
Attention-Guided Multispectral and Panchromatic Image Classification




Abstract
:
1. Introduction
2. Literature Reviews
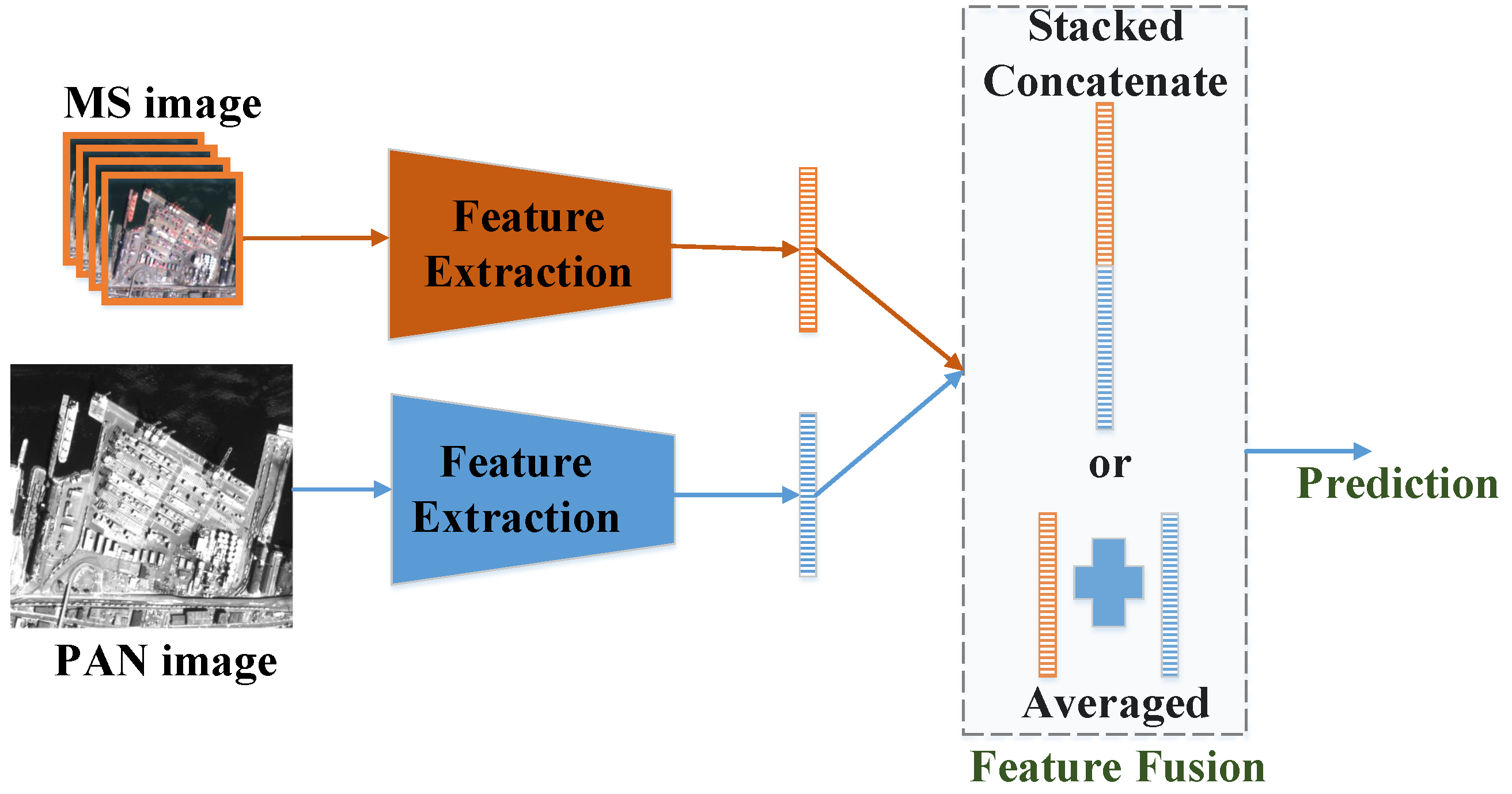
2.1. Multi-Sensor Remote Sensing Image Classification with Deep Learning
2.2. Attention Mechanisms
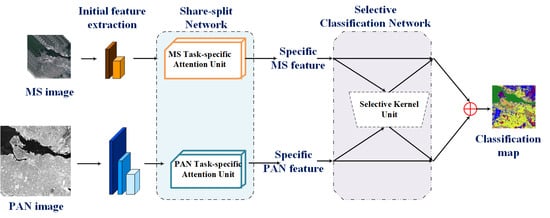
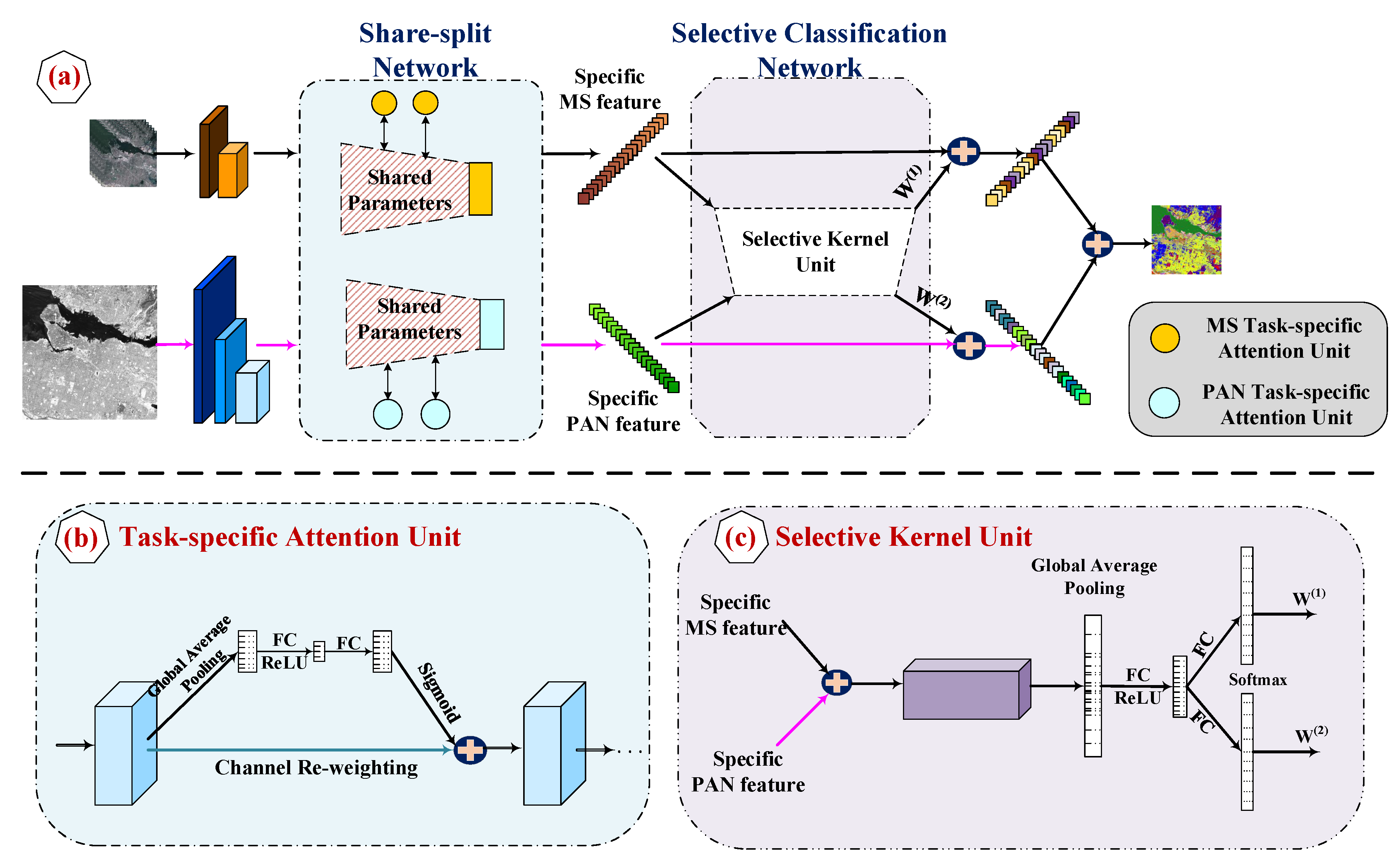
3. Learning to Attention-Guided Classification Network
3.1. Share-Split Network for Multi-Sensor Feature Extraction
3.2. Selective Classification Network for Adaptive Feature Fusion
4. Experiments and Discussions
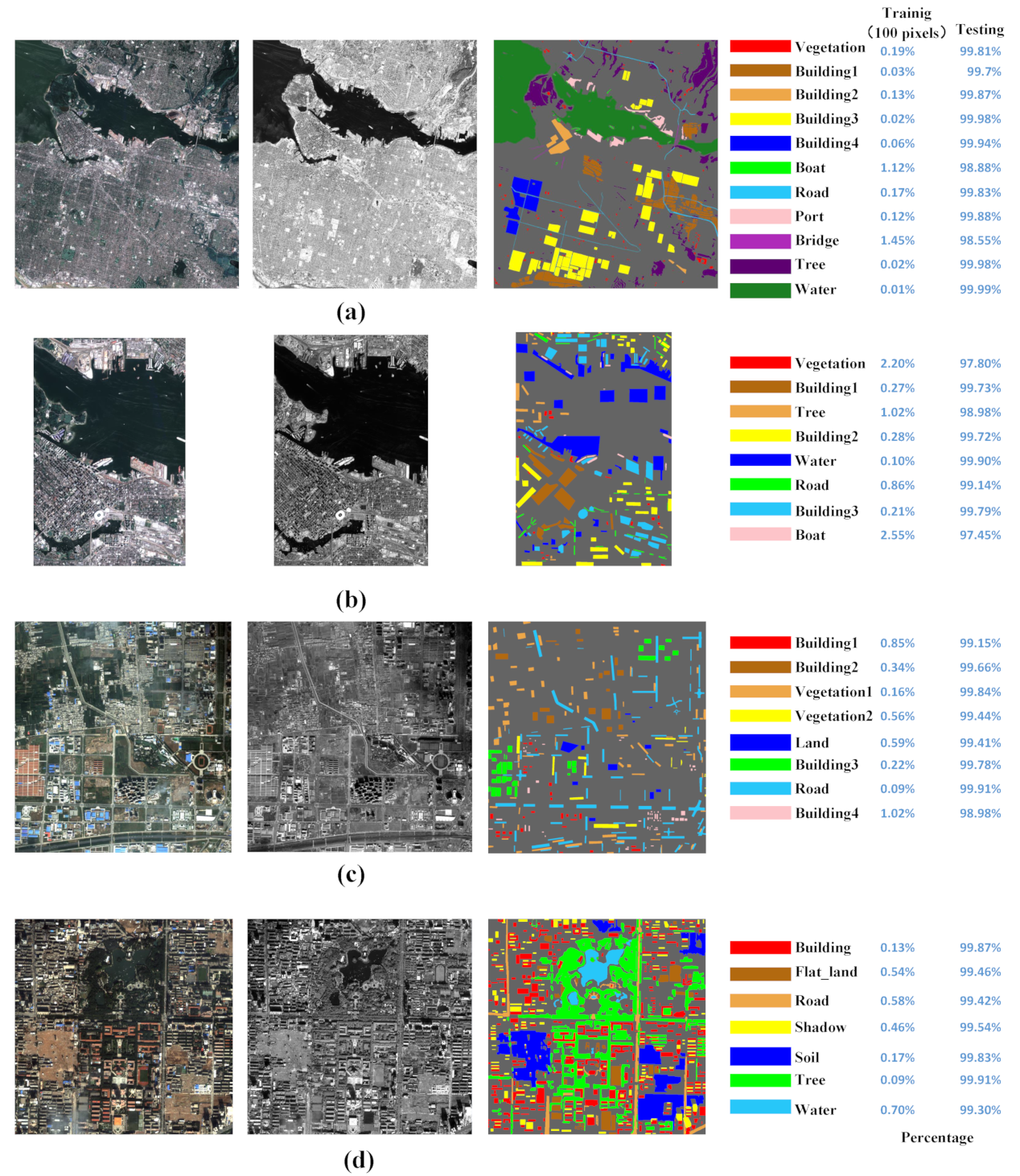
4.1. Datasets
4.2. Experimental Setup
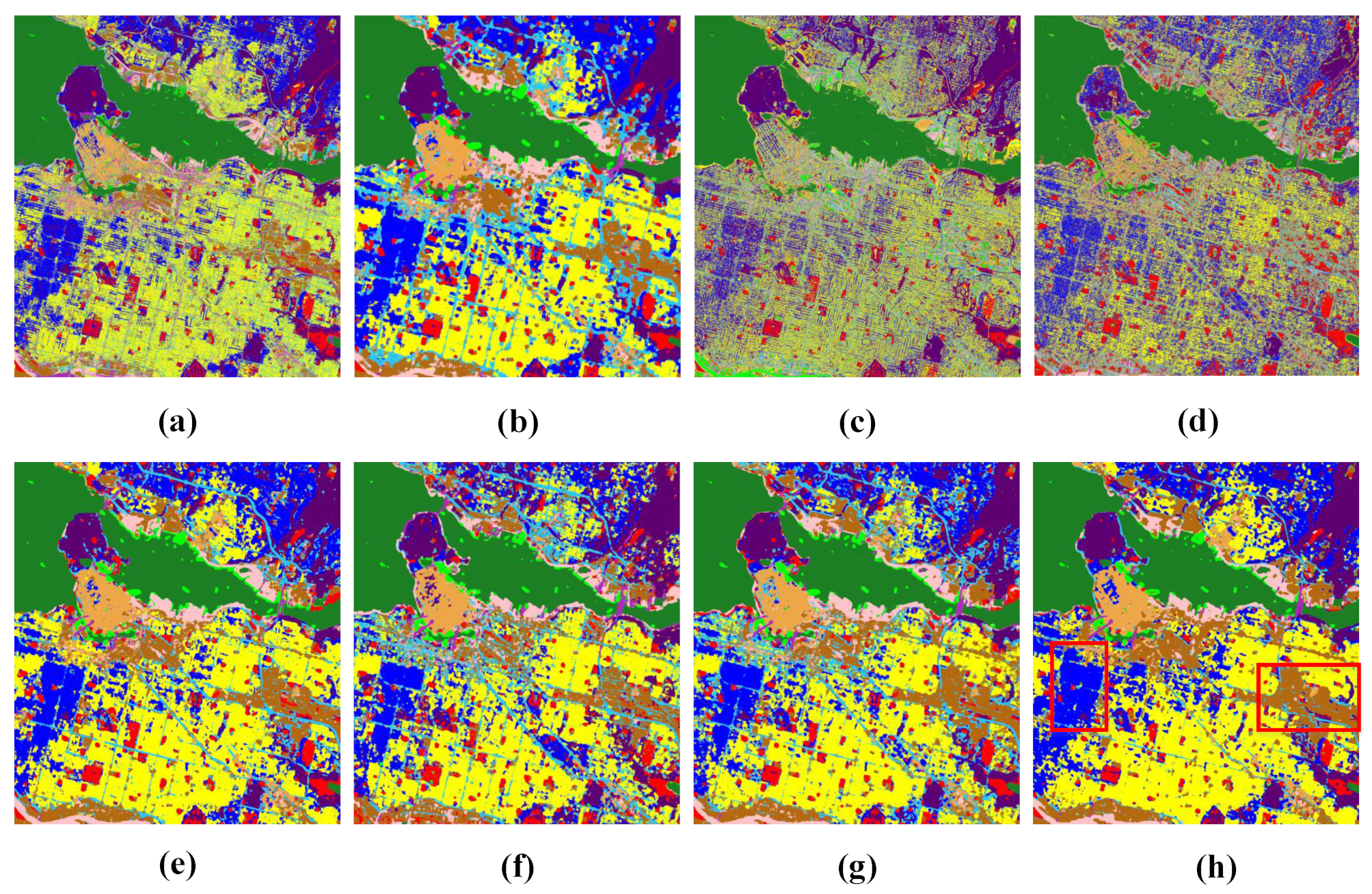
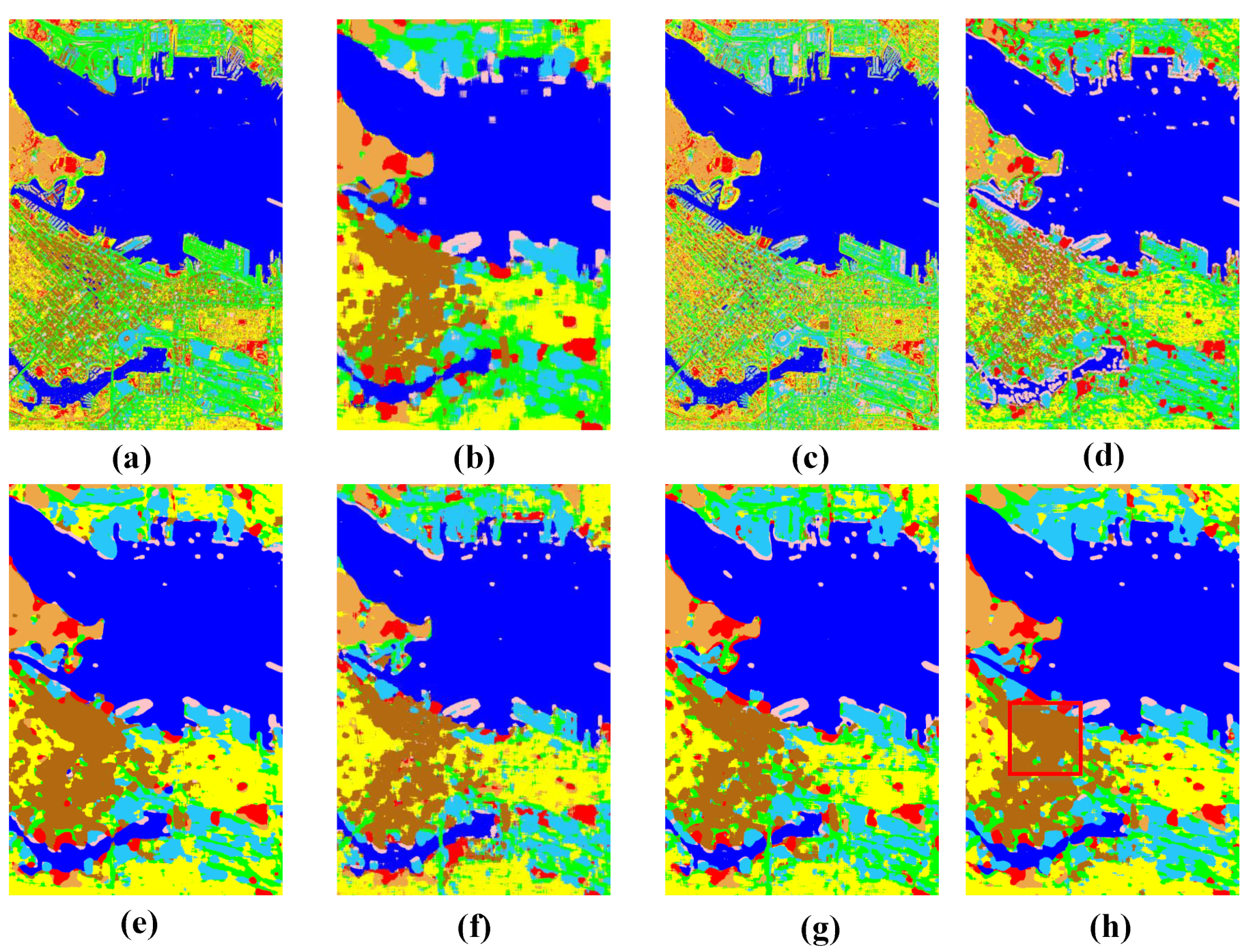
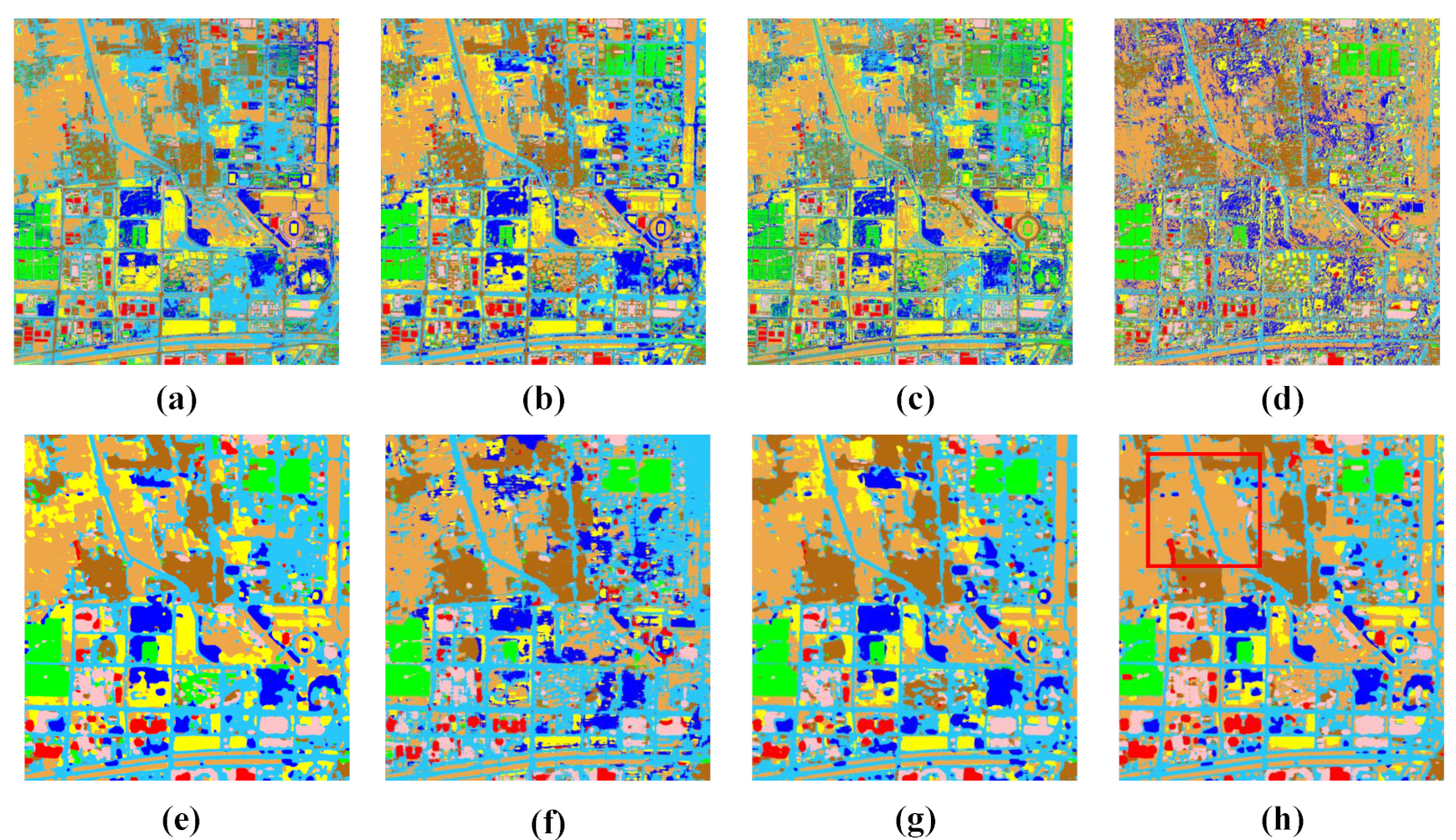
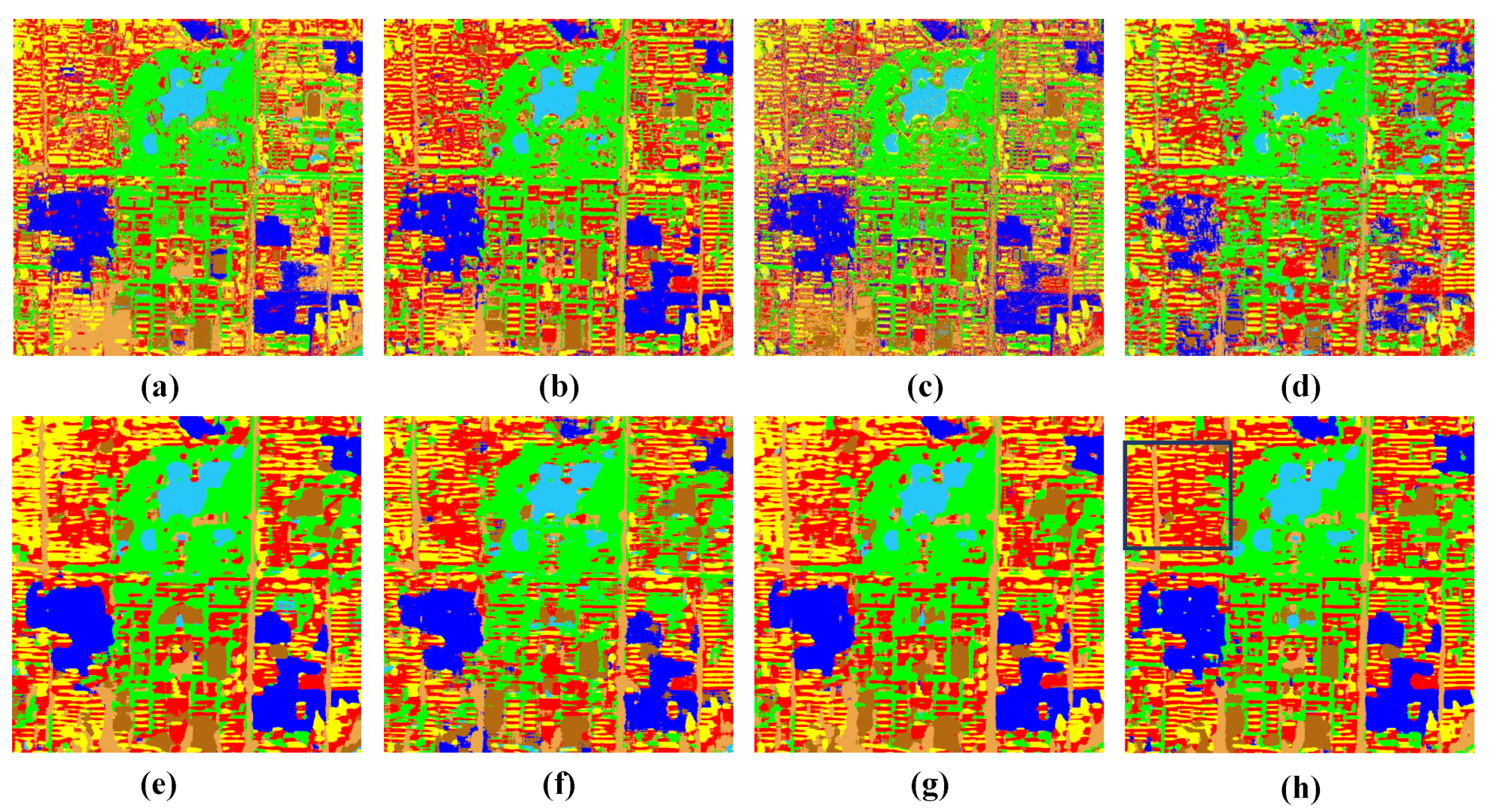
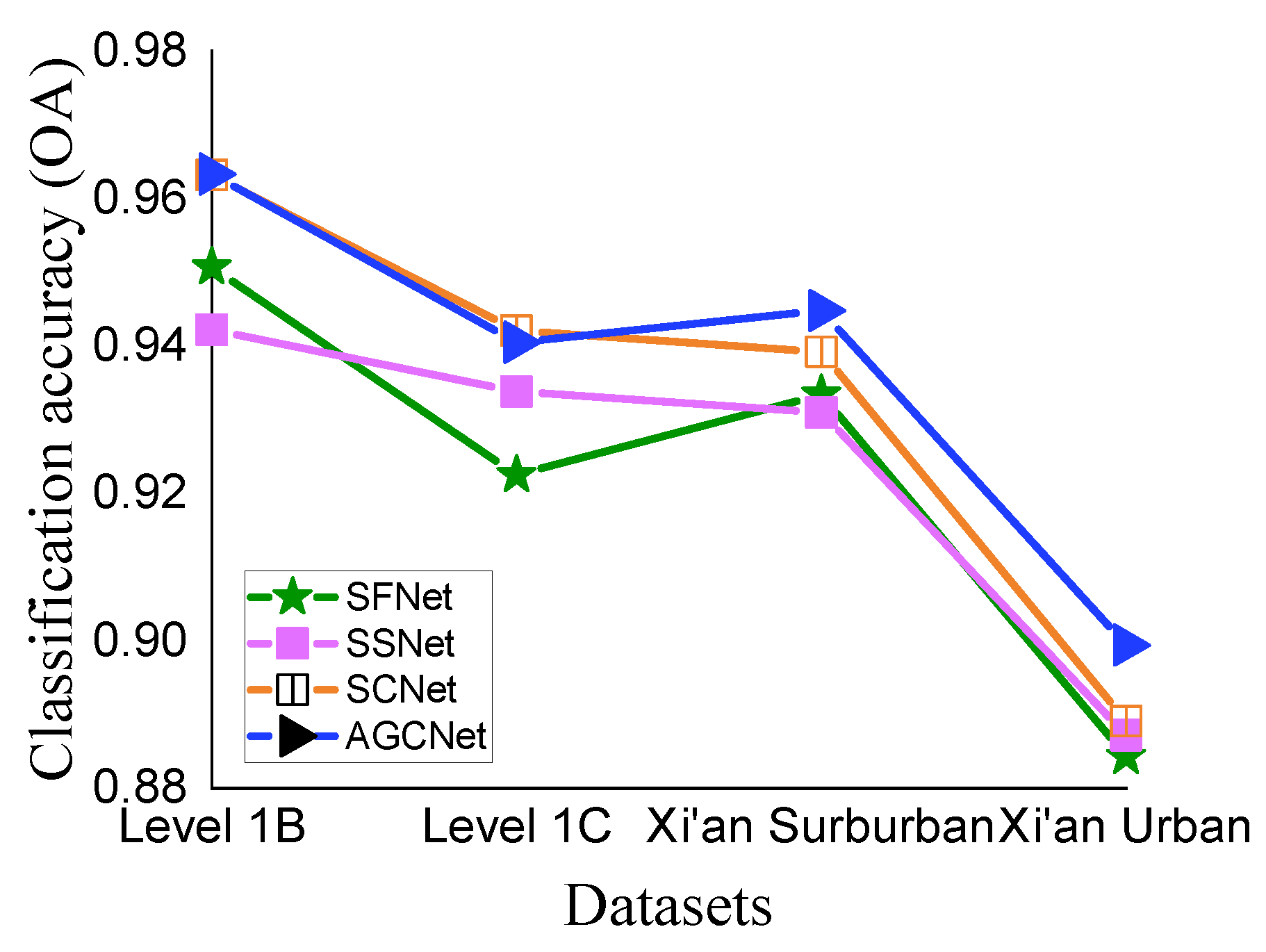
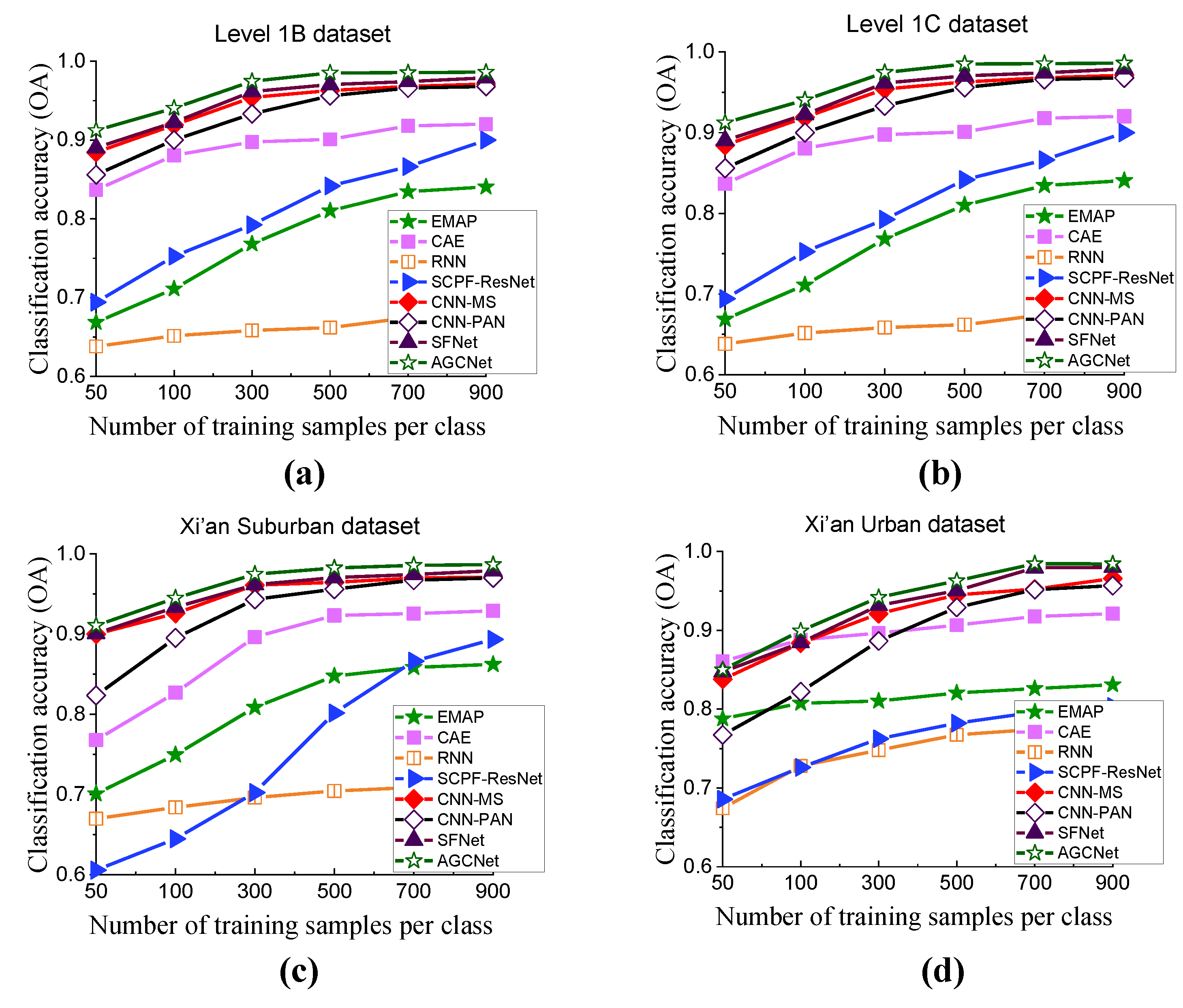
4.3. Comparison Results
4.4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lin, J.; Yu, T.; Mou, L.; Zhu, X.; Wang, Z.J. Unifying top–down views by task-specific domain adaptation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4689–4702. [Google Scholar] [CrossRef]
- Lin, J.; Qi, W.; Yuan, Y. In defense of iterated conditional mode for hyperspectral image classification. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014. [Google Scholar]
- Lv, Y.; Liu, T.F.; Benediktsson, J.A.; Falco, N. Land cover change detection techniques: Very-high-resolution optical images: A review. IEEE Trans. Remote Sens. Mag. 2021. [Google Scholar] [CrossRef]
- Lv, Z.; Liu, T.; Cheng, S.; Benediktsson, J.A. Local histogram-based analysis for detecting land cover change using VHR remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1284–1287. [Google Scholar] [CrossRef]
- Wu, Y.; Huang, M.; Li, Y.; Feng, S.; Wu, D. A Distributed Fusion Framework of Multispectral and Panchromatic Images Based on Residual Network. Remote Sens. 2021, 13, 2556. [Google Scholar] [CrossRef]
- Zhao, W.; Jiao, L.; Ma, W.; Zhao, J.; Zhao, J.; Liu, H.; Cao, X.; Yang, S. Superpixel-Based Multiple Local CNN for Panchromatic and Multispectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4141–4156. [Google Scholar] [CrossRef]
