
Cloud Transform Algorithm Based Model for Hydrological Variable Frequency Analysis

 ,
,
Abstract
:1. Introduction
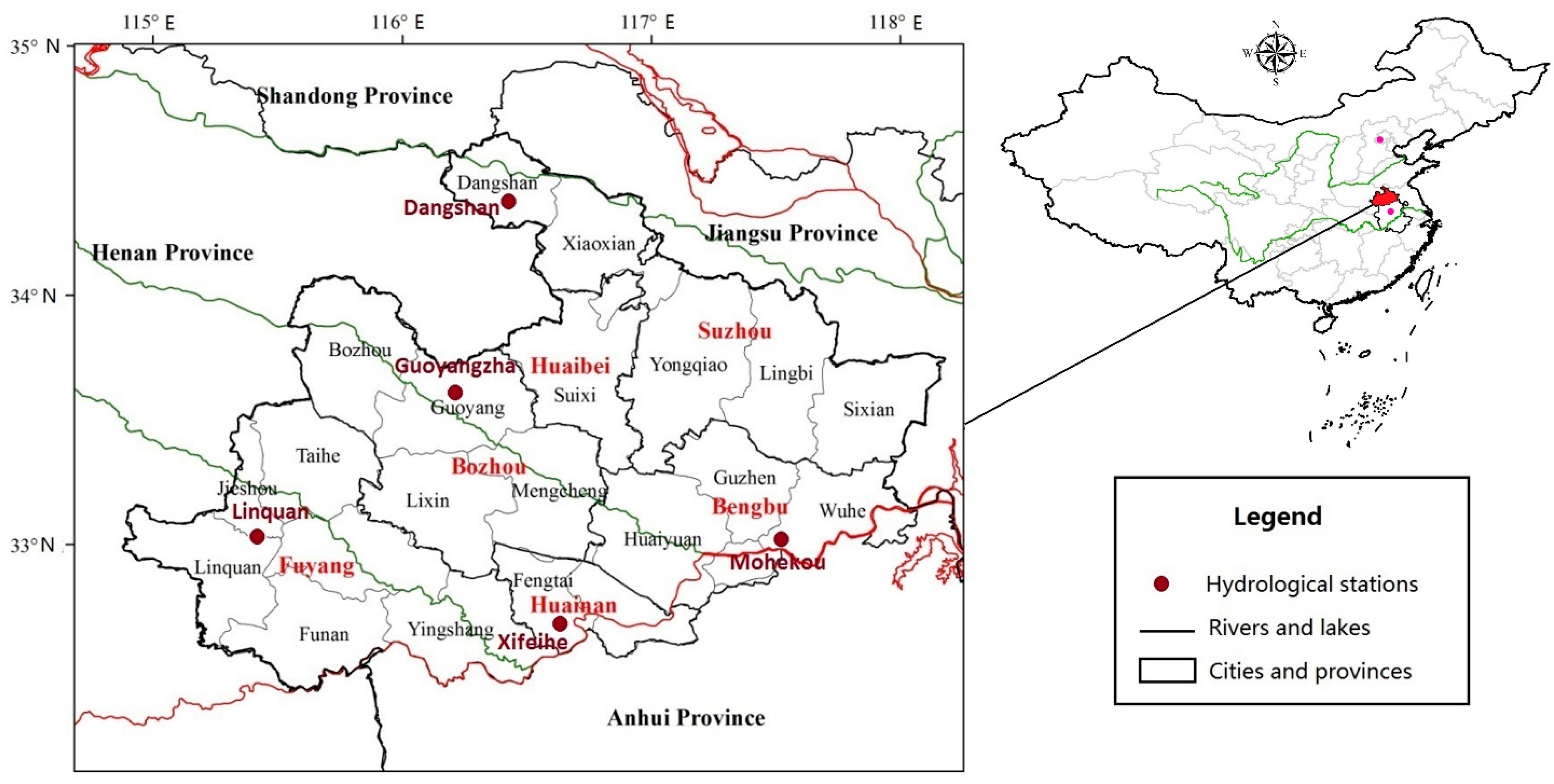
2. Overview of Study Area and Data Collection
3. Methodologies
3.1. Cloud Model and Cloud Transform Algorithm
3.2. Calculation Procedures of the CTAM Method for Hydrological Variable Frequency Analysis
4. Results and Discussion
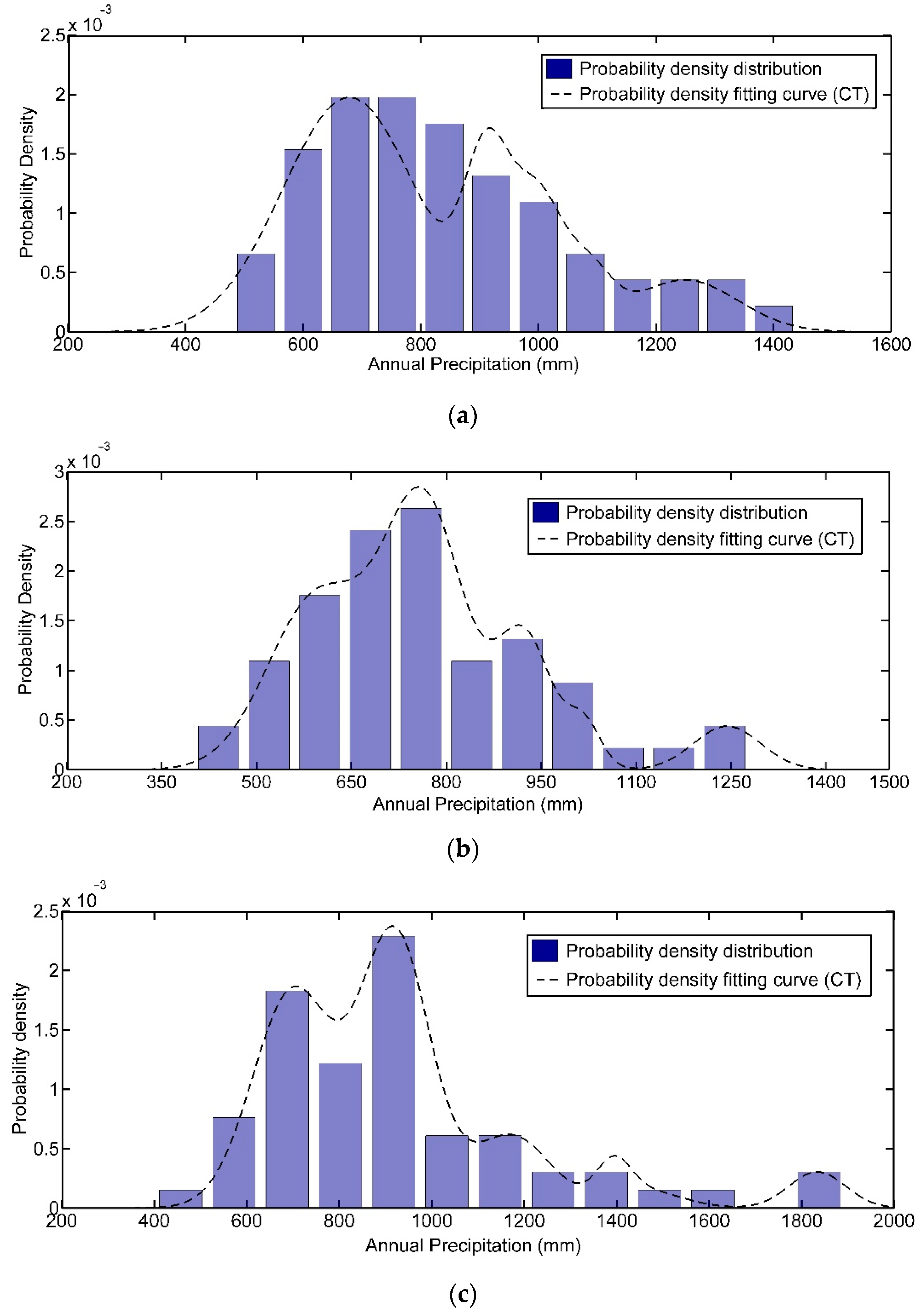
