1. Introduction
Owing to issues such as global climate change, environmental pollution, and energy shortage, the demand for renewable energy is continuously increasing, and solar energy is among the sources that can contribute to addressing these problems [
1]. In recent years, photovoltaic (PV) power plants have been constructed in many countries because of the non-polluting and renewable nature of the associated energy [
2]. Since 2009, global photovoltaic (PV) solar power production has increased at an annual rate of 41% and will increase nearly tenfold by 2040 [
3]. In recent years, the Chinese government has promoted the development of the solar industry, and PV has experienced rapid expansion since 2012, with a surge in the installation of new PV capacity. In particular, large-scale terrestrial PV installations remain an important concern [
4]. However, large-scale PV deployment may also increase instability in ecologically fragile areas, thereby creating new vulnerabilities related to energy security, biodiversity loss, and food sovereignty [
5,
6,
7,
8]. Large PV plants, which often comprise many PV arrays with dark, sunlight-absorbing panels that cover the ground, may cause local climatic changes and remain controversial [
9,
10,
11]. In addition, whether PV installations produce a ‘heat island’ effect that warms the surrounding area, potentially affecting wildlife habitats and wilderness ecosystem functions, is a growing concern [
12,
13]. PV installations can also contribute to vegetation recovery by altering soil surface microhabitats in arid sandy ecosystems [
10]. Spatially explicit location and distribution data for PV installations provide a solid foundation for addressing the potential impacts of large-scale centralized PV panels on the regional climate and ecosystems. However, PV plant-related data currently available to researchers consists only of aggregated statistics [
3]. In addition, most spatial databases have limited geographic scopes. Therefore, efficiently updating the spatial distribution data and generating dynamic data regarding PV plants using remote sensing images and machine learning approaches is broadly beneficial to the research field, including studies of the impacts of land-use changes on local climatic change.
In recent years, supervised machine learning algorithms have been applied to high-resolution remote sensing imagery and aerial photographs for the extraction of information on PV plants. For instance, neural networks, such as CNN [
14], UNet [
15], and SegNet [
16], are currently the main approaches for the extraction of PV plants from remote sensing imagery that are associated with high accuracy values (approximately 0.89–0.94 [
14,
15,
16]). In fact, hyperspectral imagery can be employed for distinguishing rooftops of PV plants using a non-negative matrix (NMF) [
17]. However, most PV extraction approaches are based on relatively small study areas, high acquisition costs of imagery, and extensive processing times [
18]. These issues hinder the extension of these methods for larger spatial coverage and temporal analysis of the emergence of PV plants.
In contrast, non-deep machine learning algorithms utilized on medium-resolution remote sensing imagery for the identification of PV plants are advantageous because of the lower acquisition costs of imagery and shorter processing times. Non-deep learning classifiers such as the support vector machine (SVM), random forest (RF), and extreme gradient boosting (XGBoost) are commonly used in remote sensing image classification. Nevertheless, these methods are still in the experimental testing stage, and thus, their accuracy values require improvements. For instance, an SVM model integrating spectral features, waveforms, textural features, and band ratios was used to identify two PV plants covering an area of 5.4 km
2 in Gansu, and the overall accuracy was 91.39% [
19]. However, even though the accuracy of the RF model for the identification of PV plants is improved by using textural features, the enhancement is insignificant [
18]. The XGBoost, which originated from the conventional boosting algorithm, is a superior algorithm for a decision tree involving the gradient boosting framework [
20]. This advanced classifier relies on the multi-threading of the central processor and the introduction of regularization terms, which are currently prominent in popular machine learning schemes [
21]. Considering that the XGBoost has been utilized to obtain results superior to those of deep learning models for the extraction of crop data from satellite imagery [
20], it was employed as a potential approach for the extraction of PV plants in the present study.
Spectral features of PV panels are similar to those of buildings and bare and sandy lands [
18,
19]. Therefore, distinguishing these using multispectral imagery is important to generate additional data to facilitate the extraction of PV plants from imagery. According to previous studies, the utilization of normalized indexes to characterize spectral features can improve the accuracy of extracting diverse features [
22,
23,
24,
25,
26,
27,
28,
29,
30,
31]. For example, the normalized difference vegetation index (NDVI) and normalized building index (NDBI) derived from the thematic mapper (TM) imagery enable the identification of built-up areas, and the associated accuracy exceeds 92.6% [
29]. Relatedly, the built-up area index (BUAI) combined with the modified normalized difference water index (MNDWI) produced an accuracy greater than 92.27% in the identification of impervious surfaces [
31]. Moreover, topographic features (e.g., slope, orientation, and altitude) significantly influence the location of PV plants [
32], and thus, these features are also important for the extraction of PV plants using satellite imagery.