- Feng, J.; Li, D.; Gu, J.; Cao, X.; Jiao, L. Deep reinforcement learning for semisupervised hyperspectral band selection. IEEE Trans. Geosci. Remote Sens. 2021, 1–19. [Google Scholar] [CrossRef]
- Cheng, S.; Li, F.; Z, L.; M, Z. Explainable scale distillation for hyperspectral image classification. Pattern Recognit. 2021, 122, 108316. [Google Scholar]
- Garcia, N.; Morerio, P.; Murino, V. Learning with privileged information via adversarial discriminative modality distillation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2581–2593. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Li, J.; Shao, W.; Peng, Z.; Zhang, R.; Wang, X.; Luo, P. Differentiable Learning-to-Group Channels via Groupable Convolutional Neural Networks. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Wang, X.; Kan, M.; Shan, S.; Chen, X. Fully Learnable Group Convolution for Acceleration of Deep Neural Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 9041–9050. [Google Scholar]
- Howard, A.; Chen, B.; Kalenichenko, D.; Weyand, T.; Zhu, M.; Andreetto, M.; Wang, W. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2011–2023. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar]
- Lin, J.; Liang, Z.; Li, S.; Ward, R.; Wang, Z.J. Active-learning-incorporated deep transfer learning for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 4048–4062. [Google Scholar] [CrossRef]
- Lin, D.; Lin, J.; Zhao, L.; Wang, Z.J.; Chen, Z. Multilabel aerial image classification with a concept attention graph neural network. IEEE Trans. Geosci. Remote Sens. 2021, 1–12. [Google Scholar] [CrossRef]
- Ma, X.; Wang, H.; Geng, J. Spectral–Spatial Classification of Hyperspectral Image Based on Deep Auto-Encoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4073–4085. [Google Scholar] [CrossRef]
- Kemker, R.; Kanan, C. Self-Taught Feature Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2693–2705. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–Spatial Classification of Hyperspectral Data Based on Deep Belief Network. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Li, Y.; Xie, W.; Li, H. Hyperspectral image reconstruction by deep convolutional neural network for classification. Pattern Recognit. 2017, 63, 371–383. [Google Scholar] [CrossRef]