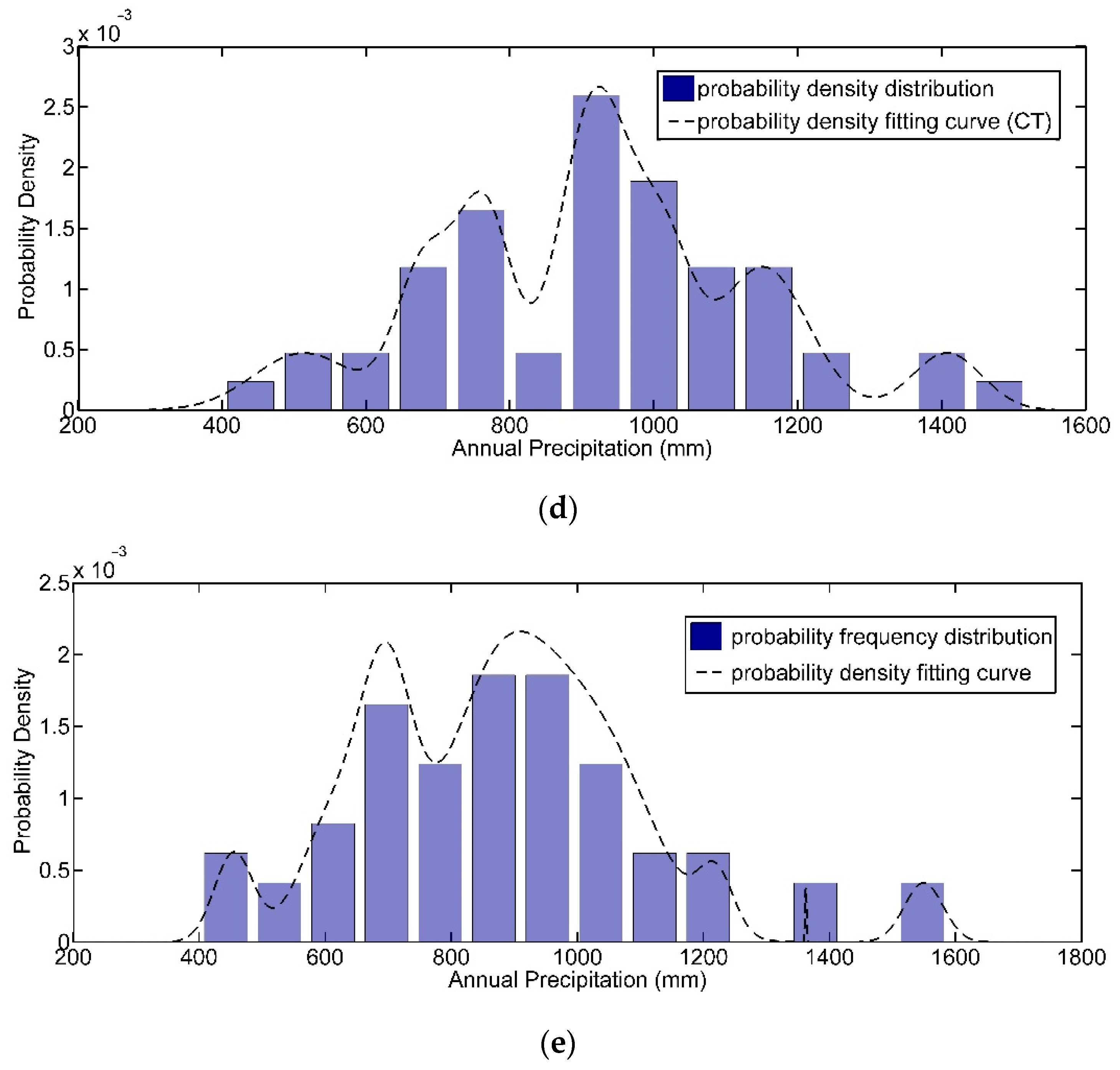
4.1. Fitting Error Analysis of Historical Samples
4.2. Fitting Error Analysis under Typical Returning Period
4.3. Variation Characteristics Analysis of Annual Precipitation Series
5. Conclusions
- (1)
- The varying trend of the annual precipitation frequency curve derived from CTAM and EFCF methods had better consistency for most of the hydrological stations in northern Anhui province, and the upper tail section of the annual precipitation frequency curve derived from the CTAM model varied below the corresponding frequency curve derived from the EFCF approach, which indicated that the CTAM model was capable of avoiding the shortage of higher distribution of the upper tail section and the larger designed value of hydrological variable leading by the traditional empirical frequency formula.
