
Spectral-Spatial Interaction Network for Multispectral Image and Panchromatic Image Fusion

Abstract
:1. Introduction
- (1)
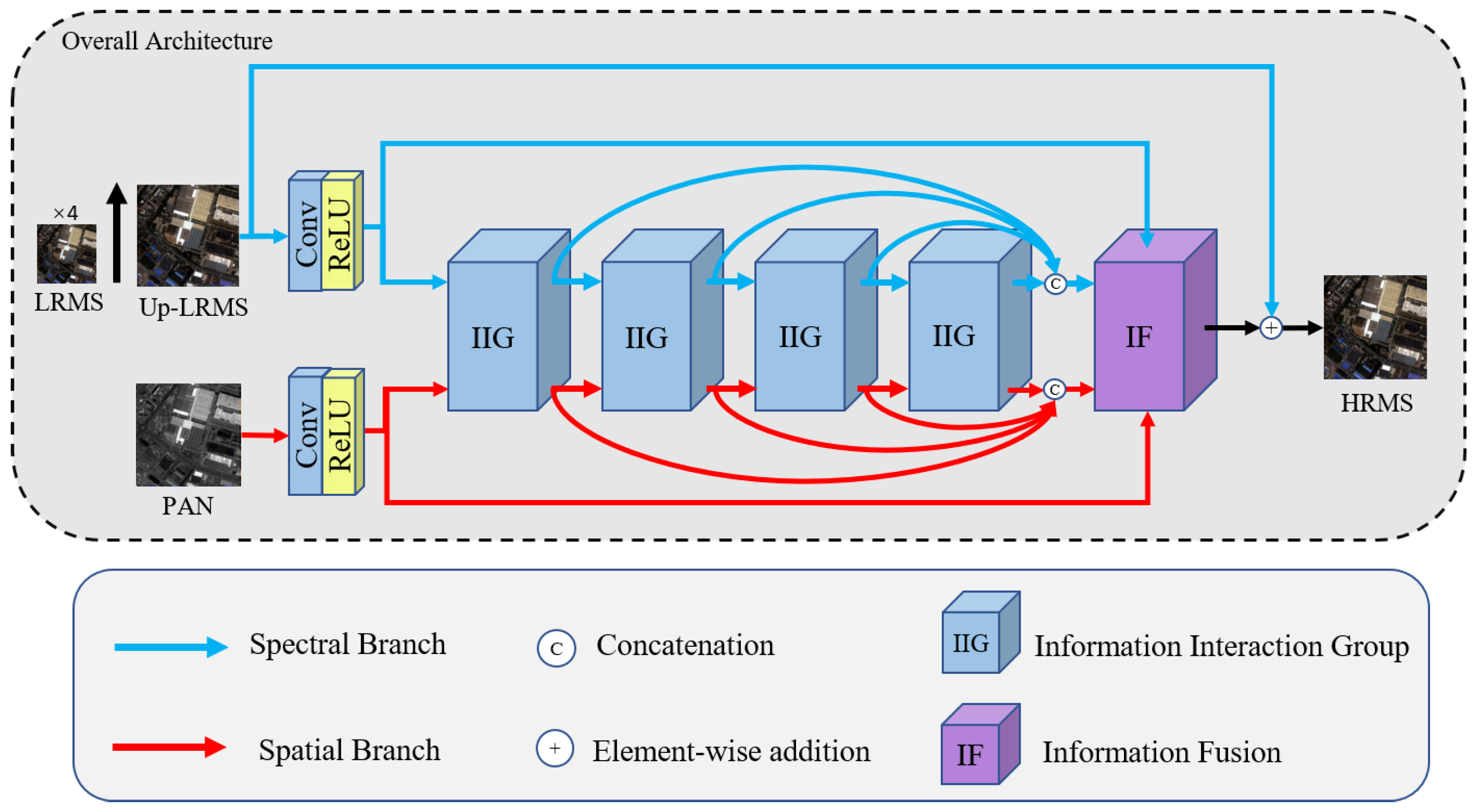
- We propose a spectral-spatial interaction network (SSIN) based on information interaction group for pansharpening. The network is designed as a dual-branch architecture. It extracts spectral and spatial information independently from the two branches and are interacted repetitively to incorporate spectral and spatial information progressively.
- (2)
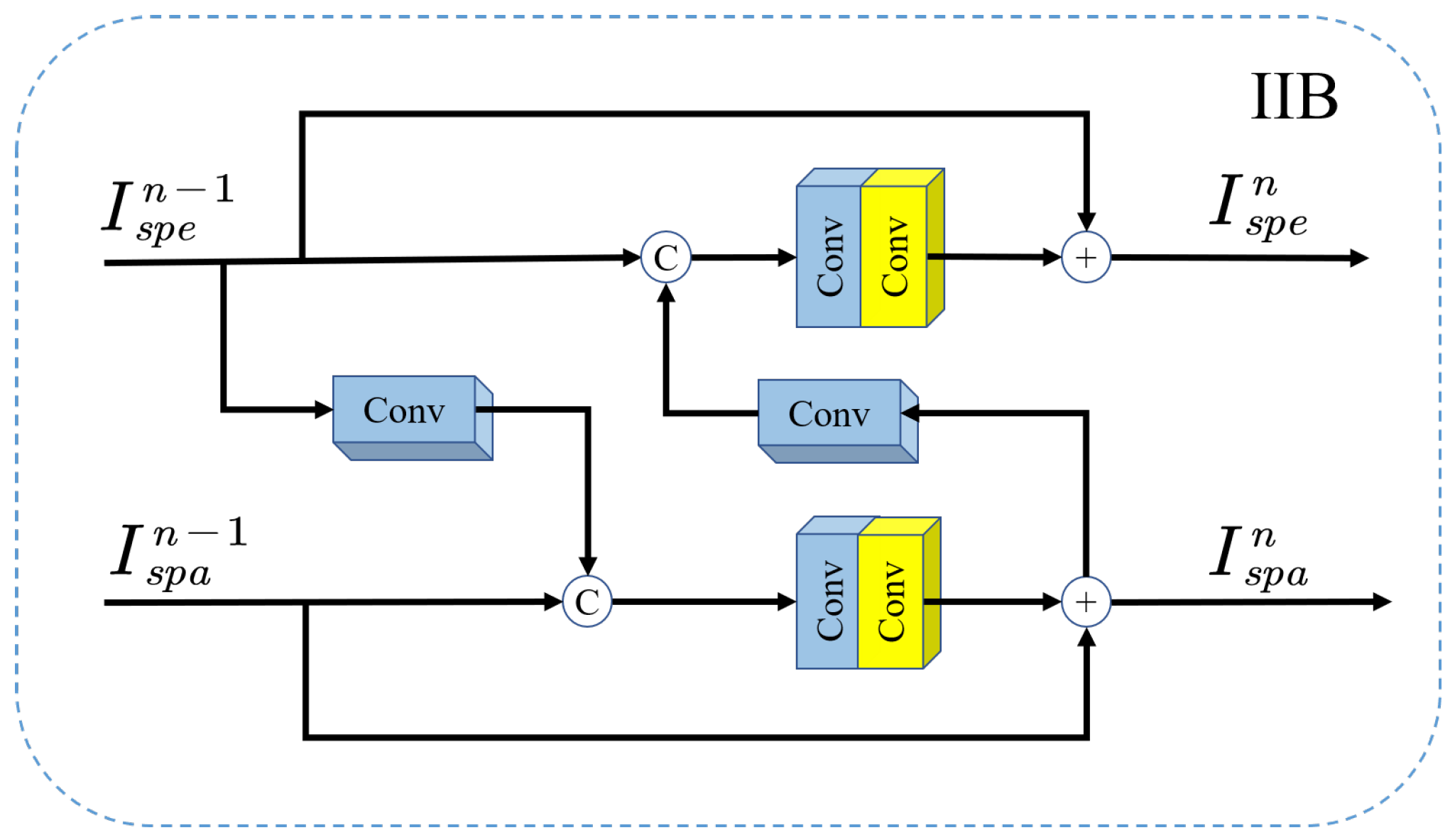
- We propose the information interaction block (IIB) to enhance the conversion and transmission of spectral and spatial information between the two branches. Because it is a dual-input and dual-output structure, it can be embedded in dual-branch networks efficiently.
