
Improving the Accuracy of Land Cover Mapping by Distributing Training Samples

 ,
, 

Abstract
:
1. Introduction
2. Study Area and Data
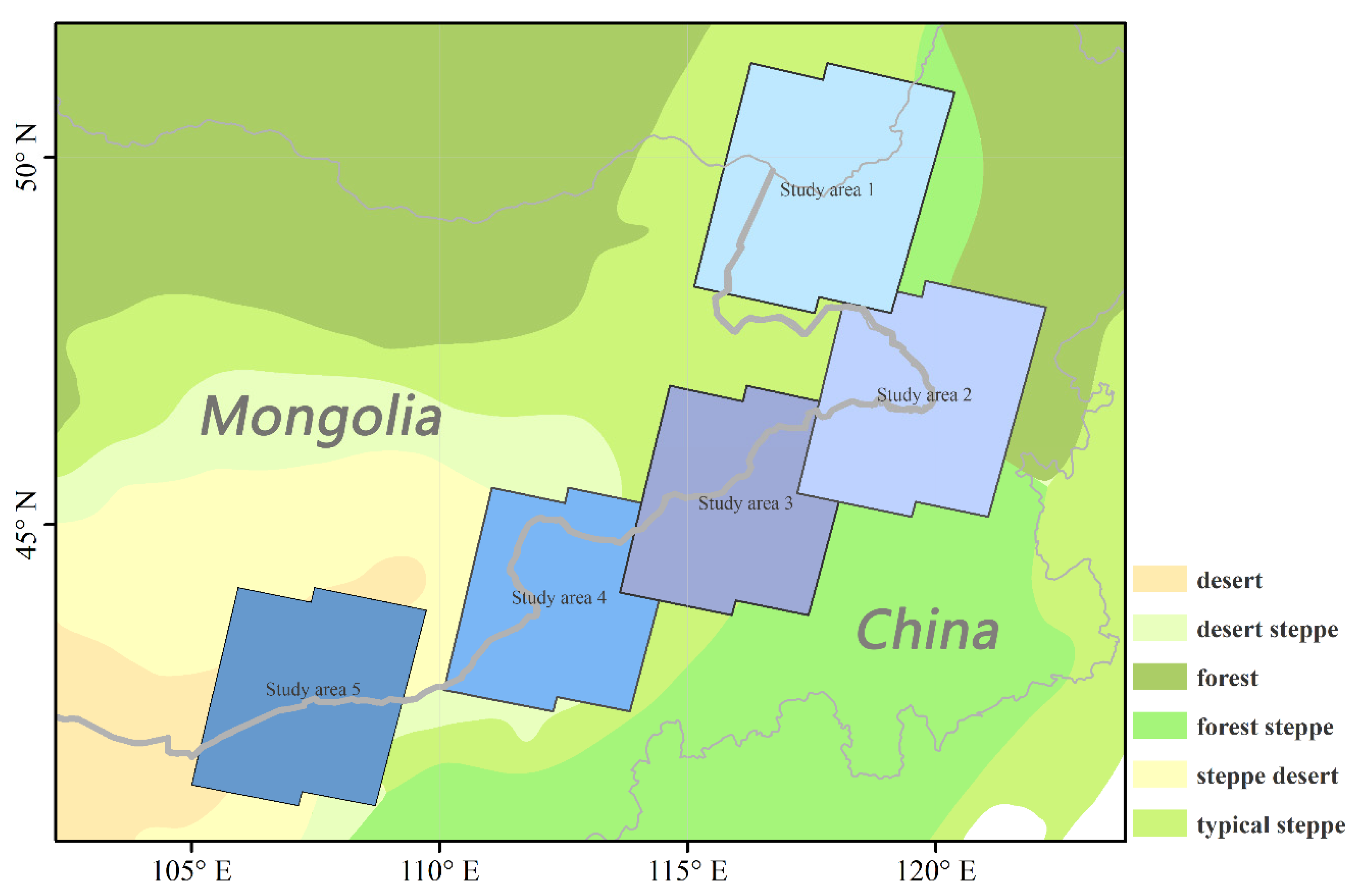
2.1. Study Area
2.2. Data
3. Methods
3.1. Classification Scheme
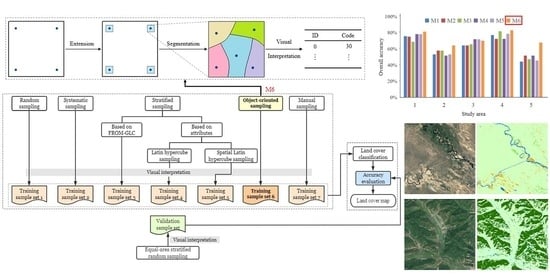
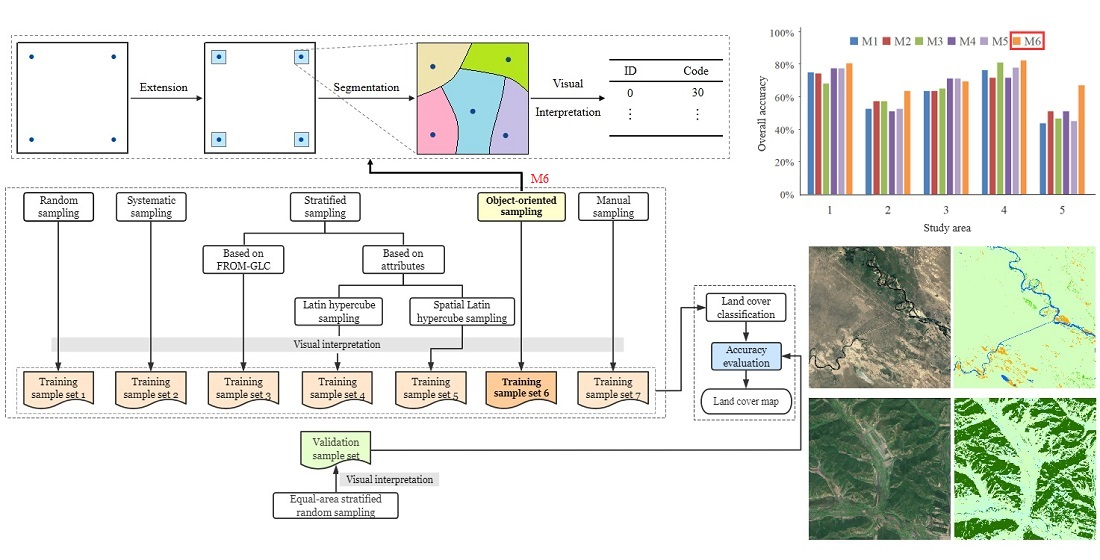
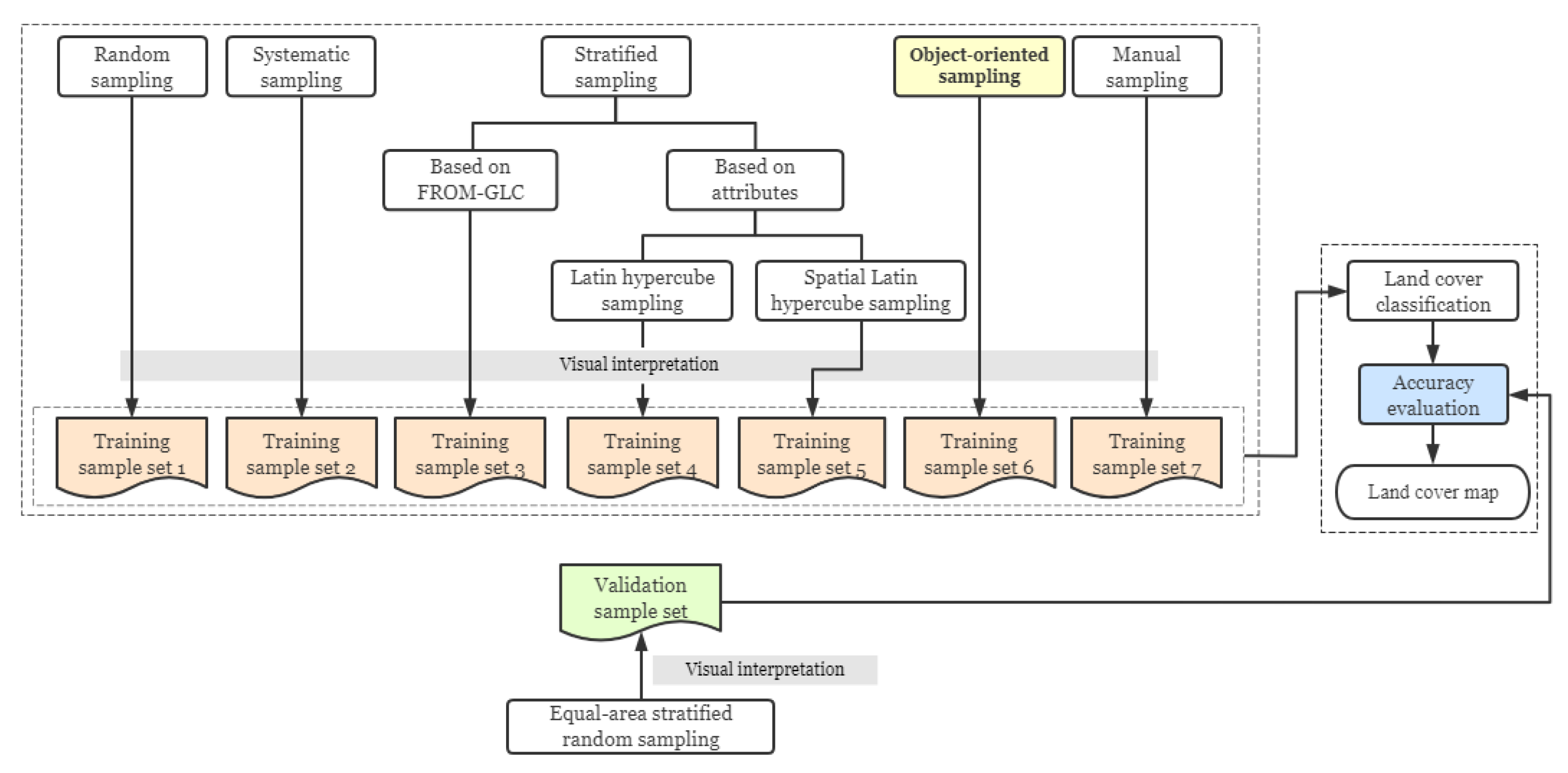
3.2. Training Sample Distribution Strategies
3.2.1. Traditional Probability Sampling
3.2.2. Stratified Sampling
3.2.3. Object-Oriented Sampling by Segmenting Image Blocks Expanded from Systematically Distributed Seeds (Object-Oriented Sampling)
3.2.4. Manual Sampling
3.3. Visual Interpretation
3.4. Classification
3.5. Diversity Evaluation
3.6. Accuracy Assessment
4. Results
4.1. Sample Diversity
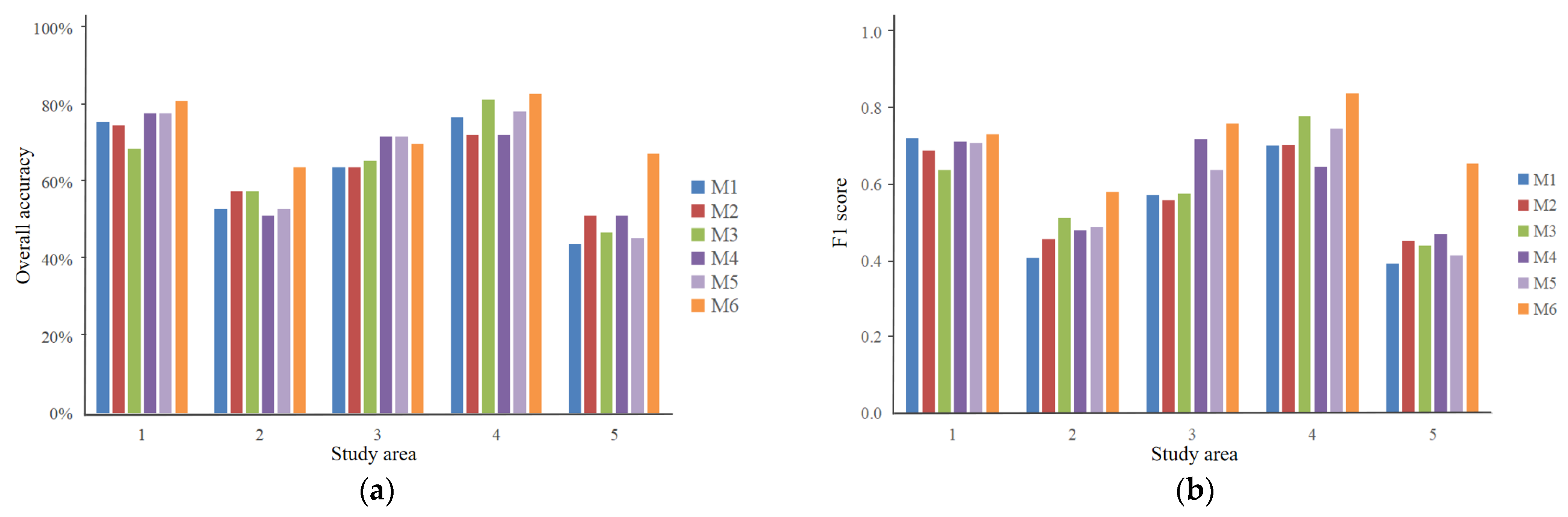
4.2. Classification Accuracy
5. Discussions
5.1. Advantages and Disadvantages of Each Sampling Method
5.2. Influence of Sample Quality and Sample Size
6. Conclusions and Perspectives
Author Contributions
Funding
Conflicts of Interest
References
- Baudoux, L.; Inglada, J.; Mallet, C. Toward a yearly country-scale CORINE land-cover map without using images: A map translation approach. Remote Sens. 2021, 13, 1060. [Google Scholar] [CrossRef]
- Das, N.; Mondal, P.; Sutradhar, S.; Ghosh, R. Assessment of variation of land use/land cover and its impact on land surface temperature of Asansol subdivision. Egypt. J. Remote Sens. Space Sci. 2021, 24, 131–149. [Google Scholar] [CrossRef]
- Ngo, K.D.; Lechner, A.M.; Vu, T.T. Land cover mapping of the Mekong Delta to support natural resource management with multi-temporal Sentinel-1A synthetic aperture radar imagery. Remote Sens. Appl. Soc. Environ. 2020, 17, 100272. [Google Scholar] [CrossRef]
- Panteras, G.; Cervone, G. Enhancing the temporal resolution of satellite-based flood extent generation using crowdsourced data for disaster monitoring. Int. J. Remote Sens. 2018, 39, 1459–1474. [Google Scholar] [CrossRef]
