
Hybrid Models Incorporating Bivariate Statistics and Machine Learning Methods for Flash Flood Susceptibility Assessment Based on Remote Sensing Datasets


 ,
,
Abstract
:1. Introduction
2. Materials
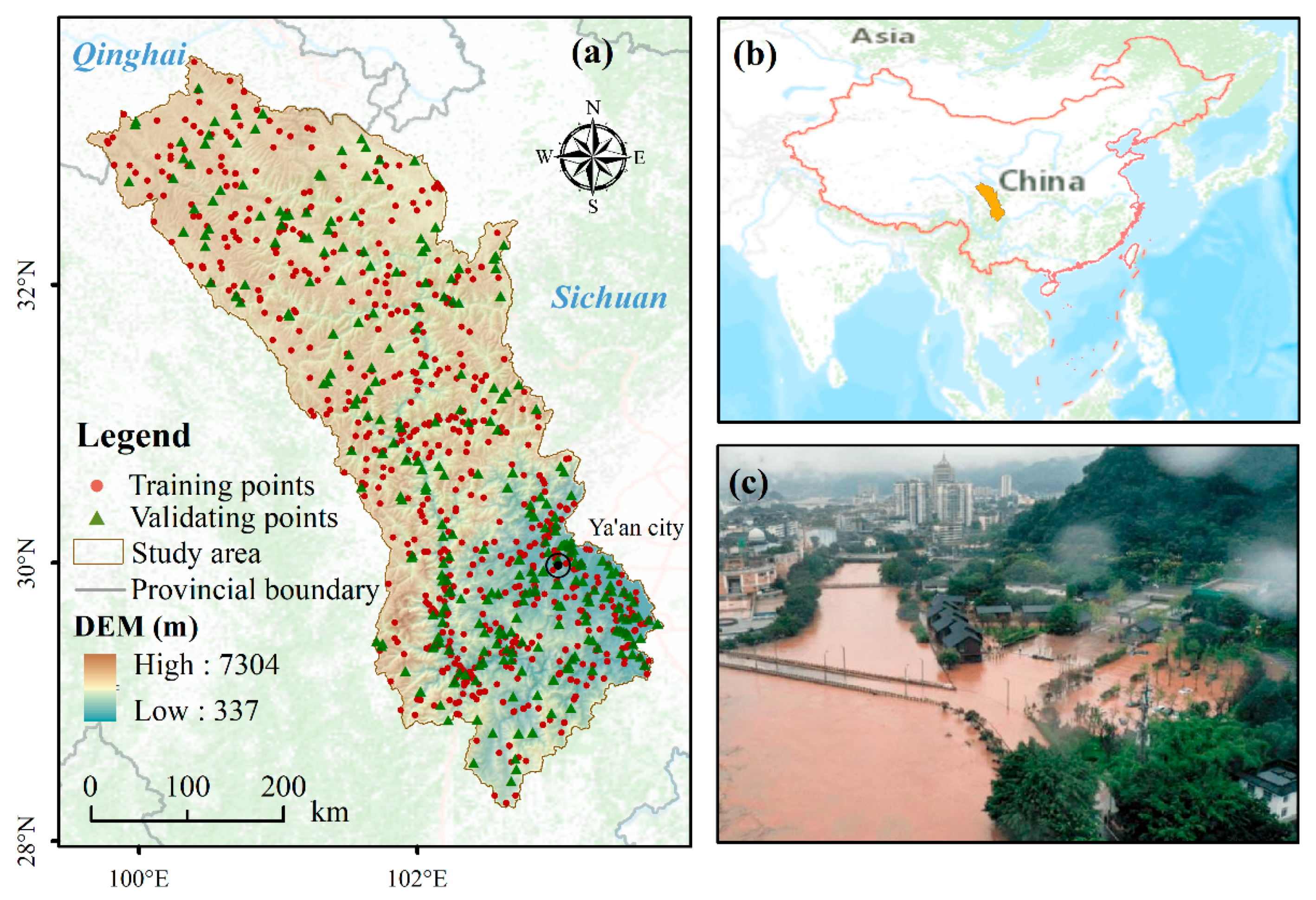
2.1. Study Area
2.2. Data
2.2.1. Flash Flood Inventory Map
2.2.2. Flash Flood Conditioning Factors
3. Methods
3.1. Feature Selection Methods
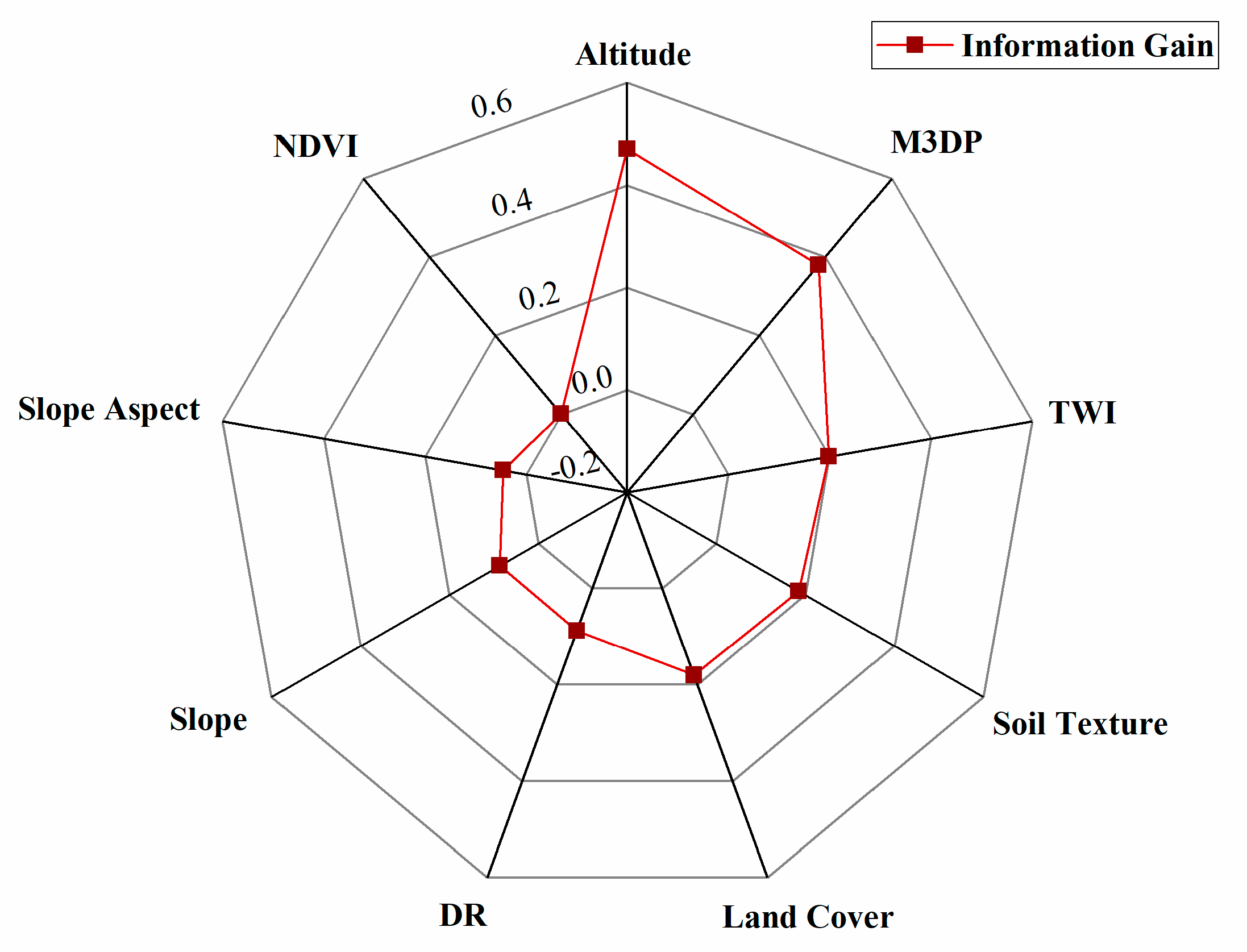
3.1.1. Information Gain Method
3.1.2. Variance Inflation and Tolerance
3.2. Bivariate Statistics Method
3.3. Machine Learning Methods
3.3.1. Support Vector Machine
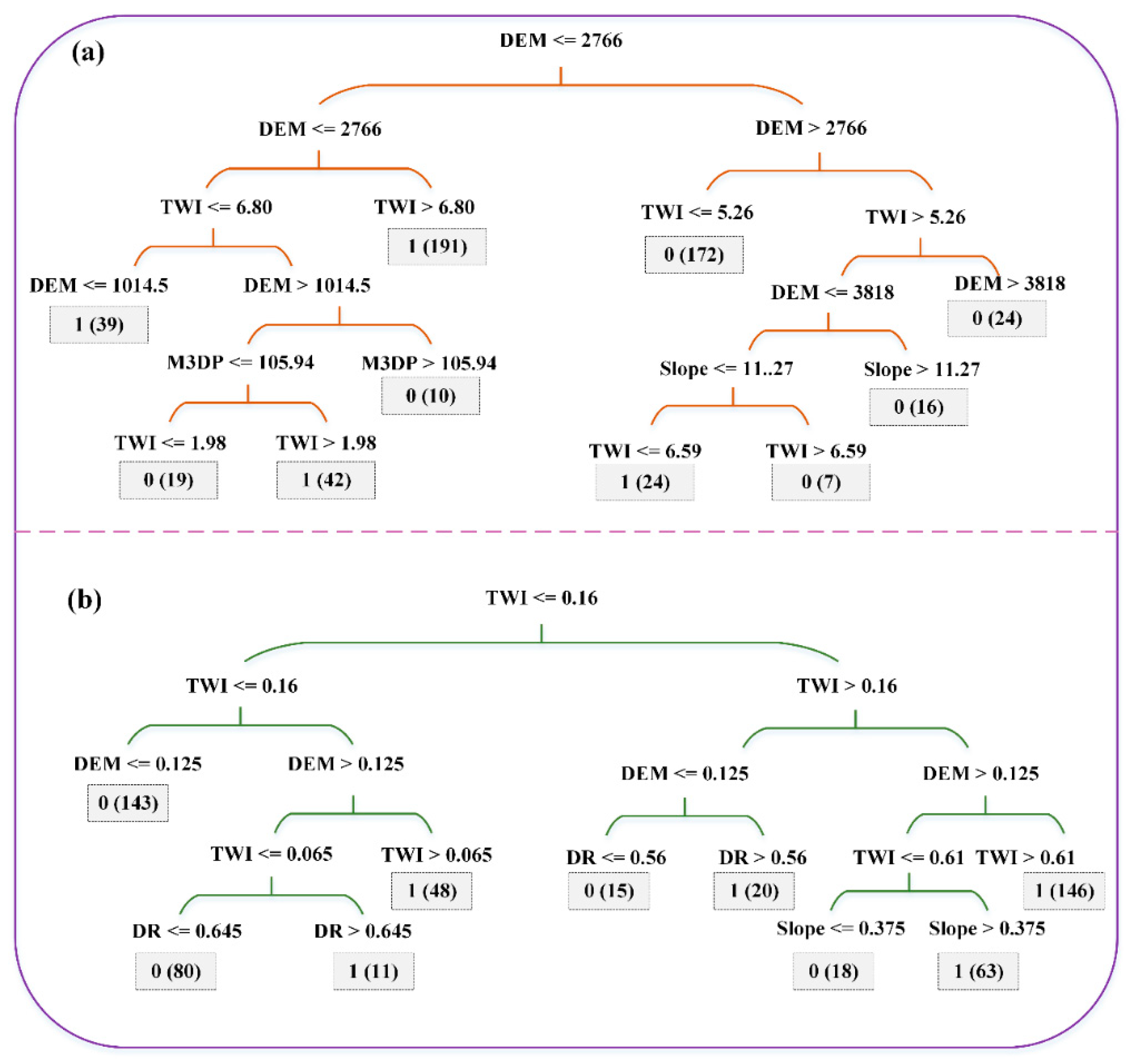
3.3.2. Classification and Regression Trees
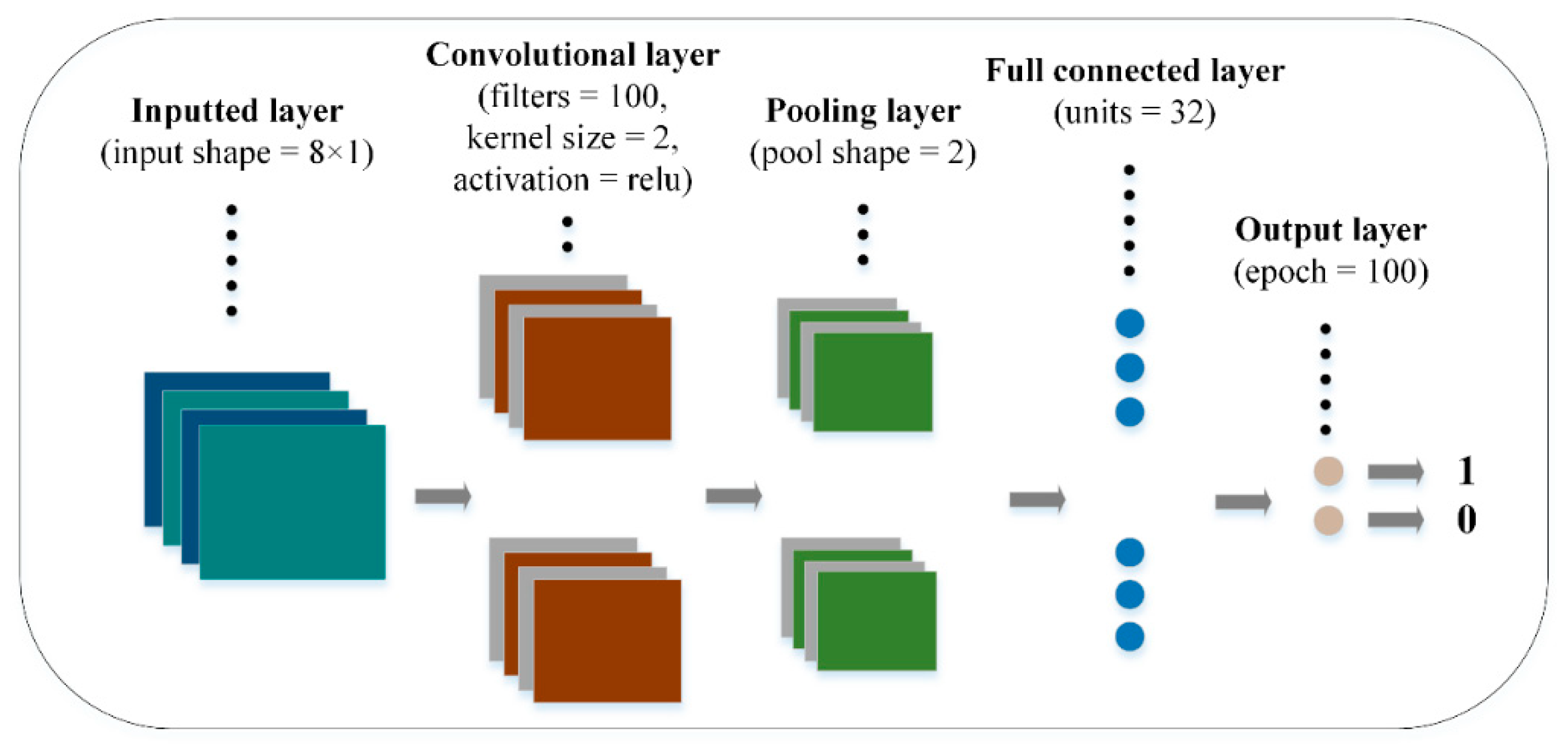
3.3.3. Convolutional Neural Network
3.4. Model Performance Evaluation Methods
3.4.1. Statistical Measures
3.4.2. ROC Curve
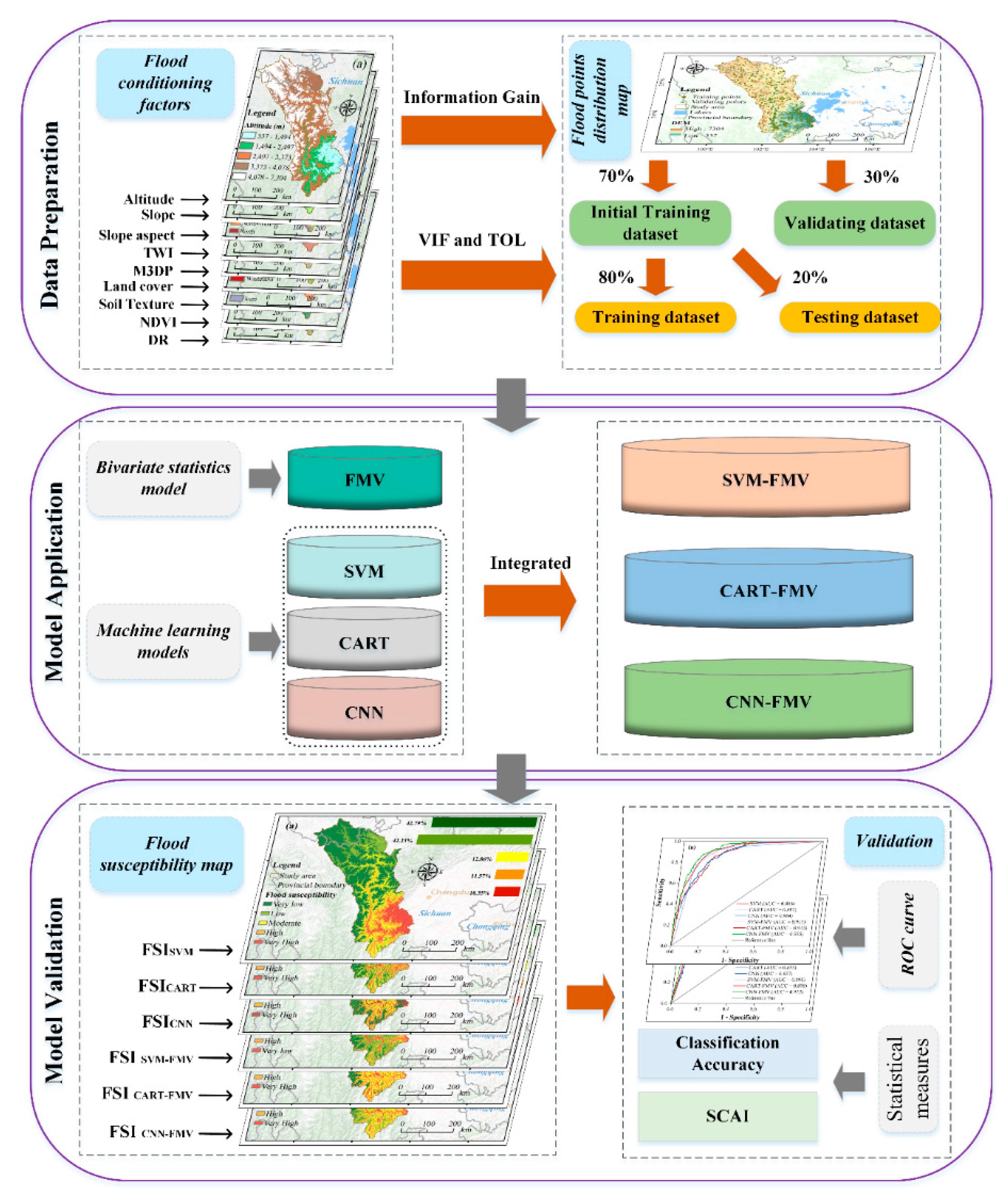
3.5. Processing
4. Results
4.1. Feature Selection
4.2. Fuzzy Membership Value
4.3. Model Training Results
4.3.1. SVM and SVM-FMV
4.3.2. CART and CART-FMV
4.3.3. CNN and CNN-FMV
4.4. Model Training Results
4.4.1. Statistical Measures
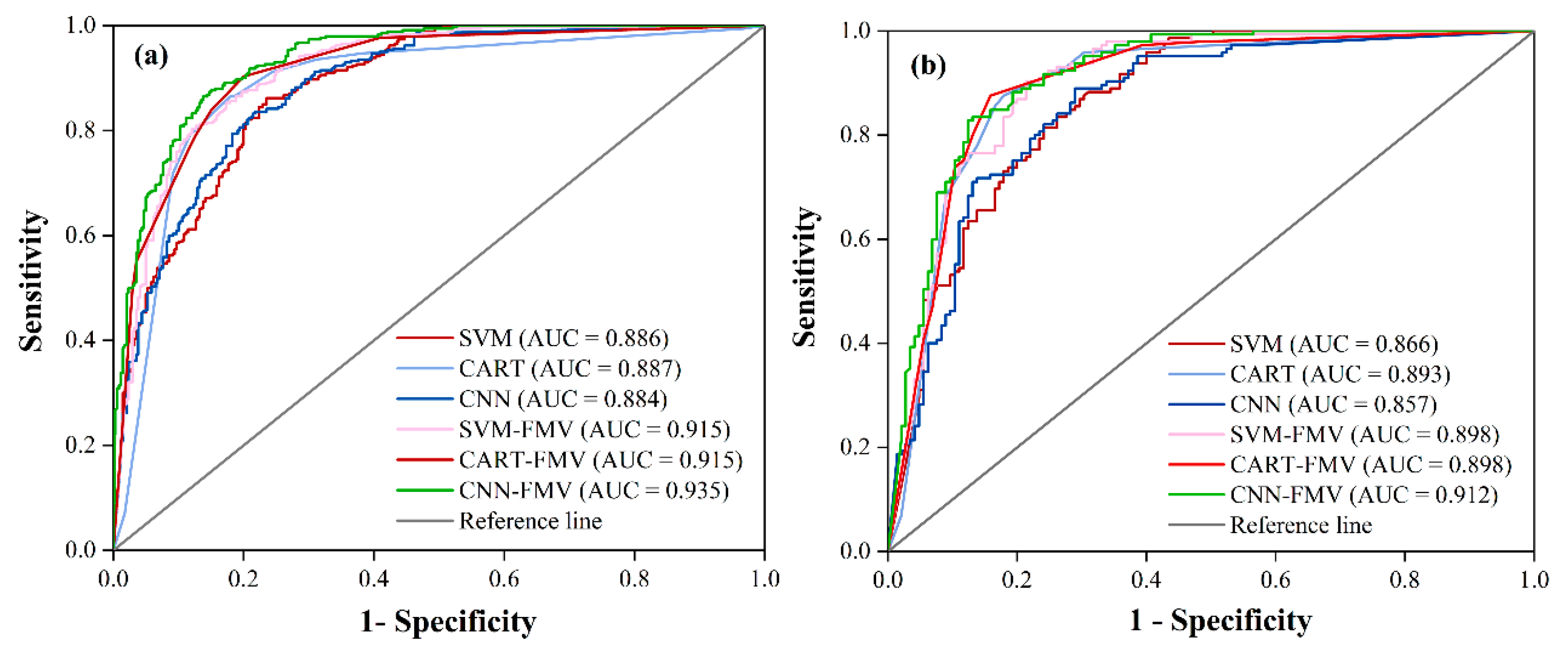
4.4.2. ROC Curve
5. Discussion
5.1. Assessment of the Methodology
5.2. Assessment of the Model Performances
5.3. Applications and Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Antonetti, M.; Horat, C.; Sideris, I.V.; Zappa, M. Ensemble flood forecasting considering dominant runoff processes—Part 1: Set-up and application to nested basins (Emme, Switzerland). Nat. Hazards Earth Syst. Sci. 2019, 19, 19–40. [Google Scholar] [CrossRef] [Green Version]
- Shen, G.; Hwang, S.N. Spatial–Temporal snapshots of global natural disaster impacts Revealed from EM-DAT for 1900-2015. Geomat. Nat. Hazards Risk 2019, 10, 912–934. [Google Scholar] [CrossRef] [Green Version]
- Arnell, N.W.; Gosling, S.N. The impacts of climate change on river flood risk at the global scale. Clim. Chang. 2016, 134, 387–401. [Google Scholar] [CrossRef] [Green Version]
- Xiong, J.N.; Ye, C.C.; Cheng, W.M.; Guo, L.; Zhou, C.H.; Zhang, X.L. The Spatiotemporal Distribution of Flash Floods and Analysis of Partition Driving Forces in Yunnan Province. Sustainability 2019, 11, 2926–2944. [Google Scholar] [CrossRef] [Green Version]
- Barredo, J.I. Major flood disasters in Europe: 1950–2005. Nat. Hazards 2007, 42, 125–148. [Google Scholar] [CrossRef]
- Pereira, S.; Diakakis, M.; Deligiannakis, G.; Zezere, J.L. Comparing flood mortality in Portugal and Greece (Western and Eastern Mediterranean). Int. J. Disaster Risk Reduct. 2017, 22, 147–157. [Google Scholar] [CrossRef]
- Ngo, P.-T.T.; Hoang, N.-D.; Pradhan, B.; Nguyen, Q.K.; Tran, X.T.; Nguyen, Q.M.; Nguyen, V.N.; Samui, P.; Tien Bui, D. A Novel Hybrid Swarm Optimized Multilayer Neural Network for Spatial Prediction of Flash Floods in Tropical Areas Using Sentinel-1 SAR Imagery and Geospatial Data. Sensors 2018, 18, 3704. [Google Scholar] [CrossRef] [Green Version]
- Vogel, R. Methodology and software solutions for multicriteria evaluation of floodplain retention suitability. Cartogr. Geogr. Inf. Sci. 2016, 43, 301–320. [Google Scholar] [CrossRef]
- Chowdary, V.M.; Chakraborthy, D.; Jeyaram, A.; Murthy, Y.V.N.K.; Sharma, J.R.; Dadhwal, V.K. Multi-Criteria Decision Making Approach for Watershed Prioritization Using Analytic Hierarchy Process Technique and GIS. Water Resour. Manag. 2013, 27, 3555–3571. [Google Scholar] [CrossRef]
