
Extraction of Floating Raft Aquaculture Areas from Sentinel-1 SAR Images by a Dense Residual U-Net Model with Pre-Trained Resnet34 as the Encoder





Abstract
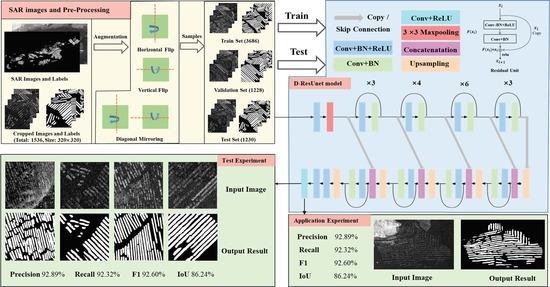
:
1. Introduction
2. Methodology
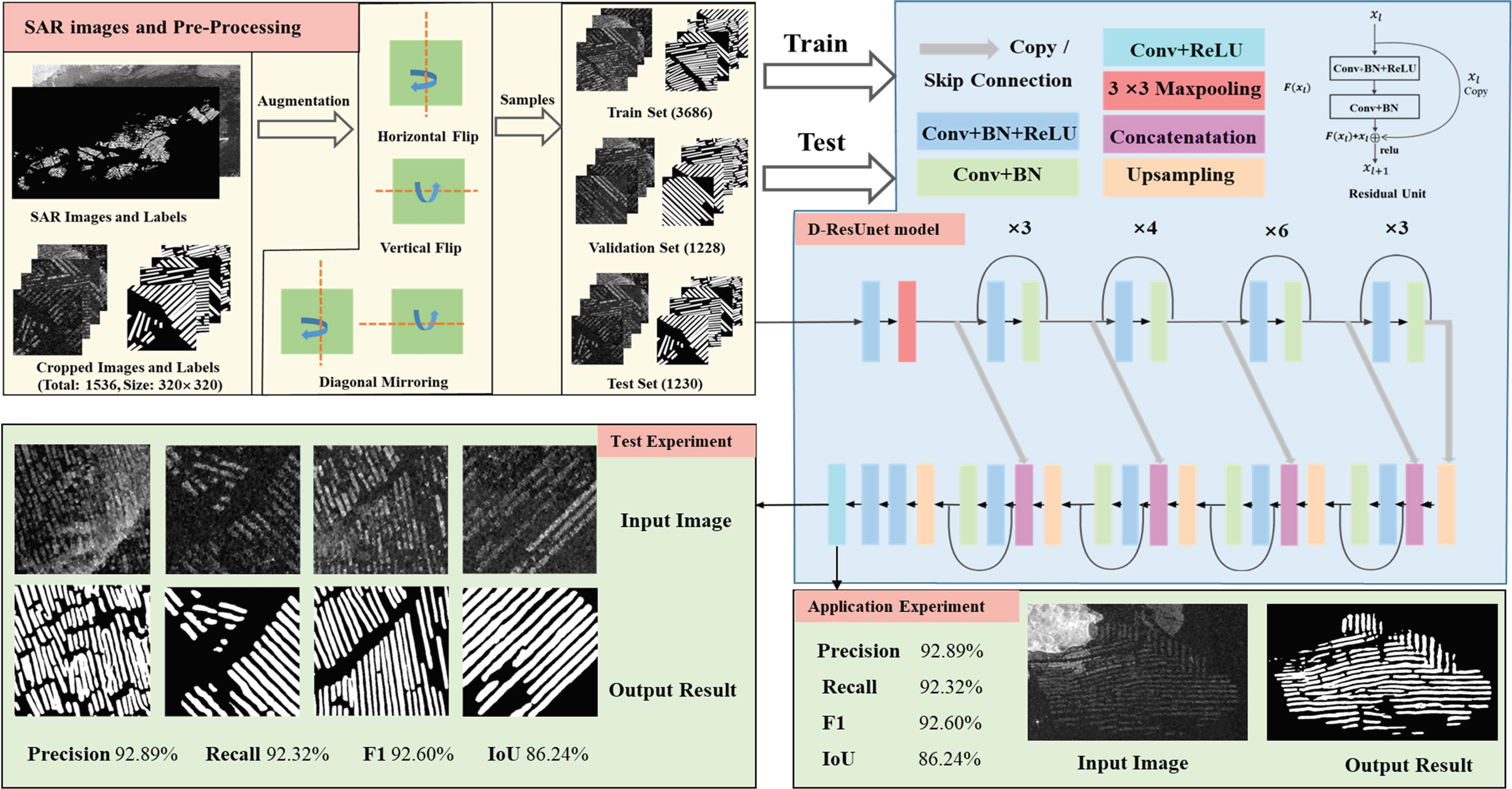
2.1. U-Net and Deep Residual Networks
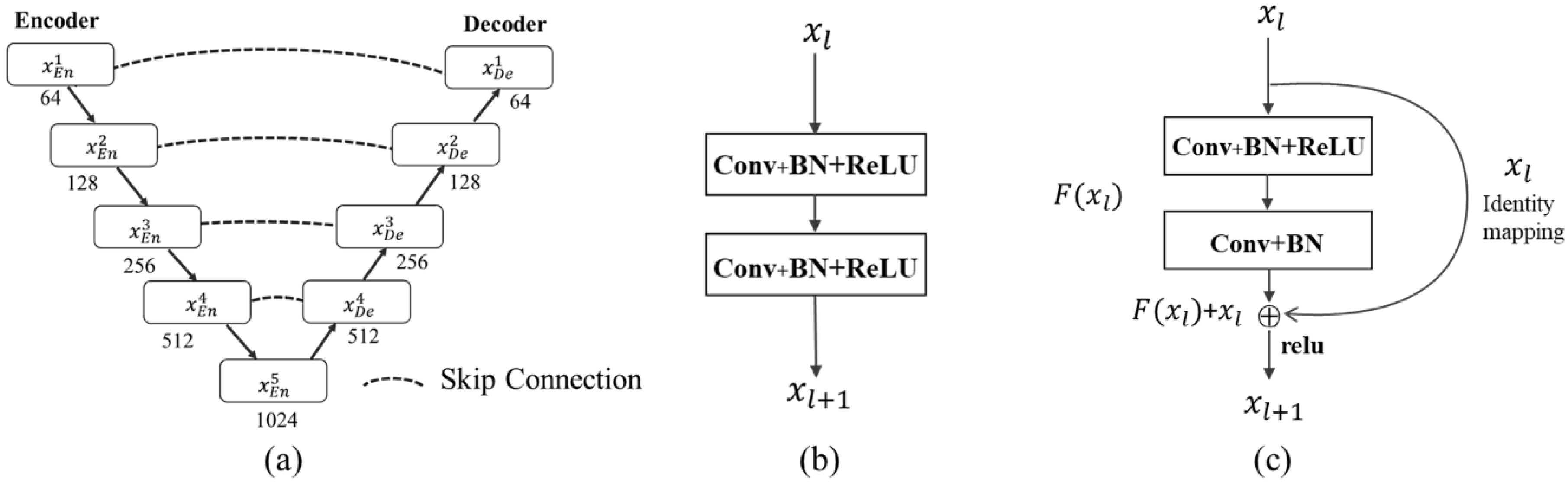
2.2. The Proposed D-ResUnet
2.3. Pre-Training
2.4. Parameters and Implementation Details
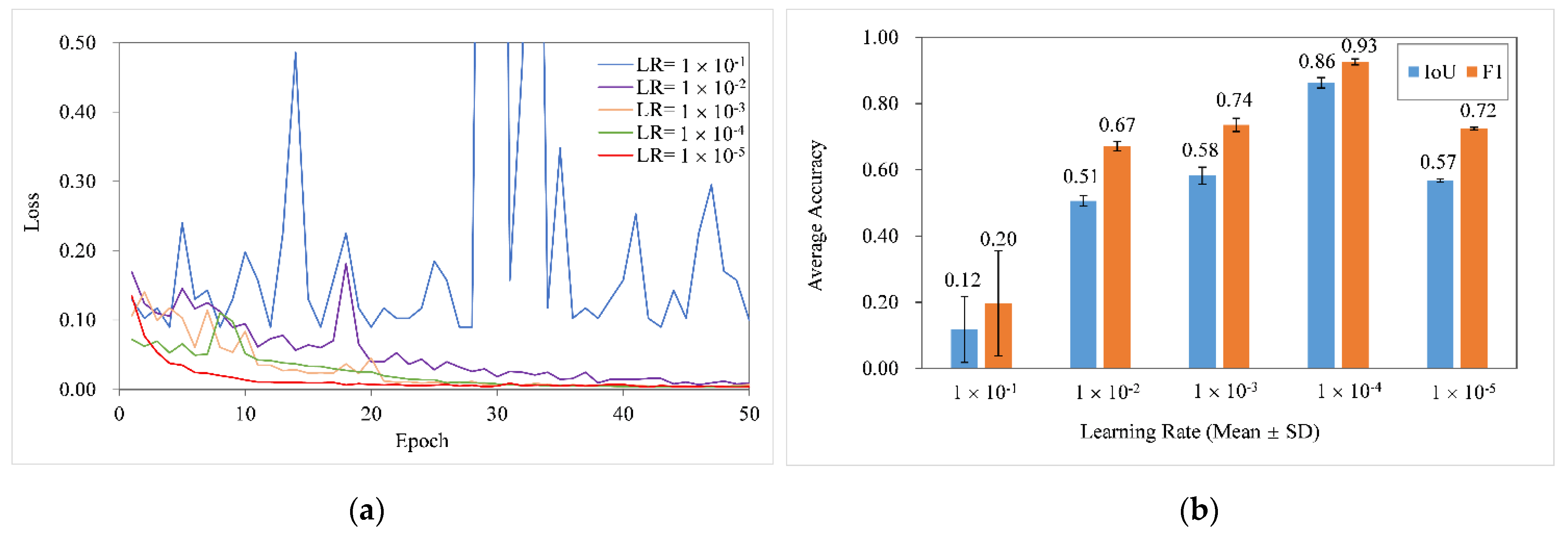
2.4.1. Learning Rate
2.4.2. Loss Function
2.4.3. Other Configurations
2.4.4. Evaluation Metrics
3. Study Area and Experiment Data
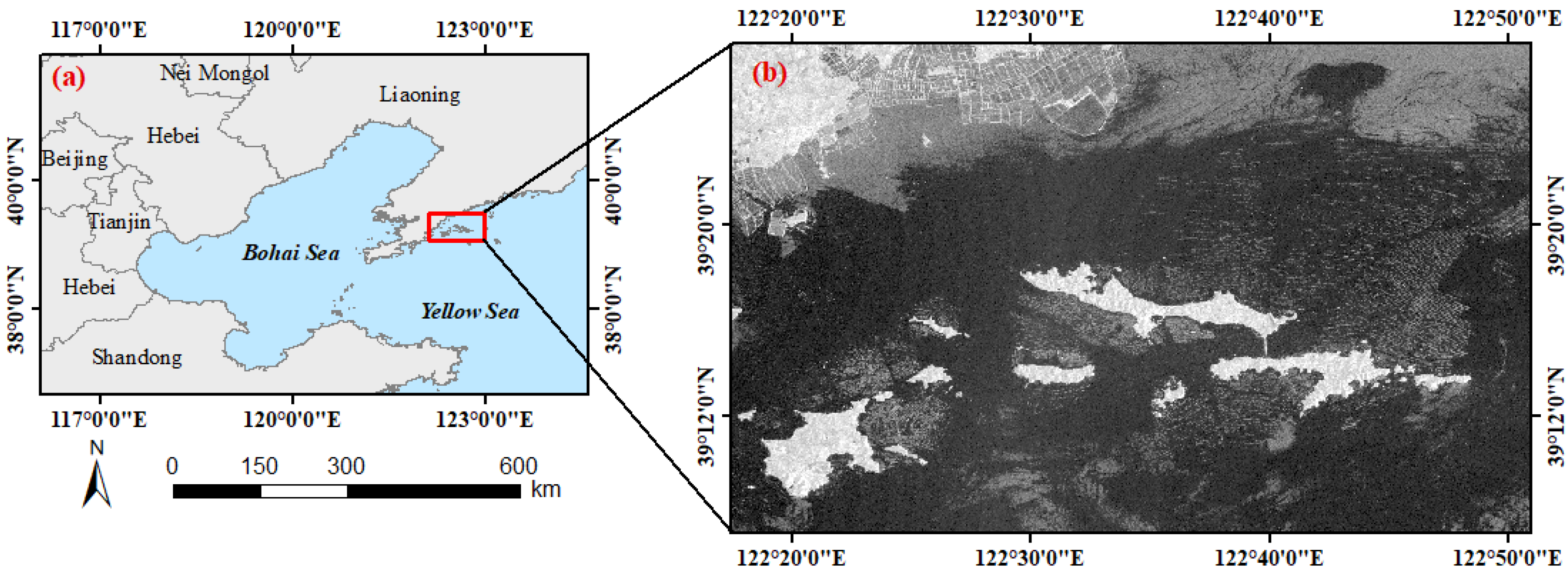
3.1. The Study Area
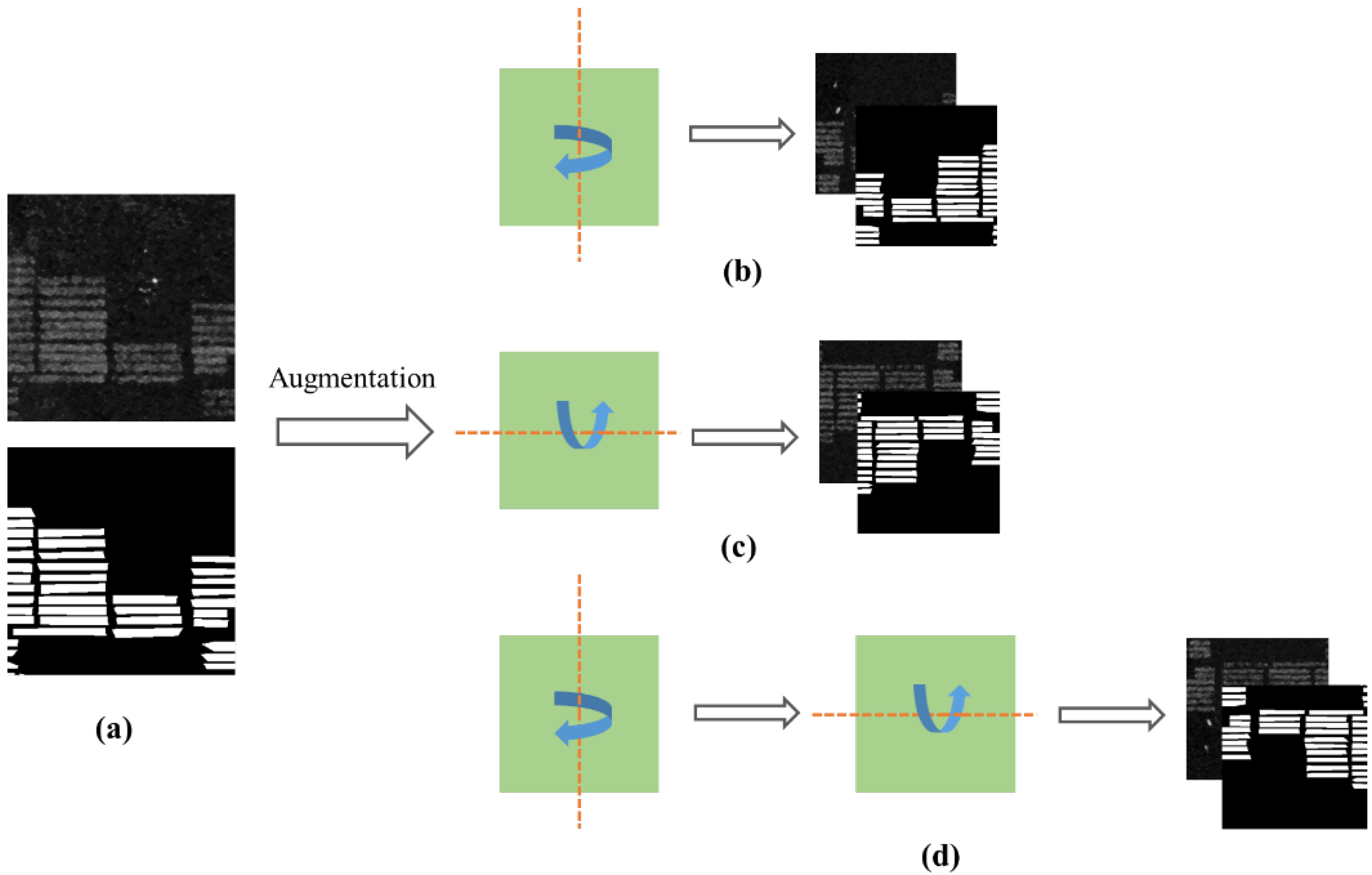
3.2. Dataset and Pre-Processing
4. Experiment, Evaluation, and Analysis
4.1. Initial Learning Rate Set
4.2. Experimental Results
4.3. Ablation Experiment
4.4. Application Experiment
5. Discussion
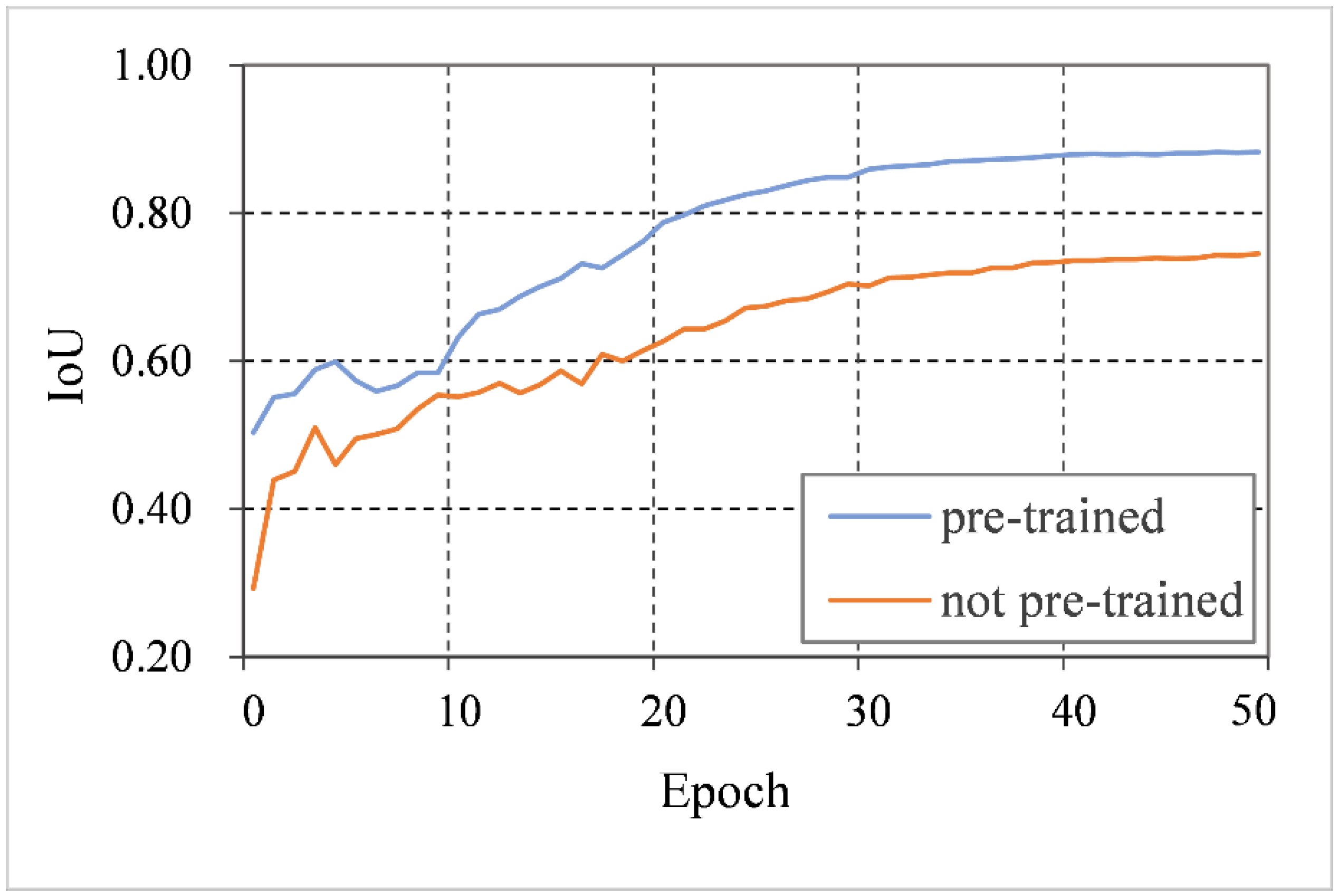
5.1. Influence of Pre-Training Strategy
5.2. Model Complexity
5.3. Error Analysis
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- FAO. The State of World Fisheries and Aquaculture 2020; FAO: Rome, Italy, 2020. [Google Scholar]
- Pan, X.; Jiang, T.; Zhang, Z.; Sui, B.; Liu, C.; Zhang, L. A New Method for Extracting Laver Culture Carriers Based on Inaccurate Supervised Classification with FCN-CRF. J. Mar. Sci. Eng. 2020, 8, 274. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, X.; Wang, Z.; Lu, C.; Li, Z.; Yang, F. Aquaculture area extraction and vulnerability assessment in Sanduao based on richer convolutional features network model. J. Oceanol. Limnol. 2019, 37, 1941–1954. [Google Scholar] [CrossRef]
