4.1. Model Performance
Among the different deep learning models that we tested, anti-aliased ResNet18 demonstrated the best accuracy overall.
Table 1 shows the test results by different algorithms.
The anti-aliased ResNet18 model achieved an overall accuracy of 84%, which is relatively higher when compared to recent studies [
50] and considering the complexity of the task and the simplicity of the approach. For the test set, the performance of the model was assessed, taking into account two possible labels “school” (236 images) and “not-school” (449 images).
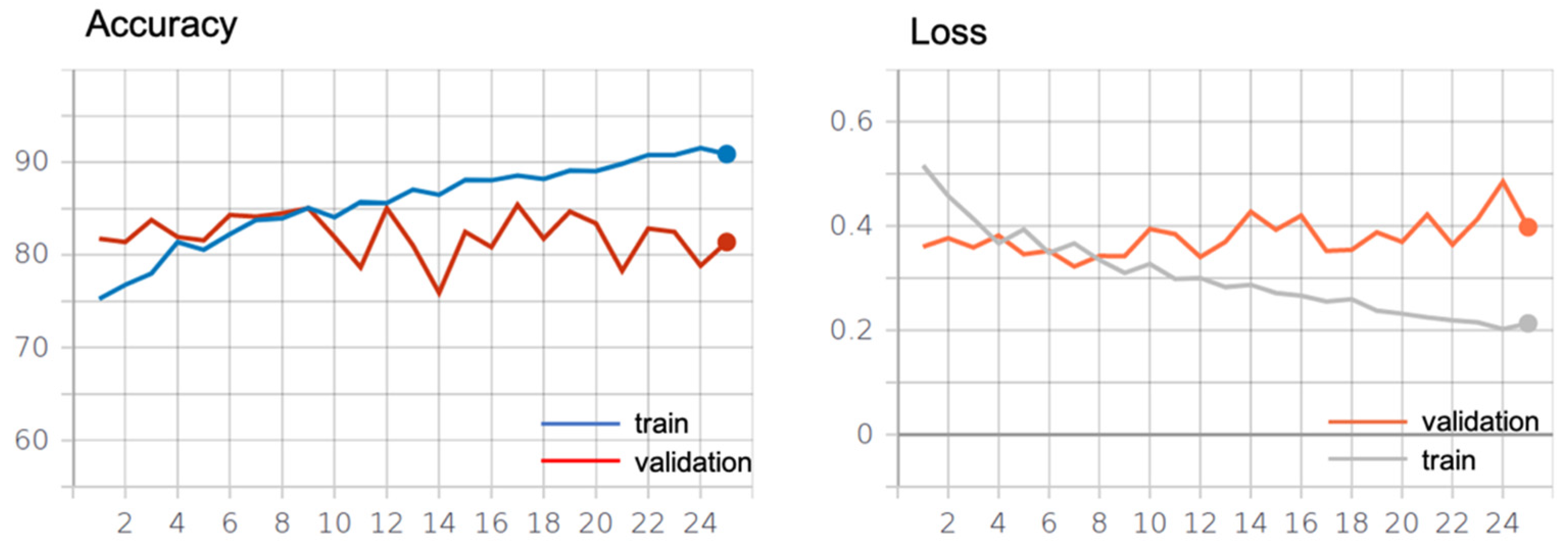
Figure 2 shows the learning curve of the anti-aliased ReseNet18 model.
The model accuracy for “school” labels was 0.84, and for images labeled “not-school”, it was 0.74. Analogously, we found that the precision was 0.74 and 0.91, respectively, the recall was 0.87 and 0.84, respectively, while the F
1-score was 0.79 and 0.87, respectively. The precision and F
1-scores for the “not-school” label were better than those for the “school” label, i.e., the classifier was more likely to fail when predicting the “school” label rather than the “not-school.”
Table 2 shows the confusion matrix between school and not-school samples.
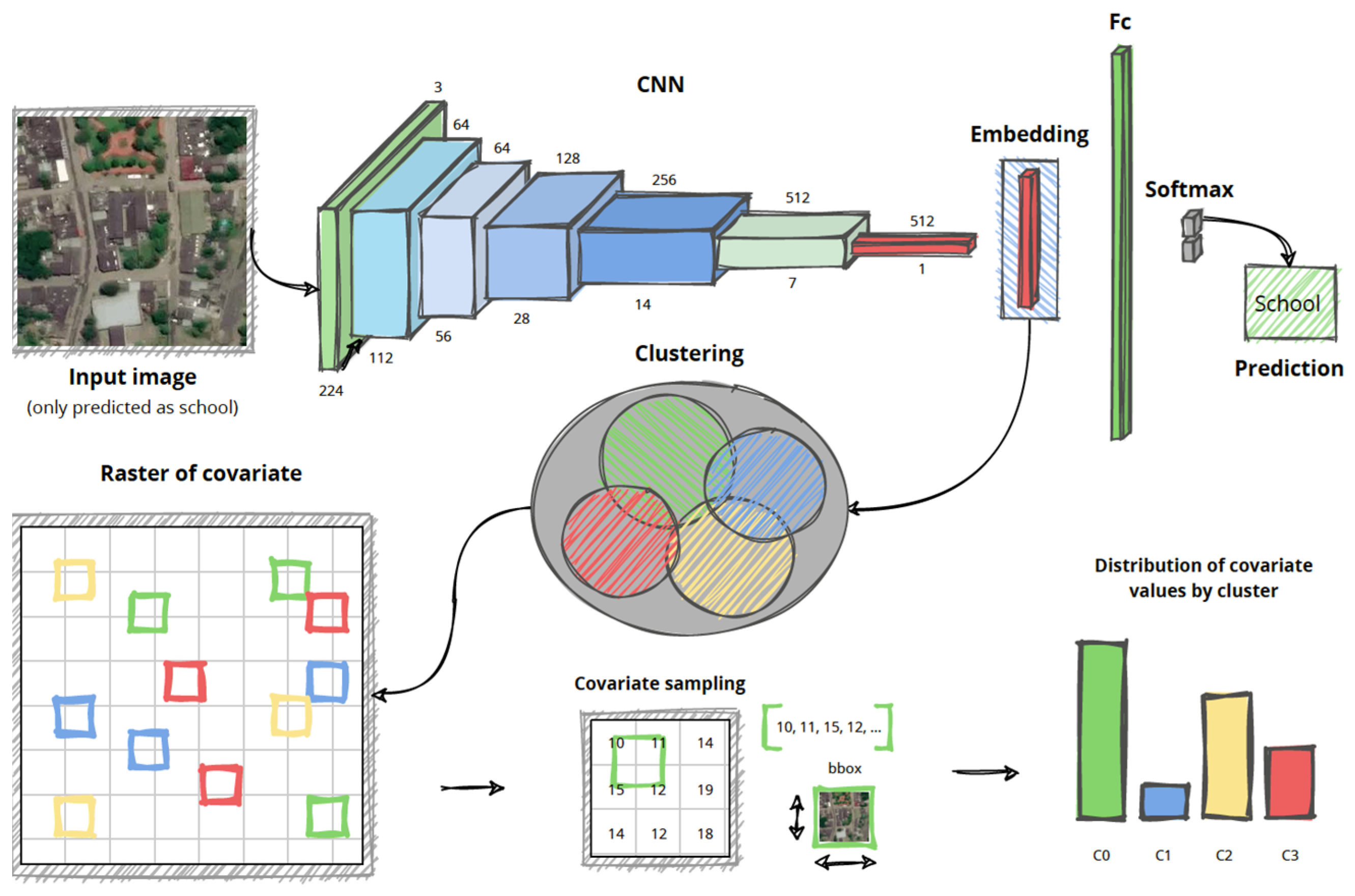
Even if the classifier correctly classifies an image as “school”, it is possible that what the neural network learned were some other characteristics common to all the samples in the dataset. To ensure that the classifier was actually detecting school buildings, we used Gradient-Weighted Class Activation Mapping (Grad-CAM), which showed where in the satellite image tile the model was looking at [
51]. A visual explanation of what the model does is depicted in
Figure 3 (each blue-yellow-red map to the right of the satellite image).
