1. Introduction
Hyperspectral images (HSIs) combine imaging technology with spectral detection technology, in which each pixel contains dozens or even hundreds of spectral bands, recording the spectral profile of the corresponding feature [
1,
2]. Similar to ordinary images, hyperspectral images also possess spatial information. However, due to the differences in the spectral profiles of different ground covers, hyperspectral images possess richer spectral information compared with normal images, which helps to determine the category of ground cover more accurately. Currently, hyperspectral observation techniques are widely used in many fields, such as water monitoring [
3,
4], agricultural monitoring [
5], and resource exploration [
6]. Common tasks of hyperspectral images include unmixing [
7], detection [
8], and classification [
9].
During the past decades, a large number of HSI classification methods have been proposed and dedicated to obtaining accurate classification results. Traditional HSI classification methods, such as support vector machine (SVM) [
10], polynomial regression (MLR) [
11], random forest [
12], and sparse representation [
13], are often used in HSI classification tasks. To further improve the classification performance, researchers have conducted extensive exploration into spectral–spatial classification methods, such as using partitional clustering [
14], joint sparse representation [
15], etc. Spectral–spatial classification methods combine spectral information and spatial contextual information, which can effectively improve the results of HSI classification compared with the classification methods based on spectra only [
16]. Although traditional HSI classification methods are capable of achieving good performance, they are usually highly reliant on manual design with poor generalization ability, which limits their performance in difficult scenarios [
16,
17].
Recently, deep-learning-based methods have gained attention due to their powerful feature extraction and representation capabilities, and have been widely used in computer vision [
18], natural language processing [
19], remote sensing image processing [
20], and other fields. In the field of HSI classification, deep-learning-based models have also been applied extensively and proved to possess excellent learning ability and feature representation [
21]. Chen et al. [
22] first introduced deep learning methods to hyperspectral image classification, and proposed an automatic stacking encoder-based HSI classification model. In the following years, many backbone networks in the area of deep learning were successfully applied to HSI classification tasks. For example, Hu et al. [
23] designed a deep convolutional neural network (CNN) for hyperspectral image classification; Hang et al. [
24] proposed a cascaded recurrent neural network (RNN) model using gated recurrent units, aiming to eliminate redundant information between adjacent spectral bands and learning complementary information between nonadjacent bands; in [
25], generative adversarial networks (GANs) were introduced into the HSI classification task, providing a new perspective; based on graph convolutional networks (GCNs) to extract features, a network called nonlocal GCN was proposed in [
26]; in [
27], a novel end-to-end, pixel-to-pixel, fully convolutional network (FCN) was proposed, consisting of a three-dimensional fully convolutional network and a convolutional spatial propagation network; and finally, a dual multiheaded contextual self-attention network for HSI classification was proposed in [
28], which used two submodules for the extraction of spectral–spatial information.
CNN-based classification models have dominated the current deep-learning-based HSI classification models. Benefiting from local connectivity and weight-sharing mechanisms, CNNs can effectively capture spatial structure information and local contextual information while reducing the number of parameters to achieve good classification results. A spectral–spatial CNN classification method was proposed earlier in [
29], and achieved better results than traditional methods; a network named context–depth CNN was proposed in [
30] to optimize local contextual interactions by exploiting the spectral–spatial information of neighboring pixels; a spectral–spatial 3-D–2-D CNN classification model was introduced in [
31], which shows the excellent potential of hybrid networks by mixing two-dimensional convolution and three-dimensional convolution for deep extraction of spectral–spatial features. Recently, more novel CNN-based classification models have been proposed; for example, the consolidated convolutional neural network (C-CNN) [
32] and the lightweight spectral–spatial convolution module (LS2CM) [
33], etc.
