


SVASeg: Sparse Voxel-Based Attention for 3D LiDAR Point Cloud Semantic Segmentation

Abstract
:1. Introduction
2. Related Work
2.1. LiDAR Semantic Segmentation
2.2. Transformer in Point Cloud
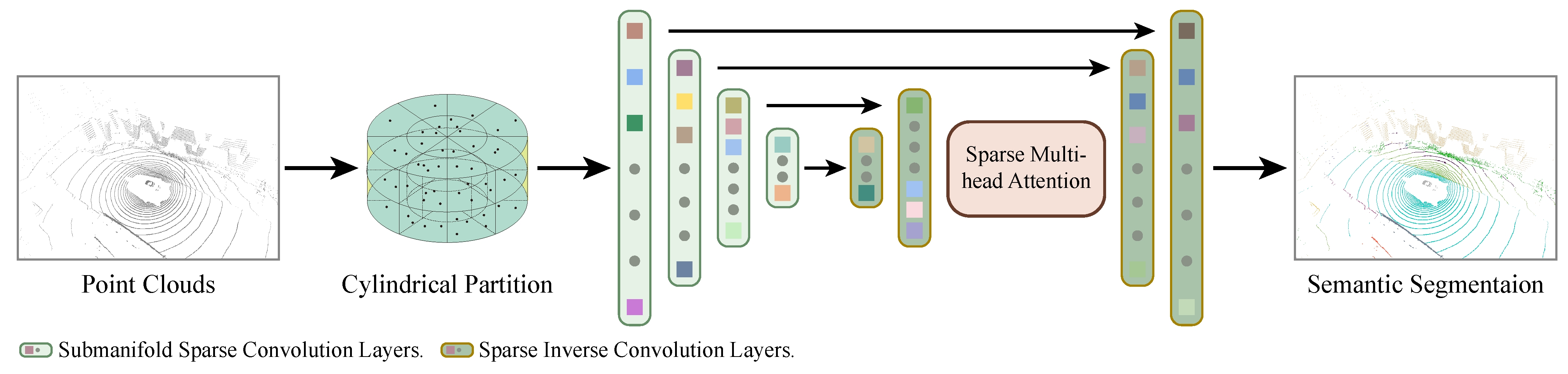
3. Proposed Method
3.1. Network Architecture
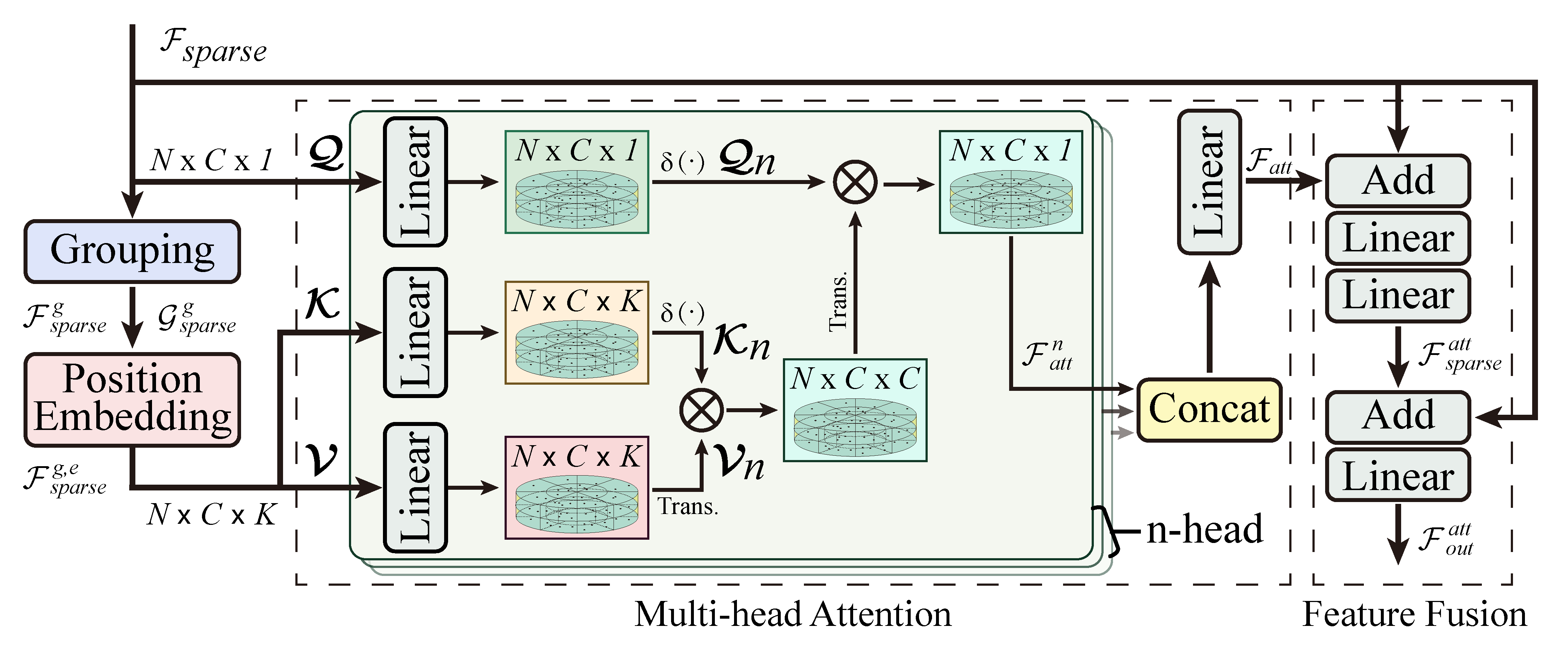
3.2. Sparse Voxel-Based Multi-Head Attention
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
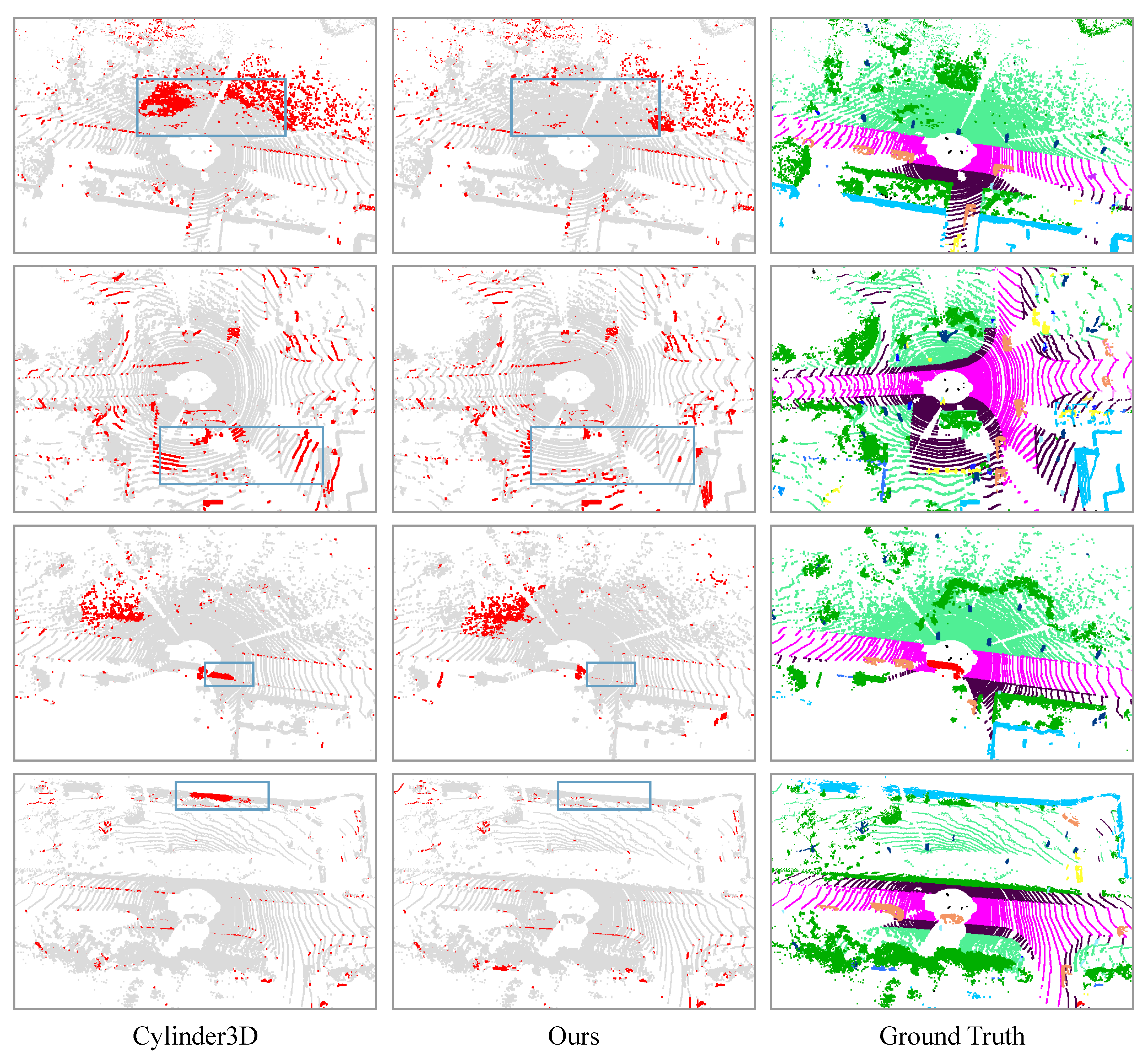
4.3. Evaluation on the SemanticKITTI Dataset
4.4. Evaluation on the nuScenes Dataset
4.5. Ablation Studies
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Liu, L.; Yu, J.; Tan, L.; Su, W.; Zhao, L.; Tao, W. Semantic Segmentation of 3D Point Cloud Based on Spatial Eight-Quadrant Kernel Convolution. Remote Sens. 2021, 13, 3140. [Google Scholar] [CrossRef]
- Xu, T.; Gao, X.; Yang, Y.; Xu, L.; Xu, J.; Wang, Y. Construction of a Semantic Segmentation Network for the Overhead Catenary System Point Cloud Based on Multi-Scale Feature Fusion. Remote Sens. 2022, 14, 2768. [Google Scholar] [CrossRef]
- Zhao, L.; Tao, W. JSNet: Joint Instance and Semantic Segmentation of 3D Point Clouds. Proc. Aaai Conf. Artif. Intell. 2020, 34, 12951–12958. [Google Scholar] [CrossRef]
- Thomas, H.; Qi, C.R.; Deschaud, J.E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October 2019–2 November 2019. [Google Scholar]
- Ballouch, Z.; Hajji, R.; Poux, F.; Kharroubi, A.; Billen, R. A Prior Level Fusion Approach for the Semantic Segmentation of 3D Point Clouds Using Deep Learning. Remote Sens. 2022, 14, 3415. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wu, W.; Qi, Z.; Fuxin, L. PointConv: Deep Convolutional Networks on 3D Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Gao, F.; Yan, Y.; Lin, H.; Shi, R. PIIE-DSA-Net for 3D Semantic Segmentation of Urban Indoor and Outdoor Datasets. Remote Sens. 2022, 14, 3583. [Google Scholar] [CrossRef]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, uncertainty-aware semantic segmentation of LiDAR point clouds. In Proceedings of the International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020; pp. 207–222. [Google Scholar]
