
RSIMS: Large-Scale Heterogeneous Remote Sensing Images Management System

 , , and
, , and
Abstract
:
1. Introduction
2. Materials and Methods
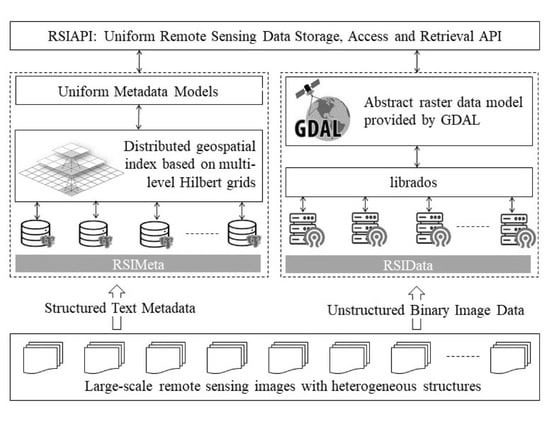
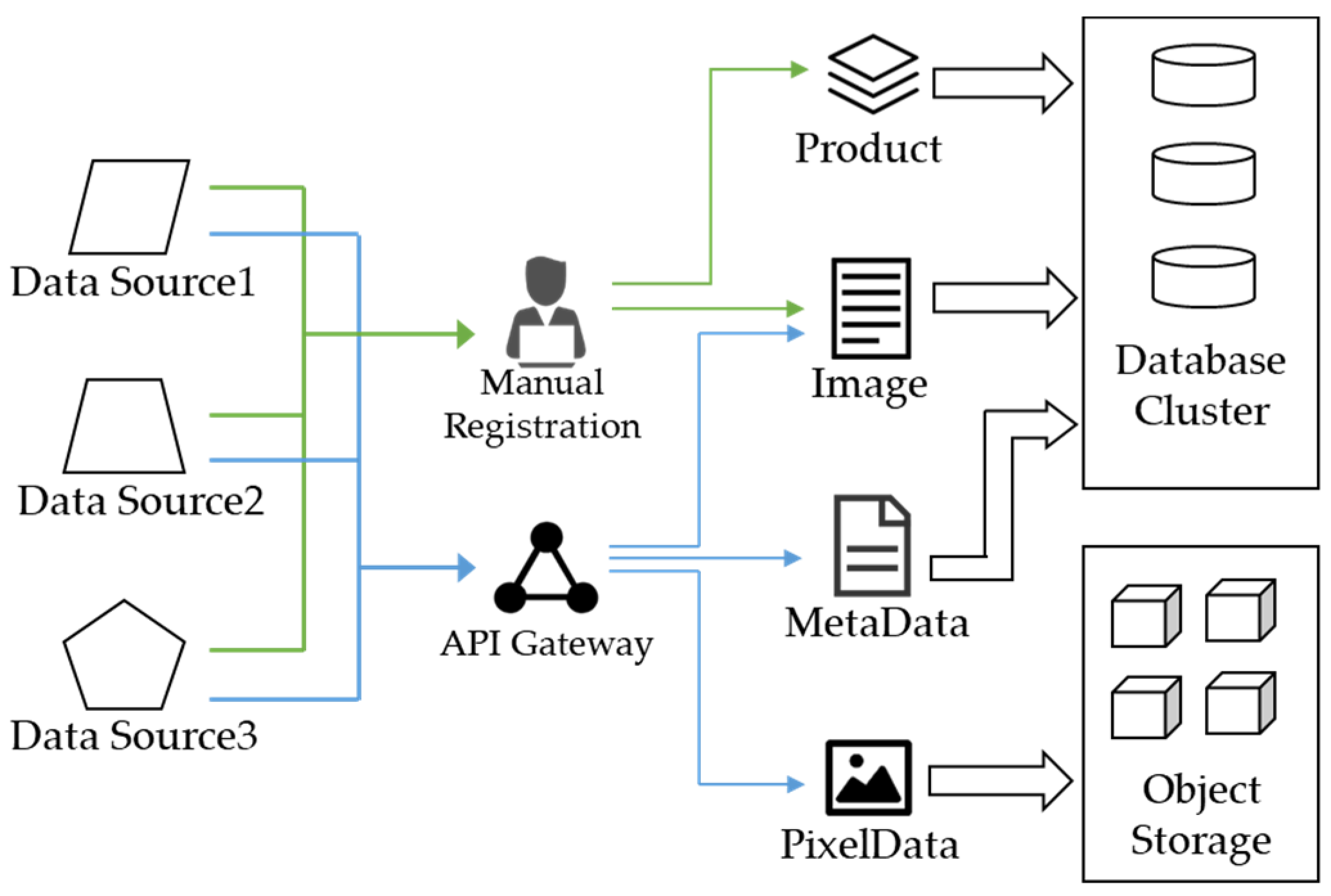
2.1. The System Architecture of RSIMS
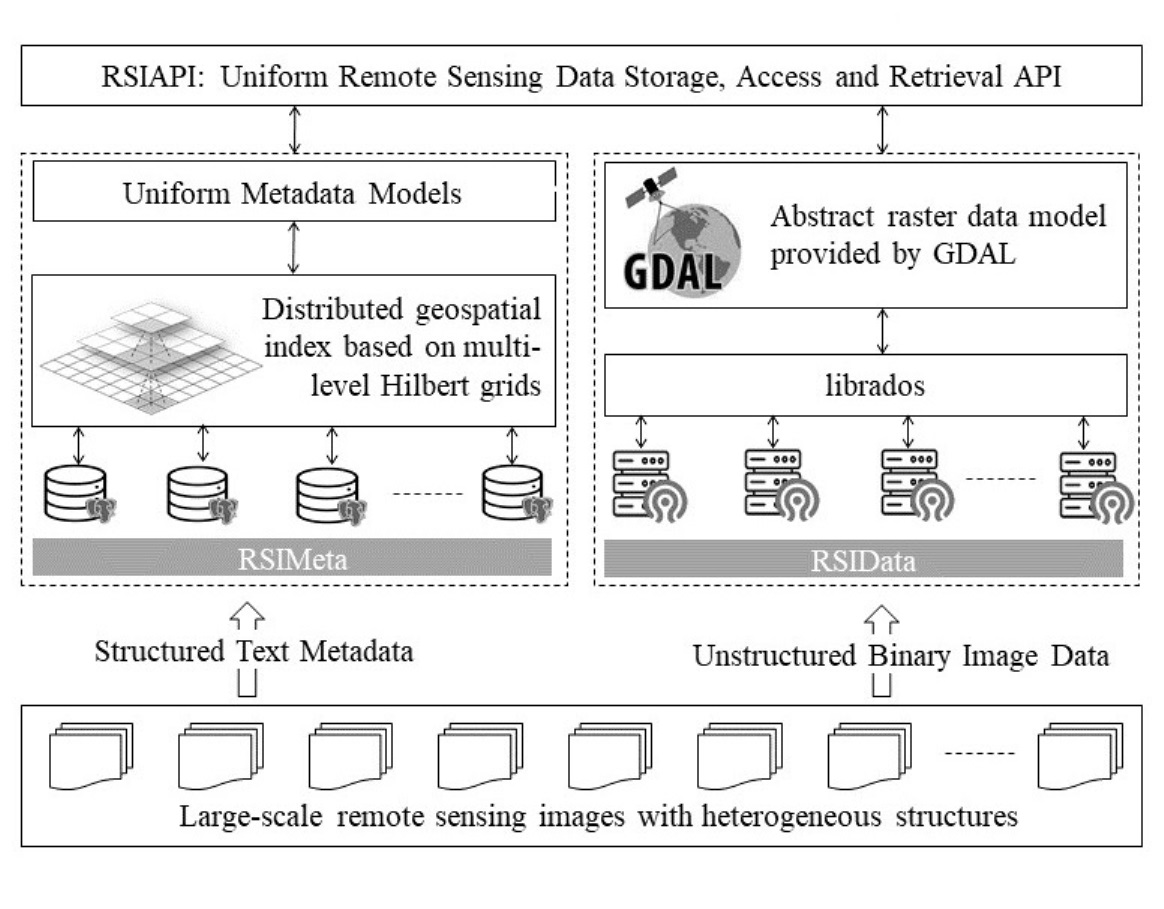
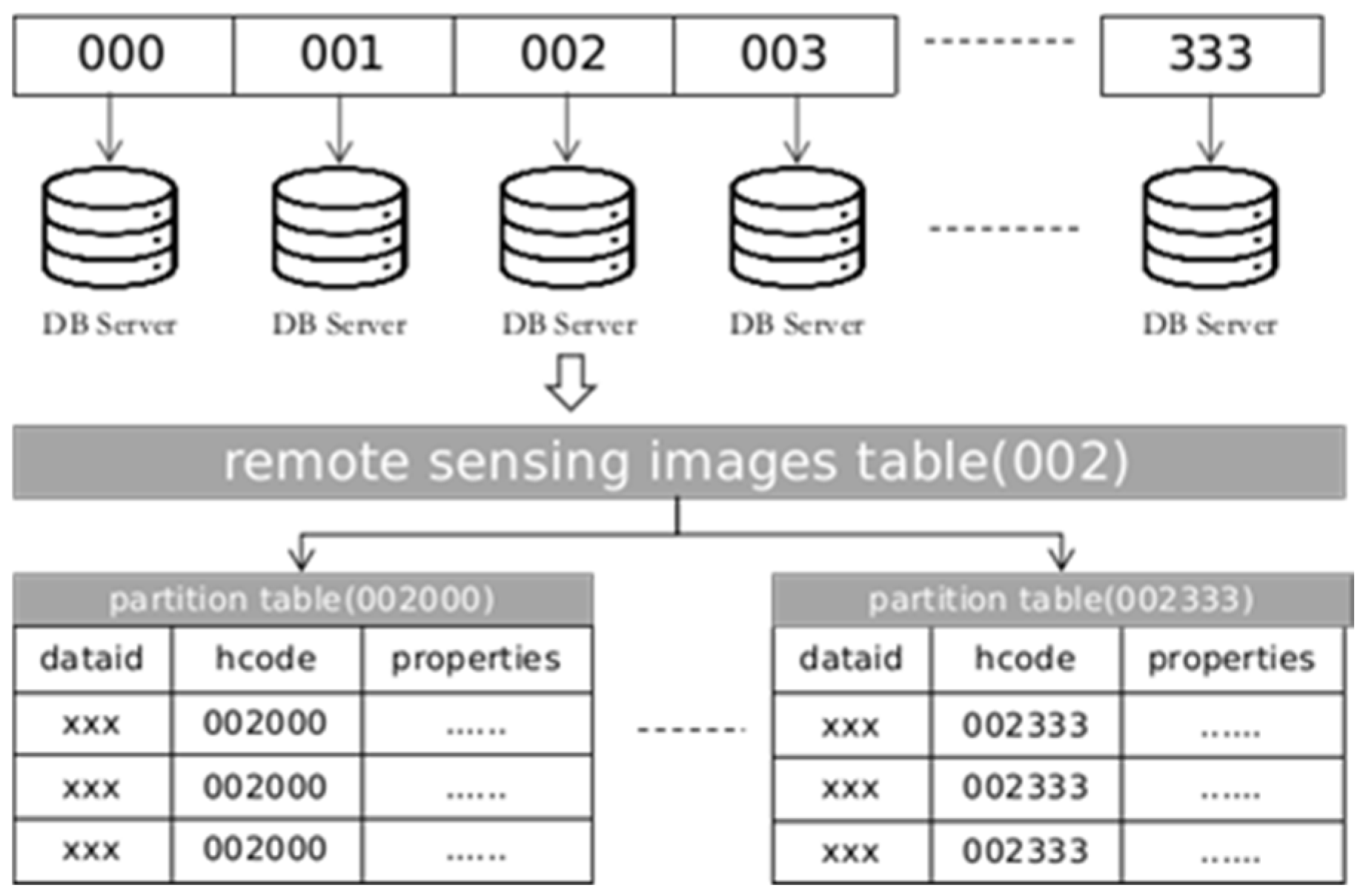
2.2. RSIMeta: Metadata Management of Large-Scale Images with Heterogeneous Structures
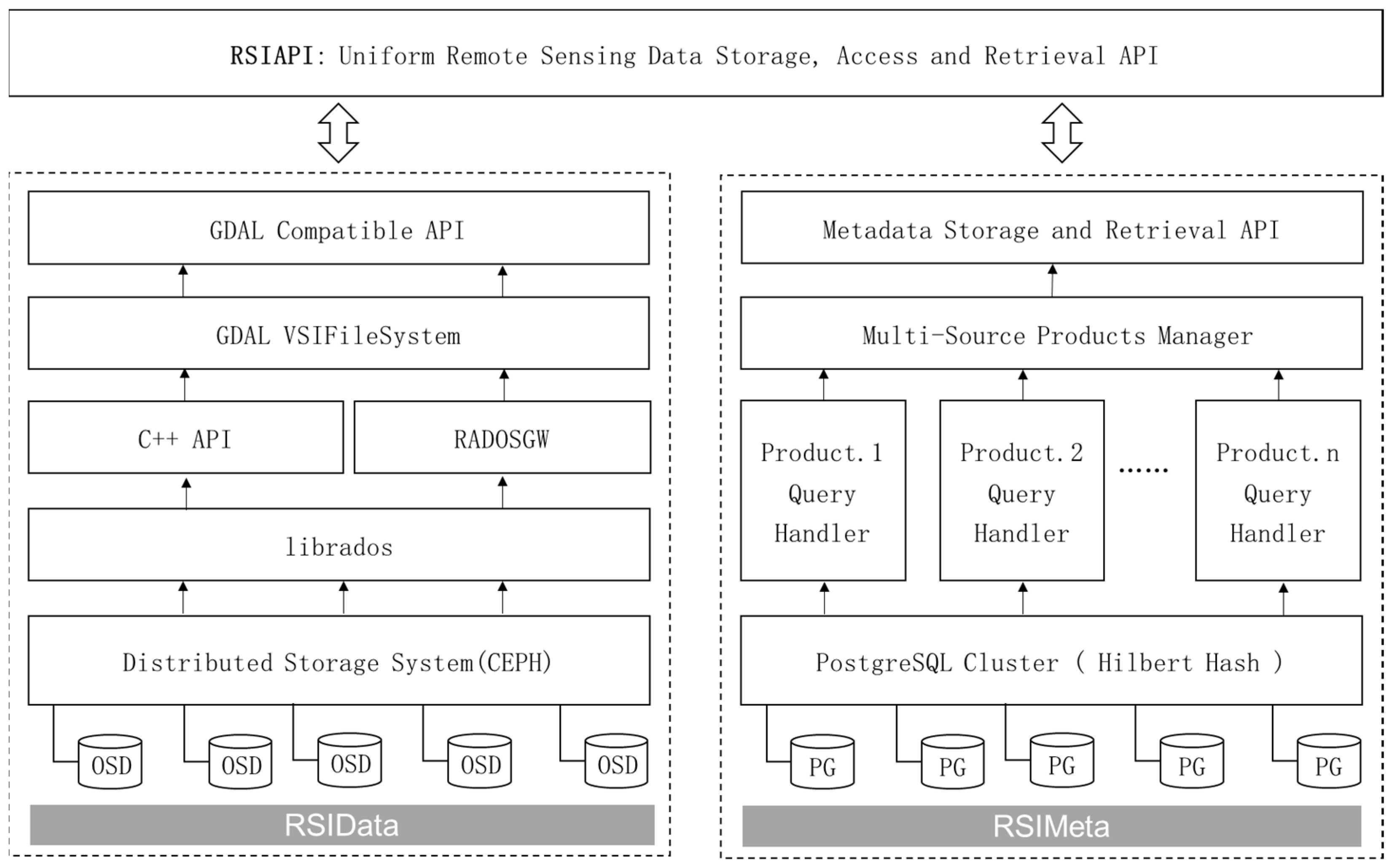
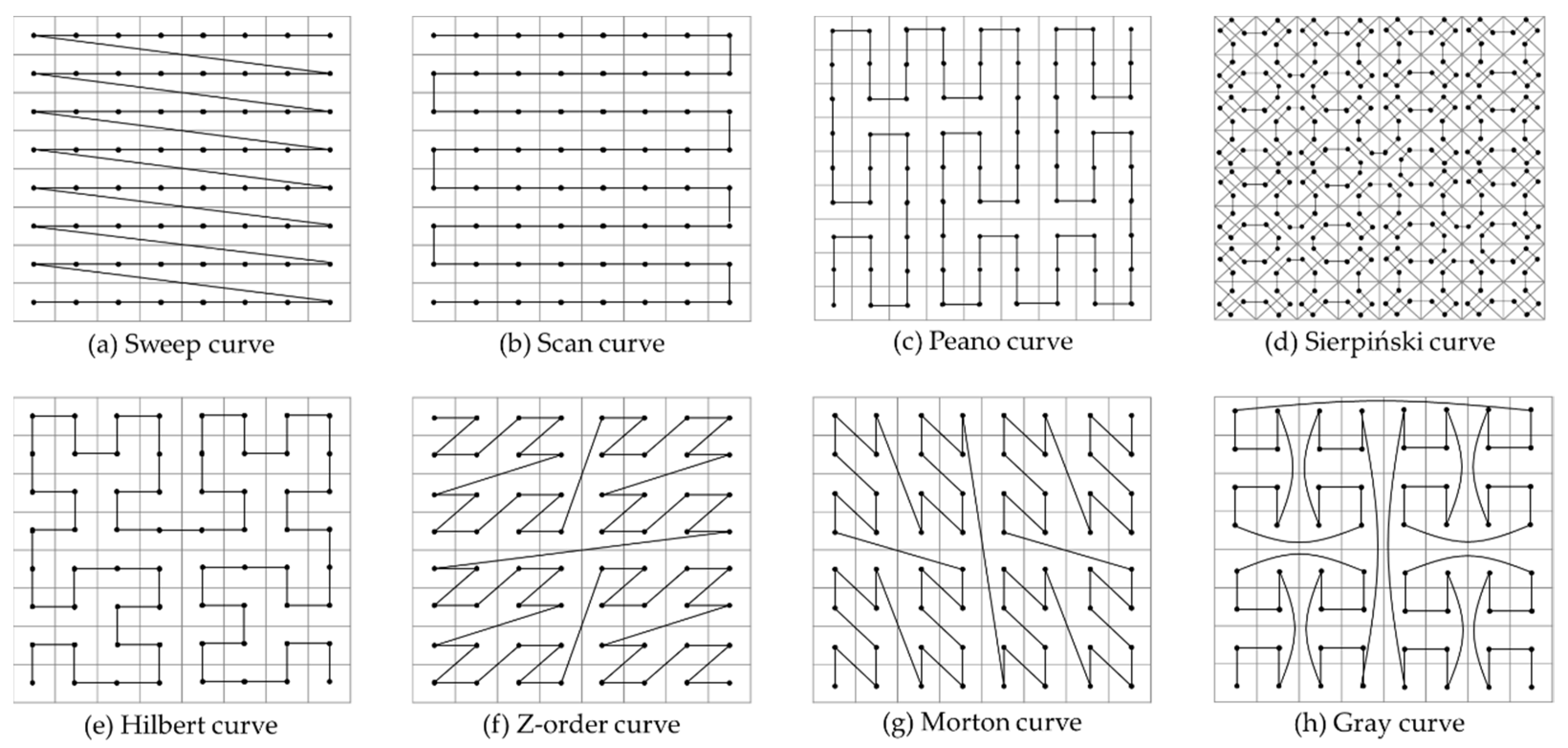
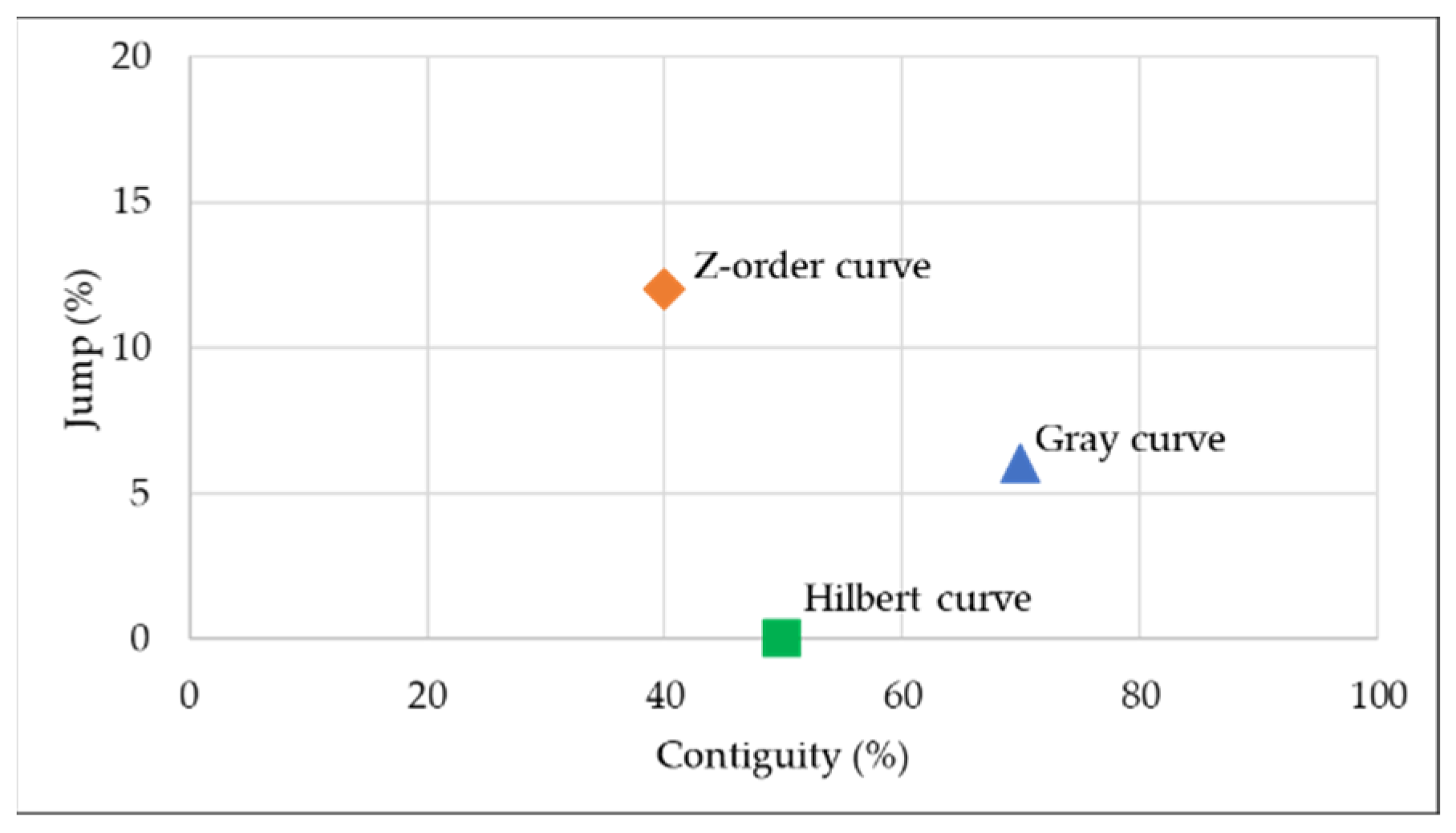
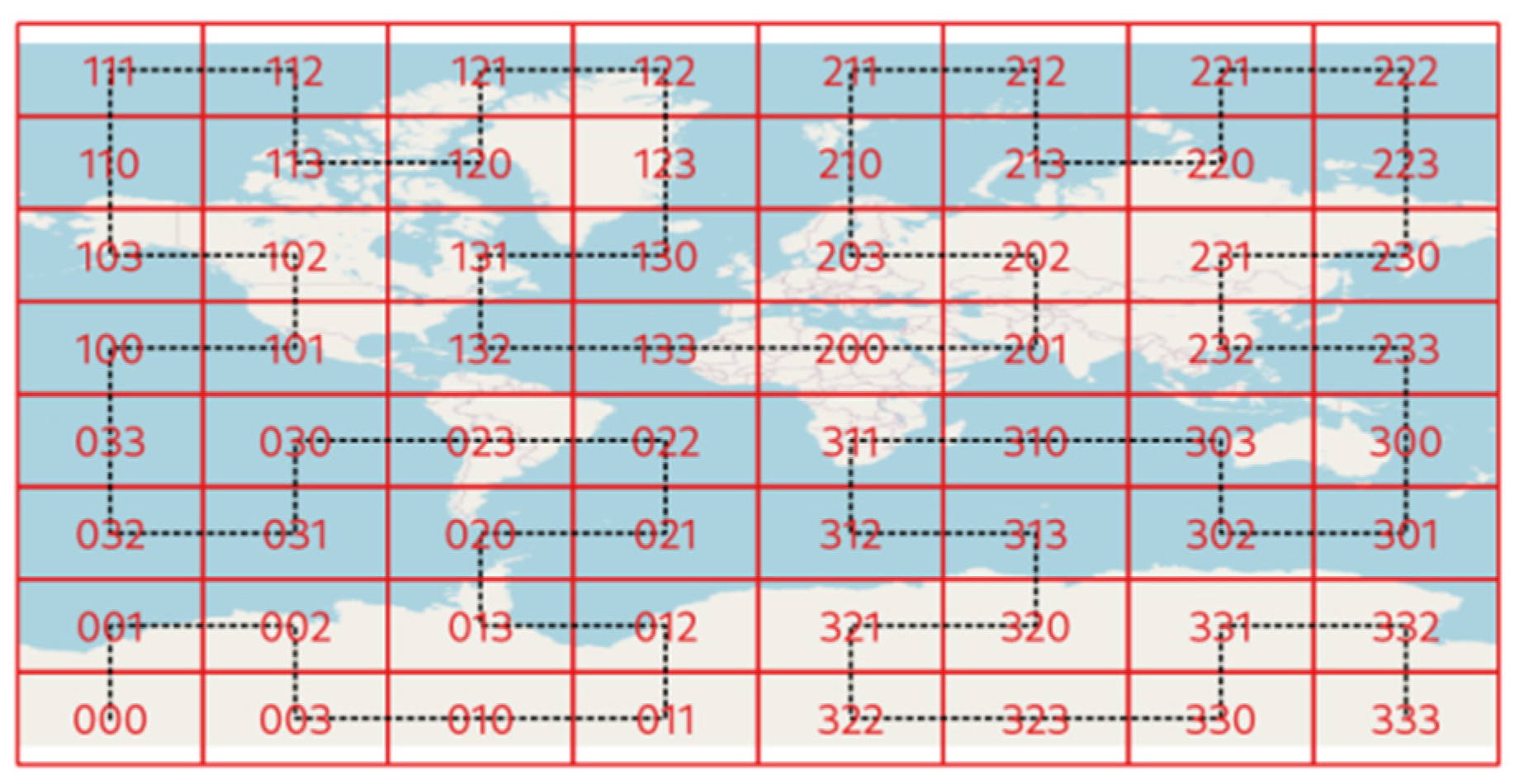
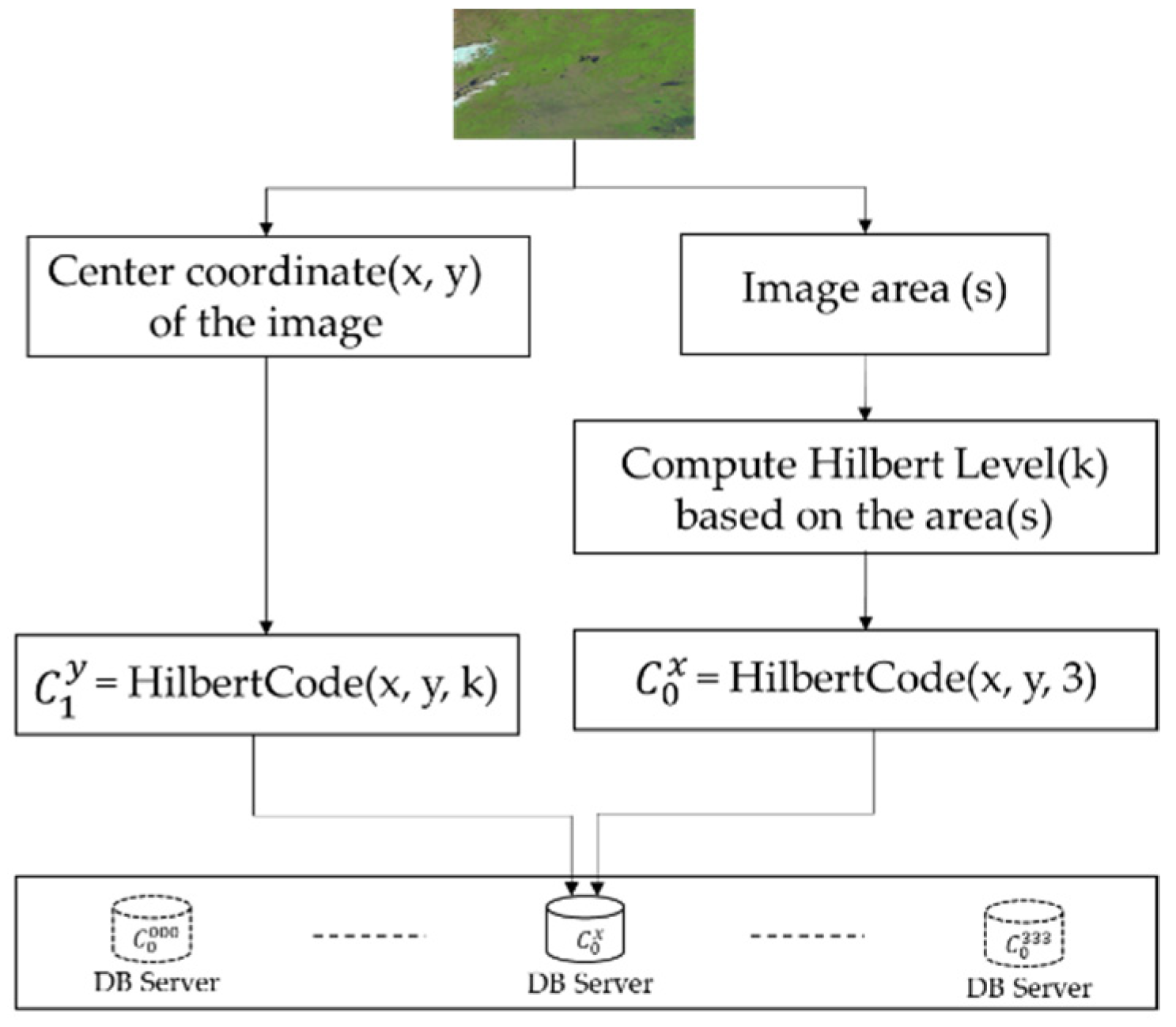
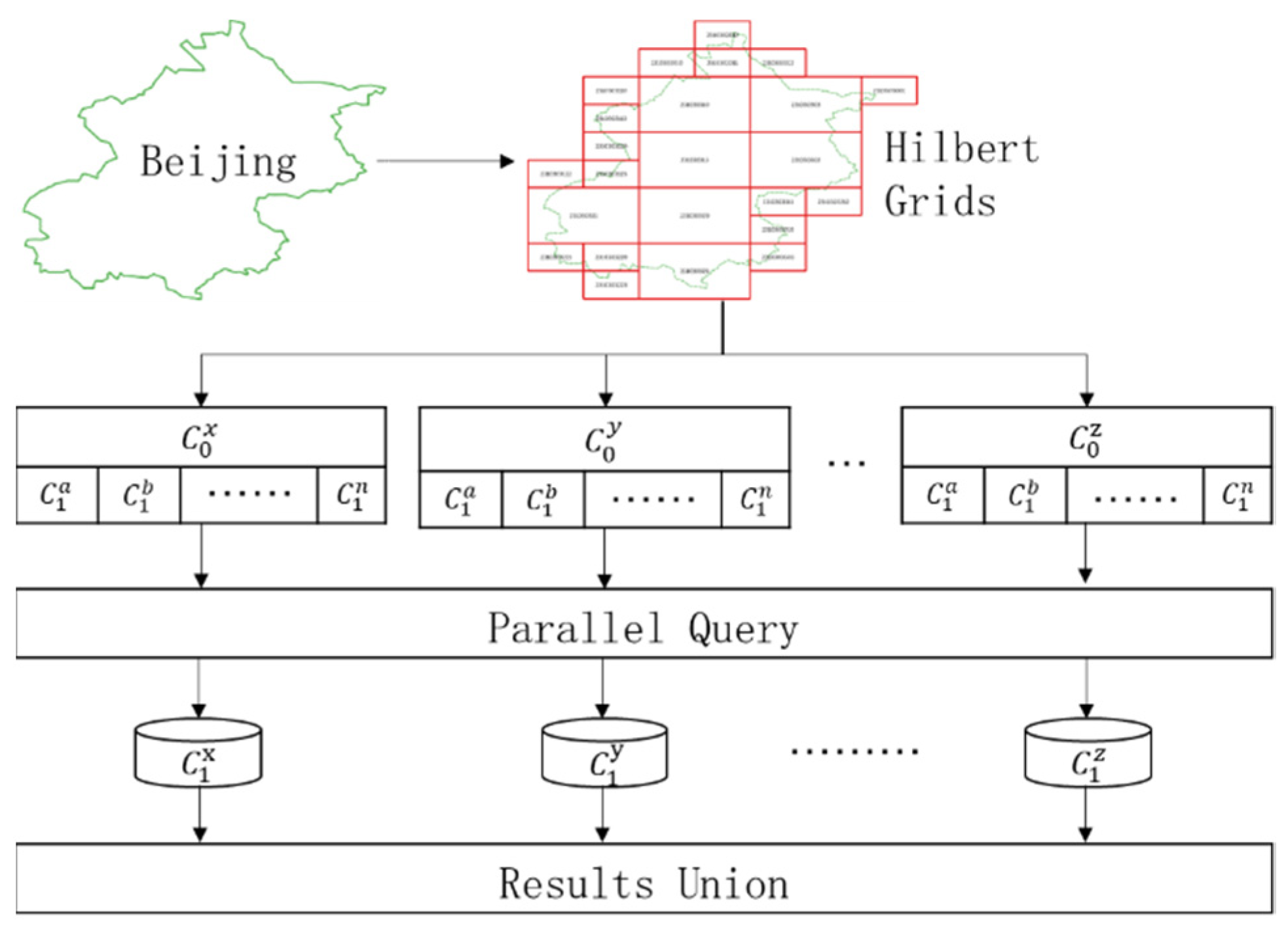
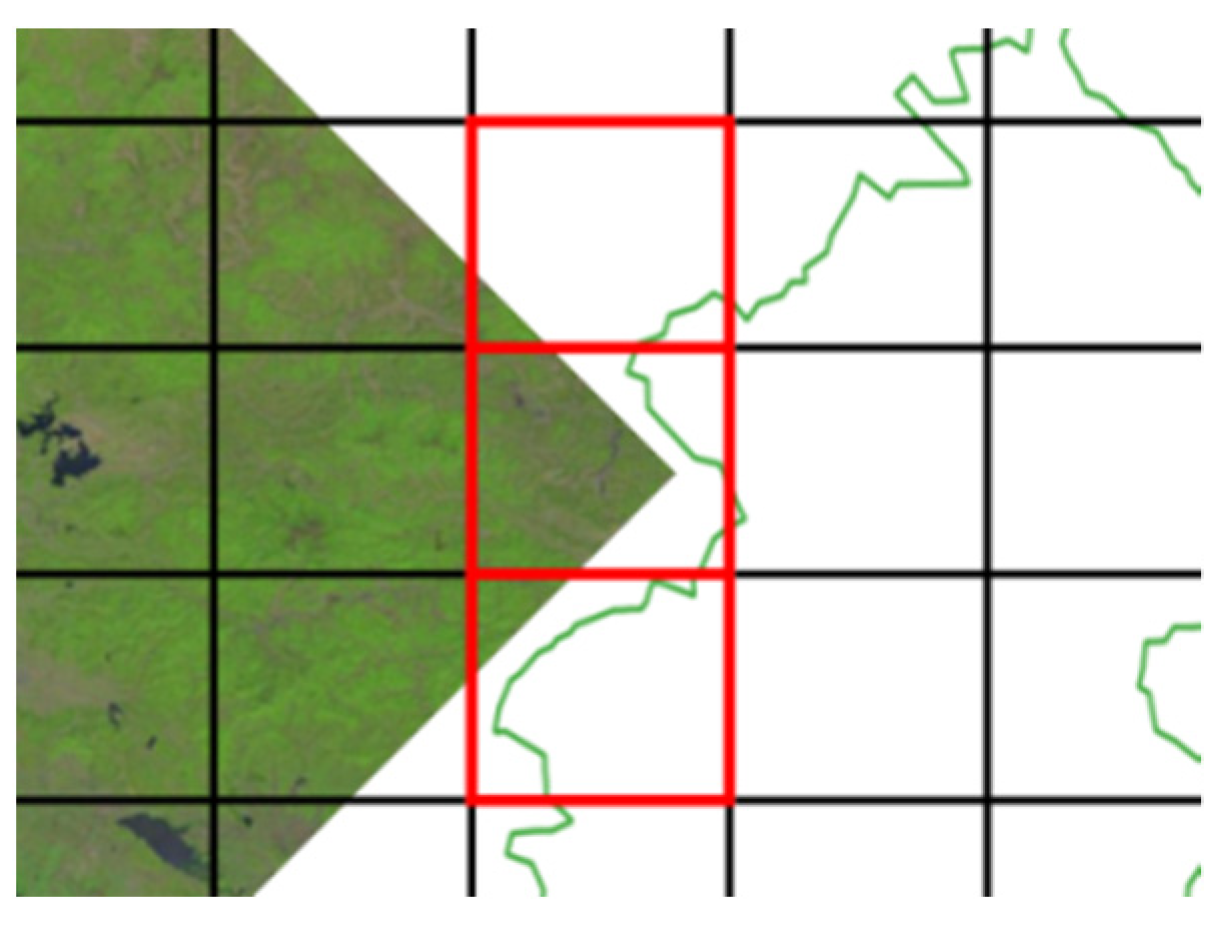
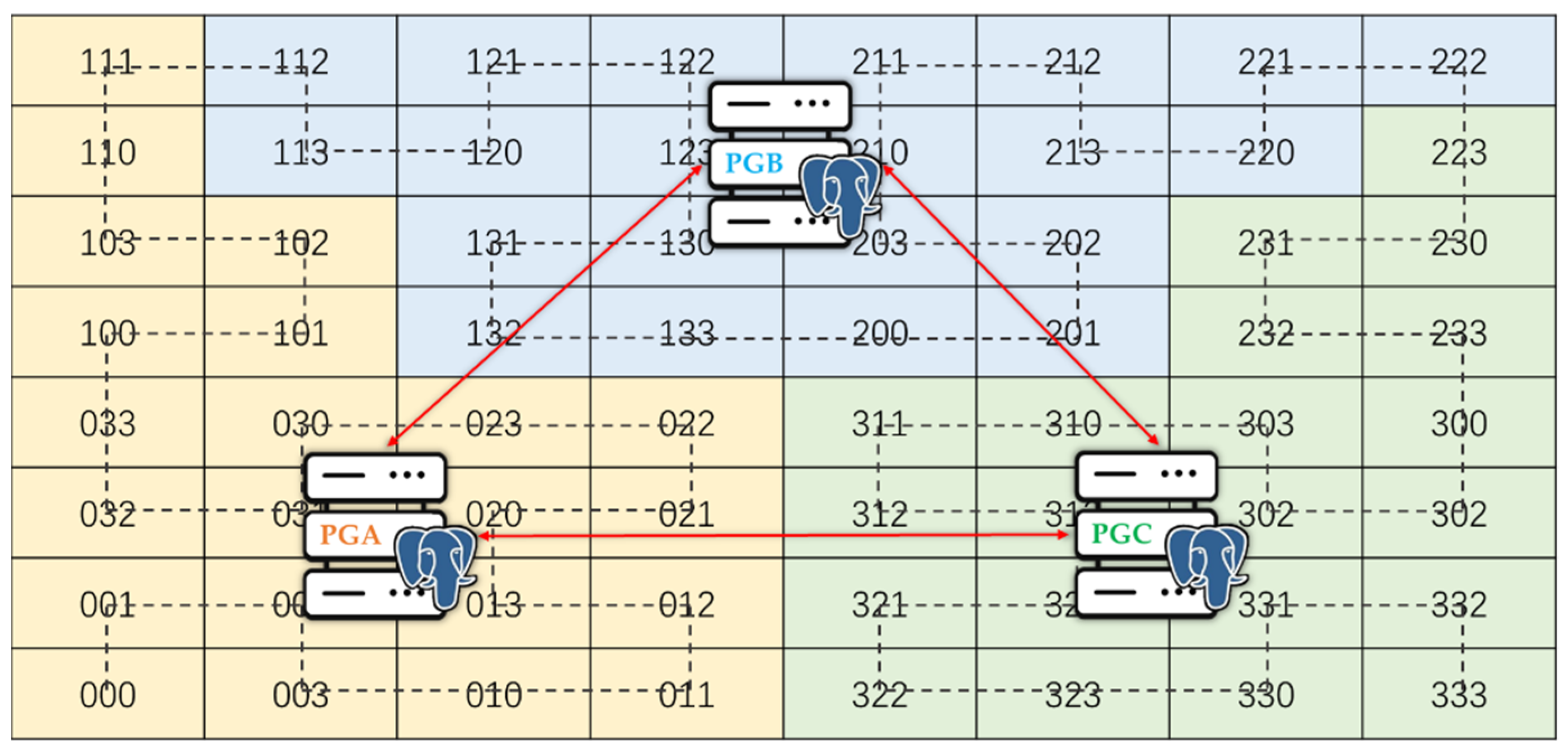
