
Can the Structure Similarity of Training Patches Affect the Sea Surface Temperature Deep Learning Super-Resolution?




Abstract
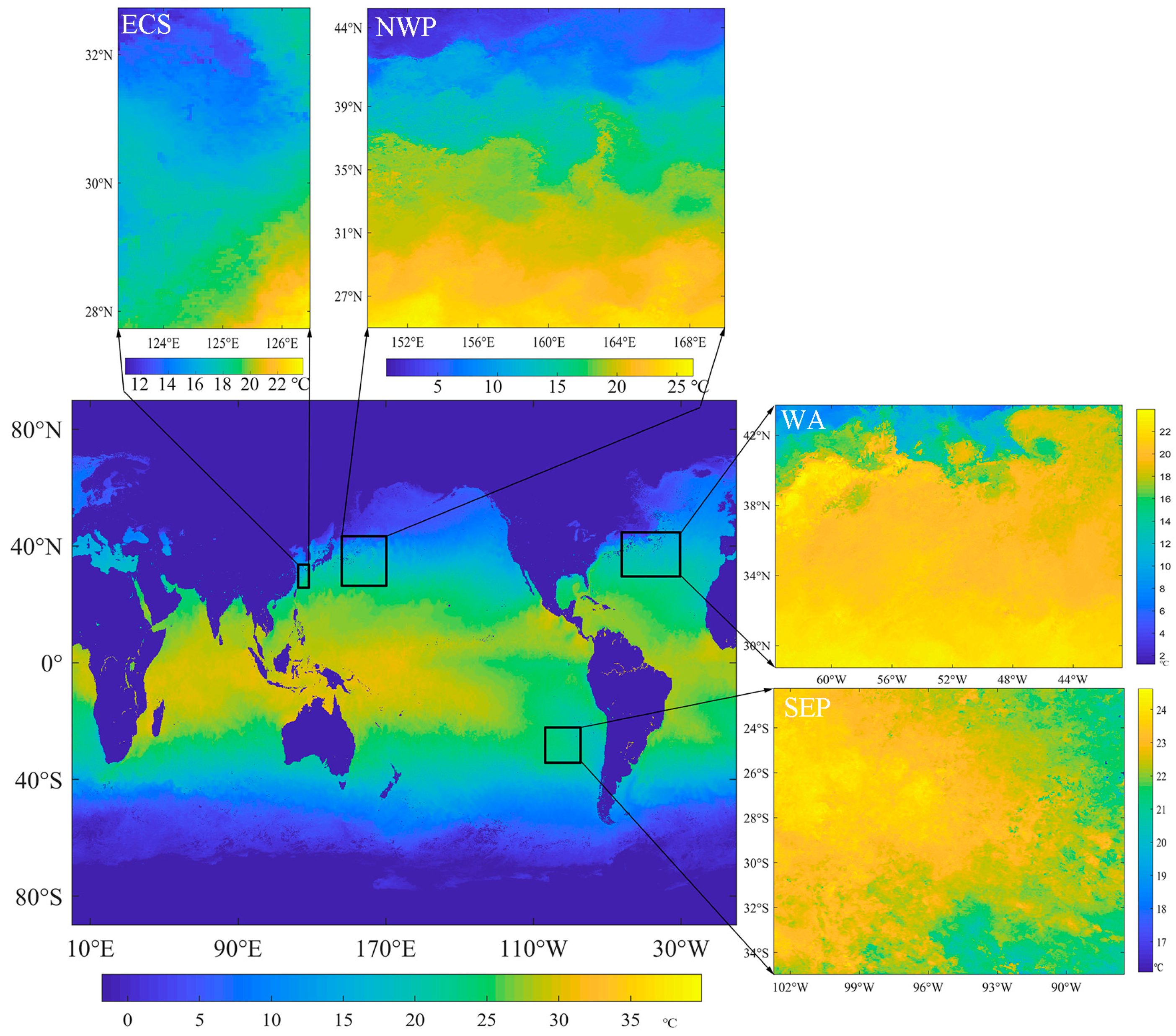
:1. Introduction
2. Data and Methods
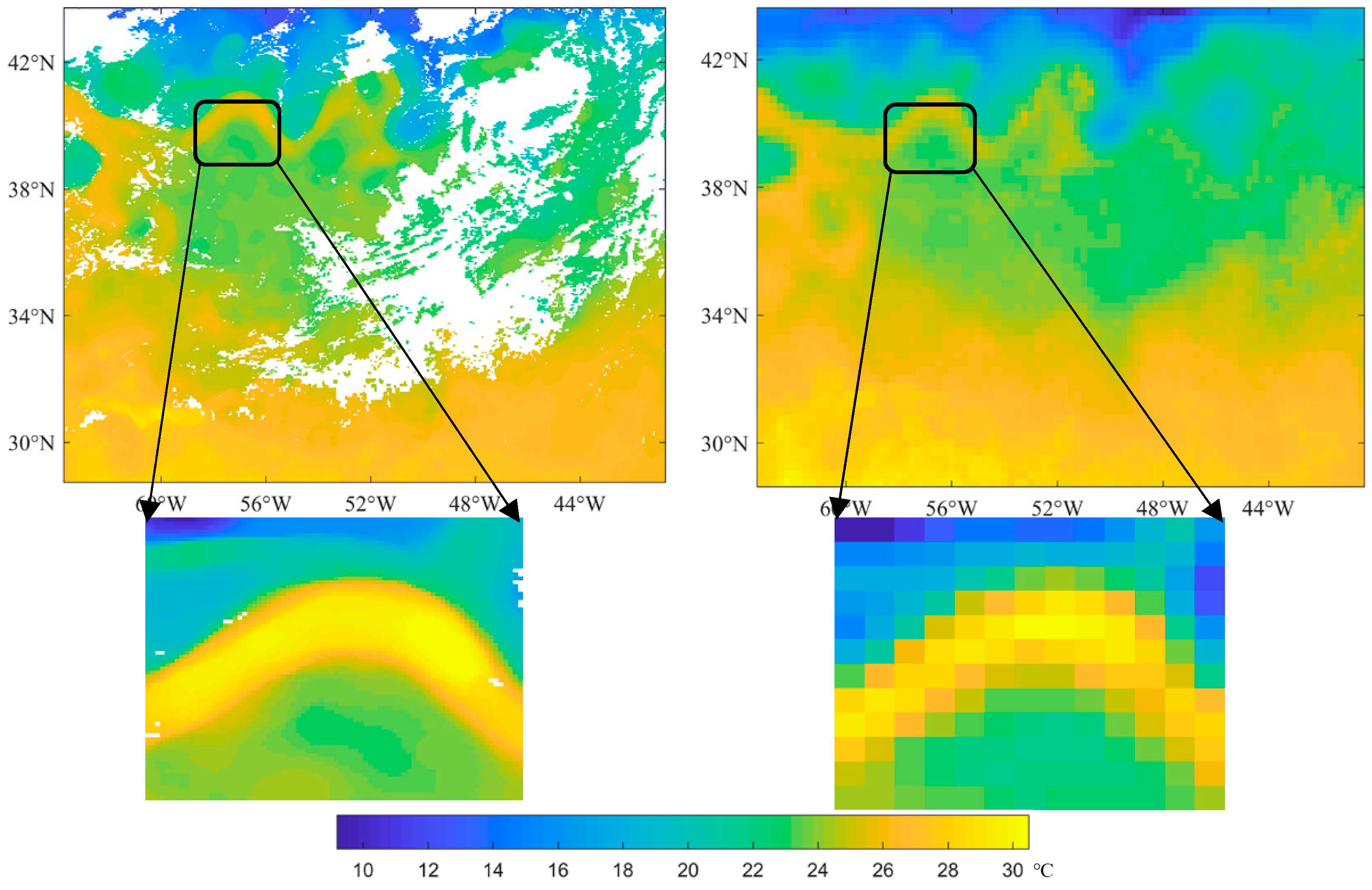
