3.3.1. Results’ Comparative Analysis of Model Validation Experiment
In order to verify the validity and advancement of the proposed model in the model validation experiment, we used traditional models [
10,
11,
12,
13,
21,
22,
23,
24,
25] and basic network models to carry out comparison experiments on same datasets. The comparison experiment models include Linear Regression Model (LR), Bayesian Regression Model (BR), Support Vector Regression Model (SVR), Regression Tree Model (RT), Random Forest Model (RF), Back Propagation Neural Network (BPNN), Convolution Neural Network (CNN), Long Short-Term Memory Network (LSTM), and a sequence model (CNN–LSTM–BPNN).
Due to the large size of L1B_Fishery datasets, the traditional models’ fitness has poor performance, so we only used Env_Fishery datasets to carry out the experiments of traditional models. For the comparison experiments of basic network models, we used L1B_Fishery datasets and Env_Fishery datasets to carry out experiments, respectively. Notably, since some models do not support high-dimensional feature datasets, we needed to reduce the dimensions for the Env_Fishery datasets.
The experiment results of different models are shown in
Table 5. The feature-extraction fusion model and decision fusion model in
Table 5 represent the heterogeneous data feature-extraction model and the decision fusion model based on the multi-source heterogeneous data feature extraction proposed, respectively.
Our analysis of
Table 5 shows that the traditional mathematical models, such as LR and BR, perform poorly in regard to habitat prediction. The prediction error reaches 0.13802, which makes it difficult to fit the correlation between ocean environment factors and CPUE. However, the prediction error of SVR decreases to 0.0846, and the R
2 improves to 0.7152, which basically fits the strong correlation between the ocean environment factors and habitat. Compared with traditional mathematical models, the improvement is very large. It proves that machine-learning models have significant advantages regarding habitat prediction.
The performance of the SVR is not excellent, due to the kernel functions. The RT model, which is also a machine-learning algorithm, reduces prediction error to 4.59%, with an R2 of 0.9161, by adjusting the number of leaf nodes and the maximum depth. Then the RF, which integrates multiple decision trees, further reduces the prediction error to 3.573%, with an R2 of 0.9492, and it obtains an excellent result. However, the disadvantages of RT and RF are that artificially setting model parameters leads to overfitting and weakens the model’s generalization ability.
Experiments show that the dropout layer and batch normalization (BN) layer in the BPNN, CNN, and LSTM can effectively prevent model overfitting. Thus, we can significantly improve the model’s generalization ability with low prediction error. As shown in
Table 3 and
Table 4, the R
2 of BPNN, CNN, and LSTM can reach 0.9248 or higher on both datasets. Among them, the BPNN and LSTM perform equally well, with the prediction error of 0.04 and R
2 of above 0.93 on the Env_Fishery datasets, and the prediction error of 0.032 and R
2 of above 0.96 on the L1B_Fishery datasets. These results are better than those of the CNN on the same datasets. The reason is that Env_Fishery datasets have the same dimensions as L1B_Fishery datasets after dimension reduction, which belongs to one-dimensional feature data, but the CNN model performs better in the face of high-dimensional feature data. In addition, the two experiment datasets have a large number of features and contain spatial and temporal factors, enabling BPNN and LSTM to perform better.
In the case of a single neural network with its own advantages and disadvantages, we tried to use the sequence model. Although the RF model performed better than the BPNN and CNN models in
Table 5, it performed poorly in the generalization experiments. Therefore, we chose a sequence model consisting of three neural network models, namely CNN, LSTM, and BPNN, which perform well in both model validation experiments and generalization experiments, and this experiment obtained a prediction error of less than 3%, and the R
2 improved to more than 0.965. Although the result is better than that of the single neural network, the combined sequence model cannot use specific network models to extract features for different data structures. For example, the LSTM module in the sequence model is good at feature extraction for spatial and temporal factors, but the feature-extraction ability of ocean environment factors is very poor. Therefore, the LSTM module should not be used to extract ocean environment factors.