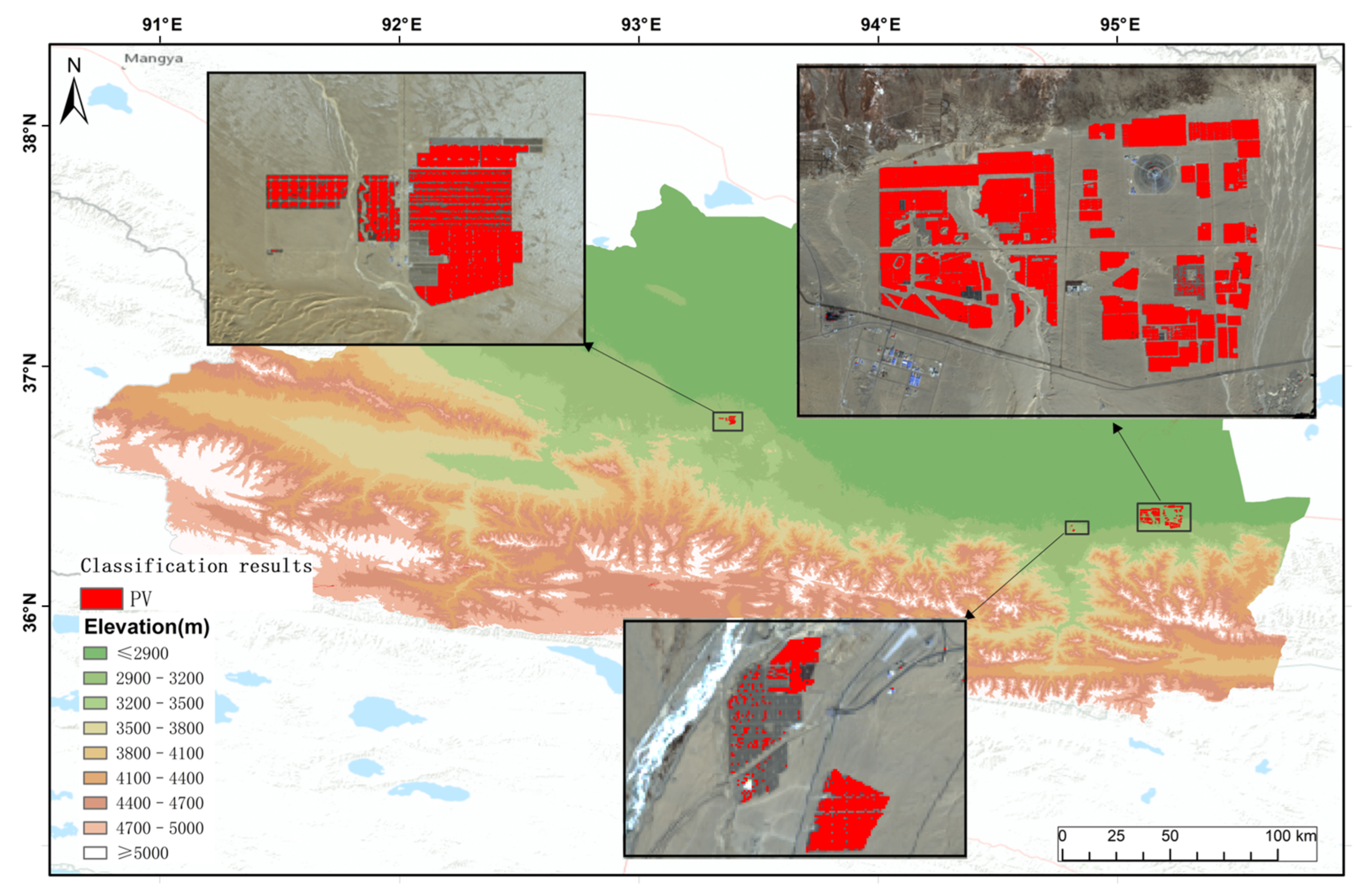
An optimal approach for the identification of PV plants must incorporate a short processing time, low computing power requirements, and high identification accuracy. Therefore, the main objective of the present study was to compare results from different identification methods, including XGBoost, RF, and SVM, and subsequently establish an efficient and effective model for the identification of PV plants in extensive areas. In addition, the impacts of the type of spectral data and terrain variables on the performances of different PV plant extraction models were evaluated. PV plants were extracted for an area covering approximately 71,298.7 km2 (area of the country of Ireland) using the optimum model. The present study enhances the understanding of the dynamics of PV plant construction and the suitability, potential, and environmental impacts of these plants.
3. Methodology
3.1. General Workflow
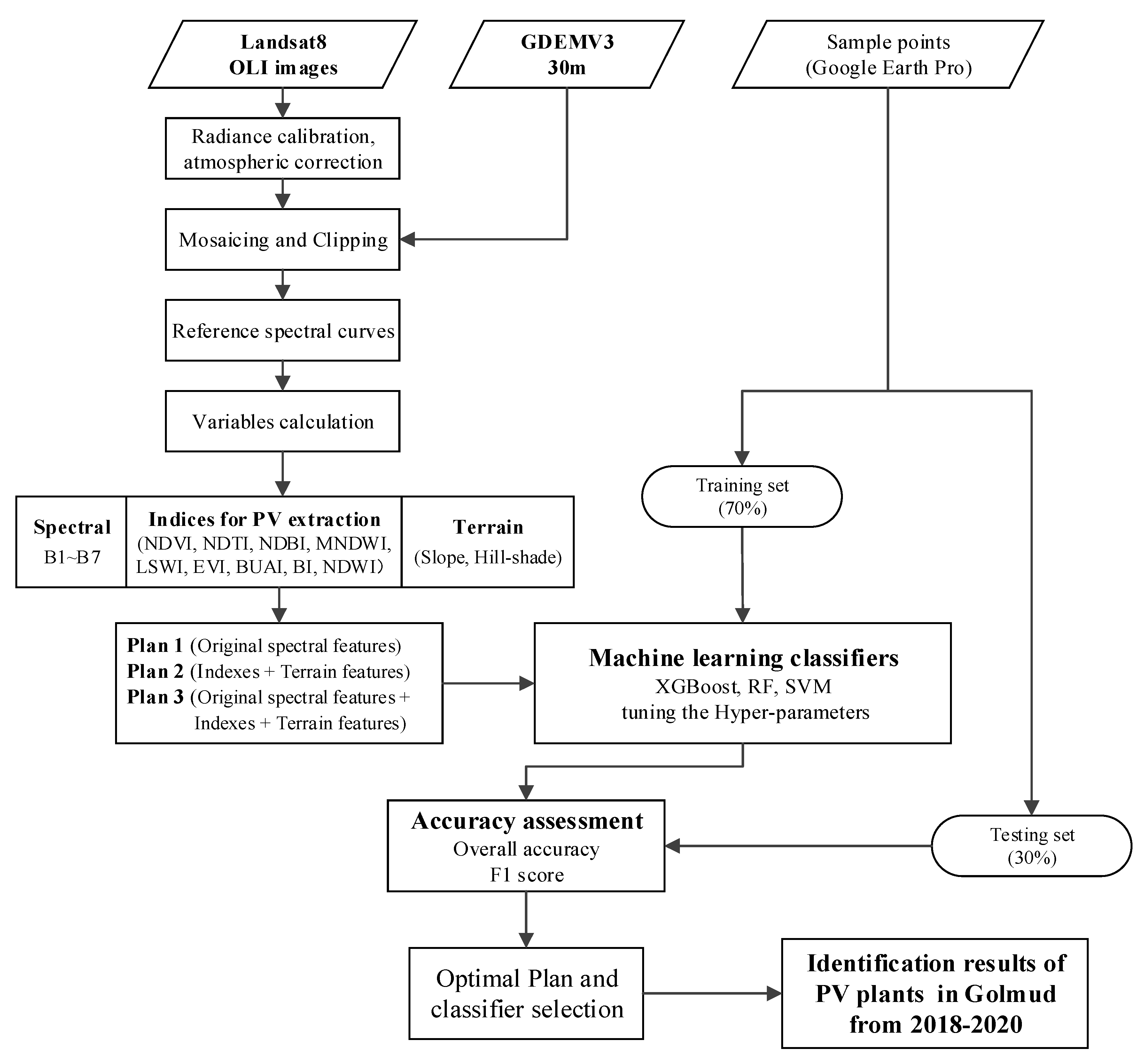
The approach pursued in the present study is shown as a flowchart in
