1. Introduction
The Magnetotelluric (MT) method, as a remote sensing tool for the subsurface, has been widely applied in geophysical prospecting scenarios, such as crust imaging, geothermal exploration, and mineral, oil and gas exploration. This method images the subsurface structures by inverting the collected natural geomagnetic and geoelectric fields at the Earth’s surface [
1,
2]. Because inversion plays a critical role in the accurate estimation of subsurface properties, it has been well studied by exploration geophysicists in the past few decades. In general, mainstream MT inversion methods can be categorized into two groups: deterministic and statistical inversion methods. The former, based on linearization theory, such as Occam [
3,
4], nonlinear conjugate gradient [
5,
6] and Gauss–Newton [
7,
8] methods, iteratively solves a nonlinear optimization problem by minimizing a so-called objective function (the data residual/misfit between the actual measurements and synthetic responses in a
norm). The deterministic methods are efficient to search for the best earth model, but usually suffer from the local optima problem and are sensitive to the initial model. The statistical methods [
9,
10,
11] convey the posterior probability distributions of parameters by conditioning the model response on the measurements and providing an assessment of non-uniqueness. These methods do not require linearizing the inverse problem, and thus they are particularly desirable for highly nonlinear problems. However, they often perform hundreds of forward simulations, which are extremely time-consuming and demand extensive process power for large surveys. Along with all these challenges, the aforementioned methods need to repeat the entire inversion process for each new measurement dataset, which can be computationally intensive.
In recent years, using deep learning (DL) techniques to solve inverse problems has been a topic of growing interest. In the DL inversion scheme, the basic idea is to train a deep neural network (DNN) to approximate the inverse operator
. DL has a strong ability to build complex nonlinear mapping from data (input) to models (output) without involving linearization theory. Although the training process of a DNN may be time-consuming, once the network is properly trained, it possesses extremely high inversion efficiency, which is significantly convenient and practical for large surveys. For example, Araya-Polo et al. [
12] used a DNN to produce accurate tomography inversion. Das et al. [
13] proposed a framework based on a convolutional neural network (CNN) to realize seismic impedance inversion successfully. Puzyrev [
14] demonstrated that a CNN can be trained to realize onshore carbon dioxide reservoir imaging using controlled source electromagnetic (CSEM) data. Bai et al. [
15] realized instantaneous inversion of airborne time-domain electromagnetic data via DNN. Wu et al. [
16] performed one-dimensional (1D) DL inversion for airborne transient electromagnetic data using CNN. For MT inversion, Wang et al. [
17] developed a DL inversion strategy based on a deep belief network for MT resistivity imaging. Liu et al. [
18] applied a deep residual CNN for audio magnetotelluric (AMT) 1D inversion. However, the aforementioned DL-based inversion approaches are fully data-driven and thus the network performance largely depends on the training dataset. A fully data-driven DL framework trained on an insufficient training dataset may not be able to accurately reconstruct the nonlinear mapping between the data and models. In other words, it cannot completely honor the physical laws of the inverse problem (e.g., electromagnetic wave propagation). These purely data-driven DL approaches require massive representative training sets to build robust networks and ensure good generalization capability. Nevertheless, supplying such large and rich data sets could be challenging. Due to the heavy burden of time and computational power, it is difficult to build a set of complex synthetic models (e.g., resistivity models) and generate the corresponding forwarding responses for generic realistic exploration scenarios, and perform training. This in turn may make DL inversion methods less appealing compared to conventional deterministic inversion.
A very recent trend is to impose the physics into the DL inversion scheme to control the network training process. For instance, Adler and Oktem [
19] performed conventional iterative inversion using a well-trained CNN to adjust the gradients produced by the gradient-descent algorithm for each successive iteration. Raissi et al. [
20] employed the physics constraint as a regularization term and added it to the loss objective function. Fuks and Tchelepi [
21] embedded the initial and boundary conditions in a composite loss function and performed training on smaller datasets. Colombo et al. [
22] incorporated DL techniques into standard deterministic inversion schemes to obtain better, more stable and unique transient electromagnetic (TEM) inversion results. Inspired by the conventional inversion considering the governing wave equation, some other works incorporated the physical laws of the inverse problem into the DL inversion architecture. For example, Sun et al. [
23] constructed an RNN-based forward operator
to emulate wave propagation and implemented unsupervised DL seismic inversion, of which the training process is equivalent to the optimization of conventional deterministic inversion methods. Wang et al. [
24] developed a closed-loop framework based on 1D CNN to model the seismic inversion and forward process simultaneously, and the forward process is responsible for providing theoretical constraints for the inversion process. In this way, the incorporation of physics could not only lead to a more reasonable and stable updating direction of parameters but also reduce the dependency on an exhaustive training dataset.
