

Hyperspectral Image Classification with IFormer Network Feature Extraction

Abstract
:
1. Introduction
- Due to the corresponding reduction in critical information when extracting non-linear features for HSI, the Ghost Module is a novel cost-effective plug-and-play module, and is capable of generating more features with fewer parameters. It not only obtains more essential feature maps without changing the size of the output feature maps, but also significantly reduces the total number of parameters required, and the computational complexity.
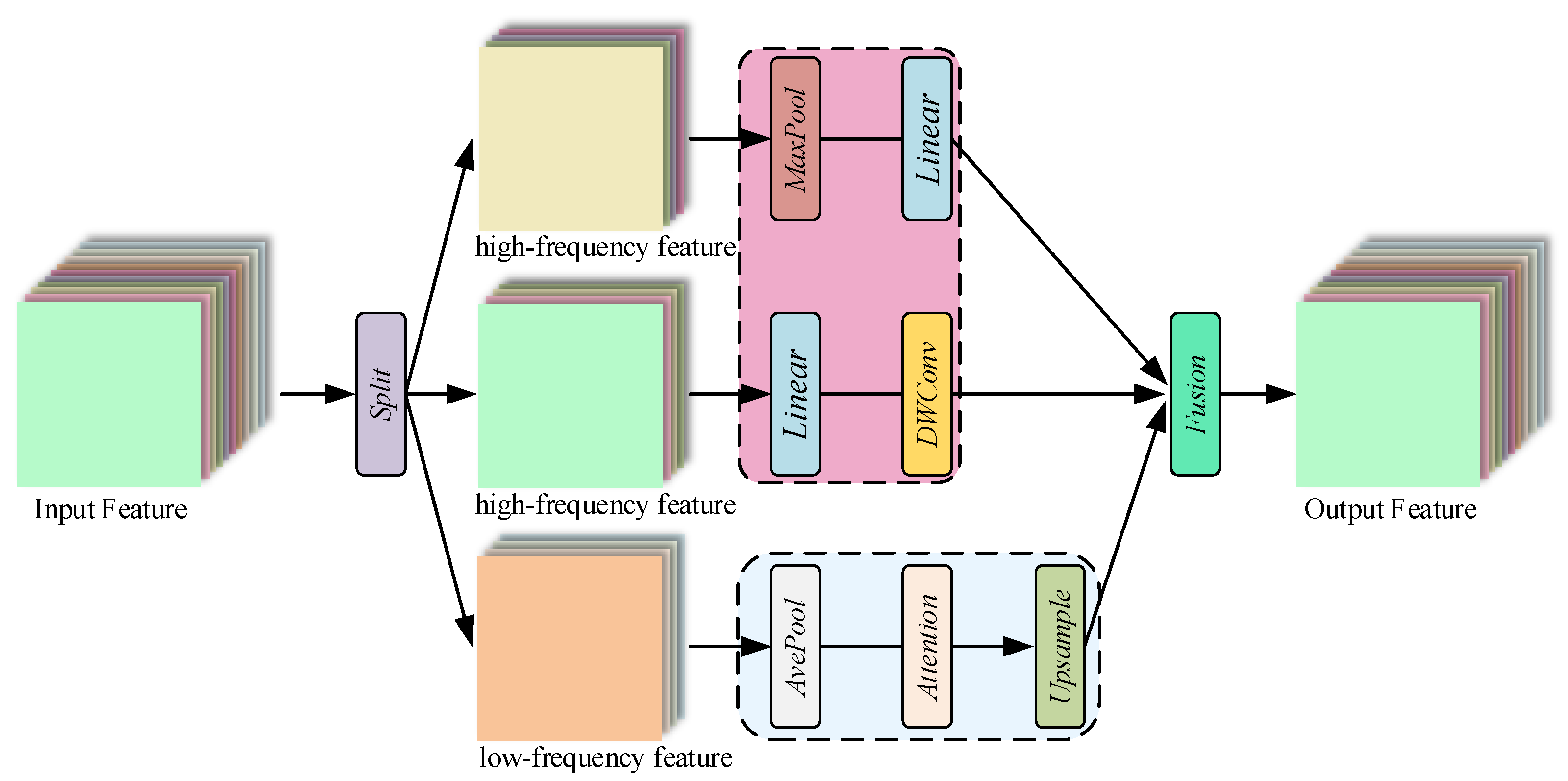
- Since the Ghost Module generates a large number of features, we introduce a simple but efficient Inception Transformer module to reasonably capture and exploit the global and local information of HSI. Inception mixer in the Inception Transformer uses the convolutional-maxpooling and self-attention paths run in parallel with the channel splitting mechanism to extract local details from high-frequency information, and global information from low-frequency information, respectively, thus reducing information loss.
- The proposed IFormer method is compared with other recent methods on four datasets, namely Indian Pines, University of Pavia, Salinas and LongKou, and the experimental results demonstrate that the model can achieve a high degree of accuracy and a low time complexity with a small number of samples.