- Lu, Y.; Xie, K.; Xu, G.; Dong, H.; Li, C.; Li, T. MTFC: A Multi-GPU Training Framework for Cube-CNN-based Hyperspectral Image Classification. IEEE Trans. Emerg. Top. Comput. 2020. [Google Scholar] [CrossRef]
- Hang, R.; Liu, Q.; Hong, D.; Ghamisi, P. Cascaded recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5384–5394. [Google Scholar] [CrossRef] [Green Version]
- Lei, T.; Li, L.; Lv, Z.; Zhu, M.; Du, X.; Nandi, A.K. Multi-modality and multi-scale attention fusion network for land cover classification from VHR remote sensing images. Remote Sens. 2021, 13, 3771. [Google Scholar] [CrossRef]
- Wang, D.; Du, B.; Zhang, L.; Xu, Y. Adaptive Spectral-Spatial Multiscale Contextual Feature Extraction for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2461–2477. [Google Scholar] [CrossRef]
- Zhang, M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef]
- Lin, Z.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative Adversarial Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar]
- Zhang, Y.; Liu, K.; Dong, Y.; Wu, K.; Hu, X. Semisupervised Classification Based on SLIC Segmentation for Hyperspectral Image. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1440–1444. [Google Scholar] [CrossRef]
- Feng, J.; Yu, H.; Wang, L.; Cao, X.; Zhang, X.; Jiao, L. Classification of Hyperspectral Images Based on Multiclass Spatial–Spectral Generative Adversarial Networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5329–5343. [Google Scholar] [CrossRef]
- Lin, J.; Mou, L.; Yu, T.; Zhu, X.; Wang, Z.J. Dual adversarial network for unsupervised ground/satellite-to-aerial scene adaptation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Xu, Y.; Du, B.; Zhang, L.; Cerra, D.; Saux, B. Advanced Multi-Sensor Optical Remote Sensing for Urban Land Use and Land Cover Classification: Outcome of the 2018 IEEE GRSS Data Fusion Contest. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019, 12, 1709–1724. [Google Scholar] [CrossRef]
- Ramirez, J.; Arguello, H. Spectral Image Classification From Multi-Sensor Compressive Measurements. IEEE Trans. Geosci. Remote Sens. 2019, 58, 626–636. [Google Scholar] [CrossRef]