2.2.1. Distributed Spatial Index Based on Multi-Level Hilbert Grids
2.2.2. Remote Sensing Images Index and Retrieval Based on Hilbert Curve
- is same as if are generate from or ;
- is generated from rotating 90 degrees clockwise if are generate from ;
- is generated from rotating 90 degrees counterclockwise if are generate from ;
| Algorithm 1 Hilbert code computing |
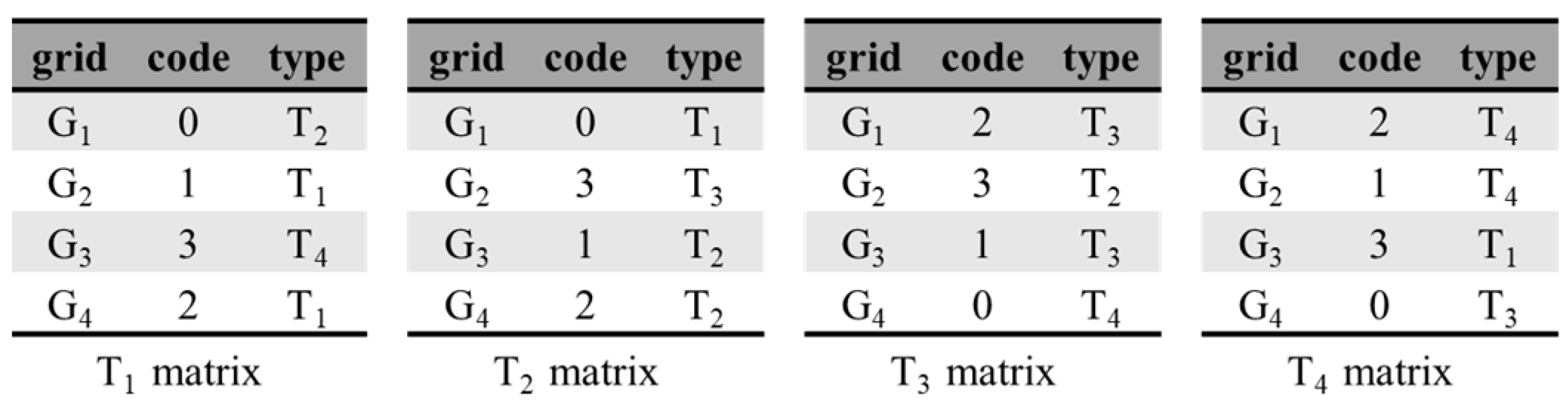
| function HilbertCode(x, y, k){ ””” params: x: the longitude value of a point, −180 ≤ x ≤ 180 y: the latitude value of a point, −90 ≤ y ≤ 90 k: the level of Hilbert grids, 0 ≤ k ≤ 32 ””” hcode, htype = 0, T1 while k > 0: m, n = HilbertGrid(k, x, y) mb, nb = binary(m), binary(n) mk, nk = mb & (2 ≪ k), nb & (2 ≪ k) grid_idx= mk*2 + nk ck = query_code(M[htype], grid_idx) hcode = hcode ≪ 2 | ck htype = query_type(M[htype], grid_idx) k = k – 1 return hcode } |
- M = [T1 matrix, T2 matrix, T3 matrix, T4 matrix];
- function HilbertGrid(k, x, y): calculate the position of the grid in Cartesian coordinate system;
- function binary(m): convert decimal to binary;
- function query_code(matrix, grid): query the code from the curve-transition matrix of some type based on the identification of the grid;
- function query_type(matrix, grid): query the Hilbert curve shape type of level(k − 1) from the curve-transition matrix of some type based on the identification of the grid.
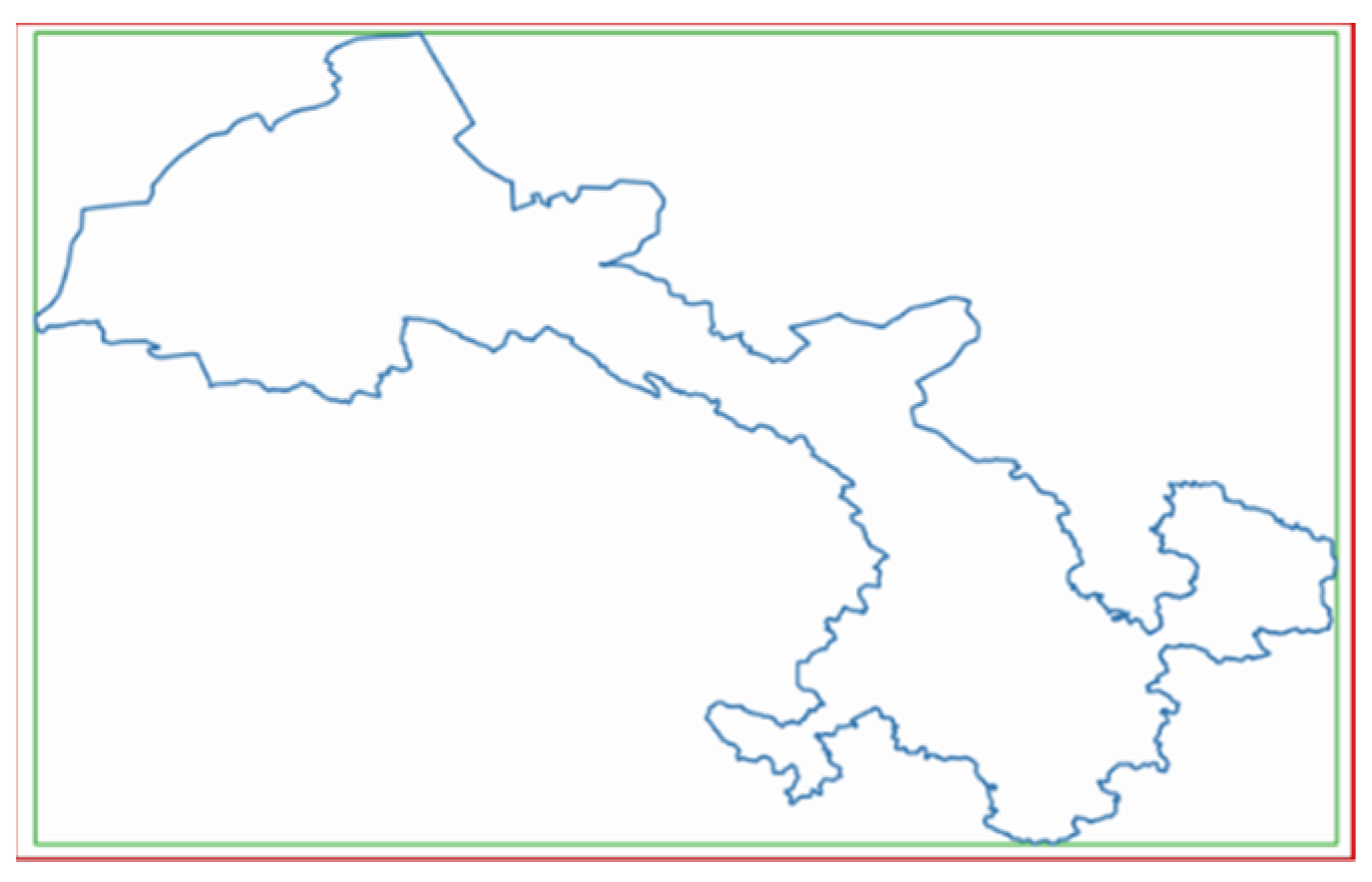
- Subdivide G into four sub-regions (represented by SG) of almost the same size;
