1. Introduction
Recent developments in remote sensing technology have made hyperspectral images (HSIs) more widely available in various fields [
1,
2,
3]. HSI contains hundreds of narrow, continuously arranged spectral bands, and each band represents a one-dimensional feature [
4]. The high spectral resolution provides a wealth of information, while yielding the Hughes effect [
5], also known as the curse of dimensionality. The Hughes effect occurs because the narrow adjacent bands [
6] of HSI result in redundant information ultimately interferes with classification. Therefore, removing redundant bands without reducing classification accuracy [
7] is an important and urgent issue. There are two typical data reduction techniques [
8]: feature extraction and FS. Feature extraction techniques (e.g., Principal Component Analysis and Linear Discriminant Analysis) are designed to compress data by using mathematical transformations. Due to every band of the HSI having its corresponding image, the way of feature extraction that the high-dimensional feature space is mapped to a low-dimensional space by linear or nonlinear transformation could not keep the primitive physical significance of the HSI [
9]. Thus, feature extraction techniques are not suitable for the dimensionality reduction of HSIs, and so FS has been one of the effective means for solving this issue on HSIs [
10], specifically by selecting the optimal subset from all the original bands to gain the desired classification performance.
FS algorithms generally contain three categories of models: filter, wrapper, and hybrid models [
11]. Filter models mainly use statistical or probabilistic characteristics of the datasets for FS [
12]. They are computationally efficient and are suitable for high-dimensional datasets, as they do not require any machine learning (ML) algorithm. In contrast to filter models, wrapper models use a predetermined ML algorithm to calculate the accuracy of the selection [
13]. They can achieve higher prediction accuracy. Still, they also have to bear the higher computational cost. Filter models and wrapper models, in other words, are the opposite in terms of advantages and disadvantages [
14]. As the combination of filter and wrapper models, hybrid models combine the benefits of both and avoid their weaknesses, thus promising better results. Many recent studies [
15,
16,
17,
18] have applied hybrid models for FS on HSIs. For instance, Xie [
15] divided the spectral interval by the filter method of information gain and then combined the GWO algorithm with the SVM classifier to form a wrapper model to obtain the best feature subset; Wang [
18] first used the correlation coefficient metric to cull the highly relevant bands and then used the wrapper model containing Sine cosine algorithm (SCA) algorithm to perform a refined search. Through the structure of the hybrid models used in the above literature, it is evident that the models can be summarized in a two-step approach [
11]. The first step is based on the filter model to select the candidate features from all the bands, and this reduces the number of features. The second step uses the wrapper model to choose the optimal subset from the candidate features. The hybrid models can thus also be called filter–wrapper (F–W) models.
The filter approaches used in the F–W model mainly fall into two categories: (1) employing one of the commonly used filter-based algorithms (e.g., ReliefF) to evaluate a score of each band according to its criterion and selecting the top-ranked bands to construct the feature subset considered in the wrapper model [
11,
19,
20,
21]; and (2) dividing all the bands into many spectral subspaces based on the information criteria (e.g., inter-spectral correlation and mutual information), selecting each subspace’s representative bands according to the wrapper model [
8,
15,
22]. The filter model can obtain the candidate features and reduce the search space for the wrapper model, but it cannot find the optimal subset from HSIs. The wrapper model combines a classifier in ML with a wrapper method that utilizes the classifier as a black box to drive the predictive power of the classifier through the wrapper method, thus evaluating the feature subsets. The model is the key to finding the optimal subset. In terms of the classifier, SVM is now the most commonly used supervised classifier, which can efficiently solve classification problems with small sample sizes and high-dimensional datasets. In particular, many studies [
10,
23,
24,
25,
26] have addressed the HSI classification problem by using SVM and obtained superior classification accuracy. Since the FS problem is an NP-hard problem [
16], combining an exhaustive search with a classifier is impractical to evaluate all feature subsets except for small-sized feature spaces. Therefore, most wrapper methods are suboptimal algorithms that search for relatively high-quality subsets with reasonable computational effort. They fall under the following categories [
11]: greedy sequential feature selection methods, nested partitioning methods, mathematical programming methods, and metaheuristic methods. In recent years, metaheuristic methods, especially Swarm Intelligence and Evolutionary Algorithms (SIEAs) [
27], have been widely applied for their excellent performance [
16].