- (3)
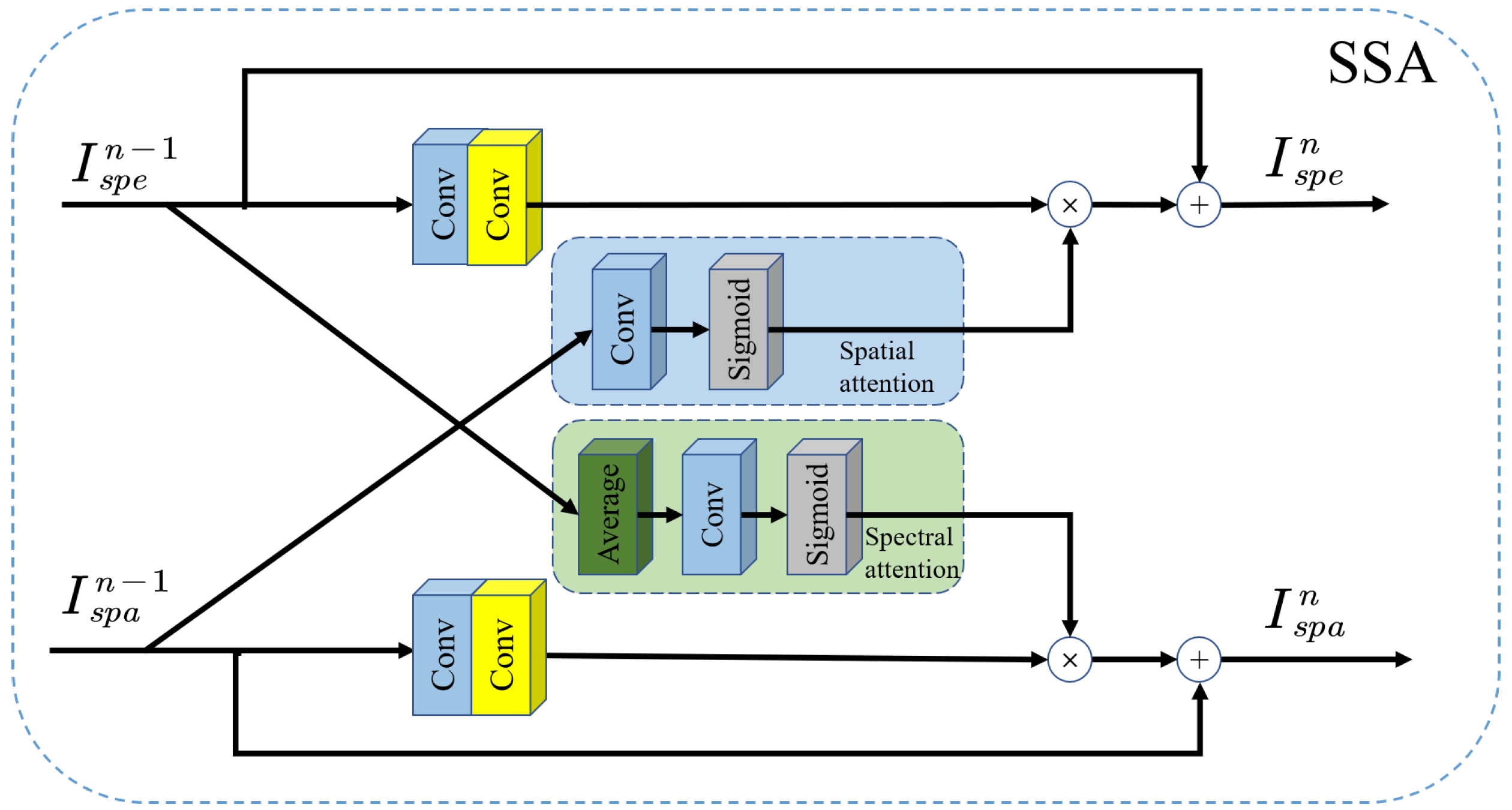
- We design a lightweight and effective spectral-spatial attention module, which is able to calculate spatial attention from the PAN branch to guide the MS branch. Similarly, it calculates spectral attention from the MS branch to guide the PAN branch. In this way, the advantages of information of MS and PAN images can be fully utilized, which facilitates the fusion of different information.
