1. Introduction
Geographical spatiotemporal big data enable us to explore urban science and obtain new insights [
1]. By using the spatiotemporal big data collected with a variety of methods (e.g., global positioning systems (GPSs), global systems for mobile communication (GSMs), smart cards (SCs), and social media (SM)), researchers can observe and analyze urban problems at multiple spatiotemporal scales; such problems include traffic congestion monitoring and urban structure planning [
2,
3,
4]. The results can provide new information for describing and understanding urban space.
Although spatiotemporal big data provide many unique advantages and opportunities for urban problem analysis, such data are also associated with notable challenges. Spatial combination is an essential analysis step when assessing the geospatial environment from personal-level geographic big data. It is usually necessary to aggregate spatiotemporal data into a spatial area according to a certain temporal unit. Areas are commonly divided into analysis units of different sizes, and the areas and shapes of these units also vary. This spatial approach for data aggregation is very sensitive to the scale and zoning effects of the modifiable areal unit problem (MAUP). Scale effects describe changes in statistical results when analyzed using data aggregated at different unit granularities. The zoning effect refers to the variability of results caused by different zoning schemes when the number of units is constant. Due to the uncertainty regarding the number (scale effect) and shape (zoning effect) of spatial units, the MAUP can lead to very different spatial patterns and statistical results [
5,
6].
In urban computing, when using geographical big data to reflect real-world spatiotemporal phenomena, the MAUP is usually ignored, and scale and zoning effects are rarely mentioned. However, many scholars have recently studied how to alleviate the MAUP. Jiang and Miao focused on the hierarchical agglomeration and heterogeneity of social media data to determine the corresponding urban structure, thus mitigating the statistical bias of the MAUP [
7]. However, they did not evaluate the effect of the MAUP or provide a strategy for optimizing the selection of spatial analysis units. Lee et al. assessed the effect of the MAUP through the rate of change of the global spatial correlation coefficient using a regular grid of units with different areas [
8]. Meng et al. proposed selecting regional analysis units based on attribute distributions to produce high global Moran’s
I values in an approach similar to that used for the segmentation of high-resolution remote sensing imagery [
9]. Moreover, Jelinski and Wu noted that the analysis results obtained at one scale provide incomplete information about the spatial pattern, and for any spatial analysis case, it is necessary to associate the analysis with a given spatial scale [
10]. Fotheringham et al. suggested that the sensitivity of parameter estimates needs to be assessed at different spatial scales before the analysis results are provided to decision makers [
11]. Based on sensitivity analysis, the influence of specific parameters on the results of statistical analysis can be quantitatively studied. Although research on the MAUP and analyses of geographical big data have proliferated, a standard solution to the MAUP has not been obtained because different geographical phenomena are generally associated with different spatiotemporal distributions.
When analyzing high-resolution geospatial-temporal datasets, the aggregation of data can be customized at various geographical levels (e.g., traffic analysis zones, grids, or street networks), thus alleviating the MAUP to some extent. However, previous studies have shown that the distributions of geographical spatiotemporal data are scale sensitive, and the interrelationships among attributes vary at different scales [
12,
13]. Specifically, when using area data for spatial analysis, the calculated results may be unstable or uncertain based on the selection of different analysis units, and a unified conclusion cannot be obtained. Therefore, determining the best research units for spatiotemporal data to enhance urban design and management has become an important topic.
Spatial autocorrelation (SA) is the main factor that leads to the MAUP. Many scholars have assessed the relationships between different analysis units and SA, especially how the overall structure of SA changes with different spatial units. These studies provided some solutions for dealing with the MAUP [
14,
15,
16]. Openshaw and Fotheringham explored the relationship between SA and the MAUP and found that when spatial aggregation occurred, the data were smoothed, resulting in reductions in variance and correlation values [
17,
18]; that is, if adjacent spatial units are aggregated to form a larger unit and their covariance is assumed to be relatively stable, the corresponding heterogeneity decreases, resulting in reductions in the variance and correlation coefficient. In addition, since MAUP effects are associated with different levels of SA, the sensitivity to MAUP effects may also vary based on the variables considered, making it difficult to analyze MAUP effects in cases with multiple variables.
In addition, indicators used to measure SA, such as Moran’s
I, are also affected by MAUP effects. Cliff and Ord found a negative correlation between spatial aggregation and SA, indicating that the larger the size of an area unit is, the smaller Moran’s
I [
19]. Similarly, Chou discussed the possible relationship between map resolution and Moran’s
I (log-linear relationship) [
14], and Qi and Wu obtained similar results from their analysis of landscape pattern data [
15]. Griffith et al. showed that the SA calculated based on Moran’s
I decreases with increasing spatial resolution of the analysis units [
16]. In the above research, the relationships between different analysis units and SA were explored. A decrease in the variance reduces the denominator of Moran’s
I, resulting in an increase in Moran’s
I. Additionally, a decrease in the variance reduces the spatial covariance difference in the numerator of Moran’s
I and thus reduces Moran’s
I. Therefore, when the reduction in the numerator is greater than that in the denominator, Moran’s
I tends to zero. In other words, different spatial analysis units lead to local SA heterogeneity, resulting in variations in Moran’s
I. Consequently, the use of different spatial units generally leads to different statistical results [
20]. Determining the spatial unit most suitable for spatially assessing geographical phenomena, that is, the dependence or sensitivity of geographical processes in different spatial units, is important for studies of geographical phenomena.
When using spatiotemporal travel data to assess urban problems, the selection of the most appropriate spatiotemporal analysis unit is complex. Because people’s movements in urban spaces are influenced by their daily activities at different times and are unevenly distributed, it is necessary to explore the relationships between the spatiotemporal processes that influence people’s activities and the spatiotemporal phenomena of interest [
21,
22]. For a certain spatial unit, the data distribution patterns vary in different time intervals; that is, the global and local spatial correlations of the data differ. Therefore, different temporal units produce different spatial distribution patterns, resulting in different spatiotemporal data analysis results [
23,
24]. That is, the temporal unit considered influences the spatial analysis results. Therefore, the determination of the best temporal unit should be considered in conjunction with that of the optimal spatial unit.