Figure 2. Medium-resolution OLI images and the GDEMV3 were utilized. First, the images were preprocessed using radiation calibration, atmospheric correction, and cropping. Indexes for the extraction of PV plants were then computed, and three plans were set. In Plan 1, unprocessed raw spectral features were utilized. Plan 2 included normalized indices derived from specific band intervals after processing the raw data to highlight or suppress the effects of different factors. Plan 3 used a combination of raw spectral data, index information, and topographic features (
Figure 2). In the present study, the performances for the extraction of PV plants using XGBoost, RF, and SVM classifiers were compared using the overall accuracy values and F1 scores. Google Earth Pro was used for the collection of training and test data samples.
3.2. Collection of Training and Test Samples
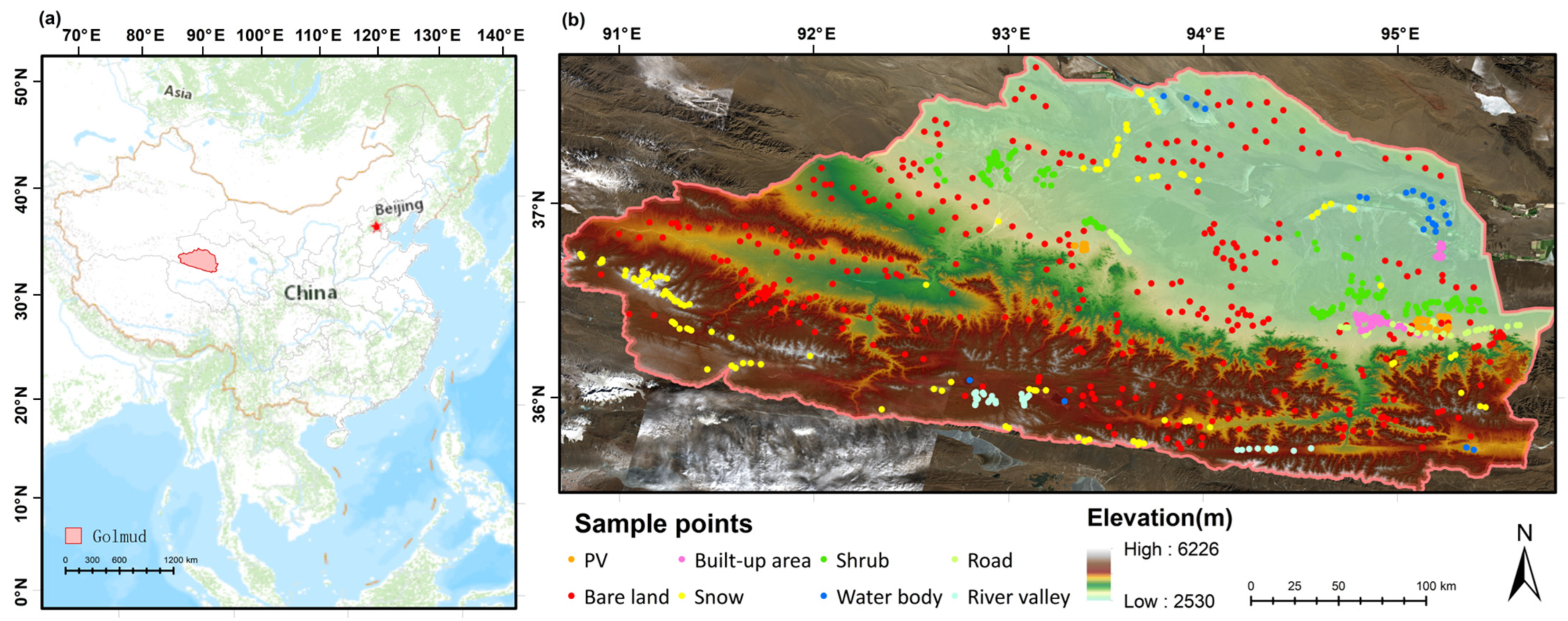
To ensure the accuracy of the classification and the stability of the model, many samples that adequately reflect the parameter space are required. In the present study, based on the distribution of land cover types, attention was devoted to those that are easily confused with PV plants, such as bare land and roads. The land in the area was partitioned into the following categories: Built-up areas, roads, PV plants, bare land, river valleys, shrubs, water bodies, and snow cover.