- Chen, C.Y.; Chen, H.W.; Sun, C.T.; Chuang, Y.H.; Nguyen, K.L.P.; Lin, Y.T. Impact assessment of river dust on regional air quality through integrated remote sensing and air quality modeling. Sci. Total Environ. 2021, 755, 142621. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, J. Research on the factors affecting the classification accuracy of ETM remote sensing image land cover/use. Remote Sens. Tech. Appl. 2012, 27, 600–608. [Google Scholar]
- Priyadarshini, K.N.; Kumar, M.; Rahaman, S.A.; Nitheshnirmal, S. A Comparative Study of Advanced Land Use/Land Cover Classification Algorithms Using Sentinel-2 Data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII–5, 665–670. [Google Scholar] [CrossRef] [Green Version]
- Talukdar, S.; Singha, P.; Mahato, S.; Pal, S.; Liou, Y.A.; Rahman, A. Land-use land-cover classification by machine learning classifiers for satellite observations—A review. Remote Sens. 2020, 12, 1135. [Google Scholar] [CrossRef] [Green Version]
- Jia, K.; Liang, S.; Wei, X.; Yao, Y.; Su, Y.; Jiang, B.; Wang, X. Land cover classification of landsat data with phenological features extracted from time series MODIS NDVI data. Remote Sens. 2014, 6, 11518–11532. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Gallant, A.L.; Woodcock, C.E.; Pengra, B.; Olofsson, P.; Loveland, T.R.; Jin, S.; Dahal, D.; Yang, L.; Auch, R.F. Optimizing selection of training and auxiliary data for operational land cover classification for the LCMAP initiative. ISPRS J. Photogramm. Remote Sens. 2016, 122, 206–221. [Google Scholar] [CrossRef] [Green Version]
- Pflugmacher, D.; Rabe, A.; Peters, M.; Hostert, P. Mapping pan-European land cover using Landsat spectral-temporal metrics and the European LUCAS survey. Remote Sens. Environ. 2019, 221, 583–595. [Google Scholar] [CrossRef]
- Foody, G.M.; Arora, M.K. An evaluation of some factors affecting the accuracy of classification by an artificial neural network. Int. J. Remote Sens. 1997, 18, 799–810. [Google Scholar] [CrossRef]
- Li, C.; Wang, J.; Wang, L.; Hu, L.; Gong, P. Comparison of classification algorithms and training sample sizes in urban land classification with landsat thematic mapper imagery. Remote Sens. 2014, 6, 964–983. [Google Scholar] [CrossRef] [Green Version]