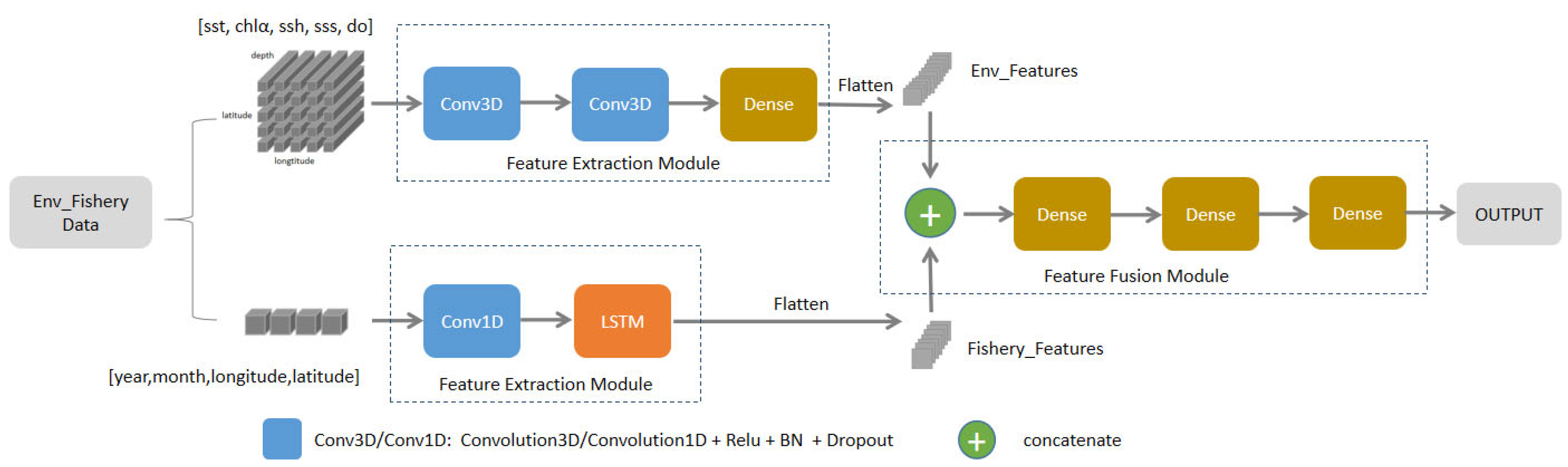
In this paper, for the different structural features of each part of the heterogeneous data, we use the strategy of separate feature extraction and then feature fusion, and we propose the heterogeneous data-feature-extraction model. This model can select the suitable feature-extraction model to fully exploit features for each part of heterogeneous data. The prediction error reduces to 0.02193 and 0.01801 on both datasets, respectively. Then the decision fusion model based on multi-source heterogeneous data feature extraction proposed fuse two datasets of different size and structure, further improving the experiment performance. The mean R2 reaches 0.9901, and the prediction error decreases to 0.01588, while avoiding overfitting, which is significantly better than the experiment results of any single dataset.
Combining the above analysis, the decision fusion model based on multi-source heterogeneous data feature extraction proposed performed outstandingly in the model validation experiment. It has a high fitness to the validation datasets, which is better than other models.
3.3.2. Results Analysis of Generalization Experiments
In order to verify the validity and advancement of the model proposed in the generalization experiment, the CNN–LSTM–BPNN, which performed well (R
2 > 0.96) on the model validation experiment of both datasets, is selected for comparison experiments. The results of the comparison experiments are shown in
Table 6.
Table 6 shows that the proposed heterogeneous data feature-extraction model performed better in the generalization experiment than in the sequence network CNN–LSTM–BPNN model. On the Env_Fishery datasets, the Feature Extraction Fusion Model reduces the prediction error by 0.6% and improves the R
2 by 0.06 compared with the CNN–LSTM–BPNN; on the L1B_Fishery datasets, the feature-extraction fusion model reduces the prediction error by 1% and improves the R
2 by 0.07. Then the decision fusion model further reduces the prediction error to 0.07849 and improves the R
2 to 0.4237 after the decision fusion of the prediction results of two heterogeneous data feature-extraction models. It shows the best prediction performance in the generalization experiment and significantly better than in any single dataset.
The prediction error of the generalization experiment is only 0.07849, but R
2 is equal to 0.4237. It shows that the model has much room for improvement in the fitness of the test datasets. As mentioned in
Section 3.2.2, there is still a gap between the generalization experiment prediction results and the high fitness-model-validation-experiment prediction results. Next, we classify the test datasets and their prediction results by month and prediction error to analyze the reasons that affect the further improvement of the generalization experiment performance.
The test datasets used in the generalization experiment is the Northwest Pacific Saury fisheries datasets from 2020. Through the experiments of the proposed models, we can obtain the datasets of CPUE prediction results containing 2603 entries for 8 months (May to December). Referring to the mean prediction error (RMSE = 0.07849), we use a prediction error of 8 ± 2% as the classification criterion to divide the samples of prediction results’ datasets into three classes. Samples with less than a 6% prediction error are high-quality prediction samples (High); samples with a prediction error greater than or equal to 6% but less than or equal to 10% are middle-quality prediction samples (Middle); and samples with prediction errors greater than 10% are low-quality prediction samples (Low).
