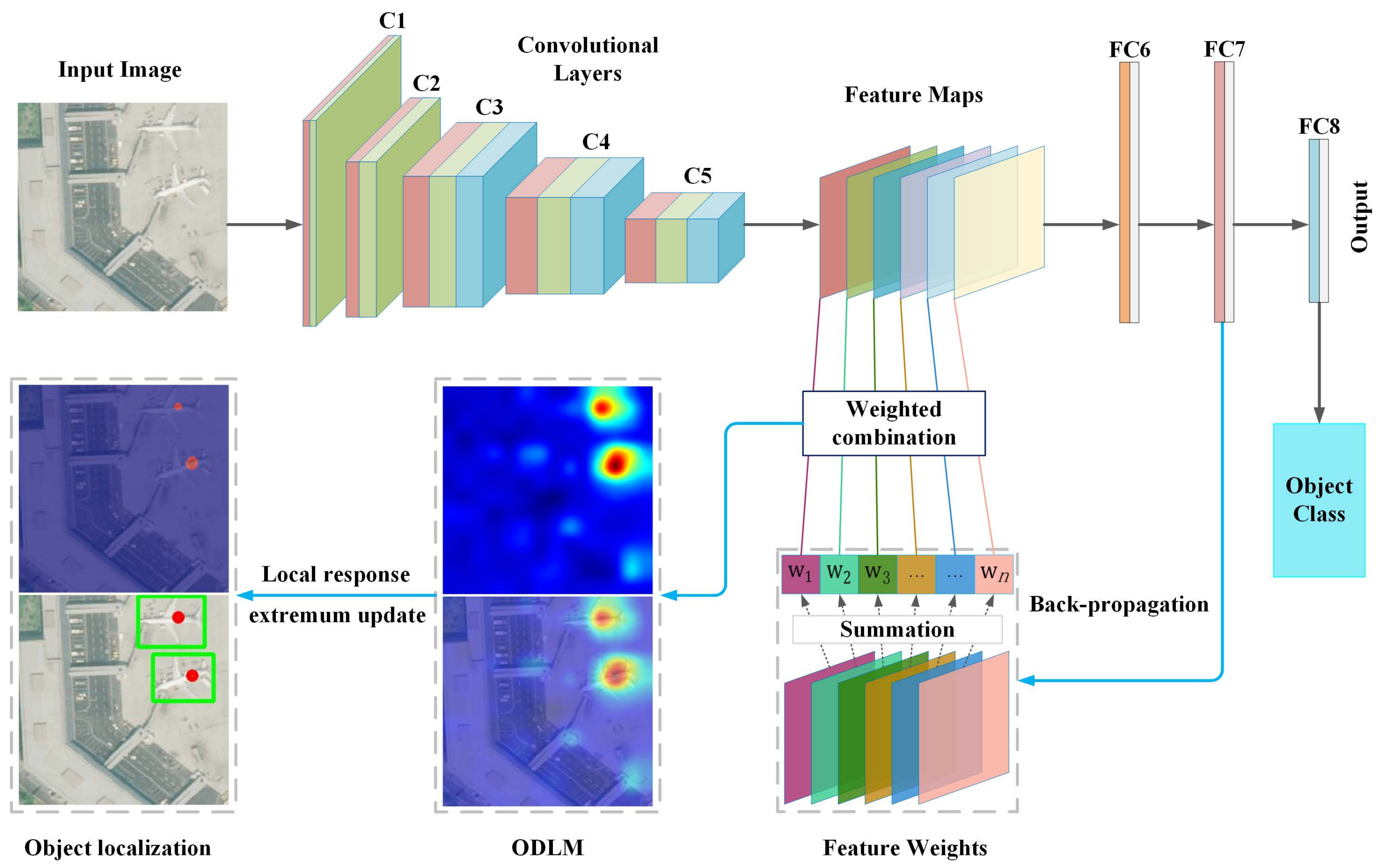
In this section, we evaluate the object localization performance based on the proposed framework. Generally, our proposed framework produces an ODLM by combining features from the convolutional and fully connected layers of a DCNN framework. When the feature from the last convolutional layer of AlexNet or VGG-16 is typically down-sampled by a pooling layer, the vector feature from the penultimate fully connected layer is typically extracted as an image feature presentation, and the vector feature from the last fully connected layer can be regarded as a class discriminative feature in a CNN model. Based on this understanding, we combine different fully connected layers with the last pooling or convolutional layer to generate the corresponding ODLMs. The resulting comparisons based on these foundations are then conducted to explore the localization performance.
