
DSDet: A Lightweight Densely Connected Sparsely Activated Detector for Ship Target Detection in High-Resolution SAR Images

Abstract
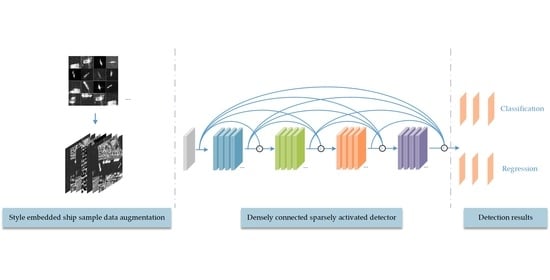
:
1. Introduction
- A new SAR ship sample data augmentation framework based on generative adversarial network (GAN) is proposed, which can purposefully generate abundant hard samples, simulate various hard situations in marine areas, and improve detection performance. Additionally, as data augmentation is only applied in the training stage, it does not incur extra inference costs;
- A cross-dimension attention style embedded ship sample generator, as well as a max-patch discriminator, are constructed;
- A lightweight densely connected sparsely activated detector is constructed, which achieves a competitive performance among state-of-the-art detection methods;
- The proposed method is proposal-free and anchor-free, thereby eliminating the complicated computation of the intersection over union (IoU) between the anchor boxes and ground truth boxes during training. As a result, this method is also completely free of the hyper-parameters related to anchor boxes, which improves its flexibility compared to its anchor-based counterparts.
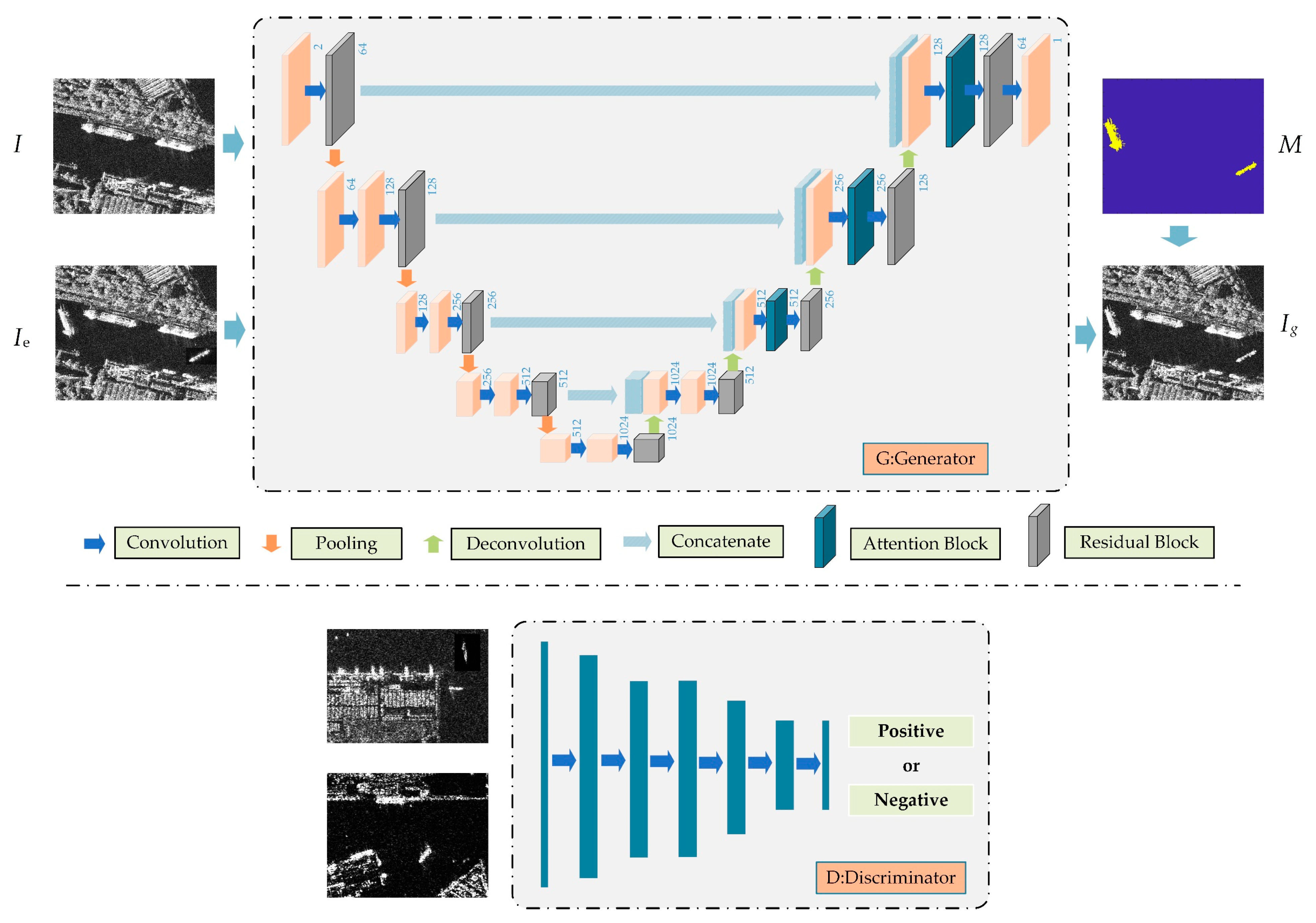
2. Style Embedded Ship Sample Data Network
2.1. Cross-Dimension Attention Style Embedded Ship Sample Generator
2.2. Max-Patch Discriminator
3. Lightweight Densely Connected Sparsely Activated Detector
3.1. Convolution Module
3.2. The Architecture of DSNet Backbone
3.3. The Location of Bounding Box
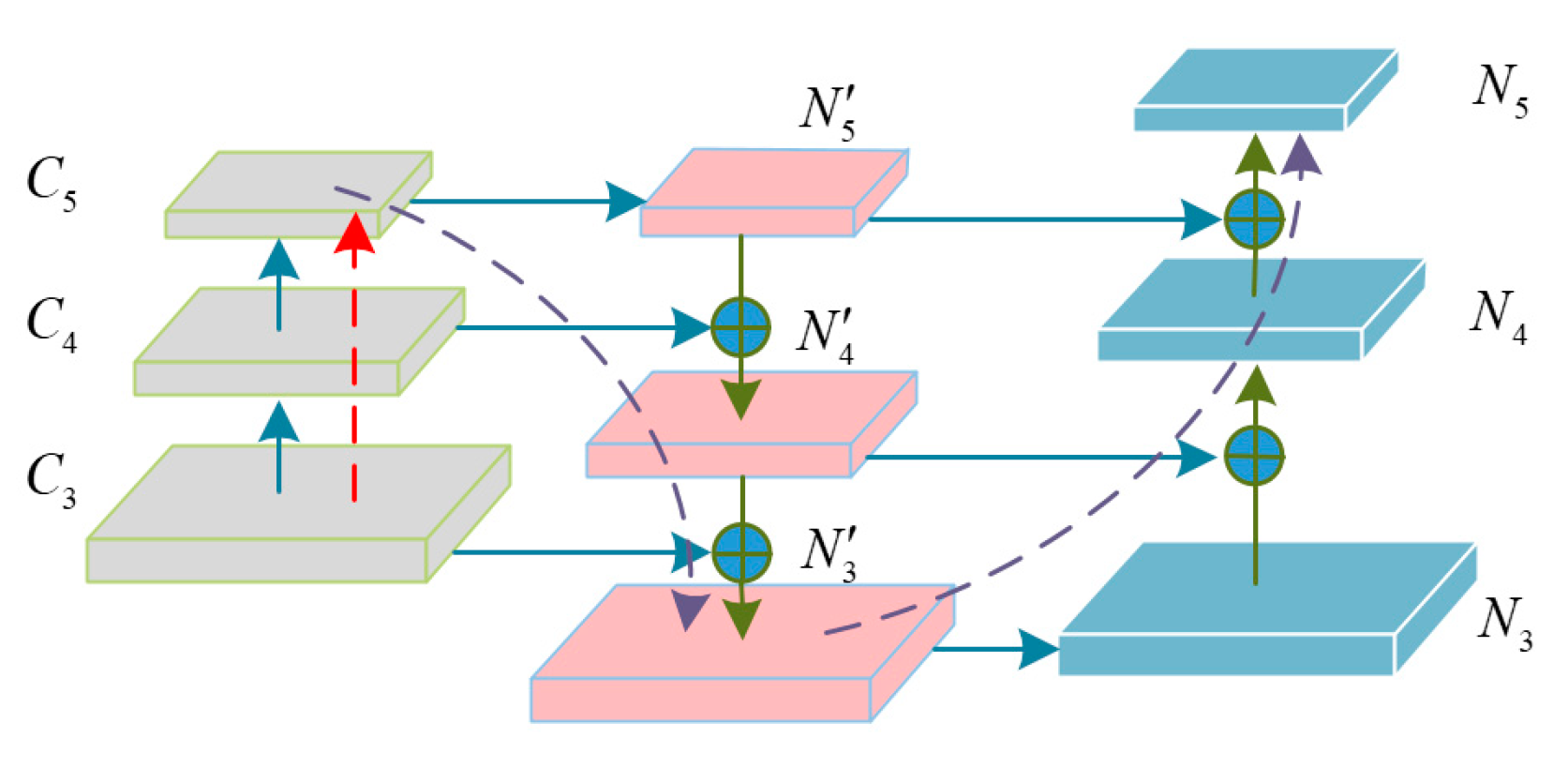
3.4. Deep Feature Fusion Pyramid
3.5. Loss Function
4. Experiments and Discussions
4.1. Dataset
4.2. Evaluation Criteria
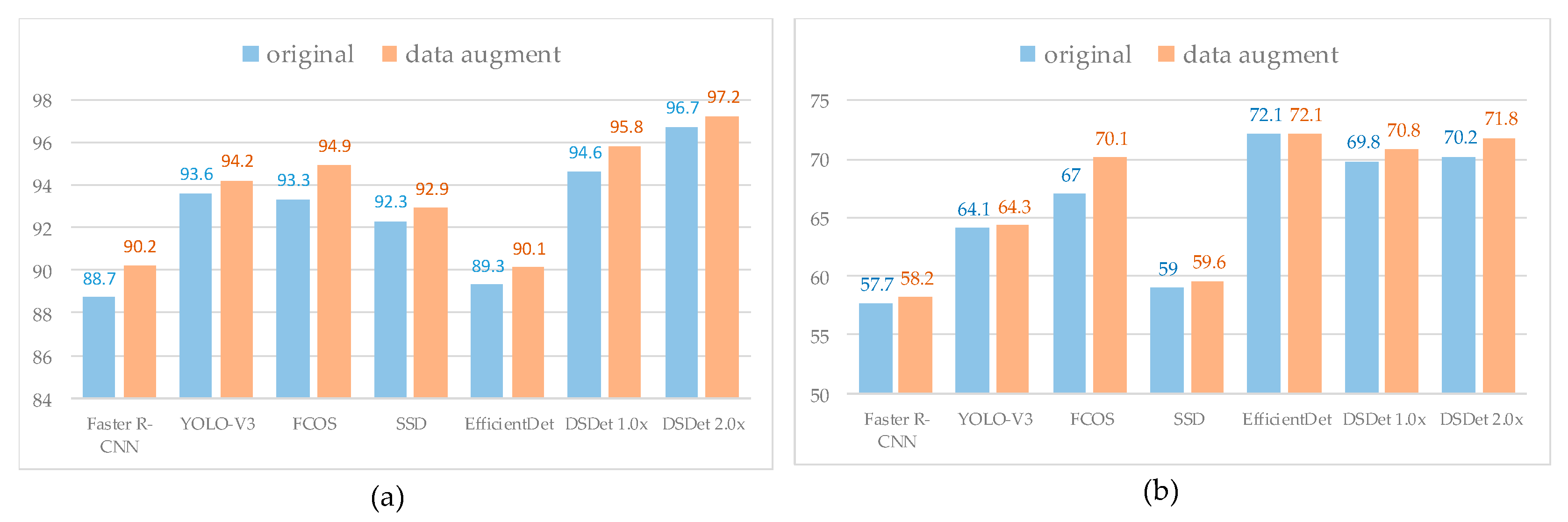
4.3. The Performance of the Ship Sample Augmentation Method
4.3.1. The Generated Results of the Proposed Method
4.3.2. The Comparison of the Generated Results between the Proposed Method and U-Net
4.3.3. The Effectiveness of the Proposed Two-Channel Input Mechanical
4.4. The Results of Ship Detection on SSDD
4.4.1. Accuracy
4.4.2. Computational Complexity
4.5. Results of Ship Detection on HRSID