- (2)
- The annual precipitation frequency analysis result for the five stations utilizing the CTAM model was basically consistent with the corresponding frequency analysis result using the traditional empirical frequency formula, the average of the CRFE index for annual precipitation frequency analysis of different stations employing the CTAM model and EFCF were 0.969176 and 0.977318, respectively, and the fitting error and its varying trend of annual precipitation frequency analysis were nearly consistent.
- (3)
- In terms of spatial distribution of annual precipitation, the proportion of dry years in Huainan city, represented by Xifeihezha station, was the highest in northern Anhui province, and the minimum in wet year and maximum in dry year of annual precipitation were 958 mm and 557 mm, respectively, in Dangshan station, located in the northernmost Anhui province, which was consistent with the actual hydrological situation of serious water resource shortages and severe drought loss in historical years in Suzhou city, represented by Dangshan station.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Luo, P.P.; Mu, D.R.; Xue, H.; Thanh, N.; Kha, D.; Takara, K.; Nover, D.; Schladow, G. Flood inundation assessment for the Hanoi Central Area, Vietnam under historical and extreme rainfall conditions. Sci. Rep. 2018, 8, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Huo, A.D.; Peng, J.B.; Cheng, Y.X.; Luo, P.P.; Zhao, Z.X.; Zheng, C.L. Hydrological analysis of loess plateau highland control schemes in Dongzhi Plateau. Front. Earth Sci. 2020, 8, 1–14. [Google Scholar] [CrossRef]
- Lyu, J.Q.; Mo, S.H.; Luo, P.P.; Zhou, M.M.; Shen, B.; Nover, D. A quantitative assessment of hydrological responses to climate change and human activities at spatiotemporal within a typical catchment on the Loess Plateau, China. Quat. Int. 2019, 527, 1–11. [Google Scholar] [CrossRef]
- Xie, P.; Chen, G.C.; Xia, J. Hydrological frequency calculation principle of inconsistent annual runoff series under Changing environments. Eng. J. Wuhan Univ. 2005, 38, 6–15. [Google Scholar]
- Zhu, Y.H.; Luo, P.P.; Zhang, S.; Sun, B. Spatiotemporal analysis of hydrological variations and their impacts on vegetation in semiarid areas from multiple satellite data. Remote Sens. 2020, 12, 4177. [Google Scholar] [CrossRef]
- Hong, X.J. Hydrological Drought Indices and Frequency Analysis Methods and Their Applications; Wuhan University: Wuhan, China, 2017. [Google Scholar]
- Song, S.B. Research challenges and suggestions of hydrological frequency calculation. J. Water Resour. Archit. Eng. 2019, 17, 12–18. [Google Scholar]
- Jin, G.Y. Empirical frequency in Hydrological analysis. Hydrology 1994, 1, 1–9. [Google Scholar]
- Jin, G.Y. A review of hydrologic frequency analysis. Adv. Water Sci. 1999, 10, 319–327. [Google Scholar]
- Zhang, M.; Jin, J.L.; Wang, G.Q.; Zhou, R.J. Drought frequency analysis using stochastic simulation with maximum entropy model. J. Hydroelectr. Eng. 2013, 32, 101–106. [Google Scholar]
