
Onboard Real-Time Dense Reconstruction in Large Terrain Scene Using Embedded UAV Platform


Abstract
:
1. Introduction
- Simultaneous localization and dense depth estimation are carried out full automatically without ground control points (GCPs) or other manual intervention;
- An efficient portable GPU-accelerated pipeline is proposed. Careful engineering considerations are taken on as highly parallel and memory efficient. The system is finally implemented on the GPU-equipped UAV platform. Usability and efficiency are proved on both the real-world and synthesized large-scene aerial data;
- A new adaptive keyframe selection method is proposed. We analyzed the relationship among the accuracy of depth estimation, the length of the keyframe baseline, and the angle of optic ray, then proposed a cost function to select the keyframe for depth estimation dynamically. This method is aimed at the large and incline scene reconstruction;
- A novel dynamic search domain for the depth estimation scheme is proposed. This method utilizes the distribution characteristic of the scene to fit the plane dynamically, and enables the algorithm to adjust the search scale to improve accuracy without increasing the iterate time or memory consumption.
2. Related Work
2.1. Localization
2.2. Depth Estimation
3. Methods
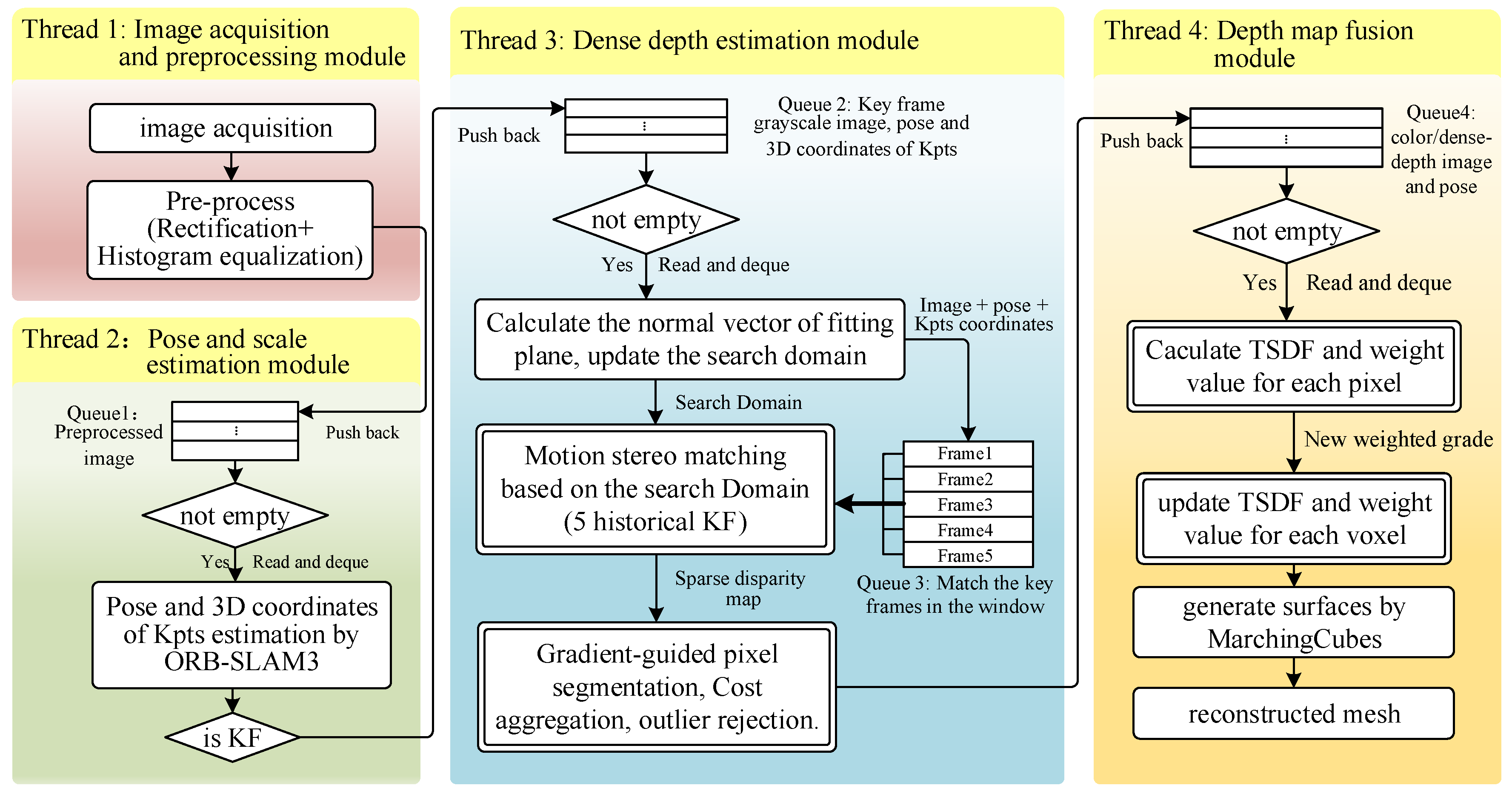
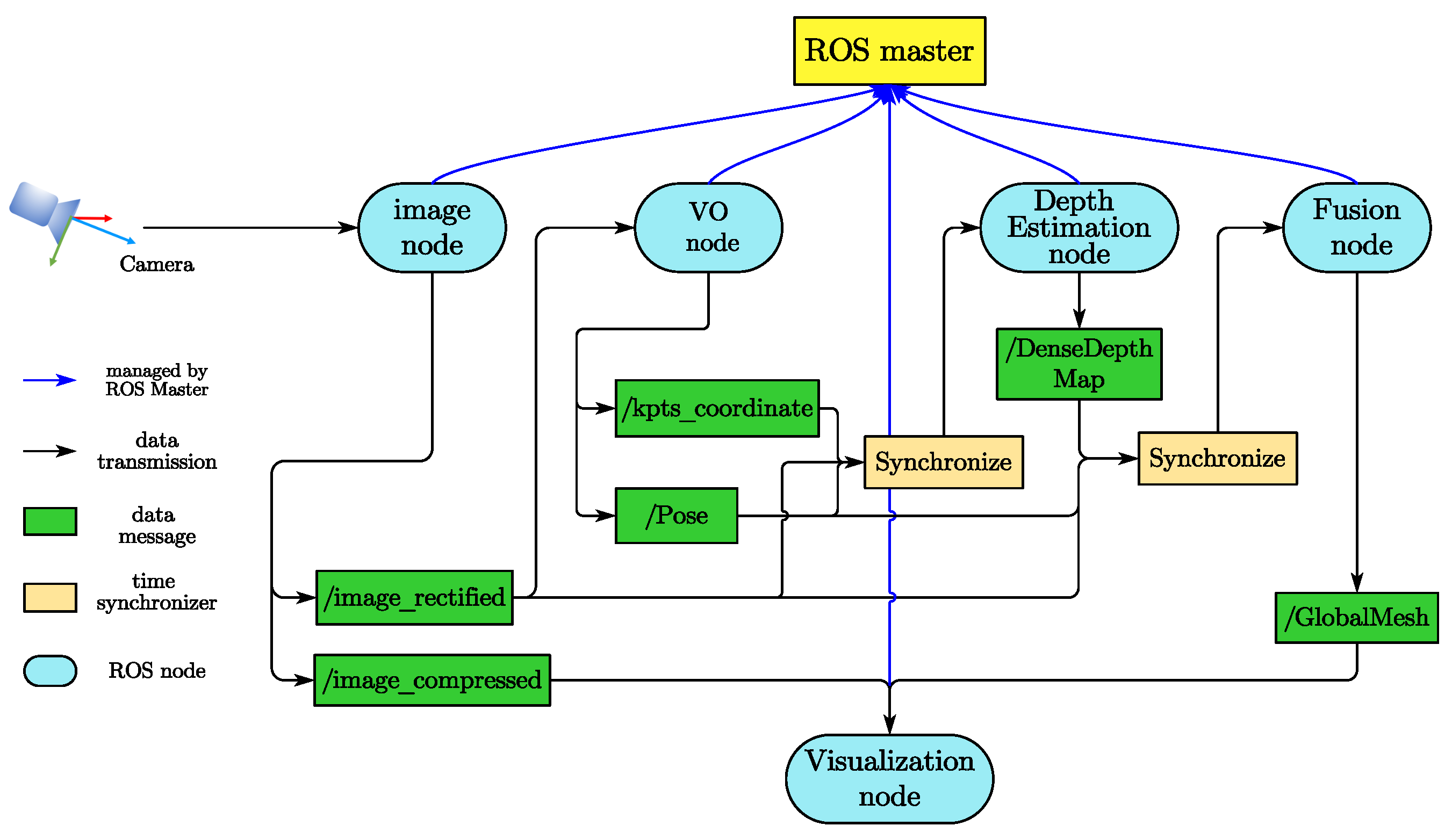
3.1. System Overview
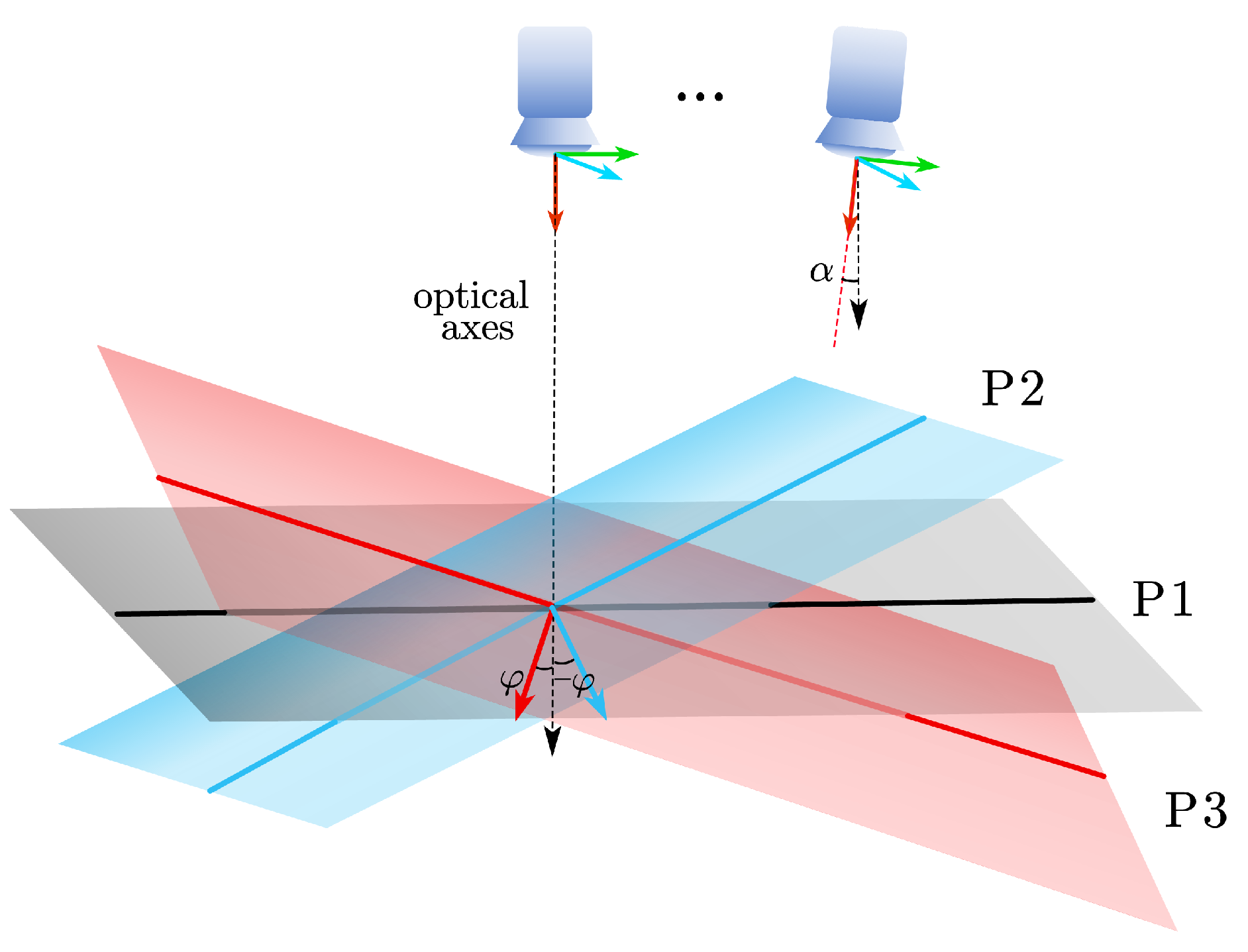
