
Edge-Preserving Convolutional Generative Adversarial Networks for SAR-to-Optical Image Translation




Abstract
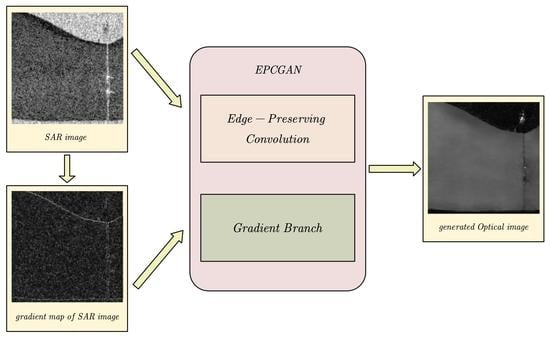
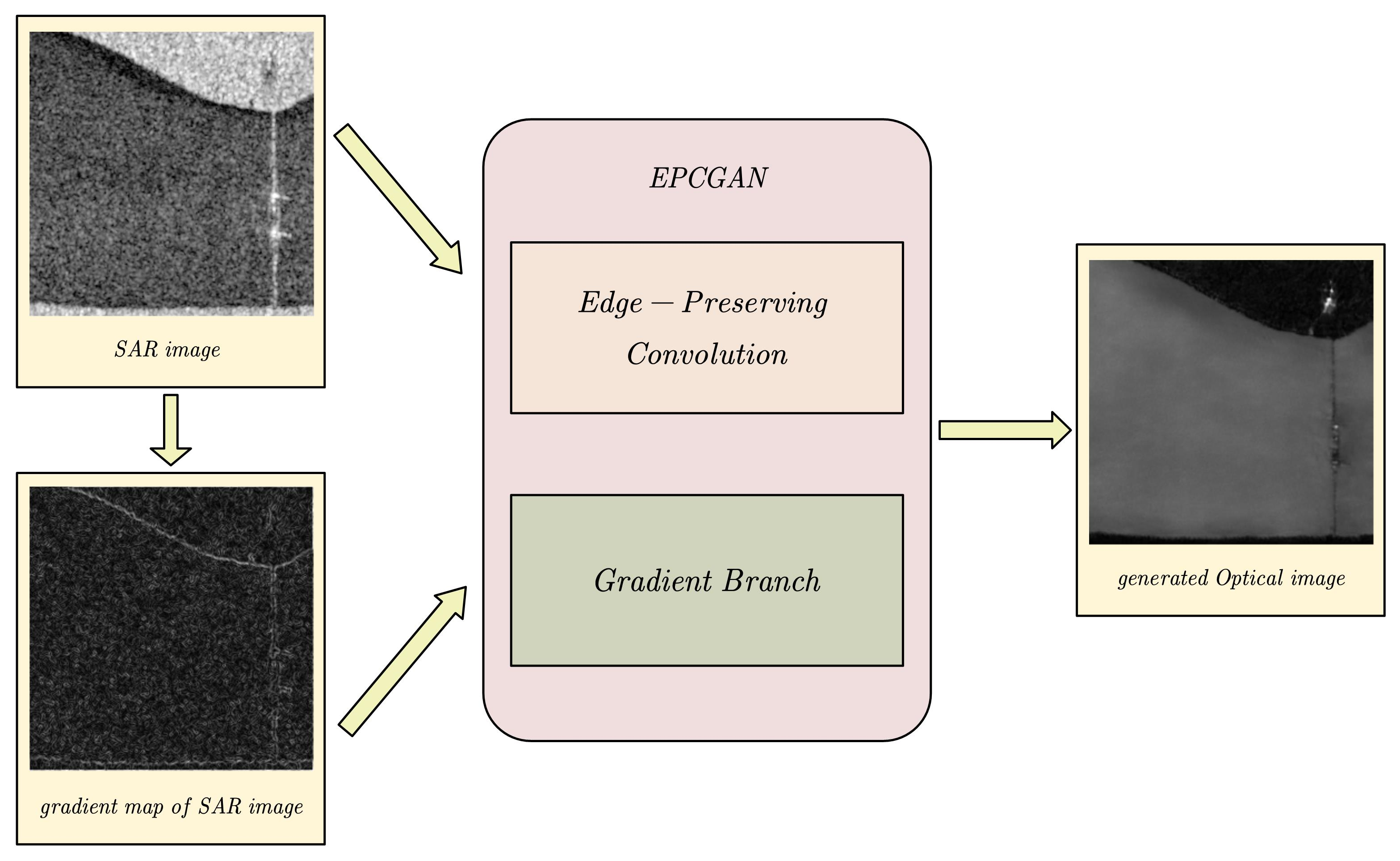
:
1. Introduction
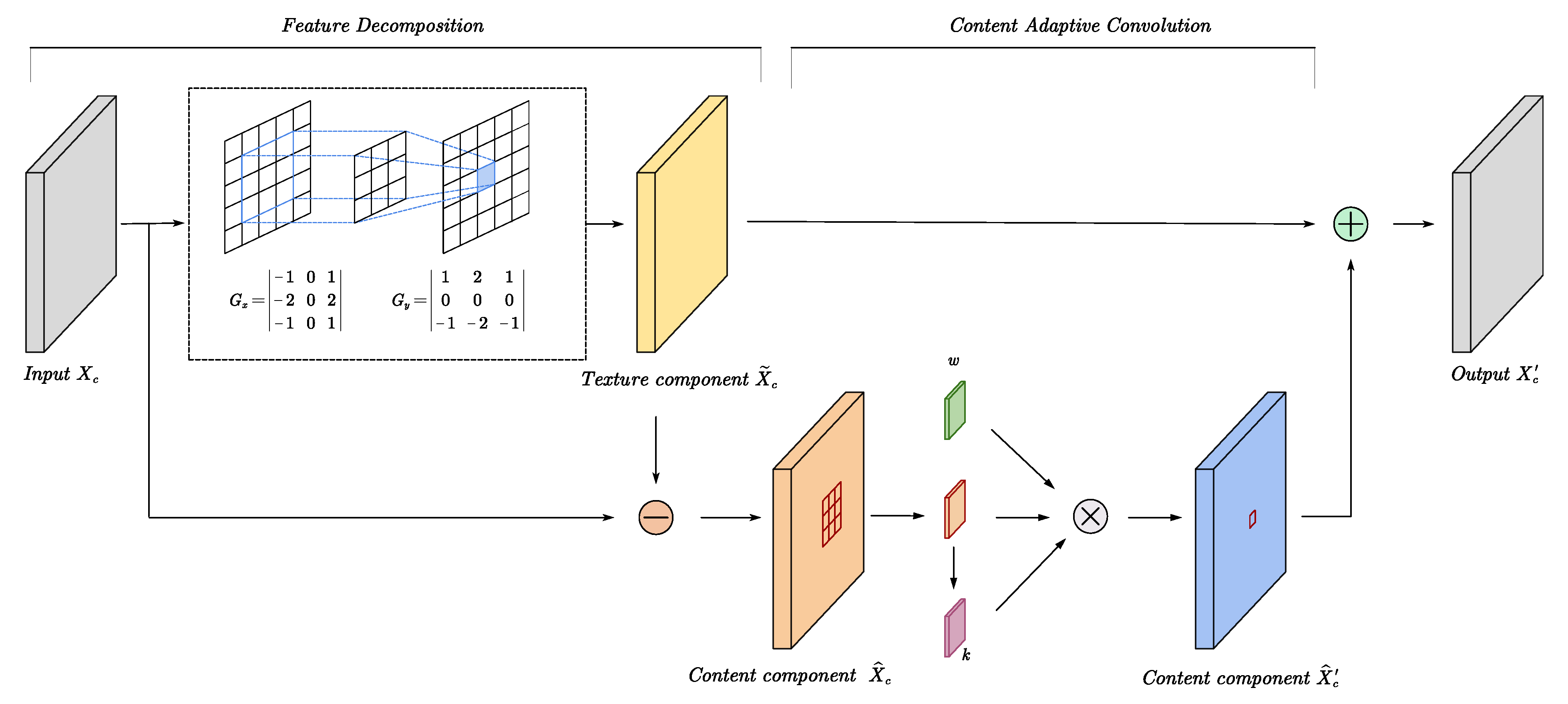
- Edge-preserving convolution (EPC) is proposed for SAR-to-optical image translation. It performs content-adaptive convolution on a feature graph while preserving structural information according to decomposition theory, leading to good structure in the generated optical images.
- For the situations in which SAR image interpretation is difficult, a novel edge-preserving convolutional generative adversarial network (EPCGAN) for SAR-to-optical image translation is proposed, which can improve the quality of the structural information in the generated optical image by utilizing the gradient information of the SAR image and the optical image as a constraint.
- The experiments on the training set selected from the SEN1-2 dataset [35] containing multi-modal data (forests, rivers, waters, plains, mountains, etc.) prove the superiority of the proposed algorithm. Meanwhile, ablation studies are given.
