
Remote Sensing Image Target Detection: Improvement of the YOLOv3 Model with Auxiliary Networks

Abstract
:
1. Introduction
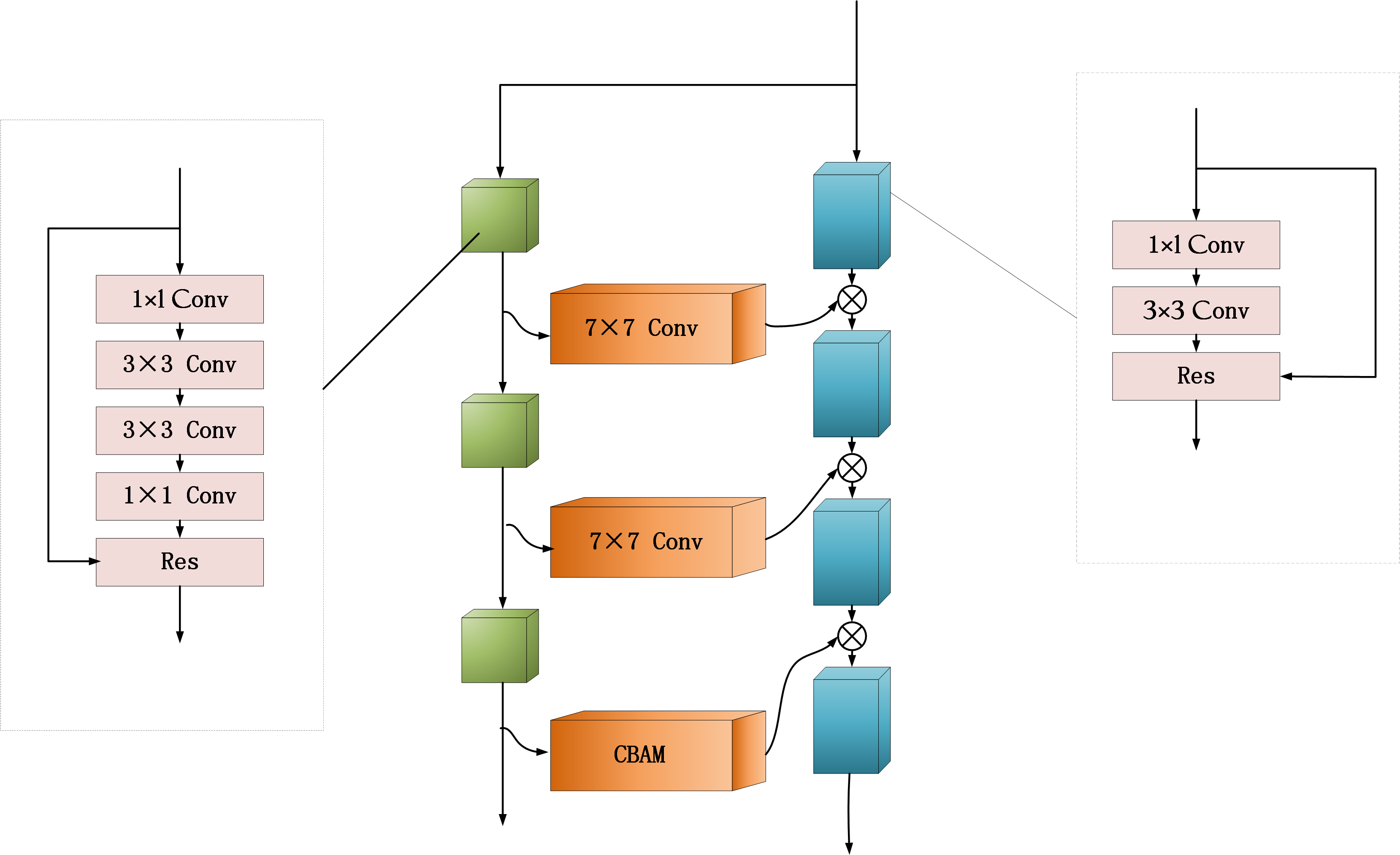
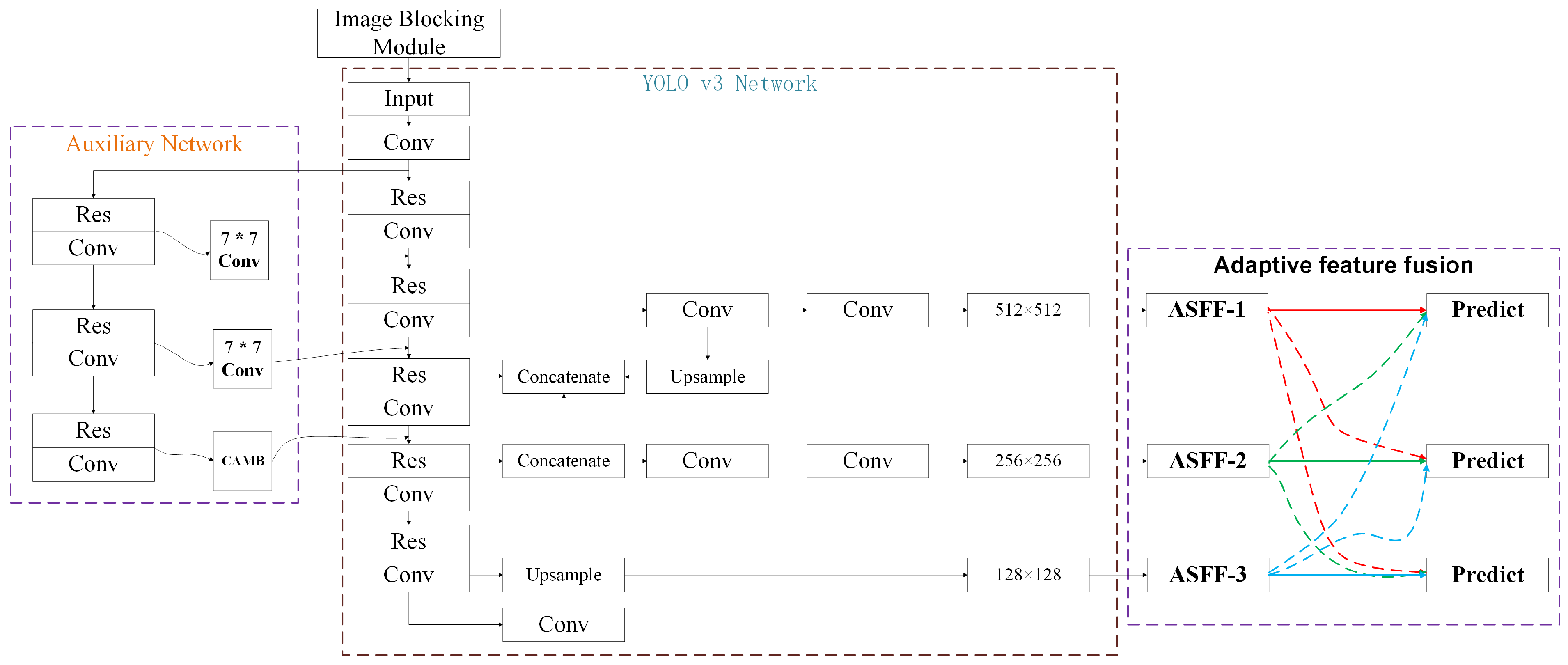
- The auxiliary network is introduced in RSI target detection, and the original SE attention mechanism in the auxiliary network is replaced by CBAM in order to make some specific features in the target more easily learned by the network;
- An image blocking module is added to the network to ensure the size of the input images are a fixed size;