Although convolutional neural networks have been proven to have good capability in HSI classification tasks, the limitations of the convolutional operation itself also hinder the further improvement of its performance. Firstly, in the spectral dimension, CNNs have difficulty in capturing the global properties of sequences well, and perform poorly when facing the extraction of long-range dependencies. Benefiting from the convolution operation in CNN, CNN can achieve powerful spatial feature extraction capability in the spatial dimension by collecting local features hierarchically. However, HSI data are more similar to a sequence in the spectral dimension, and usually have a large spectral dimension. The use of CNN may introduce a partial loss of information [
34], which causes difficulties in feature extraction. At the same time, this makes it difficult to fully utilize the dependency information among the spectral channels that are far apart, especially when there are many types of land cover and the similarity of spectral features is significant [
35]; this may become a bottleneck that prevents CNNs from achieving more refined land cover classification. Second, CNN may not be the best choice for global contextual relationship establishment in the spatial dimension. When performing classification data selection, a common method of selection is to combine the pixel to be classified and its nearby pixel information as the input of the classification model. The nearby pixels contain rich spatial contextual information, which helps to achieve better classification results. Compared to convolutional neural networks, which are more adept at local feature extraction, the self-attention mechanism may be a better choice since it is not limited by distance and is inherently better at capturing global contextual relationships. In addition, establishing such global contextual relationships will help classification models to obtain better robustness and be less susceptible to perturbations [
36].
Facing the difficulties mentioned above, one possible solution is to design HSI classification models based on attention mechanisms. The attention mechanism is capable of extracting the features that are more important for the classification task, while ignoring less-valuable features, to achieve effective information utilization. Fang et al. proposed a 3D CNN network using the attention mechanism in the spectral channel [
37], but did not use the attention mechanism for spatial information. Therefore, Li and Zheng et al. [
9] constructed a parallel network using the attention mechanism for spatial and spectral features separately, and achieved better results. Later, a network called Transformer was proposed, which is based on the self-attention mechanism, and exhibits good global feature extraction and long-range relationship capturing capability [
38]. Although the self-attention mechanism can extract important spatial and spectral features, it is impossible to obtain the location information between features with the self-attention mechanism only; thus, Transformer adds positional encoding so that the network that uses the attention mechanism can learn the positional information of features. The vision transformer [
39] model was the first to propose the use of Transformer in computer vision application, and achieved decent results. Since then, a large number of Transformer-based networks have emerged in the field of computer vision, as well as in HSI classification. For example, a backbone network called SpectralFormer was proposed in [
28] to view HSI classification from the perspective of sequences; [
40] replaced the traditional convolutional layer with Transformer, and investigated Transformer classification results along spatial and spectral dimensions, proposing a spectral–spatial HSI classification model called DSS-TRM; Sun et al. [
41] proposed a spectral–spatial feature tokenization transformer (SSFTT) model to overcome the difficulty of extracting deep semantic features by previous methods, thus making full use of the deep semantic properties of spectral–spatial features; to alleviate the problem of gradient vanishing, a novel Transformer called DenseTransformer was proposed by [
34], and applied in their spectral–spatial HSI classification framework. Attention-based and Transformer-based HSI classification models are gaining more attention from researchers, but such models are not a perfect choice; for example, although Transformer has good global feature extraction capabilities and long-range contextual relationship representation, it is usually weak in local fine-grained feature extraction [
42] and underutilizes spatial information [
41], which is usually what convolution excels at.
Reviewing the CNN-based and attention-based models, it is not difficult to find that their advantages and disadvantages are complementary. By jointly employing CNNs and attention mechanisms, it will be possible to achieve sufficient extraction of local features while further optimizing the full utilization of global contextual relationships. Related explorations have been made in the field of deep learning; for example, Gulati et al. [
42] proposed a Transformer–CNN fusion model for automatic speech recognition (ASR), expecting a win–win situation by representing local features and global contextual connections of audio sequences through convolution and Transformer; Peng and Ye [
43] et al. also proposed a network with a two-branch CNN and Transformer, thus synthesizing the representation capability of enhanced learning.
