
Maize Yield Prediction at an Early Developmental Stage Using Multispectral Images and Genotype Data for Preliminary Hybrid Selection

 ,
, 


Abstract
:1. Introduction
2. Materials and Methods
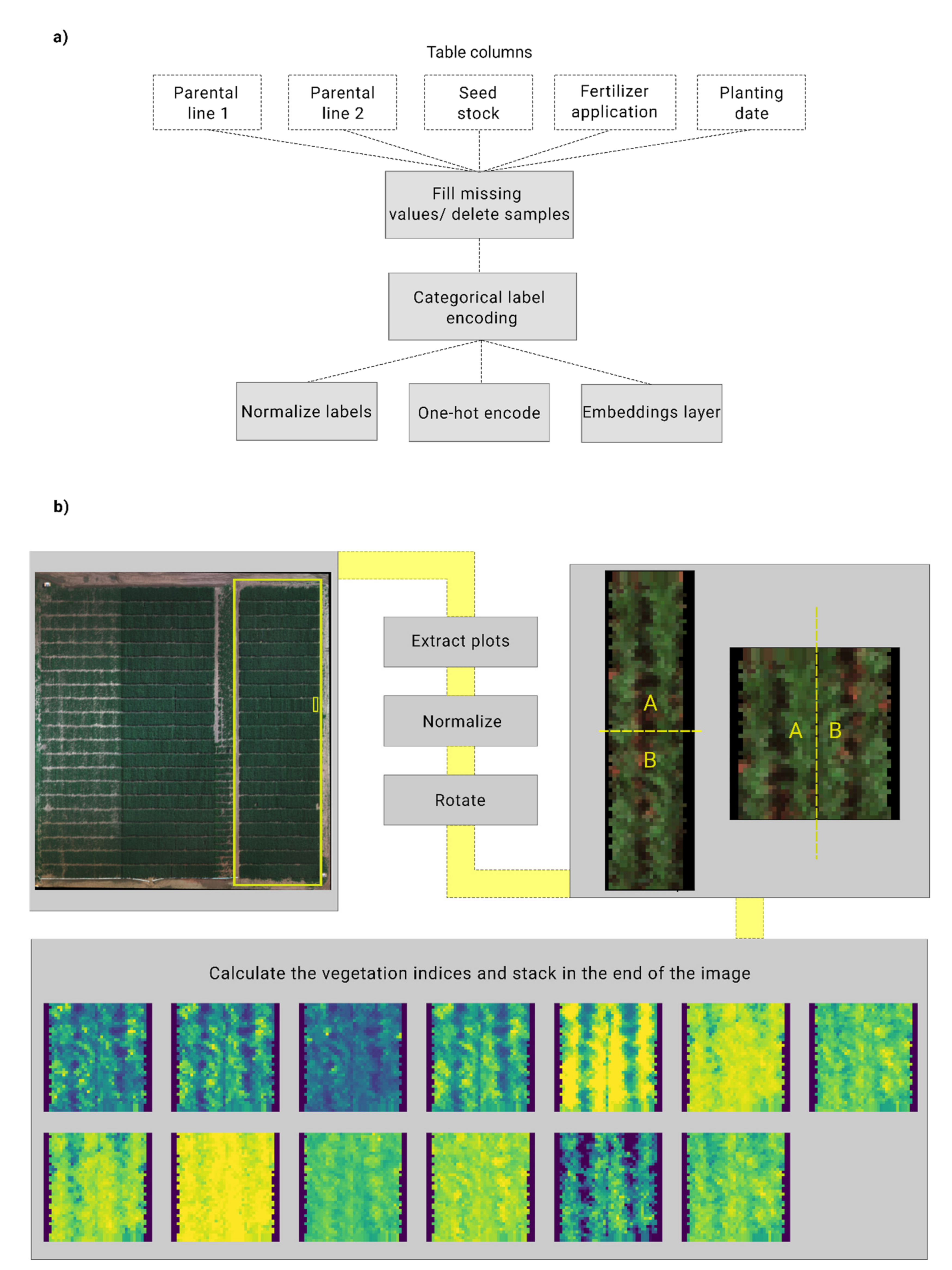
2.1. Experimental Conditions and Dataset Preparation
2.2. Multispectral Image Processing and Preparation as Model Input
2.3. Machine Learning Models
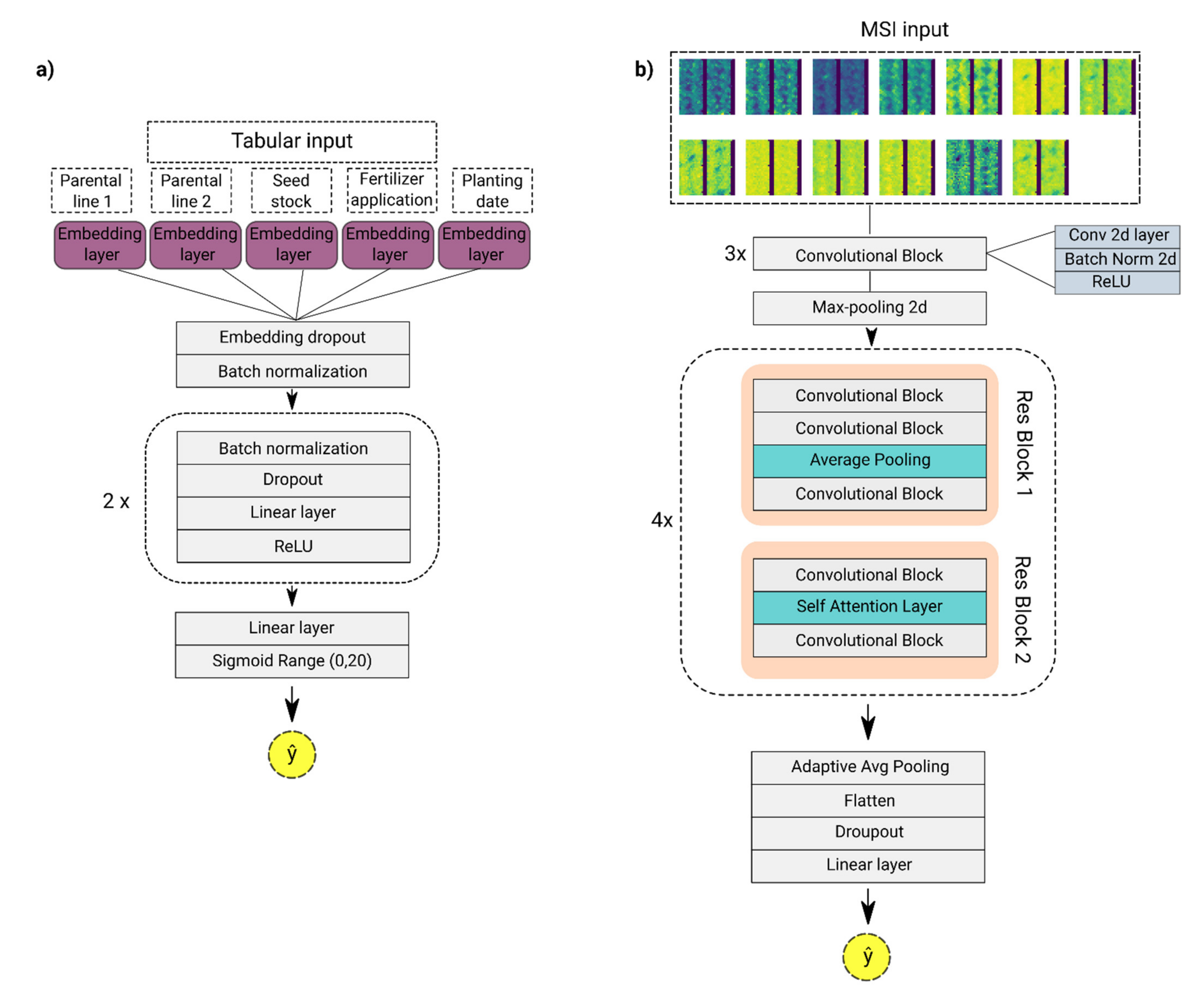
2.3.1. Machine Learning Module for Tabular Data
2.3.2. Deep Learning Module for Multispectral Imagery
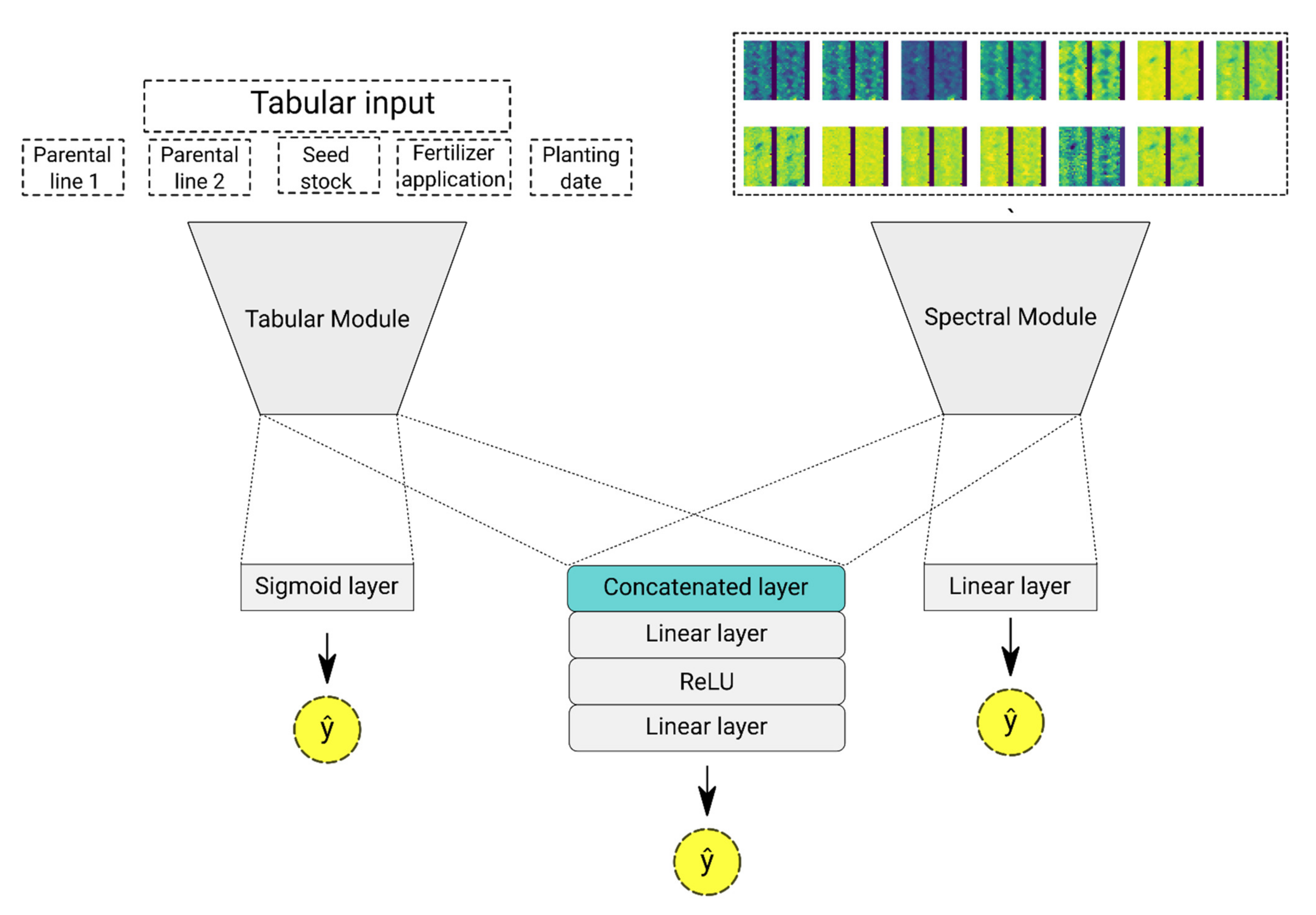
2.3.3. Multimodal Deep Learning Framework
2.4. Evaluation Metrics
3. Results
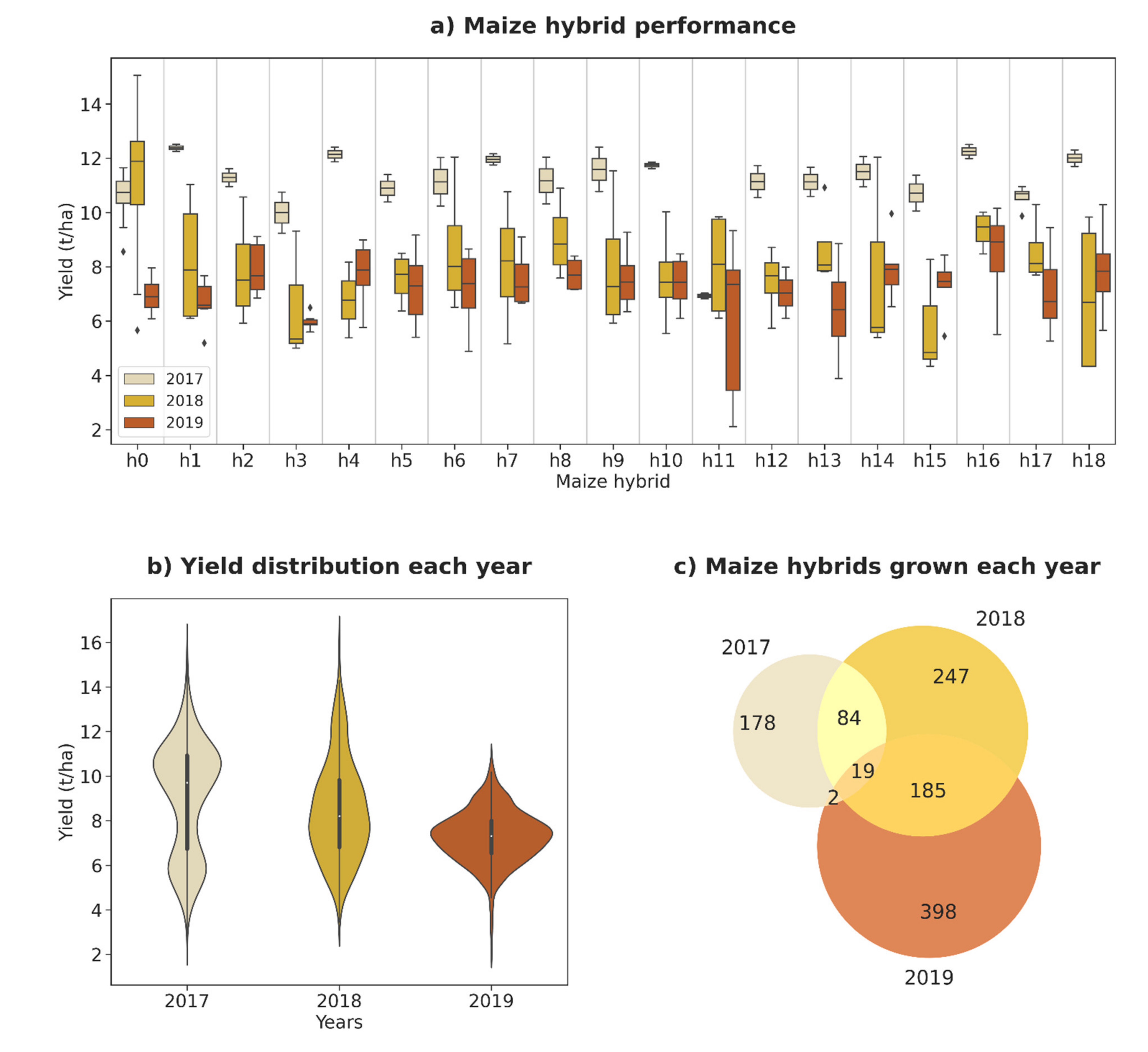
3.1. Maize Grain Yield Distribution
3.2. Machine Learning Hyperparameter Optimization
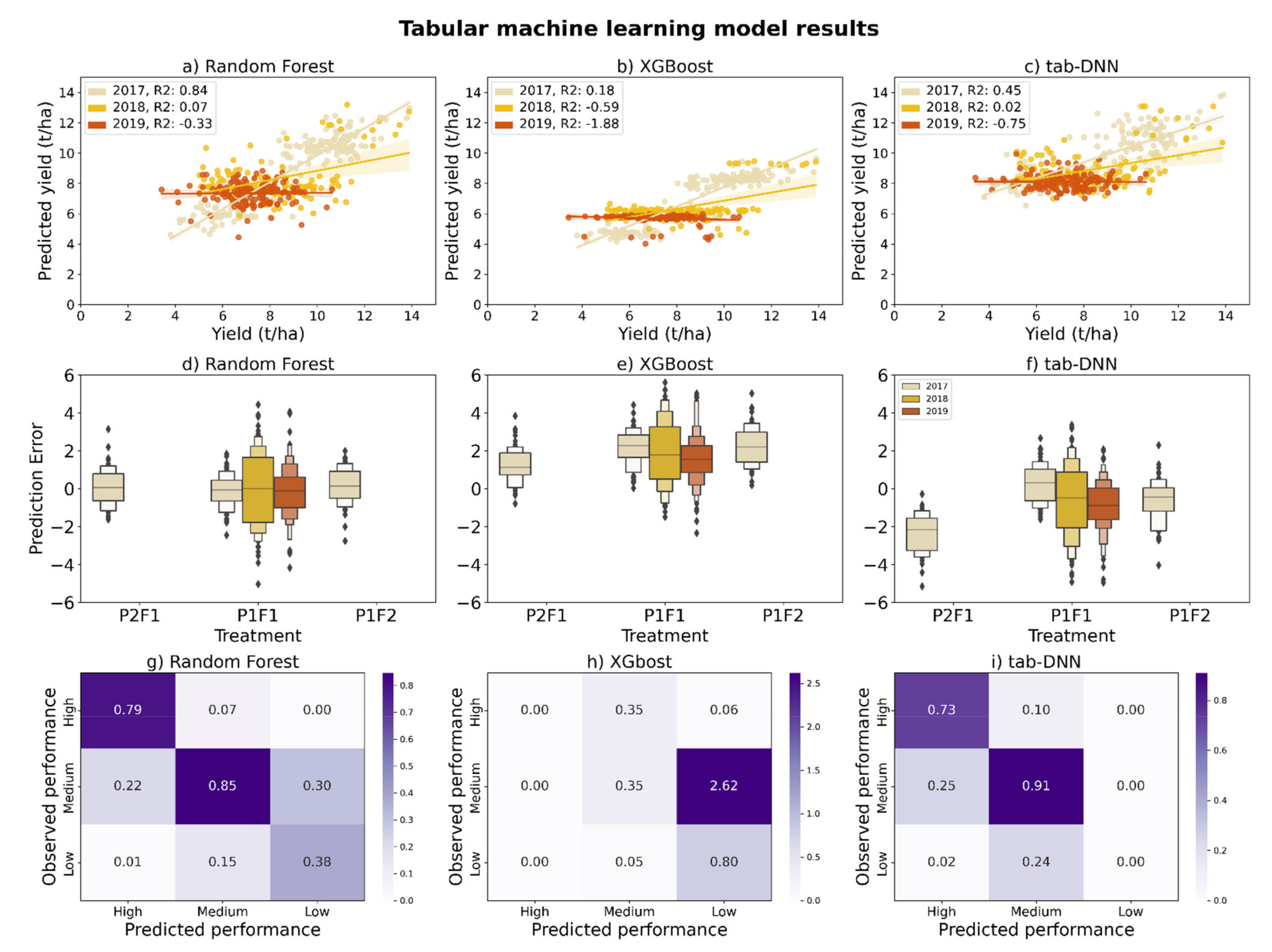
3.3. Prediction of Yield Based on Crop Metadata
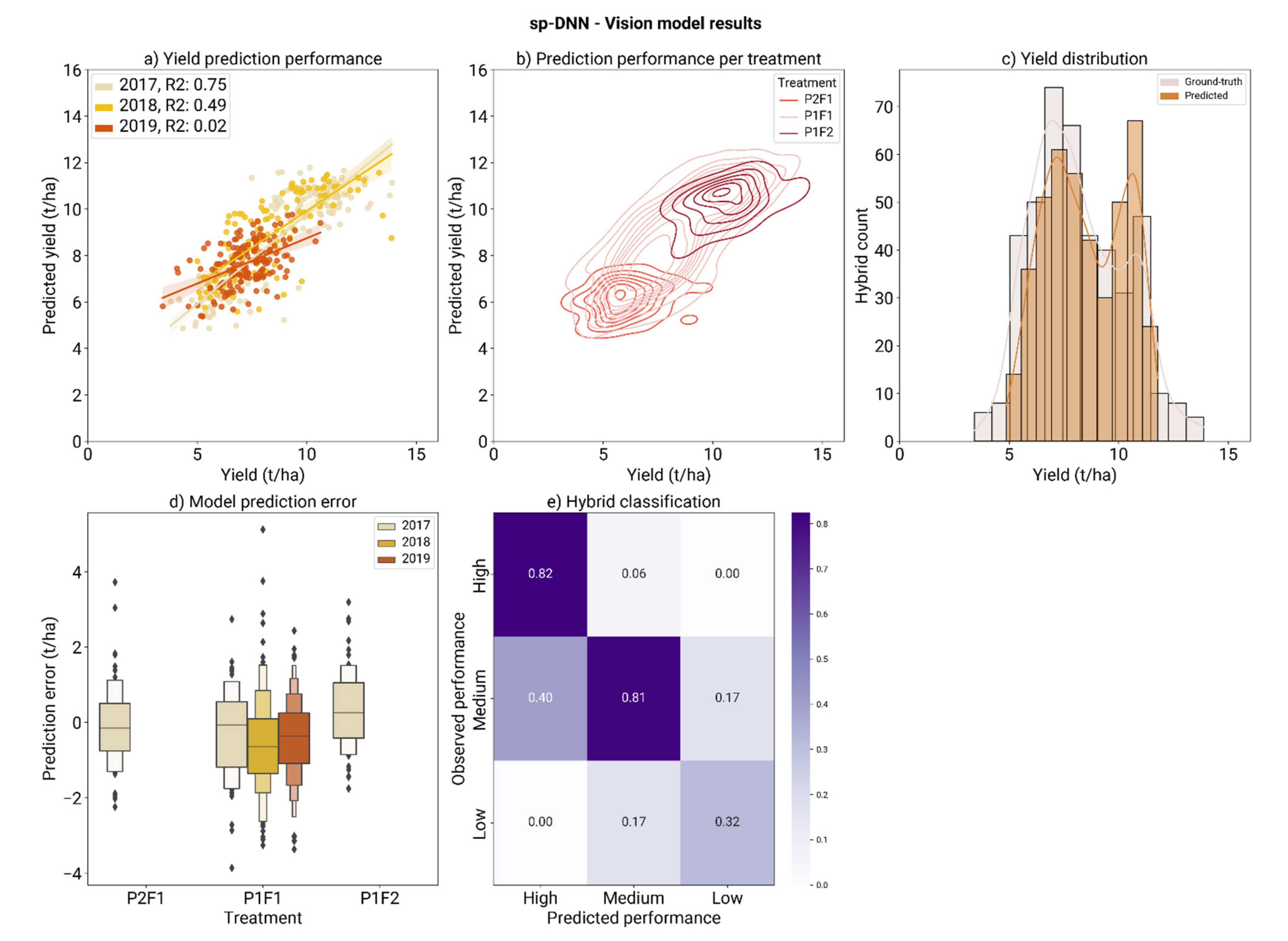
3.4. Spectral Feature Deep Learning Model Performance
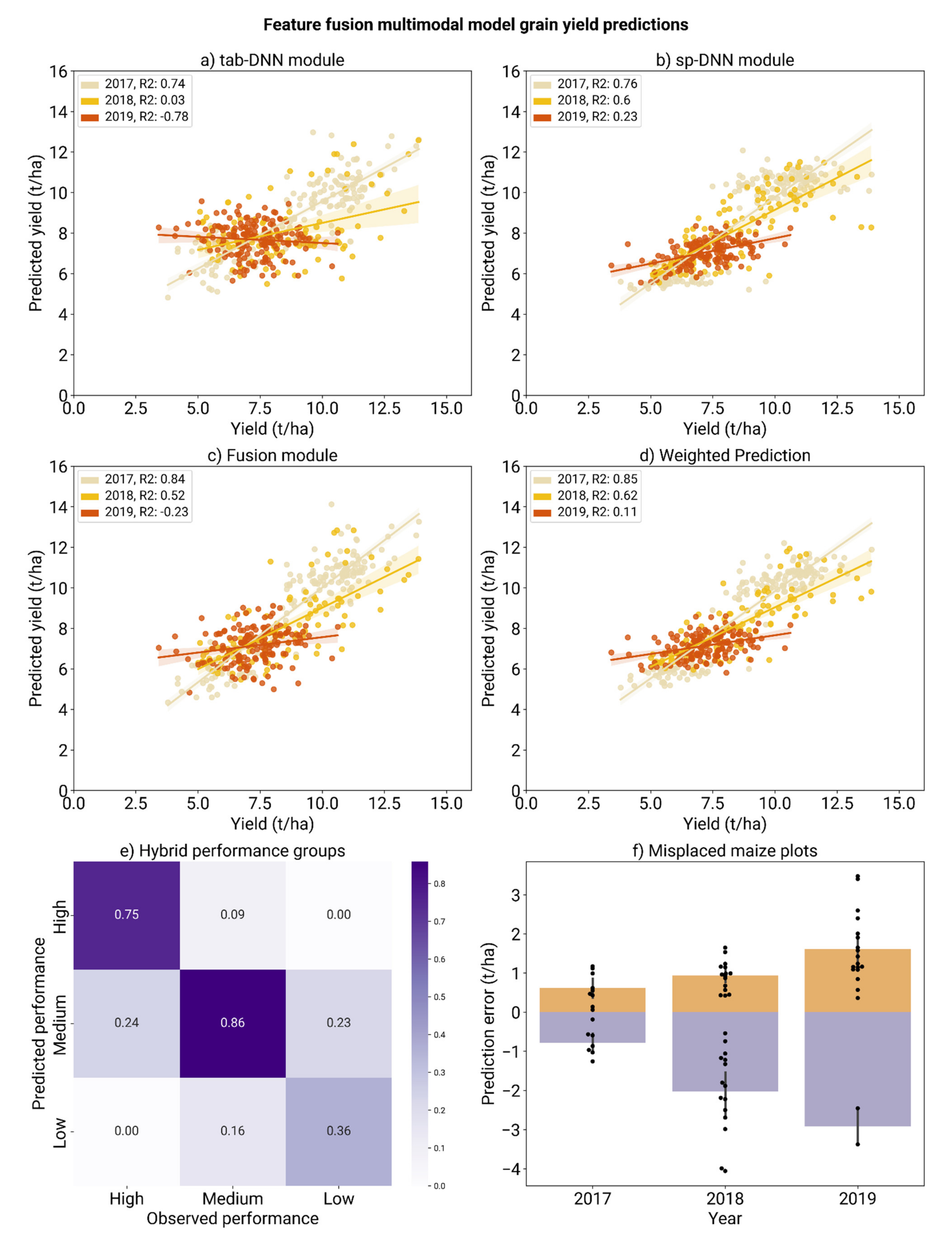
3.5. Multimodal Deep Learning Model Performance
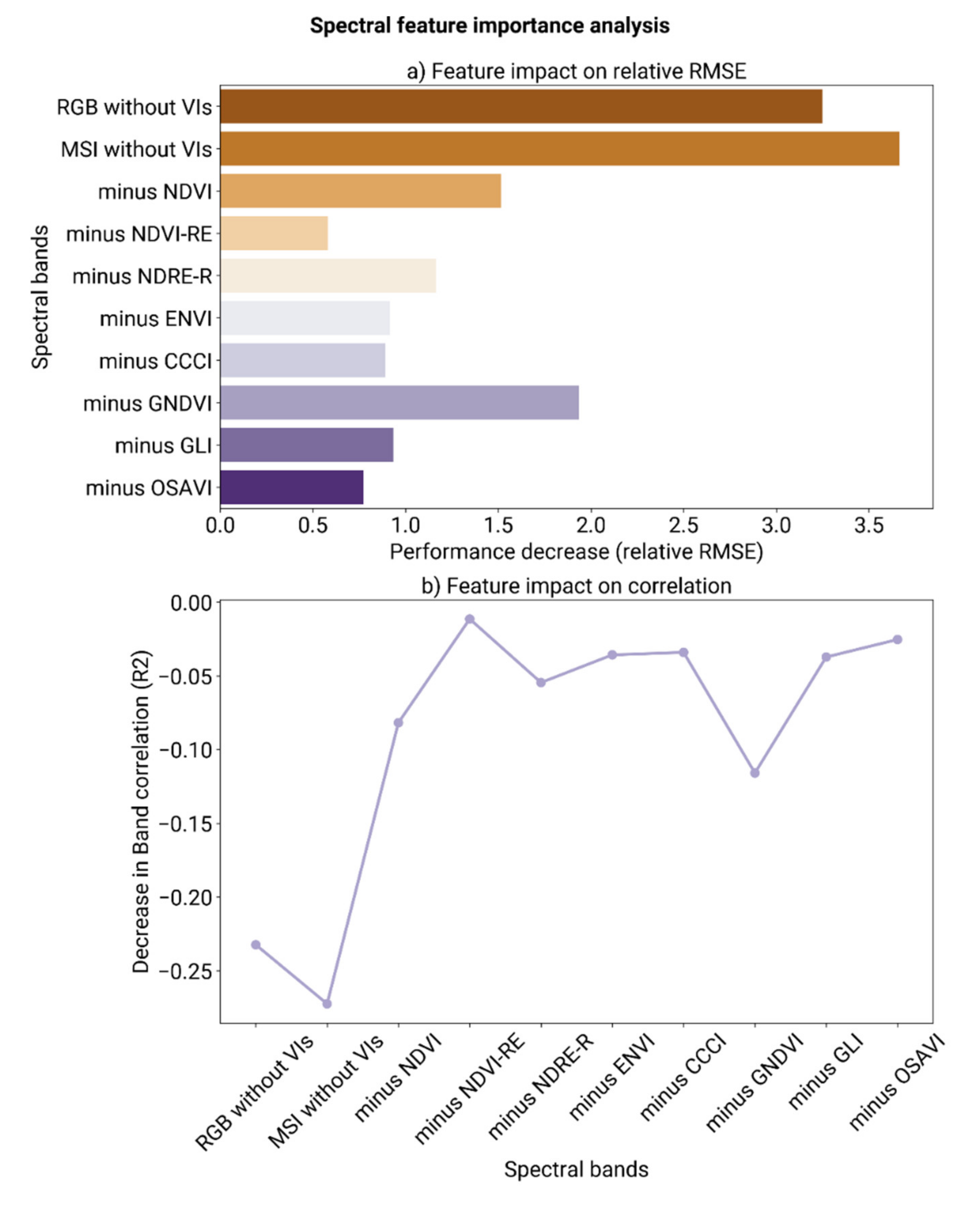
3.6. Effect of Spectral Features on the Prediction of End-of-Season Traits
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Challinor, A.J.; Koehler, A.K.; Ramirez-Villegas, J.; Whitfield, S.; Das, B. Current Warming Will Reduce Yields Unless Maize Breeding and Seed Systems Adapt Immediately. Nat. Clim. Chang. 2016, 6, 954–958. [Google Scholar] [CrossRef]
