1. Introduction
The aerial and ground collaborative unmanned systems are a heterogeneous cross-domain collaborative unmanned system composed of unmanned aerial vehicles (UAVs) and unmanned ground vehicles (UGVs), with complex functions such as perception, positioning, control and navigation. It can not only perform tasks independently, but also interacting with multiple aircraft across domains. A heterogeneous team of UAVs and UGVs can compensate for the lack of mobility, payload, and observation conditions between different platforms. UAVs can quickly cover large areas and have a good point of view for situational assessment. Ground vehicles have longer battery life, can carry large payloads, and actively interact with the environment.
In recent years, single-platform SLAM technology has been developed significantly. Early SLAM framework of sensor fusion mostly adopted the extended Kalman filter (EKF). For example, MSCKF [
1] proposed a multi-sensor location information fusion method loosely coupled with visual-inertial odometry (VIO). ORB-SLAM3 [
2] proposed by Campos e.g., revealed its potential in the aspects of high precision and high robustness. In the aspect of map fusion, the ORBSLAM-Atlas [
3] module used camera pose error covariance to estimate the observability of the camera pose to determine whether to retain the camera pose or create a new map. In the field of multi-sensor fusion SLAM, VINS-FUSION [
4] proposed a method that fused loosely-coupled global positioning information and VO/VIO positioning result. Some excellent collaborative SLAM frameworks also emerged from this foundation. When lacking external measurements, the relative position measurement between unmanned platforms mainly relies on visual position re-identification. A common way to obtain loop closures is to use visual place recognition methods, based on image or keypoint descriptors and a bag of words model, such as [
4,
5]. Some recent works have also studied closed-loop detection between distributed robots [
6,
7]. This method finds closed-loops through local communication between robots [
8], collects observation data in a central server, and obtains a motion trajectory estimation of each robot through pose graph optimization (PGO). Different from the above, Yun Chang et al. proposed a collaborative SLAM method based on deep learning semantic description features [
9].
There are two communication modes of multi-robot collaborative SLAM: distributed and centralized. [
9,
10,
11] are representative works of a distributed framework. In related research of a centralized framework, Zou et al. introduced CoSLAM [
12] in the early years, which demonstrated considerable potential of the centralized collaborative SLAM, CCM-SLAM [
13] that deploys resource-consuming computations on servers, while still ensuring each agent’s autonomy at low computational resource requirements by running a visual odometry system onboard. CVISLAM [
14] was the first collaborative SLAM framework for bidirectional communication and extended visual-inertial odometry to the collaborative SLAM domain. It achieved higher accuracy and metric scale estimation. However, this study did not integrate GPS positioning information and thus lacks flexibility. Jialing Liu et al. proposed a collaborative monocular inertial SLAM system for smart phones. This was the first multi-agent collaborative SLAM system to run on a mobile phone [
15], supporting cross-device collaboration. Similar work has reported CoVins [
16] which can perform collaborative SLAM tasks on a larger scale. This study showed advantages in removing redundant information and reducing the coordination overhead.
All the above research only provides some thought to solving the ground-air collaborative navigation problems. They did not evaluate the specific application of various methods in aerial and ground collaborative navigation problems under GNSS-challenged environments. Even so, many challenges of this application still exist. For example, how to overcome the place recognition of crossing platforms under the aerial-ground difference of visual angles, or how to correct drift errors of GNSS positioning information for different platforms. The previous research mostly considered that a single platform did not need to run a complete SLAM optimization process during collaborative SLAM and only needed to execute visual odometry or visual-inertia odometry. However, with the rapid development of the terminal equipment computing power, we considered that a deploy communication interface, loosely-coupled with two-stage optimization and a complete single-platform SLAM process on a terminal device at the same time will not only improve the positioning accuracy of the single-platform but also improve the robustness of the single-platform positioning algorithm of the whole system in the case of communication disorder. The key to collaborative positioning in GNSS-challenging environments is to ensure system initialization and positioning without GNSS signals, and to improve overall positioning accuracy with GNSS positioning when GNSS positioning information is available.
In order to solve ground-air collaborative positioning problems, Moafipoor et al. proposed a method that used UGV and UAV collaboration to navigate [
17]. When GPS is not available, the constraints of the external measurements provided by the extended Kalman filter and tracking filter are used to ensure the normal operation of the navigation function under adverse GPS conditions. In this paper, graph optimization was adopted to solve similar problems, assuming that GPS signals of each agent may be interfered with at any time. Peter Fankhauser et al. proposed a completely integrated method of relative observation between robots, independent of external positioning, and without initial guesstimates about the robot’s posture [
18]. This method was applied to the mutual positioning between a hexacopter and a quadrupedal robot. J Park et al. studied the map point registration between UAV and UGV through feature points and realized the work of spatial data collection by multiple agents in a decentralized environment [
19]. Hailong Qin proposed a two layer shared novel optimized exploration path planning and navigation framework, which provided optimal exploration paths and integrated the collaborative exploration and mapping efforts through an OctoMap-based volumetric motion planning interface [
20]. They only considered GNSS-denied environments, not GNSS-challenged environments. In practical applications, on the one hand, we hope to use GNSS positioning information when receiving GNSS signals, and on the other hand, we hope to maintain a certain navigation function in the absence of GPS.
