
A Practical 3D Reconstruction Method for Weak Texture Scenes


Abstract
:1. Introduction
2. Related Work
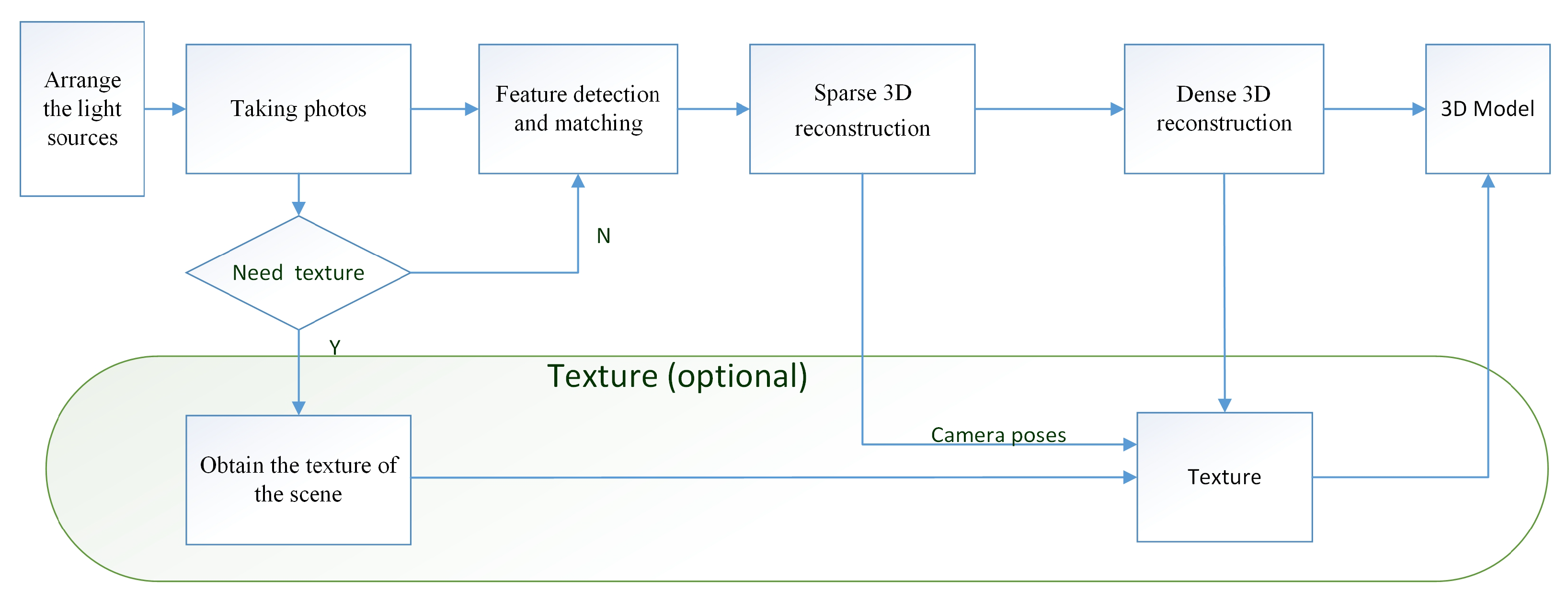
3. Materials and Methods
- Arranging the lighting sourcesSeveral lighting sources covered by films are required to light the dark scene. If the scene is large, only a few lights are used to light the scene part by part, as the lighting range is limited. The pattern can be the same or different. On every part of the scene, the pattern mapped on is always the overlaps of the spark pattern from adjacent light sources, making the features diverse and rich.
- Taking photosA digital camera is used to take high-resolution photographs of the scene and to make sure that there are overlaps between each pair of adjacent images. Note that the shadow of the photographer can be visible in these images. Because the photographer is moving, the shadows are not static patterns and will be ignored by feature detection.
