1. Introduction
The technique of automatic ship detection in optical remote sensing images has received considerable attention in the marine field, with the rapid development of space remote sensing technology [
1,
2,
3,
4]. In the automatic ship detection technology of optical remote sensing images, methods such as template matching [
5], knowledge representation [
6], and machine learning [
7] are usually used. These methods rely too much on manual specificity and are not universal, and it is difficult to express high-level semantic information with manual feature extraction, resulting in poor detection performance.
At present, encouraged by the great success of convolutional neural networks (CNN) [
8,
9,
10,
11,
12,
13,
14,
15] and deep-learning-based object detection in natural images [
16,
17,
18,
19,
20,
21], many researchers have proposed utilizing a similar methodology for ship detection [
22,
23]. Some examples of ship object detection are shown in
Figure 1. However, for remote sensing images, first of all, each remote sensing image contains objects of different sizes, and the objects at the same resolution are very different, so it is relatively difficult to accurately find all objects [
24,
25]. Secondly, visible light remote sensing images are susceptible to factors such as illumination, clouds, etc., which will cause changes in the characteristics of the object itself and affect the detection of the object [
26]. In addition, remote sensing images are taken by satellites or airplanes from a high altitude, which will cause the same object in the image to have different rotation angles, resulting in morphological differences, and seriously affecting the detection of the object. Finally, some objects in the remote sensing image may be small and dense, and interference between the objects may be difficult to detect. Therefore, although the existing CNN-based ship detection methods have achieved compelling results, there is still much room for improvement compared with object detection in natural images [
27].
In order to solve the above problems, a remote sensing image ship detection method based on active rotating filter and attention mechanism is proposed. Combined with the cognitive rules of the human brain, we designed a set of feature extraction methods that adapt to rotation changes. Further, according to people’s observation environment habits, the attention mechanism is summarized. When humans observe the environment, they will pay different attention to different things in the same picture. They usually focus their attention on certain things and then distract their attention to the surrounding environment and other elements. Inspired by this, the convolutional block attention module (CBAM) [
28] is used to optimize the fast region-based convolutional neural network model to achieve high-precision ship object detection tasks. Our contribution is as follows:
In order to improve the detection effect of remote sensing image ships, the combination of active rotation filter and neural network is used to solve the problem of poor recognition ability of convolutional neural network for multiangle rotating objects, the visual attention mechanism is used to optimize the fast region-based convolutional neural network model, and a new marine remote sensing ship object detection method based on the active rotating filter and attention mechanism is proposed.
A data set of ocean remote sensing images in PASCAL VOC [
29,
30] format that can be used for object detection is produced through data set annotation tools and a certain number of remote sensing images.
Compared with other remote sensing ship detection methods, experiments verify that our method achieves higher detection accuracy on the remote sensing image ship detection data set. At the same time, ablation experiments confirmed that all parts of our method have a positive effect on the improvement of detection performance.
The rest of this article is organized as follows.
Section 2 briefly reviews related work. In
Section 3, the proposed method for remote sensing image ship detection is introduced.
Section 4 explains the details and environment of the experimental realization, and compares the proposed method with state-of-the-art ship detection methods. The ablation experiment is carried out, and the influence of different networks on the proposed method is discussed in
Section 5. Finally,
Section 6 gives the conclusion.
2. Related Work
The object detection task includes two subtasks [
27,
31], one of which is to output the category information of this object, which belongs to the classification task. The second is to output the specific location information of the object, which belongs to the positioning task. The result of the classification task is a category label, which is a number for single classification tasks and a vector for multiple classification tasks. The output of the positioning task is a position, usually represented by a rectangular box, including the coordinates of the upper-left corner or the middle position of the rectangular box and the width and height of the rectangular box. After years of development, there are many effective methods for object detection technology. According to whether deep learning is used or not, it can be roughly divided into two categories: traditional methods and deep learning methods.
Traditional remote sensing image object detection methods can be divided into detection methods based on template matching, detection methods based on knowledge representation, detection methods based on image object analysis, and detection methods based on traditional machine learning [
32,
33,
34]. Although traditional machine learning has achieved relatively good results, the low- and middle-level features extracted by traditional feature extraction methods do not contain high-level semantic information, which makes it difficult to effectively express object features, and the recognition effect can be further improved [
35,
36,
37,
38]. Moreover, in the detection process, the location of the object is completely dependent on the initially generated object candidate frame, there is no readjustment of the object candidate frame, and the positioning is inaccurate, resulting in a poor final object detection effect.
