
STC-Det: A Slender Target Detector Combining Shadow and Target Information in Optical Satellite Images




Abstract
:
1. Introduction
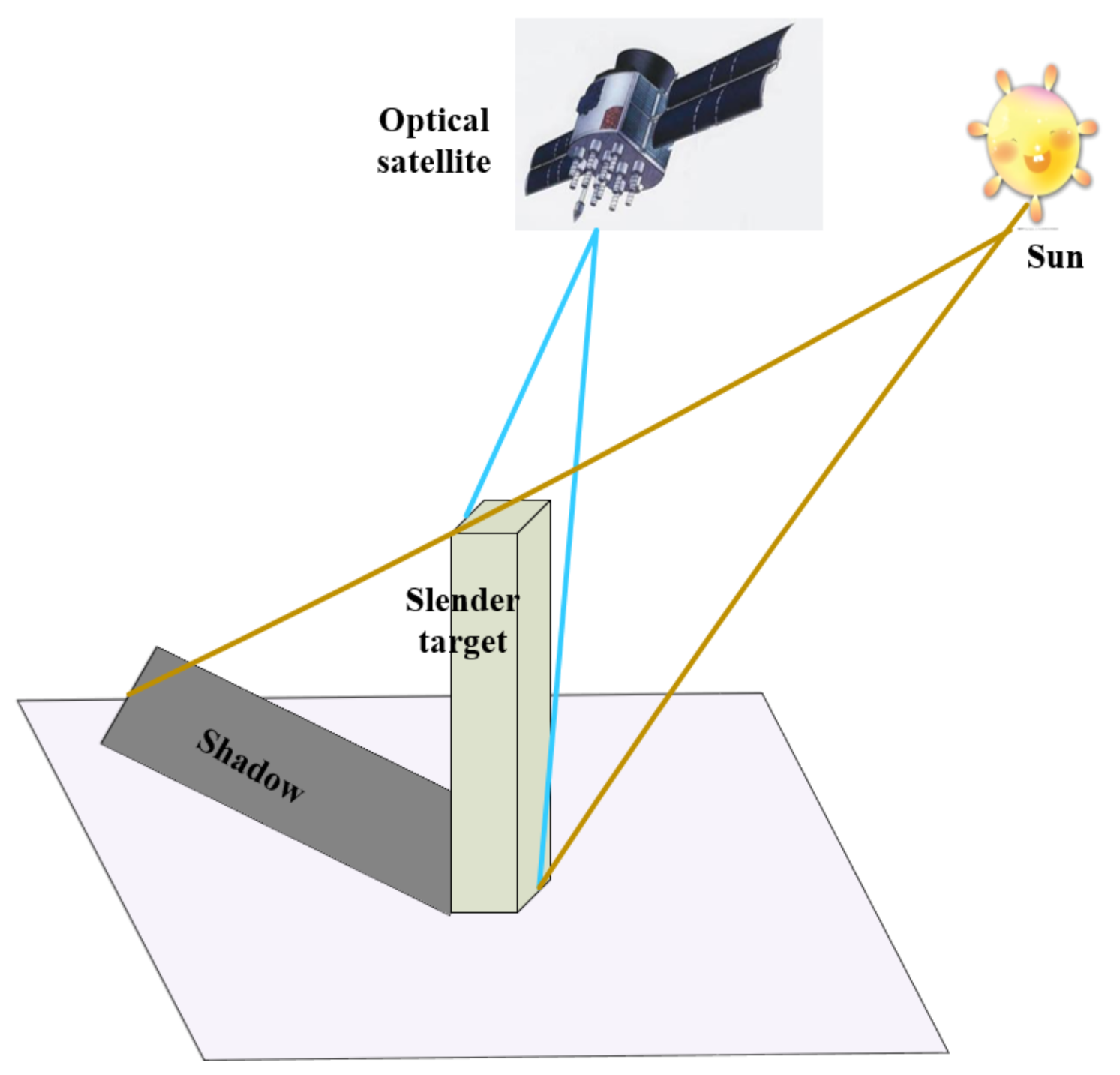
- During imaging, a large number of features of slender targets are lost. As shown in Figure 1, for traditional object detection methods, the main features of some stumpy targets such as houses are concentrated on the top. The information will not be lost during imaging and has little effect on object detection. However, the main characteristics of slender targets such as high-voltage transmission towers are concentrated on the vertical trunk. During imaging, they will be greatly compressed in the vertical direction, and many features will be lost, which is not conducive to object detection.
- According to the imaging geometry model of the optical satellite remote sensing, the imaging results are greatly affected by the satellite perspective. The same target has different image under different satellite perspective. As shown in Figure 1a,b, high-voltage power transmission towers behave differently under different satellite perspective. In different situations, target information and shadow information contribute differently to detection.
- STC-Det is proposed, which broadens the application range of slender target detection and expands the application range of satellite perspective.
