plant high-throughput phenotyping traits using UAV-based sensors. Comput. Electron. Agric. 2020, 178, 105731. [Google Scholar] [CrossRef]
- Fenner, H.; Andrew, R.; Adam, M.; March, C.; Martin, W.; Malcolm, H. High Throughput field phenotyping of wheat plant height and growth rate in field plot trials using UAV based remote sensing. Remote Sens. 2016, 8, 1031. [Google Scholar]
- Lin, Y.C.; Zhou, T.; Wang, T.; Crawford, M.; Habib, A. New orthophoto generation strategies from UAV and ground remote sensing platforms for high-throughput phenotyping. Remote Sens. 2021, 13, 860. [Google Scholar] [CrossRef]
- Di Gennaro, S.F.; Rizza, F.; Badeck, F.W.; Berton, A.; Delbono, S.; Gioli, B.; Toscano, P.; Zaldei, A.; Matese, A. UAV-based high-throughput phenotyping to discriminate barley vigour with visible and near-infrared vegetation indices. Int. J. Remote Sens. 2018, 39, 5330–5344. [Google Scholar] [CrossRef]
- Hassan, M.; Yang, M.; Rasheed, A.; Jin, X.; Xia, X.; Xiao, Y.; He, Z. Time-series multispectral indices from unmanned aerial vehicle imagery reveal senescence rate in bread wheat. Remote Sens. 2018, 10, 809. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Liu, D. Improving forest aboveground biomass estimation using seasonal Landsat NDVI time-series. ISPRS J. Photogramm. 2015, 102, 222–231. [Google Scholar] [CrossRef]
- Prananda, A.; Kamal, M.; Kusuma, D.W. The effect of using different vegetation indices for mangrove leaf area index modelling. IOP Conf. Ser. Earth Environ. Sci. 2020, 500, 012006. [Google Scholar] [CrossRef]
- Han, L.; Yang, G.; Dai, H.; Xu, B.; Yang, H.; Feng, H.; Li, Z.; Yang, X. Modeling maize above-ground biomass based on machine learning approaches using UAV remote-sensing data. Plant Methods 2019, 15, 10. [Google Scholar] [CrossRef] [Green Version]
- Dahms, T.; Seissiger, S.; Borg, E.; Vajen, H.; Fichtelmann, B.; Conrad, C. Important variables of a rapideye time series for modelling biophysical parameters of winter wheat. Photogramm. Fernerkund. Geoinf. 2016, 2016, 285–299. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Cheng, T.; Zhu, Y.; Tian, Y.; Cao, W.; Yao, X.; Wang, N. Comparative analysis of vegetation indices, non-parametric and physical retrieval methods for monitoring nitrogen in wheat using UAV-based multispectral imagery. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 7362–7365. [Google Scholar]
- Sonobe, R.; Sano, T.; Horie, H. Using spectral reflectance to estimate leaf chlorophyll content of tea with shading treatments. Biosyst. Eng. 2018, 175, 168–182. [Google Scholar] [CrossRef]
- Gleason, C.J.; Im, J. Forest biomass estimation from airborne LiDAR data using machine learning approaches. Remote Sens. Environ. 2012, 125, 80–91. [Google Scholar] [CrossRef]
- Montes, J.M.; Technow, F.; Dhillon, B.S.; Mauch, F.; Melchinger, A.E. High-throughput non-destructive biomass determination during early plant development in maize under field conditions. Field Crop. Res. 2011, 121, 268–273. [Google Scholar] [CrossRef]