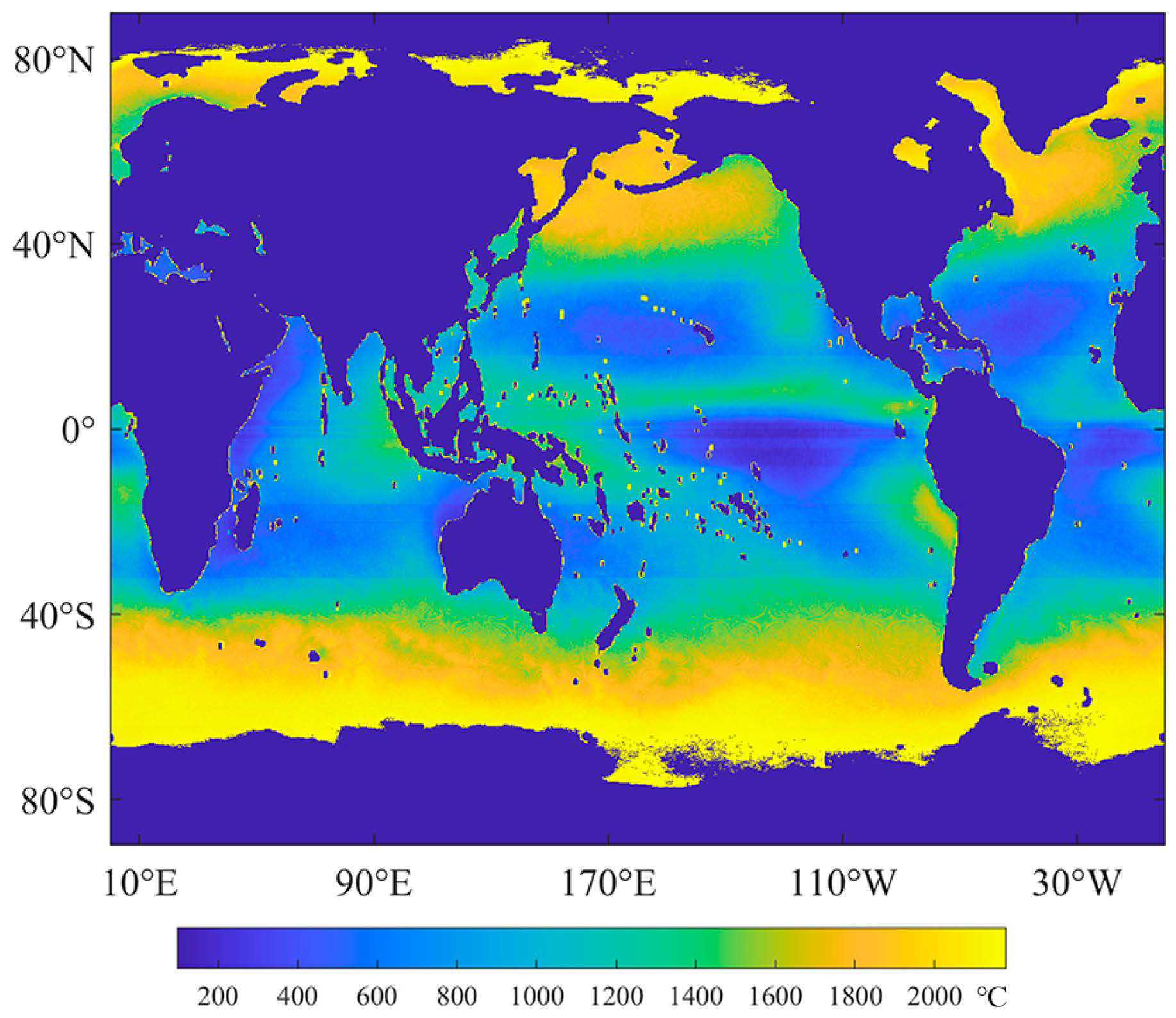
2.1. Experimental Data
2.2. SR Models
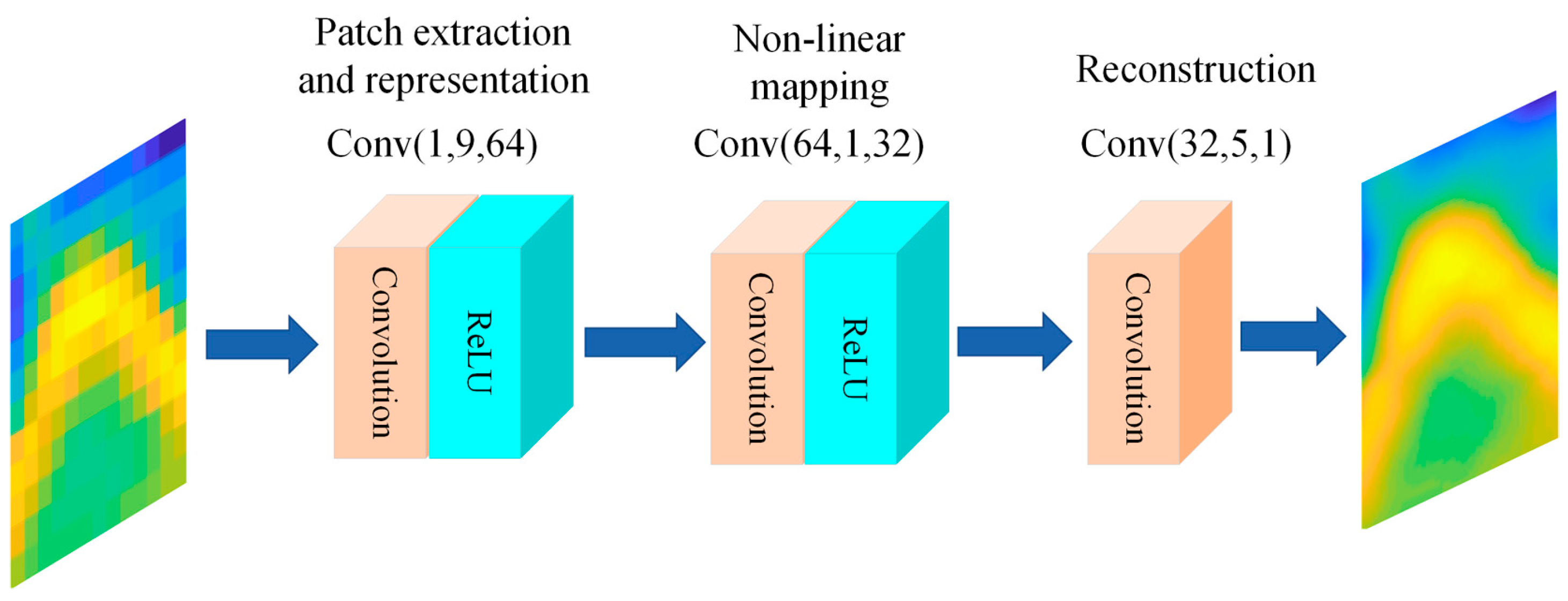
2.2.1. Super-Resolution Convolutional Neural Network (SRCNN) Model
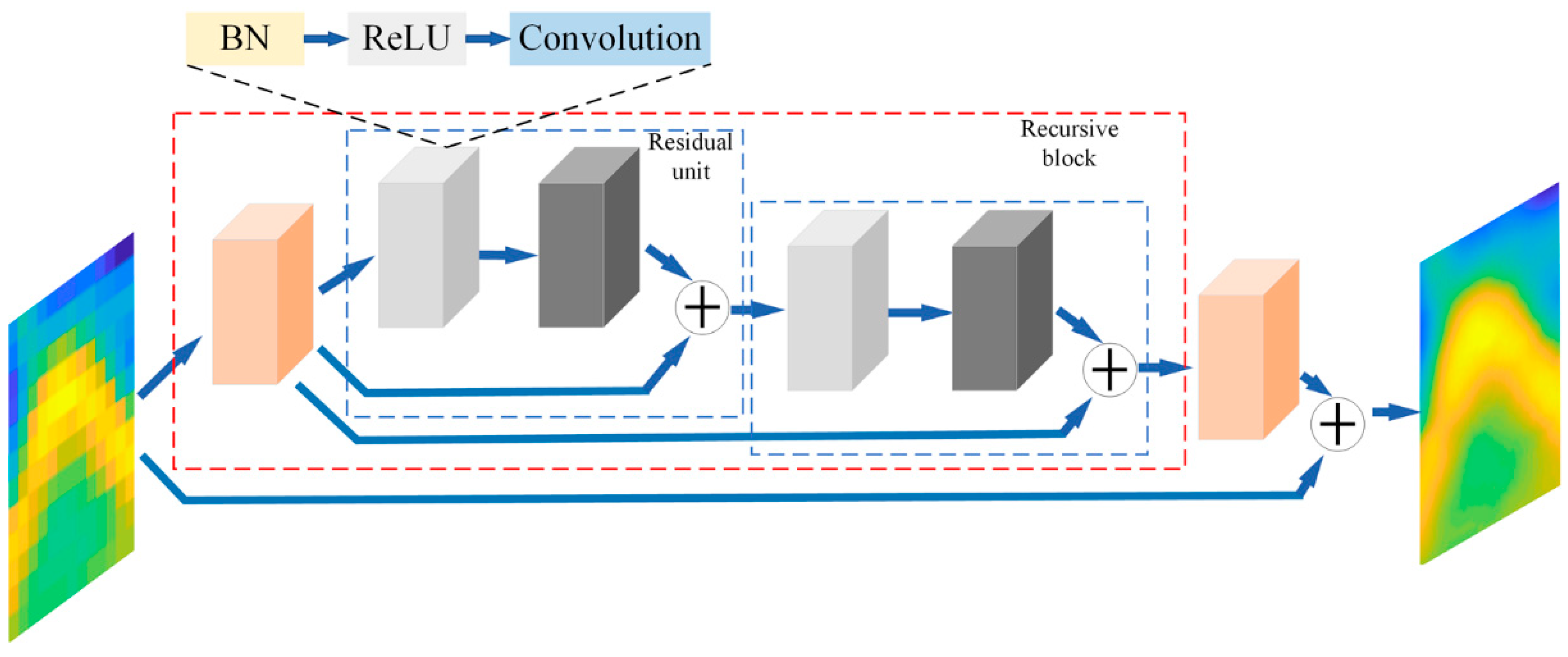
