Extracting representative features from a video sequence is of prime importance for the task of ocean-front trend recognition. In this section, we will describe a novel idea for extracting discriminative features for recognizing the ocean-front trend, based on the analysis of a whole video. The key idea of the proposed method is shown in
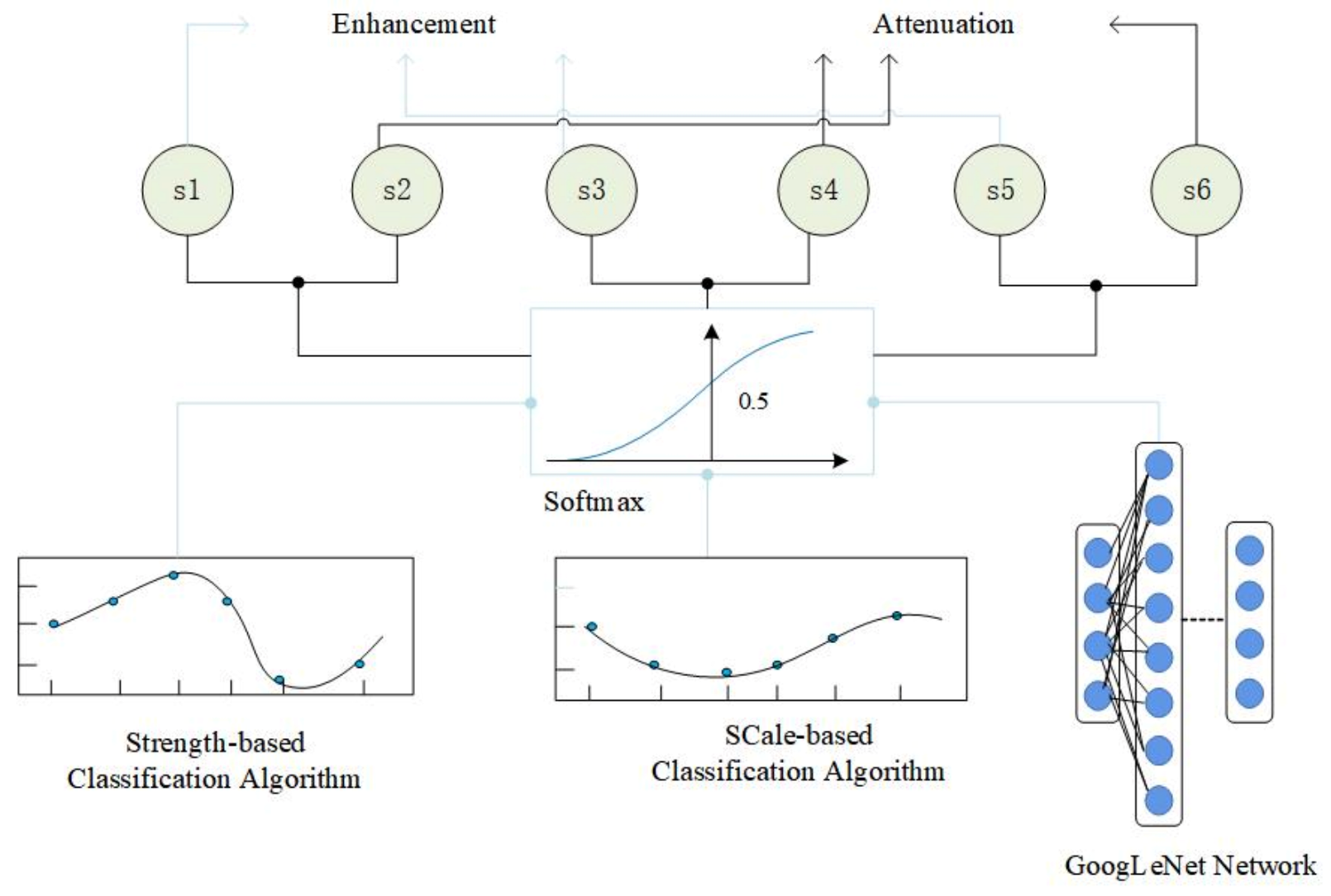
Figure 1, the proposed trend recognition method relies on the combination of the statistical algorithms and deep learning models. Softmax classifier is then applied for trend recognition of enhancement and attenuation. The proposed method avoids the complex operations required for selecting recommended frames, because the proposed method can extract representative temporal and deep features from the video sequence, and hence, it is efficient and effective.