Many studies [
10,
16,
22,
28] have used SIEAs in different F–W frameworks for HSI FS. For example, Xie [
28] first implemented subspace decomposition by calculating the correlation coefficients between adjacent bands of HSI and then performed the ABC algorithm for FS. Singh [
22] applied a similar framework—first segmented the spectral space of HSI into several spectral regions, using a cluster algorithm, and then applied the GA to each subregion to find the optimal subset and finally integrated them. These studies first performed band subspace decomposition and then applied SIEA to search for subsets, which relies too much on the researchers’ prior knowledge [
29]. There are also studies that can perform HSI FS without relying on a priori knowledge. For instance, Zhang [
16] used maximizing representativeness and minimizing redundancy (mRMR) to obtain representative subsets initially and then performed an exact search, employing the immune clone selection (ICS) algorithm. Moreover, Wang [
10] first used the correlation coefficient to remove the highly relevant bands and then used a modified ALO (MALO) and wavelet SVM (WSVM) to reduce the dimensionality of HSIs. Using existing filter methods to obtain the candidate feature subset is convenient, as there is no need for prior knowledge. However, it has been confirmed [
12] that using a single filter method on different datasets to select candidate feature subsets is not robust. Given the flaws in these frameworks, this paper aims to use multiple filter-based methods to form an integrated filter model for selecting the informative candidate features in a novel way. Specifically, we merge the bands selected by different filter methods as candidate features. This integrated model can theoretically address these drawbacks and maximize the performance of the SIEAs.
Up to now, there have been many different SIEAs applied to the FS problems [
30]. Some are historical but practical for HSIs, such as GA [
8], DE [
17], Particle Swarm Optimisation (PSO) [
31], etc. In addition, others are just emerging for real-world problems other than HSI classification. For instance, Chen et al. [
32] proposed the IDEA inspired by Chinese I-Ching in 2016, and it achieved better performance in the benchmark functions. Heidari et al. [
33] simulated Harris Hawks Optimizer (HHO) based on the predatory behavior of Harris’s hawk in 2019. Afshin et al. [
34] also proposed MPA according to the predatory behavior of marine organisms in 2020 and verified its superior performance in the engineering functions. The evidence reviewed here suggests that scholars have proposed many SIEAs, but few studies have compared the optimization performance of these algorithms for the FS problem, particularly for HSI classification.
