
Textured Mesh Generation Using Multi-View and Multi-Source Supervision and Generative Adversarial Networks


Abstract
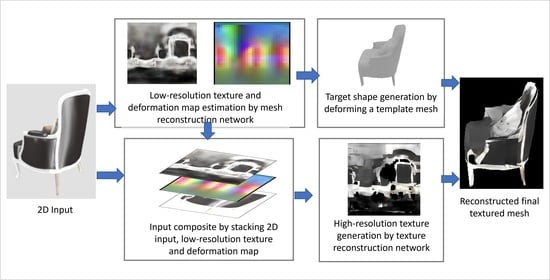
:
1. Introduction
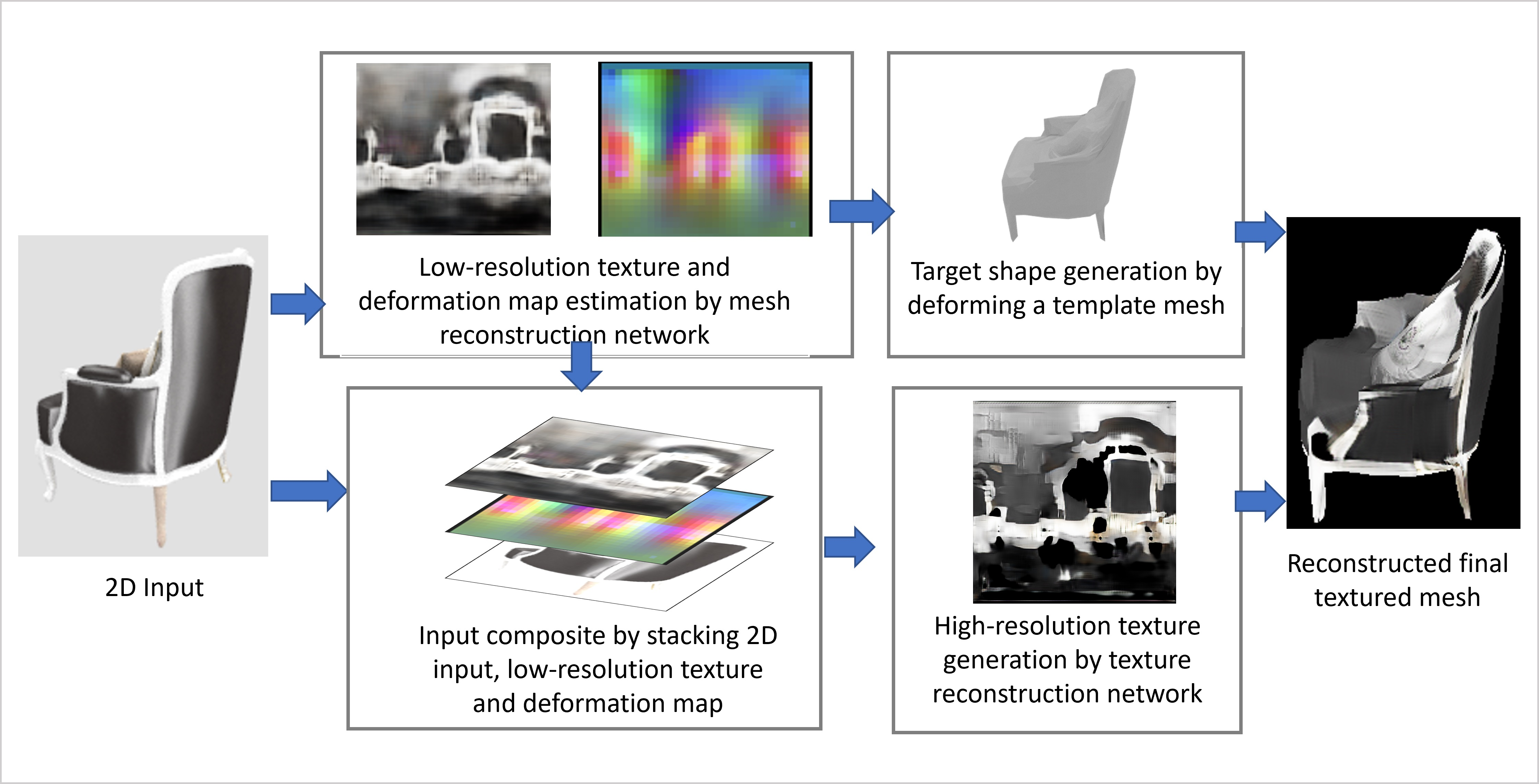
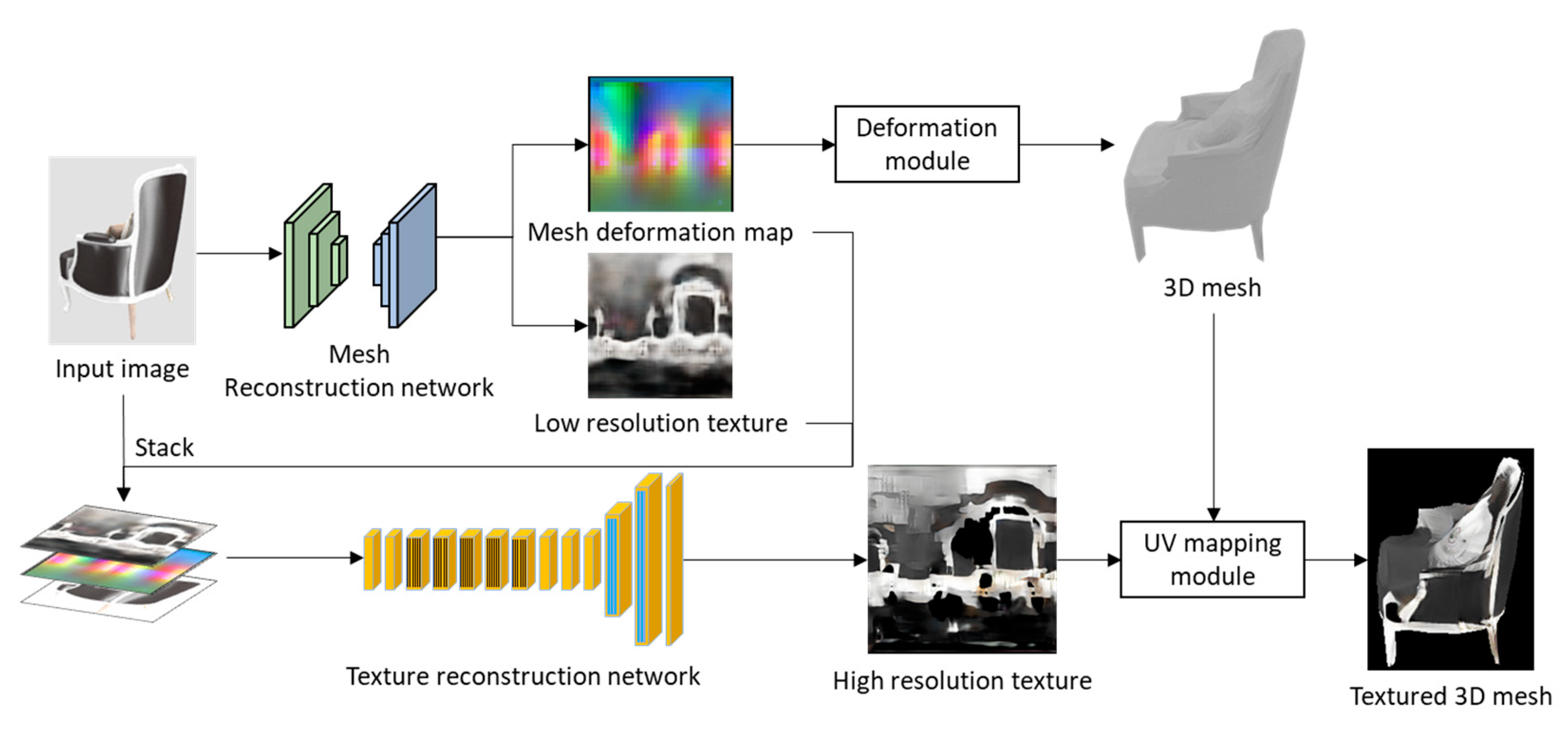
