3.1. MIM Architecture
We believe that the masked image modeling (MIM) strategy can well help self-supervised models for representation learning on unlabeled datasets. MIM methods typically mask a portion of the input image and train the model to recreate the masked area. Many MIM models employ an encoder–decoder structure followed by a projection head, such as BEiT [
45] and MAE [
33]. Here, we will adopt MAE as our MIM base model. MAE is a simple auto-encoding method that can reconstruct missing images by observing partially visible information. It is built on the Vision Transformer architecture and is divided into two components: the encoder and the decoder.
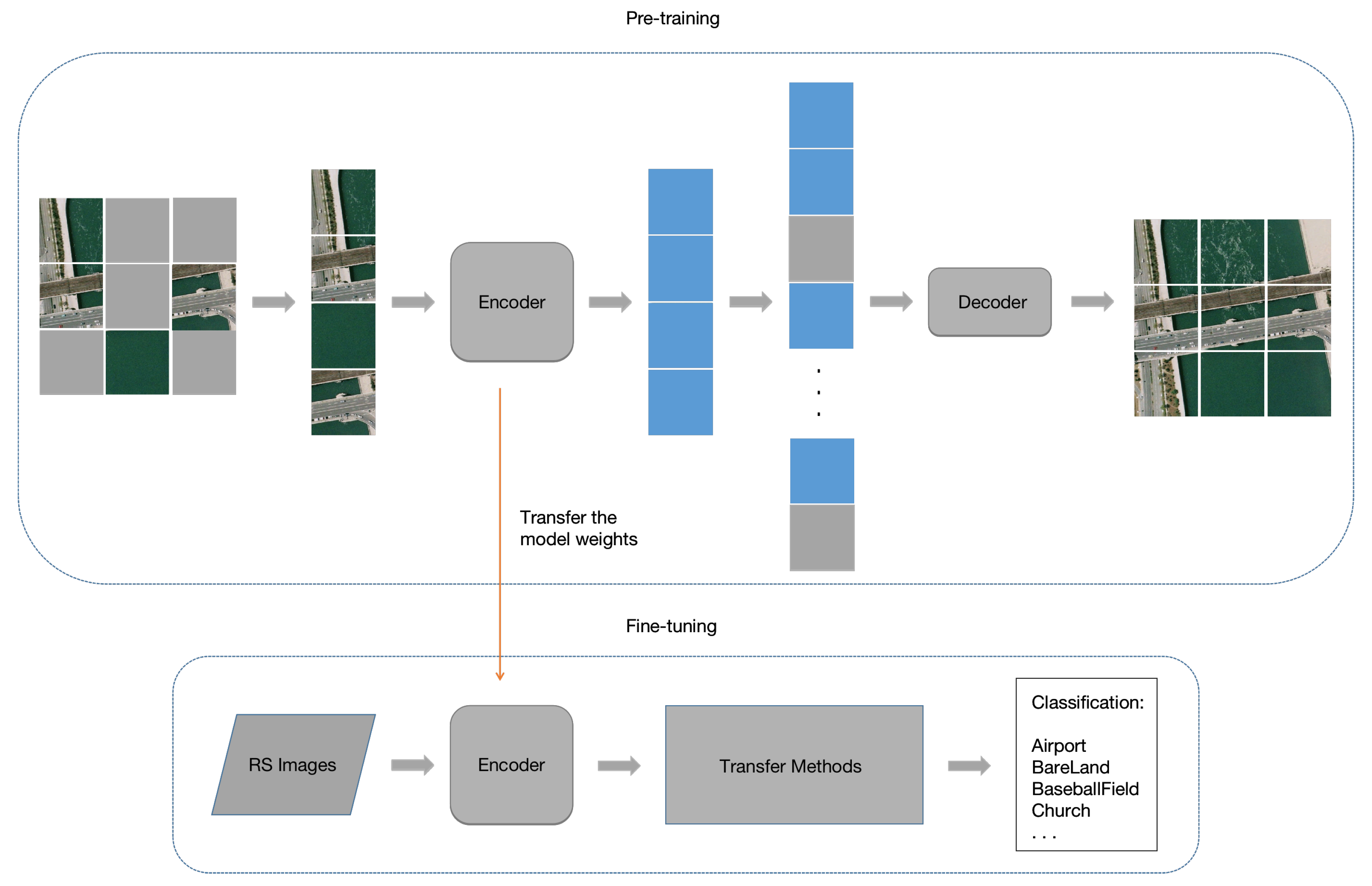
Figure 2 shows our self-supervised learning training process, and the overall architecture of MAE can be seen in the upper part of the figure. Like regular autoencoders, we use an encoder to map the input information to a latent representation, and then we use a decoder to reconstruct the original information using the latent representation. The self-supervised learning training process is divided into two stages: pre-training and fine-tuning. First, representation learning is performed on large-scale unlabeled datasets through pre-training. Then, we use transfer learning to combine self-supervised and remote sensing image classification tasks by fine-tuning a small number of epochs on the labeled dataset. During pre-training, we will use the imagenet-1k [
46] dataset, which does not contain labels for training. Additionally, a large number of patches (e.g., 75%) of image patches are randomly masked out. The encoder only performs feature processing on the unmasked part. Mask tokens are introduced after the encoder, and all encoded patch sets and mask tokens are fed into a small decoder for processing, which reconstructs the original image at the pixel level. The masking and reconstruction work on the image can be seen in