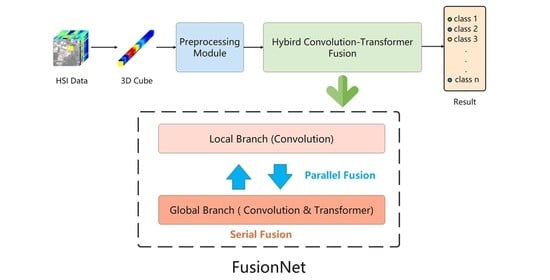
Inspired by the above works, this paper proposes a convolution–Transformer fusion network for HSI classification, known as FusionNet. FusionNet contains two branches, one of which is the Local Branch, consisting of residual-connected convolutional modules and mainly focusing on extracting local information in spatial and spectral dimensions. The other branch is the Global Branch, which is serially connected by Transformer and convolutional modules, and is mainly responsible for extracting global information of spatial and spectral dimensions. The purpose of introducing convolutional modules into this branch is to further enhance the extraction capability of Transformer for local features. In addition, a fusion mechanism is added between the Global Branch and Local branch to enable the communication of local and global information. Hyperspectral images are different from ordinary images, which express a theme as a whole image and possess local features at the spatial–channel level that are more important than hyperspectral images. Thus, CNN is added to Transformer to enhance the ability of the Global Branch to extract local information. The whole network is structured so that the Global Branch and Local Branch are parallel as a whole, while the convolution module and Transformer are serially localized inside the Global Branch. The main contributions of this article are listed as follows:
This paper proposes a novel convolution–Transformer fusion network for HSI classification. Considering the strength of convolution in local feature extraction, and the capability of Transformer in long-range contextual relationship extraction, this paper proposes a fusion solution for HSI classification. Local fine-grained features can be well extracted by the convolution module, while global features in the spectral–spatial dimension and long-distance relationships in the spectral dimension can be better extracted by the Transformer module. The fusion of convolution and Transformer successfully enables them to complement each other to achieve better HSI classification results.
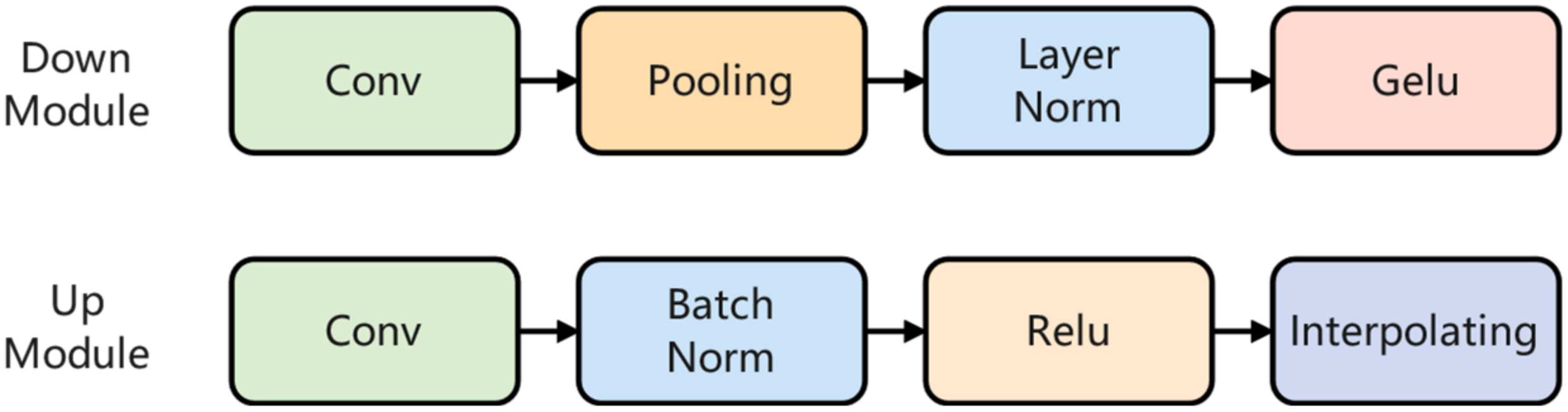
In FusionNet, a hybrid convolution–Transformer fusion pattern based on serial arrangement and parallel arrangement for a double-branch fusion mechanism was proposed for HSI classification. The Local Branch provides local feature extraction based on convolution, while the Global Branch provides global feature extraction based on convolution–Transformer serial arrangement module. The Local Branch and Global Branch are fused through a double-branch fusion mechanism in a parallel arrangement module. Furthermore, the hybrid fusion pattern enables the fusion and exchange of information between two branches to achieve effective extraction of local and global features.