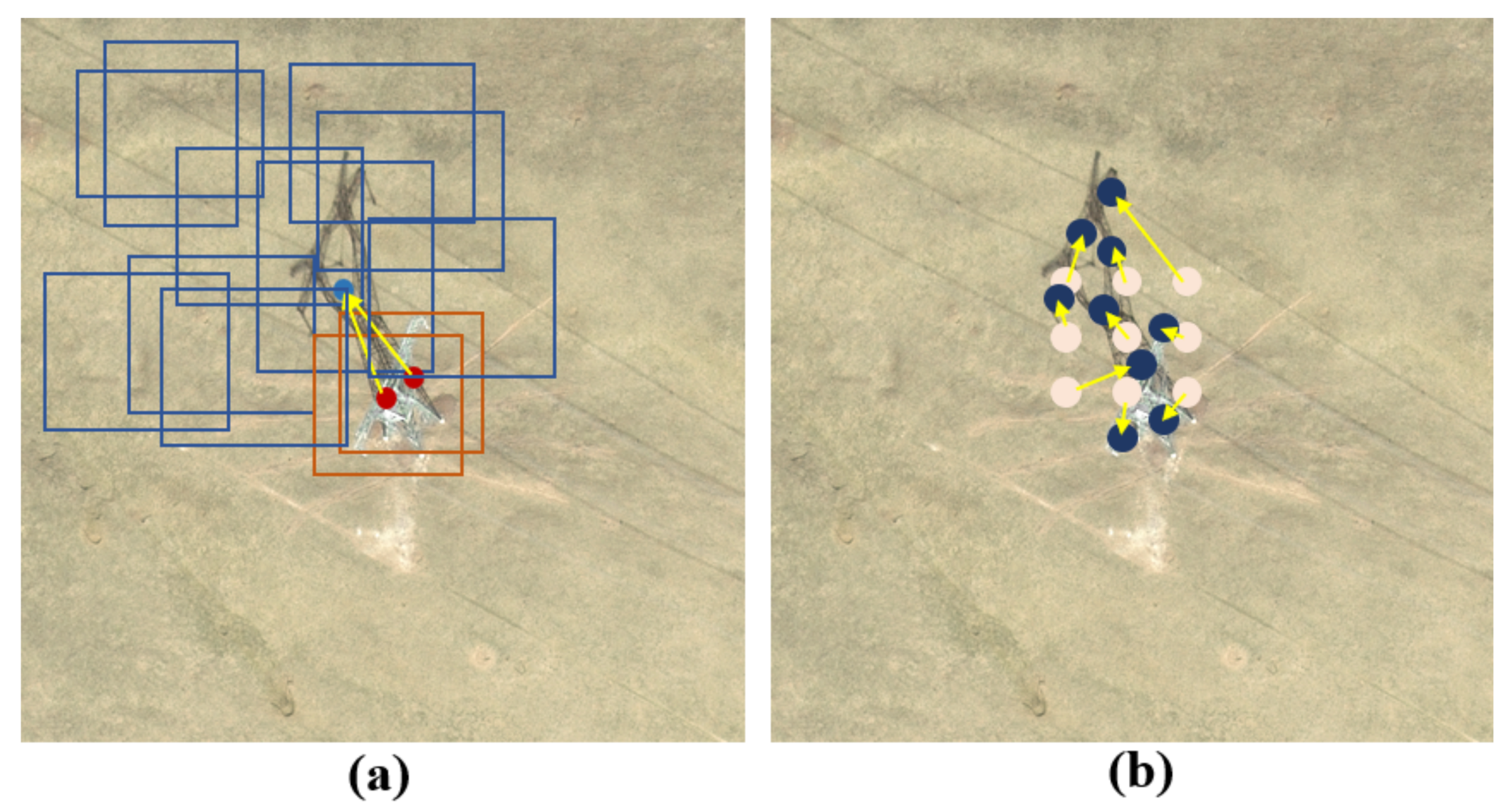
- Using deformable convolution for reference, an automatic shadow and target matching method is designed. This method achieves fast shadow and target matching with only a small increase in network complexity, improves network efficiency, and reduces computational complexity.