2.1.1. Network Structure
The proposed recognition framework, which is composed of three parallel networks, is depicted in
Figure 2. The first and second networks are designed for trend classification, based on prior physical knowledge, which will be explained in
Section 2.1.2 and
Section 2.1.3. Their inputs are the video sequences from OFTreD. The OFTreD database is proposed for the ocean-front trend recognition task. The third network is also designed for ocean-front trend classification, based on GoogLeNet Inception, whose input is the optical flow images extracted from the video sequences in OFTreD. The first, second and third networks are integrated to classify the ocean-front trends. In this paper, two kinds of ocean-front trends are defined, namely, the enhancement trend and attenuation trend. In
Figure 2, Score A and Score B are used to classify the ocean-front trend. The value of Score A denoted as
, represents the probability that an oceanfront enhancement trend, and that of Score B, denoted as
, represents the probability that an oceanfront has an attenuation trend. The scores
and
are computed as follows:
where
, are the weights, whose values will be discussed in
Section 4.
, represents the value of Score
j in
Figure 2. The larger score of
and
will be used to determine the ocean-front trend category.
Each of the three proposed networks ends with a softmax layer, which outputs two scores to represent the probabilities of the input video sequence belonging to the enhancement or the attenuation trend. In total, six classification scores are generated. The six scores, i.e., Score 1 to Score 6, are used to classify whether the oceanfront is enhancing or attenuating. In our experiments, Scores 1, 3, and 5 are used to represent the probabilities of belonging to the enhancement trend, while the Scores 2, 4, and 6 are used to represent the attenuation trend. An ocean front in a video sequence belongs to either the “enhancement” class or the “attenuation” class. Finally, we integrate these six weighted scores to make the final decision on the trend class.