At this stage, object detection methods based on deep learning can be divided into two categories: one is a two-stage object detection algorithm based on region generation [
20,
21,
39,
40,
41,
42] and the other is a one-stage object detection algorithm based on regression [
16,
17,
18,
19,
43,
44].
The first type is to first generate a series of candidate frames of samples by a specific method, then classify the samples through a convolutional neural network, and finally refine the position of the bounding box. The representative works mainly include a series of algorithms such as region-based convolutional neural networks (R-CNN) [
45], Spatial Pyramid Pooling Net (SPP-net) [
46], Fast R-CNN [
20], and Faster R-CNN [
21].
R-CNN [
45] uses selective search to control the scale area to about 2000, then scales the corresponding area frame until it has a uniform size, and sends it to the convolutional neural network for training. The object category is determined by the support vector machine, and the bounding box regression is used to locate the object using the regression machine. R-CNN has the following problem: the selective search method performs repeated convolutions on the same region to extract features. At the same time, the input of the fully connected layer needs to ensure that the size is uniform, and the network input part needs to crop and scale the pictures that do not meet the size, which causes image distortion and affects the detection effect.
In order to solve the problem of scaling in R-CNN, SPP-net [
46] no longer crops and scales images. Instead, the spatial pyramid pooling layer is connected after the last convolutional layer of R-CNN, so that any image input to the network generates a fixed-size output. The spatial pyramid pooling layer is the pooling layer after the feature extraction layer. Regardless of the size of the input image, it is assumed that the final feature map scale of a single channel is N × N. It is divided into three subgraphs of 1 × 1, 2 × 2, 4 × 4 using max pooling operation. Therefore, the original arbitrary N × N feature map is represented as a 21-dimensional (16 + 4 + 1) fixed-dimensional vector, and then input to the fully connected layer. In the actual detection task, the spatial pyramid pooling layer can be designed according to the task itself. This solves the problem of different input picture sizes and avoids operations such as cropping and scaling.
Fast R-CNN [
20] takes the entire images as input and uses CNN to get the feature map. Then, the selective search algorithm is used to obtain the candidate frames in the original image, and project these candidate frames to the feature map. For each candidate frame of different size on the feature map, Fast R-CNN uses the region of interest (RoI) pooling operation to obtain a fixed-dimensional feature representation. Finally, through two fully connected layers, softmax classification and regression model are used for detection. The difference between Fast R-CNN algorithm and R-CNN is the RoI pooling layer, which is a simplified SPP layer. However, the algorithm still uses a complex and time-consuming selective search method for candidate frame extraction, which results in slower execution speed and greater resource consumption.
None of the above methods solve the inefficient sliding window selection problem of the selective search method, and the selective search method is still used to generate a large number of invalid regions, resulting in a large waste of computing resources. Based on the above problems, the Faster R-CNN [
21] method uses Region Proposal Networks (RPN) instead of the selective search method to extract candidate frames. The core idea of RPN is to use convolutional neural networks to directly generate candidate regions, which are essentially sliding windows. Moreover, the Faster R-CNN algorithm uses a four-step alternate training method for RPN and Fast R-CNN training. At the same time, RPN and Fast-R-CNN share the convolutional layer, so that the cost of extracting candidate frames is reduced to zero, which greatly improves the running speed and training speed of the algorithm.
Nie [
40] shortened the path between the lower layer and the uppermost layer by adding a bottom-up structure to the FPN structure of Mask R-CNN, allowing the lower layer features to be more effectively used on the top layer. Further, in the bottom-up structure, the use of channel attention to assign weights in each channel allows the feature map to better respond to the features of the target to achieve ship target detection. Bi [
41] proposed a visual attention augmented network-based optical remote sensing image ship detection method, which uses a lightweight local candidate scene network to extract local candidate scenes with ships to reduce false alarms in nonship areas and improve remote sensing image detection efficiency. For selected local candidate scenes, a visual-attention-based ship detection method is used to improve the detection performance and positioning accuracy of offshore ships. Zhang [
42] used a coarse-to-fine strategy to segment nonaquatic regions from the waters to extract candidate regions that may contain ships, and used the R-CNN method to accurately detect ships in the ROI image to make progress in the detection of small ships and dense ships.