We found that nearly 83% of the model’s predictions located the correct building. The later analysis was performed manually, visually inspecting the regions obtained from the gradient class activation and comparing them against the ground truth (the real images with a dot on top of the school building). From the accuracy assessment and Grad-CAM, we confirmed that the model was correctly identifying the vast majority of school buildings.
An assumption about our model was that it may work differently in different places. To test the assumption before a further analysis on different socioeconomic contexts, we summarized the result of the classification to show the differences in the accuracies between an urban area and rural area (
Table 3). For the distinction between urban and rural areas, we used the data and definition from the Global Human Settlement Layer [
52]. From the comparison between the results for urban and rural areas, we found a very high difference in the model accuracies (diff: 0.236) between subsets. The model accuracy was better for the rural subset than the urban one. Further analysis of the confusion matrix for urban and rural areas revealed more detailed insights on the performance of our model (
Table 4).
In urban areas, our model performed much less effectively when predicting the not-school class. This implies that in the urban class compared to school areas, the model was biased towards schools and making over-predictions. Contrarily, the model performed with very high accuracy (recall: 0.952, F
1-score: 0.959) for the not-school label in the rural subset. However,
Figure 4 shows that there were many images without buildings in the rural subset, making it easy for the classifier to detect the lack of buildings as not-schools and produce higher accuracy metrics.
4.2. Clustering
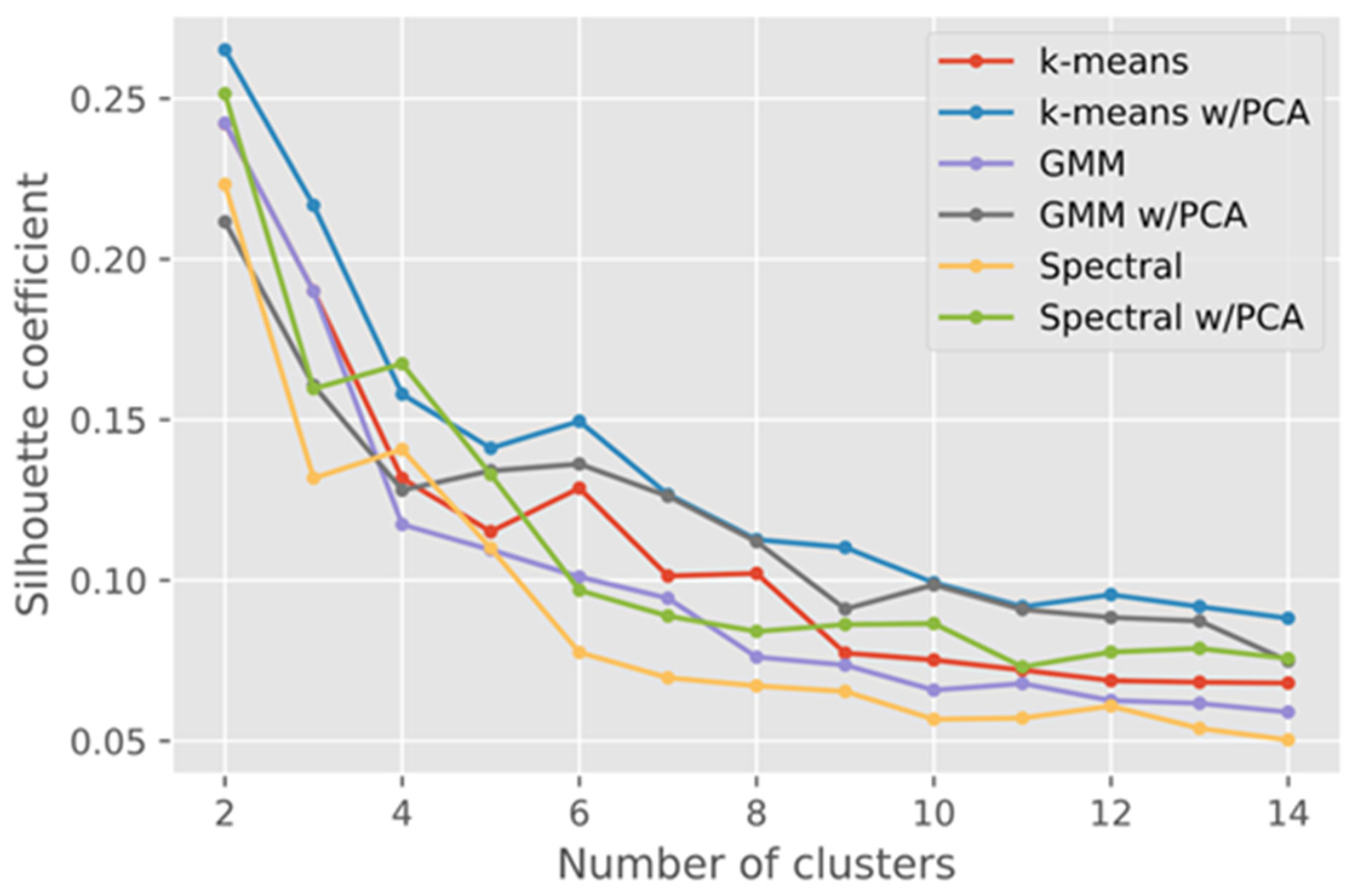
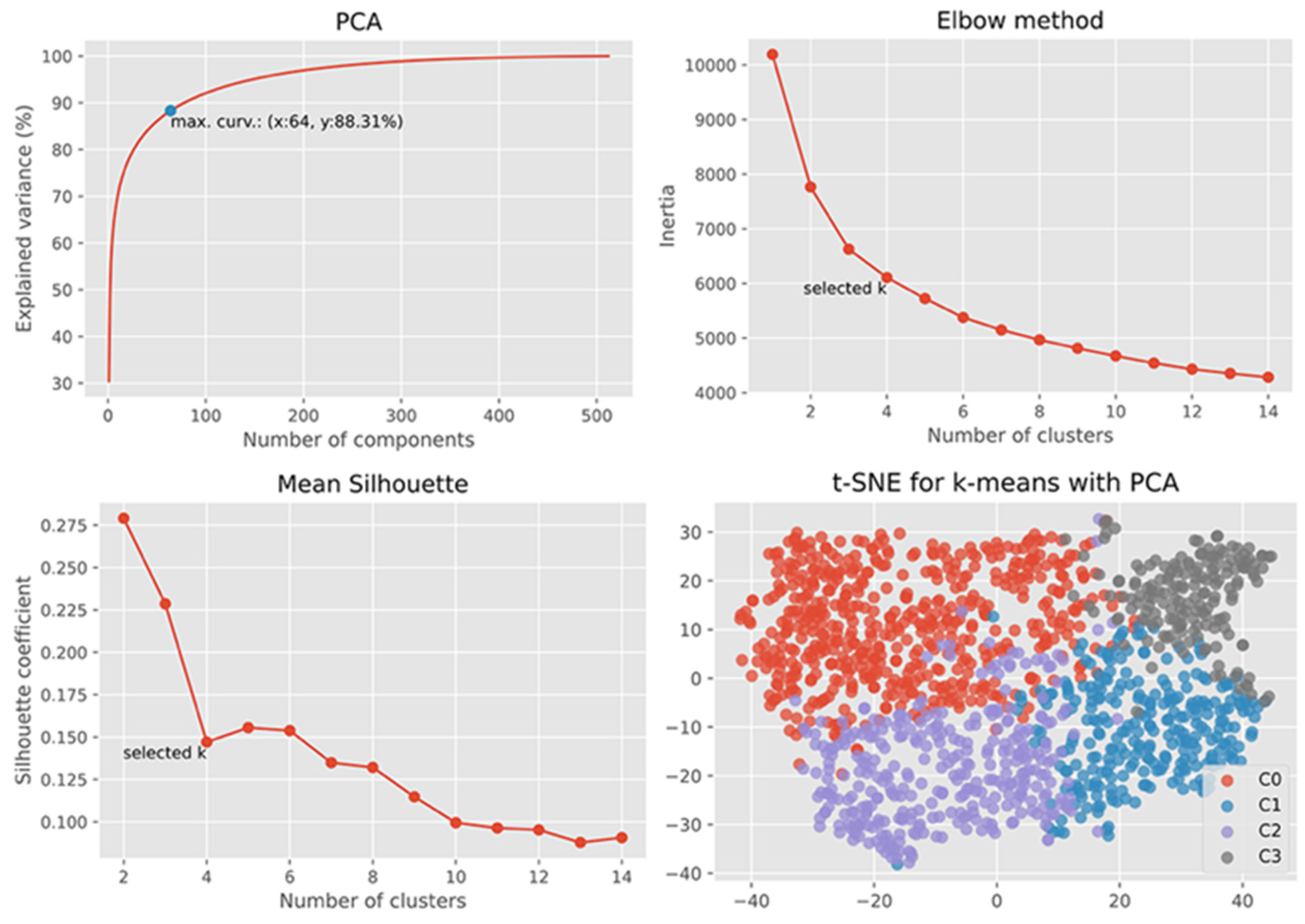