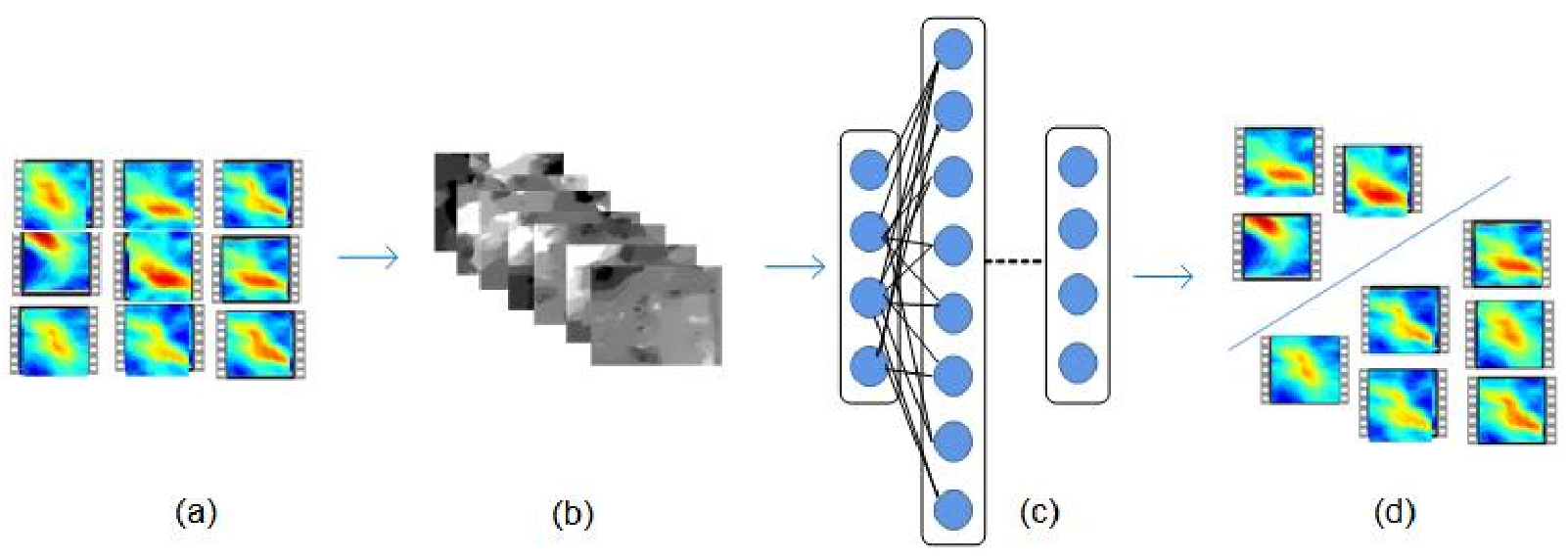
As shown in
Figure 3, we also propose an oceanfront tracking algorithm to check whether the current input video sequence contains an oceanfront and where the ocean-front trend is in the video sequence. For this task, we train a GoogLeNet network on the OFTraD dataset.
The input of this network is the RGB images from OFTraD. The network is used to determine whether the input belongs to the background or the foreground. Those images that contain a tracking target, i.e., an oceanfront, belong to the foreground class, otherwise, they belong to the background class. Based on the location information carried by the input images, the output labeled images can be reconstructed into ocean-front video sequences, and then the ocean-front trend in the video sequences can be tracked.
2.1.3. Ocean-Front Classification Algorithm Based on Scale
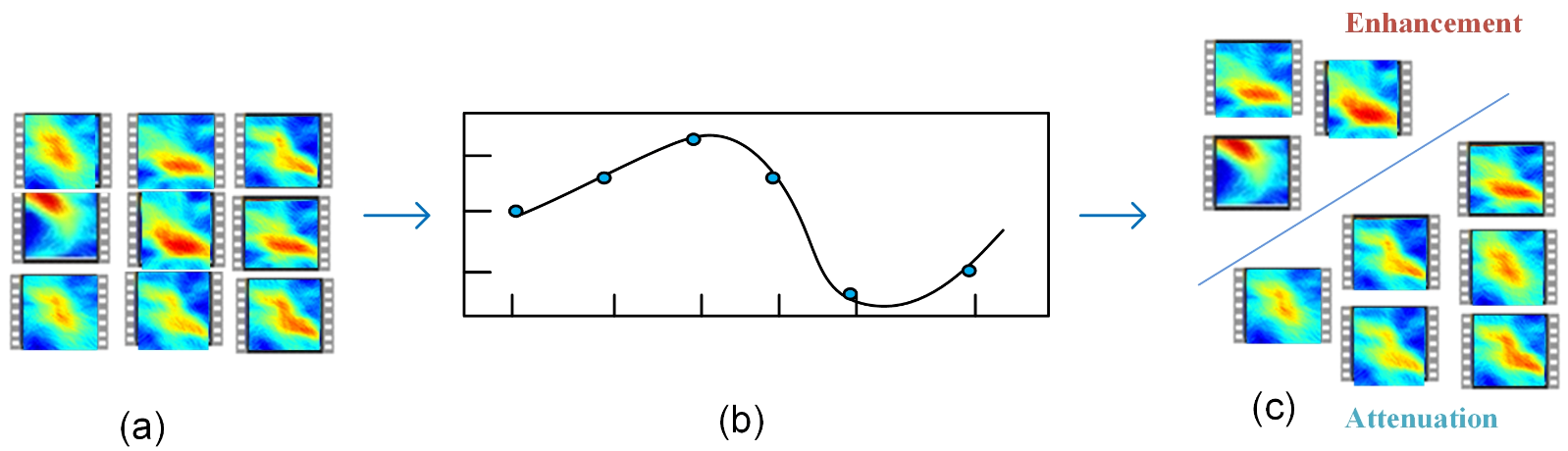
With the proposed algorithms, we will illustrate how to extract the strength and scale information about the oceanfront in a video sequence and the databases used for training and testing. Algorithm 1 is designed for recognizing ocean-front trends based on the strength of an oceanfront. To classify the trend, we need to compute the variations of the ocean-front strength. Since the strength of an oceanfront varies from point to point, we propose to use the mean intensity of an oceanfront in a frame to represent its strength. Similarly, Algorithm 2 is designed to classify the ocean-front trend based on its scale. The scale of an oceanfront is calculated based on the number of oceanfront points in a frame. The greater the number of ocean-front points, the larger the ocean-front scale is.