4.2.1. Precision and Recall Evaluation
As introduced in
Section 3, our proposed object localization method is closely related to the threshold parameter
t. In general, the threshold parameter
t is set to be 0.50, and the corresponding aircraft and oiltank localization results evaluated by the precision (
P) and recall (
R) are shown in
Table 1 and
Table 2, respectively. For convenience, we use “AF#C” to represent the localization results obtained by the
ODLM when spreading the #-th fully connected layer feature to the last convolutional layer based on the AlexNet framework. Similarly, we use “AF#P” to represent the localization results obtained by the
ODLM when spreading the #-th fully connected layer feature to the last pooling layer based on the AlexNet framework.
As shown in
Table 1, AF8C achieves the best localization performance for the aircraft objects. However, the localization precision is as low as 32.02%, even the corresponding localization recall rate reaches 89.66%. The comprehensive performance of oiltank object localization is better than that of the aircraft. Specifically, the precision rates of the AF6C, AF7C, and AF8C are all above 70.00% and the corresponding recall rates are all above 75.00%. In
Table 2, the precision of aircraft localization has been improved to 74.27% with a recall of 93.32% achieved by VF6P. In addition, the highest precision of oiltank localization by the VGG network reaches 92.84% with a relatively low precision of 70.40% achieved by VF7C. Taking
Table 1 and
Table 2 together, the object localization performance of the convolutional layer-based
ODLMs is much better than that of pooling layer-based ones. Furthermore, we can always acquire recall rates higher than the corresponding precision rates for aircraft localization, as the
is too low to suppress the noise information in
ODLMs. By contrast, the precision rates of oiltank localization generally show better performance than the corresponding recall rates, especially for the VGG-based model. An overall comparison between
Table 1 and
Table 2 indicates that the object localization performance based on the VGG model is much better than that based on AlexNet model, given that AlexNet is a shallow network while VGG is a much deeper network. Consequently, the VGG model shows stronger ability to distinguish objects from their backgrounds.
4.2.2. Threshold Analysis
The object localization performance may vary with the change of the threshold
t.
Table 3,
Table 4,
Table 5 and
Table 6 show the object localization results based on different threshold values ranging from 0 to 0.99. Note that the aircraft and oiltank localization results based on the AlexNet framework are shown in
Table 3 and
Table 4, respectively. The results based on the VGG framework are shown in
Table 5 and
Table 6, respectively. In each column, the maximum precision and recall values are reported in bold.
As shown in
Table 3,
Table 4,
Table 5 and
Table 6, the localization precision rates improve along with the increment of threshold
t while the corresponding recall rates decrease gradually. When comparing the convolutional and pooling layer-based
ODLMs in
Table 3, we can find that the recall rates acquired by the convolutional layer-based
ODLMs (e.g., AF6C, AF7C, and AF8C) can significantly outperform the corresponding pooling layer-based
ODLMs (e.g., AF6P, AF7P, and AF8P). To take a further investigation, we can see that most of the recall rates for aircraft localization are over 90% when the threshold
t is less than 0.50 when using
ODLMs based on AF6C, AF7C, and AF8C. However, the localization precision rates are much lower than the corresponding localization recall rates when the thresholds are set as small values because there are many local minimum response values appeared as noises in the
ODLMs. Nevertheless, the pooling layer-based
ODLMs can achieve higher localization precision than the convolutional layer-based
ODLMs since the pooling operation can smooth the influence of noise response values. It is worth noting that, when setting the thresholds greater than 0.50, the aircraft localization precision rates achieved by AF7C and AF8C improve significantly even if the corresponding recall rates decrease to a certain extent. Specifically, for the AF7C and AF8C-based
ODLMs, the localization precision rates are close to 70.00% while the corresponding recall rates remain above 75.00% when
. In addition, both the recall and precision rates with the threshold of 0.99 surpass 70.00% and 74.00%, respectively, indicating that the noise response information contained in the
ODLM can be effectively suppressed by a high threshold.