Having a model able to identify school buildings, we continued to identify sub-types of school images using clustering methods. We tested different clustering algorithms, different numbers of possible clusters and finally used the Silhouette Coefficient to evaluate the results obtained.
From
Figure 5, we can observe that
k-means with PCA dimensionality reduction gave the best results based on the Silhouette Coefficient [
45]. The coefficients from different clustering methods with and without applying Principal Component Analysis (PCA) were comparatively low, which means a relatively high overlap between clusters [
47]. Based on this observation,
k-means with PCA was chosen as the method for clustering. Then, using the heuristic Elbow method [
53], we obtained the optimal number of clusters of four.
Figure 6 shows the number of clusters chosen using Elbow and Silhouette methods, with a visualization of clusters in two-dimensional space using T-distributed stochastic neighbor embedding (t-SNE).
We labeled the four clusters with numbers ranging from 0 to 3: C0 (529 elements), C1 (273 elements), C2 (330 elements), and C3 (172 elements). We visually investigated each cluster for any noticeable patterns. From this, we concluded that clusters were largely decided by the characteristics of landscape (amount of vegetation, urban versus rural) in the area where the school buildings were located rather than by the features from the school buildings themselves.
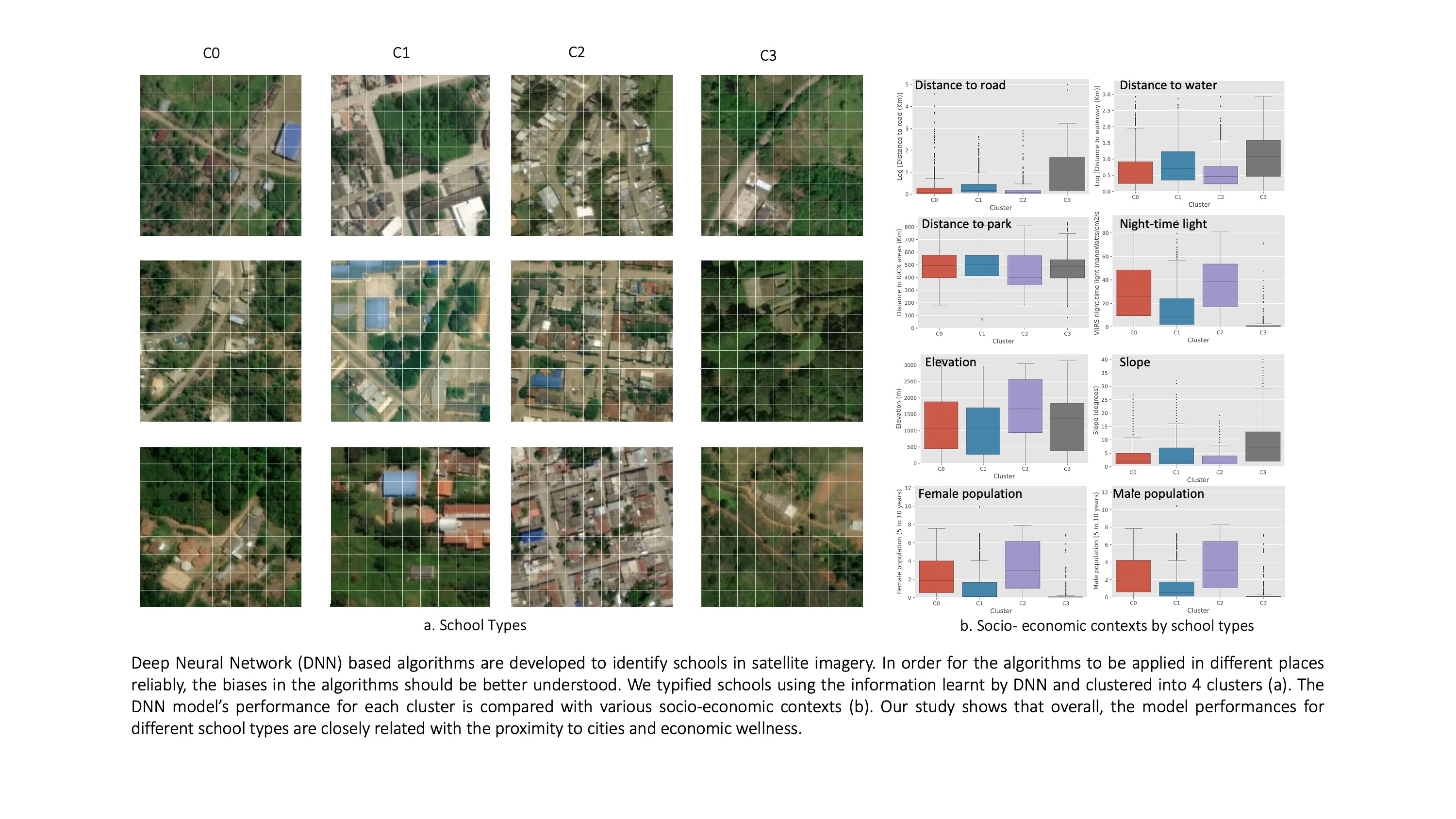
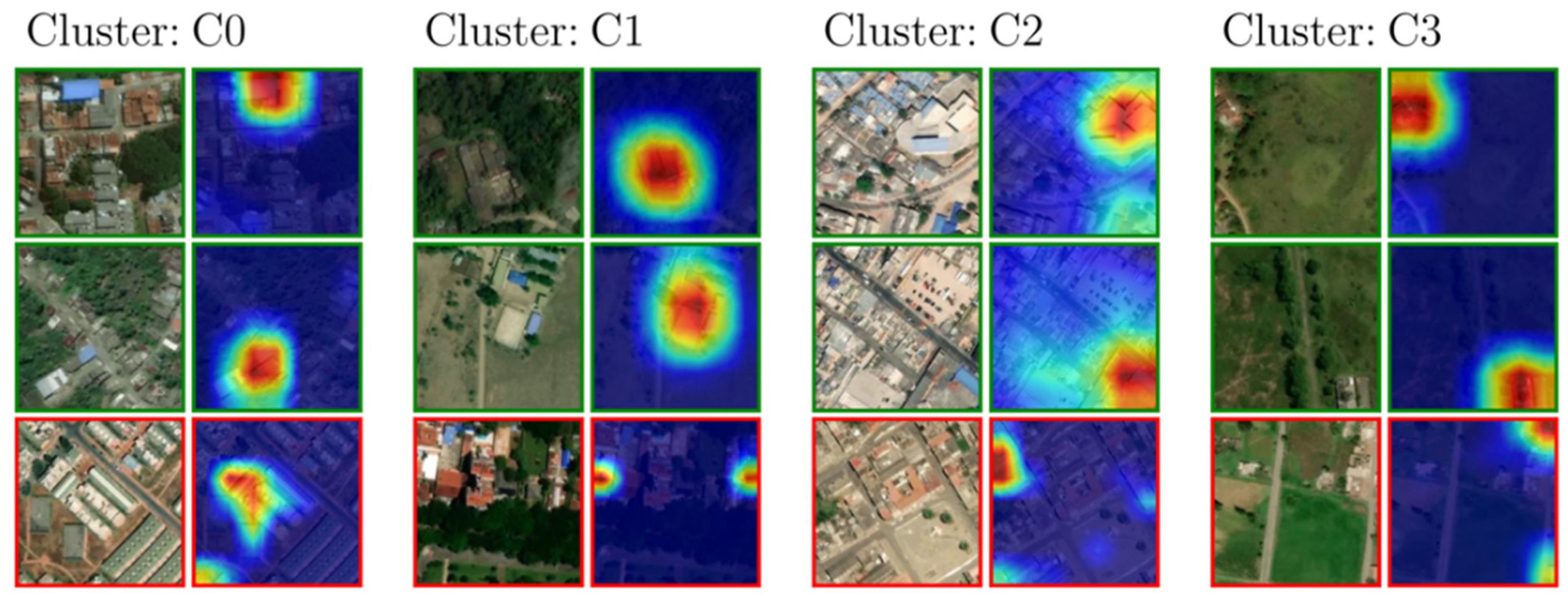
In
Figure 7, we can observe three images sampled for each cluster together with their respective Grad-CAM heatmap. The color of the border around each image indicates if a school was present or not in the image. Each group of four images corresponds to a cluster, with its corresponding label on top. From inspecting the images in each cluster, we can observe that cluster C2 was mostly urban, while cluster C3 was mostly