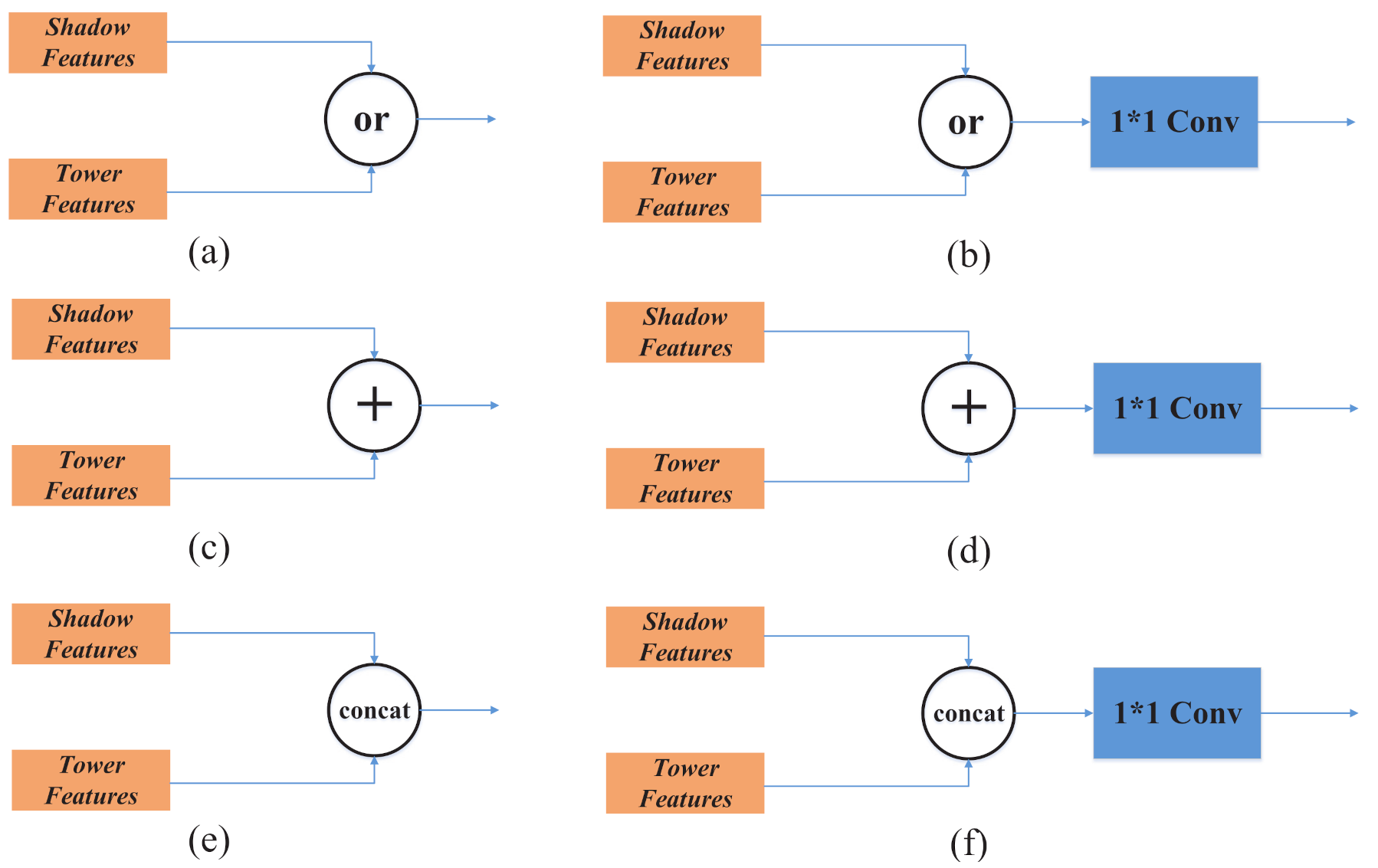
- A new feature fusion method is designed, which realizes the fusion of shadow features and target features, and can also realize automatic weighting of features, which further improves the utilization efficiency of shadow and target feature information.
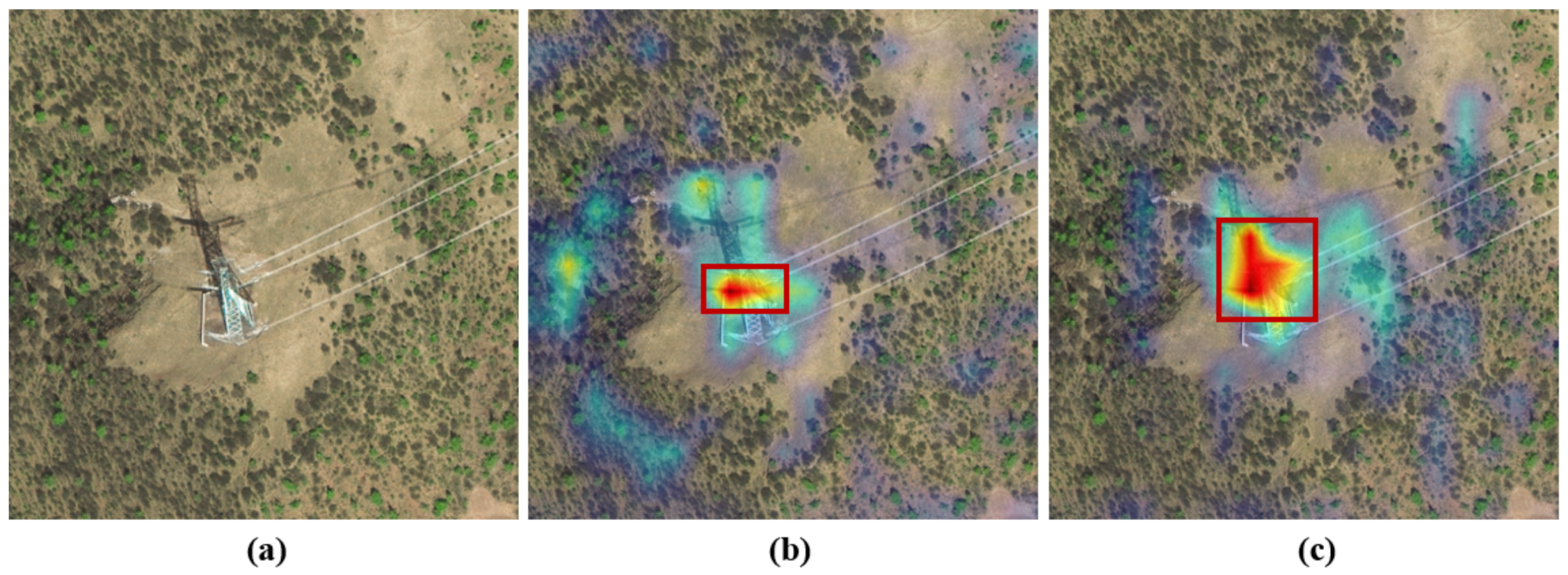
