
DeepLabV3-Refiner-Based Semantic Segmentation Model for Dense 3D Point Clouds



Abstract
:1. Introduction
2. Materials and Methods
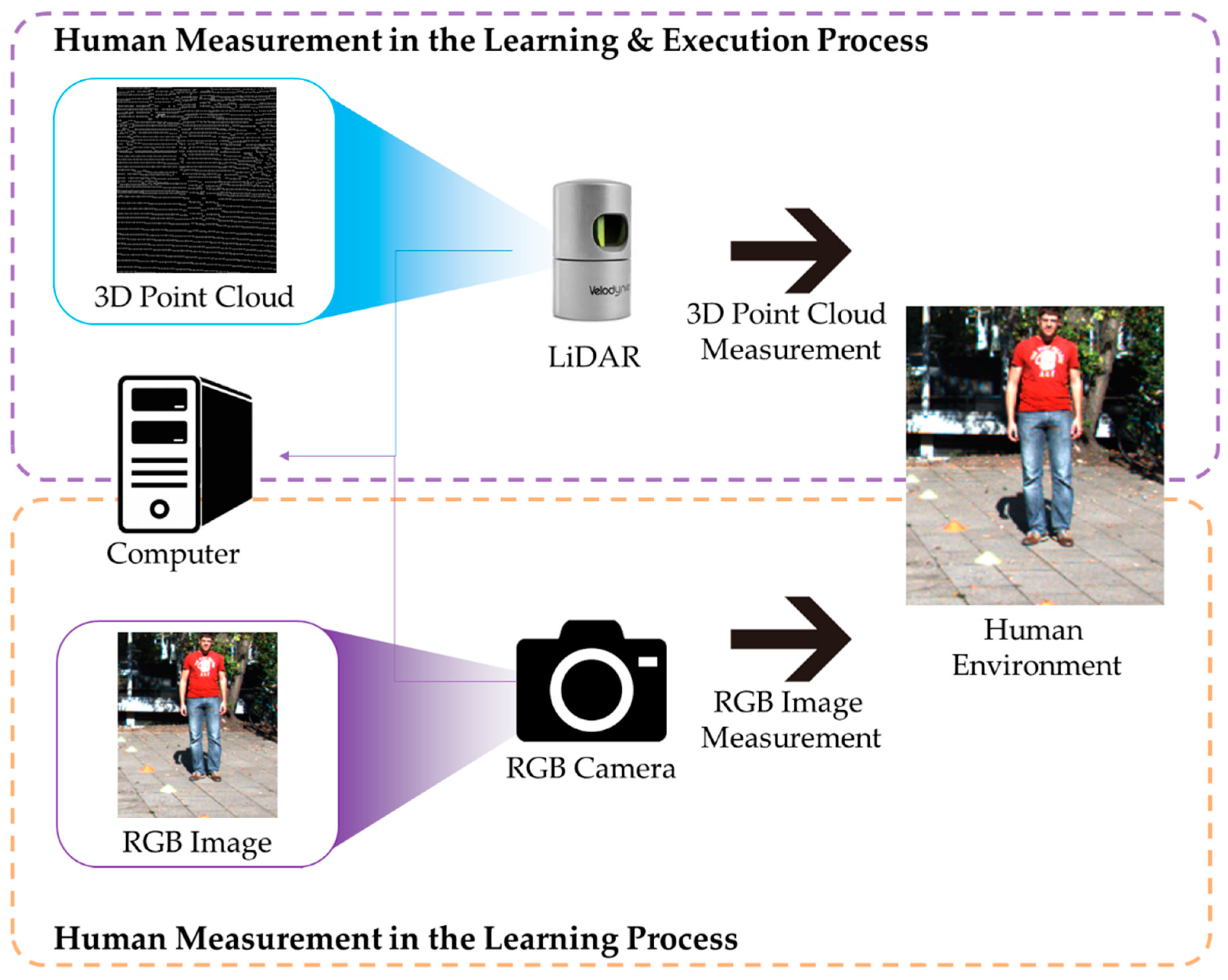
2.1. Materials
2.1.1. Segmentation Method
2.1.2. Increasing the Density of the 3D Point Cloud
2.2. Methods
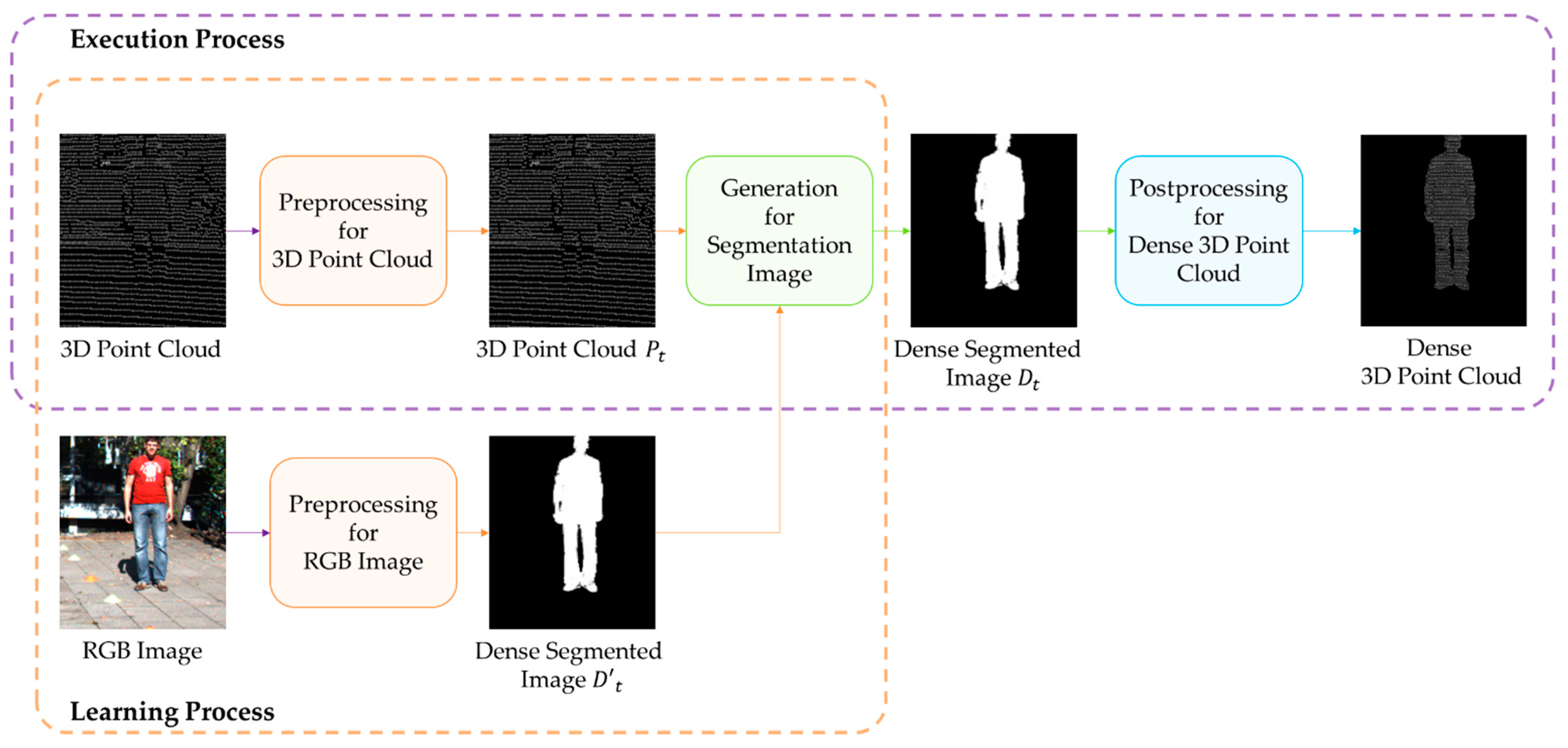
2.2.1. Overview
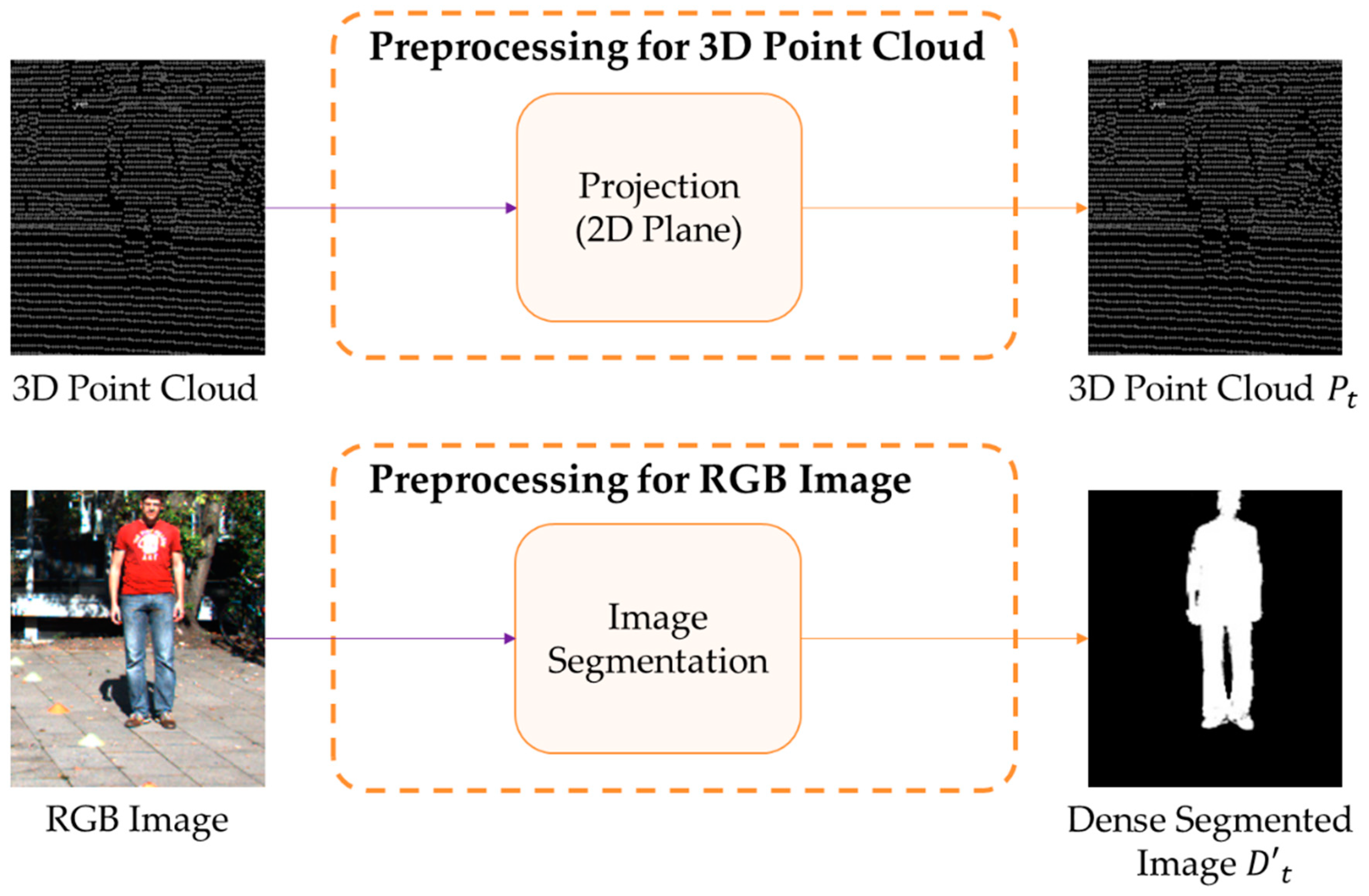
2.2.2. Preprocessing of 3D Point Cloud and RGB Image
2.2.3. Generation for Segmentation Image
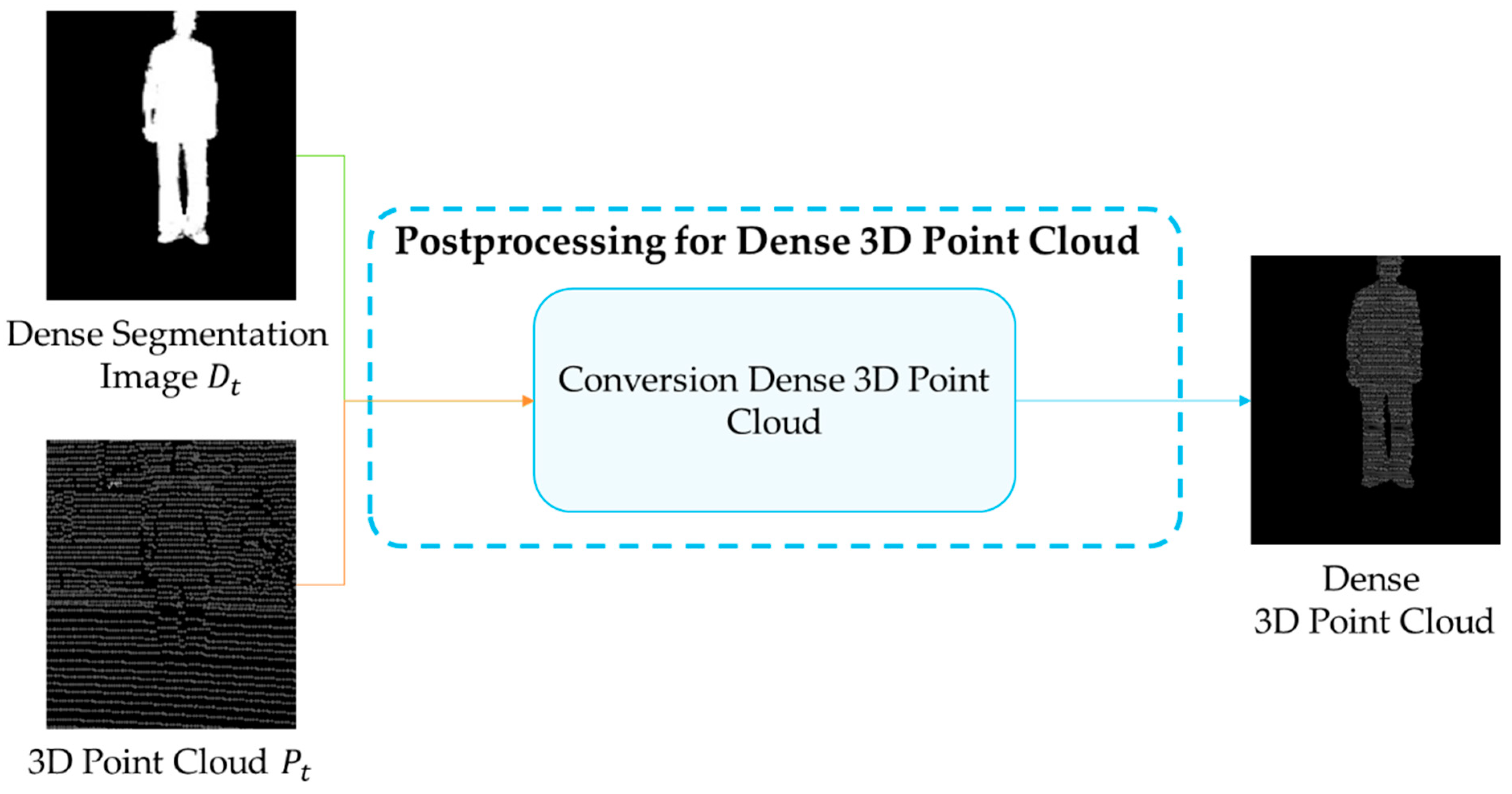
2.2.4. Postprocessing for Dense 3D Point Cloud
3. Experiment
3.1. Dataset and Preprocessing Results
3.2. Training Results of Generation for the Segmentation Image
3.3. Execution Results of Generation for the Segmentation Image
3.4. Postprocessing Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
References
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. Field Serv. Robot. 2017, 5, 621–635. [Google Scholar]
- Meftah, L.H.; Braham, R. A Virtual Simulation Environment using Deep Learning for Autonomous Vehicles Obstacle Avoidance. In Proceedings of the 2020 IEEE International Conference on Intelligence and Security Informatics (ISI), Arlington, VA, USA, 9–10 November 2020; pp. 1–7. [Google Scholar]
- Bojarski, M.; Testa, D.D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to End Learning for Self-Driving Cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Zhou, T.; Zhu, Q.; Du, J. Intuitive Robot Teleoperation for Civil Engineering Operations with Virtual Reality and Deep Learning Scene Reconstruction. Adv. Eng. Inform. 2020, 46, 101170–101191. [Google Scholar] [CrossRef]
