
Mapping Fire Susceptibility in the Brazilian Amazon Forests Using Multitemporal Remote Sensing and Time-Varying Unsupervised Anomaly Detection

 ,
,  ,
,  , , and
, , and
Abstract
:
1. Introduction
- The proposal of a fully automatic methodology for both mapping and quantifying fire-susceptible areas which relies on unsupervised anomaly detection, spectral indices differences, and satellite image time series towards better detecting patterns in complex data by learning from examples automatically.
- The applicability assessment of two anomaly detection techniques as time-varying models to select the best-performing approach for the tasks of simultaneously classifying and quantifying fire-prone areas in Brazilian Amazon rainforest portions.
- The development of an entire unsupervised training approach that integrates multiple sources of freely available satellite imagery and does not require any labeled data to generate a suitable fire detection model.
- A comparative and statistical significance analysis for each implemented method regarding areas assigned as fire against areas of true fire for two real events of wildfires in the Brazilian Amazon.
2. Theoretical Aspects and Background
2.1. Anomaly Detection as a Classification Problem
2.1.1. One-Class Support Vector Machine
2.1.2. Isolation Forest
2.2. Spectral Indexes and Burn Detection
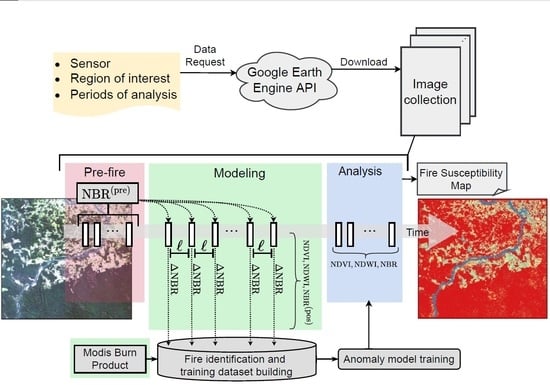
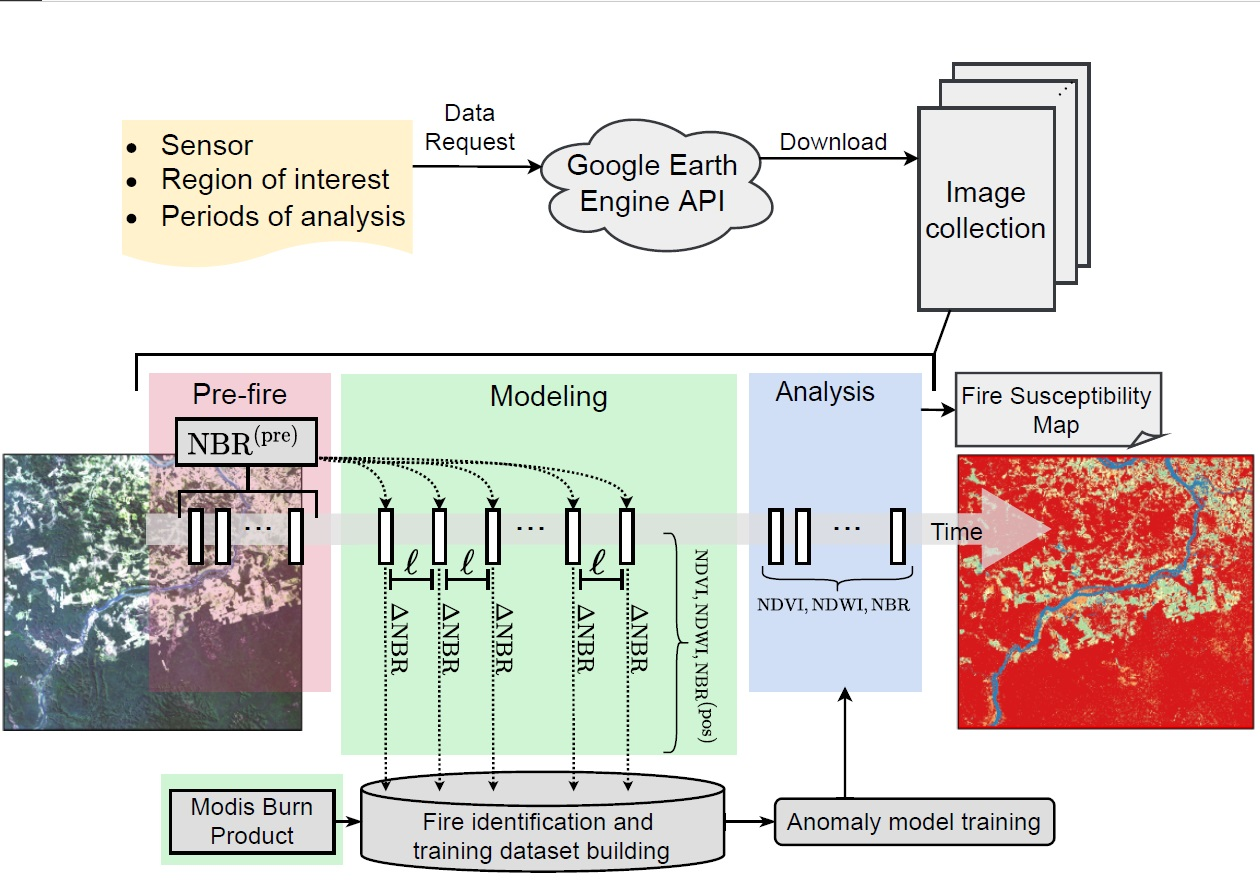
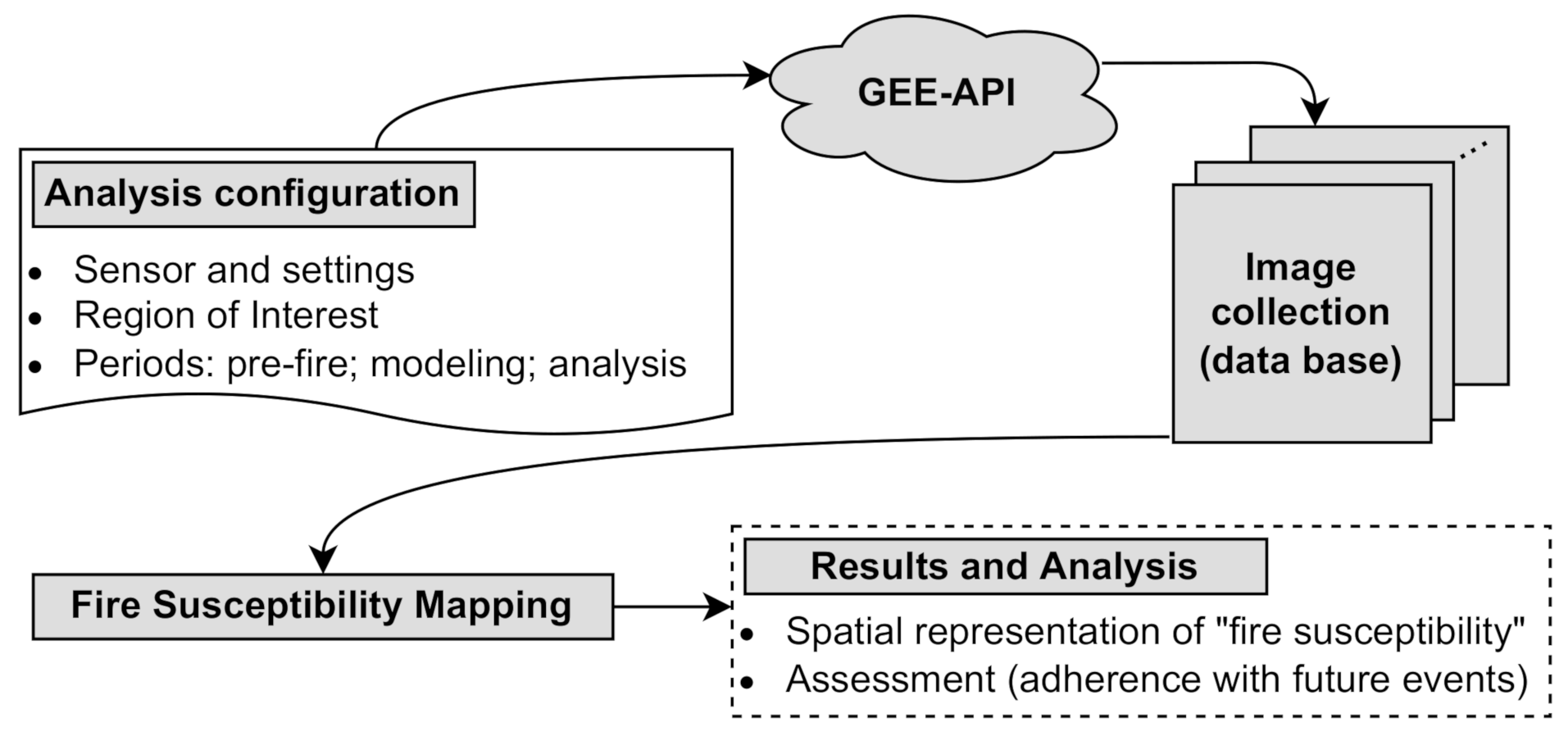
3. Fire Susceptibility Mapping
3.1. Computational Methodology
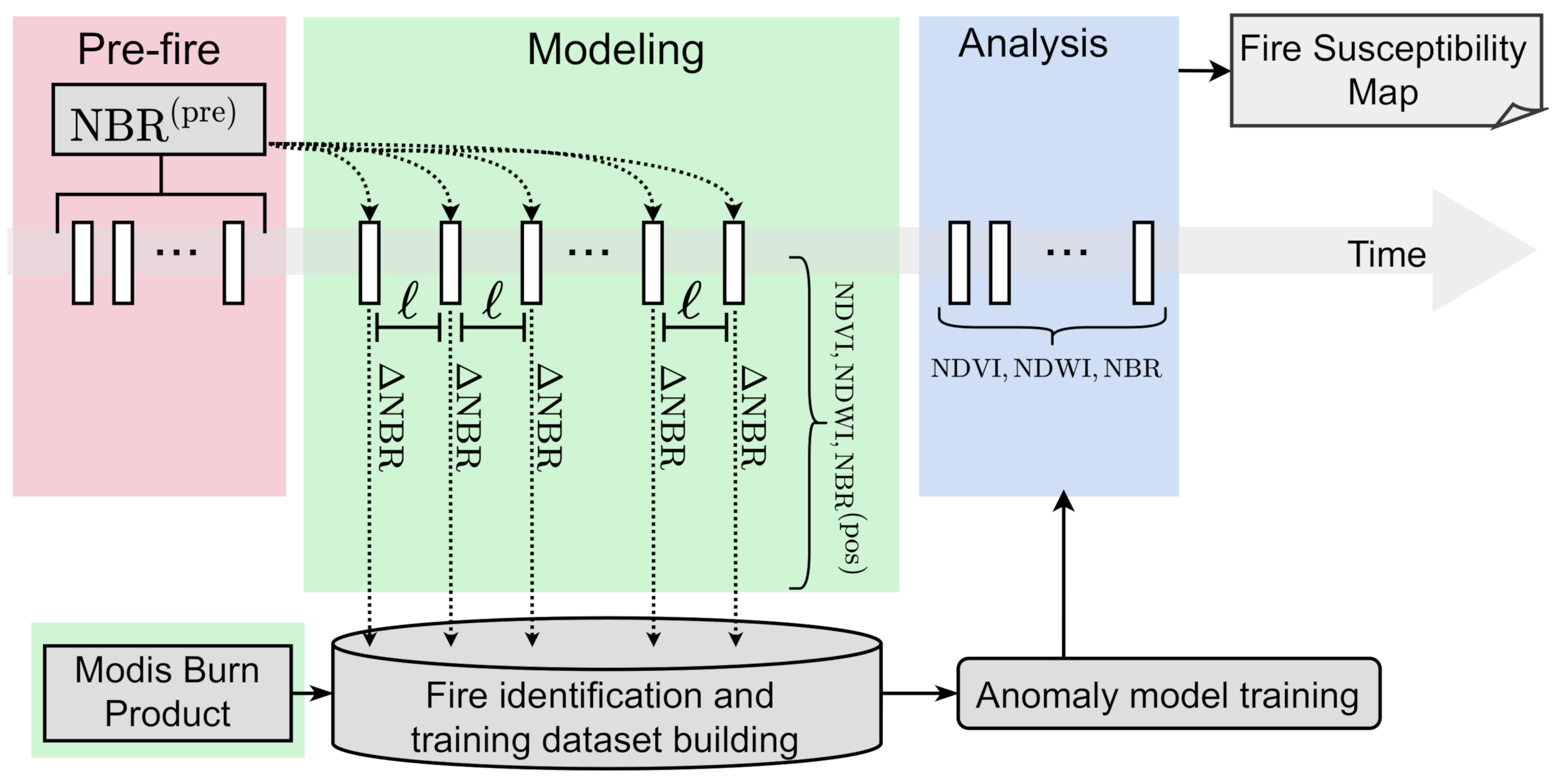
3.1.1. Multitemporal Arrangement of Remote Sensing Data
- Prefire period: Comprises an image series taken before the fire occurred. The goal here is to capture the central tendency at each position in the study area and then use this information to generate the NBR index as a benchmark before the presence of fire (i.e., ) according to the model.
- Modeling period: Covers a time interval whose data instances are exploited to identify fire events and, subsequently, build a time-varying anomaly detection model which learns the behavior of the fires immediately before they spread.
- Analysis period: Consists of the test period, where our trained anomaly detection model is applied to classify the fire-susceptible areas.