2. Related Work
3. Proposed Method
3.1. Network Architecture
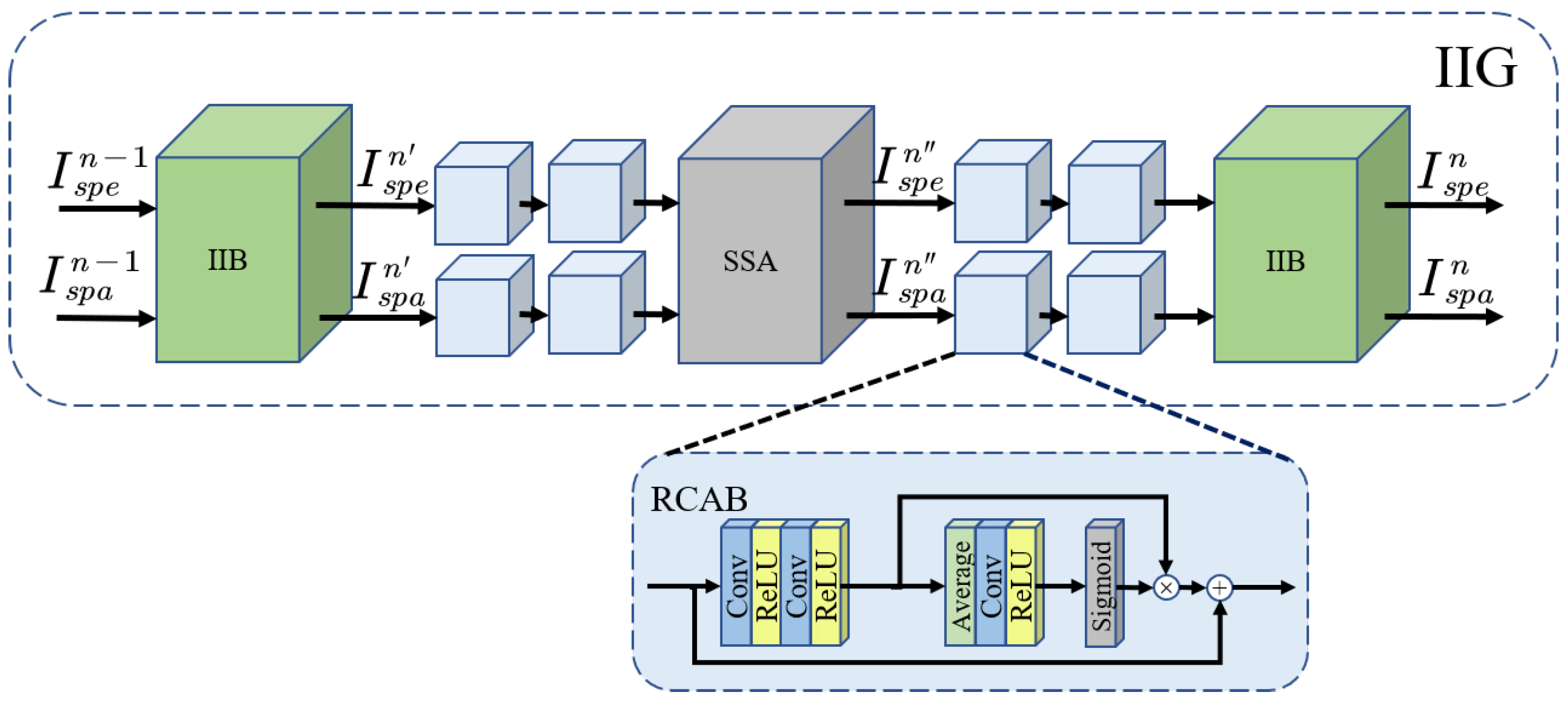
3.2. Information Interaction Group
3.3. Information Interaction Block
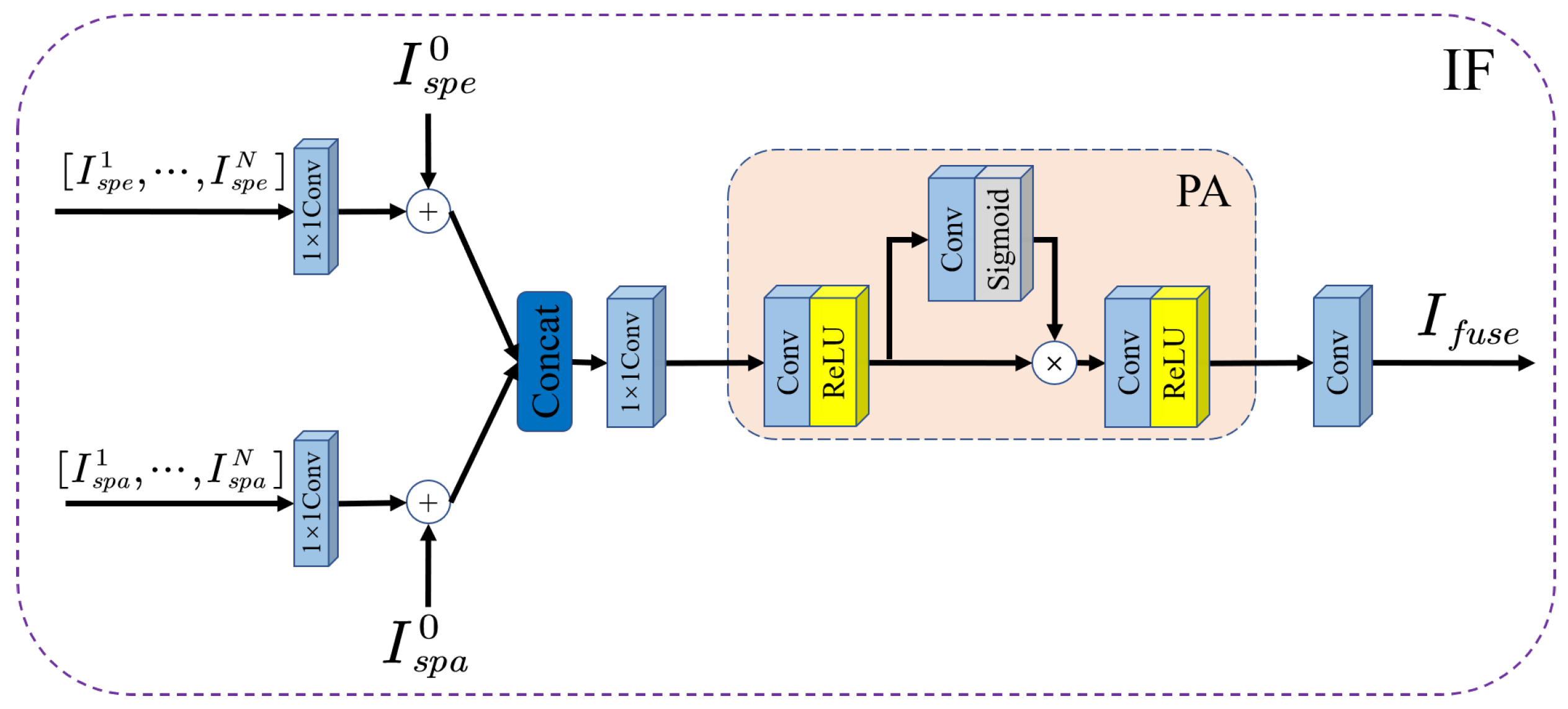
3.4. Spectral-Spatial Attention Module
3.5. Information Fusion Module
4. Experiments
4.1. Datasets
4.2. Train Details
4.3. Evaluation Index
4.4. Ablation Study
- Base: Baseline, ablate the PA block, disconnect the interaction cables in each IIB, and removes both spatial and spectral attention from each SSA.