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Input Size | Operator | Output Size | Output Channel Number |
|---|---|---|---|---|
| {Kernel size, Convolution type, Channel number, Group number, Stride} | ||||
| 1 | 12 | |||
| 2 | 18 | |||
| 24 | ||||
| 3 | 36 | |||
| 60 | ||||
| 108 | ||||
| 180 | ||||
| 228 | ||||
| 276 | ||||
| 336 | ||||
| 4 | 360 | |||
| 408 | ||||
| 504 | ||||
| 576 | ||||
| 5 | 624 | |||
| 720 | ||||
| 912 | ||||
| 1056 |
References
- Wang, X.; Chen, C. Ship detection for complex background SAR images based on a multi-scale variance weighted image entropy method. IEEE Geosci. Remote Sens. Lett. 2017, 14, 184–187. [Google Scholar] [CrossRef]
- Brusch, S.; Lehner, S.; Fritz, T.; Soccorsi, M.; Soloviev, A.; Schie, V. Ship surveillance with TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2011, 49, 1092–1103. [Google Scholar] [CrossRef]
- Gao, G.; Liu, L.; Zhao, L.; Shi, G.; Kuang, G. An adaptive and fast CFAR algorithm based on automatic censoring for target detection in high-resolution SAR images. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1685–1697. [Google Scholar] [CrossRef]
- An, W.; Xie, C.; Yuan, X. An improved iterative censoring scheme for CFAR ship detection with SAR imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4585–4595. [Google Scholar]
- Gao, G.; Shi, G. CFAR ship detection in nonhomogeneous sea clutter using polarimetric SAR data based on the notch filter. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4811–4824. [Google Scholar] [CrossRef]
- Pitz, W.; Miller, D. The TerraSAR-X satellite. IEEE Trans. Geosci. Remote Sens. 2010, 48, 615–622. [Google Scholar] [CrossRef]
- Wang, X.; Chen, C. Adaptive ship detection in SAR images using variance WIE-based method. Signal Image Video Process. 2016, 10, 1219–1224. [Google Scholar] [CrossRef]
- Wei, S.; Zeng, X.; Qu, Q.; Wang, M.; Su, H.; Shi, J. HRSID: A high-resolution SARimages dataset for ship detection and instance segmentation. IEEE Access 2020, 8, 120234–120254. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Ke, X.; Zhan, X.; Shi, J.; Wei, S.; Pan, D.; Li, J.; Su, H.; Zhou, Y.; et al. LS-SSDD-v1.0: A deep learning dataset dedicated to small ship detection from large-scale Sentinel-1 SAR images. Remote Sens. 2020, 12, 2997. [Google Scholar] [CrossRef]