2.2.2. Deep Recursive Residual Network (DRRN) Model
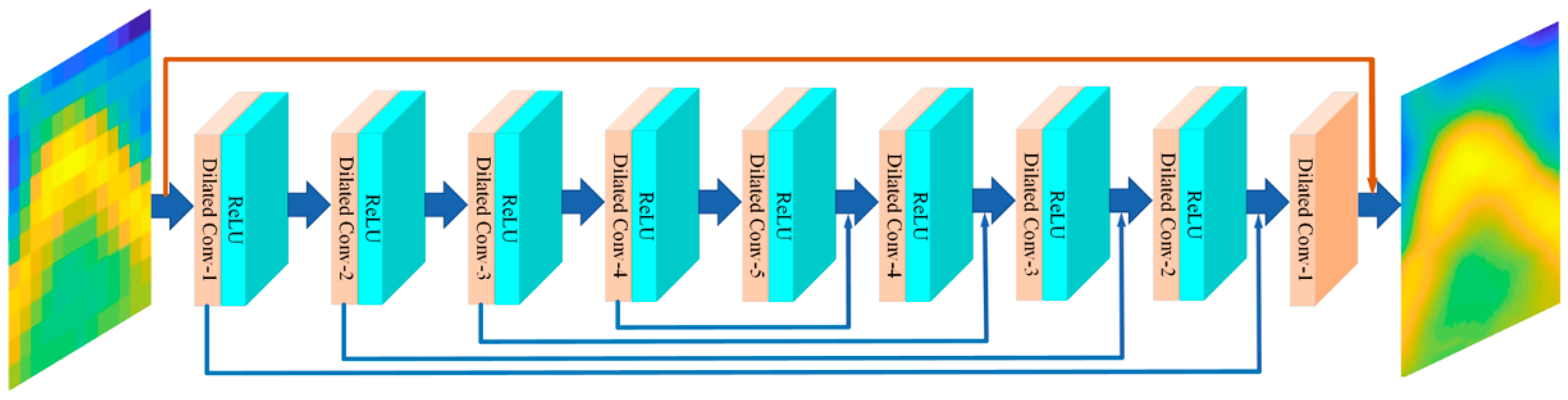
2.2.3. Symmetrical Dilated Residual Convolution Networks (FDSR) Model
2.2.4. Oceanic Data Reconstruction Network (ODRE) Model
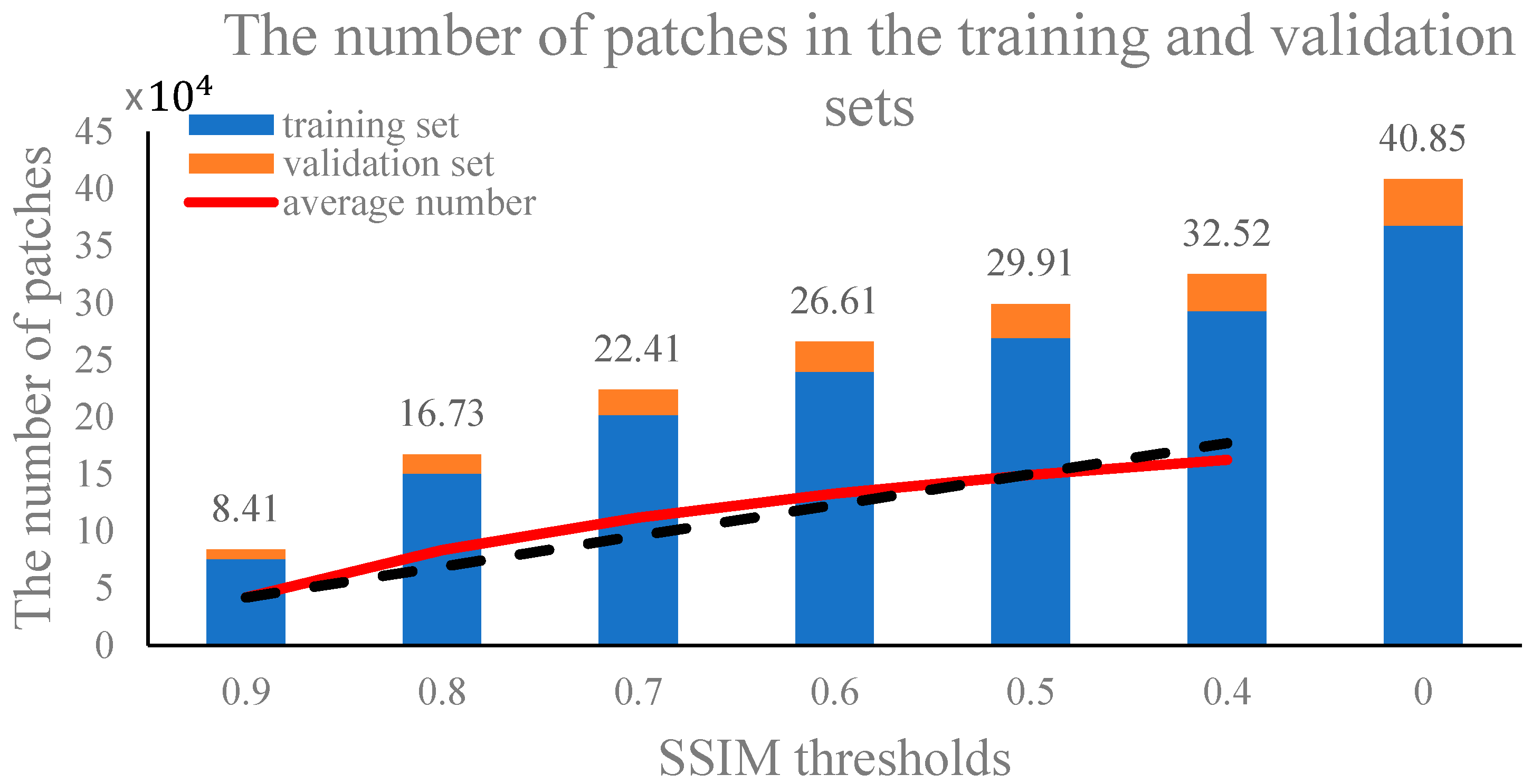