The oiltank localization results based on AlexNet are shown in
Table 4. Different from the result of aircraft localization, both the recall and precision achieved by the convolutional layer-based
ODLMs (e.g., AF6C, AF7C, and AF8C) outperform the corresponding pooling layer-based
ODLMs (e.g., AF6P, AF7P, and AF8P) when
. Furthermore, the AF6C-based
ODLMs consistently achieve the best localization results that outperform those from AF7C- and AF8C-based
ODLMs even under different threshold settings. It is interesting to find that the satisfactory overall performance of oiltank localization can be obtained by setting the threshold
t around 0.50. For example, the precision and recall rates can reach 73.29% and 78.81%, respectively, which is consistent with
Table 1. In addition, the maximum recall rate for aircraft localization based on AlexNet framework can reach 95.26% by AF6C as described in
Table 3. The maximum recall rate for oiltank localization is 88.27% by AF6C, as shown in
Table 4. These results can be achieved by setting the threshold
t to be 0.0 or 0.10, which means the disregard of noise suppression.
The object localization results for aircraft and oiltank images based on the VGG framework are shown in
Table 5 and
Table 6, respectively. As can be seen from
Table 5, the VGG model can produce the best recall rates by VF6C-based
ODLMs under different thresholds. Typically, the VF6P-based
ODLMs achieve the best precision rates when
, which is similar to the phenomenon of AlexNet-based aircraft localization shown in
Table 3. Note that the VF6C also achieves the highest localization precision when
. By further observation, we can find that both VF7C and VF8C can achieve high recall rates for aircraft localization, where the lowest recall rate can reach 81.90%. This result verifies the stability of the VGG-based network for aircraft localization. That is, the
ODLMs based on features of different fully connected layer can effectively indicate most of the aircraft locations in a remote sensing image.
As shown in
Table 6, the best oiltank localization results are mainly achieved by VF7C and VF8C under different threshold levels. Specifically, the recall rate of 80.74% and precision rate of 90.57% can be obtained when the threshold is 0.30 for VF7C. With the same threshold of 0.30, the VF8C can also achieve similar recall and precision rates, i.e., 80.21% and 90.51%, respectively. In addition, the best recall rate of oiltank achieved by the VGG framework is 88.09%, as shown in
Table 6, which is similar to that of the Alexnet-based result. The best aircraft localization recall achieved by the VGG framework is 98.28%, as shown in