- Ao, W.; Xu, F.; Li, Y.; Wang, H. Detection and discrimination of ship targets in complex background from spaceborne ALOS-2 SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 536–550. [Google Scholar] [CrossRef]
- Park, H.; Schoepflin, T.; Kim, Y. Active contour model with gradient directional information: Directional snake. IEEE Trans. Circ. Syst. Video Technol. 2001, 11, 252–256. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Liao, P.; Chen, T.; Chung, P. A fast algorithm for multilevel thresholding. J. Inf. Sci. Eng. 2001, 17, 713–727. [Google Scholar]
- Li, T.; Liu, Z.; Xie, R.; Ran, L. An improved superpixel-level CFAR detection method for ship targets in high-resolution SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 184–194. [Google Scholar] [CrossRef]
- Zhai, L.; Li, Y.; Su, Y. Inshore ship detection via saliency and context information in high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1870–1874. [Google Scholar] [CrossRef]
- Jian, M.; Lam, K.; Dong, J.; Shen, L. Visual-path-attention-aware saliency detection. IEEE Trans. Cybern. 2019, 45, 1575–1586. [Google Scholar] [CrossRef]
- El-Darymli, K.; McGuire, P.; Power, D.; Moloney, C. Target detection in synthetic aperture radar imagery: A state-of-the-art survey. J. Appl. Remote Sens. 2013, 7, 7–35. [Google Scholar]
- Zhao, Z.; Ji, K.; Xing, X.; Zou, H.; Zhou, S. Ship surveillance by integration of space-borne SAR and AIS—Review of current research. J. Navigat. 2014, 67, 177–189. [Google Scholar] [CrossRef]
- Robey, F.; Fuhrmann, D.; Kelly, E.; Nitzberg, R. A CFAR adaptive matched filter detector. IEEE Trans. Aerosp. Electron. Syst. 1992, 28, 208–216. [Google Scholar] [CrossRef] [Green Version]
- Hou, B.; Chen, X.; Jiao, L. Multilayer CFAR detection of ship targets in very high resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 811–815. [Google Scholar]
- Yu, W.; Wang, Y.; Liu, H.; He, J. Superpixel-based CFAR target detection for high-resolution SAR images. IEEE Geosci. Remote Sens. Lett. 2016, 13, 730–734. [Google Scholar] [CrossRef]