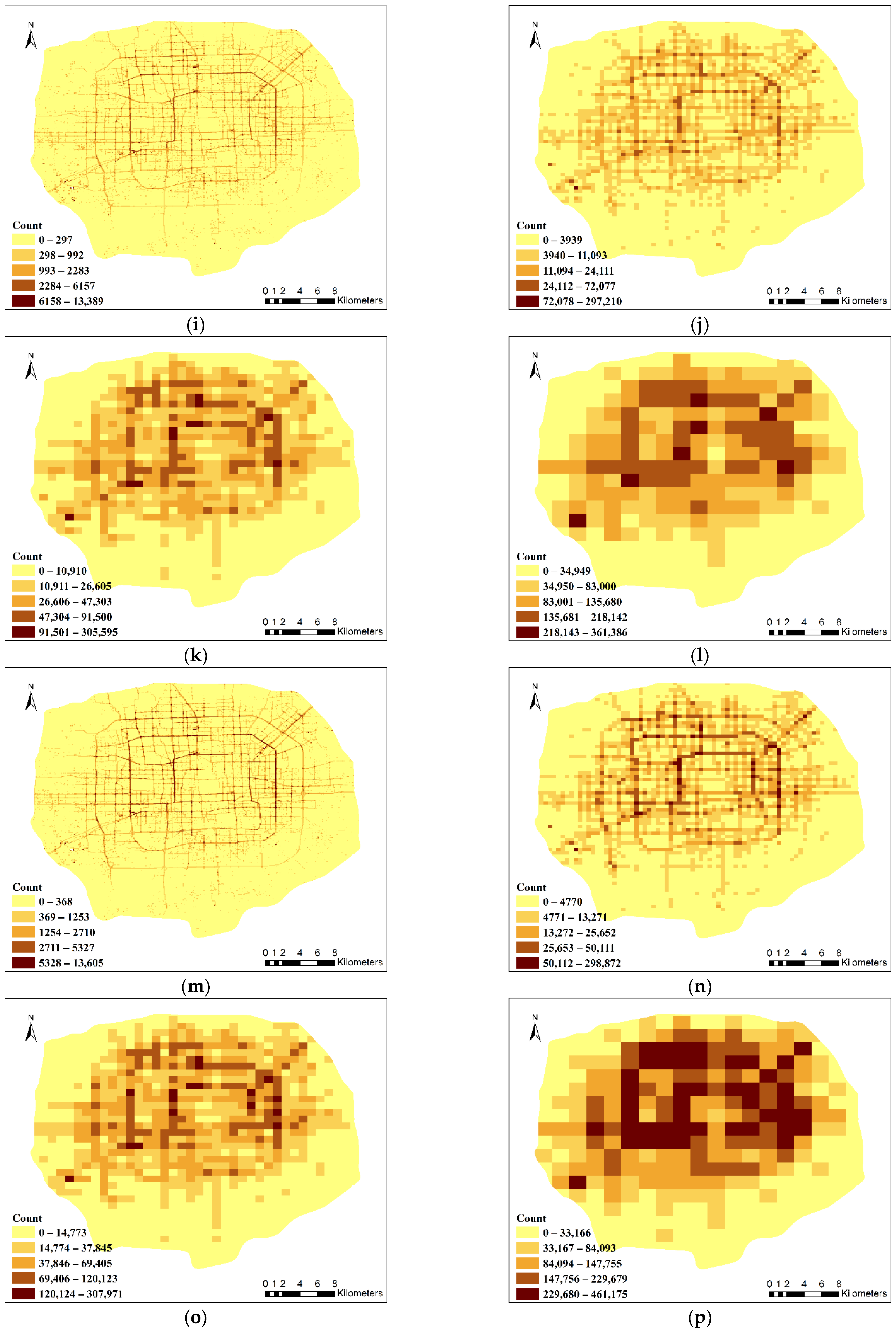
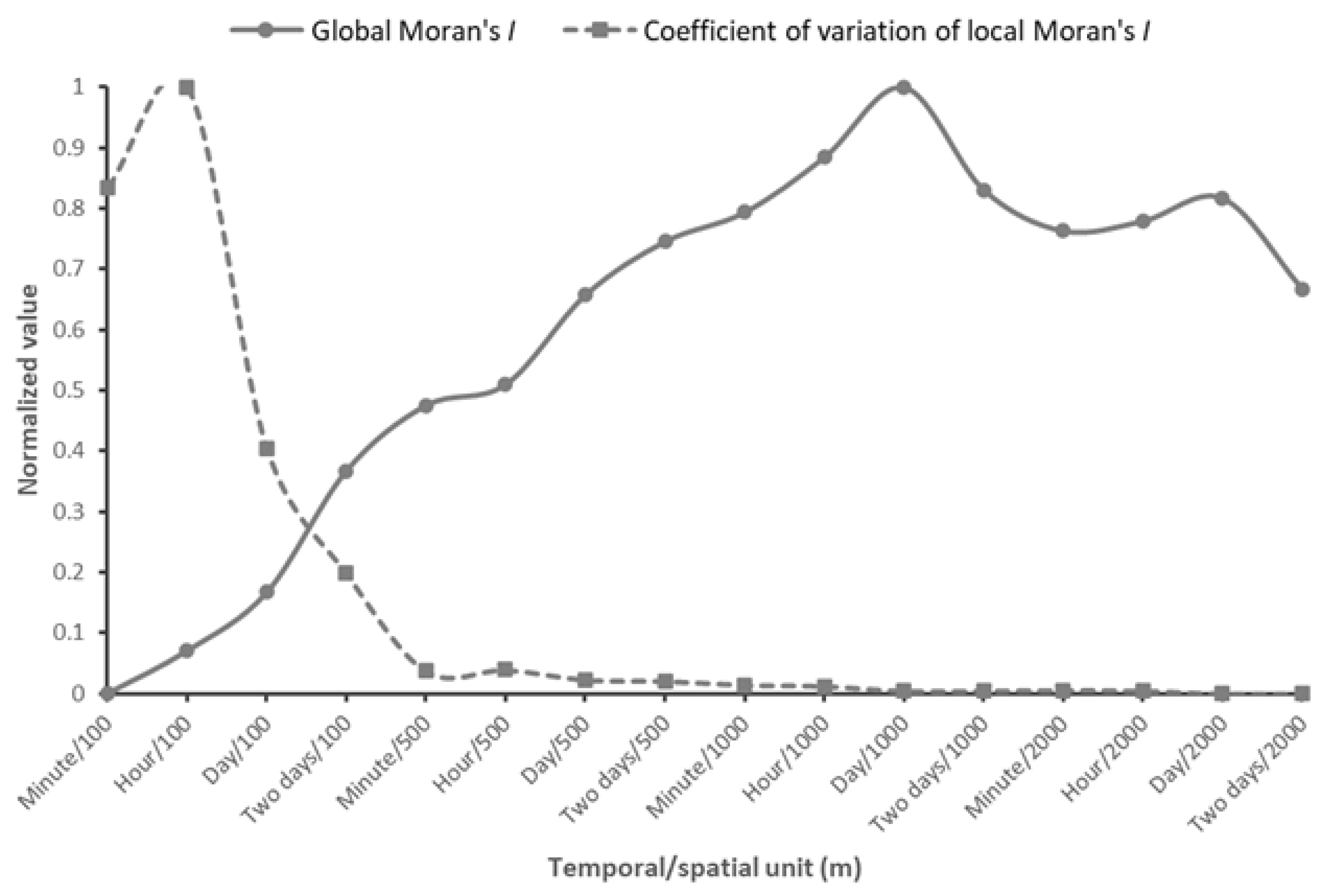
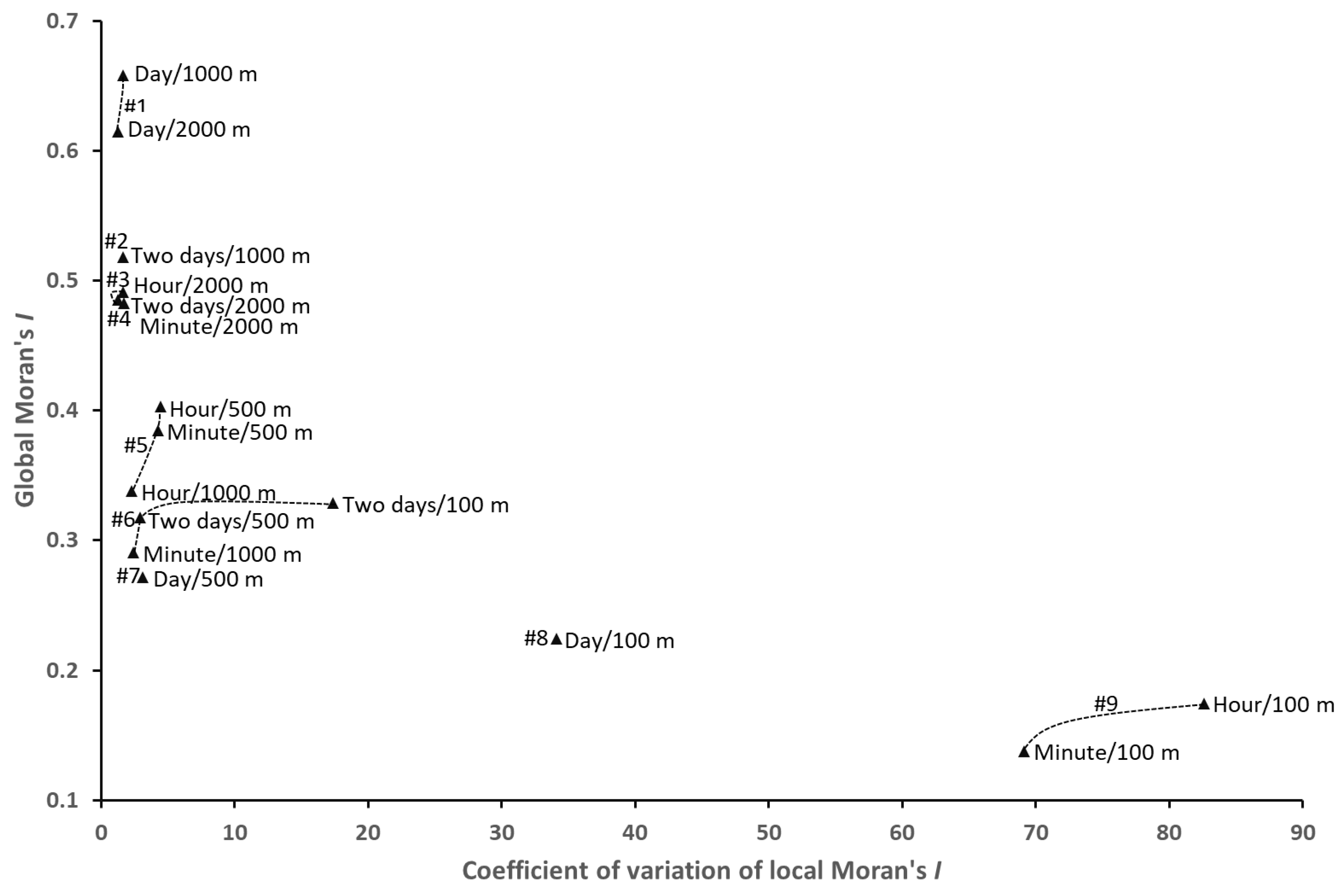
When analyzing urban geographical phenomena based on spatiotemporal data, different spatiotemporal analysis units are associated with different levels of uncertainty; notably, it is often unclear how to match the analysis unit to the scale of a geographical phenomenon. However, sensitivity analysis using spatially correlated global indicators is an effective method for mitigating the MAUP. This method considers only the overall aggregated pattern of spatiotemporal data, whereas the spatial differences and instabilities of local patterns are ignored. Therefore, applying the global Moran’s I alone is not sufficient for assessing the spatiotemporal heterogeneity of data, especially in study areas that are divided into many analysis units. Most global spatial correlation metrics assume that the corresponding data are characterized by spatial and temporal homogeneity, but geographic big data often have spatially and temporally discrete distributions. In addition, local spatial patterns are particularly important in urban analysis since the heterogeneity of the internal structure of a city affects data generation. Comprehensive analyses have shown that geographical big data are generally associated with a low/moderate level of spatiotemporal dependence (i.e., spatial correlation) and high spatiotemporal heterogeneity. Thus, the best spatiotemporal analysis units for geographical big data should be comprehensively considered based on different indicators.