- Cui, B.-G.; Zhong, Y.; Fei, D.; Zhang, Y.-H.; Liu, R.-J.; Chu, J.-L.; Zhao, J.-H. Floating Raft Aquaculture Area Automatic Extraction Based on Fully Convolutional Network. J. Coast. Res. 2019, 90, 86–94. [Google Scholar] [CrossRef]
- Cui, B.; Fei, D.; Shao, G.; Lu, Y.; Chu, J. Extracting Raft Aquaculture Areas from Remote Sensing Images via an Improved U-Net with a PSE Structure. Remote Sens. 2019, 11, 2053. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Ma, S.; Su, C.; Shang, Y.; Wang, T.; Yin, J. Coastal Oyster Aquaculture Area Extraction and Nutrient Loading Estimation Using a GF-2 Satellite Image. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4934–4946. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, Z.; Yang, X.; Zhang, Y.; Yang, F.; Liu, B.; Cai, P. Satellite-based monitoring and statistics for raft and cage aquaculture in China’s offshore waters. Int. J. Appl. Earth Obs. Geoinf. 2020, 91, 102118. [Google Scholar] [CrossRef]
- Naylor, R.; Troell, M.; Little, D.; Hardy, R.; Bush, S.; Shumway, S.; Lubchenco, J.; Cao, L.; Klinger, D.; Buschmann, A. A 20-Year Retrospective Review of Global Aquaculture. Nature 2021, 591, 551. [Google Scholar] [CrossRef]
- Palmer, S.; Gernez, P.; Thomas, Y.; Simis, S.; Miller, P.; Glize, P.; Laurent, B. Remote Sensing-Driven Pacific Oyster (Crassostrea gigas) Growth Modeling to Inform Offshore Aquaculture Site Selection. Front. Mar. Sci. 2020, 6, 802. [Google Scholar] [CrossRef]