In this work, the physical laws of MT wave propagation are incorporated into the purely data-driven approach and a physics-driven DL MT inversion scheme is constructed. In this scheme, the MT forward operator simulating wave propagation is imposed into the DL inversion architecture to help guide the network training by constructing a hybrid loss function composed of the data-driven model misfit and physics-based data misfit. The model misfit is the difference between the true models to the predicted models. The data misfit is the difference between the measurements (input) and the forward responses calculated by from the predicted models. In fact, the conventional deterministic inversion methods rely on the and usually adopt the data misfit (or plus regularization term) as the objective function to guide its search for the optimal solution. Therefore, the proposed physics-driven DL inversion approach will benefit from both the fully data-driven DL and deterministic methods, enabling it to reduce the dependency on extensive training sets and to have the ability to deal with complex realistic exploration scenarios. To our best knowledge, the MT inversion using such a physics-driven DL inversion scheme has not been reported in the literature. This novel DL inversion method is demonstrated in both synthetic and field MT cases, and it is expected to have promising application effects.
2. Methodology
2.1. Problem Statement
The MT method is used to reflect the subsurface geological structures by imaging the spatial variation of the resistivity (or the equivalent conductivity) of the underground medium. Since 3D MT forward modeling is a heavy burden of computational cost, it is significant and practical to adopt 1D parameterization modeling and inversion in fieldwork for instantaneous data interpretation and decision-making. It is common to stitch the 1D inversion results together to form a pseudo-2D (or pseudo-3D) subsurface image. Moreover, 1D inversion results delivering horizontally layered models of resistivity versus depth can provide a fundamental understanding of the subsurface structure for the survey area in advance and then facilitate moving on to realistic 3D problems.
From the viewpoint of mathematics, two crucial MT problems illustrated in
Figure 1 are introduced below.
Forward problem: Given a known geoelectric model (which, in our paper, is represented by the vector
for the resistivity distribution of the medium), the MT forward modeling delivers the electric and magnetic fields, namely simulated MT responses (in our case, the derived apparent resistivity and phase are employed and denoted as a vector
) at stations. The forward problem can then be expressed as follows:
where
is the forward operator based on Maxwell’s equations governing the electromagnetic wave propagation phenomena. It is composed of an operator to calculate the analytical electromagnetic responses and an operator to compute the apparent resistivities and phases from the electric field and magnetic fields.
Inverse problem: Given a group of measurements
(real MT responses) acquired at stations, the inverse problem can be formulated as an optimization problem aimed at finding the optimal model
that matches the measurements
. This can be described by the following expressions:
where
denotes the generalized inverse operation of the forward operation
.
In the conventional deterministic inversion process, an optimization method is employed to iteratively improve the estimated geoelectric model until the difference between the measurements and the simulated MT responses from meets the misfit tolerance. In the presented work, it is intended to approximate the inverse function using a physics-driven DL approach. When training is well conducted, the network can be regarded as a generalized function that directly maps the input (apparent resistivity and phase) to the output (resistivity model), and the process of inversion can be carried out to instantly predict the subsurface property distribution.
2.2. Network Architecture