- Prasad, R.; Pandey, A.; Singh, K.P.; Singh, V.P.; Mishra, R.K.; Singh, D. Retrieval of spinach crop parameters by microwave remote sensing with back propagation artificial neural networks: A comparison of different transfer functions. Adv. Space Res. 2012, 50, 363–370. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ounpraseuth, S. Gaussian processes for machine learning. J. Am. Stat. Assoc. 2008, 103, 429. [Google Scholar] [CrossRef]
- Tikhonov, A.N. On the stability of inverse problems. C.R. Acad. Sci. URSS 1943, 39, 176-170. [Google Scholar]
- Wang, L.A.; Zhou, X.; Zhu, X.; Dong, Z.; Guo, W. Estimation of biomass in wheat using random forest regression algorithm and remote sensing data. Crop. J. 2016, 4, 212–219. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Chen, Y.; Chen, F.; Shi, T.; Wu, G. Wavelet-based coupling of leaf and canopy reflectance spectra to improve the estimation accuracy of foliar nitrogen concentration. Agric. For. Meteorol. 2018, 248, 306–315. [Google Scholar] [CrossRef]
- Houborg, R.; McCabe, M.F. A Hybrid training approach for leaf area index estimation via cubist and random forests machine-learning. ISPRS J. Photogramm. Remote Sens. 2018, 135, 173–188. [Google Scholar] [CrossRef]
- Zhang, J.; Cheng, T.; Guo, W.; Xu, X.; Qiao, H.; Xie, Y.; Ma, X. Leaf area index estimation model for UAV image hyperspectral data based on wavelength variable selection and machine learning methods. Plant Methods 2021, 17, 49. [Google Scholar] [CrossRef]
- Shah, S.H.; Angel, Y.; Houborg, R.; Ali, S.; McCabe, M.F. A random forest machine learning approach for the retrieval of leaf chlorophyll content in wheat. Remote Sens. 2019, 11, 920. [Google Scholar] [CrossRef] [Green Version]
- Liang, L.; Geng, D.; Yan, J.; Qiu, S.; Di, L.; Wang, S.; Xu, L.; Wang, L.; Kang, J.; Li, L. Estimating crop LAI using spectral feature extraction and the hybrid inversion method. Remote Sens. 2020, 12, 3534. [Google Scholar] [CrossRef]
- Yoosefzadeh-Najafabadi, M.; Earl, H.J.; Tulpan, D.; Sulik, J.; Eskandari, M. Application of machine learning algorithms in plant breeding: Predicting yield from hyperspectral reflectance in soybean. Front. Plant Sci. 2021, 11, 624273. [Google Scholar] [CrossRef]
- Xie, R.; Darvishzadeh, R.; Skidmore, A.K.; Heurich, M.; Holzwarth, S.; Gara, T.W.; Reusen, I. Mapping leaf area index in a mixed temperate forest using fenix airborne hyperspectral data and gaussian processes regression. Int. J. Appl. Earth Obs. Geoinf. 2021, 95, 102242. [Google Scholar] [CrossRef]
- Fu, Y.; Yang, G.; Li, Z.; Song, X.; Li, Z.; Xu, X.; Wang, P.; Zhao, C. Winter wheat nitrogen status estimation using UAV-based RGB imagery and gaussian processes regression. Remote Sens. 2020, 12, 3778. [Google Scholar] [CrossRef]
- Feng, L.; Zhang, Z.; Ma, Y.; Du, Q.; Williams, P.; Drewry, J.; Luck, B. Alfalfa yield prediction using UAV-based hyperspectral imagery and ensemble learning. Remote Sens. 2020, 12, 2028. [Google Scholar] [CrossRef]
- Zhang, Z.; Pasolli, E.; Crawford, M.M.; Tilton, J.C. An active learning framework for hyperspectral image classification using hierarchical segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 640–654. [Google Scholar] [CrossRef]
- Zhang, Z.; Pasolli, E.; Crawford, M.M. An adaptive multiview active learning approach for spectral-spatial classification of hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2557–2570. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Breiman, L. Stacked regressions. Mach. Learn. 1996, 24, 49-64. [Google Scholar] [CrossRef] [Green Version]