The second type does not need to generate a budget box, directly transforms the problem of object contour positioning into a regression problem, and directly regresses the predicted object. The classic algorithms include SSD, YOLO series, etc. [
16,
17,
18,
19,
43]. The detection accuracies of the YOLO algorithm series and the SSD algorithm are generally lower than that of the Faster R-CNN algorithm, but the detection speed is much faster than the Faster R-CNN algorithm.
The core idea of YOLO [
16] is to solve object detection as a regression problem. By inputting the original image containing the object, the position frame of the object, the category to which it belongs, and the corresponding confidence level can be obtained. The YOLO algorithm is based on the Google-Net image classification model. It is a deep learning algorithm that can predict multiple objects at one time. It achieves true end-to-end object detection. The detection speed is faster, but the accuracy is lower than Faster R-CNN.
YOLOv1 [
16] lacks in accuracy and detection speed. A series of methods have been used to optimize the model structure of YOLOv1, resulting in YOLOv2 [
17]. First, batch normalization is applied to all convolutional layers. It can improve the convergence speed of the model and reduce overfitting. Secondly, the size of the image accepted by YOLOv1 is 224 × 224. YOLOv2 uses 448 × 448 ImageNet data fine-tuning to adapt the network to high-resolution input, removes the fully connected layer of YOLO, uses anchors to predict the frame, and removes a pooling layer to improve the output resolution of the convolutional layer. The network input size is also modified from 448 × 448 to 416 × 416, so that the feature map has only one center. Although the mAP is slightly reduced, the recall rate is greatly improved. Finally, through multiscale training, the model has high robustness to images of different sizes. Chang [
44] proved that YOLOv2 is very suitable for SAR image ship detection, and its detection speed is much faster than fast-R-CNN.
Compared with YOLO and YOLOv2, the detection accuracy of YOLOv3 [
18] has been greatly improved. It replaced the softmax loss function of YOLOv2 and changed it to a logistic loss function. YOLOv2 uses 5 anchors, and YOLOv3 uses 9 anchors, to increase the IOU. Secondly, YOLOv3 uses upsampling and fusion, and detection layers to detect on three different sizes of feature maps, and finally combines the three. The detection effect of small objects is significantly improved by performing independent detection on the fusion feature maps of multiple scales.
The SSD [
19] algorithm can directly predict the coordinates and category of the object, and there is no process of generating candidate frames. It uses a series of detectors to predict the category and location of the object. It mainly achieves fast and high-precision object detection effects from two aspects. One is to regress the output of the convolutional layer of different sizes, and the other is to detect objects of different shapes by increasing the aspect ratio of the detector.
3. Proposed Method
In this section, we introduce our method. The overall framework of our method is shown in
Figure 2. In the original Faster R-CNN framework, the network first zooms to a fixed size for an image of any size, and then sends the image to the network; the feature extraction network contains multiple convolutional layers, pooling layers, and activation functions. The RPN network first undergoes 3 × 3 convolution and generates the positive anchor and the corresponding bounding box regression offset, then calculates the candidate area. The ROI pooling layer uses the candidate area to extract the feature of the candidate area from the feature map and send it to the subsequent fully connected softmax network for classification. Then, an attention model that combines space and channel is introduced to detect remote sensing images. In the case of remote sensing images with different coverage areas, ratios, and different directions of objects in the images, effective ship object detection can be achieved. Details of the proposed algorithm are introduced in
Figure 2.
3.1. Directional Response Feature Extraction in Line with Brainlike Cognition
The convolutional neural network in faster RCNN has the disadvantage of poor discrimination of multiangle rotating objects. To solve this problem, we introduced an active rotating filter (ARF) and combined it with the neural network. In the convolution process, the ARFs filter is rotated to generate a feature map with angle channels, and the oriented response network (ORN) is obtained. In the process of multidirection convolution, the angle-invariant feature within the class is actively obtained, and the filter is updated by the error in the backpropagation process to obtain a rotation-invariant network while maintaining the difference between different categories in the classification task.
The feature map
M of the active rotating filter
F and the
N-direction channel can be perpendicular to the
N-direction point on the grid. We define ARF as
where the feature map
is composed of
N directional channels, and the
k-th channel is calculated as follows:
where
is the rotated version obtained by rotating F clockwise by
degrees, and
and
represent the
n-th direction channel of
and
M, respectively. In the process of multidirectional convolution, ARF actively acquires the multiangle response of the image until the feature map size of the multidirectional channel is 1, and finally, the position and angle code of the image is obtained.
