
Sentinel-2 Satellite Image Time-Series Land Cover Classification with Bernstein Copula Approach



Abstract
:1. Introduction
2. Mathematical Background
2.1. Singular Value Decomposition
2.2. Copulas
2.3. Families of Copulas
- Elliptical Copulas: In this class, we find copulas that describe the dependencies of elliptical multivariate distributions. The copula functions belonging to this class are called Gaussian and Student-t copulas.Gaussian Copula: The form of this copula is related to the joint standard Normal distribution:where the cdf has a correlation matrix , and is the quantile function of normal distribution. Gaussian copula can describe a variety of dependencies depending on its parameter. In more detail:Student-t Copula: The form of this copula is due to the joint Student-t distribution and can be determined as follows:where represent the cdf of multivariate Student-t distribution with correlation matrix and degrees of freedom , while is the univariate cdf of the Student-t distribution with degrees of freedom . As the Student copula-t converges to Gaussian copula (the difference becomes negligible after ). The Student-t copula is mostly used in finance studies since it exhibits the best fit than other families.
- Archimedean Copula: Archimedean copulas may be constructed using a function , continuous, decreasing, convex and such that . Such a function is called a generator. Let be a strict generator, with completely monotonic on . Then a d-dimensional copula C is Archimedean if it admits the representation:Depending on different generator functions, different copulas can be obtained. For a single-parameter family, there exist 22 copulas; among those, here we report only the expressions of the cdf of the archimedean copulas most used in the literature.Clayton Copula: This type of copula allows the strong dependence in the lower tail to be detected; it can be determined as follows:Frank Copula: It can describe symmetric dependence; unlike Clayton, it can describe positive and negative dependences. It has the following form:Gumbel Copula: It can describe asymmetric dependences. Like Clayton, it cannot represent negative dependence. It has the following form:
2.4. Bernstein Copula
The Bernstein Density
3. Method
3.1. The Probabilistic Classifier based on Copula Function
3.2. Fitting Copula
3.3. Marginals Estimation
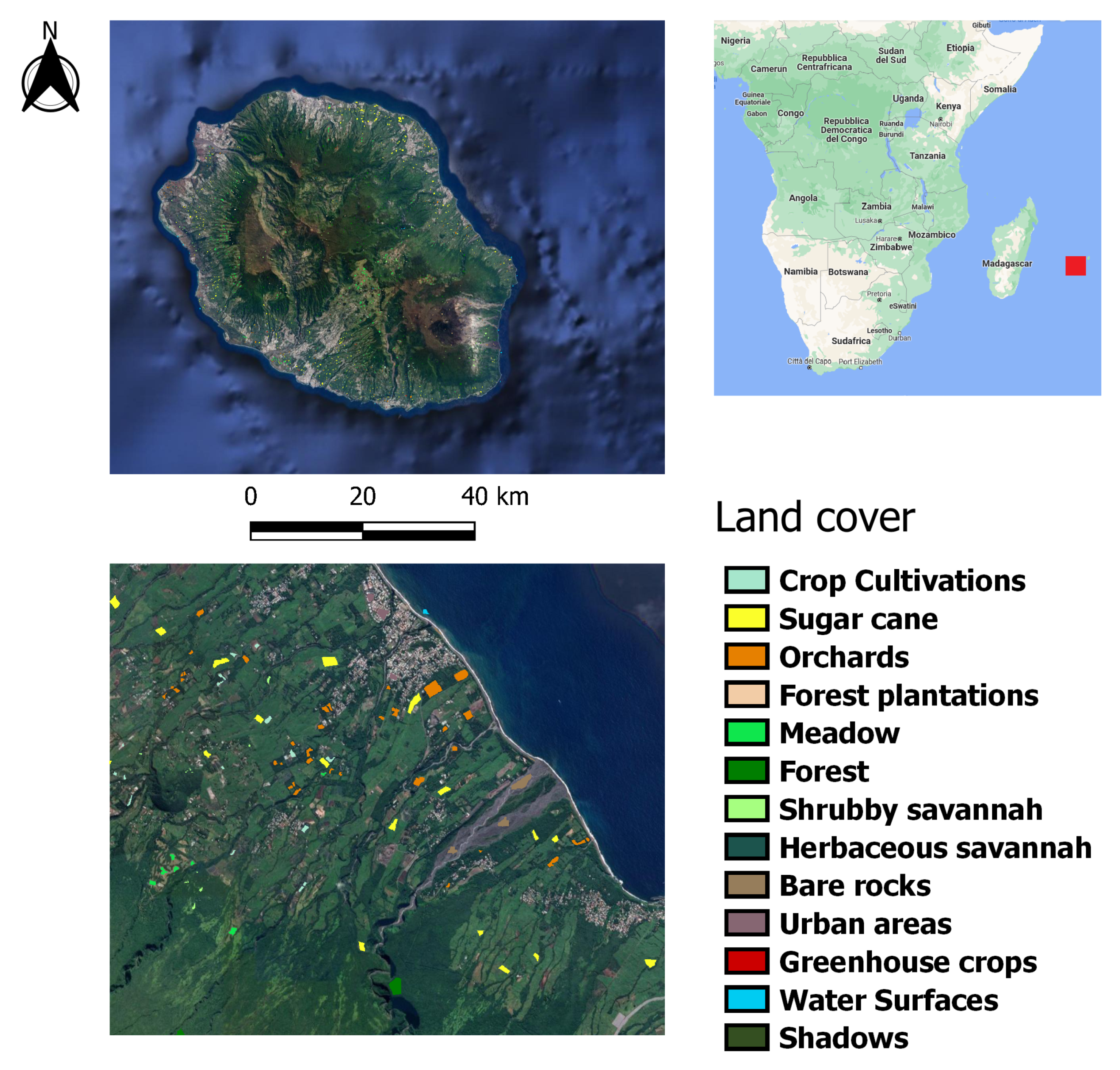
4. Data
5. Structure of the Copula-Based Classifier Algorithm
- Rearranging of all the images (tensor) , with , in a matrix of dimension . Where and denoting T as the number of images acquired over time.
- Application of the SVD algorithm to dimensionally reduce image , choosing an appropriate number of singular values r. Therefore, we get the reduced image of dimensions with .
- The concatenation of all matrices of the previous step obtains a matrix of dimensions , with R being the sum of the singular values of each image .
- Splitting of the dataset into training set, validation set and testing set.