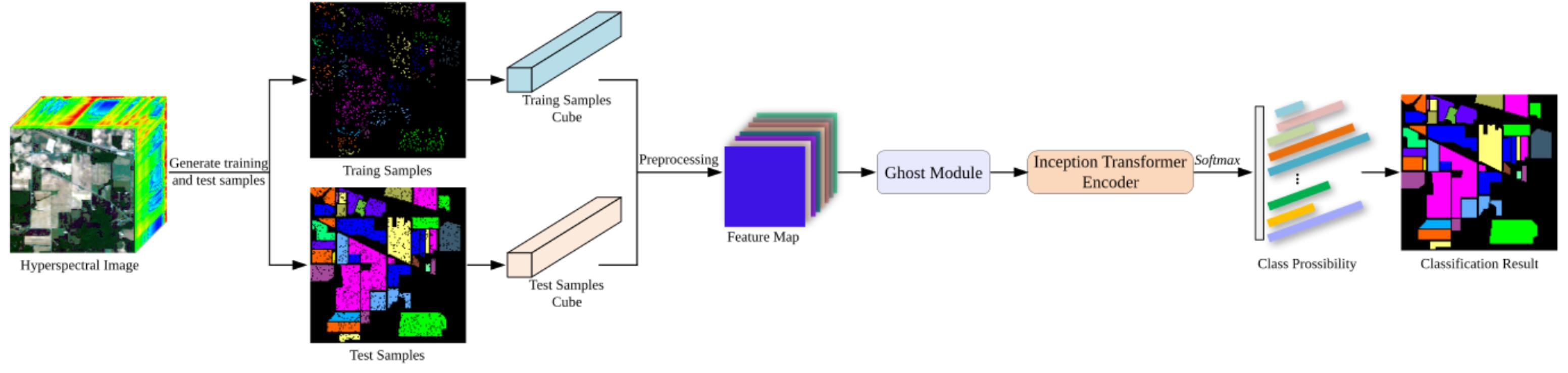
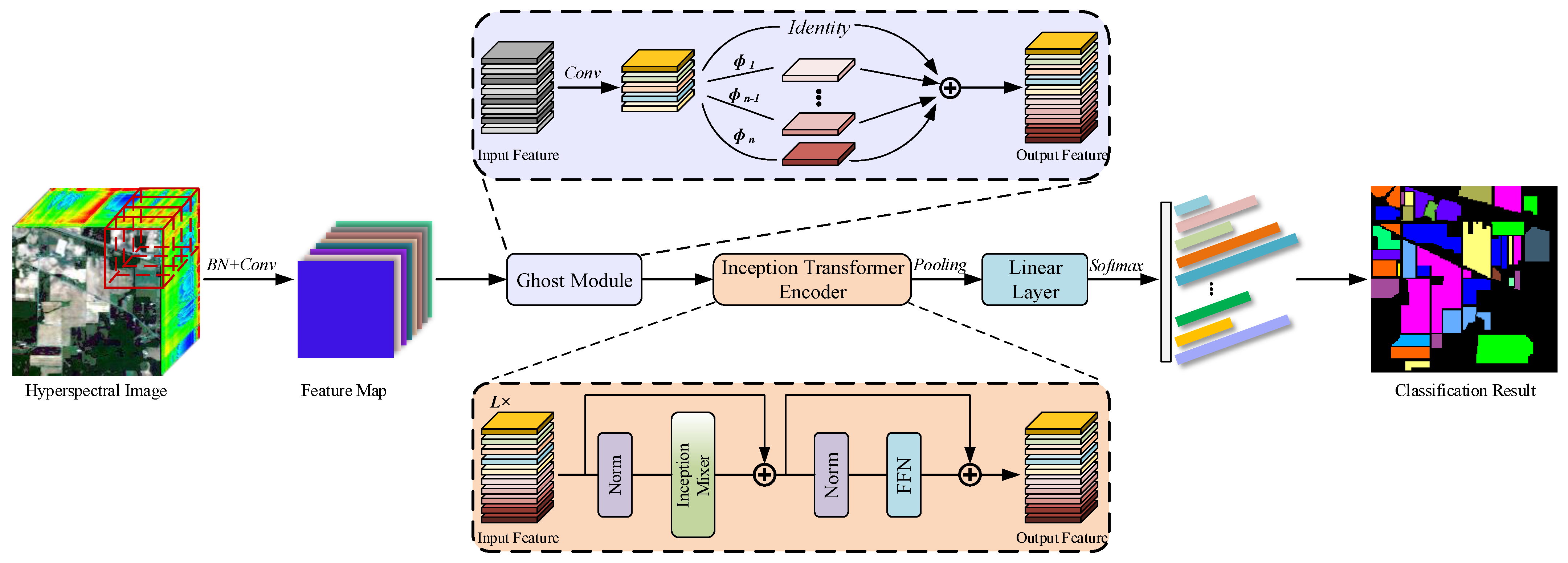
2. Methods
| Algorithm 1 IFormer method for HSI classification steps |
|
2.1. Ghost Module
2.2. Inception Transformer
3. Experimental Result and Analysis
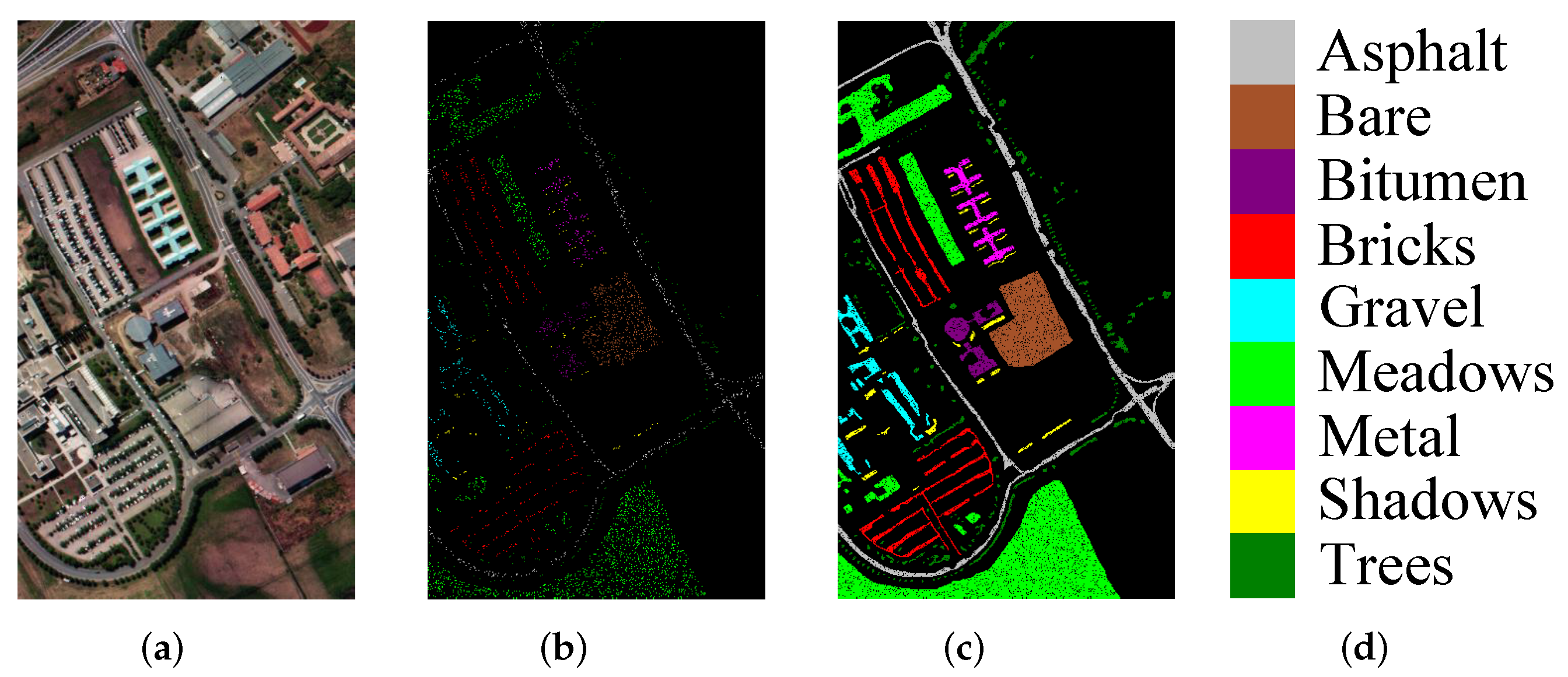
3.1. DataSets Description
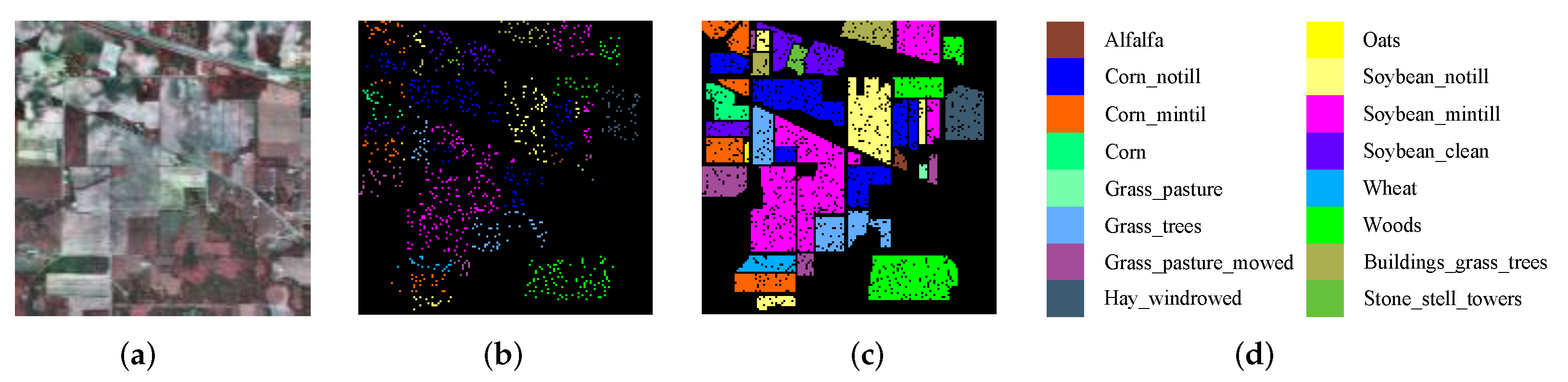
3.1.1. Indian Pines (IP) Dataset
3.1.2. University of Pavia (UP) Dataset
3.1.3. Salinas Valley (SV) Dataset
3.1.4. WHU-Hi-LongKou (LK) Dataset
3.2. Experimental Setting and Analysis
3.2.1. Experimental Setting
- The 1D-CNN [31] is structured using a convolutional layer with a filter size of 20, a BN layer, a pooling layer of size 5, a ReLU activation layer, and finally, a function that can extract only the spectral feature of HSI.