- Persello, C.; Bruzzone, L. Active and semisupervised learning for the classification of remote sensing images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6937–6956. [Google Scholar] [CrossRef]
- Ghorbanian, A.; Kakooei, M.; Amani, M.; Mahdavi, S.; Mohammadzadeh, A.; Hasanlou, M. Improved land cover map of Iran using Sentinel imagery within Google Earth Engine and a novel automatic workflow for land cover classification using migrated training samples. ISPRS J. Photogramm. Remote Sens. 2020, 167, 276–288. [Google Scholar] [CrossRef]
- Huang, H.; Wang, J.; Liu, C.; Liang, L.; Li, C.; Gong, P. The migration of training samples towards dynamic global land cover mapping. ISPRS J. Photogramm. Remote Sens. 2020, 161, 27–36. [Google Scholar] [CrossRef]
- Mountrakis, G.; Xi, B. Assessing reference dataset representativeness through confidence metrics based on information density. ISPRS J. Photogramm. Remote Sens. 2013, 78, 129–147. [Google Scholar] [CrossRef]
- Ateishi, R.T.; Yush, J.T.S.; Har, M.A.G.; Ilbisi, H.A.L.; Katani, T.O. Sampling Methods for Validation of Large Area Land Cover Mapping. J. Remote Sens. Soc. Japan 2007, 27, 195–204. [Google Scholar] [CrossRef]
- Colditz, R.R. An evaluation of different training sample allocation schemes for discrete and continuous land cover classification using decision tree-based algorithms. Remote Sens. 2015, 7, 9655–9681. [Google Scholar] [CrossRef] [Green Version]
- Jin, H.; Stehman, S.V.; Mountrakis, G. Assessing the impact of training sample selection on accuracy of an urban classification: A case study in Denver, Colorado. Int. J. Remote Sens. 2014, 35, 2067–2081. [Google Scholar] [CrossRef]
- Pagliarella, M.C.; Corona, P.; Fattorini, L. Spatially-balanced sampling versus unbalanced stratified sampling for assessing forest change: Evidences in favour of spatial balance. Environ. Ecol. Stat. 2018, 25, 111–123. [Google Scholar] [CrossRef]