- Base+PA: Add the PA block in IF on the baseline
- Base+PA+SSA: Add both spatial attention and spectral attention on the Base+PA
- Base+PA+SSA+IIB: The method proposed in this paper (SSIN) that turn on the interaction connection in each IIB on the basis of Base+PA+SSA.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | SAM↓ | ERGAS↓ | Q2n↑ | CC↑ |
|---|---|---|---|---|
| Base | 3.7354 | 2.8492 | 0.7783 | 0.9634 |
| Base+PA | 3.4086 | 2.605 | 0.7839 | 0.968 |
| Base+PA+SSA | 3.3495 | 2.563 | 0.7854 | 0.969 |
| Base+PA+SSA+IIB | 3.2598 | 2.4239 | 0.7882 | 0.9711 |
4.4.1. Effect of the PA
4.4.2. Effect of the SSA
4.4.3. Effect of the IIB
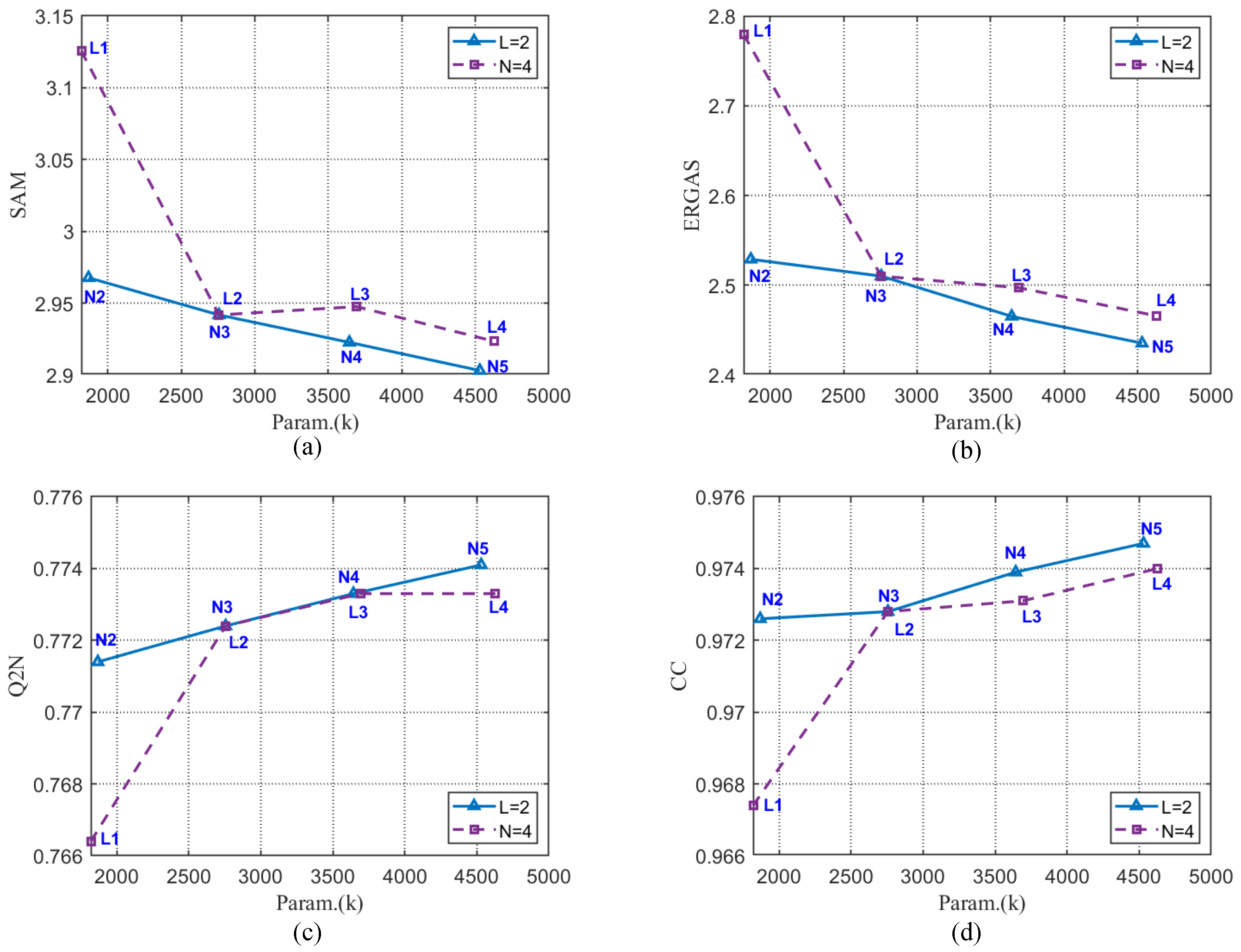
4.5. Parameters Analysis
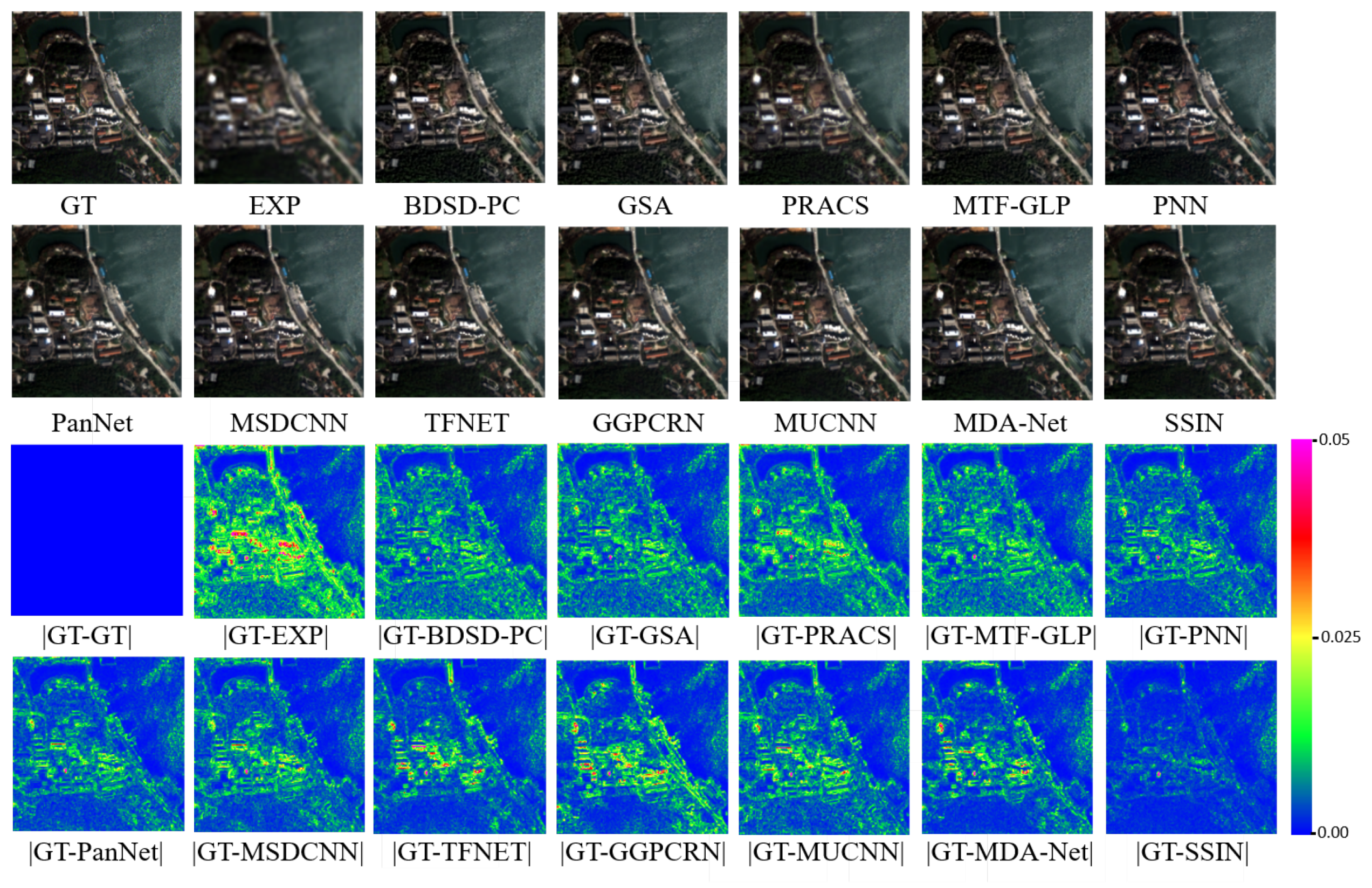
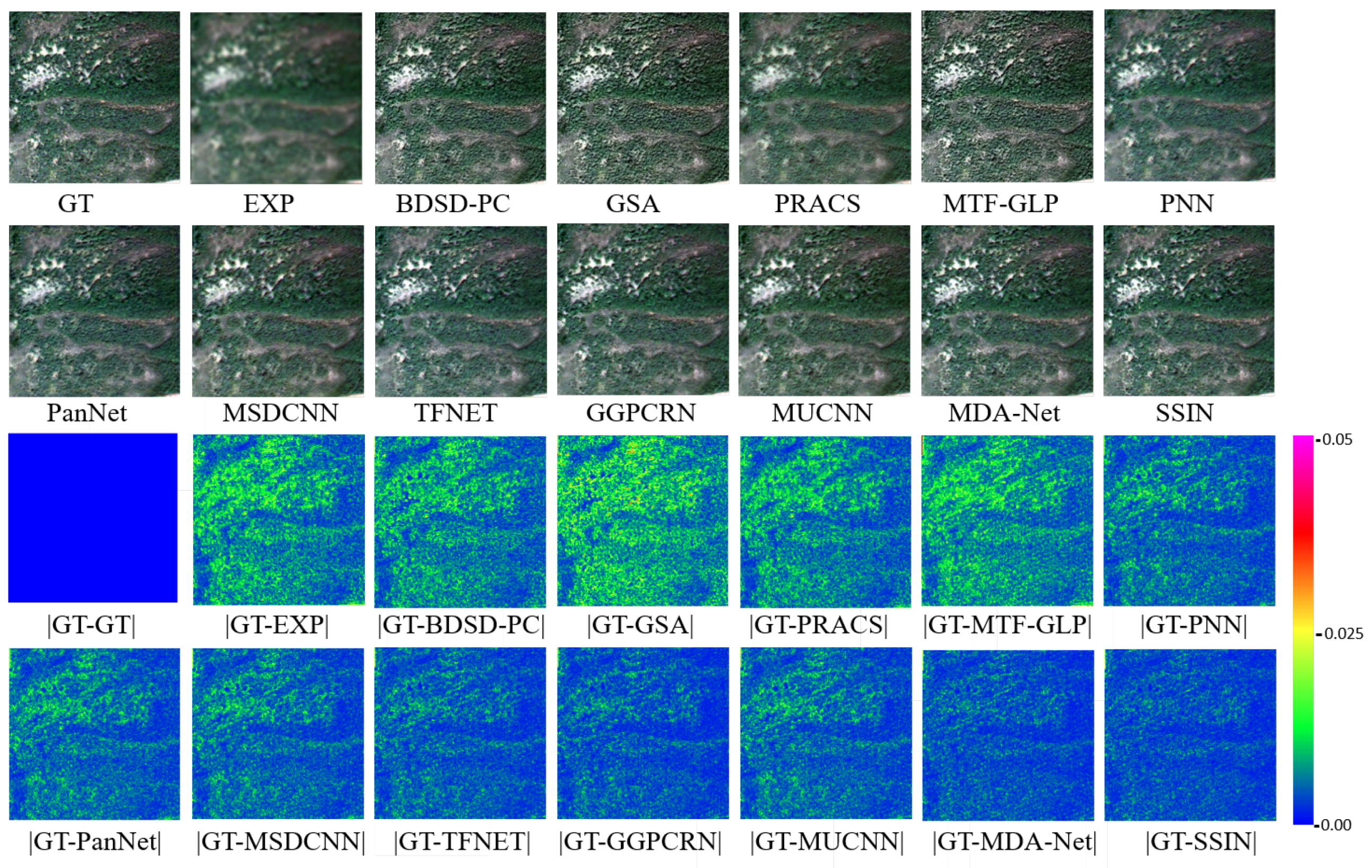
4.6. Comparison with SOTA Methods
4.6.1. Reduced-Resolution Experiments
4.6.2. Full-Resolution Experiments
| Methods | QB | WV4 | ||||
|---|---|---|---|---|---|---|
| ↓ | ↓ | QNR↑ | ↓ | ↓ | QNR↑ | |
| EXP | 0 | 0.1016 | 0.8984 | 0 | 0.0819 | 0.9181 |
| GSA | 0.0875 | 0.1743 | 0.7584 | 0.0766 | 0.1576 | 0.7803 |
| PRACS | 0.0465 | 0.1096 | 0.8510 | 0.0305 | 0.0975 | 0.8758 |
| BDSD-PC | 0.0622 | 0.1515 | 0.7998 | 0.0478 | 0.1258 | 0.8350 |
| MTF-GLP | 0.1261 | 0.2004 | 0.7056 | 0.0914 | 0.1332 | 0.7907 |
| PNN | 0.0622 | 0.1115 | 0.8374 | 0.0473 | 0.0612 | 0.8944 |
| PanNet | 0.0604 | 0.0990 | 0.8502 | 0.0326 | 0.0620 | 0.9076 |
| MSDCNN | 0.0572 | 0.1025 | 0.8493 | 0.0449 | 0.0665 | 0.8927 |
| TFNET | 0.0492 | 0.0728 | 0.8840 | 0.0569 | 0.0562 | 0.8905 |
| GGPCRN | 0.0509 | 0.0688 | 0.8858 | 0.0555 | 0.0581 | 0.8902 |
| MUCNN | 0.0488 | 0.0886 | 0.86 | 0.0611 | 0.0591 | 0.8847 |
| MDA-Net | 0.0473 | 0.0656 | 0.8921 | 0.0560 | 0.0607 | 0.8873 |
| SSIN | 0.0532 | 0.0609 | 0.8910 | 0.0483 | 0.0534 | 0.9012 |




5. Efficiency Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Meng, X.; Shen, H.; Li, H.; Zhang, L.; Fu, R. Review of the pansharpening methods for remote sensing images based on the idea of meta-analysis: Practical discussion and challenges. Inf. Fusion 2019, 46, 102–113. [Google Scholar] [CrossRef]
- Gilbertson, J.K.; Kemp, J.; van Niekerk, A. Effect of pan-sharpening multi-temporal Landsat 8 imagery for crop type differentiation using different classification techniques. Comput. Electron. Agric. 2017, 134, 151–159. [Google Scholar] [CrossRef] [Green Version]
- Du, P.; Liu, S.; Xia, J.; Zhao, Y. Information fusion techniques for change detection from multi-temporal remote sensing images. Inf. Fusion 2013, 14, 19–27. [Google Scholar] [CrossRef]
- Qu, Y.; Qi, H.; Ayhan, B.; Kwan, C.; Kidd, R. DOES multispectral/hyperspectral pansharpening improve the performance of anomaly detection? In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 6130–6133. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Masi, G.; Cozzolino, D.; Verdoliva, L.; Scarpa, G. Pansharpening by Convolutional Neural Networks. Remote Sens. 2016, 8, 594. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Fu, X.; Hu, Y.; Huang, Y.; Ding, X.; Paisley, J. PanNet: A Deep Network Architecture for Pan-Sharpening. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1753–1761. [Google Scholar] [CrossRef]
- Wei, Y.; Yuan, Q. Deep residual learning for remote sensed imagery pansharpening. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 18–21 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Chen, L.; Lai, Z.; Vivone, G.; Jeon, G.; Chanussot, J.; Yang, X. ArbRPN: A Bidirectional Recurrent Pansharpening Network for Multispectral Images With Arbitrary Numbers of Bands. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18. [Google Scholar] [CrossRef]