2.3. Network Training
2.4. Quantitative Evaluation
3. Results
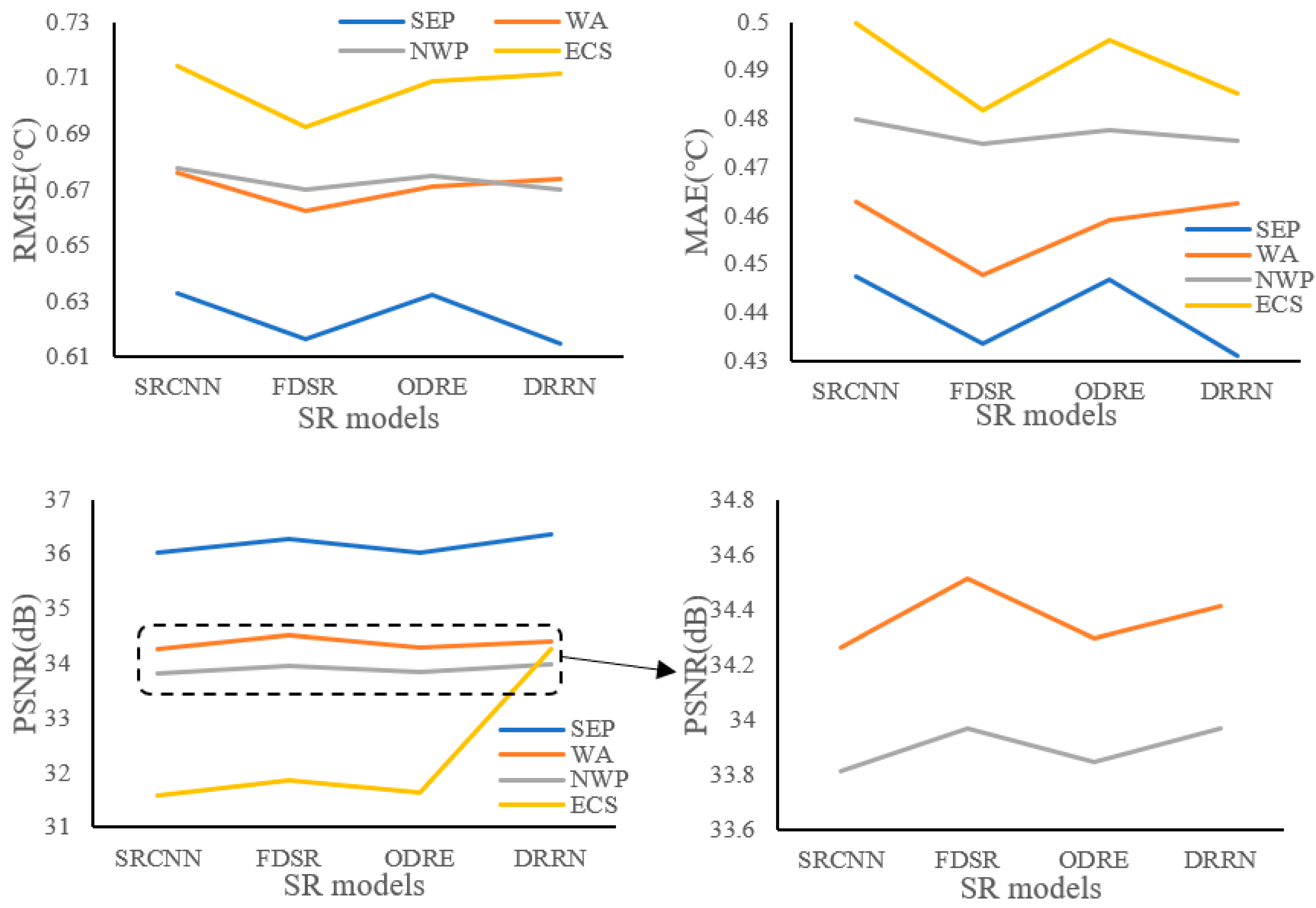
3.1. Statistical Results
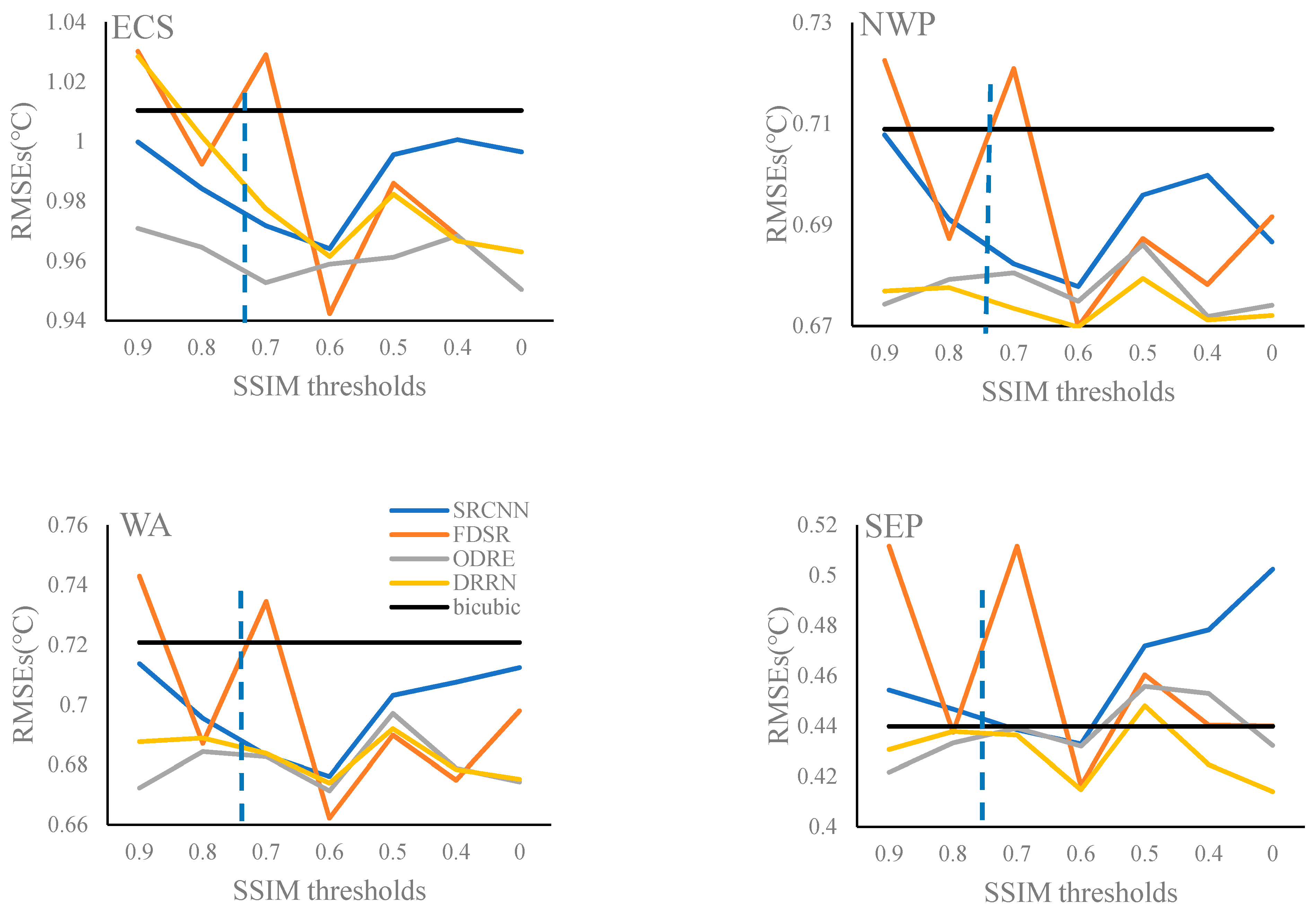
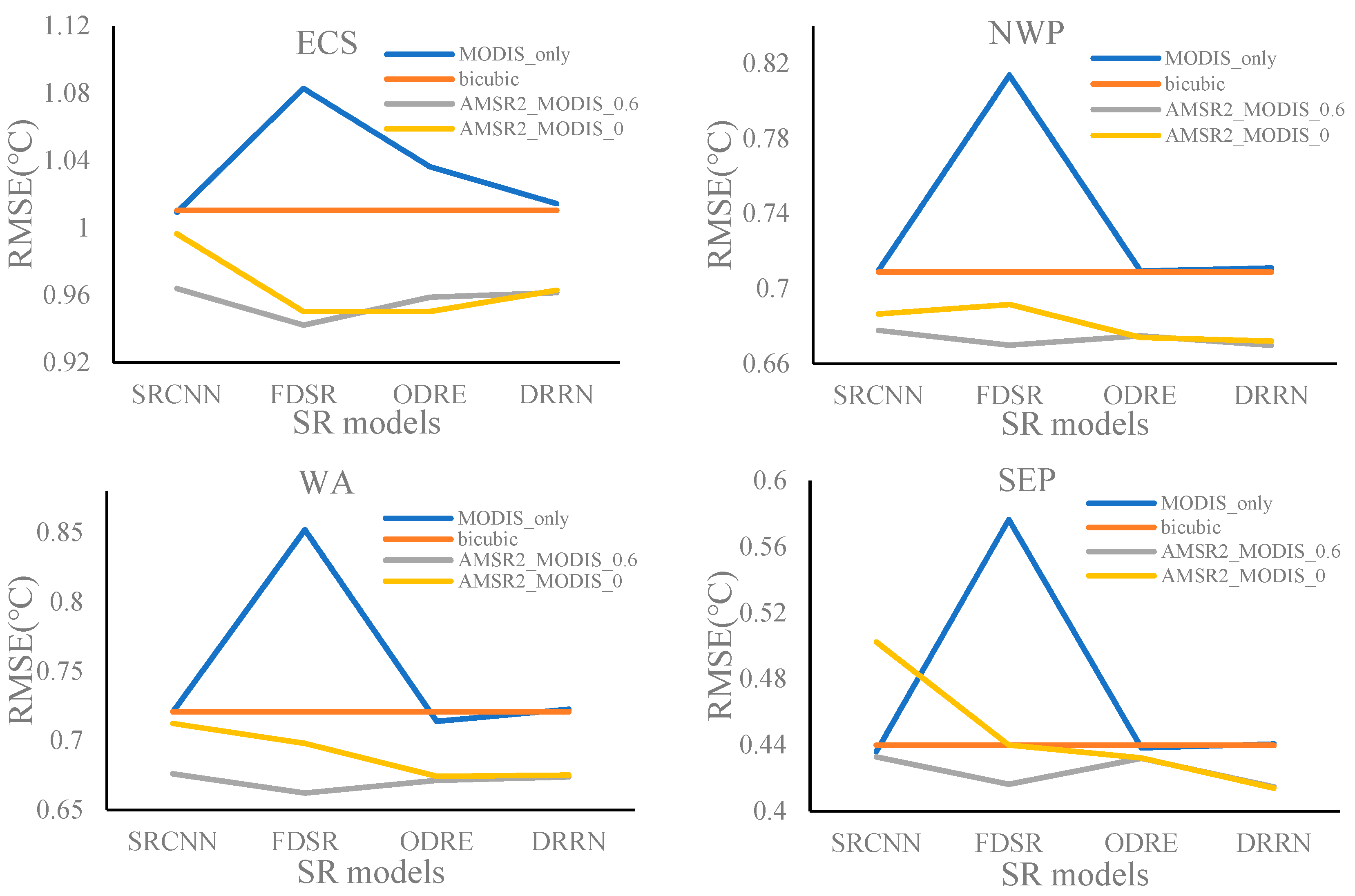
3.1.1. RMSEs in Four Regions