- Xu, C.; Wu, B.; Wang, Z.; Zhan, W.; Vajda, P.; Keutzer, K.; Tomizuka, M. Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 1–19. [Google Scholar]
- Kochanov, D.; Nejadasl, F.K.; Booij, O. KPRNet: Improving projection-based LiDAR semantic segmentation. arXiv 2020, arXiv:2007.12668. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. Polarnet: An improved grid representation for online lidar point clouds semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9601–9610. [Google Scholar]
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Liu, Z.; Tang, H.; Lin, Y.; Han, S. Point-voxel cnn for efficient 3d deep learning. arXiv 2019, arXiv:1907.03739. [Google Scholar]
- Graham, B.; Engelcke, M.; van der Maaten, L. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching efficient 3d architectures with sparse point-voxel convolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 685–702. [Google Scholar]
- Zhu, X.; Zhou, H.; Wang, T.; Hong, F.; Li, W.; Ma, Y.; Li, H.; Yang, R.; Lin, D. Cylindrical and asymmetrical 3d convolution networks for lidar-based perception. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef]
- Gerdzhev, M.; Razani, R.; Taghavi, E.; Bingbing, L. Tornado-net: Multiview total variation semantic segmentation with diamond inception module. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May–5 June 2021; pp. 9543–9549. [Google Scholar]
- Zhao, L.; Zhou, H.; Zhu, X.; Song, X.; Li, H.; Tao, W. LIF-Seg: LiDAR and Camera Image Fusion for 3D LiDAR Semantic Segmentation. arXiv 2021, arXiv:2108.07511. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3075–3084. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Li, Z.; Wang, W.; Xie, E.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Lu, T.; Luo, P. Panoptic SegFormer. arXiv 2021, arXiv:2109.03814. [Google Scholar]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3d object detection. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 3164–3173. [Google Scholar]