- Cui, X.; Su, Y.; Chen, S. A saliency detector for polarimetric SAR ship detection using similarity test. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3423–3433. [Google Scholar] [CrossRef]
- Wang, C.; Bi, F.; Zhang, W.; Chen, L. An intensity-space domain CFAR method for ship detection in HR SAR images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 529–533. [Google Scholar] [CrossRef]
- Pappas, O.; Achim, A.; Bull, D. Superpixel-level CFAR detectors for ship detection in SAR imagery. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1397–1401. [Google Scholar] [CrossRef] [Green Version]
- Schwegmann, C.; Kleynhans, W.; Salmon, B. Manifold adaptation for constant false alarm rate ship detection in South African oceans. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3329–3337. [Google Scholar] [CrossRef] [Green Version]
- Goldstein, G. False-alarm regulation in log-normal and Weibull clutter. IEEE Trans. Aerosp. Electron. Syst. 1973, 9, 84–92. [Google Scholar] [CrossRef]
- Stacy, E. A generalization of the gamma distribution. Ann. Math. Stat. 1962, 33, 1187–1192. [Google Scholar] [CrossRef]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. SAR-SIFT: A SIFT-like algorithm for SAR images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 453–466. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Ince, T.; Kiranyaz, S.; Gabbouj, M. Evolutionary RBF classifier for polarimetric SAR images. Expert Syst. Appl. 2012, 39, 4710–4717. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrel, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, K.; Pang, J.; Wang, J.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Shi, J.; Ouyang, W.; et al. Hybrid task cascade for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4974–4983. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better faster stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Fan, W.; Zhou, F.; Bai, X.; Tao, M.; Tian, T. Ship detection using deep convolutional neural networks for PolSAR images. Remote Sens. 2019, 11, 2862. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhang, X. High-speed ship detection in SAR images based on a grid convolutional neural network. Remote Sens. 2019, 11, 1206. [Google Scholar] [CrossRef] [Green Version]