Figure 3. The pre-trained encoder has a good representation learning ability, corresponding to the weights obtained by the model trained on the unlabeled dataset. Our MIM model uses ViT [
15] as the backbone, and the corresponding encoder part consists of alternating layers of Multi-Head Self-Attention (MSA) and multi-layer perceptrons (MLPs) blocks. Layernorm (LN) [
47] is applied before each block, and residual connections are applied after each block. If we denote the corresponding number of layers by
l and the resulting representation by
Z, we can obtain the following representation of the model:
After pre-training, the decoder is discarded, and we only use the encoder to perform simple fine-tuning on the labeled remote sensing image scene classification dataset, thereby transferring the model weights obtained from unsupervised pre-training to the downstream task of RS image classification.
The MIM model consists of an encoder and a decoder, where the encoder is ViT [
15], which handles visible, unmasked patches. We use the settings in ViT to embed patches via linear projection and to add positional embeddings, then we feed the patches into many Transformer blocks to obtain the output. However, the encoder here will remove the mask part and only process the unmask part of each image. Only a small fraction (e.g., 25%)) needs to be processed per image. So, the computation and memory consumption of training the encoder will be small. The input to the decoder consists of encoded visible patches and mask tokens. See
Figure 2. Each mask token is a learnable vector representing the missing part to be predicted. All tokens in this complete set have positional embedding information; masked tokens would not be able to find their relative positions without this. The decoder also uses a lot of Transformer modules. Only during pre-training does the decoder participate in the image reconstruction task (replying the mask part with the output of the encoder). The decoder is discarded, and only the encoder is used for fine-tuning on downstream tasks after pre-training.