- Snyder, J.; Boss, E.; Weatherbee, R.; Thomas, A.; Brady, D.; Newell, C. Oyster Aquaculture Site Selection Using Landsat 8-Derived Sea Surface Temperature, Turbidity, and Chlorophyll a. Front. Mar. Sci. 2017, 1, 190. [Google Scholar] [CrossRef] [Green Version]
- Liu, K.; Chen, S.; Li, X.; Chen, S. Development of a 250-m Downscaled Land Surface Temperature Data Set and Its Application to Improving Remotely Sensed Evapotranspiration Over Large Landscapes in Northern China. IEEE Trans. Geosci. Remote Sens. 2020, 60, 5000112. [Google Scholar] [CrossRef]
- Liu, K.; Chen, S.; Li, X. Comparative Assessment of Two Vegetation Fractional Cover Estimating Methods and Their Impacts on Modeling Urban Latent Heat Flux Using Landsat Imagery. Remote Sens. 2017, 9, 455. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Wu, T.; Liu, K.; Li, Y.; Zhang, L. Evaluation of the Chinese Fine Spatial Resolution Hyperspectral Satellite TianGong-1 in Urban Land-Cover Classification. Remote Sens. 2016, 8, 438. [Google Scholar] [CrossRef] [Green Version]
- Jayanthi, M. Monitoring brackishwater aquaculture development using multi-spectral satellite data and GIS-a case study near Pichavaram mangroves south-east coast of India. Indian J. Fish. 2018, 58, 85–90. [Google Scholar]
- Zhu, H.; Li, K.; Wang, L.; Chu, J.; Gao, N.; Chen, Y. Spectral Characteristic Analysis and Remote Sensing Classification of Coastal Aquaculture Areas Based on GF-1 Data. J. Coast. Res. 2019, 90, 49–57. [Google Scholar] [CrossRef]
- Geng, J.; Fan, J.; Wang, H. Weighted Fusion-Based Representation Classifiers for Marine Floating Raft Detection of SAR Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 444–448. [Google Scholar] [CrossRef]