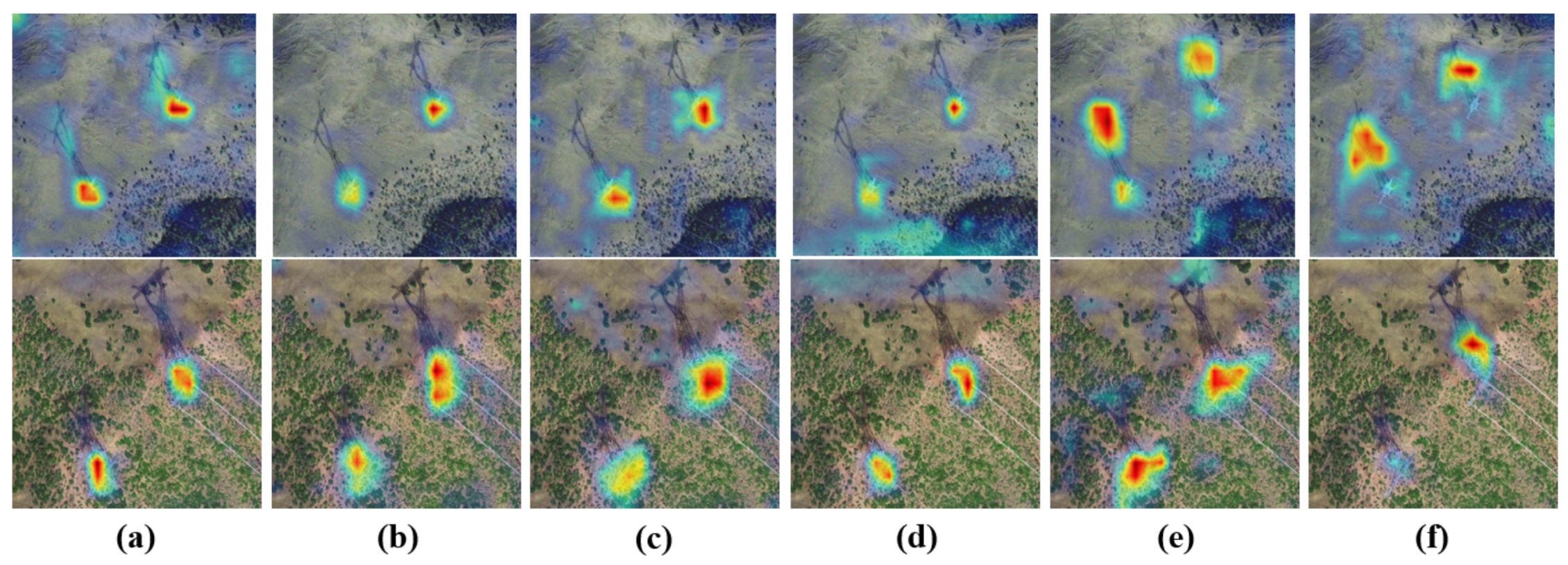
- In order to intuitively see the influence of shadow information and target information on detection when the satellite perspective changes, we have improved Group-CAM [23] so that it can be used for the visualization of the heatmap of object detection, and thereby verify the effectiveness of STC-Det.