As shown in
Table 7, the total number of samples is listed; the number and proportion of high-, middle-, and low-prediction-quality samples for each month of the test datasets are recorded; and the RMSE of the CPUE value for that month is calculated at the end.
The analysis of
Table 7 shows that the high-quality prediction samples account for 55.05% of the overall samples, while the low-quality prediction samples account for only 16.64%. It proves that the proposed model can accurately predict nearly 84% CPUE values of the samples in the test datasets, keeping the errors within 10%. For the low-quality prediction samples, we analyze the reasons of excessive prediction error monthly. Observing
Table 7, we can see that there is a high proportion of low-quality prediction samples in May and October, respectively reaching 71.43% and 32.78%, resulting in an above-mean RMSE (0.12256 and 0.009823) for that month. In addition, although the proportion of low-quality prediction samples is low in December, that RMSE is above 0.1, which is also less than ideal.
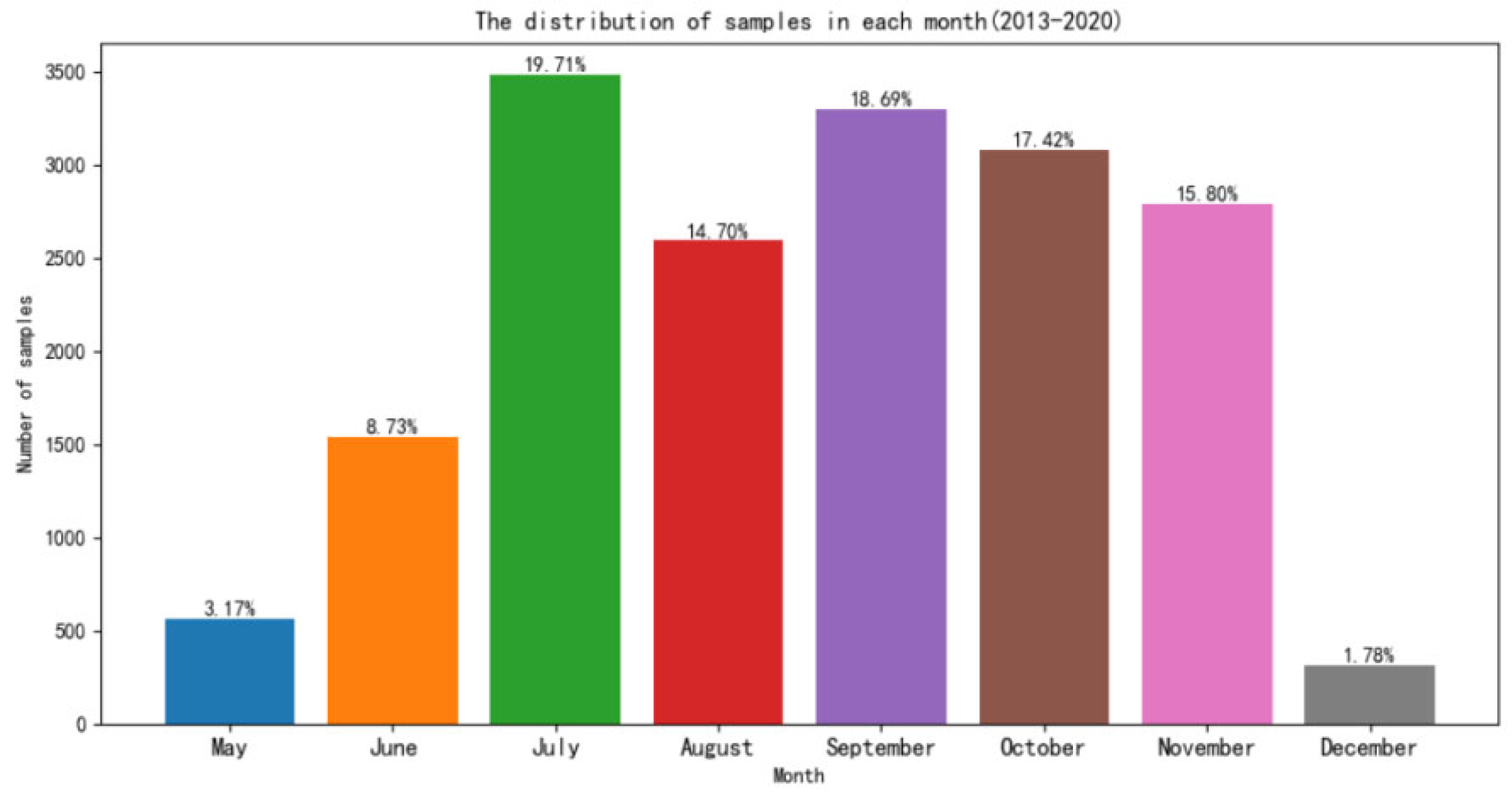
Considering that the peak season of fishing operations is summer and autumn, the number of samples in the fisheries’ datasets is not evenly distributed over the months. The distribution of samples in each month is shown in
Figure 11. Because May and December are at the beginning and end of fishing operations each year, the number of samples obtained is very small, accounting for only 3.17% and 1.78%. The December fisheries’ datasets contain only 315 entries in total, while the test datasets contain 115 entries, accounting for more than 1/3 of the total, making December datasets for training and validation even more scarce. Therefore, the uneven distribution of fisheries’ datasets leads to insufficient training in some months. It affects the prediction accuracy of the generalization experiment.