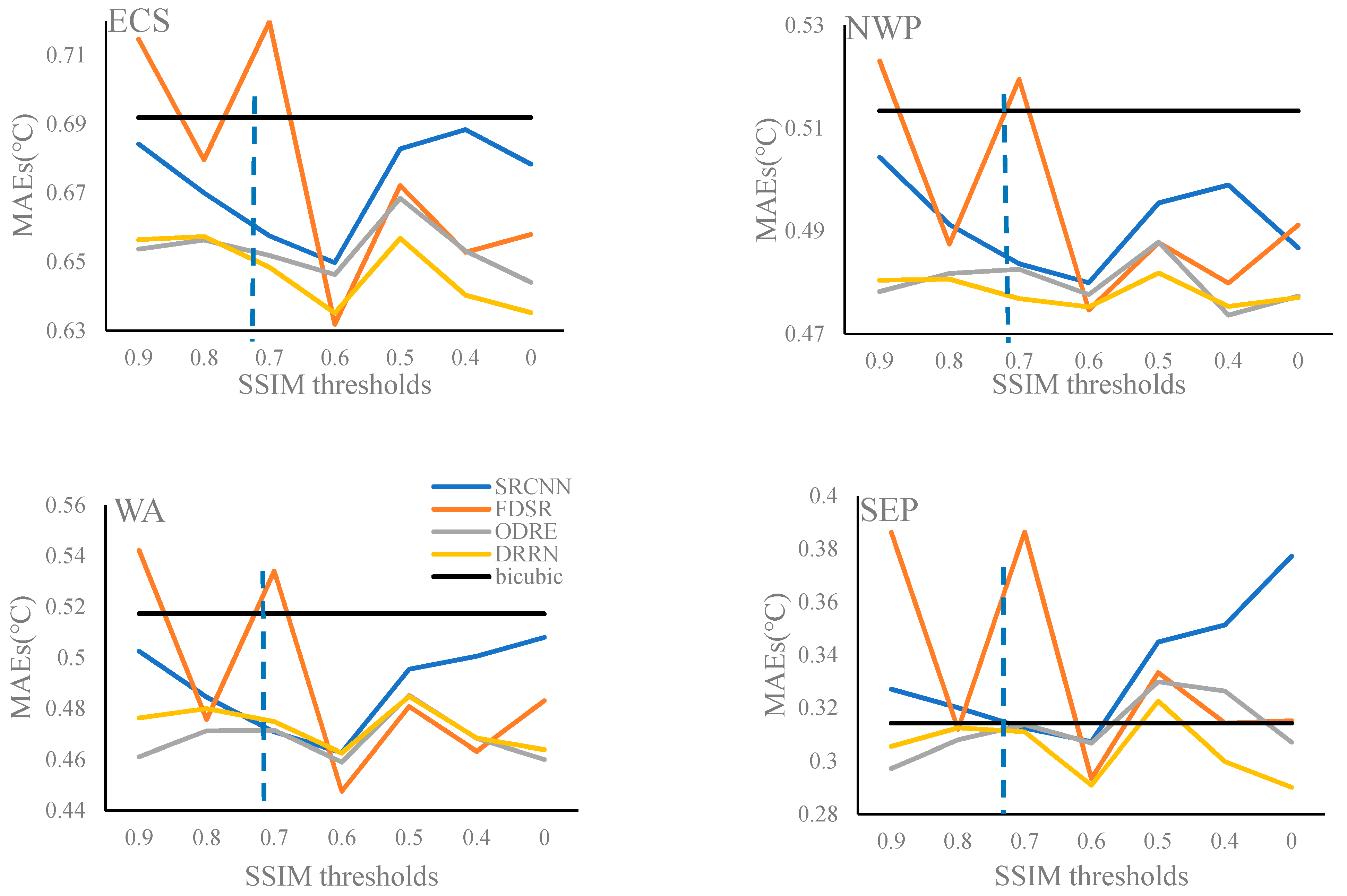
3.1.2. MAEs in Four Regions
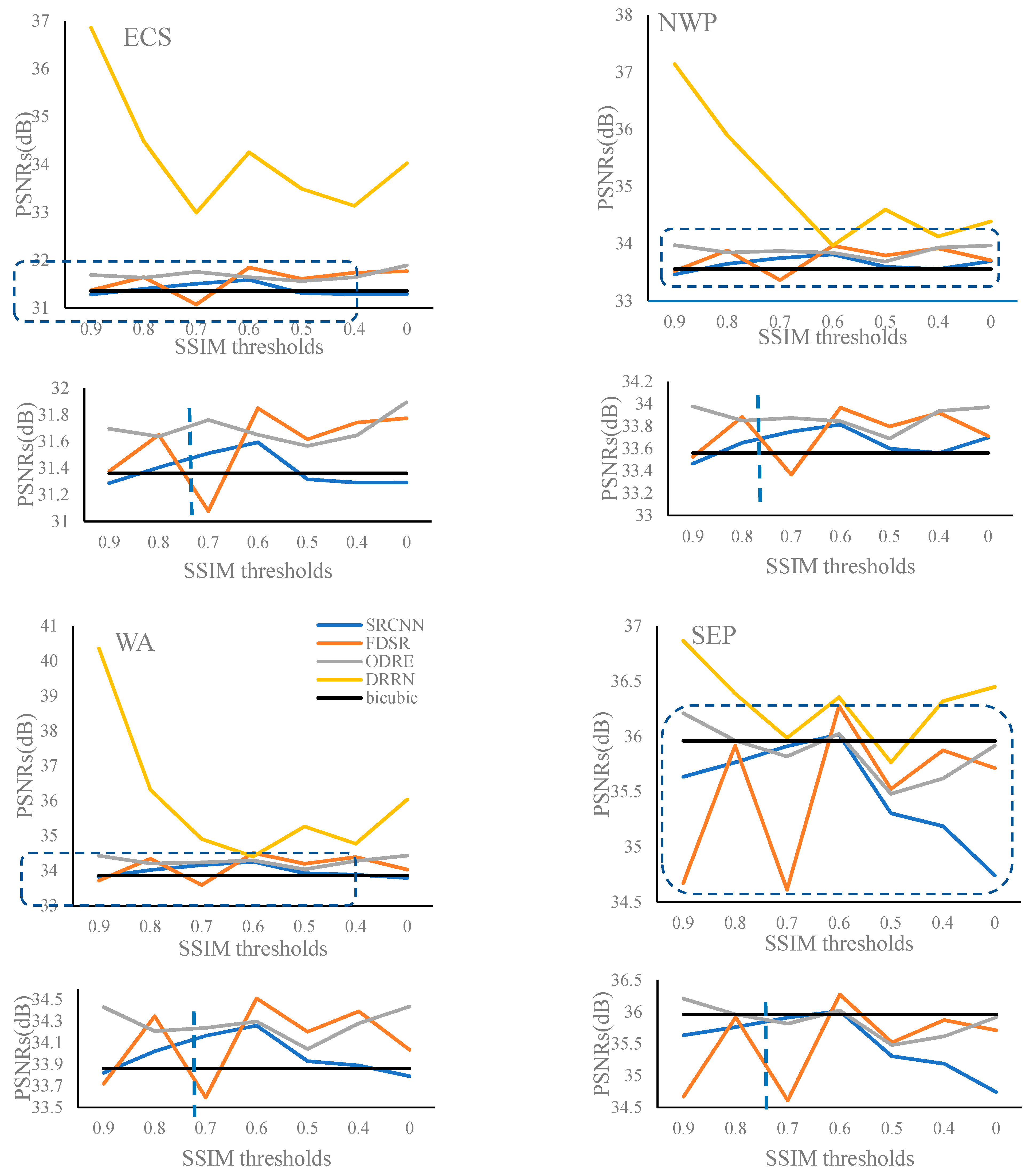
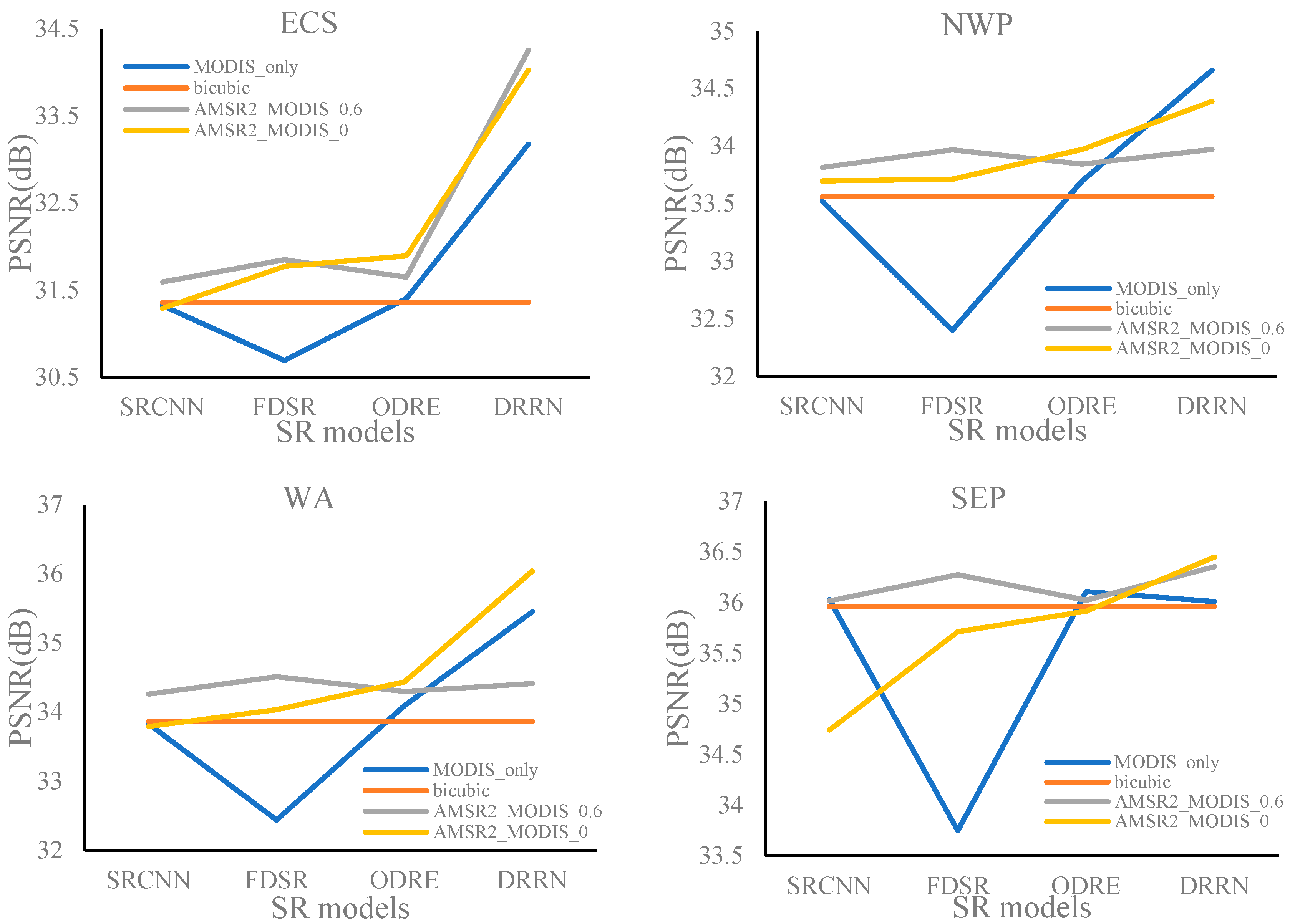
3.1.3. PSNRs in Four Regions
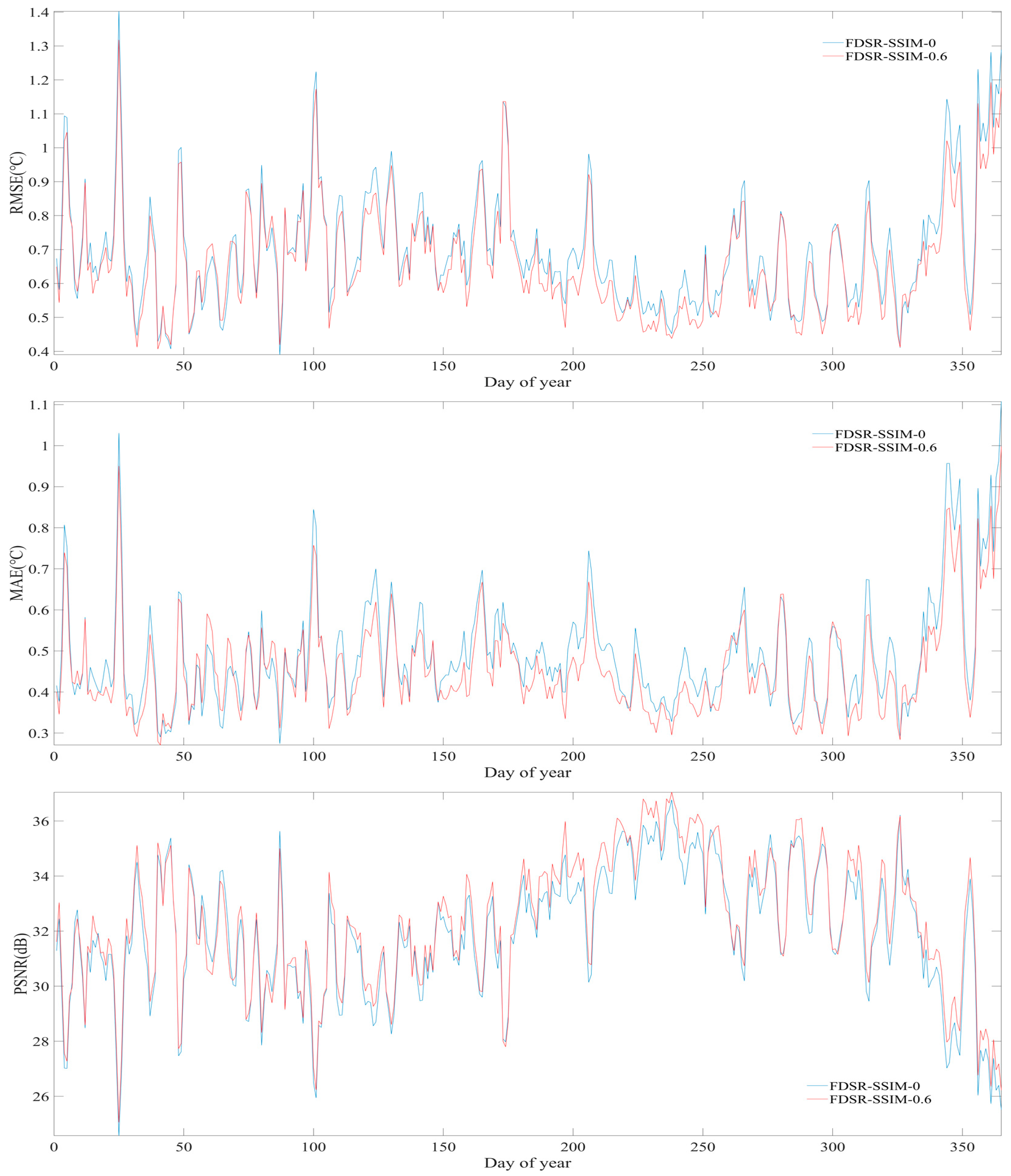