- Lei, D.; Chen, H.; Zhang, L.; Li, W. NLRNet: An Efficient Nonlocal Attention ResNet for Pansharpening. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Li, C.; Zheng, Y.; Jeon, B. Pansharpening via Subpixel Convolutional Residual Network. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2021, 14, 10303–10313. [Google Scholar] [CrossRef]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A multiscale and multidepth convolutional neural network for remote sensing imagery pan-sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Liu, Q.; Wang, Y. Remote sensing image fusion based on two-stream fusion network. Inf. Fusion 2020, 55, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Tu, W.; Huang, S.; Lu, H.; Wan, W.; Gan, L. Dual-Stream Convolutional Neural Network With Residual Information Enhancement for Pansharpening. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, L.J.; Zhang, T.J.; Wu, X. SSconv: Explicit Spectral-to-Spatial Convolution for Pansharpening. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 4472–4480. [Google Scholar]
- Fu, S.; Meng, W.; Jeon, G.; Chehri, A.; Zhang, R.; Yang, X. Two-Path Network with Feedback Connections for Pan-Sharpening in Remote Sensing. Remote Sens. 2020, 12, 1674. [Google Scholar] [CrossRef]
- Zhong, X.; Qian, Y.; Liu, H.; Chen, L.; Wan, Y.; Gao, L.; Qian, J.; Liu, J. Attention FPNet: Two-Branch Remote Sensing Image Pansharpening Network Based on Attention Feature Fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 11879–11891. [Google Scholar] [CrossRef]
- Wu, X.; Huang, T.Z.; Deng, L.J.; Zhang, T.J. Dynamic Cross Feature Fusion for Remote Sensing Pansharpening. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 14687–14696. [Google Scholar]
- Yao, J.; Hong, D.; Chanussot, J.; Meng, D.; Zhu, X.; Xu, Z. Cross-Attention in Coupled Unmixing Nets for Unsupervised Hyperspectral Super-Resolution. In Proceedings of the Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 208–224. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Vivone, G.; Dalla Mura, M.; Garzelli, A.; Restaino, R.; Scarpa, G.; Ulfarsson, M.O.; Alparone, L.; Chanussot, J. A new benchmark based on recent advances in multispectral pansharpening: Revisiting pansharpening with classical and emerging pansharpening methods. IEEE Geosci. Remote Sens. Mag. 2020, 9, 53–81. [Google Scholar] [CrossRef]
- Haydn, R. Application of the IHS color transform to the processing of multisensor data and image enhancement. In Proceedings of the International Symposium on Remote Sensing of Arid and Semi-Arid Lands, Cairo, Egypt, 19–25 January 1982. [Google Scholar]
- Carper, W.; Lillesand, T.; Kiefer, R. The use of intensity-hue-saturation transformations for merging SPOT panchromatic and multispectral image data. Photogramm. Eng. Remote Sens. 1990, 56, 459–467. [Google Scholar]
- Kwarteng, P.; Chavez, A. Extracting spectral contrast in Landsat Thematic Mapper image data using selective principal component analysis. Photogramm. Eng. Remote Sens. 1989, 55, 339–348. [Google Scholar]
- Laben, C.A.; Brower, B.V. Process for Enhancing the Spatial Resolution of Multispectral Imagery Using Pan-Sharpening. U.S. Patent 6,011,875, 4 January 2000. [Google Scholar]
