
Precise Extraction of Buildings from High-Resolution Remote-Sensing Images Based on Semantic Edges and Segmentation


Abstract
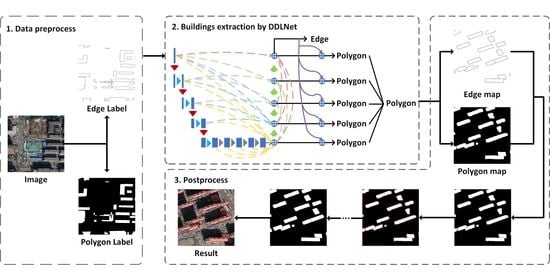
:
1. Introduction
- We designed a CNN model named Dense D-LinkNet (DDLNet) to extract buildings from high-resolution remote-sensing images. This model uses full-scale skip connections and edge guidance module to ensure the effective combination of low-level information and high-level information. DDLNet can adapt to both semantic segmentation tasks and edge detection tasks. DDLNet can effectively solve the problem of boundary blur and the problem of edge disconnection.
- We proposed an effective and universal postprocessing method that can effectively combine edge information and semantic information to improve the final result. Semantic polygon from the semantic segmentation to accurately locate and classify buildings at the pixel level. semantic edges from semantic edge detection to extract precise edges of buildings. This method uses semantic polygons to solve the problem of incompleteness of semantic edges and uses semantic edges to improve the boundary of semantic polygons, realize the accurate extraction of buildings.
2. Materials and Methods
2.1. Dense D-LinkNet
2.1.1. Full-Scale Skip Connections
2.1.2. Deep Multiscale Supervision
2.1.3. Edge Guidance Module
2.1.4. Loss
2.2. Postprocessing
- If the boundary of the semantic polygon is beyond the edge of a single pixel, it needs to be deleted.
- If the boundary of the semantic polygon is within the boundary of a single pixel, it needs to be supplemented.
3. Results
3.1. Dataset
- (1)
- The first is Beijing, the capital of China. The Beijing scene represents a typical Chinese urban landscape, including different types of buildings, which are difficult to accurately discriminate and extract. We selected four districts in the center of Beijing. The original Google images with a spatial resolution of 0.536 m are Chaoyang District, Haidian District, Dongcheng District, and Xicheng District.
- (2)
- The second is Zhonglu countryside, located in Weixi County, Diqing Prefecture, Yunnan Province. As a typical representative of rural architecture, its buildings have a relatively regular and uniform building shape. The original aerial images with a spatial resolution of 0.075 m.
3.2. Training Details
3.3. Evaluation Metrics
3.4. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gilani, S.A.N.; Awrangjeb, M.; Lu, G. Segmentation of airborne point cloud data for automatic building roof extraction. GISci. Remote Sens. 2018, 55, 63–89. [Google Scholar] [CrossRef] [Green Version]
- Lu, T.; Ming, D.; Lin, X.; Hong, Z.; Bai, X.; Fang, J. Detecting building edges from high spatial resolution remote sensing imagery using richer convolution features network. Remote Sens. 2018, 10, 1496. [Google Scholar] [CrossRef] [Green Version]
- Hung, C.-L.J.; James, L.A.; Hodgson, M.E. An automated algorithm for mapping building impervious areas from airborne LiDAR point-cloud data for flood hydrology. GISci. Remote Sens. 2018, 55, 793–816. [Google Scholar] [CrossRef]
- Yang, G.; Zhang, Q.; Zhang, G. EANet: Edge-aware network for the extraction of buildings from aerial images. Remote Sens. 2020, 12, 2161. [Google Scholar] [CrossRef]
- Bischke, B.; Helber, P.; Folz, J.; Borth, D.; Dengel, A. Multi-task learning for segmentation of building footprints with deep neural networks. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1480–1484. [Google Scholar]
- Yang, H.; Yu, B.; Luo, J.; Chen, F. Semantic segmentation of high spatial resolution images with deep neural networks. GISci. Remote Sens. 2019, 56, 749–768. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from vhr remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Sun, G.; Rong, J.; Zhang, A.; Ma, P. Multi-feature Combined for Building Shadow detection in GF-2 Images. In Proceedings of the 2018 Fifth International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Xi’an, China, 18–20 June 2018; pp. 1–4. [Google Scholar]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Liu, Y.; Cheng, M.-M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- He, J.; Zhang, S.; Yang, M.; Shan, Y.; Huang, T. Bi-directional cascade network for perceptual edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3828–3837. [Google Scholar]
- Hu, Y.; Chen, Y.; Li, X.; Feng, J. Dynamic feature fusion for semantic edge detection. arXiv 2019, arXiv:1902.09104. [Google Scholar]
- Yu, Z.; Feng, C.; Liu, M.-Y.; Ramalingam, S. Casenet: Deep category-aware semantic edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5964–5973. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Reda, K.; Kedzierski, M. Detection, Classification and Boundary Regularization of Buildings in Satellite Imagery Using Faster Edge Region Convolutional Neural Networks. Remote Sens. 2020, 12, 2240. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef] [Green Version]