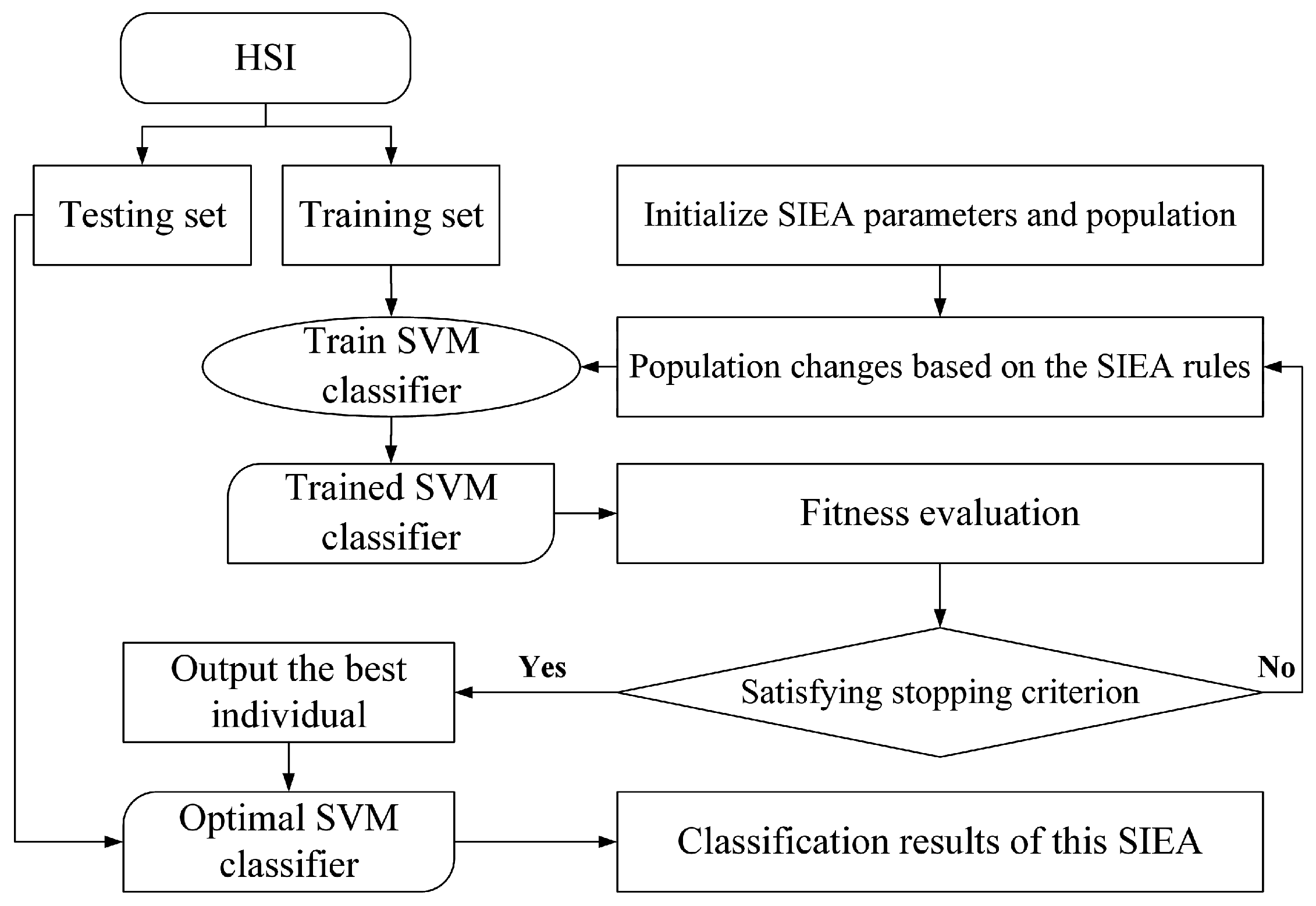
To sum up, this paper has two research objectives: (1) to build a hybrid F–W framework that can strike a good balance between the filter component’s efficiency and the wrapper component’s accuracy; and (2) to compare different SIEAs’ performance on HSI FS. To achieve the objectives, we developed a novel F–W framework that integrates several commonly used filter methods in the filter component and applies different SIEAs for comparison in the wrapper component. To demonstrate the framework’s validity, we evaluated and compared the performance of each SIEA under the F–W framework (i.e., F–W–SIEA) with each pure SIEA wrapper on the HSIs. The comparison aspects relate to classification accuracy, the number of selected bands, convergence rate, and relative runtime. Specifically, this paper investigates the following points: (1) comparisons of each F–W–SIEA with the corresponding pure SIEA wrapper; (2) comparisons of different F–W–SIEAs; and (3) comparisons of several representative F–W–SIEAs with commonly used FS techniques, as well as classification with full bands (FBs).
3. Research Data
To evaluate and compare the performance of all the methods, we used three HSI datasets in the experiment. The datasets are open-source and widely used. They include the Indian Pines image [
47], Salinas image [
48], and KSC image [
49], representing complicated farmland, simple farmland, and simple suburb.
The Indian Pines dataset was obtained by the AVIRIS sensor over the agricultural land of Indiana. This dataset was acquired in the spectral range of 0.4 to 2.5 µm that consists of 145 × 145 pixels and 220 bands. After removing the 20 water absorption bands, the remaining 200 bands were used as original features.
Figure 4a shows the ground truth image, which includes 16 classes in the area, and
Figure 4d shows the spectral reflectance curves of these land-cover classes.
The Salinas dataset was collected by the AVIRIS sensor over California’s Salinas Valley. The dataset comprises 512 × 217 pixels and 224 spectral bands. After removing the 20 water absorption bands, the remaining 204 bands were used as this dataset’s original features.
Figure 4b shows the ground truth image, which includes 16 classes in the area, and
Figure 4e shows the spectral reflectance curves of these classes.
The KSC dataset was acquired at the Kennedy Space Center of USA. The image is formed by 512 × 614 pixels and 224 bands. By removing water absorption and low signal-to-noise bands, the number of bands is reduced to 176.
Figure 4c shows the ground truth image, which includes 13 classes, and
Figure 4f shows the spectral reflectance curves of the classes.