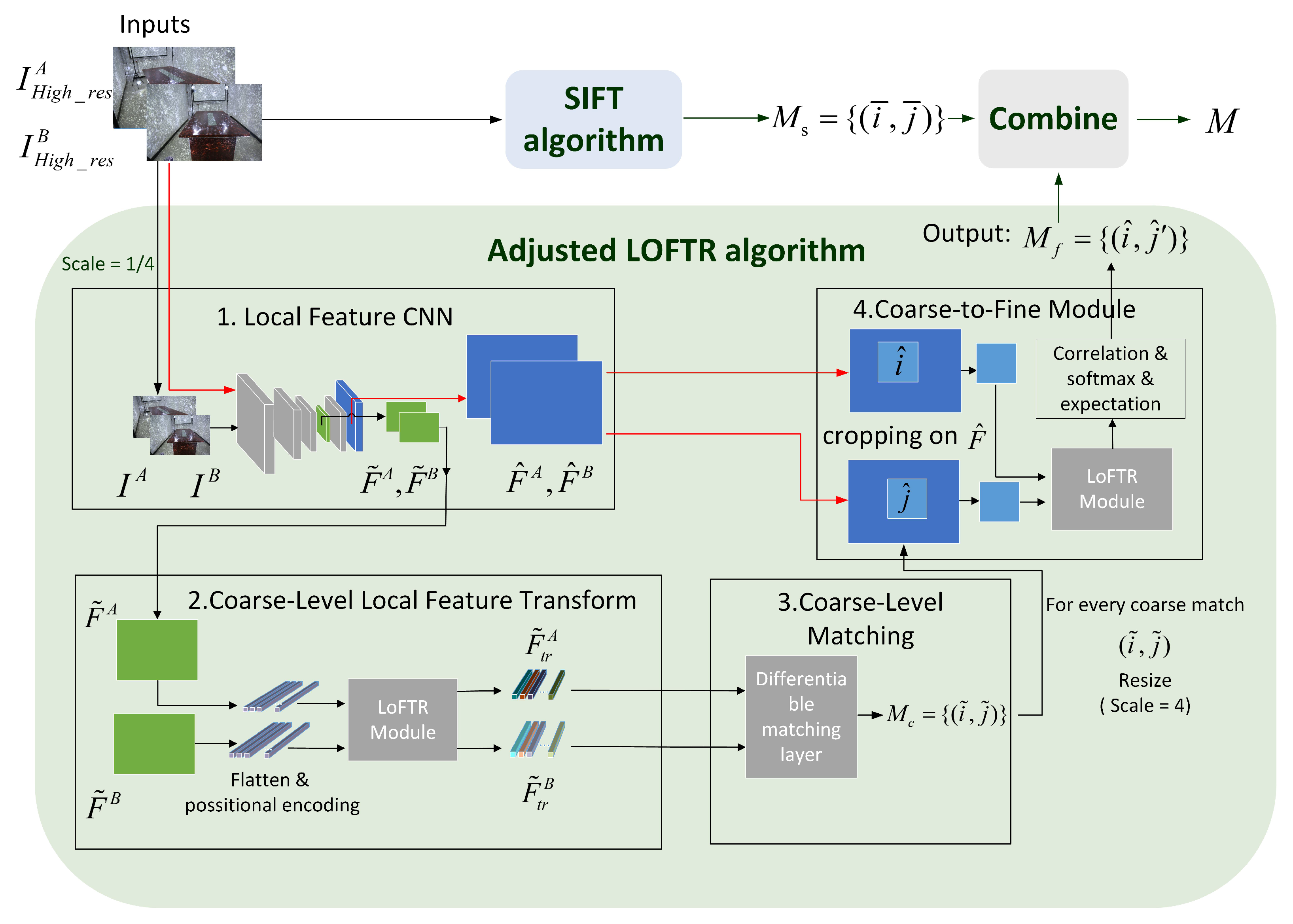
- Feature detection and matchingFor each image, we use the SIFT [18] and the LOFTR [17] algorithms together to detect and describe local features. LOFTR is a local image feature matching algorithm based on transformer; it can extract a large number of reliable matching feature points from image pairs. To balance efficiency and accuracy, we have made an adjustment to LOFTR’s process: the zoomed image is passed into the network to improve the processing speed, and after the coarse-level matching results are obtained, the fine sub-pixel matching relationship can be determined by the coarse-to-fine operation on the original resolution. The feature extraction and matching process is shown in Figure 5. These two features are relatively stable and robust. Some matching points are shown in Figure 6; the spark patterns could provide many features and matches between images from the same scene.