- Bai, G.; Ge, Y.; Hussain, W.; Baenziger, P.S.; Graef, G. A Multi-Sensor System for High Throughput Field Phenotyping in Soybean and Wheat Breeding. Comput. Electron. Agric. 2016, 128, 181–192. [Google Scholar] [CrossRef] [Green Version]
- Yuan, W.; Wijewardane, N.K.; Jenkins, S.; Bai, G.; Ge, Y.; Graef, G.L. Early Prediction of Soybean Traits through Color and Texture Features of Canopy RGB Imagery. Sci. Rep. 2019, 9, 14089. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Varela, S.; Pederson, T.; Bernacchi, C.J.; Leakey, A.D.B. Understanding Growth Dynamics and Yield Prediction of Sorghum Using High Temporal Resolution UAV Imagery Time Series and Machine Learning. Remote Sens. 2021, 13, 1763. [Google Scholar] [CrossRef]
- Rutkoski, J.; Poland, J.; Mondal, S.; Autrique, E.; Pérez, L.G.; Crossa, J.; Reynolds, M.; Singh, R. Canopy Temperature and Vegetation Indices from High-Throughput Phenotyping Improve Accuracy of Pedigree and Genomic Selection for Grain Yield in Wheat. G3 (Bethesda) 2016, 6, 2799–2808. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Niu, Y.; Zhang, H.; Han, W.; Li, G.; Tang, J.; Peng, X. Maize Canopy Temperature Extracted from UAV Thermal and RGB Imagery and Its Application in Water Stress Monitoring. Front. Plant Sci. 2019, 10, 1270. [Google Scholar] [CrossRef]
- Ihuoma, S.O.; Madramootoo, C.A. Sensitivity of Spectral Vegetation Indices for Monitoring Water Stress in Tomato Plants. Comput. Electron. Agric. 2019, 163, 104860. [Google Scholar] [CrossRef]