- Separating the pixels of the training dataset by class and fitting the copula-based classifier to each class by using the Bernstein copula according to the procedure described in Section 3.2 and Section 3.3. To find the parameter for the empirical Bernstein copula we refer to the procedure described in [30].
- Once we have chosen the Bernstein copula that best fits each class of the training set, we use the testing set to evaluate the accuracy of the classification. In particular, for each observation of the testing set, we evaluate the discriminant functions and the predicted class by using Equations (2) and (4), in which c represents the previously fitted copula on the training set.
6. Experiments
- An in-depth quantitative study is provided comparing the class’ classification accuracy results obtained with CopCLF with regard to competitor’s methods and benchmark algorithms.
- A qualitative study is also carried out through the analysis of image pieces cut from the original dataset of Reunion Island, visually analyzing the LC map obtained with the CopCLF approach and the one obtained with the approaches used in paper [18].
6.1. Experimental Settings
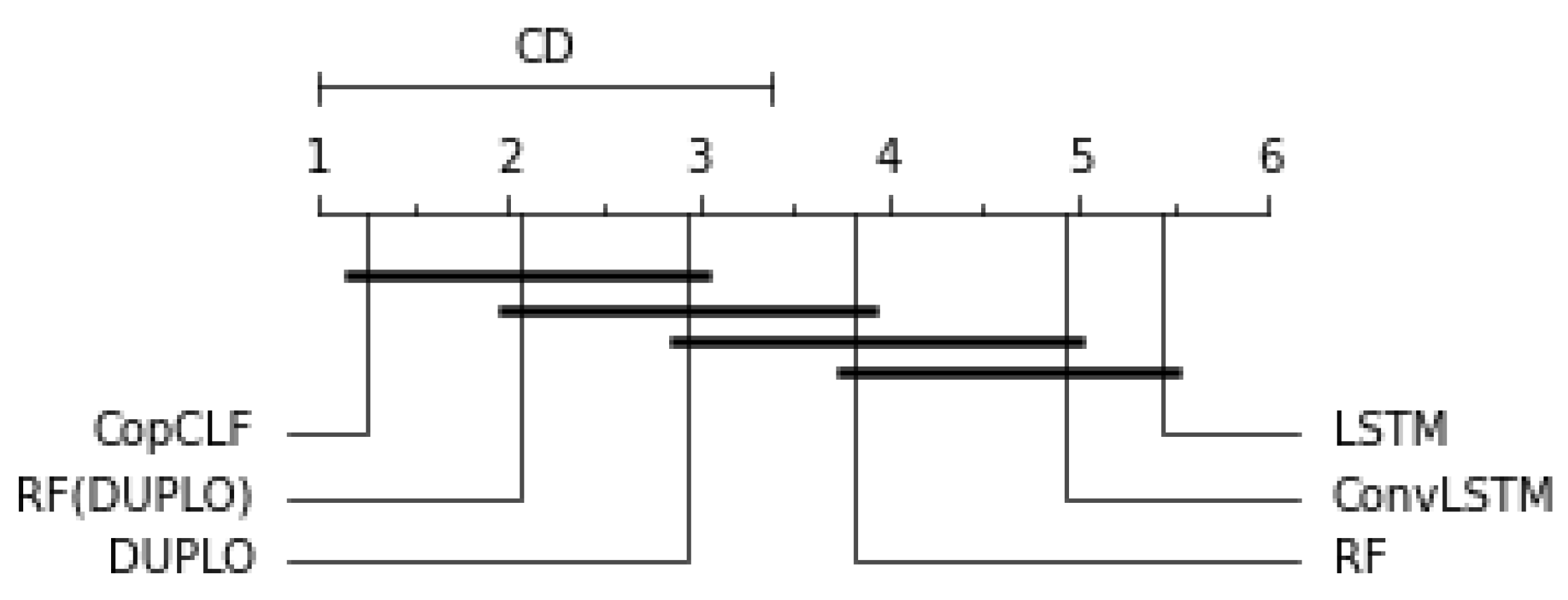
7. Experimental Results
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| F | Cumulative distribution function |
| f | Probability density function |
| Copulas and Bernstein Copula density function | |
| Copulas and Bernstein cumulative density function | |
| Likelihood function | |
| Prior Probability | |
| Posterior Probability | |
| Image tensor with dimension | |
| I | Rearranged Image matrix with dimension , |
| Satellite Image Time Series SITS | |
| Spectral bands of Image | |
| Single Band SITS | |
| r | Number of Principal Components |
| Flattened single band SITS | |
| Flattened reduced image with dimension |
References
- Kolecka, N.; Ginzler, C.; Pazur, R.; Price, B.; Verburg, P.H. Regional Scale Mapping of Grassland Mowing Frequency with Sentinel-2 Time Series. Remote Sens. 2018, 10, 1221. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Jin, Z.; Michishita, R.; Cai, J.; Yue, T.; Chen, B.; Xu, B. Dynamic monitoring of wetland cover changes using time-series remote sensing imagery. Ecol. Inform. 2014, 24, 17–26. [Google Scholar] [CrossRef]
- Bégué, A.; Arvor, D.; Bellon, B.; Betbeder, J.; De Abelleyra, D.; Ferraz, R.P.D.; Lebourgeois, V.; Lelong, C.; Simões, M.; Verón, S.R. Remote Sensing and Cropping Practices: A Review. Remote Sens. 2018, 10, 99. [Google Scholar] [CrossRef] [Green Version]
- Bellón, B.; Bégué, A.; Lo Seen, D.; De Almeida, C.A.; Simões, M. A Remote Sensing Approach for Regional-Scale Mapping of Agricultural Land-Use Systems Based on NDVI Time Series. Remote Sens. 2017, 9, 600. [Google Scholar] [CrossRef] [Green Version]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef] [Green Version]
- Wulder, M.A.; White, J.C.; Goward, S.N.; Masek, J.G.; Irons, J.R.; Herold, M.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Landsat continuity: Issues and opportunities for land cover monitoring. Remote Sens. Environ. 2008, 112, 955–969. [Google Scholar] [CrossRef]