- Sparse 3D reconstructionThe SFM algorithm is used to calculate the sparse point cloud and camera poses. Assuming that there are n points and m pictures, the traditional SFM algorithms calculate the camera poses and the 3D position of an object by minimizing the following objective function:where represent camera poses and 3D points, is the constant weight, , represent the rotation and translation of camera ; is the coordinate of 3D feature point ; is the corresponding feature point in image ; and is the pixel position projected into image . For large or complex scenes, we can also add ground control point (GCP) constraints to the objective function to ensure faster and more accurate convergence. The format of the GCP constraints is expressed aswhere represent camera poses, is the constant weight, is the th point of 3D GCP points, is the corresponding GCP pixel in image , and is the projection pixel of by camera . The total objective function with GCP becomes.The function is generally optimized through the Levenberg–Marquardt algorithm to work out reasonable camera parameters and 3D landmarks.
- Dense 3D reconstructionTo achieve the dense 3D reconstruction, we must obtain more correspondences under the color consistency constraint. Color consistency reflects the color difference between two pixels of different pictures. The color consistency measurement of pixel on the image is given by the following formula [4]:where is the square window with a fixed size in the center of pixel ; superscript “—” is the average in the window, and is the corresponding pixel transformed to picture by pixel through a homography transformationwhere the matrix is the th camera’s intrinsic; matrix and vector are the th camera’s extrinsic; and and are the 3D vertex’s norm and coordinates, respectively. We iteratively estimate pixel correspondence and depth at the same time, then produce the dense point cloud by triangulation, and reconstruct the 3D mesh model of the scene using the Delaunay triangulation algorithm.
- Obtain the texture of the sceneIn Figure 4, we present an optional route for obtaining the real texture of the scenes. We select several positions to take two images, and the two images have the same camera pose. One is the image with the spark patterns, which we can refer to as the “dark” image. The other is called a “bright” image, which is taken under the regular bright lights. After the dense 3D reconstruction is obtained, we use the texture of the bright images, and the camera poses calculated from the corresponding dark images to generate the textured 3D model. The color of each vertex in the model is calculated as follows:where is the color of each vertex, Is the -th vertex coordinate in the model, represents the number of bright images that observes , and is the color of pixel position projected into the bright image .
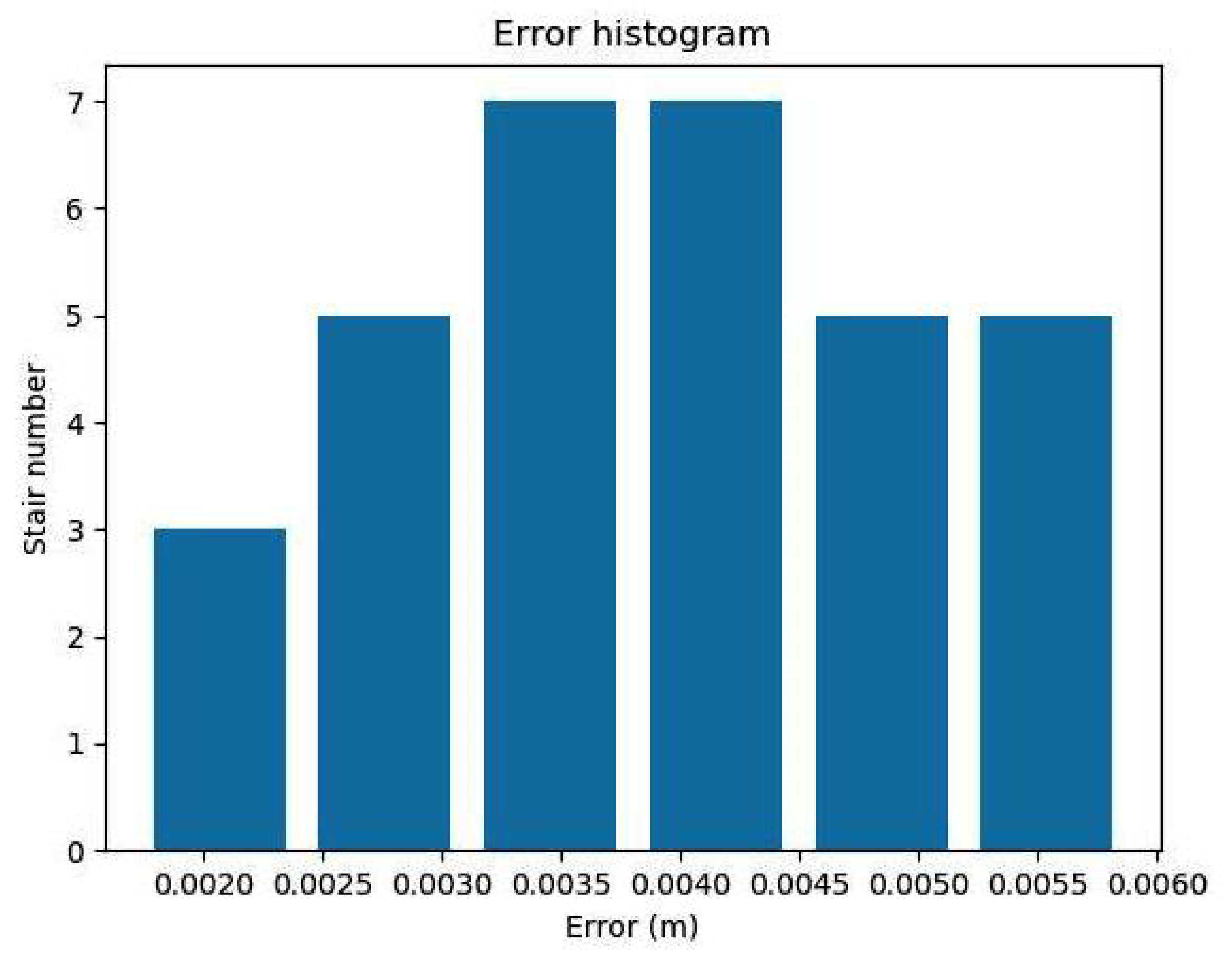
4. Experimental Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4104–4113. [Google Scholar]