- Al-Saddik, H.; Simon, J.-C.; Cointault, F. Development of Spectral Disease Indices for “flavescence Dorée” Grapevine Disease Identification. Sensors 2017, 17, 2772. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Qin, Z.; Liu, X.; Ustin, S.L. Detection of Stress in Tomatoes Induced by Late Blight Disease in California, USA, Using Hyperspectral Remote Sensing. Int. J. Appl. Earth Obs. Geoinf. 2003, 4, 295–310. [Google Scholar] [CrossRef]
- Mutka, A.M.; Bart, R.S. Image-Based Phenotyping of Plant Disease Symptoms. Front. Plant Sci. 2014, 5, 734. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Yang, C.; Guo, W.; Zhang, L.; Zhang, D. Automatic Estimation of Crop Disease Severity Levels Based on Vegetation Index Normalization. Remote Sens. 2020, 12, 1930. [Google Scholar] [CrossRef]
- Wilke, N.; Siegmann, B.; Frimpong, F.; Muller, O.; Klingbeil, L.; Rascher, U. Quantifying Lodging Percentage, Lodging Development and Lodging Severity Using a Uav-Based Canopy Height Model. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, XLII-2/W13, 649–655. [Google Scholar] [CrossRef] [Green Version]
- Chu, T.; Starek, M.J.; Brewer, M.J.; Masiane, T.; Murray, S.C. UAS Imaging for Automated Crop Lodging Detection: A Case Study over an Experimental Maize Field. In Autonomous Air and Ground Sensing Systems for Agricultural Optimization and Phenotyping II; Thomasson, J.A., McKee, M., Moorhead, R.J., Eds.; SPIE: Washington, DC, USA, 2017; Volume 10218, p. 102180. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Klompenburg, T.; Kassahun, A.; Catal, C. Crop Yield Prediction Using Machine Learning: A Systematic Literature Review. Comput. Electron. Agric. 2020, 177, 105709. [Google Scholar] [CrossRef]
