
Unifying Deep ConvNet and Semantic Edge Features for Loop Closure Detection

Abstract
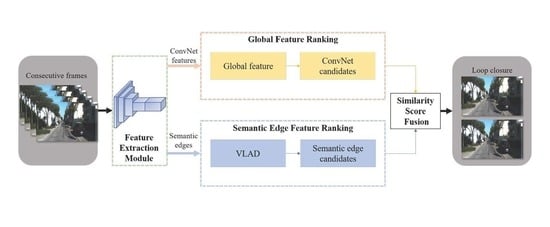
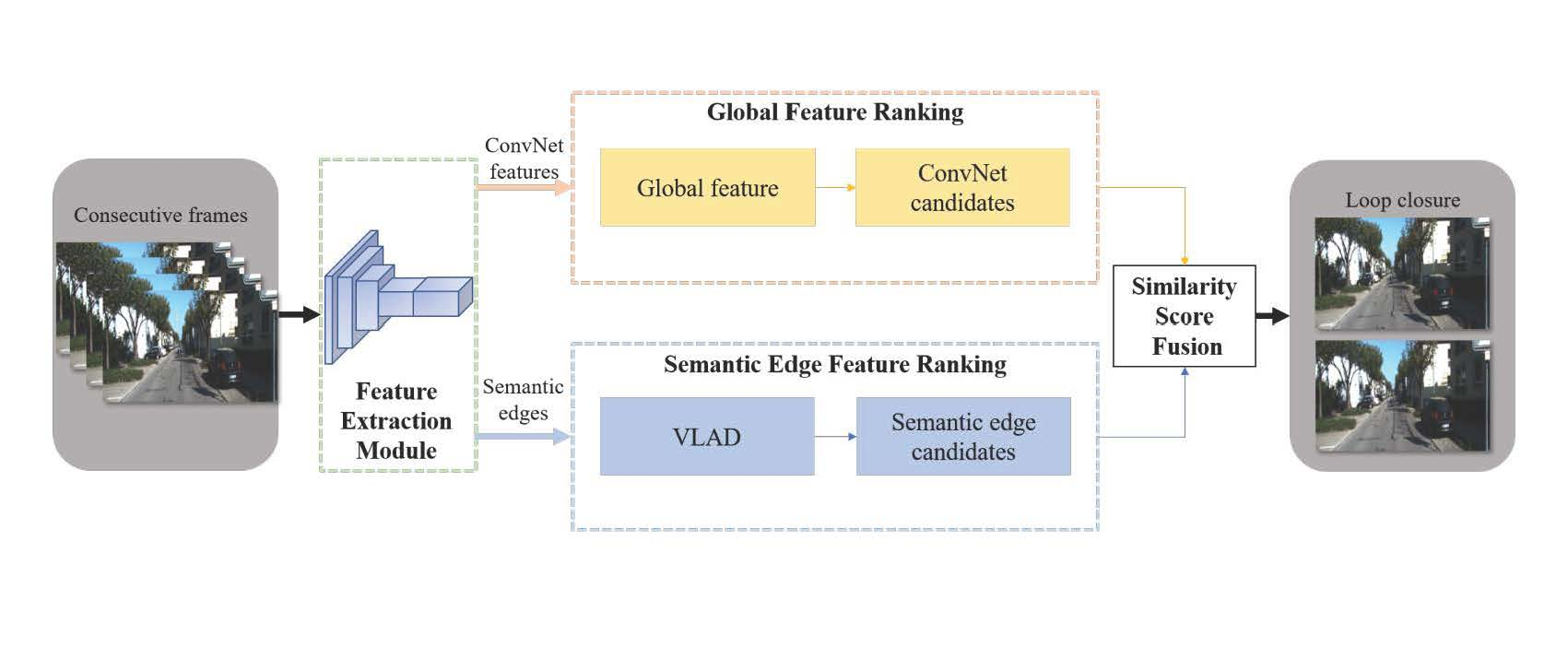
:
1. Introduction
- (1)
- A two-branch network unifying ConvNet features and semantic edge features is proposed to improve the robustness of LCD.
- (2)
- A CFE module using low-level boundary textures as mutual guidance for aggregating context information is designed to improve the robustness of the ConvNet feature descriptor.