- Wulder, M.A.; Masek, J.G.; Cohen, W.B.; Loveland, T.R.; Woodcock, C.E. Opening the archive: How free data has enabled the science and monitoring promise of Landsat. Remote Sens. Environ. 2012, 122, 2–10. [Google Scholar] [CrossRef]
- Guttler, F.; Ienco, D.; Nin, J.; Teisseire, M.; Poncelet, P. A graph-based approach to detect spatiotemporal dynamics in satellite image time series. ISPRS J. Photogramm. Remote Sens. 2017, 130, 92–107. [Google Scholar] [CrossRef] [Green Version]
- Khiali, L.; Ienco, D.; Teisseire, M. Object-oriented satellite image time series analysis using a graph-based representation. Ecol. Inform. 2018, 43, 52–64. [Google Scholar] [CrossRef] [Green Version]
- Abade, N.A.; Júnior, O.A.d.C.; Guimarães, R.F.; De Oliveira, S.N. Comparative Analysis of MODIS Time-Series Classification Using Support Vector Machines and Methods Based upon Distance and Similarity Measures in the Brazilian Cerrado-Caatinga Boundary. Remote Sens. 2015, 7, 12160–12191. [Google Scholar] [CrossRef] [Green Version]
- Flamary, R.; Fauvel, M.; Dalla Mura, M.; Valero, S. Analysis of Multitemporal Classification Techniques for Forecasting Image Time Series. IEEE Geosci. Remote Sens. Lett. 2015, 12, 953–957. [Google Scholar] [CrossRef]
- Heine, I.; Jagdhuber, T.; Itzerott, S. Classification and Monitoring of Reed Belts Using Dual-Polarimetric TerraSAR-X Time Series. Remote Sens. 2016, 8, 552. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Feng, Y. New Method Based on Support Vector Machine in Classification for Hyperspectral Data. In Proceedings of the 2008 International Symposium on Computational Intelligence and Design, Wuhan, China, 17–18 October 2008; Volume 1, pp. 76–80. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep Learning for Remote Sensing Data: A Technical Tutorial on the State of the Art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Ienco, D.; Gaetano, R.; Dupaquier, C.; Maurel, P. Land Cover Classification via Multitemporal Spatial Data by Deep Recurrent Neural Networks. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1685–1689. [Google Scholar] [CrossRef] [Green Version]
- Interdonato, R.; Ienco, D.; Gaetano, R.; Ose, K. DuPLO: A DUal view Point deep Learning architecture for time series classificatiOn. ISPRS J. Photogramm. Remote Sens. 2019, 149, 91–104. [Google Scholar] [CrossRef] [Green Version]
- Pelletier, C.; Webb, G.; Petitjean, F. Temporal Convolutional Neural Network for the Classification of Satellite Image Time Series. Remote Sens. 2019, 11, 523. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y.; Lin, L.; Liu, Q.; Hang, R.; Zhou, Z.G. SITS-Former: A pre-trained spatio-spectral-temporal representation model for Sentinel-2 time series classification. Int. J. Appl. Earth Obs. Geoinf. 2022, 106, 102651. [Google Scholar] [CrossRef]
- Ang, A.; Chen, J. Asymmetric correlations of equity portfolios. J. Financ. Econ. 2002, 63, 443–494. [Google Scholar] [CrossRef]
- Elidan, G. Copulas in machine learning. In Copulae in Mathematical and Quantitative Finance; Springer: Berlin/Heidelberg, Germany, 2013; pp. 39–60. [Google Scholar] [CrossRef] [Green Version]