Table 5, which is 5.61% higher than that from the Alexnet-based framework.
In general, the precision rates typically decrease with the increment of corresponding recall values. The high localization recall can be acquired with a small threshold value, while the comparatively high localization precision can be achieved by setting a larger threshold t close to 1 for noise suppression. Thus, we can achieve different recall and precision rates based on our proposed dynamic threshold strategy.
4.2.3. Overall Performance
From
Table 3,
Table 4,
Table 5 and
Table 6, we can find that the object localization performance varies significantly when spreading different fully connected layer features to the last convolutional or pooling layer. To further explore the comprehensive object localization performance of different feature layers, the
-score measurement is employed to evaluate the object localization results of the different
ODLM generalization schemes as shown in
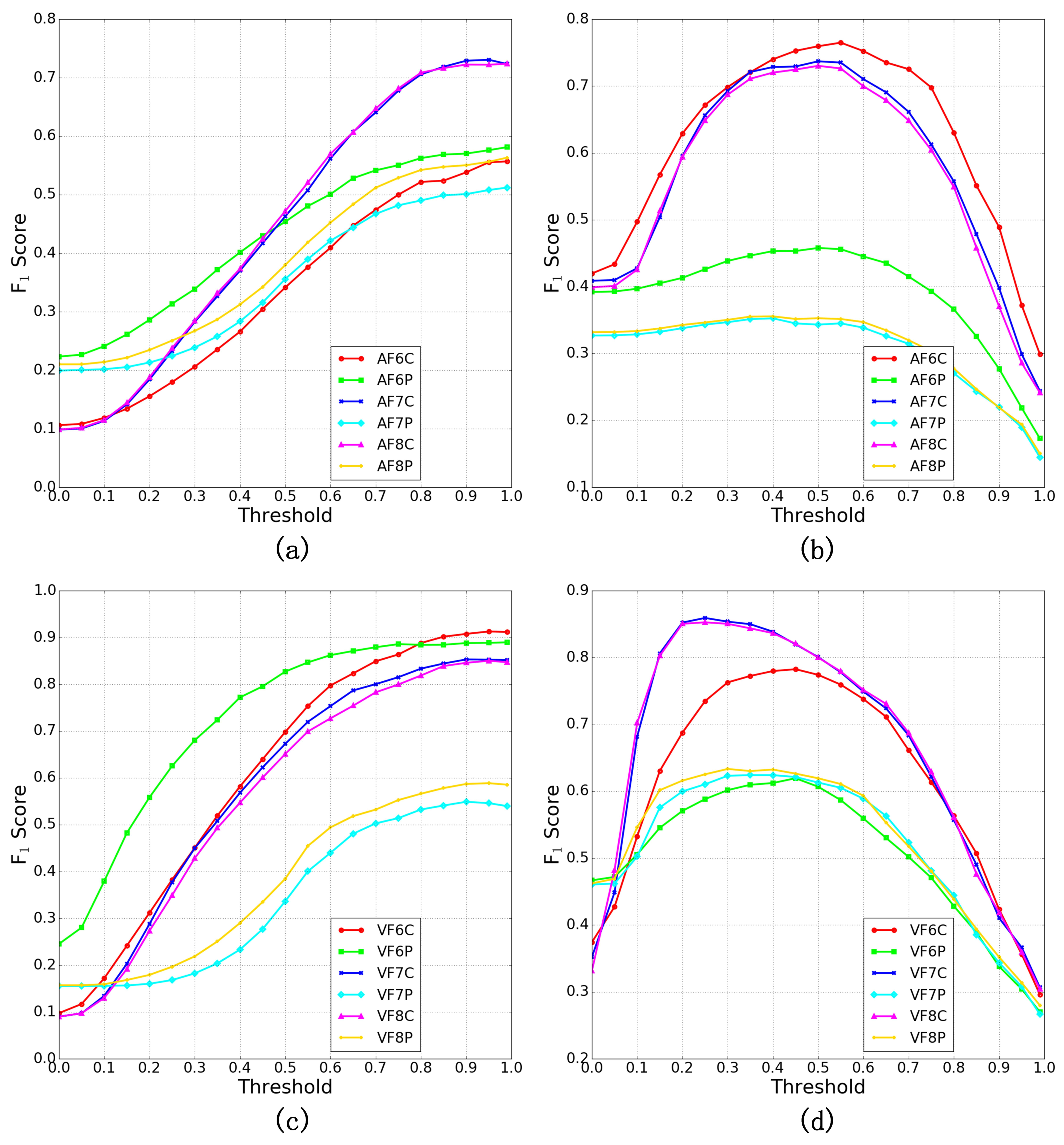
Figure 3. For a visual display, the
ODLM samples from the test dataset are presented to further evaluate and understand the localization performance, as shown in
Figure 4 and
Figure 5.
As it can be seen, the curves in
Figure 3 show similar variation trend for the objects with the same category. For example, the
-score curves for oiltank localization shown in
Figure 3b,d increase first and then decrease with the value increment of threshold
t. However, the different
ODLM generation schemes have different object localization performance even with the same threshold and CNN model. Specifically, for the AlexNet-based framework, the aircraft localization performance from AF6P, AF7P and AF8P are much better than those from AF6C, AF7C and AF8C when the threshold is below 0.20, as shown in
Figure 3a. The similar result can also be observed in the VGG-based framework when the threshold
t is smaller than 0.10 as shown in
Figure 3c. This is because there is more light scattering noise response information contained in the
ODLM when spreading the fully connected layer feature back to the last convolutional layer. By contrast, the response information is much smoother in the pooling layer-based
ODLM which helps to improve the object localization precision, as shown in the first columns of
Figure 4a and
Figure 5a where the threshold is set as
, corresponding to the original
ODLMs. Thus, more false locations are detected as positive ones through the proposed object location determination method, resulting in a negative influence on the localization precision performance. The locations represented by blue points in the first columns of
Figure 4a and
Figure 5a indicate this situation.