rural. Clusters C0 and C1 had a larger diversity with mixed urban and rural images in them. The three images depicted for each cluster follow a specific logic. The two images on the top (with the green border) are the most representative images in each cluster that were at the same time true positives (contained a school building and were classified as schools). In this case, the most representative image was measured using the highest value of the Silhouette Coefficient. On the other hand, the picture in the bottom with the red border with the least representative image in the cluster was a false positive (it did not have a school but was classified as having one). The color of the border in
Figure 7 indicates whether our classification algorithm correctly predicted a school or not. A green border represents an accurate prediction, while a red border indicates an incorrect one.
Having described the four clusters and their characteristics, we delved into the main question of the paper: is there an intrinsic bias in the model? To tackle this unknown, we studied the performance of the model per cluster instead of looking at the aggregate result.
Table 5 shows training and testing accuracies by each cluster. Clusters C0 and C3, which had characteristics of rural areas, showed a relatively lower test and train accuracy compared to clusters C1 and C2, which were mostly urban. The numbers presented above clearly show that the schools in the clusters with urban characteristics could be identified much better. The number of red and green borders in
Figure 7 is not representative of the accuracy of each cluster. Those representatives were obtained by random sampling from each cluster. Since urban areas are typically wealthier than their rural counterparts, we tried to understand if the bias in the clusters was correlated to socioeconomic covariates and, therefore, if the model was negatively biased towards poorer communities.