3.1.2. Spectral Mapping, , and Modeling Dataset
3.1.3. Time-Varying Unsupervised Anomaly Detection
3.2. Data Sets, Computational Resources, and Parameter Tuning
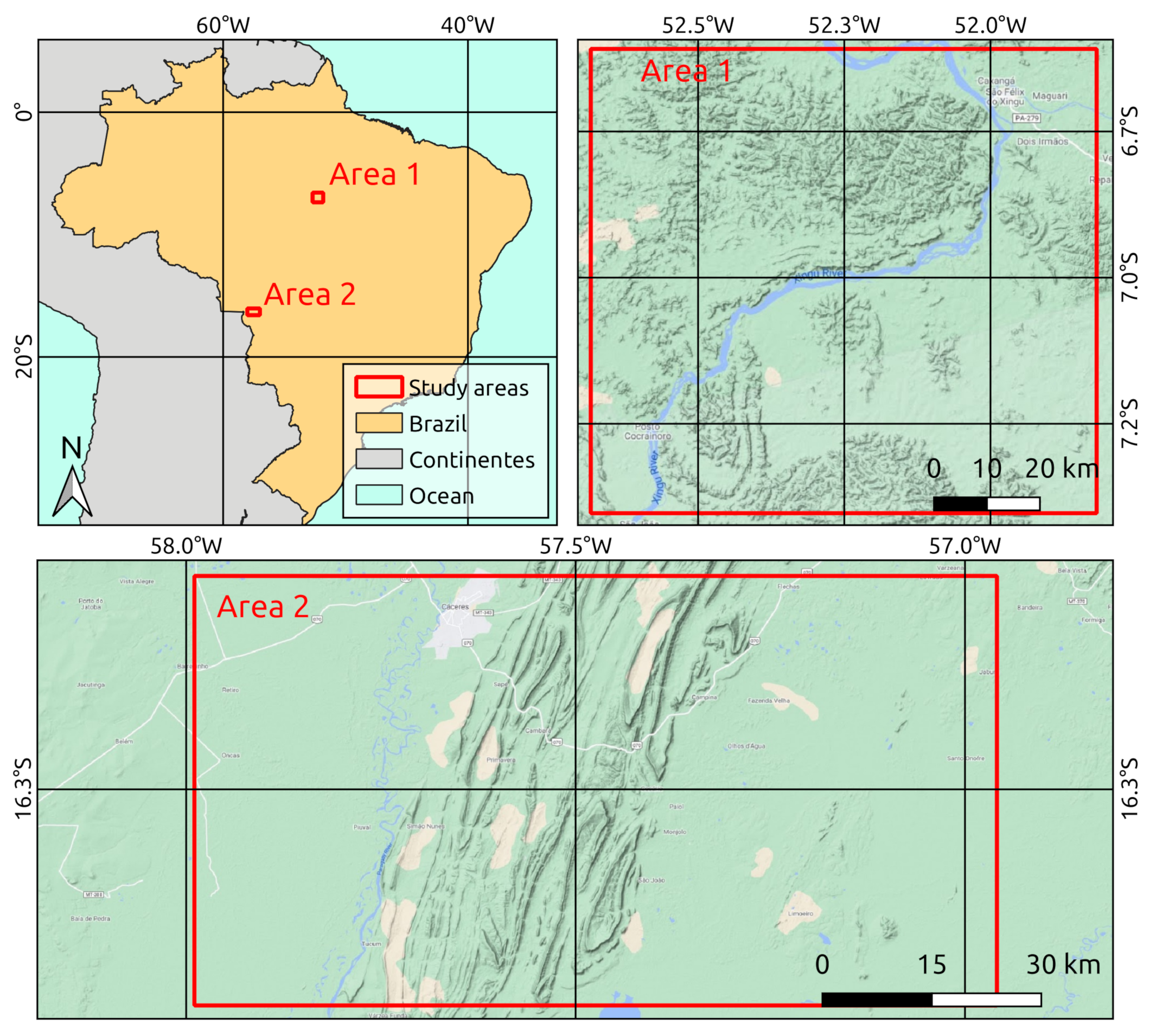
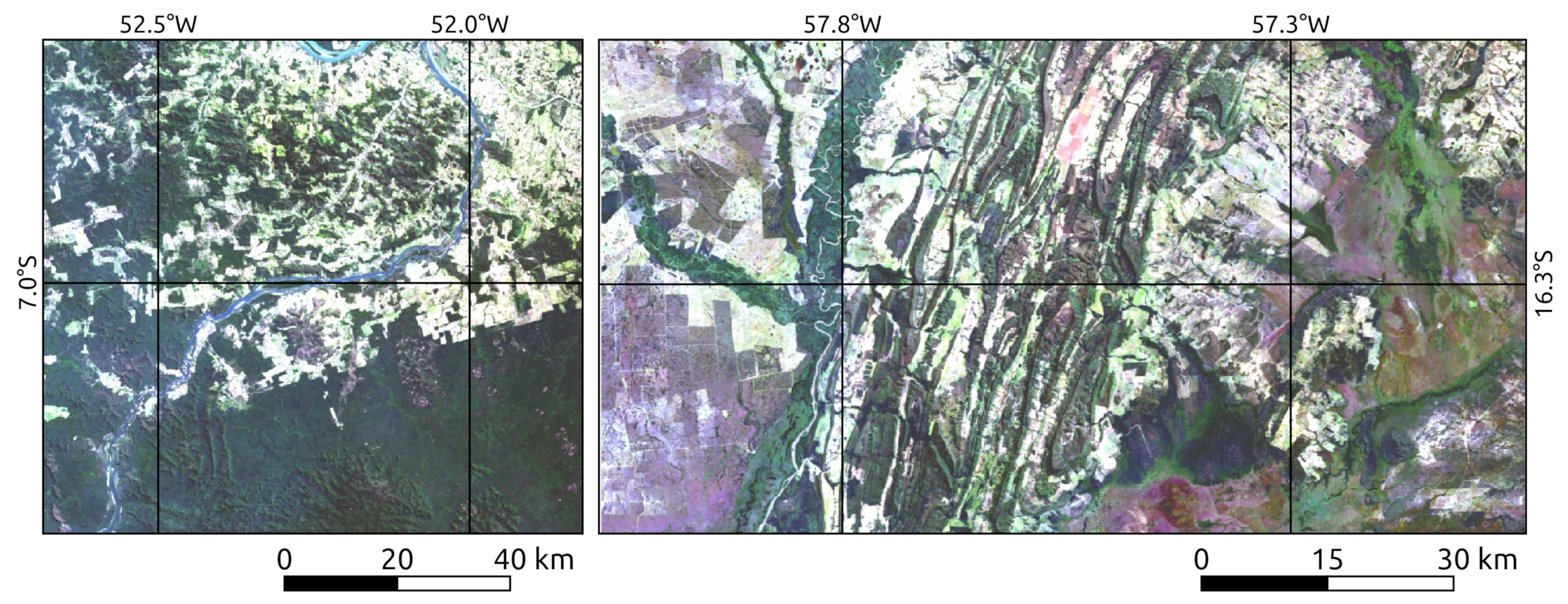
4. Study Areas and Assessment Periods
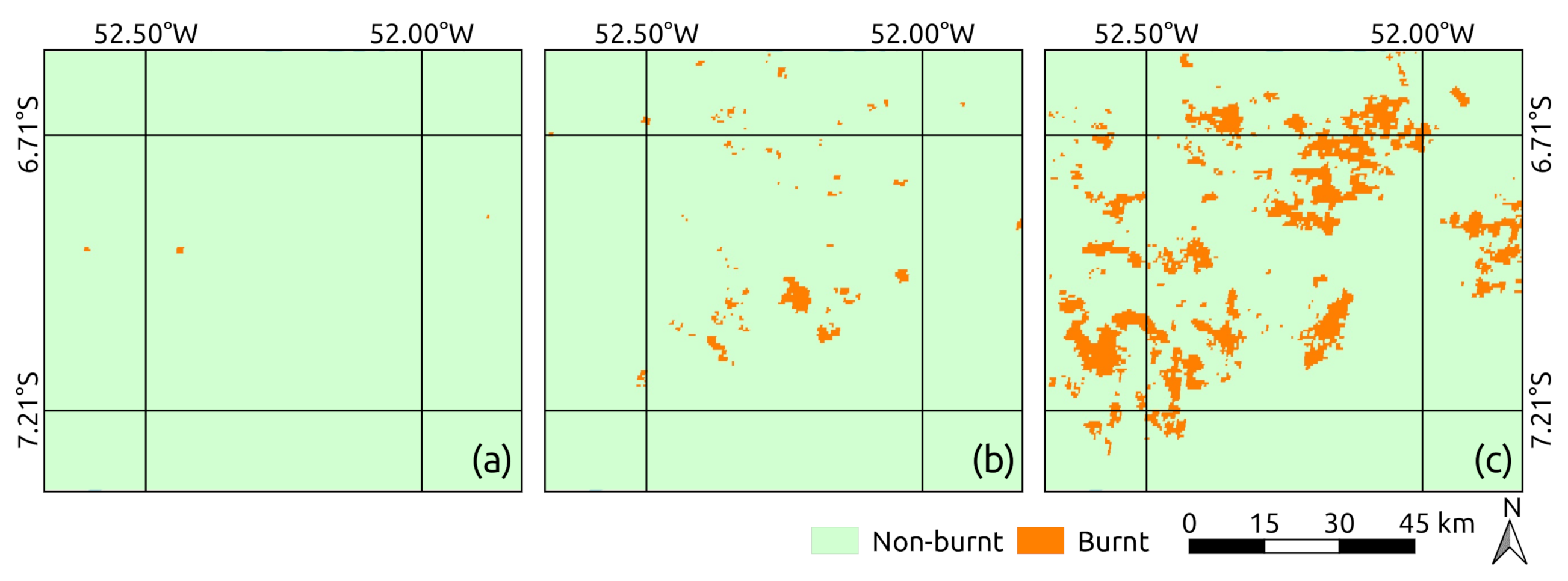
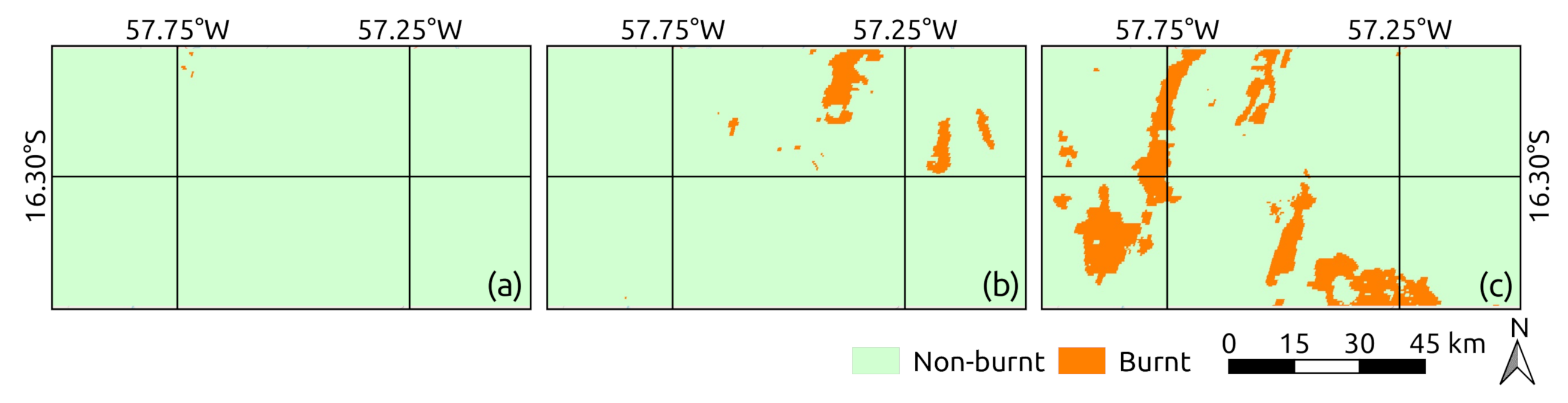
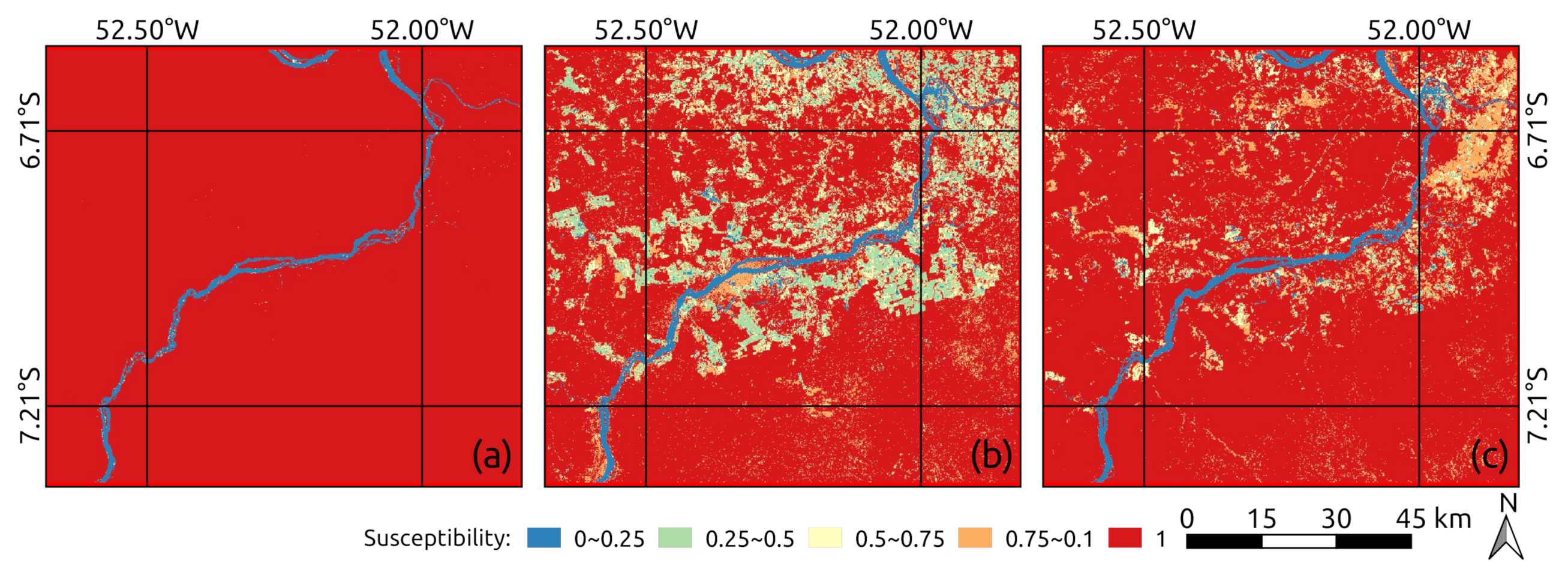
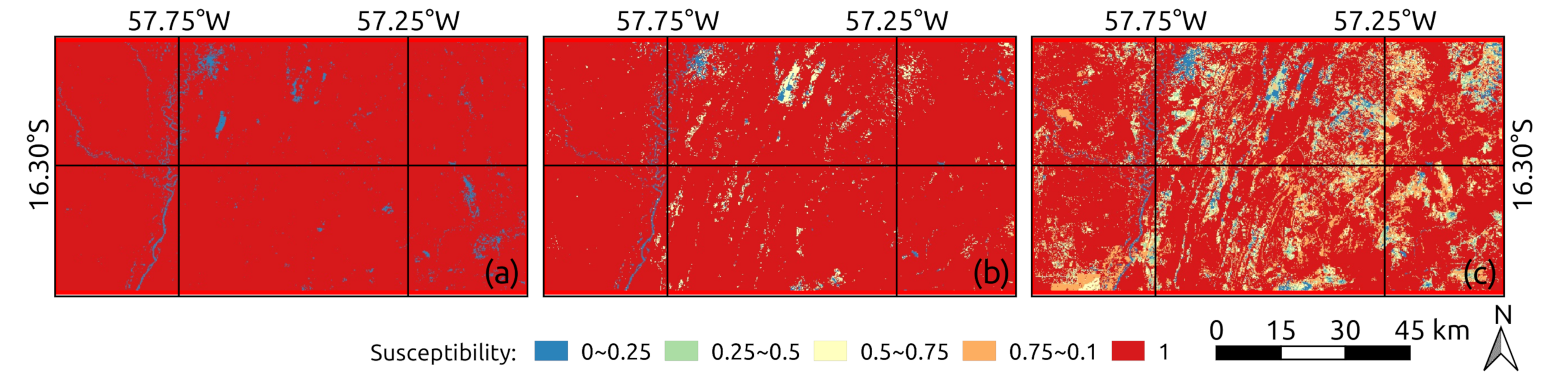
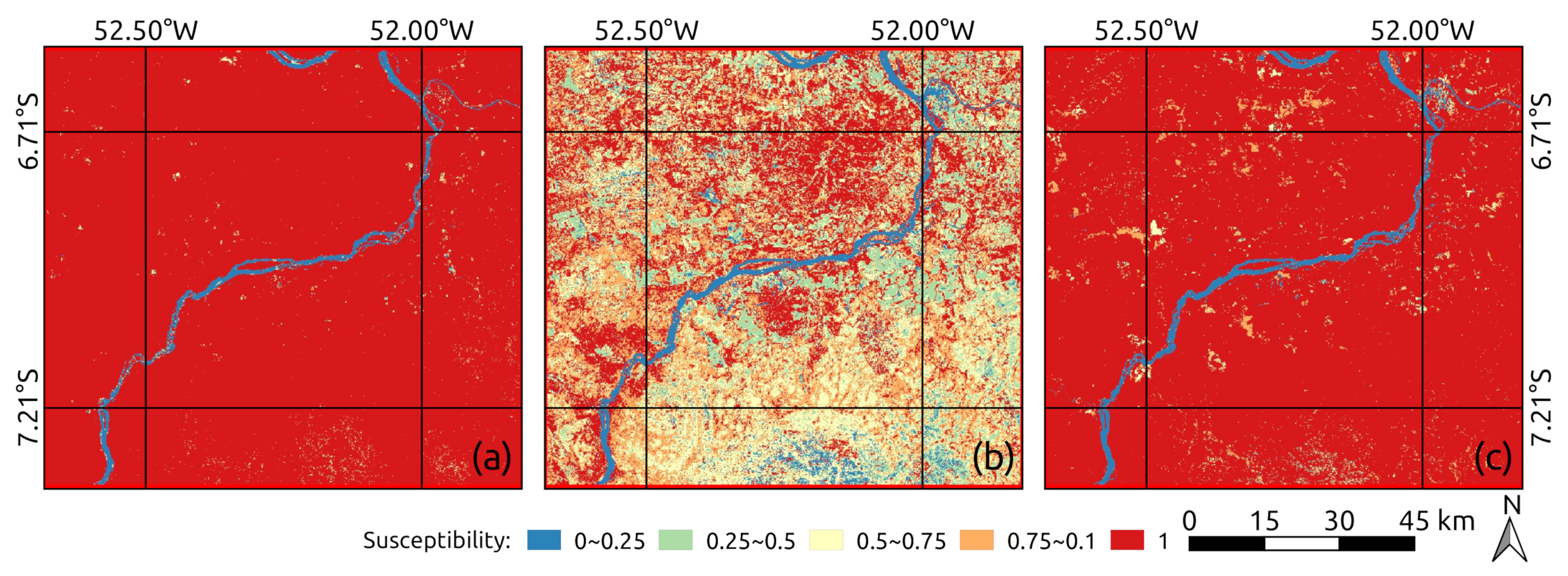