- Clinton, N.; Yu, L.; Gong, P. Geographic stacking: Decision fusion to increase global land cover map accuracy. ISPRS J. Photogramm. Remote Sens. 2015, 103, 57–65. [Google Scholar] [CrossRef]
- Healey, S.P.; Cohen, W.B.; Yang, Z.; Brewer, C.K.; Brooks, E.B.; Gorelick, N.; Hernandez, A.J.; Huang, C.; Hughes, M.J.; Kennedy, R.E.; et al. Mapping forest change using stacked generalization: An ensemble approach. Remote Sens. Environ. 2018, 204, 717–728. [Google Scholar] [CrossRef]
- Feng, L.; Li, Y.; Wang, Y.; Du, Q. Estimating hourly and continuous ground-level PM2.5 concentrations using an ensemble learning algorithm: The ST-stacking model. Atmos. Environ. 2020, 223, 117242. [Google Scholar] [CrossRef]
- Rouse, J.W., Jr.; Haas, R.H.; Schell, J.; Deering, D. Monitoring the Vernal Advancement and Retrogradation (Green Wave Effect) of Natural Vegetation: Prog. Rep. RSC 1978–1; Texas A&M University: College Station, TX, USA, 1973. [Google Scholar]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the modis vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Rondeaux, G.; Steven, M.; Baret, F. Optimization of soil-adjusted vegetation indices. Remote Sens. Environ. 1996, 55, 95–107. [Google Scholar] [CrossRef]
- Schleicher, T.D.; Bausch, W.C.; Delgado, J.A.; Ayers, P.D. Evaluation and refinement of the nitrogen reflectance index (NRI) for site-specific fertilizer management. ASAE Annu. Meet. 2001, 2001, 011151. [Google Scholar]
- Gitelson, A.A.; Merzlyak, M.N. Remote sensing of chlorophyll concentration in higher plant leaves. Adv. Space Res. 1998, 22, 689–692. [Google Scholar] [CrossRef]
- Peñuelas, J.; Filella, I. Visible and Near-infrared reflectance techniques for diagnosing plant physiological status. Trends Plant Sci. 1998, 3, 151–156. [Google Scholar] [CrossRef]
- Sims, D.A.; Gamon, J.A. Relationships between leaf pigment content and spectral reflectance across a wide range of species, leaf structures and developmental stages. Remote Sens. Environ. 2002, 81, 337–354. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Zur, Y.; Chivkunova, O.B.; Merzlyak, M.N. Assessing carotenoid content in plant leaves with reflectance spectroscopy. Photochem. Photobiol. 2002, 75, 272–281. [Google Scholar] [CrossRef]
- Nagler, P.L.; Scott, R.L.; Westenburg, C.; Cleverly, J.R.; Glenn, E.P.; Huete, A.R. Evapotranspiration on western U.S. rivers estimated using the Enhanced Vegetation Index from MODIS and data from eddy covariance and Bowen ratio flux towers. Remote Sens. Environ. 2005, 97, 337–351. [Google Scholar] [CrossRef]
- Chen, J.M. Evaluation of vegetation indices and a modified simple ratio for boreal applications. Can. J. Remote Sens. 1996, 22, 229–242. [Google Scholar] [CrossRef]
- Goel, N.S.; Qin, W. Influences of canopy architecture on relationships between various vegetation indices and LAI and FPAR: A computer simulation. Remote Sens. Rev. 1994, 10, 309–347. [Google Scholar] [CrossRef]
- Wang, K.; Shen, Z.Q.; Wang, R.C. Effects of nitrogen nutrition on the spectral reflectance characteristics of rice leaf and canopy. J. Zhejiang Agric. Univ. 1998, 24, 93–97. [Google Scholar]