- Fan, J.; Chu, J.; Geng, J.; Zhang, F. Floating raft aquaculture information automatic extraction based on high resolution SAR images. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 3898–3901. [Google Scholar] [CrossRef]
- Cheng, B.; Liang, C.; Liu, X.; Liu, Y.; Ma, X.; Wang, G. Research on a novel extraction method using Deep Learning based on GF-2 images for aquaculture areas. Int. J. Remote Sens. 2020, 41, 3575–3591. [Google Scholar] [CrossRef]
- Shen, X.; Wang, D.; Mao, K.; Anagnostou, E.; Hong, Y. Inundation Extent Mapping by Synthetic Aperture Radar: A Review. Remote Sens. 2019, 11, 879. [Google Scholar] [CrossRef] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Henry, C.; Azimi, S.; Merkle, N. Road Segmentation in SAR Satellite Images with Deep Fully Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef] [Green Version]
- Chen, S.-W.; Tao, C.-S. PolSAR Image Classification Using Polarimetric-Feature-Driven Deep Convolutional Neural Network. IEEE Geosci. Remote Sens. Lett. 2018, 15, 627–631. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep Learning Earth Observation Classification Using ImageNet Pretrained Networks. IEEE Geosci. Remote Sens. Lett. 2015, 13, 105–109. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep Learning-Based Classification of Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Geng, J.; Fan, J.C.; Chu, J.L.; Wang, H.Y. Research on marine floating raft aquaculture SAR image target recognition based on deep collaborative sparse coding network. Acta Autom. 2016, 42, 593–604. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Ji, Y.; Chen, J.; Deng, Y.; Chen, J.; Jie, Y. Combining Segmentation Network and Nonsubsampled Contourlet Transform for Automatic Marine Raft Aquaculture Area Extraction from Sentinel-1 Images. Remote Sens. 2020, 12, 4182. [Google Scholar] [CrossRef]
- Deyi, W.; Han, M. SA-U-Net++: SAR marine floating raft aquaculture identification based on semantic segmentation and ISAR augmentation. J. Appl. Remote Sens. 2021, 15, 016505. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–12. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road Extraction by Deep Residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9908, pp. 630–645. [Google Scholar]
- Iglovikov, V.; Shvets, A. TernausNet: U-Net with VGG11 Encoder Pre-Trained on ImageNet for Image Segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2014, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; An, J.; Yu, D.; Yang, L.; Wu, L.; Lv, X. Convolutional Neural Network With Attention Mechanism for SAR Automatic Target Recognition. IEEE Geosci. Remote Sens. Lett. 2020, 19, 4004205. [Google Scholar] [CrossRef]
- Qiu, M.; Zhang, Y.; Sui, C.; Yang, P. Evaluation on deep-water cage culture suitability of Changhai County based on GIS. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2019; Volume 227, p. 062038. [Google Scholar] [CrossRef]
- Ottinger, M.; Clauss, K.; Kuenzer, C. Large-Scale Assessment of Coastal Aquaculture Ponds with Sentinel-1 Time Series Data. Remote Sens. 2017, 9, 440. [Google Scholar] [CrossRef] [Green Version]
- Khelifi, L.; Mignotte, M. Deep Learning for Change Detection in Remote Sensing Images: Comprehensive Review and Meta-Analysis. IEEE Access 2020, 8, 126385–126400. [Google Scholar] [CrossRef]