- Hinojosa, C.; Ramirez, J.; Arguello, H. Spectral-Spatial Classification from Multi-Sensor Compressive Measurements Using Superpixels. In Proceedings of the IEEE International Conference on Image Processing, Taipei, Taiwan, 22–25 September 2019; pp. 3143–3147. [Google Scholar]
- Liu, X.; Jiao, L.; Zhao, J.; Zhao, J.; Zhang, D.; Liu, F.; Yang, S.; Tang, X. Deep Multiple Instance Learning-Based Spatial–Spectral Classification for PAN and MS Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 461–473. [Google Scholar] [CrossRef]
- Xu, K.; Huang, H.; Deng, P.; Shi, G. Two-stream feature aggregation deep neural network for scene classification of remote sensing images. Inf. Sci. 2020, 539, 250–268. [Google Scholar] [CrossRef]
- Wang, Z.; Zou, C.; Cai, W. Small Sample Classification of Hyperspectral Remote Sensing Images Based on Sequential Joint Deeping Learning Model. IEEE Access 2020, 8, 71353–71363. [Google Scholar] [CrossRef]
- Feng, J.; Feng, X.; Chen, J.; Cao, X.; Yu, T. Generative adversarial networks based on collaborative learning and attention mechanism for hyperspectral image classification. Remote Sens. 2020, 12, 1149. [Google Scholar] [CrossRef] [Green Version]
- Luo, F.; Zhang, L.; Du, B.; Zhang, L. Dimensionality Reduction with Enhanced Hybrid-Graph Discriminant Learning for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5336–5353. [Google Scholar] [CrossRef]
- Bell, S.; Zitnick, C.; Bala, K.; Girshick, R. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2847–2883. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass net-works for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Wang, N.; Ma, S.; Li, J.; Zhang, Y.; Zhang, L. Multistage attention network for image inpainting. Pattern Recognit. 2020, 106, 107448. [Google Scholar] [CrossRef]
- Guo, D.; Xia, Y.; Luo, X. Scene Classification of Remote Sensing Images Based on Saliency Dual Attention Residual Network. IEEE Access 2020, 8, 6344–6357. [Google Scholar] [CrossRef]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-Attention-Based DenseNet Network for Remote Sensing Image Scene Classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Zhu, P.; Tan, Y.; Zhang, L.; Wang, Y.; Wu, M. Deep Learning for Multilabel Remote Sensing Image Annotation with Dual-Level Semantic Concepts. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 58, 4047–4060. [Google Scholar] [CrossRef]