- Knebl, M.R.; Yang, Z.L.; Hutchison, K.; Maidment, D.R. Regional scale flood modeling using NEXRAD rainfall, GIS, and HEC-HMS/RAS: A case study for the San Antonio River Basin Summer 2002 storm event. J. Environ. Manag. 2005, 75, 325–336. [Google Scholar] [CrossRef] [PubMed]
- Tehrany, M.; Jones, S.; Shabani, F. Identifying the essential flood conditioning factors for flood prone area mapping using machine learning techniques. Catena 2018, 175, 174–192. [Google Scholar] [CrossRef]
- Pham, B.T.; Luu, C.; Dao, D.V.; Phong, T.V.; Nguyen, H.D.; Le, H.V.; von Meding, J.; Prakash, I. Flood risk assessment using deep learning integrated with multi-criteria decision analysis. Knowl. -Based Syst. 2021, 219, 15. [Google Scholar] [CrossRef]
- Malik, S.; Pal, S.C.; Arabameri, A.; Chowdhuri, I.; Saha, A.; Chakrabortty, R.; Roy, P.; Das, B. GIS-based statistical model for the prediction of flood hazard susceptibility. Environ. Dev. Sustain. 2021, 23, 16713–16743. [Google Scholar] [CrossRef]
- Panahi, M.; Dodangeh, E.; Rezaie, F.; Khosravi, K.; Le, H.; Lee, M.J.; Lee, S.; Pham, B.T. Flood spatial prediction modeling using a hybrid of meta-optimization and support vector regression modeling. Catena 2021, 199, 15. [Google Scholar] [CrossRef]
- Natarajan, L.; Usha, T.; Gowrappan, M.; Kasthuri, B.P.; Moorthy, P.; Chokkalingam, L. Flood Susceptibility Analysis in Chennai Corporation Using Frequency Ratio Model. J. Indian Soc. Remote Sens. 2021, 49, 1533–1543. [Google Scholar] [CrossRef]
- Rahmati, O.; Pourghasemi, H.R.; Zeinivand, H. Flood susceptibility mapping using frequency ratio and weights-of-evidence models in the Golastan Province, Iran. Geocarto Int. 2016, 31, 42–70. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Hong, H.; Costache, R.; Tang, X. Flood susceptibility mapping by integrating frequency ratio and index of entropy with multilayer perceptron and classification and regression tree. J. Environ. Manag. 2021, 289. [Google Scholar] [CrossRef]
- Costache, R.; Hong, H.; Quoc Bao, P. Comparative assessment of the flash-flood potential within small mountain catchments using bivariate statistics and their novel hybrid integration with machine learning models. Sci. Total Environ. 2020, 711. [Google Scholar] [CrossRef] [PubMed]
- Costache, R.; Bui, D.T. Spatial prediction of flood potential using new ensembles of bivariate statistics and artificial intelligence: A case study at the Putna river catchment of Romania. Sci. Total Environ. 2019, 691, 1098–1118. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.J.; Zhang, Y. Flood disaster risk assessment based on random forest algorithm. Neural Comput. Appl. 2021. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility analysis and its verification using a novel ensemble support vector machine and frequency ratio method. Stoch. Environ. Res. Risk Assess. 2015, 29, 1149–1165. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.X.; Yue, J.J.; Tu, T.B. Mapping flood susceptibility in mountainous areas on a national scale in China. Sci. Total Environ. 2018, 615, 1133–1142. [Google Scholar] [CrossRef]
- Choubin, B.; Moradi, E.; Golshan, M.; Adamowski, J.; Sajedi-Hosseini, F.; Mosavi, A. An ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci. Total Environ. 2019, 651, 2087–2096. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Kia, M.B.; Pirasteh, S.; Pradhan, B.; Mahmud, A.R.; Sulaiman, W.N.A.; Moradi, A. An artificial neural network model for flood simulation using GIS: Johor River Basin, Malaysia. Environ. Earth Sci. 2012, 67, 251–264. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Pradhan, B.; Jebur, M.N. Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J. Hydrol. 2014, 512, 332–343. [Google Scholar] [CrossRef]