- Größer, J.; Okhrin, O. Copulae: An overview and recent developments. Wiley Interdisciplinary Reviews: Computational Statistics; Wiley: Hoboken, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Slechan, L.; Górecki, J. On the Accuracy of Copula-Based Bayesian Classifiers: An Experimental Comparison with Neural Networks. In Computational Collective Intelligence; Núñez, M., Nguyen, N.T., Camacho, D., Trawiński, B., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 485–493. [Google Scholar] [CrossRef]
- Salinas-Gutiérrez, R.; Hernández-Aguirre, A.; Rivera-Meraz, M.J.J.; Villa-Diharce, E.R. Using Gaussian Copulas in Supervised Probabilistic Classification. In Soft Computing for Intelligent Control and Mobile Robotics; Springer: Berlin/Heidelberg, Germany, 2011; pp. 355–372. [Google Scholar] [CrossRef] [Green Version]
- Elidan, G. Copula Network Classifiers (CNCs). In Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, La Palma, Canary Islands, 21–23 April 2012; Volume 22, pp. 346–354. [Google Scholar]
- Tagasovska, N.; Ackerer, D.; Vatter, T. Copulas as High-Dimensional Generative Models: Vine Copula Autoencoders. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Wang, P.Z.; Wang, W.Y. Neural Gaussian Copula for Variational Autoencoder. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 4333–4343. [Google Scholar] [CrossRef]
- Zhao, Y.; Stasinakis, C.; Sermpinis, G.; Shi, Y. Neural network copula portfolio optimization for exchange traded funds. Quant. Financ. 2018, 18, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Sancetta, A.; Satchell, S. The Bernstein copula and its applications to modeling and approximations of multivariate distributions. Econ. Theory 2004, 20, 535–562. [Google Scholar] [CrossRef]
- Abdu, H.A. Classification accuracy and trend assessments of land cover- land use changes from principal components of land satellite images. Int. J. Remote Sens. 2019, 40, 1275–1300. [Google Scholar] [CrossRef]
- Imani, M.; Ghassemian, H. Principal component discriminant analysis for feature extraction and classification of hyperspectral images. In Proceedings of the 2014 Iranian Conference on Intelligent Systems (ICIS), Bam, Iran, 4–6 February 2014; pp. 1–5. [Google Scholar] [CrossRef]
- Deepa, P.; Thilagavathi, K. Feature extraction of hyperspectral image using principal component analysis and folded-principal component analysis. In Proceedings of the 2015 2nd International Conference on Electronics and Communication Systems (ICECS), Coimbatore, India, 26–27 February 2015; pp. 656–660. [Google Scholar] [CrossRef]
- Tanwar, S.; Ramani, T.; Tyagi, S. Dimensionality Reduction Using PCA and SVD in Big Data: A Comparative Case Study. In Proceedings of the International Conference on Future Internet Technologies and Trends, Surat, India, 31 August–2 September 2018. [Google Scholar] [CrossRef]
- Herries, G.; Selige, T.; Danaher, S. Singular value decomposition in applied remote sensing. In Proceedings of the IEE Colloquium on Image Processing for Remote Sensing, London, UK, 13 February 1996; pp. 5/1–5/6. [Google Scholar] [CrossRef]