- Wang, C.; Bai, X.; Wang, S.; Zhou, J.; Ren, P. Multiscale Visual Attention Networks for Object Detection in VHR Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 310–314. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, J.; Luo, Z.; Li, J.; Chen, C. Remote Sensing Image Scene Classification Based on an Enhanced Attention Module. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1926–1930. [Google Scholar] [CrossRef]
- Lin, J.; Yuan, K.; Ward, R.; Wang, Z.J. Xnet: Task-specific attentional domain adaptation for satellite-to-aerial scene. Neurocomputing 2020, 406, 215–223. [Google Scholar] [CrossRef]
- Roy, S.; Chatterjee, S.; Bhattacharyya, S.; Chaudhuri, B.; Platos, J. Lightweight Spectral-Spatial Squeeze-and-Excitation Residual Bag-of-Features Learning for Hyperspectral Classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5277–5290. [Google Scholar] [CrossRef]
- Zhu, H.; Ma, M.; Ma, W.; Jiao, L.; Hong, S.; Shen, J.; Hou, B. A spatial-channel progressive fusion ResNet for remote sensing classification. Inf. Fusion 2020, 70, 72–87. [Google Scholar] [CrossRef]
- Jin, N.; Wu, J.; Ma, X.; Yan, K.; Mo, Y. Multi-task learning model based on Multi-scale CNN and LSTM for sentiment classification. IEEE Access 2020, 8, 77060–77072. [Google Scholar] [CrossRef]
- Cavallaro, G.; Bazi, Y.; Melgani, F.; Riedel, M. Multi-Scale Convolutional SVM Networks for Multi-Class Classification Problems of Remote Sensing Images. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 875–878. [Google Scholar]
- Zhang, E.; Liu, L.; Huang, L.; Ng, K. An automated, generalized, deep-learning-based method for delineating the calving fronts of Greenland glaciers from multi-sensor remote sensing imagery. Remote Sens. Environ. 2021, 254, 112265. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep Feature Extraction and Classification of Hyperspectral Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- NYU Computer Science. 2016. Available online: https://cs.nyu.edu/home/index.html (accessed on 1 November 2021).