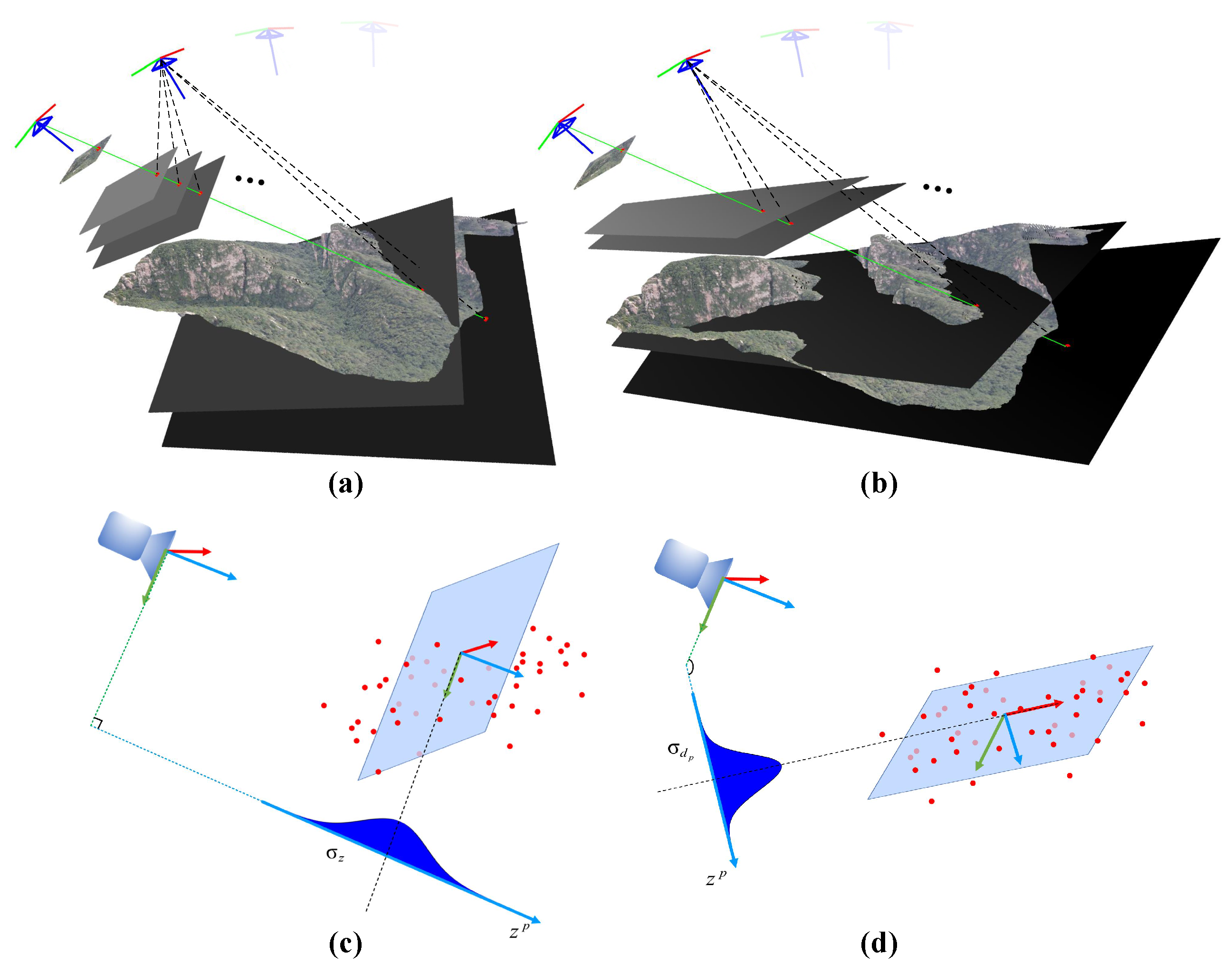
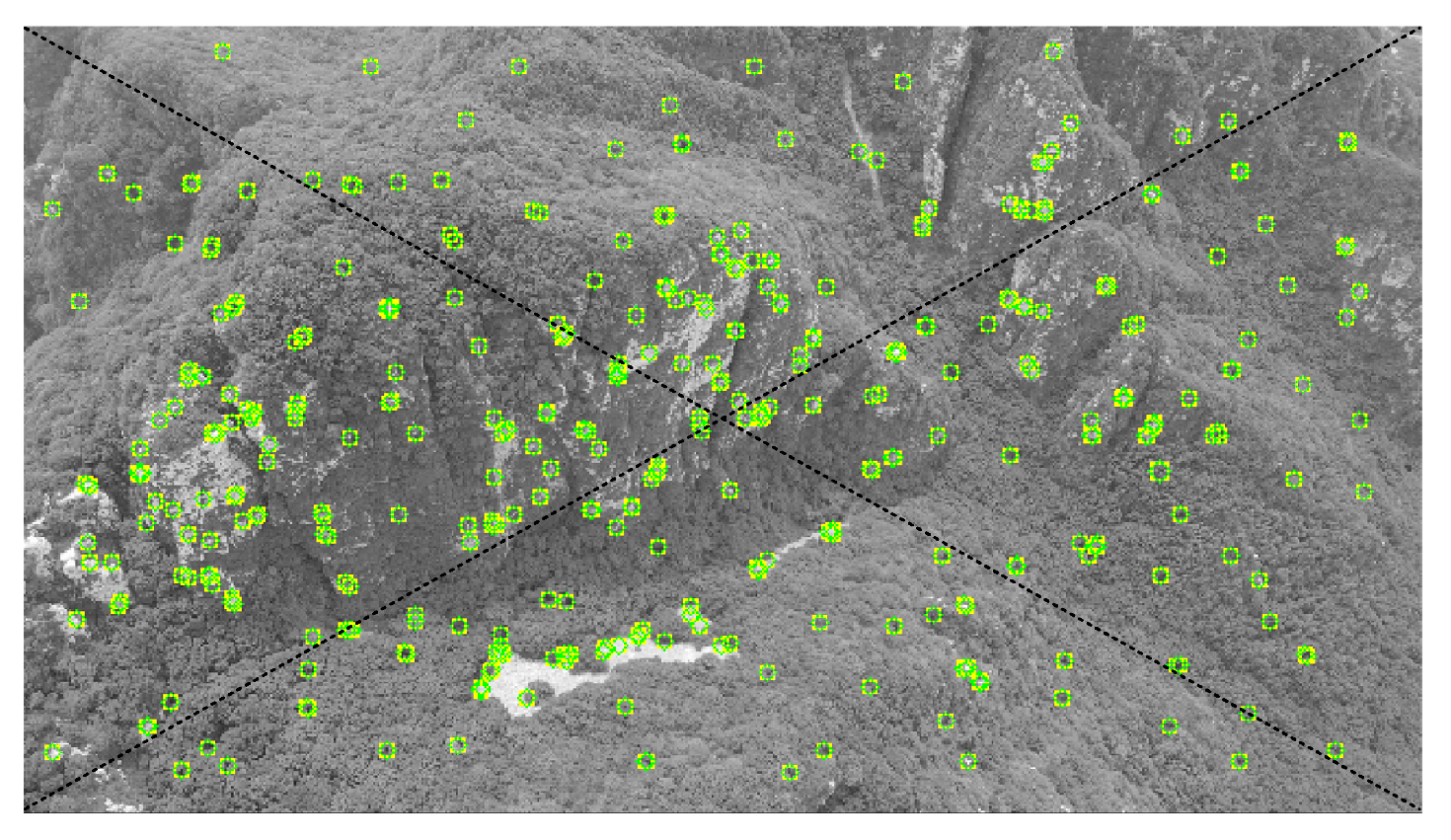
3.2. Dynamic Baseline Keyframe Selection
3.3. Multi-View Stereo Matching
3.3.1. Notation
3.3.2. Matching Cost
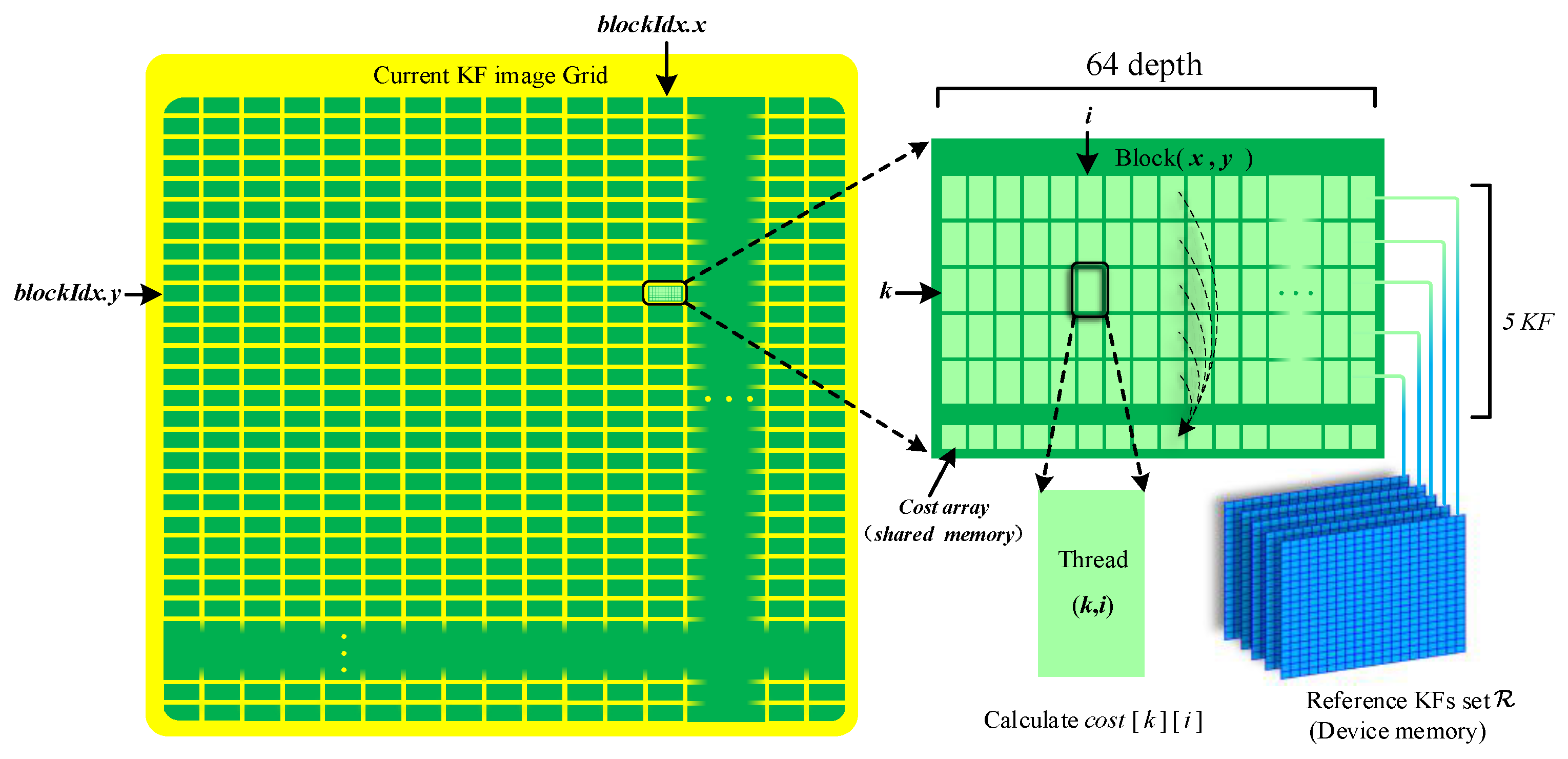
3.3.3. Parallel Computing
| Algorithm 1 Pseudocode of optimal depth extraction algorithm. |
| Input: |
| 1: blockIdx; |
| 2: threadIdx; |
| 3: image intensity of current target keyframe and measurement frame set |
| Output: optimal |
| 4: Pixel col: |
| 5: Pixel row: |
| 6: Currently matched referent keyframe index: |
| 7: Currently matched depth hypothesis index: |
| 8: define shared memory array: ⊳ Accessed by all block threads |
| 9: define shared memory array: |
| 10: define local variable: |
| 11: |
| 12: Equation (8) |
| 13: Equation (10) |
| 14: for ; ; do |
| 15: for ; ; do |
| 16: |
| 17: |
| 18: end for |
| 19: end for |
| 20: ⊳ Avoid thread blocking by using atomicAdd() |
| 21: synchronize threads |
| 22: |
| 23: for do |
| 24: if and then |
| 25: ⊳ Parallel rolling scan |
| 26: |
| 27: end if |
| 28: |
| 29: synchronize threads |
| 30: end for |
| 31: |
| 32: |
4. Experiment and Results
- Accuracy: The relative error rate (% w.r.t m), RMSE(m), and mean error(m) were calculated for the cross-method evaluations;
- Computation time (ms): The average computation time of each selected keyframe and the total computation cost;
- Density rate (%): The average percentage of the valid measurement in each depth map.