- Tsagkatakis, G.; Aidini, A.; Fotiadou, K.; Giannopoulos, M.; Pentari, A.; Tsakalides, P. Survey of Deep-Learning Approaches for Remote Sensing Observation Enhancement. Sensors 2019, 19, 3929. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Girshick, R.; Dollar, P. Rethinking ImageNet Pre-Training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 4917–4926. [Google Scholar] [CrossRef] [Green Version]
- Lu, F.; Fu, C.; Zhang, G.; Zhang, W.; Xie, Y.; Li, Z. Convolution neural network based on fusion parallel multiscale features for segmenting fractures in coal-rock images. J. Electron. Imaging 2020, 29, 023008. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Block | Conv | Channel | Stride | Feature Map Size (Default 320 × 320) |
|---|---|---|---|---|---|
| 1 | 7 × 7 | 64 | 2 | 80 × 80 | |
| / | 64 | 2 | |||
| 2 | 3 × 3 | 64 | 2/1 | 40 × 40 | |
| Encoder | 3 | 3 × 3 | 128 | 2/1 | 20 × 20 |
| 4 | 3 × 3 | 256 | 2/1 | 10 × 10 | |
| 5 | 3 × 3 | 512 | 2/1 | 5 × 5 | |
| 5 | 3 × 3 | 256 | 1 | 20 × 20 | |
| 4 | 3 × 3 | 128 | 1 | 40 × 40 | |
| Decoder | 3 | 3 × 3 | 64 | 1 | 80 × 80 |
| 2 | 3 × 3 | 64 | 1 | 160 × 160 | |
| 1 | 3 × 3 | 1 | 1 | 320 × 320 |
| Confusion Matrix | Ground Truth | ||
|---|---|---|---|
| Positive | Negative | ||
| Extraction result | Positive | True Positive (TP) | False Positive (FP) |
| Negative | False Negative (FN) | True Negative (TN) | |
| The Data Set | Number of Patches | Size of Images | Channel of Images | |
|---|---|---|---|---|
| Training dataset | SAR Image | 3686 | 320 × 320 | 1 |