- The 2D-CNN [55] is a network containing two 2D-CNN layers, three ReLU activation layers, and a max-pooling layer, which has an input patch size of 7 × 7 × B.
- CGCNN [34] takes the entire HSI as the input and extracts HSI features by guiding the CNN convolution kernel through features, where the convolution kernel size is 5 × 5.
- SF [45]: SF as a Transformer structure, learns local spectral features from HSI adjacent bands and skips connections using cross-layers; the input patch size is 7 × 7 × 3. Since the LK dataset scene is too large, the input size is set to 5 × 5 × 3.
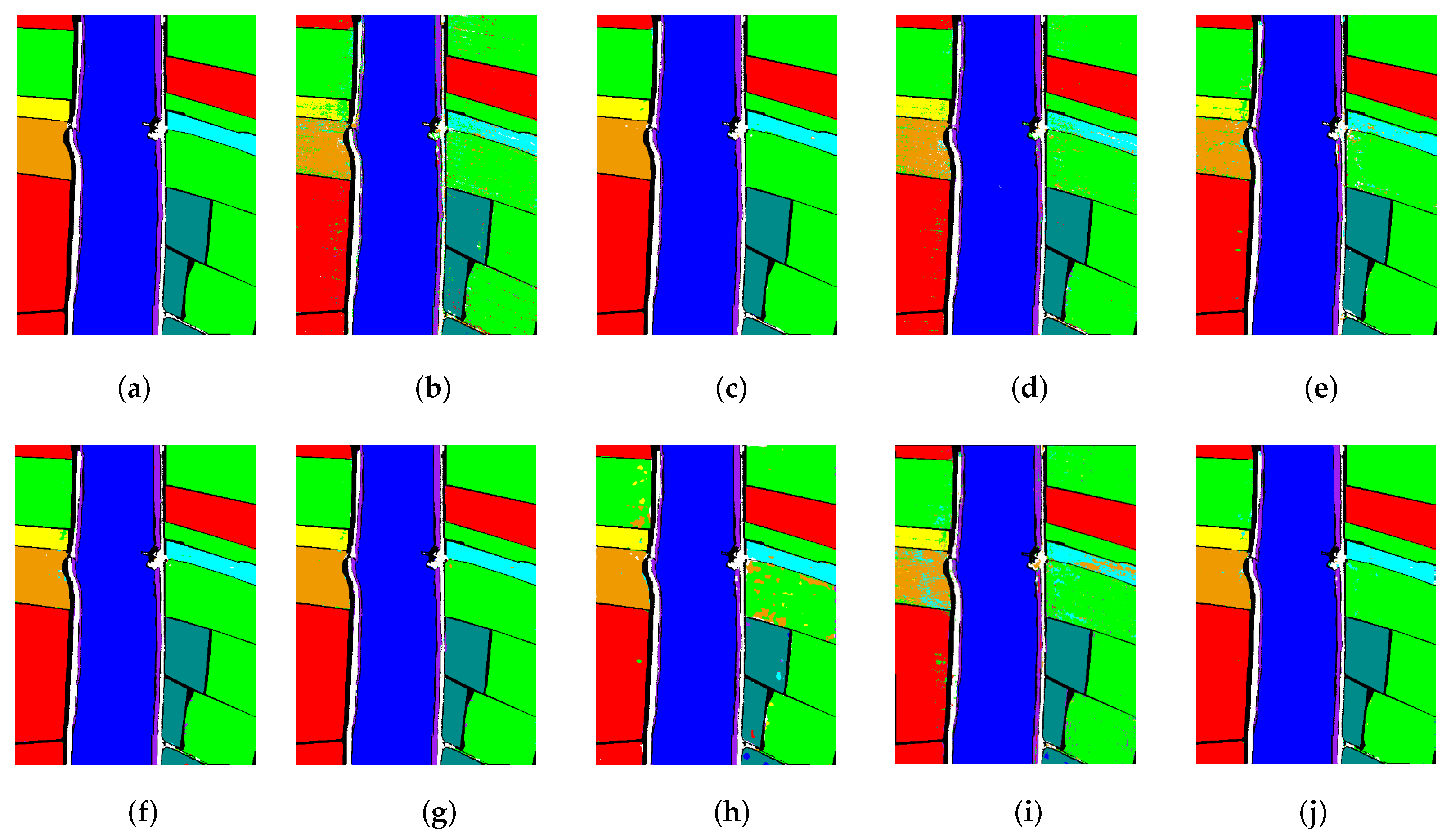
3.2.2. The Proposed Algorithm Compared with the Advancement of Existing Methods
3.3. Experimental Parameter Sensitivity Analysis
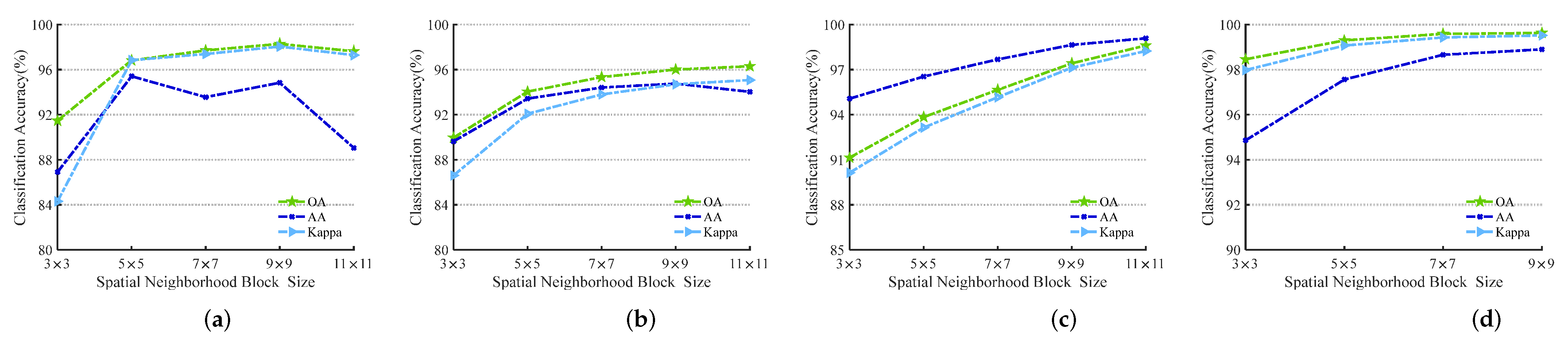
3.3.1. The Influence of Spatial Neighborhood Block Size s
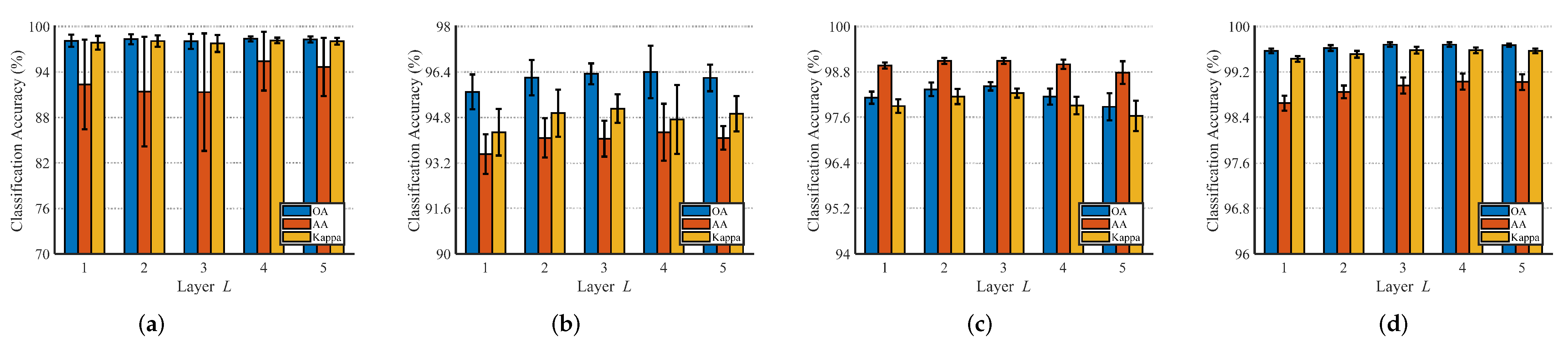
3.3.2. Analysis of the Layer L of the Inception Transformer
3.3.3. Analysis of the Ratio r of High-Frequency Information to Low-Frequency Information
3.4. Analysis of the Role of Different Training Samples on the Classification Effect of the Proposed Method and the Comparison Algorithm
3.5. Comparing the Training Times and Testing Time Consumptions of Different Algorithms
3.6. Analyzing the Impact of the Ghost Module and Inception Transformer on the IFormer Network
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gevaert, C.M.; Suomalainen, J.; Tang, J.; Kooistra, L. Generation of spectral–temporal response surfaces by combining multispectral satellite and hyperspectral UAV imagery for precision agriculture applications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3140–3146. [Google Scholar] [CrossRef]
- Noor, S.S.M.; Michael, K.; Marshall, S.; Ren, J.; Tschannerl, J.; Kao, F. The properties of the cornea based on hyperspectral imaging: Optical biomedical engineering perspective. In Proceedings of the 2016 International Conference on Systems, Signals and Image Processing (IWSSIP), Bratislava, Slovakia, 23–25 May 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Wang, J.; Zhang, L.; Tong, Q.; Sun, X. The Spectral Crust project—Research on new mineral exploration technology. In Proceedings of the 2012 4th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS), Shanghai, China, 4–7 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1–4. [Google Scholar]
- Fong, A.; Shu, G.; McDonogh, B. Farm to Table: Applications for New Hyperspectral Imaging Technologies in Precision Agriculture, Food Quality and Safety. In Proceedings of the CLEO: Applications and Technology, Optical Society of America, Washington, DC, USA, 10–15 May 2020; p. AW3K-2. [Google Scholar]
- Ardouin, J.P.; Lévesque, J.; Rea, T.A. A demonstration of hyperspectral image exploitation for military applications. In Proceedings of the 2007 10th International Conference on Information Fusion, Quebec, QC, Canada, 9–12 July 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–8. [Google Scholar]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Sun, L.; He, C.; Zheng, Y.; Tang, S. SLRL4D: Joint Restoration of Subspace Low-Rank Learning and Non-Local 4-D Transform Filtering for Hyperspectral Image. Remote Sens. 2020, 12, 2979. [Google Scholar] [CrossRef]
- He, C.; Sun, L.; Huang, W.; Zhang, J.; Zheng, Y.; Jeon, B. TSLRLN: Tensor subspace low-rank learning with non-local prior for hyperspectral image mixed denoising. Signal Process. 2021, 184, 108060. [Google Scholar] [CrossRef]
- Sun, L.; Wu, F.; Zhan, T.; Liu, W.; Wang, J.; Jeon, B. Weighted nonlocal low-rank tensor decomposition method for sparse unmixing of hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1174–1188. [Google Scholar] [CrossRef]
- Tu, B.; Yang, X.; Ou, X.; Zhang, G.; Li, J.; Plaza, A. Ensemble entropy metric for hyperspectral anomaly detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–17. [Google Scholar] [CrossRef]