- Jiao, J.; Zhang, X.; Sun, H.; Yang, X.; Gao, X.; Hong, W.; Fu, K.; Sun, X. A densely connected end-to-end neural network for multi-scale and multiscene SAR ship detection. IEEE Access 2018, 6, 20881–20892. [Google Scholar] [CrossRef]
- Cui, Z.; Li, Q.; Cao, Z.; Liu, N. Dense attention pyramid networks for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8983–8997. [Google Scholar] [CrossRef]
- Wang, J.; Lu, C.; Jiang, W. Simultaneous ship detection and orientation estimation in SAR images based on attention module and angle regression. Sensors 2018, 18, 2851. [Google Scholar] [CrossRef] [Green Version]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Yang, R.; Wang, G.; Pan, Z.; Lu, H.; Zhang, H.; Jia, X. A novel false alarm suppression method for CNN-based SAR ship detector. IEEE Geosci. Remote Sens. Lett. 2019, 16, 751–755. [Google Scholar]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention receptive pyramid network for ship detection in SAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.; Queon, I. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 4–8 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Sun, X.; Wang, Z.; Fu, K. An anchor-free method based on feature balancing and refinement network for multi-scale ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1331–1344. [Google Scholar] [CrossRef]
- Li, L.; Wang, C.; Zhang, H.; Zhang, B. SAR image ship object generation and classification with improved residual conditional generative adversarial network. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Lv, J.; Liu, Y. Data augmentation based on attributed scattering centers to train robust CNN for SAR ATR. IEEE Access 2019, 7, 25459–25473. [Google Scholar] [CrossRef]