- Lu, Q.; Ma, Y.; Xia, G.S. Active learning for training sample selection in remote sensing image classification using spatial information. Remote Sens. Lett. 2017, 8, 1210–1219. [Google Scholar] [CrossRef]
- Tuia, D.; Ratle, F.; Pacifici, F.; Kanevski, M.F.; Emery, W.J. Active learning methods for remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2218–2232. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey. Mach. Learn. 2010, 15, 201–221. [Google Scholar]
- Li, B.; Yong, S.; Zeng, S. The principle, method, and application of ecological regionalization—Explanation of the ecological regionalization map of the Inner Mongolia Autonomous Region. Chinese J. Plant Ecol. 1990, 14, 55–62. [Google Scholar]
- Amani, M.; Ghorbanian, A.; Ahmadi, S.A.; Kakooei, M.; Moghimi, A.; Mirmazloumi, S.M.; Moghaddam, S.H.A.; Mahdavi, S.; Ghahremanloo, M.; Parsian, S.; et al. Google Earth Engine Cloud Computing Platform for Remote Sensing Big Data Applications: A Comprehensive Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5326–5350. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Wang, J. Spatial sampling model for geographic data. Prog. Nat. Sci. 2002, 12, 99–102. [Google Scholar]
- Wang, J.F.; Stein, A.; Gao, B.B.; Ge, Y. A review of spatial sampling. Spat. Stat. 2012, 2, 1–14. [Google Scholar] [CrossRef]
- Lesiv, M.; See, L.; Bayas, J.C.L.; Sturn, T.; Schepaschenko, D.; Karner, M.; Moorthy, I.; McCallum, I.; Fritz, S. Characterizing the spatial and temporal availability of very high resolution satellite imagery in Google Earth and Microsoft Bing Maps as a source of reference data. Land 2018, 7, 118. [Google Scholar] [CrossRef] [Green Version]
- Schepaschenko, D.; See, L.; Lesiv, M.; Bastin, J.F.; Mollicone, D.; Tsendbazar, N.E.; Bastin, L.; McCallum, I.; Laso Bayas, J.C.; Baklanov, A.; et al. Recent Advances in Forest Observation with Visual Interpretation of Very High-Resolution Imagery. Surv. Geophys. 2019, 40, 839–862. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Feng, D.; Jayaraman, D.; Belay, D.; Sebrala, H.; Ngugi, J.; Maina, E.; Akombo, R.; Otuoma, J.; Mutyaba, J.; et al. Bamboo mapping of Ethiopia, Kenya and Uganda for the year 2016 using multi-temporal Landsat imagery. Int. J. Appl. Earth Obs. Geoinf. 2018, 66, 116–125. [Google Scholar] [CrossRef]