- (3)
- Comparable experiments on six public challenging image sequences with state-of-the-art methods show that the proposed approach achieves competitive recall rates at 100% precision.
2. Related Work
2.1. Hand-Crafted Features for LCD
2.2. ConvNet-Based Features for LCD
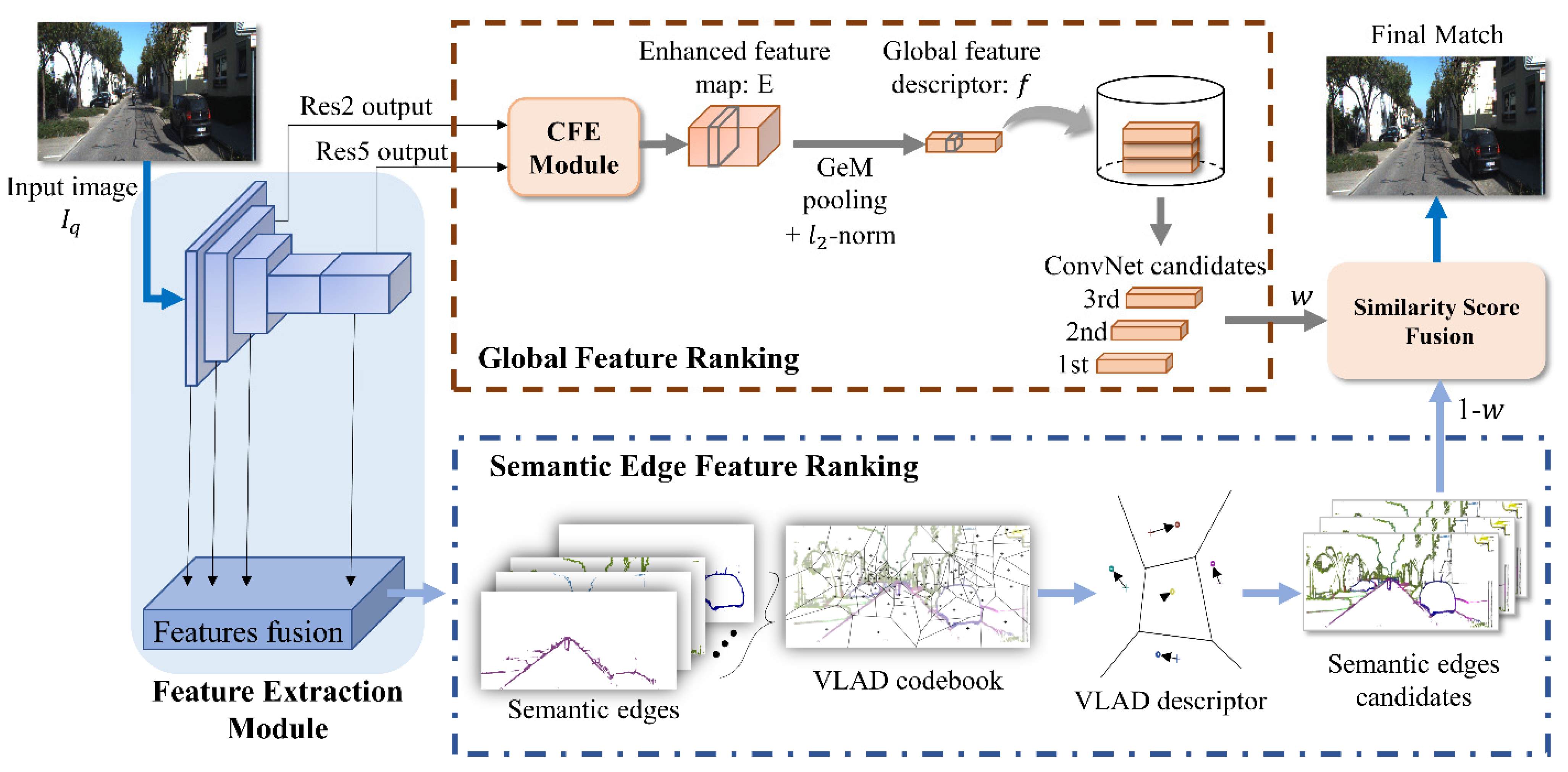
3. Methodology
3.1. Feature Extraction Module
3.2. Global Feature Ranking with Context Feature Enhanced Module
3.2.1. Context Feature Enhanced module
3.2.2. Image Descriptor and ConvNet Candidate
3.2.3. Transfer Learning and Loss Function
3.3. Semantic Edge Feature Ranking
3.3.1. Semantic Edge Features Codebook
3.3.2. Semantic Edge Descriptor and Visual Candidate
3.4. Fusion Calculation
4. Experimental Results and Discussion