- Costache, R.; Bui, D.T. Identification of areas prone to flash-flood phenomena using multiple-criteria decision-making, bivariate statistics, machine learning and their ensembles. Sci. Total Environ. 2020, 712. [Google Scholar] [CrossRef] [PubMed]
- Costache, R.D.; Thao, N.T.P.; Bui, D.T. Novel Ensembles of Deep Learning Neural Network and Statistical Learning for Flash-Flood Susceptibility Mapping. Water 2020, 12, 1549–1573. [Google Scholar] [CrossRef]
- Yang, Y.; Tang, G.Q.; Lei, X.H.; Hong, Y.; Yang, N. Can Satellite Precipitation Products Estimate Probable Maximum Precipitation: A Comparative Investigation with Gauge Data in the Dadu River Basin. Remote Sens. 2018, 10, 41. [Google Scholar] [CrossRef] [Green Version]
- Hou, Y.; Liu, R.; Zhao, J. Characteristics of flood disaster in dry-hot valley of Dadu river in Hanyuan county, Sichuan province in Qing Dynasty. Bull. Soil Water Conserv. 2019, 39, 271–277. [Google Scholar]
- Zhang, D. Research on Uncertainty Analysis of Flood Frequency; China Institute of Water Resources & Hydropower Research: Beijing, China, 2015. [Google Scholar]
- Yuan, X.M.; Liu, Y.S.; Huang, Y.H.; Tian, F.C. An approach to quality validation of large-scale data from the Chinese Flash Flood Survey and Evaluation (CFFSE). Nat. Hazards 2017, 89, 693–704. [Google Scholar] [CrossRef]
- Liu, Y.S.; Yuan, X.M.; Guo, L.; Huang, Y.H.; Zhang, X.L. Driving Force Analysis of the Temporal and Spatial Distribution of Flash Floods in Sichuan Province. Sustainability 2017, 9, 1527. [Google Scholar] [CrossRef] [Green Version]
- Xiong, J.N.; Pang, Q.; Cheng, W.M.; Wang, N.; Yong, Z.W. Reservoir risk modelling using a hybrid approach based on the feature selection technique and ensemble methods. Geocarto Int. 2020, 1–25. [Google Scholar] [CrossRef]
- Hosseini, F.S.; Choubin, B.; Mosavi, A.; Nabipour, N.; Shamshirband, S.; Darabi, H.; Haghighi, A.T. Flash-flood hazard assessment using ensembles and Bayesian-based machine learning models: Application of the simulated annealing feature selection method. Sci. Total Environ. 2020, 711, 14. [Google Scholar] [CrossRef]
- Khosravi, K.; Pham, B.T.; Chapi, K.; Shirzadi, A.; Shahabi, H.; Revhaug, I.; Prakash, I.; Bui, D.T. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, northern Iran. Sci. Total Environ. 2018, 627, 744–755. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, K.; Shahabi, H.; Pham, B.T.; Adamowski, J.; Shirzadi, A.; Pradhan, B.; Dou, J.; Ly, H.B.; Grof, G.; Ho, H.L.; et al. A comparative assessment of flood susceptibility modeling using Multi-Criteria Decision-Making Analysis and Machine Learning Methods. J. Hydrol. 2019, 573, 311–323. [Google Scholar] [CrossRef]
- Bout, B.; Jetten, V.G. The validity of flow approximations when simulating catchment-integrated flash floods. J. Hydrol. 2018, 556, 674–688. [Google Scholar] [CrossRef]
- Chaabani, C.; Chini, M.; Abdelfattah, R.; Hostache, R.; Chokmani, K. Flood Mapping in a Complex Environment Using Bistatic TanDEM-X/TerraSAR-X InSAR Coherence. Remote Sens. 2018, 10, 1873. [Google Scholar] [CrossRef] [Green Version]