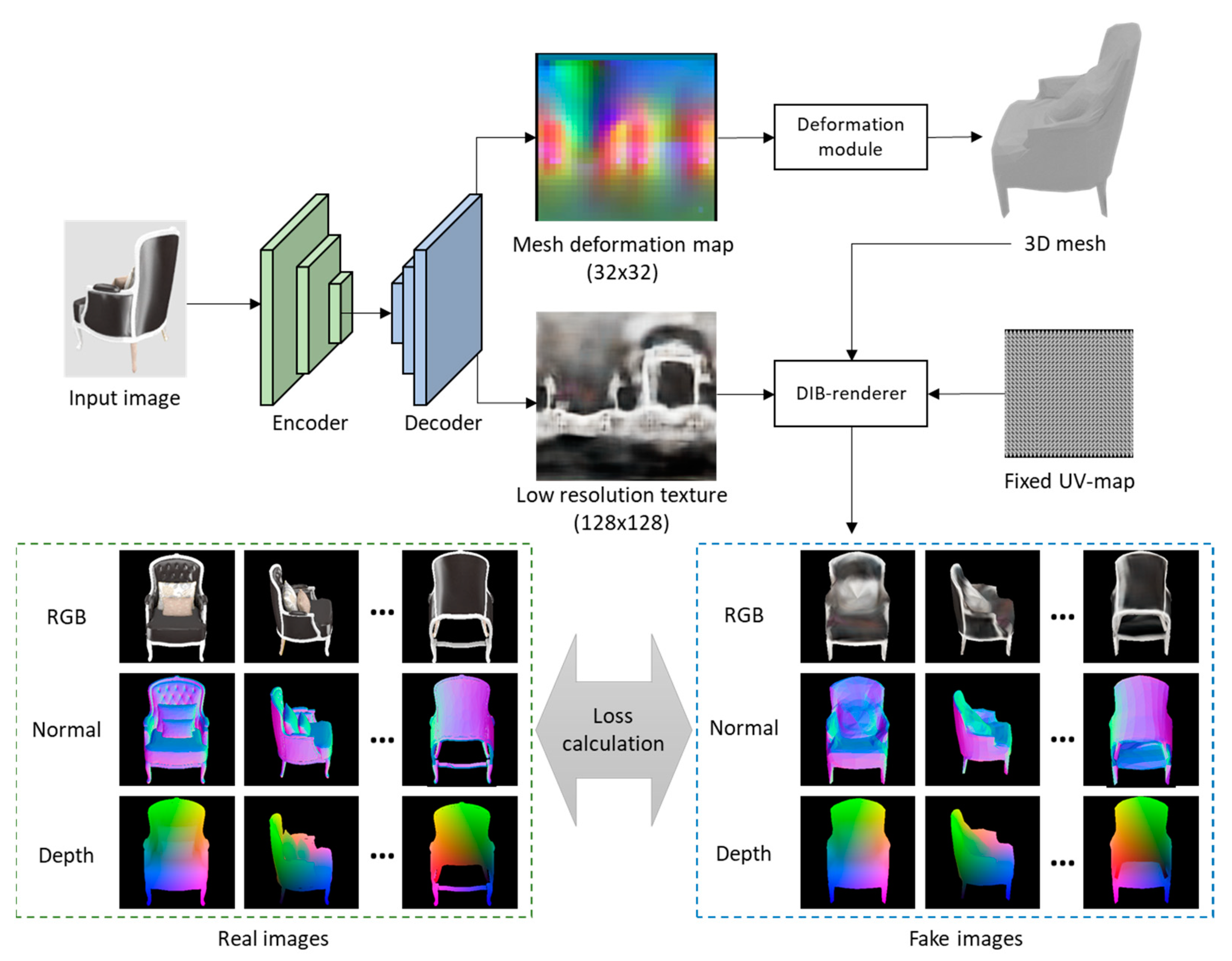
- We propose a mesh-reconstruction method based on multi-view and multi-source supervision. We leverage the differentiable rendering technique to render multi-view RGB, depth, and normal images as the ground truth. This approach enables the network to achieve increasingly robust supervision during the training process, and thus, the network can be used to generate a highly accurate deformation map for deforming the template mesh.