- Cui, Z.; Zhang, M.; Cao, Z.; Cao, C. Image data augmentation for SAR sensor via generative adversarial nets. IEEE Access 2019, 7, 42255–42268. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computer-Assisted Intervention-MICCAI 2015, 18th International Conference, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A. Rotate to attend: Convolutional triplet attention module. arXiv 2020, arXiv:2010.03045. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Huang, G.; Liu, Z.; Maaten, L.; Weinberger, Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hononlulu, HI, USA, 21–26 July 2017; pp. 2269–3361. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9626–9635. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv 2020, arXiv:2006.04388. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, J.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2019; pp. 12993–13000. [Google Scholar]
- Li, J.; Qu, C.; Peng, S.; Deng, B. Ship detection in SAR images based on convolutional neural network. Syst. Eng. Electron. 2018, 40, 1953–1959. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C. Microsoft COCO: Common objects in context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q. EcientDet: Scalable and efficient object detection. arXiv 2019, arXiv:1911.09070. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Change, L.; Lin, D. CARAFE: Content-aware reassembly of features. arXiv 2019, arXiv:1905.02188. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring RCNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6402–6411. [Google Scholar]
- Wei, S.; Su, H.; Ming, J.; Wang, C.; Yan, M.; Kumar, D.; Shi, J.; Zhang, X. Precise and robust ship detection for high-resolution SAR imagery based on HR-SDNet. Remote Sens. 2020, 12, 167. [Google Scholar] [CrossRef] [Green Version]















| Layer | Type | Size | Number | Stride | Output | Parameter |
|---|---|---|---|---|---|---|
| 0 | Input | ― | ― | ― | 512 × 512 | ― |
| 1 | Conv | 4 × 4 | 32 | 1 | 512 × 512 | 544 |
| 2 | MaxPool | ― | ― | 2 | 256 × 256 | ― |
| 3 | Conv | 3 × 3 | 32 | 1 | 256 × 256 | 9248 |
| 4 | MaxPool | ― | ― | 2 | 128 × 128 | ― |
| 5 | Conv | 3 × 3 | 32 | 1 | 128 × 128 | 9248 |
| 6 | Conv | 3 × 3 | 64 | 1 | 128 × 128 | 18,496 |
| 7 | MaxPool | ― | ― | 2 | 64 × 64 | ― |
| 8 | Conv | 3 × 3 | 32 | 1 | 64 × 64 | 18,464 |
| 9 | MaxPool | ― | ― | 2 | 32 × 32 | ― |
| 10 | Conv | 3 × 3 | 32 | 1 | 32 × 32 | 9248 |