3.2. Daily Differences Based on Different Training Datasets
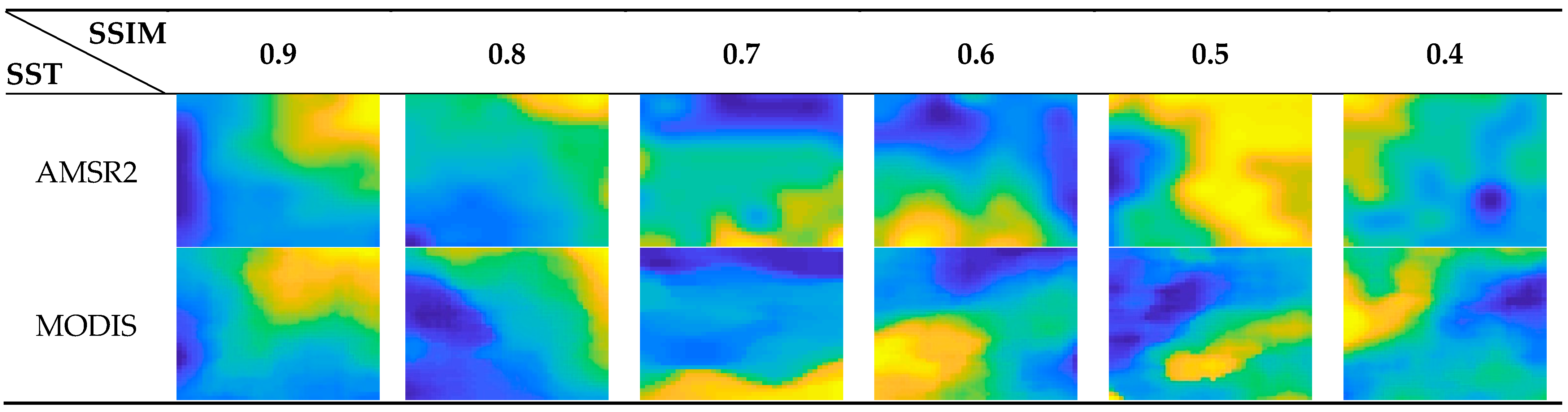
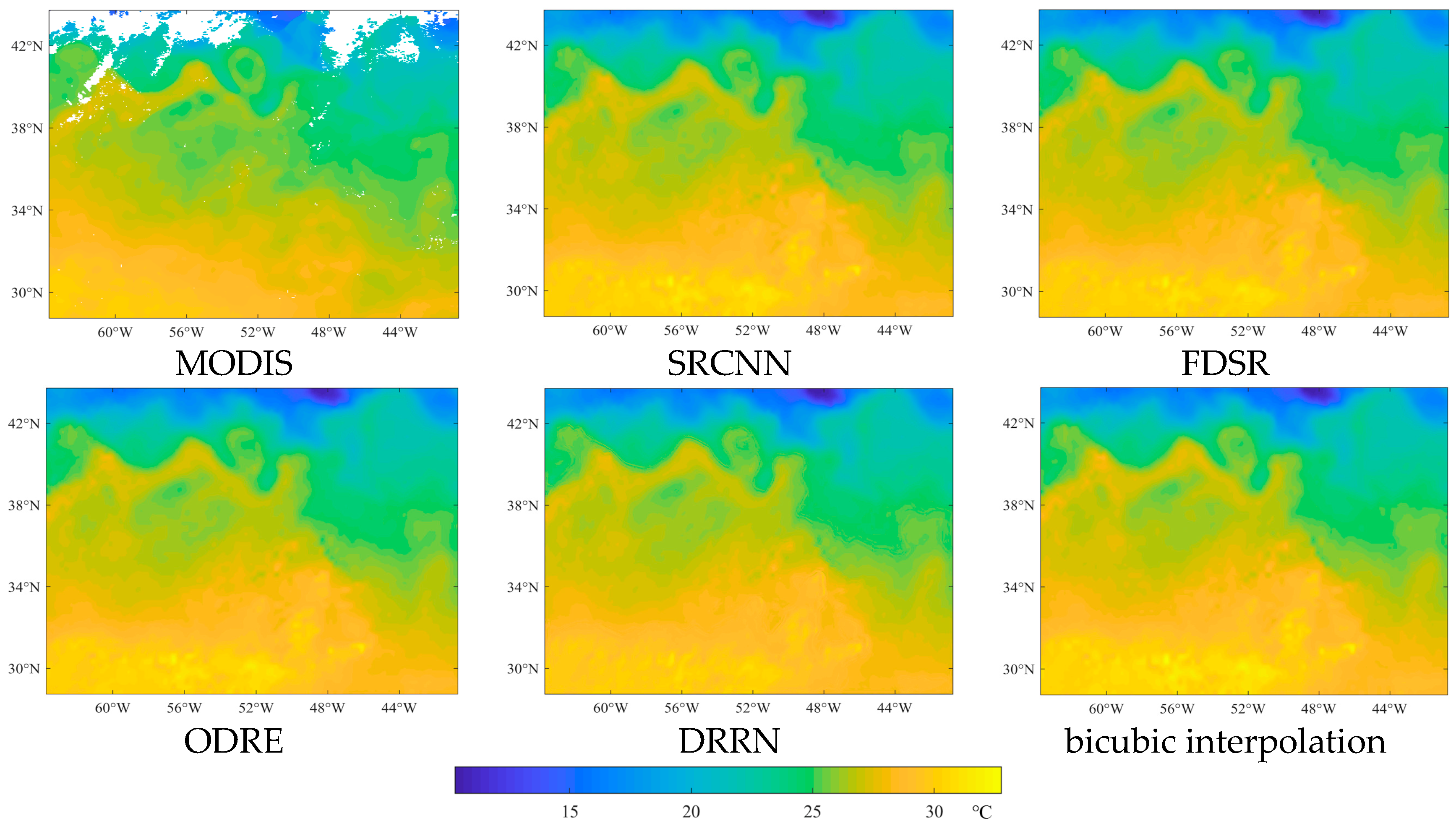
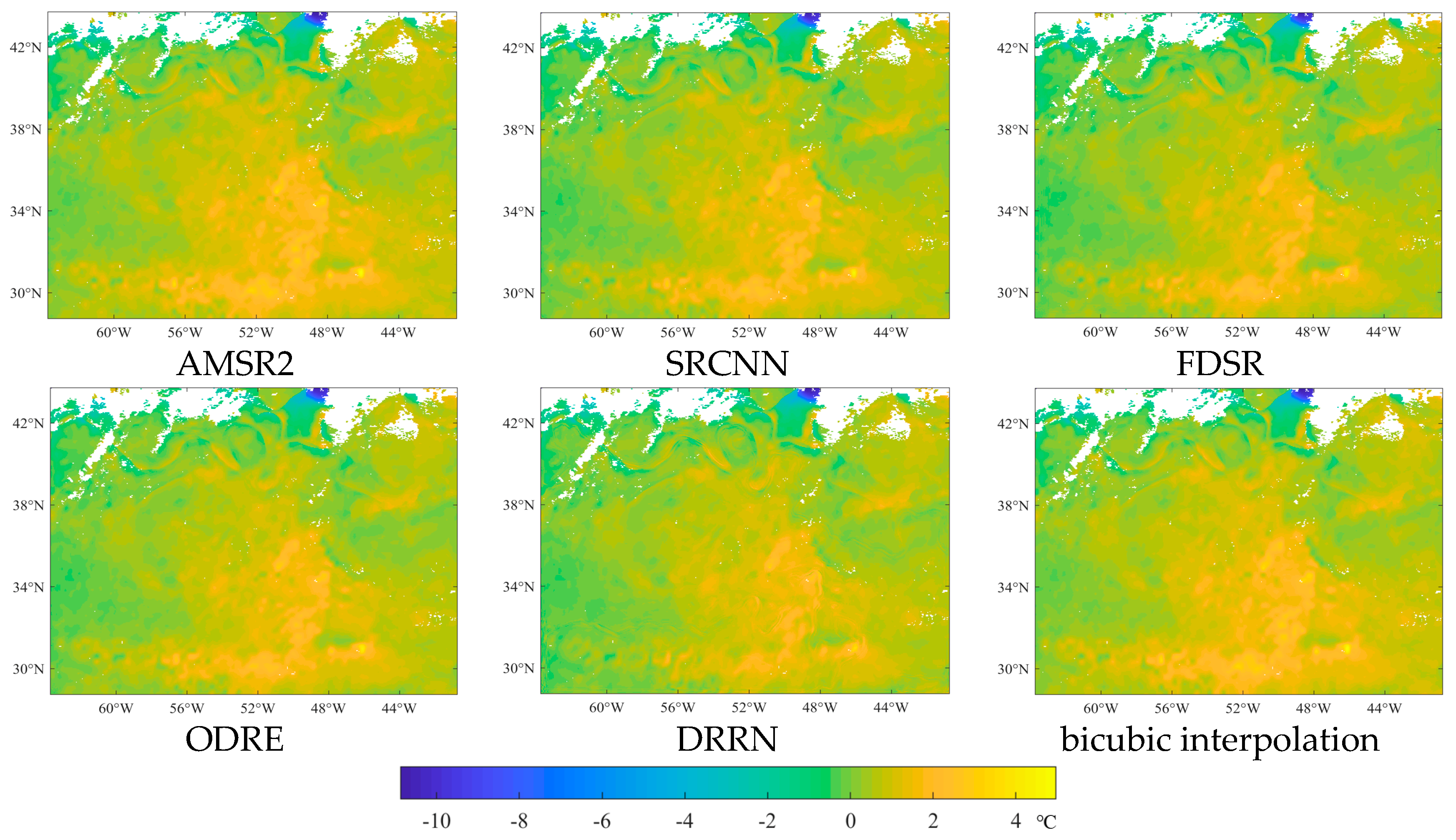
3.3. A Case Study
4. Discussion
4.1. Training Dataset Obtained from Single MODIS SST
4.2. The Comparisons between Different SR Models
5. Conclusions
- (1)
- The training dataset determined by a SSIM value of 0.6 generally resulted in the lowest RMSEs as well as MAEs, and the highest PSNRs for the four experimental areas.