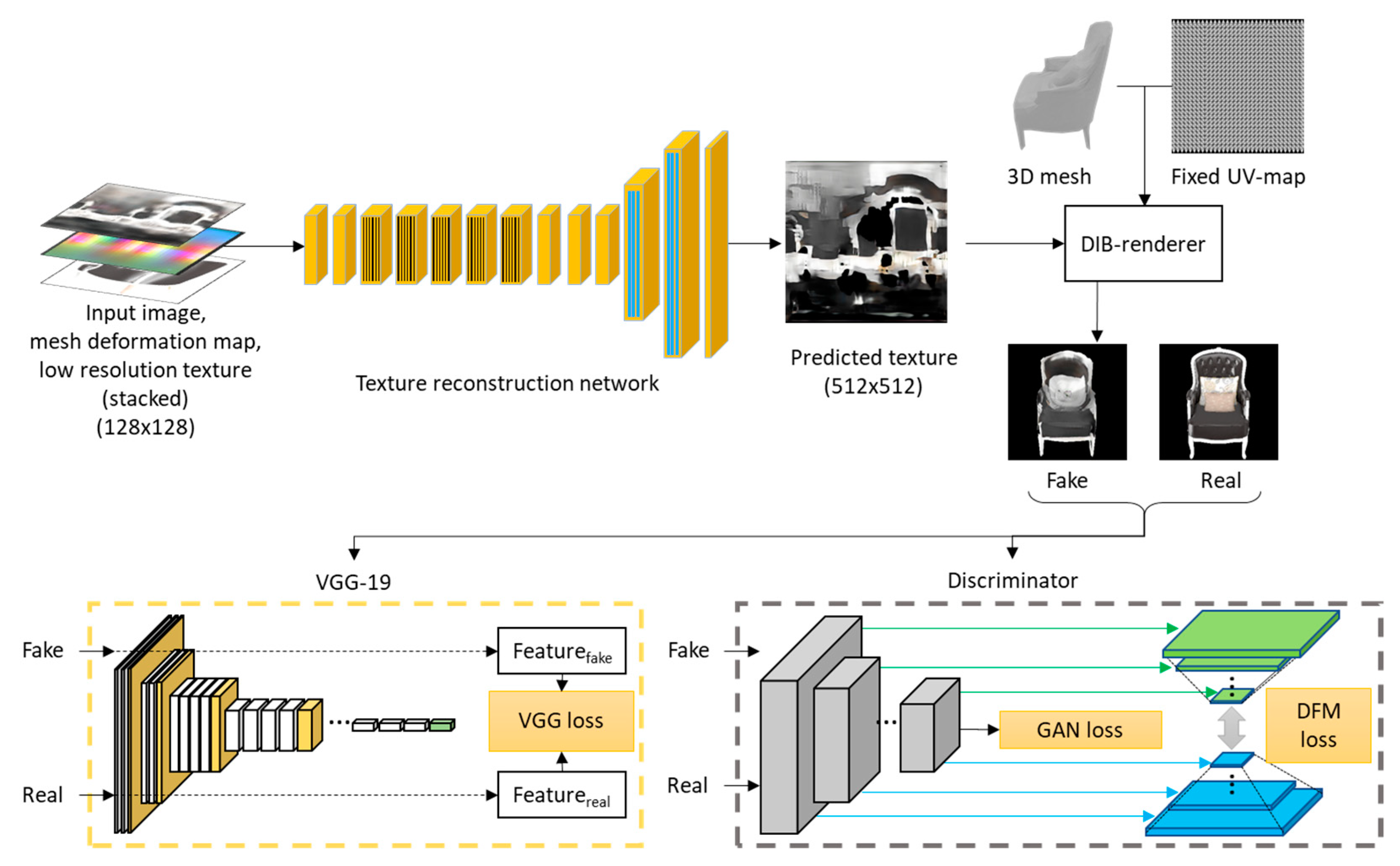
- We propose a high-resolution texture-reconstruction method, which relies on a super-resolution-based GAN. We also propose the use of the super-resolution method to enhance low-resolution textures, obtained through our proposed mesh-reconstruction network. Specifically, to ensure that the network determines the correlation among the texture, the deformation map, and the input RGB image, we stacked the low-resolution texture and the deformation map obtained using the mesh-reconstruction network, as well as the input image, channel-wise, as the input of the texture-reconstruction network. Thus, the network enhances the texture by considering the global texture information obtained from the low-resolution texture, the mesh topology obtained from the mesh deformation map, and the high-frequency texture information obtained from the input RGB image.