4.1. Experimental Setting
4.1.1. Datasets
4.1.2. Parameters Setting
4.1.3. Evaluation Metrics
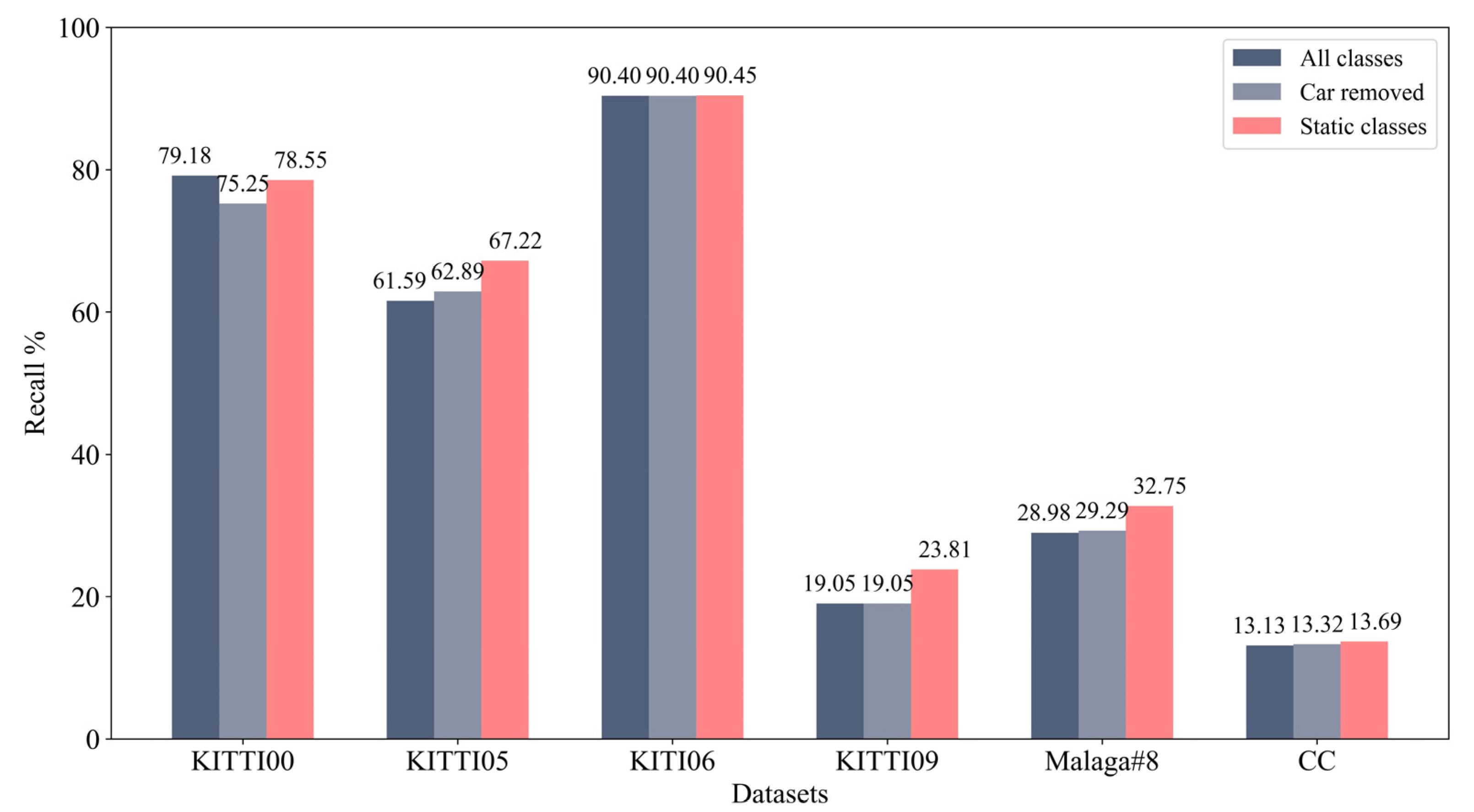
4.2. Effect of Semantic Categories for Semantic Edge Descriptor
4.3. Effectiveness of Context Feature Enhanced (CFE) Module
4.4. Effectiveness of Descriptors for Two Branches
4.5. Comparative Results
5. Discussion
5.1. Experiments Analysis
- In contrast to the LCD algorithm using only semantic edges, the proposed method incorporates abstract convolutional features as well. Furthermore, the experiment results show that the performance of the convolutional features is better than that of the semantic edge features. By fusing the two different features, the system achieves the best performance.