5. Discussion
During the application of ML classifiers (e.g., SVM) for HSI classification, the high dimensionality of the data can negatively affect the classification, with consequences [
54] that may include (1) overfitting the classification algorithm due to random variation from irrelevant bands captured as helpful information, (2) constructing complex models making model interpretation a challenging task, and finally (3) requiring additional computational effort and data storage than would be necessary for a simpler dataset. There has been evidence [
55] that the high dimensionality of image data will likely lead to reduced classification accuracy because, when the data feature space is large and the training samples are insufficient, it often leads to the Hughes effect [
56], which can be avoided by removing redundant features through FS [
30]. Overall, our experimental results can prove this (shown in
Table 6,
Table 7 and
Table 8). Although the OAs of classification with FB are high on the datasets, they are all lower than the OAs achieved by algorithms such as F–W–GA, thus indicating that higher-dimensional features are sometimes detrimental to the classifier’s performance. In contrast, the optimal feature subset searched by each F–W–SIEA can nearly remove more than 80% of the redundant features from the original dataset, significantly reducing computational effort and data storage. In addition, in classifying the FB of HSIs by using SVM, the RBF parameters still need to be optimized by employing cross-validation and grid search, which does not take much less time than finding the optimal subset using some F–W–SIEAs (e.g., F–W–GWO) [
57]. Therefore, using a suitable SIEA under the F–W framework can improve the classification performance and reduce the subsequent computational effort.
There have been many studies applying SIEAs for HSI FS in recent years. However, there has been little discussion about the performance comparison of these SIEAs. In this paper, we propose a novel F–W framework and compare the performance of ten SIEAs under this framework. Most F–W–SIEAs can obtain better results on the three datasets than the corresponding pure SIEA wrappers, and there are also exceptions. For instance, the OAs of a few F–W–SIEAs (e.g., F–W–DE and F–W–ABC) are slightly lower than those of pure SIEA wrappers. The phenomenon is considered normal, as reported by Reference [
8]. There are two objectives in HSI FS: maximizing the classification accuracy and minimizing the number of selected bands. Sometimes, it is a dilemma and should be trade-offed in particular cases.
Zhu [
45] conducted comparative experiments by using three pure SIEAs (i.e., GA, PSO, and ABC) to HSIs. They found that the GA performed the best overall. This also accords with our observations. Our results show that GA under the F–W framework obtains the best results among all algorithms. However, in their experiments, the pure GA wrapper achieves the OA of 94.60% on the Salinas dataset, slightly higher than F–W–GA (93.33%). A possible explanation for this might be that the inconsistency of our samples causes the differences in precisions. It is worth mentioning that the NB of their GA is 48.2, which is much more than that of F–W–GA (20.8). Wang [
18] proposed an improved LSCA method, which used 10% of the samples for training, but we have utilized 20% of the samples. Thus we only compare the number of bands selected, to be fair. From their results, the proposed method selects around 33 and 42 bands on the KSC and Indian Pines dataset, respectively, while most F–W–SIEAs select much fewer than the two numbers in our experiments. In short, these comparisons demonstrate that the different SIEAs combined with the framework can yield more competitive results with satisfactory accuracy but fewer bands.