- Regmi, A.D.; Devkota, K.C.; Yoshida, K.; Pradhan, B.; Pourghasemi, H.R.; Kumamoto, T.; Akgun, A. Application of frequency ratio, statistical index, and weights-of-evidence models and their comparison in landslide susceptibility mapping in Central Nepal Himalaya. Arab. J. Geosci. 2014, 7, 725–742. [Google Scholar] [CrossRef]
- Arora, A.; Arabameri, A.; Pandey, M.; Siddiqui, M.A.; Shukla, U.K.; Bui, D.T.; Mishra, V.N.; Bhardwaj, A. Optimization of state-of-the-art fuzzy-metaheuristic ANFIS-based machine learning models for flood susceptibility prediction mapping in the Middle Ganga Plain, India. Sci. Total Environ. 2021, 750, 21. [Google Scholar] [CrossRef] [PubMed]
- Chapi, K.; Singh, V.P.; Shirzadi, A.; Shahabi, H.; Bui, D.T.; Pham, B.T.; Khosravi, K. A novel hybrid artificial intelligence approach for flood susceptibility assessment. Environ. Model. Softw. 2017, 95, 229–245. [Google Scholar] [CrossRef]
- Ali, S.A.; Parvin, F.; Pham, Q.B.; Vojtek, M.; Vojtekova, J.; Costache, R.; Linh, N.T.T.; Nguyen, H.Q.; Ahmad, A.; Ghorbani, M.A. GIS-based comparative assessment of flood susceptibility mapping using hybrid multi-criteria decision-making approach, naive Bayes tree, bivariate statistics and logistic regression: A case of Topla basin, Slovakia. Ecol. Indic. 2020, 117, 23. [Google Scholar] [CrossRef]
- Liu, J.F.; Wang, X.Q.; Zhang, B.; Li, J.; Zhang, J.Q.; Liu, X.J. Storm flood risk zoning in the typical regions of Asia using GIS technology. Nat. Hazards 2017, 87, 1691–1707. [Google Scholar] [CrossRef]
- Jin, X.; Shao, H.; Zhang, C.; Yan, Y. The Applicability Evaluation of Three Satellite Products in Tianshan Mountains. J. Nat. Resour. 2016, 31, 2074–2085. [Google Scholar]
- Chen, X.; Zhong, R.; Wang, Z.; Lai, C.; Zhang, J. Evaluation on the accuracy and hydrological performance of the latest-generation GPM IMERG product over South China. J. Hydraul. Eng. 2017, 48, 1147–1156. [Google Scholar]
- Peng, Y.; Wang, Q.H.; Wang, H.T.; Lin, Y.Y.; Song, J.Y.; Cui, T.T.; Fan, M. Does landscape pattern influence the intensity of drought and flood? Ecol. Indic. 2019, 103, 173–181. [Google Scholar] [CrossRef]
- Powell, S.J.; Jakeman, A.; Croke, B. Can NDVI response indicate the effective flood extent in macrophyte dominated floodplain wetlands? Ecol. Indic. 2014, 45, 486–493. [Google Scholar] [CrossRef]
- Bui, D.T.; Ho, T.C.; Pradhan, B.; Pham, B.T.; Nhu, V.H.; Revhaug, I. GIS-based modeling of rainfall-induced landslides using data mining-based functional trees classifier with AdaBoost, Bagging, and MultiBoost ensemble frameworks. Environ. Earth Sci. 2016, 75, 22. [Google Scholar] [CrossRef]
- Yang, Q.L.; Shao, J.M.; Scholz, M.; Plant, C. Feature selection methods for characterizing and classifying adaptive Sustainable Flood Retention Basins. Water Res. 2011, 45, 993–1004. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Peng, J.B.; Hong, H.Y.; Shahabi, H.; Pradhan, B.; Liu, J.Z.; Zhu, A.X.; Pei, X.J.; Duan, Z. Landslide susceptibility modelling using GIS-based machine learning techniques for Chongren County, Jiangxi Province, China. Sci. Total Environ. 2018, 626, 1121–1135. [Google Scholar] [CrossRef] [PubMed]
- Dou, J.; Yunus, A.P.; Bui, D.T.; Merghadi, A.; Sahana, M.; Zhu, Z.F.; Chen, C.W.; Khosravi, K.; Yang, Y.; Pham, B.T. Assessment of advanced random forest and decision tree algorithms for modeling rainfall-induced landslide susceptibility in the Izu-Oshima Volcanic Island, Japan. Sci. Total Environ. 2019, 662, 332–346. [Google Scholar] [CrossRef] [PubMed]