- In the processing of semantic edge features, we artificially remove the edge feature points of dynamic semantic attributes. Additionally, it is demonstrated in the experimental results that removing dynamic features helps to achieve a higher accuracy rate. However, as edge points often have two or more attributes, the results can still be disturbed by dynamic object boundary points, especially when dynamic objects occupy a certain proportion of the picture.
- As the test datasets do not contain the ground truth of semantic edges, the feature extraction module has to use the weights pre-trained on the Cityscapes dataset, which damages the accuracy of our learning-based method. Even so, the proposed algorithm achieves competitive results.
5.2. Experiment Implementation and Runtime Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Palomeras, N.; Carreras, M.; Andrade-Cetto, J. Active SLAM for Autonomous Underwater Exploration. Remote Sens. 2019, 11, 2827. [Google Scholar] [CrossRef]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Ho, K.L.; Newman, P. Detecting Loop Closure with Scene Sequences. Int. J. Comput. Vis. 2007, 74, 261–286. [Google Scholar] [CrossRef]
- Williams, B.; Klein, G.; Reid, I. Automatic Relocalization and Loop Closing for Real-Time Monocular SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1699–1712. [Google Scholar] [CrossRef]
- Sivic, J.; Zisserman, A. Video Google: A text retrieval approach to object matching in videos. In Proceedings of the IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; pp. 1470–1477. [Google Scholar]
- Jegou, H.; Perronnin, F.; Douze, M.; Sanchez, J.; Perez, P.; Schmid, C. Aggregating Local Image Descriptors into Compact Codes. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1704–1716. [Google Scholar] [CrossRef]
- Perronnin, F.; Dance, C. Fisher Kernels on Visual Vocabularies for Image Categorization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. The Revisiting Problem in Simultaneous Localization and Mapping: A Survey on Visual Loop Closure Detection. IEEE Trans. Intell. Transp. 2022. [Google Scholar] [CrossRef]
- Radenovic, F.; Tolias, G.; Chum, O. CNN Image Retrieval Learns from BoW: Unsupervised Fine-Tuning with Hard Examples. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 3–20. [Google Scholar]
- Zhang, X.; Su, Y.; Zhu, X. Loop closure detection for visual SLAM systems using convolutional neural network. In Proceedings of the International Conference on Automation and Computing, Huddersfield, UK, 7–8 September 2017; pp. 1–6. [Google Scholar]
- Gawel, A.; Don, C.D.; Siegwart, R.; Nieto, J.; Cadena, C. X-View: Graph-Based Semantic Multi-View Localization. IEEE Robot. Autom. Lett. 2018, 3, 1687–1694. [Google Scholar] [CrossRef]
- Benbihi, A.; Aravecchia, S.; Geist, M.; Pradalier, C. Image-Based Place Recognition on Bucolic Environment Across Seasons From Semantic Edge Description. In Proceedings of the IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020; pp. 3032–3038. [Google Scholar]
- Toft, C.; Olsson, C.; Kahl, F. Long-term 3D Localization and Pose from Semantic Labellings. In Proceedings of the International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 650–659. [Google Scholar]
- Yu, X.; Chaturvedi, S.; Feng, C.; Taguchi, Y.; Lee, T.; Fernandes, C.; Ramalingam, S. VLASE: Vehicle Localization by Aggregating Semantic Edges. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 3196–3203. [Google Scholar]