- Yi, C.; Lu, D.; Xie, Q.; Liu, S.; Li, H.; Wei, M.; Wang, J. Hierarchical Tunnel Modeling from 3D Raw LiDAR Point Cloud. Comput.-Aided Des. 2019, 114, 143–154. [Google Scholar] [CrossRef]
- Zhu, Q.; Wu, J.; Hu, H.; Xiao, C.; Chen, W. LIDAR Point Cloud Registration for Sensing and Reconstruction of Unstructured Terrain. Appl. Sci. 2018, 8, 2318. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Nakamura, Y. Moving Humans Removal for Dynamic Environment Reconstruction from Slow-Scanning LIDAR Data. In Proceedings of the 2018 15th International Conference on Ubiquitous Robots (UR), Honolulu, HI, USA, 26–30 June 2018; pp. 449–454. [Google Scholar]
- Fang, Z.; Zhao, S.; Wen, S.; Zhang, Y. A Real-Time 3D Perception and Reconstruction System Based on a 2D Laser Scanner. J. Sens. 2018, 2018, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Wang, S.; Manivasagam, S.; Huang, Z.; Ma, W.; Yan, X.; Yumer, E.; Urtasun, R. S3: Neural Shape, Skeleton, and Skinning Fields for 3D Human Modeling. arXiv 2021, arXiv:2101.06571. [Google Scholar]
- Tian, Y.; Chen, L.; Sung, Y.; Kwak, J.; Sun, S.; Song, W. Fast Planar Detection System Using a GPU-based 3D Hough Transform for LiDAR Point Clouds. Appl. Sci. 2020, 10, 1744. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Luo, W.; Urtasun, R. RIXOR: Real-time 3D Object Detection from Point Clouds. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7652–7660. [Google Scholar]