- Alter, O.; Brown, P.O.; Botstein, D. Singular value decomposition for genome-wide expression data processing and modeling. Proc. Natl. Acad. Sci. USA 2000, 97, 10101–10106. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jayaprakash, C.; Damodaran, B.B.; Soman, K.V.S. Dimensionality Reduction of Hyperspectral Images for Classification using Randomized Independent Component Analysis. In Proceedings of the 2018 5th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 22–23 February 2018; pp. 492–496. [Google Scholar] [CrossRef]
- Wang, J.; Chang, C.I. Independent component analysis-based dimensionality reduction with applications in hyperspectral image analysis. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1586–1600. [Google Scholar] [CrossRef]
- Falini, A.; Castellano, G.; Tamborrino, C.; Mazzia, F.; Mininni, R.M.; Appice, A.; Malerba, D. Saliency Detection for Hyperspectral Images via Sparse-Non Negative-Matrix-Factorization and novel Distance Measures. In Proceedings of the 2020 IEEE Conference on Evolving and Adaptive Intelligent Systems, EAIS 2020, Bari, Italy, 27–29 May 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Appice, A.; Lomuscio, F.; Falini, A.; Tamborrino, C.; Mazzia, F.; Malerba, D. Saliency Detection in Hyperspectral Images Using Autoencoder-Based Data Reconstruction. In Proceedings of the Foundations of Intelligent Systems: 25th International Symposium, ISMIS 2020, Graz, Austria, 23–25 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 161–170. [Google Scholar] [CrossRef]
- Falini, A.; Tamborrino, C.; Castellano, G.; Mazzia, F.; Mininni, R.M.; Appice, A.; Malerba, D. Novel Reconstruction Errors for Saliency Detection in Hyperspectral Images. In Proceedings of the Sixth International Conference on Machine Learning, Optimization, and Data Science, LOD, Siena, Italy, 19–23 July 2020. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Durante, F.; Sempi, C. Principles of Copula Theory; Chapman and Hall/CRC: Boca Raton, FL, USA, 2015. [Google Scholar]
- Joe, H. Dependence Modeling with Copulas; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Wall, M.; Rechtsteiner, A.; Rocha, L. Singular Value Decomposition and Principal Component Analysis. In A Practical Approach to Microarray Data Analysis; Springer: Boston, MA, USA, 2002; Volume 5. [Google Scholar] [CrossRef] [Green Version]
- Brunton, S.L.; Kutz, J.N. Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control; Cambridge University Press: Cambridge, MA, USA, 2019; pp. 3–46. [Google Scholar] [CrossRef] [Green Version]
- Eckart, C.; Young, G. The approximation of one matrix by another of lower rank. Psychometrika 1936, 1, 211–218. [Google Scholar] [CrossRef]
- Salinas Gutiérrez, R.; Hernandez-Aguirre, A.; Villa Diharce, E. Copula selection for graphical models in continuous Estimation of Distribution Algorithms. Comput. Stat. 2014, 29, 685–713. [Google Scholar] [CrossRef]