- Khaki, S.; Wang, L.; Archontoulis, S.V. A CNN-RNN Framework for Crop Yield Prediction. Front. Plant Sci. 2019, 10, 1750. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Di, L.; Sun, Z.; Shen, Y.; Lai, Z. County-Level Soybean Yield Prediction Using Deep CNN-LSTM Model. Sensors 2019, 19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nevavuori, P.; Narra, N.; Linna, P.; Lipping, T. Crop Yield Prediction Using Multitemporal UAV Data and Spatio-Temporal Deep Learning Models. Remote Sens. 2020, 12, 4000. [Google Scholar] [CrossRef]
- Terliksiz, A.S.; Altylar, D.T. Use of Deep Neural Networks for Crop Yield Prediction: A Case Study of Soybean Yield in Lauderdale County, Alabama, USA. In Proceedings of the 2019 8th International Conference on Agro-Geoinformatics (Agro-Geoinformatics), Instanbul, Turkey, 16 July 2019; IEEE; pp. 1–4. [Google Scholar]
- Khaki, S.; Pham, H.; Wang, L. Simultaneous Corn and Soybean Yield Prediction from Remote Sensing Data Using Deep Transfer Learning. Sci. Rep. 2021, 11, 11132. [Google Scholar] [CrossRef]
- Nevavuori, P.; Narra, N.; Lipping, T. Crop Yield Prediction with Deep Convolutional Neural Networks. Comput. Electron. Agric. 2019, 163, 104859. [Google Scholar] [CrossRef]
- Maimaitijiang, M.; Ghulam, A.; Sidike, P.; Hartling, S.; Maimaitiyiming, M.; Peterson, K.; Shavers, E.; Fishman, J.; Peterson, J.; Kadam, S.; et al. Unmanned Aerial System (UAS)-Based Phenotyping of Soybean Using Multi-Sensor Data Fusion and Extreme Learning Machine. ISPRS J. Photogramm. Remote Sens. 2017, 134, 43–58. [Google Scholar] [CrossRef]