In this paper, a data-driven approach is adopted to determine the most suitable spatiotemporal analysis unit for assessing floating vehicle trajectory data, and a multicriteria-based optimization framework for spatiotemporal analysis units is proposed to explore spatial data distribution patterns at different scales. With the Wuhan taxi trajectory dataset as an example, the data distribution patterns at multiple grid scales are aggregated, and MAUP effects are described based on global and local indicators of spatial correlation. Then, the optimal analysis unit is determined using Pareto optimality. Additionally, a sensitivity analysis of the proposed framework is performed. Finally, with the calculation of urban hotspots as an example, the validity and rationality of the optimization framework for spatiotemporal data analysis units integrating temporal and spatial scales are further verified.
4. Empirical Study
An example involving urban hotspot extraction is used to determine whether the optimal spatiotemporal unit is the optimal scale for geographical phenomenon analysis and to verify the effectiveness of the proposed optimization framework.
4.1. Extraction of Urban Hotspots
The spatial distribution of urban hotspots represents the degree of urbanization [
35]. By extracting urban hotspots, we can understand the spatial distribution of a city and the corresponding public issues, and services can be provided to improve daily travel and urban planning. Urban hotspots are usually areas with developed commerce, large flows of people, and established facilities, resulting in dense flows of urban residents [
36,
37,
38]. In a certain area, urban hotspots often have similar function types and distribution scales. The spatial distribution of hotspots is affected by market, transportation, and administrative factors [