- Salinas Gutiérrez, R.; Hernandez-Aguirre, A.; Villa Diharce, E. Dependence trees with copula selection for continuous estimation of distribution algorithms. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO’11, Dublin, Ireland, 12–16 July 2011; pp. 585–592. [Google Scholar] [CrossRef]
- Salinas Gutiérrez, R.; Hernandez-Aguirre, A.; Villa Diharce, E. Estimation of distribution algorithms based on copula functions. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO’11, Dublin, Ireland, 12–16 July 2011; pp. 795–798. [Google Scholar] [CrossRef]
- Joe, H.; Xu, J.J. The Estimation Method of Inference Functions for Margins for Multivariate Models; Faculty Research and Publications: Vancouver, BC, Canada, 1996. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley: New York, NY, USA, 2001. [Google Scholar]
- Oakes, D. Semiparametric inference in a model for association in bivariate survival data. Biometrika 1986, 73, 353–361. [Google Scholar] [CrossRef]
- Chen, X.; Fan, Y. Estimation of copula-based semiparametric time series models. J. Econ. 2006, 130, 307–335. [Google Scholar] [CrossRef] [Green Version]
- Bouezmarni, T.; Rombouts, J.V. Semiparametric multivariate density estimation for positive data using copulas. Comput. Stat. Data Anal. 2009, 53, 2040–2054. [Google Scholar] [CrossRef] [Green Version]
- Deheuvels, P. La fonction de dépendance empirique et ses propriétés. Un test non paramétrique d’indépendance. Bull. L’Académie R. Belg. 1979, 65, 274–292. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remarks on Some Nonparametric Estimates of a Density Function. Ann. Math. Stat. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Botev, Z.; Grotowski, J.; Kroese, D. Kernel Density Estimation via Diffusion. Ann. Stat. 2010, 38, 2916–2957. [Google Scholar] [CrossRef] [Green Version]
- Hagolle, O.; Huc, M.; Villa Pascual, D.; Dedieu, G. A Multi-Temporal and Multi-Spectral Method to Estimate Aerosol Optical Thickness over Land, for the Atmospheric Correction of FormoSat-2, LandSat, VENμS and Sentinel-2 Images. Remote Sens. 2015, 7, 2668–2691. [Google Scholar] [CrossRef] [Green Version]
- Lebourgeois, V.; Dupuy, S.; Vintrou, E.; Ameline, M.; Butler, S.; Béguè, A. A Combined Random Forest and OBIA Classification Scheme for Mapping Smallholder Agriculture at Different Nomenclature Levels Using Multisource Data (Simulated Sentinel-2 Time Series, VHRS and DEM). Remote Sens. 2017, 9, 259. [Google Scholar] [CrossRef] [Green Version]
- Dupuy, S.; Gaetano, R.; Le Mézo, L. Mapping land cover on Reunion Island in 2017 using satellite imagery and geospatial ground data. Data Brief. 2020, 28, 104934. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcastinghe. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Falini, A.; Mazzia, F.; Tamborrino, C. Spline based Hermite quasi interpolation for univariate time series. Discret. Contin. Dyn. Syst. S 2022. [Google Scholar] [CrossRef]
- Czado, C.; Nagler, T. Vine Copula Based Modeling. Annu. Rev. Stat. Appl. 2022, 9, 453–477. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Label | #Objects | #Pixels |
|---|---|---|---|
| 1 | Crop cultivations | 380 | 12,090 |