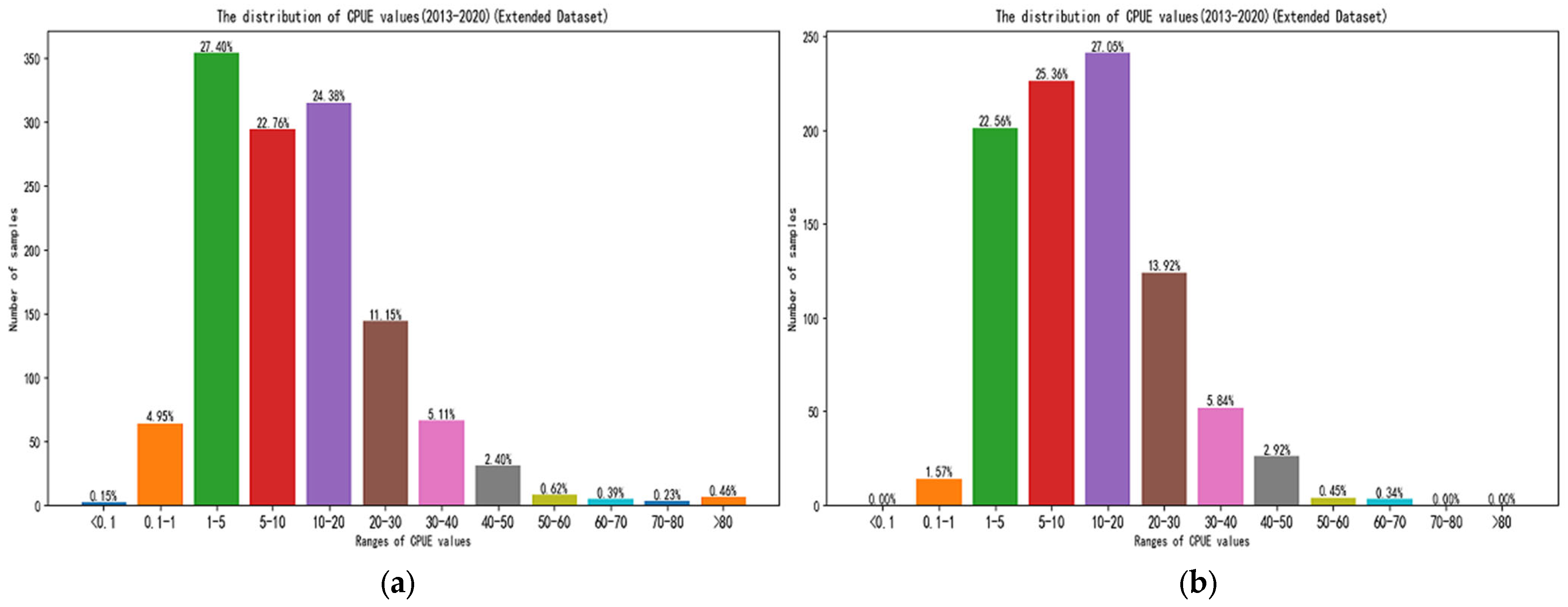
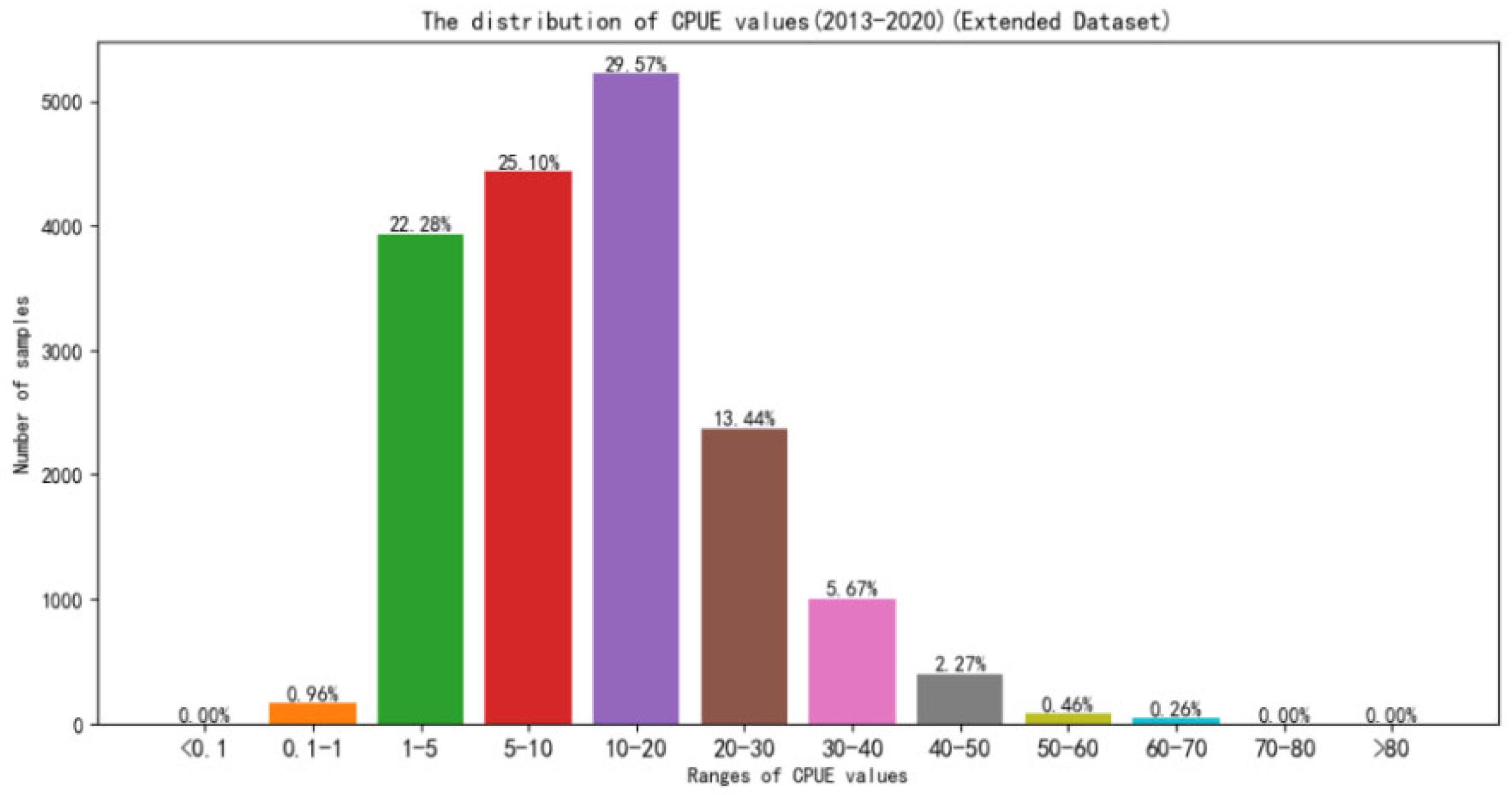
In addition, the uneven distribution of CPUE values also becomes an important reason to affect the prediction accuracy. The distribution of CPUE values after the datasets’ expansion is shown in
Figure 12. It can be seen that nearly 80% of the samples of CPUE values are in the low-to-middle level (0.1~20). Only 13.44% of the samples of CPUE values are 20 to 30, and 8.66% of the samples of high CPUE values are above 30.