- Iskakov, K.; Burkov, E.; Lempitsky, V.; Malkov, Y. Learnable Triangulation of Human Pose. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7718–7727. [Google Scholar]
- Nibali, A.; He, Z.; Morgan, S.; Prendergast, L. 3D Human Pose Estimation with 2D Marginal Heatmaps. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1477–1485. [Google Scholar]
- Luo, Z.; Golestaneh, S.A.; Kitani, K.M. 3D Human Motion Estimation via Motion Compression and Refinement. In Proceedings of the 2020 Asian Conference on Computer Vision (ACCV), Virtual, 30 November–4 December 2020; pp. 1–17. [Google Scholar]
- Te, G.; Hu, W.; Zheng, A.; Guo, A. RGCNN: Regularized Graph CNN for Point Cloud Segmentation. In Proceedings of the 26th ACM Multimedia Conference Multimedia (MM), Seoul, Korea, 22–26 October 2018; pp. 746–754. [Google Scholar]
- Meng, H.; Gao, L.; Lai, Y.; Manocha, D. VV-net: Voxel VAE Net with Group Convolutions for Point Cloud Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8500–8508. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Chibane, J.; Alldieck, T.; Pons-Moll, G. Implicit Functions in Feature Space for 3D Shape Reconstruction and Completion. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 6970–6981. [Google Scholar]
- Rao, Y.; Lu, J.; Zhou, J. Global-Local Bidirectional Reasoning for Unsupervised Representation Learning of 3D Point Clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 6970–6981. [Google Scholar]