In this paper, we proposed an algorithm framework based on feature point matching and graph optimization for ground-air collaborative positioning in GNSS-challenged environments and verify its function in the virtual simulation system. Compared with previous related work, the main contributions of this paper are summarized as follows:
GNSS information is used to eliminate drift errors of the SLAM process in a loosely-coupled way. This method can work normally even if the GNSS signal is disturbed or missing;
The cooperative location process is divided into several stages, and we try our best to balance the server computing power, communication bandwidth and algorithm performance. This allows the system to perform a complete global map initialization in the environment without GNSS signals;
The function of the proposed method is verified by using a virtual simulation system, and the positioning accuracy of the algorithm is analyzed.
2. Materials and Methods
2.1. System Overview
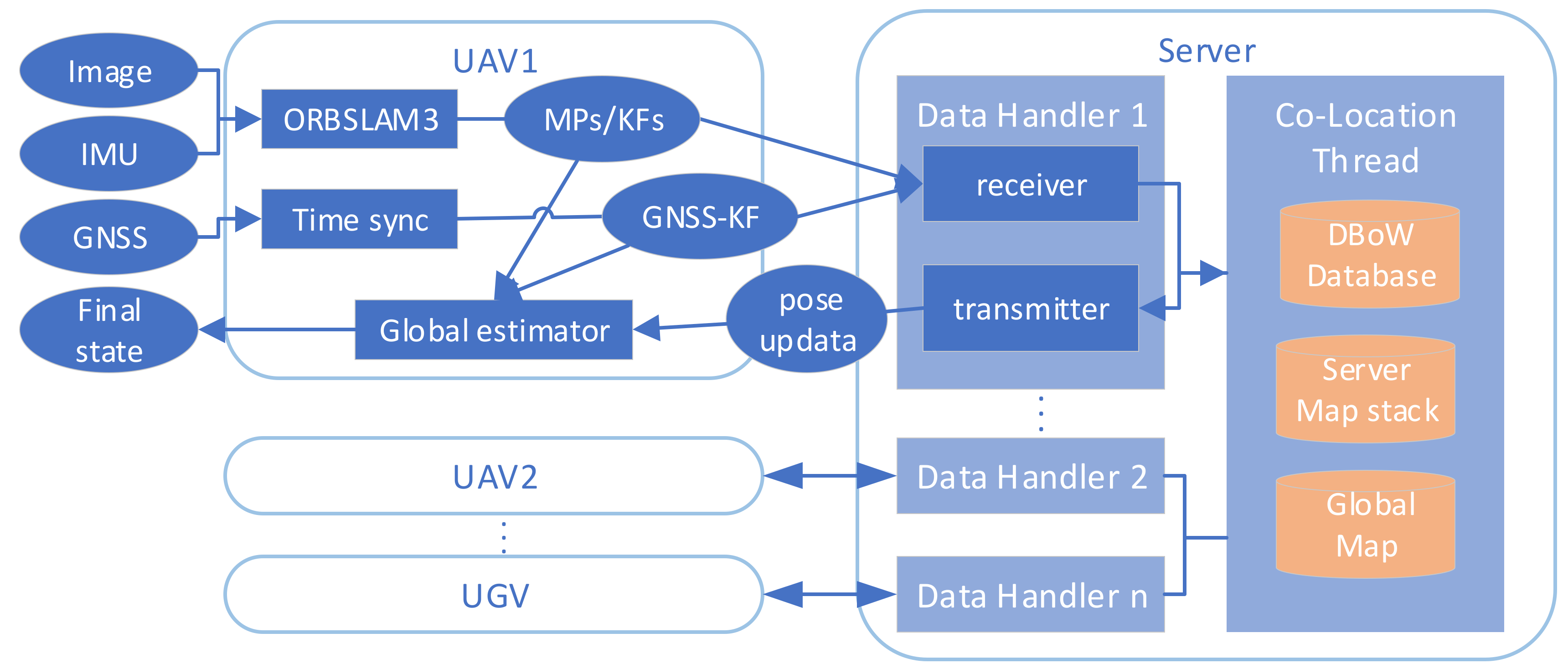
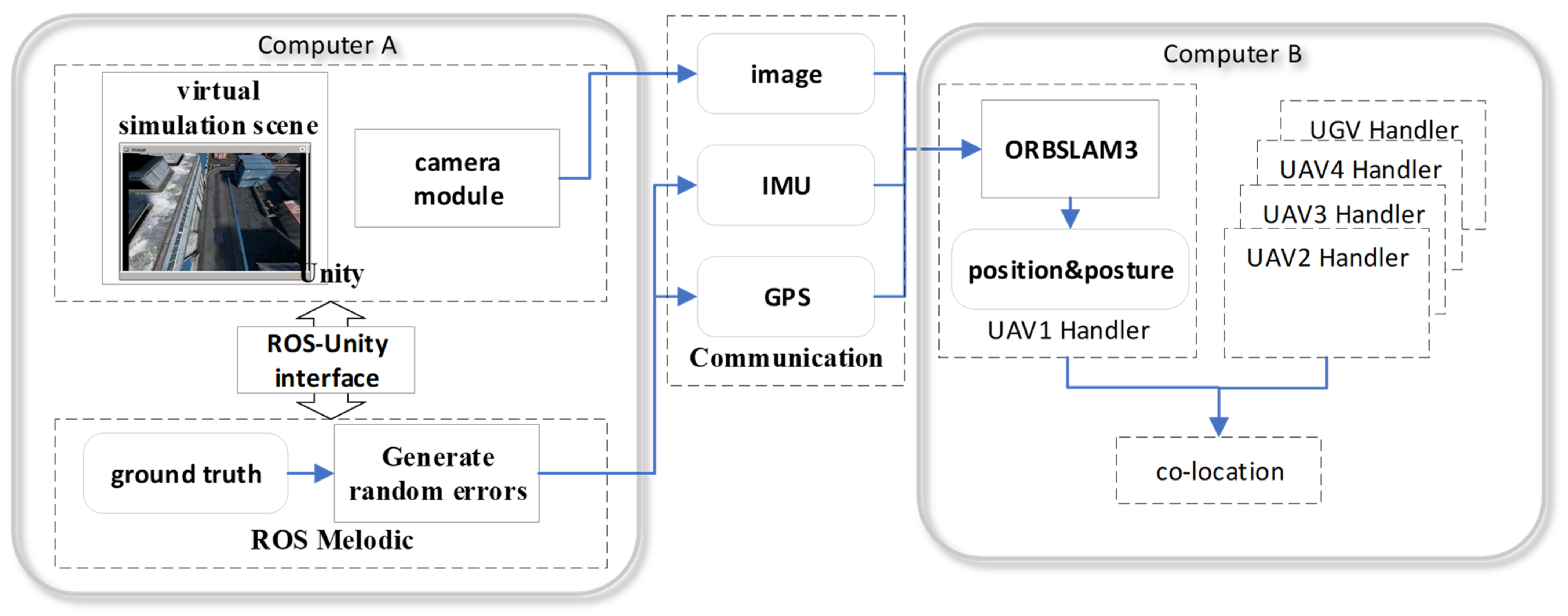
The architecture of the framework is depicted in
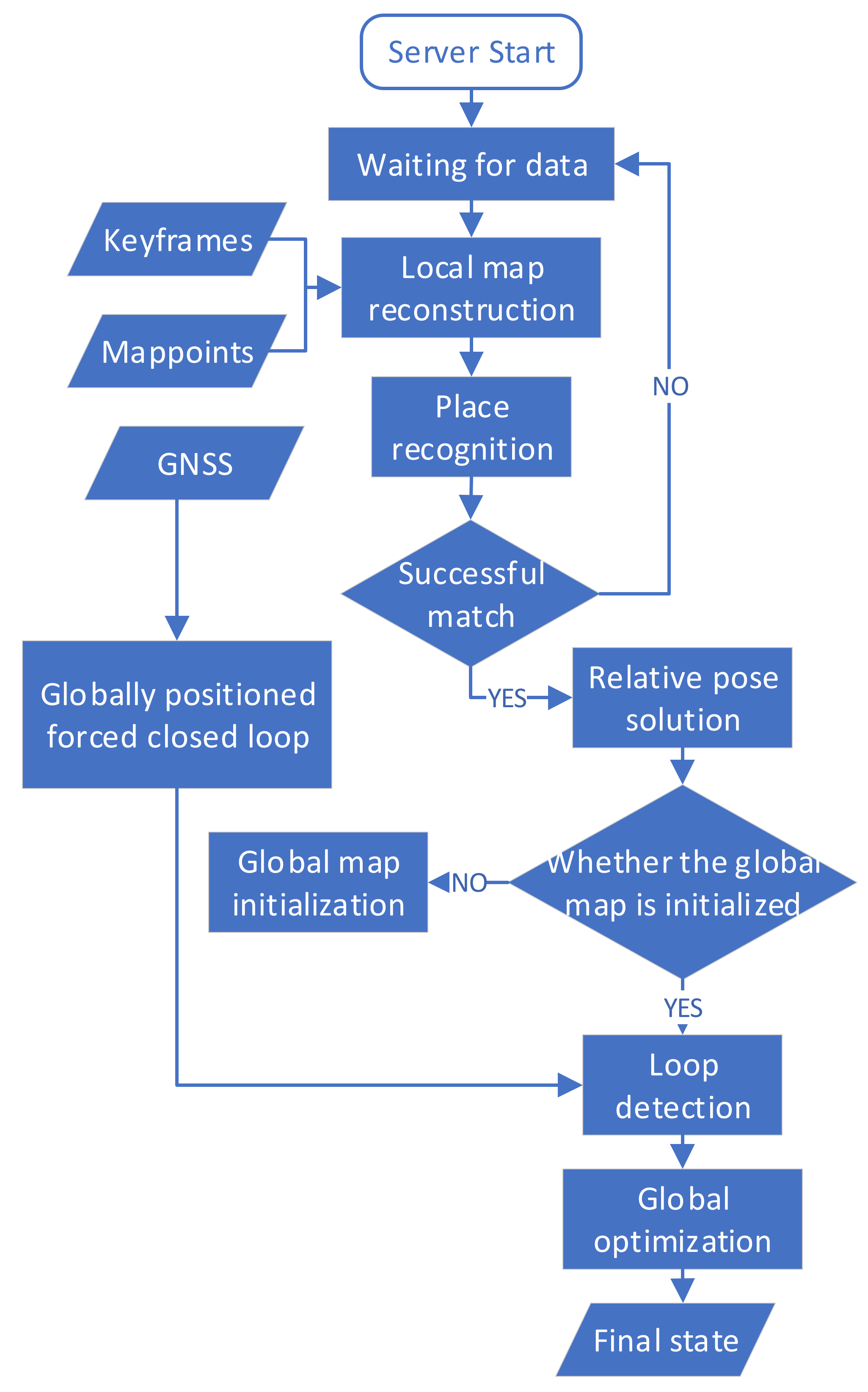
Figure 1. At the early stages of system startup, all the UAV take off from a platform on the top of a UGV. After the unmanned platform completes IMU initialization and performs the first global bundle adjustment (BA), map fusion and relative pose solutions are completed between unmanned platforms through the local map. A flowchart of the co-location program executed on the server is shown below:
For convenience of explanation, the first stage of the position estimation coordinate system for a single platform is called the VIO frame. The coordinate system where each agent’s local map is located after a single platform has completed the second stage of position estimation is called the local frame. The coordinate system where the global map is located after map fusion is completed on the server is called the global frame. The co-location program on the server is shown in
Figure 2. When there is no GNSS positioning or collaborative positioning information, the VIO frame will overlap with the local frame. The global frame overlaps with the local frame of the UGV before initialization, and the process of global map initialization is to obtain the relative positioning relation between each UAV and UGV through PnP solutions and convert the local map of each agent to a global map based on UGV’s local map. After initialization, the local frame of each agent will overlap with the global frame. As the unmanned platform continues to move, each agent generates a new keyframe during the local SLAM process and sends these new keyframes and map points to the server through wireless data communication. The server stack will cache map information from each agent. These keyframes and map points will be added to the global map through the initialized relative position changes between platforms. After the program discovers place recognition among platforms through detecting feature points, loop-closure and map fusion of the global map will be executed, as well as optimization. The optimized position and pose will be used to estimate that in the second stage, together with the GNSS positioning from each platform. Finally, the new pose of the new keyframes after collaborative positioning in the closed-loop position will be sent back to the corresponding agent. And the agent that accepts the collaborative positioning information will adjust their pose during the second stage of local optimization.