- Furukawa, Y.; Hernández, C. Multi-view stereo: A tutorial. Found. Trends Comput. Graph. Vis. 2015, 9, 1–148. [Google Scholar] [CrossRef] [Green Version]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.I.; Fitzgibbon, A.W. Bundle adjustment—a modern synthesis. In International Workshop on Vision Algorithms; Springer: Berlin/Heidelberg, Germany, 1999; pp. 298–372. [Google Scholar]
- Shen, S. Accurate multiple view 3d reconstruction using patch-based stereo for large-scale scenes. IEEE Trans. Image Process. 2013, 22, 1901–1914. [Google Scholar] [CrossRef]
- Furukawa, Y.; Ponce, J. Accurate, Dense, and Robust Multi-View Stereopsis. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1362–1376. [Google Scholar] [CrossRef]
- Cernea, D. Openmvs: Open Multiple View Stereovision. 2015. Available online: https://cdcseacave.github.io/openMVS (accessed on 5 August 2021).
- Khoshelham, K. Automated localization of a laser scanner in indoor environments using planar objects. In Proceedings of the 2010 International Conference on Indoor Positioning and Indoor Navigation, Zurich, Switzerland, 15–17 September 2010; pp. 1–7. [Google Scholar]
- Costabile, P.; Costanzo, C.; De Lorenzo, G.; De Santis, R.; Penna, N.; Macchione, F. Terrestrial and airborne laser scanning and 2-D modelling for 3-D flood hazard maps in urban areas: New opportunities and perspectives. Environ. Model. Softw. 2021, 135, 104889. [Google Scholar] [CrossRef]
- Ummenhofer, B.; Zhou, H.; Uhrig, J.; Mayer, N.; Ilg, E.; Dosovitskiy, A.; Brox, T. Demon: Depth and motion network for learning monocular stereo. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5038–5047. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1983–1992. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent mvsnet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5525–5534. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Sormann, C.; Knöbelreiter, P.; Kuhn, A.; Rossi, M.; Pock, T.; Fraundorfer, F. BP-MVSNet: Belief-Propagation-Layers for Multi-View-Stereo. arXiv 2020, arXiv:2010.12436. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superpoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 224–236. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T.; Rabinovich, A. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4938–4947. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 8922–8931. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Atkinson, G.A.; Hancock, E.R. Multi-view surface reconstruction using polarization. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 1, pp. 309–316. [Google Scholar]
- Garcia, N.M.; De Erausquin, I.; Edmiston, C.; Gruev, V. Surface normal reconstruction using circularly polarized light. Opt. Express 2015, 23, 14391–14406. [Google Scholar] [CrossRef] [PubMed]
- Shi, B.; Yang, J.; Chen, J.; Zhang, R.; Chen, R. Recent Progress in Shape from Polarization. In Advances in Photometric 3D-Reconstruction; Springer: Cham, Switzerland, 2020; pp. 177–203. [Google Scholar]
- Siegel, Z.S.; Kulp, S.A. Superimposing height-controllable and animated flood surfaces into street-level photographs for risk communication. Weather. Clim. Extrem. 2021, 32, 100311. [Google Scholar] [CrossRef]
- Lin, Y.C.; Manish, R.; Bullock, D.; Habib, A. Comparative Analysis of Different Mobile LiDAR Mapping Systems for Ditch Line Characterization. Remote Sens. 2021, 13, 2485. [Google Scholar] [CrossRef]
