
DSNUNet: An Improved Forest Change Detection Network by Combining Sentinel-1 and Sentinel-2 Images


Abstract
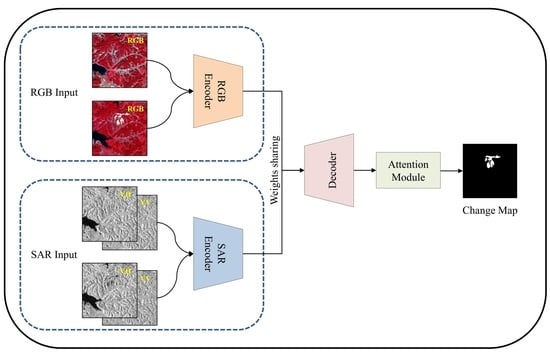
:
1. Introduction
2. Materials and Methods
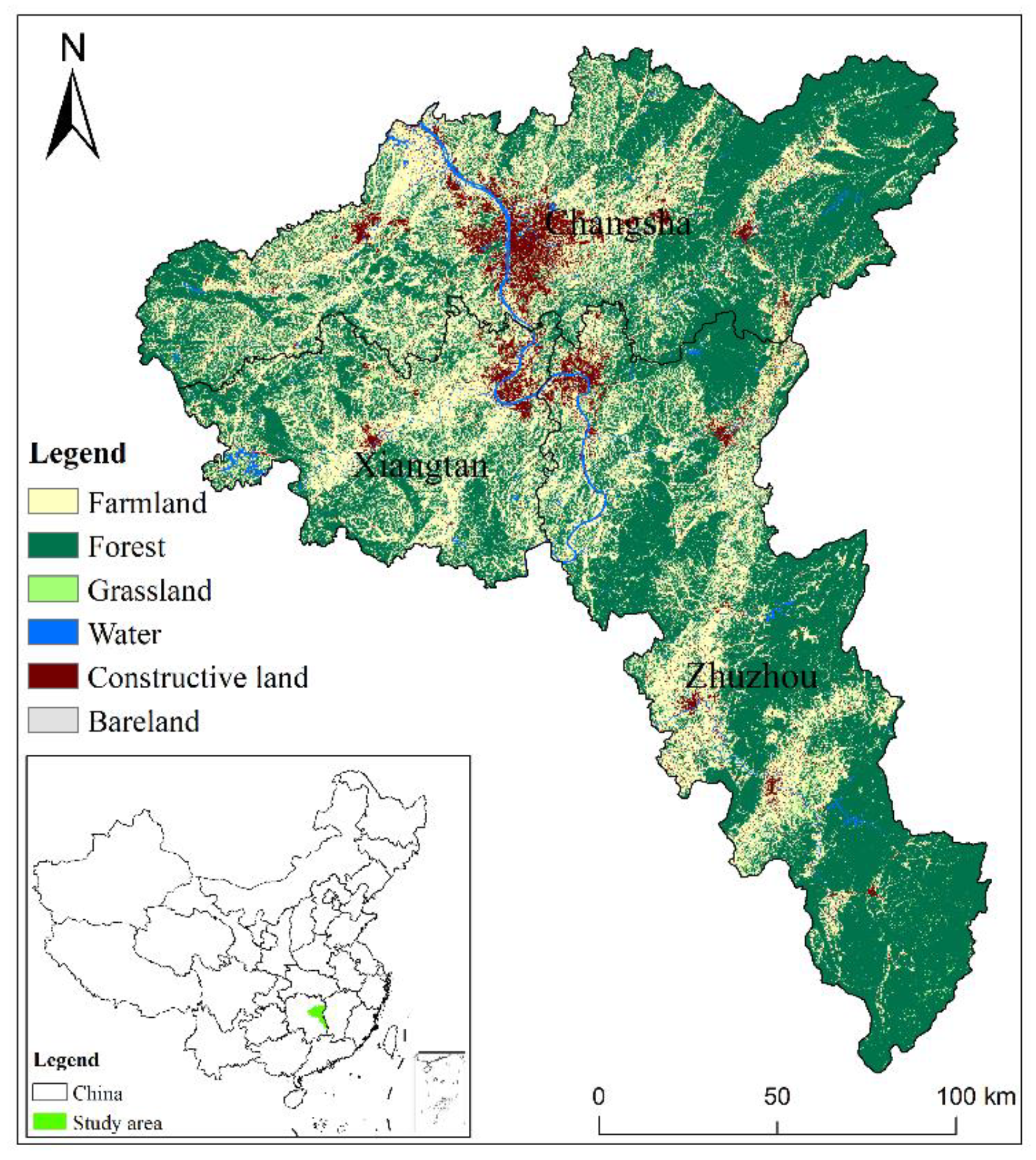
2.1. Study Area
2.2. Data Acquisition and Dataset Construction
2.2.1. Acquisition of Optical Image
2.2.2. Acquisition of SAR Image
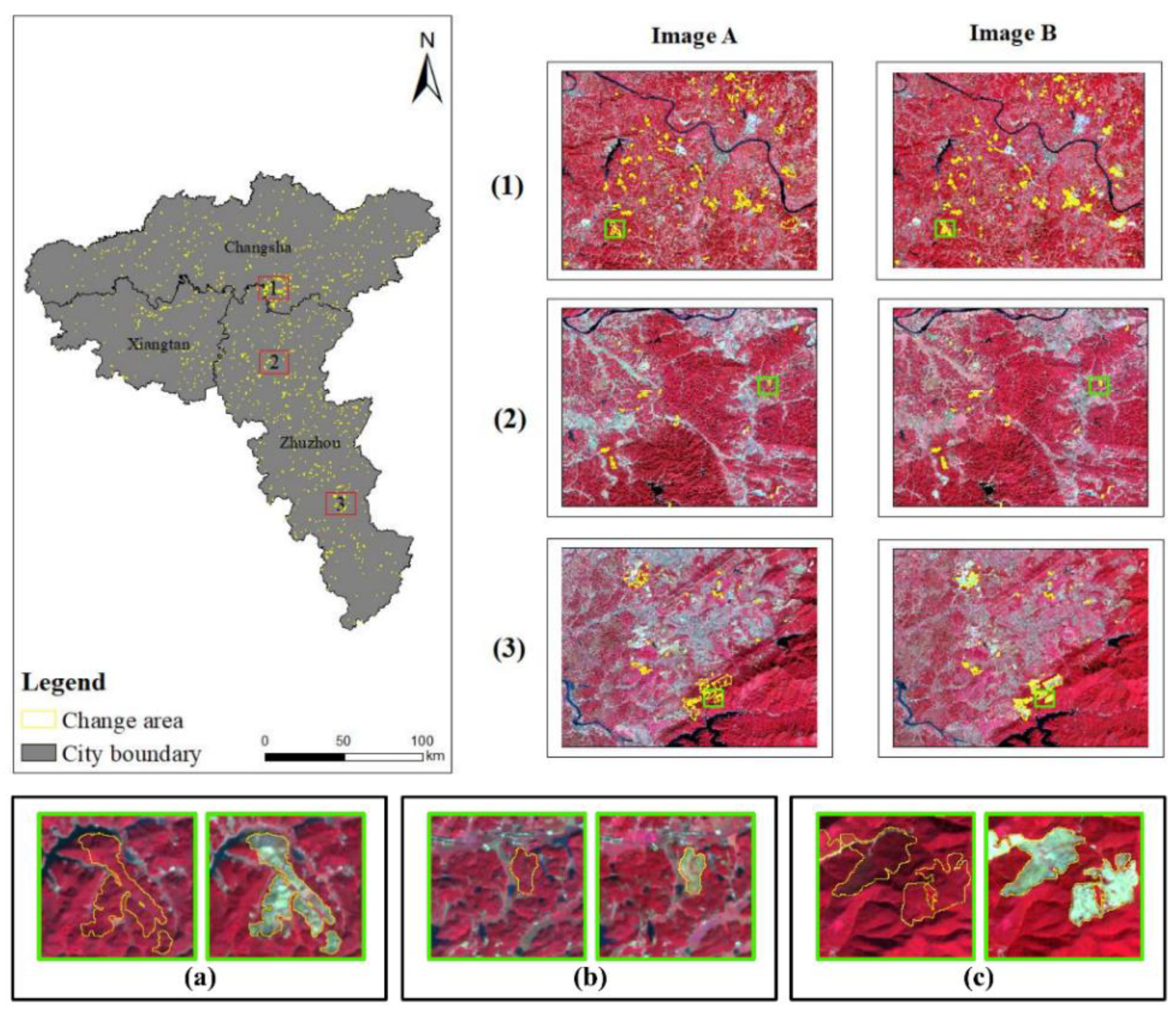
2.2.3. Label Annotation and Dataset Construction
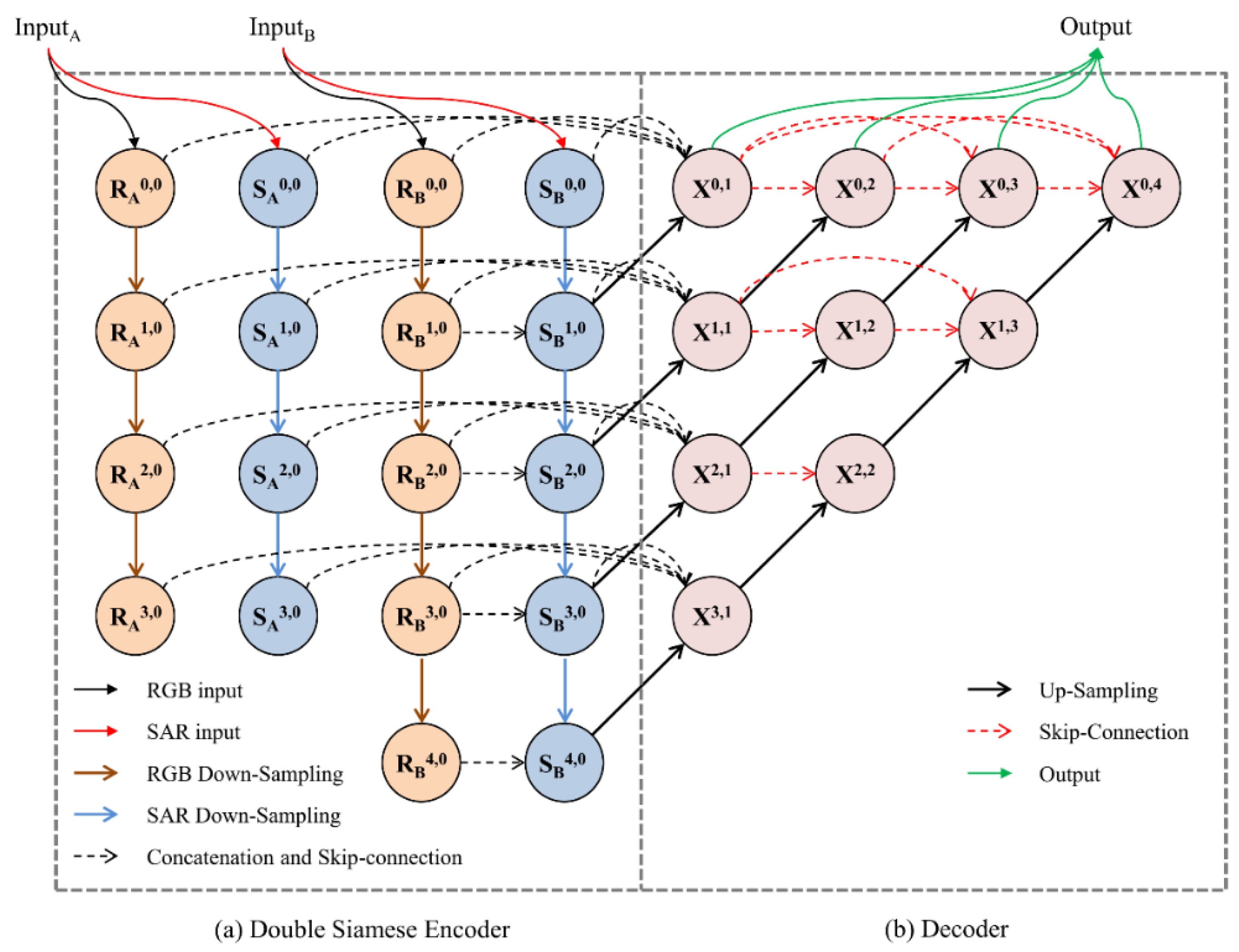
2.3. Model Structure
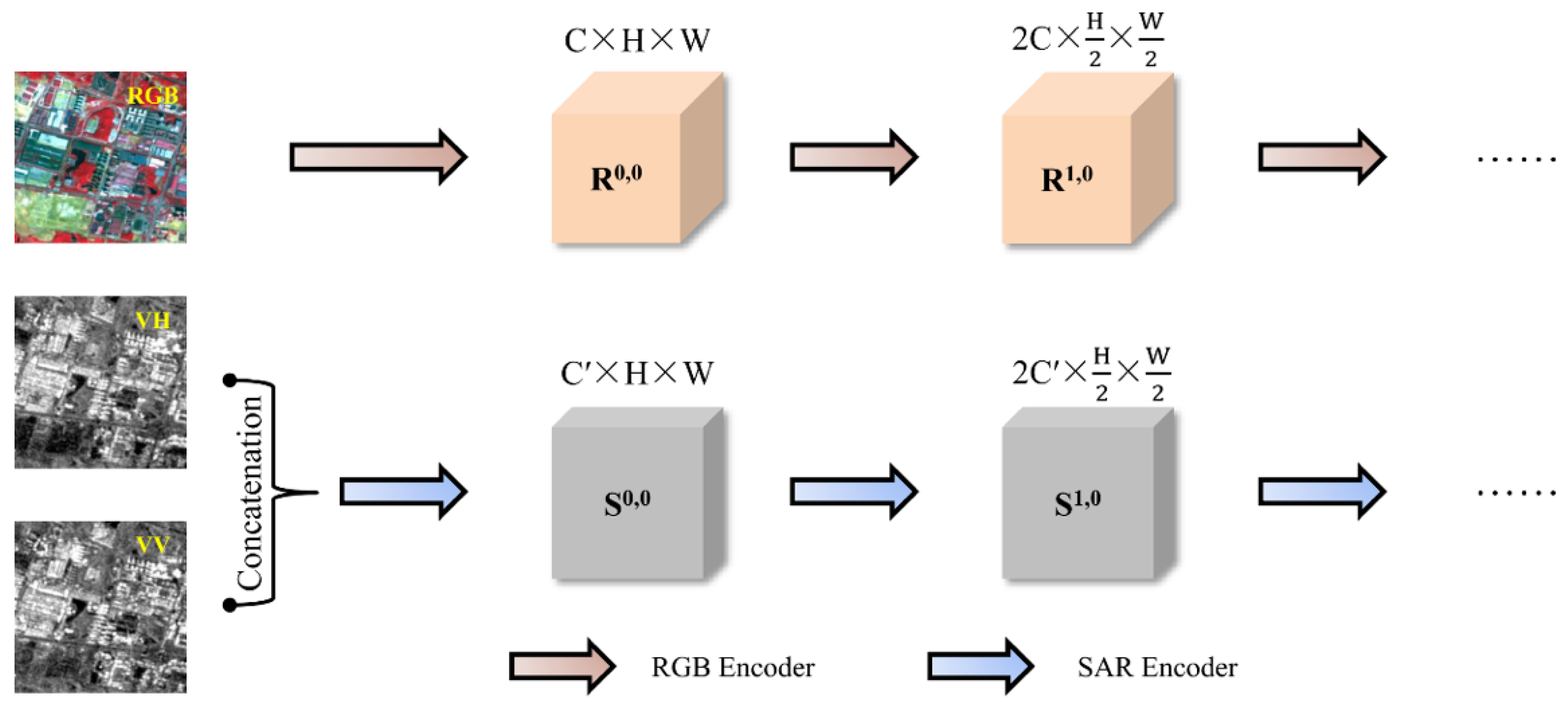
2.3.1. Double Siamese Encoder Structure
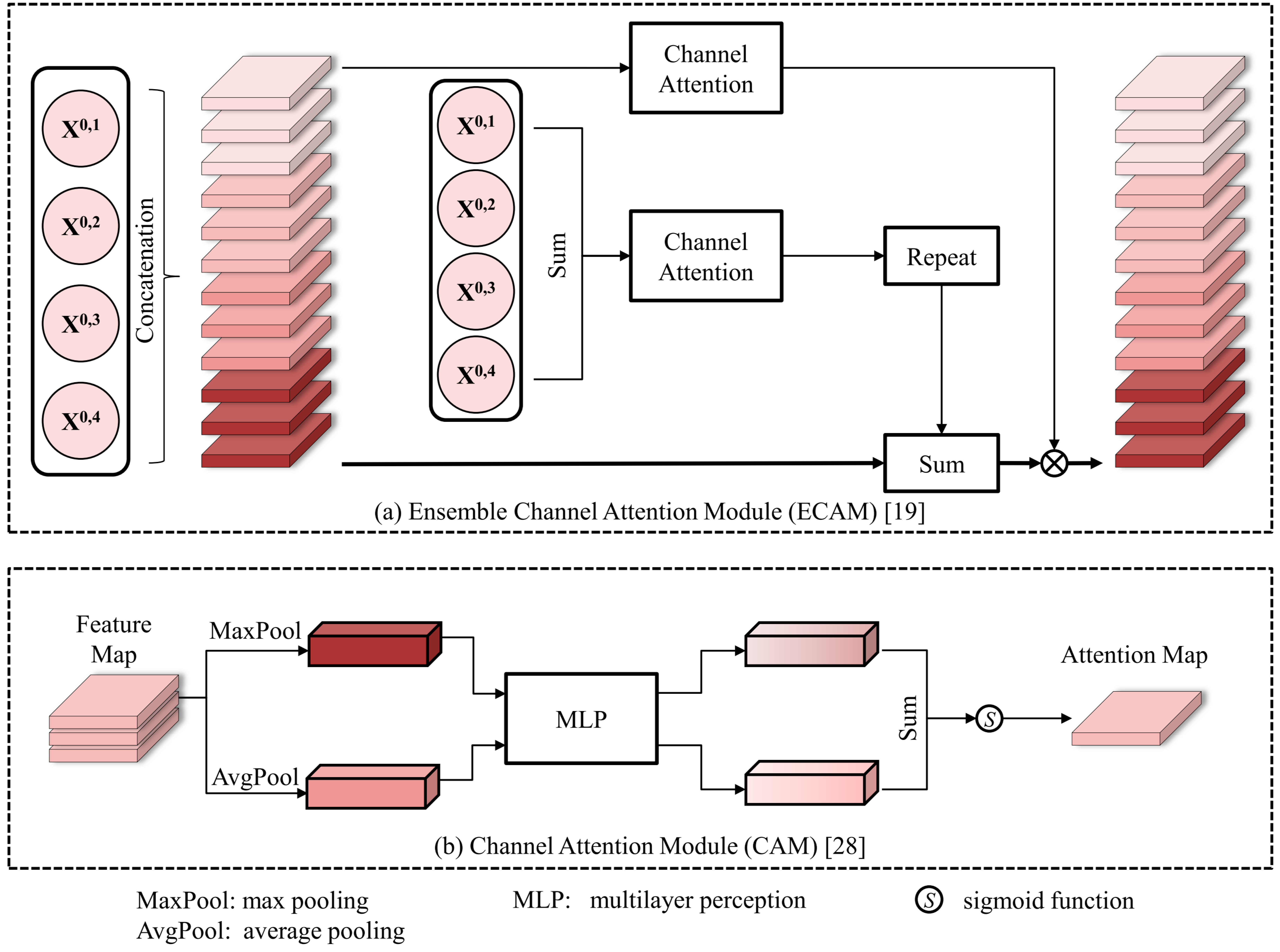
2.3.2. Decoder Structure
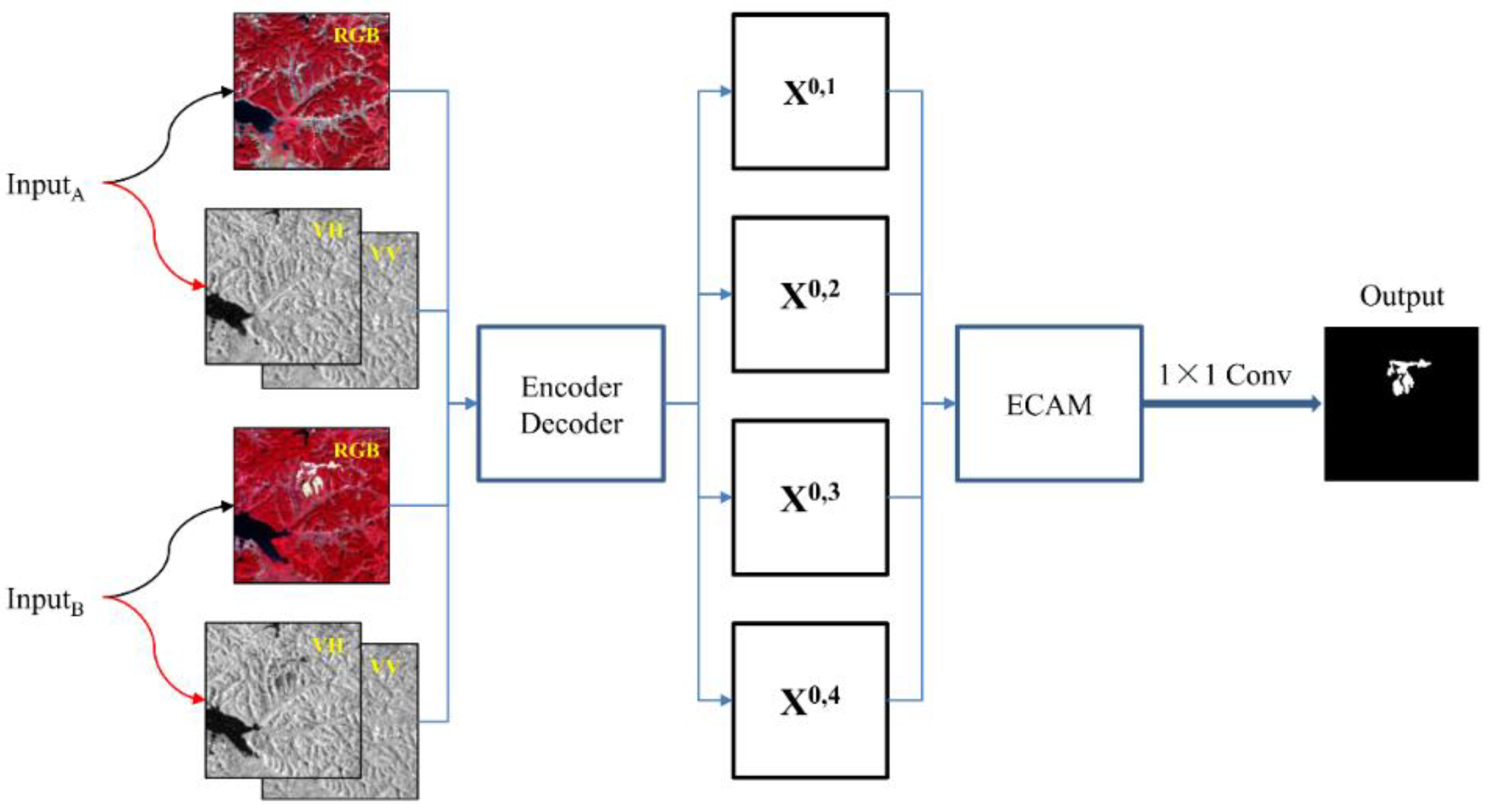
2.3.3. Complete DSNUNet Structure
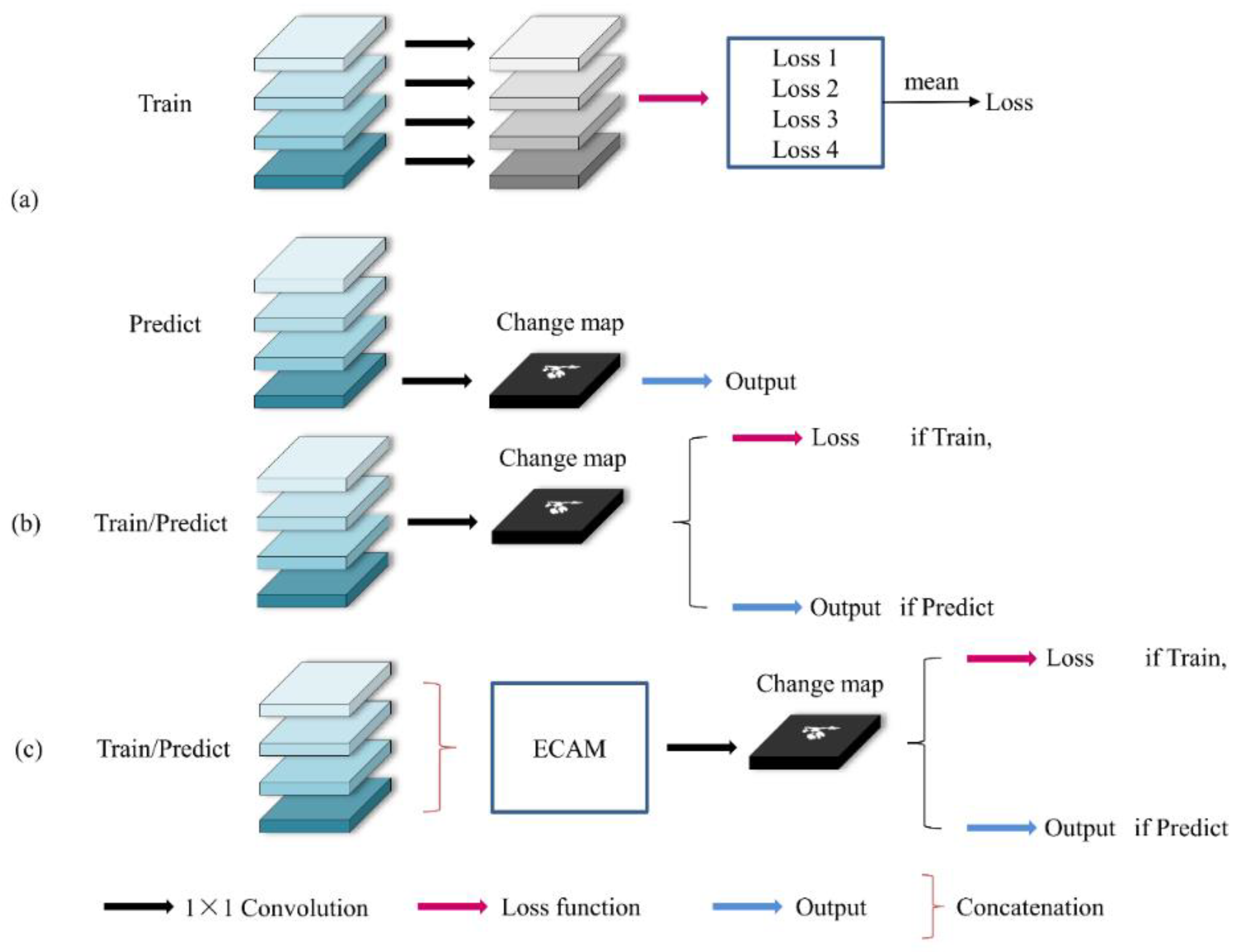
2.4. Loss Function
2.5. Evaluation Metrics
2.6. Implementation Details
3. Results
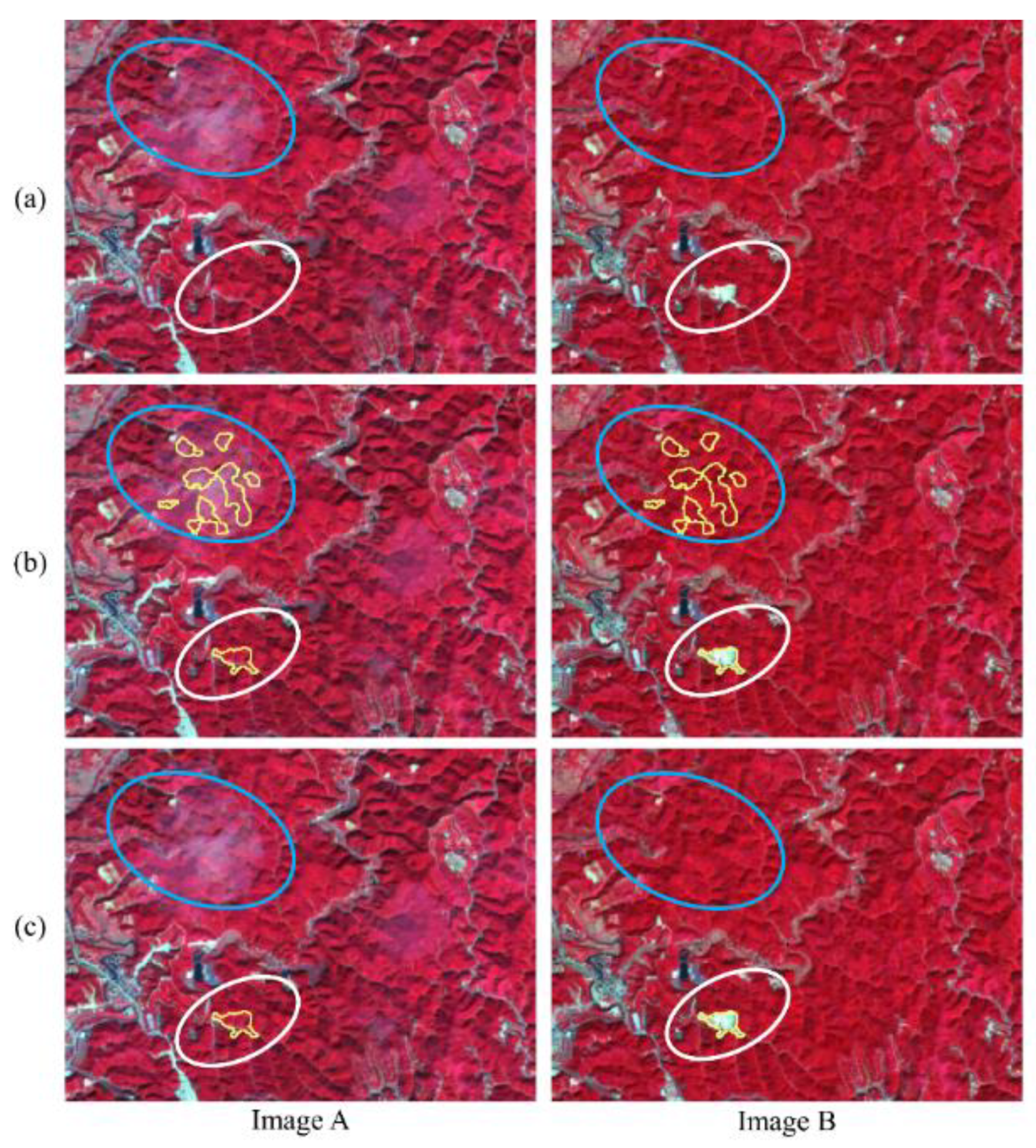
3.1. Comparison of Different Models
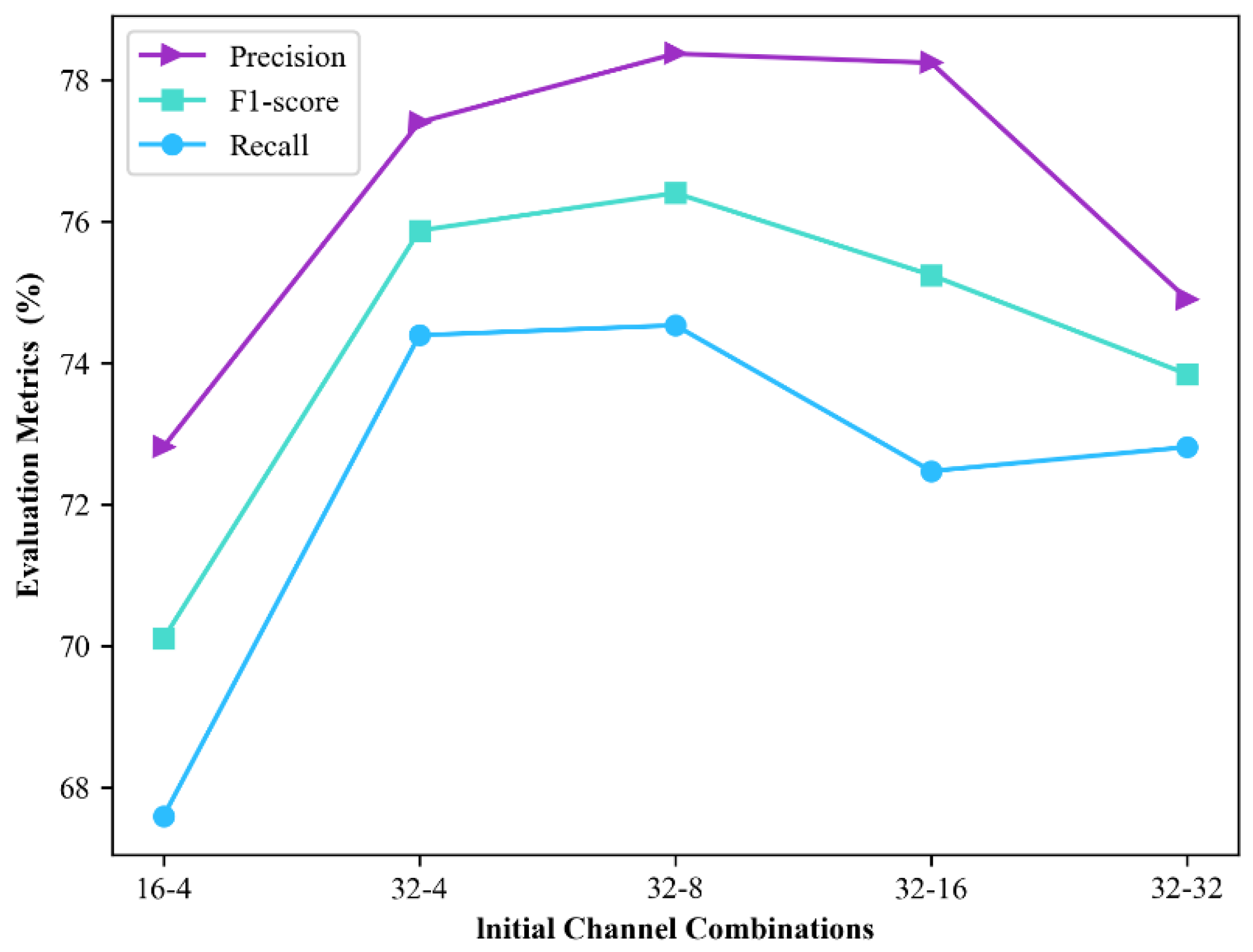
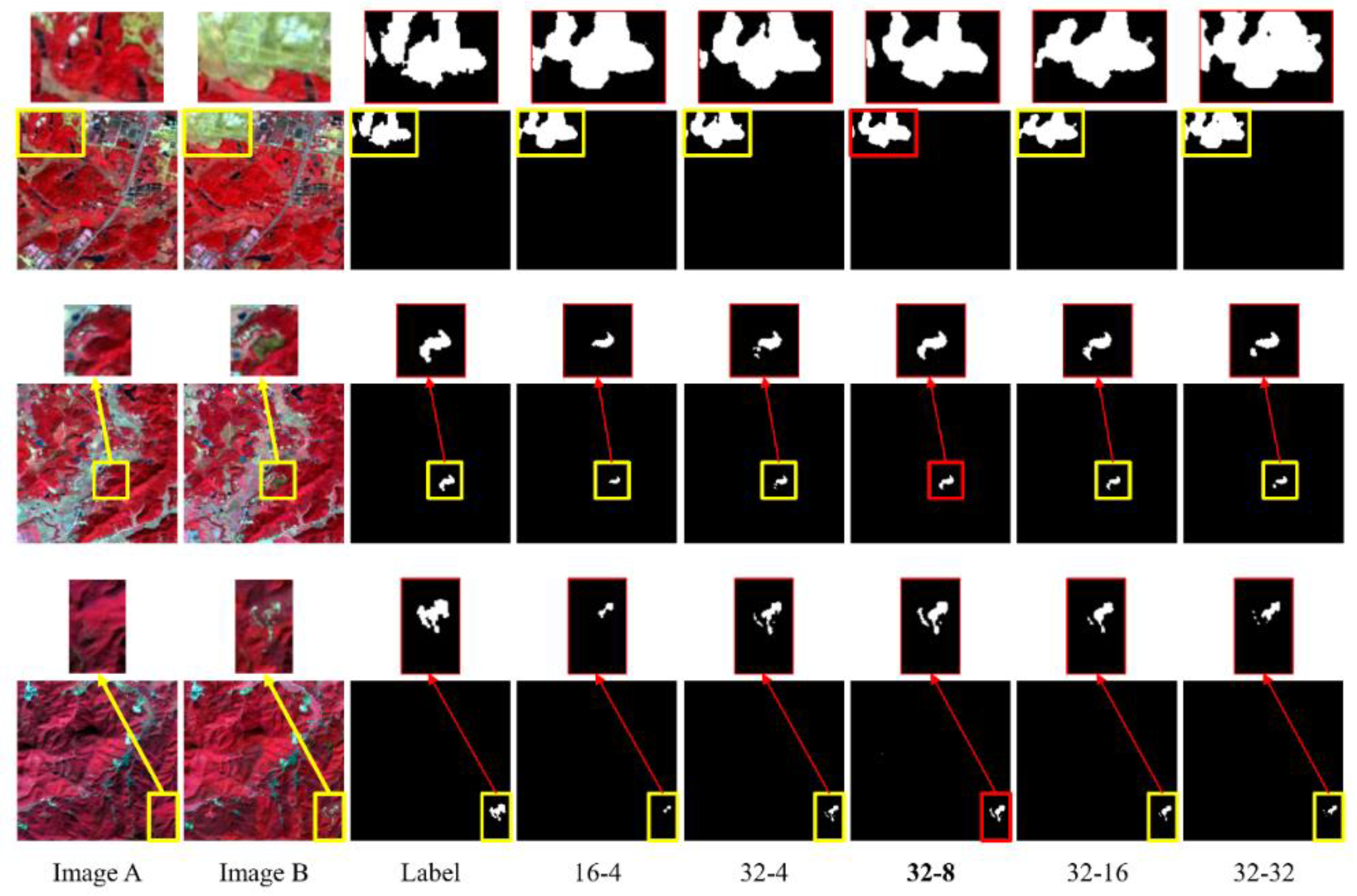
3.2. Comparison of Different Channel Combinations
3.3. Comparison of Different Feature Fusion Methods