For specific calibrations at the sample sites, we first used the Global Power Plant Database to target the locations of PV plant construction in the Golmud region. We then used Google Earth Pro to mark 2059 PV sample sites in the study area based on the specific shape and concentrated distribution of PVs, which are easily observed in high-resolution imagery. In the meantime, we carried out a field survey of the selected PV plants and compared the PV sample points on Google Earth with the measured GPS coordinates data to ensure the reliability of the PV sample points and the feasibility of using Google Earth to sample the PV plants. Samples were then collected evenly across carefully selected typical land types in the study area, resulting in a total of 63,323 sample points: PVs (2059), built-up land (1461), roads (397), bare land (41,607, e.g., deserts, semi-deserts, and the Gobi), river valleys (2210), shrubs (965), water bodies (12,830), and snow (1095).
To ensure consistency and robustness, the sample points were selected independently by two technicians with remote sensing backgrounds and then cross-validated. If both agreed, the point was incorporated into the final selection. A third technician was consulted for points that were ambiguous and then discussed until the results of the sample points were agreed upon. We used Google Earth Pro for sample point selection, and contemporaneous historical Landsat8 OLI images were used as references. In addition to visually assessing the accuracy of the sample site selection, we also ensured adequate separation between the sampled features (
Table 1). We calculated the Jeffries–Matusita and Transformed Divergence separability of the ROI using ENVI (all ≥ 1.9), demonstrating the good separation of the sample points [
33]. Finally, a stratified random sample of the eight land classes was used to allocate the training and validation datasets, ensuring that 70% of the random samples for each class were used for training, while the remaining 30% were used for validation. The training and validation datasets were evenly distributed throughout the study area, which was conducted using ArcGIS.
3.3. Spectral Characteristics of Confusing Features
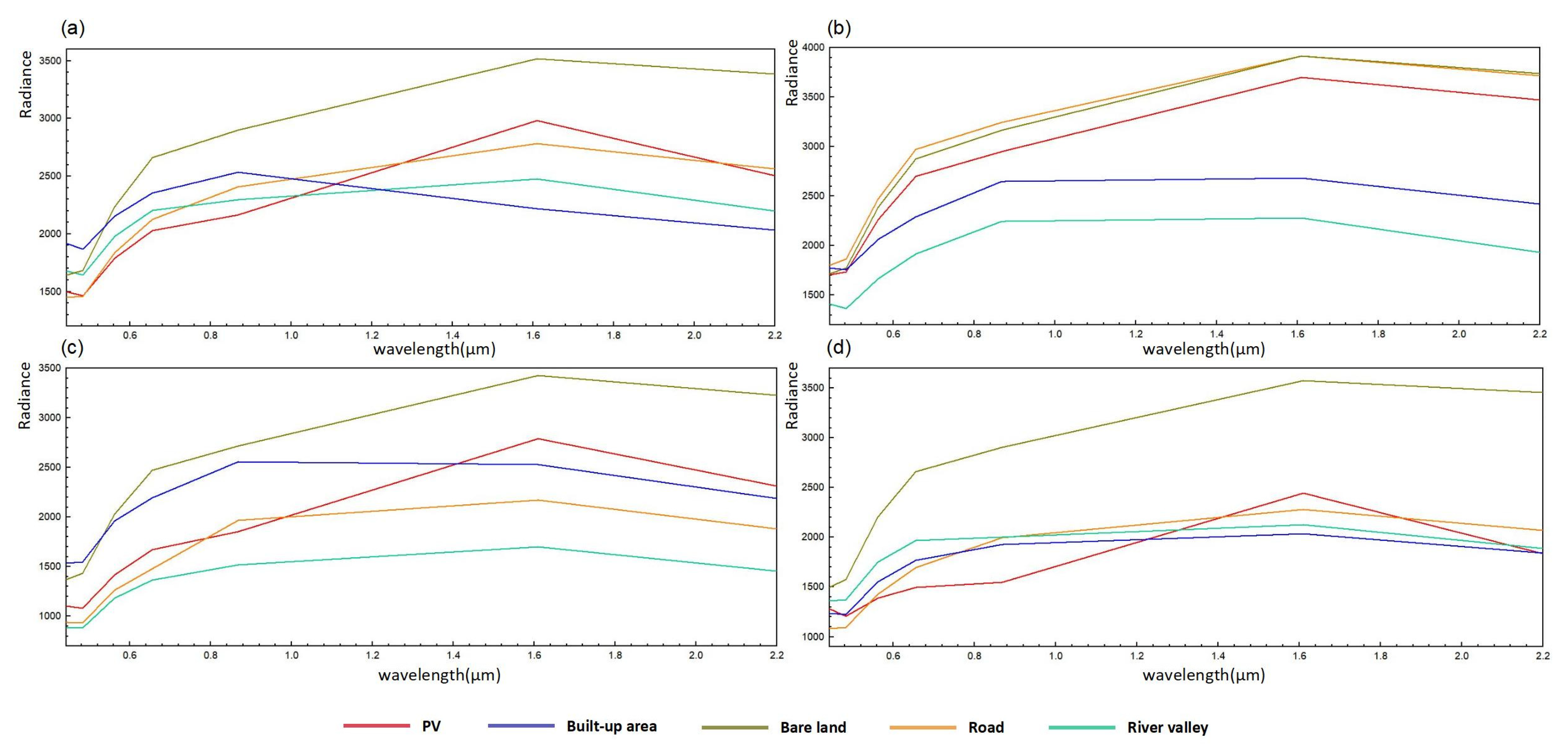
In the present study, PV plants were easily confused with the surrounding bare land (especially between mountain ranges). Spectral curves of land cover types vary according to the spectral reflectance of materials on the surface. Therefore, the surrounding environment, temperature, and land cover types can also cause changes in spectral profiles. Spectral curves of PV plants and land cover types, such as water bodies, snow, and built-up areas significantly differ, and thus, these can be easily distinguished. Those of PV plants and land cover types containing high Si, such as bare land and roads, are similar. However, even though spectral profiles of confusing features exhibit an overall similarity, some differences exist. In particular, the spectral curve of PV plants rises sharply from the near-infrared (NIR) to the short-wave infrared (SWIR) region (0.85–1.65 μm), and it falls significantly in the SWIR region (1.65–2.2 μm).