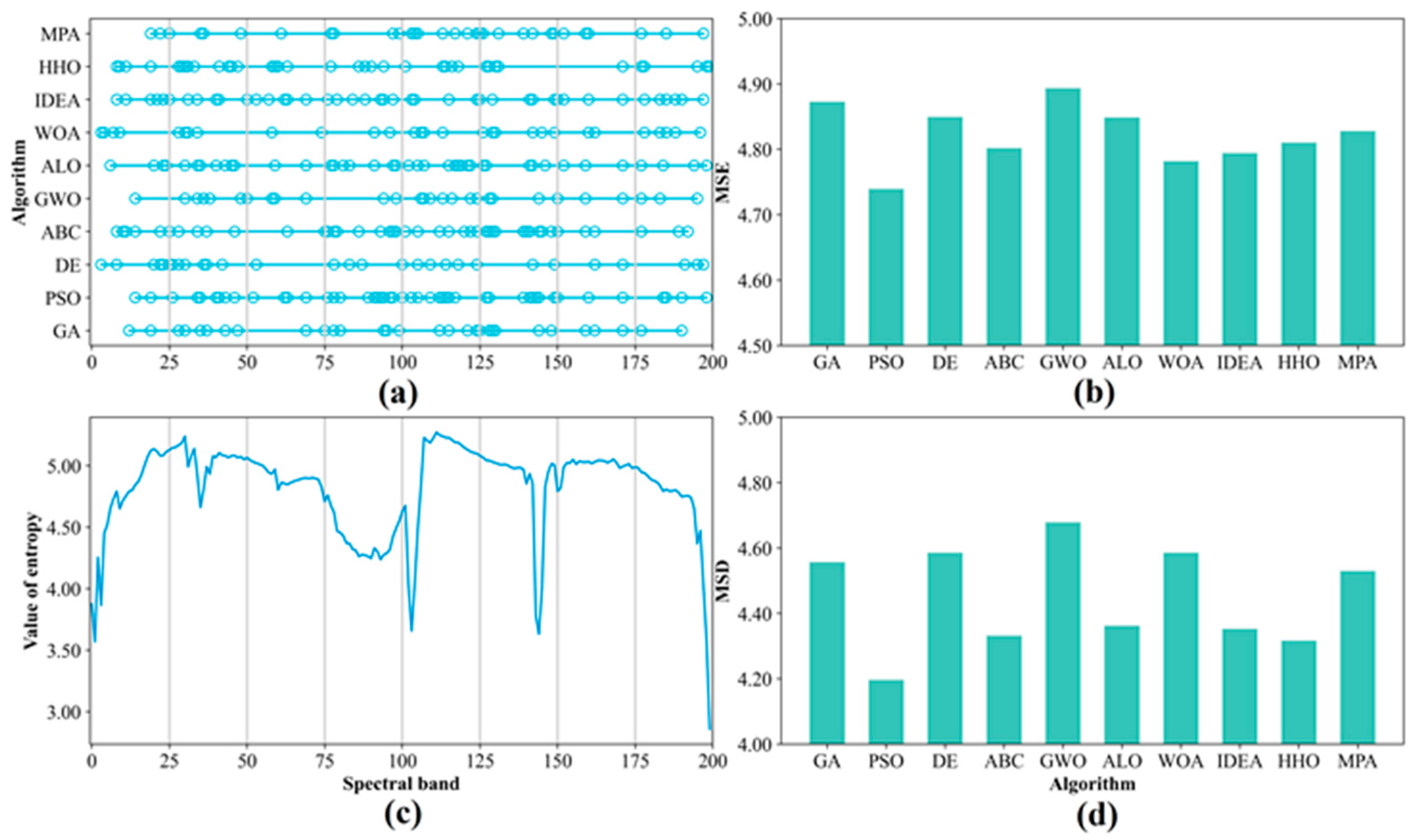
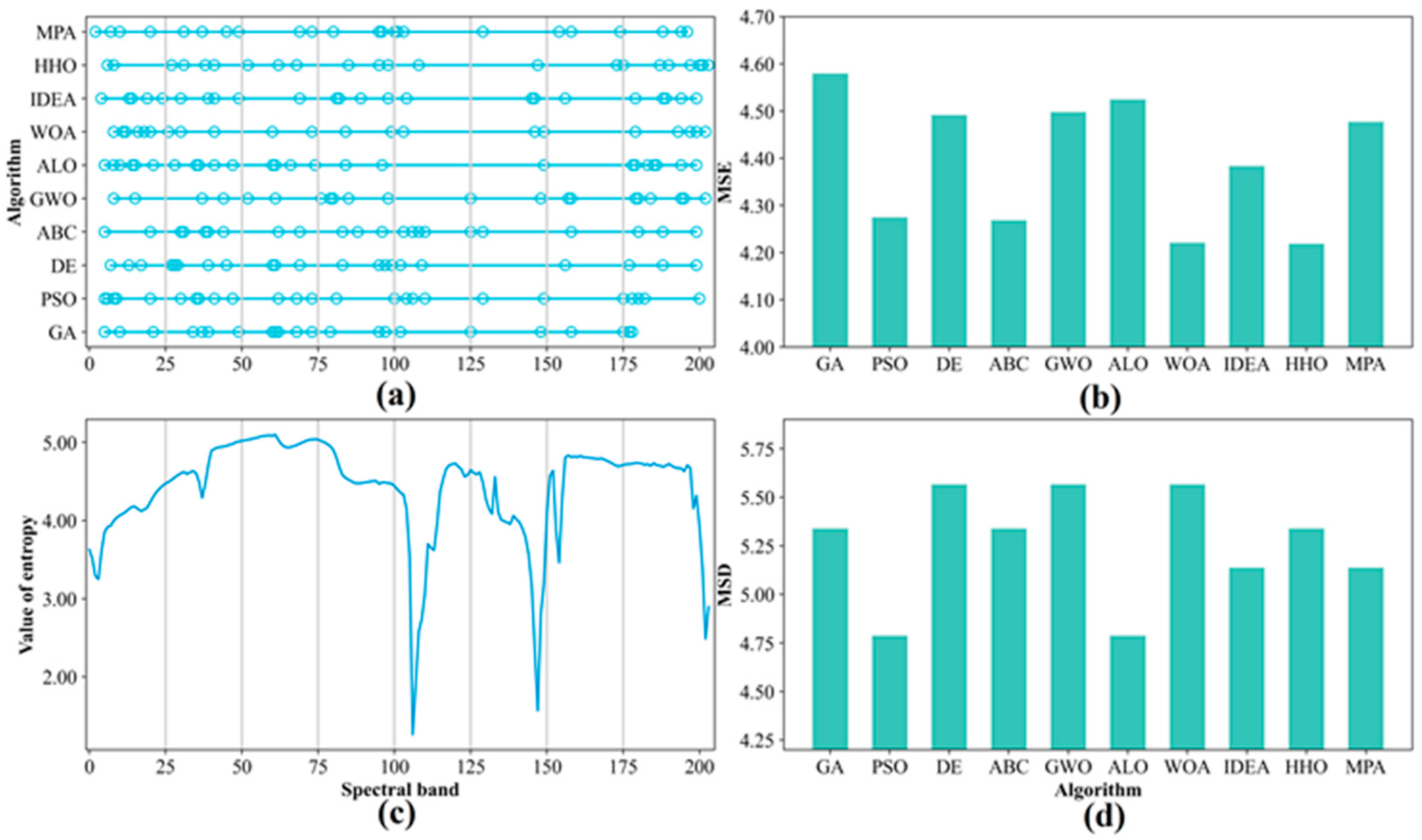
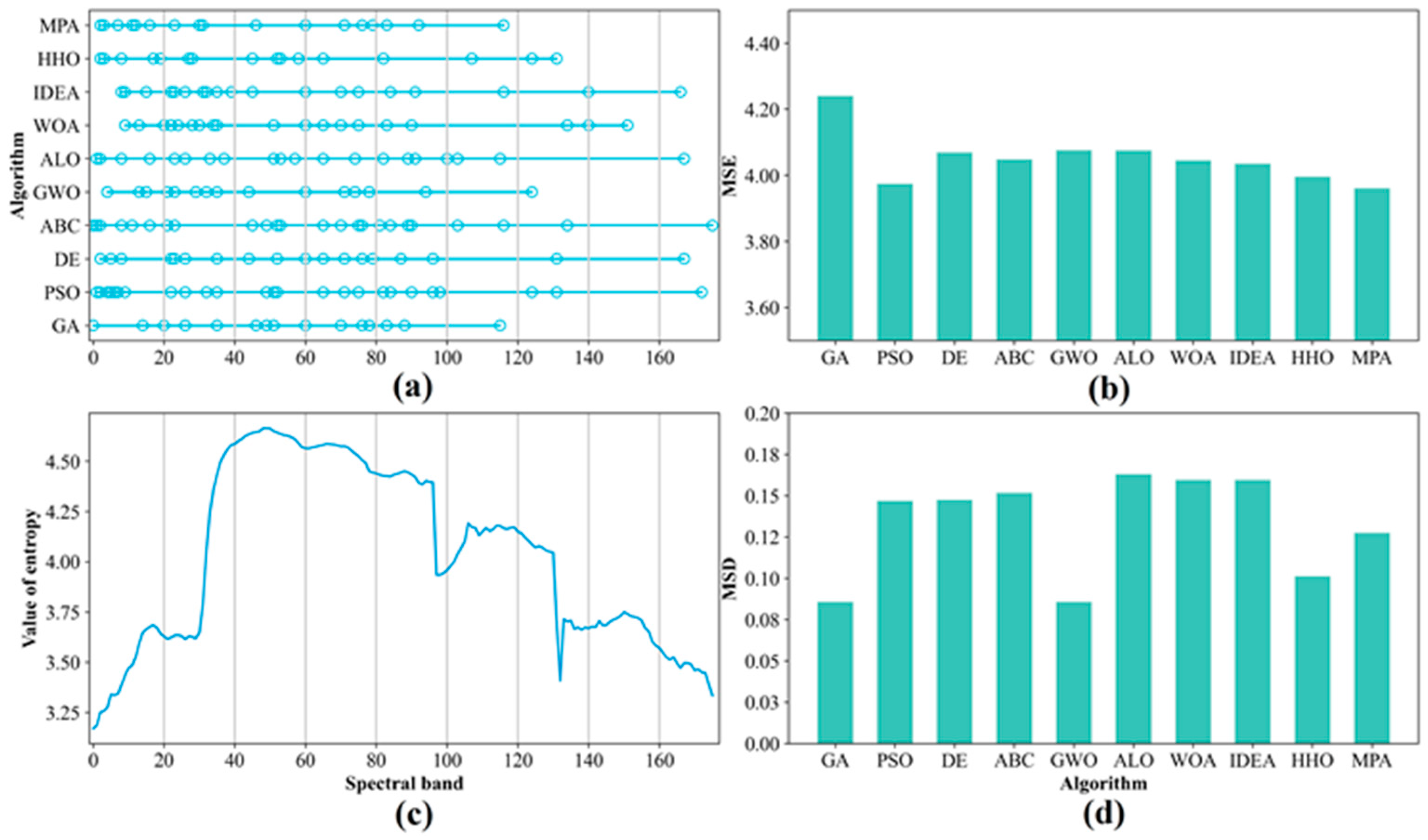
The performances of the F–W–SIEAs on the different datasets are different. For instance, the fitness of F–W–PSO is lower than F–W–ABC on the Indian Pines data but higher than F–W–ABC on the Salinas and KSC datasets. Moreover, the fitness value of F–W–ALO is higher than F–W–IDEA on the Indian Pines data, but the other two datasets have similar fitness values. F–W–ALO has higher fitness values than F–W–IDEA on the Indian Pines data, but the two algorithms have similar fitness values on the other datasets. This result may be explained by the different spectral complexity of the different datasets [
45]. As shown in
Figure 4, the Indian Pines dataset has a more complex scene than the other datasets. Moreover, several classes have similar spectral characteristics; in other words, the classification difficulty of the datasets is different, which may be the direct cause of the various performances of F–W–SIEAs on different datasets. In