- Song, S.B.; Kang, Y.; Song, X.Y.; Wang, X.J.; Jin, J.L. Frequency Calculation Principles and Their Application of Single Variable Hydrological Sequence; Science Press: Beijing, China, 2018. [Google Scholar]
- Guo, S.L.; Ye, S.Z. Discussion of empirical frequency in hydrology calculation. J. Wuhan Univ. Hydraul. Electr. Eng. 1992, 25, 38–45. [Google Scholar]
- Singh, V.P. Entropy-Based Parameters Estimation in Hydrology; Kluwer Academic Publishers: London, UK, 1998. [Google Scholar]
- Huang, Z.P.; Sa, D.Y.; Huang, C.X.; Ma, J.J. Study on formulas for calculation of empirical frequency in curve-fitting method. Adv. Sci. Technol. Water Resour. 2002, 5, 69. [Google Scholar]
- Li, Y. Research on New Theory and Application of Hydrologic Frequency Analysis; Xi’an, Northwest A&F University: Xianyang, China, 2013. [Google Scholar]
- Qin, K.; Wang, P. New method of curve fitting based on cloud transform. Comput. Eng. Appl. 2008, 44, 56–74. [Google Scholar]
- Zhang, G.Y. Study on Prediction Interval Estimation and Generation Scheduling Method for Power System with Large-Scale Wind Power Integration; Huazhong University of Science & Technology: Wuhan, China, 2015. [Google Scholar]
- Tian, H.; Li, C.; Zhang, S.Y. The climate change in the Yangtze-Huaihe river valley over the past 50 years. Period. Ocean. Univ. China 2005, 35, 539–544. [Google Scholar]
- Qi, H. Analysis of precipitation changes in Huaibei Plain over last 50 years. Chin. J. Agrometeorol. 2009, 30, 138–142. [Google Scholar]
- Jin, J.L.; Song, Z.Z.; Jiang, S.M.; Zhou, Y.L.; Zhang, M. Spatiotemporal distribution of potential evapotranspiration in Huaibei Plain based on cloud model. South–North Water Transf. Water Sci. Technol. 2017, 15, 25232. [Google Scholar]
- Li, D.Y.; Liu, C.Y. Study on the Universality of the Normal Cloud Model. Engineering Science. Eng. Sci. 2004, 6, 28–34. [Google Scholar]
- Yang, J.; Wang, G.Y.; Pang, Z.L. Acceleration mechanism of cloud transformation based on density peaks. J. Chin. Comput. Syst. 2018, 39, 1299–1304. [Google Scholar]
- Meng, H.; Wang, S.L.; Li, D.Y. Concept extraction and concept hierarchy construction based on cloud transformation. J. Jilin Univ. 2010, 40, 782–787. [Google Scholar]
- Li, D.Y.; Du, Y. Uncertainty Artificial Intelligence; National Defense Industry Press: Beijing, China, 2014. [Google Scholar]
- Du, Y.; Li, D.Y. Concept partition based on cloud and its application to mining association rules. J. Softw. 2001, 12, 196–203. [Google Scholar]
- Ren, J. Linguistic-stochastic multi-criterion decision-making method based on cloud model. Comput. Integr. Manuf. Syst. 2012, 18, 2792–2797. [Google Scholar]
- Hu, B.Q.; Wu, Y.G.; Cheng, T. Research on the Selection of Typical Hydrologic Year with the Cloud Model. China Rural. Water Hydropower 2016, 5, 97–100. [Google Scholar]
- Keyantash, J.A.; Dracup, J.A. An aggregate drought index-assessing drought severity based on fluctuations in the hydrologic cycle and surface water storage. Water Resour. Res. 2004, 40, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Mu, D.R.; Luo, P.P.; Lyu, J.Q.; Zhou, M.M.; Huo, A.D.; Duan, W.L.; Nover, D.; He, B.; Zhao, X.L. Impact of temporal rainfall patterns on flash floods in Hue City, Vietnam. J. Flood Risk Manag. 2020, 14, e12668. [Google Scholar] [CrossRef]