- Broge, N.H.; Leblanc, E. Comparing Prediction power and stability of broadband and hyperspectral vegetation indices for estimation of green leaf area index and canopy chlorophyll density. Remote Sens. Environ. 2001, 76, 156–172. [Google Scholar] [CrossRef]
- Haboudane, D.; Miller, J.R.; Pattey, E.; Zarco-Tejada, P.J.; Strachan, I.B. Hyperspectral vegetation indices and novel algorithms for predicting green LAI of crop canopies: Modeling and validation in the context of precision agriculture. Remote Sens. Environ. 2004, 90, 337–352. [Google Scholar] [CrossRef]
- Barnes, E.M.; Clarke, T.R.; Richards, S.E.; Colaizzi, P.D.; Haberland, J.; Kostrzewski, M.; Waller, P.; Choi, C.; Riley, E.; Thompson, T. Coincident detection of crop water stress, nitrogen status and canopy density using ground-based multispectral data. In Proceedings of the Fifth International Conference on Precision Agriculture and Other Resource Management, Bloomington, MN, USA, 16–19 July 2000; pp. 1–15. [Google Scholar]
- Chen, P.; Feng, H.k.; Li, C.C.; Yang, G.J.; Yang, J.S.; Yang, W.P.; Liu, S.B. Estimation of chlorophyll content in potato using fusion of texture and spectral features derived from UAV multispectral image. Trans. CSAE 2019, 35, 63–74. [Google Scholar]
- Gitelson, A.A.; Viña, A.; Verma, S.B.; Rundquist, D.C.; Arkebauer, T.J.; Keydan, G.; Leavitt, B.; Ciganda, V.; And, G.; Suyker, A.E. Relationship between gross primary production and chlorophyll content in crops: Implications for the synoptic monitoring of vegetation productivity. J. Geophys. Res. Atmos. 2006, 111, D8. [Google Scholar] [CrossRef] [Green Version]
- Hoerl, A.E.; Kennard, R.W. Ridge Regression: Applications to nonorthogonal problems. Technometrics 1970, 12, 69–82. [Google Scholar] [CrossRef]
- Sehgal, D.; Skot, L.; Singh, R.; Srivastava, R.K.; Das, S.P.; Taunk, J.; Sharma, P.C.; Pal, R.; Raj, B.; Hash, C.T.; et al. Exploring potential of pearl millet germplasm association panel for association mapping of drought tolerance traits. PLoS ONE 2015, 10, e0122165. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.; Hassan, M.A.; Xu, K.; Zheng, C.; Rasheed, A.; Zhang, Y.; Jin, X.; Xia, X.; Xiao, Y.; He, Z. Assessment of water and nitrogen use efficiencies through UAV-based multispectral phenotyping in winter wheat. Front. Plant Sci. 2020, 11, 927. [Google Scholar] [CrossRef]
- Messina, G.; Modica, G. Applications of UAV thermal imagery in precision agriculture: State of the art and future research outlook. Remote Sens. 2020, 12, 1491. [Google Scholar] [CrossRef]
- Sagan, V.; Maimaitijiang, M.; Sidike, P.; Eblimit, K.; Peterson, K.; Hartling, S.; Esposito, F.; Khanal, K.; Newcomb, M.; Pauli, D.; et al. UAV-based high resolution thermal 663 imaging for vegetation monitoring, and plant phenotyping using ICI 8640 P, FLIR 664 Vue Pro R 640, and thermoMap Cameras. Remote Sens. 2019, 11, 330. [Google Scholar] [CrossRef] [Green Version]
- Qu, J.; Ren, K.; Shi, X. Binary Grey wolf optimization-regularized extreme learning machine wrapper coupled with the boruta algorithm for monthly streamflow forecasting. Water Resour. Manag. 2021, 35, 1029–1045. [Google Scholar] [CrossRef]