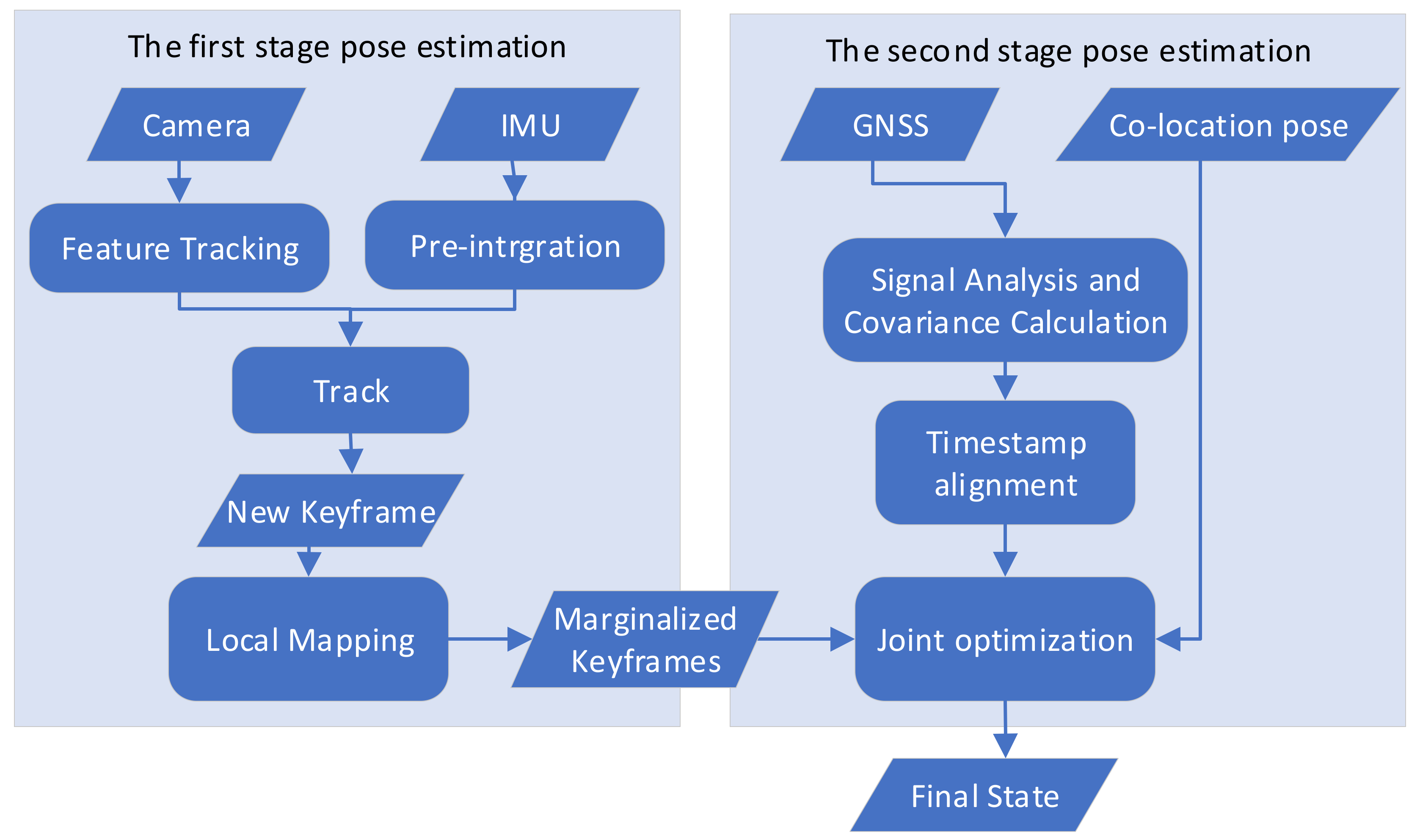
2.2. Keyframe-Based SLAM Algorithm Fusing GNSS Positioning Information and Co-Location Information
We deployed a SLAM framework modified and based on ORB-SLAM3 on each agent to run independently, to ensure each agent can complete independent navigation tasks in the situation where communication links are lost. The algorithm’s flow is shown in
Figure 3. ORB-SLAM3 was modified as follows:
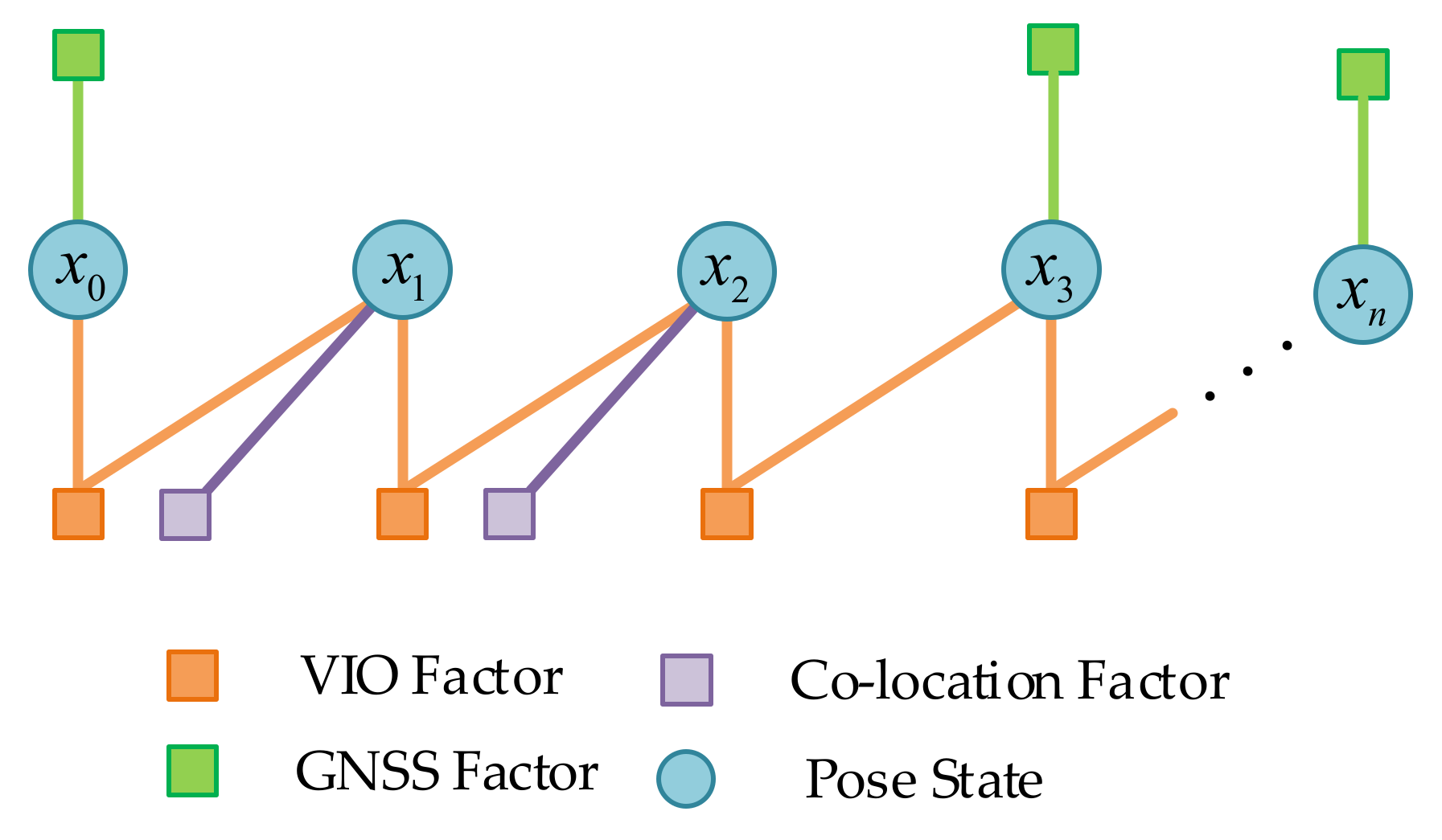
Each node represents a keyframe position and pose in the world frame. In
Figure 4, the line between two nodes is called an “edge”, which represents the constraint of the amount to be optimized in the optimization of the factor graph. The edge between two consecutive nodes is a local constraint, which comes from ORB-SLAM3′s pose estimation. The other edge is the constraint from the co-location results of the server and GNSS satellite positioning information. We used the VIO factor as the local constraints, and GNSS location information and co-location information as global constraints. An illustration of the second-stage global pose graph structure is shown in
Figure 4.
Construction of residuals with local constraints refer to ORBSLAM3 [
1], supposing that there are two continuous keyframes
and
, we define
as the attitude quaternion
under the VIO coordinate system, and
as the three-dimensional coordinate under the VIO coordinate system of
. Similarly,
and
are the quaternion and coordinates under the global coordinate system. The VIO local factor is derived as:
where
is the measured value, provided by the results of the one-stage position estimation;
is the state prediction; and
is the observation equation.
is calculated from the pose transformation between the two moments. The specific method used in this paper uses the relative pose of the current moment and the previous moment obtained from the position estimation in the first stage to add to the position coordinate
at the previous moment to obtain the position coordinate
at the current moment.
is the minus operation on the error state of quaternion. We take the pose covariance matrix generated during SLAM as the covariance of local measurements. The essence of the local factor is the relative change in the pose in two keyframes.