2. Related Works
2.1. Image-to-Image Translation
2.2. Deep Learning-Based Methods for SAR Data
3. Methods
3.1. Edge-Preserving Convolution
3.2. Edge-Preserving Convolutional Generative Adversarial Networks
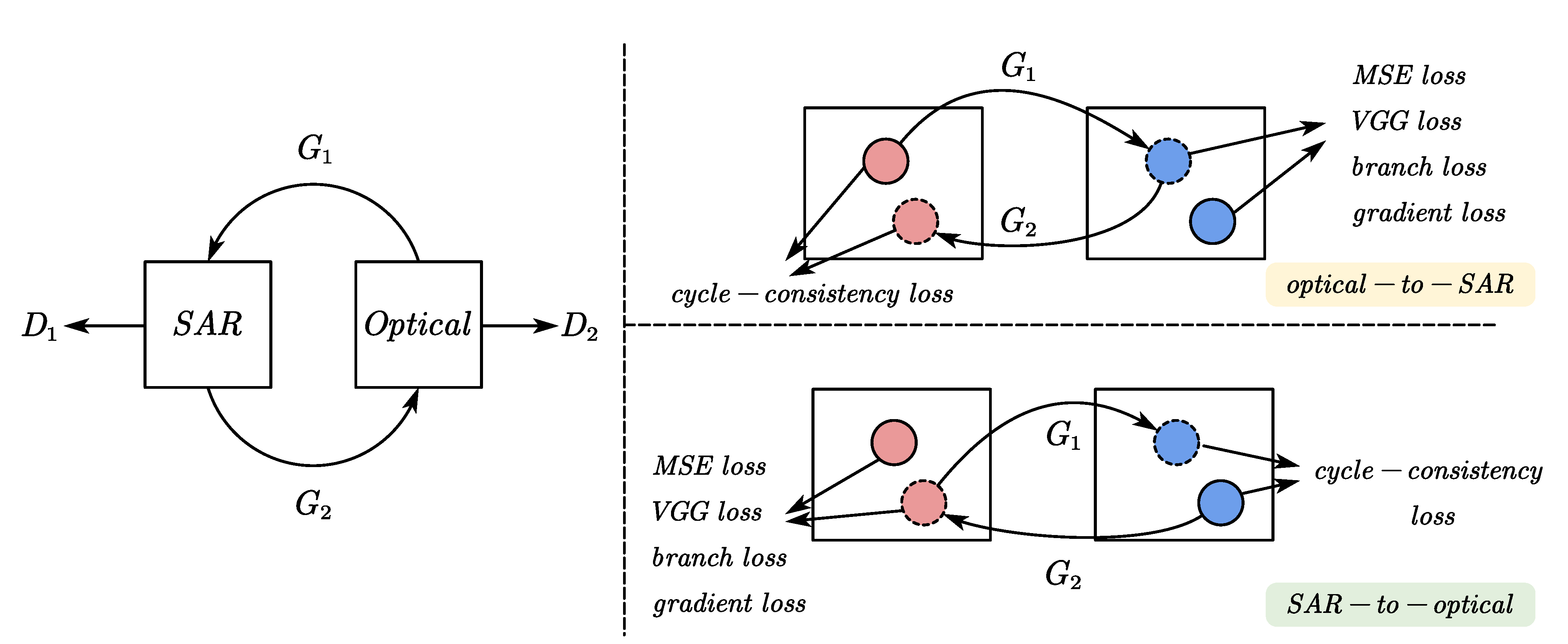
3.2.1. Network Framework
3.2.2. Generator
3.2.3. Discriminator
3.3. Loss Function
4. Experiments
4.1. Implementation Details
4.1.1. Dataset
4.1.2. Training Details
4.2. Results and Analysis
4.3. A comparison of Textural and Structural Information
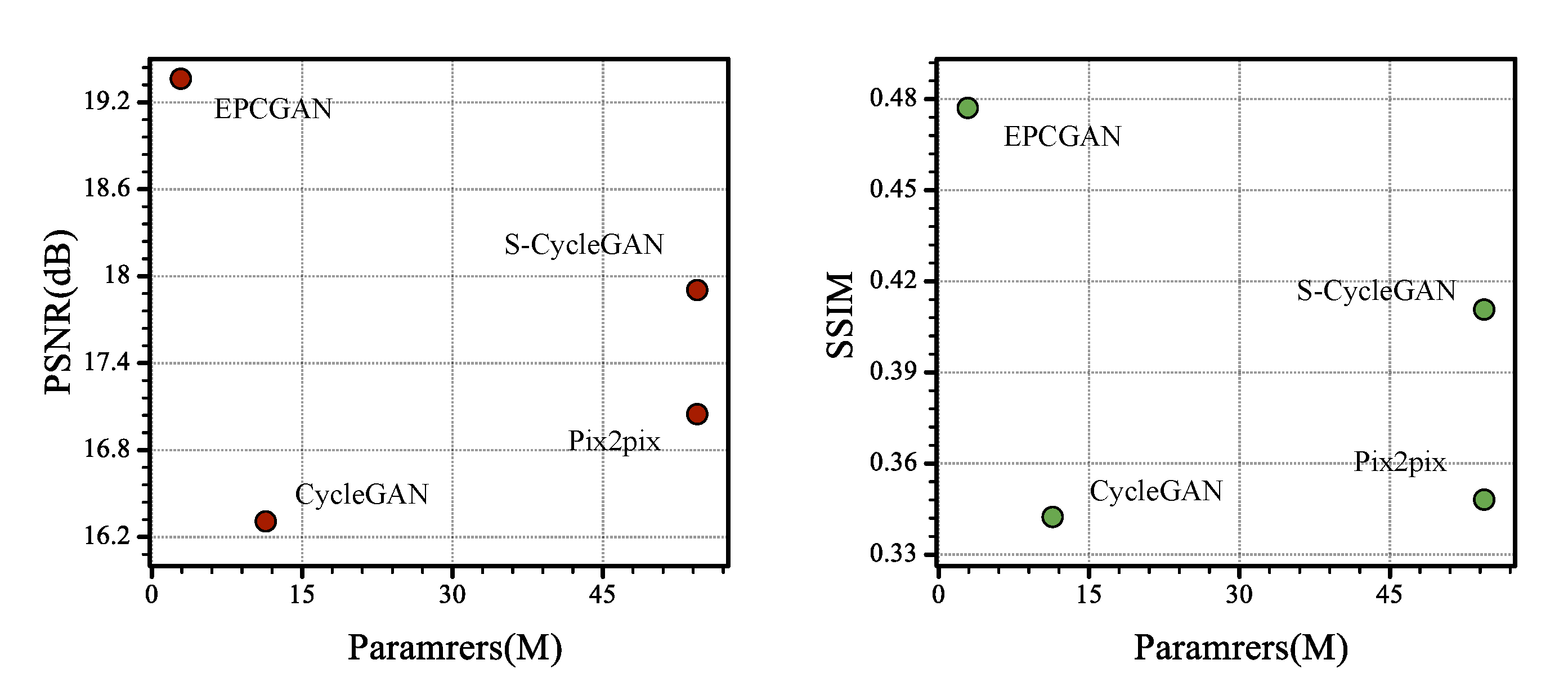
4.4. Model Complexity Analysis
4.5. Ablation Experiment
5. Discussion
5.1. Goals and Difficulties for SAR-to-Optical Translation
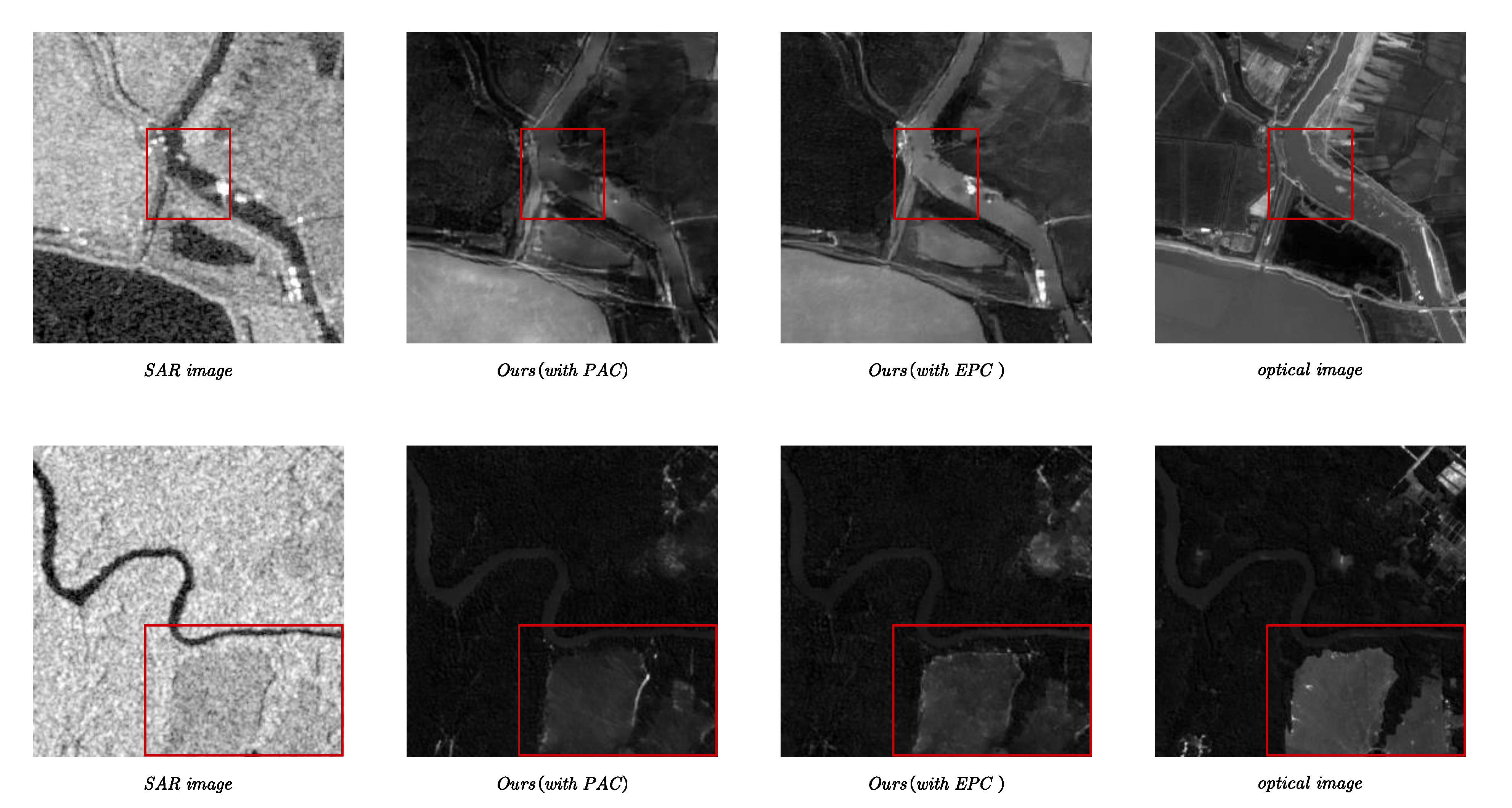
5.2. Comparative Analysis of PAC and EPC
5.3. Network Structure and Loss Function for SAR-to-Optical Translation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bazzi, H.; Baghdadi, N.; Amin, G.; Fayad, I.; Zribi, M.; Demarez, V.; Belhouchette, H. An Operational Framework for Mapping Irrigated Areas at Plot Scale Using Sentinel-1 and Sentinel-2 Data. Remote Sens. 2021, 13, 2584. [Google Scholar] [CrossRef]
- Huang, L.; Yang, J.; Meng, J.; Zhang, J. Underwater Topography Detection and Analysis of the Qilianyu Islands in the South China Sea Based on GF-3 SAR Images. Remote Sens. 2021, 13, 76. [Google Scholar] [CrossRef]
- Bayramov, E.; Buchroithner, M.; Kada, M.; Zhuniskenov, Y. Quantitative Assessment of Vertical and Horizontal Deformations Derived by 3D and 2D Decompositions of InSAR Line-of-Sight Measurements to Supplement Industry Surveillance Programs in the Tengiz Oilfield (Kazakhstan). Remote Sens. 2021, 13, 2579. [Google Scholar] [CrossRef]
- Rajaneesh, A.; Logesh, N.; Vishnu, C.L.; Bouali, E.H.; Oommen, T.; Midhuna, V.; Sajinkumar, K.S. Monitoring and Mapping of Shallow Landslides in a Tropical Environment Using Persistent Scatterer Interferometry: A Case Study from the Western Ghats, India. Geomatics 2021, 1, 3–17. [Google Scholar] [CrossRef]
- Fuentes Reyes, M.; Auer, S.; Merkle, N.; Henry, C.; Schmitt, M. SAR-to-Optical Image Translation Based on Conditional Generative Adversarial Networks—Optimization, Opportunities and Limits. Remote Sens. 2019, 11, 2067. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.S. Speckle suppression and analysis for synthetic aperture radar image. Opt. Eng. 1986, 25, 255636. [Google Scholar] [CrossRef]
- Simard, M.; DeGrandi, G.; Thomson, K.P.B.; Benie, G.B. Analysis of speckle noise contribution on wavelet decomposition of SAR images. IEEE Trans. Geosci. Remote Sens. 1998, 36, 1953–1962. [Google Scholar] [CrossRef]