general, the findings indicate that F–W–GA and F–W–GWO have similar optimization abilities and perform the best on all the datasets. They can achieve the highest OAs by compressing above 85% of the bands from the original HSIs, but F–W–GWO requires less runtime than F–W–GA. Therefore, F–W–GA and F–W–GWO are preferred for HSI FS, especially in complex scenes. If considering the runtime, F–W–GWO should be the best choice.
Many SIEAs are proposed yearly, and these algorithms are often generated by simulating natural or manmade processes. Invariably, the authors of such papers promise that their new SIEA is superior to algorithms previously published in the literature. However, contrary to expectations, we do not find evidence that the newer the SIEA, the better the optimization results (i.e., OA and NB). For instance, the just emerging SIEAs (e.g., HHO) do not perform better than SIEAs (e.g., GA and GWO) proposed earlier on HSI classification. A possible explanation for the results is the new SIEAs can solve many numerical optimization problems. Still, there are a few exceptions; for instance, they may not be reliable for some specific real-world problems [
27]. Choosing the appropriate approach is crucially important rather than directly applying the latest algorithm. Therefore, when using SIEAs for specific issues, it is necessary to conduct the pre-experiments to determine how well they work, and wrong choices of optimization methods may lead to unsatisfactory results. This pre-experiment practice has also been suggested in selecting suitable filter-based methods [
12]. In addition, the academic community has proposed considerable SIEAs, where many algorithms may only be proposed but are not widely used in various real-world problems. Hence, the future of the metaheuristic field should perhaps not be to keep creating new SIEAs, but to apply and improve existing ones. Future studies may focus on the different algorithms’ operational mechanisms [
58]. Brezocnik et al. [
30] also suggest that combining the strengths of different SIEAs to improve existing ones is significant for the metaheuristic field.