39]. Therefore, based on residents’ travel data, we can mine urban hot-spots and then perform regional analysis.
Getis and Ord proposed
Gi* statistics to measure whether there is local spatial correlation between an observation and its surrounding neighbors [
40,
41]. Within a given distance range, the attribute sum of an element and its adjacent elements is compared with the attribute sum of all elements, and then, the aggregation degree of attribute values in the local space is described, as shown in Equation (5).
In this equation,
n represents the total number of grid units,
represents the trajectory frequency in the
jth grid, and
is the spatial weight of grids
i and
j. Here, if the distance between the
ith and
jth grid units is within the given critical distance, they are considered neighbors, and the spatial weight is 1; otherwise, the weight is 0. In this paper, weights are set by determining whether two grids are adjacent. If the two grids are adjacent, the weight is set to 1; otherwise, it is 0. The Getis–Ord
Gi* metric can be expressed in normalized form, as shown in Equation (6).
If is positive and the value is large, the frequency of trajectories around grid unit i is relatively large (higher than the average value), and a high-value spatial cluster (hotspot) is present. When the value is negative and small, a low-value spatial cluster (cold spot) is present in grid unit i.
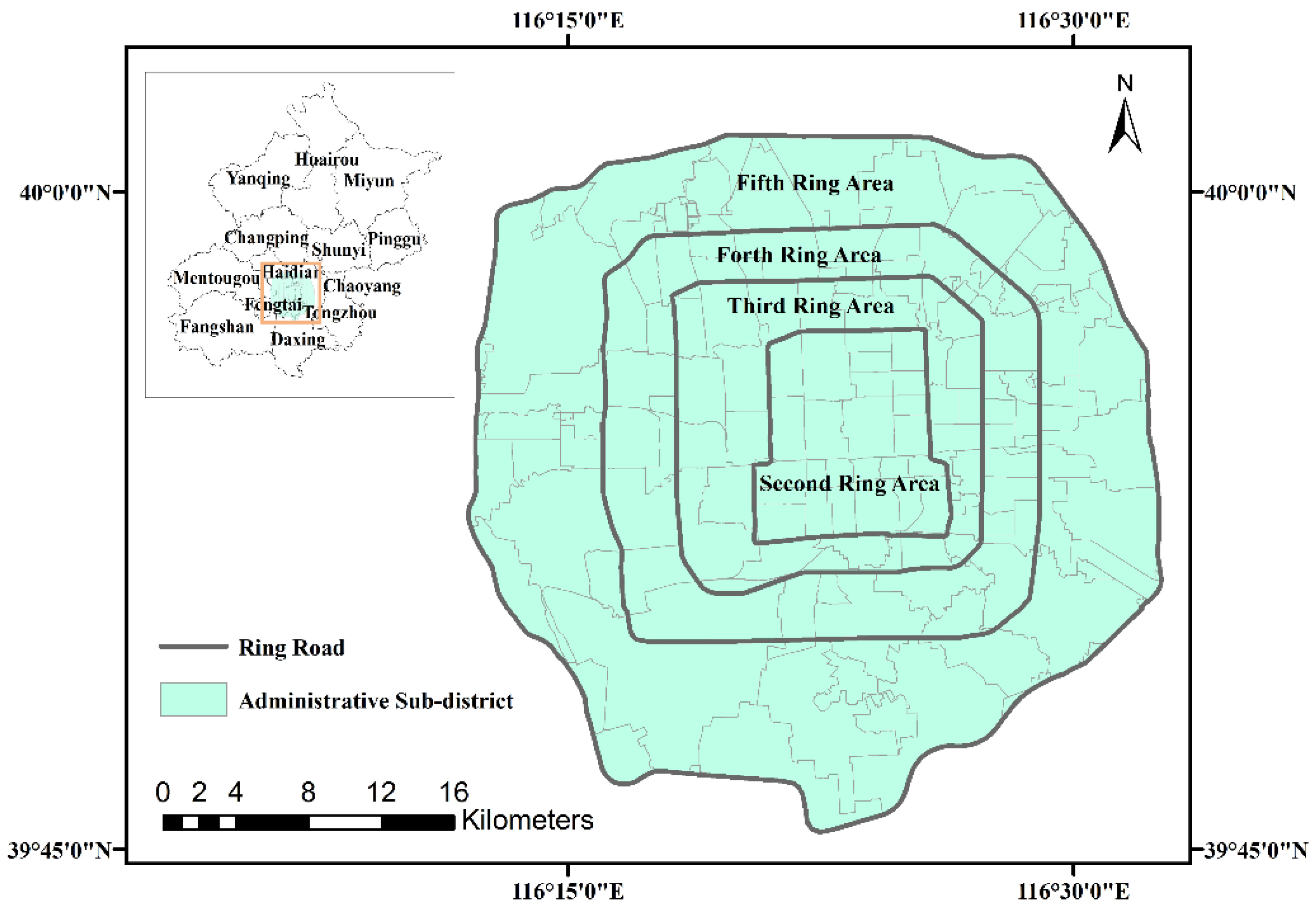
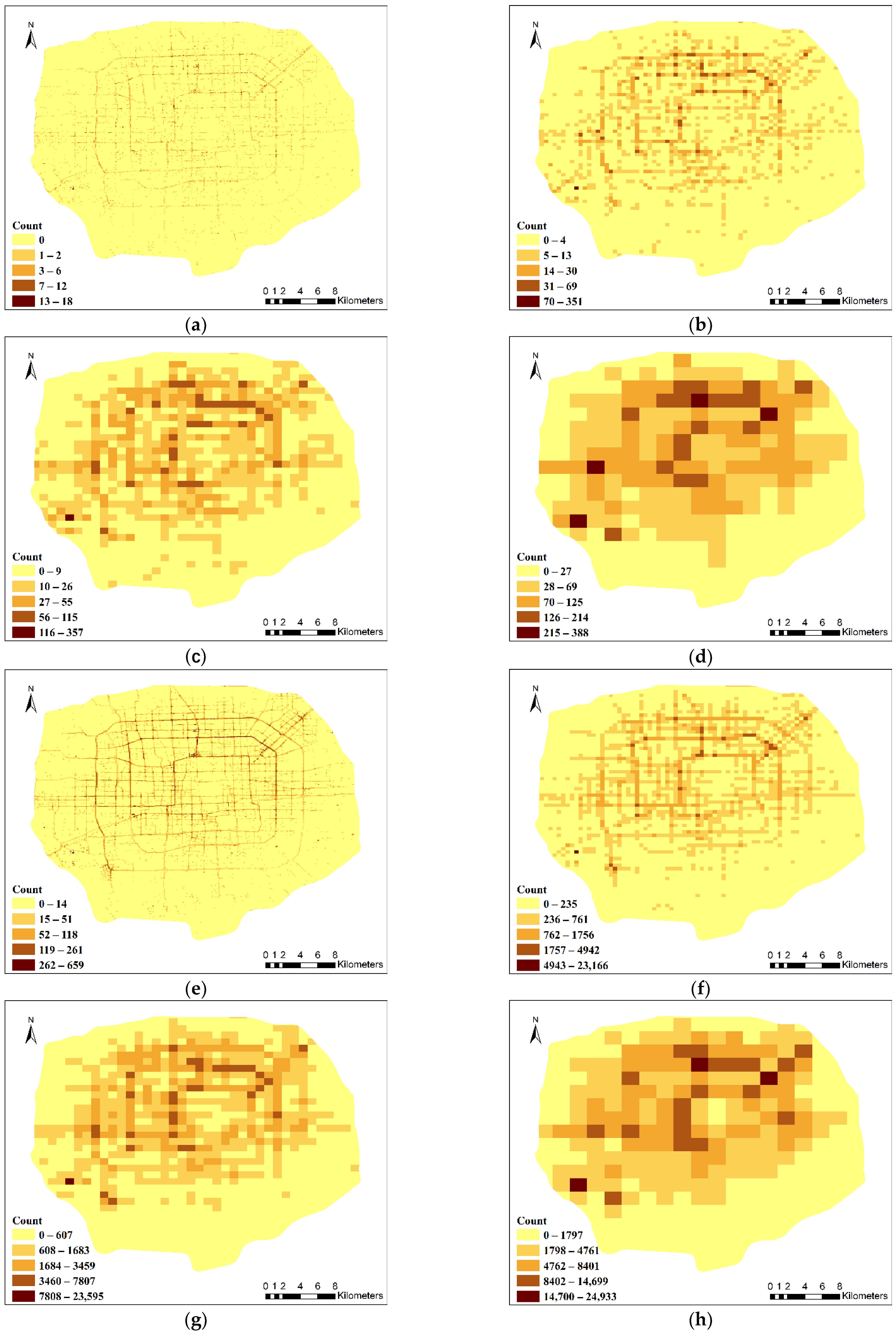
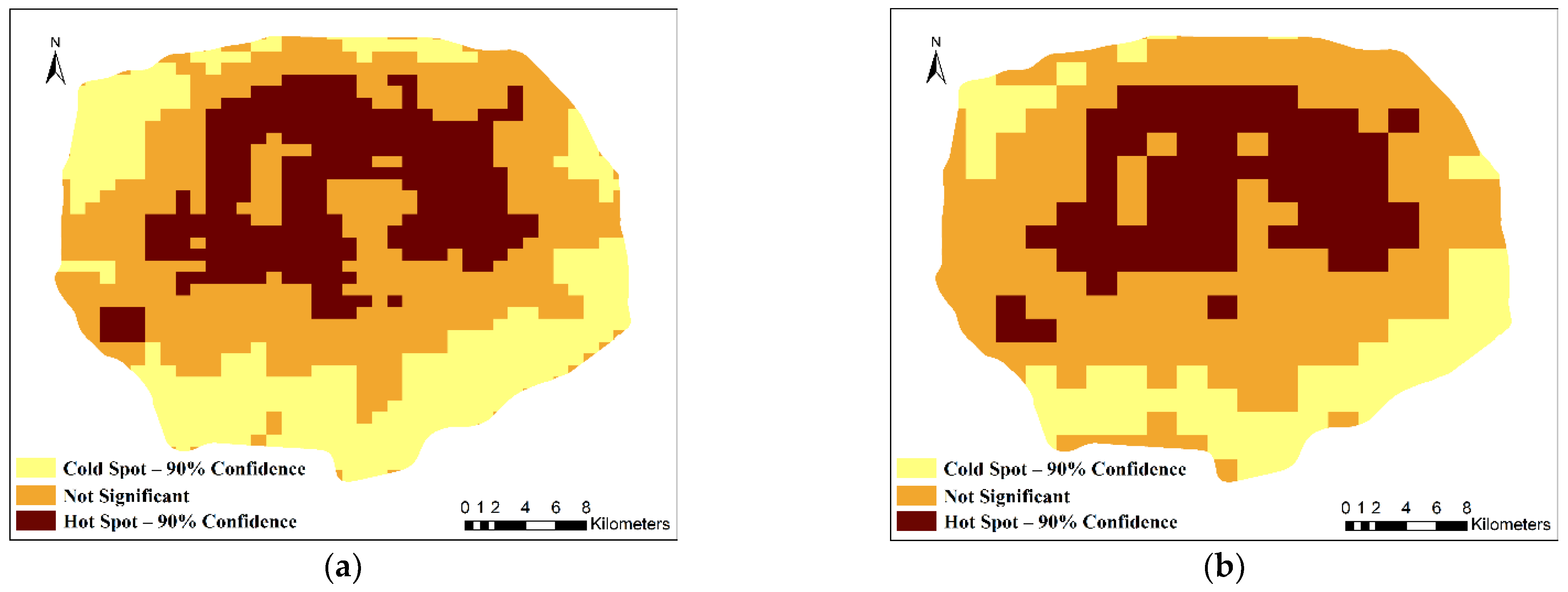
Based on the Getis–Ord