- Argenti, F.; Lapini, A.; Bianchi, T.; Alparone, L. A tutorial on speckle reduction in synthetic aperture radar images. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–35. [Google Scholar] [CrossRef] [Green Version]
- Auer, S.; Hinz, S.; Bamler, R. Ray-Tracing Simulation Techniques for Understanding High-Resolution SAR Images. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1445–1456. [Google Scholar] [CrossRef] [Green Version]
- Chambenoit, Y.; Classeau, N.; Trouvé, E. Performance assessment of multitemporal SAR images’ visual interpretation. In Proceedings of the 2003 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Toulouse, France, 21–25 July 2003; pp. 3911–3913. [Google Scholar]
- Zhang, B.; Wang, C.; Zhang, H.; Wu, F. An adaptive two-scale enhancement method to visualize man-made objects in very high resolution SAR images. Remote Sens. Lett. 2015, 6, 725–734. [Google Scholar] [CrossRef]
- Li, Y.; Gong, H.; Feng, D.; Zhang, Y. An adaptive method of speckle reduction and feature enhancement for SAR images based on curvelet transform and particle swarm optimization. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3105–3116. [Google Scholar] [CrossRef]
- Odegard, J.E.; Guo, H.; Lang, M.; Burrus, C.S.; Hiett, M. Wavelet Based SAR Speckle Reduction and Image Compression. In Proceedings of the SPIE—The International Society for Optical Engineering, San Diego, CA, USA, 9 July 1995; p. 2487. [Google Scholar]
- Dellepiane, S.G.; Angiati, E. A new method for cross-normalization and multitemporal visualization of SAR images for the detection of flooded areas. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2765–2779. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, C.; Li, S. A perceptive uniform pseudo-color coding method of SAR images. In Proceedings of the 2006 CIE International Conference on Radar, Shanghai, China, 16–19 October 2006; pp. 1–4. [Google Scholar]
- Uhlmann, S.; Kiranyaz, S.; Gabbouj, M. Polarimetric SAR classification using visual color features extracted over pseudo color images. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Melbourne, Australia, 21–26 July 2013; pp. 1999–2002. [Google Scholar]
- Chen, Y.X.; Wu, W.B. Pseudo-color Coding of SAR Images Based on Roberts Gradient and HIS Color Space. Geomat. Spat. Inf. Technol. 2017, 4, 85–88. [Google Scholar]
- Wang, L.; Xu, X.; Yu, Y.; Yang, R.; Gui, R.; Xu, Z.; Pu, F. SAR-to-optical image translation using supervised cycle-consistent adversarial networks. IEEE Access 2019, 7, 129136–129149. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017(CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision 2017(ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8798–8807. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2849–2857. [Google Scholar]