- Abdel-Rahman, E.M.; Mutanga, O.; Adam, E.; Ismail, R. Detecting sirex noctilio grey-attacked and lightning-struck pine trees using airborne hyperspectral data, random forest and support vector machines classifiers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 48–59. [Google Scholar] [CrossRef]
- Hernandez, J.; Lobos, G.; Matus, I.; Del Pozo, A.; Silva, P.; Galleguillos, M. Using ridge regression models to estimate grain yield from field spectral data in bread wheat (Triticum aestivum L.) grown under three water regimes. Remote Sens. 2015, 7, 2109–2126. [Google Scholar] [CrossRef] [Green Version]
- Hang, R.; Liu, Q.; Song, H.; Sun, Y.; Pei, H. Graph regularized nonlinear ridge regression for remote sensing data analysis. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 277–285. [Google Scholar] [CrossRef]
- Takeuchi, F.; Kato, N. Nonlinear ridge regression improves cell-type-specific differential expression analysis. BMC Bioinform. 2021, 22, 1–25. [Google Scholar] [CrossRef]
- Yu, C.; Gao, F.; Wen, Q. An improved quantum algorithm for ridge regression. IEEE Trans. Knowl. Data Eng. 2019, 33, 1. [Google Scholar] [CrossRef] [Green Version]
- Lazaridis, D.C.; Verbesselt, J.; Robinson, A.P. Penalized regression techniques for prediction: A case study for predicting tree mortality using remotely sensed vegetation indices. Can. J. For. Res. 2011, 41, 24–34. [Google Scholar] [CrossRef]
- Yue, J.; Yang, G.; Li, C.; Li, Z.; Wang, Y.; Feng, H.; Xu, B. Estimation of winter wheat above-ground biomass using unmanned aerial vehicle-based snapshot hyperspectral sensor and crop height improved models. Remote Sens. 2017, 9, 708. [Google Scholar] [CrossRef] [Green Version]
- Montesinos-Lopez, O.A.; Martin-Vallejo, J.; Crossa, J.; Gianola, D.; Hernandez-Suarez, C.M.; Montesinos-Lopez, A.; Juliana, P.; Singh, R. A Benchmarking between deep learning, support vector machine and Bayesian threshold best linear unbiased prediction for predicting ordinal traits in plant breeding. G3 Genes Genomes Genet. 2019, 9, 601–618. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Ding, S.; Sun, Y. MBSVR: Multiple birth support vector regression. Inform. Sci. 2021, 552, 65–79. [Google Scholar] [CrossRef]
- Band, S.S.; Janizadeh, S.; Pal, S.C.; Saha, A.; Chakrabortty, R.; Melesse, A.M.; Mosavi, A. Flash flood susceptibility modeling using new approaches of hybrid and ensemble tree-based machine learning algorithms. Remote Sens. 2020, 12, 3568. [Google Scholar] [CrossRef]
- Fu, P.; Meacham-Hensold, K.; Guan, K.; Bernacchi, C.J. Hyperspectral leaf reflectance as proxy for photosynthetic capacities: An ensemble approach based on multiple machine learning algorithms. Front. Plant Sci. 2019, 10, 730. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Statist. Soc. B 2005, 67, 301–320. [Google Scholar]
- Tibshirani, R.J. Regression shrinkage and selection via the lasso. J. R. Statist. Soc. B Stat. Methodol. 1996, 73, 273–282. [Google Scholar] [CrossRef]
- Montesinos-López, O.A.; Montesinos-López, A.; Crossa, J.; Cuevas, J.; Singh, R. A bayesian genomic multi-output regressor stacking model for predicting multi-trait multi-environment plant breeding data. G3-Genes Genom. Genet. 2019, 9. [Google Scholar] [CrossRef] [Green Version]