4.3. Socioeconomic Covariates Analysis
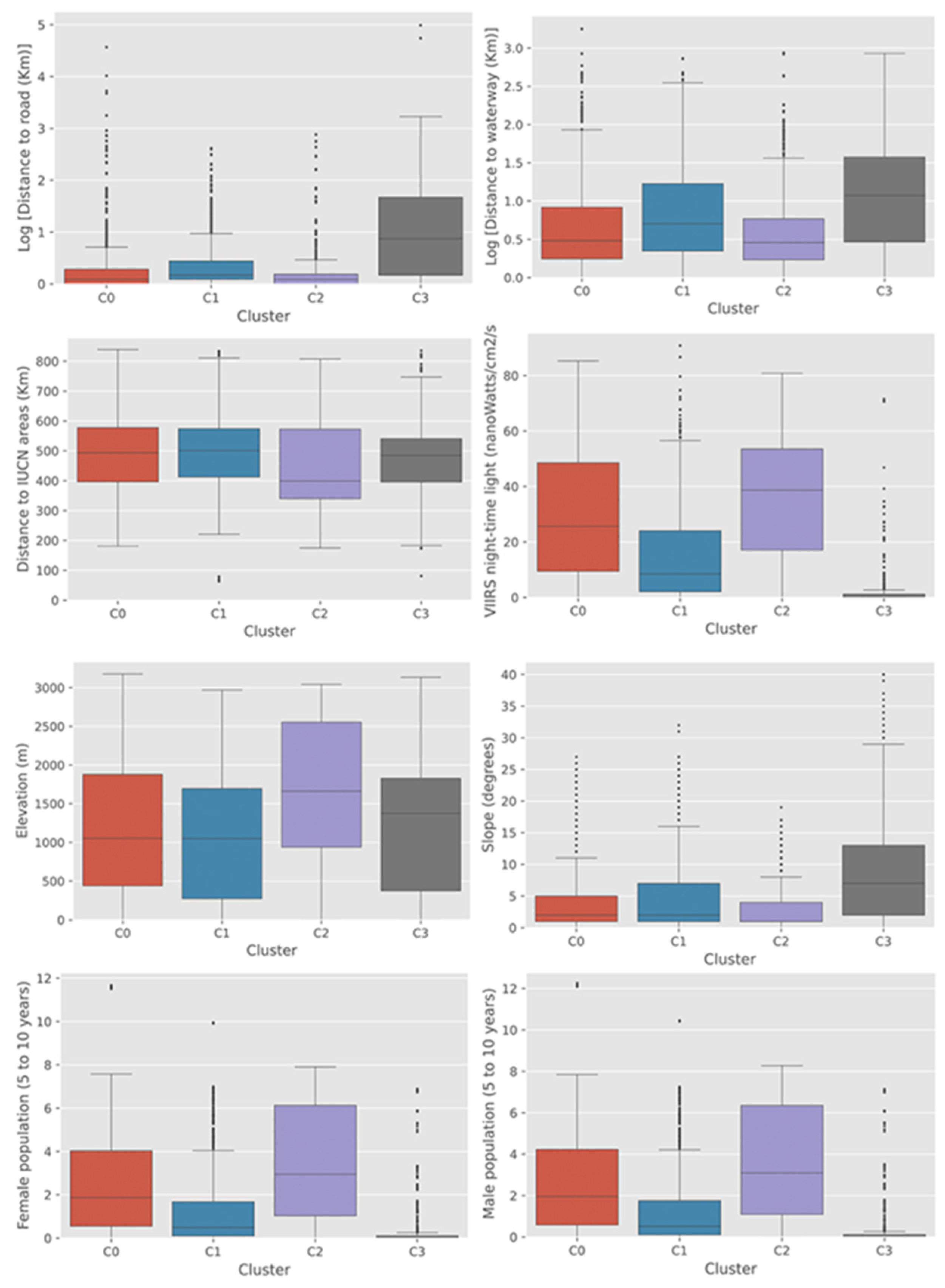
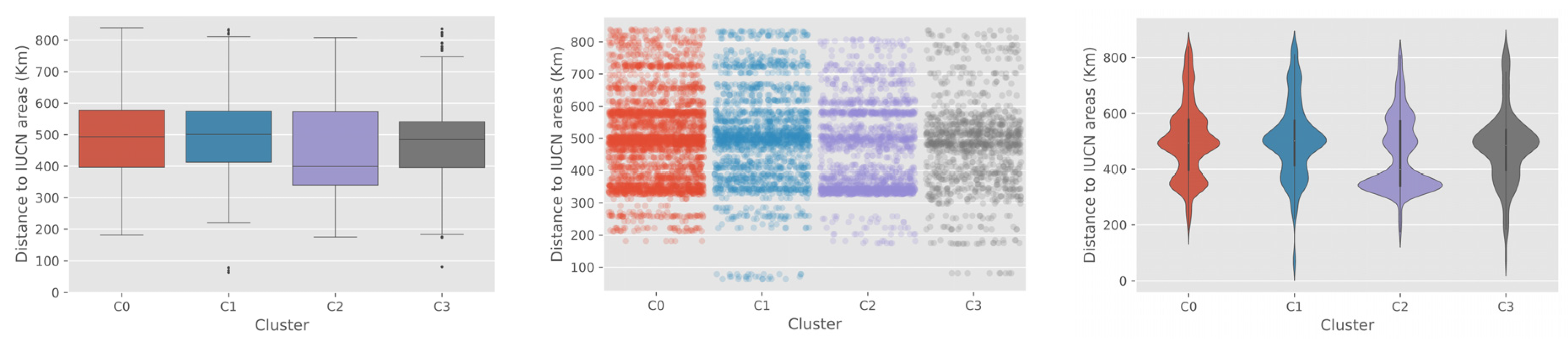
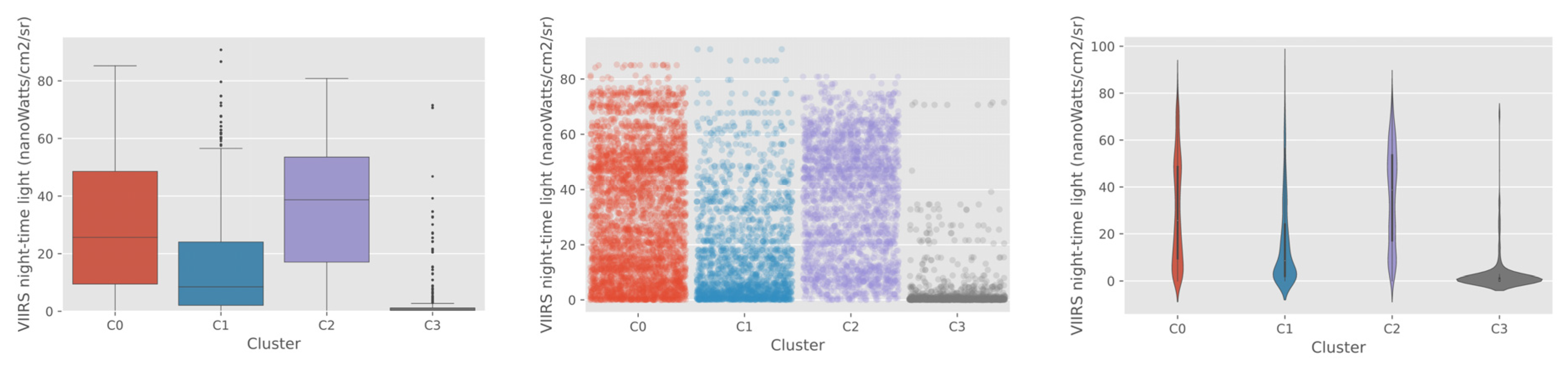
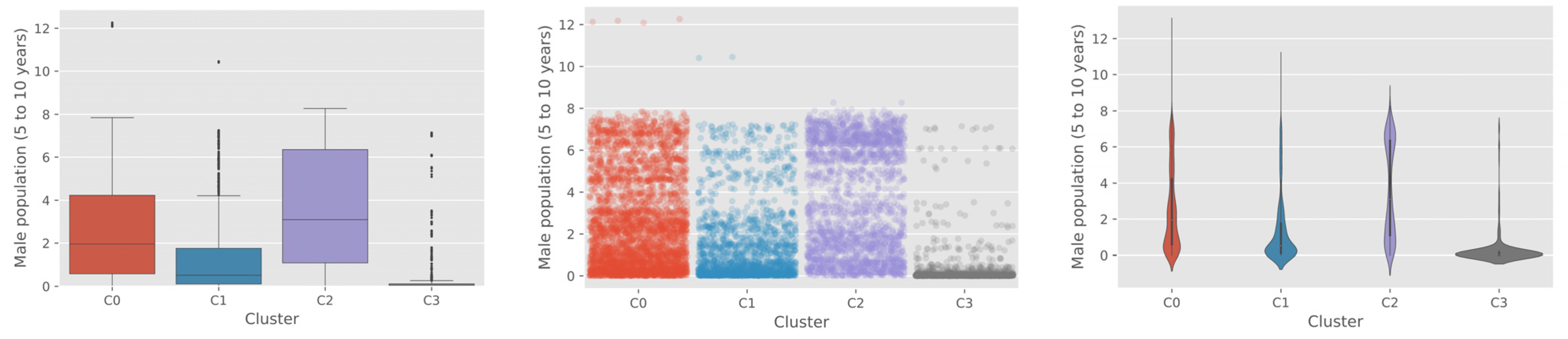
The distribution of various socioeconomic values within each cluster is presented in
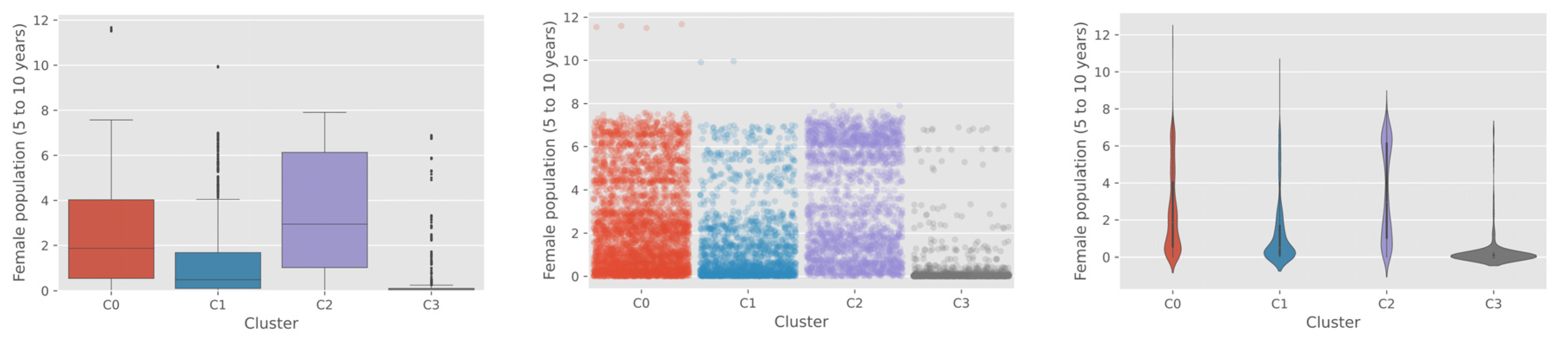
Figure 7. The most noticeable and clear findings from the socioeconomic covariate analysis was that cluster C3 was located in the most rural and remote regions with the lowest income level and the smallest child population, as shown in
Figure 8.
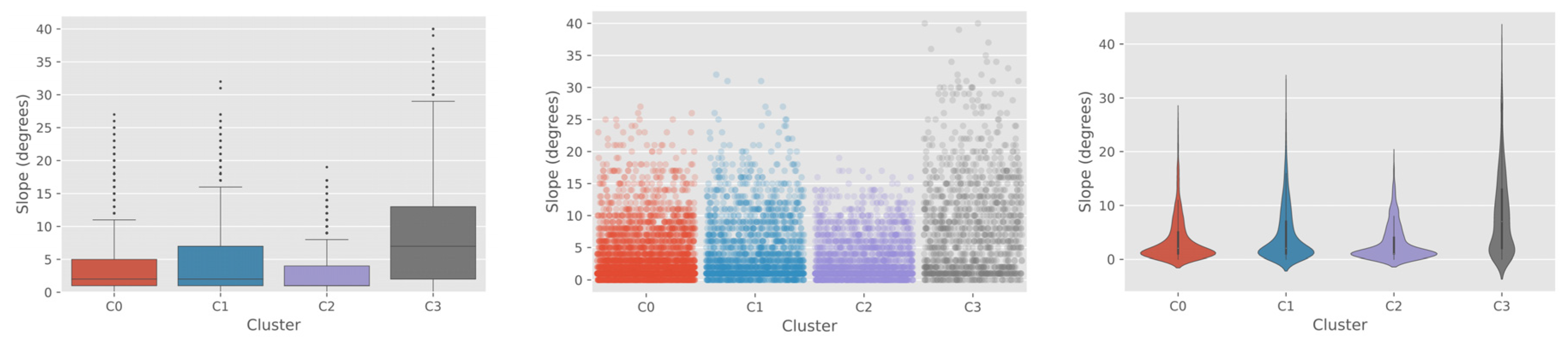
The high slope values observed for cluster C3 also represent a characteristic of the impoverished areas in general [
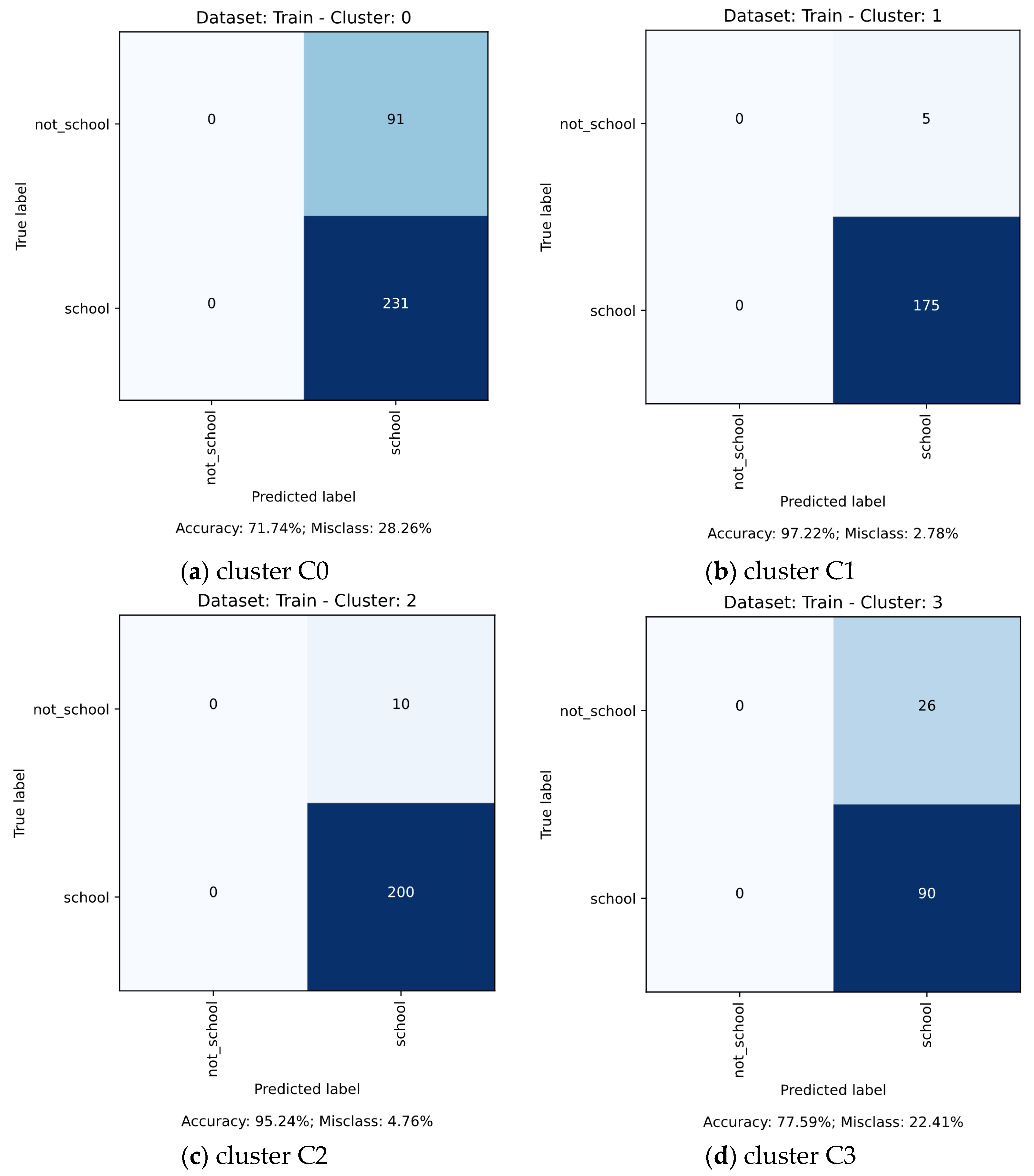
48]. We have identified that the accuracy of the deep learning model was lowest in the cluster C3 (0.78 and 0.57 for the train and test dataset, respectively), and these findings confirm our original assumption and previous studies [
21,
22,
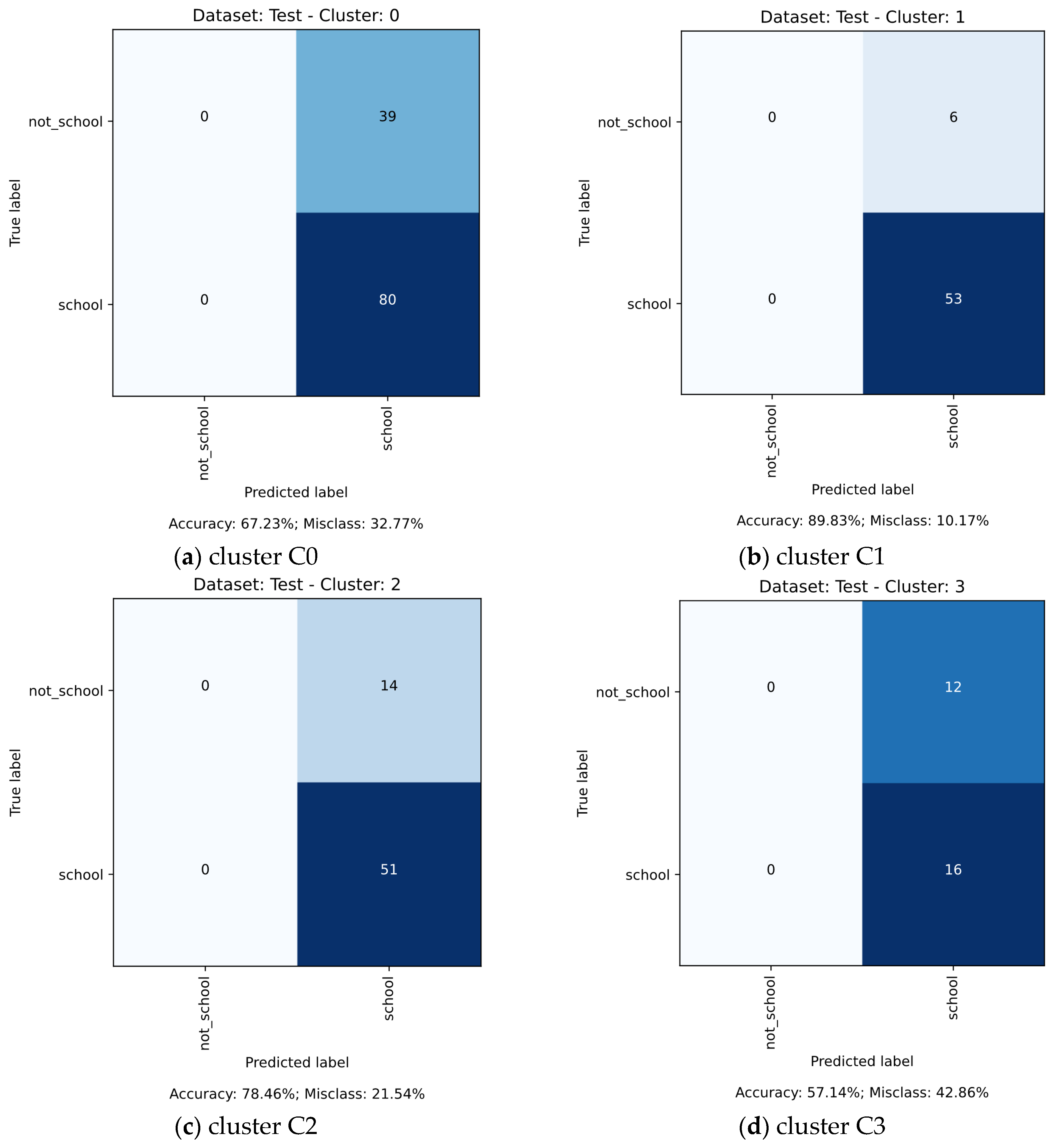
23] that DNN would be less effective in the context of landscape linked with vulnerability. More detailed accuracy matrices are shown in
Figure A1 and
Figure A2.
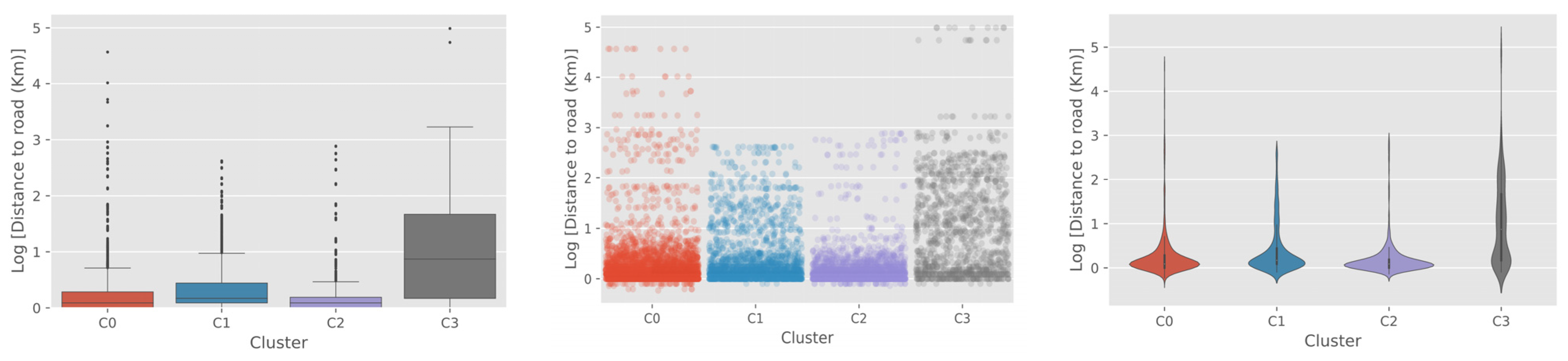
Figure 8 also reveals differences between clusters in multiple dimensions, which we could not recognize from a simple visual inspection using the natural color composite of optical remote sensing data. From the visual inspection using satellite imagery, C3 and C0 looked similar, both showing the typical characteristics of rural areas (
Figure 7). However, when the two clusters were compared for the distribution of night-time light values, which is commonly used as a proxy for economic status [
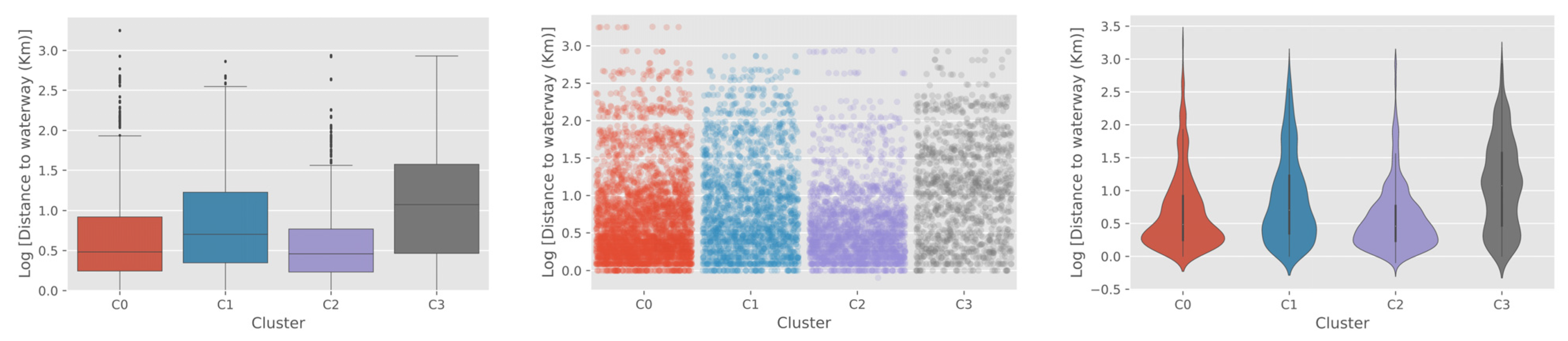