- Lin, S.; Wang, J.; Xu, M.; Zhao, H.; Chen, Z. Topology Aware Object-Level Semantic Mapping Towards More Robust Loop Closure. IEEE Robot. Autom. Lett. 2021, 6, 7041–7048. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Building the gist of a scene: The role of global image features in recognition. Prog. Brain Res. 2006, 155, 23–36. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Cummins, M.; Newman, P. FAB-MAP: Probabilistic localization and mapping in the space of appearance. Int. J. Robot. Res. 2008, 27, 647–665. [Google Scholar] [CrossRef]
- Galvez-Lopez, D.; Tardos, J.D. Bags of Binary Words for Fast Place Recognition in Image Sequences. IEEE Trans. Robot. 2012, 28, 1188–1197. [Google Scholar] [CrossRef]
- Garcia-Fidalgo, E.; Ortiz, A. Hierarchical Place Recognition for Topological Mapping. IEEE Trans. Robot. 2017, 33, 1061–1074. [Google Scholar] [CrossRef]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Assigning Visual Words to Places for Loop Closure Detection. In Proceedings of the IEEE International Conference on Robotics and Automation, Brisbane, QLD, Australia, 21–25 May 2018; pp. 5979–5985. [Google Scholar]
- Tsintotas, K.A.; Bampis, L.; Gasteratos, A. Modest-vocabulary loop-closure detection with incremental bag of tracked words. Robot. Auton. Syst. 2021, 141, 103782. [Google Scholar] [CrossRef]
- Lategahn, H.; Beck, J.; Kitt, B.; Stiller, C. How to Learn an Illumination Robust Image Feature for Place Recognition. In Proceedings of the IEEE Intelligent Vehicles Symposium, Gold Coast, Australia, 23–26 June 2013; pp. 285–291. [Google Scholar]
- Chen, Z.; Lam, O.; Jacobson, A.; Milford, M. Convolutional Neural Network-based Place Recognition. arXiv 2014, arXiv:1411.1509. [Google Scholar]
- An, S.; Che, G.; Zhou, F.; Liu, X.; Ma, X.; Chen, Y. Fast and Incremental Loop Closure Detection Using Proximity Graphs. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019; pp. 378–385. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN Architecture for Weakly Supervised Place Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1437–1451. [Google Scholar] [CrossRef]
- Yu, J.; Zhu, C.; Zhang, J.; Huang, Q.; Tao, D. Spatial Pyramid-Enhanced NetVLAD With Weighted Triplet Loss for Place Recognition. IEEE Trans. Neural Netw. Learn. 2020, 31, 661–674. [Google Scholar] [CrossRef]
- Wang, Z.; Li, J.; Khademi, S.; van Gemert, J. Attention-Aware Age-Agnostic Visual Place Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop, Seoul, Korea, 27–28 October 2019; pp. 1437–1446. [Google Scholar]
- Chen, Z.; Liu, L.; Sa, I.; Ge, Z.; Chli, M. Learning Context Flexible Attention Model for Long-Term Visual Place Recognition. IEEE Robot. Autom. Lett. 2018, 3, 4015–4022. [Google Scholar] [CrossRef]
- Kim, H.J.; Dunn, E.; Frahm, J. Learned Contextual Feature Reweighting for Image Geo-Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3251–3260. [Google Scholar]
- Acuna, D.; Kar, A.; Fidler, S. Devil is in the Edges: Learning Semantic Boundaries from Noisy Annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11067–11075. [Google Scholar]