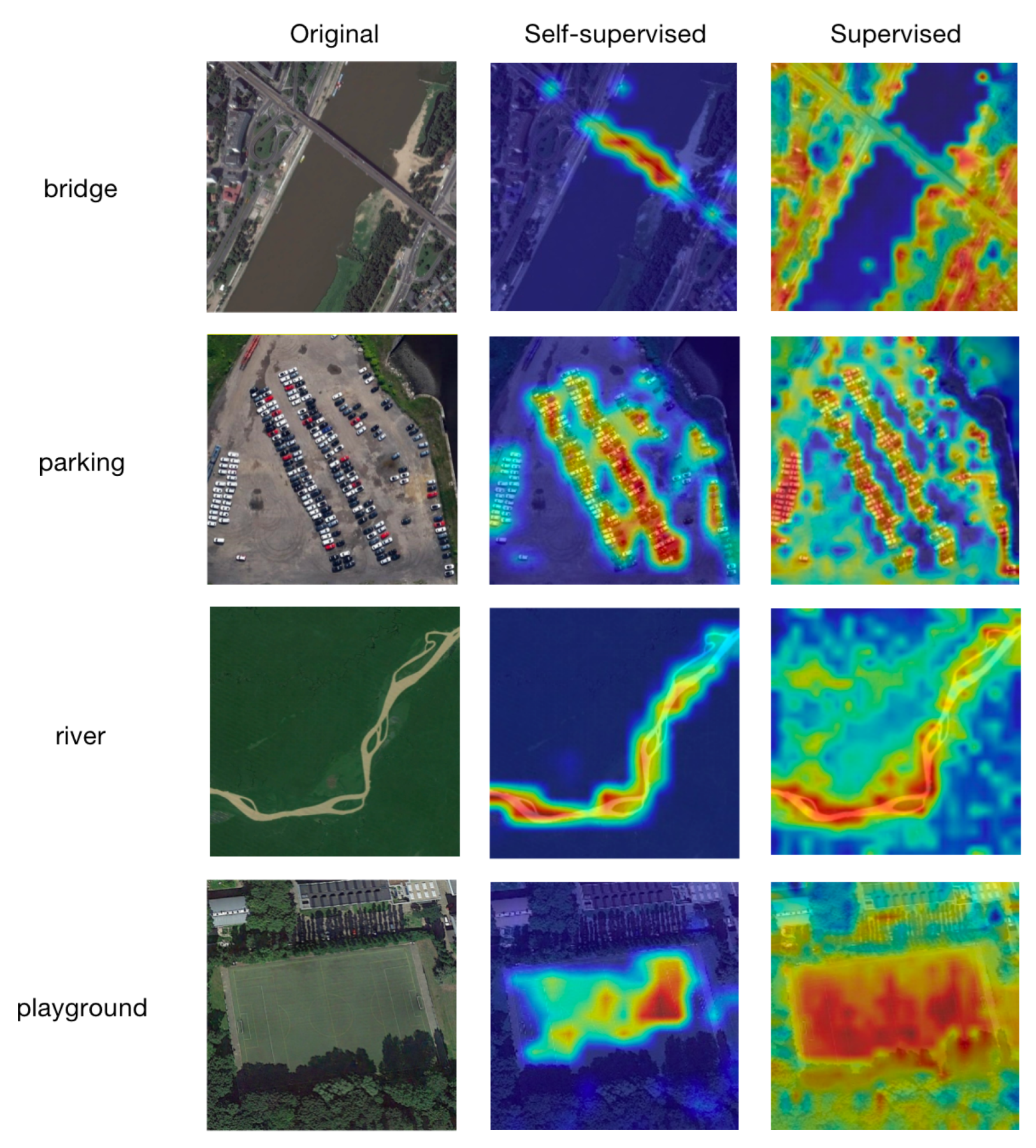
The MIM method uses only a small amount of information to restore the complete picture by masking out most of the redundant information in the picture. Due to the focus on the correlation and continuity of different parts, MIM will be more suitable for the representation learning of a small amount of complex information and transfer to downstream tasks. Especially when there are few target objects in the picture and there is a lot of background information, the MIM method can pay more attention to the object itself. In the subsequent visualization, we can also clearly see that the method focuses on the target object itself and has a clear sense of boundaries.
In this paper, we use the MIM model, using it to perform unlabeled self-supervised learning training results on the imagenet-1k dataset. To further combine self-supervised learning with remote sensing images, we will perform transfer learning for remote sensing image scene classification tasks. In order to study the various effects of self-supervision on remote sensing images, we developed three transfer learning techniques.
3.2. Three Methods for Transfer Learning
By using a large-scale unlabeled dataset and by designing effective pretext tasks, self-supervised learning can theoretically learn a global knowledge representation, but how to ensure that this knowledge representation can be effectively transferred to the target task is not yet conclusive. If a unified feature transfer method is adopted, the transfer may be invalid or even damage the generalization of the model. Another core research question for establishing an effective self-supervised remote sensing interpretation framework is which transfer strategy should be adopted to achieve the best effect. In order to combine MIM-based self-supervised learning and remote sensing image scene classification tasks well, we designed three transfer learning methods to transfer the pre-trained models to downstream tasks. The first two methods need to set hyperparameters and adjust the model: 1. Linear probing [
48] (only the last linear layer parameter is updated). 2. End-to-end fine-tuning [
48], also known as fine-tuning (update all model parameters). In addition, in order to exclude the influence of hyperparameters on downstream tasks, we also use the method of KNN classification [
8] to complete the classification task. Below, we describe these three methods.