- Iterate over SG, and evaluate the spatial relationship between each sub-region of SG and S. If the sub-region is contained in S, then put the sub-region in the list of results; if the sub-region intersects with S, then set the sub-region as a new G, and then return to step (1); if the sub-region and S are disjoint, then omit the sub-region.
| Algorithm 2 Hilbert grid coverage |
| GridRegions = [ ] function HilbertCoverage(region) { ext = GridExtent(region) if ext < GRID_EXT * 4: GridRegions.push(ext) return rgs = QuarterDivide(region) for rg in rgs: if S.contains(rg): GridRegions.push(rg) if S.intersects(rg): HilbertGrids(rg) |
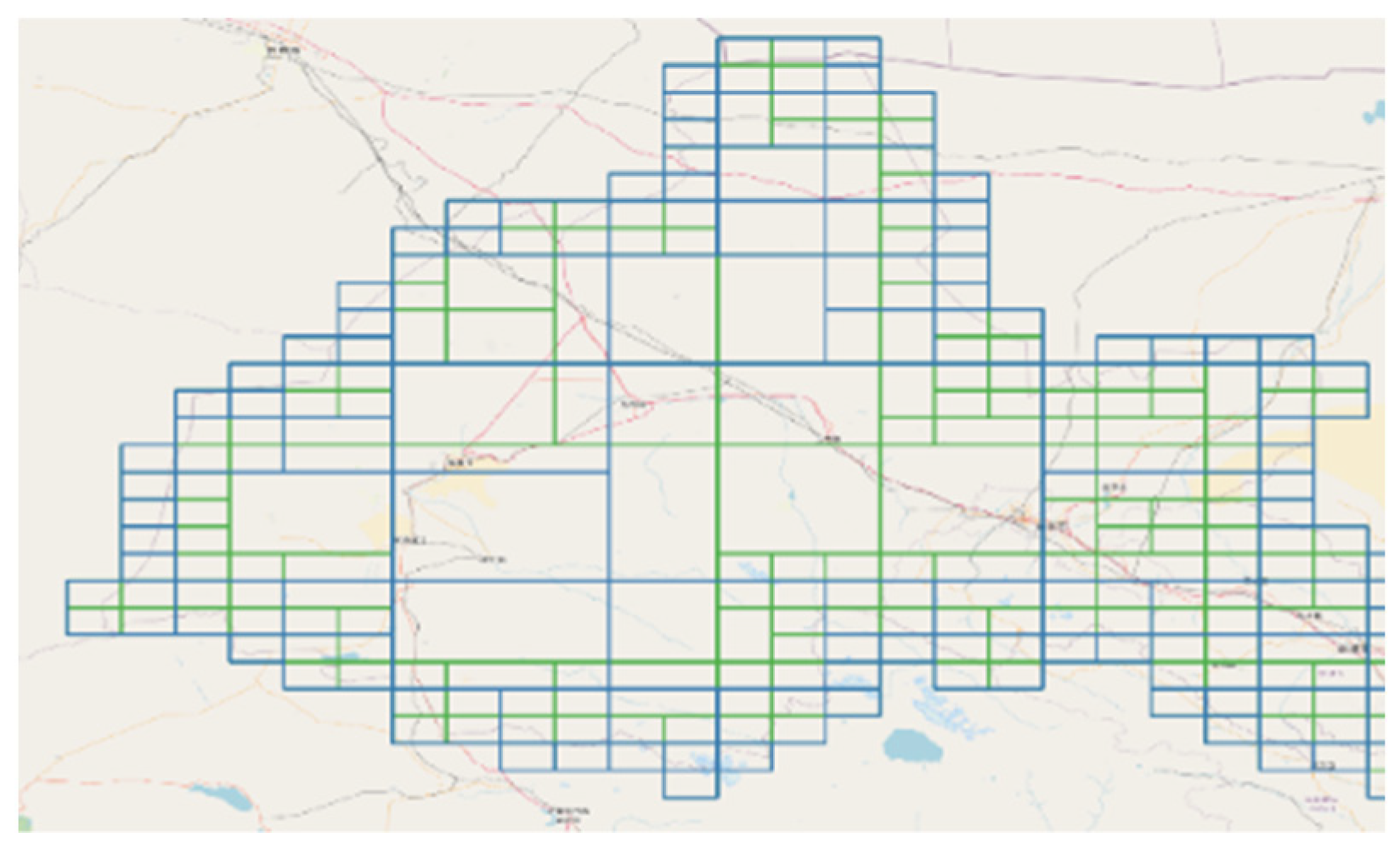
- Divide all the sub-regions into basic Hilbert grids and encode these grids.