- Delassus, R.; Giot, R. CNNs Fusion for Building Detection in Aerial Images for the Building Detection Challenge. In Proceedings of the CVPR Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 242–246. [Google Scholar]
- Lin, J.; Jing, W.; Song, H.; Chen, G. ESFNet: Efficient network for building extraction from high-resolution aerial images. IEEE Access 2019, 7, 54285–54294. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, L.; He, P.; Quan, D.; Zhao, Q.; Liang, X.; Hou, B. An Improved Fully Convolutional Network for Learning Rich Building Features. In Proceedings of the IGARSS 2019–2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 6444–6447. [Google Scholar]
- Batra, A.; Singh, S.; Pang, G.; Basu, S.; Jawahar, C.; Paluri, M. Improved road connectivity by joint learning of orientation and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 15–20 June 2019; pp. 10385–10393. [Google Scholar]
- Zhang, Y.; Yang, Q. A survey on multi-task learning. IEEE Trans. Knowl. Data Eng. 2021. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-LinkNet: LinkNet With Pretrained Encoder and Dilated Convolution for High Resolution Satellite Imagery Road Extraction. In Proceedings of the CVPR Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), Saint Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual Conference, Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- He, C.; Li, S.; Xiong, D.; Fang, P.; Liao, M. Remote Sensing Image Semantic Segmentation Based on Edge Information Guidance. Remote Sens. 2020, 12, 1501. [Google Scholar] [CrossRef]
- Vincent, L.; Soille, P. Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study Area | Methods | Boundary IoU | Polygon IoU | F1 Score |
|---|---|---|---|---|
| Beijing | RCF | 0.2815 | 0.2751 | 0.4300 |
| BDCN | 0.4087 | 0.5110 | 0.6341 | |
| DexiNed | 0.4503 | 0.1724 | 0.6124 | |
| DDLNet | 0.5116 | 0.5295 | 0.7049 |
| Study Area | Methods | Boundary IoU | Polygon IoU | F1 Score |
|---|---|---|---|---|
| Zhonglu | RCF | 0.4378 | 0.5824 | 0.5677 |
| BDCN | 0.7050 | 0.7009 | 0.7182 | |
| DexiNed | 0.6326 | 0.6452 | 0.6604 | |
| DDLNet | 0.7399 | 0.8719 | 0.7582 |
| Study Area | Methods | Boundary IoU | Polygon IoU | F1 Score |
|---|---|---|---|---|
| Beijing | U-Net | 0.4281 | 0.6726 | 0.8048 |
| U-Net3+ | 0.4731 | 0.7161 | 0.8352 | |
| D-LinkNet | 0.4438 | 0.7212 | 0.8398 | |
| DDLNet | 0.4746 | 0.7527 | 0.8607 |
| Study Area | Methods | Boundary IoU | Polygon IoU | F1 Score |
|---|---|---|---|---|
| Zhonglu | U-Net | 0.4180 | 0.7067 | 0.9004 |
| U-Net3+ | 0.5396 | 0.8855 | 0.9122 | |
| D-LinkNet | 0.6861 | 0.9261 | 0.9537 | |
| DDLNet | 0.6905 | 0.9364 | 0.9584 |
| Study Area | Methods | Boundary IoU | Polygon IoU |
|---|---|---|---|
| Beijing | DDLNet&DDLNet | 0.5227 | 0.7531 |
| DDLNet&D-LinkNet | 0.5067 | 0.7297 | |
| DDLNet&U-Net3+ | 0.5075 | 0.7217 | |
| DDLNet&U-Net | 0.4909 | 0.7072 | |
| DexiNed&D-LinkNet | 0.4775 | 0.7239 | |
| DexiNed&U-Net | 0.4525 | 0.6784 |
| Study Area | Methods | Boundary IoU | Polygon IoU |
|---|---|---|---|
| Zhonglu | DDLNet&DDLNet | 0.7428 | 0.9415 |
| DDLNet&D-LinkNet | 0.7368 | 0.9360 | |
| DDLNet&U-Net3+ | 0.7265 | 0.9212 | |
| DDLNet&U-Net | 0.7256 | 0.9225 | |
| DexiNed&U-Net3+ | 0.7085 | 0.9124 | |
| DexiNed&U-Net | 0.7134 | 0.9131 | |
| BDCN&DDLNet | 0.7123 | 0.9371 | |
| BDCN&D-LinkNet | 0.7068 | 0.9291 | |
| BDCN&U-Net3+ | 0.6815 | 0.9038 | |
| BDCN&U-Net | 0.6809 | 0.8906 | |
| RCF&U-Net | 0.6270 | 0.8643 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, L.; Zhang, J.; Zhang, X.; Yang, H.; Xu, M. Precise Extraction of Buildings from High-Resolution Remote-Sensing Images Based on Semantic Edges and Segmentation. Remote Sens. 2021, 13, 3083. https://doi.org/10.3390/rs13163083
Xia L, Zhang J, Zhang X, Yang H, Xu M. Precise Extraction of Buildings from High-Resolution Remote-Sensing Images Based on Semantic Edges and Segmentation. Remote Sensing. 2021; 13(16):3083. https://doi.org/10.3390/rs13163083
Chicago/Turabian StyleXia, Liegang, Junxia Zhang, Xiongbo Zhang, Haiping Yang, and Meixia Xu. 2021. "Precise Extraction of Buildings from High-Resolution Remote-Sensing Images Based on Semantic Edges and Segmentation" Remote Sensing 13, no. 16: 3083. https://doi.org/10.3390/rs13163083
APA StyleXia, L., Zhang, J., Zhang, X., Yang, H., & Xu, M. (2021). Precise Extraction of Buildings from High-Resolution Remote-Sensing Images Based on Semantic Edges and Segmentation. Remote Sensing, 13(16), 3083. https://doi.org/10.3390/rs13163083