- Herrero-Huerta, M.; Rodriguez-Gonzalvez, P.; Rainey, K.M. Yield Prediction by Machine Learning from UAS-Based Mulit-Sensor Data Fusion in Soybean. Plant Methods 2020, 16, 78. [Google Scholar] [CrossRef]
- Baltrusaitis, T.; Ahuja, C.; Morency, L.-P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, J.; Li, P.; Chen, Z.; Zhang, J. A Survey on Deep Learning for Multimodal Data Fusion. Neural Comput. 2020, 32, 829–864. [Google Scholar] [CrossRef] [PubMed]
- Khaki, S.; Khalilzadeh, Z.; Wang, L. Classification of Crop Tolerance to Heat and Drought—A Deep Convolutional Neural Networks Approach. Agronomy 2019, 9, 833. [Google Scholar] [CrossRef] [Green Version]
- Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.L.; Mouazen, A.M. Wheat Yield Prediction Using Machine Learning and Advanced Sensing Techniques. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Maimaitijiang, M.; Sagan, V.; Sidike, P.; Hartling, S.; Esposito, F.; Fritschi, F.B. Soybean Yield Prediction from UAV Using Multimodal Data Fusion and Deep Learning. Remote Sens. Environ. 2020, 237, 111599. [Google Scholar] [CrossRef]
- McFarland, B.A.; AlKhalifah, N.; Bohn, M.; Bubert, J.; Buckler, E.S.; Ciampitti, I.; Edwards, J.; Ertl, D.; Gage, J.L.; Falcon, C.M.; et al. Maize Genomes to Fields (G2F): 2014-2017 Field Seasons: Genotype, Phenotype, Climatic, Soil, and Inbred Ear Image Datasets. BMC Res. Notes 2020, 13, 71. [Google Scholar] [CrossRef] [Green Version]
- Anderson, S.L.; Murray, S.C. R/UAStools::Plotshpcreate: Create Multi-Polygon Shapefiles for Extraction of Research Plot Scale Agriculture Remote Sensing Data. BioRxiv 2020, 11, 1419. [Google Scholar] [CrossRef]