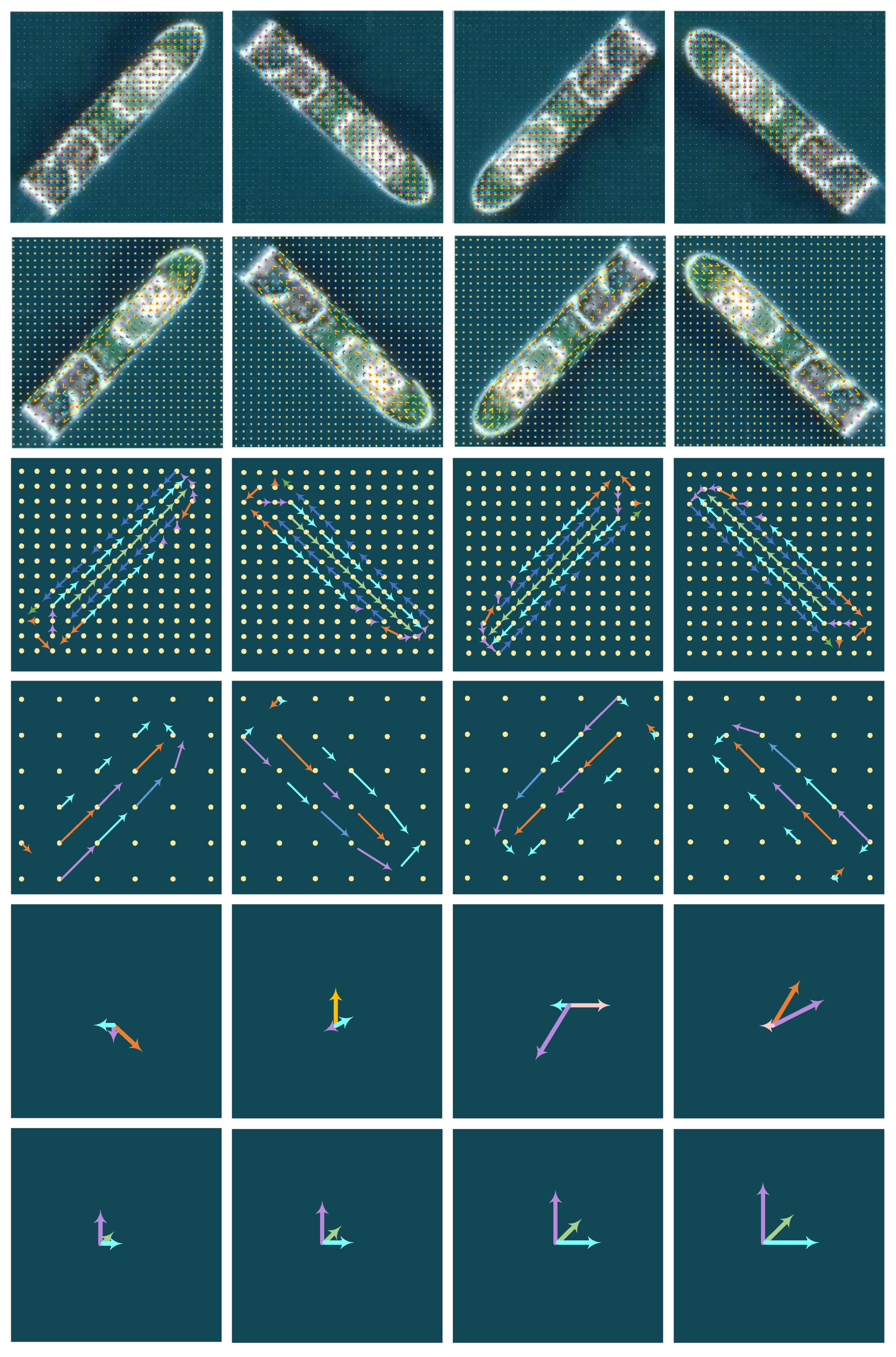
Figure 3 is an example of using the ORN network to train on our data set. Each row represents a layer of the neural network, and each column represents a feature map obtained by an input sample through the network. The rightmost column zooms in on a region in the feature map. It can be seen that the feature map obtained by ARF can obtain the position and angle information of the object. In the second layer, the omnidirectional expansion of the image of the unidirectional channel facilitates the subsequent multiangle convolution. From the ORConv1 layer to the last ORConv4 layer of the network, the values in the feature maps obtained by the numbers under different rotation angles are similar, but the directions are different. The last layer is the ORAlign layer, which uses a method similar to SIFT to align the main directions to achieve rotation invariance.