Here, the vectors and represent the strength and scale information, respectively, and the matrices and represent the points extracted from the corresponding curves, and the feature vectors and represent the filtered output from the corresponding matrices and . Thus, the feature vectors and represent the processed strength and scale information, respectively. We use the feature vectors and to classify the ocean-front trend. Then, these feature vectors are sent to softmax for classification and generate the output .
2.1.4. Feature Matrices Generation Method
In the ocean-front trend algorithms, the number of frames of different videos may be different, so the dimensions of the strength vector
and the scale vector
of different videos, as described in Algorithms 1 and 2, respectively, are different. To make the two vectors always have the same length, Algorithms 1 and 2 apply curve fitting to the vectors
and
, then resamples the two curves with a fixed number of points. Specifically, as shown in
Figure 5, we use the cubic polynomial interpolation method to fit the curves. With a fixed number of points on the curve, two matrices,
and
, are generated. The matrices generation process is shown in
Figure 6, starting from the point representing the strength/scale of the first frame, we sample points on the curve at regular intervals until the point that represents the last frame. We set
in our experiments, because we need to extract more than 40 points from the curve. As analyzed in
Section 4, the best vector dimension is
, too small will not meet the requirement, too large is unnecessary. After that, the matrices
and
are processed by three pooling filters to obtain fixed-dimensional vectors
and
.
Given matrices
and
, we vectorize the matrices
and
to acquire the feature vectors
and
. The elements of the matrices
and
are denoted as
and
, and hence the vector
,
, whose dimension is
. As shown in Algorithm 3, according to the dimension of the matrices
and
, we use different pooling filters. If the dimension of the feature vectors
and
is greater than
, average pooling is performed every 5 elements from the first and the last 50 elements in the feature vectors, that is
,
,
, and
, the filter size is
. Then, We assign
,
,
, and
the value of the processed data. Then, the number of the remaining elements in the feature vectors
and
is
. The pooling size is set at
, the stride is set at
. Average pooling is performed every
elements from
and
. And then we assign
and
the value of the processed data.
| Algorithm 3 The matrix processing method |
- 1:
Input: Matrices and Given matrices and , we vectorize them to acquire its feature vectors and . - 2:
if the dimension of the feature vectors and do Average pooling is performed every 5 elements from the first 50 elements and the last 50 elements of the matrices, the filter size is , the stride is 5. The processed data is assigned to and . Average pooling is applied to the remaining elements in the feature vectors and , the filter size is set according to the number of the remaining elements. - 3:
else if the dimension of the feature vectors and do Average pooling is performed every 2 elements from the first and the last 30 elements, the filter size is , the stride is 2. The processed data is assigned to and . Average pooling is applied to the remaining elements in the feature vectors and , the filter size is set according to the number of the remaining elements. - 4:
else do The first and the last 15 elements of the vectorized matrices and are assigned to and . Average pooling is applied to the remaining elements in the feature vectors and , the filter size is set according to the number of the remaining elements. - 5:
Output Feature vectors and
|
Otherwise, if the the dimension of the feature vectors and , average pooling is performed every 2 elements from the first and the last 30 elements in the feature vectors, that is , , , and , the filter size is . We assign , , , and the value of the processed data. Then, the number of the remaining elements in the feature vectors and is . The pooling size is set at , the stride is set at . Average pooling is performed every elements from and . We assign and the value of the processed data, assign and the value of the processed data.