- Zhao, Y.; Feng, D.; Yu, L.; Wang, X.; Chen, Y.; Bai, Y.; Hernández, H.J.; Galleguillos, M.; Estades, C.; Biging, G.S.; et al. Detailed dynamic land cover mapping of Chile: Accuracy improvement by integrating multi-temporal data. Remote Sens. Environ. 2016, 183, 170–185. [Google Scholar] [CrossRef]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Yu, X.; Lu, D.; Jiang, X.; Li, G.; Chen, Y.; Li, D.; Chen, E. Examining the roles of spectral, spatial, and topographic features in improving land-cover and forest classifications in a subtropical region. Remote Sens. 2020, 12, 2907. [Google Scholar] [CrossRef]
- Rujoiu-Mare, M.R.; Olariu, B.; Mihai, B.A.; Nistor, C.; Săvulescu, I. Land cover classification in Romanian Carpathians and Subcarpathians using multi-date Sentinel-2 remote sensing imagery. Eur. J. Remote Sens. 2017, 50, 496–508. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Feng, D.; Yu, L.; Cheng, Y.; Zhang, M.; Liu, X.; Xu, Y.; Fang, L.; Zhu, Z.; Gong, P. Long-term land cover dynamics (1986–2016) of Northeast China derived from a multi-temporal landsat archive. Remote Sens. 2019, 11, 599. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Huang, B.; Xu, B. Multi-source remotely sensed data fusion for improving land cover classification. ISPRS J. Photogramm. Remote Sens. 2017, 124, 27–39. [Google Scholar] [CrossRef]
- Hurskainen, P.; Adhikari, H.; Siljander, M.; Pellikka, P.K.E.; Hemp, A. Auxiliary datasets improve accuracy of object-based land use/land cover classification in heterogeneous savanna landscapes. Remote Sens. Environ. 2019, 233, 111354. [Google Scholar] [CrossRef]
- Breiman, L. Random Forest. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Zhao, Y.; Gong, P.; Yu, L.; Hu, L.; Li, X.; Li, C.; Zhang, H.; Zheng, Y.; Wang, J.; Zhao, Y.; et al. Towards a common validation sample set for global land-cover mapping. Int. J. Remote Sens. 2014, 35, 4795–4814. [Google Scholar] [CrossRef]