- Guan, K.; Wu, J.; Kimball, J.; Anderson, M.; Frolking, S.; Li, B.; Hain, C.; Lobell, D. The shared and unique values of optical, fluorescence, thermal and microwave satellite data for estimating large-scale crop yields. Remote Sens. Environ. 2017, 199, 333–349. [Google Scholar] [CrossRef] [Green Version]











| Band | Bandwidth | Wavelength | Definition | Image Resolution |
|---|---|---|---|---|
| Blue | 475 | 32 | 1.4 mp | 1280 × 960 |
| Green | 560 | 27 | 1.4 mp | 1280 × 960 |
| Red | 668 | 14 | 1.4 mp | 1280 × 960 |
| Red-edge | 717 | 12 | 1.4 mp | 1280 × 960 |
| Near infrared | 842 | 57 | 1.4 mp | 1280 × 960 |
| Growth Stage | Zadok’s Stage | Flight Altitude (m) | Snap Shoot Interval (s) | Ground Resolution (cm) |
|---|---|---|---|---|
| Heading | ZS-56 | 40 | 1.5 | 3.0 |
| Flowering | ZS-65 | 40 | 1.5 | 3.0 |
| Early grain filling | ZS-73 | 30 | 1.5 | 2.5 |
| Mid-grain filling | ZS-85 | 30 | 1.5 | 2.5 |
| Vegetation Index | Full Name | Equation | Reference |
|---|---|---|---|
| NDVI | Normalized Difference Vegetation Index | (NIR − R)/(NIR + R) | [45] |
| SAVI | Soil-Adjusted Vegetation Index | (NIR − R)/(NIR + R + 0.5) × 1.5 | [46] |
| OSAVI | Optimized Soil-Adjusted Vegetation Index | (NIR − R)/(NIR + R + 1.6) × 1.16 | [47] |
| NRI | Nitrogen Reflectance Index | (G − R)/(G + R) | [48] |
| GDNVI | Green Normalized Difference Vegetation Index | (NIR − G)/(NIR + G) | [49] |
| SIPI | Structure Insensitive Pigment Index | (NIR − B)/(NIR + B) | [50] |
| PSRI | Plant Senescence Reflectance Index | (R − B)/NIR | [51] |
| CRI | Carotenoid Reflectance Index | 1/G + 1/NIR | [52] |
| EVI | Enhanced Vegetation Index | 2.5 × (NIR − R)/(1 + NIR + 6 × R − 7.5 × B) | [53] |
| MSR | Modified Simple Ratio Index | ((NIR/R) − 1)/((NIR/R) +1) × 0.5 | [54] |
| NLI | Nonlinear Vegetation Index | (NIR × NIR − R)/(NIR × NIR + R) | [55] |
| RDVI | Re-normalized Difference Vegetation Index | (NIR − R)/(NIR + R) × 0.5 | [56] |
| TVI | Transformational Vegetation Index | (NDVI + 0.5)0.5 | [57] |
| MTVI | Modified Triangular Vegetation Index | 1.5 × [1.2 × (NIR − G) − 2.5 × (R − G)]/[(2 × (NIR − G) − 6 × NIR + 5 × R0.5)0.5–0.5] | [58] |
| NDRE | Red edge Normalized Difference Vegetation Index | (NIR − REG)/(NIR + REG) | [59] |
| DVIREG | Red-edge Difference Vegetation Index | NIR − REG | [60] |
| OSAVIREG | Red-edge optimized Soil-Adjusted Vegetation Index | (NIR − REG)/(NIR + REG + 1.6) × 1.16 | [60] |
| RDVIREG | Red-edge Re-normalized Difference Vegetation Index | (NIR − REG)/(NIR + REG)0.5 | [60] |
| MSRREG | Red edge modified Simple Ratio Index | ((NIR/REG) − 1)/((NIR/REG) +1)0.5 | [60] |
| MTCI | MERIS Terrestrial Chlorophyll Index | (NIR − REG)/(REG − R) | [61] |
| Number | RF | SVM | RR | GP | ||
|---|---|---|---|---|---|---|
| Ntree | Mtry | Cost | Gamma | Lambda | Sigma | |
| 1 | 405 | 3 | 0.250 | 0.450 | 0.00058 | 0.41 |
| 2 | 410 | 4 | 0.263 | 0.453 | 0.00063 | 0.42 |
| 3 | 415 | 5 | 0.275 | 0.455 | 0.00067 | 0.43 |
| 4 | 420 | 6 | 0.288 | 0.458 | 0.00072 | 0.44 |
| 5 | 425 | 7 | 0.300 | 0.460 | 0.00077 | 0.45 |
| 6 | 430 | 8 | 0.313 | 0.463 | 0.00083 | 0.46 |