2. Related Works
2.1. Mesh Reconstruction
2.2. Texture Reconstruction
3. Proposed Methods for Generating Textured Meshes
3.1. Mesh Reconstruction Network Based on Multi-View and Multi-Source Supervision
3.2. Texture Reconstruction Network Based on Super-Resolution
4. Experimental Results and Evaluation
4.1. Dataset Processing for the Training and Evaluation of the Mesh-Reconstruction Network
4.2. Experimental Results of Mesh Reconstruction
4.3. Dataset Generation for Texture Reconstruction
4.4. Experimental Results of Texture Generation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sun, Y.; Liu, Z.; Wang, Y.; Sarma, S.E. Im2avatar: Colorful 3d reconstruction from a single image. arXiv 2018, arXiv:1804.06375. [Google Scholar]
- Tulsiani, S.; Zhou, T.; Efros, A.A.; Malik, J. Multi-view supervision for single-view reconstruction via differentiable ray consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2626–2634. [Google Scholar]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4460–4470. [Google Scholar]
- Oechsle, M.; Mescheder, L.; Niemeyer, M.; Strauss, T.; Geiger, A. Texture fields: Learning texture representations in function space. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 4531–4540. [Google Scholar]
- Alldieck, T.; Pons-Moll, G.; Theobalt, C.; Magnor, M. Tex2shape: Detailed full human body geometry from a single image. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 2293–2303. [Google Scholar]
- Novotny, D.; Shapovalov, R.; Vedaldi, A. Canonical 3D Deformer Maps: Unifying Parametric and Non-Parametric Methods for Dense Weakly-Supervised Category Reconstruction. In Advances in Neural Information Processing Systems, Proceedings of the 34th Conference on Neural Information Processing Systems, Online Event, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2020; Volume 33, pp. 20901–20912. [Google Scholar]
- Pavllo, D.; Spinks, G.; Hofmann, T.; Moens, M.F.; Lucchi, A. Convolutional Generation of Textured 3D Meshes. In Advances in Neural Information Processing Systems, Proceedings of the 34th Conference on Neural Information Processing Systems, Online Event, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2020; Volume 33, pp. 870–882. [Google Scholar]
- Kanazawa, A.; Tulsiani, S.; Efros, A.A.; Malik, J. Learning category-specific mesh reconstruction from image collections. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 371–386. [Google Scholar]
- Hong, D.; Gao, L.; Yokoya, N.; Yao, J.; Chanussot, J.; Du, Q.; Zhang, B. More diverse means better: Multimodal deep learningmeets remote-sensing imagery classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4340–4354. [Google Scholar] [CrossRef]
- Zhou, X.; Gan, Y.; Xiong, J.; Zhang, D.; Zhao, Q.; Xia, Z. A method for tooth model reconstruction based on integration of multimodal images. J. Healthc. Eng. 2018, 2018, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Pontes, J.K.; Kong, C.; Sridharan, S.; Lucey, S.; Eriksson, A.; Fookes, C. Image2mesh: A Learning Framework for Single Image 3d Reconstruction. In Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 365–381. [Google Scholar]
- Wu, J.; Wang, Y.; Xue, T.; Sun, X.; Freeman, W.T.; Tenenbaum, J. MarrNet: 3D Shape Reconstruction via 2.5D Sketches. In Advances in Neural Information Processing Systems, Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Long Beach, CA, USA, 2017; Volume 30, pp. 540–550. [Google Scholar]
- Kato, H.; Ushiku, Y.; Harada, T. Neural 3d mesh renderer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3907–3916. [Google Scholar]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. A papier-mâché approach to learning 3d surface generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 216–224. [Google Scholar]
- Pan, J.; Han, X.; Chen, W.; Tang, J.; Jia, K. Deep mesh reconstruction from single rgb images via topology modification networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 9964–9973. [Google Scholar]