- Kurtzer, G.M.; Sochat, V.; Bauer, M.W. Singularity: Scientific Containers for Mobility of Compute. PLoS ONE 2017, 12, e0177459. [Google Scholar] [CrossRef]
- Howard, J.; Gugger, S. Fastai: A Layered API for Deep Learning. Information 2020, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-Generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining - KDD ’19, New York, NY, USA, 4 August 2019; pp. 2623–2631. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NIPS), Vancouver, Canada, 14 December 2019; Volume 32. [Google Scholar]
- Guo, C.; Berkhahn, F. Entity Embeddings of Categorical Variables. arXiv 2016, arXiv:1604.06737. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27 June 2016; pp. 770–778. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15 June 2019; pp. 558–567. [Google Scholar]
- Hu, G.; Qian, L.; Liang, D.; Wan, M. Self-Adversarial Training and Attention for Multi-Task Wheat Phenotyping. Appl. Eng. Agric. 2019, 35, 1009–1014. [Google Scholar] [CrossRef]
- Wang, W.; Tran, D.; Feiszli, M. What Makes Training Multi-Modal Classification Networks Hard? arXiv 2019, arXiv:1905.12681. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Fisher, A.; Rudin, C.; Dominici, F. All Models Are Wrong, but Many Are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. arXiv 2019, arXiv:1801.01489. [Google Scholar]
- Molnar, C. Interpretable Machine Learning. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 4 January 2021).