To evaluate the impacts of seasons on different land cover types, spectral curves were generated for the samples for four months (
Figure 3). In general, the curves for PV plants are stable throughout the year, but these plants were distinguished more easily from confusing land cover types in December (winter).
3.4. Selection of Principal PV Extraction Variables
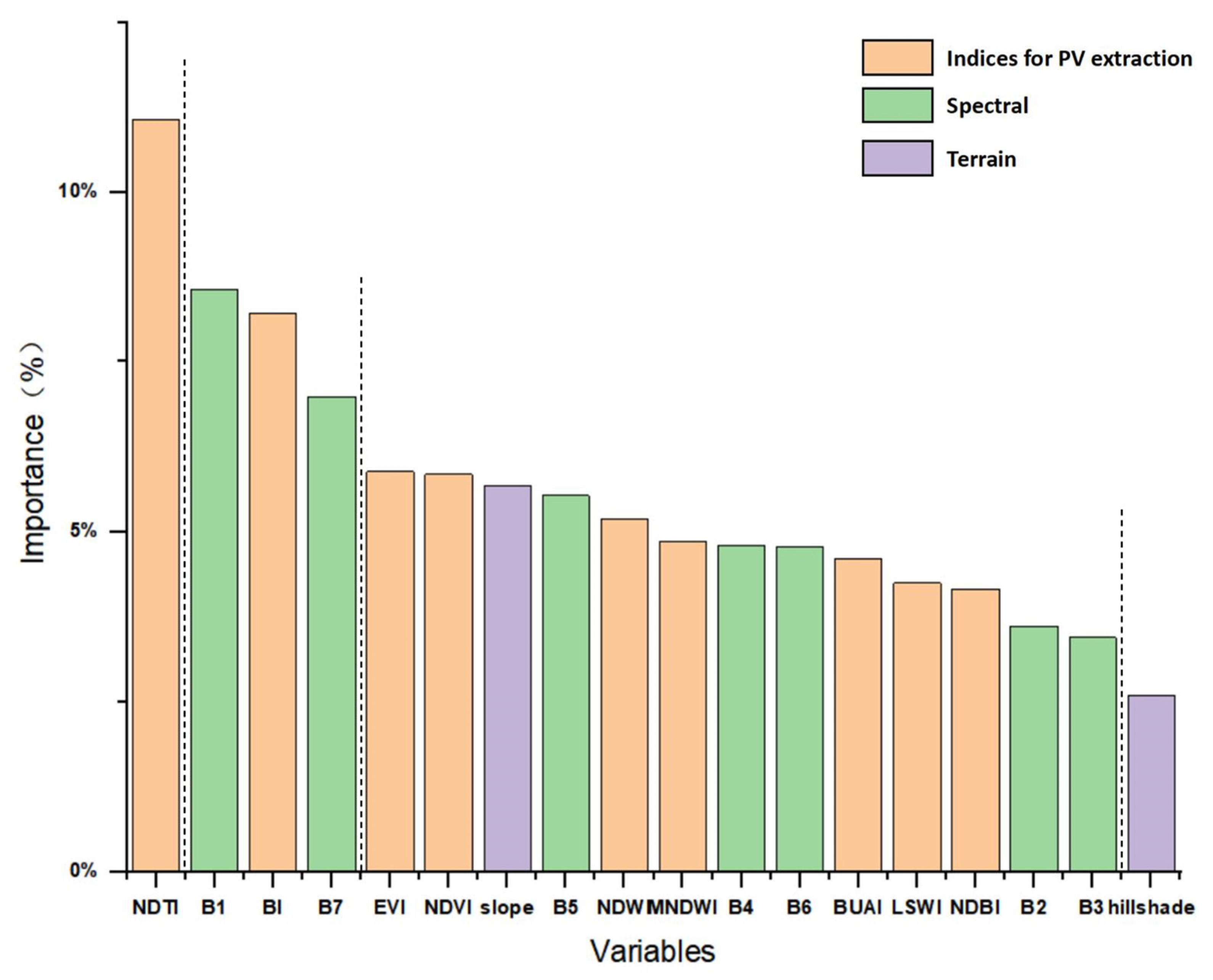
The variables were divided into the following groups: Raw reflectance spectral, PV extraction index, and terrain features (
Table 2). The raw reflectance spectral variables comprised seven bands including the aerosol, blue, green, red, and NIR as well as two SWIR (1 and 2). The nine indexes associated with PV plants extraction (NDVI, EVI, NDBI, LSWI, NDTI, NDWI, MNDWI, BUAI, and BI) were selected by observing changes in the spectral curves (
Figure 3). These indexes are sensitive to changes in the PV plants, surrounding vegetation, soil, built-up areas, impervious surfaces, water bodies, and bare ground. The terrain variables, such as the slope and hill-shade, were calculated using the ASTER GDEM elevation data with a resolution of 30 m.
To highlight the effects of different features on the identification of PV plants, three experimental schemes (Plans 1, 2 and 3) based on features were designed (
Table 3). In Plan 1, the original spectral features were utilized, and thus, it involved all band values. Conversely, Plan 2 comprised normalized indexes derived from specific band intervals after processing the original data to highlight or suppress the impact of different factors. Plan 3 is a combination of the original spectral and index information as well as terrain features, and thus, it is associated with the most information. Owing to the relatively coarse resolution of OLI imagery, the widths of and distances between PV panels are within a few meters, and textures are almost undetectable. Therefore, the inclusion of textures minimally enhanced the accuracy of the model.