In the backpropagation process, the vertical angle version of the filter needs to be updated with the total error. The error signal
is obtained by summarizing the error
of ARF and all its rotating versions:
where
L represents the training error and
represents the learning rate. Since ARF is composed of an implemented main filter and an unimplemented rotation filter, only the main filter is updated during the backpropagation process. Therefore, the errors generated by samples with similar appearance but different angles can be combined. When there are a large number of structures with similar features and different directions in the training image, the method of updating the main filter using the error at multiple angles has more advantages than traditional CNN, and can learn more “pure” filters.
The angle information of the feature map obtained by ORNs is discrete and does not have rotation invariance. A new layer needs to be added after the convolutional layer, and the rotation-invariant direction encoding information is obtained through ORAlign or ORPooling. To put it simply, the deep convolutional network is used to gradually shrink the size of the feature map to
, where
N is the number of directional channels. The feature map obtained by the last multidirectional convolutional layer in the network is the high-level feature representation of the pattern, as shown in
Figure 4.
The ORAlign method assumes that the i-th feature map in the feature map obtained by the last multidirectional convolution layer is
, and its
n-th direction channel is
. In order to record the
N-dimensional tensor of responses in different directions,
adopts the method of aligning the main directions of features to achieve rotation robustness. First, calculate the main direction—that is, calculate the direction with the strongest response:
Then, rotate the feature map by degrees. The ORPooling method transfers the feature map of the direction channel with the largest feature response to the next layer of the network through a simple maximum pooling operation. This strategy will reduce the loss of feature arrangement information when the feature dimensions are the same.
3.2. Channelwise and Spatial Attention Mechanisms
In general, the features obtained by different channels contain different semantic information. In order to make full use of this information, we introduce the attention model to detect remote sensing images and add the convolutional block attention module (CABM) to each residual block of the network. The structure is shown in
Figure 5. Since CBAM is a lightweight module that can be integrated into the CNN framework, the overhead is negligible, and end-to-end training can be carried out with CNN. The experiment in
Section 4 proves that the addition of this module fully improves the detection performance of the network.
When the input
M is used as the input feature map, the CBAM proposed in this paper mainly performs the following two operations on it:
where ⊗ represents the dot product of each element,
represents the attention extraction in the channel dimension, and
represents the attention extraction in the spatial dimension.
Figure 6 shows the channel attention module.
Figure 7 shows the spatial attention module.
Channel attention module: this part of the work is very similar to SENet, which first compresses the characteristic in the channel dimension to obtain one-dimensional vector. Operation: unlike SENet, the average poolization is considered for the input feature, and the average pool is considered, and the maximum pool is introduced as a supplement. After two pilot functions, two one-dimensional vectors can be obtained.
The specific practices are as follows:
M represents the feature of the input feature,
and
represent the characteristics of the average poolization and maximum pool.
and
represent two layers of parameters in multilayer perception machines. The calculation in this section can be represented as follows:
Space Note Module: This part of the work is an important contribution to the difference between the papers. In addition to generating a focal model on the channel, there is also a higher response on the spatial level to understand which portions in the feature should have a higher response. First, the input feature is compressed using the average poolization and maximum piligeration, as the compression here is compressed, and the input feature is performed on the channel dimension in the channel dimension. Average and maximum operation. Finally, two two-dimensional features were obtained, and they were spliced by the channel dimension together to obtain a characteristic of one channel number 2, and then the hidden layer containing a single convoluence was convolved to ensure that, finally, the feature is consistent with the characteristic of the input in spatial dimensions.
The characteristics after the average pilotization and the maximum pilotization operation are
and
. This part is calculated as
where
is indicated by the sigmoid activation function, and the convolution layer uses a
convolutionary core, empirically.
4. Experiments and Results
In this section, we first introduce a new ocean remote sensing image data set established for experimentation. Then, we apply it to our models and evaluate it on the ship detection task. Finally, to verify the detection performance of our method, we compare our method with some state-of-the-art approaches.