- Cao, Z.; Wang, J.; Li, L.; Jiang, C. Strata Efficiency and Optimization strategy of Stratified Sampling on Spatial Population. Prog. Geogr. 2008, 27, 152–160. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data/Product | Source | Resolution |
|---|---|---|
| Elevation | https://www.worldclim.org/ (accessed on 10 May 2021) | 30 s |
| Average temperature | 30 s | |
| Precipitation | 30 s | |
| Bioclimatic variables | 30 s | |
| MOD13Q1 | https://modis.gsfc.nasa.gov/ (accessed on 10 May 2021) | 250 m |
| MCD12Q1 | 500 m |
| Name | Description | Resolution (m) |
|---|---|---|
| Band1 | Aerosols | 60 |
| Band2 | Blue | 10 |
| Band3 | Green | 10 |
| Band4 | Red | 10 |
| Band5 | Red Edge 1 | 20 |
| Band6 | Red Edge 2 | 20 |
| Band7 | Red Edge 3 | 20 |
| Band8 | NIR | 10 |
| Band8A | Red Edge 4 | 20 |
| Band9 | Water Vapor | 60 |
| Band11 | SWIR 1 | 20 |
| Band12 | SWIR 2 | 20 |
| Name | Code | Description |
|---|---|---|
| Croplands | 10 | Cropland refers to the land where crops are planted. It has obvious characteristics of human-intensive activities and needs human activities to maintain for a long time. It includes rice fields, fallow, greenhouse, and orchards. |
| Forests | 20 | Forest refers to the land where woody plants grow mainly, the vegetation coverage rate is more than 15% and generally up to 60%, and the vegetation height is more than 3 m. It includes coniferous forests, broad-leaved forests, and mixed forests. |
| Grasslands | 30 | Grassland refers to the land where herbaceous plants are grown, with herbaceous coverage >15%, and arbor and shrub coverage <10%. It includes grazing-based shrub grassland and open forest grassland with canopy closure below 10%. |
| Shrublands | 40 | The height of the shrub is between 0.3 and 5 m. It includes canopy shrub with shrub canopy coverage >60% and sparse shrub with shrub canopy coverage of 10–60%. |