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lu, D.; Mausel, P.; Brondízio, E.; Moran, E. Change detection techniques. Int. J. Remote Sens. 2004, 25, 2365–2401. [Google Scholar] [CrossRef]
- Chen, C.-F.; Son, N.-T.; Chang, N.-B.; Chen, C.-R.; Chang, L.-Y.; Valdez, M.; Centeno, G.; Thompson, C.A.; Aceituno, J.L. Multi-Decadal Mangrove Forest Change Detection and Prediction in Honduras, Central America, with Landsat Imagery and a Markov Chain Model. Remote Sens. 2013, 5, 6408–6426. [Google Scholar] [CrossRef] [Green Version]
- Coppin, P.R.; Bauer, M.E. Digital change detection in forest ecosystems with remote sensing imagery. Remote Sens. Rev. 1996, 13, 207–234. [Google Scholar] [CrossRef]
- Lu, D.; Li, G.; Moran, E. Current situation and needs of change detection techniques. Int. J. Image Data Fusion 2014, 5, 13–38. [Google Scholar] [CrossRef]
- Zhao, F.; Sun, R.; Zhong, L.; Meng, R.; Huang, C.; Zeng, X.; Wang, M.; Li, Y.; Wang, Z. Monthly mapping of forest harvesting using dense time series Sentinel-1 SAR imagery and deep learning. Remote Sens. Environ. 2022, 269, 112822. [Google Scholar] [CrossRef]