The DL inversion workflow is comprised of three steps, namely sample data generation, network designing and training, and network prediction. These three steps jointly determine the performance of the DL inversion. Hence, it is of significance to build a reliable and efficient DNN model.
The built DNN model in this work combines the prevalently used U-Net [
25] and residual network (ResNet) [
26] architectures. The U-Net is based on a fully CNN [
27] and consists of an encoder (or down-sampling) and a decoder (or up-sampling) part, and is well-known for its skip connection operation, which concatenates the low-level feature from the shallow layer (encoder part) to the high-level feature from the deep layer (decoder part). It, together with convolution and deconvolution, enables the U-Net to have better localization and feature representation capabilities and allows fewer training samples, compared to other fully CNNs. The ResNet is built on the concept of shortcut connection and can overcome the gradient vanishing and network degradation problems when the network depth considerably increases.
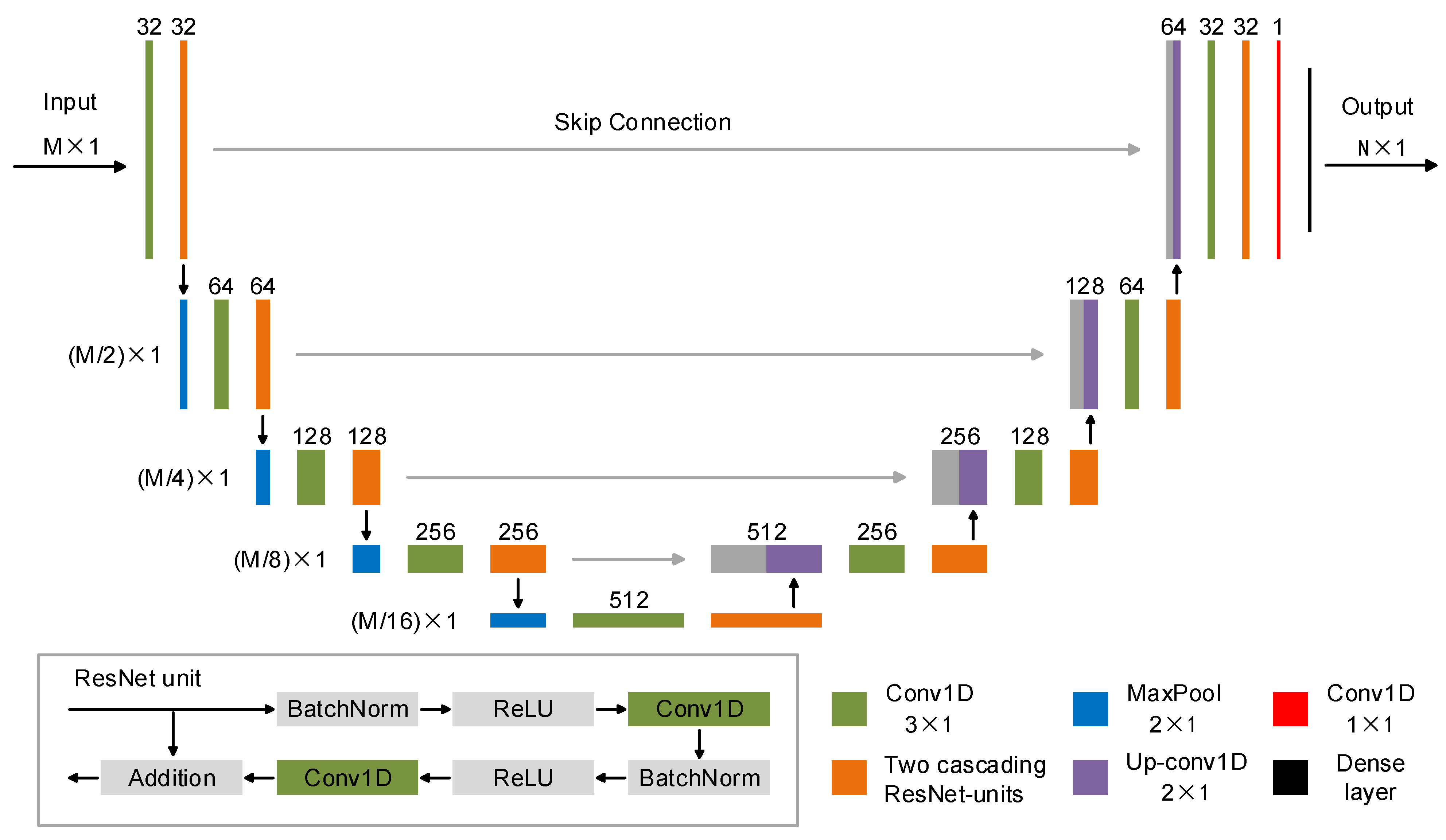
As illustrated in
Figure 2, to adapt to our 1D MT inverse regression problem, a Unet-like 1D CNN model (1DUResNet) is designed and built by embedding the ResNet unit into the U-Net architecture. The encoder path on the left side consists of four down-sampling blocks. In every block, each repeated convolutional layer (3 × 1 kernel, 1 stride, ‘SAME’ padding) is followed by two cascading ResNet units (3 × 1 kernel, 1 stride, ‘SAME’ padding) and a max-pooling operation (2 × 2 kernel, 2 stride). The number of feature channels increases from 32 to 512. The decoder path on the right side consists of four up-sampling blocks. Each block is composed of a deconvolution operation (3 × 1 kernel, 2 stride, ‘SAME’ padding) and a concatenation operation of low-level and high-level features, followed by a convolutional layer and two cascading ResNet units. In the last block, a convolutional layer (1 × 1 kernel, 1 stride, 1 channel, ‘SAME’ padding) and a dense layer (50 neurons) are added to adjust the network output to match the desired output. The input and output sizes are 128 × 1 and 50 × 1, respectively. In order to reduce overfitting and improve generalization ability, the dropout operation (0.1 ratio) after the max-pooling operation is applied in the encoder part and the concatenation operation in the decoder part, to regulate the learning process.
2.3. Physics-Driven DL Inversion Scheme
Most DL-based methods for solving MT inverse problems are fully data-driven. These methods take the model misfit
that measures the difference between the true models
and the predicted models
as the loss objective function
:
where
is the number of sample pairs
involved in training,
is the number of model parameters,
is the measurements, and
is the feed-forward network parameterized by
. During the training process, the network performs the learning by minimizing the loss function
, (written as):
Once the network is well trained, the feed-forward network can be used as an inverse operator, , to produce predictions, , from a new set of measurements, .
Though a fully data-driven DL approach can be a powerful tool to solve the MT inverse problem, it requires an exhaustive synthetic training dataset related to the exploration scenario to build robust networks and ensure good generalization ability. Unlike the purely data-driven DL methods, a physics-driven DL inversion scheme by integrating the 1D forward operation
modeling MT wave propagation into the DNN training loop is proposed in this work. As shown in
Figure 3, in this scheme, the loss objective function is a weighted sum of model misfit
and physics-based data misfit
. The data misfit
measures the difference between the measurements
and the simulated MT responses
calculated by
from the predicted models
, defined as:
where
is the number of measurement parameters. Then, the loss objective function
controlling the network training is as follows:
where the weighted parameters
,
are used to balance the relative contributions of the two misfit terms and are both set to 0.5 in our work.