| 11 | Conv | 3 × 3 | 1 | 2 | 16 × 16 | 289 |
| Parameter | SSDD | HRSID |
|---|---|---|
| Satellite | RadarSat-2, TerraSAR-X, Sentinel-1 | Sentinel-1B, TerraSAR-X, TanDem |
| Polarization | HH, HV, VV, VH | HH, VV, HV |
| Location | Yantai, Visakhapatnam | Houston, Sao Paulo, etc. |
| Resolution (m) | 1–15 | 0.5, 1, 3 |
| Cover width (km) | ~10 | ~4 |
| Image size (pixel) | ― | 800 × 800 |
| Number of training images | 928 | 3642 |
| Number of testing images | 232 | 1962 |
| Total number of ships | 2456 | 16,951 |
| Method | Backbone | AP (%) | AP50 (%) | AP75 (%) | APs (%) | APm (%) | APl (%) |
|---|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet-100 + FPN | 52.0 | 88.7 | 57.7 | 49.9 | 56.4 | 34.2 |
| ResNet-100 + FPN + † | 53.1 | 90.2 | 58.2 | 53.6 | 55.4 | 40.4 | |
| YOLO-V3 | DarkNet-53 | 56.9 | 93.6 | 64.1 | 52.0 | 65.1 | 64.7 |
| DarkNet-53 + † | 57.8 | 94.2 | 64.3 | 53.5 | 68.4 | 68.8 | |
| FCOS | ResNet-50 + FPN | 58.8 | 93.3 | 67.0 | 52.9 | 68.3 | 67.8 |
| ResNet-50 + FPN + † | 61.5 | 94.9 | 70.1 | 53.4 | 68.0 | 68.2 | |
| SSD | VGG16 | 55.2 | 92.3 | 59.0 | 48.3 | 66.2 | 63.6 |
| VGG16 + † | 56.7 | 92.9 | 59.6 | 48.1 | 67.1 | 66.1 | |
| EfficientDet | EfficientNet-D4 | 59.3 | 89.3 | 72.1 | 54.6 | 66.5 | 71.1 |
| EfficientNet-D4 + † | 59.3 | 90.1 | 72.1 | 55.3 | 66.4 | 70.4 | |
| DSDet | DSNet 1.0× | 59.8 | 94.6 | 69.8 | 55.0 | 66.9 | 61.8 |
| DSNet 1.0× + † | 60.9 | 95.8 | 70.8 | 56.4 | 68.9 | 67.4 | |
| DSNet 2.0× | 60.5 | 96.7 | 70.2 | 56.3 | 68.1 | 58.9 | |
| DSNet 2.0× + † | 61.5 | 97.2 | 71.8 | 56.5 | 69.4 | 65.1 |
| Method | Backbone | Parameters (M) | Model Size (M) | AP (%) | AP50 (%) | AP75 (%) | APs (%) | APm (%) | APl (%) |
|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | ResNet-50 + FPN | 41.3 | 330.2 | 63.5 | 86.7 | 73.3 | 64.4 | 65.1 | 16.4 |
| ResNet-100 + FPN | 60.3 | 482.4 | 63.9 | 86.7 | 73.6 | 64.8 | 66.2 | 24.2 | |
| Cascade R-CNN [65] | ResNet-50 + FPN | 69.1 | 552.6 | 66.6 | 87.7 | 76.4 | 67.5 | 67.7 | 28.8 |
| ResNet-100 + FPN | 88.1 | 704.8 | 66.8 | 87.9 | 76.6 | 67.5 | 67.5 | 27.7 | |
| RetinaNet [66] | ResNet-50 + FPN | 36.3 | 290.0 | 60 | 84.7 | 67.2 | 60.9 | 60.9 | 26.8 |