Nevertheless, with the increase of the threshold
t, the overall performance of the convolutional layer-based
ODLMs improves quickly for aircraft localization. Particularly, the
-score curves of AF7C and AF8C are far above those of AF6P, AF7P, and AF8P when
as shown in
Figure 3a. Similarly, the
-score curves of VF6C, VF7C, and VF8C significantly outperform those of VF7P and VF8P when
as shown in
Figure 3c. This is because the light scattering object location response information in the convolutional layer-based
ODLMs is effectively suppressed by the threshold parameter as shown in
Figure 4 and
Figure 5. Consequently, the precision rate of aircraft localization by the convolutional layers improves quickly, which is consistent with the results in
Table 3 and
Table 5. Note that the curve of VF6P shows comparable performance with those of VF6C, VF7C, and VF8C. This result is mainly attributed to the high recall rate achieved by the VF6P-based
ODLM as shown in
Table 5. Nevertheless, the AF6C-based
ODLM can achieve higher precision of aircraft localization when the threshold value goes beyond 0.8, resulting in better overall localization performance as shown in
Table 5 and
Figure 3c. On the other hand, the pooling layers in a CNN structure can easily lead to the loss of the spatial information for localizing local objects. Therefore, the pooling layer-based
ODLMs (e.g., AF6P, AF7P, AF8P, VF7P, and VF8P) show weak localization ability if more than one aircraft appears in an image, as shown in
Figure 4 and
Figure 5.
As for the oiltank localization results, the
-score curves of the convolutional feature-based
ODLMs in general are all above those of the pooling layer-based
ODLMs, as shown in
Figure 3b,d. This indicates that the convolutional feature-based
ODLMs can achieve higher recall and precision for oiltank localization, which is consistent with the results from
Table 4 and
Table 6. Corresponding to the above observation, the
ODLMs presented in
Figure 4b and
Figure 5b show that the convolutional layer-based
ODLMs can effectively recognize the location of each oiltank, while the pooling layer-based
ODLMs tend to discriminate the regions of all oiltank locations as a whole. As a result, the oiltank localization performance of the convolutional layer-based
ODLMs is much better than that of the pooling layer-based
ODLMs. Specifically, though the noise response information is scattered over the background areas in the original
ODLMs, the most salient regions can indicate the locations of oiltanks, allowing the oiltanks in an image to be effectively recognized and localized. Furthermore, it is interesting to find that the
-score curves produced by the features from the last two fully connected layers always show the same performance, i.e., the he VF7C and VF8C shown in
Figure 3d. The same phenomenon can also be observed in
Figure 3a–c. A potential explanation is that the features from the last two fully connected layers can be trained well to represent the semantic content of a scene image. Comparatively, the feature from the shallower fully connected layer are immediately produced by the feature from the last convolutional layer. Thus, the combination of the features from the shallower fully connected layer and the last convolutional layer may lead to instability for the object’s position and semantics integration, i.e., AF6C and VF6C for aircraft and oiltank localization, respectively. Therefore, the
ODLMs generated by features from the deep fully connected layers show better stability for object localization.
Note that there are an unexpected number of oiltanks in a remote sensing image, as shown in
Figure 4b and
Figure 5b. These oiltanks may appear at any location in an image and vary in scale and distribution density. These properties pose challenges to our proposed weakly supervised object localization method. Consequently, the degrees of response information may change for different oiltanks in an image. This effect is normal because the proposed weakly supervised object localization framework is merely constructed on the basis of a remote sensing image scene classifier of a CNN model. Moreover, the CNN classifier may focus on parts of the object regions in an image. As a result, the recall rate is high and the precision rate is much lower with a small noise threshold value. Similarly, the precision rate becomes high while the recall rate declines sharply as the threshold value increases. Thus, the
-score curve rises at first and then drops sharply with the change of threshold values, which is different from the
-score curves of aircraft localization. Nevertheless, the
-score curves show that the proposed method can retain high comprehensive localization performance when the threshold values are approximately 0.5 for AlexNet-based and 0.3 for VGG-based localization schemes, as shown in
Figure 3b,d, respectively. It is actually a balance between the localization precision and recall rates. In addition, these results are also consistent with those shown in
Table 4 and
Table 6.