- Zhu, J.; Xie, J.; Fang, Y. Learning adversarial 3d model generation with 2d image enhancer. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7615–7622. [Google Scholar]
- Xu, Q.; Wang, W.; Ceylan, D.; Mech, R.; Neumann, U. DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction. In Advances in Neural Information Processing Systems, Proceedings of the 33st Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2019; Volume 32, pp. 492–502. [Google Scholar]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. ACM Siggraph Comput. Graph. 1987, 21, 163–169. [Google Scholar] [CrossRef]
- Saito, S.; Huang, Z.; Natsume, R.; Morishima, S.; Kanazawa, A.; Li, H. Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 2304–2314. [Google Scholar]
- Chen, W.; Ling, H.; Gao, J.; Smith, E.; Lehtinen, J.; Jacobson, A.; Fidler, S. Learning to predict 3d objects with an interpolation-based differentiable renderer. Adv. Neural Inf. Process. Syst. 2019, 32, 9609–9619. [Google Scholar]
- Henderson, P.; Tsiminaki, V.; Lampert, C.H. Leveraging 2d data to learn textured 3d mesh generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7498–7507. [Google Scholar]
- Deng, J.; Cheng, S.; Xue, N.; Zhou, Y.; Zafeiriou, S. Uv-gan: Adversarial facial UV map completion for pose-invariant face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7093–7102. [Google Scholar]
- Saito, S.; Wei, L.; Hu, L.; Nagano, K.; Li, H. Photorealistic facial texture inference using deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5144–5153. [Google Scholar]
- Park, E.; Yang, J.; Yumer, E.; Ceylan, D.; Berg, A.C. Transformation-grounded image generation network for novel 3d view synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3500–3509. [Google Scholar]
- Rematas, K.; Nguyen, C.H.; Ritschel, T.; Fritz, M.; Tuytelaars, T. Novel views of objects from a single image. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1576–1590. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Tulsiani, S.; Sun, W.; Malik, J.; Efros, A.A. View Synthesis by Appearance Flow. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 286–301. [Google Scholar]
- Liu, S.; Li, T.; Chen, W.; Li, H. Soft rasterizer: A differentiable renderer for image-based 3d reasoning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 7708–7717. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Dosovitskiy, A.; Brox, T. Generating images with perceptual similarity metrics based on deep networks. In Advances in Neural Information Processing Systems, Proceedings of the 30st Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Barcelona, Spain, 2016; Volume 29, pp. 658–666. [Google Scholar]
- Fu, H.; Jia, R.; Gao, L.; Gong, M.; Zhao, B.; Maybank, S.; Tao, D. 3D-FUTURE: 3D Furniture shape with TextURE. arXiv 2020, arXiv:2009.09633. [Google Scholar]
- The Blender Foundation. Available online: https://www.blender.org/ (accessed on 5 August 2021).
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. Caltech-UCSD Birds 200; Technical Report CNS-TR-2010-001; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- Xiang, Y.; Mottaghi, R.; Savarese, S. Beyond pascal: A benchmark for 3d object detection in the wild. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; pp. 75–82. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems, Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Long Beach, CA, USA, 2017; Volume 30, pp. 6629–6640. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Nie, Y.; Han, X.; Guo, S.; Zheng, Y.; Chang, J.; Zhang, J.J. Total3dunderstanding: Joint layout, object pose and mesh reconstruction for indoor scenes from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 55–64. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category/Method | CD (×10−3) | Mean F-Score (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| OccNet | SV (Convmesh) | Ours (SVMS) | Ours (MVMS) | OccNet | SV (Convmesh) | Ours (SVMS) | Ours (MVMS) | |