4.1. Accuracy Evaluation
4.1.1. Evaluation Data Acquisition
4.1.2. Depth Accuracy Evaluation
4.2. Global Mapping Evaluation
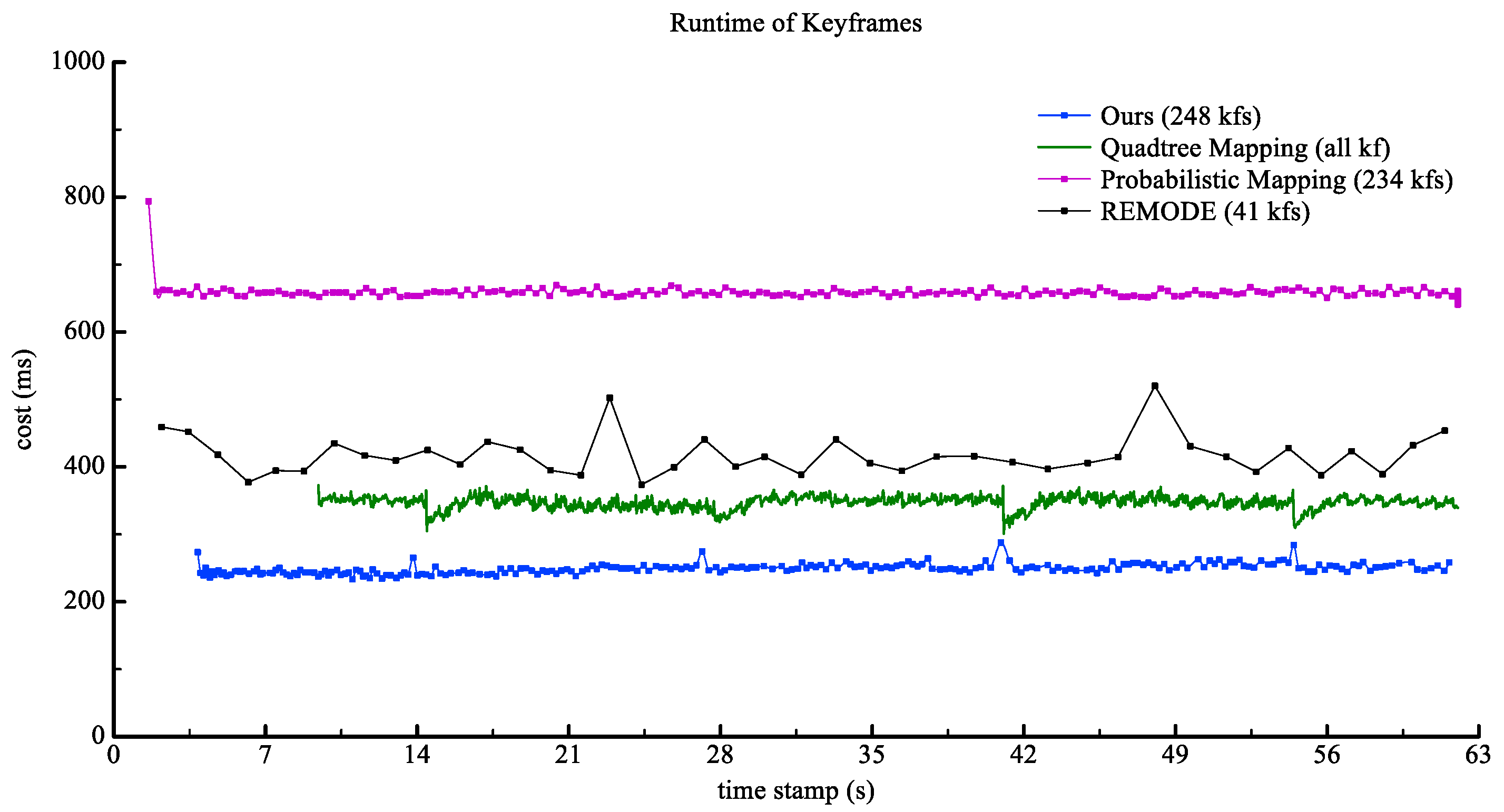
4.3. Speed Evaluation
4.4. Evaluation in Real-World Terrain Scenes
5. Discussion and Future Works
- We only did preliminary research with the aim of real-time terrain 3D reconstruction and proposed a calculation framework. This study focused on the use of a single camera for 3D reconstruction, which resulted in the lack of scale of the established 3D model. Thus, the points cannot be registered with the real-world terrain. Using IMU, GPS or other scale-aware sensors to fuse cameras together for scale registration can provide constraints under the condition of lack of vision, and the stability of the system could be improved as well.