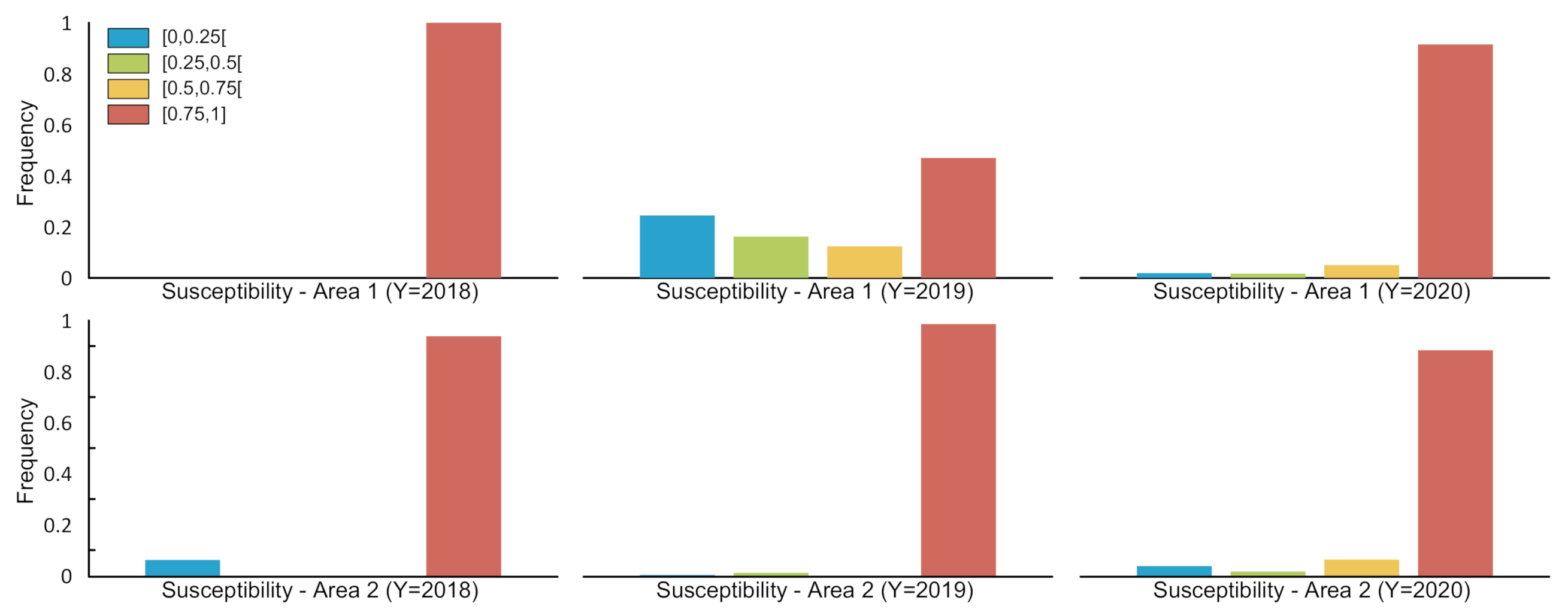
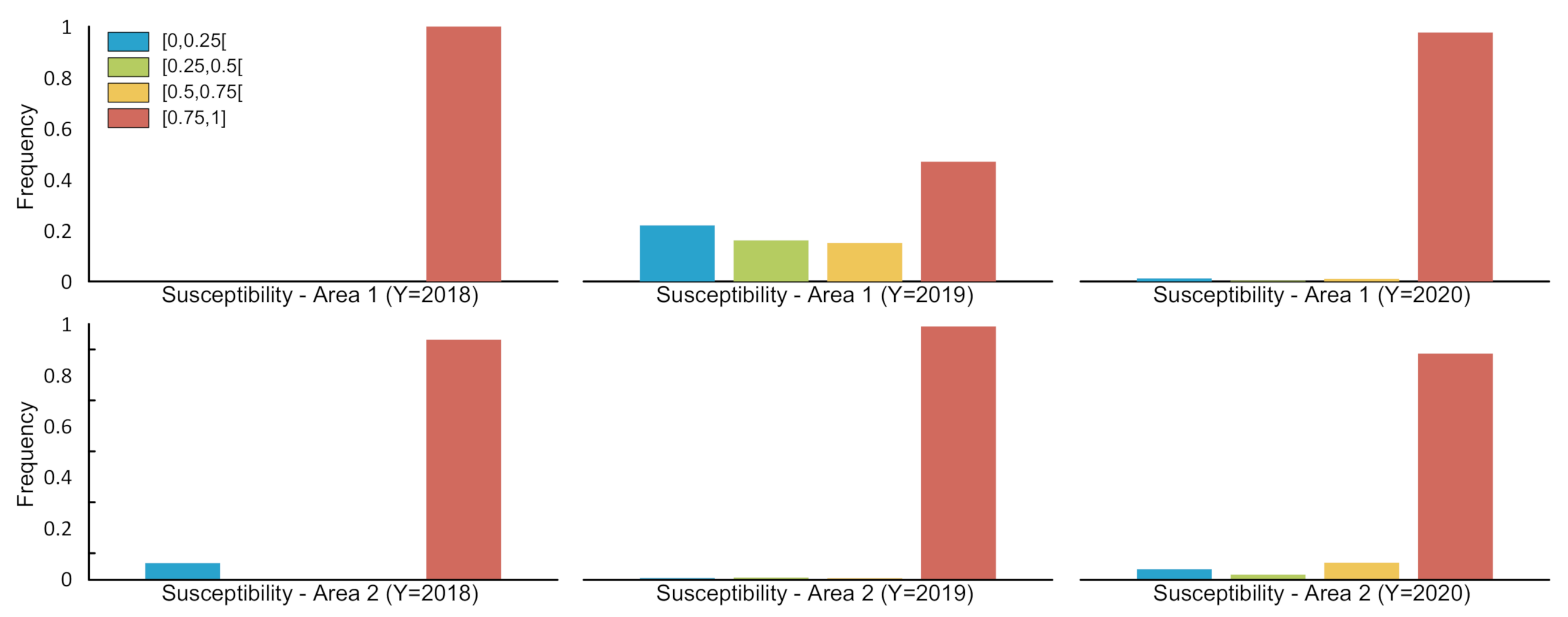
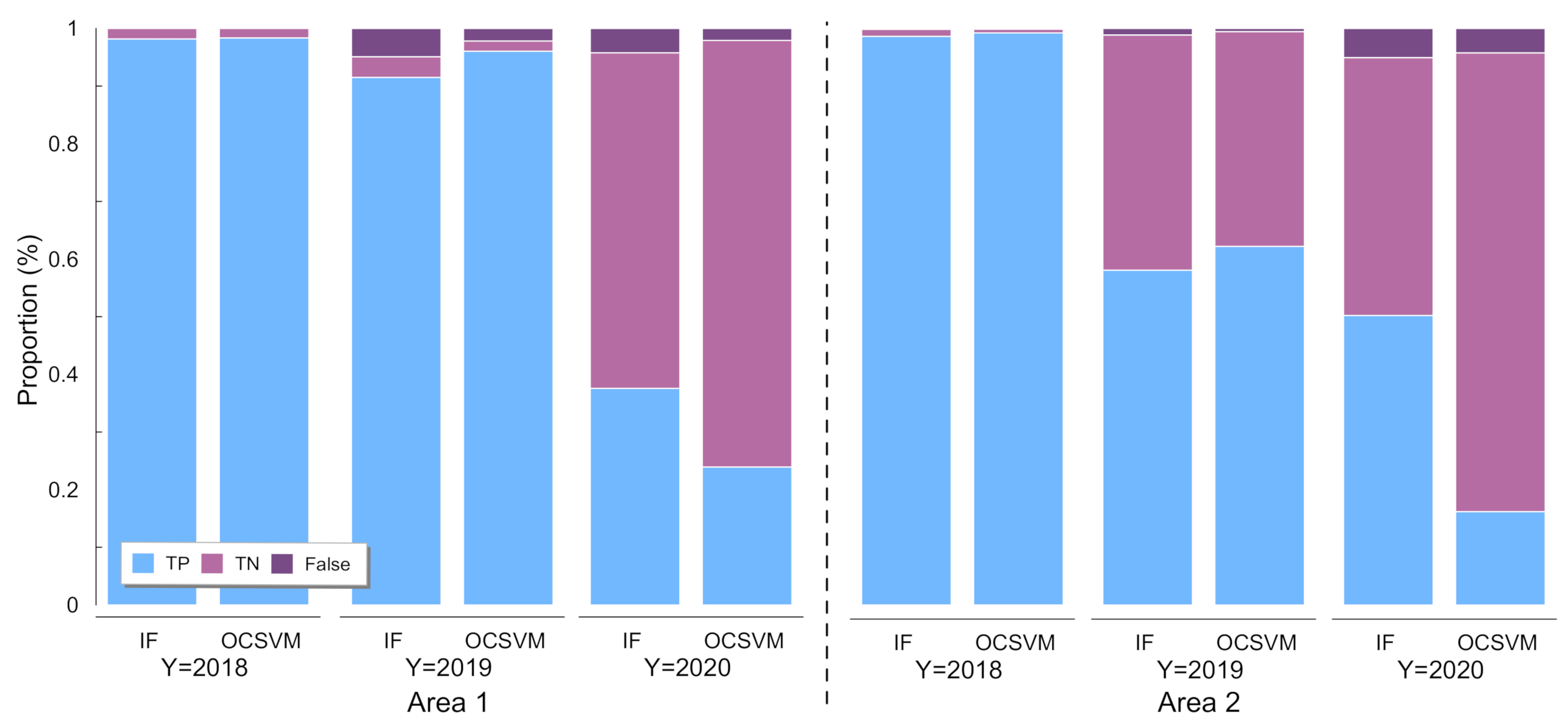
5. Experiments and Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Artés, T.; Oom, D.; De Rigo, D.; Durrant, T.H.; Maianti, P.; Libertà, G.; San-Miguel-Ayanz, J. A global wildfire dataset for the analysis of fire regimes and fire behaviour. Sci. Data 2019, 6, 296. [Google Scholar] [CrossRef] [PubMed]
- Caúla, R.; Oliveira-Júnior, J.F.; Lyra, G.B.; Delgado, R.; Heilbron Filho, P. Overview of fire foci causes and locations in Brazil based on meteorological satellite data from 1998 to 2011. Environ. Earth Sci. 2015, 74, 1497–1508. [Google Scholar] [CrossRef]
- Cochrane, M.A.; Barber, C.P. Climate change, human land use and future fires in the Amazon. Glob. Chang. Biol. 2009, 15, 601–612. [Google Scholar] [CrossRef]
- Garcia, L.C.; Szabo, J.K.; de Oliveira Roque, F.; Pereira, A.d.M.M.; da Cunha, C.N.; Damasceno-Júnior, G.A.; Morato, R.G.; Tomas, W.M.; Libonati, R.; Ribeiro, D.B. Record-breaking wildfires in the world’s largest continuous tropical wetland: Integrative fire management is urgently needed for both biodiversity and humans. J. Environ. Manag. 2021, 293, 112870. [Google Scholar] [CrossRef]
- INPE. Instituto Nacional de Pesquisas Espaciais—Banco de Dados de Queimadas. 2021. Available online: https://queimadas.dgi.inpe.br/queimadas/bdqueimadas (accessed on 29 March 2021).