- Seo, D.K.; Kim, Y.H.; Eo, Y.D.; Lee, M.H.; Park, W.Y. Fusion of SAR and Multispectral Images Using Random Forest Regression for Change Detection. ISPRS Int. J. Geo-Inform. 2018, 7, 401. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Xu, Y.J. Comparison of remote sensing change detection techniques for assessing hurricane damage to forests. Environ. Monit. Assess. 2010, 162, 311–326. [Google Scholar] [CrossRef]
- Nackaerts, K.; Vaesen, K.; Muys, B.; Coppin, P. Comparative performance of a modified change vector analysis in forest change detection. Int. J. Remote Sens. 2005, 26, 839–852. [Google Scholar] [CrossRef]
- Yang, J.; Zhou, Y.; Cao, Y.; Feng, L. Heterogeneous image change detection using Deep Canonical Correlation Analysis. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2917–2922. [Google Scholar]
- Meli Fokeng, R.; Gadinga Forje, W.; Meli Meli, V.; Nyuyki Bodzemo, B. Multi-temporal forest cover change detection in the Metchie-Ngoum Protection Forest Reserve, West Region of Cameroon. Egypt. J. Remote Sens. Space Sci. 2020, 23, 113–124. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A review of deep learning methods for semantic segmentation of remote sensing imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Daudt, R.C.; Saux, B.L.; Boulch, A. Fully Convolutional Siamese Networks for Change Detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 4063–4067. [Google Scholar]
- Rahman, F.; Vasu, B.; Cor, J.V.; Kerekes, J.; Savakis, A. Siamese network with multi-level features for patch-based change detection in satellite imagery. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–29 November 2018; pp. 958–962. [Google Scholar]
- Zhan, Y.; Fu, K.; Yan, M.; Sun, X.; Wang, H.; Qiu, X. Change Detection Based on Deep Siamese Convolutional Network for Optical Aerial Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1845–1849. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection With Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Hethcoat, M.G.; Edwards, D.P.; Carreiras, J.M.; Bryant, R.G.; Franca, F.M.; Quegan, S. A machine learning approach to map tropical selective logging. Remote Sens. Environ. 2019, 221, 569–582. [Google Scholar] [CrossRef]