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How Many Trees in a Random Forest. In Machine learning and Data Mining in Pattern Recognition; Lecture notes in computer science; Perner, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2012; ISBN 978-3-642-31536-7. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv arXiv:1412.6980.
- Rodríguez, P.; Bautista, M.A.; Gonzàlez, J.; Escalera, S. Beyond One-Hot Encoding: Lower Dimensional Target Embedding. Image Vis. Comput. 2018, 75, 21–31. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Huang, C.; Wu, D.; Qiao, F.; Li, W.; Duan, L.; Wang, K.; Xiao, Y.; Chen, G.; Liu, Q.; et al. High-Throughput Phenotyping and QTL Mapping Reveals the Genetic Architecture of Maize Plant Growth. Plant Physiol. 2017, 173, 1554–1564. [Google Scholar] [CrossRef] [Green Version]
- Adak, A.; Murray, S.C.; Anderson, S.L.; Popescu, S.C.; Malambo, L.; Romay, M.C.; de Leon, N. Unoccupied Aerial Systems Discovered Overlooked Loci Capturing the Variation of Entire Growing Period in Maize. Plant Genome 2021, e20102. [Google Scholar] [CrossRef]
- Marques Ramos, A.P.; Prado Osco, L.; Elis Garcia Furuya, D.; Nunes Gonçalves, W.; Cordeiro Santana, D.; Pereira Ribeiro Teodoro, L.; Antonio da Silva Junior, C.; Fernando Capristo-Silva, G.; Li, J.; Henrique Rojo Baio, F.; et al. A Random Forest Ranking Approach to Predict Yield in Maize with Uav-Based Vegetation Spectral Indices. Comput. Electron. Agric. 2020, 178, 105791. [Google Scholar] [CrossRef]
- Han, J.; Zhang, Z.; Cao, J.; Luo, Y.; Zhang, L.; Li, Z.; Zhang, J. Prediction of Winter Wheat Yield Based on Multi-Source Data and Machine Learning in China. Remote Sens. 2020, 12, 236. [Google Scholar] [CrossRef] [Green Version]
- Jeong, J.H.; Resop, J.P.; Mueller, N.D.; Fleisher, D.H.; Yun, K.; Butler, E.E.; Timlin, D.J.; Shim, K.-M.; Gerber, J.S.; Reddy, V.R.; et al. Random Forests for Global and Regional Crop Yield Predictions. PLoS ONE 2016, 11, e0156571. [Google Scholar] [CrossRef]
- Yang, S.; Hu, L.; Wu, H.; Ren, H.; Qiao, H.; Li, P.; Fan, W. Integration of Crop Growth Model and Random Forest for Winter Wheat Yield Estimation from UAV Hyperspectral Imagery. IEEE J. Sel. Top Appl. Earth Obs. Remote Sens. 2021, 14, 6253–6269. [Google Scholar] [CrossRef]
- Lee, H.; Wang, J.; Leblon, B. Using Linear Regression, Random Forests, and Support Vector Machine with Unmanned Aerial Vehicle Multispectral Images to Predict Canopy Nitrogen Weight in Corn. Remote Sens. 2020, 12, 2071. [Google Scholar] [CrossRef]
- Obsie, E.Y.; Qu, H.; Drummond, F. Wild Blueberry Yield Prediction Using a Combination of Computer Simulation and Machine Learning Algorithms. Comput. Electron. Agric. 2020, 178, 105778. [Google Scholar] [CrossRef]
- Kang, Y.; Ozdogan, M.; Zhu, X.; Ye, Z.; Hain, C.; Anderson, M. Comparative Assessment of Environmental Variables and Machine Learning Algorithms for Maize Yield Prediction in the US Midwest. Environ. Res. Lett. 2020, 15, 064005. [Google Scholar] [CrossRef]
- Näsi, R.; Viljanen, N.; Kaivosoja, J.; Alhonoja, K.; Hakala, T.; Markelin, L.; Honkavaara, E. Estimating Biomass and Nitrogen Amount of Barley and Grass Using UAV and Aircraft Based Spectral and Photogrammetric 3D Features. Remote Sens. 2018, 10, 1082. [Google Scholar] [CrossRef] [Green Version]
- Prabhakara, K.; Hively, W.D.; McCarty, G.W. Evaluating the Relationship between Biomass, Percent Groundcover and Remote Sensing Indices across Six Winter Cover Crop Fields in Maryland, United States. Int. J. Appl. Earth Obs. Geoinf. 2015, 39, 88–102. [Google Scholar] [CrossRef] [Green Version]
- Gracia-Romero, A.; Kefauver, S.C.; Vergara-Díaz, O.; Zaman-Allah, M.A.; Prasanna, B.M.; Cairns, J.E.; Araus, J.L. Comparative Performance of Ground vs. Aerially Assessed RGB and Multispectral Indices for Early-Growth Evaluation of Maize Performance under Phosphorus Fertilization. Front. Plant Sci. 2017, 8, 2004. [Google Scholar] [CrossRef] [Green Version]
- Feng, A.; Zhou, J.; Vories, E.D.; Sudduth, K.A.; Zhang, M. Yield Estimation in Cotton Using UAV-Based Multi-Sensor Imagery. Biosyst. Eng. 2020, 193, 101–114. [Google Scholar] [CrossRef]
- Buchaillot, M.L.; Gracia-Romero, A.; Vergara-Diaz, O.; Zaman-Allah, M.A.; Tarekegne, A.; Cairns, J.E.; Prasanna, B.M.; Araus, J.L.; Kefauver, S.C. Evaluating Maize Genotype Performance under Low Nitrogen Conditions Using RGB UAV Phenotyping Techniques. Sensors 2019, 19, 1815. [Google Scholar] [CrossRef] [Green Version]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable Are Features in Deep Neural Networks? arXiv 2014, arXiv:1411.1792. [Google Scholar]
- Danilevicz, M.F.; Bayer, P.E.; Nestor, B.J.; Bennamoun, M.; Edwards, D. Resources for Image-Based High Throughput Phenotyping in Crops and Data Sharing Challenges. Plant Physiol. 1–17. [CrossRef]
- Shook, J.; Gangopadhyay, T.; Wu, L.; Ganapathysubramanian, B.; Sarkar, S.; Singh, A.K. Crop yield prediction integrating genotype and weather variables using deep learning. PLoS ONE 2021, 16, e0252402. [Google Scholar] [CrossRef]