- Fan, L.; Pang, Z.; Zhang, T.; Wang, Y.X.; Zhao, H.; Wang, F.; Wang, N.; Zhang, Z. Embracing Single Stride 3D Object Detector with Sparse Transformer. arXiv 2021, arXiv:2112.06375. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Cao, H.; Lu, Y.; Lu, C.; Pang, B.; Liu, G.; Yuille, A. Asap-net: Attention and structure aware point cloud sequence segmentation. arXiv 2020, arXiv:2008.05149. [Google Scholar]
- Yan, X.; Zheng, C.; Li, Z.; Wang, S.; Cui, S. Pointasnl: Robust point clouds processing using nonlocal neural networks with adaptive sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5589–5598. [Google Scholar]
- Gan, L.; Zhang, R.; Grizzle, J.W.; Eustice, R.M.; Ghaffari, M. Bayesian spatial kernel smoothing for scalable dense semantic mapping. IEEE Robot. Autom. Lett. 2020, 5, 790–797. [Google Scholar] [CrossRef]
- Cheng, M.; Hui, L.; Xie, J.; Yang, J.; Kong, H. Cascaded non-local neural network for point cloud semantic segmentation. In Proceedings of the 2020 IEEE International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October–24 January 2020; pp. 8447–8452. [Google Scholar]
- Fang, Y.; Xu, C.; Cui, Z.; Zong, Y.; Yang, J. Spatial transformer point convolution. arXiv 2020, arXiv:2009.01427. [Google Scholar]
- Geng, X.; Ji, S.; Lu, M.; Zhao, L. Multi-scale attentive aggregation for LiDAR point cloud segmentation. Remote Sens. 2021, 13, 691. [Google Scholar] [CrossRef]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. Rangenet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Duerr, F.; Pfaller, M.; Weigel, H.; Beyerer, J. LiDAR-based recurrent 3D semantic segmentation with temporal memory alignment. In Proceedings of the 2020 International Conference on 3D Vision, Fukuoka, Japan, 25–28 November 2020; pp. 781–790. [Google Scholar]
- Razani, R.; Cheng, R.; Taghavi, E.; Bingbing, L. Lite-hdseg: Lidar semantic segmentation using lite harmonic dense convolutions. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation, Xi’an, China, 30 May 2021–5 June 2021; pp. 9550–9556. [Google Scholar]
- Park, J.; Kim, C.; Jo, K. PCSCNet: Fast 3D Semantic Segmentation of LiDAR Point Cloud for Autonomous Car using Point Convolution and Sparse Convolution Network. arXiv 2022, arXiv:2202.10047. [Google Scholar]