- Benediktsson, J.; Palmason, J.; Sveinsson, J. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Benediktsson, J. Feature Extraction for Hyperspectral Imagery: The Evolution from Shallow to Deep: Overview and Toolbox. IEEE Geosci. Remote Sens. Mag. 2020, 8, 60–88. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Structure/Operator | Convolution/Full Connection Size | [Stride Padding Poolin Activation] | Convolution/Full Connection Size | [Stride Padding Pooling Activation] | |
|---|---|---|---|---|---|
| Initial Feature Extraction | – | – | [1 1 Max-pooling(2) ReLU] | ||
| [1 1–ReLU] | [1 1 Max-pooling(2) ReLU] | ||||
| [1 1 Max-pooling(2) ReLU] | [1 1 Max-pooling(2) ReLU] | ||||
| Share split network | Shared branch | [1 1 Max-pooling(2) ReLU] | Shared Parameters | ||
| Task specific attention unit | – | [– – Avg-pooling –] | – | [– – Avg-pooling –] | |
| Activation = ReLU | Activation = ReLU | ||||
| Activation=Sigmoid | Activation=Sigmoid | ||||
| Selective classification network | Selective kernel unit | – | [– – Avg-pooling –] | – | [– – Avg-pooling –] |
| Activation = ReLU | Activation = ReLU | ||||
| Softmax | Softmax | ||||
| classification | Softmax | ||||
| Class | EMAP | CAE | RNN | SCPF-ResNet | CNN-MS | CNN-PAN | SFNet | AGCNet |
|---|---|---|---|---|---|---|---|---|
| 1 (Vegetation) | 0.9422 | 0.9493 | 0.9178 | 0.8642 | 0.9894 | 0.9444 | 0.9751 | 0.9351 |
| 2 (Building1) | 0.5993 | 0.8160 | 0.1738 | 0.3039 | 0.8582 | 0.7538 | 0.9006 | 0.9217 |
| 3 (Building2) | 0.6831 | 0.9694 | 0.2841 | 0.6673 | 0.9821 | 0.9697 | 0.9748 | 0.9805 |
| 4 (Building3) | 0.6692 | 0.8863 | 0.4932 | 0.6019 | 0.9258 | 0.8947 | 0.9184 | 0.9628 |
| 5 (Building4) | 0.7528 | 0.9524 | 0.4987 | 0.6637 | 0.9492 | 0.8825 | 0.9358 | 0.9742 |
| 6 (Boat) | 0.7962 | 0.9810 | 0.5602 | 0.8127 | 0.9941 | 0.9800 | 0.9636 | 0.9765 |
| 7 (Road) | 0.3883 | 0.7225 | 0.5186 | 0.5580 | 0.8252 | 0.8189 | 0.8125 | 0.6940 |
| 8 (Port) | 0.5034 | 0.8703 | 0.4025 | 0.2836 | 0.9066 | 0.8615 | 0.9356 | 0.8639 |
| 9 (Bridge) | 0.6893 | 0.9303 | 0.2724 | 0.8916 | 0.9605 | 0.9662 | 0.9477 | 0.9589 |
| 10 (Tree) | 0.9173 | 0.9288 | 0.9136 | 0.4574 | 0.9278 | 0.8947 | 0.9544 | 0.9709 |