Unlike other MT DL inversion works [
17,
18] which used the apparent resistivity as network input alone, both the apparent resistivity and phase derived from measurements are employed for inversion. Liu et al. [
17] have demonstrated that the network performance is worse using the concatenation of apparent resistivity and phase than individual apparent resistivity as input, due to the significant difference between the apparent resistivity (usually covers several orders of magnitude) and the phase (between 0 and 90). Hence, a multi-head DNN is constructed as shown in
Figure 3, which consists of two individual network paths based on 1DUResNet with each using apparent resistivity and phase as input, respectively. Then the outputs of two paths are transferred to the scaling layer after the concatenation operation. The scaling layer serves as the prior knowledge to constrain the predictions to a proper value range and is defined as:
where
denotes the scaling layer parameterized by
,
is the preceding concatenation result,
,
represent the predetermined upper and lower bounds of predictions, respectively.
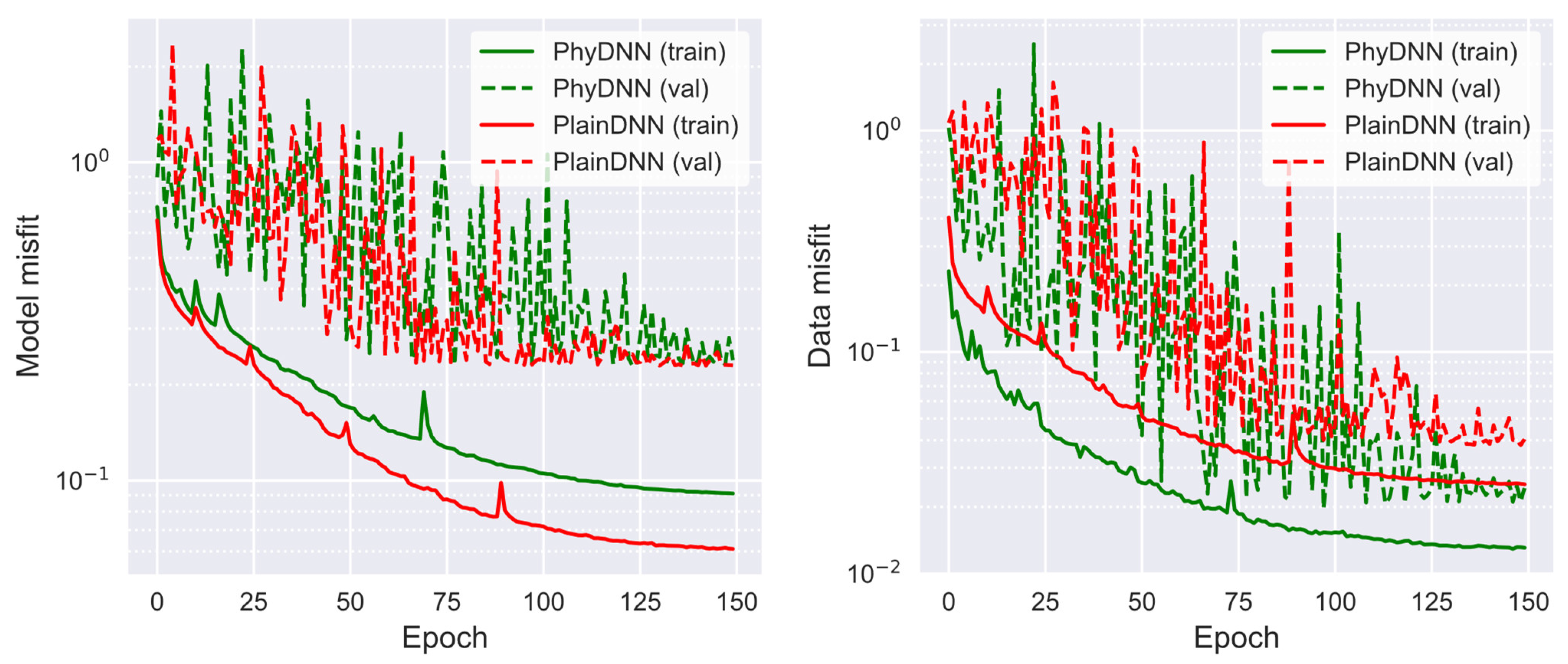
Compared to the purely data-driven DL (PlainDNN), the proposed physics-driven DL (PhyDNN) scheme will reduce the dependency on exhaustive training sets and produce more accurate, stable and reliable inversion results. During the DL training, the early-stopping technique with a patience of 50 (total epochs of 150 in our following work) is used to avoid overfitting the training data. The popular Adam optimization algorithm is employed to minimize the loss objective function with a batch size of 128. In order to accelerate the convergence and prevent the DNN from falling into local optima prematurely, a dynamic learning rate scheme that the learning rate will decrease by a factor of 0.8 if the loss on the validation sets fails to reduce or remains constant for five consecutive epochs is adopted. The implementation is based on TensorFlow using a desktop (system: Intel(R) Core (TM) i7-9700 CPU @ 3.00GHz, 16.9 GB RAM. GPU: GeForce RTX3060 with 8G VRAM).