- Sort these Hilbert codes into an ordered list and then split the list into successive segments.
- Iterate over these segments, and merge grids of each segment into a bigger Hilbert grid.
| Algorithm 3 Hilbert grid split-and-merge |
| LEVEL = k function HilbertGrids(regions) { hcodes = [ ] for reg in regions: grids = HilbertSplit(reg) for grid in grids: x, y = GridCenter(grid) code = HilbertCode(x, y, LEVEL) hcodes.push(code) segments = HilbertSplit(hcodes) results = [ ] for seg in segments: codes = HilbertMerge(seg) results.merge(codes) return results |
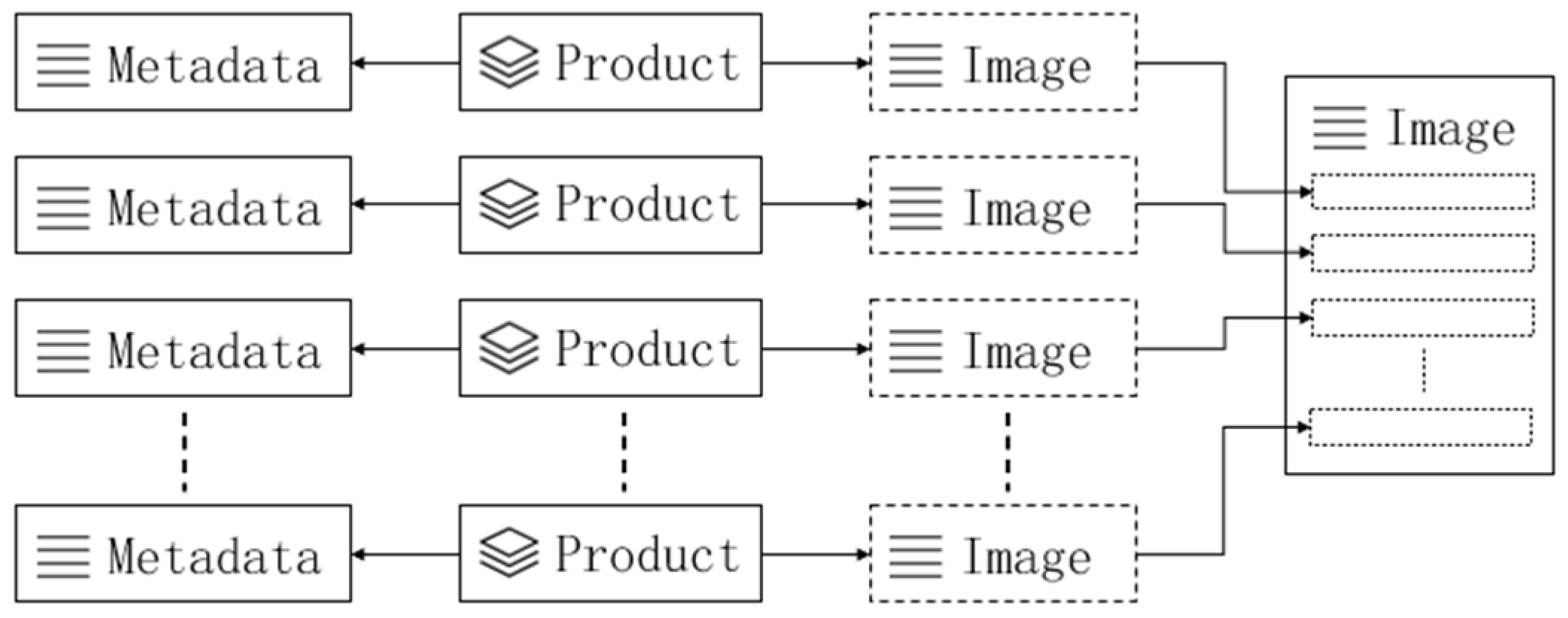
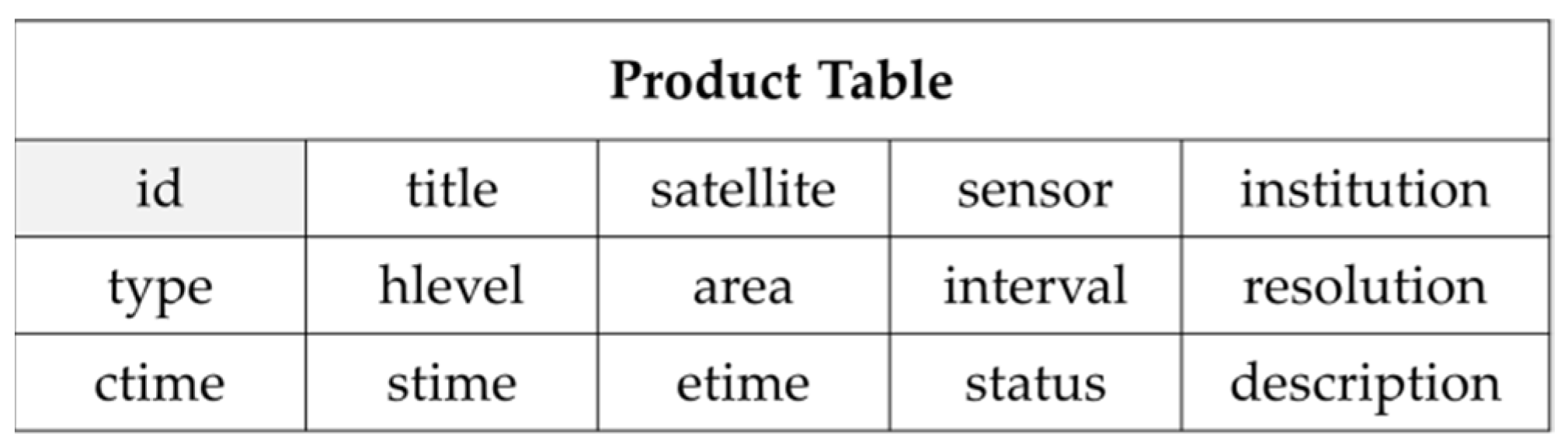
2.2.3. Multi-Source Heterogeneous Remote Sensing Images Integration
- “status”: a tag identifying whether the satellite and sensor are still working properly.
- “resolution”: a list including all the distinct resolutions of different bands.
- “type”: the type of the product.
- “hlevel”: the Hilbert level from 0 to 31 which is calculated based on the average image size of the product.
- “interval”: the interval between the time-sequence adjacent images at the same location.
- “area”: the average coverage area of images, whose unit is km2.
- “ctime”: the time when the product is created in the table.
- “stime”: the time when the first scene of the product is generated.
- “etime”: the time when the last scene of the product is generated.
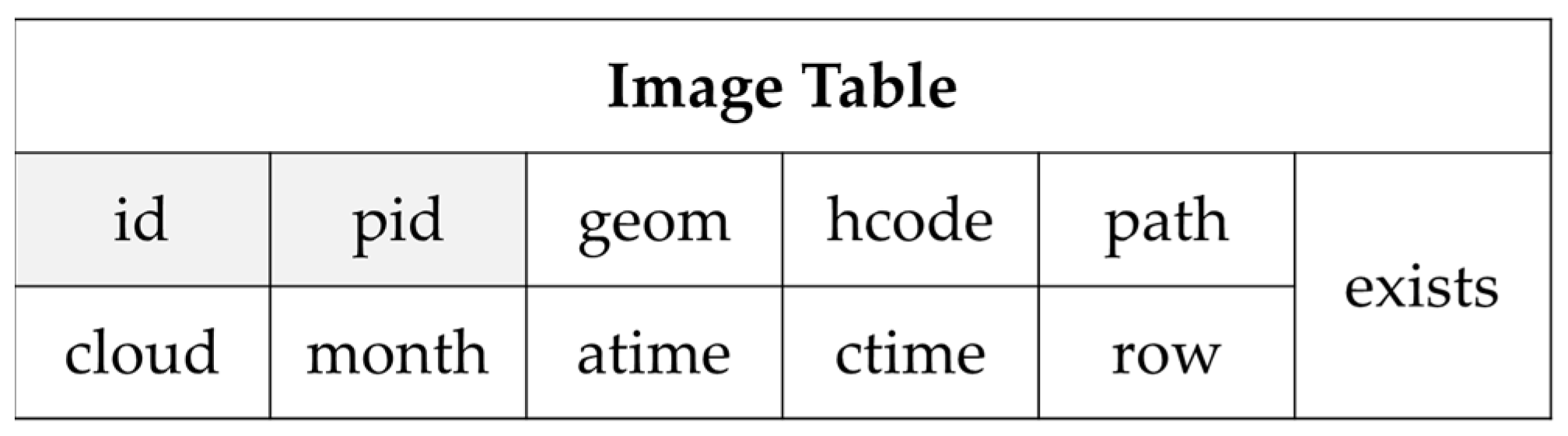
- “id”: the unique identification of the image which is defined by the data providers.
- “productid”: identification of the product including the image.
- “hcode”: the code of Hilbert grid calculated based on the image’s center coordinate and the Hilbert level from the corresponding product.
- “geom”: the spatial bounding box of the image whose type is Polygon or MultiPolygon.
- “cloud” is the proportion of the data which is covered by cloud.
- “month” is the month when the data is collected, which can be used to identify season.
- “atime”: the time when the image was acquired.
- “ctime”: the time when the image was stored in the table.
- Manual products registration, described with green lines;
- Data ingestion through API gateway, described with blue lines.