3.5. Machine Learning Models
In the present study, the XGBoost, RF, and SVM models were tested for the identification of PV plants, and their performances were compared. The SVM model is mainly used to solve problems based on the optimization theory. This approach principally involves finding a hyperplane, such that a sub-hyperplane adequately separates data points of two classes and ensures the separated data points of both classes are furthest from the classification plane. Consequently, the SVM model is characterized by a good generalization capability for classification problems. Moreover, in SVM models, kernel functions can be utilized for nonlinear classifications [
34]. Conversely, an RF model is a collection of decision trees based on bagging techniques, and it involves the construction of several decision trees from a random subset of the training data [
35]. Therefore, the RF model produces good results in feature-based classifications [
36], and it is the most effective model for the recognition of features from remote sensing data using the Google Earth Engine (GEE) [
37]. The XGBoost is a recently proposed advanced decision-tree gradient-boosting framework. This classifier involves multi-threading of the central processor and the introduction of regularization terms, which are mainstream in popular machine learning schemes [
21]. This model has shown high performance in the identification of crops, and it is described as superior to some deep learning models [
20]. The XGBoost model runs fast and involves high computational accuracy and low complexity. However, to date, no large-area pixel-based recognition of PV plants has been reported using this model.
To compare the performance of the three machine learning classifiers, the Python packages “XGBoost” (
https://xgboost.readthedocs.io/en/latest/python/index.html, accessed on 24 December 2021) and “Scikit-learn” (
https://scikit-learn.org/stable/index.html, accessed on 24 December 2021) were used to process the remote sensing images. The processing of the OLI images, evaluation of the DEM datasets, and raster calculation of normalized indexes were performed using ENVI 5.3 (
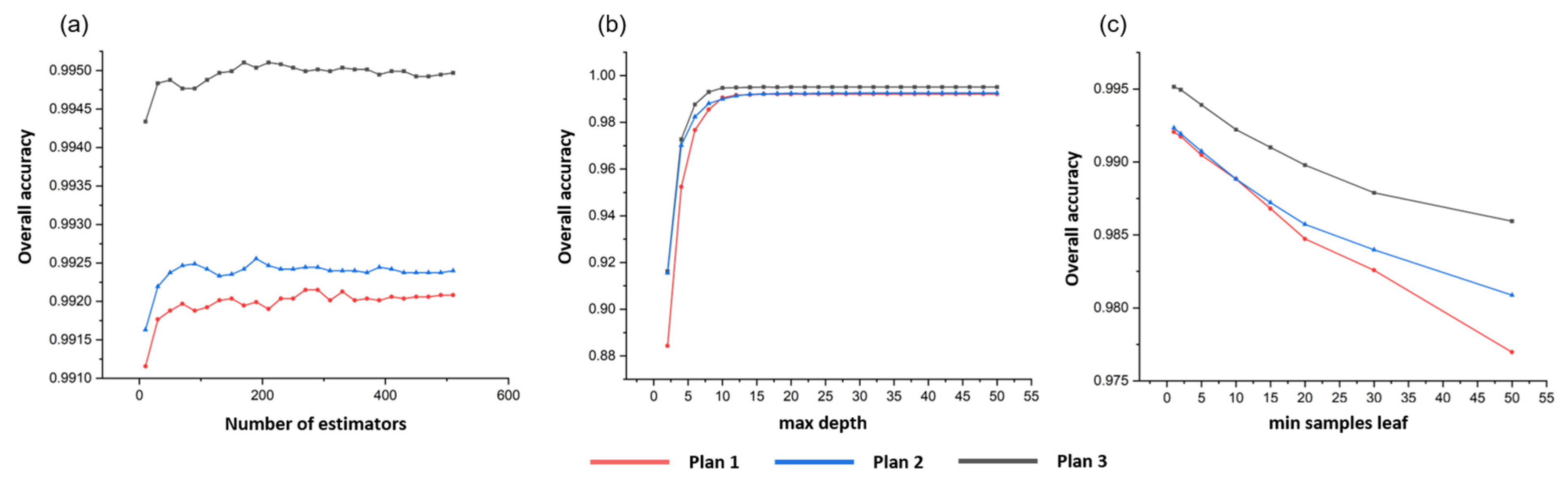
Figure 4). During the development of the classification model, hyperparameters (
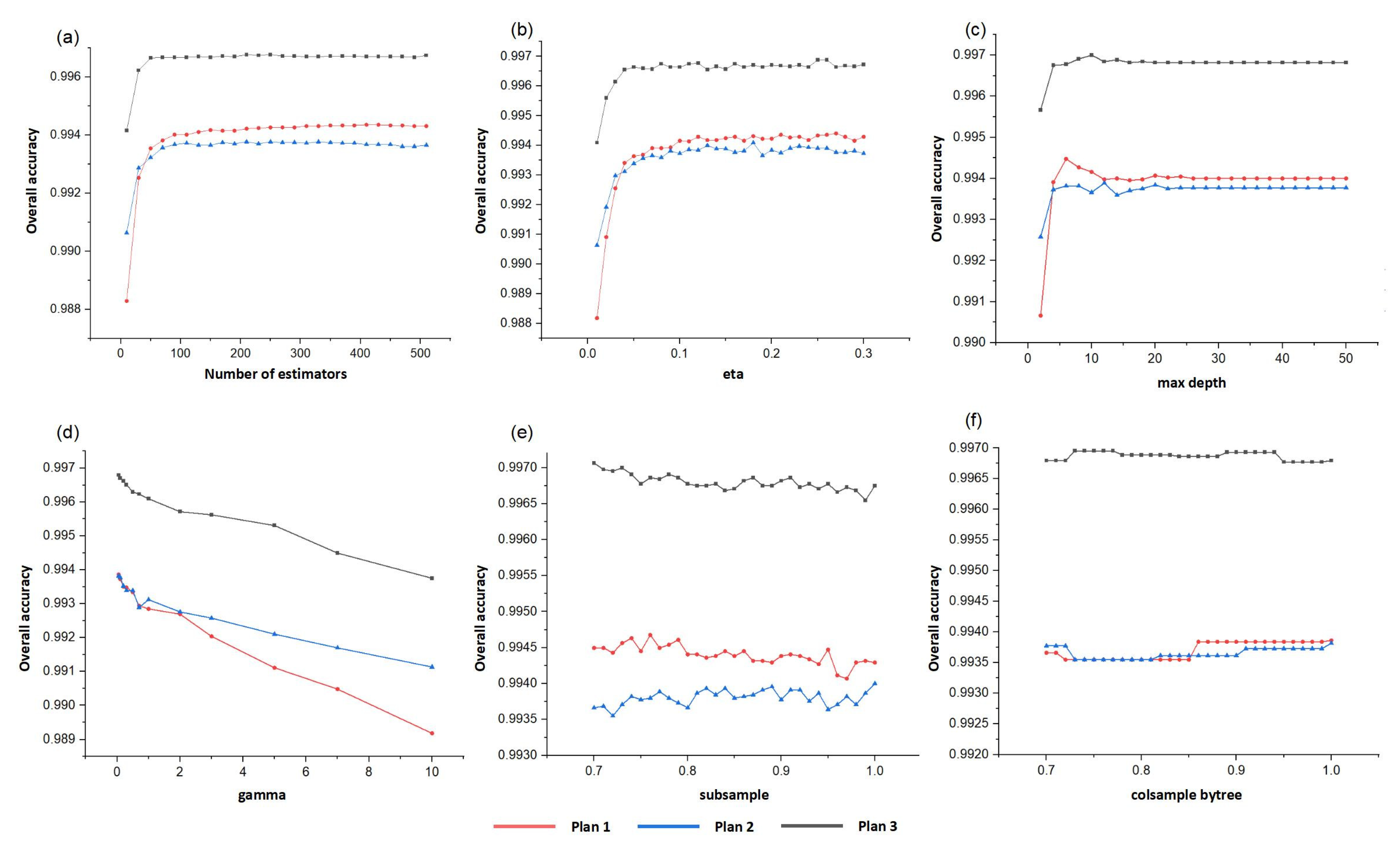
Table 4) must be configured for each classifier. A combination of “grid search” and “learning curve” strategies was utilized to optimize and select the best values of the main hyperparameters for a chosen classifier (
Figure 5 and
Figure 6), and the classifier was trained via several iterations. Considering that the performance of a classifier is mainly controlled by the subset of hyperparameters, a grid search improves the efficiency of the hyperparameter optimization according to test results.
The parameters were adjusted by selecting the training set (70%), and the objective function was the overall accuracy (OA). To eliminate the effect of sample selection on the results for a model, cross-validation associated with stratified random sampling (k = 5) was utilized for the parameter evaluation. The accuracy of each model was the average overall accuracy of five tests.
Considering that the grid search is an exhaustive method, parameter optimization can be performed using the GridSearchCV module in the “Scikit-learn”. However, the model in the present study involved many hyperparameters, and because of limitations in the computing power, a one-on-one optimization strategy was adopted. After many experiments, we optimized each of the models (