54], C0 showed a much wider distribution of values and a higher mean value compared to C3. This implies the income level in C0 would be comparatively higher than C3, which might have resulted in forming the physical characteristics of school buildings in the cluster. In terms of distance to road and water, C0 showed a similar distribution and mean values with the urban clusters C1 and C2. This reaffirms the difference between clusters C0 and C3, which might have caused the difference in model performance. In contrast, C1 and C2 showed higher accuracy and were linked with characteristics of well-developed and well-connected urban areas, as shown in
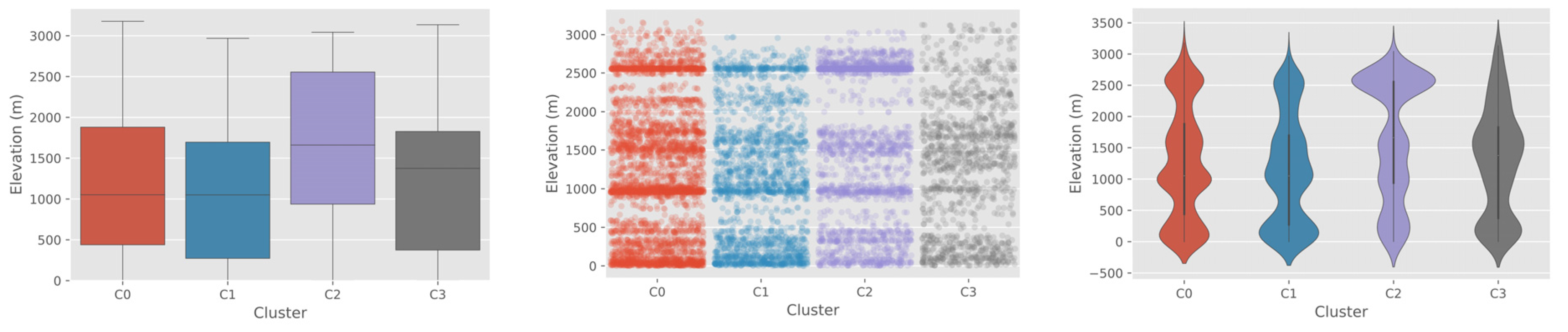
Figure 8, which supports our original assumption. However, differences between those two clusters were also identified in the distributions of socioeconomic covariates. While C2 showed a typical characteristic of densely populated city area with the highest level of night-time light values, short distance to road and water, the largest child population, and the overall highest level of elevation [
55], C1 showed the characteristics of sub-urban area with a proximity to infrastructures but with low population density. The slightly different model accuracy between C1 and C2 seems to have been driven by such a difference between the two clusters. More details on each socioeconomic variable can be found in
Appendix B (
Figure A3,
Figure A4,
Figure A5,
Figure A6,
Figure A7,
Figure A8,
Figure A9 and
Figure A10).
In this study, we could typify schools in Colombia in different contexts using cluster analysis based on feature information extracted from a deep learning algorithm model trained from satellite imagery to identify school buildings. This allowed us to understand how the algorithm performed in heterogeneous socioeconomic contexts. While we could confirm our initial assumption that the model accuracy is lowest in the places where the most vulnerable populations are, there are some limitations that need to be addressed in future studies.