Gi* method, the presence of statistically significant high and low values in the trajectory data within the Fifth Ring Road in Beijing is evaluated, and a visual method is used to display the clustered areas. The hotspot distribution based on floating car data in different spatiotemporal units is obtained with the Getis–Ord
Gi* method. Representative results are shown in
Figure 7.
According to the temporal and spatial distributions of urban hotspots, the proportion of grids with hotspots in the study area can be counted, as shown in
Table 5 (90% confidence). Overall, at the same temporal scale, as the spatial analysis scale increases, the proportion of hotspots decreases, and at the same spatial scale, the proportion of hotspots increases as the temporal scale increases. However, within the same spatial unit (1000 m and 2000 m), the proportion of hotspots with day as the temporal unit is slightly higher than that for other temporal units; under the same temporal unit (day), the proportion of hotspots with 1000 m and 2000 m as the spatial units is slightly higher than that for other spatial units. This finding suggests that the highest amount of hotspot distributions is obtained for day/1000 m and day/2000 m. It is optimal to analyze the functional categories of hotspots at these two spatiotemporal units.
4.2. Comparison of the Functions of Urban Hotspots in Different Spatiotemporal Units
Urban hotspots usually have developed commerce, well-established service facilities, and accessible transportation and are areas of concentrated public activities, such as shopping malls, leisure and entertainment facilities, schools, and catering facilities. Therefore, the differences in the distribution of hotspots at different spatiotemporal scales are analyzed from the perspective of the distribution of types of urban spatial functions.