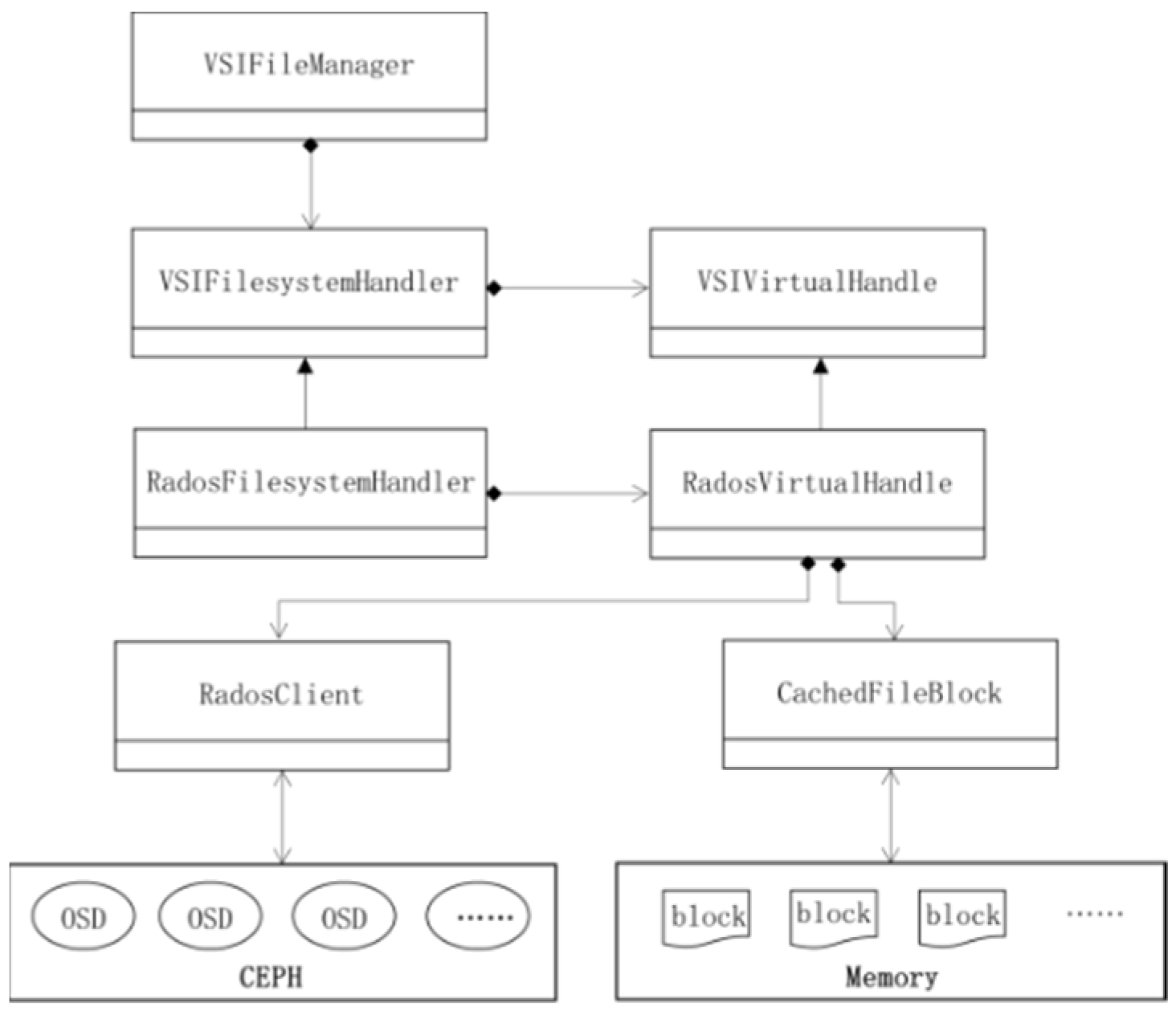
2.3. RSIData: Large-Scale Image Files Storage and GDAL-Compatible Interfaces Design
2.4. RSIAPI: Uniform Python Interfaces for Images Storage, Access and Retrieval
3. Results
3.1. Experimental Environment Setup
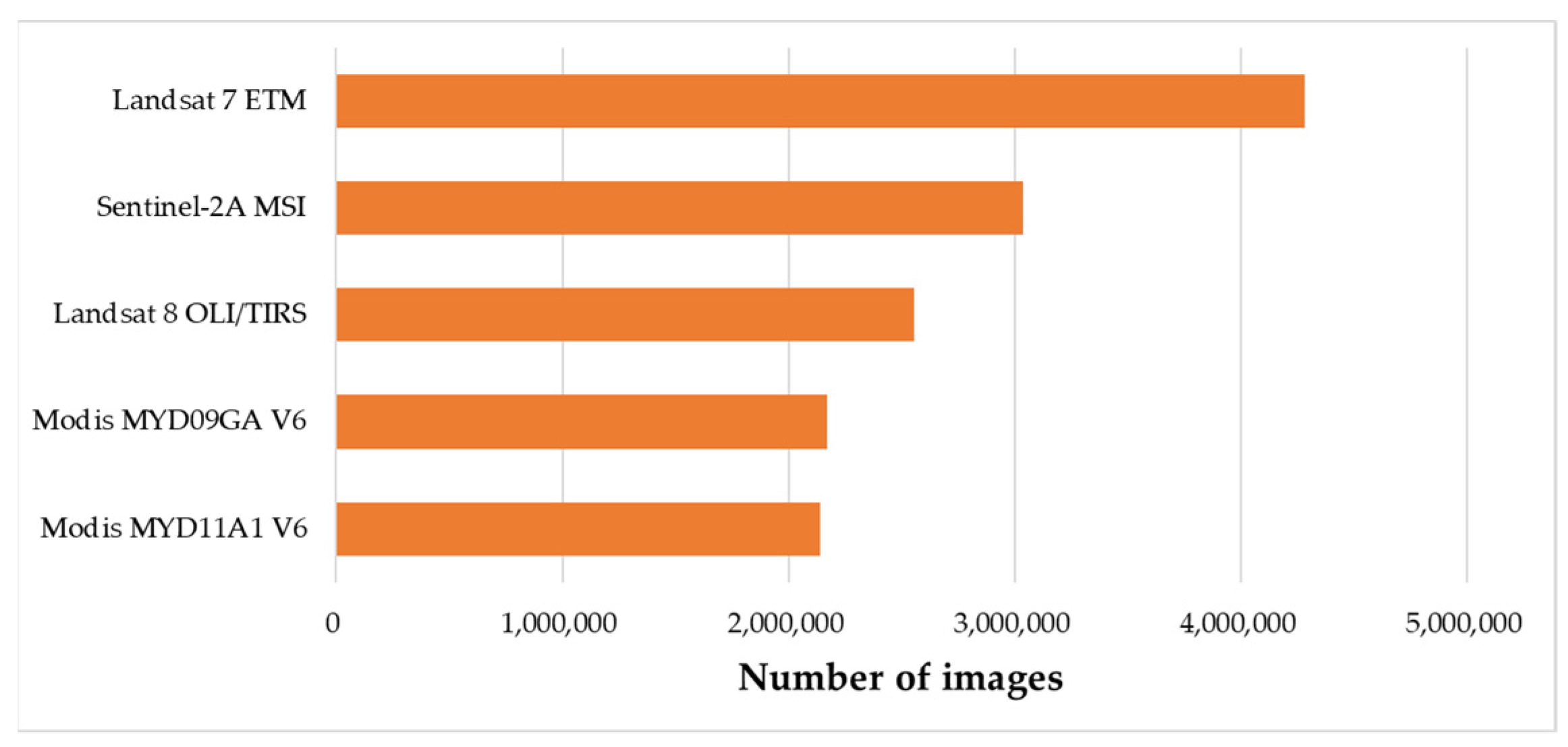
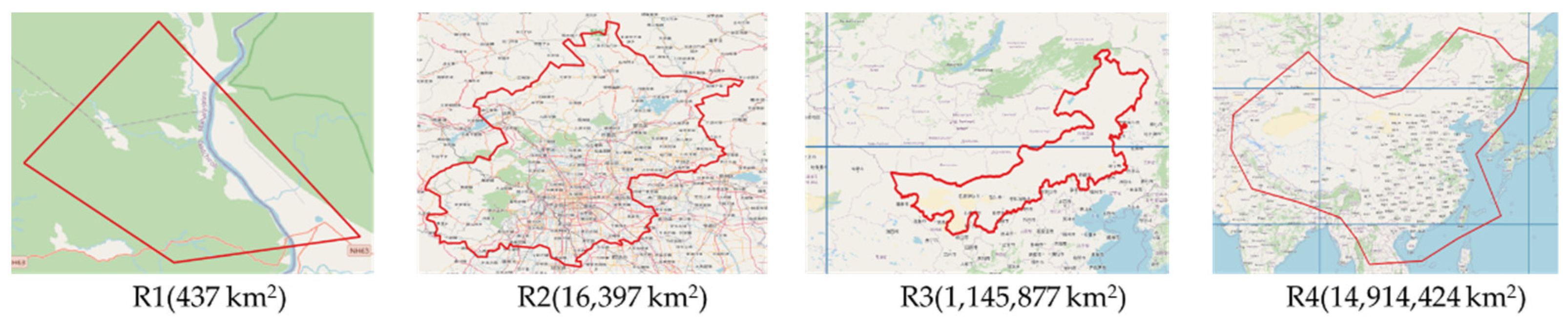
3.2. Experimental Datasets
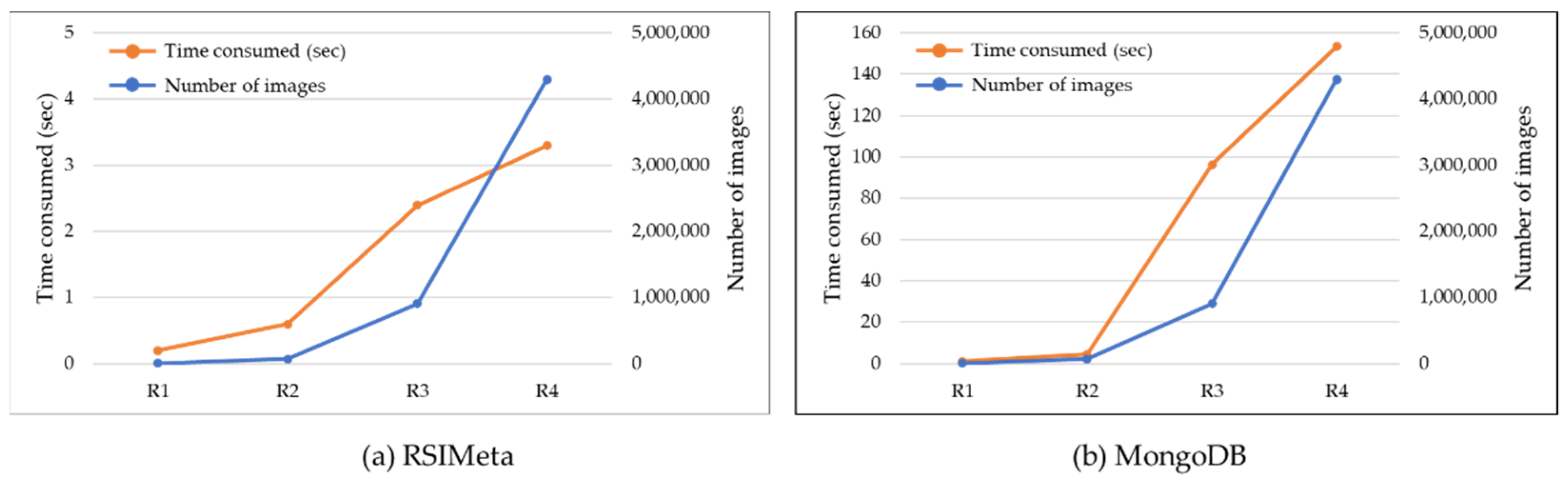
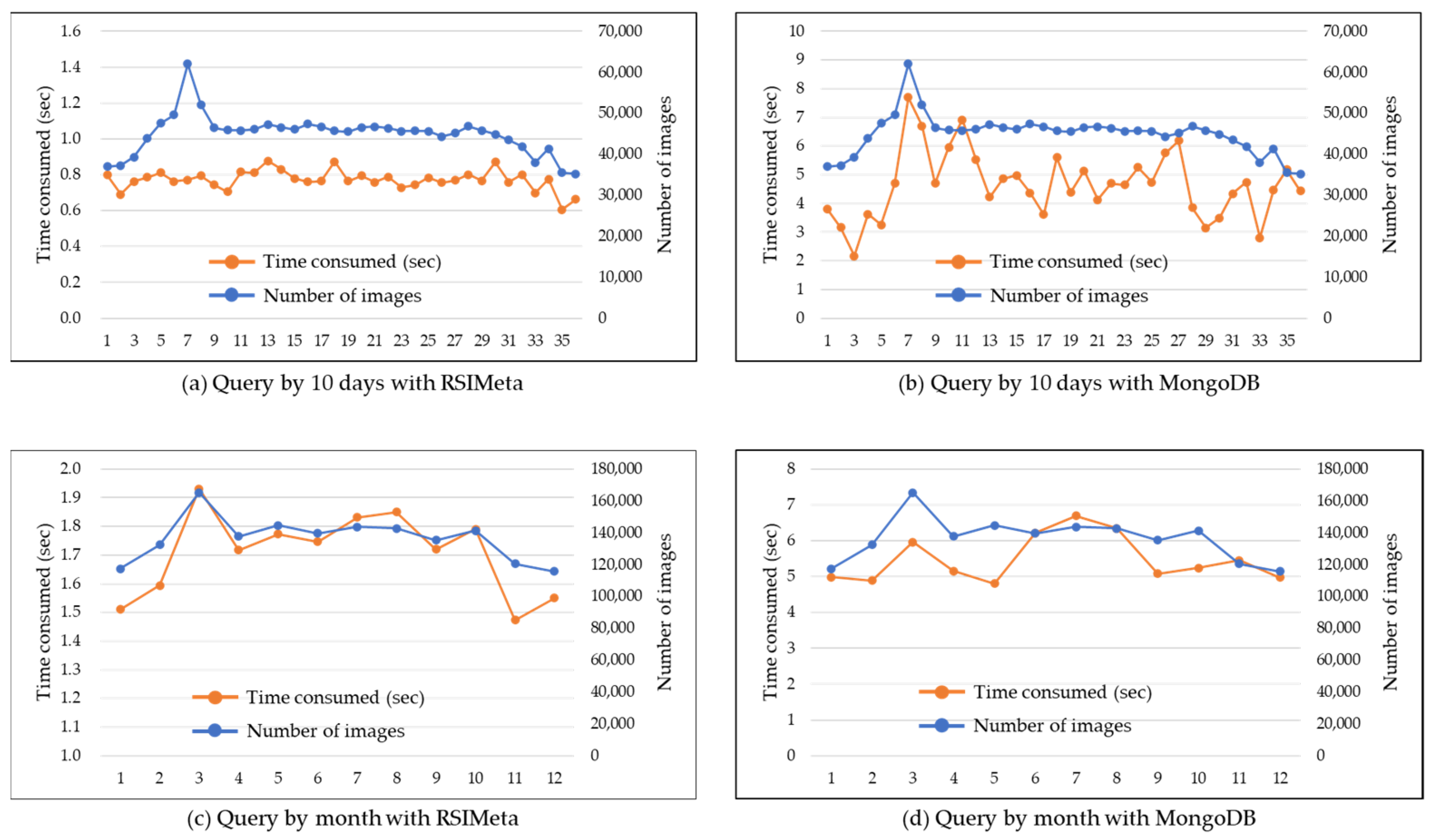
3.3. Spatiotemporal Retrieval Performance of RSIMeta
- -
- The average time consumed of RSIMeta and MongoDB are 0.77 s and 4.64 s respectively when the time window is 10 days.
- -
- The average time consumed of RSIMeta and MongoDB are 1.7 s and 5.48 s respectively when the time window is a natural month.