- Yang, B.; Qin, L.; Liu, J.; Liu, X. UTRNet: An Unsupervised Time-Distance-Guided Convolutional Recurrent Network for Change Detection in Irregularly Collected Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Yang, S.; Shi, Z. Hyperspectral image target detection improvement based on total variation. IEEE Trans. Image Process. 2016, 25, 2249–2258. [Google Scholar] [CrossRef]
- Tu, B.; Ren, Q.; Zhou, C.; Chen, S.; He, W. Feature Extraction Using Multidimensional Spectral Regression Whitening for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8326–8340. [Google Scholar] [CrossRef]
- Ren, Q.; Tu, B.; Li, Q.; He, W.; Peng, Y. Multiscale Adaptive Convolution for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 5115–5130. [Google Scholar] [CrossRef]
- Sun, L.; Ma, C.; Chen, Y.; Shim, H.J.; Wu, Z.; Jeon, B. Adjacent superpixel-based multiscale spatial-spectral kernel for hyperspectral classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1905–1919. [Google Scholar] [CrossRef]
- Cariou, C.; Chehdi, K. A new k-nearest neighbor density-based clustering method and its application to hyperspectral images. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 6161–6164. [Google Scholar]
- SahIn, Y.E.; Arisoy, S.; Kayabol, K. Anomaly detection with Bayesian Gauss background model in hyperspectral images. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Plaza, J.; Plaza, A. Deep&dense convolutional neural network for hyperspectral image classification. Remote Sens. 2018, 10, 1454. [Google Scholar]
- Chen, Y.N.; Thaipisutikul, T.; Han, C.C.; Liu, T.J.; Fan, K.C. Feature line embedding based on support vector machine for hyperspectral image classification. Remote Sens. 2021, 13, 130. [Google Scholar] [CrossRef]
- Zhou, C.; Tu, B.; Ren, Q.; Chen, S. Spatial peak-aware collaborative representation for hyperspectral imagery classification. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Peng, J.; Sun, W.; Li, H.C.; Li, W.; Meng, X.; Ge, C.; Du, Q. Low-rank and sparse representation for hyperspectral image processing: A review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 10–43. [Google Scholar] [CrossRef]
- Prasad, S.; Bruce, L.M. Limitations of principal components analysis for hyperspectral target recognition. IEEE Geosci. Remote Sens. Lett. 2008, 5, 625–629. [Google Scholar] [CrossRef]
- Villa, A.; Benediktsson, J.A.; Chanussot, J.; Jutten, C. Hyperspectral image classification with independent component discriminant analysis. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4865–4876. [Google Scholar] [CrossRef]
- Fu, L.; Li, Z.; Ye, Q.; Yin, H.; Liu, Q.; Chen, X.; Fan, X.; Yang, W.; Yang, G. Learning robust discriminant subspace based on joint L2, p-and L2, s-norm distance metrics. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 130–144. [Google Scholar] [CrossRef]
- Fauvel, M.; Benediktsson, J.A.; Chanussot, J.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 3804–3814. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- Dalla Mura, M.; Villa, A.; Benediktsson, J.A.; Chanussot, J.; Bruzzone, L. Classification of hyperspectral images by using extended morphological attribute profiles and independent component analysis. IEEE Geosci. Remote Sens. Lett. 2010, 8, 542–546. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 258619. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Spectral–spatial feature extraction for hyperspectral image classification: A dimension reduction and deep learning approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Liu, Q.; Xiao, L.; Yang, J.; Chan, J.C.W. Content-guided convolutional neural network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6124–6137. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Wang, W.; Dou, S.; Jiang, Z.; Sun, L. A fast dense spectral–spatial convolution network framework for hyperspectral images classification. Remote Sens. 2018, 10, 1068. [Google Scholar] [CrossRef]