| 11 (Water) | 0.9895 | 0.9802 | 0.9872 | 0.9823 | 0.9876 | 0.9836 | 0.9806 | 9864 |
| OA | 0.8378 | 0.9297 | 0.7377 | 0.7152 | 0.9475 | 0.9190 | 0.9507 | 0.9633 |
| Kappa | 0.7865 | 0.9071 | 0.6560 | 0.6288 | 0.9304 | 0.8928 | 0.9347 | 0.9512 |
| AA | 0.7210 | 0.9079 | 0.5475 | 0.6442 | 0.9370 | 0.9046 | 0.9363 | 0.9300 |
| Class | EMAP | CAE | RNN | SCPF-ResNet | CNN-MS | CNN-PAN | SFNet | AGCNet |
|---|---|---|---|---|---|---|---|---|
| 1 (Vegetation) | 0.8698 | 0.9865 | 0.9206 | 0.9280 | 0.9775 | 0.9294 | 0.9931 | 0.9851 |
| 2 (Building1) | 0.5241 | 0.9601 | 0.2897 | 0.5980 | 0.9604 | 0.9331 | 0.9515 | 0.9626 |
| 3 (Tree) | 0.8315 | 0.9735 | 0.8356 | 0.8679 | 0.9805 | 0.9349 | 0.9339 | 0.9414 |
| 4 (Building2) | 0.3973 | 0.8058 | 0.3366 | 0.5555 | 0.8534 | 0.8578 | 0.8926 | 0.9248 |
| 5 (Water) | 0.9963 | 0.9077 | 0.9924 | 0.9346 | 0.9865 | 0.9810 | 0.9755 | 0.9772 |
| 6 (Road) | 0.7889 | 0.7009 | 0.6410 | 0.7102 | 0.7013 | 0.7428 | 0.8024 | 0.7533 |
| 7 (Building3) | 0.4607 | 0.8256 | 0.4229 | 0.6052 | 0.8296 | 0.7890 | 0.8534 | 0.9072 |
| 8 (Boat) | 0.5849 | 0.9911 | 0.5092 | 0.9198 | 0.9668 | 0.9694 | 0.9910 | 0.9936 |
| OA | 0.7111 | 0.8806 | 0.6515 | 0.7525 | 0.9191 | 0.9051 | 0.9225 | 0.9405 |
| Kappa | 0.6297 | 0.8465 | 0.5557 | 0.6853 | 0.8943 | 0.8763 | 0.9034 | 0.9254 |
| AA | 0.6817 | 0.8939 | 0.6185 | 0.7649 | 0.9070 | 0.8922 | 0.9242 | 0.9307 |
| Class | EMAP | CAE | RNN | SCPF-ResNet | CNN-MS | CNN-PAN | SFNet | AGCNet |
|---|---|---|---|---|---|---|---|---|
| 1 (Building1) | 0.9986 | 0.9991 | 0.9976 | 0.8636 | 1.0000 | 0.9741 | 0.9990 | 1.0000 |
| 2 (Building2) | 0.7956 | 0.8663 | 0.5506 | 0.7498 | 0.9796 | 0.9911 | 0.9951 | 0.9960 |
| 3 (Vegetation1) | 0.9127 | 0.8615 | 0.8480 | 0.7185 | 0.8244 | 0.8055 | 0.8780 | 0.9100 |
| 4 (Vegetation2) | 0.8808 | 0.9147 | 0.8168 | 0.6860 | 0.9488 | 0.8726 | 0.9340 | 0.9421 |
| 5 (Land) | 0.9135 | 0.9742 | 0.8516 | 0.5820 | 0.9944 | 0.9210 | 0.9917 | 0.9991 |
| 6 (Building3) | 0.6717 | 0.8832 | 0.7468 | 0.8954 | 0.9935 | 0.9895 | 0.9981 | 0.9975 |
| 7 (Road) | 0.5850 | 0.7072 | 0.4990 | 0.4291 | 0.9135 | 0.8657 | 0.9014 | 0.9114 |
| 8 (Building4) | 0.9820 | 0.9835 | 0.9643 | 0.9545 | 0.9990 | 0.9900 | 0.9990 | 0.9985 |