- Adaptive feature fusion is used in the rear and serves to filter conflicting information spatially to suppress inconsistencies arising from back propagation, thereby improving the scale invariance of features and reducing inference overhead;
- To increase the training speed of the network, the DIoU loss function is used in the calculation of the loss function. The role of DIoU is that it can directly minimize the distance between two target frames and accelerate the convergence of losses.
2. Materials and Methods
2.1. Image Blocking Module
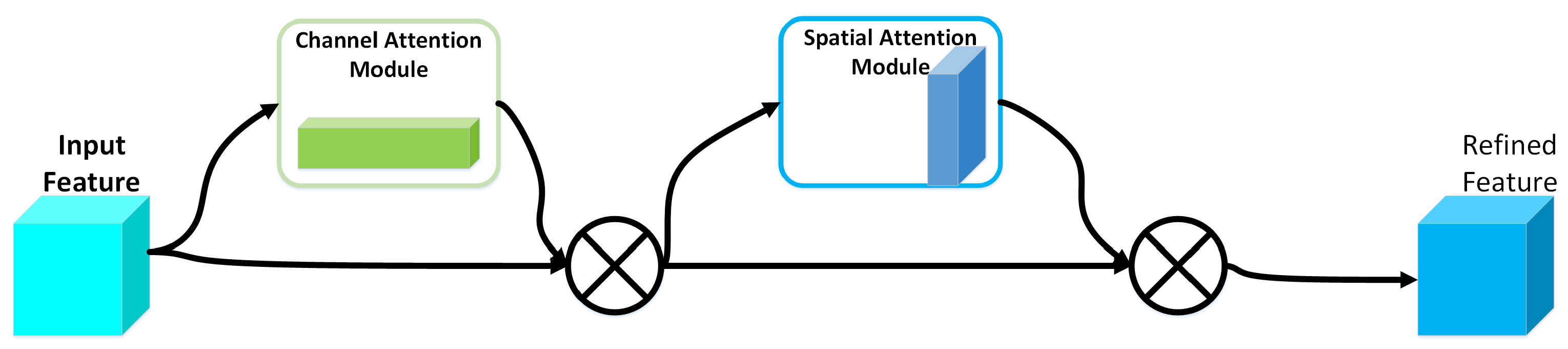
2.2. Convolutional Block Attention Module
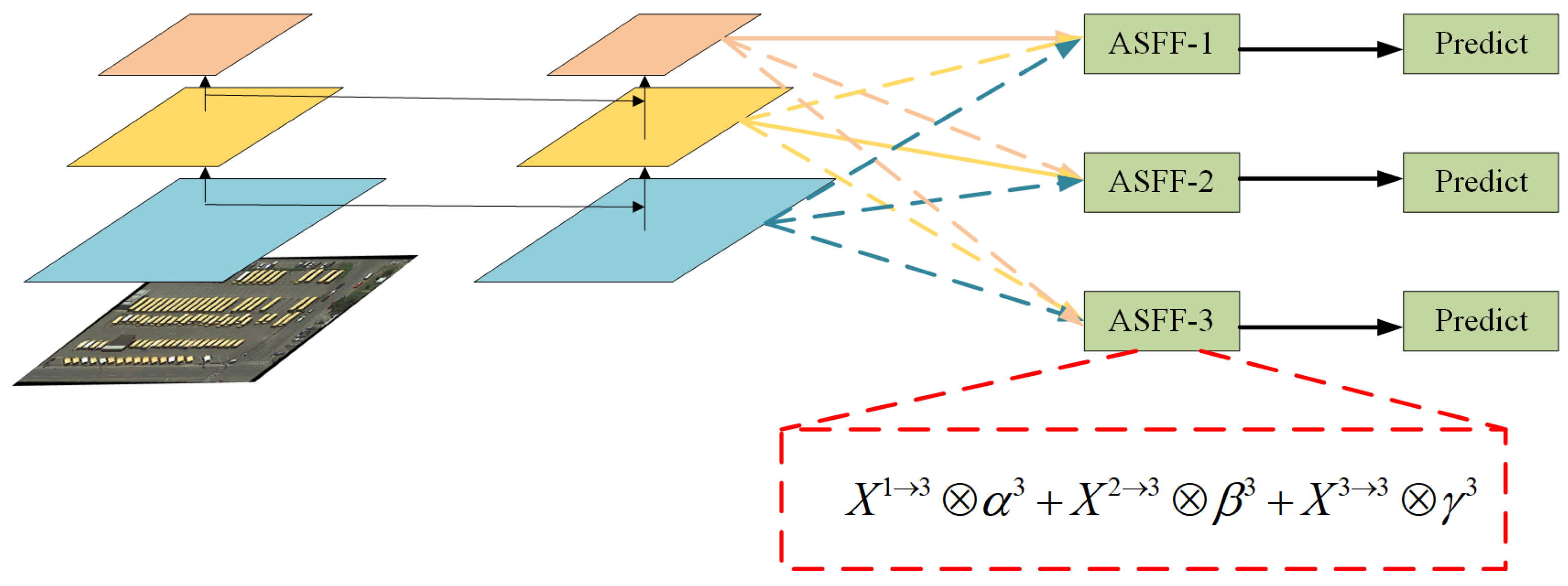
2.3. Adaptive Feature Fusion
2.3.1. Scale Transformation
2.3.2. Adaptive Fusion
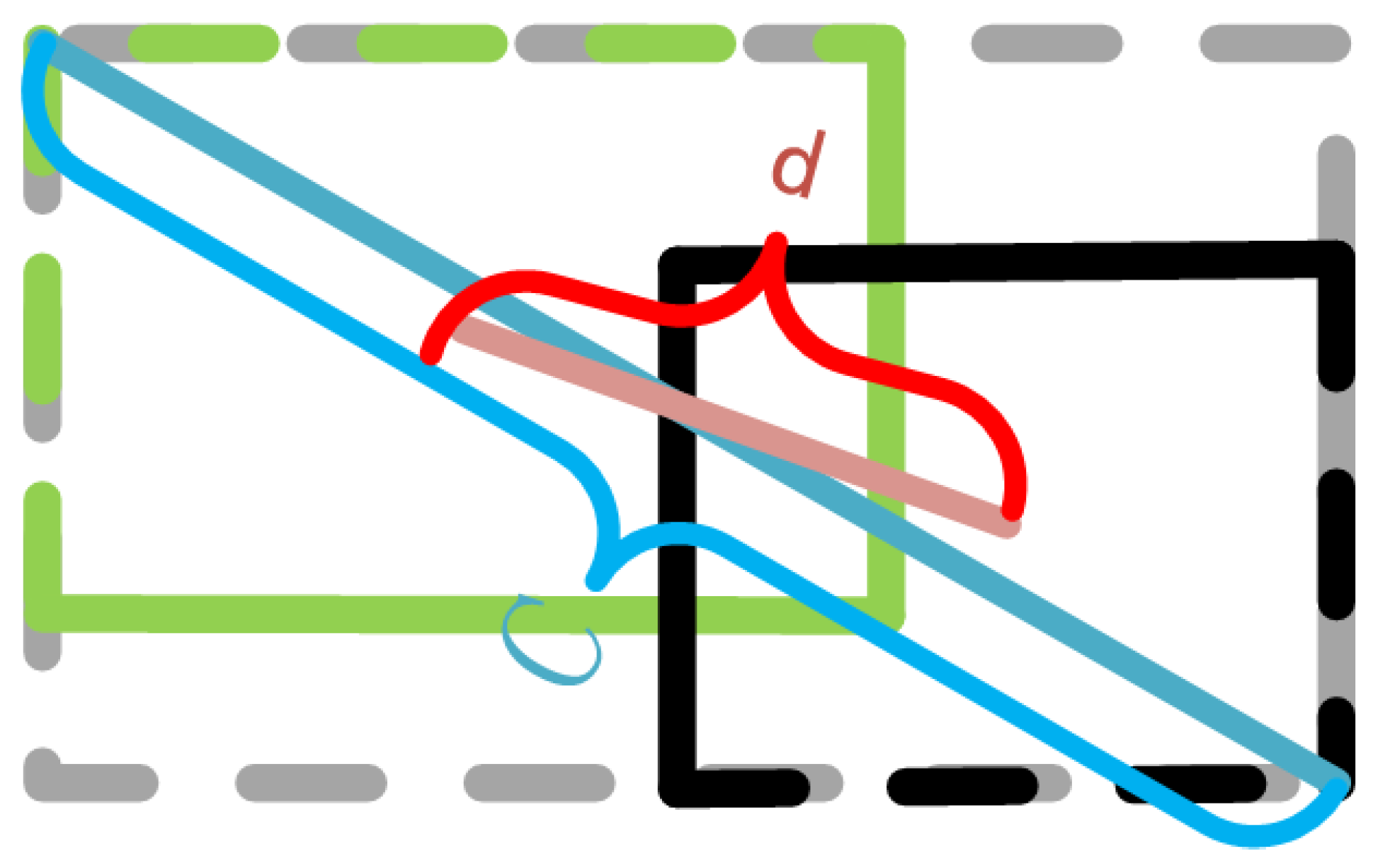
2.4. Loss Function
- The normalized distance between predicted box and target box was directly minimized for achieving faster convergence;
- The regression was made more accurate and faster when having an overlap of inclusion with target box.