| 7 | 435 | 9 | 0.325 | 0.465 | 0.00089 | 0.47 |
| 8 | 440 | 10 | 0.338 | 0.468 | 0.00095 | 0.48 |
| 9 | 445 | 11 | 0.350 | 0.470 | 0.00102 | 0.49 |
| 10 | 450 | 12 | 0.363 | 0.473 | 0.00110 | 0.50 |
| 11 | 455 | 13 | 0.375 | 0.475 | 0.00118 | 0.51 |
| 12 | 460 | 14 | 0.388 | 0.478 | 0.00126 | 0.52 |
| 13 | 465 | 15 | 0.400 | 0.480 | 0.00136 | 0.53 |
| 14 | 470 | 16 | 0.413 | 0.483 | 0.00146 | 0.54 |
| 15 | 475 | 17 | 0.425 | 0.485 | 0.00156 | 0.55 |
| 16 | 480 | 18 | 0.438 | 0.488 | 0.00168 | 0.56 |
| 17 | 485 | 19 | 0.450 | 0.490 | 0.00180 | 0.57 |
| 18 | 490 | 20 | 0.463 | 0.493 | 0.00193 | 0.58 |
| 19 | 495 | 21 | 0.475 | 0.495 | 0.00207 | 0.59 |
| 20 | 500 | 22 | 0.488 | 0.498 | 0.00058 | 0.60 |
| Model | Full Irrigation | Limited Irrigation | ||||||
|---|---|---|---|---|---|---|---|---|
| Coefficient of Determination (R2) | Coefficient of Determination (R2) | |||||||
| Heading | Flowering | EGF | MGF | Heading | Flowering | EGF | MGF | |
| RF | 0.485 | 0.505 | 0.602 | 0.531 | 0.541 | 0.604 | 0.599 | 0.626 |
| SVM | 0.435 | 0.469 | 0.540 | 0.519 | 0.510 | 0.580 | 0.506 | 0.537 |
| GP | 0.465 | 0.520 | 0.589 | 0.563 | 0.550 | 0.595 | 0.512 | 0.573 |
| RR | 0.488 | 0.515 | 0.588 | 0.604 | 0.561 | 0.611 | 0.531 | 0.612 |
| RF-SVM | 0.488 | 0.522 | 0.620 | 0.562 | 0.543 | 0.614 | 0.617 | 0.628 |
| RF-GP | 0.492 | 0.534 | 0.620 | 0.589 | 0.555 | 0.612 | 0.618 | 0.625 |
| RF-RR | 0.502 | 0.515 | 0.611 | 0.601 | 0.564 | 0.619 | 0.609 | 0.629 |
| SVM-GP | 0.467 | 0.526 | 0.591 | 0.567 | 0.549 | 0.600 | 0.517 | 0.579 |
| SVM-RR | 0.472 | 0.547 | 0.616 | 0.610 | 0.569 | 0.617 | 0.541 | 0.578 |
| GP-RR | 0.496 | 0.551 | 0.618 | 0.622 | 0.570 | 0.616 | 0.542 | 0.613 |
| RF-SVM-GP | 0.490 | 0.528 | 0.619 | 0.588 | 0.549 | 0.612 | 0.615 | 0.628 |
| RF-SVM-RR | 0.499 | 0.533 | 0.624 | 0.607 | 0.563 | 0.620 | 0.613 | 0.627 |
| SVM-GP-RR | 0.493 | 0.546 | 0.619 | 0.623 | 0.564 | 0.617 | 0.540 | 0.613 |
| RF-GP-RR | 0.500 | 0.544 | 0.621 | 0.620 | 0.568 | 0.616 | 0.613 | 0.628 |
| RF-SVM-GP-RR | 0.498 | 0.538 | 0.622 | 0.620 | 0.562 | 0.617 | 0.611 | 0.628 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fei, S.; Hassan, M.A.; He, Z.; Chen, Z.; Shu, M.; Wang, J.; Li, C.; Xiao, Y. Assessment of Ensemble Learning to Predict Wheat Grain Yield Based on UAV-Multispectral Reflectance. Remote Sens. 2021, 13, 2338. https://doi.org/10.3390/rs13122338
Fei S, Hassan MA, He Z, Chen Z, Shu M, Wang J, Li C, Xiao Y. Assessment of Ensemble Learning to Predict Wheat Grain Yield Based on UAV-Multispectral Reflectance. Remote Sensing. 2021; 13(12):2338. https://doi.org/10.3390/rs13122338
Chicago/Turabian StyleFei, Shuaipeng, Muhammad Adeel Hassan, Zhonghu He, Zhen Chen, Meiyan Shu, Jiankang Wang, Changchun Li, and Yonggui Xiao. 2021. "Assessment of Ensemble Learning to Predict Wheat Grain Yield Based on UAV-Multispectral Reflectance" Remote Sensing 13, no. 12: 2338. https://doi.org/10.3390/rs13122338
APA StyleFei, S., Hassan, M. A., He, Z., Chen, Z., Shu, M., Wang, J., Li, C., & Xiao, Y. (2021). Assessment of Ensemble Learning to Predict Wheat Grain Yield Based on UAV-Multispectral Reflectance. Remote Sensing, 13(12), 2338. https://doi.org/10.3390/rs13122338