- Gheshlaghi, H.A.; Feizizadeh, B. An integrated approach of analytical network process and fuzzy based spatial decision making systems applied to landslide risk mapping. J. Afr. Earth Sci. 2017, 133, 15–24. [Google Scholar] [CrossRef]
- Yaghoob Nejad Asl, N. Application of fuzzy logic in the evaluation of land suitability for urban. Sci. J. Iran. Geogr. Assoc 2013, 36, 231–249. [Google Scholar]
- Hong, H.Y.; Ilia, I.; Tsangaratos, P.; Chen, W.; Xu, C. A hybrid fuzzy weight of evidence method in landslide susceptibility analysis on the Wuyuan area, China. Geomorphology 2017, 290, 1–16. [Google Scholar] [CrossRef]
- Gheshlaghi, H.A.; Feizizadeh, B. GIS-based ensemble modelling of fuzzy system and bivariate statistics as a tool to improve the accuracy of landslide susceptibility mapping. Nat. Hazards 2021, 107, 1981–2014. [Google Scholar] [CrossRef]
- Choubin, B.; Darabi, H.; Rahmati, O.; Sajedi-Hosseini, F.; Klove, B. River suspended sediment modelling using the CART model: A comparative study of machine learning techniques. Sci. Total Environ. 2018, 615, 272–281. [Google Scholar] [CrossRef] [PubMed]
- Naghibi, S.A.; Ahmadi, K.; Daneshi, A. Application of Support Vector Machine, Random Forest, and Genetic Algorithm Optimized Random Forest Models in Groundwater Potential Mapping. Water Resour. Manag. 2017, 31, 2761–2775. [Google Scholar] [CrossRef]
- Pham, Q.B.; Yang, T.C.; Kuo, C.M.; Tseng, H.W.; Yu, P.S. Combing Random Forest and Least Square Support Vector Regression for Improving Extreme Rainfall Downscaling. Water 2019, 11, 451. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.N. The Nature of Statistical Learning Theory. IEEE Trans. Neural Netw. 1995, 8, 1564. [Google Scholar] [CrossRef]
- Xu, C.; Dai, F.; Xu, X.; Lee, Y. GIS-based support vector machine modeling of earthquake-triggered landslide susceptibility in the Jianjiang River watershed, China. Geomorphology 2012, 145–146, 70–80. [Google Scholar] [CrossRef]
- Ripley, B. Tree: Classification and Regression Trees. Available online: https://cran.r-project.org/web/packages/tree/tree.pdf (accessed on 17 October 2021).
- Choubin, B.; Zehtabian, G.; Azareh, A.; Rafiei-Sardooi, E.; Sajedi-Hosseini, F.; Kisi, O. Precipitation forecasting using classification and regression trees (CART) model: A comparative study of different approaches. Environ. Earth Sci. 2018, 77. [Google Scholar] [CrossRef]
- Elmahdy, S.; Ali, T.; Mohamed, M. Flash Flood Susceptibility Modeling and Magnitude Index Using Machine Learning and Geohydrological Models: A Modified Hybrid Approach. Remote Sens. 2020, 12, 2695. [Google Scholar] [CrossRef]
- Li, H.; Sun, J.; Wu, J. Predicting business failure using classification and regression tree: An empirical comparison with popular classical statistical methods and top classification mining methods. Expert Syst. Appl. 2010, 37, 5895–5904. [Google Scholar] [CrossRef]
- Khosravi, K.; Panahi, M.; Golkarian, A.; Keesstra, S.D.; Saco, P.M.; Dieu Tien, B.; Lee, S. Convolutional neural network approach for spatial prediction of flood hazard at national scale of Iran. J. Hydrol. 2020, 591. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Zuo, D. Urban flood susceptibility assessment based on convolutional neural networks. J. Hydrol. 2020, 590. [Google Scholar] [CrossRef]
- Baratloo, A.; Hosseini, M.; Negida, A.; El Ashal, G. Evidence Based Emergency Medicine; Part 1: Simple Definition and Calculation of Accuracy, Sensitivity and Specificity. Emergency 2015, 3, 48–49. [Google Scholar] [PubMed]