2.4.1. Distance-IoU Loss
2.4.2. Non-Maximum Suppression Using DIoU
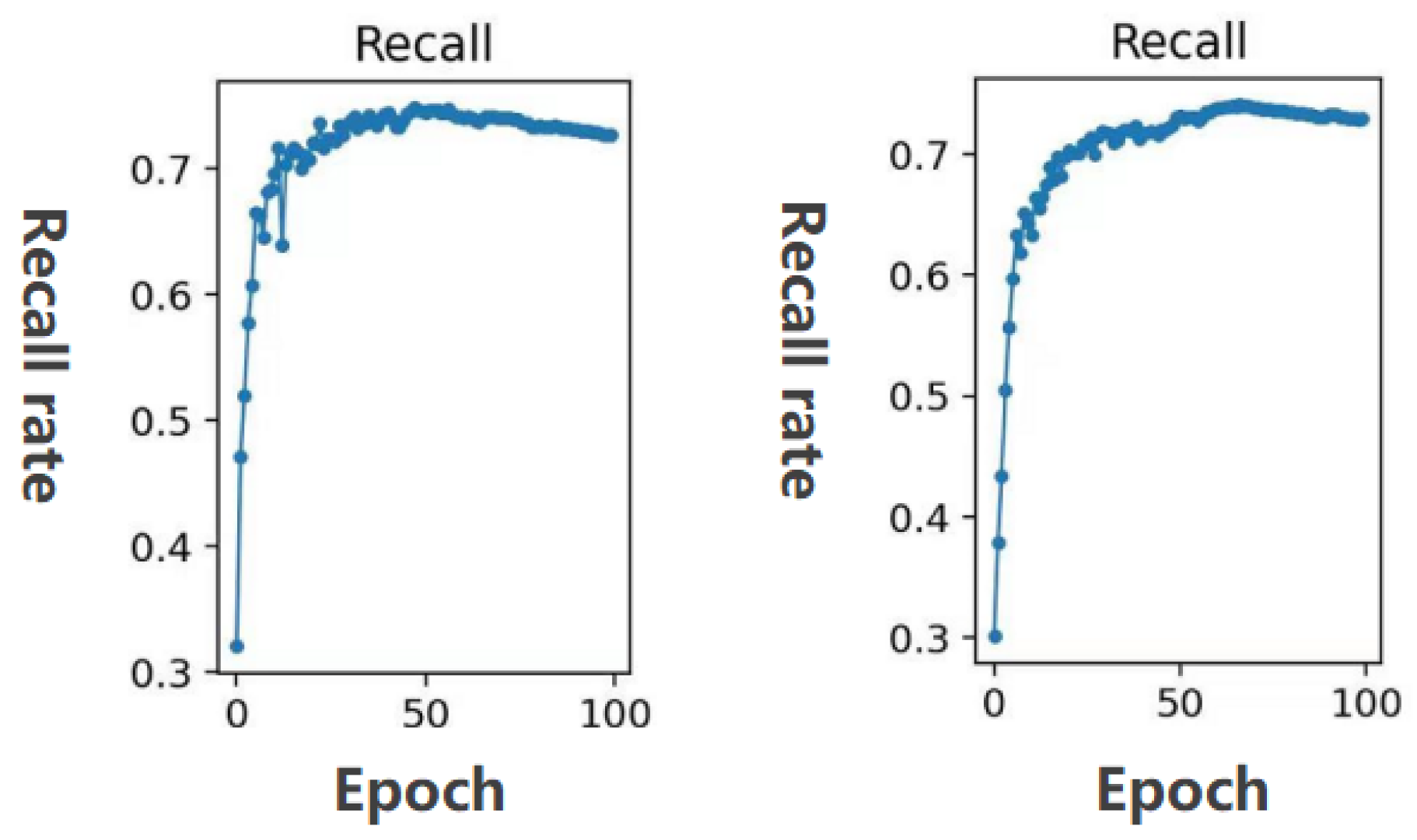
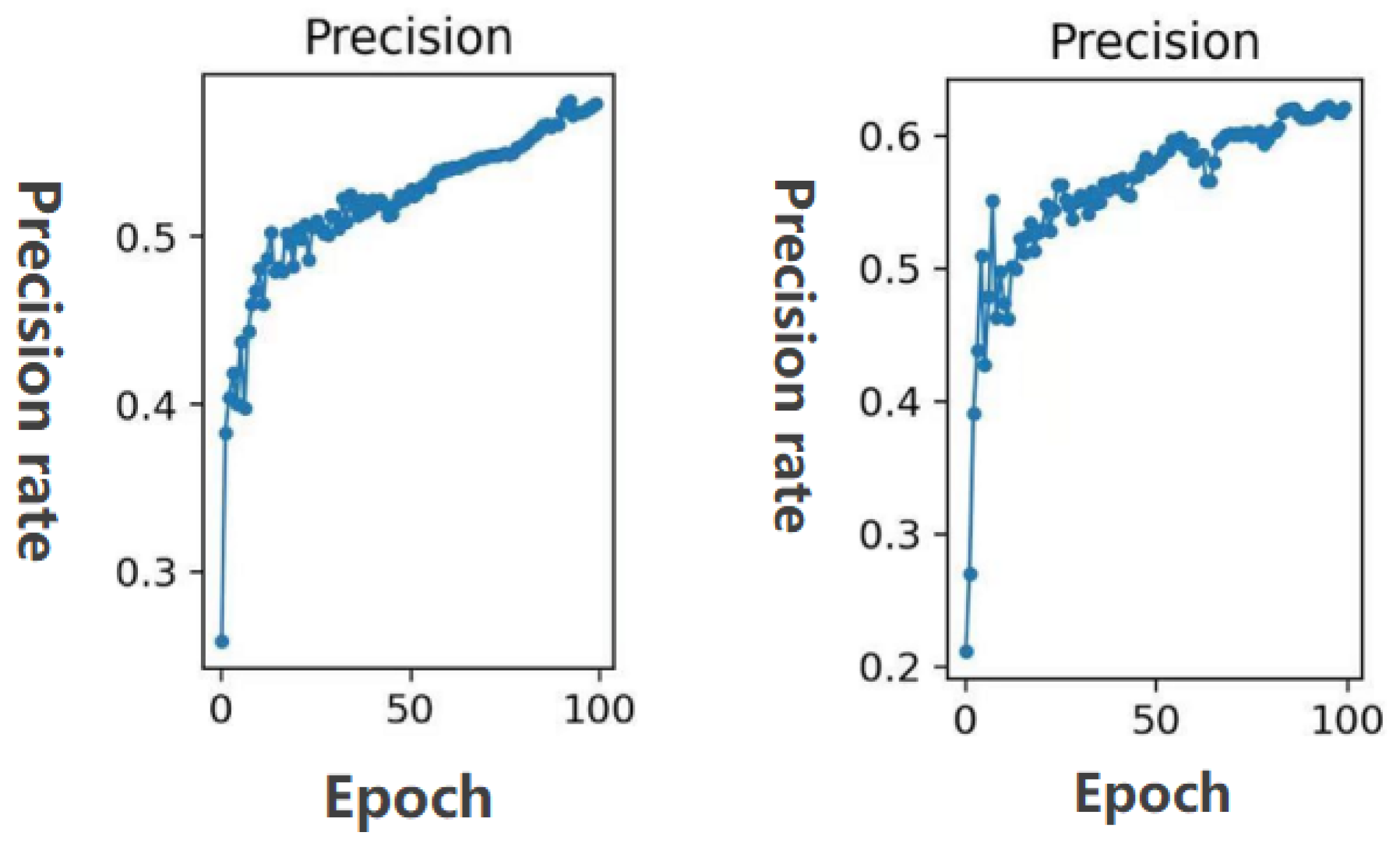
3. Experimental Results and Discussion
3.1. DOTA Datasets and Evaluation Indicators
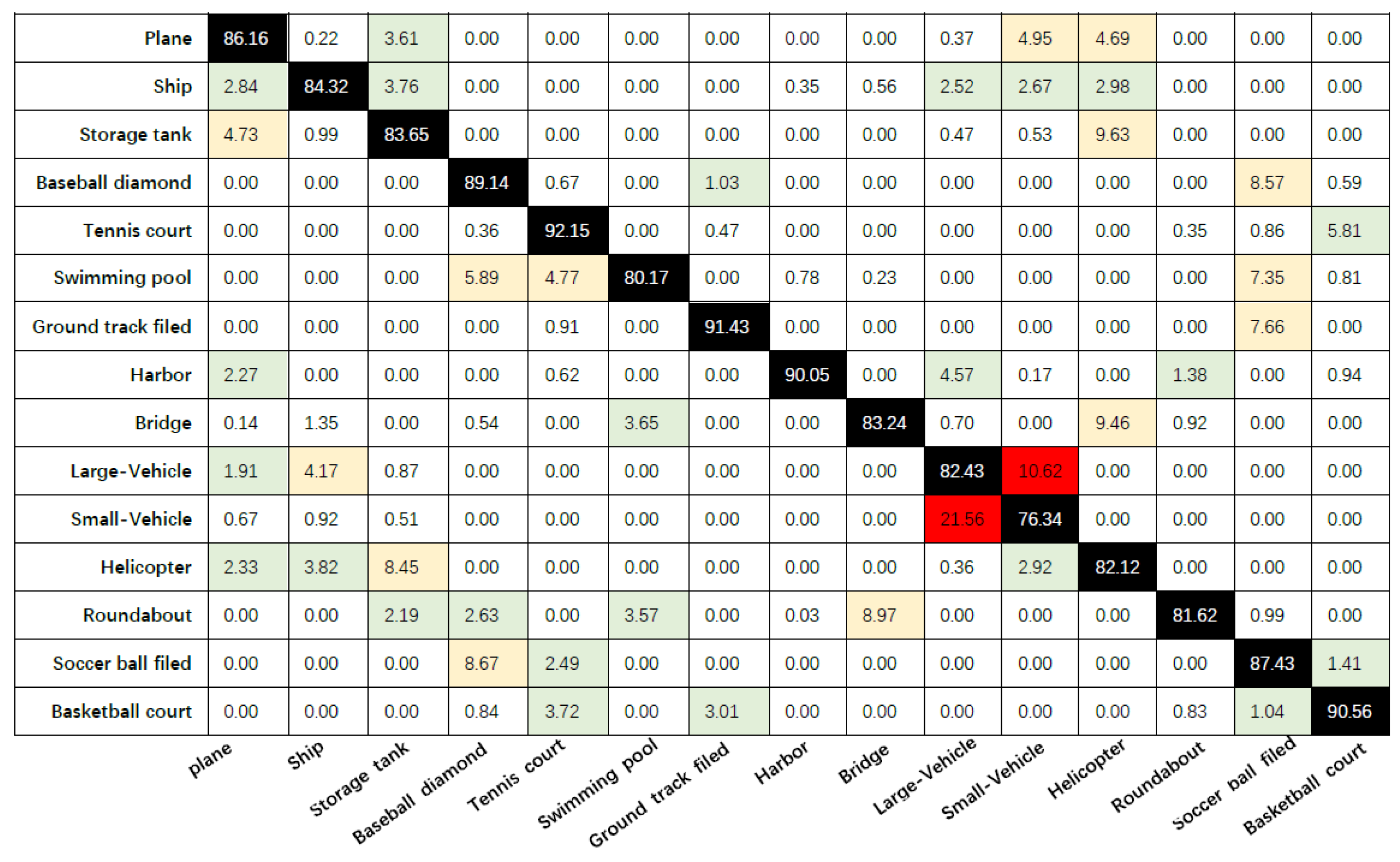
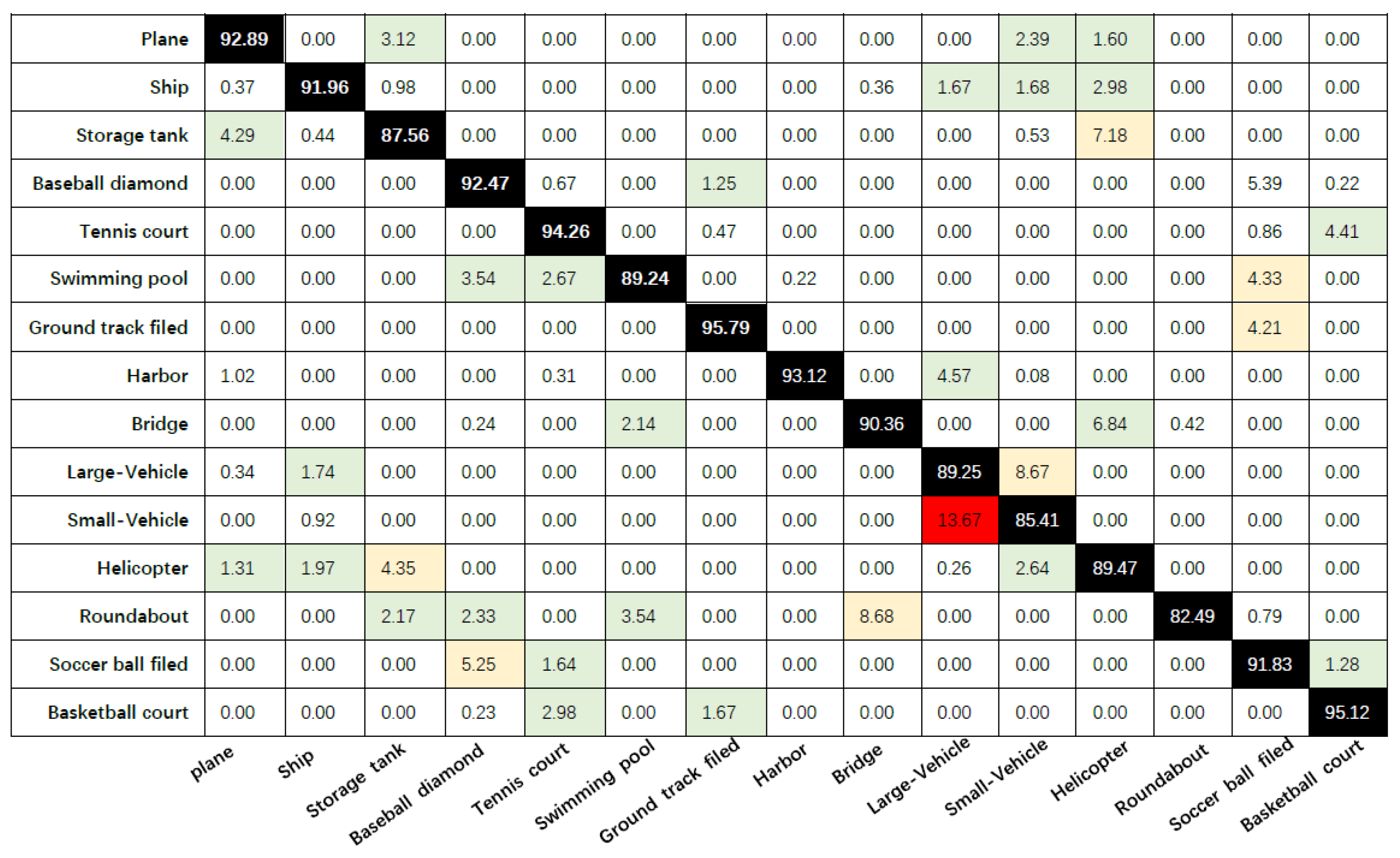
3.2. Result on DOTA
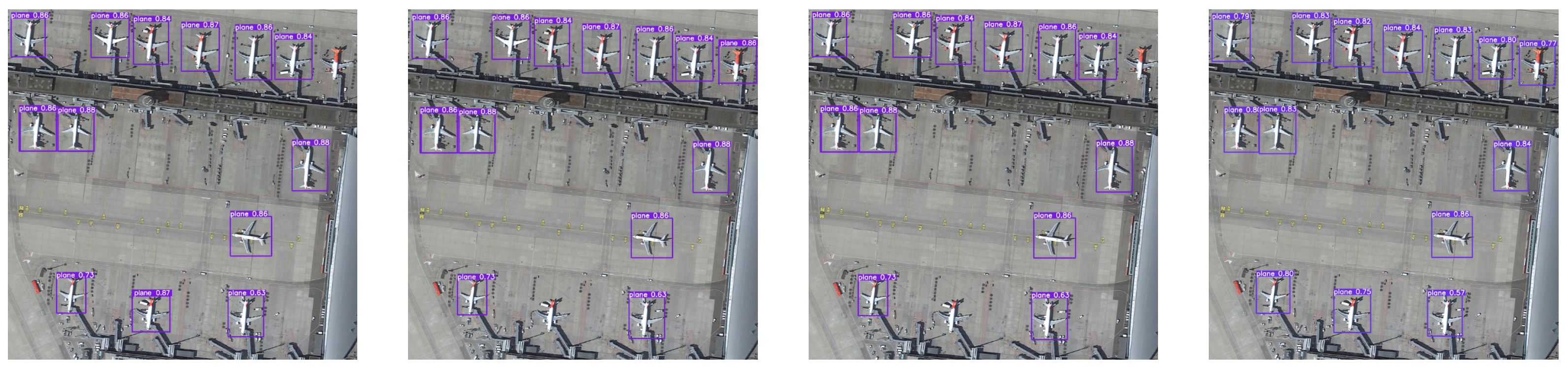
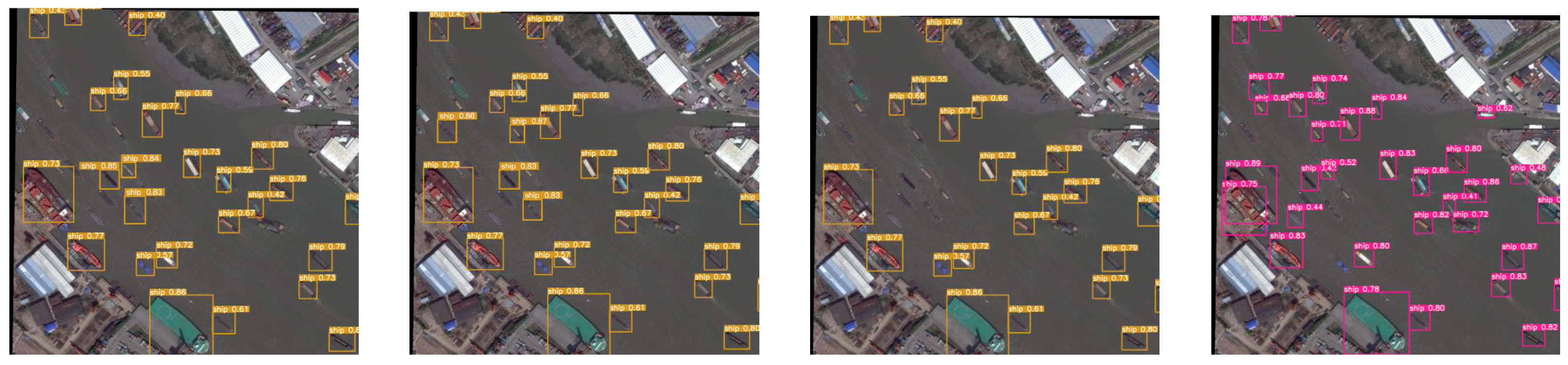
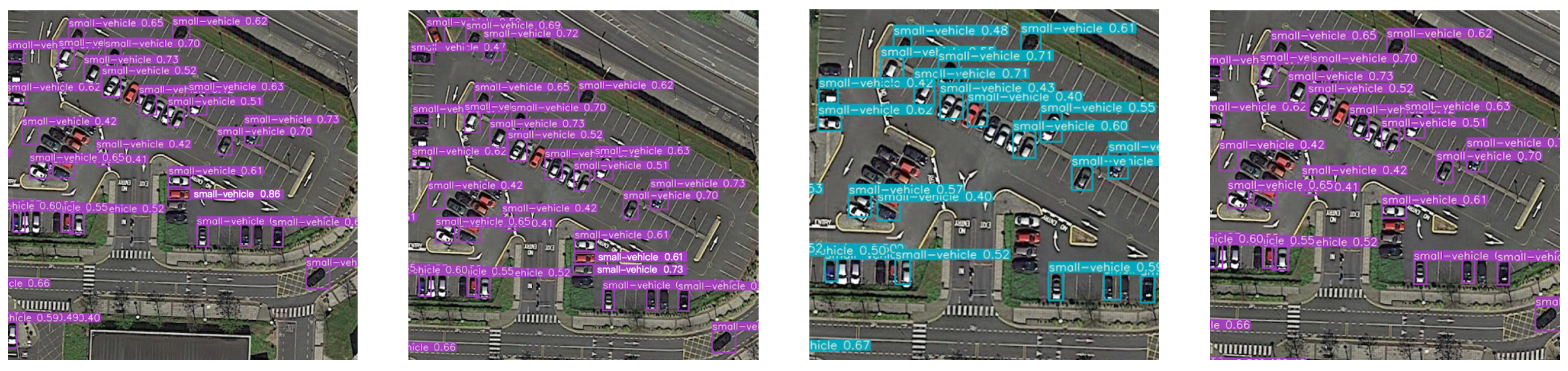
3.3. Qualitative Results and Analysis of the Bounding Box
3.4. Detection Effect and Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| RSI | Remote Sensing Image |
| CBAM | Convolutional Block Attention Module |
| CNN | Convolutional Neural Network |
| MLP | Multi-layer perceptrons |
| ASFF | Asaptive Feature Fusion |
References
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogram. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogram. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, Q.; Gao, J.; Li, X. Weakly supervised adversarial domain adaptation for semantic segmentation in urban scenes. IEEE Trans. Image Process. 2019, 28, 4376–4386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maatten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision ( ICCV), Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Hu, Y.; Li, X.; Zhou, N.; Yang, L.; Peng, L.; Xiao, S. A sample update-based convolutional neural network framework for object detection in large-area remote sensing images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 947–951. [Google Scholar] [CrossRef]