- Hao, L.; Zhang, X.Y.; Liu, S. Risk assessment to China’s agricultural drought disaster in county unit. Nat. Hazards 2012, 61, 785–801. [Google Scholar] [CrossRef]
- Zhang, Y.G.; Li, Y.L. Application of Cloud Model in Logging Curve Hierarchical. Comput. Digit. Eng. 2014, 42, 1613–1616. [Google Scholar]
- Zhou, Z.T.; Guo, B.; Xing, W.X.; Zhou, J.; Xu, Y. Comprehensive evaluation of latest GPM era IMERG and GSMaP precipitation products over mainland china. Atmos. Res. 2020, 246, 1–15. [Google Scholar] [CrossRef]
- Guo, B.; Bian, Y.; Zhang, M.; Su, Y.; Wang, X.X.; Zhang, B.; Wang, Y.; Chen, Q.J.; Wu, Y.R.; Luo, P.P. Estimating socio-economic parameters via machine learning methods using Luojia1-01 nighttime light remotely sensed images at multiple scales of China in 2018. IEEE Access 2021, 99, 1–15. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Cloud Number | Ex | En | He | Amplitude Coefficient |
|---|---|---|---|---|---|
| Guoyangzha | 1 | 678.24 | 97.43 | 208.10 | 0.001974 |
| 2 | 912.28 | 36.28 | 24.26 | 0.001316 | |
| 3 | 998.40 | 41.40 | 29.37 | 0.001096 | |
| 4 | 1086.9 | 37.41 | 16.89 | 0.000439 | |
| 5 | 1248.85 | 82.27 | 104.11 | 0.000439 | |
| Dangshan | 1 | 765.34 | 57.60 | 74.49 | 0.002632 |
| 2 | 598.24 | 68.56 | 138.09 | 0.001754 | |
| 3 | 923.13 | 42.09 | 23.37 | 0.001316 | |
| 4 | 1017.65 | 25.32 | 21.65 | 0.000439 | |
| 5 | 1243.70 | 49.07 | 52.59 | 0.000439 | |
| Linquan | 1 | 920.53 | 65.66 | 126.72 | 0.002288 |
| 2 | 700.09 | 73.71 | 170.34 | 0.001831 | |
| 3 | 1171.83 | 76.48 | 92.27 | 0.00061 | |
| 4 | 1393.40 | 34.09 | 36.54 | 0.000305 | |
| 5 | 1833.45 | 59.34 | 31.02 | 0.000305 | |
| 6 | 1454.6 | 79.71 | 41.67 | 0.000153 | |
| Mohekou | 1 | 958.61 | 80.27 | 168.55 | 0.002516 |
| 2 | 746.8 | 29.95 | 60.96 | 0.001509 | |
| 3 | 666.98 | 32.24 | 52.53 | 0.001258 | |
| 4 | 1134.87 | 25.68 | 11.97 | 0.000755 | |
| 5 | 513.9 | 53.53 | 57.37 | 0.000503 | |
| 6 | 1251.8 | 38.77 | 29.14 | 0.000503 | |
| 7 | 1407.55 | 44.75 | 47.96 | 0.000503 | |
| Xifeihezha | 1 | 877.89 | 79.58 | 107.92 | 0.001858 |
| 2 | 697.08 | 37.69 | 53.75 | 0.001651 | |
| 3 | 1037.62 | 81.76 | 66.61 | 0.001238 | |
| 4 | 611.53 | 46.33 | 67.99 | 0.000826 | |
| 5 | 455.07 | 29.47 | 18.54 | 0.000619 | |
| 6 | 1219.90 | 26.57 | 13.89 | 0.000413 | |
| 7 | 1362.5 | 1.13 | 0.59 | 0.000413 | |
| 8 | 1549.45 | 29.64 | 15.49 | 0.000413 |
| Station | Name | Statistical Parameters of Curve Fitting | ||
|---|---|---|---|---|
| Ex | Cv | Cs | ||
| Guoyangzha | EFCF | 838.83 | 0.27 | 1.05 |
| CTAM | 838.83 | 0.33 | 1.08 | |
| Dangshan | EFCF | 760.88 | 0.25 | 0.71 |
| CTAM | 760.88 | 0.22 | 0.59 | |
| Linquan | EFCF | 927.10 | 0.31 | 1.24 |
| CTAM | 927.10 | 0.28 | 1.11 | |
| Mohekou | EFCF | 927.08 | 0.24 | 0.49 |
| CTAM | 927.08 | 0.24 | 0.48 | |
| Xifeihezha | EFCF | 888.37 | 0.27 | 0.54 |
| CTAM | 888.37 | 0.25 | 0.61 | |
| Name | Guoyangzha | Dangshan | Linquan | Mohekou | Xifeihezha |