- Costache, R.; Quoc Bao, P.; Avand, M.; Nguyen Thi Thuy, L.; Vojtek, M.; Vojtekova, J.; Lee, S.; Dao Nguyen, K.; Pham Thi Thao, N.; Tran Duc, D. Novel hybrid models between bivariate statistics, artificial neural networks and boosting algorithms for flood susceptibility assessment. J. Environ. Manag. 2020, 265. [Google Scholar] [CrossRef] [PubMed]
- Arabameri, A.; Saha, S.; Mukherjee, K.; Blaschke, T.; Chen, W.; Ngo, P.T.T.; Band, S.S. Modeling Spatial Flood using Novel Ensemble Artificial Intelligence Approaches in Northern Iran. Remote Sens. 2020, 12, 3423. [Google Scholar] [CrossRef]
- Singh, J.; Knapp, H.V.; Arnold, J.G.; De Missie, M. HYDROLOGICAL MODELING OF THE IROQUOIS RIVER WATERSHED USING HSPF AND SWAT. JAWRA J. Am. Water Resour. Assoc. 2005, 41, 343–360. [Google Scholar] [CrossRef]
- Gupta, R.P.; Kanungo, D.P.; Arorac, M.K.; Sarkar, S. Approaches for comparative evaluation of raster GIS-based landslide susceptibility zonation maps. Int. J. Appl. Earth Obs. Geoinf. 2008, 10, 330–341. [Google Scholar] [CrossRef]
- Sahana, M.; Rehman, S.; Sajjad, H.; Hong, H. Exploring effectiveness of frequency ratio and support vector machine models in storm surge flood susceptibility assessment: A study of Sundarban Biosphere Reserve, India. Catena 2020, 189. [Google Scholar] [CrossRef]
- Termeh, S.V.R.; Kornejady, A.; Pourghasemi, H.R.; Keesstra, S. Flood susceptibility mapping using novel ensembles of adaptive neuro fuzzy inference system and metaheuristic algorithms. Sci. Total Environ. 2018, 615, 438–451. [Google Scholar] [CrossRef] [PubMed]
- Kastridis, A.; Kirkenidis, C.; Sapountzis, M. An integrated approach of flash flood analysis in ungauged Mediterranean watersheds using post-flood surveys and unmanned aerial vehicles. Hydrol. Process. 2020, 34, 4920–4939. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.X.; Chen, W. Application of fuzzy weight of evidence and data mining techniques in construction of flood susceptibility map of Poyang County, China. Sci. Total Environ. 2018, 625, 575–588. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Zhao, L. Review on landslide susceptibility mapping using support vector machines. Catena 2018, 165, 520–529. [Google Scholar] [CrossRef]
- Sutton, C.D. Classification and Regression Trees, Bagging, and Boosting. In Handbook of Statistics; Rao, C.R., Wegman, E.J., Solka, J.L., Eds.; Elsevier: Amsterdam, The Netherlands, 2005; Volume 24, pp. 303–329. [Google Scholar]
- Farsal, W.; Anter, S.; Ramdani, M.; Assoc Comp, M. Deep Learning: An Overview. In International Conference on Intelligent Systems, Theories and Applications, Proceedings of the 12th International Conference on Intelligent Systems: Theories and Applications, Rabat, Morocco, 24–25 October 2018; Assoc Computing Machinery: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Wang, Y.; Fang, Z.C.; Hong, H.Y.; Peng, L. Flood susceptibility mapping using convolutional neural network frameworks. J. Hydrol. 2020, 582, 15. [Google Scholar] [CrossRef]
- Dodangeh, E.; Panahi, M.; Rezaie, F.; Lee, S.; Bui, D.T.; Lee, C.W.; Pradhan, B. Novel hybrid intelligence models for flood-susceptibility prediction: Meta optimization of the GMDH and SVR models with the genetic algorithm and harmony search. J. Hydrol. 2020, 590. [Google Scholar] [CrossRef]