- Zhang, J.; Singh, S. Low-drift and real-time lidar odometry and mapping. Auton. Robot. 2017, 41, 401–416. [Google Scholar] [CrossRef]
- Ren, Z.; Wang, L.; Bi, L. Robust GICP-based 3D LiDAR SLAM for underground mining environment. Sensors 2019, 19, 2915. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.; Zhou, B.; Jiang, C.; Xue, W.; Li, Q. A LiDAR/Visual SLAM Backend with Loop Closure Detection and Graph Optimization. Remote Sens. 2021, 13, 2720. [Google Scholar] [CrossRef]
- Du, S.; Li, Y.; Li, X.; Wu, M. LiDAR Odometry and Mapping Based on Semantic Information for Outdoor Environment. Remote Sens. 2021, 13, 2864. [Google Scholar] [CrossRef]
- Qian, C.; Liu, H.; Tang, J.; Chen, Y.; Kaartinen, H.; Kukko, A.; Zhu, L.; Liang, X.; Chen, L.; Hyyppä, J. An integrated GNSS/INS/LiDAR-SLAM positioning method for highly accurate forest stem mapping. Remote Sens. 2017, 9, 3. [Google Scholar] [CrossRef] [Green Version]
- Ren, R.; Fu, H.; Xue, H.; Sun, Z.; Ding, K.; Wang, P. Towards a Fully Automated 3D Reconstruction System Based on LiDAR and GNSS in Challenging Scenarios. Remote Sens. 2021, 13, 1981. [Google Scholar] [CrossRef]
- Xue, Y.; Zhang, S.; Zhou, M.; Zhu, H. Novel SfM-DLT method for metro tunnel 3D reconstruction and Visualization. Undergr. Space 2021, 6, 134–141. [Google Scholar] [CrossRef]
- Zlot, R.; Bosse, M. Efficient large-scale 3D mobile mapping and surface reconstruction of an underground mine. In Field and Service Robotics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 479–493. [Google Scholar]
- Pahwa, R.S.; Chan, K.Y.; Bai, J.; Saputra, V.B.; Do, M.N.; Foong, S. Dense 3D Reconstruction for Visual Tunnel Inspection using Unmanned Aerial Vehicle. arXiv 2019, arXiv:1911.03603. [Google Scholar]
- Schreiberhuber, S.; Prankl, J.; Patten, T.; Vincze, M. Scalablefusion: High-resolution mesh-based real-time 3D reconstruction. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 140–146. [Google Scholar]
- Albert, J.A.; Owolabi, V.; Gebel, A.; Brahms, C.M.; Granacher, U.; Arnrich, B. Evaluation of the pose tracking performance of the azure kinect and kinect v2 for gait analysis in comparison with a gold standard: A pilot study. Sensors 2020, 20, 5104. [Google Scholar] [CrossRef] [PubMed]
- Djordjevic, D.; Cvetković, S.; Nikolić, S.V. An accurate method for 3D object reconstruction from unordered sparse views. Signal Image Video Process. 2017, 11, 1147–1154. [Google Scholar] [CrossRef]
- Li, J.; Gao, W.; Li, H.; Tang, F.; Wu, Y. Robust and efficient cpu-based rgb-d scene reconstruction. Sensors 2018, 18, 3652. [Google Scholar] [CrossRef] [Green Version]
- Kawasaki, H.; Furukawa, R.; Sagawa, R.; Yagi, Y. Dynamic scene shape reconstruction using a single structured light pattern. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Jones, B.; Sodhi, R.; Murdock, M.; Mehra, R.; Benko, H.; Wilson, A.; Ofek, E.; MacIntyre, B.; Raghuvanshi, N.; Shapira, L. Roomalive: Magical experiences enabled by scalable, adaptive projector-camera units. In Proceedings of the 27th Annual ACM Symposium on User Interface Software and Technology, Honolulu, HI, USA, 5–8 October 2014; pp. 637–644. [Google Scholar]