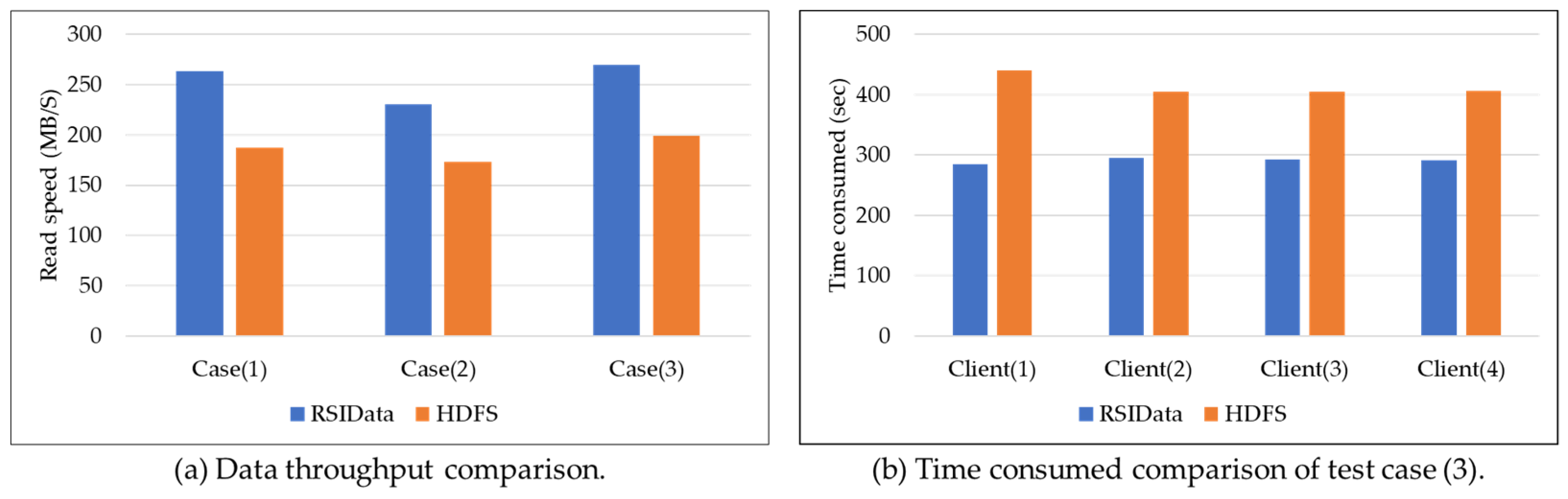
3.4. I/O Performance of RSIData
3.5. Example: Make a Composite Landsat Image of China Mainland
| import boto3 import rasterio from rsims import Product from multiprocessing import Pool from rasterio.session import AWSSession session = boto3.Session(aws_access_key_id=access_key, aws_secret_access_key=secret_key) china_image_path = ‘/vsis3/landsat/2019/china.tiff’ with open(“china.geojson”) as f: geom = f.read() def landsat_moasic(img): with rasterio.Env(AWSSession(session), **AWS_Options) as env: with rasterio.open(‘/vsis3/landsat/’+img.b3, ‘r’) as ds: _b3 = ds.read(1) with rasterio.open(‘/vsis3/landsat/’+img.b4, ‘r’) as ds: _b4 = ds.read(1) with rasterio.open(‘/vsis3/landsat/’+img.b5, ‘r’) as ds: _b5 = ds.read(1) landsat_rgb_moasic(china_image_path, _b3, _b4, _b5) prdt = Product( satellite = “landsat”, sensor = “oli/tirs”, type = “c01_t1_sr” ) images = prdt.filterBounds(geom).filterDate(“2019-05-01”, “2019-10-01”) with Pool(processes = 20) as pool: for img in images: pool.apply_async(landsat_moasic, (img,)) |
4. Discussion
4.1. Spatial-Temporal Retrieval Performance of RSIMS
4.2. Binary Remote Sensing Image Files I/O Performance
4.3. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Remote Sensing: Introduction and History. Available online: https://earthobservatory.nasa.gov/features/RemoteSensing (accessed on 23 April 2021).
- Big Data. Available online: http://www.gartner.com/it-glossary/big-data (accessed on 1 February 2021).
- DigitalGlobe Satellite and Product Overview. Available online: https://calval.cr.usgs.gov/apps/sites/default/files/jacie/DigitalGlobeOverview_JACIE_9_19_17.pdf (accessed on 1 February 2021).
- Grawinkel, M.; Nagel, L.; Padua, F.; Masker, M.; Brinkmann, A.; Sorth, L. Analysis of the ECMWF storage landscape. In Proceedings of the 13th USENIX Conference on File and Storage Technologies, Santa Clara, CA, USA, 15–19 February 2015; p. 83. [Google Scholar]
- Guo, C.-l.; Zhao, Y. Research on Application of Blockchain Technology in Field of Spatial Information Intelligent Perception. Comput. Sci. 2020, 47, 354–358, 362. [Google Scholar]
- Fan, J.; Yan, J.; Ma, Y.; Wang, L. Big Data Integration in Remote Sensing across a Distributed Metadata-Based Spatial Infrastructure. Remote Sens. 2018, 10, 7. [Google Scholar] [CrossRef] [Green Version]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gibson, R.; Danaher, T.; Hehir, W.; Collins, L. A remote sensing approach to mapping fire severity in south-eastern Australia using sentinel 2 and random forest. Remote Sens. Environ. 2020, 240, 111702. [Google Scholar] [CrossRef]
- Weiss, M.; Jacob, F.; Duveiller, G. Remote sensing for agricultural applications: A meta-review. Remote Sens. Environ. 2020, 236, 111402. [Google Scholar] [CrossRef]
- Wang, F.; Oral, S.; Shipman, G.; Drokin, O.; Wang, T.; Huang, I. Understanding Lustre Filesystem Internals; Technical Paper; Oak Ridge National Laboratory, National Center for Computational Sciences: Oak Ridge, TN, USA, 2009. [Google Scholar]
- Ghemawat, S.; Gobioff, H.; Leung, S.-T. The Google file system. In Proceedings of the 19th ACM Symposium on Operating Systems Principles, Bolton Landing, NY, USA, 19–22 October 2003. [Google Scholar]
- Dana, P.; Silviu, P.; Marian, N.; Marc, F.; Daniela, Z.; Radu, C.; Adrian, D. Earth observation data processing in distributed systems. Informatica 2010, 34, 463–476. [Google Scholar]
- Qiao, X. The distributed file system about moose fs and application. Inspur 2009, 5, 9–10. [Google Scholar]
- Weil, S.A.; Brandt, S.A.; Miller, E.L.; Long, D.D.E.; Maltzahn, C. Ceph: A scalable, high-performance distributed file system. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation, Seattle, WA, USA, 6–8 November 2006. [Google Scholar]
- Li, H.; Ghodsi, A.; Zaharia, M.; Shenker, S.; Stoica, I. Tachyon: Reliable, memory speed storage for cluster computing frameworks. In Proceedings of the ACM Symposium on Cloud Computing, Seattle, WA, USA, 3–5 November 2014. [Google Scholar]
- Beaver, D.; Kumar, S.; Li, H.C.; Sobel, J.; Vajgel, P. Finding a needle in Haystack: Facebook’s photo storage. In Proceedings of the Usenix Conference on Operating Systems Design & Implementation, Vancouver, ON, Canada, 4–6 October 2010. [Google Scholar]
- Ma, Y.; Wang, L.; Zomaya, A.; Chen, D.; Ranjan, R. Task-tree based large-scale mosaicking for massive remote sensed imageries with dynamic DAG scheduling. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 2126–2137. [Google Scholar] [CrossRef]
- Kou, W.; Yang, X.; Liang, C.; Xie, C.; Gan, S. HDFS enabled storage and management of remote sensing data. In Proceedings of the 2016 2nd IEEE International Conference on Computer and Communications (ICCC 2016), Chengdu, China, 14–17 October 2016; pp. 80–84. [Google Scholar]
- Wang, P.; Wang, J.; Chen, Y.; Ni, G. Rapid processing of remote sensing images based on cloud computing. Future Gener. Comput. Syst. 2013, 29, 1963–1968. [Google Scholar] [CrossRef]
- Almeer, M.H. Cloud Hadoop Map Reduce for Remote Sensing Image Analysis. J. Emerg. Trends Comput. Inf. Sci. 2014, 4, 637–644. [Google Scholar]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Earth on AWS. Available online: https://aws.amazon.com/earth (accessed on 1 February 2021).
- R-tree. Available online: https://en.wikipedia.org/wiki/R-tree (accessed on 1 February 2021).
- Peano, G. Sur une courbe, qui remplit toute une aire plane. In Arbeiten zur Analysis und zur Mathematischen Logik; Springer: Vienna, Austria, 1990. [Google Scholar]
- March, V.; Yong, M.T. Multi-Attribute Range Queries on Read-Only DHT. In Proceedings of the 15th International Conference on Computer Communications and Networks (ICCCN), Arlington, VA, USA, 9–11 October 2006. [Google Scholar]
- Huang, Y.-K. Indexing and querying moving objects with uncertain speed and direction in spatiotemporal databases. J. Geogr. Syst. 2014, 16, 139–160. [Google Scholar] [CrossRef]
- Zhang, R.; Qi, J.; Stradling, M.; Huang, J. Towards a painless index for spatial objects. ACM Trans. Database Syst. 2014, 39, 1–42. [Google Scholar] [CrossRef]
- Nivarti, G.V.; Salehi, M.M.; Bushe, W.K. A mesh partitioning algorithm for preserving spatial locality in arbitrary geometries. J. Comput. Phys. 2015, 281, 352–364. [Google Scholar] [CrossRef]
- Xia, X.; Liang, Q. A GPU-accelerated smoothed particle hydrodynamics (SPH) model for the shallow water equations. Environ. Model. Softw. 2016, 75, 28–43. [Google Scholar] [CrossRef]
- Herrero, R.; Ingle, V.K. Space-filling curves applied to compression of ultraspectral images. Signal Image Video Process. 2015, 9, 1249–1257. [Google Scholar] [CrossRef]
- Wang, L.; Ma, Y.; Zomaya, A.Y.; Ranjan, R.; Chen, D. A parallel file system with application-aware data layout policies for massive remote sensing image processing in digital earth. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 1497–1508. [Google Scholar] [CrossRef]
- Hilbert, D. Über die stetige Abbildung einer Linie auf ein Flächenstück. Mathematische Annalen 1891, 38, 459–460. [Google Scholar] [CrossRef] [Green Version]
- Weisstein, E.W. Sierpiński Curve. Available online: https://en.wikipedia.org/wiki/MathWorld (accessed on 5 April 2021).