- Schroeder, T.A.; Wulder, M.A.; Healey, S.P.; Moisen, G.G. Mapping wildfire and clearcut harvest disturbances in boreal forests with Landsat time series data. Remote Sens. Environ. 2011, 115, 1421–1433. [Google Scholar] [CrossRef]
- Cohen, W.B.; Fiorella, M.; Gray, J.; Helmer, E.; Anderson, K. An efficient and accurate method for mapping forest clearcuts in the Pacific Northwest using Landsat imagery. Photogramm. Eng. Remote Sens. 1998, 64, 293–299. [Google Scholar]
- Hethcoat, M.G.; Carreiras, J.M.B.; Edwards, D.P.; Bryant, R.G.; Quegan, S. Detecting tropical selective logging with C-band SAR data may require a time series approach. Remote Sens. Environ. 2021, 259, 112411. [Google Scholar] [CrossRef]
- Reiche, J.; Hamunyela, E.; Verbesselt, J.; Hoekman, D.; Herold, M. Improving near-real time deforestation monitoring in tropical dry forests by combining dense Sentinel-1 time series with Landsat and ALOS-2 PALSAR-2. Remote Sens. Environ. 2018, 204, 147–161. [Google Scholar] [CrossRef]
- Maretto, R.V.; Fonseca, L.M.G.; Jacobs, N.; Körting, T.S.; Bendini, H.N.; Parente, L.L. Spatio-Temporal Deep Learning Approach to Map Deforestation in Amazon Rainforest. IEEE Geosci. Remote Sens. Lett. 2021, 18, 771–775. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Data | Download Source | Spatial Resolution (m) | Time/Synthetic Method | Cloud Cover |
|---|---|---|---|---|
| Sentinel-2 L1C | Google Earth Engine | 10 | 2020: autumn(Month 9~11)/Median | below 5% |
| 2021: autumn(Month 9~11)/Median | below 5% |
| Name of Data | Download Source | Spatial Resolution (m) | Time/Synthetic Method | Polarization |
|---|---|---|---|---|
| Sentinel-1 GRD | Google Earth Engine | 10 | 2020: autumn(Month 9~11)/Median | VV, VH |
| 2021: autumn(Month 9~11)/Median | VV, VH |
| Model | Params (M) | FlOP (G) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|
| FC-Siam-Diff | 1.35 | 9.40 | 66.71 | 63.39 | 65.01 |
| FC-Siam-Conc | 1.54 | 10.60 | 64.41 | 69.25 | 66.75 |
| FC-EF | 1.35 | 7.10 | 68.66 | 67.41 | 68.03 |
| STANet | 12.21 | 25.40 | 73.35 | 65.97 | 69.47 |
| BIT | 11.91 | 16.94 | 70.69 | 70.36 | 70.52 |
| LF UNet | 9.95 | 46.64 | 77.42 | 67.36 | 72.04 |