- Yoo, J.J.; Ahn, N.H.; Sohn, K.A. Rethinking Data Augmentation for Image Super-Resolution: A Comprehensive Analysis and a New Strategy. Available online: https://arxiv.org/abs/2004.00448 (accessed on 23 April 2020).
- Girshick, R.; Donahue, J.; Darrell, T. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dolloor, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2961–2969.
- Redmon, J.; Divvala, S.; Girshick, R. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Las Vegas, NV, USA, 27–30 June 2016; pp. 1063–6919. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J. YOLOv3: An Incremental Improvement. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).
- Lin, T.Y.; Dolloor, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. Proc. Adv. Neural Inf. Process. Syst. 2016, 10, 3630–3638. [Google Scholar]
- Dai, Z.G.; Cai, B.L.; Lin, Y.G.; Chen, J.Y. UP-DETR: Unsupervised Pre-Training for Object Detection with Transformers. Available online: https://arxiv.org/abs/2011.09094 (accessed on 7 April 2021).
- Volpi, M.; Morsier, F.D.; Camps-Valls, G.; Kanevski, M.; Tuia, D. Multi-sensor change detection based on nonlinear canonical correlations. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium-IGARSS, Melbourne, VIC, Australia, 21–26 July 2013; pp. 1944–1947. [Google Scholar]