2.4. Sample Data Generation
Sample data generation is a key step of DL-based inversion methods. Though the generation of 1D MT data typically does not pose significant problems because of the low number of model parameters and the availability of analytical solutions, it could be time-consuming to perform network training using an extremely massive dataset. Hence, it is necessary to construct a reasonable-sized and high-quality sample dataset. In the presented work, the number and thickness of layers for all synthetic resistivity models are fixed. The number of layers is set to 50 and the bottom depth of the models is 50 km. The thickness of layers is set following Krieger and Peacock [
28], with 44 layers within the 10 km target depth and five extended layers between the target depth and bottom depth. The deepest layer that is below 50 km is a uniform half-space whose thickness is infinite.
A popular method adopted by most 1D DL inversions in electromagnetic exploration is to generate a set of layered geoelectric models with smooth resistivity using spline interpolation methods. Nonetheless, the actual subsurface geoelectric structures are usually complex, and the resistivity values of layers may not be strictly smooth and gradual-changing. Hence, a novel method, that randomly adds perturbations of different amplitudes to the general smooth resistivity models is proposed to generate fine resistivity model samples that could better delineate the realistic subsurface structures. The specific steps are the following:
- (a)
Select eleven layers from layer one to layer fifty evenly, and randomly assign the resistivity values ranging from 1 to 10,000 Ωm in the form of a logarithm to the eleven layers.
- (b)