- Mazzoleni, M.; Bacchi, B.; Barontini, S.; Baldassarre, G.D.; Pilotti, M.; Ranzi, R. Flooding Hazard Mapping in Floodplain Areas Affected by Piping Breaches in the Po River, Italy. J. Hydrol. Eng. 2013, 19, 717–731. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factors | Sub-Factors | Source of Data | Time | Resolution |
|---|---|---|---|---|
| Flood inventory map | Historical flash flood points | National Flash Flood Investigation and Evaluation Project (NFFIEP) | 1949–2015 | 1:50,000 |
| DEM | Altitude | Geospatial Data Cloud (www.gscloud.cn) (accessed on 8 May 2021) | 2010 | 30 m × 30 m |
| Slope | ||||
| Slope aspect | ||||
| TWI | ||||
| GPM | Maximum three-day precipitation (M3DP) | National Aeronautics and Space Administration (https://pmm.nasa.gov/precipitation-measurement-missions) (accessed on 26 March 2021) | 2000–2018 | 0.1° × 0.1° |
| Land use | Land cover | Resource and Environment Data Cloud Platform (https://www.resdc.cn/) (accessed on 6 April 2021) | 2010 | 1 km × 1 km |
| Soil | Soil texture | Resource and Environment Data Cloud Platform (https://www.resdc.cn/) (accessed on 16 April 2021) | 2010 | 1 km × 1 km |
| Vegetation | NDVI | National Earth System Science Data Center (https://www.geodata.cn/) (accessed on 23 April 2021) | 2015 | 1 km × 1 km |
| River | Distance to river (DR) | National Flash Flood Investigation and Evaluation Project (NFFIEP) | 2013 | 1:1,000,000 |
| Flash Flood Conditioning Factors | Collinearity Statistics | |
|---|---|---|
| Tolerance | VIF | |
| Altitude | 0.183 | 5.476 |
| M3DP | 0.235 | 4.252 |
| TWI | 0.570 | 1.756 |
| DR | 0.727 | 1.376 |
| Slope | 0.784 | 1.276 |
| Land Cover | 0.800 | 1.251 |
| Soil Texture | 0.934 | 1.071 |
| Slope Aspect | 0.950 | 1.053 |
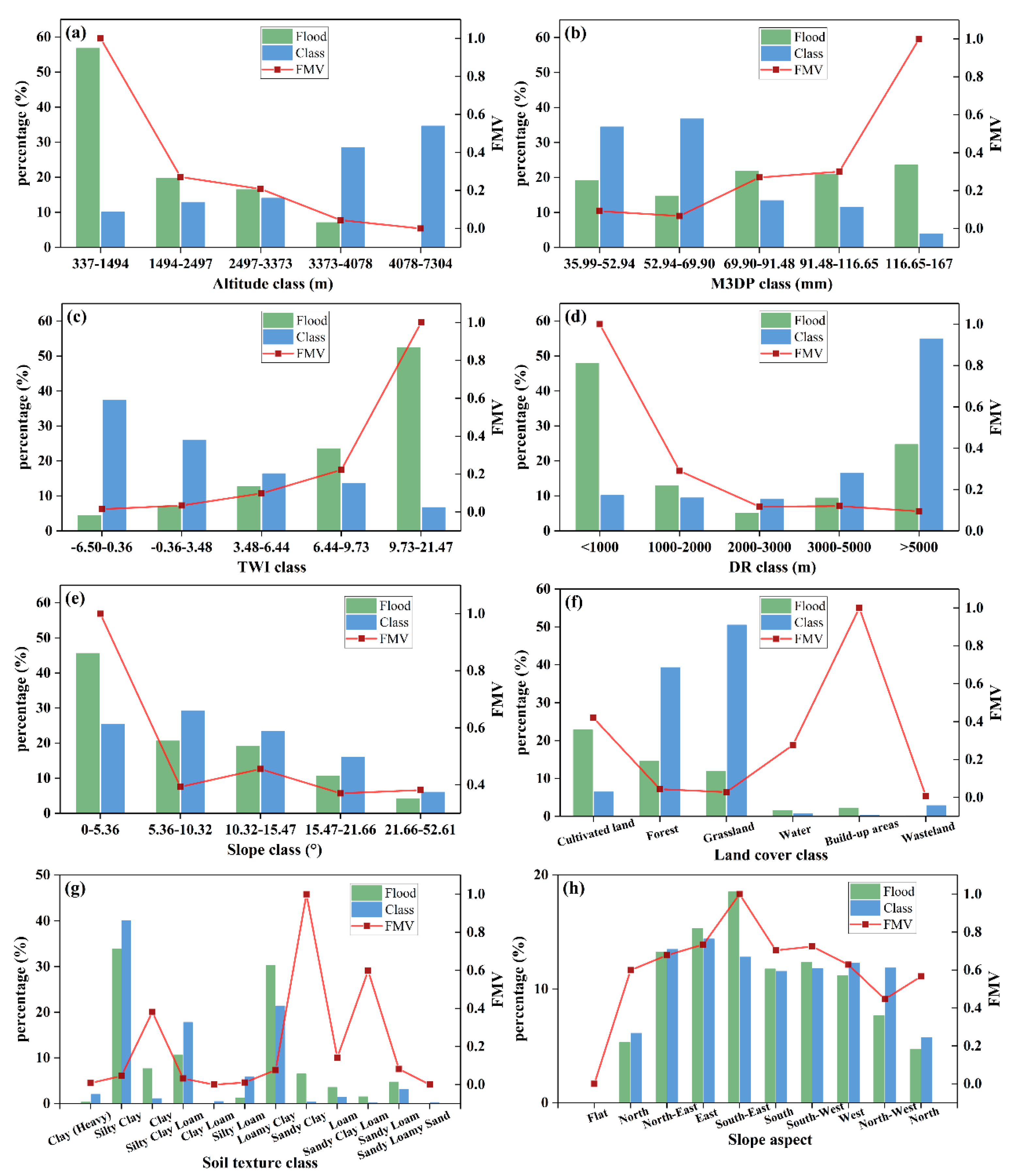
| Factors | Classes | Flood Pixels | Class Pixels | FR | FMV |
|---|---|---|---|---|---|
| Altitude (m) | 337–1494 | 193 | 12,150 | 5.65 | 1.00 |
| 1494–2497 | 67 | 15,551 | 1.53 | 0.27 | |
| 2497–3373 | 56 | 16,957 | 1.17 | 0.21 | |
| 3373–4078 | 24 | 34,442 | 0.25 | 0.04 | |
| 4078–7304 | 0 | 41,845 | 0.00 | 0.00 | |
| M3DP (mm) | 35.99–52.94 | 65 | 41,668 | 0.55 | 0.09 |
| 52.94–69.90 | 50 | 44,415 | 0.40 | 0.07 | |
| 69.90–91.48 | 74 | 16,184 | 1.63 | 0.27 | |
| 91.48–116.65 | 71 | 13,955 | 1.81 | 0.30 | |
| 116.65–167 | 80 | 4723 | 6.03 | 1.00 | |
| TWI | −6.50–0.36 | 15 | 45,278 | 0.12 | 0.02 |
| −0.36–3.48 | 24 | 31,427 | 0.27 | 0.03 | |
| 3.48–6.44 | 43 | 19,784 | 0.77 | 0.10 | |
| 6.44–9.73 | 80 | 16,359 | 1.74 | 0.22 | |
| 9.73–21.47 | 178 | 8097 | 7.82 | 1.00 | |
| DR (m) | <1000 | 163 | 12,271 | 4.73 | 1.00 |
| 1000–2000 | 44 | 11,403 | 1.37 | 0.29 | |
| 2000–3000 | 17 | 10,866 | 0.56 | 0.12 | |
| 3000–5000 | 32 | 19,994 | 0.57 | 0.12 | |
| >5000 | 84 | 66,411 | 0.45 | 0.10 | |
| Slope (°) | 0–5.36 | 155 | 30757 | 1.79 | 1.00 |
| 5.36–10.32 | 70 | 35,319 | 0.71 | 0.39 | |
| 10.32–15.47 | 65 | 28,303 | 0.82 | 0.46 | |
| 15.47–21.66 | 36 | 19,294 | 0.66 | 0.37 | |
| 21.66–52.61 | 14 | 7272 | 0.68 | 0.38 | |
| Land Cover | Agriculture land | 146 | 7772 | 3.55 | 0.42 |
| Forests | 93 | 47,515 | 0.37 | 0.04 | |
| Grassland | 76 | 61,071 | 0.24 | 0.03 | |
| Water | 10 | 808 | 2.34 | 0.28 | |
| Built-up areas | 14 | 313 | 8.45 | 1.00 | |
| Wasteland | 1 | 3466 | 0.05 | 0.01 | |
| Soil Texture | Heavy-Clay | 1 | 2577 | 0.15 | 0.01 |
| Silty-Clay | 115 | 51,601 | 0.85 | 0.05 | |
| Clay | 26 | 1402 | 7.04 | 0.38 | |
| Silty-Clay-Loam | 36 | 22,955 | 0.60 | 0.03 | |
| Clay-Loam | 0 | 554 | 0.00 | 0.00 | |
| Silty-Loam | 4 | 7575 | 0.20 | 0.01 | |
| Loamy-Clay | 103 | 27,590 | 1.42 | 0.08 | |