Another interesting aspect of this study would be finding that the performance of the commonly used FS techniques is also related to the HSI scene. For instance, for the Indian Pines dataset, the representative F–W–SIEAs obtain much higher OAs than the commonly used filter algorithms; meanwhile, for the KSC dataset with simple scenes, several F–W–SIEAs do not achieve higher OAs than the filter algorithms. Furthermore, it is well-known that the wrapper methods are much more time-consuming than the filter methods. Therefore, we can first choose whether to use filter or wrapper methods depending on the complexity of the HSI. If the image is a somewhat “easy” dataset and the task is urgent, we should try the filter methods rather than wrapper methods, as these methods can basically obtain the desired results and save much runtime.
This study also has some limitations. To make a fair comparison of these ten algorithms, we used MATLAB to build an experimental environment based on the same computer platform. We reproduced the algorithms according to the corresponding papers. However, the performance of one SIEA depends not only on factors related to those mentioned above (i.e., the specific code, the programming language, and the software or hardware used) but also on other factors beyond the control of the algorithm (e.g., individual coding skills). In addition, we compared the performances of a total of ten SIEAs for HSI FS. In fact, there are still many other excellent SIEAs in existence, but a discussion of all SIEAs lies beyond our ability.
6. Conclusions
To compensate for the drawbacks of existing filter–wrapper models and compare the performances of various SIEAs for HSI FS, we proposed a novel filter–wrapper framework to optimize the SVM and classify HSIs. The framework integrates several commonly used filter methods in the filter component and applies each of the ten SIEAs for comparison in the wrapper component. Based on the classification results of these F–W–SIEAs, we compared different methods’ performances in regard to the accuracy, number of selected bands, convergence rate, and relative runtime. Our results show the following:
For the three HSI datasets, most F–W–SIEAs can obtain better results than the corresponding pure SIEA wrappers. Specifically, each F–W–SIEA can obtain higher classification accuracy with a smaller feature subset size in a shorter time than the pure SIEA wrapper. In other words, the framework can combine with different SIEAs to reduce their computational complexity and enhance their classification performances on HSI classification. This framework also provides a new hybrid idea for other FS problems.
The performance of different F–W–SIEAs on different datasets varies slightly, as influenced by the algorithms’ optimization abilities, the complexity of the study area, etc. Specifically, the accuracy, the number of selected bands, the convergence rate, and the relative runtime of the ten F–W–SIEAs are different, but some have similar optimization abilities. On average, among the ten F–W–SIEAs, F–W–GA and F–W–GWO have similar optimization abilities and perform the best on the datasets. They achieve the highest OAs by reducing above 85% of the bands from original HSIs, but F–W–GWO requires the least runtime among the ten. F–W–MPA is also excellent, second only to the above two algorithms and slightly better than the F–W–DE. While F–W–ALO, F–W–IDEA, and F–W–WOA have moderate optimization capabilities, the F–W–IDEA takes the most runtime of all methods. The algorithms that perform poorly overall are F–W–PSO, F–W–ABC, and F–W–HHO. The difference in the optimization results between the ten methods becomes even more significant in more complex scenes (e.g., Indian Pines). We also find that the number of iterations to reach convergence differs between algorithms. In general, the better the algorithm’s optimization ability, the more uniform the band distribution and the higher the MSE and MSD of the selected bands. Despite the differences in optimization ability between the ten F–W–SIEAs, four representative algorithms at different levels still perform better than commonly used FS methods (e.g., CMIM, mRMR, and ReliefF) overall, especially in complex scenes.
This paper is a reference for people who would like to conduct FS on HSIs by applying SIEAs under the proposed framework. It can help them choose appropriate algorithms according to their computational resources, image scenes, etc. Future studies will use our analyses to combine different models to enhance their classification performance. Our analyses could also be extended by considering other FS methods apart from the ten SIEAs, which were out of scope for this analysis. In addition, we used various SIEAs to optimize the SVM classifier for comparison. We will also consider the effect of SIEAs on optimizing other advanced classifiers (e.g., K-Nearest Neighbor and Artificial Neural Networks).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}