Consider the following two situations where GNSS does not work: the GNSS signal is poor or has interference, resulting in a large error in the GNSS positioning information, resulting in a large drift in an agent’s navigation trajectory; the GNSS signal is completely disabled, and there is no GNSS positioning information. Upon receipt of a valid GNSS location, the longitudinal dimension heights of the original measurements will be transformed into x, y, z coordinates in the local Cartesian coordinates system (ENU) during GNSS data preprocessing.
is the coordinate of the GNSS information in the transformed ENU coordinate system.
is the measured value of GNSS at that moment,
. The uncertainty of measurement is assumed to be a Gaussian distribution with mean and covariance.
is the assumed GNSS estimate. The GNSS factor is derived as:
When each agent receives a new pose about a keyframe’s collaborative positioning from the server, we introduce the result of collaborative positioning as a new measured value into the process of secondary optimization. We assume that the result obtained by
in the first-stage pose estimation at that moment in the VIO coordinate system is
. The pose obtained by
after the co-location is transformed into
on the local framework of the agent. The co-location factor is derived as:
Lastly, in order to prevent VIO from drifting too much, the transformation of the VIO coordinate system to the global coordinate system should be updated after each optimization. The operation must make the position after fusion overlap with the results of GNSS positioning and cooperative positioning as much as possible, and the difference between the two frames should be as equal as possible with VIO. The data from VIO does not impose constraints on the absolute position after fusion, and only requires that the incremental error of the position after fusion and the incremental error of VIO should be as small as possible.
2.3. Communication
The communication modules on the agents and server was based on The ROS communication infrastructure [
21]. It was used for message passing over a wireless network. The communication interface supports two-way communication between the agents and the server, we applied it to update the keyframe pose at a given moment for single-platform SLAM. The server uses it to receive map information from each agent. With this module, the objects waiting to be sent were first serialized/deserialized. Since ROS is not a real-time communication system, time stamps needed to be attached to packets.
2.3.1. Agent-to-Server Communication
In order to realize map data sharing from agent to server and save data bandwidth as much as possible, we added several state variables into the ORB-SLAM3 program to monitor the running status of SLAM on a single platform, including: IMU initialization process, whether visual-inertial bundle adjustment (VIBA) is completed, and tracking the running status of threads. After the IMU completes initialization and VIBA, all the previous keyframes and map point information is serialized and sent. The keyframe information includes the unique ID of this keyframe on the agent, its pose and time stamp, the information of feature points it contains, and the numbers of all map points observed by this keyframe. The map point information contains the ID of this map point on the agent, its three-dimensional coordinates, its descriptors, and the ID of all keyframes that have observed this map point so far. Unique IDs ensure that these messages are not sent repeatedly to reduce the required network bandwidth. The communication module distinguishes between dynamic information (such as the pose of a keyframe that may be adjusted according to the running state of SLAM) and static information (descriptors of feature points). In the process of communicating with the server, each agent will send the smallest packet at the highest frequency (including at least one newly added keyframe information).
2.3.2. Server-to-Agent Communication
Each agent handler thread is responsible for processing keyframes and map points from the corresponding agent on the server. Each keyframe is not processed until all of its observed map points have been deserialized by an agent handler and inserted into the map stack. The server map stack contains separate maps that contain data from each agent. When the server maps complete location identification and merge, the two maps are removed from the map stack and replaced with their merged map until there is only one global map in the entire server map stack. When the server detects the new closed-loop and completes the global pose optimization, it sends the ID and pose of the keyframe back to the corresponding agent to be updated.
2.4. Global Map Initialization and Intra-Agent Measurements
In order to enable the system to complete the positioning of each agent without GNSS at the initial stage of operation, we let the UAVs and UGVs start from the same position with the same angle of view. In this paper, UAVs are set to take off from the top platform of the UGV. After the IMU initialization is completed (which commonly needs 15–35 keyframes and takes 5–10 s), the agents perform a visual-inertial bundle adjustment. The aim of this action is to improve the precision of the initial map. Then, each agent sends its initial optimized local map to the server. For a certain terminal , the server will start the alignment from the keyframe at the most recent moment sent in the . First, a subset of maps from the server map stack and brute-force descriptors are chosen that match all keyframes contained within that map with through DBoW2, and obtained the most likely matched candidate (We set to four times that of the number of agents). For each keyframe, among all the feature points contained in it and its five best common-view keyframes, the 2D-2D feature point matching provided by DBoW2 is used to obtain the 3D-3D matching between their corresponding map points. The map points of candidacy will be converted to through . If the reprojection error is less than the threshold, a vote is cast for the corresponding , and the frame with the most votes is selected as the matching frame. For further improvement of the closed-loop’s robustness, the matching frame and its common-view frame together need to achieve three successful matches to be considered as the complete place recognition. If, at this moment, is a UAV, is a UGV, then the UAV’s local map will be fused into the UGV’s through . If both and are UAVs, the relative pose transformation will be saved until one of them is fused with the UGV’s map, and another will complete fusion through . After the above pairwise pairing of the unmanned platforms, the local map of each UAV is finally converted into the coordinate system of the local map of the unmanned vehicle. New incremental keyframes and map points received by the server during subsequent operations will be transferred to the global map with the corresponding poses until a new loop closure or GNSS location provides a new location constraint.