| ResNet-100 + FPN | 55.3 | 442.3 | 59.8 | 84.8 | 67.2 | 60.4 | 62.7 | 26.5 | |
| Mask R-CNN [33] | ResNet-50 + FPN | 43.9 | 351.2 | 65.0 | 88.0 | 75.2 | 66.1 | 66.1 | 17.3 |
| ResNet-100 + FPN | 62.9 | 503.4 | 65.4 | 88.1 | 75.7 | 66.3 | 68.0 | 23.2 | |
| Mask Scoring R-CNN [67] | ResNet-50 + FPN | 60.1 | 481.1 | 64.1 | 87.6 | 75 | 65.3 | 65.8 | 22.2 |
| ResNet-100 + FPN | 79.1 | 633.1 | 64.9 | 88.6 | 75.4 | 66.2 | 67.3 | 19.6 | |
| Cascade Mask R-CNN [36] | ResNet-50 + FPN | 77.0 | 615.6 | 67.5 | 88.5 | 77.4 | 68.6 | 67.4 | 22.6 |
| ResNet-100 + FPN | 96.0 | 767.8 | 67.6 | 88.8 | 77.4 | 68.4 | 69.9 | 23.9 | |
| Hibrid Task Cascade [36] | ResNet-50 + FPN | 79.9 | 639.3 | 68.2 | 87.7 | 78.8 | 69 | 71.2 | 38.1 |
| ResNet-100 + FPN | 99.0 | 791.6 | 68.4 | 87.7 | 78.8 | 69.2 | 72 | 31.9 | |
| HRSDNet [68] | HRFPN-W32 | 74.8 | 598.1 | 68.6 | 88.4 | 79 | 69.6 | 70 | 25.2 |
| HRFPN-W40 | 91.2 | 728.2 | 69.4 | 89.3 | 79.8 | 70.3 | 71.1 | 28.9 | |
| DSDet | DSNet 1.0× | 0.7 | 5.6 | 59.8 | 90.3 | 73.3 | 65.5 | 62.2 | 23.1 |
| DSNet 2.0× | 0.7 | 5.6 | 60.5 | 90.7 | 74.6 | 66.8 | 64.0 | 7.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, K.; Liang, Y.; Ma, X.; Huai, Y.; Xing, M. DSDet: A Lightweight Densely Connected Sparsely Activated Detector for Ship Target Detection in High-Resolution SAR Images. Remote Sens. 2021, 13, 2743. https://doi.org/10.3390/rs13142743
Sun K, Liang Y, Ma X, Huai Y, Xing M. DSDet: A Lightweight Densely Connected Sparsely Activated Detector for Ship Target Detection in High-Resolution SAR Images. Remote Sensing. 2021; 13(14):2743. https://doi.org/10.3390/rs13142743
Chicago/Turabian StyleSun, Kun, Yi Liang, Xiaorui Ma, Yuanyuan Huai, and Mengdao Xing. 2021. "DSDet: A Lightweight Densely Connected Sparsely Activated Detector for Ship Target Detection in High-Resolution SAR Images" Remote Sensing 13, no. 14: 2743. https://doi.org/10.3390/rs13142743
APA StyleSun, K., Liang, Y., Ma, X., Huai, Y., & Xing, M. (2021). DSDet: A Lightweight Densely Connected Sparsely Activated Detector for Ship Target Detection in High-Resolution SAR Images. Remote Sensing, 13(14), 2743. https://doi.org/10.3390/rs13142743