- Kwak, J.; Sung, Y. Automatic 3D Landmark Extraction System based on an Encoder-decoder using Fusion of Vision and LiDAR for Feature Extraction. Remote Sens. 2020, 12, 1142. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–12. [Google Scholar]
- Lin, C.; Kong, C.; Lucey, S. Learning Efficient Point Cloud Generation for Dense 3D Object Reconstruction. Thirty-Second Aaai Conf. Artif. Intell. 2018, 32, 7114–7121. [Google Scholar]
- Park, K.; Kim, S.; Sohn, K. High-Precision Depth Estimation Using Uncalibrated LiDAR and Stereo Fusion. IEEE Trans. Intell. Transp. Syst. 2020, 21, 321–335. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 2017 Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Tian, Y.; Song, W.; Chen, L.; Sung, Y.; Kwak, J.; Sun, S. A Fast Spatial Clustering Method for Sparse LiDAR Point Clouds Using GPU Programming. Sensors 2020, 20, 2309. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tina, Y.; Chen, L.; Song, W.; Sung, Y.; Woo, S. DGCB-Net: Dynamic Graph Convolutional Broad Network for 3D Object Recognition in Point Cloud. Remote Sens. 2021, 13, 66. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5079–5088. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection from RGB-D Data. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar]
- Simon, M.; Milz, S.; Amende, K.; Gross, H. Complex-YOLO: An Euler-Region-Proposal for Real-time 3D Object Detection on Point Clouds. arXiv 2018, arXiv:1803.06199. [Google Scholar]