- Liong, V.E.; Nguyen, T.N.T.; Widjaja, S.; Sharma, D.; Chong, Z.J. AMVNet: Assertion-based Multi-View Fusion Network for LiDAR Semantic Segmentation. arXiv 2020, arXiv:2012.04934. [Google Scholar]
- Wang, Y.; Fathi, A.; Kundu, A.; Ross, D.; Pantofaru, C.; Funkhouser, T.; Solomon, J. Pillar-based object detection for autonomous driving. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Zhou, Y.; Sun, P.; Zhang, Y.; Anguelov, D.; Gao, J.; Ouyang, T.; Guo, J.; Ngiam, J.; Vasudevan, V. End-to-end multi-view fusion for 3d object detection in lidar point clouds. In Proceedings of the Conference on Robot Learning, PMLR, Virtual, 16–18 November 2020; pp. 923–932. [Google Scholar]
- Zhang, F.; Fang, J.; Wah, B.; Torr, P. Deep fusionnet for point cloud semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 644–663. [Google Scholar]
- Chen, K.; Oldja, R.; Smolyanskiy, N.; Birchfield, S.; Popov, A.; Wehr, D.; Eden, I.; Pehserl, J. MVLidarNet: Real-Time Multi-Class Scene Understanding for Autonomous Driving Using Multiple Views. arXiv 2020, arXiv:2006.05518. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16259–16268. [Google Scholar]
- Mazur, K.; Lempitsky, V. Cloud transformers: A universal approach to point cloud processing tasks. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10715–10724. [Google Scholar]
- Wang, J.; Chakraborty, R.; Stella, X.Y. Spatial transformer for 3D point clouds. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. Pct: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The lovász-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4413–4421. [Google Scholar]
- Shen, Z.; Zhang, M.; Zhao, H.; Yi, S.; Li, H. Efficient attention: Attention with linear complexities. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3531–3539. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhuang, Z.; Li, R.; Jia, K.; Wang, Q.; Li, Y.; Tan, M. Perception-aware Multi-sensor Fusion for 3D LiDAR Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 16280–16290. [Google Scholar]
- Rosu, R.A.; Schütt, P.; Quenzel, J.; Behnke, S. Latticenet: Fast point cloud segmentation using permutohedral lattices. arXiv 2019, arXiv:1912.05905. [Google Scholar]