- (2)
- SR reconstruction was more successful for regions with large SST spatial variations, such as ECS, NWP, and WA, because of the apparent SST structures.
- (3)
- Spatial similarity between the low-resolution input and the objective high-resolution output is a key factor affecting the quality of the SST SR reconstruction.
- (4)
- The training dataset obtained from the actual AMSR2 and MODIS SST images is more suitable for SST SR, probably caused by the skin and sub-skin temperature difference and the footprint difference between the simulated and real low-resolution SST images.
- (5)
- The SST reconstruction accuracies (RMSE and MAE) obtained from different SR models for the four experimental regions were quite consistent, while the differences in image quality (PSNR) were rather significant.
- (6)
- The SSIM was used to determine the training dataset, yet whether this index is the best option for SST SR is still an open question.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Reynolds, R.W.; Smith, T.M. Improved global sea surface temperature analyses using optimum interpolation. J. Clim. 1994, 7, 929–948. [Google Scholar] [CrossRef] [Green Version]
- Reynolds, R.W.; Rayner, N.A.; Smith, T.M.; Stokes, D.C.; Wang, W. An improved in situ and satellite SST analysis for climate. J. Clim. 2002, 15, 1609–1625. [Google Scholar] [CrossRef]
- Reynolds, R.W.; Smith, T.M.; Liu, C.; Chelton, D.B.; Casey, K.; Schlax, M.G. Daily high-resolution-blended analyses for sea surface temperature. J. Clim. 2007, 20, 5473–5496. [Google Scholar] [CrossRef]
- Alvera-Azcarate, A.; Barth, A.; Rixen, M.; Beckers, J.-M. Reconstruction of incomplete oceanographic data sets using empirical orthogonal functions: Application to the Adriatic Sea surface temperature. Ocean. Model. 2005, 9, 325–346. [Google Scholar] [CrossRef] [Green Version]
- Alvera-Azcarate, A.; Barth, A.; Beckers, J.M.; Weisberg, R.H. Multivariate reconstruction of missing data in sea surface temperature, chlorophyll, and wind satellite fields. J. Geophys. Res. -Ocean. 2007, 112, C03008. [Google Scholar]
- Alvera-Azcarate, A.; Vanhellemont, Q.; Ruddick, K.; Barth, A.; Beckers, J.-M. Analysis of high frequency geostationary ocean colour data using DINEOF. Estuar. Coast. Shelf Sci. 2015, 159, 28–36. [Google Scholar] [CrossRef] [Green Version]
- Alvera-Azcárate, A.; Barth, A.; Parard, G.; Beckers, J.-M. Analysis of SMOS sea surface salinity data using DINEOF. Remote Sens. Environ. 2016, 180, 137–145. [Google Scholar] [CrossRef] [Green Version]
- Ping, B.; Su, F.Z.; Meng, Y.S. Reconstruction of satellite-derived sea surface temperature data based on an improved DINEOF algorithm. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4181–4188. [Google Scholar] [CrossRef]
- Ping, B.; Su, F.Z.; Meng, Y.S. An improved DINEOF algorithm for filling missing values in spatio-temporal sea surface temperature data. PLoS ONE 2016, 11, e0155928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, D.Y.; Wang, Y.Q. Trends of satellite derived chlorophyll-a (1997–2011) in the Bohai and Yellow Seas, China: Effects of bathymetry on seasonal and inter-annual patterns. Prog. Oceanogr. 2013, 116, 154–166. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Gao, Z.Q.; Liu, D.Y. Multivariate DINEOF reconstruction for creating long-term cloud-free chlorophyll-a data records from SeaWiFS and MODIS: A case study in Bohai and Yellow Seas, China. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1383–1395. [Google Scholar] [CrossRef]
- Barth, A.; Alvera-Azcárate, A.; Licer, M.; Beckers, J.-M. DINCAE 1.0: A convolutional neural network with error estimates to reconstruct sea surface temperature satellite observations. Geosci. Model Dev. 2020, 13, 1609–1622. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar]
- Hui, Z.; Wang, X.M.; Gao, X.B. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 723–731. [Google Scholar]
- Zhang, Y.L.; Li, K.P.; Li, K.; Wang, L.C.; Zhong, B.N.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Volume 11211, pp. 294–310. [Google Scholar]
- Chang, Y.P.; Luo, B. Bidirectional convolutional LSTM neural network for remote sensing image super-resolution. Remote Sens. 2019, 11, 2333. [Google Scholar] [CrossRef] [Green Version]
- Gargiulo, M.; Mazza, A.; Gaetano, R.; Ruello, G.; Scarpa, G. Fast super-resolution of 20 m Sentinel-2 bands using convolutional neural networks. Remote Sens. 2019, 11, 2635. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Yang, J.L.; Liu, Z.; Yang, X.M.; Jeon, G.; Wu, W. Feedback network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3862–3871. [Google Scholar]
- Galar, M.; Sesma, R.; Ayala, C.; Albizua, L.; Aranda, C. Super-resolution of sentinel-2 images using convolutional neural networks and real ground truth data. Remote Sens. 2020, 12, 2941. [Google Scholar] [CrossRef]
- He, Z.W.; Cao, Y.P.; Du, L.; Xu, B.; Yang, J.; Cao, Y.; Tang, S.; Zhuang, Y. MRFN: Multi-receptive-field network for fast and accuracy single image super-resolution. IEEE Trans. Multimed. 2020, 22, 1042–1054. [Google Scholar] [CrossRef]
- Jiang, K.; Wang, Z.; Yi, P.; Jiang, J. Hierarchical dense recursive network for image super-resolution. Pattern Recognit. 2020, 107, 107475. [Google Scholar] [CrossRef]
- Shen, H.; Lin, L.; Li, J.; Yuan, Q.; Zhao, L. A residual convolutional neural network for polarimetric SAR image super-resolution. ISPRS J. Photogramm. Remote Sens. 2020, 161, 90–108. [Google Scholar] [CrossRef]
- Tian, C.; Zhuge, R.; Wu, Z.; Xu, Y.; Zuo, W.; Chen, C.; Lin, C.-W. Lightweight image super-resolution with enhanced CNN. Knowl.-Based Syst. 2020, 205, 106235. [Google Scholar] [CrossRef]
- Yang, A.; Yang, B.; Ji, Z.; Pang, Y.; Shao, L. Lightweight group convolutional network for single image super-resolution. Inf. Sci. 2020, 516, 220–233. [Google Scholar] [CrossRef]
- Dong, X.; Sun, X.; Jia, X.; Xi, Z.; Gao, L.; Zhang, B. Remote sensing image super-resolution using novel dense-sampling networks. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1618–1633. [Google Scholar] [CrossRef]
- Lan, R.; Sun, L.; Liu, Z.; Lu, H.; Pang, C.; Luo, X. MADNet: A fast and lightweight network for single-image super resolution. IEEE Trans. Cybern. 2021, 51, 1443–1453. [Google Scholar] [CrossRef] [PubMed]
- Ping, B.; Su, F.; Han, X.; Meng, Y. Applications of deep learning-based super-resolution for sea surface temperature reconstruction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 887–896. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Univ Cent Florida, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Zhang, L.; Zhang, Y.; Peng, Y.L.; Li, S.G.; Wu, X.J.; Gang, L.; Yuan, R. Fast single image super-resolution via dilated residual networks. IEEE Access 2018, 6, 109729–109738. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.M.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tai, Y.; Yang, J.; Liu, X.M. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2790–2798. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ECS | NWP | WA | SEP | |
|---|---|---|---|---|
| AMSR2 | 2.26% | 0.89% | 0.94% | 0.61% |
| MODIS | 46.90% | 54.19% | 46.74% | 41.77% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ping, B.; Meng, Y.; Xue, C.; Su, F. Can the Structure Similarity of Training Patches Affect the Sea Surface Temperature Deep Learning Super-Resolution? Remote Sens. 2021, 13, 3568. https://doi.org/10.3390/rs13183568
Ping B, Meng Y, Xue C, Su F. Can the Structure Similarity of Training Patches Affect the Sea Surface Temperature Deep Learning Super-Resolution? Remote Sensing. 2021; 13(18):3568. https://doi.org/10.3390/rs13183568
Chicago/Turabian StylePing, Bo, Yunshan Meng, Cunjin Xue, and Fenzhen Su. 2021. "Can the Structure Similarity of Training Patches Affect the Sea Surface Temperature Deep Learning Super-Resolution?" Remote Sensing 13, no. 18: 3568. https://doi.org/10.3390/rs13183568
APA StylePing, B., Meng, Y., Xue, C., & Su, F. (2021). Can the Structure Similarity of Training Patches Affect the Sea Surface Temperature Deep Learning Super-Resolution? Remote Sensing, 13(18), 3568. https://doi.org/10.3390/rs13183568