- Merkle, N.; Fischer, P.; Auer, S.; Müller, R. On the possibility of conditional adversarial networks for multi-sensor image matching. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Forth Worth, TX, USA, 23–28 July 2017; pp. 2633–2636. [Google Scholar]
- Merkle, N.; Auer, S.; Muller, R.; Reinartz, P.; Pu, F. Exploring the potential of conditional adversarial networks for optical and SAR image matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1811–1820. [Google Scholar] [CrossRef]
- Wang, P.; Patel, V.M. Generating high quality visible images from SAR images using CNNs. In Proceedings of the IEEE Radar Conference 2018(RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018; pp. 0570–0575. [Google Scholar]
- Ley, A.; Dhondt, O.; Valade, S.; Haensch, R.; Hellwich, O. Exploiting GAN-based SAR to optical image transcoding for improved classification via deep learning. In Proceedings of the European Conference on Synthetic Aperture Radar 2018 (EUSAR), Aachen, Germany, 4–7 June 2018; pp. 1–6. [Google Scholar]
- Grohnfeldt, C.; Schmitt, M.; Zhu, X. A conditional generative adversarial network to fuse SAR and multispectral optical data for cloud removal from Sentinel-2 images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spian, 22–27 July 2018; pp. 1726–1729. [Google Scholar]
- Gao, J.; Yuan, Q.; Li, J.; Zhang, H.; Su, X. Cloud removal with fusion of high resolution optical and SAR images using generative adversarial networks. Remote Sens. 2020, 12, 191. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhou, J.; Lu, X. Feature-Guided SAR-to-Optical Image T ranslation. IEEE Access 2020, 8, 70925–70937. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, X.; Liu, M.; Zou, X.; Zhu, L.; Ruan, X. Comparative Analysis of Edge Information and Polarization on SAR-to-Optical Translation Based on Conditional Generative Adversarial Networks. Remote Sens. 2021, 13, 128. [Google Scholar] [CrossRef]
- Xue, T.; Wu, J.; Bouman, K.L.; Freeman, W.T. Visual dynamics: Probabilistic future frame synthesis via cross convolutional networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 91–99. [Google Scholar]
- Bako, S.; Vogels, T.; McWilliams, B.; Meyer, M.; Novák, J.; Harvill, A.; Rousselle, F. Kernel-predicting convolutional networks for denoising Monte Carlo renderings. ACM Trans. Graph. 2017, 36, 97:1–97:14. [Google Scholar] [CrossRef] [Green Version]
- Su, H.; Jampani, V.; Sun, D.; Gallo, O.; Learned-Miller, E.; Kautz, J. Pixel-adaptive convolutional neural networks. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 11166–11175. [Google Scholar]