- Aiazzi, B.; Baronti, S.; Selva, M. Improving component substitution pansharpening through multivariate regression of MS + Pan data. IEEE Trans. Geosci. Remote Sens. 2007, 45, 3230–3239. [Google Scholar] [CrossRef]
- Choi, J.; Yu, K.; Kim, Y. A new adaptive component-substitution-based satellite image fusion by using partial replacement. IEEE Trans. Geosci. Remote Sens. 2010, 49, 295–309. [Google Scholar] [CrossRef]
- Garzelli, A.; Nencini, F.; Capobianco, L. Optimal MMSE Pan Sharpening of Very High Resolution Multispectral Images. IEEE Trans. Geosci. Remote Sens. 2008, 46, 228–236. [Google Scholar] [CrossRef]
- Ghassemian, H. A review of remote sensing image fusion methods. Inf. Fusion 2016, 32, 75–89. [Google Scholar] [CrossRef]
- Pradhan, P.S.; King, R.L.; Younan, N.H.; Holcomb, D.W. Estimation of the number of decomposition levels for a wavelet-based multiresolution multisensor image fusion. IEEE Trans. Geosci. Remote Sens. 2006, 44, 3674–3686. [Google Scholar] [CrossRef]
- Burt, P.J.; Adelson, E.H. The Laplacian pyramid as a compact image code. In Readings in Computer Vision; Elsevier: Amsterdam, The Netherlands, 1987; pp. 671–679. [Google Scholar]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A. Context-driven fusion of high spatial and spectral resolution images based on oversampled multiresolution analysis. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2300–2312. [Google Scholar] [CrossRef]
- Shah, V.P.; Younan, N.H.; King, R.L. An efficient pan-sharpening method via a combined adaptive PCA approach and contourlets. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1323–1335. [Google Scholar] [CrossRef]
- Yang, Y.; Lu, H.; Huang, S.; Tu, W. Pansharpening based on joint-guided detail extraction. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 14, 389–401. [Google Scholar] [CrossRef]
- Meng, X.; Xiong, Y.; Shao, F.; Shen, H.; Sun, W.; Yang, G.; Yuan, Q.; Fu, R.; Zhang, H. A large-scale benchmark data set for evaluating pansharpening performance: Overview and implementation. IEEE Geosci. Remote Sens. Mag. 2020, 9, 18–52. [Google Scholar] [CrossRef]
- Mascarenhas, N.; Banon, G.; Candeias, A. Multispectral image data fusion under a Bayesian approach. Int. J. Remote Sens. 1996, 17, 1457–1471. [Google Scholar] [CrossRef]
- Ballester, C.; Caselles, V.; Igual, L.; Verdera, J.; Rougé, B. A variational model for P+ XS image fusion. Int. J. Comput. Vis. 2006, 69, 43–58. [Google Scholar] [CrossRef]
- Meng, X.; Shen, H.; Yuan, Q.; Li, H.; Zhang, L.; Sun, W. Pansharpening for cloud-contaminated very high-resolution remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 2840–2854. [Google Scholar] [CrossRef]
- Zhang, L.; Shen, H.; Gong, W.; Zhang, H. Adjustable model-based fusion method for multispectral and panchromatic images. IEEE Trans. Syst. Man Cybern. Part (Cybern.) 2012, 42, 1693–1704. [Google Scholar] [CrossRef]
- Li, S.; Yang, B. A new pan-sharpening method using a compressed sensing technique. IEEE Trans. Geosci. Remote Sens. 2010, 49, 738–746. [Google Scholar] [CrossRef]
- Zhu, X.X.; Bamler, R. A sparse image fusion algorithm with application to pan-sharpening. IEEE Trans. Geosci. Remote Sens. 2012, 51, 2827–2836. [Google Scholar] [CrossRef]
- Lai, Z.; Chen, L.; Jeon, G.; Liu, Z.; Zhong, R.; Yang, X. Real-time and effective pan-sharpening for remote sensing using multi-scale fusion network. J.-Real-Time Image Process. 2021, 18, 1635–1651. [Google Scholar] [CrossRef]
- Lai, Z.; Chen, L.; Liu, Z.; Yang, X. Gradient Guided Pyramidal Convolution Residual Network with Interactive Connections for Pan-sharpening. Int. J. Remote. Sens. 2021, 1–31. [Google Scholar] [CrossRef]