- Prestes, N.C.C.d.S.; Massi, K.G.; Silva, E.A.; Nogueira, D.S.; de Oliveira, E.A.; Freitag, R.; Marimon, B.S.; Marimon-Junior, B.H.; Keller, M.; Feldpausch, T.R. Fire effects on understory forest regeneration in southern Amazonia. Front. For. Glob. Chang. 2020, 3, 10. [Google Scholar] [CrossRef]
- Field, C.B.; Barros, V.; Stocker, T.F.; Dahe, Q. Managing the Risks of Extreme Events and Disasters to Advance Climate Change Adaptation: Special Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Brando, P.M.; Balch, J.K.; Nepstad, D.C.; Morton, D.C.; Putz, F.E.; Coe, M.T.; Silvério, D.; Macedo, M.N.; Davidson, E.A.; Nóbrega, C.C.; et al. Abrupt increases in Amazonian tree mortality due to drought—Fire interactions. Proc. Natl. Acad. Sci. USA 2014, 111, 6347–6352. [Google Scholar] [CrossRef] [Green Version]
- Pan, Y.; Birdsey, R.A.; Fang, J.; Houghton, R.; Kauppi, P.E.; Kurz, W.A.; Phillips, O.L.; Shvidenko, A.; Lewis, S.L.; Canadell, J.G.; et al. A large and persistent carbon sink in the world’s forests. Science 2011, 333, 988–993. [Google Scholar] [CrossRef] [Green Version]
- Birch, D.S.; Morgan, P.; Kolden, C.A.; Abatzoglou, J.T.; Dillon, G.K.; Hudak, A.T.; Smith, A.M. Vegetation, topography and daily weather influenced burn severity in central Idaho and western Montana forests. Ecosphere 2015, 6, 1–23. [Google Scholar] [CrossRef]
- Mann, M.L.; Batllori, E.; Moritz, M.A.; Waller, E.K.; Berck, P.; Flint, A.L.; Flint, L.E.; Dolfi, E. Incorporating anthropogenic influences into fire probability models: Effects of human activity and climate change on fire activity in California. PLoS ONE 2016, 11, e0153589. [Google Scholar] [CrossRef] [Green Version]
- Pereira, A.A.; Pereira, J.; Libonati, R.; Oom, D.; Setzer, A.W.; Morelli, F.; Machado-Silva, F.; De Carvalho, L.M.T. Burned area mapping in the Brazilian Savanna using a one-class support vector machine trained by active fires. Remote Sens. 2017, 9, 1161. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Q.; Shen, H.; Li, T.; Li, Z.; Li, S.; Jiang, Y.; Xu, H.; Tan, W.; Yang, Q.; Wang, J.; et al. Deep learning in environmental remote sensing: Achievements and challenges. Remote Sens. Environ. 2020, 241, 111716. [Google Scholar] [CrossRef]
- Martínez-Álvarez, F.; Tien Bui, D. Advanced Machine Learning and Big Data Analytics in Remote Sensing for Natural Hazards Management. Remote Sens. 2020, 12, 301. [Google Scholar] [CrossRef] [Green Version]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.X.; Xu, C. Applying genetic algorithms to set the optimal combination of forest fire related variables and model forest fire susceptibility based on data mining models. The case of Dayu County, China. Sci. Total Environ. 2018, 630, 1044–1056. [Google Scholar] [CrossRef] [PubMed]
- Leuenberger, M.; Parente, J.; Tonini, M.; Pereira, M.G.; Kanevski, M. Wildfire susceptibility mapping: Deterministic vs. stochastic approaches. Environ. Model. Softw. 2018, 101, 194–203. [Google Scholar] [CrossRef]
- Shirazi, Z.; Wang, L.; Bondur, V.G. Modeling Conditions Appropriate for Wildfire in South East China—A Machine Learning Approach. Front. Earth Sci. 2021, 9, 361. [Google Scholar] [CrossRef]
- Achu, A.; Thomas, J.; Aju, C.; Gopinath, G.; Kumar, S.; Reghunath, R. Machine-learning modeling of fire susceptibility in a forest-agriculture mosaic landscape of southern India. Ecol. Inform. 2021, 64, 101348. [Google Scholar] [CrossRef]
- Mirzaei, S.; Vafakhah, M.; Pradhan, B.; Alavi, S.J. Flood susceptibility assessment using extreme gradient boosting (EGB), Iran. Earth Sci. Inform. 2021, 14, 51–67. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, Y.; Zhou, Y.; Wang, H. Prediction of urban water accumulation points and water accumulation process based on machine learning. Earth Sci. Inform. 2021, 14, 2317–2328. [Google Scholar] [CrossRef]
- Fallah-Zazuli, M.; Vafaeinejad, A.; Alesheykh, A.A.; Modiri, M.; Aghamohammadi, H. Mapping landslide susceptibility in the Zagros Mountains, Iran: A comparative study of different data mining models. Earth Sci. Inform. 2019, 12, 615–628. [Google Scholar] [CrossRef]
- Dickson, B.G.; Prather, J.W.; Xu, Y.; Hampton, H.M.; Aumack, E.N.; Sisk, T.D. Mapping the probability of large fire occurrence in northern Arizona, USA. Landsc. Ecol. 2006, 21, 747–761. [Google Scholar] [CrossRef]
- Kamalakannan, J.; Chakrabortty, A.; Bothra, G.; Pare, P.; Kumar, C.P. Forest fire prediction to prevent environmental hazards using data mining approach. In Proceedings of the 2nd International Conference on Data Engineering and Communication Technology, Pune, India, 15–16 December 2017; Springer: Singapore, 2017; pp. 615–622. [Google Scholar]
- Pourghasemi, H.R.; Kariminejad, N.; Amiri, M.; Edalat, M.; Zarafshar, M.; Blaschke, T.; Cerda, A. Assessing and mapping multi-hazard risk susceptibility using a machine learning technique. Sci. Rep. 2020, 10, 3203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Z.; Li, J.; Zhou, S.; Pirasteh, S. Developing an algorithm for local anomaly detection based on spectral space window in hyperspectral image. Earth Sci. Inform. 2015, 8, 741–749. [Google Scholar] [CrossRef]
- Dias, M.A.; Silva, E.A.d.; Azevedo, S.C.d.; Casaca, W.; Statella, T.; Negri, R.G. An Incongruence-Based Anomaly Detection Strategy for Analyzing Water Pollution in Images from Remote Sensing. Remote Sens. 2020, 12, 43. [Google Scholar] [CrossRef] [Green Version]
- Xie, Z.; Song, W.; Ba, R.; Li, X.; Xia, L. A Spatiotemporal Contextual Model for Forest Fire Detection Using Himawari-8 Satellite Data. Remote Sens. 2018, 10, 1992. [Google Scholar] [CrossRef] [Green Version]
- Coca, M.; Datcu, M. Anomaly Detection in Post Fire Assessment. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Brussels, Belgium, 11–16 July 2021; pp. 8620–8623. [Google Scholar]
- Saad, L. Predicting, Understanding, and Visualizing Fire Dynamics with Neural Networks. Master’s Thesis, Technical University of Munich, Munich, Germany, 2021. [Google Scholar]
- Mohammed, Z.; Hanae, C.; Larbi, S. Comparative Study on Machine Learning Algorithms for early fire forest detection system using geodata. Int. J. Electr. Comput. Eng. (IJECE) 2020, 10, 5507–5513. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. Comparisons of Diverse Machine Learning Approaches for Wildfire Susceptibility Mapping. Symmetry 2020, 12, 604. [Google Scholar]
- Ban, Y.; Zhang, P.; Nascetti, A.; Bevington, A.R.; Wulder, M.A. Near real-time wildfire progression monitoring with Sentinel-1 SAR time series and deep learning. Sci. Rep. 2020, 10, 1322. [Google Scholar] [CrossRef] [Green Version]
- Khosravi, K.; Panahi, M.; Tien Bui, D. Spatial prediction of groundwater spring potential mapping based on an adaptive neuro-fuzzy inference system and metaheuristic optimization. Hydrol. Earth Syst. Sci. 2018, 22, 4771–4792. [Google Scholar] [CrossRef] [Green Version]
- Negri, R.G.; Frery, A.C.; Casaca, W.; Azevedo, S.; Dias, M.A.; Silva, E.A.; Alcântara, E.H. Spectral–Spatial-Aware Unsupervised Change Detection With Stochastic Distances and Support Vector Machines. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2863–2876. [Google Scholar] [CrossRef]
- Akoglu, L.; Tong, H.; Koutra, D. Graph based anomaly detection and description: A survey. Data Min. Knowl. Discov. 2015, 29, 626–688. [Google Scholar] [CrossRef] [Green Version]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.T.; Ting, K.M.; Zhou, Z. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar] [CrossRef]
- Gu, S.; Hu, Q.; Cheng, Y.; Bai, L.; Liu, Z.; Xiao, W.; Gong, Z.; Wu, Y.; Feng, K.; Deng, Y.; et al. Application of organic fertilizer improves microbial community diversity and alters microbial network structure in tea (Camellia sinensis) plantation soils. Soil Tillage Res. 2019, 195, 104356. [Google Scholar] [CrossRef]