- Cai, Z.; Liu, X.; Peng, X.; Gao, B.Z. Ray calibration and phase mapping for structured-light-field 3D reconstruction. Opt. Express 2018, 26, 7598–7613. [Google Scholar] [CrossRef]
- Albitar, C.; Graebling, P.; Doignon, C. Robust structured light coding for 3D reconstruction. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–6. [Google Scholar]
- Salvi, J.; Pages, J.; Batlle, J. Pattern codification strategies in structured light systems. Pattern Recognit. 2004, 37, 827–849. [Google Scholar] [CrossRef] [Green Version]
- Salvi, J.; Fernandez, S.; Pribanic, T.; Llado, X. A state of the art in structured light patterns for surface profilometry. Pattern Recognit. 2010, 43, 2666–2680. [Google Scholar] [CrossRef]
- Hafeez, J.; Lee, J.; Kwon, S.; Ha, S.; Hur, G.; Lee, S. Evaluating Feature Extraction Methods with Synthetic Noise Patterns for Image-Based Modelling of Texture-Less Objects. Remote Sens. 2020, 12, 3886. [Google Scholar] [CrossRef]
- Hafeez, J.; Kwon, S.C.; Lee, S.H.; Hamacher, A. 3D surface reconstruction of smooth and textureless objects. In Proceedings of the 2017 International Conference on Emerging Trends & Innovation in ICT (ICEI), Pune, India, 3–5 February 2017; pp. 145–149. [Google Scholar]
- Ahmadabadian, A.H.; Karami, A.; Yazdan, R. An automatic 3D reconstruction system for texture-less objects. Robot. Auton. Syst. 2019, 117, 29–39. [Google Scholar] [CrossRef]
- Ahmadabadian, A.H.; Yazdan, R.; Karami, A.; Moradi, M.; Ghorbani, F. Clustering and selecting vantage images in a low-cost system for 3D reconstruction of texture-less objects. Measurement 2017, 99, 185–191. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Real length (m) | 3 | 0.2 | 1 | 0.15 | 3 | 1 |
| Scaled model length (m) | 3.018 | 0.212 | 0.982 | 0.1522 | 3.05 | 1.00015 |
| Index | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Real length (m) | 0.3 | 0.225 | 0.225 | 1.45 | 0.65 | 1 | 2.4 | 1.2 | 0.045 |
| Scaled model length (m) | 0.3058 | 0.2276 | 0.219 | 1.4224 | 0.6519 | 1.00015 | 2.4038 | 1.2019 | 0.0465 |
| Index | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| Real length (m) | 0.955 | 0.55 | 0.45 | 0.2 | 1.5 | 0.2 | 0.086 | 0.086 | 0.95 |
| Scaled model length (m) | 0.9573 | 0.5475 | 0.4524 | 0.1948 | 1.4969 | 0.1977 | 0.0853 | 0.0851 | 0.9545 |
| Index | 19 | 20 | 21 | 22 | 23 | 24 | 25 | ||
| Real length (m) | 1.72 | 0.7 | 0.735 | 0.7 | 0.735 | 1.2 | 0.95 | ||
| Scaled model length (m) | 1.7228 | 0.6994 | 0.7327 | 0.6957 | 0.7344 | 1.1992 | 0.9539 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Jiang, G. A Practical 3D Reconstruction Method for Weak Texture Scenes. Remote Sens. 2021, 13, 3103. https://doi.org/10.3390/rs13163103
Yang X, Jiang G. A Practical 3D Reconstruction Method for Weak Texture Scenes. Remote Sensing. 2021; 13(16):3103. https://doi.org/10.3390/rs13163103
Chicago/Turabian StyleYang, Xuyuan, and Guang Jiang. 2021. "A Practical 3D Reconstruction Method for Weak Texture Scenes" Remote Sensing 13, no. 16: 3103. https://doi.org/10.3390/rs13163103
APA StyleYang, X., & Jiang, G. (2021). A Practical 3D Reconstruction Method for Weak Texture Scenes. Remote Sensing, 13(16), 3103. https://doi.org/10.3390/rs13163103