- Ma, W.; Yang, Q.; Wu, Y.; Zhao, W.; Zhang, X. Double-branch multi-attention mechanism network for hyperspectral image classification. Remote Sens. 2019, 11, 1307. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of hyperspectral image based on double-branch dual-attention mechanism network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef] [Green Version]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward transformer-based object detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Fang, Y.; Liao, B.; Wang, X.; Fang, J.; Qi, J.; Wu, R.; Niu, J.; Liu, W. You only look at one sequence: Rethinking transformer in vision through object detection. Adv. Neural Inf. Process. Syst. 2021, 34, 26183–26197. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- He, X.; Chen, Y.; Lin, Z. Spatial-spectral transformer for hyperspectral image classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Qing, Y.; Liu, W.; Feng, L.; Gao, W. Improved transformer net for hyperspectral image classification. Remote Sens. 2021, 13, 2216. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Kauffmann, L.; Ramanoël, S.; Peyrin, C. The neural bases of spatial frequency processing during scene perception. Front. Integr. Neurosci. 2014, 8, 37. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Si, C.; Yu, W.; Zhou, P.; Zhou, Y.; Wang, X.; Yan, S. Inception Transformer. arXiv 2022, arXiv:2205.12956. [Google Scholar]
- Zhong, Y.; Hu, X.; Luo, C.; Wang, X.; Zhao, J.; Zhang, L. WHU-Hi: UAV-borne hyperspectral with high spatial resolution (H2) benchmark datasets and classifier for precise crop identification based on deep convolutional neural network with CRF. Remote Sens. Environ. 2020, 250, 112012. [Google Scholar] [CrossRef]
- Zhong, Y.; Wang, X.; Xu, Y.; Wang, S.; Jia, T.; Hu, X.; Zhao, J.; Wei, L.; Zhang, L. Mini-UAV-borne hyperspectral remote sensing: From observation and processing to applications. IEEE Geosci. Remote Sens. Mag. 2018, 6, 46–62. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef]
- Gao, H.; Lin, S.; Yang, Y.; Li, C.; Yang, M. Convolution neural network based on two-dimensional spectrum for hyperspectral image classification. J. Sens. 2018, 2018, 8602103. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class No. | Class Name | Total Sample | Training | Validation | Test |
|---|---|---|---|---|---|
| 1 | Alfalfa | 46 | 5 | 2 | 39 |
| 2 | Corn_N | 1428 | 143 | 14 | 1271 |
| 3 | Corn_M | 830 | 83 | 8 | 739 |
| 4 | Corn | 237 | 24 | 2 | 211 |
| 5 | Grass_P | 483 | 49 | 4 | 430 |
| 6 | Grass_T | 730 | 73 | 7 | 650 |
| 7 | Grass_P_M | 28 | 3 | 2 | 23 |
| 8 | Hay_W | 478 | 48 | 4 | 426 |
| 9 | Oats | 20 | 2 | 1 | 17 |
| 10 | Soybean_N | 972 | 98 | 9 | 865 |
| 11 | Soybean_M | 2455 | 246 | 24 | 2185 |
| 12 | Soybean_C | 593 | 60 | 6 | 527 |
| 13 | Wheat | 205 | 21 | 2 | 182 |
| 14 | Woods | 1265 | 127 | 12 | 1126 |
| 15 | Buildings_G_T | 386 | 39 | 3 | 344 |
| 16 | Stone_S_T | 93 | 10 | 2 | 81 |
| Class No. | Class Name | Total Sample | Training | Validation | Test |
|---|---|---|---|---|---|
| 1 | Asphalt | 6631 | 67 | 66 | 6498 |
| 2 | Meadows | 18,649 | 187 | 187 | 18,275 |
| 3 | Gravel | 2099 | 21 | 21 | 2057 |
| 4 | Trees | 3064 | 31 | 31 | 3002 |
| 5 | Metal | 1345 | 14 | 14 | 1317 |
| 6 | Bare | 5029 | 51 | 50 | 4928 |
| 7 | Bitumen | 1330 | 14 | 11 | 1305 |
| 8 | Bricks | 3682 | 37 | 37 | 3608 |
| 9 | Shadows | 947 | 10 | 10 | 927 |
| Class No. | Class Name | Total Sample | Training | Validation | Test |
|---|---|---|---|---|---|
| 1 | Brocoli_G_W_1 | 2009 | 21 | 20 | 1968 |
| 2 | Brocoli_G_W_2 | 3726 | 38 | 36 | 3652 |
| 3 | Fallow | 1976 | 20 | 20 | 1936 |
| 4 | Fallow_R_P | 1394 | 14 | 14 | 1366 |
| 5 | Fallow_S | 2678 | 27 | 26 | 2625 |
| 6 | Celery | 3579 | 36 | 36 | 3507 |
| 7 | Stubble | 3959 | 40 | 40 | 3879 |
| 8 | Grapes_U | 11,271 | 113 | 113 | 11,045 |
| 9 | Soil_V_D | 6203 | 63 | 62 | 6078 |
| 10 | Corn_S_G_W | 3278 | 33 | 33 | 3212 |
| 11 | Letttuce_R_4 | 1068 | 11 | 11 | 1046 |
| 12 | Letttuce_R_5 | 1927 | 20 | 19 | 1888 |
| 13 | Letttuce_R_6 | 916 | 10 | 9 | 897 |