Generally, the convolutional layer-based
ODLMs show much better object localization abilities, as reflected in
Table 3,
Table 4,
Table 5 and
Table 6 and
Figure 3,
Figure 4 and
Figure 5 since the
ODLMs can effectively discriminate different objects and their backgrounds in a remote sensing image, as shown in
Figure 4 and
Figure 5. This capability ensures high recall rates while using a small threshold value for noise response information suppression, which is consistent with the results shown in
Table 3,
Table 4,
Table 5 and
Table 6. Specifically,
Figure 3 shows that both the AlexNet and VGG framework can achieve excellent performance for aircraft localization with
. In addition, satisfactory oiltank localization results can be obtained by setting the threshold between 0.30 and 0.50 for different CNN models.
4.2.4. Performance Comparison
Comparison of different networks:
Table 7 and
Table 8 show the best object localization performance measured by
-score with the corresponding precision, recall, noise oppression parameter, distance error (DE), and the accuracy of image classification (
) achieved by the employed AlexNet and VGG frameworks, respectively. The corresponding
ODLMs and object localization results are also shown in
Figure 6. As shown in
Table 7, the
-score of aircraft localization achieved by AlexNet-based framework reaches 73.06%. The
-score of oiltank localization reaches 76.49%, which is 3.43% higher than that of the aircraft localization. Compared with AlexNet, the VGG-based framework shows much better localization performance with
-scores of 91.56% and 85.97% for aircraft and oiltank localization, respectively. In fact, the shallower AlexNet framework mainly focuses on the local content while the deeper VGG framework can accurately localize different objects in an image to adapt to the semantic scene classification task. As shown in the first four lines of
Figure 6, the VGG-based framework can localize most of the aircrafts even if they vary in appearance, scale, orientation, position, and spatial arrangement. The last column of the first four lines, which show the localization results for a small aircraft, also indicate the localization ability difference between different CNN models. Similarly, the oiltanks can also be localized with excellent performance, as shown in last column of lines 5–8 in
Figure 6. Benefiting from the deep CNN architecture, the VGG-based framework achieved 18.5.% and 9.48% higher
-scores than those of the AlexNet framework for aircraft and oiltank localization, respectively. However, both the AlexNet and VGG frameworks show weaknesses in localizing the mini-scale oiltanks, especially when they are adjacent to those oiltanks of large sizes. Nevertheless, both the AlexNet-based and VGG-based frameworks show remarkable effectivity in localizing the oiltanks, although there are an unexpected number of objects holding different positions, as shown in the last four lines of
Figure 6.
Through aborative observation, we find that both the AlexNet-based and VGG-based frameworks tend to localize an oiltank by the borders between the object and its background. One possible explanation is that the trained CNN models tend to discriminate an oiltank from its backgrounds by focusing on the image content around object borders. Therefore, the AlexNet and VGG frameworks share approximate distance errors of oiltank localization, i.e., 18.27% and 15.64%, respectively. Similarly, the AlexNet-based framework localizes an aircraft by focusing on the aerofoil, tail, and head of an aircraft. Different from the aircraft localization results from AlexNet, the deeper CNN framework can recognize an aircraft with the location falling onto its body. Furthermore, the localized position by the VGG is much closer to the center of an aircraft’s annotated bounding box than that by AlexNet. As a result, the distance error of the aircraft localization by the VGG is much lower than that by AlexNet, as shown in
Table 7 and
Table 8. Furthermore, both the AlexNet and VGG frameworks achieve high accuracy of oiltank image scene classification, i.e., 93.20% and 98.00%, respectively. And the scene classification accuracy of aircraft images also reaches 94.40% and 95.20% by AlexNet and VGG, respectively. These results confirm that the extracted fully connected layer features can be powerful and class discriminative. Thus, the class information and spatial information could be effectively integrated while spreading the fully connected layer features back to the convolutional layers. Then, the excellent object localization performance can be achieved, which proves the rationality and effectivity of our proposed weakly supervised object localization framework.