- There is still room for improvement in accuracy. The monocular SLAM algorithm generally has problems relating to scale drift due to error accumulation. A loop-closure detection module is necessary for pose correction. Similar concepts can be used in the 3D reconstruction system. The localization module with closed-loop function can fuse the previous and current point clouds to build a drift-free 3D model, which can build a larger scale of terrain scene.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eltner, A.; Kaiser, A.; Castillo, C.; Rock, G.; Neugirg, F.; Abellan, A. Image-based surface reconstruction in geomorphometry—Merits, limits and developments. Earth Surf. Dyn. 2016, 4, 359–389. [Google Scholar] [CrossRef] [Green Version]
- Meinen, B.U.; Robinson, D.T. Mapping erosion and deposition in an agricultural landscape: Optimization of UAV image acquisition schemes for SfM-MVS. Remote Sens. Environ. 2020, 239. [Google Scholar] [CrossRef]
- Mohammed, F.; Idries, A.; Mohamed, N.; Al-Jaroodi, J.; Jawhar, I. UAVs for smart cities: Opportunities and challenges. In Proceedings of the 2014 International Conference on Unmanned Aircraft Systems (ICUAS), Orlando, FL, USA, 27–30 May 2014; pp. 267–273. [Google Scholar] [CrossRef]
- Bash, E.A.; Moorman, B.J.; Gunther, A. Detecting Short-Term Surface Melt on an Arctic Glacier Using UAV Surveys. Remote Sens. 2018, 10, 1547. [Google Scholar] [CrossRef] [Green Version]
- Jaud, M.; Passot, S.; Le Bivic, R.; Delacourt, C.; Grandjean, P.; Le Dantec, N. Assessing the Accuracy of High Resolution Digital Surface Models Computed by PhotoScan® and MicMac® in Sub-Optimal Survey Conditions. Remote Sens. 2016, 8, 465. [Google Scholar] [CrossRef] [Green Version]
- Hinzmann, T.; Schönberger, J.L.; Pollefeys, M.; Siegwart, R. Mapping on the Fly: Real-Time 3D Dense Reconstruction, Digital Surface Map and Incremental Orthomosaic Generation for Unmanned Aerial Vehicles. In Field and Service Robotics; Springer: Cham, Switzerland, 2018; Volume 5, pp. 383–396. [Google Scholar]
- Panigrahi, N.; Tripathy, S. Design Criteria of a UAV for ISTAR and Remote Sensing Applications. J. Indian Soc. Remote Sens. 2021, 49, 665–669. [Google Scholar] [CrossRef]
- Tran, D.Q.; Park, M.; Jung, D.; Park, S. Damage-Map Estimation Using UAV Images and Deep Learning Algorithms for Disaster Management System. Remote Sens. 2020, 12, 4169. [Google Scholar] [CrossRef]
- Meinen, B.U.; Robinson, D.T. Streambank topography: An accuracy assessment of UAV-based and traditional 3D reconstructions. Int. J. Remote Sens. 2020, 41, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Microsoft Azure-Kinect-DK. Available online: https://azure.microsoft.com/en-us/services/kinect-dk/ (accessed on 1 July 2021).
- Intel RealSense Sensor. Available online: https://www.intelrealsense.com/ (accessed on 1 July 2021).
- Jiang, S.; Jiang, C.; Jiang, W. Efficient structure from motion for large-scale UAV images: A review and a comparison of SfM tools. Isprs J. Photogramm. Remote Sens. 2020, 167, 230–251. [Google Scholar] [CrossRef]
- Gupta, S.K.; Shukla, D.P. Application of drone for landslide mapping, dimension estimation and its 3D reconstruction. J. Indian Soc. Remote Sens. 2018, 46, 1–12. [Google Scholar] [CrossRef]
- Snavely, N.; Seitz, S.M.; Szeliski, R. Photo tourism: Exploring photo collections in 3D. Acm Trans. Graph. (TOG) 2006, 25, 835–846. [Google Scholar] [CrossRef]
- Schmid, S.; Fritsch, D. Fast Radiometry Guided Fusion of Disparity Images. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLI-B3, 91–97. [Google Scholar] [CrossRef] [Green Version]
- Smith, R.C.; Cheeseman, P. On the Representation and Estimation of Spatial Uncertainty. Int. J. Robot. Res. 1986, 5, 56–68. [Google Scholar] [CrossRef]
- Montemerlo, M.; Thrun, S.; Koller, D.; Wegbreit, B. FastSLAM: A Factored Solution to the Simultaneous Localization and Mapping Problem; MIT Press: Cambridge, UK, 2002; pp. 593–598. [Google Scholar]
- Davison, A.J.; Reid, I.D.; Molton, N.D.; Stasse, O. MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1052–1067. [Google Scholar] [CrossRef] [Green Version]
- Jinyu, L.; Bangbang, Y.; Danpeng, C.; Nan, W.; Guofeng, Z.; Hujun, B. Survey and evaluation of monocular visual-inertial SLAM algorithms for augmented reality. Virtual Real. Intell. Hardw. 2019, 1, 386–410. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, J.; Liu, J. A Survey of Simultaneous Localization and Mapping with an Envision in 6G Wireless Networks. arXiv 2020, arXiv:1909.05214. [Google Scholar]