Calculate the resistivity values of the remaining layers by the cubic spline interpolation method, and thus obtain the smooth resistivity model .
- (c)
Use the following equations to add perturbations to the smooth resistivity model , and thus obtain the perturbed resistivity model :
where
with the same dimension as
returns random floats in the half-open interval [0, 1).
- (d)
Apply 1D interpolating spline to to slightly smooth the perturbations.
- (e)
Replace the resistivity values outside the predetermined range with the upper and lower bounds, and finally, obtain the fine resistivity model .
Figure 4 shows three representative comparison examples of the general smooth and our proposed fine resistivity models. The fine resistivity models are all evolved from the smooth resistivity models. It can be clearly seen that the proposed fine resistivity model set not only includes models that are noticeably not strictly smooth and gradual-changing but also contains models that are similar and close to the smooth models because the added perturbations are extremely small. Compared with the smooth model set, the proposed fine model set is expected to delineate the realistic subsurface geoelectric structures.
When the resistivity model set is built, the corresponding MT forward responses are then calculated with a total number of 56 frequencies ranging from 0.001 Hz to 1000 Hz. Herein, a dataset composed of 50,000 samples, of which each sample represents one response-model pair, is constructed for network training. In the DNN training stage, 40,000 samples are used as the training sets and the remaining act as the validation sets, which corresponds to an 80/20 split. The apparent resistivity and phase values derived from the MT forward responses are used as the input and the corresponding resistivity models