- Li, S.; Chen, X.; Liu, Y.; Dai, D.; Stachniss, C.; Gall, J. Multi-scale interaction for real-time lidar data segmentation on an embedded platform. IEEE Robot. Autom. Lett. 2021, 7, 738–745. [Google Scholar] [CrossRef]
- Alonso, I.; Riazuelo, L.; Montesano, L.; Murillo, A.C. 3d-mininet: Learning a 2d representation from point clouds for fast and efficient 3d lidar semantic segmentation. IEEE Robot. Autom. Lett. 2020, 5, 5432–5439. [Google Scholar] [CrossRef]
- Cheng, R.; Razani, R.; Taghavi, E.; Li, E.; Liu, B. AF2-S3Net: Attentive Feature Fusion with Adaptive Feature Selection for Sparse Semantic Segmentation Network. arXiv 2021, arXiv:2102.04530. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Methods | mIoU | Car | Bicycle | Motorcycle | Truck | Other-Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalk | Other-Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic-Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #Points (k) | - | 6384 | 44 | 52 | 101 | 471 | 127 | 129 | 5 | 21434 | 974 | 8149 | 67 | 6304 | 1691 | 20391 | 882 | 8125 | 317 | 64 |
| RandLANet [1] | 50.0 | 92.0 | 8.0 | 12.8 | 74.8 | 46.7 | 52.3 | 46.0 | 0.0 | 93.4 | 32.7 | 73.4 | 0.1 | 84.0 | 43.5 | 83.7 | 57.3 | 73.1 | 48.0 | 27.3 |
| RangeNet++ [34] | 51.2 | 89.4 | 26.5 | 48.4 | 33.9 | 26.7 | 54.8 | 69.4 | 0.0 | 92.9 | 37.0 | 69.9 | 0.0 | 83.4 | 51.0 | 83.3 | 54.0 | 68.1 | 49.8 | 34.0 |
| SequeezeSegV3 [11] | 53.3 | 87.1 | 34.3 | 48.6 | 47.5 | 47.1 | 58.1 | 53.8 | 0.0 | 95.3 | 43.1 | 78.2 | 0.3 | 78.9 | 53.2 | 82.3 | 55.5 | 70.4 | 46.3 | 33.2 |
| MinkowskiNet [21] | 58.5 | 95.0 | 23.9 | 50.4 | 55.3 | 45.9 | 65.6 | 82.2 | 0.0 | 94.3 | 43.7 | 76.4 | 0.0 | 87.9 | 57.6 | 87.4 | 67.7 | 71.5 | 63.5 | 43.6 |
| SalsaNext [10] | 59.4 | 90.5 | 44.6 | 49.6 | 86.3 | 54.6 | 74.0 | 81.4 | 0.0 | 93.4 | 40.6 | 69.1 | 0.0 | 84.6 | 53.0 | 83.6 | 64.3 | 64.2 | 54.4 | 39.8 |
| SPVNAS [17] | 62.3 | 96.5 | 44.8 | 63.1 | 59.9 | 64.3 | 72.0 | 86.0 | 0.0 | 93.9 | 42.4 | 75.9 | 0.0 | 88.8 | 59.1 | 88.0 | 67.5 | 73.0 | 63.5 | 44.3 |
| PMF [51] | 63.9 | 95.4 | 47.8 | 62.9 | 68.4 | 75.2 | 78.9 | 71.6 | 0.0 | 96.4 | 43.5 | 80.5 | 0.1 | 88.7 | 60.1 | 88.6 | 72.7 | 75.3 | 65.5 | 43.0 |