- Guan, P.; Lam, E.Y. Multistage Dual-Attention Guided Fusion Network for Hyperspectral Pansharpening. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Yang, J.; An, W.; Yu, J.; Guo, Y. Spatial-angular interaction for light field image super-resolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 290–308. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhao, H.; Kong, X.; He, J.; Qiao, Y.; Dong, C. Efficient image super-resolution using pixel attention. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 56–72. [Google Scholar]
- Wald, L.; Ranchin, T.; Mangolini, M. Fusion of satellite images of different spatial resolutions: Assessing the quality of resulting images. Photogramm. Eng. Remote Sens. 1997, 63, 691–699. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Yuhas, R.H.; Goetz, A.F.; Boardman, J.W. Discrimination among semi-arid landscape endmembers using the spectral angle mapper (SAM) algorithm. In Proceedings of the JPL, Summaries of the Third Annual JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 1–5 June 1992. [Google Scholar]
- Wald, L. Data Fusion: Definitions and Architectures: Fusion of Images of Different Spatial Resolutions; Presses des MINES: Paris, France, 2002. [Google Scholar]
- Palsson, F.; Sveinsson, J.R.; Benediktsson, J.A.; Aanaes, H. Classification of pansharpened urban satellite images. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2011, 5, 281–297. [Google Scholar] [CrossRef]
- Garzelli, A.; Nencini, F. Hypercomplex quality assessment of multi/hyperspectral images. IEEE Geosci. Remote. Sens. Lett. 2009, 6, 662–665. [Google Scholar] [CrossRef]
- Alparone, L.; Aiazzi, B.; Baronti, S.; Garzelli, A.; Nencini, F.; Selva, M. Multispectral and panchromatic data fusion assessment without reference. Photogramm. Eng. Remote. Sens. 2008, 74, 193–200. [Google Scholar] [CrossRef] [Green Version]
- Vivone, G.; Alparone, L.; Chanussot, J.; Dalla Mura, M.; Garzelli, A.; Licciardi, G.A.; Restaino, R.; Wald, L. A critical comparison among pansharpening algorithms. IEEE Trans. Geosci. Remote. Sens. 2014, 53, 2565–2586. [Google Scholar] [CrossRef]
- Vivone, G. Robust band-dependent spatial-detail approaches for panchromatic sharpening. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6421–6433. [Google Scholar] [CrossRef]
- Aiazzi, B.; Alparone, L.; Baronti, S.; Garzelli, A.; Selva, M. MTF-tailored multiscale fusion of high-resolution MS and Pan imagery. Photogramm. Eng. Remote Sens. 2006, 72, 591–596. [Google Scholar] [CrossRef]









| Satellite Sensors | Image Type | Spatial Dimension | Spectral Dimension | Dimension Size | Bits |
|---|---|---|---|---|---|
| QuickBird | MS PAN | 2.44 m 0.61 m | Four band one band | 256 × 256 × 4 1024 × 1024 | 11 bit |
| WorldView4 | MS PAN | 1.24 m 0.31 m | Four band one band | 256 × 256 × 4 1024 × 1024 | 11 bit |
| WorldView2 | MS PAN | 2 m 0.5 m | Eight band one band | 256 × 256 × 8 1024 × 1024 | 11 bit |
| Methods | SAM↓ | ERGAS↓ | Q2n↑ | CC↑ | #Params |
|---|---|---|---|---|---|
| SSIN (N = 2, L = 2) | 2.9677 | 2.5289 | 0.7714 | 0.9726 | 1.87 M |
| SSIN (N = 3, L = 2) | 2.9418 | 2.5101 | 0.7724 | 0.9728 | 2.76 M |
| SSIN (N = 4, L = 2) | 2.9227 | 2.4653 | 0.7733 | 0.9739 | 3.64 M |
| SSIN (N = 5, L = 2) | 2.9031 | 2.4354 | 0.7741 | 0.9747 | 4.53 M |
| SSIN (N = 3, L = 1) | 3.1256 | 2.7793 | 0.7664 | 0.9674 | 1.82 M |
| SSIN (N = 3, L = 2) | 2.9418 | 2.5101 | 0.7724 | 0.9728 | 2.75 M |