| SNUNet * | 12.03 | 109.76 | 77.74 | 70.91 | 74.17 |
| DSNUNet * | 13.33 | 119.76 | 78.37 | 74.53 | 76.40 |
| Model | Params (M) | FlOP (G) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|
| FC-Siam-Diff | 1.35 | 9.46 | 69.22 | 66.16 | 67.65 |
| FC-Siam-Conc | 1.54 | 10.68 | 67.26 | 67.18 | 67.22 |
| FC-EF | 1.35 | 7.18 | 69.53 | 67.78 | 68.65 |
| STANet | 12.22 | 25.82 | 78.79 | 65.06 | 71.27 |
| BIT | 11.92 | 17.36 | 73.28 | 65.27 | 69.04 |
| LF UNet | 9.95 | 46.78 | 76.19 | 72.88 | 74.50 |
| SNUNet * | 12.04 | 109.90 | 75.75 | 73.79 | 74.75 |
| DSNUNet * | 13.33 | 119.76 | 78.37 | 74.53 | 76.40 |
| Initial Channel Number Combination * | Params (M) | FlOP (G) | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|---|---|
| 16-4 | 3.34 | 30.14 | 72.81 | 67.59 | 70.10 |
| 32-4 | 12.59 | 114.40 | 77.40 | 74.39 | 75.87 |
| 32-8 | 13.33 | 119.76 | 78.37 | 74.53 | 76.40 |
| 32-16 | 15.38 | 132.74 | 78.24 | 72.47 | 75.24 |
| 32-32 | 21.78 | 167.58 | 74.90 | 72.81 | 73.84 |
| Method | Precision (%) | Recall (%) | F1-Score (%) |
|---|---|---|---|