2.5. Loop Closure and Global Optimization
The place recognition of loop closure is similar to the global map initialization, which depends on the feature point matching provided by DBoW2, and the initial matching through RANSAC and the PnP algorithm. Different from the global map initialization, considering the long-term drift of single-platform SLAM, a finer relative position transition is required. As above, we suppose that of and of have complete initial matching and . All converted map points contained within the common-view frame of , and those found matching to the key points in . After the above intra-agent measurements have been completed, we need to adjust the map information according to the new closed-loop and fuse all the positioning information from each agent to perform global optimization. The details are as follows.
2.5.1. Refinement of Transformation Matrix
is used to convert all map points contained within the common-view keyframe of , and matching map points are located in the feature points of . To obtain as many matches as possible, the map points are found that matches in and all of its keyframes at the same time. The nonlinear optimization of is carried out by using all the map point matching relationships found (the initial value of s is 1), and the goal function is the bidirectional reprojection error
2.5.2. Pose Graph Optimization
After obtaining the optimized transformation matrix , the redundant map points need to be eliminated in the above matching process for each pair of matching map points describing the same feature point. Then propagation of the corrections must be disseminated to the rest of the map through pose graph optimization. To eliminate duplicate points, for each pair of matches the points from are removed, and the points from inherit all the observations of the removed points. By adding edges to the co-visibility and essential graphs, the observability is propagating between the common-view frames of and .
As it has sufficient computing power on the server and is not sensitive to the time cost, global BA optimization can be directly carried out on the adjusted visibility and essential graphs.
2.5.3. Global the Second-Stage Pose Estimation
The factor graph structure of the global two-stage optimization is similar to that of the single platform, the difference is that in the global optimization process only the GNSS positioning information (if any) is needed to be taken into consideration. This is due to the GNSS positioning information from different agents will also generate new position constraints on the global map making the track change significantly and intersect, even if there is no visual re-location at that position. In this case, we would lower the threshold in line with the RANSAC algorithm. If it can pass the detection after reducing the number of inner points, a new closed-loop will be established here. The subsequent processing is consistent with the closed-loop process described above.
4. Discussion
From the experiments described in
Section 3 we draw the following three conclusions.
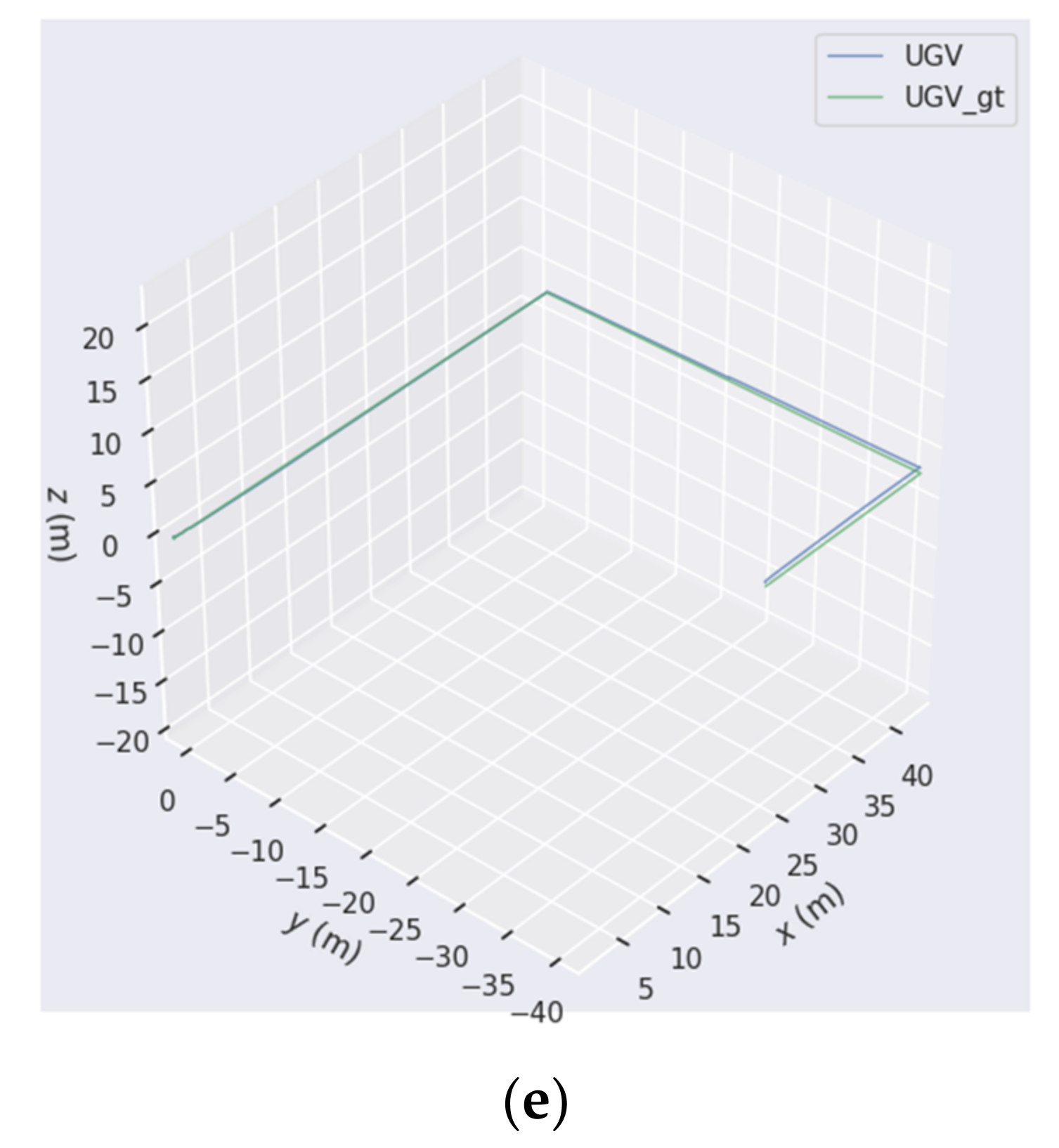
Experiments in the virtual simulation platform demonstrated that the co-location framework we designed can maintain usable positioning accuracy over hundreds of meters of trajectory when the GNSS signal is rejected. At the same time, the co-location framework outperforms the single platform in terms of accuracy. This is essentially attributed to the new position constraints arising from place recognition between the different platforms.