- Ali, W.; Abdelkarim, S.; Zidan, M.; Zahran, M.; Sallab, A.E. YOLO3D: End-to-End Real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–12. [Google Scholar]
- Qi, X.; Liao, R.; Jia, J.; Fidler, S.; Urtasun, R. 3D Graph Neural Networks for RGBD Semantic Segmentation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5199–5208. [Google Scholar]
- Gojcic, Z.; Zhou, C.; Wegner, J.D.; Wieser, A. The Perfect Match: 3D Point Cloud Matching with Smoothed Densities. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 5545–5554. [Google Scholar]
- Yifan, W.; Wu, S.; Huang, H.; Cohen-Or, D.; Sorkine-Hornung, O. Patch-based Progressive 3D Point Set Upsampling. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; pp. 5958–5967. [Google Scholar]
- Dai, H.; Shao, L. PointAE: Point Auto-encoder for 3D Statistical Shape and Texture Modelling. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Korea, 15–21 June 2019; pp. 5410–5419. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Robust 3D Hand Pose Estimation in Single Depth Images: From Single-View CNN to Multi-View CNNs. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3593–3601. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Cambridge, MA, USA, 18–20 June 2012; pp. 3354–3361. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]






| Architecture | Parameter | |
|---|---|---|
| Backbone | ResNet-50 | - |
| ASPP | ASPP | 3, 6, 9 |
| Decoder | Conv2D + Batch Normalization + Relu | 288 |
| Conv2D + Batch Normalization + Relu | 152 | |