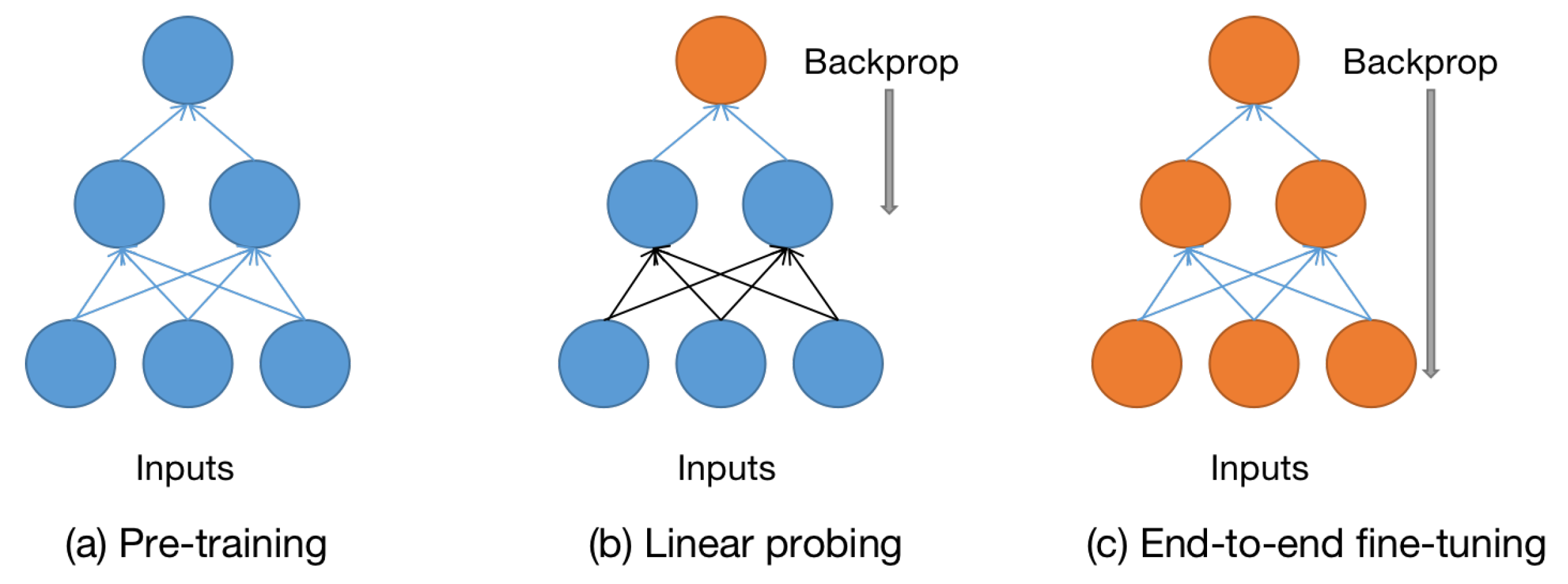
Linear probing and end-to-end fine-tuning are used to optimize the pre-trained model based on the dataset of the downstream task. The principle of fine-tuning is to use the known network structure and known network parameters, modify the corresponding output layer according to the requirements, and fine-tune the parameters of several layers. The difference between these two fine-tuning methods and pre-training methods can be seen from
Figure 4. Since the pre-trained model has learned a certain representation ability, fine-tuning does not require the model to be trained from scratch on large-scale data. This is also a good thing for the small-scale remote sensing image scene classification dataset. This method effectively utilizes the powerful generalization ability of deep neural networks, and avoids designing complex models and time-consuming training.