| Cylinder3D [18] | 64.9 | 96.4 | 61.5 | 78.2 | 66.3 | 69.8 | 80.8 | 93.3 | 0.0 | 94.9 | 41.5 | 78.0 | 1.4 | 87.5 | 50.0 | 86.7 | 72.2 | 68.8 | 63.0 | 42.1 |
| AMVNet [38] | 65.2 | 95.6 | 48.8 | 65.4 | 88.7 | 54.8 | 70.8 | 86.2 | 0.0 | 95.5 | 53.9 | 83.2 | 0.15 | 90.9 | 62.1 | 87.9 | 66.8 | 74.2 | 64.7 | 49.3 |
| SVASeg (Ours) | 66.1 | 96.8 | 53.0 | 80.2 | 88.9 | 62.8 | 78.1 | 91.4 | 1.1 | 93.7 | 41.0 | 78.7 | 0.1 | 89.7 | 55.1 | 89.2 | 65.8 | 76.7 | 65.1 | 49.0 |
| Methods | mIoU | Car | Bicycle | Motorcycle | Truck | Other-Vehicle | Person | Bicyclist | Motorcyclist | Road | Parking | Sidewalk | Other-Ground | Building | Fence | Vegetation | Trunk | Terrain | Pole | Traffic-Sign |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S-BKI [30] | 51.3 | 83.8 | 30.6 | 43.0 | 26.0 | 19.6 | 8.5 | 3.4 | 0.0 | 92.6 | 65.3 | 77.4 | 30.1 | 89.7 | 63.7 | 83.4 | 64.3 | 67.4 | 58.6 | 67.1 |
| PointNL [31] | 52.2 | 92.1 | 42.6 | 37.4 | 9.8 | 20.0 | 49.2 | 57.8 | 28.3 | 90.5 | 48.3 | 72.5 | 19.0 | 81.6 | 50.2 | 78.5 | 54.5 | 62.7 | 41.7 | 55.8 |
| RangeNet++ [34] | 52.2 | 91.4 | 25.7 | 34.4 | 25.7 | 23.0 | 38.3 | 38.8 | 4.8 | 91.8 | 65.0 | 75.2 | 27.8 | 87.4 | 58.6 | 80.5 | 55.1 | 64.6 | 47.9 | 55.9 |
| LatticeNet [52] | 52.9 | 92.9 | 16.6 | 22.2 | 26.6 | 21.4 | 35.6 | 43.0 | 46.0 | 90.0 | 59.4 | 74.1 | 22.0 | 88.2 | 58.8 | 81.7 | 63.6 | 63.1 | 51.9 | 48.4 |
| RandLANet [1] | 53.9 | 94.2 | 26.0 | 25.8 | 40.1 | 38.9 | 49.2 | 48.2 | 7.2 | 90.7 | 60.3 | 73.7 | 20.4 | 86.9 | 56.3 | 81.4 | 61.3 | 66.8 | 49.2 | 47.7 |
| PolarNet [13] | 54.3 | 93.8 | 40.3 | 30.1 | 22.9 | 28.5 | 43.2 | 40.2 | 5.6 | 90.8 | 61.7 | 74.4 | 21.7 | 90.0 | 61.3 | 84.0 | 65.5 | 67.8 | 51.8 | 57.5 |
| MinkNet42 [21] | 54.3 | 94.3 | 23.1 | 26.2 | 26.1 | 36.7 | 43.1 | 36.4 | 7.9 | 91.1 | 63.8 | 69.7 | 29.3 | 92.7 | 57.1 | 83.7 | 68.4 | 64.7 | 57.3 | 60.1 |
| STPC [32] | 54.6 | 94.7 | 31.1 | 39.7 | 34.4 | 24.5 | 51.1 | 48.9 | 15.3 | 90.8 | 63.6 | 74.1 | 5.3 | 90.7 | 61.5 | 82.7 | 62.1 | 67.5 | 51.4 | 47.9 |
| MINet [53] | 55.2 | 90.1 | 41.8 | 34.0 | 29.9 | 23.6 | 51.4 | 52.4 | 25.0 | 90.5 | 59.0 | 72.6 | 25.8 | 85.6 | 52.3 | 81.1 | 58.1 | 66.1 | 49.0 | 59.9 |