| Deep supervision | 79.18 | 69.71 | 74.14 |
| 1 × 1 convolution | 75.35 | 74.09 | 74.71 |
| ECAM | 78.37 | 74.53 | 76.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, J.; Xing, Y.; Wei, W.; Yan, E.; Xiang, J.; Mo, D. DSNUNet: An Improved Forest Change Detection Network by Combining Sentinel-1 and Sentinel-2 Images. Remote Sens. 2022, 14, 5046. https://doi.org/10.3390/rs14195046
Jiang J, Xing Y, Wei W, Yan E, Xiang J, Mo D. DSNUNet: An Improved Forest Change Detection Network by Combining Sentinel-1 and Sentinel-2 Images. Remote Sensing. 2022; 14(19):5046. https://doi.org/10.3390/rs14195046
Chicago/Turabian StyleJiang, Jiawei, Yuanjun Xing, Wei Wei, Enping Yan, Jun Xiang, and Dengkui Mo. 2022. "DSNUNet: An Improved Forest Change Detection Network by Combining Sentinel-1 and Sentinel-2 Images" Remote Sensing 14, no. 19: 5046. https://doi.org/10.3390/rs14195046
APA StyleJiang, J., Xing, Y., Wei, W., Yan, E., Xiang, J., & Mo, D. (2022). DSNUNet: An Improved Forest Change Detection Network by Combining Sentinel-1 and Sentinel-2 Images. Remote Sensing, 14(19), 5046. https://doi.org/10.3390/rs14195046