serve as the desired output. Since the input size of the proposed 1DUResNet is 128 × 1, both the apparent resistivity and phase of 128 × 1 size are obtained by applying the linear interpolation method to the original apparent resistivity and phase of 56 × 1 size. The input and desired output data are standardized following:
where
and
denote the mean and standard deviation values on the corresponding training dataset.
5. Discussion and Conclusions
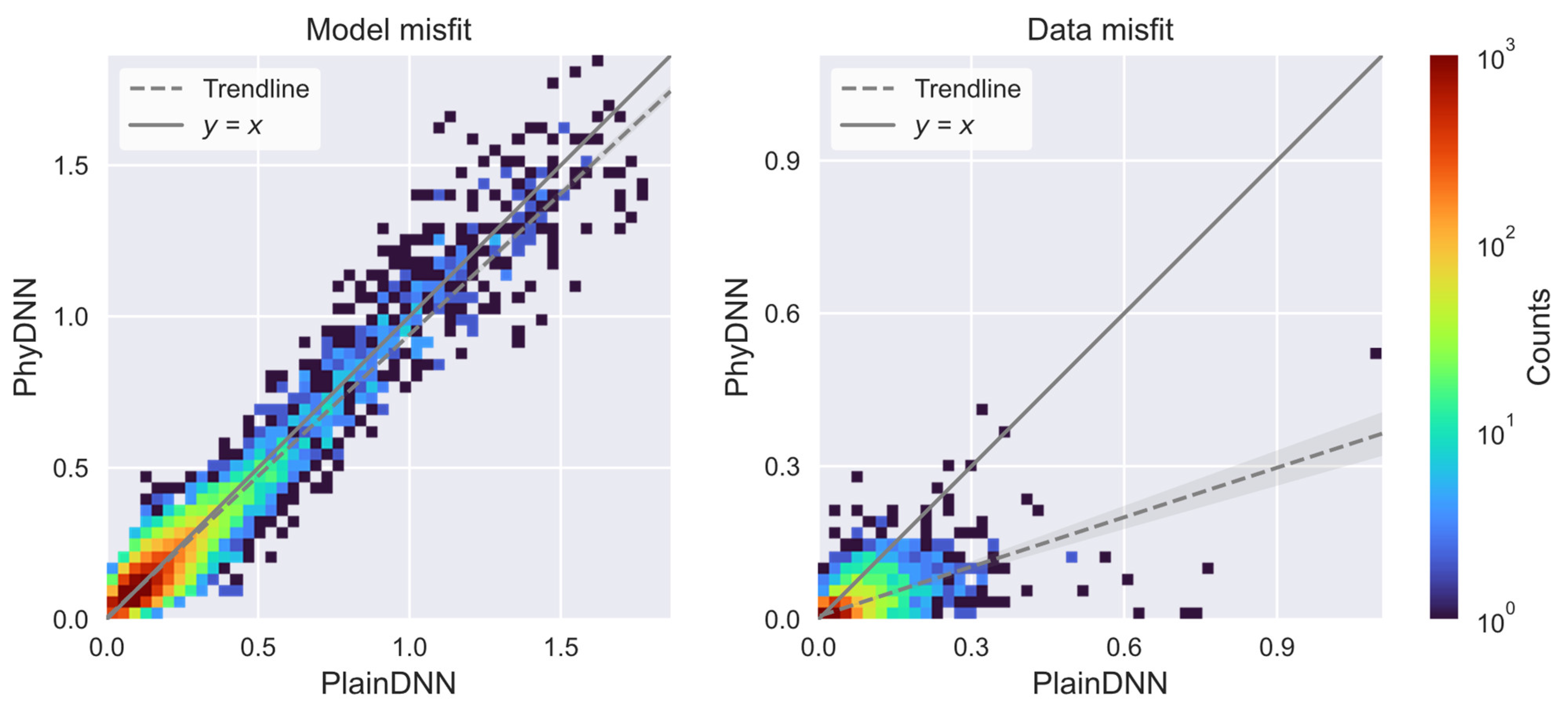
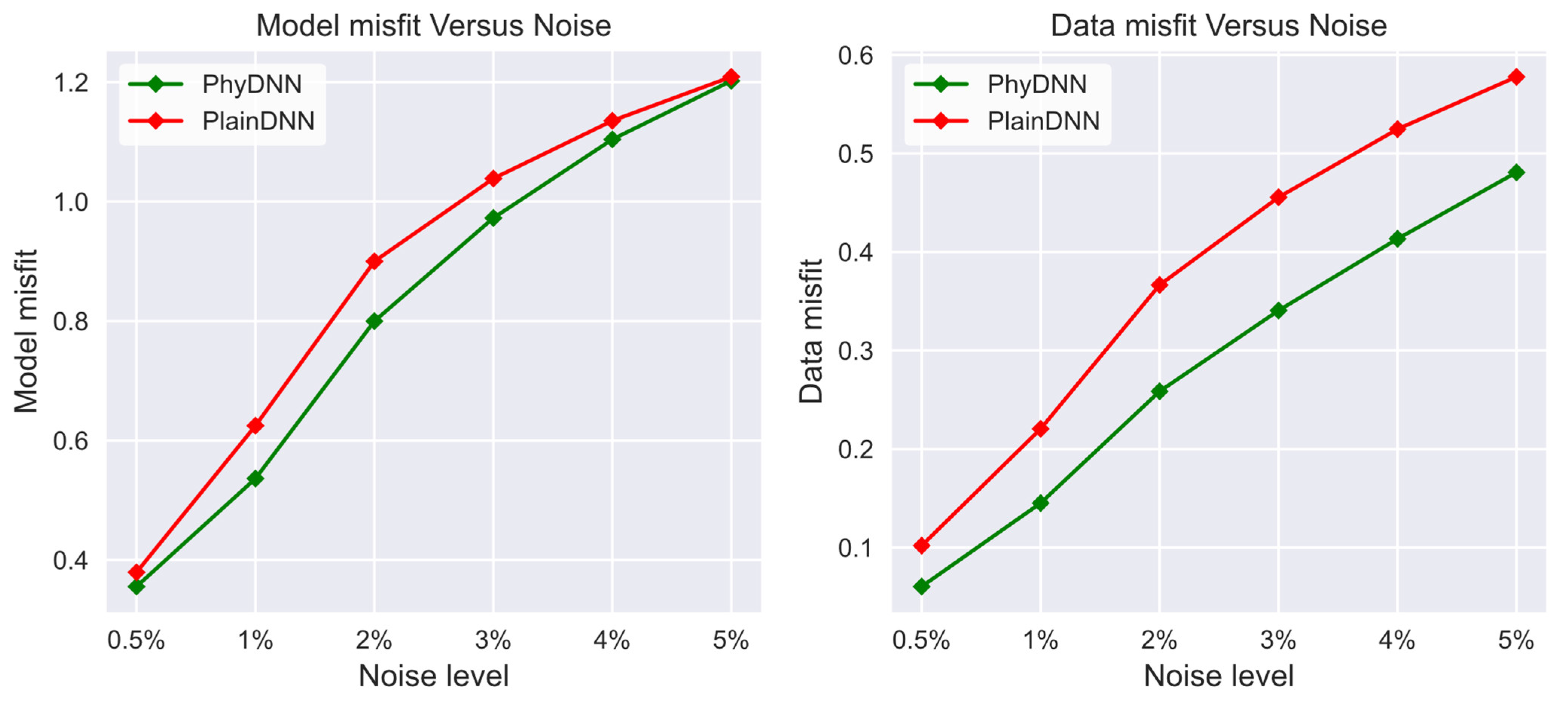
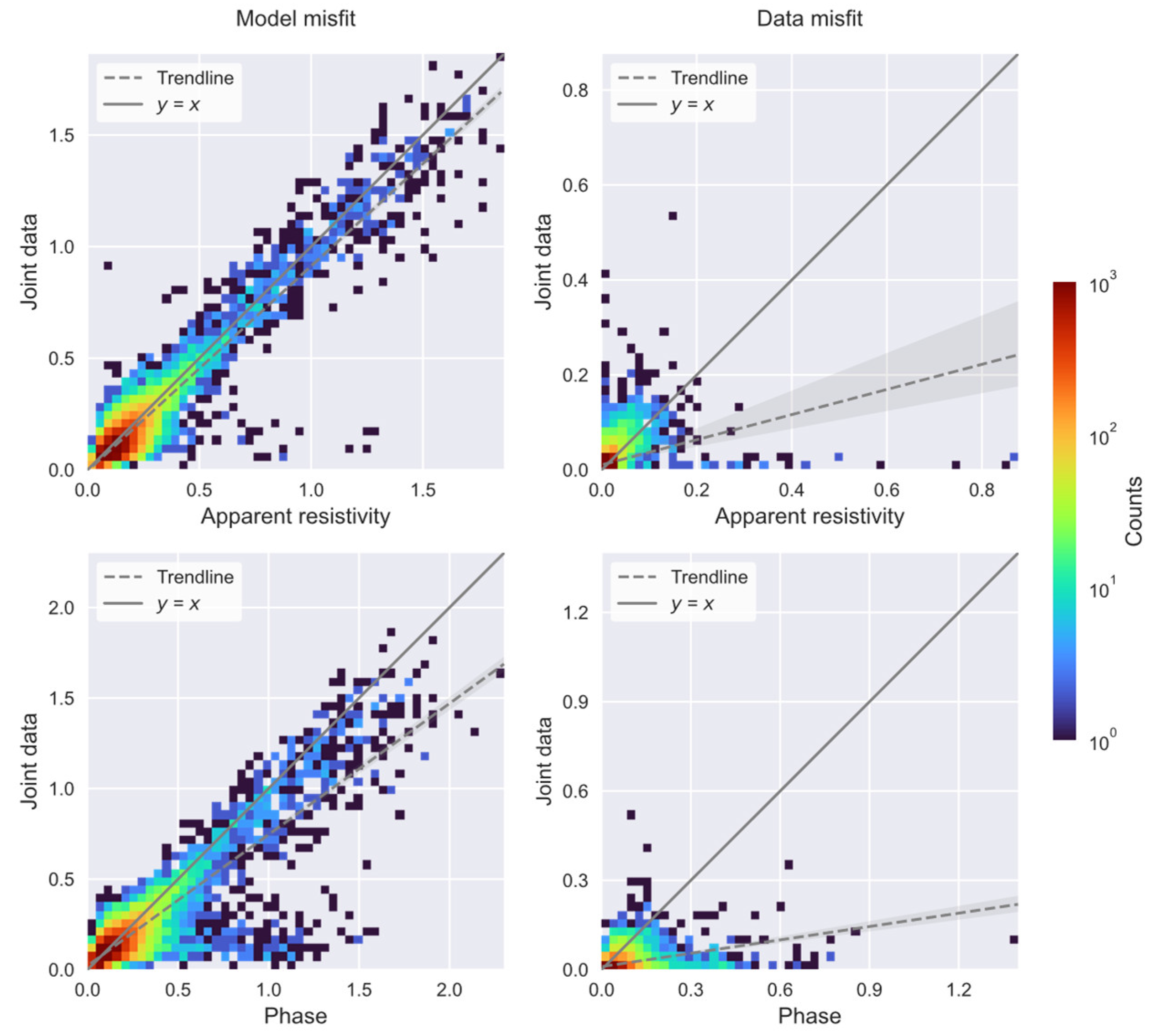
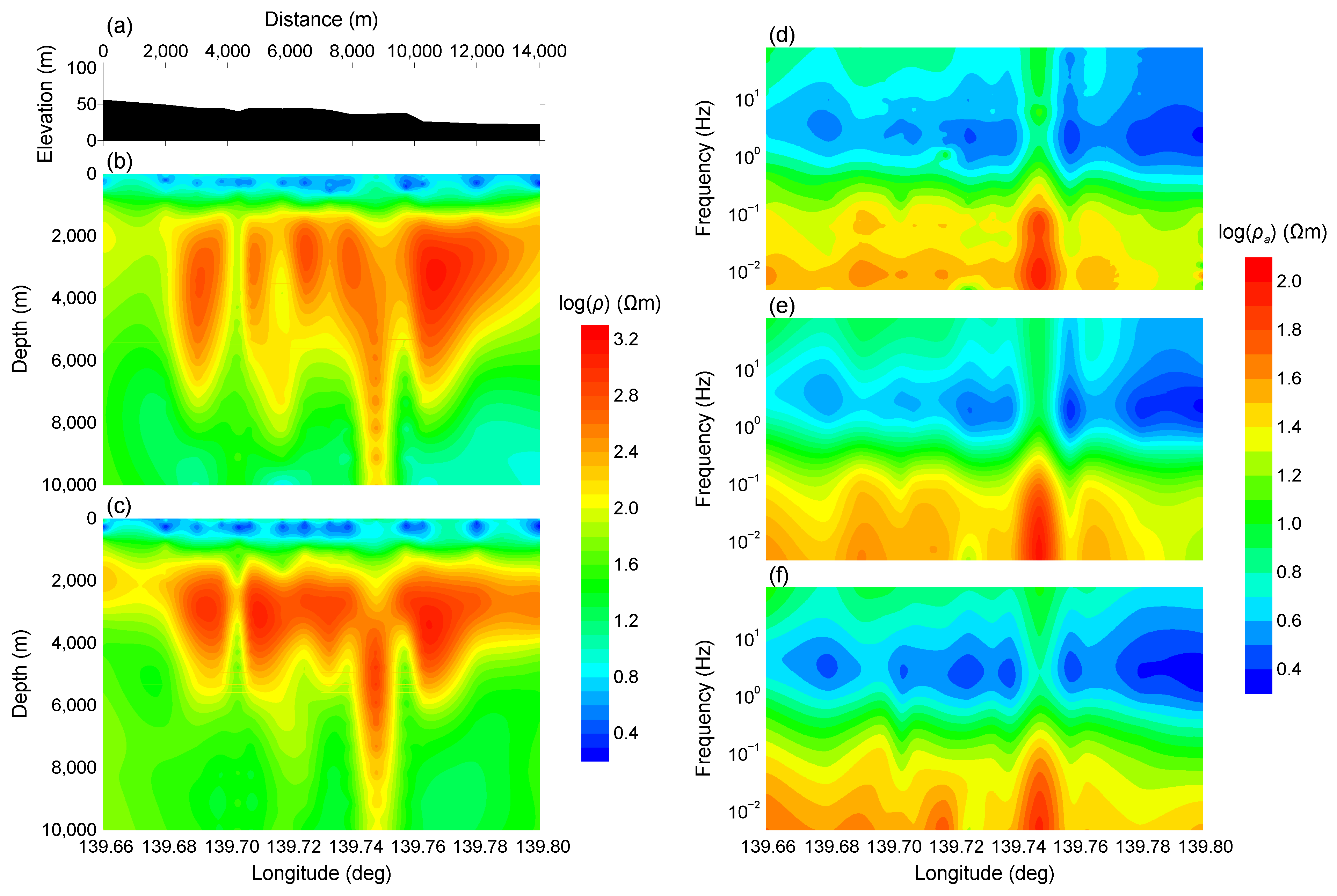
This work proposes a novel physics-driven DL-based MT inversion method (named PhyDNN), which embeds the forward operator modeling MT wave propagation into the network architecture in the form of using the weighted sum of model misfit and physics-based data misfit as the loss objective function to guide the network training. Consequently, the proposed PhyDNN can take advantage of the fully data-driven DL and deterministic methods, thus reducing the dependency on extensive training sets and having the ability to deal with complex realistic exploration scenarios. It is demonstrated that the PhyDNN can honor the physical laws of the MT inverse problem and accurately reconstruct the nonlinear mapping from the input (apparent resistivity and phase) to the output (resistivity model). Quantitative and qualitative analysis results show that the PhyDNN inversion outperforms the PlainDNN inversion in model misfit and particularly in physics-based data misfit and that the former is more robust and can yield more reliable inversion results when dealing with noisy measurements. Compared with the classical deterministic Occam inversion method, the built DL-based