- Togliatti, K.; Archontoulis, S.V.; Dietzel, R.; Puntel, L.; VanLoocke, A. How Does Inclusion of Weather Forecasting Impact In-Season Crop Model Predictions? Field Crops Res. 2017, 214, 261–272. [Google Scholar] [CrossRef] [Green Version]
- Samek, W.; Wiegand, T.; Müller, K.R. Explainable Artificial Intelligence: Understanding, Visualizing and Interpreting Deep Learning Models. arXiv 2017, arXiv:1708.08296. [Google Scholar]
- Anche, M.T.; Kaczmar, N.S.; Morales, N.; Clohessy, J.W.; Ilut, D.C.; Gore, M.A.; Robbins, K.R. Temporal Covariance Structure of Multi-Spectral Phenotypes and Their Predictive Ability for End-of-Season Traits in Maize. Theor. Appl. Genet. 2020, 133, 2853–2868. [Google Scholar] [CrossRef]
- Heidarian Dehkordi, R.; Burgeon, V.; Fouche, J.; Placencia Gomez, E.; Cornelis, J.-T.; Nguyen, F.; Denis, A.; Meersmans, J. Using UAV Collected RGB and Multispectral Images to Evaluate Winter Wheat Performance across a Site Characterized by Century-Old Biochar Patches in Belgium. Remote Sens. 2020, 12, 2504. [Google Scholar] [CrossRef]
- Marino, S.; Alvino, A. Detection of Spatial and Temporal Variability of Wheat Cultivars by High-Resolution Vegetation Indices. Agronomy 2019, 9, 226. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; McGee, R.J.; Vandemark, G.J.; Sankaran, S. Crop Performance Evaluation of Chickpea and Dry Pea Breeding Lines across Seasons and Locations Using Phenomics Data. Front. Plant Sci. 2021, 12, 640259. [Google Scholar] [CrossRef] [PubMed]
- Hatfield, J.L.; Prueger, J.H. Value of Using Different Vegetative Indices to Quantify Agricultural Crop Characteristics at Different Growth Stages under Varying Management Practices. Remote Sens. 2010, 2, 562. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band Number | Identification | Equation |
|---|---|---|
| 6 | Normalized Difference Vegetation Index (NDVI) | |
| 7 | Normalized Difference Vegetation Index Red Edge (NDVI-RE) | |
| 8 | Normalised Difference Red Edge Red (NDRE-R) | |
| 9 | Enhanced Normalized Difference Vegetation Index (ENDVI) | |
| 10 | Canopy Chlorophyll Content Index (CCCI) | |
| 11 | Green Normalized Difference Vegetation Index (GNDVI) | |
| 12 | Green Leaf Index (GLI) | |
| 13 | Optimized Soil-Adjusted Vegetation Index (OSAVI) |
| Model | Feature Encoding | Validation Dataset | Holdout Dataset | ||||
|---|---|---|---|---|---|---|---|
| RMSE | RMSE % | R2 | RMSE | RMSE % | R2 | ||
| Random Forests | Ordinal encoding | 1.48 ± 0.05 | 10.46 ± 0.37 | 0.53 ± 0.04 | 1.48 | 10.59 | 0.49 |
| One-hot encoding | 1.46 ± 0.08 | 10.35 ± 0.54 | 0.55 ± 0.05 | 1.43 | 10.11 | 0.53 | |
| XGBoost | Ordinal encoding | 2.17 ± 0.05 | 15.40 ± 0.38 | 0.00 ± 0.06 | 2.28 | 15.77 | −0.14 |
| One-hot encoding | 2.21 ± 0.08 | 15.67 ± 0.57 | −0.04 ± 0.05 | 2.12 | 15.02 | −0.03 | |
| DNN | Embeddings | 1.67 ± 0.04 | 11.87 ± 0.33 | 0.41 ± 0.02 | 1.77 | 12.57 | 0.27 |
| RMSE | RMSE % | R2 | |
|---|---|---|---|
| Validation dataset | 1.46 ± 0.14 | 10.35 ± 1.01 | 0.55 ± 0.08 |
| Holdout dataset | 1.27 | 8.99 | 0.63 |
| Multimodal Framework | Validation Dataset | Holdout Dataset | |||||
|---|---|---|---|---|---|---|---|
| RMSE | RMSE % | R2 | RMSE | RMSE % | R2 | ||
| Feature Fusion | Tabular module | 1.29 ± 0.20 | 9.15 ± 1.40 | 0.64 ± 0.11 | 1.53 | 10.84 | 0.47 |
| Spectral module | 1.27 ± 0.17 | 9.02 ± 1.22 | 0.65 ± 0.10 | 1.14 | 8.06 | 0.71 | |
| Fusion module | 1.16 ±0.05 | 8.24 ± 0.38 | 0.71 ± 0.02 | 1.17 | 8.27 | 0.69 | |
| Weighted prediction | 1.13 ± 0.04 | 8.00 ± 0.31 | 0.73 ± 0.016 | 1.07 | 7.60 | 0.73 | |
| Feature Fusion with pre-trained modules | Tabular module | 1.29 ± 0.21 | 9.10 ± 1.50 | 0.64 ± 0.12 | 2.16 | 15.31 | −0.07 |
| Spectral module | 1.27 ± 0.18 | 8.96 ± 1.31 | 0.65 ± 0.11 | 1.19 | 8.44 | 0.67 | |
| Fusion module | 1.14 ± 0.04 | 8.09 ± 0.25 | 0.72 ± 0.02 | 1.22 | 8.63 | 0.66 | |
| Weighted prediction | 1.12 ± 0.02 | 7.90 ± 0.16 | 0.74 ± 0.01 | 1.21 | 8.55 | 0.66 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Danilevicz, M.F.; Bayer, P.E.; Boussaid, F.; Bennamoun, M.; Edwards, D. Maize Yield Prediction at an Early Developmental Stage Using Multispectral Images and Genotype Data for Preliminary Hybrid Selection. Remote Sens. 2021, 13, 3976. https://doi.org/10.3390/rs13193976
Danilevicz MF, Bayer PE, Boussaid F, Bennamoun M, Edwards D. Maize Yield Prediction at an Early Developmental Stage Using Multispectral Images and Genotype Data for Preliminary Hybrid Selection. Remote Sensing. 2021; 13(19):3976. https://doi.org/10.3390/rs13193976
Chicago/Turabian StyleDanilevicz, Monica F., Philipp E. Bayer, Farid Boussaid, Mohammed Bennamoun, and David Edwards. 2021. "Maize Yield Prediction at an Early Developmental Stage Using Multispectral Images and Genotype Data for Preliminary Hybrid Selection" Remote Sensing 13, no. 19: 3976. https://doi.org/10.3390/rs13193976
APA StyleDanilevicz, M. F., Bayer, P. E., Boussaid, F., Bennamoun, M., & Edwards, D. (2021). Maize Yield Prediction at an Early Developmental Stage Using Multispectral Images and Genotype Data for Preliminary Hybrid Selection. Remote Sensing, 13(19), 3976. https://doi.org/10.3390/rs13193976