2. Materials and Methods
2.1. The Imaging Geometry Model of Optical Satellite Images
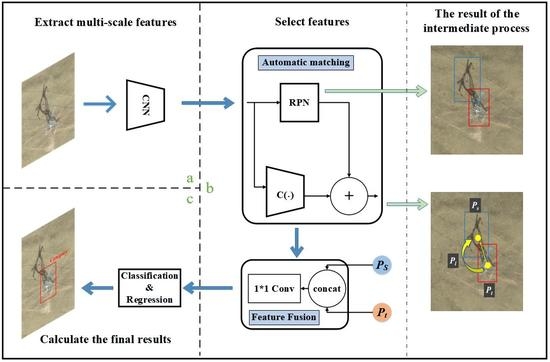
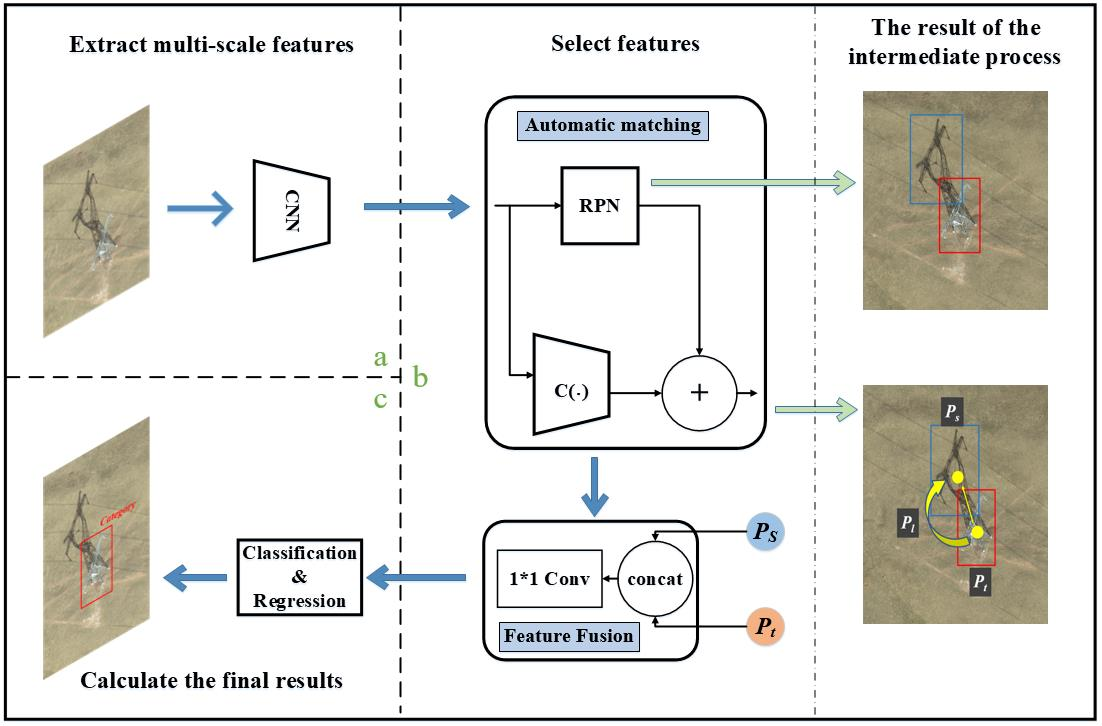
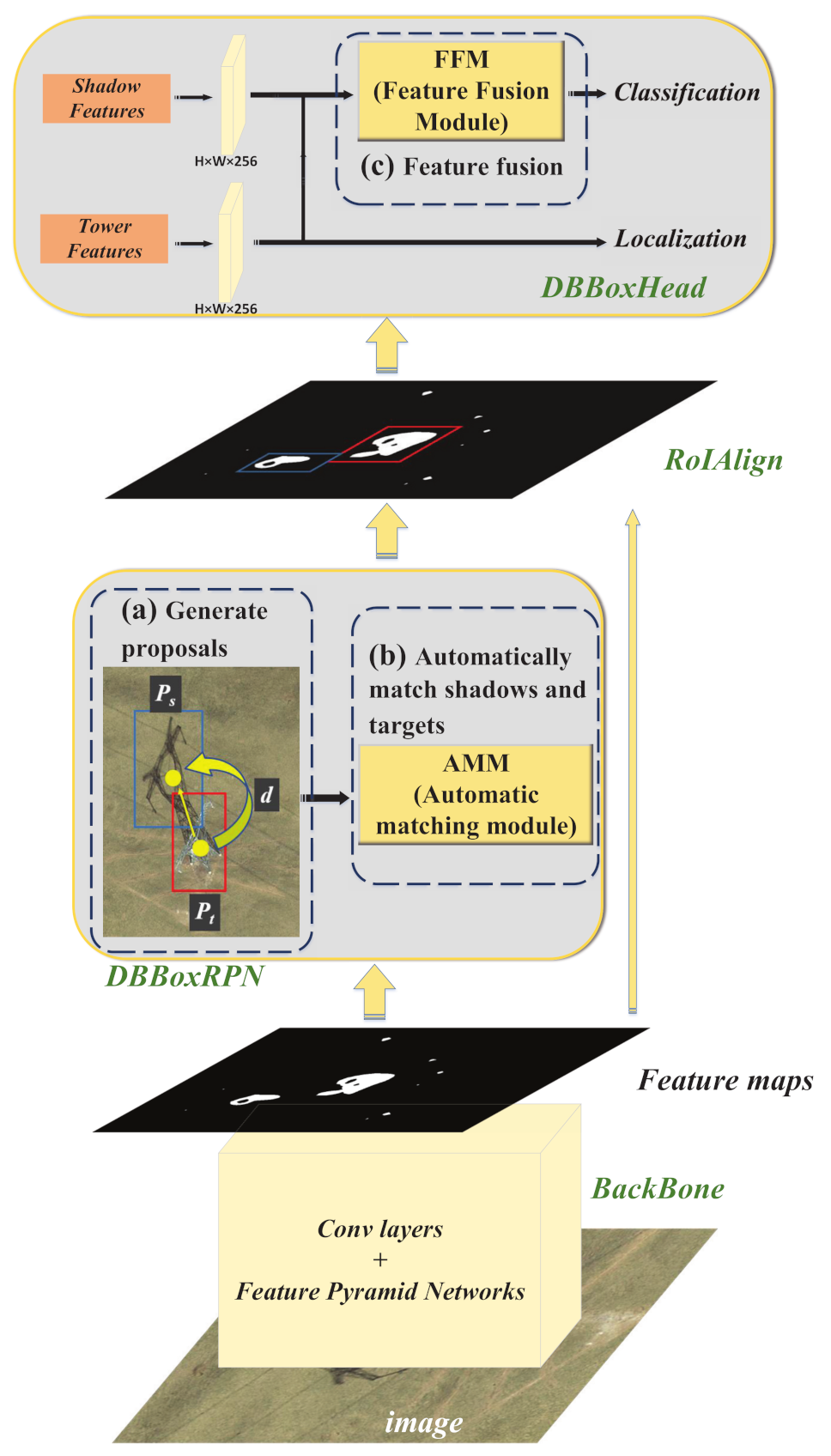
2.2. STC-Det
2.3. AMM
2.4. FFM
2.5. Heatmap Visualization Algorithm
- Input the original image into the network F and extract the characteristic layer A and the corresponding gradient value W to be viewed.