- Schmitt, M.; Hughes, L.H.; Zhu, X.X. The SEN1-2 dataset for deep learning in SAR-optical data fusion. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 141–146. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Li, J.; Wang, W.; Gao, X. Compositional Model-Based Sketch Generator in Facial Entertainment. IEEE Trans. Cybern. 2018, 48, 904–915. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Wang, N.; Li, Y.; Gao, X. Deep Latent Low-Rank Representation for Face Sketch Synthesis. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3109–3123. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Wang, N.; Li, Y.; Gao, X. Neural Probabilistic Graphical Model for Face Sketch Synthesis. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2623–2637. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, N.; Li, Y.; Gao, X. Bionic Face Sketch Generator. IEEE Trans. Cybern. 2020, 50, 2701–2714. [Google Scholar] [CrossRef]
- Zhang, M.; Wang, R.; Li, J.; Gao, X.; Tao, D. Dual-transfer Face Sketch-Photo Synthesis. IEEE Trans. Image Process. 2019, 28, 642–657. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zhou, J.; Li, M.; Zhou, H.; Yu, T. Quality Assessment of SAR-to-Optical Image Translation. Remote Sens. 2020, 12, 3472. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8789–8797. [Google Scholar]
- Li, X.; Zhang, S.; Hu, J.; Cao, L.; Hong, X.; Mao, X.; Ji, R. Image-to-image Translation via Hierarchical Style Disentanglement. In Proceedings of the 2021 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtually, 19–25 June 2021; pp. 8639–8648. [Google Scholar]
- Chen, R.; Huang, W.; Huang, B.; Sun, F.; Fang, B. Reusing discriminators for encoding: Towards unsupervised image-to-image translation. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 8168–8177. [Google Scholar]
- Liu, M.Y.; Huang, X.; Mallya, A.; Karras, T.; Aila, T.; Lehtinen, J.; Kautz, J. Few-shot unsupervised image-to-image translation. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 10551–10560. [Google Scholar]
- Berthelot, D.; Schumm, T.; Metz, L. Began: Boundary equilibrium generative adversarial networks. arXiv 2017, arXiv:1703.10717. [Google Scholar]
- Marmanis, D.; Yao, W.; Adam, F.; Datcu, M.; Reinartz, P.; Schindler, K.; Stilla, U. Artificial generation of big data for improving image classification: A generative adversarial network approach on SAR data. In Proceedings of the 2017 conference on Big Data from Space (BiDS), Toulouse, France, 28–30 November 2017; pp. 293–296. [Google Scholar]
- Chierchia, G.; Cozzolino, D.; Poggi, G.; Verdoliva, L. SAR Image Despeckling Through Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5438–5441. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ao, D.; Dumitru, C.O.; Schwarz, G.; Datcu, M. Dialectical GAN for SAR Image Translation: From Sentinel-1 to TerraSAR-X. Remote Sens. 2018, 10, 1597. [Google Scholar] [CrossRef] [Green Version]