- Bai, X.; Zhang, H.; Hou, J. VHR object detection based on structural feature extraction and query expansion. IEEE Trans. Geosci. Remote Sens. 2014, 10, 6508–6520. [Google Scholar]
- Bi, F.; Zhu, B.; Gao, L.; Bian, M. A visual search inspired computational model for ship detection in optical satellite images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 749–753. [Google Scholar]
- Huang, X.; Zhang, L. Road centreline extraction from high-resolution imagery based on multiscale structural features and support vector machines. Int. J Remote Sens. 2009, 30, 1977–1987. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and robust convolutional neural network for very high-resolution remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation insensitive and context augmented object detection in remote sensing images. IEEE Trans Geosci. Remote Sens. 2018, 56, 2337–2348. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zou, Z.; Shi, Z. Ship detection in spaceborne optical image with SVD networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Lin, H.; Shi, Z.; Zou, Z. Fully convolutional network with task partitioning for inshore ship detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1665–1669. [Google Scholar] [CrossRef]
- Liu, W.; Ma, L.; Chen, H. Arbitrary oriented ship detection frame-work in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 937–941. [Google Scholar] [CrossRef]
- Tang, T.; Zhou, S.; Deng, Z.; Lei, L.; Zou, H. Arbitrary oriented vehicle detection in aerial imagery with single convolutional neural networks. Remote Sens. 2017, 9, 1170. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Pan, Z.; Lei, B. Learning a rotation invariant detector with rotatable bounding box. IEEE Geosci. Remote Sens. Lett. 2017, 9, 960. [Google Scholar]
- Liu, W. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Zhong, J.; Lei, T.; Yao, G. Robust vehicle detection in aerial images based on cascaded convolutional neural networks. Sensors 2017, 17, 2720. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Zhong, Y.; Zhang, L. An efficient and robust integrated geospatical object detection framework for high spatial resolution remote geospatial sensing imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Xu, X.; Wang, L.; Yang, R.; Pu, F. Deformable ConvNet with aspect ratio constrained NMS for object detection in remote sensing imagery. Remote Sens. 2017, 9, 1312. [Google Scholar] [CrossRef] [Green Version]
- Xun, Q.W.; Lin, R.Z.; Yue, H.; Huang, H. Research on Small Target Detection in Driving Scenarios Based on Improved Yolo Network. IEEE Access 2019, 8, 27574–27583. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y. CBAM: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018; p. 112211. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. Available online: https://arxiv.org/abs/1911.09516 (accessed on 21 September 2019).