Table 4). After a parameter was optimized, the optimal value was transferred to the next step in the optimization process, thereby traversing all parameters (
Table 4;
Figure 5 and
Figure 6). This parameter was then chosen as the highest OA value in the relative stability interval.
To optimize the performance of the XGBoost model, parameters of the n_estimators, subsample, eta, gamma, max_depth, etc. were tuned. First, we adjusted the three important hyperparameters of the integration algorithm itself: “n_estimators”, “subsample”, and “eta”. The “n_estimators parameter” is the number of weak estimators in the integration, which must be adjusted first. The “subsample” controls the random sampling, and in each put-back process, the weight of samples that were misjudged by a previous tree increases. The new decision tree then favors the samples with higher weights that are likely to be judged incorrectly, and this elevates the accuracy of the model. The “eta” is the step size (also known as the “learning rate”) process of an iterative decision tree. The higher the value of the eta, the faster the iteration; however, this is associated with the risk of non-optimal convergence. In contrast, the lower the value of eta, the higher the chance of finding the best value; however, the iterations may be slower. Therefore, to select an appropriate eta, a trade-off is necessary. In gradient boosting, the “gamma” is a regularization hyperparameter that controls complexity, and thus, it is an influential parameter in XGBoost. Therefore, as the gamma increases, the regularization also increases, and the algorithm becomes more conservative. The “max_depth” determines the maximum number of end nodes in the leaves of trees (
Figure 5). These hyperparameters were calculated based on the grid search and cross-validation in Python, and the best results after tuning using the XGBoost are presented in
Table 4.
We also adjusted the parameters of the RF and SVM models. Larger n_estimators values indicate that the model learns more and that it is easier to over-fit in RF. Therefore, n_estimators was the first parameter tuned in the RF model, and the remaining parameters were tuned in a similar way for XGBoost (
Figure 6). In the adopted SVM model, the radial basis function kernel (RBF) produced an outstanding performance. The model was optimized using the hyperparametric “gamma” and “C” (cost) to address nonlinearity and overfitting. The optimal model was obtained using limited computational power, and the results were satisfactorily validated.
In addition, the XGBoost algorithm can be used to retrieve the importance scores of the variables, thereby obtaining the importance ranking of the independent variables. When more variables are used for key decisions in the decision tree, the relative importance score is higher. This importance score is calculated explicitly for each variable in the dataset, allowing the variables to be ranked and compared. The key influences for the simulation were filtered by calculating and ranking the importance of independent variables using the XGBoost algorithm [
38]. The independent variable importance (Equation (1)) was calculated as follows:
where
xi denotes the characteristic information gain.
3.6. Model Evaluation
First, a confusion matrix was constructed, and the overall accuracy (Equation (2)) was calculated. The Macro F1 score (Equation (4)) was then used to evaluate the performance of the three classifiers.