Comparison with existing methods: From above analyses, we can see that the proposed object localization method relies heavily on the quality of object discriminative localization map. Therefore, we compare our proposed method with the existing state-of-the-art (SOTA) class activation methods, including LayerCAM [
81], XGradCAM [
82], ScoreCAM [
71], and ISCAM [
83], etc. Specifically, we employ the VGG-based framework to generate
ODLMs using different class activation methods. Then, the proposed dynamic updating method of local response extremum is utilized to obtain the object localization result. The quantitative results of object localization using different methods are presented in
Table 9. As can be seen, our proposed method achieves the highest on
-scores for both aircraft and oiltank localization. XGradCAM [
82] typically propagates the class score at classification layer to the convolutional layer and generates class-related
ODLMs. Thus, they achieve approximate performance of aircraft localization. LayerCAM [
81] utilizes pixel-wise weights to integrate the convolutional features and generates an
ODLM that can indicate the key parts of an object. However, the pixel-wise integration strategy can make the discriminative region of an object presented with scattered components, yielding massive noise and resulting in low aircraft localization precision, i.e., 52.17% and 10.22% for aircraft and oiltank, respectively. Score-CAM [
71] and its improved version ISCAM [
83] generate
ODLMs by a linear combination of weights and activation maps, which can suppress the noise information. Thus, the ISCAM achieves the 91.31% of
-score for aircraft localization. Nevertheless, our proposed method obtains comparable
-score (91.56%) of aircraft localization. When it comes to the oiltank object localization, the compared methods observe sharp declines of localization performance. By contrast, our presented method can consistently outperform the compared methods on
-score, precision, and recall, showing the strong stability of object localization ability of our proposed method.
Table 9.
Comparison of object localization performance among different methods.
Table 9.
Comparison of object localization performance among different methods.
| Method | Aircraft | Oiltank |
|---|
| F1 | P | R | t | DE | F1 | P | R | t | DE |
|---|
| LayerCAM [81] | 0.6628 | 0.5217 | 0.9083 | 0.93 | 12.55 | 0.1661 | 0.1022 | 0.4431 | 0.70 | 15.77 |
| ScoreCAM [71] | 0.7531 | 0.6577 | 0.8807 | 0.99 | 8.84 | 0.6602 | 0.7825 | 0.5709 | 0.39 | 17.33 |
| XGradCAM [82] | 0.7725 | 0.6623 | 0.9266 | 0.87 | 9.54 | 0.2850 | 0.2978 | 0.2732 | 0.89 | 13.43 |
| ISCAM [83] | 0.9131 | 0.8833 | 0.9450 | 0.81 | 9.92 | 0.4483 | 0.4483 | 0.4483 | 0.62 | 19.58 |
| Ours | 0.9156 | 0.9450 | 0.8879 | 0.98 | 14.86 | 0.8597 | 0.8912 | 0.8304 | 0.23 | 15.64 |
Figure 7 provides the intuitive visualization of object localization results. As can be seen from the first and second rows, the ISCAM, XGradCAM, and our proposed method can accurately localize the aircrafts in the image while the ScoreCAM and LayerCAM only focus on localizing one object in the image. Particularly, our proposed method can discriminate the aircraft of small size in the image while the compared methods fail to recognize the aircraft, as shown in the third and fourth rows of
Figure 7. Consequently, our proposed method can achieve high aircraft localization precision that outperforms the compared methods as shown in
Table 9. However, conventional class activation methods are usually designed to discriminate single object in an image. Thus, they tend to recognize the object areas as a whole, which makes the discrimination of multiple objects difficult as shown in the last four rows of
Figure 7. By contrast, our proposed method tends to discriminate each object in the image, and thus, achieving significantly higher precision and recall for oiltank localization as shown in
Table 9. Intuitively, conventional methods generate the
ODLM only using the class score, which may cause the loss of information contained in the fully connected feature from classification layer. By contrast, our presented method backpropagates the class discriminative feature of the fully convolutional layer to the convolutional layer, which achieves the combination of class semantic and spatial information of objects. Therefore, the regions of multiple objects can be distinctly discriminated from theirs backgrounds, achieving high precision and recall of object localization.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