| Children Cabinet | 158.11 | 26.74 | 7.54 | 6.28 | 31.49 | 72.43 | 92.91 | 94.90 |
| Nightstand | 131.17 | 32.88 | 17.34 | 13.82 | 30.51 | 73.31 | 86.43 | 89.15 |
| Bookcase | 219.01 | 14.84 | 10.25 | 10.53 | 30.28 | 83.82 | 88.64 | 90.80 |
| Wardrobe | 167.27 | 17.94 | 7.17 | 6.40 | 31.67 | 82.97 | 94.06 | 95.38 |
| Coffee Table | 129.96 | 47.92 | 26.34 | 17.82 | 35.60 | 60.27 | 79.02 | 85.76 |
| Corner/Side Table | 149.49 | 107.50 | 64.38 | 42.22 | 33.52 | 55.41 | 75.65 | 81.21 |
| Side Cabinet | 262.03 | 17.32 | 9.28 | 6.46 | 24.61 | 80.82 | 91.64 | 94.74 |
| Wine Cabinet | 224.54 | 11.51 | 6.52 | 6.68 | 29.70 | 87.83 | 93.64 | 94.23 |
| TV Stand | 258.91 | 8.93 | 5.25 | 3.70 | 26.17 | 88.59 | 95.91 | 97.30 |
| Drawer Chest | 179.88 | 17.7577 | 8.45 | 6.90 | 31.43 | 80.29 | 92.69 | 95.01 |
| Shelf | 164.90 | 33.04 | 28.88 | 12.53 | 30.02 | 73.90 | 78.65 | 86.36 |
| Round End Table | 65.35 | 51.40 | 36.40 | 17.38 | 49.32 | 55.13 | 73.96 | 80.90 |
| Double/Queen/King Bed | 88.11 | 25.12 | 14.72 | 13.67 | 45.17 | 71.63 | 83.68 | 86.71 |
| Bunk Bed | 165.46 | 42.38 | 27.44 | 25.56 | 29.27 | 59.71 | 65.54 | 68.69 |
| Bed Frame | 129.69 | 56.34 | 30.11 | 66.19 | 44.38 | 65.18 | 87.20 | 71.93 |
| Single Bed | 99.20 | 18.08 | 12.23 | 10.06 | 44.45 | 78.25 | 85.97 | 90.11 |
| Kid’s Bed | 160.13 | 29.81 | 22.02 | 16.64 | 33.46 | 66.44 | 76.27 | 81.29 |
| Dining Chair | 122.08 | 34.36 | 14.35 | 18.27 | 45.18 | 77.75 | 89.13 | 85.66 |
| Lounge/Office Chair | 122.59 | 41.81 | 19.42 | 12.64 | 40.94 | 66.37 | 81.31 | 89.15 |
| Dressing Chair | 182.86 | 45.69 | 30.28 | 25.85 | 29.50 | 58.51 | 70.59 | 75.39 |
| Classical Chinese Chair | 80.71 | 37.06 | 33.02 | 22.11 | 49.01 | 72.55 | 74.37 | 78.69 |
| Barstool | 96.35 | 79.20 | 38.93 | 30.71 | 41.42 | 63.62 | 82.81 | 79.90 |
| Dressing Table | 238.09 | 68.22 | 18.82 | 8.74 | 21.83 | 51.00 | 84.35 | 93.53 |
| Dining Table | 181.60 | 80.11 | 37.84 | 18.97 | 30.38 | 47.01 | 73.44 | 89.57 |
| Desk | 270.61 | 68.27 | 31.71 | 12.43 | 22.30 | 51.68 | 76.69 | 88.99 |
| Three-Seat Sofa | 198.80 | 10.91 | 7.86 | 6.50 | 31.85 | 84.34 | 89.81 | 92.80 |
| Armchair | 105.91 | 29.48 | 17.44 | 12.44 | 39.53 | 68.24 | 81.47 | 89.15 |
| Loveseat Sofa | 191.80 | 12.69 | 9.40 | 7.58 | 29.97 | 82.65 | 88.35 | 91.76 |
| L-shaped Sofa | 176.48 | 12.90 | 10.27 | 9.60 | 34.34 | 85.10 | 90.79 | 93.23 |
| Lazy Sofa | 120.35 | 19.18 | 11.44 | 7.27 | 35.99 | 81.42 | 89.44 | 95.37 |
| Chaise Longue Sofa | 157.61 | 14.07 | 10.46 | 7.80 | 37.25 | 79.47 | 87.07 | 91.81 |
| Stool | 125.78 | 29.02 | 19.46 | 16.32 | 33.90 | 78.58 | 88.81 | 91.87 |
| Pendant Lamp | 169.55 | 81.31 | 73.23 | 60.29 | 34.49 | 58.88 | 58.44 | 64.75 |
| Ceiling Lamp | 102.73 | 29.27 | 22.18 | 20.18 | 40.50 | 75.39 | 79.76 | 82.55 |
| Mean | 159.57 | 38.13 | 23.12 | 18.11 | 34.56 | 71.57 | 83.35 | 87.50 |
| Method | FID |
|---|---|
| Mesh reconstruction (ours) 1 | 85.39 |
| Convmesh | 77.28 |
| Texture super-resolution (ours) | 58.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wen, M.; Park, J.; Cho, K. Textured Mesh Generation Using Multi-View and Multi-Source Supervision and Generative Adversarial Networks. Remote Sens. 2021, 13, 4254. https://doi.org/10.3390/rs13214254
Wen M, Park J, Cho K. Textured Mesh Generation Using Multi-View and Multi-Source Supervision and Generative Adversarial Networks. Remote Sensing. 2021; 13(21):4254. https://doi.org/10.3390/rs13214254
Chicago/Turabian StyleWen, Mingyun, Jisun Park, and Kyungeun Cho. 2021. "Textured Mesh Generation Using Multi-View and Multi-Source Supervision and Generative Adversarial Networks" Remote Sensing 13, no. 21: 4254. https://doi.org/10.3390/rs13214254
APA StyleWen, M., Park, J., & Cho, K. (2021). Textured Mesh Generation Using Multi-View and Multi-Source Supervision and Generative Adversarial Networks. Remote Sensing, 13(21), 4254. https://doi.org/10.3390/rs13214254