- Use filter to filter the original image to get , use the extracted gradient value W to weight the feature layer A and group to get the feature mask , L is to be divided into a number of groups.
- The feature mask M is respectively weighted and merged with the original image after the illusion, and the masked image I is obtained. Input I into the network to obtain the weight of the corresponding feature layer.
- Use the obtained feature layer weights to weight the corresponding feature layers to obtain the final heat map.
3. Experiment
3.1. Data Set
3.2. Training Configurations
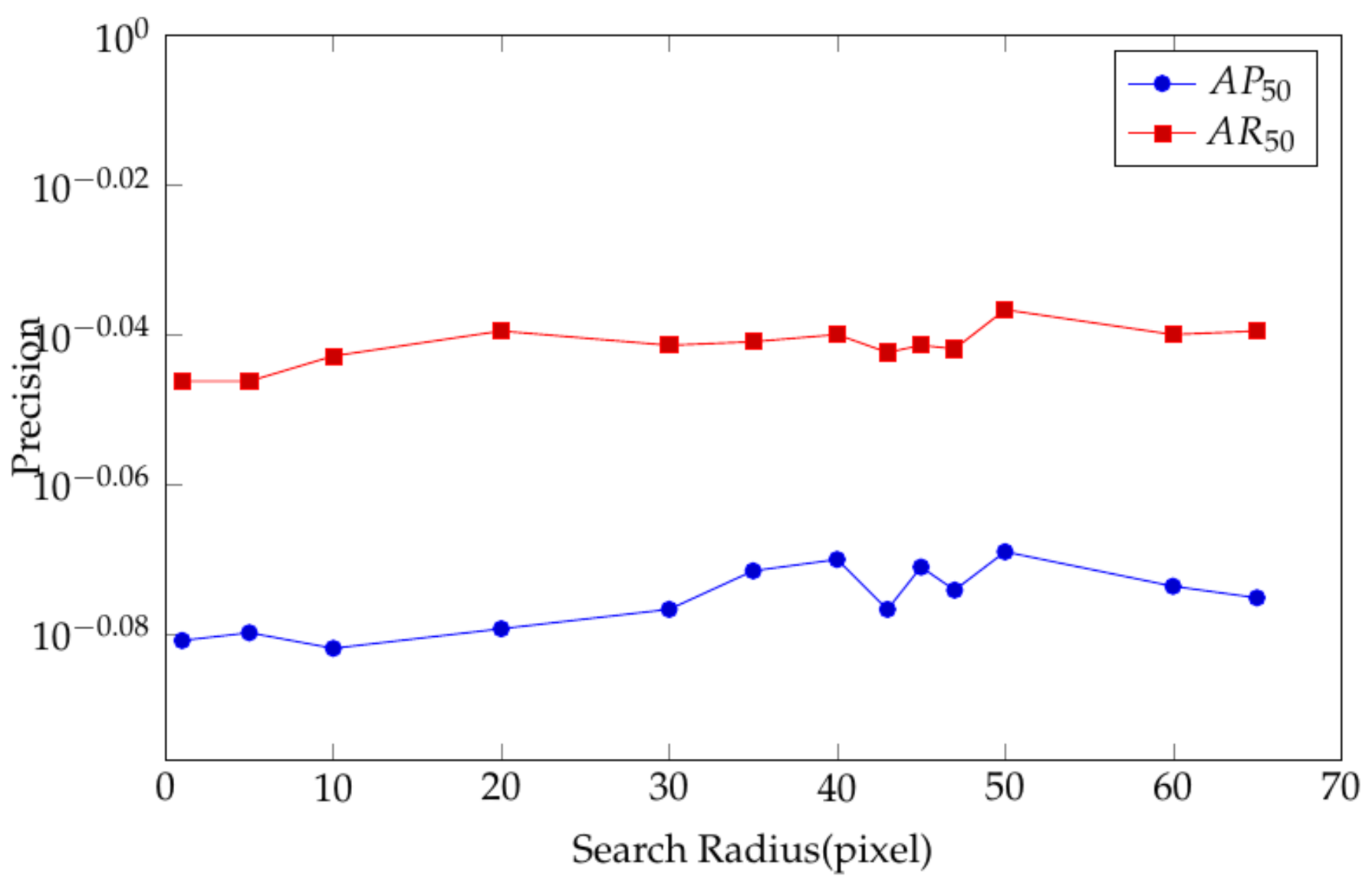
3.3. Parameter Selection and Ablation Experiment
3.4. Results
3.4.1. Performance on the Two Data Sets
3.4.2. Visualization of Results
3.5. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. SAR Image Classification Using Few-Shot Cross-Domain Transfer Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Xu, D.; Wu, Y. Improved YOLO-V3 with DenseNet for Multi-Scale Remote Sensing Target Detection. Sensors 2020, 20, 4276. [Google Scholar] [CrossRef]
- Nie, X.; Duan, M.; Ding, H.; Hu, B.; Wong, E.K. Attention Mask R-CNN for ship detection and segmentation from remote sensing images. IEEE Access 2020, 8, 9325–9334. [Google Scholar] [CrossRef]
- Yin, S.; Li, H.; Teng, L. Airport Detection Based on Improved Faster RCNN in Large Scale Remote Sensing Images. Sens. Imaging 2020, 21, 49. [Google Scholar] [CrossRef]
- Wu, L.; Ma, Y.; Fan, F.; Wu, M.; Huang, J. A Double-Neighborhood Gradient Method for Infrared Small Target Detection. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1476–1480. [Google Scholar] [CrossRef]
- Sun, X.; Huang, Q.; Jiang, L.J.; Pong, P.W.T. Overhead High-Voltage Transmission-Line Current Monitoring by Magnetoresistive Sensors and Current Source Reconstruction at Transmission Tower. IEEE Trans. Magn. 2014, 50, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Tragulnuch, P.; Kasetkasem, T.; Isshiki, T.; Chanvimaluang, T.; Ingprasert, S. High Voltage Transmission Tower Identification in an Aerial Video Sequence using Object-Based Image Classification with Geometry Information. In Proceedings of the 2018 15th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Chiang Rai, Thailand, 18–21 July 2018; pp. 473–476. [Google Scholar] [CrossRef]
- Zhao, J.; Zhao, T.; Jiang, N.Q. Power transmission tower type determining method based on aerial image analysis. In Proceedings of the CICED 2010 Proceedings, Nanjing, China, 13–16 September 2010; pp. 1–5. [Google Scholar]
- Li, Z.; Mu, S.; Li, J.; Wang, W.; Liu, Y. Transmission line intelligent inspection central control and mass data processing system and application based on UAV. In Proceedings of the 2016 4th International Conference on Applied Robotics for the Power Industry (CARPI), Jinan, China, 11–13 October 2016; pp. 1–5. [Google Scholar] [CrossRef]