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014. [Google Scholar] [CrossRef] [Green Version]
- Campos, C.; Elvira, R.; Gómez, J.J.; Montiel, J.M.M.; Tardós, J.D. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM. arXiv 2020, arXiv:2007.11898. [Google Scholar]
- Seitz, S.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A Comparison and Evaluation of Multi-View Stereo Reconstruction Algorithms. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 519–528. [Google Scholar] [CrossRef]
- Furukawa, Y.; Hernández, C. Multi-View Stereo: A Tutorial; Now Publishers, Inc.: Hanover, MA, USA, 2015; pp. 1–148. [Google Scholar]
- Piazza, P.; Cummings, V.; Guzzi, A.; Hawes, I.; Lohrer, A.; Marini, S.; Marriott, P.; Menna, F.; Nocerino, E.; Peirano, A. Underwater photogrammetry in Antarctica: Long-term observations in benthic ecosystems and legacy data rescue. Polar Biol. 2019, 42, 1061–1079. [Google Scholar] [CrossRef] [Green Version]
- Xiao, X.; Guo, B.; Li, D.; Li, L.; Yang, N.; Liu, J.; Zhang, P.; Peng, Z. Multi-View Stereo Matching Based on Self-Adaptive Patch and Image Grouping for Multiple Unmanned Aerial Vehicle Imagery. Remote Sens. 2016, 8, 89. [Google Scholar] [CrossRef] [Green Version]
- Mohamed, H.; Nadaoka, K.; Nakamura, T. Towards Benthic Habitat 3D Mapping Using Machine Learning Algorithms and Structures from Motion Photogrammetry. Remote Sens. 2020, 12, 127. [Google Scholar] [CrossRef] [Green Version]
- Hornung, A.; Kobbelt, L. Robust and efficient photo-consistency estimation for volumetric 3D reconstruction. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; Volume 3952, pp. 179–190. [Google Scholar]
- Starck, J.; Hilton, A.; Miller, G. Volumetric Stereo with Silhouette and Feature Constraints. In Proceedings of the British Machine Vision Conference, Edinburgh, UK, 4–7 September 2006; pp. 1189–1198. [Google Scholar] [CrossRef] [Green Version]
- Tran, S.; Davis, L. 3D surface reconstruction using graph cuts with surface constraints. In Proceedings of the European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; Volume 3952, pp. 219–231. [Google Scholar]
- Vu, H.H.; Labatut, P.; Pons, J.P.; Keriven, R. High Accuracy and Visibility-Consistent Dense Multiview Stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 889–901. [Google Scholar] [CrossRef] [PubMed]
- Hirschmüller, H. Semi-Global Matching-Motivation, Developments and Applications. In Proceedings of the Invited Paper at the 54th Photogrammetric Week, Stuttgart, Germany, 5–11 September 2011; pp. 173–184. [Google Scholar]
- Luo, Q.; Li, Y.; Qi, Y. Distributed Refinement of Large-Scale 3D Mesh for Accurate Multi-View Reconstruction. In Proceedings of the 2018 International Conference on Virtual Reality and Visualization (ICVRV), Qingdao, China, 22–24 October 2018. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Gao, F.; Shen, S. Real-time monocular dense mapping on aerial robots using visual-inertial fusion. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4552–4559. [Google Scholar] [CrossRef]
- Wang, K.; Ding, W.; Shen, S. Quadtree-Accelerated Real-Time Monocular Dense Mapping. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 199–208. [Google Scholar] [CrossRef] [Green Version]
- Gallup, D.; Frahm, J.M.; Mordohai, P.; Pollefeys, M. Variable baseline/resolution stereo. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Aguilar-González, A.; Arias-Estrada, M. Dense mapping for monocular-SLAM. In Proceedings of the 2016 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Alcala de Henares, Spain, 4–7 October 2016; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Evans, T.J.; Yu, A.B.; Yang, R.Y. A GPU-based DEM for modelling large scale powder compaction with wide size distributions. Powder Technol. 2018, 333, 219–228. [Google Scholar] [CrossRef]
- Pizzoli, M.; Forster, C.; Scaramuzza, D. REMODE: Probabilistic, monocular dense reconstruction in real time. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2609–2616. [Google Scholar] [CrossRef] [Green Version]
- Ling, Y.; Wang, K.; Shen, S. Probabilistic Dense Reconstruction from a Moving Camera. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6364–6371. [Google Scholar] [CrossRef]