- He, W.; Yokoya, N. Multi-Temporal Sentinel-1 and -2 Data Fusion for Optical Image Simulation. ISPRS Int. J. Geo-Inf. 2018, 7, 389. [Google Scholar] [CrossRef] [Green Version]
- Bermudez, J.; Happ, P.; Oliveira, D.; Feitosa, R. SAR to optical image synthesis for cloud removal with generative adversarial networks. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 4, 1. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Durand, F.; Dorsey, J. Fast bilateral filtering for the display of high-dynamic-range images. In Proceedings of the 29th Annual Conference on Computer Graphics and Interactive Techniques, San Antonio, TX, USA, 23–26 July 2002; pp. 257–266. [Google Scholar]
- Paris, S.; Hasinoff, S.W.; Kautz, J. Local Laplacian filters: Edge-aware image processing with a Laplacian pyramid. ACM Trans. Graph. 2011, 20, 68. [Google Scholar]
- Bovik, A.C. Nonlinear filtering for image analysis and enhancement. In The Essential Guide to Image Processing; Academic Press: New York, NY, USA, 2000; pp. 263–291. [Google Scholar]
- Jing, W.; Jin, T.; Xiang, D. Edge-Aware superpixel generation for SAR imagery with one iteration merging. IEEE Geosci. Remote Sens. Lett. 2020, 99, 1–5. [Google Scholar] [CrossRef]
- Choi, H.; Jeong, J. Speckle Noise Reduction Technique for SAR Images Using Statistical Characteristics of Speckle Noise and Discrete Wavelet Transform. Remote Sens. 2019, 11, 1184. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Change Loy, C. Esrgan: Enhanced super-resolution generative adversarial networks. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops; Stefan, R., Laura, L., Eds.; Springer: Cham, Switzerland, 2018; pp. 63–79. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV); Bastian, L., Jiri, M., Nicu, S., Max, W., Eds.; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number | Scene Content |
|---|---|---|
| train | 1551 | bridge rivers road mountain forests town farmland |
| Test_1 | 289 | bridge rivers road mountain forests town farmland |
| Test_2 | 45 | bridge rivers road |
| Test_3 | 62 | mountain road |
| Test_4 | 111 | farmland town rivers road |
| IQA | Dataset | Pix2pix | CycleGAN | S-CycleGAN | EPCGAN |
|---|---|---|---|---|---|
| PSNR | Test_1 | 17.0482 | 16.3082 | 17.9046 | 19.3627 |
| Test_2 | 22.1012 | 22.4319 | 23.2056 | 23.8345 | |
| Test_3 | 16.2285 | 15.7547 | 16.1178 | 17.4944 | |
| Test_4 | 15.9798 | 15.4854 | 16.0738 | 17.0195 | |
| MSE | Test_1 | 0.0318 | 0.0322 | 0.0222 | 0.0151 |