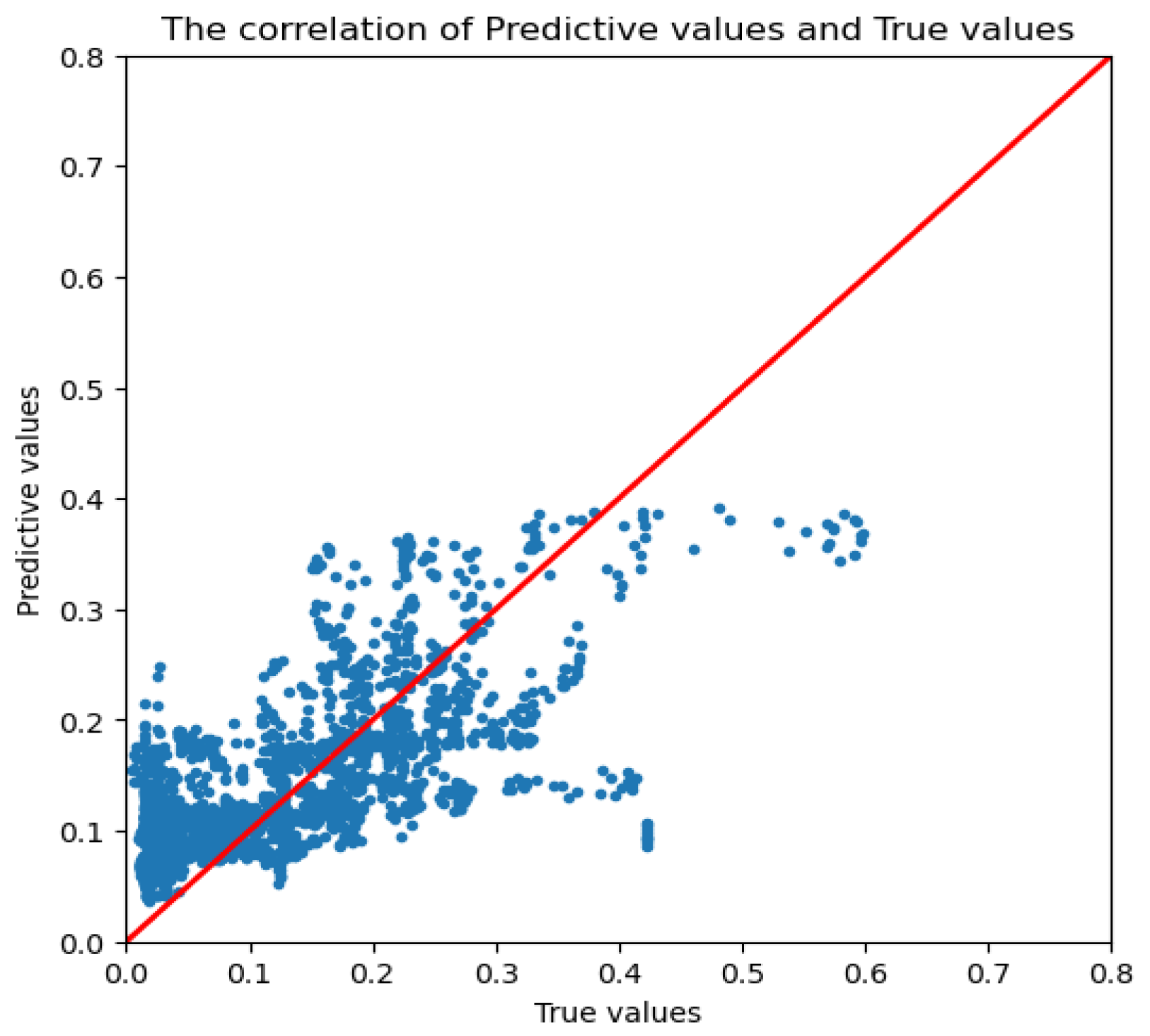
As shown in
Figure 13, we obtained the correlation of the prediction results of CPUE values and true values of an experiment by using a decision fusion model based on multi-source heterogeneous data feature extraction for generalization experiment. The x-axis in the figure represents the true value of this experiment result, and the y-axis represents the predicted value of this experiment result. If the sample point lies on the y = x function line (red line), it indicates that this predicted value is consistent with its true value, and a sample point below the red line illustrates that the predictive value is lower than the true value. Conversely, it means that the predictive value is higher than the true value. Obviously, for the samples with middle-to-high CPUE values, most of the sample points are below the red line. It illustrates that the uneven distribution of CPUE values affects the training of the model for the samples with medium and high CPUE values. It leads to the poor fitting of the model for the samples of middle and high CPUE values, and its prediction results are low.