| 2 | Sugar cane | 496 | 84,136 |
| 3 | Orchards | 299 | 15,477 |
| 4 | Forest plantations | 67 | 9783 |
| 5 | Meadow | 257 | 50,596 |
| 6 | Forest | 292 | 55,108 |
| 7 | Shrubby savannah | 371 | 20,287 |
| 8 | Herbaceous savannah | 78 | 5978 |
| 9 | Bare rocks | 107 | 18,659 |
| 10 | Urbanized areas | 125 | 36,178 |
| 11 | Greenhouse crops | 50 | 1877 |
| 12 | Water surfaces | 96 | 7349 |
| 13 | Shadows | 38 | 5230 |
| Method | 1—Crop cultivations | 2—Sugar cane | 3—Orchards | 4—Forest Plantations | 5—Meadow | 6—Forest | 7—Shrubby savannah |
| RF | 61.67% | 91.94% | 70.12% | 65.63% | 83.10% | 85.91% | 73.23% |
| LSTM | 42.68% | 88.20% | 64.20% | 53.56% | 76.51% | 79.51% | 59.01% |
| ConvLSTM | 49.07% | 89.86% | 66.78% | 67.07% | 79.37% | 84.18% | 64.55% |
| DuPLO | 62.36% | 92.09% | 73.24% | 70.40% | 82.88% | 84.59% | 70.29% |
| RF(DuPLO) | 65.72% | 92.98% | 75.39% | 73.22% | 85.40% | 87.30% | 75.76% |
| CopCLF | 78.59% | 94.25% | 69.88% | 69.56% | 91.98% | 89.17% | 83.67% |
| Method | 8—Herbaceous savannah | 9—Bare rocks | 10—Urbanized areas | 11—Greenhouse crops | 12—Water surfaces | 13—Shadows | |
| RF | 67.47% | 73.96% | 82.98% | 10.87% | 92.53% | 88.40% | |
| LSTM | 60.53% | 70.86% | 81.61% | 18.23% | 92.16% | 86.55% | |
| ConvLSTM | 65.05% | 74.99% | 86.73% | 37.74% | 91.71% | 89.61% | |
| DuPLO | 63.40% | 82.02% | 90.47% | 40.31% | 93.26% | 90.76% | |
| RF(DuPLO) | 67.97% | 86.32% | 92.05% | 43.88% | 93.87% | 90.29% | |
| CopCLF | 78.19% | 90.15% | 91.88% | 62.82% | 95.80% | 95.26% |
| Accuracy | F-Measure | Kappa | |
|---|---|---|---|
| RF | 82.99% ± 1.04% | 82.40% ± 1.09% | 0.7989 ± 0.0119 |
| LSTM | 76.66% ± 1.21% | 76.57% ± 1.11% | 0.7260 ± 0.0140 |
| ConvLSTM | 80.35% ± 1.12% | 80.32% ± 1.10% | 0.7697 ± 0.0124 |
| DuPLO | 83.72% ± 1.08% | 83.73% ± 1.03% | 0.8089 ± 0.0122 |
| RF(DuPLO) | 86.12% ± 1.21% | 86.00% ± 1.24% | 0.8366 ± 0.0143 |
| CopCLF | 87.13% ± 0.13 % | 86.92% ± 0.13% | 0.8548 ± 0.0015 |
| CopCLF Time Efficiency Analysis | |||
|---|---|---|---|
| SVD Stage | Learning Stage | Predictive Stage | Total Time |
| 5.674 | 4.823 | 285.819 | 296.316 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tamborrino, C.; Interdonato, R.; Teisseire, M. Sentinel-2 Satellite Image Time-Series Land Cover Classification with Bernstein Copula Approach. Remote Sens. 2022, 14, 3080. https://doi.org/10.3390/rs14133080
Tamborrino C, Interdonato R, Teisseire M. Sentinel-2 Satellite Image Time-Series Land Cover Classification with Bernstein Copula Approach. Remote Sensing. 2022; 14(13):3080. https://doi.org/10.3390/rs14133080
Chicago/Turabian StyleTamborrino, Cristiano, Roberto Interdonato, and Maguelonne Teisseire. 2022. "Sentinel-2 Satellite Image Time-Series Land Cover Classification with Bernstein Copula Approach" Remote Sensing 14, no. 13: 3080. https://doi.org/10.3390/rs14133080
APA StyleTamborrino, C., Interdonato, R., & Teisseire, M. (2022). Sentinel-2 Satellite Image Time-Series Land Cover Classification with Bernstein Copula Approach. Remote Sensing, 14(13), 3080. https://doi.org/10.3390/rs14133080