- NVidia TX2. Available online: https://www.nvidia.cn/autonomous-machines/embedded-systems/jetson-tx2/ (accessed on 1 July 2021).
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura–Algarve, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 1524–1531. [Google Scholar] [CrossRef] [Green Version]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar] [CrossRef]
- Gazebo Simulator. Available online: http://www.gazebosim.org/ (accessed on 1 July 2021).
- Terrain.Party. Available online: https://terrain.party/ (accessed on 1 July 2021).
- OpenStreetMap. Available online: www.openstreetmap.org (accessed on 1 July 2021).
- Cloud Compare. Available online: http://www.cloudcompare.org (accessed on 1 July 2021).
- Agisoft PhotoScan Professional. Available online: http://www.agisoft.com/ (accessed on 1 July 2021).



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
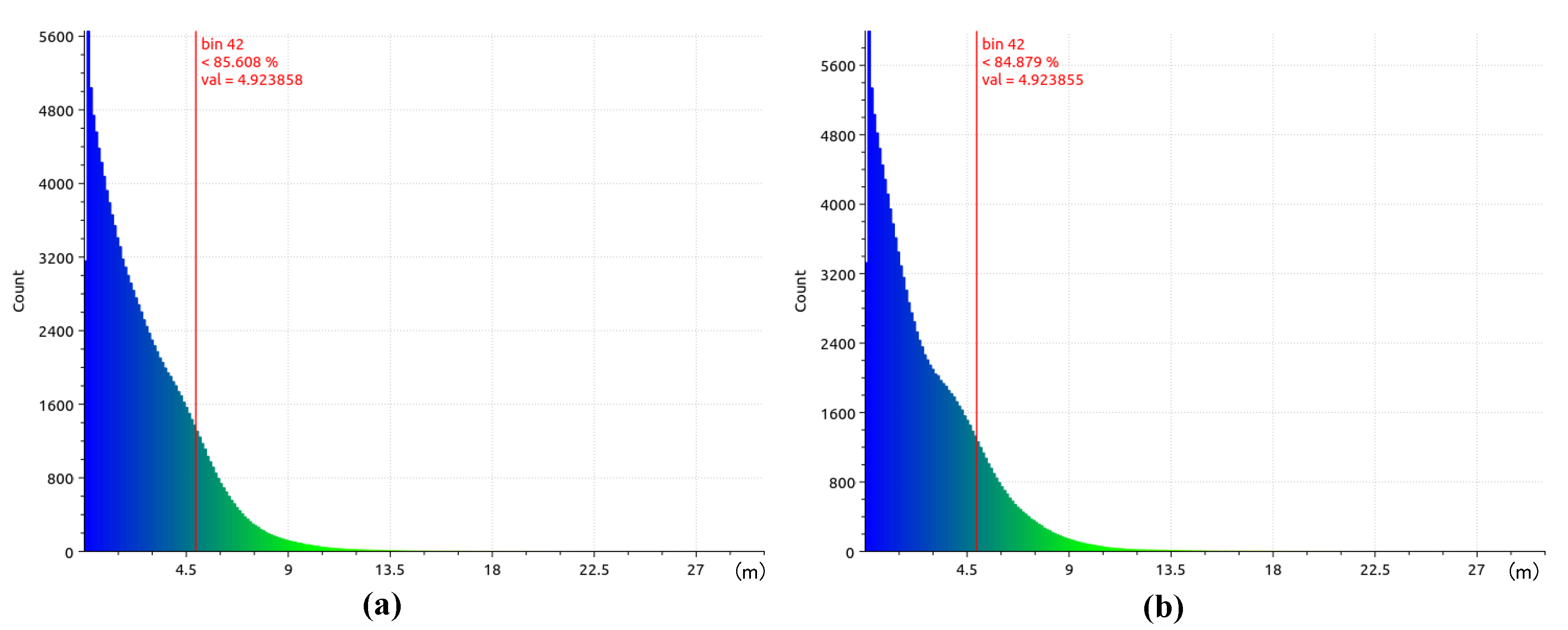{kind=link}
| Method | Metrics | Flying Ground Height | Terrain Height Difference | ||||
|---|---|---|---|---|---|---|---|
| 800 m | 1000 m | 1200 m | 100 m | 200 m | 300 m | ||
| Ours | Error Rate within 1% (%) | 83.741 | 81.542 | 85.974 | 77.273 | 83.791 | 78.389 |
| Outlier Rate (%) | 0.706 | 1.227 | 1.261 | 0.612 | 1.347 | 1.682 | |
| RMSE (m) | 5.767 | 7.608 | 8.288 | 2.441 | 2.020 | 2.448 | |
| Mean Error (m) | 4.537 | 5.957 | 6.516 | 1.970 | 1.544 | 1.910 | |
| Quadtree Mapping | Error Rate within 1% (%) | 82.101 | 77.053 | 80.62 | 69.998 | 74.016 | 76.113 |
| Outlier Rate (%) | 0.632 | 1.182 | 0.934 | 0.899 | 1.591 | 0.719 | |
| RMSE (m) | 5.940 | 8.322 | 9.352 | 2.996 | 2.559 | 2.541 | |
| Mean (m) | 4.701 | 6.574 | 7.445 | 2.296 | 2.066 | 2.018 | |
| Probabilistic Mapping | Error Rate within 1% (%) | 64.821 | 60.124 | 57.403 | 70.511 | 76.068 | 69.464 |
| Outlier rate (%) | 3.410 | 6.183 | 9.433 | 2.493 | 2.533 | 3.558 | |
| RMSE (m) | 8.081 | 12.258 | 12.953 | 2.882 | 2.465 | 2.879 | |
| Mean (m) | 6.534 | 10.024 | 10.486 | 2.274 | 1.941 | 2.271 | |
| REMODE | Error Rate within 1% (%) | 67.632 | 73.210 | 62.288 | 69.086 | 76.842 | 69.419 |
| Outlier rate (%) | 5.113 | 2.760 | 13.641 | 3.3186 | 1.874 | 2.610 | |
| RMSE (m) | 7.839 | 9.136 | 11.223 | 2.985 | 2.428 | 2.836 | |
| Mean (m) | 6.168 | 7.106 | 9.016 | 2.348 | 1.949 | 2.280 | |
| Method | Number of Keyframe | Mean Cost Per Keyframe (s) | Total Run-Time (s) | Density Rate (%) |
|---|---|---|---|---|
| Ours | 248 | 0.229 | 62.762 | 93.391 |
| Quadtree-Mapping | 1577 | 0.346 | 646.999 | 97.189 |
| REMODE | 41 | 0.417 | 64.981 | 50.695 |
| Probabilistic-Mapping | 234 | 0.657 | 153.866 | 96.693 |
| Image Sequences | No. | Image Amount | Approximate Ground Height (m) | Pitch Angle (°) | Point Amount |
|---|---|---|---|---|---|
| Towns | 1 | 1811 | 400 | 75 | 632,758 |
| 2 | 1805 | 500 | 75 | 596,257 | |
| 3 | 1823 | 500 | 90 | 613,125 | |
| Mountains | 1 | 1806 | 600 | 75 | 563,649 |
| 2 | 1851 | 800 | 75 | 513,699 | |
| 3 | 1864 | 800 | 90 | 533,461 | |
| Mixed Zone | 1 | 1835 | 800 | 75 | 476,533 |
| 2 | 1840 | 800 | 75 | 451,128 | |
| 3 | 1862 | 1000 | 90 | 419,561 |
| Methods | CPU | GPU | Time Costs on Aerial Datasets (m′s″) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| T1 | T2 | T3 | M1 | M2 | M3 | MZ1 | MZ2 | MZ3 | |||
| Ours | Arm Cortex A57 | TX2 Embedded GPU | |||||||||
| Photoscan | Intel Core i9 10850 | NVidia RTX2080ti | |||||||||
| Percentage of Difference < 5 m(%) | 75.31 | 78.23 | 81.27 | 81.68 | 83.14 | 88.25 | 83.85 | 84.87 | 89.25 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, Z.; Liu, F.; Guo, S.; Meng, X.; Han, S.; Li, W. Onboard Real-Time Dense Reconstruction in Large Terrain Scene Using Embedded UAV Platform. Remote Sens. 2021, 13, 2778. https://doi.org/10.3390/rs13142778
Lai Z, Liu F, Guo S, Meng X, Han S, Li W. Onboard Real-Time Dense Reconstruction in Large Terrain Scene Using Embedded UAV Platform. Remote Sensing. 2021; 13(14):2778. https://doi.org/10.3390/rs13142778
Chicago/Turabian StyleLai, Zhengchao, Fei Liu, Shangwei Guo, Xiantong Meng, Shaokun Han, and Wenhao Li. 2021. "Onboard Real-Time Dense Reconstruction in Large Terrain Scene Using Embedded UAV Platform" Remote Sensing 13, no. 14: 2778. https://doi.org/10.3390/rs13142778
APA StyleLai, Z., Liu, F., Guo, S., Meng, X., Han, S., & Li, W. (2021). Onboard Real-Time Dense Reconstruction in Large Terrain Scene Using Embedded UAV Platform. Remote Sensing, 13(14), 2778. https://doi.org/10.3390/rs13142778