- He, T.; Zeng, Y.; Hu, Z. Research of Multi-Rotor UAVs Detailed Autonomous Inspection Technology of Transmission Lines Based on Route Planning. IEEE Access 2019, 7, 114955–114965. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, X.; Liu, Y. Application of Unmanned Aerial Vehicle Hangar in Transmission Tower Inspection Considering the Risk Probabilities of Steel Towers. IEEE Access 2019, 7, 159048–159057. [Google Scholar] [CrossRef]
- Shajahan, N.M.; Kuruvila, T.; Kumar, A.S.; Davis, D. Automated Inspection of Monopole Tower Using Drones and Computer Vision. In Proceedings of the 2019 2nd International Conference on Intelligent Autonomous Systems (ICoIAS), Singapore, 28 February–2 March 2019; pp. 187–192. [Google Scholar] [CrossRef]
- Chen, D.Q.; Guo, X.H.; Huang, P.; Li, F.H. Safety Distance Analysis of 500kV Transmission Line Tower UAV Patrol Inspection. IEEE Lett. Electromagn. Compat. Pract. Appl. 2020, 2, 124–128. [Google Scholar] [CrossRef]
- IEEE Guide for Unmanned Aerial Vehicle-Based Patrol Inspection System for Transmission Lines. IEEE Std 2821-2020. [CrossRef]
- Tragulnuch, P.; Chanvimaluang, T.; Kasetkasem, T.; Ingprasert, S.; Isshiki, T. High Voltage Transmission Tower Detection and Tracking in Aerial Video Sequence using Object-Based Image Classification. In Proceedings of the 2018 International Conference on Embedded Systems and Intelligent Technology International Conference on Information and Communication Technology for Embedded Systems (ICESIT-ICICTES), Khon Kaen, Thailand, 7–9 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, H.; Yang, G.; Li, E.; Tian, Y.; Zhao, M.; Liang, Z. High-Voltage Power Transmission Tower Detection Based on Faster R-CNN and YOLO-V3. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8750–8755. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhou, X.; Liu, X.; Chen, Q.; Zhang, Z. Power Transmission Tower CFAR Detection Algorithm Based on Integrated Superpixel Window and Adaptive Statistical Model. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 2326–2329. [Google Scholar] [CrossRef]
- Wenhao, O.U.; Yang, Z.; Zhao, B.B.; Fei, X.Z.; Yang, G. Research on Automatic Extraction Technology of Power Transmission Tower Based on SAR Image and Deep Learning Technology. In Proceedings of the 2019 6th International Conference on Information Science and Control Engineering (ICISCE), Shanghai, China, 20–22 December 2019. [Google Scholar]
- Tian, G.; Meng, S.; Bai, X.; Liu, L.; Zhi, Y.; Zhao, B.; Meng, L. Research on Monitoring and Auxiliary Audit Strategy of Transmission Line Construction Progress Based on Satellite Remote Sensing and Deep Learning. In Proceedings of the 2020 2nd International Conference on Information Technology and Computer Application (ITCA), Guangzhou, China, 18–20 December 2020; pp. 73–78. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, F.; You, H.; Hu, Y. Shadow Information-Based Slender Targets Detection Method in Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2021, 1–5. [Google Scholar] [CrossRef]