| 14 | Letttuce_R_7 | 1070 | 11 | 11 | 1048 |
| 15 | Vinyard_U | 7268 | 73 | 73 | 7122 |
| 16 | Vinyard_V_T | 1807 | 19 | 18 | 1770 |
| Class No. | Class Name | Total Sample | Training | Validation | Test |
|---|---|---|---|---|---|
| 1 | Corn | 34,511 | 346 | 346 | 33,819 |
| 2 | Cotton | 8374 | 84 | 84 | 8206 |
| 3 | Sesame | 3031 | 31 | 30 | 2970 |
| 4 | Broad_L_S | 63,212 | 633 | 632 | 61,947 |
| 5 | Narrow_L_S | 4151 | 42 | 41 | 4068 |
| 6 | Rice | 11,854 | 119 | 118 | 11,617 |
| 7 | Water | 67,056 | 671 | 670 | 65,715 |
| 8 | Roads_Houses | 7124 | 72 | 71 | 6981 |
| 9 | Mixed_Weed | 5229 | 53 | 52 | 5124 |
| Class No. | Classification Accuracy Obtained by the Proposed Method and Different Comparison Methods (in %) 1 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SVM | SSRN | 1D-CNN | 2D-CNN | FDSSC | DBDA | CGCNN | SF | IFormer | |
| 1 | 65.61(15.6) | 97.85(6.42) | 33.41(7.32) | 70.48(17.4) | 99.72(0.81) | 95.37(7.67) | 94.51(6.54) | 25.12(6.45) | 80.98(19.7) |
| 2 | 79.69(1.98) | 97.14(2.27) | 79.30(2.18) | 93.19(1.67) | 98.45(1.54) | 98.18(1.06) | 98.04(1.08) | 87.85(4.05) | 97.95(0.54) |
| 3 | 69.73(2.68) | 98.01(1.34) | 64.32(3.41) | 92.51(2.20) | 98.47(2.12) | 98.81(1.08) | 90.19(6.60) | 86.15(2.14) | 99.31(0.27) |
| 4 | 62.44(8.34) | 96.71(3.74) | 52.39(6.97) | 86.19(4.18) | 98.03(2.83) | 97.04(4.03) | 92.79(3.66) | 90.98(4.49) | 96.16(3.17) |
| 5 | 89.40(2.74) | 98.63(1.04) | 88.34(4.91) | 95.47(2.43) | 99.23(1.09) | 97.41(1.72) | 96.36(2.98) | 89.07(1.71) | 97.49(1.54) |
| 6 | 95.48(1.85) | 99.04(0.97) | 97.51(0.71) | 99.16(0.36) | 98.84(0.97) | 99.25(1.05) | 99.43(0.82) | 97.64(1.68) | 98.95(0.29) |
| 7 | 76.40(7.41) | 50.00(50.0) | 36.40(24.5) | 74.80(12.9) | 94.44(12.9) | 92.67(13.5) | 98.80(1.83) | 48.40(8.48) | 85.80(15.3) |
| 8 | 98.09(1.36) | 98.63(1.41) | 97.65(2.18) | 99.76(0.20) | 99.31(1.36) | 100.00(0.0) | 99.92(0.15) | 99.62(0.31) | 100.00(0.0) |
| 9 | 42.78(19.8) | 10.00(30.0) | 28.33(20.3) | 90.55(7.47) | 79.56(28.6) | 95.06(7.59) | 99.44(1.66) | 38.23(17.6) | 65.88(20.5) |
| 10 | 78.40(3.14) | 92.30(9.24) | 71.70(4.72) | 94.36(2.17) | 95.70(4.06) | 95.73(3.18) | 95.09(2.42) | 89.92(2.35) | 98.19(2.41) |
| 11 | 85.54(0.89) | 97.51(4.13) | 80.65(1.99) | 94.99(0.95) | 98.31(1.42) | 99.07(0.60) | 98.47(1.28) | 93.42(3.03) | 98.98(0.62) |
| 12 | 73.60(3.56) | 95.58(3.06) | 77.75(2.45) | 83.29(4.37) | 91.32(18.5) | 98.16(0.60) | 96.10(2.83) | 81.53(4.48) | 96.33(2.41) |
| 13 | 96.41(2.64) | 99.56(0.72) | 98.43(1.14) | 99.94(0.16) | 99.24(1.55) | 98.77(2.17) | 99.56(0.21) | 99.78(0.26) | 99.78(0.27) |
| 14 | 94.92(2.37) | 99.27(0.37) | 95.01(1.04) | 98.10(1.04) | 98.79(0.96) | 98.84(0.84) | 99.35(0.52) | 95.56(1.05) | 99.59(0.27) |
| 15 | 57.12(3.74) | 98.05(1.75) | 63.48(6.36) | 89.91(4.69) | 98.25(2.40) | 98.62(1.33) | 98.82(1.09) | 60.83(6.22) | 98.34(0.80) |
| 16 | 85.18(4.02) | 96.21(5.32) | 84.16(3.06) | 96.78(4.39) | 96.41(4.30) | 93.39(6.67) | 98.19(3.37) | 99.03(1.18) | 99.88(0.37) |
| OA(%) | 83.12(0.90) | 97.11(1.55) | 80.91(0.75) | 94.28(0.38) | 97.19(2.95) | 98.28(0.61) | 97.31(0.75) | 90.05(0.89) | 98.44(0.45) |
| AA(%) | 80.69(1.03) | 89.03(3.45) | 71.80(2.65) | 91.22(1.12) | 96.50(2.39) | 97.27(1.29) | 97.19(0.82) | 80.20(1.71) | 94.54(3.13) |
| Kappa | 78.17(2.14) | 96.71(1.77) | 78.16(0.85) | 93.47(0.44) | 96.82(3.30) | 98.04(0.69) | 96.93(0.85) | 88.64(1.00) | 98.22(0.52) |
| Class No. | Classification Accuracy Obtained by the Proposed Method and Different Comparison Methods (in %) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SVM | SSRN | 1D-CNN | 2D-CNN | FDSSC | DBDA | CGCNN | SF | IFormer | |
| 1 | 89.56(3.10) | 97.82(2.41) | 91.07(1.52) | 94.09(1.74) | 97.00(1.89) | 97.21(1.96) | 92.41(2.28) | 72.80(7.11) | 99.94(0.06) |
| 2 | 88.36(3.04) | 95.26(5.24) | 81.74(2.41) | 90.02(3.85) | 99.46(0.29) | 98.15(2.07) | 95.23(2.71) | 89.33(4.91) | 99.85(0.04) |
| 3 | 75.27(6.85) | 97.75(3.60) | 75.70(4.33) | 83.96(4.29) | 85.84(15.7) | 96.94(4.22) | 97.29(5.33) | 57.48(8.14) | 94.18(1.60) |