| OA | 0.7495 | 0.8268 | 0.6840 | 0.6448 | 0.9258 | 0.8951 | 0.9334 | 0.9448 |
| Kappa | 0.6945 | 0.7863 | 0.6169 | 0.5753 | 0.9062 | 0.8675 | 0.9160 | 0.9301 |
| AA | 0.8425 | 0.8987 | 0.7843 | 0.7361 | 0.9566 | 0.9262 | 0.9620 | 0.9693 |
| Class | EMAP | CAE | RNN | SCPF-ResNet | CNN-MS | CNN-PAN | SFNet | AGCNet |
|---|---|---|---|---|---|---|---|---|
| 1 (Building) | 0.6603 | 0.8142 | 0.4668 | 0.7607 | 0.7927 | 0.7508 | 0.8261 | 0.8086 |
| 2 (Flat land) | 0.5485 | 0.8504 | 0.6192 | 0.5739 | 0.9231 | 0.8892 | 0.9220 | 0.9274 |
| 3 (Road) | 0.7349 | 0.8786 | 0.7012 | 0.6096 | 0.8969 | 0.8993 | 0.9112 | 0.8825 |
| 4 (Shadow) | 0.8789 | 0.9248 | 0.7954 | 0.9190 | 0.9233 | 0.8583 | 0.9079 | 0.8894 |
| 5 (Soil) | 0.9318 | 0.9502 | 0.8794 | 0.5169 | 0.9644 | 0.8696 | 0.9564 | 0.9750 |
| 6 (Tree) | 0.8677 | 0.8954 | 0.8169 | 0.8158 | 0.8729 | 0.7952 | 0.8599 | 0.9089 |
| 7 (Water) | 0.9300 | 0.9717 | 0.8739 | 0.9106 | 0.9857 | 0.9754 | 0.9654 | 0.9944 |
| OA | 0.8076 | 0.8880 | 0.7280 | 0.7261 | 0.8836 | 0.8222 | 0.8843 | 0.8994 |
| Kappa | 0.7583 | 0.8577 | 0.6620 | 0.6533 | 0.8524 | 0.7759 | 0.8535 | 0.8716 |
| AA | 0.7932 | 0.8979 | 0.7361 | 0.7151 | 0.9084 | 0.8626 | 0.9070 | 0.9123 |
| Methods | CNN-MS | CNN-PAN | SFNet | SCPF-ResNet | AGCNet |
|---|---|---|---|---|---|
| The number of learn-able parameters |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, C.; Dang, Y.; Fang, L.; Lv, Z.; Shen, H. Attention-Guided Multispectral and Panchromatic Image Classification. Remote Sens. 2021, 13, 4823. https://doi.org/10.3390/rs13234823
Shi C, Dang Y, Fang L, Lv Z, Shen H. Attention-Guided Multispectral and Panchromatic Image Classification. Remote Sensing. 2021; 13(23):4823. https://doi.org/10.3390/rs13234823
Chicago/Turabian StyleShi, Cheng, Yenan Dang, Li Fang, Zhiyong Lv, and Huifang Shen. 2021. "Attention-Guided Multispectral and Panchromatic Image Classification" Remote Sensing 13, no. 23: 4823. https://doi.org/10.3390/rs13234823
APA StyleShi, C., Dang, Y., Fang, L., Lv, Z., & Shen, H. (2021). Attention-Guided Multispectral and Panchromatic Image Classification. Remote Sensing, 13(23), 4823. https://doi.org/10.3390/rs13234823