- Zhang, Q.; Rao, L.; Yang, Y. Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks. arXiv 2021, arXiv:2103.13859. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2016, arXiv:1612.03144. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 2980–2988. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef] [Green Version]
- Song, G.; Liu, Y.; Wang, X. Revisiting the Sibling Head in Object Detector. arXiv 2020, arXiv:2003.07540. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–18 June 2020. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Selection | Postoperation | ||||||
|---|---|---|---|---|---|---|---|
| Shadow | Tower | Add | Concat | None | 1*1 Conv | ||
| √ | √ | 0.077 | 0.921 | ||||
| √ | √ | 0.068 | 0.881 | ||||
| √ | √ | 0.802 | 0.901 | ||||
| √ | √ | 0.821 | 0.893 | ||||
| √ | √ | 0.834 | 0.907 | ||||
| √ | √ | 0.842 | 0.913 | ||||
| √ | √ | 0.816 | 0.901 | ||||
| √ | √ | 0.853 | 0.919 | ||||
| Model | AP | AR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AVG | SD | AVG | SD | AVG | SD | AVG | SD | |||
| Faster R-CNN | 0.412 | 0.002 | 0.806 | 0.002 | 0.392 | 0.0 | 0.518 | 0.001 | 31.9 | 44.1 |
| TSD | 0.412 | 0.001 | 0.792 | 0.0 | 0.391 | 0.003 | 0.518 | 0.0 | 15.0 | 72.3 |
| ATSS | 0.397 | 0.001 | 0.776 | 0.0 | 0.377 | 0.001 | 0.528 | 0.0 | 20.2 | 32.2 |
| Retinanet | 0.432 | 0.002 | 0.821 | 0.002 | 0.393 | 0.002 | 0.549 | 0.002 | 36.1 | 36.1 |
| SI-STD | 0.313 | 0.003 | 0.770 | 0.002 | 0.170 | 0.005 | 0.448 | 0.001 | 18.1 | 35.2 |
| STC-Det | 0.449 | 0.003 | 0.852 | 0.005 | 0.424 | 0.006 | 0.536 | 0.001 | 9.8 | 55.2 |
| Model | AP | AR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| AVG | SD | AVG | SD | AVG | SD | AVG | SD | |||
| Faster R-CNN | 0.269 | 0.006 | 0.614 | 0.003 | 0.184 | 0.001 | 0.417 | 0.0 | 44.1 | 30.4 |
| TSD | 0.253 | 0.004 | 0.575 | 0.005 | 0.170 | 0.001 | 0.378 | 0.002 | 72.3 | 15.1 |
| ATSS | 0.250 | 0.002 | 0.572 | 0.003 | 0.175 | 0.002 | 0.405 | 0.001 | 32.2 | 19.7 |
| Retinanet | 0.207 | 0.003 | 0.470 | 0.006 | 0.167 | 0.003 | 0.420 | 0.001 | 36.1 | 35.9 |
| SI-STD | 0.267 | 0.007 | 0.742 | 0.023 | 0.103 | 0.021 | 0.434 | 0.002 | 35.2 | 17.4 |
| STC-Det | 0.321 | 0.007 | 0.746 | 0.006 | 0.224 | 0.018 | 0.450 | 0.007 | 55.2 | 9.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Wang, F.; You, H.; Hu, Y. STC-Det: A Slender Target Detector Combining Shadow and Target Information in Optical Satellite Images. Remote Sens. 2021, 13, 4183. https://doi.org/10.3390/rs13204183
Huang Z, Wang F, You H, Hu Y. STC-Det: A Slender Target Detector Combining Shadow and Target Information in Optical Satellite Images. Remote Sensing. 2021; 13(20):4183. https://doi.org/10.3390/rs13204183
Chicago/Turabian StyleHuang, Zhaoyang, Feng Wang, Hongjian You, and Yuxin Hu. 2021. "STC-Det: A Slender Target Detector Combining Shadow and Target Information in Optical Satellite Images" Remote Sensing 13, no. 20: 4183. https://doi.org/10.3390/rs13204183
APA StyleHuang, Z., Wang, F., You, H., & Hu, Y. (2021). STC-Det: A Slender Target Detector Combining Shadow and Target Information in Optical Satellite Images. Remote Sensing, 13(20), 4183. https://doi.org/10.3390/rs13204183