- Dereszynski, E.W.; Dietterich, T.G. Spatiotemporal Models for Data-Anomaly Detection in Dynamic Environmental Monitoring Campaigns. ACM Trans. Sens. Netw. (TOSN) 2011, 8, 1–36. [Google Scholar] [CrossRef]
- Havens, T.C.; Bezdek, J.C. An efficient formulation of the improved visual assessment of cluster tendency (iVAT) algorithm. IEEE Trans. Knowl. Data Eng. 2011, 24, 813–822. [Google Scholar] [CrossRef]
- Bruzzone, L.; Persello, C. A novel context-sensitive semisupervised SVM classifier robust to mislabeled training samples. IEEE Trans. Geosci. Remote Sens. 2009, 47, 2142–2154. [Google Scholar] [CrossRef] [Green Version]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Gu, Y.; Feng, K. Optimized Laplacian SVM with distance metric learning for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 1109–1117. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Bi, C.; Jiang, X. Revisiting transductive support vector machines with margin distribution embedding. Knowl.-Based Syst. 2018, 152, 200–214. [Google Scholar] [CrossRef]
- Negri, R.G.; da Silva, E.A.; Casaca, W. Inducing Contextual Classifications With Kernel Functions Into Support Vector Machines. IEEE Geosci. Remote Sens. Lett. 2018, 15, 962–966. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Cristianini, N. Kernel Methods for Pattern Analysis; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data (TKDD) 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Kumar, A.; Bhandari, A.K.; Padhy, P. Improved normalised difference vegetation index method based on discrete cosine transform and singular value decomposition for satellite image processing. IET Signal Process. 2012, 6, 617–625. [Google Scholar] [CrossRef]
- Schepers, L.; Haest, B.; Veraverbeke, S.; Spanhove, T.; Vanden Borre, J.; Goossens, R. Burned area detection and burn severity assessment of a heathland fire in Belgium using airborne imaging spectroscopy (APEX). Remote Sens. 2014, 6, 1803–1826. [Google Scholar] [CrossRef] [Green Version]
- Veraverbeke, S.; Harris, S.; Hook, S. Evaluating spectral indices for burned area discrimination using MODIS/ASTER (MASTER) airborne simulator data. Remote Sens. Environ. 2011, 115, 2702–2709. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W. Monitoring vegetation systems in the Great Plains with ERTS. NASA Spec. Publ. 1974, 351, 309. [Google Scholar]
- Gao, B.C. NDWI—A normalized difference water index for remote sensing of vegetation liquid water from space. Remote Sens. Environ. 1996, 58, 257–266. [Google Scholar] [CrossRef]
- Key, C.H.; Benson, N.C. Landscape assessment (LA). In FIREMON: Fire Effects Monitoring and Inventory System; Gen. Tech. Rep., RMRS-GTR-164-CD; Lutes, D.C., Keane, R.E., Caratti, F., Key, C.H., Benson, N.C., Sutherland, S., Gangi, L.J., Eds.; US Department of Agriculture Forest Service, Rocky Mountain Research Station: Fort Collins, CO, USA, 2006; Volume 164, p. LA-1-55. [Google Scholar]
- Tran, B.N.; Tanase, M.A.; Bennett, L.T.; Aponte, C. Evaluation of spectral indices for assessing fire severity in Australian temperate forests. Remote Sens. 2018, 10, 1680. [Google Scholar] [CrossRef] [Green Version]
- Sobrino, J.A.; Llorens, R.; Fernández, C.; Fernández-Alonso, J.M.; Vega, J.A. Relationship between soil burn severity in forest fires measured in situ and through spectral indices of remote detection. Forests 2019, 10, 457. [Google Scholar] [CrossRef] [Green Version]
- USGS. MODIS/Terra+Aqua Burned Area Monthly L3 Global 500 m SIN Grid. 2021. Available online: https://lpdaac.usgs.gov/products/mcd64a1v006/ (accessed on 29 March 2021).
- Van Rossum, G.; Drake, F.L. The Python Language Reference Manual; Network Theory Ltd.: Surrey, UK, 2011. [Google Scholar]
- Van Der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy array: A structure for efficient numerical computation. Comput. Sci. Eng. 2011, 13, 22–30. [Google Scholar] [CrossRef] [Green Version]
- McKinney, W. Data structures for statistical computing in python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Volume 445, pp. 51–56. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- GEE-API. Google Earth Engine API. 2021. Available online: https://developers.google.com/earth-engine (accessed on 22 November 2021).
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- LaValle, S.M.; Branicky, M.S.; Lindemann, S.R. On the relationship between classical grid search and probabilistic roadmaps. Int. J. Robot. Res. 2004, 23, 673–692. [Google Scholar] [CrossRef]
- Devore, J.L. Probability and Statistics for Engineering and the Sciences; Cengage Learning: Boston, MA, USA, 2011. [Google Scholar]
- Rijsbergen, C.J.V. Information Retrieval, 2nd ed.; Butterworth-Heinemann: Oxford, UK, 1979. [Google Scholar]
- Yasen Jiao, P.D. Performance measures in evaluating machine learning based bioinformatics predictors for classifications. Quant. Biol. 2016, 4, 320. [Google Scholar] [CrossRef] [Green Version]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Joachims, T. Transductive Inference for Text Classification using Support Vector Machines. In Proceedings of the ICML-99, 16th International Conference on Machine Learning, Bled, Slovenia, 27–30 June 1999; pp. 200–209. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pre-Fire | Modeling | Analysis | Assessment |
|---|---|---|---|
| 1 January (Y-3) to | 1 June (Y-1) to | 1 July Y to | 1 September Y to |
| 31 December (Y-1) | 31 March Y | 31 August Y | 31 December Y |
| Epochs | I | II | III |
| Reference year (Y) | 2018 | 2019 | 2020 |
| Method | Y | Area 1 | Area 2 | ||||
|---|---|---|---|---|---|---|---|
| F1-Score | Kappa | Var. Kappa | F1-Score | Kappa | Var. Kappa | ||
| IF | 2018 | 1.00 | 1.00 | 0 | 1.00 | 0.94 | 356.6 |
| 2019 | 0.97 | 0.57 | 1.1 | 0.99 | 0.98 | 18.94 | |
| 2020 | 0.95 | 0.91 | 1.5 | 0.95 | 0.90 | 1.1 | |
| OC-SVM | 2018 | 1.00 | 1.00 | 0 | 1.00 | 0.90 | 226.9 |
| 2019 | 0.99 | 0.61 | 1.2 | 1.00 | 0.99 | 35.8 | |
| 2020 | 0.96 | 0.94 | 3.8 | 0.88 | 0.86 | 2.2 | |
| 2018 | 2019 | 2020 | ||
|---|---|---|---|---|
| Area 1 | p-value | 0.5 | 0.003 | 0.077 |
| decision | non-significant | OC-SVM | non-significant | |
| Area 2 | p-value | 0.442 | 0.437 | 0.013 |
| decision | nonsignificant | nonsignificant | IF |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luz, A.E.O.; Negri, R.G.; Massi, K.G.; Colnago, M.; Silva, E.A.; Casaca, W. Mapping Fire Susceptibility in the Brazilian Amazon Forests Using Multitemporal Remote Sensing and Time-Varying Unsupervised Anomaly Detection. Remote Sens. 2022, 14, 2429. https://doi.org/10.3390/rs14102429
Luz AEO, Negri RG, Massi KG, Colnago M, Silva EA, Casaca W. Mapping Fire Susceptibility in the Brazilian Amazon Forests Using Multitemporal Remote Sensing and Time-Varying Unsupervised Anomaly Detection. Remote Sensing. 2022; 14(10):2429. https://doi.org/10.3390/rs14102429
Chicago/Turabian StyleLuz, Andréa Eliza O., Rogério G. Negri, Klécia G. Massi, Marilaine Colnago, Erivaldo A. Silva, and Wallace Casaca. 2022. "Mapping Fire Susceptibility in the Brazilian Amazon Forests Using Multitemporal Remote Sensing and Time-Varying Unsupervised Anomaly Detection" Remote Sensing 14, no. 10: 2429. https://doi.org/10.3390/rs14102429
APA StyleLuz, A. E. O., Negri, R. G., Massi, K. G., Colnago, M., Silva, E. A., & Casaca, W. (2022). Mapping Fire Susceptibility in the Brazilian Amazon Forests Using Multitemporal Remote Sensing and Time-Varying Unsupervised Anomaly Detection. Remote Sensing, 14(10), 2429. https://doi.org/10.3390/rs14102429