| 4 | 77.20(4.41) | 90.00(3.67) | 84.18(1.83) | 90.00(1.87) | 98.60(0.88) | 88.97(4.78) | 91.98(8.47) | 94.15(3.29) | 97.13(0.26) |
| 5 | 94.04(1.93) | 99.60(0.51) | 87.71(1.39) | 90.57(1.81) | 99.45(0.31) | 96.63(1.45) | 98.51(0.78) | 99.91(0.10) | 99.97(0.05) |
| 6 | 68.03(4.39) | 85.20(16.7) | 69.76(3.23) | 78.21(3.72) | 99.45(0.31) | 97.46(3.33) | 39.97(21.9) | 33.61(9.55) | 97.09(2.13) |
| 7 | 91.92(0.74) | 99.18(0.46) | 96.34(0.45) | 98.44(0.36) | 98.96(0.31) | 99.41(0.40) | 86.13(9.54) | 95.12(1.74) | 100.00(0.0) |
| 8 | 98.33(1.55) | 99.91(0.09) | 98.61(0.64) | 99.74(0.37) | 92.69(5.68) | 99.37(1.13) | 99.99(0.02) | 67.67(10.2) | 92.06(3.03) |
| 9 | 99.97(0.05) | 99.30(1.43) | 99.55(0.26) | 96.99(2.96) | 98.45(1.63) | 93.89(4.84) | 99.86(0.21) | 96.97(2.02) | 95.64(1.03) |
| OA(%) | 88.68(0.68) | 96.62(1.79) | 90.34(0.42) | 94.05(0.68) | 97.27(1.12) | 97.49(0.56) | 88.38(4.60) | 77.73(1.66) | 98.30(0.46) |
| AA(%) | 86.96(1.23) | 96.00(2.06) | 87.19(0.59) | 91.34(0.63) | 96.65(1.30) | 96.95(0.65) | 89.04(3.09) | 78.56(1.38) | 97.32(0.53) |
| Kappa | 84.84(0.92) | 95.54(2.35) | 87.12(0.57) | 92.08(0.91) | 96.38(1.30) | 96.67(0.75) | 85.08(5.66) | 70.29(2.05) | 97.74(0.61) |
| Class No. | Classification Accuracy Obtained by the Proposed Method and Different Comparison Methods (in %) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SVM | SSRN | 1D-CNN | 2D-CNN | FDSSC | DBDA | CGCNN | SF | IFormer | |
| 1 | 99.73(0.57) | 99.98(0.02) | 99.47(0.48) | 99.25(0.67) | 100.00(0.0) | 100.00(0.0) | 100.00(0.0) | 87.72(10.6) | 100.00(0.0) |
| 2 | 99.09(0.28) | 99.80(0.25) | 99.59(1.05) | 99.32(1.40) | 99.93(0.13) | 99.97(0.04) | 99.81(0.35) | 99.09(0.79) | 100.00(0.0) |
| 3 | 92.50(1.65) | 98.16(1.33) | 98.17(1.11) | 97.10(2.71) | 98.61(1.64) | 98.80(1.20) | 33.29(6.20) | 92.51(5.26) | 100.00(0.0) |
| 4 | 97.20(0.63) | 98.90(0.58) | 98.89(0.29) | 99.23(0.31) | 97.81(2.27) | 95.72(3.65) | 99.83(0.09) | 96.31(1.42) | 98.60(0.39) |
| 5 | 97.19(1.04) | 99.84(0.24) | 97.99(0.57) | 97.20(1.11) | 99.51(0.60) | 97.14(4.92) | 76.48(22.1) | 89.19(5.51) | 99.57(0.25) |
| 6 | 98.69(0.82) | 100.0(0.00) | 99.65(0.12) | 99.56(0.25) | 99.99(0.01) | 99.65(0.61) | 99.91(0.05) | 99.99(0.12) | 100.00(0.0) |
| 7 | 99.95(0.06) | 99.98(0.03) | 99.61(0.19) | 99.84(0.23) | 100.00(0.0) | 99.99(0.01) | 99.85(0.12) | 96.09(2.62) | 99.96(0.04) |
| 8 | 75.58(1.05) | 91.72(3.98) | 86.04(1.17) | 84.13(1.48) | 95.33(4.39) | 93.27(6.55) | 88.08(7.10) | 83.84(6.82) | 95.79(0.91) |
| 9 | 98.73(0.35) | 99.69(0.13) | 99.46(0.31) | 99.68(0.34) | 99.60(0.29) | 99.36(0.58) | 84.50(17.4) | 98.75(0.39) | 100.00(0.0) |
| 10 | 88.95(2.66) | 99.11(0.73) | 92.51(1.38) | 91.87(2.29) | 98.34(1.41) | 98.63(1.19) | 86.50(6.46) | 92.76(2.64) | 96.50(0.59) |
| 11 | 90.58(4.15) | 97.56(2.39) | 95.73(2.66) | 95.85(1.84) | 96.99(2.29) | 96.57(3.05) | 89.53(22.1) | 89.83(5.80) | 99.66(0.54) |
| 12 | 96.24(0.79) | 99.31(0.83) | 99.92(0.11) | 99.77(0.42) | 99.19(0.79) | 99.32(1.37) | 85.14(14.5) | 91.70(9.17) | 99.60(0.58) |
| 13 | 93.37(3.23) | 99.25(1.04) | 98.88(0.84) | 97.87(1.69) | 99.57(0.68) | 99.83(0.15) | 34.97(31.5) | 96.25(3.79) | 99.97(0.07) |
| 14 | 94.75(2.30) | 98.68(0.88) | 90.82(3.83) | 95.89(1.48) | 98.57(1.01) | 96.97(3.07) | 98.34(1.77) | 97.70(2.27) | 99.39(0.35) |
| 15 | 74.66(2.89) | 89.14(5.35) | 65.08(2.66) | 74.65(3.31) | 84.68(12.9) | 89.05(11.5) | 60.47(25.6) | 64.95(13.8) | 97.37(0.78) |
| 16 | 98.08(0.71) | 100.0(0.00) | 96.76(2.11) | 93.58(4.83) | 99.46(0.83) | 99.97(0.08) | 97.21(1.59) | 82.17(5.75) | 99.77(0.17) |
| OA(%) | 89.64(0.48) | 96.31(0.36) | 91.20(0.50) | 91.96(0.56) | 95.73(2.25) | 95.84(2.40) | 84.02(4.30) | 88.47(2.39) | 98.46(0.17) |
| AA(%) | 93.46(0.51) | 98.19(0.19) | 94.91(0.52) | 95.30(0.49) | 97.97(0.74) | 97.77(0.98) | 83.37(4.37) | 91.18(2.56) | 99.14(0.10) |
| Kappa | 88.24(0.53) | 95.90(0.40) | 90.19(0.56) | 91.05(0.62) | 95.26(2.48) | 95.37(2.66) | 82.17(4.81) | 87.14(2.68) | 98.28(0.19) |