| Sandy-Clay | 22 | 453 | 18.43 | 1.00 | |
| Loam | 12 | 1749 | 2.60 | 0.14 | |
| Sandy-Clay-Loam | 5 | 172 | 11.03 | 0.60 | |
| Sandy-Loam | 16 | 4030 | 1.51 | 0.08 | |
| Sandy/Loamy-Sand | 0 | 287 | 0.00 | 0.00 | |
| Slope Aspect | Flat zones | 0 | 24 | 0.00 | 0.00 |
| North | 18 | 7380 | 0.87 | 0.60 | |
| North-East | 45 | 16,311 | 0.98 | 0.68 | |
| East | 52 | 17,402 | 1.06 | 0.73 | |
| South-East | 63 | 15,482 | 1.45 | 1.00 | |
| South | 40 | 13,972 | 1.02 | 0.70 | |
| South-West | 42 | 14,249 | 1.05 | 0.72 | |
| West | 38 | 14,866 | 0.91 | 0.63 | |
| North-West | 26 | 14,317 | 0.65 | 0.45 | |
| North | 16 | 6942 | 0.82 | 0.57 |
| Models | TP | TN | FP | FN | Sensitivity | Specificity | Accuracy | SD | RMSE | |
|---|---|---|---|---|---|---|---|---|---|---|
| Training | SVM | 222 | 214 | 50 | 58 | 79.29 | 81.06 | 80.15 | 0.41 | 0.37 |
| SVM-FMV | 229 | 218 | 43 | 54 | 80.92 | 83.52 | 82.17 | 0.38 | 0.36 | |
| CART | 253 | 229 | 19 | 43 | 85.47 | 92.34 | 88.60 | 0.33 | 0.30 | |
| CART-FMV | 245 | 213 | 27 | 59 | 80.59 | 88.75 | 84.49 | 0.36 | 0.35 | |
| CNN | 187 | 237 | 85 | 35 | 84.23 | 73.60 | 77.94 | 0.40 | 0.41 | |
| CNN-FMV | 242 | 216 | 30 | 56 | 81.21 | 87.80 | 84.19 | 0.35 | 0.33 | |
| Testing | SVM | 55 | 55 | 13 | 13 | 80.88 | 80.88 | 80.88 | 0.39 | 0.38 |
| SVM-FMV | 62 | 59 | 6 | 9 | 87.32 | 90.77 | 88.97 | 0.32 | 0.29 | |
| CART | 55 | 58 | 13 | 10 | 84.62 | 81.69 | 83.09 | 0.34 | 0.35 | |
| CART-FMV | 62 | 59 | 6 | 9 | 87.32 | 90.77 | 88.97 | 0.31 | 0.29 | |
| CNN | 43 | 62 | 25 | 6 | 87.76 | 71.26 | 77.21 | 0.40 | 0.40 | |
| CNN-FMV | 64 | 56 | 4 | 12 | 84.21 | 93.33 | 88.24 | 0.32 | 0.30 |
| Models | TP | TN | FP | FN | Sensitivity | Specificity | Accuracy | SD | RMSE | |
|---|---|---|---|---|---|---|---|---|---|---|
| Validating | SVM | 120 | 107 | 25 | 38 | 75.95 | 81.06 | 78.28 | 0.42 | 0.39 |
| SVM-FMV | 121 | 119 | 24 | 26 | 82.31 | 83.22 | 82.76 | 0.37 | 0.36 | |
| CART | 124 | 121 | 21 | 24 | 83.78 | 85.21 | 84.48 | 0.36 | 0.35 | |
| CART-FMV | 127 | 122 | 18 | 23 | 84.67 | 87.14 | 85.86 | 0.35 | 0.35 | |
| CNN | 104 | 123 | 41 | 22 | 82.54 | 75.00 | 78.28 | 0.40 | 0.41 | |
| CNN-FMV | 128 | 116 | 17 | 29 | 81.53 | 87.22 | 84.14 | 0.33 | 0.34 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Wang, J.; Xiong, J.; Cheng, W.; Sun, H.; Yong, Z.; Wang, N. Hybrid Models Incorporating Bivariate Statistics and Machine Learning Methods for Flash Flood Susceptibility Assessment Based on Remote Sensing Datasets. Remote Sens. 2021, 13, 4945. https://doi.org/10.3390/rs13234945
Liu J, Wang J, Xiong J, Cheng W, Sun H, Yong Z, Wang N. Hybrid Models Incorporating Bivariate Statistics and Machine Learning Methods for Flash Flood Susceptibility Assessment Based on Remote Sensing Datasets. Remote Sensing. 2021; 13(23):4945. https://doi.org/10.3390/rs13234945
Chicago/Turabian StyleLiu, Jun, Jiyan Wang, Junnan Xiong, Weiming Cheng, Huaizhang Sun, Zhiwei Yong, and Nan Wang. 2021. "Hybrid Models Incorporating Bivariate Statistics and Machine Learning Methods for Flash Flood Susceptibility Assessment Based on Remote Sensing Datasets" Remote Sensing 13, no. 23: 4945. https://doi.org/10.3390/rs13234945
APA StyleLiu, J., Wang, J., Xiong, J., Cheng, W., Sun, H., Yong, Z., & Wang, N. (2021). Hybrid Models Incorporating Bivariate Statistics and Machine Learning Methods for Flash Flood Susceptibility Assessment Based on Remote Sensing Datasets. Remote Sensing, 13(23), 4945. https://doi.org/10.3390/rs13234945