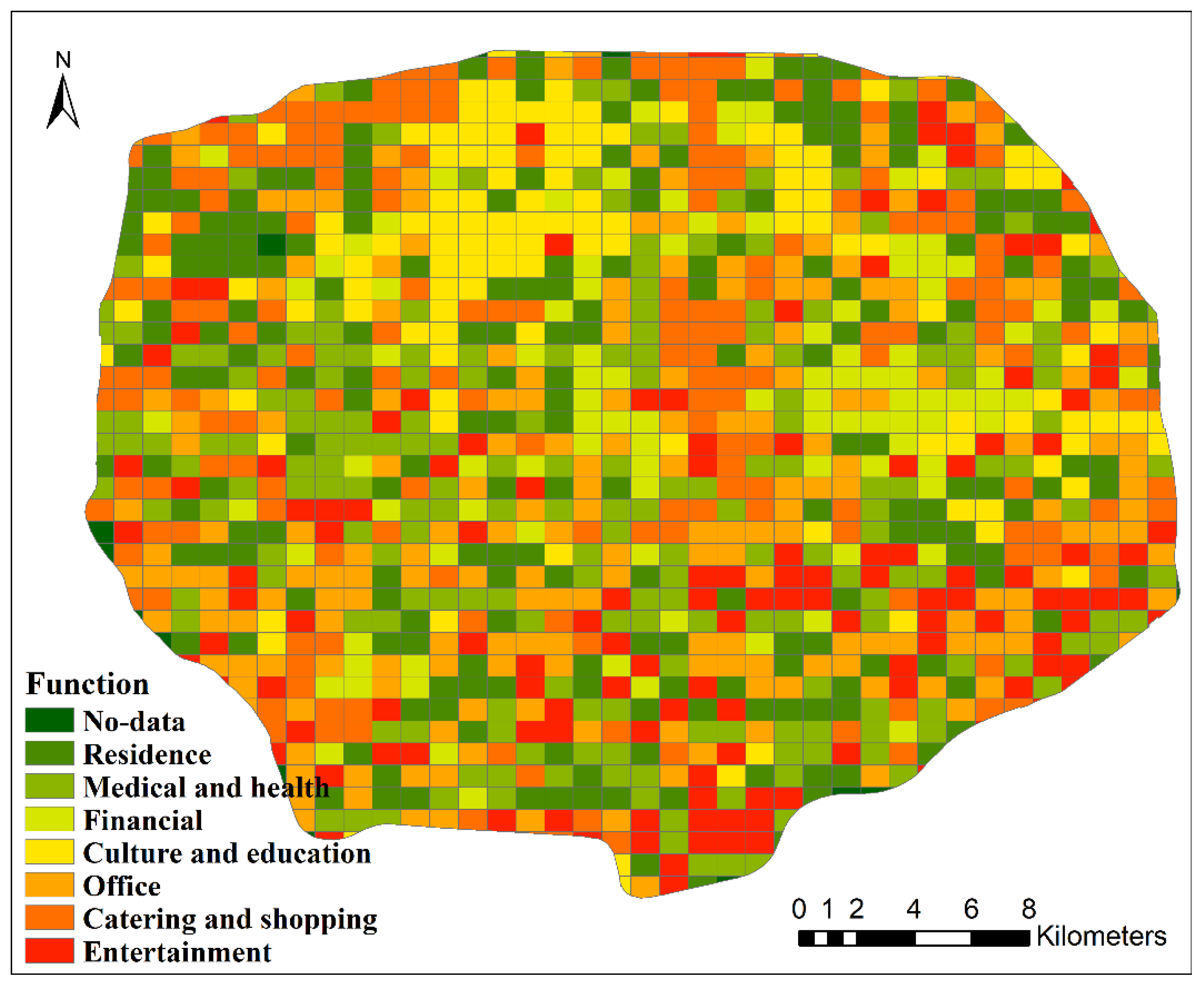
Point of interest (POI) data are closely related to people’s lives and can be used to define the different functional structures of cities. Therefore, POI data can reflect the functional distribution of an urban space. In this paper, POI data are used to calculate the land use types in the study area and then identify the functional distribution of urban hotspot areas. A total of 345,177 POIs with geographic entity location and attribute information were obtained in the study area and divided into 7 functional categories (residence, medical and health, financial, culture and education, office, catering and shopping, and entertainment). The details are shown in
Table 6.
According to the distribution of POIs at different scales,
FD/
CP indicators are used to determine the urban function types for different analysis units [
42]; this approach can eliminate the influence of the frequency of different types of POIs on the function identification results. The corresponding equations are shown in (7) and (8).
where
i is a POI category,
m is the total number of POI categories,
is the number of POIs in category
i in cluster
c,
is the total number of POIs in category
i,
represents the frequency density of the
ith category of the POI in cluster
c, and
represents the proportion of the frequency density of the
ith category of the POI in cluster
c to the frequency density of all categories of POIs in the cluster.
In this paper, the POI category with the largest
CP is used as the functional type for the region, and the distribution of the final identified functional types is shown in
Figure 8. With this method, the function types can be determined for different hotspot areas with different spatiotemporal units, and the corresponding distribution proportions can be obtained, as shown in
Table 7.
The functional category calculated by the POI data corresponds to the hotspot distribution area, and the functional category of the hotspot is obtained. According to the definition of hotspots, the areas that meet the functional characteristics of hotspots can be known.
Table 7 shows that the types of hotspot functions at the temporal scale of day and the spatial scales of 1000 m and 2000 m best reflect the actual functions of urban hotspots. At these spatial and temporal scales, catering and entertainment hotspots account for nearly 40% of all hotspots; if office and cultural function types are added, this total increases to more than 70%. Hotspots are usually distributed in densely populated areas. According to the analysis of national demographic data, from the perspective of population distribution, the calculated hotspot areas are consistent with the population distribution pattern of Beijing (the northern part of Beijing’s Fifth Ring Road zone is more populated than the southern part). According to the calculation of the distribution of urban hotspots, it is shown that the spatiotemporal units of day/1000 m and day/2000 m are the optimal spatiotemporal scales, which are consistent with the results calculated by the spatiotemporal analysis unit optimization framework. Therefore, from the distribution of functional types and population distribution in relation to urban hotspots, the accuracy of the optimization framework for spatiotemporal data analysis units is further verified.
4.3. Consistency of Urban Hotspots in Different Spatiotemporal Units
The kappa coefficient is an indicator of the consistency of tests and can be used to measure the effect of classification [
43,
44]. In classification problems, consistency is used to determine whether the results of a model are consistent with the actual values. That is, the kappa value can measure the degree of consistency between two observed objects. The kappa coefficient is calculated with Equation (9).
where
is the sum of the number of correctly classified samples for each class divided by the total number of samples, which is the overall classification accuracy. Assuming that the number of real samples of each class is
, the number of predicted samples of each class is
, and the total number of samples is
n, then
. Therefore, the kappa coefficient is calculated based on the confusion matrix of the actual class and the predicted class, and its value falls within the range of [−1, 1]. Usually, the kappa coefficient varies from 0~1, and values in this range can be divided into five groups to indicate different levels of consistency (0.0~0.20 for slight consistency, 0.21~0.40 for fair consistency, 0.41~0.60 for moderate consistency, 0.61~0.80 for substantial consistency, and 0.81~1 for very high consistency).