|---|---|---|---|---|---|
| EFCF | 0.960642 | 0.992969 | 0.972185 | 0.980417 | 0.980378 |
| CTAM | 0.954421 | 0.978128 | 0.968479 | 0.972718 | 0.972126 |
| Station | Name | Frequency (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.02 | 0.05 | 0.10 | 0.20 | 0.5 | 1 | 2 | 5 | 10 | 20 | ||
| Guoyangzha | EFCF | 2140 | 2004 | 1900 | 1794 | 1652 | 1541 | 1428 | 1271 | 1145 | 1010 |
| CTAM | 2219 | 2076 | 1967 | 1856 | 1705 | 1589 | 1469 | 1303 | 1169 | 1024 | |
| RFE/% | 3.70 | 3.60 | 3.52 | 3.41 | 3.24 | 3.08 | 2.86 | 2.48 | 2.06 | 1.43 | |
| Dangshan | EFCF | 1694 | 1605 | 1537 | 1466 | 1370 | 1295 | 1216 | 1104 | 1012 | 910 |
| CTAM | 1556 | 1483 | 1427 | 1368 | 1289 | 1225 | 1159 | 1064 | 985 | 896 | |
| RFE/% | −8.15 | −7.61 | −7.16 | −6.67 | −5.96 | −5.35 | −4.67 | −3.62 | −2.66 | −1.47 | |
| Linquan | EFCF | 2653 | 2466 | 2324 | 2180 | 1987 | 1838 | 1685 | 1477 | 1312 | 1136 |
| CTAM | 2405 | 2250 | 2131 | 2010 | 1847 | 1721 | 1592 | 1414 | 1272 | 1118 | |
| RFE/% | −9.33 | −8.78 | −8.32 | −7.80 | −7.01 | −6.32 | −5.52 | −4.25 | −3.05 | −1.54 | |
| Mohekou | EFCF | 1945 | 1855 | 1785 | 1713 | 1612 | 1533 | 1448 | 1328 | 1226 | 1110 |
| CTAM | 1921 | 1833 | 1765 | 1694 | 1597 | 1519 | 1437 | 1319 | 1220 | 1107 | |
| RFE/% | −1.27 | −1.20 | −1.14 | −1.07 | −0.97 | −0.89 | −0.80 | −0.64 | −0.50 | −0.32 | |
| Xifeihezha | EFCF | 1993 | 1894 | 1816 | 1737 | 1627 | 1539 | 1447 | 1316 | 1206 | 1081 |
| CTAM | 1941 | 1844 | 1769 | 1691 | 1585 | 1501 | 1412 | 1287 | 1183 | 1065 | |
| RFE/% | −2.60 | −2.61 | −2.61 | −2.60 | −2.56 | −2.51 | −2.42 | −2.21 | −1.95 | −1.50 | |
| Station | Wet Year | Partial Wet Year | Normal Year | Partial Dry Year | Dry Year |
|---|---|---|---|---|---|
| Guoyangzha | p > 1123 | 875 < p ≤ 1123 | 726 < p ≤ 875 | 581 < p ≤ 726 | p < 581 |
| Dangshan | p > 958 | 799 < p ≤ 958 | 693 < p ≤ 799 | 574 < p ≤ 693 | p < 557 |
| Linquan | p > 1223 | 962 < p ≤ 1223 | 808 < p ≤ 962 | 661 < p ≤ 808 | p < 661 |
| Mohekou | p > 1185 | 981 < p ≤ 1185 | 841 < p ≤ 981 | 680 < p ≤ 841 | p < 580 |
| Xifeihezha | p > 1146 | 937 < p ≤ 1146 | 798 < p ≤ 937 | 644 < p ≤ 798 | p < 644 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, X.; Jin, J.; Ning, S.; Wu, C.; Zhou, Y.; Zhang, L.; Cui, Y. Cloud Transform Algorithm Based Model for Hydrological Variable Frequency Analysis. Remote Sens. 2021, 13, 3586. https://doi.org/10.3390/rs13183586
Bai X, Jin J, Ning S, Wu C, Zhou Y, Zhang L, Cui Y. Cloud Transform Algorithm Based Model for Hydrological Variable Frequency Analysis. Remote Sensing. 2021; 13(18):3586. https://doi.org/10.3390/rs13183586
Chicago/Turabian StyleBai, Xia, Juliang Jin, Shaowei Ning, Chengguo Wu, Yuliang Zhou, Libing Zhang, and Yi Cui. 2021. "Cloud Transform Algorithm Based Model for Hydrological Variable Frequency Analysis" Remote Sensing 13, no. 18: 3586. https://doi.org/10.3390/rs13183586
APA StyleBai, X., Jin, J., Ning, S., Wu, C., Zhou, Y., Zhang, L., & Cui, Y. (2021). Cloud Transform Algorithm Based Model for Hydrological Variable Frequency Analysis. Remote Sensing, 13(18), 3586. https://doi.org/10.3390/rs13183586