| Water bodies | 60 | Water bodies refer to natural waters and land used for water conservancy facilities. It includes lakes, reservoirs/ponds, rivers, and oceans. The spectral characteristics of the water body change greatly, and the water area changes with the seasons. |
| Impervious surfaces | 80 | Impervious surface refers to the land covered by buildings and other man-made structures, generally based on artificial covering materials, such as asphalt, concrete, sand, brick, glass, and other covering materials. |
| Barren land | 90 | Bare land refers to land where the vegetation coverage does not exceed 10%. It includes bare soil, sand, gravel, and rocks. |
| Diversity | Study Area 1 | Study Area 2 | Study Area 3 | Study Area 4 | Study Area 5 |
|---|---|---|---|---|---|
| M1 | 0.2401 | 0.4542 | 0.2713 | 0.2810 | 0.1869 |
| M2 | 0.2490 | 0.4729 | 0.3185 | 0.2540 | 0.1692 |
| M3 | 0.2481 | 0.4992 | 0.2760 | 0.2357 | 0.1971 |
| M4 | 0.2473 | 0.4858 | 0.2700 | 0.2777 | 0.2700 |
| M5 | 0.2521 | 0.4883 | 0.3301 | 0.3218 | 0.1724 |
| M6 | 0.2600 | 0.5052 | 0.2859 | 0.3106 | 0.3266 |
| M7 | 0.2517 | 0.4956 | 0.2713 | 0.2926 | 0.3268 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, C.; Ma, Z.; Wang, L.; Yu, W.; Tan, D.; Gao, B.; Feng, Q.; Guo, H.; Zhao, Y. Improving the Accuracy of Land Cover Mapping by Distributing Training Samples. Remote Sens. 2021, 13, 4594. https://doi.org/10.3390/rs13224594
Li C, Ma Z, Wang L, Yu W, Tan D, Gao B, Feng Q, Guo H, Zhao Y. Improving the Accuracy of Land Cover Mapping by Distributing Training Samples. Remote Sensing. 2021; 13(22):4594. https://doi.org/10.3390/rs13224594
Chicago/Turabian StyleLi, Chenxi, Zaiying Ma, Liuyue Wang, Weijian Yu, Donglin Tan, Bingbo Gao, Quanlong Feng, Hao Guo, and Yuanyuan Zhao. 2021. "Improving the Accuracy of Land Cover Mapping by Distributing Training Samples" Remote Sensing 13, no. 22: 4594. https://doi.org/10.3390/rs13224594
APA StyleLi, C., Ma, Z., Wang, L., Yu, W., Tan, D., Gao, B., Feng, Q., Guo, H., & Zhao, Y. (2021). Improving the Accuracy of Land Cover Mapping by Distributing Training Samples. Remote Sensing, 13(22), 4594. https://doi.org/10.3390/rs13224594