| 3D-MiniNet [54] | 55.8 | 90.5 | 42.3 | 42.1 | 28.5 | 29.4 | 47.8 | 44.1 | 14.5 | 91.6 | 64.2 | 74.5 | 25.4 | 89.4 | 60.8 | 82.8 | 60.8 | 66.7 | 48.0 | 56.6 |
| SqueezeSegV3 [11] | 55.9 | 92.5 | 38.7 | 36.5 | 29.6 | 33.0 | 45.6 | 46.2 | 20.1 | 91.7 | 63.4 | 74.8 | 26.4 | 89.0 | 59.4 | 82.0 | 58.7 | 65.4 | 49.6 | 58.9 |
| TemporalLidarSeg [35] | 58.2 | 94.1 | 50.0 | 45.7 | 28.1 | 37.1 | 56.8 | 47.3 | 9.2 | 91.7 | 60.1 | 75.9 | 27.0 | 89.4 | 63.3 | 83.9 | 64.6 | 66.8 | 53.6 | 60.5 |
| KPConv [5] | 58.8 | 96.0 | 32.0 | 42.5 | 33.4 | 44.3 | 61.5 | 61.6 | 11.8 | 88.8 | 61.3 | 72.7 | 31.6 | 95.0 | 64.2 | 84.8 | 69.2 | 69.1 | 56.4 | 47.4 |
| SalsaNext [10] | 59.5 | 91.9 | 48.3 | 38.6 | 38.9 | 31.9 | 60.2 | 59.0 | 19.4 | 91.7 | 63.7 | 75.8 | 29.1 | 90.2 | 64.2 | 81.8 | 63.6 | 66.5 | 54.3 | 62.1 |
| FusionNet [41] | 61.3 | 95.3 | 47.5 | 37.7 | 41.8 | 34.5 | 59.5 | 56.8 | 11.9 | 91.8 | 68.8 | 77.1 | 30.8 | 92.5 | 69.4 | 84.5 | 69.8 | 68.5 | 60.4 | 66.5 |
| PCSCNet [37] | 62.7 | 95.7 | 48.8 | 46.2 | 36.4 | 40.6 | 55.5 | 68.4 | 55.9 | 89.1 | 60.2 | 72.4 | 23.7 | 89.3 | 64.3 | 84.2 | 68.2 | 68.1 | 60.5 | 63.9 |
| KPRNet [12] | 63.1 | 95.5 | 54.1 | 47.9 | 23.6 | 42.6 | 65.9 | 65.0 | 16.5 | 93.2 | 73.9 | 80.6 | 30.2 | 91.7 | 68.4 | 85.7 | 69.8 | 71.2 | 58.7 | 64.1 |
| TORANDONet [19] | 63.1 | 94.2 | 55.7 | 48.1 | 40.0 | 38.2 | 63.6 | 60.1 | 34.9 | 89.7 | 66.3 | 74.5 | 28.7 | 91.3 | 65.6 | 85.6 | 67.0 | 71.5 | 58.0 | 65.9 |
| SPVCNN [17] | 63.8 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| Lite-HDSeg [36] | 63.8 | 92.3 | 40.0 | 55.4 | 37.7 | 39.6 | 59.2 | 71.6 | 54.1 | 93.0 | 68.2 | 78.3 | 29.3 | 91.5 | 65.0 | 78.2 | 65.8 | 65.1 | 59.5 | 67.7 |
| SVASeg (Ours) | 65.2 | 96.7 | 56.4 | 57.0 | 49.1 | 56.3 | 70.6 | 67.0 | 15.4 | 92.3 | 65.9 | 76.5 | 23.6 | 91.4 | 66.1 | 85.2 | 72.9 | 67.8 | 63.9 | 65.2 |
| Methods | mIoU | Barrier | Bicycle | Bus | Car | Construction | Motorcycle | Pedestrian | Traffic-Cone | Trailer | Truck | Driveable | Other | Sidewalk | Terrain | Manmade | Vegetation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #Points (k) | - | 1629 | 21 | 851 | 6130 | 194 | 81 | 417 | 112 | 370 | 2560 | 56048 | 1972 | 12631 | 13620 | 31667 | 21948 |