| Test_2 | 0.0069 | 0.0068 | 0.0057 | 0.0047 | |
| Test_3 | 0.0240 | 0.0285 | 0.0268 | 0.0197 | |
| Test_4 | 0.0296 | 0.0351 | 0.0272 | 0.0228 | |
| SSIM | Test_1 | 0.3481 | 0.3424 | 0.4107 | 0.4771 |
| Test_2 | 0.4840 | 0.5331 | 0.5547 | 0.5799 | |
| Test_3 | 0.2833 | 0.3140 | 0.2998 | 0.3827 | |
| Test_4 | 0.2658 | 0.2944 | 0.2799 | 0.3399 |
| Pix2pix | CycleGAN | S-CycleGAN | EPCGAN | |
|---|---|---|---|---|
| Training time (h) | 3 | 9 | 12 | 31 |
| FLOPs (G) | 17.8 | 56.0 | 17.8 | 64.4 |
| IQA | Dataset | Ours (w/o EPC and Gradient Branch) | Ours (w/o EPC) | Ours (w/o Gradient Branch) | Ours |
|---|---|---|---|---|---|
| SSIM | Test_1 | 0.4199 | 0.4647 | 0.4602 | 0.4771 |
| Test_2 | 0.4335 | 0.5195 | 0.5152 | 0.5799 | |
| Test_3 | 0.3375 | 0.3783 | 0.3650 | 0.3827 | |
| Test_4 | 0.3041 | 0.3362 | 0.3102 | 0.3399 |
| IQA | Dataset | EPCGAN (PAC) | EPCGAN |
|---|---|---|---|
| PSNR | Test_1 | 18.9468 | 19.3627 |
| Test_2 | 22.7652 | 23.8345 | |
| Test_3 | 17.3758 | 17.4944 | |
| Test_4 | 16.9336 | 17.0195 | |
| SSIM | Test_1 | 0.4575 | 0.4771 |
| Test_2 | 0.5272 | 0.5799 | |
| Test_3 | 0.3631 | 0.3827 | |
| Test_4 | 0.3389 | 0.3399 |
| IQA | Dataset | EPCGAN (w/o MSE Loss) | EPCGAN (w/o VGG Loss) | EPCGAN (w/o Grad Loss) | EPCGAN |
|---|---|---|---|---|---|
| PSNR | Test_1 | 18.4377 | 18.6029 | 19.3625 | 19.3627 |
| Test_2 | 22.2648 | 20.7552 | 22.5868 | 23.8345 | |
| Test_3 | 16.4162 | 17.4345 | 16.9904 | 17.4944 | |
| Test_4 | 15.6180 | 16.9060 | 16.9023 | 17.0195 | |
| SSIM | Test_1 | 0.4454 | 0.4369 | 0.4594 | 0.4771 |
| Test_2 | 0.5174 | 0.4550 | 0.5587 | 0.5799 | |
| Test_3 | 0.3427 | 0.3722 | 0.3669 | 0.3827 | |
| Test_4 | 0.3357 | 0.3044 | 0.3362 | 0.3399 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, J.; He, C.; Zhang, M.; Li, Y.; Gao, X.; Song, B. Edge-Preserving Convolutional Generative Adversarial Networks for SAR-to-Optical Image Translation. Remote Sens. 2021, 13, 3575. https://doi.org/10.3390/rs13183575
Guo J, He C, Zhang M, Li Y, Gao X, Song B. Edge-Preserving Convolutional Generative Adversarial Networks for SAR-to-Optical Image Translation. Remote Sensing. 2021; 13(18):3575. https://doi.org/10.3390/rs13183575
Chicago/Turabian StyleGuo, Jie, Chengyu He, Mingjin Zhang, Yunsong Li, Xinbo Gao, and Bangyu Song. 2021. "Edge-Preserving Convolutional Generative Adversarial Networks for SAR-to-Optical Image Translation" Remote Sensing 13, no. 18: 3575. https://doi.org/10.3390/rs13183575
APA StyleGuo, J., He, C., Zhang, M., Li, Y., Gao, X., & Song, B. (2021). Edge-Preserving Convolutional Generative Adversarial Networks for SAR-to-Optical Image Translation. Remote Sensing, 13(18), 3575. https://doi.org/10.3390/rs13183575