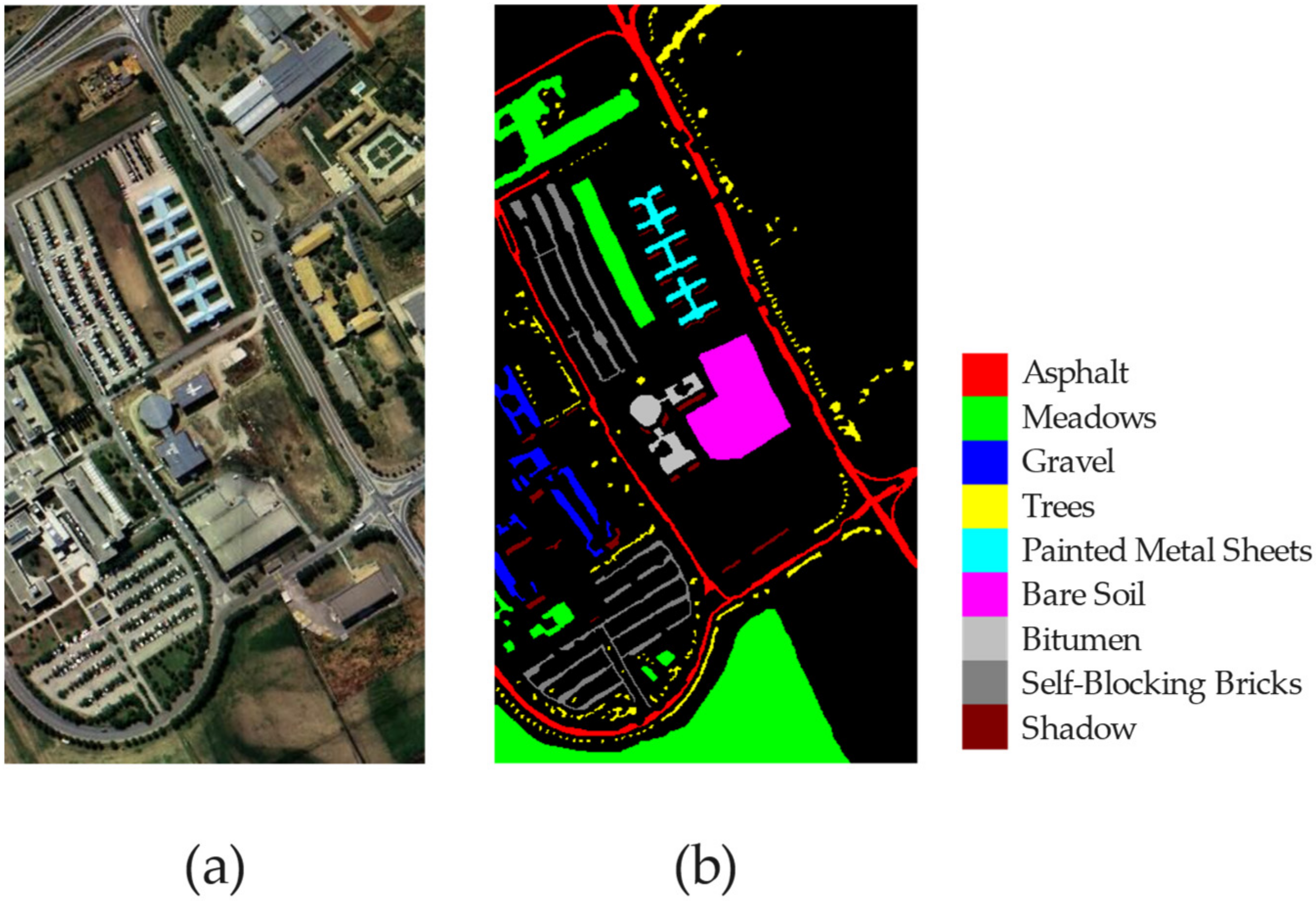
FusionNet achieves competitive results on the three most commonly used datasets. This suggests that the fusion of convolution and Transformer may be a better solution for HSI classification, and provides a reference for further research in the future.
The remainder of the article is organized as follows:
Section 2 presents the materials and methods of FusionNet, including the related works and detailed structure of FusionNet. The comparison results of the network on several datasets are given in
Section 3.
Section 4 presents a discussion of the experimental results and design of FusionNet to further investigate the effectiveness of the structure. Finally,
Section 5 summarizes the entire work and the future directions.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}