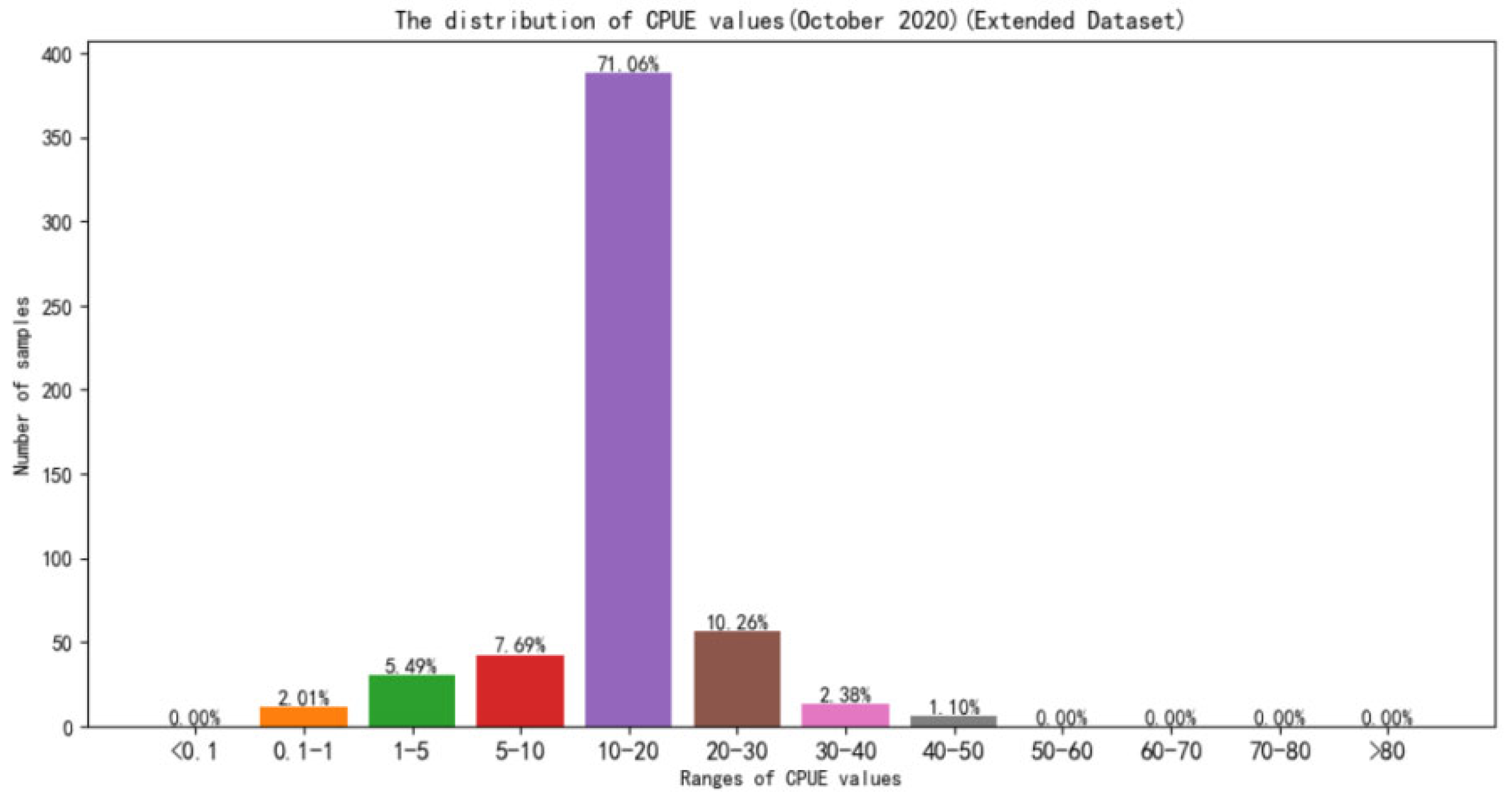
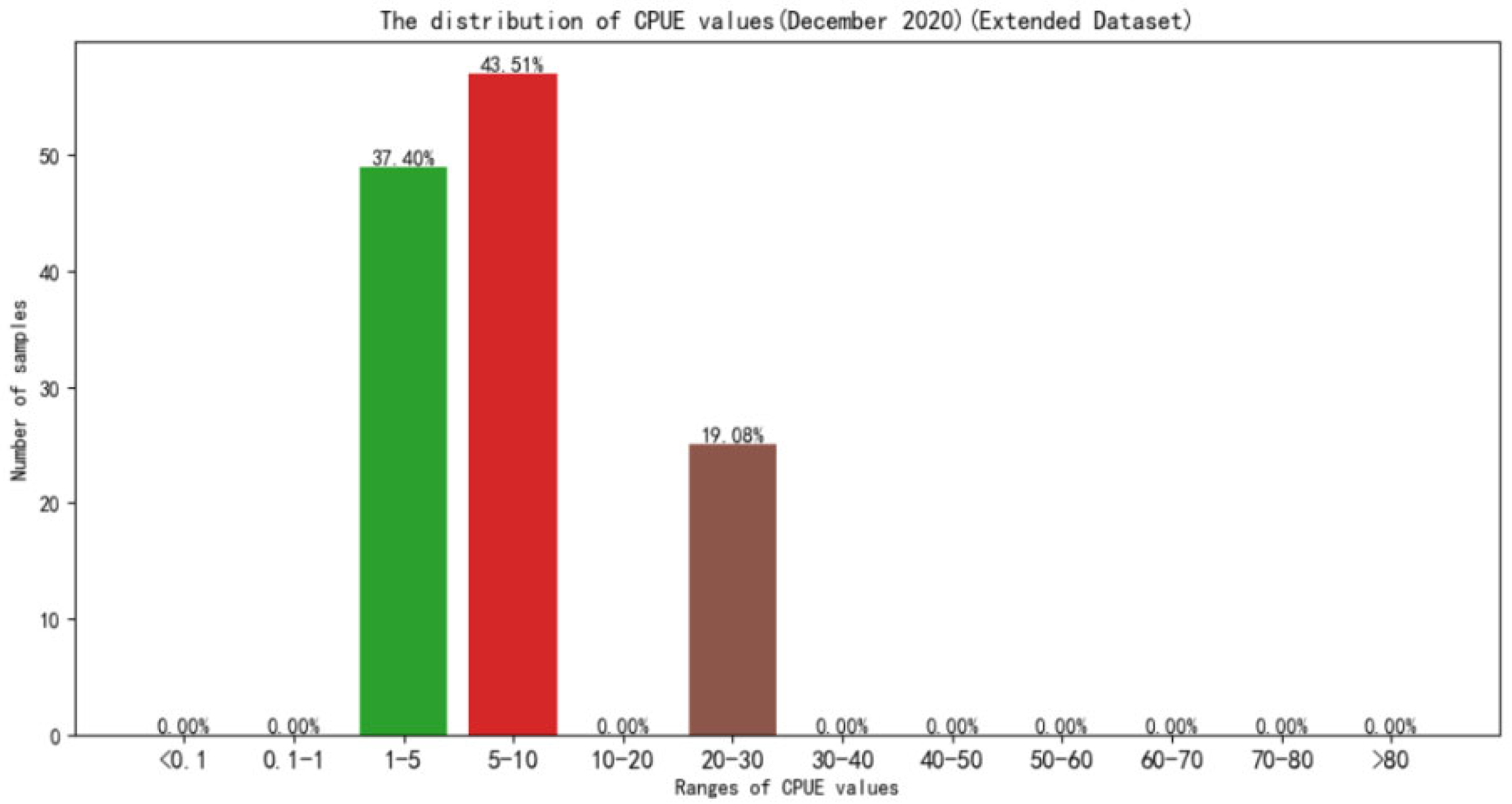
The distribution of CPUE values in October and December on the test datasets are respectively shown in
Figure 14 and
Figure 15. From the
Figure 14, it can be seen that the samples of middle-to-high CPUE values (CPUE > 20) in the October is 13.74%. Although it does not account for a large proportion of the overall, it contains 3.48% samples with high CPUE values (CPUE > 30), accounting for 100% of the samples with high CPUE values in the test datasets. It means that all samples of the high CPUE values in the test datasets are found in October. The reason for the concentration of high CPUE values is related to the peak fishing season in October, when there is a large amount of work, and the quality of the Northwest Pacific Saury is higher than in previous months. Combined with the higher penalty weight given by RMSE to larger prediction error, RMSE is excessively high, nearly 0.1. In addition,
Figure 15 shows that, although the December does not have the effect of high CPUE values, nearly 20% of the samples of the CPUE values are in the 20–30 range. This proportion exceeds the average of the fisheries datasets. Coupled with too little data of December fisheries datasets used to train the model, the training model is under-fitting, resulting in an RMSE of more than 0.1.
In summary, the proposed decision fusion model based on multi-source heterogeneous data feature extraction performed excellently in the generalization experiment. It fit most of the data well and kept the overall prediction error at less than 8%, which is better than other models. However, due to the unevenness of fisheries’ data in the distribution of month and CPUE value, the prediction accuracy is not ideal for samples from months with less data and samples of middle-to-high CPUE values. It limits the further improvement of the model prediction accuracy in the generalization experiment.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}