| Ground truth map | ||||
| Validation dataset | SAR Image | 1228 | 320 × 320 | 1 |
| Ground truth map | ||||
| Test dataset | SAR Image | 1230 | 320 × 320 | 1 |
| Ground truth map | ||||
| Methods | Precision (%) (Mean ± SD) | Recall (%) (Mean ± SD) | F1 (%) (Mean ± SD) | IoU (%) (Mean ± SD) |
|---|---|---|---|---|
| LinkNet | 78.81 ± 0.95 | 74.23 ± 2.19 | 76.44 ± 1.46 | 61.89 ± 1.88 |
| DeepLabV3 | 78.95 ± 1.96 | 82.96 ± 2.23 | 80.91 ± 2.05 | 67.98 ± 2.84 |
| U-Net | 80.75 ± 1.17 | 81.20 ± 1.48 | 80.97 ± 1.28 | 68.04 ± 1.82 |
| D-ResUnet | 92.89 ± 1.06 | 92.32 ± 0.77 | 92.60 ± 0.91 | 86.24 ± 1.57 |
| Strategy | Method | Precision (%) (Mean ± SD) | Recall (%) (Mean ± SD) | F1 (%) (Mean ± SD) | IoU (%) (Mean ± SD) |
|---|---|---|---|---|---|
| 1 | U-Net | 80.75 ± 1.17 | 81.20 ± 1.48 | 80.97 ± 1.28 | 68.04 ± 1.82 |
| 2 | ResNet34 + U-Net | 66.91 ± 1.16 | 85.33 ± 0.69 | 75.00 ± 0.65 | 60.00 ± 0.83 |
| 3 | ResNet34 + residual decoder + U-Net | 84.95 ± 0.61 | 85.24 ± 0.78 | 85.09 ± 0.46 | 74.05 ± 0.70 |
| 4 | Pre-trained ResNet34 + residual decoder + U-Net | 92.89 ± 1.06 | 92.32 ± 0.77 | 92.60 ± 0.91 | 86.24 ± 1.57 |
| Methods | Precision (%) (Mean ± SD) | Recall (%) (Mean ± SD) | F1 (%) (Mean ± SD) | IoU (%) (Mean ± SD) |
|---|---|---|---|---|
| DeepLabV3 | 73.74 ± 0.88 | 58.60 ± 4.96 | 65.17 ± 3.17 | 48.42 ± 3.39 |
| LinkNet | 80.68 ± 1.93 | 61.50 ± 4.41 | 69.64 ± 2.35 | 53.47 ± 2.71 |
| U-Net | 83.77 ± 0.63 | 60.38 ± 1.21 | 70.17 ± 0.75 | 54.05 ± 0.90 |
| D-ResUnet | 76.49 ± 1.03 | 74.40 ± 1.22 | 75.42 ± 0.86 | 60.55 ± 1.11 |