- Avdoshin, S.M.; Beresneva, E.N. The Metric Travelling Salesman Problem: The Experiment on Pareto-optimal Algorithms. Proc. ISP RAS 2017, 29, 123–138. [Google Scholar] [CrossRef] [Green Version]
- Meister, O.; Rahnema, K.; Bader, M. Parallel memory-efficient adaptive mesh refinement on structured triangular meshes with billions of grid cells. ACM Trans. Math. Software 2016, 43, 1–27. [Google Scholar] [CrossRef]
- Mokbel, M.F.; Aref, W.G.; Kamel, I. Analysis of Multi-Dimensional Space-Filling Curves. GeoInformatica 2003, 7, 179–209. [Google Scholar] [CrossRef]
- Moon, B.; Jagadish, H.; Faloutsos, C.; Saltz, J.H. Analysis of the Clustering Properties of Hilbert Space-filling Curve. IEEE Trans. Knowl. Data Eng. 2001, 13, 124–141. [Google Scholar] [CrossRef] [Green Version]
- Jagadish, H.V. Linear clustering of objects with multiple attributes. In Proceedings of the 1990 ACM SIGMOD International Conference on Management of data, Atlantic City, NJ, USA, 23–25 May 1990. [Google Scholar]
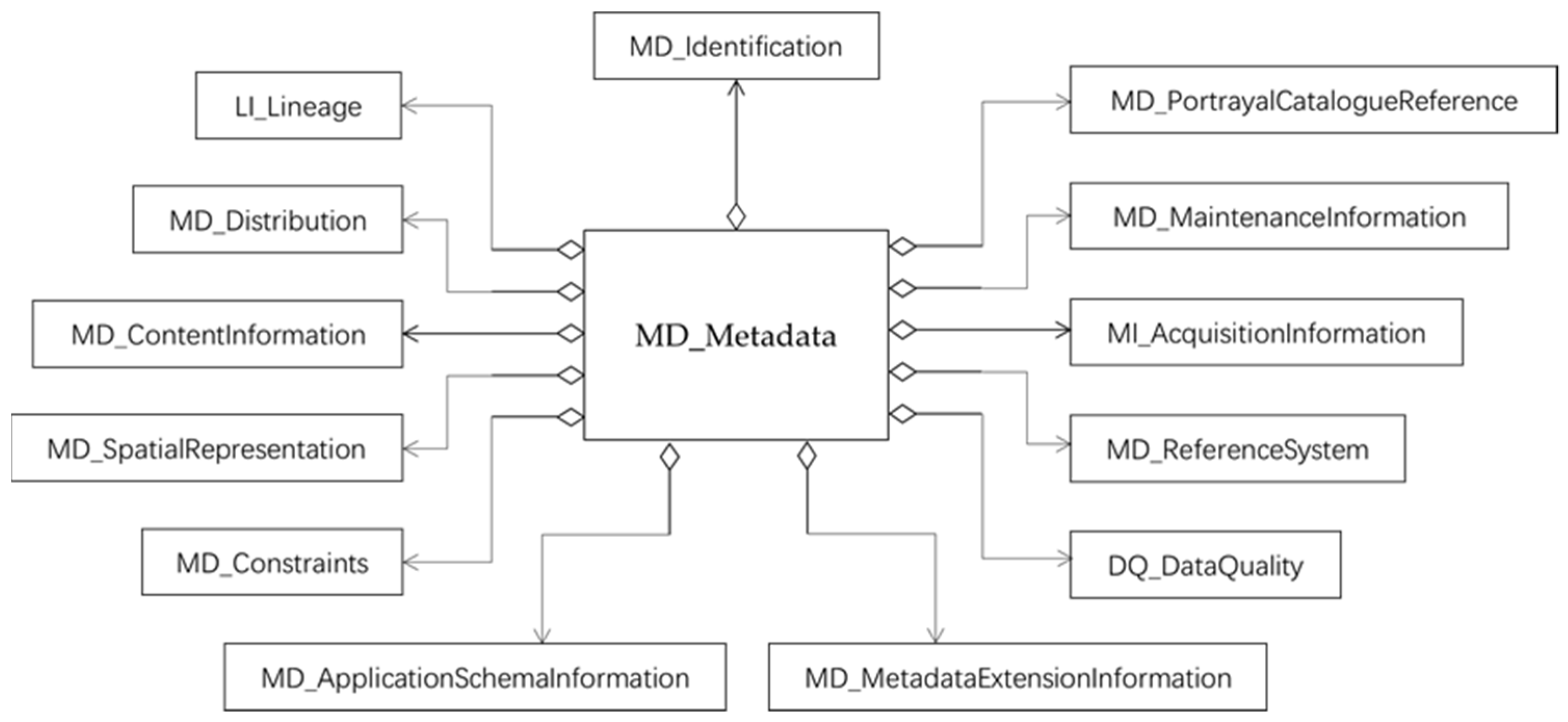
- ANZLIC. ANZLIC Working Group on Metadata: Core Metadata Elements; Australia and New Zealand Land Information Council: Sydney, Australia, 1995. [Google Scholar]
- FGDC. FGDC-STD-001-1998—Content Standard for Digital Geographic Metadata; Federal Geographic Data Committee: Washington, DC, USA, 1998; p. 78. [Google Scholar]
- Moellering, H.; Aalders, H.; Crane, A. World Spatial Metadata Standards; Elsevier Ltd.: London, UK, 2005; p. 689. [Google Scholar]
- Brodeur, J.; Coetzee, S.; Danko, D.; Garcia, S.; Hjelmager, J. Geographic information metadata—an outlook from the international standardization perspective. ISPRS Int. J. Geo. Inf. 2019, 8, 280. [Google Scholar] [CrossRef] [Green Version]
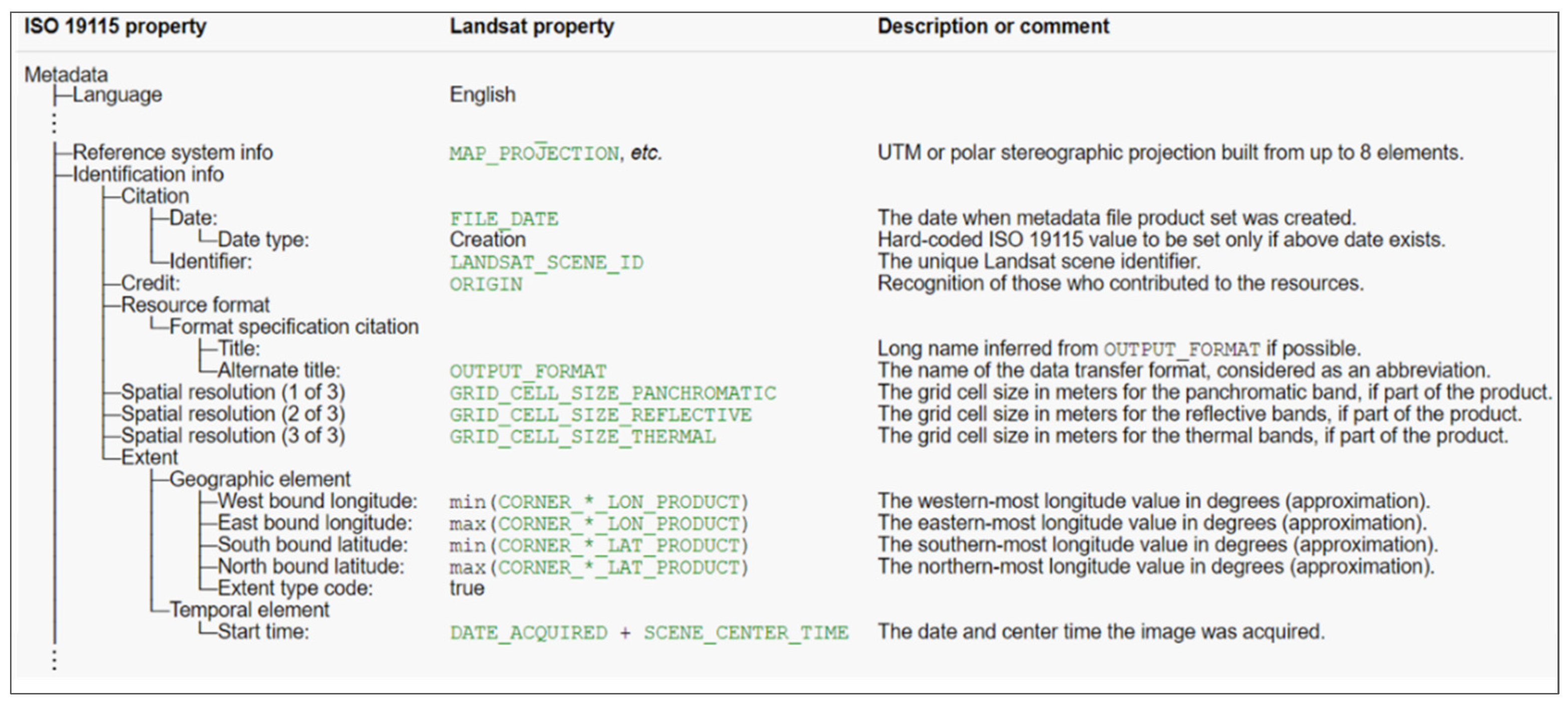
- ISO/TC 211. ISO19115:2003. Geographic Information—Metadata; International Organization for Standardization: Geneva, Switzerland, 2003. [Google Scholar]
- ISO/TC 211. ISO19115-2:2009. Geographic Information—Metadata—Part 2: Extensions for Imagery and Gridded Data; International Organization for Standardization: Geneva, Switzerland, 2009. [Google Scholar]
- ISO/TC 211. ISO19115-2:2019. Geographic Information—Metadata—Part 2: Extensions for Acquisition and Processing; International Organization for Standardization: Geneva, Switzerland, 2019. [Google Scholar]
- Unified Metadata Model (UMM). Available online: https://earthdata.nasa.gov/eosdis/science-system-description/eosdis-components/cmr/umm (accessed on 7 April 2021).
- van der Veen, J.S.; Sipke, J.; van der Waaij, B.; Meijer, R.J. Sensor data storage performance: SQL or NoSQL, physical or virtual. In Proceedings of the 5th IEEE International Conference on Cloud Computing, Honololu, HI, USA, 24–29 June 2012. [Google Scholar]
- Makris, A.; Tserpes, K.; Spiliopoulos, G.; Anagnostopoulos, D. Performance Evaluation of MongoDB and PostgreSQL for Spatio-temporal Data. In Proceedings of the EDBT/ICDT 2019 Joint Conference on CEUR-WS.org, Lisbon, Portugal, 26 March 2019. [Google Scholar]
- Weil, S.A.; Brandt, S.A.; Miller, E.L.; Maltzahn, C. CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data. In Proceedings of the 2006 ACM/IEEE Conference on Supercomputing, Tampa, FL, USA, 11–17 November 2006. [Google Scholar]
- Coverity Scan: GDAL. Available online: https://scan.coverity.com/projects/gdal (accessed on 1 February 2021).
- Raster Data Model. Available online: https://gdal.org/user/raster_data_model.html (accessed on 1 February 2021).
- Vector Data Model. Available online: https://gdal.org/user/vector_data_model.html (accessed on 1 February 2021).
- Introduction to Librados. Available online: https://docs.ceph.com/en/latest/rados/api/librados-intro (accessed on 7 April 2021).
- 2nd Index Internals. Available online: https://docs.mongodb.com/manual/core/geospatial-indexes (accessed on 7 April 2021).





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Product | Start Time | Latest Time | Resolutions | Dimensions | HLevel | Size |
|---|---|---|---|---|---|---|
| Landsat 4 MSS | 6 August 1982 | 15 October 1992 | 80 m | 185 km × 185 km | 6 | 341,759 |
| Landsat 4 TM | 22 August 1982 | 18 November 1993 | 30 m | 185 km × 185 km | 6 | 65,870 |
| Landsat 5 MSS | 4 March 1984 | 7 January 2013 | 80 m | 185 km × 185 km | 6 | 1,206,592 |
| Landsat 5 TM | 5 March 1984 | 5 May 2012 | 30 m | 185 km × 185 km | 6 | 4,553,146 |
| Landsat 7 ETM | 28 May 1999 | 30 July 2019 | 30 m | 185 km × 185 km | 6 | 4,281,514 |
| Landsat 8 OLI/TIRS | 18 March 2013 | 30 July 2019 | 30 m | 185 km × 185 km | 6 | 2,554,265 |
| MODIS MCD12Q1 V6 | 1 January 2001 | 31 December 2019 | 500 m | 1200 km × 1200 km | 4 | 5983 |
| MODIS MOD09A1 V6 | 24 February 2000 | 15 February 2021 | 500 m | 1200 km × 1200 km | 4 | 283,456 |
| MODIS MYD09A1 V6 | 4 July 2002 | 2 February 2021 | 500 m | 1200 km × 1200 km | 4 | 251,623 |
| MODIS MYD09GA V6 | 4 July 2002 | 24 February 2021 | 500 m | 1200 km × 1200 km | 4 | 2,173,235 |
| MODIS MYD11A1 V6 | 4 July 2002 | 16 February 2021 | 1000 m | 1200 km × 1200 km | 4 | 2,142,872 |
| Sentinel-1 SAR GRD | 3 October 2014 | 24 February 2021 | 10 m | 400 km × 400 km | 5 | 41,915 |
| Sentinel-2A MSI | 28 March 2017 | 24 February 2021 | 10 m 20 m 30 m | 290 km × 290 km | 6 | 9,064,645 |
| Package | API | Description |
|---|---|---|
| product | Product(*args) | create a Product object from id, title or type |
| count(hasfile = None) | return the number of images in the product, and can filter based on whether the image file exists | |
| filter(expression) | apply the expression to filter the images in the product and return a new Product object including the filtered images | |
| filterBounds(geometry) | return a new Product object including the images whose spatial area intersects with the geometry | |
| filterDate(stime, etime) | return a new Product object including the images whose acquisition time between stime and etime | |
| sort(field, ascending) | sort all images in the product | |
| first(num = 1) | return the top num Image objects in the images list of the product | |
| description() | return the detailed description of the product in XML format | |
| image | Image(args) | create a Product object from id |
| bands() | return the number of bands in the image | |
| read(band) | return data of corresponding band file in the type of NumPy Array | |
| resolution(band) | return the resolution of the image in the unit of meter | |
| size() | return width and length of the image, represented by the number of pixels | |
| crs() | return the projected coordinate system in the form of PROJ.4 | |
| geometry(fmt = “GeoJSON”) | return the spatial area in the format of GeoJSON(default) or WKT | |
| s3path(band) | return the S3 path of image’s band file | |
| radospath(band) | return the vsirados path of image’s band file | |
| description() | return the detailed description of the image in XML format | |
| utils | createProduct(**params) | create a new product. Keys of params are the fields of Product table. |
| createImage(pid,**params) | create a new image. Keys of params are the fields of Image table. | |
| search(**params) | retrieve images based on the params. Keys of params are the fields of Image table. | |
| listProducts() | list all the products in RSIMS |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Wang, X.; Zhou, Y.; Lin, Q.; Zhao, J.; Meng, X. RSIMS: Large-Scale Heterogeneous Remote Sensing Images Management System. Remote Sens. 2021, 13, 1815. https://doi.org/10.3390/rs13091815
Zhou X, Wang X, Zhou Y, Lin Q, Zhao J, Meng X. RSIMS: Large-Scale Heterogeneous Remote Sensing Images Management System. Remote Sensing. 2021; 13(9):1815. https://doi.org/10.3390/rs13091815
Chicago/Turabian StyleZhou, Xiaohua, Xuezhi Wang, Yuanchun Zhou, Qinghui Lin, Jianghua Zhao, and Xianghai Meng. 2021. "RSIMS: Large-Scale Heterogeneous Remote Sensing Images Management System" Remote Sensing 13, no. 9: 1815. https://doi.org/10.3390/rs13091815
APA StyleZhou, X., Wang, X., Zhou, Y., Lin, Q., Zhao, J., & Meng, X. (2021). RSIMS: Large-Scale Heterogeneous Remote Sensing Images Management System. Remote Sensing, 13(9), 1815. https://doi.org/10.3390/rs13091815