| SSIN (N = 3, L = 3) | 2.9476 | 2.4972 | 0.7733 | 0.9731 | 3.70 M |
| SSIN (N = 3, L = 4) | 2.9234 | 2.4658 | 0.7733 | 0.974 | 4.63 M |
| Methods | SAM↓ | ERGAS↓ | Q2N↑ | CC↑ |
|---|---|---|---|---|
| EXP | 1.8768 | 1.8316 | 0.6913 | 0.8776 |
| GSA | 1.4291 | 1.1440 | 0.8329 | 0.9447 |
| PRACS | 1.4681 | 1.1957 | 0.8210 | 0.9406 |
| BDSD-PC | 1.4268 | 1.1099 | 0.8388 | 0.9470 |
| MTF-GLP | 1.4162 | 1.1602 | 0.8282 | 0.9438 |
| PNN | 1.1802 | 0.9451 | 0.8660 | 0.9601 |
| PanNet | 1.0350 | 0.8068 | 0.8825 | 0.9686 |
| MSDCNN | 1.0011 | 0.7787 | 0.8830 | 0.9696 |
| TFNET | 0.8475 | 0.6494 | 0.8991 | 0.9778 |
| GGPCRN | 0.7714 | 0.5951 | 0.9091 | 0.9809 |
| MUCNN | 0.9134 | 0.7121 | 0.8950 | 0.9737 |
| MDA-Net | 0.7740 | 0.5908 | 0.9104 | 0.9815 |
| SSIN | 0.7292 | 0.5427 | 0.914 | 0.9833 |
| Methods | SAM↓ | ERGAS↓ | Q2N↑ | CC↑ |
|---|---|---|---|---|
| EXP | 2.5639 | 3.2561 | 0.6957 | 0.9026 |
| GSA | 2.6454 | 2.5375 | 0.7735 | 0.9372 |
| PRACS | 2.5875 | 2.4452 | 0.7753 | 0.9412 |
| BDSD-PC | 2.6018 | 2.4424 | 0.7876 | 0.9435 |
| MTF-GLP | 2.5785 | 2.5715 | 0.7783 | 0.9409 |
| PNN | 1.9677 | 1.9709 | 0.8371 | 0.9583 |
| PanNet | 1.9605 | 1.9341 | 0.8361 | 0.9594 |
| MSDCNN | 1.8648 | 1.8522 | 0.8492 | 0.9618 |
| TFNET | 1.4589 | 1.3066 | 0.8909 | 0.9788 |
| GGPCRN | 1.3167 | 1.1445 | 0.9025 | 0.9826 |
| MUCNN | 1.7308 | 1.7138 | 0.8676 | 0.9675 |
| MDA-Net | 1.3068 | 1.1487 | 0.9040 | 0.9828 |
| SSIN | 1.1994 | 1.0399 | 0.9095 | 0.9853 |
| Methods | SAM↓ | ERGAS↓ | Q2N↑ | CC↑ |
|---|---|---|---|---|
| EXP | 5.3078 | 7.3730 | 0.4887 | 0.8017 |
| GSA | 4.9165 | 5.0016 | 0.6764 | 0.9089 |
| PRACS | 5.1933 | 5.8450 | 0.6111 | 0.8844 |
| BDSD-PC | 4.8530 | 4.7933 | 0.6853 | 0.9169 |
| MTF-GLP | 4.7501 | 4.8380 | 0.6899 | 0.9150 |
| PNN | 3.7671 | 3.4542 | 0.7422 | 0.9535 |
| PanNet | 3.6355 | 3.2757 | 0.7545 | 0.9574 |
| MSDCNN | 3.4789 | 3.0815 | 0.7528 | 0.9608 |
| TFNET | 3.1212 | 2.6381 | 0.7642 | 0.9702 |
| GGPCRN | 3.0029 | 2.5669 | 0.7699 | 0.9715 |
| MUCNN | 3.3052 | 2.9356 | 0.7576 | 0.9642 |
| MDA-Net | 2.9554 | 2.5030 | 0.7737 | 0.9729 |
| SSIN | 2.9227 | 2.4653 | 0.7733 | 0.9739 |
| Methods | Time(s) | #Parameters | |
|---|---|---|---|
| Traditional methods | EXP | 0.1136 | - |
| BDSD-PC | 0.199 | - | |
| GSA | 0.5937 | - | |
| PRACS | 0.97 | - | |
| MTF-GLP | 0.4555 | - | |
| DL-based methods | PNN | 0.008 | 80 K |
| PanNet | 0.009 | 77 k | |
| MSDCNN | 0.0089 | 190 K | |
| TFNET | 0.0095 | 2.36 M | |
| GGPCRN | 0.014 | 1.77 M | |
| MUCNN | 0.0081 | 1.36 M | |
| MDA-Net | 0.0172 | 12 M | |
| SSIN | 0.0157 | 3.63 M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nie, Z.; Chen, L.; Jeon, S.; Yang, X. Spectral-Spatial Interaction Network for Multispectral Image and Panchromatic Image Fusion. Remote Sens. 2022, 14, 4100. https://doi.org/10.3390/rs14164100
Nie Z, Chen L, Jeon S, Yang X. Spectral-Spatial Interaction Network for Multispectral Image and Panchromatic Image Fusion. Remote Sensing. 2022; 14(16):4100. https://doi.org/10.3390/rs14164100
Chicago/Turabian StyleNie, Zihao, Lihui Chen, Seunggil Jeon, and Xiaomin Yang. 2022. "Spectral-Spatial Interaction Network for Multispectral Image and Panchromatic Image Fusion" Remote Sensing 14, no. 16: 4100. https://doi.org/10.3390/rs14164100
APA StyleNie, Z., Chen, L., Jeon, S., & Yang, X. (2022). Spectral-Spatial Interaction Network for Multispectral Image and Panchromatic Image Fusion. Remote Sensing, 14(16), 4100. https://doi.org/10.3390/rs14164100