4.1. Ocean Remote Sensing Image Data Set
In order to fully verify the detection performance of the algorithm in this paper under the conditions of multiple scales and different ship orientations, we used network satellite maps to collect nearly 2000 ocean remote sensing images as experimental data sets. The data set contains ocean remote sensing images from different perspectives and locations. The set image sizes range from 300 × 300 to 1500 × 900 (90% of which are larger than 1000 × 600), while the resolutions are between 3 and 0.5 m. There are a certain number of ships on each picture.
Figure 8 shows some examples of the data set.
To facilitate training, we use the COCO annotation format to label the data. The data set is randomly divided into three parts: training set, verification set, and test set at a ratio of 6:2:2.
4.2. Implementation Details
The proposed method was tested and evaluated on a computer with an Intel Core i7-10070 3.80 GHz CPU, GeForce GTX 2080 Ti GPU with 11 GB memory, and 16 GB computer memory, implemented using the open-source Pytorch framework [
47], and the basic code used was Facebook Research’s Faster R-CNN Benchmark. In our experiments, we use the pretrained ResNet-50 model for initialization. The network is trained with an Adam optimizer employed with a learning rate of 0.001 for the model for 40k minibatches and 0.0001 for the next 40k minibatches. We take the intersection over union (IoU) threshold of 0.5 for proposal classification.
4.3. Metrics
In the field of object detection, the main indicator for judging the detection accuracy of an object detection algorithm is the mean average precision (mAP). The basis of mAP is AP, which is obtained by a combination of precision and recall.
Precision: Positive and negative samples will be generated during object detection, and errors may occur during the detection process. Assuming that at the end of the recognition, some of the objects recognized as correct are correct objects (true positive), but some of them are wrong objects (false positive); the precision is defined as
Recall rate: Define the misidentified object as false negative, and the correctly classified object as true negative; then, the recall rate is defined as
Since the relationship between precision and recall is that one of them increases and the other must decrease, you can draw an image and obtain the AP value through the image, which is the area under the Recall and Precision curves. mAP is to average the value of AP.
Intersection over Union (IoU): IoU is an evaluation index used in object detection and a standard for measuring the accuracy of detecting relative objects in a specific data set.
IoU represents the overlap rate between the generated candidate box and the original title box, which is the ratio of the intersection and union between them. The higher the IoU value, the higher the detection accuracy. The most ideal situation is complete overlap, and the IOU value is 1. IoU calculation formula is as follows:
4.4. Experiments Comparing Different Methods
In order to evaluate the effectiveness of our method, we compare our method with SSD, YOLO, YOLOv2, YOLOv3, the method in Fast R-CNN and Faster R-CNN methods. We use the standard metrics average precision to evaluate our results. We reported the mean of AP obtained in the last 20 periods as the final result and calculated the standard deviation. Experimental results under the same training data are shown in
Table 1. Some examples of the detection results by different methods are shown in
Figure 9, where we only use the solid red line to mark the successfully detected ships in each image.
From
Table 1, we can see that under the same training sample, our method can obtain the highest average accuracy and the smallest standard deviation, with an average accuracy of 80.12% and a standard deviation of 0.24. Compared with Faster R-CNN, the AP obtained by the method in [
39] is slightly higher, 2.25% higher than the accuracy of Faster R-CNN, and the performance of YOLO is the worst, with an average accuracy of only 62.15%. In terms of FPS, YOLOv3 reached the highest FPS, and our method also achieved the highest FPS in the two-stage object detection algorithm.
From
Figure 9, we can see that although all the methods can successfully detect the ships in the first row, our method can generate a more accurate bounding box and select all ships when the selected area is as small as possible. Nevertheless, in the third row, the other five methods produced poorer detection results;, the detected ships framed a larger area; and, even worse, they failed to detect the black ships moored on the dock.
Table 1 shows that our method has the highest accuracy, and it can be seen from the figure that our method is more robust in complex scenarios. In
Figure 9, we can see that other methods have produced false detection results on land and on the dock that looks like a ship.
In ship inspection, the more difficult challenge is to detect the densely packed ships docked in the port. In ports with more ships, it is difficult to accurately locate each individual ship in the densely packed ships, especially when they are docked in an oblique direction or size.
Figure 10 further shows the detection results of our method when there are many ships in ports and sea areas. It can be seen that our method can accurately detect and select all ship objects regardless of whether it is in a port with dense ships or in a sea area where ships are densely sailing.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}