| Class No. | Classification Accuracy Obtained Using the Proposed Method and Different Comparison Methods (in %) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| SVM | SSRN | 1D-CNN | 2D-CNN | FDSSC | DBDA | CGCNN | SF | IFormer | |
| 1 | 98.91(0.27) | 99.84(0.09) | 99.11(0.34) | 98.94(0.33) | 99.43(0.12) | 99.83(0.07) | 98.90(0.73) | 99.06(0.89) | 99.97(0.01) |
| 2 | 86.00(2.70) | 98.35(2.42) | 86.89(3.35) | 87.72(1.97) | 98.94(1.17) | 98.28(2.61) | 95.60(5.03) | 84.99(2.51) | 99.62(0.20) |
| 3 | 76.79(2.82) | 99.38(1.08) | 81.71(4.10) | 82.32(5.09) | 99.60(0.33) | 97.02(5.36) | 93.25(5.09) | 80.32(8.96) | 98.70(0.58) |
| 4 | 97.22(0.24) | 99.26(0.55) | 97.26(0.48) | 97.01(0.41) | 99.56(0.32) | 99.59(0.18) | 86.09(9.44) | 96.32(2.43) | 99.83(0.06) |
| 5 | 77.32(3.60) | 97.05(5.71) | 74.85(5.25) | 77.37(2.99) | 98.18(1.61) | 95.79(3.37) | 88.04(11.2) | 80.55(8.91) | 98.47(0.54) |
| 6 | 99.27(0.35) | 99.77(0.51) | 98.92(1.43) | 99.35(0.02) | 99.94(0.05) | 99.94(0.04) | 96.59(1.54) | 97.87(1.46) | 99.97(0.02) |
| 7 | 99.93(0.04) | 99.97(0.02) | 99.97(0.00) | 99.96(0.02) | 99.97(0.01) | 99.97(0.03) | 99.82(0.31) | 99.86(0.12) | 99.95(0.02) |
| 8 | 86.99(2.31) | 95.53(3.25) | 90.97(1.75) | 91.34(1.29) | 95.70(3.78) | 93.22(7.26) | 97.72(1.24) | 93.05(5.97) | 96.17(0.81) |
| 9 | 81.38(2.61) | 96.90(1.88) | 87.85(3.05) | 86.90(3.15) | 94.70(2.18) | 95.40(2.66) | 90.19(2.68) | 81.28(4.53) | 97.96(0.71) |
| OA(%) | 96.59(0.18) | 99.32(0.21) | 96.99(0.18) | 96.99(0.16) | 99.43(0.16) | 99.22(0.34) | 94.41(3.16) | 96.51(0.89) | 99.67(0.02) |
| AA(%) | 95.51(0.23) | 98.45(0.82) | 90.84(0.63) | 91.21(0.54) | 98.48(0.31) | 97.67(1.05) | 94.02(2.43) | 90.36(2.51) | 98.96(0.16) |
| Kappa | 89.31(0.55) | 99.11(0.28) | 96.04(0.23) | 96.04(0.21) | 99.26(0.21) | 98.98(0.45) | 92.81(3.98) | 95.42(1.16) | 99.57(0.03) |
| Dataset | Evaluations | Calculated Cost Consumption of the Comparison Method and the Proposed Method (in s) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| SVM | SSRN | 1D-CNN | 2D-CNN | FDSSC | DBDA | CGCNN | SF | IFormer | ||
| IP | Training | 0.16 | 4299 | 161.15 | 216.84 | 10,196.12 | 1583.52 | 459.91 | 142.31 | 121.85 |
| Test | 3.52 | 38.25 | 1.07 | 1.34 | 49.93 | 63.56 | 1.52 | 1.86 | 0.86 | |
| UP | Training | 0.01 | 2116.45 | 137.98 | 159.84 | 5484.60 | 432.94 | 947.43 | 204.32 | 51.88 |
| Test | 5.34 | 117.82 | 4.29 | 1.14 | 188.71 | 190.39 | 4.28 | 7.77 | 4.19 | |
| SV | Training | 0.03 | 1370.59 | 180.3 | 261.4 | 7188.72 | 710.25 | 353.74 | 374.46 | 65.98 |
| Test | 6.95 | 109.85 | 1.21 | 1.73 | 322.42 | 411.31 | 3.83 | 9.62 | 5.75 | |
| LK | Training | 0.18 | 10433.04 | 682.89 | 1099.33 | 16,044.62 | 3144.63 | 1623.79 | 1809.78 | 281.09 |
| Test | 26.99 | 936.83 | 4.27 | 8.66 | 2222.2 | 2095.54 | 8.96 | 24.47 | 19.65 | |
| Ghost Module | Inception Transformer | IP | UP | SV | LK |
|---|---|---|---|---|---|
| 88.94(2.11) | 84.80(1.54) | 89.66(1.12) | 97.82(0.37) | ||
| ✓ | 95.83(1.09) | 96.92(0.41) | 97.21(0.31) | 99.29(0.11) | |
| ✓ | 96.84(0.87) | 96.27(0.31) | 97.08(0.29) | 99.39(0.06) | |
| ✓ | ✓ | 98.44(0.45) | 98.30(0.46) | 98.46(0.17) | 99.67(0.02) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Q.; Tu, B.; Liao, S.; Chen, S. Hyperspectral Image Classification with IFormer Network Feature Extraction. Remote Sens. 2022, 14, 4866. https://doi.org/10.3390/rs14194866
Ren Q, Tu B, Liao S, Chen S. Hyperspectral Image Classification with IFormer Network Feature Extraction. Remote Sensing. 2022; 14(19):4866. https://doi.org/10.3390/rs14194866
Chicago/Turabian StyleRen, Qi, Bing Tu, Sha Liao, and Siyuan Chen. 2022. "Hyperspectral Image Classification with IFormer Network Feature Extraction" Remote Sensing 14, no. 19: 4866. https://doi.org/10.3390/rs14194866
APA StyleRen, Q., Tu, B., Liao, S., & Chen, S. (2022). Hyperspectral Image Classification with IFormer Network Feature Extraction. Remote Sensing, 14(19), 4866. https://doi.org/10.3390/rs14194866