- Wang, Y.; Qiu, Y.; Cheng, P.; Duan, X. Robust Loop Closure Detection Integrating Visual-Spatial-Semantic Information via Topological Graphs and CNN Features. Remote Sens. 2020, 12, 3890. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Radenovic, F.; Tolias, G.; Chum, O. Fine-Tuning CNN Image Retrieval with No Human Annotation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1655–1668. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE. 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, Y.; Li, S.; Wang, R.; Du, J.; Cremers, D.; Stilla, U. SOE-Net: A Self-Attention and Orientation Encoding Network for Point Cloud based Place Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11343–11352. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Blanco-Claraco, J.; Moreno-Duenas, F.; Gonzalez-Jimenez, J. The Malaga urban dataset: High-rate stereo and LiDAR in a realistic urban scenario. Int. J. Robot. Res. 2014, 33, 207–214. [Google Scholar] [CrossRef]
- Kazmi, S.M.A.M.; Mertsching, B. Detecting the Expectancy of a Place Using Nearby Context for Appearance-Based Mapping. IEEE Trans. Robot. 2019, 35, 1352–1366. [Google Scholar] [CrossRef]
- Yuan, Z.; Xu, K.; Zhou, X.; Deng, B.; Ma, Y. SVG-Loop: Semantic-Visual-Geometric Information-Based Loop Closure Detection. Remote Sens. 2021, 13, 3520. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Description | Image Resolution | #Images | Frame Rate (Hz) | Distance (km) | |
|---|---|---|---|---|---|---|
| KITTI | Seq#00 | Outdoor dynamic | 1241 376 | 4541 | 10 | 3.7 |
| Seq#02 | 1241 376 | 4661 | 5.0 | |||
| Seq#05 | 1226 370 | 2761 | 2.2 | |||
| Seq#06 | 1226 370 | 1101 | 1.2 | |||
| Seq#09 | 1221 370 | 1591 | 1.7 | |||
| Malaga dataset | Urban#8 | Outdoor slightly dynamic | 1024 768 | 10026 | 20 | 4.5 |
| Oxford | City Center | Outdoor dynamic | 640 480 | 1237 | 10 | 1.9 |
| Datasets | Without CFE Module | With CFE Module | ||
|---|---|---|---|---|
| Precision (%) | Recall (%) | Precision (%) | Recall (%) | |
| KITTI00 | 100 | 91.12 | 100 | 91.37 |
| KITTI05 | 100 | 85.06 | 100 | 87.22 |
| KITTI06 | 100 | 90.41 | 100 | 97.03 |
| KITTI09 | 100 | 90.48 | 100 | 95.23 |
| Malaga#8 | 100 | 57.03 | 100 | 57.80 |
| CC | 100 | 62.68 | 100 | 68.97 |
| Approach | KITTI00 | KITTI05 | KITTI06 | KITTI09 | Malaga#8 | CC |
|---|---|---|---|---|---|---|
| DloopDetector [19] | 78.42 | 67.59 | 90.44 | 41.87 | 17.80 | 30.59 |
| Tsintotas et al. [21] | 76.50 | 53.07 | 95.53 | 87.89 | 26.80 | 82.03 |
| Kazmi et al. [41] | 90.39 | 81.41 | 97.39 | - | - | 75.58 |
| FILD [25] | 91.23 | 65.11 | 93.38 | - | - | 66.48 |
| BoTW-LCD [22] | 93.78 | 83.13 | 94.46 | 90.48 | 41.37 | 36.00 |
| SVG-Loop [42] | 73.51 | 47.87 | 58.11 | 50.46 | - | - |
| Proposed | 91.50 | 87.46 | 97.78 | 95.23 | 59.53 | 68.61 |
| Average Time (s) | |||
|---|---|---|---|
| KITTI00 | Malage#8 | CC | |
| Feature extraction | 0.3878 | 0.3901 | 0.3817 |
| Global feature ranking | |||
| Semantic descriptor generation | 0.4458 | 0.4004 | 0.4029 |
| Fusion calculation | 0.0041 | 0.0109 | 0.0006 |
| Total | 0.8377 | 0.8014 | 0.7852 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, J.; Bai, J.; Xu, Y.; Huang, J. Unifying Deep ConvNet and Semantic Edge Features for Loop Closure Detection. Remote Sens. 2022, 14, 4885. https://doi.org/10.3390/rs14194885
Jin J, Bai J, Xu Y, Huang J. Unifying Deep ConvNet and Semantic Edge Features for Loop Closure Detection. Remote Sensing. 2022; 14(19):4885. https://doi.org/10.3390/rs14194885
Chicago/Turabian StyleJin, Jie, Jiale Bai, Yan Xu, and Jiani Huang. 2022. "Unifying Deep ConvNet and Semantic Edge Features for Loop Closure Detection" Remote Sensing 14, no. 19: 4885. https://doi.org/10.3390/rs14194885
APA StyleJin, J., Bai, J., Xu, Y., & Huang, J. (2022). Unifying Deep ConvNet and Semantic Edge Features for Loop Closure Detection. Remote Sensing, 14(19), 4885. https://doi.org/10.3390/rs14194885