The
OA is an important parameter for testing the accuracy of a model. In the present study, it was used to assess the model by evaluating the proportion of correctly classified samples relative to all samples, and this is expressed as follows:
Regarding each class, the
F1 score was co-determined using the producer and user precision values as follows:
whereas the
Macro F1 score, which represents the average result of all classes, was calculated as follows:
In the test set, an accuracy of 1% corresponded to an area of approximately 17 km2.
3.7. Image Post-Processing
As the target subject was concentrated PVs, the PV pixels were centrally distributed, and no isolated pixel points were present. We therefore used 3 × 3 median filtering to eliminate isolated noise points after classification. Median filtering is a non-linear smoothing technique in which the value of each pixel is replaced by the median of the values of all pixels in a neighborhood window such that the surrounding pixel values are similar to the true value, thereby eliminating isolated noise points [
39].
6. Conclusions
In the present study, PV extraction models were established using indexes, such as the NDTI, BI, NDVI, BUAI, NDWI, etc., and terrain variables. A scheme integrating original spectral features, PV extraction indexes, and terrain features provided optimum results. High-performance machine learning algorithms were combined with the PV extraction models and utilized to compare the performance of the XGBoost, RF, and SVM algorithms. The XGBoost model produced the highest accuracy ((OA = 99.65%, F1score = 0.9631) for a raster-based extraction of PV plants using OLI imagery involving a resolution of 30 m. This approach reduces the reliance on high-resolution imagery and high-performance computers during the extraction of PV plants from satellite imagery.
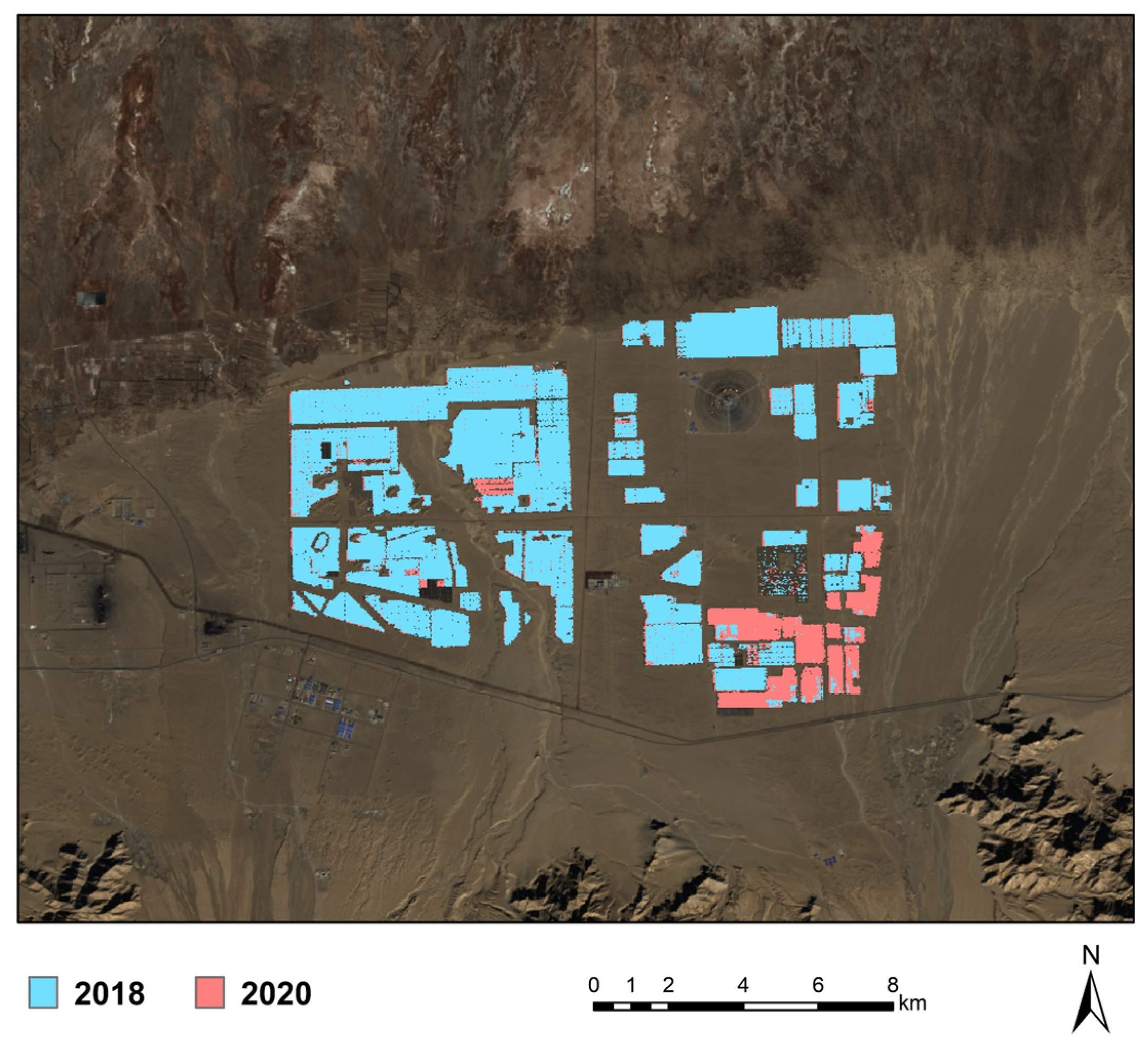
The calculated area occupied by PV plants in the Golmud region in 2020 was 10,715.85 ha. A comparison of the area associated with PV plants in the east of the region based on 2018 imagery revealed an increase of 10% from 2018 (5344.2 ha) to 2020 (5879.34 ha), and this demonstrated the robustness of the proposed approach. The present study represents the foundation for future studies involving longer durations and larger areas.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