For linear probing, we only update the classifier, keeping the other parameters of the pre-trained model unchanged. As shown in
Figure 4, linear probing only updates the linear classifier in the last layer of the model, freezing all previous layers. In general, regularization is not good for linear detection, so we remove many common regularization strategies: we do not use cutmix [
49], mixup [
50], color jittering, or drop path [
51]. We only perform some weak augmentations, such as RandomResizedCrop and RandomHorizontalFlip. We chose LARS [
52] as our optimizer when doing linear probing, and the weight decay was set to zero. Normally, when training a linear classifier (e.g., SVM [
53]), the normalized input is passed to the classifier. Here, we normalize the pre-trained features and use them to train a linear classifier. Following [
28], we use an additional BatchNorm(BN) layer [
54] without affine transformation (affine = False). It is beneficial to use BN to normalize the pre-trained features when training the linear probing classifier. We use B to denote a mini-batch of size m for the entire training set, and x to denote its elements. The empirical mean and variance of B could thus be denoted through function (3). The outcome of normalization is
. Here,
is an arbitrarily small constant that is added to the denominator to improve numerical stability. Finally, the results of BN can be obtained using two learnable hyperparameters.
This layer should be placed before the linear classifier to process the pre-trained features generated by the encoder. We note that one layer does not harm the classification performance, and it can be absorbed into the linear classifier after training: it is better at parameterizing the linear classifier. For linear probing and end-to-end fine-tuning, the classifier uses cross-entropy (CE) loss to calculate the difference between the predicted result and the real result. The expression is then as follows:
where
is the ground truth label and
is the prediction of our model for each input picture. The CE loss function closes the gap between the predicted result and the real result, making the predicted result more like the real result.
For end-to-end fine-tuning, we will train and update all the parameters of the network on the remote sensing dataset. We will compute the gradients of the entire model (rather than just computing the gradients of the final linear classifier as in linear probing), optimize the pre-trained model on the remote sensing scene dataset, and update all network parameters. We will unfreeze the entire pre-trained model and retrain it on remote sensing data with a very low learning rate. By gradually adapting the pre-trained features to new data, the accuracy of the pre-trained model on downstream tasks can be improved. After some fine-tuning after epochs, our model achieves high accuracy. Here, we choose the data augmentation method of RandomAug [
55], mixup, and cutmix. Like most Transformer models, we use AdamW [
56] as the optimizer. Similar to linear probing, we also normalize the input to the linear classifier. Here, we use the LayerNorm (LN) [
47] layer for normalization. LN is an algorithm independent of batch size, so no matter the number of samples, it will not affect the amount of data involved in LN calculation. Let
H be the number of hidden layer nodes in a layer, and let
l be the number of layers; we can calculate the normalized statistics
and
of LN:
The calculation of the statistics here has nothing to do with the number of samples, and it is easier to ensure that the normalized statistics of LN are sufficiently representative. The normalized value
can be obtained by
and
.
is a small decimal, preventing division by 0. In LN, we also need a set of parameters called gain
g and bias
b, to ensure that the normalization operation does not destroy the previous information. Assuming that the activation function is
f, the output of the final LN is
.
Combining the above two formulas and ignoring the parameter
l, we have:
Finally, our end-to-end fine-tuning achieves good results on three publicly available remote sensing datasets, surpassing most fully supervised CNN-based models and approaching SOTA’s fully supervised Transformer-based models.