The SLAM front-ends we currently employ were not sufficiently stable under poor observation conditions. For example, poor visibility environments or poor near-orthogonal viewing angles affected the proper function and positioning accuracy of the air-ground co-location system. The main reason is that the ORB feature-based SLAM front-end we adopted often cannot provide a sufficient number of feature points for matching to achieve robust location re-identification. Other common front-end methods, such as optical flow method, have more stringent requirements on observation conditions and viewing angles. In the SLAM front-end process, if the threshold of hamming distance for ORB detection is lowered in order to increase the number of matched pairs, it will lead to excessive false matches affecting the accuracy of VIO. Therefore, place recognition that relies on ORB features can only be adapted to the images generated under more optimum observation conditions. The visual front-end used in this manuscript fulfills the basic requirements for cooperative air-ground localization but is not yet sufficiently robust for weak observation conditions.
The method described in this manuscript allows the location information of each agent in the entire unmanned cluster to be propagated to the other agents in the cluster. This process improves the positioning accuracy while also allowing the server and the individual unmanned platforms to acquire relative positions to each other. We designed a comparison of four cases. They were GPS-challenged co-location, GPS-denied co-location, single-platform independent operation of ORBSLAM3, and single-platform independent operation of ORBSLAM3 fusion GPS. In GPS-denied mode, the simulation was performed on a solar body with no GNSS fix except of Earth, or on Earth but the GNSS signal had interference. In this case, the positioning of each agent completely depended on the camera and IMU. It can be seen from
Table 8 that the accuracy of co-location was significantly improved compared with the positioning accuracy of ORBSLAM3 running on a single platform. Assuming that some agents in the system obtained satellite positioning information, the positioning accuracy of all agents was improved. It is worth noting that even if we assume in the experiment that the UGV cannot obtain satellite positioning signals at all, its positioning accuracy still benefits from the co-location algorithm. This is due to the fact that the new constraints brought by the satellite positioning information are propagated to the local maps of all agents through the global map. Through the comparison of the two GPS-challenged modes, we found that only a few GPS points were enough to greatly improve the positioning accuracy. The GPS-challenged 1 mode used several times more GPS positioning points than the GPS-challenged 2 mode, but the positioning accuracy was not significantly improved compared with the latter.
In the experiments designed in this manuscript, we set the UAV to use high-precision GNSS positioning information, while the UGV could not obtain GNSS signals. There were two main reasons for this assumption. The first point was that, in practice, UAVs located in the sky can often obtain GNSS positions with good accuracy through RTK or relative positioning measurements. Whereas vehicles located on the ground may temporarily lose their GNSS position due to obstruction by reinforced concrete buildings, or by entering tunnels and interiors. The second point was that ORBSLAM3 itself is an excellent single-platform SLAM algorithm, which can have a trajectory drift error of less than 1% with a closed-loop bottleneck. This makes it difficult for the meter-level errors inherent in GNSS to contribute to the improvement in positioning accuracy if differential-free GNSS positioning is used in a virtual scene of limited size. If the scale of the motion trajectory reaches several kilometers, however, even differential-free GNSS positioning information can greatly optimize the positioning accuracy.
In our paper, we focused on collaborative localization. However, in engineering applications, the movement of each agent in the system was not infinite due to the limitation of communication bandwidth and communication distance. Due to the lack of prior information of the global map, the pose information of each agent and the local map information received by the server had time delays, and the global positioning pose updated through the visual closed-loop had no gradient information. In this case, if a motion strategy for convex online learning to train unmanned clusters is required, delayed mirror descent (DMD) [
24] would be a good choice. We will use this approach in the subsequent work. In the aspect of multi-agent motion control, our method only used the most basic D* Lite algorithm. Only the trajectory of a single agent was considered to fit the route generated in advance. However, in practical applications, there may be obstacles in the waypoints planned in advance, and the route itself is unreachable. Cooperation among multiple agents can be difficult to achieve. Collaborative algorithms such as [
25] realize the decentralized and real-time cooperative pursuit of a single evader in the planar domain. By improving the method proposed in this paper, the control of the prior map obtained by the UAV would be improved.
Finally, it is worth mentioning that in the statistics of network bandwidth usage, we found that the peak bandwidth usage occurs in the map initialization phase, which is about three times the average value. In the case of long distance or interference, this will put higher requirements on the performance of wireless communication devices. When there is a prior map, it will greatly relieve the bandwidth pressure during system initialization. During system initialization, at least four high-quality GNSS positioning points are needed to convert the VIO coordinate system to the northeast sky coordinate system. Meanwhile, ORBSLAM3′s IMU initialization requires initial zero-bias estimation and gravity direction estimation to obtain scale information, which makes the initialization of the global map take too long. How to complete global map initialization more efficiently and quickly or to make better use of prior map information is the next urgent problem to be solved.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}