- Zheng, Z.; Wang, P.; Liu, W. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicator | Computation Formula | Meaning |
|---|---|---|
| Precision | Among the detected targets, the proportion of positive samples. | |
| Recall | The recall rate is the ratio of the number of correctly identified targets to the number of all targets in the test set. | |
| mAP | Average value of each category of AP | |
| AP | Average accuracy of a category | |
| AMC | AMC represents the average minimum confidence that a specific target is correctly detected in the picture | |
| Miss | Missed detection rate for specific targets |
| Plane | Ship | Storage Tank | Baseball Diamond | Tennis Court | Swimming Pool | Ground Track Filed | Harbor | |
|---|---|---|---|---|---|---|---|---|
| Faster R-CNN(ResNet101) | 88.37% | 86.74% | 84.43% | 95.45% | 95.63% | 82.24% | 92.32% | 94.24% |
| Faster R-CNN(VGG16) | 87.43% | 85.79% | 84.24% | 92.82% | 94.12% | 80.62% | 92.24% | 93.56% |
| Fast R-CNN | 85.29% | 83.14% | 82.67% | 90.13% | 94.56% | 79.57% | 93.19% | 92.12% |
| YOLO v3(Darknet53) | 77.16% | 72.37% | 80.24% | 83.56% | 86.47% | 70.24% | 90.64% | 87.12% |
| YOLO v3(Auxiliary network) | 86.16% | 84.32% | 83.65% | 89.14% | 92.15% | 80.17% | 91.43% | 90.05% |
| OUR YOLO v3 | 92.89% | 91.96% | 87.56% | 92.47% | 94.26% | 89.24% | 95.79% | 93.12% |
| Bridge | Large-Vehicle | Small-Vehicle | Helicopter | Roundabout | Soccer Ball Filed | Basketball Court | mAP | |
| Faster R-CNN(ResNet101) | 90.15% | 83.36% | 80.65% | 83.29% | 83.56% | 90.21% | 93.33% | 88.26% |
| Faster R-CNN(VGG16) | 89.34% | 83.25% | 79.65% | 81.11% | 82.41% | 90.24% | 92.11% | 87.20% |
| Fast R-CNN | 86.83% | 81.60% | 78.99% | 79.63% | 80.15% | 89.17% | 92.81% | 85.99% |
| YOLO v3(Darknet53) | 70.24% | 79.17% | 68.23% | 78.67% | 69.89% | 86.54% | 87.29% | 79.19% |
| YOLO v3(Auxiliary network) | 83.24% | 82.43% | 76.34% | 82.12% | 81.62% | 87.43% | 90.56% | 85.39% |
| OUR-YOLO v3 | 90.36% | 89.25% | 85.41% | 89.47% | 82.49% | 91.83% | 95.12% | 90.75% |
| mAP | FPS | Standard Deviation | |
|---|---|---|---|
| Faster R-CNN(ResNet101) | 88.26% | 6.97FPS | 4.99% |
| Faster R-CNN(VGG16) | 87.20% | 6.97FPS | 4.97% |
| Fast R-CNN | 85.99% | 5.57FPS | 5.42% |
| YOLO v3(Darknet53) | 79.19% | 42.56FPS | 7.32% |
| YOLO v3(Auxiliary Network) | 85.39% | 37.69FPS | 4.75% |
| OUR-YOLOV3(without ASFF) | 89.64% | 38.41FPS | 4.21% |
| OUR-YOLOV3 | 90.75% | 40.76FPS | 3.52% |
| AP | AP75 | |
|---|---|---|
| 47.12% | 50.36% | |
| 49.37% | 53.15% | |
| 51.69% | 55.41% |
| Descriotion | Top-1 Error (%) | Top-5 Error (%) |
|---|---|---|
| Our-YoloV3(with SE) | 25.14 | 8.11 |
| Our-YoloV3(with CBAM) | 23.89 | 7.51 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, Z.; Zhu, F.; Qi, C. Remote Sensing Image Target Detection: Improvement of the YOLOv3 Model with Auxiliary Networks. Remote Sens. 2021, 13, 3908. https://doi.org/10.3390/rs13193908
Qu Z, Zhu F, Qi C. Remote Sensing Image Target Detection: Improvement of the YOLOv3 Model with Auxiliary Networks. Remote Sensing. 2021; 13(19):3908. https://doi.org/10.3390/rs13193908
Chicago/Turabian StyleQu, Zhenfang, Fuzhen Zhu, and Chengxiao Qi. 2021. "Remote Sensing Image Target Detection: Improvement of the YOLOv3 Model with Auxiliary Networks" Remote Sensing 13, no. 19: 3908. https://doi.org/10.3390/rs13193908
APA StyleQu, Z., Zhu, F., & Qi, C. (2021). Remote Sensing Image Target Detection: Improvement of the YOLOv3 Model with Auxiliary Networks. Remote Sensing, 13(19), 3908. https://doi.org/10.3390/rs13193908