| Conv2D + Batch Normalization + Relu | 80 | |
| Conv2D | 4 |
| Index | Architecture | Parameter |
|---|---|---|
| 1 | Concatenate | - |
| 2 | Conv2D + Batch Normalization + Relu | 6 |
| 3 | Conv2D + Batch Normalization + Relu | 24 |
| 4 | UpSampling | 2 |
| 5 | Concatenate | - |
| 6 | Conv2D + Batch Normalization + Relu | 16 |
| 7 | Conv2D + Batch Normalization + Relu | 12 |
| 8 | Conv2D | 2 |
| Model | Loss | Accuracy |
|---|---|---|
| DeepLabV3 [21] | 0.1103 | 91.40% |
| DeepLabV3 [21] (Use Background) | 0.1039 | 91.74% |
| Proposed Method | 0.1464 () 0.1053 () 0.00004 () 0.0410 () | 91.75% |
| Proposed Method (Use Background) | 0.1294 () 0.0917 () 0.00001 () 0.0376 () | 92.38% |
| Index | Collected RGB Image | Collected 3D Point Cloud | Ground Truth | Difference Image-Based Density Correction [20] |
|---|---|---|---|---|
| 1 |  |  |  |  |
| 2 |  |  |  |  |
| 3 |  |  |  |  |
| 4 |  |  |  |  |
| 5 |  |  |  |  |
| 6 |  |  |  |  |
| Index | DeepLabV3 [21] | DeepLabV3 [21] (Using Background) | Proposed Method | Proposed Method (Using Background) |
| 1 |  |  |  |  |
| 2 |  |  |  |  |
| 3 |  |  |  |  |
| 4 |  |  |  |  |
| 5 |  |  |  |  |
| 6 |  |  |  |  |
| Method | Number of 3D Point Clouds for Human Object | Number of 3D Point Clouds | Ratio with of Number of 3D Point Clouds for Human Object | ||
|---|---|---|---|---|---|
| Suitable 3D Point Clouds | Unsuitable 3D Point Clouds | Suitable 3D Point Clouds | Unsuitable 3D Point Clouds | ||
| Difference Image-Based Density Correction [20] | 617,407 | 1,937,792 | 2,173,354 | 3.138 | 3.520 |