| Methods | Precision (%) (Mean ± SD) | Recall (%) (Mean ± SD) | F1 (%) (Mean ± SD) | IoU (%) (Mean ± SD) |
|---|---|---|---|---|
| Not Pre-trained D-ResUet | 84.95 ± 0.61 | 85.24 ± 0.78 | 85.09 ± 0.46 | 74.05 ± 0.70 |
| Pre-trained D-ResUet | 92.89 ± 1.06 | 92.32 ± 0.77 | 92.60 ± 0.91 | 86.24 ± 1.57 |
| Methods | Parameters | FLOPs |
|---|---|---|
| LinkNet | 21.77 M | 8.38 G |
| DeepLabV3 | 26 M | 42.56 G |
| U-Net | 31.04 M | 85.43 G |
| D-ResUnet | 24.83 M | 21.49 G |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, L.; Wang, C.; Liu, K.; Chen, S.; Dong, G.; Su, H. Extraction of Floating Raft Aquaculture Areas from Sentinel-1 SAR Images by a Dense Residual U-Net Model with Pre-Trained Resnet34 as the Encoder. Remote Sens. 2022, 14, 3003. https://doi.org/10.3390/rs14133003
Gao L, Wang C, Liu K, Chen S, Dong G, Su H. Extraction of Floating Raft Aquaculture Areas from Sentinel-1 SAR Images by a Dense Residual U-Net Model with Pre-Trained Resnet34 as the Encoder. Remote Sensing. 2022; 14(13):3003. https://doi.org/10.3390/rs14133003
Chicago/Turabian StyleGao, Long, Chengyi Wang, Kai Liu, Shaohui Chen, Guannan Dong, and Hongbo Su. 2022. "Extraction of Floating Raft Aquaculture Areas from Sentinel-1 SAR Images by a Dense Residual U-Net Model with Pre-Trained Resnet34 as the Encoder" Remote Sensing 14, no. 13: 3003. https://doi.org/10.3390/rs14133003
APA StyleGao, L., Wang, C., Liu, K., Chen, S., Dong, G., & Su, H. (2022). Extraction of Floating Raft Aquaculture Areas from Sentinel-1 SAR Images by a Dense Residual U-Net Model with Pre-Trained Resnet34 as the Encoder. Remote Sensing, 14(13), 3003. https://doi.org/10.3390/rs14133003