If the dimension of the feature vectors and , we assign , , , and the value of the first and the last 15 elements in the feature vectors, that is , , , and . Then, the number of the remaining elements in the feature vectors and is . The pooling size is set at , the stride is set at . Average pooling is performed every elements of and . Then we assign and the value of the processed data. In this way, feature vectors and can be constructed.
2.1.6. Ocean-Front Tracking Algorithm Based on GoogLeNet
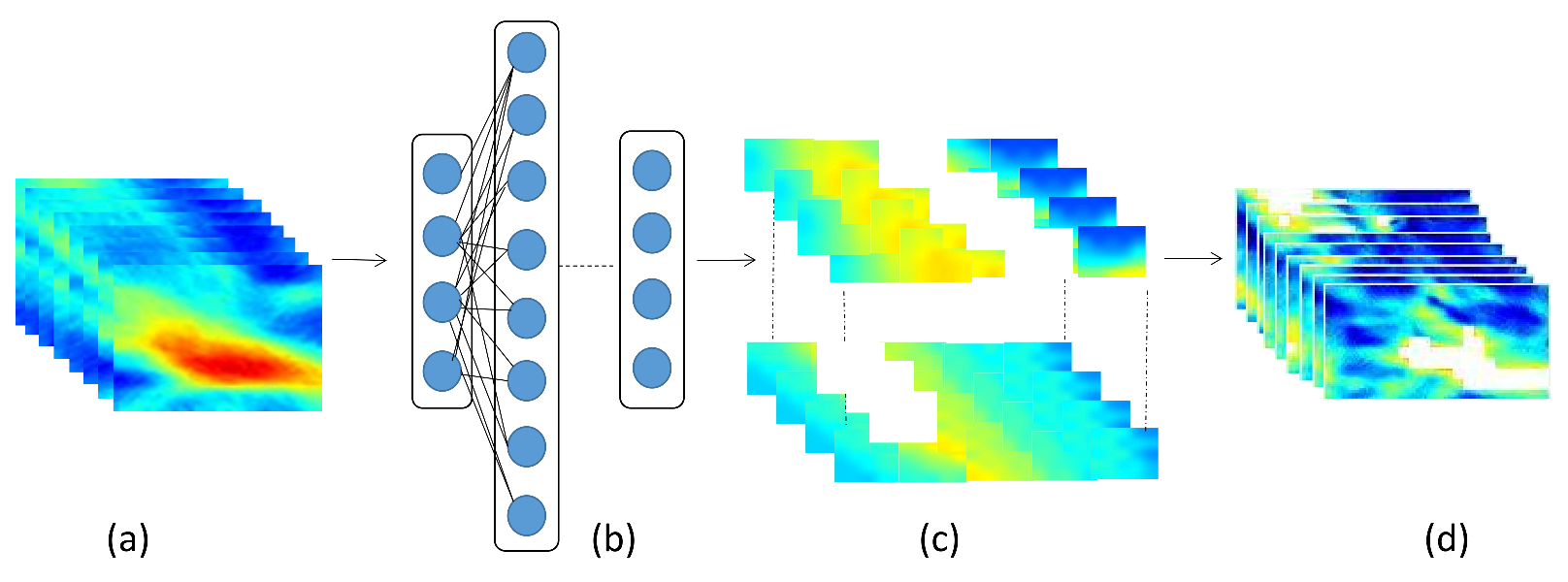
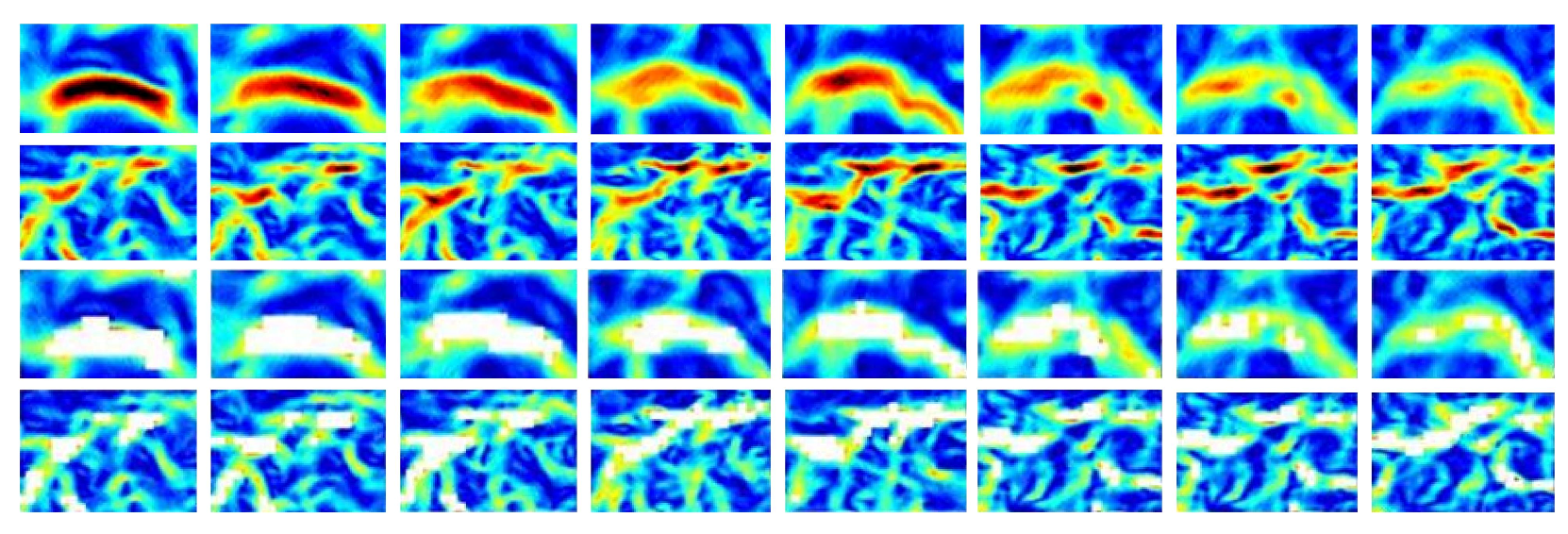
As shown in
Figure 9, the ocean-front tracking algorithm is also based on the GoogLeNet Inception network. The network is used to classify image blocks into two classes: the oceanfront and the background. We first colored the oceanfront image blocks in white, and then, we further use the location information and place them back to the same position in the original frame. In this way, we can track the ocean-front location in a video sequence. It is worth noting that this network is trained on OFTraD, with 8000 and 2000 image blocks from the database used for training and testing, respectively.
The input of our algorithm is the image blocks and their time-position information. Firstly, we extract the RGB image blocks from each video sequence, and feed them into the GoogLeNet Inception network for classification. The color of the image blocks is set to white, if the image block is classified as the oceanfront. In our experiments, the block size is set to , because this size can cover mesoscale ocean fronts. If the size of the blocks is too large, it will be hard to find the exact location of the background. If the block is too small, the classification accuracy will be reduced. Then, according to the corresponding time-position information, the blocks are put together to form a video sequence. When dividing an ocean-front frame into image blocks, we label their names with the time-position information, so that when getting their classification labels, we can put them back to their original time-position location. Therefore, the location of the oceanfront in a video sequence can be located.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}