| DeepLabV3 [21] | 3,116,982 | 1,1407,208 | 5.048 | 2.279 | |
| DeepLabV3 [21] (Using Background) | 2,710,732 | 459,594 | 4.390 | 0.744 | |
| Proposed Method | 2,063,935 | 342,018 | 3.343 | 0.553 | |
| Proposed Method (Using Background) | 2,901,549 | 324,842 | 4.699 | 0.526 | |
| Method | Inference Time (s) |
|---|---|
| DeepLabV3 [21] | 0.22 |
| DeepLabV3 [21] (Using Background) | 0.23 |
| Proposed Method | 0.13 |
| Proposed Method (Using Background) | 0.14 |
| Index | Collected RGB Image | Collected 3D Point Cloud | Proposed Method | Proposed Method (Using Background) |
|---|---|---|---|---|
| 1 | | |  |  |
| 2 | | |  |  |
| 3 | | |  |  |
| 4 | | |  |  |
| 5 | | |  |  |
| 6 | | |  |  |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kwak, J.; Sung, Y. DeepLabV3-Refiner-Based Semantic Segmentation Model for Dense 3D Point Clouds. Remote Sens. 2021, 13, 1565. https://doi.org/10.3390/rs13081565
Kwak J, Sung Y. DeepLabV3-Refiner-Based Semantic Segmentation Model for Dense 3D Point Clouds. Remote Sensing. 2021; 13(8):1565. https://doi.org/10.3390/rs13081565
Chicago/Turabian StyleKwak, Jeonghoon, and Yunsick Sung. 2021. "DeepLabV3-Refiner-Based Semantic Segmentation Model for Dense 3D Point Clouds" Remote Sensing 13, no. 8: 1565. https://doi.org/10.3390/rs13081565
APA StyleKwak, J., & Sung, Y. (2021). DeepLabV3-Refiner-Based Semantic Segmentation Model for Dense 3D Point Clouds. Remote Sensing, 13(8), 1565. https://doi.org/10.3390/rs13081565