inversion methods, particularly the proposed PhyDNN, perform better in retrieving the resistivity values and delineating the resistivity distribution. To further verify the feasibility and applicability of PhyDNN, a comparison inversion for field data between the PhyDNN and Occam methods is implemented. The PhyDNN inversion results are quite compatible with the Occam method, and the corresponding simulated MT responses are in good agreement with the actual measurements. Moreover, compared with the conventional deterministic method, the DL-based method can realize instantaneous inversion without any iterations once the network is well-trained in advance, which is particularly desirable for large-scale measurements and practical for instant decision-making in fieldwork. In addition, the fine resistivity models generated by the proposed novel method could better delineate the real-world subsurface structure compared to the commonly-used smooth resistivity models, which facilitates the DL inversion for complex subsurface structures whose resistivities appear to fluctuate. This model construction method could be applied to other existing geophysical techniques for solving 1D inverse problems.
The proposed physics-driven DL inversion strategy can be extended to 2D and 3D MT inverse problems. However, unless sufficient computational power is available, it is extremely difficult or impossible to perform (the number of samples involved in training) times 2D (or 3D) MT forwarding in every training loop. Hence, how to reasonably introduce the 2D (or 3D) forward operator simulating the MT wave propagation into the network architecture to improve MT inversion is a challenging problem and will be our future work.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}