The kappa coefficient can be used to verify the consistency of hotspots identified at different spatial and temporal scales to illustrate the effects of considering various scales on the data analysis results. Assuming that the distributions of hotspots at scales A and B are compared (here, A and B correspond to certain spatiotemporal scales, respectively, and A and B are different) and that the hotspots obtained at scale B are correct, then represents the sum of the correctly identified hotspot grids in A divided by the total number of grids, and represents the product of the number of correctly identified hotspot grids in A and the total number of hotspot grids divided by the square of the total number of grids.
To analyze the consistency of the hotspot distribution more precisely, this paper uses the overall kappa coefficient proposed by Hagen to compare hotspots at different spatiotemporal scales [
45]. The overall kappa coefficient is calculated by the product of the independent indicators Khisto and Klocation. Klocation is an indicator that measures the similarity of two categories based on spatial location. Khisto is a measure of the similarity of two categories based on statistics. Therefore, the overall kappa coefficient can be expressed as a combination of quantitative and positional similarity.
By using the calculation method proposed by Hagen, the overall kappa coefficients at different temporal scales and the same spatial scale (
Table 8) and at different spatial scales and the same temporal scale (
Table 9) can be obtained. Furthermore, the effects of spatial and temporal scales on the distribution of urban hotspots are studied.
The mean values in
Table 8 show that when the spatial scales are the same, the distribution of hotspots at different temporal scales is highly consistent. Thus, in a certain study area, the temporal scale of data analysis has little effect on the study of geographical phenomena.
The mean values in
Table 9 indicate that when the temporal scales are the same, the distribution of hotspots at different spatial scales displays low consistency. Notably, in a certain study area, the spatial scale of data analysis, that is, the unit size, has a large impact on the study of geographical phenomena. This result verifies the importance of MAUP effects.
In summary, compared with the temporal scale, the spatial scale has a greater impact on the analysis of geographical phenomena. The larger the temporal unit selected for data analysis, the more data are included, whereas the smaller the temporal unit is, the less data are included. Even if the data volume increases, the data distribution in the study area does not considerably change; that is, the selection of the temporal scale has little effect on the data analysis. However, different spatial scales have a greater impact on the data distribution and influence the calculation results for geographical phenomena. Therefore, when analyzing geographical phenomena, optimization of the spatial analysis unit should be prioritized.
5. Discussion
The traditional spatiotemporal analysis unit is subjectively established according to the analyst’s point of view and application field [
46,
47,
48]. There are often no criteria or reasons to ensure the representativeness of the analytical units, which may give rise to MAUP effects [
7,
8]. This paper argues that a multicriteria-based data-driven approach can be used to provide analysis units that fit the real world.
Geographical phenomenon analysis is generally affected by both temporal and spatial scales and involves analyzing as many temporal and spatial scales as possible to determine optimal units, and using multiple criteria to automatically evaluate the analysis results. The previous determination methods of analytical units based on a single criterion such as global correlation have uncertainties [
49]. Different standards affect the selection of units from different angles and lead to differences in the analysis results. Therefore, we propose a framework based on Pareto optimality methods, which can flexibly select suitable units based on multiple criteria to satisfy arbitrary optimization criteria for different datasets and analysis regions. Furthermore, this paper considers not only the spatial scale but also the temporal scale. Time segmentation and aggregation are means of analyzing real-world spatiotemporal processes, and data aggregation at different temporal scales imposes an impact on the results [
50].
In this paper, there may be conflicts when applying a data-driven approach based on multiple criteria, such as global correlation versus local correlation. The optimal spatiotemporal unit that fits one criterion may not conform to the other; so, it is necessary to define the size of the unit and the criteria for judgement according to the research topic and knowledge reserve. In addition, the use of regular grids in this paper to divide the space unit has limitations. Geographic phenomena are irregularly distributed. Different types of area units may be studied in the future. At the same time, the uncertainty of the optimal unit increases with the increase in the number of criteria, and more expertise is required to determine the optimal spatiotemporal unit. The optimal spatiotemporal analysis unit may change due to different research data, times, and cases. In the future, other cases and criteria can be used to evaluate the framework proposed in this paper to obtain broader results.
6. Conclusions
The determination of the spatiotemporal scale is the basis for analyses of geographical phenomena using spatiotemporal data. In this paper, a multicriteria-based spatiotemporal analysis unit optimization framework is proposed to assist in determining the optimal spatiotemporal analysis units in spatiotemporal data analyses. Based on Pareto optimality, the framework can be used to evaluate candidate spatiotemporal analysis units based on any number of criteria, thus overcoming the subjectivity and randomness of traditional methods of establishing analysis units and mitigating MAUP effects to a certain extent.
Floating car data are applied to the multicriteria-based spatiotemporal analysis unit optimization framework, and the optimal spatiotemporal analysis unit is determined by combining the global spatial autocorrelation index and the coefficient of variation of local spatial autocorrelation. The results show that the optimal spatiotemporal analysis units (day/1000 m and day/2000 m) provide a more consistent spatial pattern than other analysis units and may provide more reliable analysis results. The optimal spatiotemporal analysis unit based on multiple criteria also provides a reference analysis scale for studies of urban problems. Moreover, urban hotspot extraction was performed to further illustrate the reliability of the method proposed in this paper. By introducing the proposed method for determining a suitable analysis scale according to the spatial and temporal characteristics of spatiotemporal data, the accuracy of the calculation results for geographical phenomena is improved.
However, due to MAUP effects, the use of different indicators, and differences in application fields, the uncertainty of spatiotemporal analysis units is often an issue. Therefore, when determining the best spatiotemporal analysis unit in studies of geographical phenomena, as many factors as possible, such as other spatial unit shapes and sizes and new evaluation criteria, should be considered.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}