We clustered school image tiles into four clusters and later interpreted each as a type of school. However, the results of clustering seem widely based on the context of landscapes in which the schools were located, and we could not identify features directly from the school building itself. Urban, wealthy, and closely located schools were much better identified by DNN. This may be related to some quantifiable physical characteristics of school buildings, such as size, color, and material. In this study, we did not measure such attributes of school buildings directly. We envision that such variables about individual school buildings can be used to typify school buildings better.
Geospatial variables were selected considering their availability and relevance to the characteristics of the landscape, which we assumed would have been linked to the performance of the deep learning model. That is to say that socioeconomic covariates, which we assumed to be related to vulnerability and representativeness, such as poverty and child population, were selected and proved to have a strong relationship with the model’s performance. Nevertheless, we admit that the list of socioeconomic variables used in this study is far from inclusive from the list of all potential factors linked with the contexts of landscapes and land use characterization. Furthermore, we are aware of the potential measurement bias that arises from our choice of covariates as proxies. One difficulty in the process of covariate selection was that there is virtually no previous study that tried to prove the relationships between DNN’s performance to characterize land use and the socioeconomic context of landscapes where the subjects of the models are located. This study has benefited enormously from the socioeconomic geospatial dataset from WorldPop [
39]. Such public repositories providing up-to-date and disaggregated geospatial datasets are essential for such an approach as taken by our study.
Retraining the model with a new, balanced dataset of tiles would be the next step to obtaining greater accuracy and minimizing bias. While we recommend our framework to assess biases and to make strategies to rectify them, it should be noted that sampling for a new training dataset based on an analysis of a limited number of covariates is not desirable before a comprehensive analysis of them. For example, one may normally expect that the values of a covariate most present in cluster C3 are those less represented in the dataset since it was the cluster with the worst accuracy (
Figure 8). Nevertheless, this was not the case for the female and male child population and night-time light data (
Figure 8). In fact, the low range values for those covariates, which were mostly seen in cluster C3, were well represented in the training dataset.
It is also worth mentioning that the DNN used in this study was fine-tuned and not trained from scratch. Since it is well known that some datasets used to pre-train these networks are biased (such as ImageNet [
56]), some bias found can be due to the original bias in the pre-trained network, of which development was heavily concentrated on the developed world [
18]. Given the case, it would be important to devise a procedure to understand and reduce the pre-existing biases before proceeding to train the model with one’s own data.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