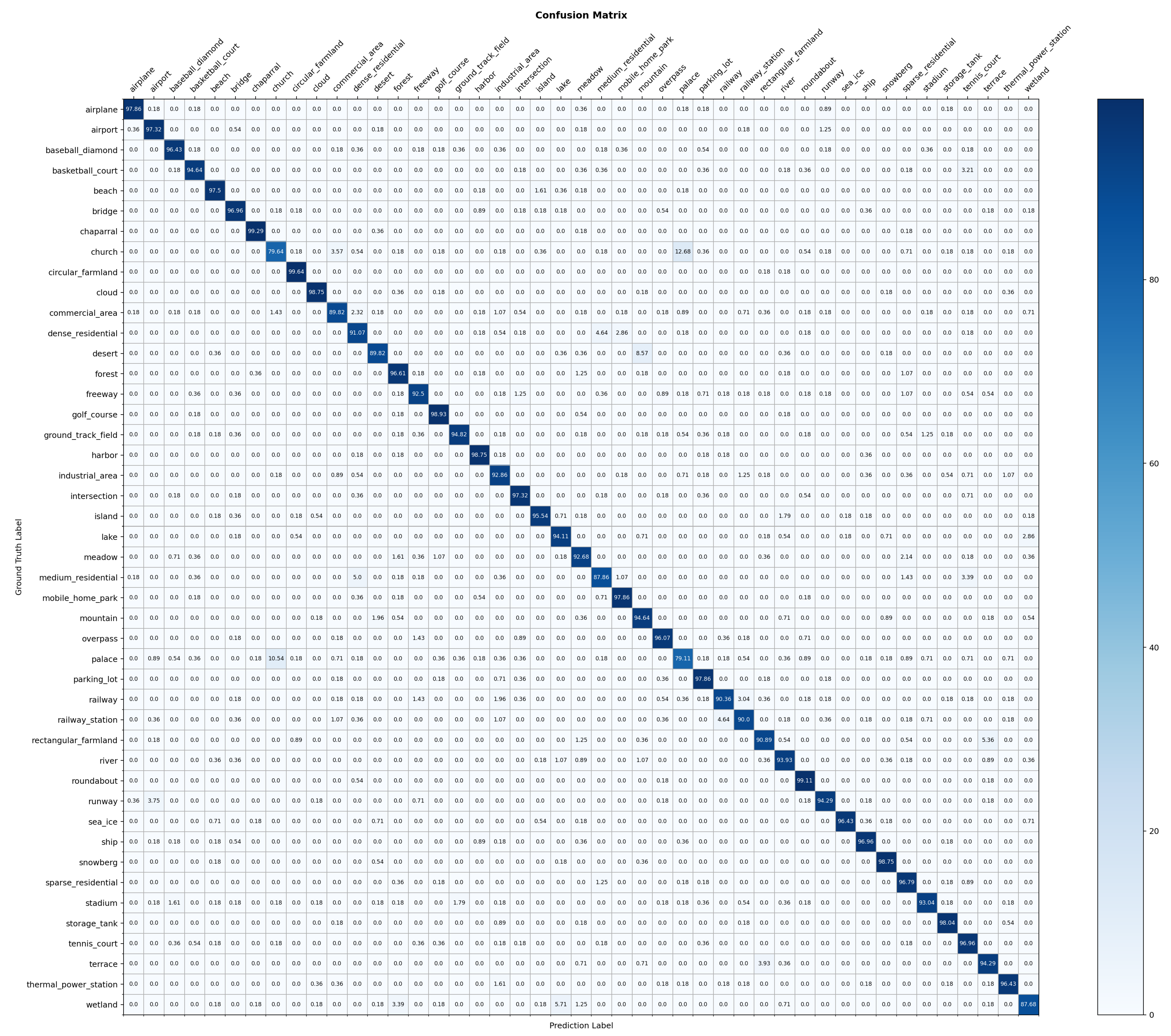
KNN classification directly utilizes the weights obtained via pre-training to directly study the representational ability of self-supervised pre-trained models. The KNN method freezes the entire pre-trained model, and computes and stores the features of the training data for downstream tasks. Regarding the feature selection of the model output, there are generally two kinds—class tokens as global features, and a series of patch tokens composed of each patch. If a patch token is selected, an average pooling operation is required to obtain the final feature result. If a class token is selected, it can be directly used as a global feature for the next calculation. For the classification effect, there is not much difference between the two methods on the classification effect, so for the sake of convenience, we choose the class token for processing. After that, we extract features for each image in the test set and training set, and save the feature results output by the model. For each image in the test set, we multiply its feature matrix with all the training set feature matrices. According to the sorting, we select the k training set images with the smallest difference between their features (here, we set k to 10 according to the scale of the dataset). For the k images in the training set, we count their class labels and use the class with the most occurrences as the new label for this test set image. Finally, we calculate the accuracy of the entire dataset based on the inference results of each test set image. The KNN classification method does not require any other hyperparameter tuning or data augmentation, and can be run only with downstream datasets, which greatly simplifies the transfer of pre-trained models to downstream tasks.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}