| -S3Net [55] | 62.2 | 60.3 | 12.6 | 82.3 | 80.0 | 20.1 | 62.0 | 59.0 | 49.0 | 42.2 | 67.4 | 94.2 | 68.0 | 64.1 | 68.6 | 82.9 | 82.4 |
| RangeNet++ [34] | 65.5 | 66.0 | 21.3 | 77.2 | 80.9 | 30.2 | 66.8 | 69.6 | 52.1 | 54.2 | 72.3 | 94.1 | 66.6 | 63.5 | 70.1 | 83.1 | 79.8 |
| PolarNet [13] | 71.0 | 74.7 | 28.2 | 85.3 | 90.9 | 35.1 | 77.5 | 71.3 | 58.8 | 57.4 | 76.1 | 96.5 | 71.1 | 74.7 | 74.0 | 87.3 | 85.7 |
| PCSCNet [37] | 72.0 | 73.3 | 42.2 | 87.8 | 86.1 | 44.9 | 82.2 | 76.1 | 62.9 | 49.3 | 77.3 | 95.2 | 66.9 | 69.5 | 72.3 | 83.7 | 82.5 |
| Salsanext [10] | 72.2 | 74.8 | 34.1 | 85.9 | 88.4 | 42.2 | 72.4 | 72.2 | 63.1 | 61.3 | 76.5 | 96.0 | 70.8 | 71.2 | 71.5 | 86.7 | 84.4 |
| Cylinder3D * [18] | 74.0 | 74.5 | 36.6 | 89.5 | 88.0 | 47.9 | 76.5 | 78.1 | 63.0 | 59.7 | 80.3 | 96.3 | 70.8 | 74.5 | 75.0 | 87.5 | 86.7 |
| SVASeg (Ours) | 74.7 | 73.1 | 44.5 | 88.4 | 86.6 | 48.2 | 80.5 | 77.7 | 65.6 | 57.5 | 82.1 | 96.5 | 70.5 | 74.7 | 74.6 | 87.3 | 86.9 |
| Baseline | Hash Size K | Cylinder3D | ||||
|---|---|---|---|---|---|---|
| 16 | 24 | 32 | Original | +SHMA | ||
| 65.2 | 65.7 | 66.0 | 66.1 | 64.9 | 65.6 | |
| Method | Memory | Model Size | Time | |
|---|---|---|---|---|
| Baseline | 3041 | 214 | 102 | 65.2 |
| Baseline + SHMA | 3149 | 216 | 110 | 66.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Xu, S.; Liu, L.; Ming, D.; Tao, W. SVASeg: Sparse Voxel-Based Attention for 3D LiDAR Point Cloud Semantic Segmentation. Remote Sens. 2022, 14, 4471. https://doi.org/10.3390/rs14184471
Zhao L, Xu S, Liu L, Ming D, Tao W. SVASeg: Sparse Voxel-Based Attention for 3D LiDAR Point Cloud Semantic Segmentation. Remote Sensing. 2022; 14(18):4471. https://doi.org/10.3390/rs14184471
Chicago/Turabian StyleZhao, Lin, Siyuan Xu, Liman Liu, Delie Ming, and Wenbing Tao. 2022. "SVASeg: Sparse Voxel-Based Attention for 3D LiDAR Point Cloud Semantic Segmentation" Remote Sensing 14, no. 18: 4471. https://doi.org/10.3390/rs14184471
APA StyleZhao, L., Xu, S., Liu, L., Ming, D., & Tao, W. (2022). SVASeg: Sparse Voxel-Based Attention for 3D LiDAR Point Cloud Semantic Segmentation. Remote Sensing, 14(18), 4471. https://doi.org/10.3390/rs14184471